附註:
- 此教學課程需要存取 Oracle Cloud。若要註冊免費帳戶,請參閱開始使用 Oracle Cloud Infrastructure Free Tier 。
- 其使用 Oracle Cloud Infrastructure 證明資料、租用戶以及區間的範例值。完成實驗室時,請將這些值替代為雲端環境特定的值。
使用 OCI Generative AI 以自然語言分析 PDF 文件
簡介
Oracle Cloud Infrastructure Generative AI (OCI Generative AI) 是先進的生成式人工智慧解決方案,可讓公司和開發人員使用先進的語言模型建立智慧型應用程式。此解決方案以大型語言模型 (LLM) 等強大的技術為基礎,可自動化複雜的工作,讓流程更快、更有效率,並可透過自然語言互動存取。
OCI Generative AI 的其中一個最具影響力的應用程式正在進行 PDF 文件分析。公司經常處理大量文件,例如合約、財務報告、技術手冊和研究論文。在這些檔案中手動搜尋資訊可能相當耗時,而且容易發生錯誤。
藉由使用生成式人工智慧,可以即時且準確地擷取資訊,讓使用者只需以自然語言提出問題即可查詢複雜的文件。這表示使用者只要詢問模型,即可根據分析的內容快速傳回答案,而不必讀取整個頁面來尋找合約中的特定條款或報表中的相關資料點。
除了資訊擷取之外,OCI Generative AI 還可用於總結冗長的文件、比較內容、分類資訊,甚至產生策略洞察分析。這些功能讓法律、財務、醫療照護和工程等各個領域的技術變得至關重要,從而最佳化決策並提高生產力。
透過將此技術與 Oracle AI 服務、OCI 資料科學和文件處理 API 等工具整合,企業可以建立完全改變與資料互動方式的智慧解決方案,從而更快、更有效率地擷取資訊。
必備條件
- 安裝 Python
version 3.10或更新版本和 Oracle Cloud Infrastructure 命令行介面 (OCI CLI)。
作業 1:安裝 Python 套裝軟體
Python 程式碼需要使用 OCI Generative AI 的特定程式庫。執行下列指令以安裝必要的 Python 套裝軟體。
pip install -r requirements.txt
工作 2:瞭解 Python 程式碼
這是用於查詢 Oracle SOA Suite 和 Oracle Integration 功能的 OCI Generative AI 示範。這兩種工具目前都用於混合式整合策略,這表示它們在雲端和內部部署環境中運作。
由於這些工具共用功能與處理程序,因此此代碼有助於瞭解如何在每個工具中實施相同的整合方法。此外,它可讓使用者探索通用特性和差異。
從這裡下載 Python 程式碼:
您可以在此處找到 PDF 文件:
建立名為 Manuals 的資料夾,並將這些 PDF 移至該處。
-
匯入程式庫:
匯入必要的程式庫以處理 PDF、OCI Generative AI、文字向量化和向量資料庫中的儲存 (Facebook AI Similarity Search (FAISS) 和 ChromaDB)。
-
UnstructuredPDFLoader用於從 PDF 擷取文字。 -
ChatOCIGenAI可使用 OCI Generative AI 模型來回答問題。 -
OCIGenAIEmbeddings會建立語意搜尋的內嵌文字 (向量表示法)。
-
-
載入和處理 PDF:
列出要處理的 PDF 檔案。
-
UnstructuredPDFLoader會讀取每份文件並將其分割成頁面,以便輕鬆編製索引和搜尋。 -
儲存文件 ID 以供日後參考。

-
-
設定 OCI Generative AI 模型:
設定 OCI 上代管的
Llama-3.1-405b模型,以根據載入的文件產生回應。定義參數,例如
temperature(隨機性控制)、top_p(多樣性控制) 以及max_tokens(權杖限制)。
注意:可用的 LLaMA 版本可能會隨時間變更。請檢查您租用戶中的目前版本,並視需要更新您的程式碼。
-
建立內嵌項目和向量索引:
使用 Oracle 的內嵌模型將文字轉換為數值向量,促進文件中的語意搜尋。

-
FAISS 會儲存 PDF 文件的內嵌內容,以便快速查詢。
-
retriever允許根據使用者查詢的語意相似性擷取最相關的摘錄。

-
-
在第一次處理執行時,向量資料會儲存在 FAISS 資料庫中。

-
定義提示:
為生成式模型建立智慧型提示,引導它只考慮每個查詢的相關文件。
這樣可以改善回應的準確性,並避免不必要的資訊。

-
建立處理鏈 (RAG - 擷取增強生成):
實行 RAG 流程,其中:
retriever會搜尋最相關的文件摘錄。prompt會組織查詢以獲得更好的相關資訊環境。llm會根據擷取的文件產生回應。StrOutputParser會格式化最終輸出。

-
問題與答案迴圈:
維護迴圈,讓使用者可以詢問所載入文件的相關問題。
-
AI 會使用從 PDF 擷取的知識庫來回應。
-
如果您輸入
quit,則會結束程式。

-
現在,您可以選擇 3 個選項來處理文件。您可以考慮:
- 您需要處理多少次電力?
- 您需要處理多少時間?
- 您的回應品質如何?
因此,您有下列選項:
固定大小分區:這是處理文件的較快速替代方案。這足以讓您取得想要的內容。
語意分區:此流程會比固定大小的分區慢,但會傳遞更多品質的分區。
使用 GraphRAG 的語意分區:它會提供更精確的方法,因為它會組織分區文字和知識圖表。
固定大小分區
請從此處下載程式碼:oci_genai_llm_context_fast.py 。
-
什麼是固定大小分塊?
「固定大小分塊」是一種簡單且有效率的文字分割策略,其中文件會根據預先定義的大小限制 (通常以記號、字元或線條測量) 分成區塊。
此方法不會分析文字的意義或結構。它只會以固定的間隔切分內容,不論切斷是否是在句子、段落或想法的中間。
-
固定大小分區的運作方式:
-
範例規則:每隔 1000 個記號 (或每 3000 個字元) 分割文件。
-
選擇性重疊:為了降低分割相關 context 的風險,部分實作會在連續區塊之間新增重疊 (例如,200 記號重疊),以確保 context 在邊界不會遺失。
-
-
固定大小分區的優點:
-
快速處理:無需進行語意分析、LLM 推論或內容理解。只需計算和切斷。
-
低資源使用量:最低 CPU/GPU 和記憶體使用量,使其可擴展至大型資料集。
-
容易實行:適用於簡單的命令檔或標準文字處理程式庫。
-
-
固定尺寸分區限制:
-
語意意識不佳:區塊可能會截斷句子、段落或邏輯區段,導致想法不完整或分散。
-
降低擷取精確度:在語意搜尋或檢索增強生成 (RAG) 等應用程式中,區塊界限不佳可能會影響所擷取答案的相關性和品質。
-
-
何時使用固定大小分區:
-
處理速度和可擴展性是首要任務。
-
對於語意精確度不重要的大型文件擷取管線。
-
作為案例的第一步,稍後會進行精簡或語意分析。
-
這是分割文字非常簡單的方法。

-
這是固定區塊的主要程序。

備註:請下載此代碼,更快處理固定分區:
oci_genai_llm_context_fast.py -
語意分區
請從此處下載程式碼:oci_genai_llm_context.py 。
-
什麼是語意分區?
「語意分區」是一種文字前處理技術,其中大型文件 (例如 PDF、簡報或文章) 分割成稱為分區的較小部分,每個分區代表語意一致的文字區塊。
與傳統的固定大小分塊不同 (例如,每 1000 個記號或每 X 個字元分割一次),語意分區使用人工智慧 (通常是大型語言模型 - LLM) 來偵測自然內容界限、尊重主題、區段和 context。
語意分區 (Semantic Chunking) 會嘗試保留每個區段的完整意義,而不是任意切割文字,從而建立獨立的情境感知片段。
-
為什麼語意分塊會讓處理速度變慢?
根據固定大小的傳統分區處理速度很快。系統只會計算記號或字元,並據此剪下。使用「語意分區」時,需要數個額外的語意分析步驟:
- 在分割之前讀取和解譯全文 (或大型區塊): LLM 需要瞭解內容,以識別最佳的區塊界限。
- 執行 LLM 提示或主題分類模型:系統通常會向 LLM 查詢問題,例如這是想法的結尾嗎?或本段是否開始新區段?。
- 較高的記憶體和 CPU/GPU 使用量:因為模型會先處理較大的文字區塊,再進行分區決策,所以資源使用量顯著提高。
- 循序漸增式決策:語意分區通常在步驟中運作 (例如,分析 10,000 個記號區塊,然後縮小該區塊內的區塊界限),這會增加總處理時間。
注意:
- 視您的機器處理能力而定,您將等待很長的時間,使用語意分區完成第一次執行。
- 您可以使用此演算法來產生使用 OCI Generative AI 的自訂分區。
-
語意分區的運作方式:
-
smart_split_text():以 10kb 的小部分分隔全文 (您可以設定採用其他策略)。感知最後一段的機制。如果段落的某個部分位於下一個文字片段中,則處理時會忽略此部分,並將附加在下一個處理文字群組中。 -
semantic_chunk():此方法將使用 OCI LLM 機制分隔段落。它包括識別標題、表格元件的智慧,以及執行智慧區塊的段落。此處的策略是使用語意區塊技術。與一般處理相比,完成任務需要更多時間。因此,第一個處理需要很長的時間,但下一個處理會載入所有 FAISS 預存資料。 -
split_llm_output_into_chapters():此方法會結束區塊,分隔章節。
備註:請下載此代碼以處理語意分區:
oci_genai_llm_context.py -
使用 GraphRAG 進行語意分區
請從此處下載程式碼:oci_genai_llm_graphrag.py 。
GraphRAG (Graph-Augmented Retrieval-Augmented Generation) 是一種先進的 AI 架構,將傳統向量型擷取與結構化知識圖形相結合。在標準 RAG 管線中,語言模型會使用向量資料庫 (例如 FAISS) 的語意相似度來擷取相關文件區塊。然而,以向量為基礎的檢索以非結構化方式運作,完全依賴內嵌和距離指標,有時候會錯過更深的內容或關聯意義。
GraphRAG 透過引入知識圖表層來增強此流程,其中實體、概念、元件及其關係會明確表示為節點與邊緣。這個以圖形為基礎的 context 可讓語言模型推斷僅向量相似性無法擷取的關係、階層和相依性。
-
為什麼要將語意分區與 GraphRAG 結合?
語意分區是根據內容結構 (例如章節、標題、區段或邏輯分區) 將大型文件智慧地分割成有意義單位或「分區」的程序。Rather than breaking documents purely by character limits or naive paragraph splitting, semantic chunking produces higher-quality, context-aware chunks that align better with human understanding.
-
具備 GraphRAG 優點的語意區塊:
-
增強的知識代表:
- 語意區塊會保留內容中的邏輯界限。
- 從這些區塊擷取的知識圖表可維持實體、系統、API、流程或服務之間的準確關係。
-
多重模式內容擷取 (語言模型會擷取兩者):
- 向量資料庫中的非結構化 context (語意相似性)。
- 知識圖中的結構化 context (實體關聯三元組)。
- 這種混合方式可帶來更完整且更準確的答案。
-
改進的推理功能:
- 以圖形為基礎的擷取可啟用關聯式推理。
- LLM 可以回答下列問題:
- 訂單 API 依賴哪些服務?
- 哪些元件是 SOA Suite 的一部分?
- 這些關聯式查詢通常只適用於內嵌方法。
-
更高的可解釋性和可追溯性:
- 圖形關係是人為可讀且透明的。
- 使用者可以檢查答案是如何從文字和結構知識衍生而來。
-
減少虛構:圖形可作為 LLM 的限制,錨定對已驗證關係的回應,以及從來源文件擷取的事實連線。
-
跨複雜網域的擴展性:
- 在技術領域 (例如 API、微服務、法律合約、健康照護標準) 中,元件之間的關係與元件本身非常重要。
- GraphRAG 與這些環境中的語意分區可有效地縮放,同時保留文字深度和關聯式結構。
注意:
- 從此處下載使用 graphRAG 處理語意區塊的程式碼:
oci_genai_llm_graphrag.py。 - 您需要:
- 已安裝 docker 且使用 Neo4J 開放原始碼圖形作業系統資料庫進行測試。
- 安裝 neo4j Python 程式庫。
此程式碼中有 2 個方法:
-
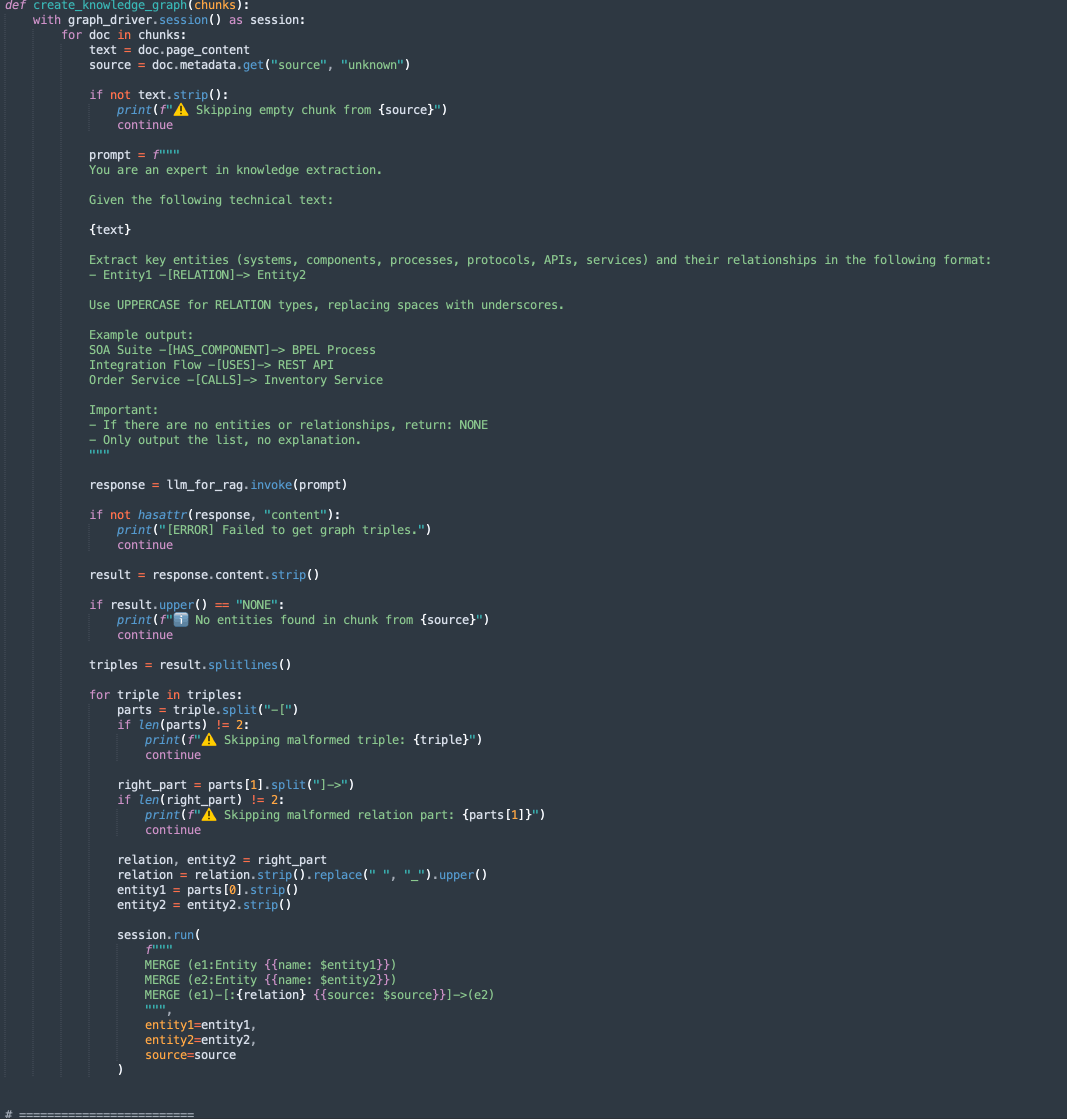
create_knowledge_graph:-
此方法會自動從文字區塊擷取實體與關係,並將其儲存在 Neo4j 知識圖表中。
-
對於每個文件區塊,它會傳送內容至 LLM (大型語言模型),並提示要求擷取實體 (例如系統、元件、服務、API) 及其關係。
-
它會剖析每一行,擷取 Entity1、RELATION 和 Entity2。
-
使用 Cypher 查詢將此資訊儲存為 Neo4j 圖表資料庫中的節點和邊緣:
MERGE (e1:Entity {name: $entity1}) MERGE (e2:Entity {name: $entity2}) MERGE (e1)-[:RELATION {source: $source}]->(e2)
-
-
-
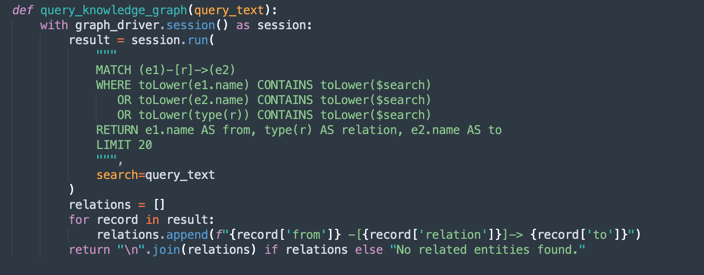
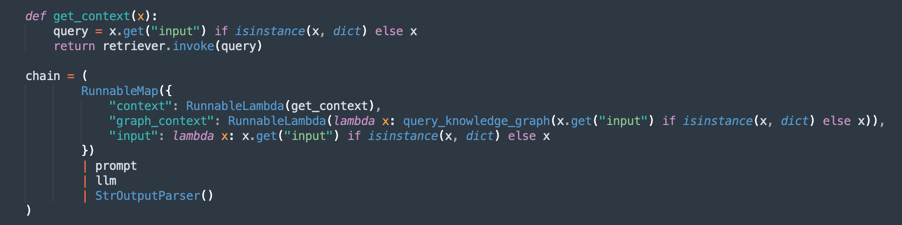
query_knowledge_graph:-
此方法會查詢 Neo4j 知識圖表,以擷取與特定關鍵字或概念相關的關係。
-
執行搜尋下列項目的 Cypher 查詢:
Any relationship (e1)-[r]->(e2) Where e1.name, e2.name, or the relationship type contains the query_text (case-insensitive). -
傳回最多 20 個相符的三元組,格式為:
Entity1 -[RELATION]-> Entity2
-
注意:
Neo4j 用法:
此實作使用 Neo4j 作為用於示範和原型設計的嵌入式知識圖資料庫。雖然 Neo4j 是功能強大且彈性的圖表資料庫,適合開發、測試及中小型工作負載,但可能不符合企業級、關鍵任務或高度安全的工作負載需求,特別是在需要高可用性、擴展性及進階安全規範的環境中。
對於生產環境和企業情境,我們建議利用 Oracle Database 和圖表功能,提供:
企業級的可靠性和安全性。
關鍵任務工作負載的擴展性。
與關聯式資料整合的原生圖形模型 (Property Graph 與 RDF)。
進階分析、安全性、高可用性及災難復原功能。
完整的 Oracle Cloud Infrastructure (OCI) 整合。
透過使用 Oracle Database 進行圖形工作負載,企業可以在單一、安全且可擴展的企業平台內統一結構化、半結構化和圖形資料。
作業 3:執行 Oracle Integration 與 Oracle SOA Suite 內容的查詢
執行下列命令。
FOR FIXED CHUNKING TECHNIQUE (MORE FASTER METHOD)
python oci_genai_llm_context_fast.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING TECHNIQUE
python oci_genai_llm_context.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
FOR SEMANTIC CHUNKING COMBINED WITH GRAPHRAG TECHNIQUE
python oci_genai_llm_graphrag.py --device="mps" --gpu_name="M2Max GPU 32 Cores"
備註:如果您的機器具有 GPU,您可以使用
--device和--gpu_name參數來加速 Python 中的處理。請考慮此代碼也可以與本機模型搭配使用。
提供的相關資訊環境區分了 Oracle SOA Suite 和 Oracle Integration,您可以考慮下列幾點來測試程式碼:
- 只能針對 Oracle SOA Suite 進行查詢:因此,應該只考慮使用 Oracle SOA Suite 文件。
- 只應針對 Oracle Integration 進行查詢:因此,只應考慮使用 Oracle Integration 文件。
- 查詢需要在 Oracle SOA Suite 與 Oracle Integration 之間進行比較:因此,應考慮所有文件。
我們可以定義下列環境定義,這有助於正確解譯文件。
下圖顯示 Oracle SOA Suite 與 Oracle Integration 之間的比較範例。

接下來的步驟
此程式碼示範 OCI Generative AI 的應用程式,以進行智慧型 PDF 分析。它可讓使用者使用語意搜尋和生成式 AI 模型,有效率地查詢大量文件,以產生準確的自然語言回應。
此方法可應用於各種領域,例如法律、合規性、技術支援和學術研究,讓資訊更快、更聰明。
相關連結
確認
- 作者 - Cristiano Hoshikawa (Oracle LAD A 團隊解決方案工程師)
其他學習資源
在 docs.oracle.com/learn 上探索其他實驗室,或在 Oracle Learning YouTube 頻道上存取更多免費學習內容。此外,請造訪 education.oracle.com/learning-explorer 以成為 Oracle Learning Explorer。
如需產品文件,請造訪 Oracle Help Center 。
Analyze PDF Documents in Natural Language with OCI Generative AI
G29545-05
Copyright ©2025, Oracle and/or its affiliates.