注意:
- 此教學課程需要存取 Oracle Cloud。若要註冊免費帳戶,請參閱開始使用 Oracle Cloud Infrastructure Free Tier 。
- 它會使用 Oracle Cloud Infrastructure 證明資料、租用戶及區間的範例值。完成實驗室時,請將這些值替代為您雲端環境特定的值。
搭配 Apache Spark Streaming 使用 OCI 資料流程,以可擴展且接近即時的應用程式處理 Kafka 主題
簡介
Oracle Cloud Infrastructure (OCI) 資料流程是名為 Apache Spark 之開源專案的託管服務。基本上,使用 Spark 時,您可以將它用於大量處理檔案、串流以及資料庫作業。您可以建置具有非常高可擴展處理的應用程式。Spark 可以調整及使用叢集化機器,以最少的組態對待工作。
您可以使用 Spark 作為託管服務 (資料流程),新增許多可擴展的服務來乘上雲端處理的強大功能。資料流程具有處理 Spark Streaming 的能力。
串流處理應用系統需要長期執行,且通常延續超過 24 小時,而且可能只要幾週或甚至幾個月即可。如果發生未預期的失敗狀況,串流應用程式必須從失敗點重新啟動,而不會產生不正確的運算結果。資料流程倚賴 Spark 結構化串流檢查點,以記錄可儲存在物件儲存的儲存桶中已處理的偏移量。
注意:如果您需要以批次策略的方式處理資料,可以閱讀此文章:使用 Oracle Cloud Infrastructure Data Flow 處理 Autonomous Database 和 Kafka 中的大型檔案

在本教學課程中,您可以看到最常用於處理資料磁碟區串流、查詢資料庫,以及合併 / 結合資料以形成記憶體中的另一個表格,或是將資料傳送至任何接近即時的目的地。您可以將此大量資料寫入資料庫和 Kafka 佇列中,此佇列具備非常低的成本和高效率的效能。
目標
- 瞭解如何使用資料流程在可擴展且近乎即時的應用系統中處理大量資料。
必要條件
-
作業中的 Oracle Cloud 租用戶:您可以建立一個每月 $ 300.00 美元的免費 Oracle Cloud 帳戶,試用本教學課程。請參閱建立免費 Oracle Cloud 帳戶
-
在您的本機機器上安裝 OCI CLI (Oracle Cloud 命令行介面):這是安裝 OCI CLI 的連結。
-
安裝在您本機機器中的 Apache Spark 應用程式。檢閱在本機開發 Oracle Cloud Infrastructure Data Flow 應用系統、部署至雲端,以瞭解如何在本機和資料流程中進行開發。
注意:這是安裝的正式頁面:Apache Spark 。為每種類型的作業系統 (Linux/Mac OS/Windows) 安裝 Apache Spark 的替代程序。
-
已安裝 Spark submit CLI 。這是安裝 Spark submit CLI 的連結。
-
您的本機機器中已安裝 Maven 。
-
OCI 概念知識:
- 區間
- IAM 原則
- 租用戶
- 您資源的 OCID
作業 1:建立物件儲存體結構
物件儲存將作為預設檔案儲存區域使用。您可以使用其他類型的檔案儲存區域,但物件儲存體是一種既簡單又低成本的方式,會以效能操控檔案。本教學課程中,兩應用系統都將從物件儲存體載入一個大型 CSV 檔案,其中顯示 Apache Spark 如何快速且智慧地處理大量資料。
-
建立區間:區間可用於組織及隔離您的雲端資源。您可以依據 IAM 原則將資源隔離。
-
您可以使用此連結瞭解及設定區間的原則:管理區間
-
建立一個區間以代管此教學課程中 2 個應用程式的所有資源。建立一個名為 analytics 的區間。
-
前往 Oracle Cloud 主功能表,然後搜尋:身分識別與安全、區間。在「區間」區段中,按一下建立區間並輸入名稱。

注意:您必須授予使用者群組的存取權並加入您的使用者。
-
按一下建立區間以包含您的區間。
-
-
在物件儲存中建立儲存桶:儲存桶是儲存物件的邏輯容器,因此用於此示範的所有檔案都將儲存在此儲存桶中。
-
前往 Oracle Cloud 主功能表,然後搜尋儲存和儲存桶。在「儲存桶」區段中,選取先前建立的區間 (分析)。

-
按一下建立儲存桶 (Create Bucket) 。建立 4 個儲存桶:應用程式、資料、資料流程日誌、公事包

-
輸入這 4 個儲存桶的儲存桶名稱資訊,然後使用預設選項維護其他參數。
-
針對每個儲存桶,按一下建立 (Create) 。您可以查看建立的儲存桶。

-
注意: 複查儲存桶的 IAM 原則。如果您要在示範應用程式中使用這些儲存桶,就必須設定原則。您可以在這裡檢視概念與設定物件儲存體簡介和 IAM 原則。
作業 2:建立 Autonomous Database
Oracle Cloud Autonomous Database 是 Oracle Database 的託管服務。本教學課程基於安全理由,應用程式將透過公事包連線至資料庫。
-
依此處所述建立 Autonomous Database:佈建 Autonomous Database 。
-
從 Oracle Cloud 主功能表中選取資料倉儲選項,選取 Oracle Database 和 Autonomous Data Warehouse ;選取區間分析,然後依照教學課程建立資料庫執行處理。
-
將執行處理命名為已處理的日誌,選擇日誌作為資料庫名稱,而且您不需要變更應用程式中的任何程式碼。
-
輸入 ADMIN 密碼並下載公事包壓縮檔。

-
建立資料庫之後,您可以設定 ADMIN 使用者密碼,並下載 Wallet zip 檔案。



-
儲存您的 Wallet zip 檔案 (
Wallet_logs.zip) 並加註您的 ADMIN 密碼,您需要設定應用程式代碼。 -
前往儲存、儲存桶。變更為分析區間,您會看到公事包儲存桶。按一下即可。
-
若要上傳您的 Wallet zip 檔案,只要按一下上傳,然後附加 Wallet_logs.zip 檔案。

注意:請複查此處存取 Autonomous Database 的 IAM 原則:Autonomous Database 的 IAM 原則
作業 3:上傳 CSV 範例檔案
為了示範 Apache Spark 的強大功能,應用程式會讀取 1,000,000 行的 CSV 檔案。這個資料只會插入 Autonomous Data Warehouse 資料庫中,而且會在 Kafka 串流處理 (Oracle Cloud Streaming) 上發布。所有這些資源都可擴展,非常適合大量資料使用。
-
下載這 2 個連結並上傳至資料儲存桶:
-
注意:
- organizations.csv 只有 100 行可以測試本機機器上的應用程式。
- organizations1M.csv 包含 1,000,000 行,將用於在「資料流程」執行處理上執行。
-
從 Oracle Cloud 主功能表,前往儲存和儲存桶。按一下資料儲存桶,然後從上一個步驟上傳 2 個檔案。


-
將輔助表格上傳至 ADW 資料庫
-
下載此檔案以上傳至 ADW 資料庫: GDP PER CAPTA COUNTRY.csv
-
從 Oracle Cloud 主功能表中,選取 Oracle Database 和 Autonomous Data Warehouse 。
-
按一下已處理的日誌執行處理以檢視詳細資訊。
-
按一下資料庫動作 (Database Actions) 移至資料庫公用程式。

-
輸入 ADMIN 使用者的證明資料。

-
按一下 SQL 選項即可移至「查詢公用程式」。

-
按一下資料載入。

-
將 GDP PER CAPTA COUNTRY.csv 檔案置於主控台面板,然後繼續將資料匯入表格。

-
您可以順利匯入新的名為 GDPPERCAPTA 的表格。

作業 4:為您的 ADW ADMIN 密碼建立 Secret Vault
基於安全理由,ADW ADMIN 密碼將會儲存在 Vault 上。Oracle Cloud Vault 可以透過安全性代管此密碼,而且可以使用 OCI 認證在您的應用程式上存取此密碼。
-
如下列文件所述,在保存庫中建立您的加密密碼:將資料庫管理員密碼新增至保存庫
-
在您的應用程式中建立一個名為 PASSWORD_SECRET_OCID 的變數,然後輸入 OCID。



注意:請從以下網址複查 OCI Vault 的 IAM 原則: OCI Vault IAM 原則。
工作 5:建立 Kafka 串流處理 (Oracle Cloud Streaming)
Oracle Cloud Streaming 是一種類似託管串流服務的 Kafka。您可以使用 Kafka API 和通用 SDK 來開發應用系統。在本教學課程中,您將建立 Streaming 的執行處理,並將其設定為在兩個應用程式中執行,以發布及使用大量資料。
-
從 Oracle Cloud 主功能表,前往分析與 AI 、串流。
-
將區間變更為分析。此示範中的每個資源都將在此區間上建立。這是更安全且更容易控制的 IAM。
-
按一下建立串流。

-
將名稱輸入為 kafka_like (例如),您也可以使用預設值維護所有其他參數。

-
按一下建立以起始執行處理。
-
等待作用中狀態。現在,您可以使用此執行處理。
注意:在串流建立處理作業中,您可以選取自動建立預設串流集區選項,以自動建立預設集區。
-
按一下 DefaultPool 連結。

-
檢視連線設定值。


-
將此資訊加註,如下一步將需要。
注意:請在此處複查 OCI Streaming 的 IAM 原則: OCI Streaming 的 IAM 原則。
作業 6:產生 AUTH TOKEN 以存取 Kafka
您可以使用與 OCI IAM 上使用者關聯的認證權杖,存取 Oracle Cloud 中的 OCI 串流處理 (Kafka API) 和其他資源。在 Kafka 連線設定值中,SASL 連線字串有一個名為 password 的參數和 AUTH_TOKEN 的值,如上一個作業所述。若要啟用 OCI 串流的存取,您必須前往 OCI 主控台的使用者並建立 AUTH TOKEN。
-
從 Oracle Cloud 主功能表,前往身分識別與安全性、使用者。
注意:請記住,建立 AUTH TOKEN 的使用者是使用您的 OCI CLI 設定的使用者,而且到目前為止所建立資源的所有 IAM 原則組態設定。資源為:
- Oracle Cloud Autonomous Data Warehouse
- Oracle Cloud 串流
- Oracle Object Storage
- Oracle 資料流程
-
按一下您的使用者名稱即可檢視詳細資訊。

-
按一下主控台左側的 Auth 權杖選項,然後按一下產生權杖。
注意:此步驟只會產生記號,在您完成此步驟之後將不會顯示。因此,請複製值並加以儲存。如果遺失權杖值,就必須重新產生認證權杖。


作業 7:設定示範應用程式
本教學課程有一個示範應用程式,我們將為其設定所需的資訊。
- DataflowSparkStreamDemo:這個應用程式會連線到 Kafka 串流,並使用每個資料並與名為 GDPPERCAPTA 的 ADW 表格合併。串流資料將會與 GDPPERCAPTA 合併,並儲存為 CSV 檔案,但可公開給其他 Kafka 主題。
-
使用下列連結下載應用程式:
-
在 Oracle Cloud 主控台中找到下列詳細資訊:
-
租用戶命名空間


-
密碼加密密碼
-
串流處理連線設定值
-
認證權杖
-
-
開啟下載的壓縮檔 (
Java-CSV-DB.zip和JavaConsumeKafka.zip)。移至 /src/main/java/example 資料夾,找出 Example.java 代碼。
以下是需要使用您的租用戶資源值變更的變數。
變數名稱 資源名稱 資訊標題 bootstrapServers 串流處理連線設定值 啟動安裝伺服器 streamPoolId 串流處理連線設定值 ocid1.streampool.oc1.iad..... SASL 連線字串中的值 kafkaUsername 串流處理連線設定值 SASL 連線字串中 " " 的 usename 值 kafkaPassword 認證權杖 值只會顯示在建立步驟中 OBJECT_STORAGE_NAMESPACE 租用戶命名空間 租用戶 命名空間 租用戶命名空間 租用戶 PASSWORD_SECRET_OCID PASSWORD_SECRET_OCID OCID
備註:為此示範建立的所有資源皆位於美國 -ASHBURN-1 區域。存入您要使用的區域。如果您變更區域,則必須變更 2 個程式碼檔案中的 2 個點:
Example.java :變更 bootstrapServers 變數,將 "us-ashburn-1" 取代為您的新區域
OboTokenClientConfigurator.java :以您的新區域變更 CANONICAL_REGION_NAME 變數
作業 8:瞭解 Java 程式碼
此教學課程使用 Java 建立,而且此程式碼也可移植到 Python。為了證明效率與擴展性,應用系統開發時會在整合流程的通用使用案例中展現一些可能性。因此,應用程式的程式碼會顯示下列範例:
- 連線至 Kafka 串流及讀取資料
- 使用 ADW 表格處理 JOINS 以建立有用資訊
- 輸出 CSV 檔,並產生每個有用的資訊 Name
此示範可以在您的本機機器中執行,並部署至「資料流程」執行處理,以作為工作執行。
注意:對於資料流程工作和本機機器,請使用 OCI CLI 組態存取 OCI 資源。在「資料流程」端,所有項目都已預先設定,因此不需要變更參數。在您的本機機器端,您必須安裝 OCI CLI 並設定租用戶、使用者和私密金鑰以存取您的 OCI 資源。
讓我們在區段中顯示 Example.java 程式碼:
-
Apache Spark 初始化:此部分的程式碼代表 Spark 初始化。許多執行處理作業的參數都是自動設定的,因此非常容易使用 Spark 引擎。如果您是在資料流程或本機機器中執行,則初始化會有所不同。如果您是在資料流程中,您不需要載入 ADW 公事包壓縮檔,則載入、解壓縮及讀取公事包檔案的作業會在資料流程環境中自動執行,但在本機機器中,則必須使用一些命令來完成。

-
讀取 ADW 保存庫加密密碼:此部分的程式碼會存取您的保存庫,以取得您 Autonomous Data Warehouse 執行處理的加密密碼。

-
查詢 ADW 表格:此段落顯示如何對表格執行查詢。

-
Kafka 作業:這是使用 Kafka API 連線至 OCI 串流的準備工作。
注意:Oracle Cloud Streaming 與大多數 Kafka API 相容。

有一個程序可將來自 Kafka 主題的 JSON 資料剖析為具有正確結構 (組織 ID、名稱、國家 / 地區) 的 資料集。
-
將 Kafka 資料集和 Autonomous Data Warehouse 資料集的資料合併:此區段顯示如何執行含有 2 個資料集的查詢。

-
輸出至 CSV 檔案:以下是合併資料如何產生輸出至 CSV 檔案。

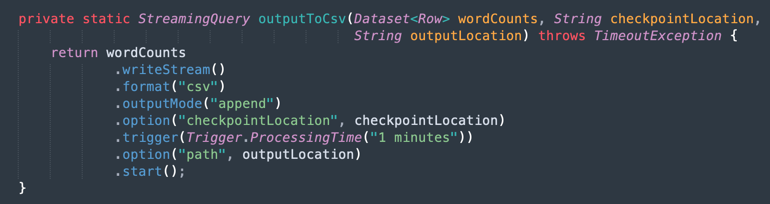
作業 9:將您的應用程式以 Maven 封裝
在 Spark 中執行工作之前,必須先使用 Maven 封裝您的應用程式。
-
移至 /DataflowSparkStreamDemo 資料夾並執行此指令:
mvn package -
您可以看到 Maven 開始封裝。

-
如果一切都正確,您可以看到成功 (Success) 訊息。

作業 10:驗證執行
-
執行下列命令,在本機 Spark 機器中測試您的應用程式:
spark-submit --class example.Example target/consumekafka-1.0-SNAPSHOT.jar -
前往您的 Oracle Cloud Streaming Kafka 執行處理,然後按一下產生測試訊息來產生一些資料,以測試您的即時應用程式。
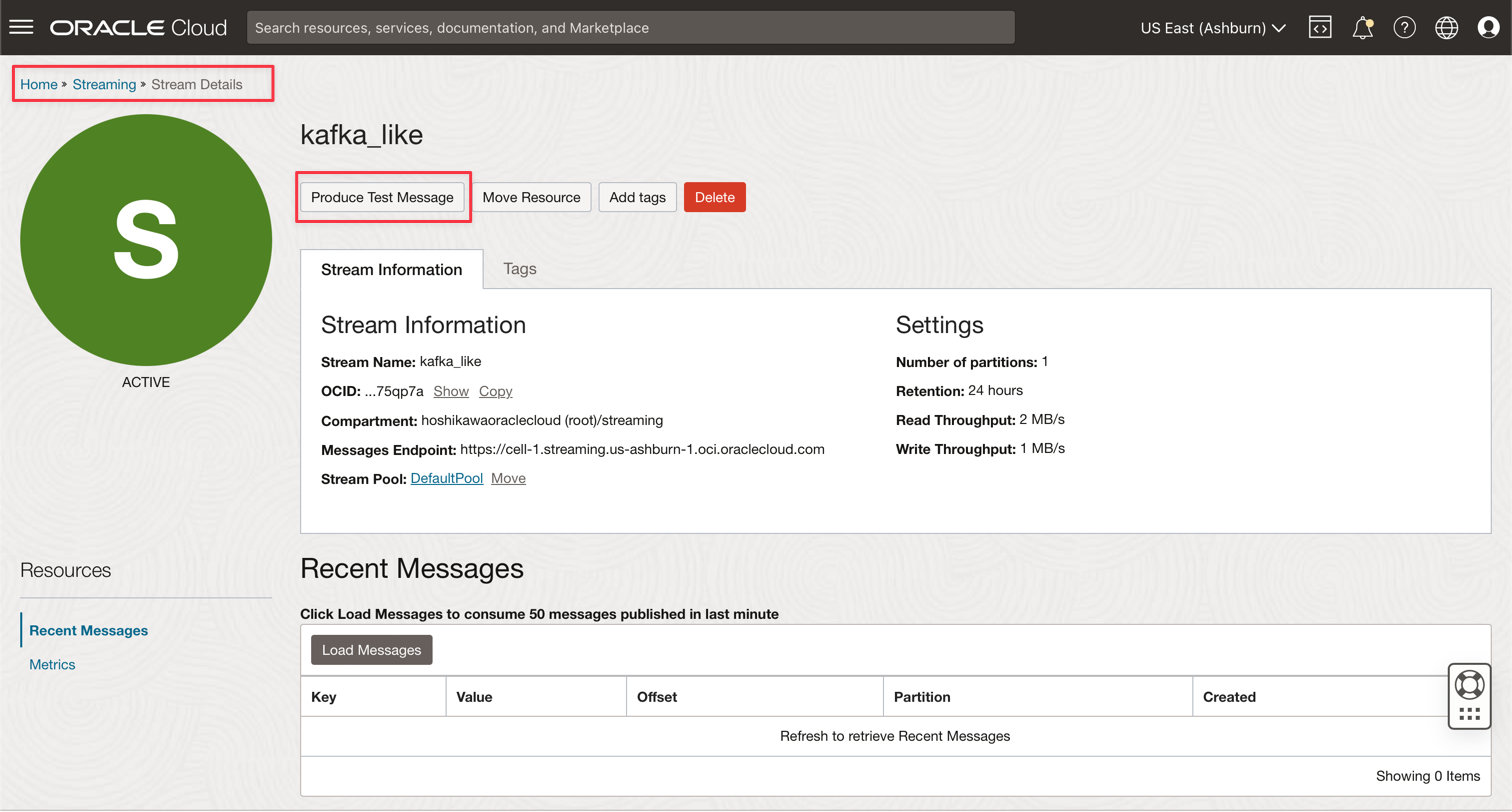
-
您可以將此 JSON 訊息放入 Kafka 主題中。
{"Organization Id": "1235", "Name": "Teste", "Country": "Luxembourg"}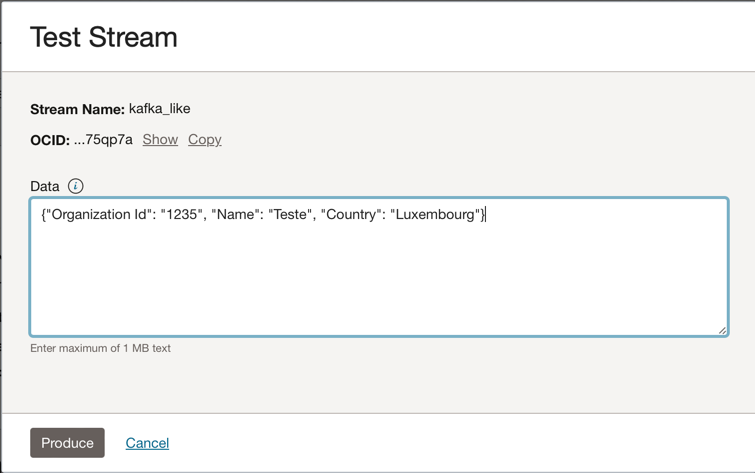
-
每次按一下產生時,都會傳送一則訊息給應用程式。您可以看到應用程式的輸出日誌,如下所示:
-
這是從 kafka 主題讀取的資料。

-
這是 ADW 表格的合併資料。

-
作業 11:建立並執行資料流程工作
現在,由於這兩個應用程式都會在您的本機 Spark 機器中成功執行,因此您可以將它們部署到您租用戶的 Oracle Cloud 資料流程中。
注意: 請參閱 Spark Streaming 文件,以設定對 Oracle Object Storage 和 Oracle Streaming (Kafka) 等資源的存取:啟用資料流程的存取權
-
將套裝程式上傳至物件儲存體。
- 建立資料流程應用程式之前,您需要將 Java 使用者自建物件應用程式 (您的 ***-SNAPSHOT.jar 檔案) 上傳到名為 apps 的物件儲存儲存桶中。
-
建立資料流程應用程式。
-
選取 Oracle Cloud 主功能表,然後前往分析與 AI 和資料流程。建立資料流程應用程式之前,請務必先選取您的分析區間。
-
按一下建立應用程式。

-
填入如此類的參數。

-
按一下建立。
-
建立之後,按一下調整示範規模連結以檢視詳細資訊。若要執行工作,請按一下 RUN 。
注意: 按一下顯示進階選項,即可啟用 Spark Stream 執行類型的 OCI 安全。

-
-
啟用下列選項。

-
按一下執行以執行工作。
-
確認參數,然後再按一下執行 (Run) 。

-
可以檢視工作的狀態。

-
等到「狀態」變成成功 (Succeeded) ,您就可以看到結果。

-
相關連結
確認
- 作者 - Cristiano Hoshikawa (Oracle LAD A-Team Solution Engineer)
其他學習資源
探索 docs.oracle.com/learn 的其他實驗室,或者存取更多 Oracle Learning YouTube 頻道上的免費學習內容。此外,請瀏覽 education.oracle.com/learning-explorer 以成為 Oracle Learning 檔案總管。
如需產品文件,請造訪 Oracle Help Center 。
Use OCI Data Flow with Apache Spark Streaming to process a Kafka topic in a scalable and near real-time application
F79979-02
May 2023
Copyright © 2023, Oracle and/or its affiliates.