Release 1 (9.0.1)
Part Number A89870-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Deployment and Performance Release 1 (9.0.1) Part Number A89870-02 |
|
![]()
![]()
This chapter discusses the deployment of online e-commerce (OLTP) and data warehousing applications in Oracle Real Application Clusters environments. This chapter also briefly describes application performance tuning.
This chapter includes the following topics:
Cache Fusion processing makes the Real Application Clusters database the optimal deployment server for online e-commerce applications. This is because these types of applications require:
To accommodate high availability, Cache Fusion offers multi-instance processing capabilities to re-distribute workloads to surviving instances without interrupting processing. Real Application Clusters also automatically re-masters resources to give the instance with the most activity on a particular datafile, for example, a greater share of control over the resources for that datafile.
Cache Fusion also provides excellent scalability so that if you add or replace nodes, Oracle automatically re-masters resources and evenly distributes processing loads without reconfiguration or application re-partitioning. Real Application Clusters also takes advantage of Oracle load balancing features.
Real Application Clusters' application workload management is dynamic. Real Application Clusters can alter workloads in real-time based on changing business requirements. This occurs in a manageable environment with minimal administrative overhead. The dynamic resource allocation capabilities of the Cache Fusion architecture provide optimal performance for online applications with great deployment flexibility.
E-commerce requirements, especially the requirements of online transaction processing systems, have workloads that change frequently. To accommodate this, Real Application Clusters deployments remain flexible and dynamic. They provide a wide range of service levels that, for example, might fluctuate due to:
To address these requirements, it is impractical and often too complex to partition packaged e-commerce applications, due to the limited access to table partitioning. Once deployed, such applications can access hundreds, or even thousands, of tables. Moreover, application partitioning is a difficult if not impossible task. A common recommendation is that you use a larger server or that you segment the application or application modules across distinct databases.
Segmenting applications, however, can fragment data and constrain a global enterprise-wide view of your information. Cache Fusion eliminates such requirements by dynamically migrating database resources to adapt to changing business requirements and workloads.
Cache Fusion dynamically allocates database resources to nodes based on data access patterns. This makes the data available on demand. In other words, if an instance recently accessed the data, the data is always in a local cache. The Cache Fusion architecture also migrates resources to accelerate data access, thus making Real Application Clusters a high performance e-commerce database platform.
Because re-partitioning efforts cannot keep pace with the rapid changes in system demand, Real Application Clusters also takes advantage of other features such as the shared server. Shared server greatly enhances scalability by providing connection pooling and Connection Load Balancing.
Tightly integrated, two-, three-, and n-tier architectures are rapidly replacing traditional, distributed designs. These architectures use a component-based approach to systems deployment. This means that in addition to the design and front-end development tasks required to launch viable web-based applications for Real Application Clusters, you may also need to consider your middleware performance requirements.
Expensive servers residing in multiple locations are being rapidly replaced by individual servers connected to middleware components. Newer n-tier architectures are obviously less costly because they eliminate redundant server hardware. They also eliminate redundant database connections and reduce the amount of data that must travel through the network.
In addition, traditional architectures are transitioning from requiring static, inflexible connections to using full-time, internet-based connectivity. This is especially true for business-to-business (B2B) models. Real Application Clusters allows seamless integration into the n-tier model's component-based architecture as shown in Figure 2-1.
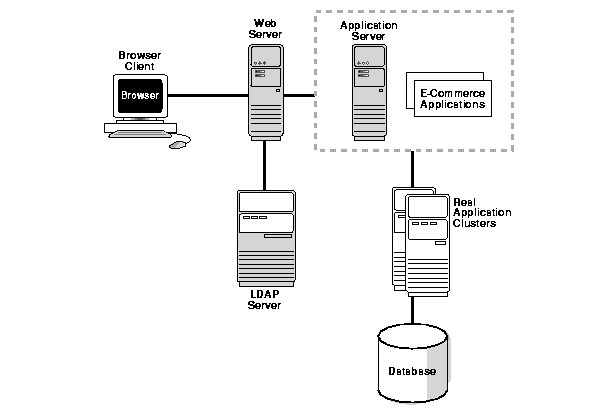
N-tier architectures provide enhanced scalability by encapsulating application functions within smaller subcomponents. These components are then linked within the n-tier framework. This combination:
N-tier architectures also improve manageability by reducing hardware and software overhead. In addition, n-tier architectures offer high availability and increased reliability by providing connection pooling and enhanced load balancing.
Because n-tier environments have more interrelated, interdependent components than traditional models, you should monitor and tune the performance of your Real Application Clusters environment at the following levels:
The Oracle9i Database Performance Guide and Reference and the Oracle9i Data Warehousing Guide for information that is specific to tuning the Oracle database, and your vendor's documentation for operating system tuning information
See Also:
This section discusses deploying data warehousing systems in Real Application Clusters environments by briefly describing the data warehousing features available in shared disk architectures. The topics in this section are:
Oracle9i Data Warehousing Guide for detailed information about implementing data warehousing in Real Application Clusters environments
See Also:
E-businesses strategically use data warehousing systems to acquire customers and expand markets. For example, company product promotions gather information using data warehousing systems to customize client lists that best fit the profiles of the company's target demographics.
Real Application Clusters is ideal for data warehousing applications because it augments the single instance benefits of Oracle. Real Application Clusters does this by maximizing the processing available on all nodes of a cluster to provide speed-up and scale-up for data warehousing systems.
Oracle's parallel execution feature uses multiple processes to execute SQL statements on one or more CPUs. Parallel execution is available on both single instance and Real Application Clusters databases.
Real Application Clusters takes full advantage of parallel execution by distributing parallel processing to all the nodes in your cluster. The number of processes that can participate in parallel operations depends on the degree of parallelism (DOP) assigned to each table or index.
On loosely coupled systems, Oracle's parallel execution technology uses a function shipping strategy to perform work on remote nodes. Oracle's parallel architecture uses function shipping when the target data is located on the remote node. This delivers efficient parallel execution and eliminates unneeded inter-node data transfers over the interconnect.
On some hardware systems, powerful data locality capabilities were more relevant when shared nothing hardware systems were popular. However, almost all current cluster systems use a shared disk architecture.
On shared nothing systems, each node has direct hardware connectivity to a subset of disk devices. On these systems it is more efficient to access local devices from the owning nodes. Real Application Clusters exploits this affinity of devices to nodes and delivers performance that is superior to shared nothing systems using multi-computer configurations and a shared disk architecture.
As with other elements of Cache Fusion, Oracle's strategy works transparently without data partitioning. Oracle dynamically detects the disk on which the target data resides and makes intelligent use of the data's location in the following two ways:
Oracle's cost-based optimizer considers parallel execution when determining the optimal execution plans. The optimizer dynamically computes intelligent heuristic defaults for parallelism based on the number of processors.
An evaluation of the costs of alternative access paths--table scans versus indexed access, for example--takes into account the degree of parallelism available for the operation. This results in Oracle selecting execution plans that are optimized for parallel execution.
Oracle also makes intelligent decisions in Real Application Clusters environments, with regard to intra-node and inter-node parallelism. In intra-node parallelism, for example, if a SQL statement requires six query sub-processes and six CPUs are idle on the local node (the node to which the user is connected), the SQL statement is processed using local resources. This eliminates query coordination overhead across multiple nodes.
Continuing with this example: if there are only two CPUs on the local node, then those two CPUs and four CPUs of another node are used to complete the SQL statement. In this manner, Oracle uses both inter-node and intra-node parallelism to provide speed-up for query operations.
In all real world data warehousing applications, SQL statements are not perfectly partitioned across the different parallel execution servers. Therefore, some CPUs in the system complete the assigned work and become idle sooner than others. Oracle's parallel execution technology is able to dynamically detect idle CPUs and assign work to these idle CPUs from the execution queue of the CPUs with greater workloads. In this way, Oracle efficiently re-distributes the query workload across all of the CPUs in the system. Real Application Clusters extends these efficiencies to clusters by re-distributing the work across all the nodes of the cluster.
Load balancing distributes parallel execution server processes to spread CPU and memory use evenly among nodes. It also minimizes communication and remote I/O among nodes. Oracle does this by allocating servers to the nodes that are running the fewest number of processes.
The load balancing algorithm maintains an even load across all nodes. For example, if a DOP of 8 is requested on an 8-node system with 1 CPU for each node, the algorithm places 2 servers on each node. If the entire parallel execution server group fits on one node, the load balancing algorithm places all the processes on a single node to avoid communications overhead. For example, if you use a DOP of 8 on a 2-node cluster with 16 CPUs for each node, the algorithm places all 16 parallel execution server processes on one node.
You can control which instances allocate parallel execution server processes with instance groups. To do this, assign each active instance to at least one or more instance groups. Then dynamically control which instances spawn parallel processes by activating a particular group of instances.
Establish instance group membership on an instance-by-instance basis by setting the INSTANCE_GROUPS initialization parameter to a name representing one or more instance groups. For example, on a 32-node system owned by both a Marketing and a Sales organization, you could assign half the nodes to one organization and the other half to the other organization using instance group names. To do this, assign nodes 1-16 to the Marketing organization using the following parameter syntax in your initialization parameter file:
sid|1-16|.INSTANCE_GROUPS=marketing
Then assign nodes 17-32 to Sales using the following syntax in the parameter file:
sid|17-32|.INSTANCE_GROUPS=sales
Activate the nodes owned by Sales to spawn a parallel execution server process by entering the following:
ALTER SESSION SET PARALLEL_INSTANCE_GROUP = 'sales';
In response, Oracle allocates parallel execution server processes to nodes 17-32. The default value for PARALLEL_INSTANCE_GROUP is all active instances.
Disk affinity refers to the relationship of an instance to the data that it accesses. The more often an instance accesses a particular set of data, the greater the affinity that instance has to the disk on which the data resides.
Disk affinity minimizes data shipping and internode communication on a shared nothing architecture. Disk affinity can thus significantly increase parallel operation throughput and decrease response time.
Disk affinity is used for parallel table scans, parallel temporary tablespace allocation, parallel DML, and parallel index scans. It is not used for parallel table creation or parallel index creation. Access to temporary tablespaces preferentially uses local datafiles. It guarantees optimal space management extent allocation. Disks striped by the operating system are treated by disk affinity as a single unit.
Without disk affinity, Oracle attempts to balance the allocation of parallel execution servers evenly across instances. With disk affinity, Oracle allocates parallel execution servers for parallel table scans on the instances that are closest to the requested data.
In the disk affinity example in Figure 2-2, table T is distributed across 3 nodes, and a full table scan on table T is being performed.
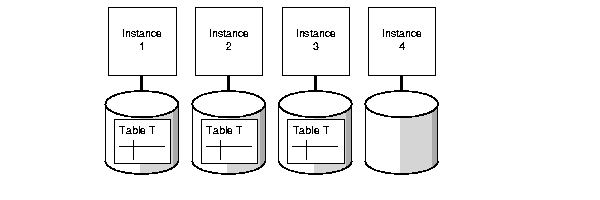
T, each requiring 3 instances (and enough processes are available on the instances for both operations), then both operations use instances 1, 2, and 3. Instance 4 is not used. In contrast, without disk affinity, instance 4 is used.
Testing application scalability, availability, and load balancing is one of the most challenging aspects of internet-based deployment. In rapid prototyping environments, you can internally test and benchmark your site with a limited number of Real Application Clusters instances on a test hardware platform.
All applications have limits on the number of users they support given the constraints of specific hardware and software architectures. To accommodate anticipated demand, you can estimate the traffic loads on your system and determine how many nodes you need. You should also consider peak workloads.
Your scalability tests must also simulate user access to your web site. To do this, configure your traffic generator to issue pseudo get commands as used in the Hypertext Transfer Protocol (http). This tests your system's performance and load processing capabilities under fairly realistic conditions.
You can then conduct structured, web-based testing using traffic generators to stress-test your system. This type of persistent testing against your most aggressive performance goals should reveal design and capacity limitations.
After making further enhancements as dictated by your testing results, prototype your site to early adopters. This enables you to obtain real-world benchmarks against which you can further tune your system's performance.
As mentioned in Chapter 1, Real Application Clusters takes advantage of several features that enhance scalability. For example, the shared server allows more users to access your system and efficiently controls database connectivity among users.
Optimizing application performance requires that you develop a representative workload profile using a tool that computes each application module's CPU and Program Global Area (PGA) memory usage. Oracle also records statistics about programs as well as information about how program modules connect to the database. The recommendations for developing workload profiles and tuning applications for Real Application Clusters appear in Chapter 3, "Scaling Applications for Real Application Clusters".
You may need to add nodes before deployment or during production to accommodate growth requirements or to replace failed hardware. Adding a node to your Real Application Clusters environment involves two main steps:
To add a node, connect the hardware according to your vendor's installation instructions. Then install the clusterware and the operating system-dependent layer (OSD). Complete the installation of the instance on the new node using the Oracle Universal Installer (OUI) and the Oracle Database Configuration Assistant (DBCA).
|
See Also:
Oracle9i Real Application Clusters Administration for detailed procedures on adding nodes and instances |
The next part of this book describes application scaling and database design for Real Application Clusters.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|