備註:
- 此教學課程需要存取 Oracle Cloud。若要註冊免費帳戶,請參閱開始使用 Oracle Cloud Infrastructure Free Tier。
- 此範例使用 Oracle Cloud Infrastructure 證明資料、租用戶及區間的範例值。完成實驗室時,請將這些值替代成雲端環境的特定值。
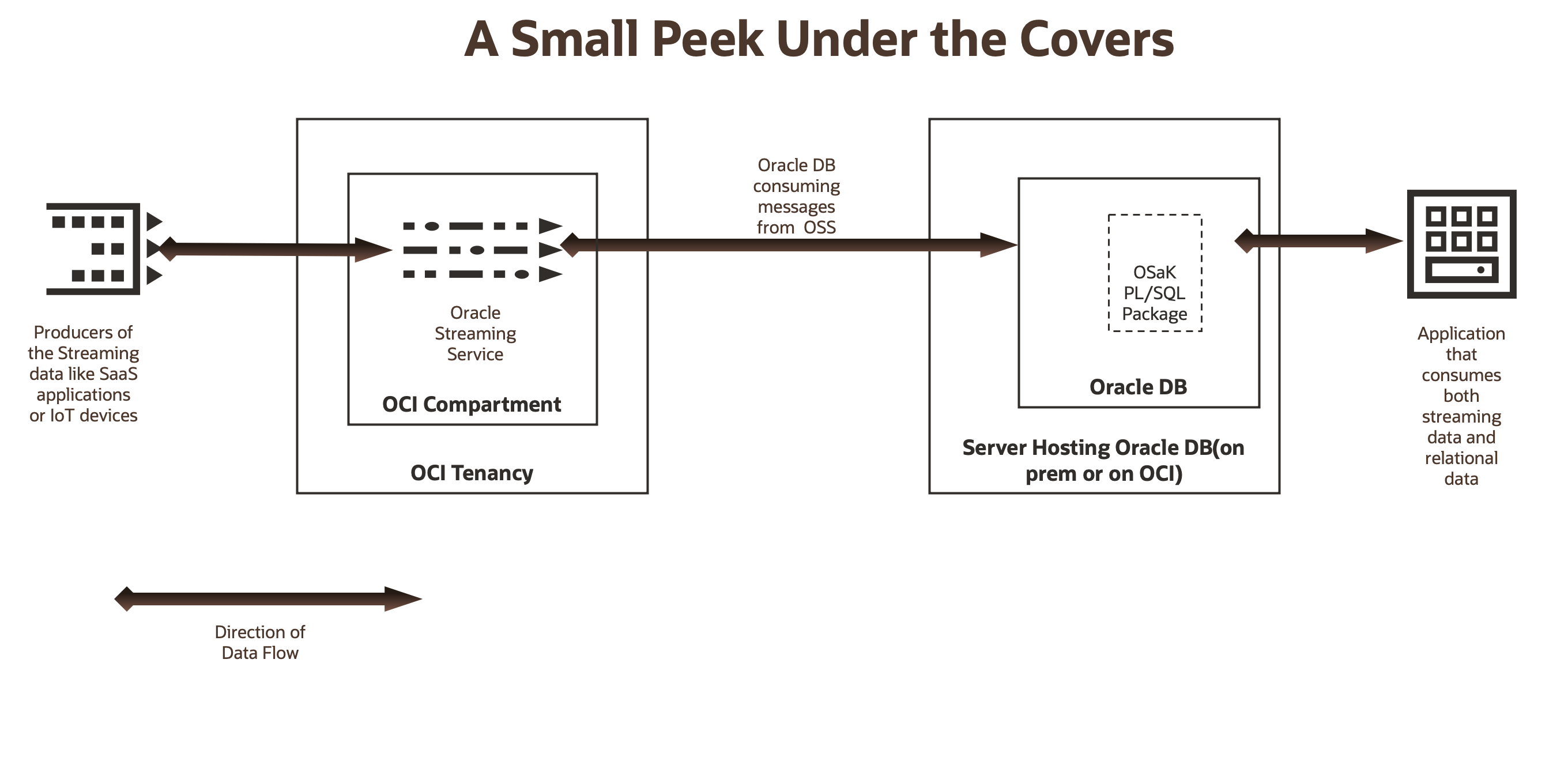
使用 Oracle Cloud Infrastructure Streaming 和 Oracle Database 進行串流分析
簡介
Oracle Cloud Infrastructure Streaming 是 Oracle Cloud Infrastructure (OCI) 上的高可用性串流服務。串流服務提供完全無伺服器,且與 Apache Kafka 相容。
存取 Kafka 的 Oracle SQL 是一項 Oracle PL/SQL 套裝程式和外部表格預先處理器。它可讓 Oracle Database 從 Kafka 主題作為 Oracle Database 中的檢視或表格讀取和處理事件和訊息。Kafka 中的資料位於 Oracle Database 表格中或從 Oracle Database 檢視中看見之後,只要與 Oracle Database 中的任何其他資料一樣,就能查詢 Oracle PL/SQL 的完整強大功能。
以已啟用 Kafka 之檢視的 Oracle SQL 存取擷取資料時,資料不會保留在 Oracle Database 中。不過,當您使用 Oracle SQL 存取 Kafka 支援的表格時,會保留在 Oracle Database 中。因此,以 Kafka 存取 Oracle SQL 就能提供開發者完整彈性,協助他們保存 Oracle Database 上的串流資料。如需 Oracle SQL 存取 Kafka 的良好簡介和使用案例,請參閱此部落格文章,使用 Oracle SQL Access to Kafka View 整合靜態資料。
簡而言之,Oracle SQL 存取 Kafka 時可讓靜態資料 (在 Oracle Database 表格內) 使用 Oracle PL/SQL 處理資料。因此,舉例來說,Java 資料庫連線 (JDBC) 應用程式可以在提供 ACID 保證的 Oracle Database 交易中處理 Kafka 與重要 Oracle Database 資料的即時事件。當應用系統個別擷取 Oracle Database 的 Kafka 事件和資料時,很不容易就能完成此動作。
福利
- 客戶可以使用 Oracle SQL 存取 Kafka 來執行即時串流分析工作,無需將它移到外部資料存放區,即可直接讀取來自串流服務的資料,藉此執行即時串流分析工作。
- 客戶也可以透過 Oracle SQL 存取 Kafka,純粹管從串流服務搬移至 Oracle Database,而無須進行任何處理。
- 串流處理作業可以在應用程式所控制的 Oracle ACID 異動相關資訊環境中執行。
- Kafka 存取權只能作為 Kafka 用戶使用,且絕對不是 Kafka 產生器。整個偏移管理是由 OSaK 處理。它會將此資訊儲存在 Oracle Database 的描述資料表格中。因此,Oracle SQL 存取 Kafka 可啟用精確的處理語意,因為它能夠以單一 ACID 相容的 Oracle Database 交易形式,確保 Kafka 和串流服務的分割區偏移量,以及應用程式資料 (單一 ACID 相容的 Oracle Database 交易)。這樣可以減少串流記錄的遺失或重新讀取。
使用案例
想像使用或加入您的串流資料 (例如:
- 您想要將來自聊天 IoT 裝置的串流資料 (最可能出現在您的客戶企業內部部署) 與相關的客戶資訊 (儲存在您的來源事實關聯 Oracle Database 中)。
- 您要計算串流處理至串流服務中之庫存價格的精確指數移動平均值。您需要完全符合一次語意。想要將此資料與與該股票有關的靜態資訊相結合,例如儲存在 Oracle Database 中的名稱、公司 ID、市場容量等。
請注意,由於 Oracle SQL 存取 Kafka 是需要手動安裝於 Oracle 伺服器主機上的 PL/SQL 套裝程式,因此它只能與自行管理 (企業內部部署環境或雲端) 的 Oracle Database 安裝搭配使用。無法與 Oracle Cloud Infrastructure (OCI) 上的 Oracle Autonomous Database 等無伺服器 Oracle Database 方案搭配使用。
由於串流服務是與 Kafka 相容的 API,因此它可與 Kafka 的 Oracle SQL 存取完美運作。從 Oracle SQL 存取 Kafka 檢視點,串流服務串流集區是一個 Kafka 叢集,而串流服務串流則是 Kafka 叢集中的主題。
本教學課程將說明我們如何輕鬆整合 Oracle SQL 存取 Kafka 與串流服務。
注意:如果您熟悉 Kafka、串流服務和 Kafka 的 Oracle SQL 存取,而且想要使用 Kafka 存取該串流服務的 Oracle SQL,可以直接跳到設定 Oracle Cloud Infrastructure Streaming 叢集,以進行 Kafka 步驟 2.1 的 Oracle SQL 存取。視需要略過其他教學課程。
必要條件
- 具備建立並使用串流服務授權之 OCI 帳戶或租用戶。
- Apache Kafka 叢集 0.10.2 或更新版本。「串流」服務滿足這項要求。
- Oracle Database 12。2 或更新版本,其中 Kafka 的 Oracle SQL 存取將會安裝 (本教學課程採用版本 19c)。我們使用 Oracle Linux 作為 Oracle Database 的平台作業系統。其他平台的指示和大型項目仍相同。
- Oracle Database 主機上安裝的 Java 8 或更新版本。
Kafka 整合的 Oracle Cloud Infrastructure Streaming 和 Oracle SQL 存取
在 Oracle Cloud Infrastructure 中建立串流集區與串流
-
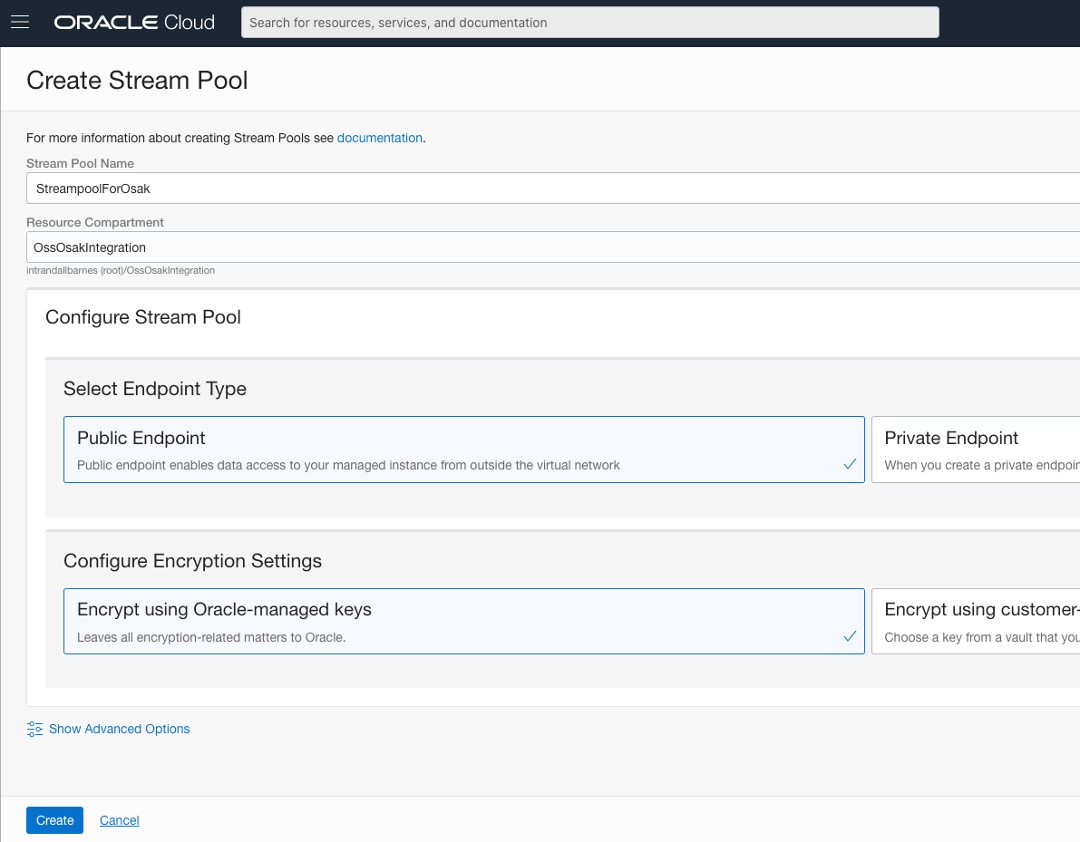
登入您的 OCI 帳戶 / 租用戶,並設定名為 StreampoolForOsak 的串流服務串流集區,以及名稱為 StreamForOsak 的串流,如下所示。
-
我們現在會在我們剛建立的串流集區 StreampoolForOsak 中建立名為 StreamForOsak 的串流。
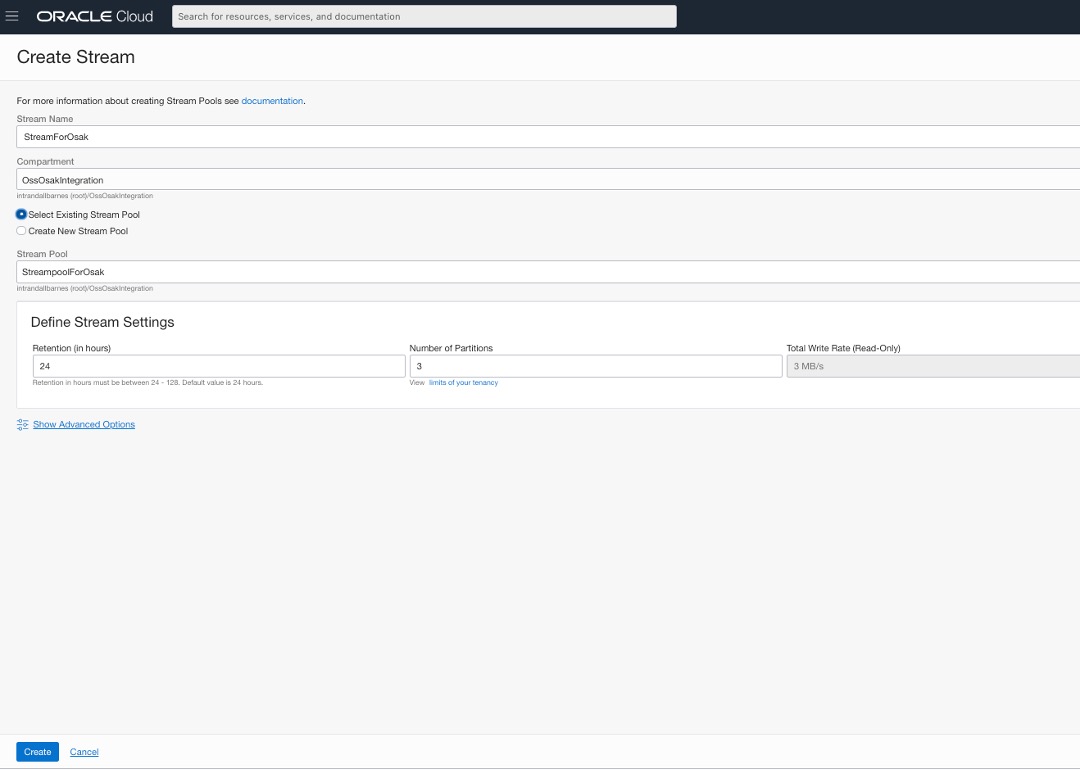
您可以針對這些資源建立,使用您現有的任一區間。為了便於使用,我們建立了名為 OssOsakIntegration 的新區間,並且所有資源都位於相同的區間。
在「串流」服務術語中,Kafka 主題稱為「串流」。因此,從 Oracle SQL 存取 Kafka 檢視點,串流 StreamForOsak 是包含三個分割區的 Kafka 主題。
現在我們只需建立串流服務串流即可完成。之後,串流服務和 Kafka 這兩個術語是可互換的。同樣地,串流和 Kafka 主題可以交換。
在 Oracle Cloud Infrastructure 中建立使用者、群組和原則
如果您已經有使用 Stream 服務授權正確的使用者,可以略過步驟 2。
-
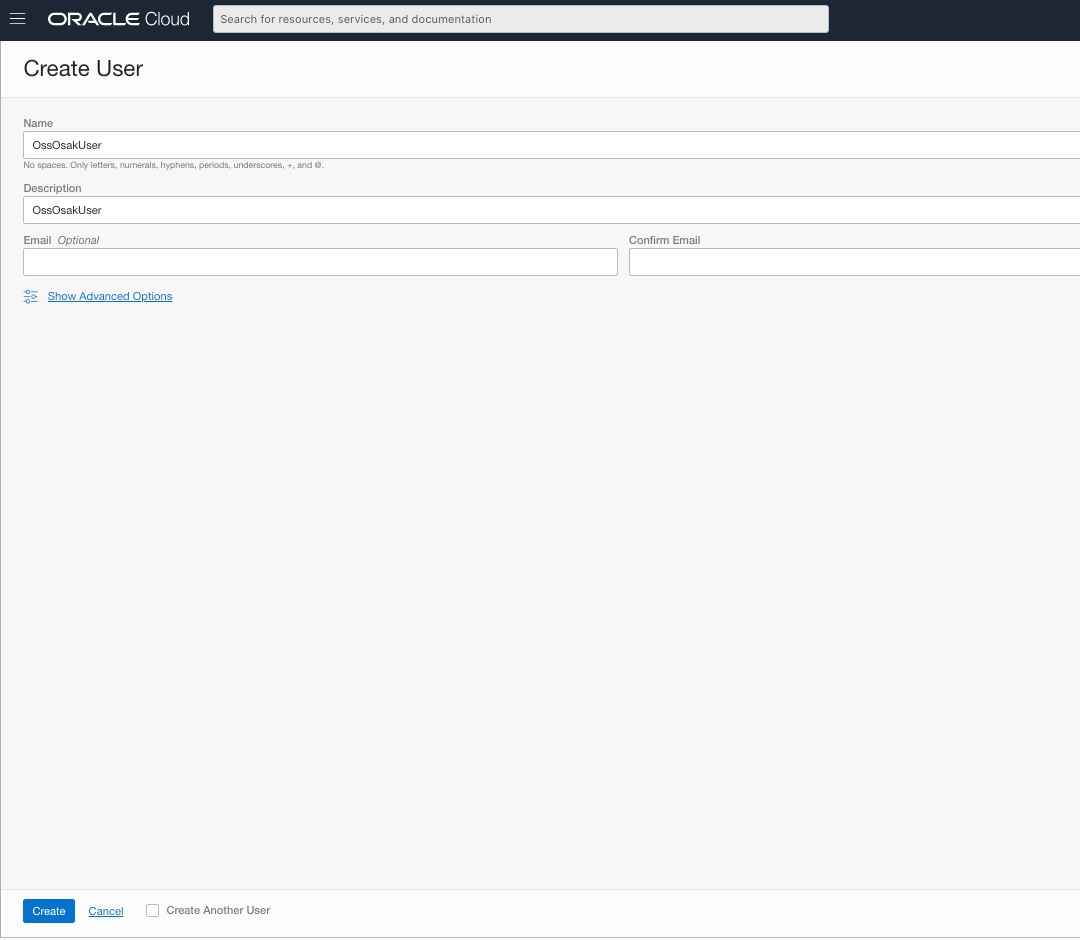
若要在 Kafka 的 Oracle SQL 存取中使用串流服務串流,您必須為其建立新的 OCI 使用者。我們在 OCI Web 主控台中,使用使用者名稱 OssOsakUser 為此建立新的使用者,如下所示:
-
若要讓使用者 OssOsakUser 向串流服務認證本身 (使用 Kafka API),我們必須為此新使用者建立 auth-token,如下所示:
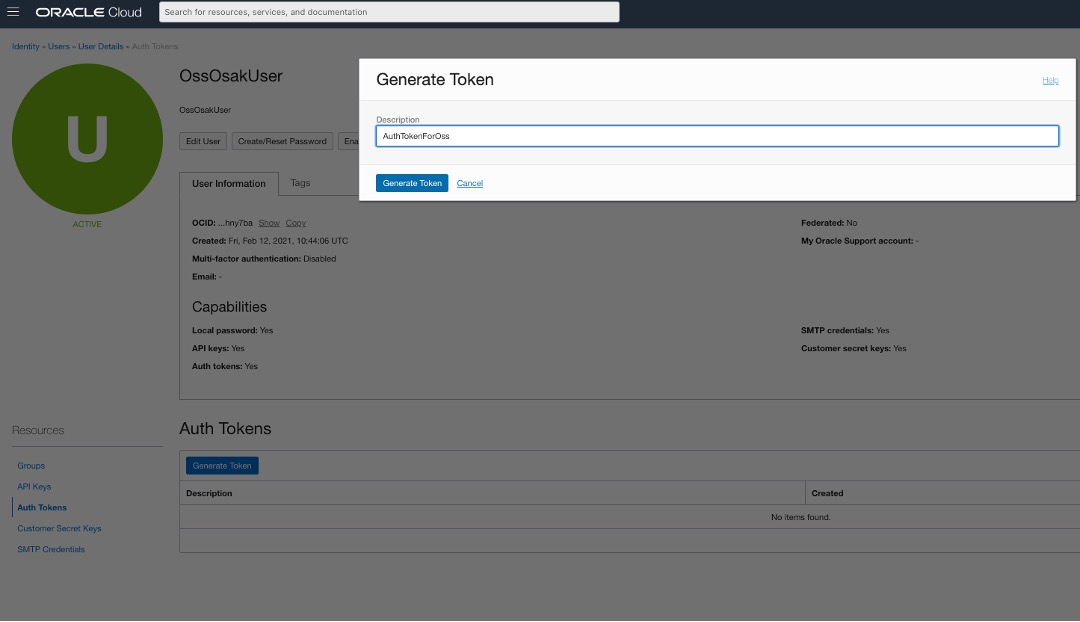
產生記號之後,您會先取得記號,而是查看並複製 auth-token 的唯一機會。因此,請複製 auth-token 並安全地在您可以稍後存取的地方。在稍後的步驟中,特別是當我們設定 Kafka 叢集以進行 Kafka 存取時,才需要此步驟。對 Kafka 的 Oracle SQL 存取將使用此使用者名稱 (即 OssOsakUser) 及其認證權杖,以內部使用 Kafka 用戶 API 存取串流服務。
-
OssOsakUser 也需要在 OCI IAM 中具備一組正確的權限,才能存取串流服務叢集。
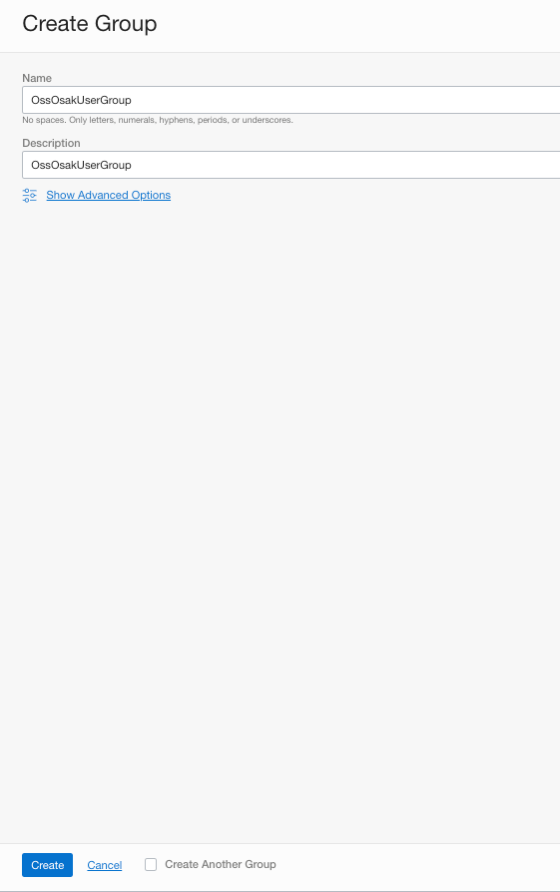
在 OCI 中,使用者以指定給他們所屬使用者群組的原則協助獲得權限。因此,我們需要為 OssOsakUser 建立群組,然後為該群組建立原則。
建立使用者群組,如下所示:
-
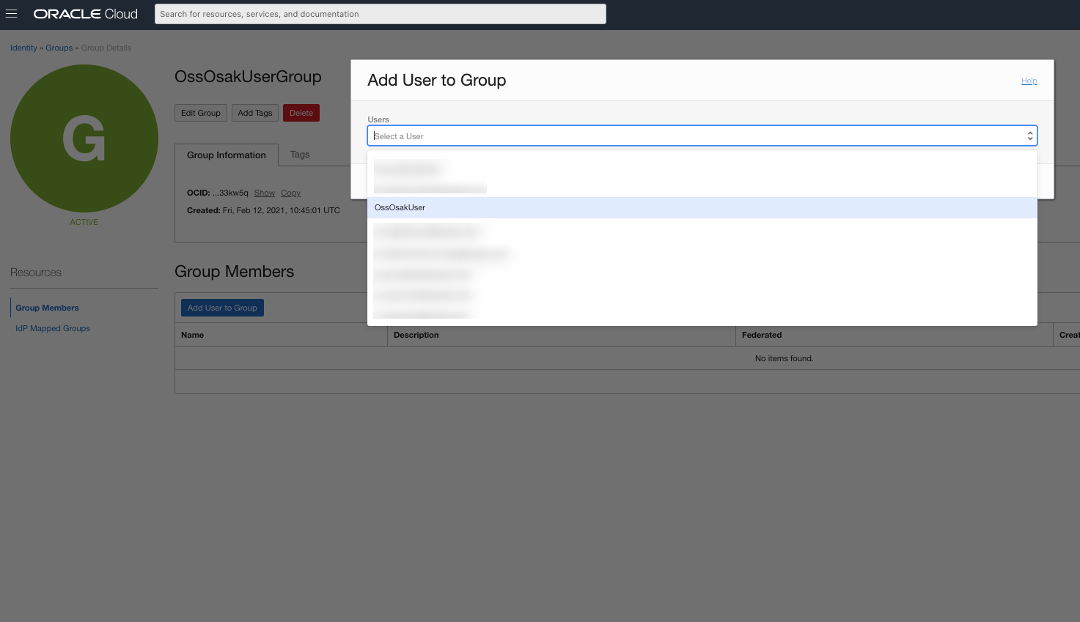
新增使用者 OssOsakUser 到使用者群組 OssOsakUserGroup。
-
若要授權 OssOsakUser 使用串流服務串流 (特別是發布及讀取來自串流的訊息),我們必須在租用戶中建立下列原則。此原則,建立之後將權限授予群組 OssOsakUserGroup 中的所有使用者。由於 OssOsakUser 使用者位於相同群組中,因此會取得相同的權限。
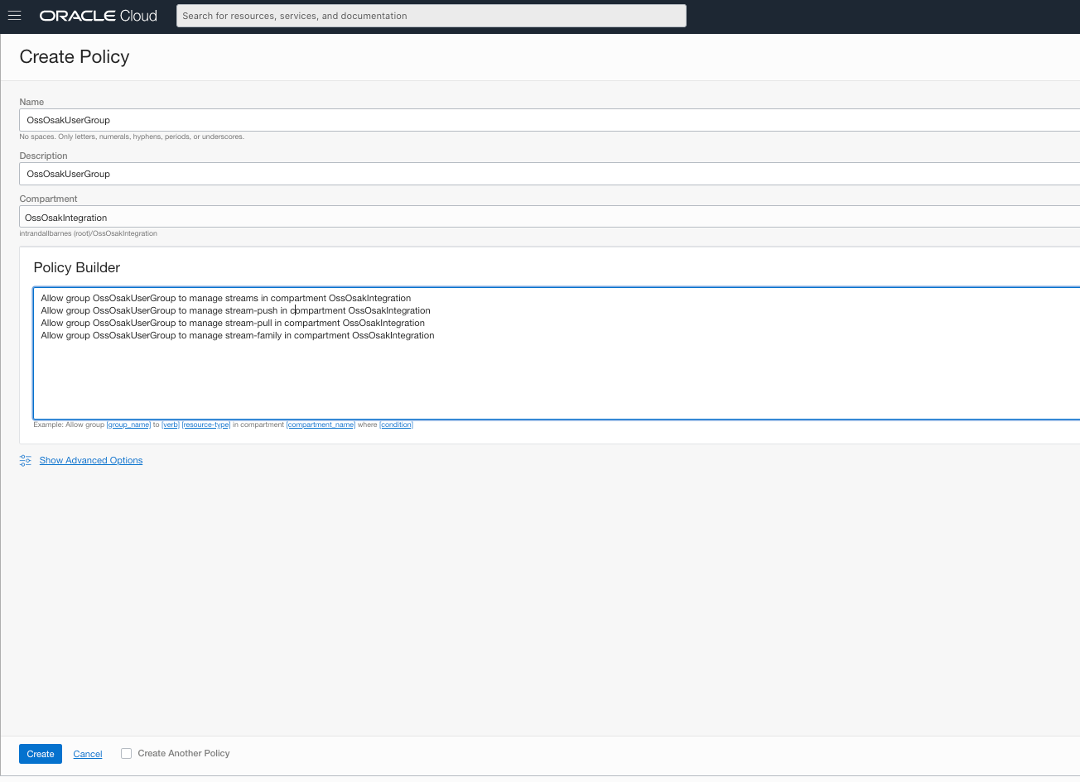
上述相同原則的文字片段如下。
Allow group OssOsakUserGroup to manage streams in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-push in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-pull in compartment OssOsakIntegration Allow group OssOsakUserGroup to manage stream-family in compartment OssOsakIntegration
在 Oracle Database 主機上安裝 Kafka 的 Oracle SQL 存取
-
Kafka 套件的 Oracle SQL 存取已成為廣泛使用 SQL Developer 的一部分。
使用官方 SQL Developer 連結下載最新版本的 SQL Developer。截至撰寫此教學課程時,最新的 SQL Developer 版本為 20.4。
請務必下載與 Oracle Database 主機相同平台的 Oracle SQL Developer。在我們的開發盒上,我們下載適用於 Oracle Linux RPM 的 Oracle SQL Developer (Oracle Database 在 Oracle Linux 平台上執行)。
下載完成後,請使用
unzip或tar命令將 Oracle SQL Developer 的 RPM/zip 檔案內容擷取至任何目錄 / 資料夾。tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm -
前往擷取 Oracle SQL Developer 內容的目錄,並尋找名稱為
orakafka.zip之 Kafka ZIP 檔案的 Oracle SQL 存取,如下所示:$ find . -name 'orakafta*' ./sqldeveloper/orakafta ./sqldeveloper/orakafta/orakafta.zipKafka 套件的 Oracle SQL 存取權位於
orakafka.zip檔案中。我們對於此示範的 SQL 開發人員其餘內容不感興趣。對 Kafka 進行安裝的 Oracle SQL 存取和使用狀況時,我們都需要提供orakafka.zip。 -
使用
scp命令或以 GUI 為基礎的 FTP 從屬端 (例如 FileZilla),將orakafka.zip檔案複製到 Oracle Database 主機。SSH 登入 Oracle Database 節點,並使用
mv_ command將orakafka.zip移至/home/oracle(oracle 使用者本位目錄)。 -
如需安裝 Kafka Oracle SQL 存取權的其餘指示,我們需要切換到 Oracle Database 主機上的 oracle 使用者。
確定您目前的工作目錄是
/home/oracle。我們的orakafka.zip已經位於相同的目錄中。[opc@dbass ~]$ sudo su - oracle Last login: Sat Feb 20 09:31:12 UTC 2021 [oracle@dbass ~]$ pwd /home/oracle [oracle@dbass ~]$ ls -al total 3968 drwx------ 6 oracle oinstall 4096 Feb 19 17:39 . drwxr-xr-x 5 root root 4096 Feb 18 15:15 .. -rw------- 1 oracle oinstall 4397 Feb 20 09:31 .bash_history -rw-r--r-- 1 oracle oinstall 18 Nov 22 2019 .bash_logout -rw-r--r-- 1 oracle oinstall 203 Feb 18 15:15 .bash_profile -rw-r--r-- 1 oracle oinstall 545 Feb 18 15:20 .bashrc -rw-r--r-- 1 oracle oinstall 172 Apr 1 2020 .kshrc drwxr----- 3 oracle oinstall 4096 Feb 19 17:37 .pki drwxr-xr-x 2 oracle oinstall 4096 Feb 18 15:20 .ssh -rw-r--r-- 1 oracle oinstall 4002875 Feb 19 17:38 orakafka.zip -
擷取或解壓縮
orakafka.zip。這會以擷取的內容建立名為orakafka-<version>的新目錄。在我們的案例中,orakafka-1.2.0如下所示:[oracle@dbass ~]$ unzip orakafka.zip Archive: orakafka.zip creating: orakafka-1.2.0/
擷取中:orakafka-1.2.0/kit_version.txt
inflating:orakafka-1.2.0/orakafka_distro_install.sh
擷取:orakafka-1.2.0/orakafka.zip
inflating:orakafka-1.2.0/README
6. Now we follow the instructions found in the _**orakafka-1.2.0/README**_ for the setup of Oracle SQL access to Kafka. We follow _simple install_ for single-instance Oracle Database.
This README doc has instructions for Oracle SQL access to Kafka installation on Oracle Real Application Clusters (Oracle RAC) as well. By and large, in the case of Oracle RAC, we need to replicate the following steps on all nodes of Oracle RAC. Please follow the README for details.
[oracle@dbass ~]$ cd orakafka-1.2.0/
[oracle@dbass orakafka-1.2.0]$ ls -al
total 3944
drwxrwxr-x 2 oracle oinstall 4096 Feb 20 09:12 .
drwx—— 6 oracle oinstall 4096 Feb 19 17:39 ..
-rw-r–r– 1 oracle oinstall 6771 Oct 16 03:11 README
-rw-r–r– 1 oracle oinstall 5 Oct 16 03:11 kit_version.txt
-rw-rw-r– 1 oracle oinstall 3996158 Oct 16 03:11 orakafka.zip
-rwxr-xr-x 1 oracle oinstall 17599 Oct 16 03:11 orakafka_distro_install.sh
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
7. As per _./orakafka-1.2.0/README_, we install Oracle SQL access to Kafka on the Oracle Database host with the help of _./orakafka-1.2.0/orakafka\_distro\_install.sh_ script. Argument -p lets us specify the location or base directory for the Oracle SQL access to Kafka installation on this host.
We choose the newly created empty directory named ora\_kafka\_home as the OSaK base directory on this host. So the full path of the OSaK base directory will be _/home/oracle/ora\_kafka\_home_.
[oracle@dbass ~]$ ./orakafka-1.2.0/orakafka_distro_install.sh -p ./ora_kafka_home/
Step Create Product Home::
————————————————————–
…../home/oracle/ora_kafka_home already exists..
Step Create Product Home: completed.
PRODUCT_HOME=/home/oracle/ora_kafka_home
Step Create app_data home::
————————————————————–
….. creating /home/oracle/ora_kafka_home/app_data and subdirectories
……Generated CONF_KIT_HOME_SCRIPT=/home/oracle/ora_kafka_home/app_data/scripts/configure_kit_home.sh
……Generated CONF_APP_DATA_HOME_SCRIPT=/home/oracle/ora_kafka_home/configure_app_data_home.sh
Step Create app_data home: completed.
APP_DATA_HOME=/home/oracle/ora_kafka_home/app_data
Step unzip_kit::
————————————————————–
…..checking for existing binaries in /home/oracle/ora_kafka_home/orakafka
…..unzip kit into /home/oracle/ora_kafka_home/orakafka
Archive: /home/oracle/orakafka-1.2.0/orakafka.zip
creating: /home/oracle/ora_kafka_home/orakafka/
extracting: /home/oracle/ora_kafka_home/orakafka/kit_version.txt
inflating: /home/oracle/ora_kafka_home/orakafka/README
creating: /home/oracle/ora_kafka_home/orakafka/doc/
inflating: /home/oracle/ora_kafka_home/orakafka/doc/README_INSTALL
creating: /home/oracle/ora_kafka_home/orakafka/jlib/
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/osakafka.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/kafka-clients-2.5.0.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-simple-1.7.28.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/lz4-java-no-jni-1.7.1.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/snappy-java-no-jni-1.1.7.3.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/zstd-no-jni-1.4.4-7.jar
inflating: /home/oracle/ora_kafka_home/orakafka/jlib/slf4j-api-1.7.30.jar
creating: /home/oracle/ora_kafka_home/orakafka/bin/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka_stream.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/orakafka.sh
creating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/removeuser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/setup_all.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/remove_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/verify_install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/add_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/config_util.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_views.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/install.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/set_java_home.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/list_clusters.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/adduser_cluster.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/uninstall.sh
inflating: /home/oracle/ora_kafka_home/orakafka/bin/scripts/test_cluster.sh
creating: /home/oracle/ora_kafka_home/orakafka/conf/
inflating: /home/oracle/ora_kafka_home/orakafka/conf/orakafka.properties.template
creating: /home/oracle/ora_kafka_home/orakafka/sql/
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkatab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catnoorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/catorakafka.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaus.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_uninstall.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkab.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/pvtorakafkaub.plb
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafka_pkg_install.sql
inflating: /home/oracle/ora_kafka_home/orakafka/sql/orakafkas.sql
creating: /home/oracle/ora_kafka_home/orakafka/lib/
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libsnappyjava.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/libzstd-jni.so
inflating: /home/oracle/ora_kafka_home/orakafka/lib/liblz4-java.so
Step unzip_kit: completed.
Successfully installed orakafka kit in /home/oracle/ora_kafka_home
8. Configure JAVA\_HOME for Oracle SQL access to Kafka. We find the Java path on the node as follows:
[oracle@dbass ~]$ java -XshowSettings:properties -version 2>&1 > /dev/null | grep 'java.home'
java.home = /usr/java/jre1.8.0_271-amd64
[oracle@dbass ~]$ export JAVA_HOME=/usr/java/jre1.8.0_271-amd64
To set Java home for OSaK, we use the script _/home/oracle/ora\_kafka\_home/orakafka/bin/orakafka.sh_ script, with _set\_java\_home_ option.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh set_java_home -p $JAVA_HOME
Step1: Check for valid JAVA_HOME
————————————————————–
Found /usr/java/jre1.8.0_271-amd64/bin/java, JAVA_HOME path is valid.
Step1 succeeded.
Step2: JAVA version check
————————————————————–
java version “1.8.0_271”
Java(TM) SE Runtime Environment (build 1.8.0_271-b09)
Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
Java version >= 1.8
Step2 succeeded.
Step3: Creating configure_java.sh script
————————————————————–
Wrote to /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
Step3 succeeded.
Successfully configured JAVA_HOME in /home/oracle/ora_kafka_home/app_data/scripts/configure_java.sh
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/set_java_home.log.2021.02.20-04.38.23
[oracle@dbass bin]$
9. Verify installation of OSaK with _verify\_install_ option of script _orakafka.sh_ as follows:
[oracle@dbass ~]$ cd ora_kafka_home/
[oracle@dbass ora_kafka_home]$ cd orakafka/bin/
[oracle@dbass bin]$ 。/orakafka.sh verify_install
檢查所有檔案 / 目錄擁有權 - 傳遞
檢查目錄權限 - 傳送
檢查預期的可執行檔 - 傳送
上述資訊會寫入 /home/oracle/ora_kafka_home/app_data/logs/verify_install.log.2021.02.19-18.10.15
### Set Up Oracle Cloud Infrastructure Stream Clusters for Oracle SQL Access to Kafka
1. Under _ora\_kafka\_home_, that is _/home/oracle/ora\_kafka\_home_, we have two more READMEs as follows:
[oracle@dbass ~]$ 尋找 ora_kafka_home/ -name "README*"
ora_kafka_home/orakafka/README
ora_kafka_home/orakafka/doc/README_INSTALL
_~/ora\_kafka\_home/orakafka/README_ is the readme for this release of OSaK that we have installed. Please read through this readme.
And _ora\_kafka\_home/orakafka/doc/README\_INSTALL_ is the README for the actual setup of a Kafka cluster for Oracle SQL access to Kafka. The rest of the steps 2 onwards below follow this README by and large. As per the same, we will leverage _~/ora\_kafka\_home/orakafka/bin/orakafka.s_h script, for adding a Kafka cluster, adding an Oracle Database user for using the Kafka cluster in the next steps.
2. Add our Stream service stream pool to Oracle SQL access to Kafka.
As mentioned earlier, from the Oracle SQL access to Kafka point of view, the Stream service stream pool is a Kafka cluster.
We use the _add\_cluster_ option of the _orakafka.sh_ script to add the cluster to OSaK. We use the _\-c_ argument to name the cluster as _kc1_.
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh add_cluster -c kc1
Step1:建立檔案系統叢集組態目錄
---------------------
完成建立檔案系統叢集目錄。
在 /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties 設定安全特性。
Step1 成功。
Step2:產生建立叢集組態 DB 目錄的 DDL
---------------------
以 sysdba 身分連線時執行下列 SQL 命令檔
,以建立叢集組態資料庫目錄:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Step2 成功產生的命令檔。
****SUMMARY*****
TODO 作業:
- 在 /home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties 設定安全特性
- 以 sysdba 身分連線時執行下列 SQL:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
上述資訊會寫入 /home/oracle/ora_kafka_home/app_data/logs/add_cluster.log.2021.02.20-05.23.30
[oracle@dbass bin]$
We get two TODO tasks as per output from the above execution of the _add\_cluster_ command.
1. For the first task, we add security properties for our Stream service stream to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties`.
Where to get Kafka-compatible security configs for the Stream service cluster also known as (AKA) streampool? We get these security configs from the OCI web console as shown below.
Please take note of the bootstrap server endpoint(_cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092_ from the screenshot below) as well. It is not related to the security configs of the cluster, but we need it in later steps for connecting to our Stream service and Kafka cluster.

We write the above config values to OSaK in the following format, to `/home/oracle/ora_kafka_home/app_data/clusters/KC1/conf/orakafka.properties` file using any text editor like say vi.

For clarity, we have the same configs in text format as follows:
```
security.protocol=SASL_SSL
sasl.mechanism=PLAIN
sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>" password=" YOUR_AUTH_TOKEN";
sasl.plain.username="<YOUR_TENANCY_NAME>/<YOUR_OCI_USERID_HERE>/<YOUR_OCI_STREAMPOOL_OCID>"
sasl.plain.password ="YOUR_AUTH_TOKEN";
```
**Note:** default Kafka Consumer Configs are already pre-populated in _orakafka.properties_ for this cluster. If there is a need, one can modify these configs.
2. For the second TODO task, do SQL script execution as follows:
```
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 05:37:28 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_create_KC1_CONF_DIR.sql
Creating database directory "KC1_CONF_DIR"..
Directory created.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_create_KC1_CONF_DIR.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
```
Take note of directory object _KC1\_CONF\_DIR_ created by the above SQL script.
**Note:** As dictated in add\_cluster output, we run the SQL script as a _SYSDBA_ user, inside the PDB of our interest (_p0_ PDB here).
3. To make sure that the cluster configuration is working, we can leverage the _test\_cluster_ option of script _orakafka.sh_.
We pass cluster name with -c argument and bootstrap server with -b argument. We have from bootstrap server info from step 4.2.1.
```
[oracle@dbass bin]$ pwd
/home/oracle/ora_kafka_home/orakafka/bin
[oracle@dbass bin]$ ./orakafka.sh test_cluster -c kc1 -b cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
Kafka cluster configuration test succeeded.
Kafka cluster configuration test - "KC1"
------------------------------------------------------
KAFKA_BOOTSTRAP_SERVERS=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
LOCATION_FILE="/home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/orakafka_stream_KC1.loc"
ora_kafka_operation=metadata
kafka_bootstrap_servers=cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092
List topics output:
StreamForOsak,3
...
For full log, please look at /home/oracle/ora_kafka_home/app_data/clusters/KC1/logs/test_KC1.log.2021.02.20-09.01.12
Test of Kafka cluster configuration for "KC1" completed.
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/test_cluster.log.2021.02.20-09.01.12
[oracle@dbass bin]$
```
As you can see our Kafka cluster configuration test succeeded! We get the list of topics, AKA the Stream service streams in the output here. Topic names are followed by the number of partitions for that stream. Here we have the number of partitions as three, as the Stream service stream StreamForOsak has exactly three partitions.
3. Configure an Oracle Database user for the added Kafka cluster.
We already have created an Oracle Pluggable Databases (PDB) level Oracle Database user with username books\_admin, for the PDB named _p0_. We use the _adduser\_cluster_ option to grant required permissions for user books\_admin on Kafka cluster _kc1_.
[oracle@dbass bin]$ ./orakafka.sh adduser_cluster -c kc1 -u books_admin
Step1: Generate DDL to grant permissions on cluster configuration directory to "BOOKS_ADMIN"
--------------------------------------------------------------------------------------------
Execute the following script while connected as sysdba
to grant permissions on cluster conf directory :
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
Step1 successfully generated script.
***********SUMMARY************
TODO tasks:
1. Execute the following SQL while connected as sysdba:
@/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
The above information is written to /home/oracle/ora_kafka_home/app_data/logs/adduser_cluster.log.2021.02.20-10.45.57
[oracle@dbass bin]$
與上一個步驟類似,我們有一個要執行的 TODO 任務。
我們每個輸出都有一個自動產生的 SQL 命令檔。我們需要執行此命令檔 (以 sysdba 身分),為叢集 kc1 的叢集組態目錄提供 Oracle Database 使用者 books_admin 權限。
我們的情況是 /home/oracle/ora_kafka_home/app_data/clusters/KC1。
[oracle@dbass ~]$ sqlplus / as sysdba
SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 10:56:17 2021
Version 19.9.0.0.0
Copyright (c) 1982, 2020, Oracle. All rights reserved.
Connected to:
Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
SQL> alter session set container=p0;
Session altered.
SQL> @/home/oracle/ora_kafka_home/app_data/scratch/orakafka_adduser_cluster_KC1_user1.sql
PL/SQL procedure successfully completed.
Granting permissions on "KC1_CONF_DIR" to "BOOKS_ADMIN"
Grant succeeded.`
`The above information is written to /home/oracle/ora_kafka_home/app_data/logs/orakafka_adduser_cluster_KC1_user1.log
Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production
Version 19.9.0.0.0
[oracle@dbass ~]$
-
我們現在可以使用 orakafka.sh 的 install 選項。我們會將他所新增之 Kafka 叢集上,此使用者與其 OSaK 活動相關之資料的父項目錄 (使用 -p 引數)。
此命令會為我們自動產生兩個「資料定義語言 (DDL)」命令檔,如下所示:
[oracle@dbass bin]$ ./orakafka.sh install -u books_admin -r /home/oracle/ora_kafka_home/books_admin_user_data_dir Step1: Creation of filesystem location and default directories -------------------------------------------------------------- Created filesystem location directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir Created filesystem default directory at /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir Step1 succeeded. Step2: Generate DDL for creation of DB location and default directories -------------------------------------------------------------- Execute the following SQL script while connected as sysdba to setup database directories: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql On failure, to cleanup location and default directory setup, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step2 successfully generated script. Step3: Install ORA_KAFKA package in "BOOKS_ADMIN" user schema -------------------------------------------------------------- Execute the following script in user schema "BOOKS_ADMIN" to install ORA_KAFKA package in the user schema @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql On failure, to cleanup ORA_KAFKA package from user schema, please run "./orakafka.sh uninstall -u 'BOOKS_ADMIN'" Step3 successfully generated script. ***********SUMMARY************ TODO tasks: 1. Execute the following SQL while connected as sysdba: @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql 2. Execute the following SQL in user schema: @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install.log.2021.02.20-11.33.09 [oracle@dbass bin] -
第一個作業是執行 SQL 命令檔,以將 /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_location_dir 與 Oracle DB 的 /home/oracle/ora_kafka_home/books_admin_user_data_dir/orakafka_default_dir
註冊為目錄物件。如輸出中所述,我們需要以 SYSDBA 權限執行,如下所示:
[oracle@dbass ~]$ sqlplus / as sysdba SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:46:04 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> alter session set container=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/setup_db_dirs_user1.sql Checking if user exists.. PL/SQL procedure successfully completed. Creating location and default directories.. PL/SQL procedure successfully completed. Directory created. Directory created. Grant succeeded. Grant succeeded. Creation of location dir "BOOKS_ADMIN_KAFKA_LOC_DIR" and default dir "BOOKS_ADMIN_KAFKA_DEF_DIR" completed. Grant of required permissions on "BOOKS_ADMIN_KAFKA_LOC_DIR","BOOKS_ADMIN_KAFKA_DEF_DIR" to "BOOKS_ADMIN" completed. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/setup_db_dirs_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$記下上述 SQL 命令檔所建立的目錄物件,即 BOOKS_ADMIN_KAFKA_LOC_DIR 與 BOOKS_ADMIN_KAFKA_DEF_DIR。
現在我們開始前往第二個 TODO 工作。
-
此處會在 p0 PDB 上以 books_admin (而非 sysdba) 身分執行另一個 SQL 命令檔。此命令檔將安裝 Oracle SQL 存取 Kafka 套裝程式,以及屬於 books_admin 之綱要中的物件。
[oracle@dbass ~]$ sqlplus books_admin@p0pdb #p0pdb is tns entry for p0 pdb SQL*Plus: Release 19.0.0.0.0 - Production on Sat Feb 20 11:52:33 2021 Version 19.9.0.0.0 Copyright (c) 1982, 2020, Oracle. All rights reserved. Enter password: Last Successful login time: Fri Feb 19 2021 14:04:59 +00:00 Connected to: Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 SQL> ALTER SESSION SET CONTAINER=p0; Session altered. SQL> @/home/oracle/ora_kafka_home/app_data/scratch/install_orakafka_user1.sql Verifying user schema.. PL/SQL procedure successfully completed. Verifying that location and default directories are accessible.. PL/SQL procedure successfully completed. Installing ORA_KAFKA package in user schema.. .. Creating ORA_KAFKA artifacts Table created. Table created. Table created. Table created. Package created. No errors. Package created. No errors. Package body created. No errors. Package body created. No errors. The above information is written to /home/oracle/ora_kafka_home/app_data/logs/install_orakafka_user1.log Disconnected from Oracle Database 19c Standard Edition 2 Release 19.0.0.0.0 - Production Version 19.9.0.0.0 [oracle@dbass ~]$
以 Oracle Database 註冊串流服務叢集及建立串流檢視
在此步驟中,我們將使用 Oracle Database 進行叢集 kc1,並針對串流 StreamForOsak 建立視觀表。
此步驟的所有 SQL 查詢都是以使用者 books_admin 和 p0 PDB 身分執行。
- 使用 Oracle SQL 存取 Kafka 程序 ORA_KAFKA.REGISTER_CLUSTER 來註冊叢集。
BEGIN
ORA_KAFKA.REGISTER_CLUSTER
('kc1', -- cluster name
'cell-1.streaming.ap-mumbai-1.oci.oraclecloud.com:9092', -- fill up your bootstrap server here
'BOOKS_ADMIN_KAFKA_DEF_DIR', -- default directory for external table created in previous steps
'BOOKS_ADMIN_KAFKA_LOC_DIR', -- this directory object too is created in previous steps
'KC1_CONF_DIR', --config dir for cluster
'Registering kc1 for this session'); --description
END;
/
- 建立一個名為 BOOKS 的 Oracle Database 表格,此表格的綱要必須與 Kafka 主題 StreamForOsak 中的訊息相同。
CREATE TABLE BOOKS ( -- reference table. It is empty table. Schema of this table must correspond to Kafka Messages
id int,
title varchar2(50),
author_name varchar2(50),
author_email varchar2(50),
publisher varchar2(50)
);
/
- 使用 Oracle SQL 存取 Kafka 套裝程式 viz CREATE_VIEWS 的說明,建立 StreamForOsak 主題的檢視,如下所示。
DECLARE
application_id VARCHAR2(128);
views_created INTEGER;
BEGIN
ORA_KAFKA.CREATE_VIEWS
('kc1', -- cluster name
'OsakApp0', -- consumer group name that OSS or Kafka cluster sees.
'StreamForOsak', -- Kafka topic aka OSS stream name
'CSV', -- format type
'BOOKS', -- database reference table
views_created, -- output
application_id); --output
dbms_output.put_line('views created = ' || views_created);
dbms_output.put_line('application id = ' || application_id);
END;
/
Kafka 訊息、CSV 及 JSON 支援兩種格式:Oracle SQL 存取。此處使用 CSV。因此,Kafka 訊息符合 BOOKS 表格綱要的範例可以是 101、Famous Book、John Smith、john@smith.com、First Software。
tar xvf sqldeveloper-20.4.0.379.2205-20.4.0-379.2205.noarch.rpm
- 上述步驟將會為主題的每個分割區建立檢視。由於 StreamForOsak 主題有三個分割區,因此我們將使用三個檢視。每個檢視的名稱格式為 KV_<CLUSTER_NAME>_<GROUP_NAME>_TOPIC_<NUM_OF_PARTITION>。
此處有三個檢視,如下所示:每個分割區一個。
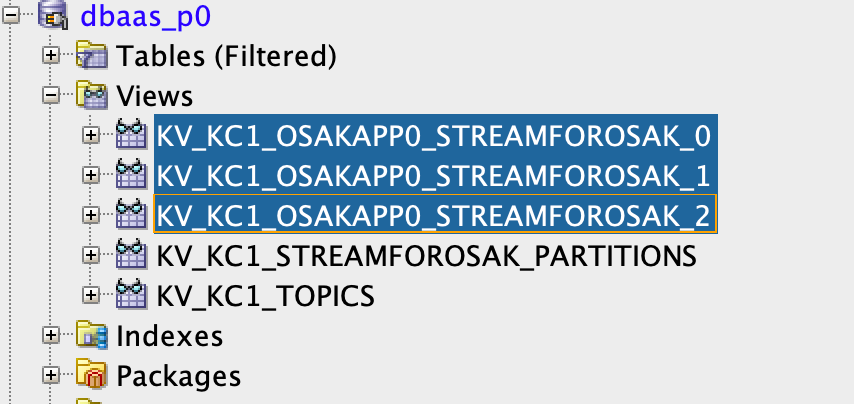
So view KV_KC1_OSAKAPP0_STREAMFOROSAK_0 is mapped to partition 0, view KV_KC1_OSAKAPP0_STREAMFOROSAK_2 is mapped to partition 1 and lastly, KV_KC1_OSAKAPP0_STREAMFOROSAK_0 is mapped to partition 2 of the topic StreamForOsak.
產生資料至串流
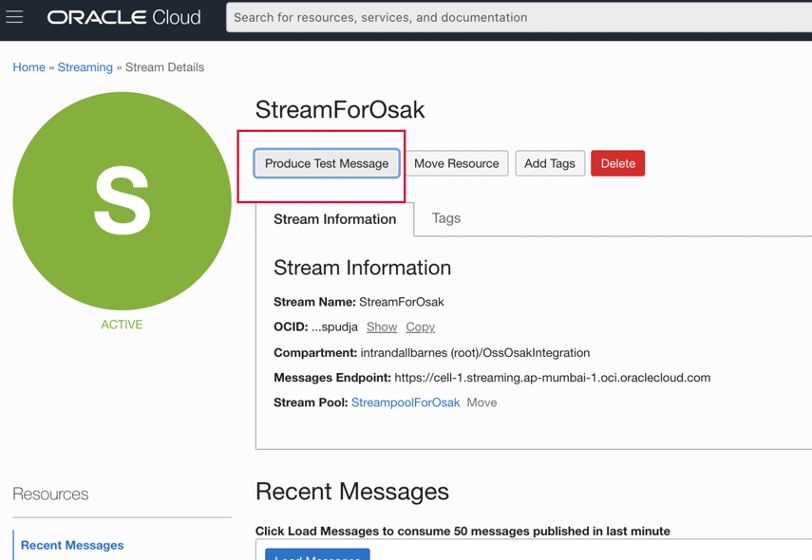
- 使用 Oracle Cloud Infrastructure (OCI) Web 主控台的「測試訊息」按鈕,產生串流 StreamForOsak 的測試訊息,如下所示。
按一下產生測試訊息時,會顯示含有欄位以輸入測試訊息的視窗,如下所示。
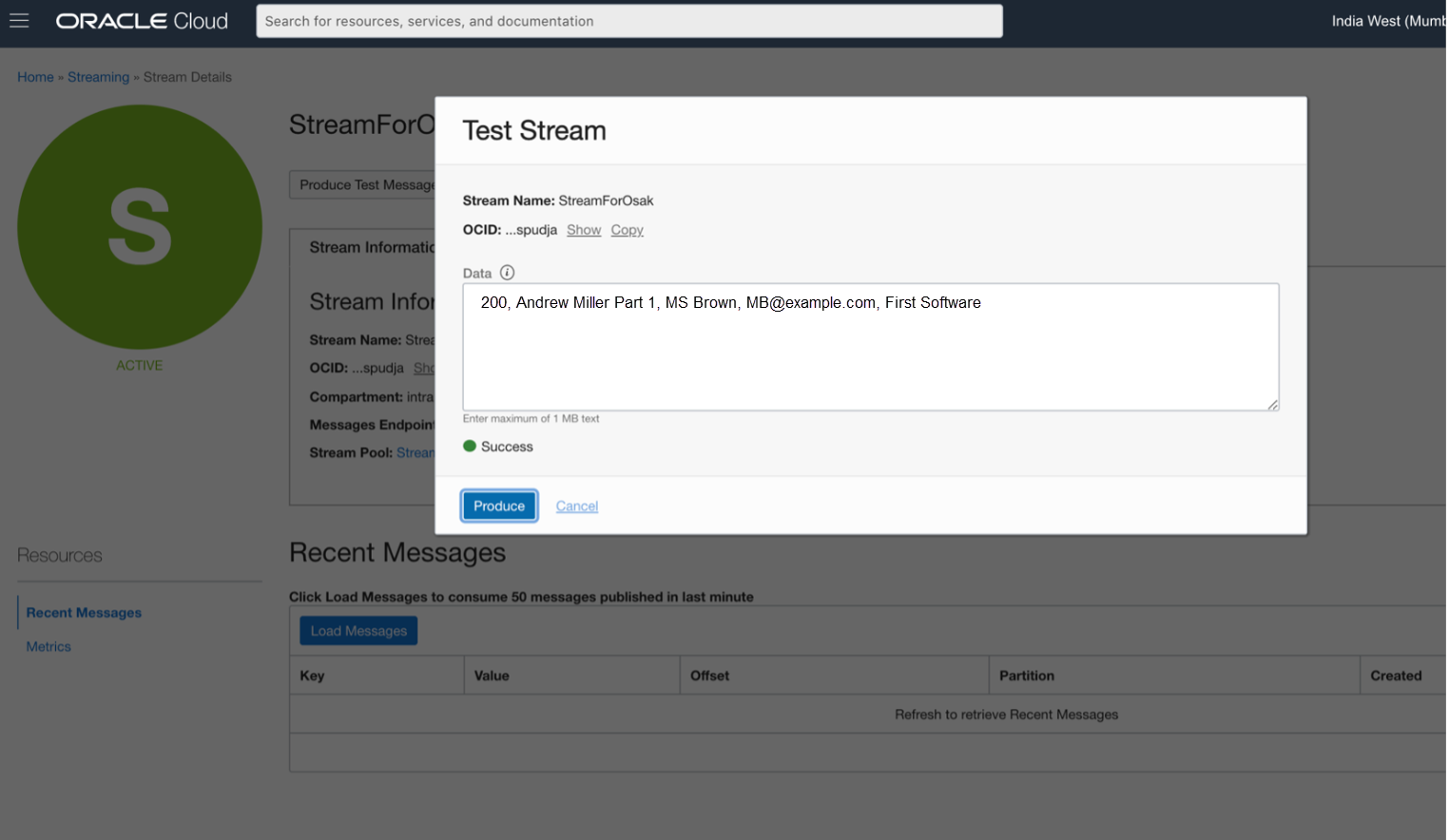
我們輸入下列訊息:
200,Andrew Miller 第 1 部分,MS Brown,mb@example.com,第一個軟體
不必說,我們可能還在串流服務的 Java/Python 或 OCI SDK 中使用標準 Kafka 產生器 API,以提供串流服務串流的訊息。
- 在上方視窗按一下產生之後,我們會發布訊息以串流 StreamForOsak。我們可以使用載入訊息公用程式查看訊息所在位置的分割區。
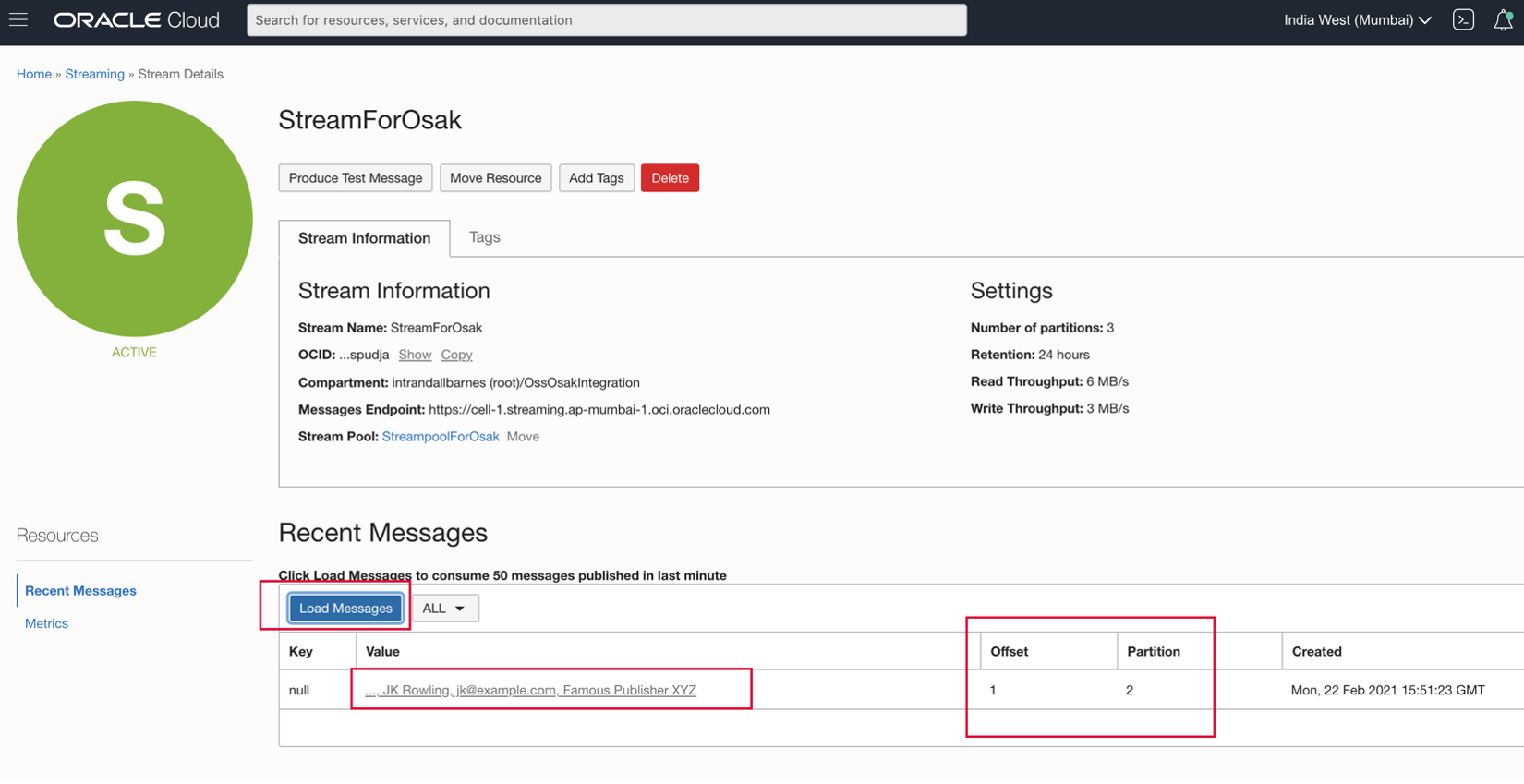
如上所示,我們的訊息位於 StreamForOsak 主題的分割區 2 中。
使用 Oracle SQL 對 Kafka 預存程序設定的資料庫檢視,擷取串流服務訊息
我們可以執行簡單的 SQL 查詢:
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_
或者,我們只要開啟檢視 SQL 開發人員查看檢視 KV_KC1_OSAKAPP0_STREAMFOROSAK_2 中的資料即可:

我們選擇檢視 KV_KC1_OSAKAPP0_STREAMFOROSAK_2,因為它對應至串流 StreamForOsak 的分割區 2。因此每次在此視觀表執行 SELECT SQL 查詢時,它會傳送至其相關主題的對應分割區,並以視觀表中的資料列方式擷取新的未確認訊息 (針對用戶群組 OsakApp0)。每則訊息會在檢視中取得自己的資料列。請注意,這些視觀表的資料不會保存。
好奇的眼睛,再加上 Oracle SQL 存取 Kafka 擷取和儲存描述資料資訊,例如訊息、其分割區和時戳在額外資料欄中。
大部分來說,您都想要再次查詢此檢視,而且對於每一次查詢執行,您希望該檢視在串流中循序移動。您可以使用下列正規程式碼片段來達到此目的:
LOOP
ORA_KAFKA.NEXT_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
SELECT * FROM KV_KC1_OSAKAPP0_STREAMFOROSAK_2_;
ORA_KAFKA.UPDATE_OFFSET(‘_KV_KC1_OSAKAPP0_STREAMFOROSAK_2_’);
COMMIT;
END LOOP;
如先前所述,當我們使用 Oracle SQL 存取 Kafka 時,串流偏移量是由 Oracle Database 所管理,而非串流服務。它們會保留在系統表格中,追蹤由 KV_KC1_OSAKAPP0_STREAMFOROSAK_2 檢視存取之所有分割區的偏移位置。
NEXT_OFFSET 呼叫只會將 KV_KC1_OSAKAPP0_STREAMFOROSAK_2 視觀表連結至一組新的偏移,這些偏移代表處於由視觀表存取之 Oracle Cloud Infrastructure Streaming 分割區中的新資料。UPDATE_OFFSET 代表每個分割區已讀取的資料列數目,並將偏移量提升到新位置。
COMMIT 保證這單位的工作符合 ACID 規範。
結論
本教學課程將焦點放在我們如何安裝 Oracle SQL 存取 Kafka 並搭配串流服務使用。由於串流服務相容於 Kafka,因此就像 Kafka 存取 Oracle SQL 的 Kafka 叢集一樣。
請注意,在這裡,我們與 Kafka 的存取權大到了由 Oracle SQL 提供的功能外表,速度幾乎非常密切。Kafka 的 Oracle SQL 存取權非常可設定。我們甚至可以將串流資料儲存在 Oracle Database 表格中,這些表格保存到磁碟中,與視觀表不同。請參考 Oracle SQL 中對 Kafka 安裝存取權所提供的 README 檔案,以及下列參照以瞭解詳細資訊。
相關連結
- 適用於 Oracle SQL 存取 Kafka 的 Oracle PL/SQL 開發人員文件
- Oracle SQL 上的 Oracle 部落格存取 Kafka
- 在 Oracle Big Data SQL 內存取 Kafka 的 Oracle SQL
- Oracle Cloud Infrastructure Streaming
- 串流服務 Kafka API 相容性
致謝
- 作者 - 解決方案設計師 Mayur Raleraskar
"`
其他學習資源
探索 docs.oracle.com/learn 上的其他實驗室,或是存取更多免費學習內容至 Oracle Learning YouTube 通道。此外,瀏覽 education.oracle.com/learning-explorer 以成為 Oracle Learning Explorer。
如需產品文件,請瀏覽 Oracle Help Center。
Stream analytics using Oracle Cloud Infrastructure Streaming and Oracle Database
F50458-01
November 2021
Copyright © 2021, Oracle and/or its affiliates.