Release 1 (9.0.1)
Part Number A89870-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Deployment and Performance Release 1 (9.0.1) Part Number A89870-02 |
|
![]()
![]()
This chapter provides an overview of tuning issues for Oracle Real Application Clusters. It presents a general methodology for tuning applications for Real Application Clusters environments and includes the following topics:
Chapter 7, "Monitoring Performance with Oracle Performance Manager" for more information on using Oracle Enterprise Manager to monitor and tune Real Application Clusters databases
See Also :
Cache Fusion resolves the types of inter-instance contention that were once responsible for most Real Application Clusters overhead: read/write and write/write contention. Because Cache Fusion virtually eliminates forced disk writes, release 1 (9.0.l) of Real Application Clusters requires less tuning than previous releases to achieve scalability.
Many single instance tuning practices are useful for Real Application Clusters applications. However, you must also effectively size the buffer cache and shared pool. You must also tune your shared disk subsystems with Real Application Clusters-specific goals in mind. In addition, you should collect Real Application Clusters-specific statistics and monitor views using the methods described in this chapter.
With experience, you can anticipate many performance problems before deploying Real Application Clusters applications. However, even the most effective tuning cannot overcome problems caused by poor analysis or database and application design flaws. Therefore, make sure you have thoroughly considered the issues discussed in Part II of this book, "Scaling Applications and Designing Databases for Real Application Clusters", before evaluating and tuning performance.
This section provides a brief description of Real Application Clusters application performance statistics. Topics in this section include:
Oracle maintains most statistics in the local System Global Area (SGA). Access these statistics using SQL statements against V$ views as described in this chapter.
Real Application Clusters-specific statistics appear as message request counters or timed statistics. Message request counters include statistics showing the number of a certain type of block mode conversion. Timed statistics, for example, reveal the total or average time waited for read and write I/O on particular operations.
Oracle Corporation recommends that you record statistics about the rates at which certain events occur. Also record information about specific transactions within your Real Application Clusters environment. Do this with utilities such as Oracle9i Statspack or UTLBSTAT and UTLESTAT by recording statistics over a period of time to capture them for specific measurement intervals. In addition, Oracle9i Statspack has a page dedicated to displaying Real Application Clusters performance information.
These utilities compute statistics counts per second and per transaction. You can also use them to measure the number of statement executions and the number of business transactions that applications submit.
For example, an insurance application might define a transaction as the processing of an insurance quote. This transaction might be composed of several DML operations and queries. If you know how many of these quotes your system processes in a certain time interval, then divide that value by the number of quotes completed in the interval. Do this over a period of time to gauge performance.
Performance trends in application profiles appear in terms of the resources used per transaction and the application workload. The counts per transaction are useful for detecting changing workload patterns, while rates indicate the workload intensity.
You can trace the execution history of Oracle using the TRACE_ENABLED parameter. The TRACE_ENABLED parameter is set to true by default to control tracing of the execution history, or code path, of Oracle. Oracle Support uses this information for debugging.
In Real Application Clusters, you must set this parameter to the same value for all instances. You can set TRACE_ENABLED within your initialization parameter file, or by using the ALTER SYSTEM SET statement.
When TRACE_ENABLED is set to true, Oracle records information in specific files when errors occur. Table 5-1 shows the types of files and the UNIX default destination directories in which Oracle records the execution history.
| Trace File Type | Destination Directory |
|---|---|
|
User |
|
|
Background |
|
|
Core |
|
Oracle records this information for all instances, even if only one instance terminates. This allows Oracle to retain diagnostics for the entire cluster.
Although the overhead incurred from this processing is not excessive, you can improve performance by setting TRACE_ENABLED to false. You might do this, for example, to meet high-end benchmark requirements. However, if you leave this parameter set to false, you may lose valuable diagnostic information. Therefore, always set TRACE_ENABLED to true to trace system problems and to reduce diagnostic efforts in the event of unexplained instance failures.
The most significant statistics for Real Application Clusters are:
Two of the most important views for displaying Real Application Clusters-specific statistics are V$SYSSTAT and V$SYSTEM_EVENT. The next section provides more details about the contents of these and other views for tuning Real Application Clusters.
This section describes the content and use of several views for monitoring Real Application Clusters. The topics in this section are:
The V$SYSSTAT view provides statistics about your entire Real Application Clusters environment. That is, the statistics are global. Real Application Clusters-specific statistics in V$SYSSTAT belong to classes 8, 32, and 40 as shown in Table 5-2.
The V$SYSTEM_EVENT view provides statistics about the frequency with which Oracle processes have to wait for events. They also show the number of timeouts for these events and their cumulative and average durations. These events are also referred to as waits. The statistics in V$SYSTEM_EVENT that are relevant to Real Application Clusters are:
You can also analyze operating system statistics that reveal CPU use and disk I/O. The procedures in this chapter can help you analyze these statistics to determine the amount of CPU that Oracle uses for certain background processes such as:
Other important statistics appear in the following views:
The statistics in these views that are relevant to Real Application Clusters relate to the following performance issues:
In Real Application Clusters, application performance and scalability are determined by the rate and cost of synchronization among instances. You can measure the costs by identifying how effectively transactions use CPU resources to:
You can also calculate CPU time spent:
Statistics about these events appear in V$ tables such as V$SYSTEM_EVENT. The response time for each transaction depends on the number of resource operations. Response time also depends on the time required to process the instructions, plus the delay or wait time for each request. Disk I/O incurred when using non-default resource control increases response time.
Contention on certain resources adds to the cost of each measurable component. For example, the following events can result in waits for busy buffers:
This can in turn increase costs for each transaction and increase your operating system overhead.
As described in Chapter 3, you can create Real Application Clusters applications that are more scalable and that perform well by designing them to minimize inter-node synchronization and communication requirements. Scalable applications meet user service level requirements by minimizing either the rate or the cost of synchronization.
Consider some of the tuning recommendations to improve workload performance as described in this section. The topics in this section are:
In Real Application Clusters, application performance and scalability are determined by the rate and cost of synchronization among instances. Overhead from the Global Cache and Global Enqueue Services might occur when transactions wait for I/O events and block access mode convert requests. Conflicts for blocks between local and remote transactions while opening or converting block access modes can increase synchronization costs. For example, you can estimate the cost of a transaction or request using the following formula:
Use the V$CLASS_CACHE_TRANSFER and V$FILE_CACHE_TRANSFER views to determine the rate of cache block transfers and their block access mode conversion rates. V$CLASS_CACHE_TRANSFER provides a summary of forced disk write activity for each block class. V$FILE_CACHE_TRANSFER shows the amount of cache transfer activity occurring in your environment on a per-file basis.
Both of these views have several different types of forced write columns. There is one forced write column for each type of conversion. However, the columns in these views that refer to forced writes remain 0 (zero). A non-zero value indicates that cache transfers are occurring.
The V$CACHE, V$CACHE_TRANSFER, and V$BH views show the block classes and blocks that Oracle transfers over the interconnect on a per-object basis. Use the FORCED_READS and FORCED_WRITES columns in these views to determine which objects and blocks your Real Application Clusters instances use. This information can help characterize your system's workload. The FORCED_WRITES column provides a count of how often a certain block experiences a forced disk write out of a local buffer cache because the current version was requested by another instance.
Also use V$FILE_CACHE_TRANSFER to identify files that experience cache transfers. If a file shows significant cache transfer activity, then it could also mean the file is experiencing excessive forced disk write activity.
I/O synchronization costs can adversely affect performance. To evaluate the effects of I/O synchronization, use the V$SYSSTAT view for the counts of the following request statistics:
Also refer to the V$SYSTEM_EVENT view for time waited and average waits for the following statistics:
To estimate the time waited for reads incurred by re-reading data blocks that Oracle had to write to disk due to requests from other instances, divide the statistic, for example, the time waited for db file sequential reads, by the percentage of read I/O caused by previous cache flushes as shown in this formula where lock buffers for read is the value for block access mode conversions from N to S derived from V$LOCK_ACTIVITY and physical reads is a value from the V$SYSSTAT view:
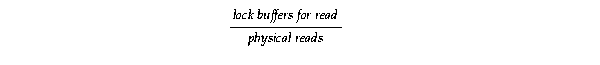
Similarly, estimate the proportion of the time waited for database file cross-instance writes caused by cache transfers by dividing the db file parallel write time in V$SYSTEM_EVENTS where DBWR cross-instance writes and physical writes are values from V$SYSSTAT:
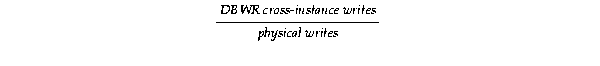
This section explains how to determine the cost incurred by synchronization and coherency processing between instances due to additional CPU time, I/O, and global resource processing and contention. To do this, examine Oracle statistics as described in the following sections:
To derive the CPU service time required per transaction, divide the CPU used by a session as shown in V$SYSSTAT by the number of user commits or the number of business transactions. Note that this is the amount of time required by the user process to execute in either user or kernel mode. This does not include the time spent by the operating system kernel on behalf of a transaction.
This measure is useful for comparing how single instance environment applications behave when running in exclusive mode as compared to how application run in Real Application Clusters environments. This measure is also useful for comparing the effects of different workloads and application design changes.
Table 5-3 describes some of the statistics in the V$SYSSTAT and V$SYSTEM_EVENT global cache coherency-related views.
| View | Statistics |
|---|---|
|
Refer to |
global cache gets (count of new resources opened) global cache converts (count of conversions for blocks) global cache cr blocks received (count of consistent read buffers received from the Global Cache Service process (LMS)) global cache cr blocks served (count of consistent read buffers sent by LMS) global cache current blocks received (count of current blocks received) global cache current blocks served (count of current buffers sent to remote instance)
Note: Also refer to the convert type-specific rows in |
|
Refer to |
global cache cr block receive time global cache cr block build time global cache cr block flush time global cache cr block send time global cache current block receive time global cache current block pin time |
|
Refer to |
Refer to the following statistics and views for indicators of high contention or excessive delays:
V$SYSSTAT
V$SYSTEM_EVENT
As mentioned, it is useful to maintain application profiles per transaction and per unit of time. This enables you to compare two distinct workloads and to detect workload changes. These rates are also helpful in determining capacities and for identifying throughput issues. To do this, Oracle Corporation recommends that you incorporate the following ratios of statistics in your performance monitoring scripts:
The Global Cache Service (GCS) performs block mode conversions at a per transaction rate of:
Block transfer throughput consists of the per transaction rates of:
Or per transaction rates of cache convert waits for block mode conversions such as:
Or per transaction rates of cache open waits for block mode conversions such as:
Calculate the same statistics per second or per minute by dividing the total counts or times waited by the appropriate measurement interval.
The percentage of buffers accessed for global work, or the percentage of cache-to-cache block transfers caused by inter-instance synchronization, can be important measures of how efficiently your application processes share data. These percentages can also reveal whether you have designed your database for optimum scalability.
Use the following calculation based on statistics from V$SYSSTAT to determine the percentage of buffer accesses for local operations, in other words, reads and changes of database buffers that are not subject to block mode conversions:
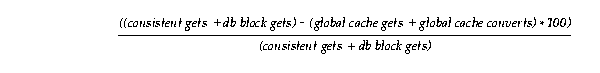
Also consider the following formula where lock buffers for read is from V$LOCK_ACTIVITY:
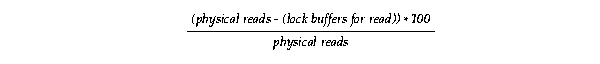
This calculation implies the percent of physical reads by user processes for local work only; it does not refer to forced reads.
In the previous formula, subtract lock buffers for read from the physical read statistic in V$SYSSTAT. Base the local write ratio entirely on the corresponding values from V$SYSSTAT.
Apart from determining the proportion of local and global work (the degree of partitioning) you can also use these percentages to detect changing workload patterns. Moreover, these percentages represent the probability that a data block access is either local or global. You can therefore use this information as a rough estimator in scalability calculations.
In addition to these ratios, the proportion of delays due to unavailable resources is easy to derive using the formula:
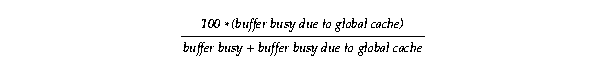
Or more generally:
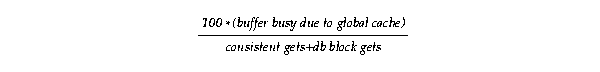
When the GCS opens resources and performs block mode conversions, the percentage of waits that are caused by unavailable resources (resources that are being acquired or released) can indicate contention. The contention can be due to either delays in opening or converting block modes or very high contention on small sets of buffers.
Once you identify a problem area, such as a high ratio of global busy waits, converts, and gets, obtain more detail about the problem by referring to the following three views:
The statistics in these views identify the files and blocks shared by all instances. These shared files may be responsible for most inter-instance synchronization costs and global cache coherency processing.
You can also query these views to learn about block mode conversions for each file or for each block class. Indirectly, this also indicates the number cache transfers due to the shared cache architecture.
Reduced throughput and degradation of transaction response times are the result of increased inter-instance synchronization costs. These problems can have several sources as described in this section under the following headings:
Contention for the same data blocks occurs if rows commonly accessed from multiple instances are spread over a limited range of blocks. The probability of this happening depends on the access distribution of the data within the table as a result of the application's behavior.
The probability of contention can also depend on the block size. For example, more rows fit into an 8K block than into a 4K block. The PCTFREE that you defined for the table can also affect the level of contention. In fact, database block size and PCTFREE can be part of your Real Application Clusters design strategy: your goal is to reduce the number of rows for each block and thus the probability of conflicting access. Indicators of very hot globally accessed blocks include frequent convert timeouts or consistent read timeouts.
If you see a high proportion of global cache resource waits per transaction, then consider determining which files and blocks are accessed frequently from all nodes. The following describes how to use three views to identify files that are experiencing contention.
The V$CACHE, V$CACHE_TRANSFER, and V$BH views show the block classes and blocks that Oracle transfers over the interconnect on a per-object basis. The value for FORCED_WRITES in these views should always be 0 (zero). This is because an LMS process transfers blocks directly to the remote instance's cache. LMS processes ship both the consistent read and the current blocks. In this case, the LMS process starts, but its role is reduced.
With Cache Fusion, the values in the FORCED_READS column indicates the number of times Oracle transferred a current version of particular block from another cache. Therefore, evaluating the values in the FORCED_READS column helps identify tables and indexes that are subject to high cache fusion activity.
Contention for segment headers can occur when Oracle must read table or index headers while many transactions simultaneously update them. This usually happens when transactions search for blocks with enough free space to hold the data to be inserted or updated. Oracle also updates a segment header if Oracle adds new extents or additional free blocks the table.
New applications that insert a significant amount of data from multiple nodes can become serious performance bottlenecks. This is because Oracle copies the segment header block containing the free lists into another instance's cache. This can result in a single point of contention.
You can significantly improve this situation by creating free list groups for the tables and indexes causing the problem. The advantage of using free list groups is to partition access to segment free lists according to instance. This reduces conflicts between among when the INSERT and DELETE rates are excessive.
Contention for resources other than database blocks should be infrequent. However, when this occurs, it adversely affects performance. Usually, there are two areas that can exhibit such problems as discussed in the following sections:
The use of uncached Oracle sequences or poorly configured space parameters for a table or tablespace can cause frequent data dictionary changes. If Oracle frequently reads data dictionary objects and updates them from more than one instance, then Oracle flushes the changes to the redo log and sends the block to the requesting instance. Unfortunately, these objects are often used in recursive, internal transactions while other resources are held. Due to the complexity of these internal data dictionary transactions, this processing can cause serious delays.
These delays increase the values for the row cache lock wait count and time waited statistics in V$SYSTEM_EVENT. Thus, these events become two of the most waited-for events. The percentage of time waited for row cache locks should never be more than 5% of the total wait time.
Query the V$ROWCACHE view to determine which objects in the row cache might be causing delays. Oracle's response to your query is the name of the row cache object type, such as DC_SEQUENCES or DC_USED EXTENTS, as well as the GCS requests and GCS conflicts for these objects. If the conflicts exceed 10 to 15 percent of the requests, and if the row cache lock wait time is excessive, then resolve the conflicts by caching sequence numbers, defragmenting the tablespaces, or by tuning the space parameters.
Most frequently, problems occur when Oracle creates sequences without the CACHE option. In these cases, the values for DC_SEQUENCES show high GCS conflict rates. Frequent space management operations due to fragmented tablespaces or inadequate extent sizes can result in cache transfers for DC_USED_EXTENTS and DC_FREE_EXTENTS objects in the data dictionary cache.
Frequent data dictionary changes usually affect data blocks from the data dictionary tables. These blocks normally belong to file number 1. In this situation, you can find copies of these blocks in each instance's buffer cache when you query V$CACHE or V$CACHE_TRANSFER.
Library cache performance problems in Real Application Clusters are rare. They usually manifest themselves as excessive wait times for library cache pins. They can result from frequent re-parsing of cursors or from the loading of procedures and packages. Query the DLM columns in the V$LIBRARYCACHE view to obtain more detail about this problem.
Cross-instance invalidations of library cache objects should be rare. However, such invalidations can occur if you drop objects referenced by a cursor that is executed in two instances.
There are some significant contention problems that you should avoid in Real Application Clusters environments. These contention problems result from inserts into index blocks when multiple instances share sequence generators for primary key values. You can minimize these problems by doing the following as described in this section:
A sequence number multiplier can prevent instances from inserting new entries into the same index. For example, use a multiplier such as SEQUENCE_NUMBER x INSTANCE_NUMBER x 1,000,000,000. This multiplier greatly increases the likelihood that a sequence number for an instance is unique.
Always use the CACHE clause when creating Oracle sequences. Creating sequences without using the CACHE clause can create excess overhead. It can also cause synchronization overhead if both instances use the same sequence.
|
See Also:
Oracle9i SQL Reference for more information about |
This section explains how to identify and resolve performance problems in Real Application Clusters-based applications. It contains the following topics:
Query-intensive applications benefit from tuning techniques that maximize the amount of data for each I/O request. Before trying these techniques, monitor performance both before and after implementing them to assess their effectiveness. The techniques are:
Use a large block size to increase the number of rows that each operation retrieves. A large block size also reduces the depth of your application's index trees. Your block size should be at least 8K if your database is used primarily for processing queries.
Also set the value for DB_FILE_MULTIBLOCK_READ_COUNT to the largest possible value. Doing this improves the speed of full table scans by reducing the number of reads required to scan the table. Note that your system I/O is limited by the block size multiplied by the number of blocks read.
If you use operating system striping, then set the stripe size to DB_FILE_MULTIBLOCK_READ_COUNT multiplied by the DB_BLOCK_SIZE times 2. If your system can differentiate index stripes from table data stripes, then use a stripe size of DB_BLOCK_SIZE multiplied by 2 for indexes.
Also remember to:
TEMPORARY
Transaction-based applications generally write more data to disk than other application types. You can use several methods to optimize transaction-based applications. However, you cannot use these techniques on all types of systems. Monitor your application's performance both before and after initiating these methods to make sure it is acceptable.
To improve the ability of the database writer processes (DBWn) to write large amounts of data quickly, use asynchronous I/O. Oracle uses multiple DBWn processes to improve performance.
If you have partitioned users by instance and if you have enough space to accommodate the multiple free lists, then use free list groups. This helps your application avoid dynamic data partitioning. You can also manually partition tables by value. If the access is random, then consider using a smaller block size.
In addition to these points, also:
If your application is not performing well, then analyze each component of the application to identify which components are causing problems. To do this, check the operating system and GCS statistics for signs of contention or excessive CPU usage as explained under the next heading. Measurable block mode conversions that are excessive can reveal high read/write activity or high CPU requirements by GCS components.
If your application is not performing optimally, then consider examining statistics as described in the following points:
UTLBSTAT and UTLESTAT. Then query the V$SQL view. Examine the statistics from this view and analyze the hit ratios in the shared pool and the buffer cache.
CATCLUST.SQL.
V$LOCK_ACTIVITY table to monitor block mode conversion rates.
V$BH table to identify which blocks are being forced written to disk. The V$BH table sums the number of times each block's access modes are downgraded from exclusive to null.
V$CACHE_TRANSFER view shows rows from the V$CACHE table where the exclusive-to-null count is non-zero.
Using advanced queuing in Real Application Clusters environments introduces functionality and performance-related issues as described in this section:
Queue table instance affinity enables you to assign primary and secondary instance properties to queue tables. This allows automatic assignment of queue table ownership when instances shut down and restart. You can evaluate queue table instance affinity by querying the following views:
GCS resource acquisition is more expensive than local resource or local enqueue acquisition. If you improperly deploy advanced queuing, then its resource control behavior can adversely affect performance in Real Application Clusters environments. To avoid this, consider implementing the following:
"Disabling Table Locks for Individual Tables" for more information on disabling table locks
See Also:
In general, cache transfers of queue table data blocks and queue table index blocks can occur under the following circumstances:
You can reduce the frequency of cache block transfers by:
Oracle9i Application Developer's Guide - Advanced Queuing for general information about using Advanced Queuing
See Also :
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|