Release 1 (9.0.1)
Part Number A89870-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Real Application Clusters Deployment and Performance Release 1 (9.0.1) Part Number A89870-02 |
|
![]()
![]()
This chapter describes Oracle Real Application Clusters- and Cache Fusion-related statistics and provides procedures that explain how to use them to monitor and tune performance. This chapter also briefly explains how Cache Fusion resolves reader/writer and writer/writer conflicts in Real Application Clusters by describing Cache Fusion's benefits in general terms that apply to most system and application types. The topics in this chapter include:
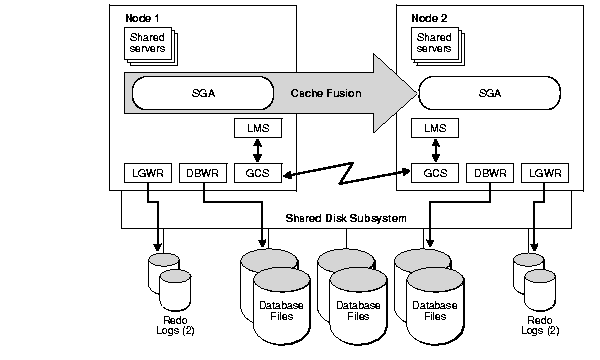
When one instance requests the most current copy of a data block and that copy is in the memory cache of a remote instance, Cache Fusion resolves the read/write or write/write conflict using remote memory access, not disk access.
When an instance sends a request for a consistent-read copy or current image of a block to a holding instance, the holding instance logs the changes made to the block and forces a log flush. Global Cache Service Processes (LMSn) on the holding instance transmit the requested image of the block, as consistent read blocks or current blocks, directly from the holding instance's buffer cache to the requesting instance's buffer cache across a high speed interconnect.
Figure 6-1 illustrates how Cache Fusion enables the buffer cache of one node to send data blocks directly to the buffer cache of another node using low latency, high speed interconnects. This reduces the need for expensive disk I/O. Cache Fusion also leverages new interconnect technologies for low latency, user-space based, interprocessor communication. This potentially lowers CPU use by reducing operating system context switches for inter-node messages.
Cache Fusion improves application transaction throughput and scalability by providing:
Applications with hot spots due to blocks read or modified by multiple instances or benefit the most from Cache Fusion. Packaged applications also scale better as a result of Cache Fusion. Applications in which online transaction processing (OLTP) and reporting functions execute on separate nodes can also take advantage of Cache Fusion. In particular, the more critical OLTP response times benefit significantly from Cache Fusion.
Reporting functions that access data from tables modified by OLTP functions receive consistent read versions of data blocks by way of high speed interconnects. Oracle9i release 1 (9.0.1) reduces the forced disk writes of data blocks. Performance gains are derived primarily from reduced X-to-S block access mode conversions and the corresponding reduction in disk I/O for X-to-S block access mode conversions.
Furthermore, the instance that was changing the cached data block before it received a read request for that block from another instance did not have to request exclusive access to the block again for subsequent changes. This is because the instance that was changing the block retains the block in exclusive mode after the block is shipped to the reading instance.
With Cache Fusion in Oracle9i release 1 (9.0.1), when an instance requests a block in exclusive mode that is currently dirty and in another instance's cache, Oracle still performs an X-to-N block mode conversion (or X-to-S if the block was globally clean). However, this down-convert operation is less expensive in release 1 (9.0.1) in terms of overhead, because the requesting instance receives the block by way of the interconnect. This is significantly faster than the forced disk write processing typical of previous Oracle releases.
Because Cache Fusion exploits high speed IPCs, Real Application Clusters benefits from the performance gains of the latest technologies for low latency communication across cluster interconnects. You can expect even greater performance gains if you use more efficient protocols, such as Virtual Interface Architecture (VIA) and user-mode IPCs.
Cache Fusion reduces CPU use by taking advantage of user-mode IPCs, also known as memory-mapped IPCs, for UNIX, Windows NT, and Windows 2000 platforms. If the appropriate hardware support is available, then operating system context switches are minimized beyond the basic reductions achieved with Cache Fusion alone. This also eliminates costly data copying and system calls.
If efficiently implemented by your hardware, then user-mode IPCs can reduce CPU use. This is because user processes can communicate without using the operating system kernel in user-mode IPC architectures. In other words, user processes do not have to switch from user execution mode to kernel execution mode.
Cache Fusion practically eliminates disk I/O for data and undo segment blocks by transmitting current block mode versions and consistent-read blocks directly from one instance's buffer cache to another. This can reduce the latency required to resolve writer/writer and reader/writer conflicts by as much as 90 percent.
Cache Fusion resolves concurrency, as mentioned, without disk I/O. Cache Fusion expends only one tenth of the processing effort that was required by disk-based parallel cache management. To do this, Cache Fusion only incurs overhead for:
Or when requesting a consistent read version:
On some platforms this can take less than one millisecond.
You can accurately assess hot spots due to blocks modified by multiple instances by evaluating global cache resource busy and buffer busy due to global cache statistics using V$SYSTEM_EVENT as described in Table 5-3. If your application has hot spots, consider using one of the partitioning techniques in Chapter 3 to further reduce the cost of writer/writer conflicts.
The primary components affecting Cache Fusion performance are the interconnect and the inter-node communication protocols. The interconnect bandwidth, its latency, and the efficiency of the IPC protocol determine the speed with which Cache Fusion processes consistent-read block requests.
|
See Also:
Oracle9i Real Application Clusters Installation and Configuration for a list of the supported interconnect protocols |
Once your interconnect is operative, you cannot significantly influence its performance. However, you can influence an interconnect protocol's efficiency by adjusting the IPC buffer sizes.
Cache Fusion performance levels can vary in terms of latency and throughput from application to application. Performance is further influenced by the type and mixture of transactions that your system processes.
The performance gains from Cache Fusion also vary with each workload. The hardware, the interconnect protocol specifications, and the operating system resource use also affect performance.
If your application did not demonstrate a significant amount of consistent-read or write/write contention prior to Cache Fusion, then your performance with Cache Fusion will likely remain unchanged. However, if your application experienced numerous block mode conversions and heavy disk I/O as a result of consistent-read or writer/writer conflicts, your performance with Cache Fusion should improve significantly.
The following section, "Monitoring Cache Fusion and Inter-Instance Performance", describes how to evaluate Cache Fusion performance in more detail.
This section describes how to obtain and analyze Real Application Clusters and Cache Fusion statistics to monitor inter-instance performance. Topics in this section include:
The main goal of monitoring Cache Fusion and Real Application Clusters performance is to determine the cost of global processing and to quantify the resources required to maintain coherency and synchronize the instances. Do this by analyzing the performance statistics from several views as described in the following sections. Use these monitoring procedures on an on-going basis to observe processing trends and to optimize processing.
Many statistics measure the work done by different components of the database kernel, such as the cache layer, the transaction layer, or the I/O layer. Moreover, timed statistics allow you to accurately determine the amount of time spent processing certain requests or the amount of time waited for specific events. From these statistics, you can derive work rates, wait times, and efficiency ratios.
|
See Also:
|
Oracle collects Cache Fusion-related performance statistics from the buffer cache and Global Cache Service (GCS) layers. Oracle also collects general Real Application Clusters statistics for block requests and block mode conversion waits. You can use several views to examine these statistics.
Maintaining an adequate history of system performance helps identify trends as these statistics change. This helps identify problems that contribute to increased response times and reduced throughput. A history of performance trends is also helpful in identifying workload changes and peak processing requirements.
Procedures in this section use statistics grouped according to the following topics:
As described in Chapter 5, consider maintaining statistics from the V$SYSSTAT view and the V$SYSTEM_EVENT view on a per second and per transaction basis. This reveals a general profile of the workload. Relevant observations from these views are:
By maintaining these statistics, you can accurately estimate the effect of an increasing cost for a certain type of operation on transaction response times. Major increases in work rates or average delays also contribute to identifying capacity issues.
You must set the parameter TIMED_STATISTICS to true to make Oracle collect statistics for most views discussed in the procedures in this section. The timed statistics from views discussed in this chapter are displayed in units of 1/100ths of a second.
You must run CATCLUST.SQL to create Real Application Cluster-related views and tables for storing and viewing statistics. To run this script, you must have SYSDBA privileges.
CATCLUST.SQL creates the standard V$ dynamic views, as well as:
GV$CACHE
GV$CACHE_TRANSFER
GV$CLASS_CACHE_TRANSFER
GV$FILE_CACHE_TRANSFER
GV$ROWCACHE
GV$LIBRARYCACHE
Even though the shared disk architecture eliminates forced disk writes, V$FILE_CACHE_TRANSFER, V$CLASS_CACHE_TRANSFER, and V$CACHE_TRANSFER still show the number of block mode conversions per block class or object. However, as mentioned, the FORCED_WRITES column will be 0 (zero). This indicates that, for example, an X-to-N conversion resulted in a cache block transfer without incurring forced disk writes.
Each active instance has its own set of instance-specific views. You can also query global dynamic performance views to retrieve the V$ view information from all qualified instances. Global dynamic performance views' names are prefixed with GV$. A global fixed view is available for all dynamic performance views except:
The global view contains all columns from the instance-specific view, with an additional column, INST_ID of datatype INTEGER. This column displays the instance number from which the associated V$ information was obtained. You can use the INST_ID column as a filter to retrieve V$ information from a subset of available instances. For example, the query retrieves information from the V$ views on instances 2 and 5:
SELECT * FROM GV$LOCK WHERE INST_ID = 2 or INST_ID = 5;
Each global view contains a GLOBAL hint that creates a query executed in parallel to retrieve the contents of the local views on each instance.
If you have reached the limit of PARALLEL_MAX_SERVERS on an instance and you attempt to query a GV$ view, then Oracle spawns one additional parallel execution server process for this purpose. The extra process is not available for parallel operations other than GV$ queries.
If you have reached the limit of PARALLEL_MAX_SERVERS on an instance and issue multiple GV$ queries, then all but the first query will fail. In most parallel queries, if a server process could not be allocated it would result in either an error or a sequential execution of the query by the query coordinator.
|
See Also:
|
Oracle collects global cache statistics at the buffer cache layer within an instance. These statistics include counts and timings of requests for global resources.
Requests for global resources for data blocks originate in the buffer cache of the requesting instance. Before a request enters the GCS request queue, Oracle allocates data structures in the System Global Area (SGA) to track the state of the request. These structures are called resources.
To monitor global cache statistics, query the V$SYSSTAT view and analyze its output as described in the following procedures and equations.
Complete the following steps to analyze global cache statistics.
V$SYSSTAT:
SELECT NAME,VALUE FROM V$SYSSTAT WHERE NAME LIKE '%global cache%';
Oracle responds with output similar to:
NAME VALUE ------------------------------------------- ---------- global cache blocks corrupt 0 global cache blocks lost 0 global cache claim blocks lost 0 global cache convert time 287709 global cache convert timeouts 0 global cache converts 137879 global cache cr block build time 4328 global cache cr block flush time 9565 global cache cr block receive time 742421 global cache cr block send time 10119 global cache cr blocks received 448301 global cache cr blocks served 442322 global cache current block flush time 10944 global cache current block pin time 27318 global cache current block receive time 254702 global cache current block send time 2819 global cache current blocks received 132248 global cache current blocks served 130538 global cache defers 4836 global cache freelist waits 0 global cache get time 15613 global cache gets 9178 global cache prepare failures 0 23 rows selected.
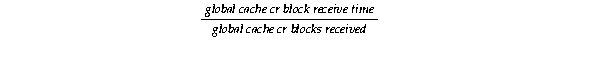
Text description of the illustration sps81119.gif
The result, which should typically be about 15 milliseconds depending on your system configuration and volume, is the average latency of a consistent-read request round-trip from the requesting instance to the holding instance and back to the requesting instance. If your CPU has limited idle time and your system typically processes long-running queries, then the latency may be higher. However, it is possible to have an average latency of less than one millisecond with User-mode IPC.
Request latency can also be influenced by a high value for the DB_MULTI_BLOCK_READ_COUNT parameter. This is because a requesting process can issue more than one request for a block depending on the setting of this parameter. Correspondingly, the requesting process may wait longer.
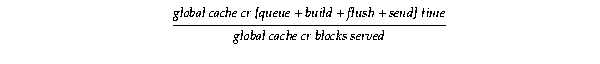
Text description of the illustration psadm020.gif
Over a period of time during peak processing intervals, track the average LMS service time per request and the total round-trip time per request as presented in this step.
To determine which part of the service time correlates most with the total service time, derive the time waited to queue the consistent-read request, the time needed to build the consistent-read block, the time waited for a log flush and the time spent to send the completed request using the following three equations.
Time needed to build the consistent-read block:

Time waited for a log flush:
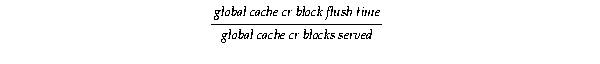
Time spent to send the completed request:
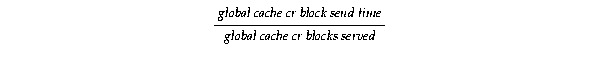
By calculating these averages, you can account for almost all the processing steps of a consistent read block request. The remaining difference between the total round-trip time and the LMS service time per request is the queuing time for the Global Enqueue Service Daemon (LMD) to dispatch the request to the LMS process and the processing time for LMS and network IPC time.

Text description of the illustration psadm032.gif
The following equation is for receiving a current block:
The service time for a current block request encompasses the pin time and the send time. The next two equations help you determine processing times for the various steps of a cache transfer.
Determining pin time:

Text description of the illustration psadm028.gif
Determining send time:
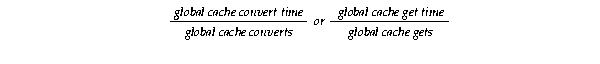
Text description of the illustration sps81121.gif
When analyzing the results from this step, consider the following points:
Oracle increments global cache gets when a new resource is opened. A convert is counted when there is already an open resource and Oracle converts the resource to another mode.
Therefore, the elapsed time for a get includes the allocation and initialization of new resources. If the average cache get or average convert times are excessive, then your system may be experiencing timeouts.
If the global cache convert times or global cache get times are excessive, then refer to statistics in the V$SYSTEM_EVENT view to identify events with a high value for TIME_WAITED statistics.
V$SYSSTAT output shows a value other than zero for this statistic, then check your system for congestion or high contention. In general, convert timeouts should not occur; their existence indicates serious performance problems.
V$SYSSTAT output. Oracle increments this statistic after the system waits too long for the completion of a consistent-read request. If this statistic shows a value other than zero, then too much time has elapsed after the initiation of a consistent-read request and a timeout has occurred. If this happens, then you also usually find that the average time for consistent-read request completions has increased. If you have timeouts and the latency is high, then your system may have an excessive workload or there may be excessive contention for data blocks. Timeouts might also indicate IPC or network problems.
Global enqueue statistics provide latencies and counts for Global Enqueue Service (GES) activity. Oracle collects global enqueue statistics from the GES API layer. All Oracle clients to the GES make their requests to the GES through this layer. Thus, global resource statistics include global enqueue requests originating from all layers of the kernel while global cache statistics relate to buffer cache activity.
Use the procedures in this section to monitor data from the V$SYSSTAT view to derive GES latencies, counts, and averages. This helps estimate the Real Application Clusters workload generated by an instance.
Use the following procedures to view and analyze statistics from the V$SYSSTAT view for global enqueue processing.
V$SYSSTAT:
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME LIKE '%global lock%';
Oracle responds with output similar to:
NAME VALUE ---------------------------------------------------------------- ---------- global lock sync gets 703 global lock async gets 12748 global lock get time 1071 global lock sync converts 303 global lock async converts 41 global lock convert time 93 global lock releases 573 7 rows selected.
Use your V$SYSSTAT output to perform the calculations and analyses described in procedures 2 through 5.
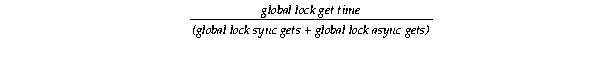
Text description of the illustration sps81123.gif
If the result is more than 20 or 30 milliseconds, then query the TIME_WAITED column in the V$SYSTEM_EVENT view using the descending (DESC) keyword to identify which resource events are waited for most frequently using this query:
SELECT TIME_WAITED, AVERAGE_WAIT FROM V$SYSTEM_EVENT ORDER BY TIME_WAITED DESC;
Oracle increments global lock gets when Oracle opens a new global enqueue for a resource. A convert is counted when there is already an open global enqueue on a resource and Oracle converts the global enqueue access mode to another mode.
Thus, the elapsed time for a get includes the allocation and initialization of a new global enqueue. If the average global enqueue get (global cache get time) or average global enqueue (from the above formula) conversion times are excessive, then your system may be experiencing timeouts.
If the global enqueue conversion times or global enqueue get times are high, then refer to statistics in the V$SYSTEM_EVENT view to identify events with a high value for TIME_WAITED statistics.
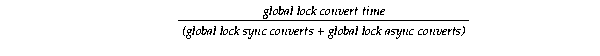
Text description of the illustration sps81124.gif
If the result is more than 20 milliseconds, then query the TIME_WAITED column in the V$SYSTEM_EVENT view using the DESC keyword to identify the event causing the delay.
Synchronous global enqueue gets include, for example, global lock sync gets. To determine the proportion of the time required for synchronous global enqueue gets, divide the global lock gets time or global lock convert time by the corresponding number of synchronous operations.
Asynchronous global enqueue operations include, for example, global lock async gets. These are typically global enqueue operations from non-blocking process to synchronize inter-instance activity. You can derive the proportion of the total time using the same calculation as you used for synchronous operations. In this way, you can determine the proportion of work and the cost of global enqueue requests.
Normally, if the proportion of global enqueue requests other than global cache requests dominates the cost for all global resource operations, the V$SYSTEM_EVENT view shows high wait times for row cache locks, enqueues or library cache pins.
V$LIBRARYCACHE and V$ROWCACHE views to observe GES activity on local resources. These views have GES-specific columns that identify GES resource use. Analyze these views for GES activity if you have frequent and extended waits for library cache pins, enqueues, or DFS Lock Handles.
Use GES resource and message statistics to monitor GES latency and workloads. These statistics appear in the V$GES_CONVERT_LOCAL and V$GES_CONVERT_REMOTE views.
These views record average convert times, count information, and timed statistics for global enqueue requests. The V$GES_CONVERT_LOCAL view shows statistics for local GES enqueue operations. The V$GES_CONVERT_REMOTE view shows values for remote GES enqueue conversions. These views display the average convert times in 100ths of a second.
The Global Enqueue Service (GES) manages all the non-Cache Fusion intra- and inter-instance resource operations. High GES workload request rates can adversely affect performance. The GES performs local enqueue resource operations entirely within the local node, or in other words, without sending messages. Remote enqueue resource operations require sending messages to and waiting for responses from other nodes. Most down-converts, however, are local operations for the GES.
The following procedures for analyzing GES resource and message statistics appear in two groups. The first group of procedures explains how to monitor GES resources. The second group explains how to monitor message statistics.
Use the following procedures to obtain and analyze statistics from the V$GES_CONVERT_LOCAL and V$GES_CONVERT_REMOTE views for GES resource processing.
You must enable event 29700 to populate the V$GES_CONVERT_LOCAL and V$GES_CONVERT_REMOTE views. Do this by entering the following syntax in your initialization parameter file:
EVENT="29700 TRACE NAME CONTEXT FOREVER"
V$GES_CONVERT_LOCAL view:
SELECT CONVERT_TYPE, AVERAGE_CONVERT_TIME, CONVERT_COUNT FROM V$GES_CONVERT_LOCAL;
Oracle responds with output similar to:
CONVERT_TYPE AVERAGE_CONVERT_TIME CONVERT_COUNT -------------------------------------- -------------------- ------------- NULL -> SS 0 0 NULL -> SX 0 0 NULL -> S 1 146 NULL -> SSX 0 0 NULL -> X 1 92 SS -> SX 0 0 SS -> S 0 0 SS -> SSX 0 0 SS -> X 0 0 SX -> S 0 0 SX -> SSX 0 0 SX -> X 0 0 S -> SX 0 0 S -> SSX 0 0 S -> X 3 46 SSX -> X 0 0 16 rows selected.
V$GES_CONVERT_REMOTE view:
SELECT * FROM V$GES_CONVERT_REMOTE;
Oracle responds with output that is identical in format to the output from the V$GES_CONVERT_LOCAL view.
Use output from the V$GES_CONVERT_LOCAL and V$GES_CONVERT_REMOTE views to perform the calculation described in the following procedure that performs a join over the two views.
SELECT r.CONVERT_TYPE, r.AVERAGE_CONVERT_TIME, l.AVERAGE_CONVERT_TIME, r.CONVERT_COUNT, l.CONVERT_COUNT, FROM V$GES_CONVERT_LOCAL l, V$GES_CONVERT_REMOTE r WHERE r.convert_count <> 0 OR l.convert_count <> 0 GROUP BY r.CONVERT_TYPE;
V$SYSTEM_EVENT view.
For a quick estimate of the CPU time spent by LMD, transform the wait time event for LMD presented in the V$SYSTEM_EVENT view. To do this, look for the event name ges remote messages that represents the time that the LMD process is idle. The TIME_WAITED column contains the accumulated idle time for LMD in units of hundredths of a second.
To derive the busy time, divide the value for TIME_WAITED by the length of the measurement interval after normalizing it to seconds. In other words, a value of 17222 centiseconds is 172.22 seconds. The result is the idle time of the LMD process, or the percentage of idle time. Subtract that value from 1 and the result is the busy time for the LMD process. This is a fairly accurate estimate when compared with operating system utilities that provide information about CPU utilization per process.
The GES sends messages for both Global Cache and Global Enqueue Services either directly or with flow control. For both methods, the GES attaches a marker, known as a ticket, to each message. The allotment of tickets for each GES is limited. However, the GES can re-use tickets indefinitely.
The LMS process, with the LMD process, manages flow-controlled messaging. LMS sends messages to remote instances, and it does this until no more tickets are available. When the GES runs out of tickets, messages must wait in a flow control queue until outstanding messages have been acknowledged and more tickets are available.
The rationing of tickets prevents one node from sending an excessive amount of messages to another node during periods of heavy inter-instance communication. This also prevents one node with heavy remote consistent-read block requirements from assuming control of messaging resources throughout a cluster at the expense of other, less-busy nodes.
The V$GES_STATISTICS view contains the following statistics about message activity:
Use the following procedure to obtain and analyze message statistics in the V$GES_STATISTICS view.
V$GES_STATISTICS view:
SELECT * FROM V$GES_STATISTICS;
Oracle responds with output similar to:
STATISTIC# NAME VALUE ---------- ---------------------------------------------- ---------- 0 messages sent directly 140019 1 messages flow controlled 1211 2 messages sent indirectly 9485 3 messages received 155287 4 flow control messages sent 0 5 flow control messages received 0 6 dynamically allocated enqueues 0 7 dynamically allocated resources 0 8 gcs msgs received 154079 9 gcs msgs process time(ms) 192866 10 ges msgs received 1198 11 ges msgs process time(ms) 355 12 msgs causing lmd to send msgs 256 13 lmd msg send time(ms) 0 14 gcs side channel msgs actual 1304 15 gcs side channel msgs logical 130400 16 gcs pings refused 68 17 gcs writes refused 3 18 gcs error msgs 0 19 gcs out-of-order msgs 30 20 gcs immediate (null) converts 1859 21 gcs immediate cr (null) converts 5 22 gcs immediate (compatible) converts 38 23 gcs immediate cr (compatible) converts 5 24 gcs blocked converts 49570 25 gcs queued converts 159 26 gcs blocked cr converts 124860 27 gcs compatible basts 0 28 gcs compatible cr basts 0 29 gcs cr basts to PIs 0 30 dynamically allocated gcs resources 0 31 dynamically allocated gcs shadows 0 32 gcs recovery claim msgs actual 0 33 gcs recovery claim msgs logical 0 34 gcs write request msgs 17 35 gcs flush pi msgs 7 36 gcs write notification msgs 0 37 rows selected.
This section describes how to analyze output from three views to quantify block mode conversions by type. The tasks and the views discussed in this section are:
The V$LOCK_ACTIVITY view summarizes how many block mode up- and down-converts have occurred during an instance's lifetime. X-to-N or X-to-S down-converts denote the number of times a block mode was down-converted because another instance attempted to modify a block that is currently held in exclusive mode on another instance.
The V$CLASS_CACHE_TRANSFER view summarizes block mode conversion activity.
With a shared disk architecture, the FORCED_WRITES column is always 0 (zero) because X-to-N or X-to-S down-converts do not result in forced disk writes.
The V$CACHE_TRANSFER view helps identify hot blocks and hot objects.
All three views provide different levels of detail. You can monitor the V$LOCK_ACTIVITY view to generate an overall Real Application Clusters workload profile. Use information from the V$LOCK_ACTIVITY view to record the rate at which block mode conversions occur.
For more details, use the V$CLASS_CACHE_TRANSFER view to identify the type of block on which block mode conversions are occurring. Once you have identified the class, use the V$CACHE_TRANSFER view to obtain details about a particular table or index and the file and block numbers on which there is significant block mode conversion activity.
If your response time or throughput requirements are no longer being met, then examine the V$LOCK_ACTIVITY, V$CLASS_CACHE_TRANSFER, V$CACHE, V$CACHE_TRANSFER or V$FILE_CACHE_TRANSFER views. In addition, you might also examine:
V$SYSSTAT to identify an increase in resource requests per transaction
V$SYSSTEM_EVENT to identify longer waits for global cache resources or consistent read server requests per transaction
In summary, a change in your application profile and work rates typically warrants a detailed analysis using the previously-mentioned views. Apart from diagnosing performance problems of existing applications, these views are also useful when developing applications or when deciding on a partitioning strategy.
Latches are low-level locking mechanisms that protect SGA data structures. You can use the V$LATCH and V$LATCH_MISSES views to monitor latch contention within the GCS. These views show information about a particular latch, its statistics, and the location in the code from where the latch is acquired.
For normal operations, the value of latch statistics is limited. In some cases, multiple latches can improve performance to a limited degree for certain layers. Excessive latch contention degrades performance and is often the result of one or both of the following:
Use the following procedures to identify latch contention. However, Oracle does not recommend that you monitor these statistics on a regular basis and derive conclusions solely on the basis of latching issues.
In the majority of cases, latch contention will not be your actual performance problem. On the other hand, record information from these procedures if the TIME_WAITED value for the latch free wait event is excessive and if it ranks among the events that accrue the largest times as indicated by the V$SYSTEM_EVENT view. In addition, gathering this information might be useful to Oracle Support or Oracle Development.
Use the following procedures to analyze latch, Real Application Clusters, and GCS- and GES-related statistics.
V$LATCH view using this syntax:
SELECT NAME, GETS, MISSES, SLEEPS FROM V$LATCH;
V$LATCH_MISSES view:
SELECT PARENT_NAME, WHERE, SLEEP_COUNT FROM V$LATCH_MISSES ORDER BY SLEEP_COUNT DESC;
Oracle responds with output similar to:
Use your V$LATCH and V$LATCH_MISSES output to perform the following procedures.
V$LATCH output from step 1 in this section using the following formula:
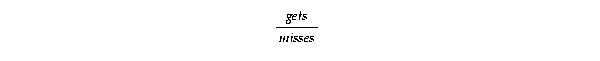
Text description of the illustration sps81132.gif
Excessive numbers for misses usually indicate contention for the same resources. Acceptable ratios range from 90 to 95%.
V$LATCH_MISSES output from step 1 in this section. This ratio determines how often a process sleeps when it cannot immediately get a latch. V$LATCH_MISSES view, the WHERE column shows the function in which the latch is acquired. This information is useful in determining internal performance problems. Usually, the latch slept on for long periods shows up in the V$SESSION_WAIT or V$SYSTEM_EVENT views under the 'latch free' wait event category.
The next section describes using the V$SYSTEM_EVENT view in more detail.
Data about Cache Fusion and Real Application Clusters events appears in the V$SYSTEM_EVENT view. To identify events for which processes have waited the longest, query the V$SYSTEM_EVENT view on the TIME_WAITED column using the descend (DESC) keyword. The TIME_WAITED column shows the total wait time for each system event listed.
By generating an ordered list of wait events, you can easily locate performance bottlenecks. Each COUNT represents a voluntary context switch. The TIME_WAIT value is the cumulative time that processes waited for particular system events. The values in the TOTAL_TIMEOUT and AVERAGE_WAIT columns provide additional information about system efficiency.
Oracle Corporation recommends dividing the sum of values from the TOTAL_WAITS and TIME_WAITED columns by the number of transactions, as outlined in Chapter 5. Transactions in this sense can be defined as business transactions, for example, insurance quotes, order entry, and so on. Or you can define them on the basis of user commits or executions, depending on your perspective.
The goal is to estimate which event type contributes the most to transaction response times, because in general:
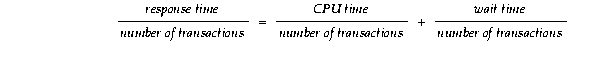
By this rationale, the total wait time can be divided into subcomponents of the wait time as shown in the following equations where tm is time waited:

It is also useful to derive the total wait time by adding the individual events and observing the percentages that are spent waiting for each event. This enables you to derive the major cost factors for transaction response times. Reducing the time for the largest proportion of the waits has the most significant effect on response time.
The following events appearing in the V$SYSTEM_EVENT output represent waits for Real Application Clusters events:
You can monitor other events in addition to those listed under the previous heading because performance problems can be related to server coordination processing within Real Application Clusters. These events are:
If the time waited for global cache events is high relative to other types of waits, then look for increased latencies, contention, or excessive system workloads. Do this using V$SYSSTAT statistics and operating system performance monitors. Excessive global cache busy or buffer busy waits indicates increased contention in the buffer cache.
If excessive wait time is used by waits for non-buffer cache resources as shown by statistics in the rows row cache lock, enqueues, and library cache pin, then monitor the V$ROWCACHE and V$LIBRARYCACHE views for Real Application Cluster-related issues. Specifically, observe the values in the DLM columns of each of these views.
Real Application Clusters problems commonly arise from poorly managed space parameters or sequence numbers that are not cached. In such cases, processes wait for row cache locks and enqueues and the V$ROWCACHE view shows excessive conflicts for certain dictionary caches.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|

