注:
- 此教程需要访问 Oracle Cloud。要注册免费账户,请参阅开始使用 Oracle Cloud Infrastructure Free Tier 。
- 它使用 Oracle Cloud Infrastructure 身份证明、租户和区间示例值。完成实验室时,请将这些值替换为特定于云环境的那些值。
将 OCI 数据流与 Apache Spark 流处理结合使用,以可扩展且近乎实时的应用处理 Kafka 主题
简介
Oracle Cloud Infrastructure (OCI) 数据流是面向名为 Apache Spark 的开源项目的托管服务。基本上,通过 Spark,您可以将其用于处理大量文件、流处理和数据库操作。您可以使用高度可扩展的处理来构建应用程序。Spark 可以扩展和使用群集计算机来同时处理具有最低配置的任务。
通过将 Spark 用作托管服务(数据流),您可以添加许多可伸缩服务以乘以云处理的力量。数据流能够处理 Spark Streaming 。
流处理应用需要长时间的持续执行,并且通常会超过 24 小时,并且可能长达数周甚至数月。如果出现意外故障,流处理应用程序必须从故障点重新启动,而不会产生不正确的计算结果。数据流依赖 Spark 结构化流检查点来记录处理的偏移,可将其存储在对象存储桶中。
注:如果您需要将数据作为批处理策略进行处理,可以阅读以下文章:使用 Oracle Cloud Infrastructure Data Flow 在 Autonomous Database 和 Kafka 中处理大型文件

在本教程中,您可以看到用于处理数据卷流、查询数据库以及合并/联接数据以在内存中形成另一个表或近乎实时地将数据发送到任何目标的最常见活动。您可以将此海量数据写入数据库,并在 Kafka 队列中写入具有非常低成本的高效性能。
目标
- 了解如何使用数据流处理可扩展和近乎实时的应用中的大量数据。
先决条件
-
一个可操作的 Oracle Cloud 租户:您可以在一个月内创建价值为 300.00 美元的免费 Oracle Cloud 账户,以尝试此教程。请参阅创建免费的 Oracle Cloud 账户
-
本地计算机上安装了 OCI CLI (Oracle Cloud 命令行界面):这是用于安装 OCI CLI 的链接。
-
安装在本地计算机中的 Apache Spark 应用程序。查看本地开发 Oracle Cloud Infrastructure Data Flow 应用程序、部署到云,了解如何在本地和数据流中开发。
注:这是要安装的官方页面:Apache Spark 。为每种类型的操作系统 (Linux/Mac OS/Windows) 安装 Apache Spark 有其他过程。
-
已安装 Spark 提交 CLI 。这是用于安装 Spark 提交 CLI 的链接。
-
本地计算机中安装了 Maven 。
-
了解 OCI 概念:
- 划分
- IAM 策略
- 租户
- 资源的 OCID
任务 1:创建对象存储结构
对象存储将用作默认文件存储库。您可以使用其他类型的文件资料档案库,但对象存储是一种简单且低成本的方法来处理具有性能的文件。在本教程中,两个应用程序都将从对象存储加载大型 CSV 文件,展示 Apache Spark 如何快速而智能地处理大量数据。
-
创建区间:区间对于组织和隔离云资源很重要。您可以按 IAM 策略隔离资源。
-
您可以使用此链接了解和设置区间的策略:管理区间
-
创建一个区间来托管本教程中 2 个应用程序的所有资源。创建名为 analytics 的区间。
-
转到 Oracle Cloud 主菜单并搜索:身份与安全性、区间。在“区间”部分中,单击创建区间并输入名称。

注:您需要向一组用户授予访问权限并包括您的用户。
-
单击创建区间以包括您的区间。
-
-
在对象存储中创建存储桶:存储桶是用于存储对象的逻辑容器,因此用于此演示的所有文件都将存储在此存储桶中。
-
转到 Oracle Cloud 主菜单并搜索存储和存储桶。在“Buckets(存储桶)”部分,选择之前创建的区间 (analytics)。

-
单击创建存储桶。创建 4 个存储桶:应用、数据、数据流日志、Wallet

-
输入包含这 4 个存储桶的存储桶名称信息,并使用默认选择维护其他参数。
-
对于每个存储桶,单击创建。您可以看到创建的存储桶。

-
注:查看存储桶的 IAM 策略。如果要在演示应用程序中使用这些存储桶,则必须设置策略。您可以在对象存储概览和 IAM 策略中了解这些概念和设置。
任务 2:创建 Autonomous Database
Oracle Cloud Autonomous Database 是 Oracle Database 的托管服务。对于本教程,应用程序将出于安全原因通过 Wallet 连接到数据库。
-
按如下所述实例化 Autonomous Database: Provision Autonomous Database 。
-
从 Oracle Cloud 主菜单中,选择数据仓库选项,选择 Oracle Database 和 Autonomous Data Warehouse ;选择区间 analytics ,然后按照教程创建数据库实例。
-
将实例命名为已处理日志,选择日志作为数据库名称,您无需更改应用程序中的任何代码。
-
输入 ADMIN 密码并下载 Wallet zip 文件。

-
创建数据库后,您可以设置 ADMIN 用户密码并下载 Wallet zip 文件。



-
保存 Wallet zip 文件 (
Wallet_logs.zip) 并注释您的 ADMIN 密码,您需要设置应用程序代码。 -
转至存储、存储桶。转到 analytics 区间,您将看到 Wallet 存储桶。单击它。
-
要上载 Wallet zip 文件,只需单击上载并附加 Wallet_logs.zip 文件。

注:在此处查看用于访问 Autonomous Database 的 IAM 策略:IAM Policy for Autonomous Database
任务 3:上载 CSV 示例文件
为了演示 Apache Spark 的强大功能,应用程序将读取包含 1,000,000 行的 CSV 文件。此数据将仅使用一个命令行插入 Autonomous Data Warehouse 数据库,并在 Kafka 流处理 (Oracle Cloud Streaming) 上发布。所有这些资源都可扩展且非常适合高数据量。
-
下载这 2 个链接并上载到数据存储桶:
-
注:
- organizations.csv 只有 100 行,仅用于测试本地计算机上的应用程序。
- organizations1M.csv 包含 1,000,000 行,用于在数据流实例上运行。
-
从 Oracle Cloud 主菜单中,转至存储和存储桶。单击数据存储桶并从上一步上载 2 个文件。


-
将辅助表上载到 ADW 数据库
-
下载此文件以上载到 ADW 数据库: GDP PER CAPTA COUNTRY.csv
-
从 Oracle Cloud 主菜单中,选择 Oracle Database 和 Autonomous Data Warehouse 。
-
单击已处理日志实例以查看详细信息。
-
单击数据库操作可转至数据库实用程序。

-
为 ADMIN 用户输入身份证明。

-
单击 SQL 选项可转至查询实用程序。

-
单击数据加载。

-
将 GDP PER CAPTA COUNTRY.csv 文件放置到控制台面板中,然后继续将数据导入表中。

-
您可以看到名为 GDPPERCAPTA 的新表已成功导入。

任务 4:为 ADW ADMIN 密码创建密钥储存库
出于安全原因,ADW ADMIN 密码将保存在 Vault 上。Oracle Cloud Vault 可以安全地托管此密码,并且可以通过 OCI 验证在您的应用中访问。
-
按以下文档所述在 Vault 中创建密钥:将数据库管理员密码添加到 Vault
-
在应用程序中创建名为 PASSWORD_SECRET_OCID 的变量并输入 OCID。



注:请在此处查看 OCI Vault 的 IAM 策略: OCI Vault IAM 策略。
任务 5:创建 Kafka 流处理 (Oracle Cloud Streaming)
Oracle Cloud Streaming 是一种类似于托管流处理服务的 Kafka。您可以使用 Kafka API 和常用 SDK 开发应用。在本教程中,您将创建流处理实例并配置为在两个应用程序中执行以发布和使用大量数据。
-
从 Oracle Cloud 主菜单中,转至 Analytics & AI 、 Streams 。
-
将区间更改为 analytics 。将在此区间中创建此演示中的每个资源。这样可以更安全、更轻松地控制 IAM。
-
单击创建流。

-
将名称输入为 kafka_like (例如),您可以使用默认值维护所有其他参数。

-
单击创建以初始化实例。
-
等待 Active(活动)状态。现在,您可以使用该实例。
注:在流创建过程中,您可以选择自动创建默认流池选项以自动创建默认池。
-
单击 DefaultPool 链接。

-
查看连接设置。


-
在下一步中根据需要添加此信息注释。
注:请在此处查看 OCI 流处理的 IAM 策略: OCI 流处理的 IAM 策略。
任务 6:生成 AUTH TOKEN 以访问 Kafka
您可以使用与 OCI IAM 上的用户关联的验证令牌来访问 Oracle Cloud 中的 OCI 流处理 (Kafka API) 和其他资源。在 Kafka 连接设置中,SASL 连接字符串有一个名为 password 的参数和一个 AUTH_TOKEN 值,如上一个任务中所述。要启用对 OCI 流处理的访问,您需要转到 OCI 控制台上的用户并创建 AUTH TOKEN。
-
从 Oracle Cloud 主菜单中,转至身份与安全性、用户。
注:请记住,创建 AUTH TOKEN 所需的用户是配置有 OCI CLI 的用户,以及直到现在为止创建的资源的所有 IAM 策略配置。资源为:
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud 流处理
- Oracle Object Storage
- Oracle Data Flow
-
单击您的用户名以查看详细信息。

-
单击控制台左侧的 Auth Tokens 选项,然后单击 Generate Token(生成令牌)。
注:标记将仅在此步骤中生成,在完成该步骤后将不可见。因此,请复制值并保存该值。如果丢失令牌值,则必须再次生成验证令牌。


任务 7:设置演示应用程序
本教程有一个演示应用程序,我们将为其设置所需的信息。
- DataflowSparkStreamDemo:此应用程序将连接到 Kafka 流处理,并使用每个数据并与名为 GDPPERCAPTA 的 ADW 表合并。流数据将与 GDPPERCAPTA 合并,并另存为 CSV 文件,但可以公开给另一个 Kafka 主题。
-
使用以下链接下载应用程序:
-
在 Oracle Cloud 控制台中找到以下详细信息:
-
租户名称空间


-
密码密钥
-
流处理连接设置
-
验证标记
-
-
打开下载的 zip 文件(
Java-CSV-DB.zip和JavaConsumeKafka.zip)。转到 /src/main/java/example 文件夹并查找 Example.java 代码。
这些变量需要随租户资源值一起更改。
变量名称 资源名称 信息标题 bootstrapServers 流处理连接设置 引导服务器 streamPoolId 流处理连接设置 ocid1.streampool.oc1.iad..... SASL 连接字符串中的值 kafkaUsername 流处理连接设置 SASL 连接字符串中 "" 内的用户名的值 kafkaPassword 验证标记 该值仅显示在创建步骤中 OBJECT_STORAGE_NAMESPACE 租户名称空间 租户 名称空间 租户名称空间 租户 PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
注:为此演示创建的所有资源都位于 US-ASHBURN-1 区域中。检查要使用的区域。如果更改区域,则需要更改 2 个代码文件中的 2 个点:
Example.java :更改 bootstrapServers 变量,将 "us-ashburn-1" 替换为新区域
OboTokenClientConfigurator.java :使用新区域更改 CANONICAL_REGION_NAME 变量
任务 8:了解 Java 代码
此教程是用 Java 创建的,此代码也可以移植到 Python。为了证明效率和可扩展性,开发了应用程序以在集成过程的常见用例中显示一些可能性。因此,应用程序的代码显示以下示例:
- 连接到 Kafka 流并读取数据
- 使用 ADW 表处理联接以构建有用信息
- 输出包含每个有用信息的 CSV 文件来自 Kafka
此演示可以在本地计算机中执行,并部署到数据流实例中,以作为作业执行运行。
注:对于数据流作业和本地计算机,请使用 OCI CLI 配置访问 OCI 资源。在“数据流”端,所有内容都已预先配置,因此无需更改参数。在本地计算机端,您应该已安装 OCI CLI 并配置租户、用户和私有密钥来访问您的 OCI 资源。
让我们在以下部分中显示 Example.java 代码:
-
Apache Spark 初始化:此部分代码表示 Spark 初始化。许多用于执行执行进程的参数都是自动配置的,因此很容易使用 Spark 引擎。如果在数据流或本地计算机中运行,则初始化会有所不同。如果您位于数据流中,则无需加载 ADW Wallet zip 文件,加载、解压缩和读取 Wallet 文件的任务在数据流环境中是自动的,但在本地计算机中,需要使用一些命令完成。

-
阅读 ADW Vault 密钥:此部分代码访问您的 Vault,以获取 Autonomous Data Warehouse 实例的密钥。

-
查询 ADW 表:本部分说明如何对表执行查询。

-
Kafka 操作:这是为使用 Kafka API 连接到 OCI 流处理的准备。
注意:Oracle Cloud 流处理与大多数 Kafka API 兼容。

有一个进程可以将来自 Kafka 主题的 JSON 数据解析为结构正确的数据集(组织 ID、名称、国家/地区)。
-
合并 Kafka 数据集和 Autonomous Data Warehouse 数据集中的数据:此部分说明如何执行包含 2 个数据集的查询。

-
输出到 CSV 文件:下面是合并的数据如何将输出生成到 CSV 文件中。

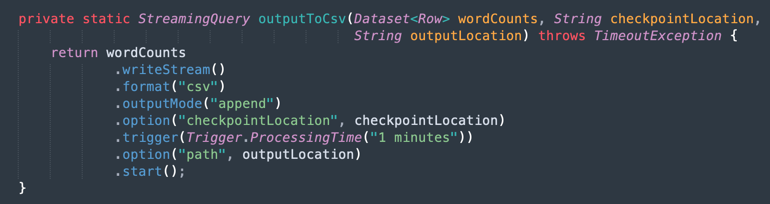
任务 9:使用 Maven 为您的应用打包
在 Spark 中执行作业之前,必须使用 Maven 打包应用程序。
-
转到 /DataflowSparkStreamDemo 文件夹并执行以下命令:
mvn package -
您可以看到 Maven 正在开始打包。

-
如果一切正确,您可以看到成功消息。

任务 10:验证执行
-
通过运行以下命令在本地 Spark 计算机中测试应用程序:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
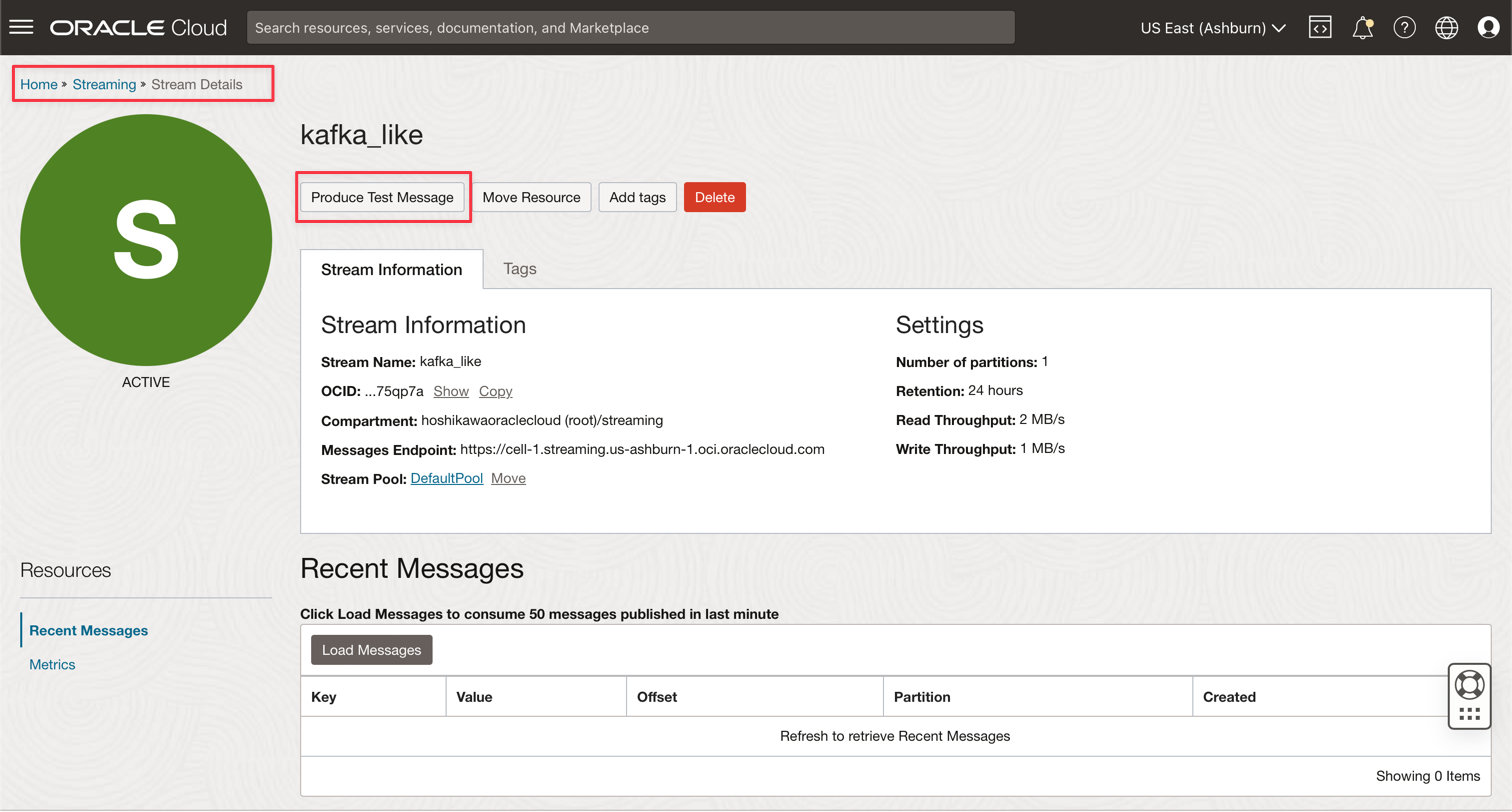
转到 Oracle Cloud Streaming Kafka 实例,然后单击生成测试消息以生成一些数据来测试实时应用程序。
-
您可以将此 JSON 消息放入 Kafka 主题。
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}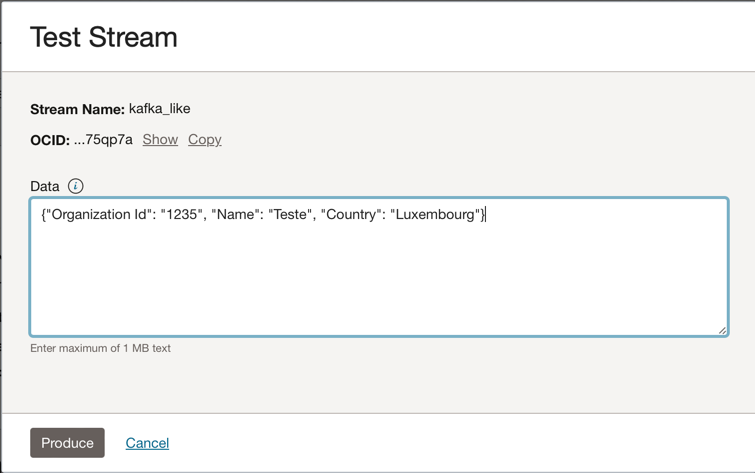
-
每次单击生成时,都会向应用程序发送一条消息。您可以查看应用程序的输出日志,如下所示:
-
这是从 kafka 主题读取的数据。

-
这是 ADW 表中的合并数据。

-
任务 11:创建和执行数据流作业
现在,在本地 Spark 计算机成功运行两个应用后,您可以将其部署到租户中的 Oracle Cloud 数据流中。
注:要配置对 Oracle 对象存储和 Oracle 流处理 (Kafka) 等资源的访问,请参阅 Spark 流处理文档:启用对数据流的访问
-
将程序包上载到对象存储中。
- 在创建数据流应用程序之前,您需要将 Java Artifact 应用程序(您的 ***-SNAPSHOT.jar 文件)上载到名为 apps 的对象存储存储桶中。
-
创建数据流应用程序。
-
选择 Oracle Cloud 主菜单,然后转至分析和 AI 和数据流。在创建数据流应用程序之前,请确保选择分析区间。
-
单击创建应用程序。

-
填充此类参数。

-
单击创建。
-
创建后,单击缩放演示链接可查看详细信息。要运行作业,请单击 RUN 。
注:单击显示高级选项可为 Spark Stream 执行类型启用 OCI 安全性。

-
-
激活以下选项。

-
单击运行以执行作业。
-
确认参数,然后再次单击运行。

-
可以查看作业的状态。

-
等待状态转至成功,您可以看到结果。

-
相关链接
确认
- 作者 - Cristiano Hoshikawa(Oracle LAD A-Team 解决方案工程师)
更多学习资源
探索 docs.oracle.com/learn 上的其他实验室,或者访问 Oracle Learning YouTube 频道上的更多免费学习内容。此外,请访问 education.oracle.com/learning-explorer 成为 Oracle Learning Explorer。
有关产品文档,请访问 Oracle 帮助中心。
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.