注意:
- 本教程需要访问 Oracle Cloud。要注册免费账户,请参阅开始使用 Oracle Cloud Infrastructure 免费套餐。
- 它使用 Oracle Cloud Infrastructure 身份证明、租户和区间的示例值。完成实验室时,请将这些值替换为特定于云环境的值。
使用 OCI Generative AI 以自然语言分析 PDF 文档
简介
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) 是一个先进的生成式人工智能解决方案,可帮助企业和开发人员使用先进的语言模型创建智能应用。此解决方案基于大型语言模型 (LLM) 等强大技术,可实现复杂任务的自动化,使流程更快、更高效,并可通过自然语言交互进行访问。
OCI Generative AI 的影响最大的应用之一是 PDF 文档分析。公司经常处理大量文件,如合同、财务报告、技术手册和研究论文。手动搜索这些文件中的信息可能非常耗时且容易出错。
通过使用生成式人工智能,可以即时、准确地提取信息,让用户只需用自然语言提出问题即可查询复杂的文档。这意味着,用户不必阅读整个页面来查找合同中的特定条款或报表中的相关数据点,而只需询问模型,该模型可以根据分析的内容快速返回答案。
除了信息检索之外,OCI Generative AI 还可用于汇总冗长的文档、比较内容、对信息进行分类,甚至生成战略洞察。这些功能使该技术对法律、财务、医疗保健和工程等各个领域至关重要,有助于优化决策和提高生产力。
通过将此技术与 Oracle AI 服务、OCI 数据科学和用于文档处理的 API 等工具相集成,企业可以构建智能解决方案,全面转变与数据的交互方式,从而更快、更有效地检索信息。
Prerequisites
- 安装 Python
version 3.10或更高版本和 Oracle Cloud Infrastructure 命令行界面 (OCI CLI)。
任务 1:安装 Python 软件包
Python 代码需要某些库才能使用 OCI Generative AI。运行以下命令以安装所需的 Python 软件包。
pip install -r requirements.txt
任务 2:了解 Python 代码
这是用于查询 Oracle SOA Suite 和 Oracle Integration 功能的 OCI Generative AI 演示。这两种工具目前都用于混合集成策略,这意味着它们在云和本地环境中运行。
由于这些工具共享功能和流程,因此该代码有助于了解如何在每个工具中实施相同的集成方法。此外,它允许用户探索共同的特征和差异。
从这里下载 Python 代码:
您可以在此处找到 PDF 文档:
创建一个名为 Manuals 的文件夹,并将这些 PDF 移动到此处。
-
导入库:
导入必要的库,以便在向量数据库中处理 PDF、OCI Generative AI、文本向量化和存储(Facebook AI Similarity Search (FAISS) 和 ChromaDB)。
-
UnstructuredPDFLoader用于从 PDF 中提取文本。 -
ChatOCIGenAI支持使用 OCI Generative AI 模型回答问题。 -
OCIGenAIEmbeddings创建用于语义搜索的文本嵌入(向量表示)。
-
-
加载和处理 PDF:
列出要处理的 PDF 文件。
-
UnstructuredPDFLoader读取每个文档并将其拆分为多个页面,以便于索引和搜索。 -
将存储文档 ID 以供将来参考。

-
-
配置 OCI Generative AI Model:
将 OCI 上托管的
Llama-3.1-405b模型配置为基于加载的文档生成响应。定义参数,例如
temperature(随机性控制)、top_p(多样性控制)和max_tokens(令牌限制)。
注:可用的 LLaMA 版本可能会随时间而变化。请检查租户中的当前版本,并根据需要更新代码。
-
创建嵌入和向量索引:
使用 Oracle 嵌入模型将文本转换为数字向量,从而简化文档中的语义搜索。

-
FAISS 存储 PDF 文档的嵌入以进行快速查询。
-
retriever允许根据用户查询的语义相似性检索最相关的摘录。

-
-
在第一次处理执行时,向量数据将保存在 FAISS 数据库中。

-
定义提示:
为生成模型创建智能提示,引导生成模型仅考虑每个查询的相关文档。
这样可以提高响应的准确性并避免不必要的信息。

-
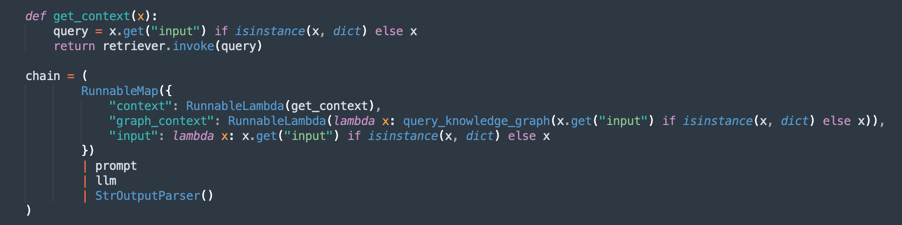
创建处理链(RAG - 检索增强生成):
实施 RAG 流,其中:
retriever搜索最相关的文档摘录。prompt组织查询以获得更好的上下文。llm根据检索到的文档生成响应。StrOutputParser设置最终输出的格式。

-
问题和答案循环:
维护一个循环,用户可以在该循环中询问有关加载的文档的问题。
-
AI 使用从 PDF 中提取的知识库进行响应。
-
如果输入
quit,它将退出程序。

-
现在,您可以选择 3 个选项来处理文档。您可以思考:
- 您需要处理多少功率?
- 您需要处理多少时间?
- 您的回应的质量如何?
因此,您可以选择以下选项:
固定大小分块:这是处理文档的更快替代方法。这足以得到你想要的东西。
Semantic Chunking(语义分块):此过程将比固定大小的分块慢,但它将提供更高质量的分块。
Semantic Chunking with GraphRAG:它将提供更精确的方法,因为它将组织分块文本和知识图。
固定大小分块
请从此处下载代码:oci_genai_llm_context_fast.py 。
-
什么是固定大小分块?
Fixed Size Chunking(固定大小分块)是一种简单高效的文本分块策略,其中文档根据预定义的大小限制分为块,通常以令牌、字符或行来衡量。
此方法不分析文本的含义或结构。它只是按固定间隔对内容进行切片,而不管切片发生在句子、段落或想法的中间。
-
固定大小的分块如何工作:
-
示例规则:每 1000 个令牌(或每 3000 个字符)拆分一次文档。
-
可选重叠:为了降低拆分相关 context 的风险,一些实现会在连续块之间添加重叠(例如,200 个令牌重叠),以确保重要的 context 不会在边界上丢失。
-
-
固定大小分块的优点:
-
快速处理:无需语义分析、LLM 推断或内容理解。数数和切。
-
低资源消耗:尽可能减少 CPU/GPU 和内存使用量,使其适用于大型数据集。
-
易于实施:适用于简单脚本或标准文本处理库。
-
-
固定大小分块的限制:
-
语义意识差:块可能会切断句子、段落或逻辑段落,从而导致思想不完整或支离破碎。
-
检索精度降低:在语义搜索或检索增强生成 (Retrieval-Augmented Generation,REG) 等应用程序中,块边界较差可能会影响检索到的答案的相关性和质量。
-
-
何时使用固定大小分块:
-
当处理速度和可扩展性是首要任务时。
-
对于语义精度不重要的大型文档摄取管道。
-
在后来的改进或语义分析将在下游发生的情况中,这是第一步。
-
这是一个非常简单的方法来分割文本。

-
这是固定分块的主要过程。

注:下载此代码以更快处理固定分块:
oci_genai_llm_context_fast.py -
语义分块
请从此处下载代码:oci_genai_llm_context.py 。
-
什么是语义分块?
语义分块是一种文本预处理技术,其中大型文档(例如 PDF、演示文稿或文章)被拆分为称为块的小部分,每个块表示语义上连贯的文本块。
与传统的固定大小的分块(例如,每 1000 个令牌或每个 X 字符进行拆分)不同,语义分块使用人工智能(通常是大型语言模型 - LLM)来检测自然内容边界,尊重主题,章节和 context。
语义分块 (Semantic Chunking) 不是任意剪切文本,而是试图保留每个部分的全部含义,创建独立的上下文感知片段。
-
为什么语义分块会使处理速度变慢?
基于固定大小的传统分块过程非常快。系统只计算令牌或字符,并相应地进行分段。使用语义分块时,需要额外执行几个语义分析步骤:
- 在拆分之前读取和解释全文(或大块): LLM 需要了解内容以识别最佳块边界。
- 运行 LLM 提示或主题分类模型:系统通常会向 LLM 查询诸如这是创意的结尾吗?或此段落是否开始新部分?之类的问题。
- 更高的内存和 CPU/GPU 使用率:由于模型在做出分块决策之前处理较大的文本块,因此资源消耗显著增加。
- 顺序和增量决策:语义分块通常按步骤工作(例如,分析 10,000 个令牌块,然后细化该块内的块边界),从而增加总处理时间。
注:
- 根据您的计算机处理能力,您将等待很长时间才能使用语义分块完成第一次执行。
- 您可以使用此算法使用 OCI Generative AI 生成定制分块。
-
语义分块如何工作:
-
smart_split_text():将全文分成 10kb 的小部分(您可以进行配置以采用其他策略)。该机制理解最后一段。如果段落的一部分位于下一个文本片段中,则此部分将在处理中忽略,并将附加到下一个处理文本组中。 -
semantic_chunk():此方法将使用 OCI LLM 机制来分隔段落。它包括识别标题的智能,表的组件,执行智能块的段落。此处的策略是使用 Semantic Chunk 技术。与共同处理相比,完成任务需要更多时间。因此,第一次处理将花费很长时间,但下一个将加载所有 FAISS 预保存的数据。 -
split_llm_output_into_chapters():此方法将最终化块,分隔各章。
注:下载此代码以处理 semantic chunking :
oci_genai_llm_context.py -
使用 GraphRAG 进行语义分块
请从此处下载代码:oci_genai_llm_graphrag.py 。
GraphRAG(Graph-Augmented Retrieval-Augmented Generation,图形增强检索增强生成)是将传统基于向量的检索与结构化知识图相结合的高级 AI 体系结构。在标准 RAG 管道中,语言模型使用向量数据库(如 FAISS)的语义相似性检索相关文档块。但是,基于向量的检索以非结构化方式运行,完全依赖于嵌入和距离度量,这有时会错过更深层次的上下文或关系含义。
GraphRAG 引入了知识图层,其中实体、概念、组件及其关系显式表示为节点和边缘,从而增强了此过程。此基于图形的 context 使语言模型能够推理仅向量相似性无法捕获的关系、层次和依赖项。
-
为什么要将语义分块与 GraphRAG 结合使用?
语义分块是根据内容结构(如章节、标题、章节或逻辑划分)智能地将大型文档拆分为有意义的单元或“块”的过程。语义分块不是纯粹通过字符限制或天真的段落分割来破坏文档,而是产生更高质量的、context 感知的块,这些块与人类的理解更好地一致。
-
带有 GraphRAG 的语义分块的优点:
-
增强的知识表示:
- 语义块保留内容中的逻辑边界。
- 从这些块中提取的知识图可维护实体、系统、API、流程或服务之间的准确关系。
-
多模式上下文检索(语言模型可检索两者):
- 来自向量数据库的非结构化 context(语义相似性)。
- 知识图(实体关系三元组)中的结构化 context。
- 这种混合方法可以提供更完整、更准确的答案。
-
改进的推理能力:
- 基于图形的检索支持关系推理。
- LLM 可以回答如下问题:
- Order API 依赖于哪些服务?
- SOA Suite 的哪些组件?
- 这些关系查询通常无法通过仅嵌入的方法进行。
-
更高的可解释性和可追溯性:
- 图形关系是人类可读和透明的。
- 用户可以检查如何从文本和结构知识中得出答案。
-
减少幻觉:此图可作为 LLM 的约束,将响应锚定到从源文档中提取的已验证关系和事实连接。
-
跨复杂域的可扩展性:
- 在技术领域(例如,API、微服务、法律合同、医疗保健标准)中,组件之间的关系与组件本身同样重要。
- GraphRAG 与语义分块在这些上下文中有效缩放,同时保留文本深度和关系结构。
注:
- 从此处下载代码以使用 graphRAG 处理 semantic chunking :
oci_genai_llm_graphrag.py。 - 您将需要:
- 已安装并处于活动状态的 docker,可使用 Neo4J 开源图形操作系统数据库进行测试。
- 安装 neo4j Python 库。
此代码中有 2 个方法:
-
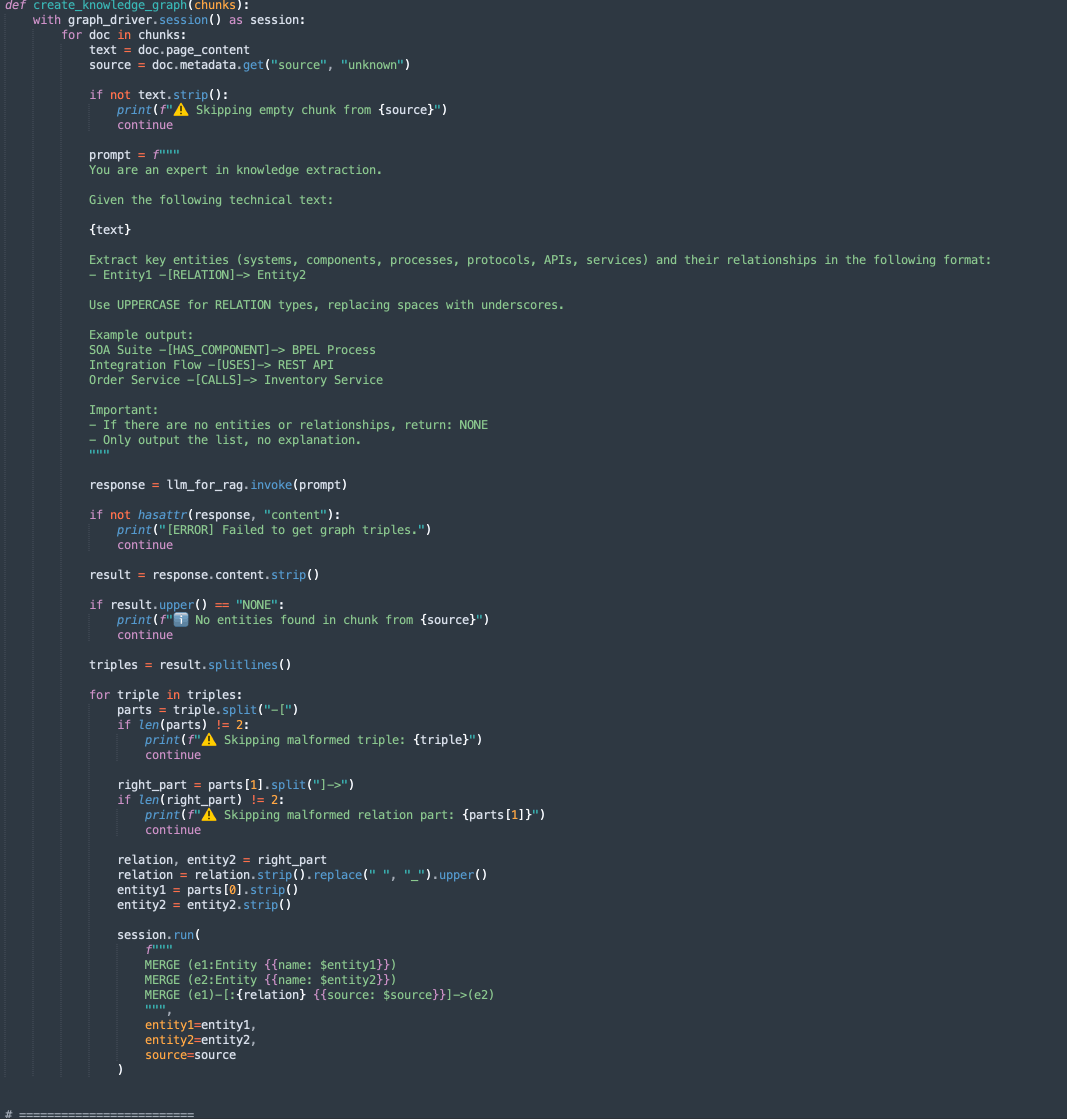
create_knowledge_graph:-
此方法自动从文本块中提取实体和关系,并将其存储在 Neo4j 知识图中。
-
对于每个文档块,它会将内容发送到 LLM(大型语言模型),并提示您提取实体(如系统、组件、服务、API)及其关系。
-
它解析每一行,提取 Entity1、RELATION 和 Entity2。
-
使用密码查询将此信息存储为 Neo4j 图形数据库中的节点和边缘:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
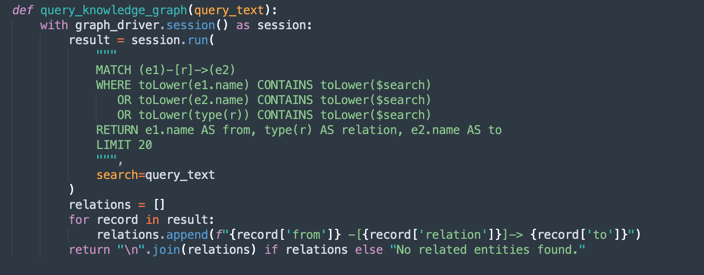
query_knowledge_graph:-
此方法查询 Neo4j 知识图来检索与特定关键字或概念相关的关系。
-
执行搜索以下项的密码查询:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
返回最多 20 个匹配三元组,格式为:
Entity1 -[RELATION]-> Entity2
-
注:
Neo4j 用法:
此实施使用 Neo4j 作为嵌入式知识图数据库,用于演示和原型制作。虽然 Neo4j 是一个功能强大且灵活的图形数据库,适用于开发、测试以及中小型工作负载,但可能无法满足企业级、关键任务或高度安全工作负载的要求,尤其是在需要高可用性、可扩展性和高级安全合规性的环境中。
对于生产环境和企业方案,我们建议您利用 Oracle Database 和 Graph 功能,这些功能提供:
企业级可靠性和安全性。
面向关键任务工作负载的可扩展性。
与关系数据集成的原生图形模型(属性图形和 RDF)。
高级分析、安全性、高可用性和灾难恢复功能。
完整的 Oracle Cloud Infrastructure (OCI) 集成。
通过将 Oracle Database 用于图形工作负载,企业可以在一个安全、可扩展的企业平台中统一结构化、半结构化和图形数据。
任务 3:为 Oracle Integration 和 Oracle SOA Suite 内容运行查询
运行以下命令。
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
注意:
--device和--gpu_name参数可用于在 Python 中加速处理,如果您的计算机具有 GPU,则使用 GPU。考虑一下,此代码也可以与本地模型一起使用。
提供的上下文区分了 Oracle SOA Suite 和 Oracle Integration,您可以根据以下几点测试代码:
- 只能对 Oracle SOA Suite 进行查询:因此,只应考虑 Oracle SOA Suite 文档。
- 只能对 Oracle Integration 进行查询:因此,只应考虑 Oracle Integration 文档。
- 此查询需要在 Oracle SOA Suite 和 Oracle Integration 之间进行比较:因此,应考虑所有文档。
我们可以定义以下上下文,这极大地有助于正确解释文档。
下图显示了 Oracle SOA Suite 与 Oracle Integration 之间的比较示例。

后续步骤
此代码演示了 OCI Generative AI 的智能 PDF 分析应用。它使用户能够使用语义搜索和生成式 AI 模型高效地查询大量文档,从而生成准确的自然语言响应。
这种方法可以应用于各个领域,如法律,合规性,技术支持和学术研究,使信息检索更快,更智能。
相关链接
确认
- 作者 - Cristiano Hoshikawa(Oracle LAD A-Team 解决方案工程师)
更多学习资源
通过 docs.oracle.com/learn 浏览其他实验室,或者通过 Oracle Learning YouTube 频道访问更多免费学习内容。此外,请访问 education.oracle.com/learning-explorer 以成为 Oracle Learning Explorer。
有关产品文档,请访问 Oracle 帮助中心。
Analyze PDF Documents in Natural Language with OCI Generative AI
G29544-05
Copyright ©2025, Oracle and/or its affiliates.