Release 1 (9.0.1)
Part Number A90192-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Database Utilities Release 1 (9.0.1) Part Number A90192-01 |
|
![]()
![]()
This chapter explains the basic concepts of loading data into an Oracle database with SQL*Loader. This chapter covers the following topics:
SQL*Loader loads data from external files into tables of an Oracle database. It has a powerful data parsing engine that puts little limitation on the format of the data in the datafile. You can use SQL*Loader to do the following:
A typical SQL*Loader session takes as input a control file, which controls the behavior of SQL*Loader, and one or more datafiles. The output of SQL*Loader is an Oracle database (where the data is loaded), a log file, a bad file, and potentially, a discard file. An example of the flow of a SQL*Loader session is shown in Figure 3-1.
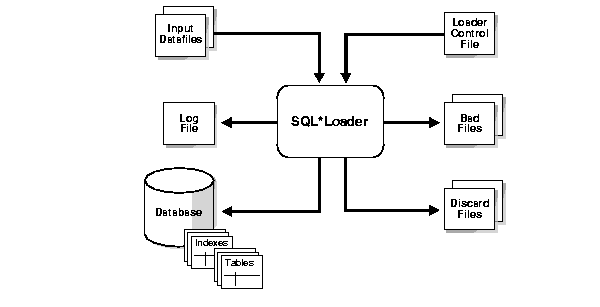
Text description of the illustration sut81088.gif
The control file is a text file written in a language that SQL*Loader understands. The control file tells SQL*Loader where to find the data, how to parse and interpret the data, where to insert the data, and more.
Although not precisely defined, a control file can be said to have three sections.
The first section contains session-wide information, for example:
INFILE clauses to specify where the input data is located
The second section consists of one or more INTO TABLE blocks. Each of these blocks contains information about the table into which the data is to be loaded, such as the table name and the columns of the table.
The third section is optional and, if present, contains input data.
Some control file syntax considerations to keep in mind are:
CONSTANT keyword has special meaning to SQL*Loader and is therefore reserved. To avoid potential conflicts, Oracle Corporation recommends that you do not use the word CONSTANT as a name for any tables or columns.
Chapter 5 for details about control file syntax and semantics
See Also:
SQL*Loader reads data from one or more files (or operating system equivalents of files) specified in the control file. From SQL*Loader's perspective, the data in the datafile is organized as records. A particular datafile can be in fixed record format, variable record format, or stream record format. The record format can be specified in the control file with the INFILE parameter. If no record format is specified, the default is stream record format.
A file is in fixed record format when all records in a datafile are the same byte length. Although this format is the least flexible, it results in better performance than variable or stream format. Fixed format is also simple to specify. For example:
INFILEdatafile_name"fixn"
This example specifies that SQL*Loader should interpret the particular datafile as being in fixed record format where every record is n bytes long.
Example 3-1 shows a control file that specifies a datafile that should be interpreted in the fixed record format. The datafile in the example contains five physical records. Assuming that a period (.) indicates a space, the first physical record is [001,...cd,.] which is exactly eleven bytes (assuming a single-byte character set). The second record is [0002,fghi,\n] followed by the newline character (which is the eleventh byte), and so on. Note that newline characters are not required with the fixed record format.
Note that the length is always interpreted in bytes, even if character-length semantics are in effect for the file. This is necessary because the file could contain a mix of fields, some of which are processed with character-length semantics and others which are processed with byte-length semantics. See Character-Length Semantics.
load data infile 'example.dat' "fix 11" into table example fields terminated by ',' optionally enclosed by '"' (col1, col2) example.dat: 001, cd, 0002,fghi, 00003,lmn, 1, "pqrs", 0005,uvwx,
A file is in variable record format when the length of each record in a character field is included at the beginning of each record in the datafile. This format provides some added flexibility over the fixed record format and a performance advantage over the stream record format. For example, you can specify a datafile that is to be interpreted as being in variable record format as follows:
INFILE "datafile_name" "varn"
In this example, n specifies the number of bytes in the record length field. If n is not specified, SQL*Loader assumes a length of 5 bytes. Specifying n larger than 40 will result in an error.
Example 3-2 shows a control file specification that tells SQL*Loader to look for data in the datafile example.dat and to expect variable record format where the record length fields are 3 bytes long. The example.dat datafile consists of three physical records. The first is specified to be 009 (that is, 9) bytes long, the second is 010 bytes long (that is, 10, including a 1-byte newline), and the third is 012 bytes long (also including a 1-byte newline). Note that newline characters are not required with the variable record format. This example also assumes a single-byte character set for the datafile.
Note that the lengths are always interpreted in bytes, even if character-length semantics are in effect for the file. This is necessary because the file could contain a mix of fields, some processed with character-length semantics and others processed with byte-length semantics. See Character-Length Semantics.
load data infile 'example.dat' "var 3" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: 009hello,cd,010world,im, 012my,name is,
A file is in stream record format when the records are not specified by size; instead SQL*Loader forms records by scanning for the record terminator. Stream record format is the most flexible format, but there can be a negative effect on performance. The specification of a datafile to be interpreted as being in stream record format looks similar to the following:
INFILEdatafile_name["str terminator_string"]
The terminator_string is specified as either 'char_string' or X'hex_string' where:
'char_string' is a string of characters enclosed in single or double quotation marks
X'hex_string' is a byte string in hexadecimal format
When the terminator_string contains special (nonprintable) characters, it should be specified as a X'hex_string'. However, some nonprintable characters can be specified as ('char_string') by using a backslash. For example:
|
\n |
linefeed |
|
\t |
horizontal tab |
|
\f |
formfeed |
|
\v |
vertical tab |
|
\r |
carriage return |
If the character set specified with the NLS_LANG parameter for your session is different from the character set of the datafile, character strings are converted to the character set of the datafile.
Hexadecimal strings are assumed to be in the character set of the datafile, so no conversion is performed.
If no terminator_string is specified, it defaults to the newline (end-of-line) character (line feed in UNIX-based platforms, carriage return followed by a line feed on Microsoft platforms, and so on). The newline character is converted to the character set of the datafile.
Example 3-3 illustrates loading data in stream record format where the terminator string is specified using a character string, '|\n'. The use of the backslash character allows the character string to specify the nonprintable linefeed character.
load data infile 'example.dat' "str '|\n'" into table example fields terminated by ',' optionally enclosed by '"' (col1 char(5), col2 char(7)) example.dat: hello,world,| james,bond,|
SQL*Loader organizes the input data into physical records, according to the specified record format. By default a physical record is a logical record, but for added flexibility, SQL*Loader can be instructed to combine a number of physical records into a logical record.
SQL*Loader can be instructed to follow one of the following two logical record forming strategies:
See Also:
Once a logical record is formed, field setting on the logical record is done. Field setting is a process in which SQL*Loader uses control-file field specifications to determine which parts of logical record data correspond to which control-file fields. It is possible for two or more field specifications to claim the same data. Also, it is possible for a logical record to contain data that is not claimed by any control-file field specification.
Most control-file field specifications claim a particular part of the logical record. This mapping takes the following forms:
n number of bytes of the data field contain information about how long the rest of the data field is.
LOB data can be lengthy enough that it makes sense to load it from a LOBFILE. In LOBFILEs, LOB data instances are still considered to be in fields (predetermined size, delimited, length-value), but these fields are not organized into records (the concept of a record does not exist within LOBFILEs). Therefore, the processing overhead of dealing with records is avoided. This type of organization of data is ideal for LOB loading.
For example, you might use LOBFILEs to load employee names, employee IDs, and employee resumes. You could read the employee names and IDs from the main datafiles and you could read the resumes, which can be quite lengthy, from LOBFILEs.
You might also use LOBFILEs to facilitate the loading of XML data. You can use XML columns to hold data that models structured and semistructured data. Such data can be quite lengthy.
Secondary datafiles (SDFs) are similar in concept to primary datafiles. Like primary datafiles, SDFs are a collection of records, and each record is made up of fields. The SDFs are specified on a per control-file-field basis. Only a collection_fld_spec can name an SDF as its data source.
SDFs are specified using the SDF parameter. The SDF parameter can be followed by either the file specification string, or a FILLER field that is mapped to a data field containing one or more file specification strings.
During a conventional path load, data fields in the datafile are converted into columns in the database (direct path loads are conceptually similar, but the implementation is different). There are two conversion steps:
INSERT statement using that data.
INSERT statement to store the data in the database.
The Oracle database server uses the datatype of the column to convert the data into its final, stored form. Keep in mind the distinction between a field in a datafile and a column in the database. Remember also that the field datatypes defined in a SQL*Loader control file are not the same as the column datatypes.
Records read from the input file might not be inserted into the database. Such records are placed in either a bad file or a discard file.
The bad file contains records that were rejected, either by SQL*Loader or by the Oracle database server. Some of the possible reasons for rejection are discussed in the next sections.
Records are rejected by SQL*Loader when the input format is invalid. For example, if the second enclosure delimiter is missing, or if a delimited field exceeds its maximum length, SQL*Loader rejects the record. Rejected records are placed in the bad file.
After a record is accepted for processing by SQL*Loader, a row is sent to the Oracle database server for insertion. If Oracle determines that the row is valid, then the row is inserted into the database. If not, the record is rejected, and SQL*Loader puts it in the bad file. The row may be rejected, for example, because a key is not unique, because a required field is null, or because the field contains invalid data for the Oracle datatype.
|
See Also:
|
As SQL*Loader executes, it may create a file called the discard file. This file is created only when it is needed, and only if you have specified that a discard file should be enabled. The discard file contains records that were filtered out of the load because they did not match any record-selection criteria specified in the control file.
The discard file therefore contains records that were not inserted into any table in the database. You can specify the maximum number of such records that the discard file can accept. Data written to any database table is not written to the discard file.
When SQL*Loader begins execution, it creates a log file. If it cannot create a log file, execution terminates. The log file contains a detailed summary of the load, including a description of any errors that occurred during the load.
|
See Also:
|
SQL*Loader provides the following methods to load data:
During conventional path loads, the input records are parsed according to the field specifications, and each data field is copied to its corresponding bind array. When the bind array is full (or no more data is left to read), an array insert is executed.
SQL*Loader stores LOB fields after a bind array insert is done. Thus, if there are any errors in processing the LOB field (for example, the LOBFILE could not be found), the LOB field is left empty. Note also that because LOB data is loaded after the array insert has been performed, BEFORE and AFTER row triggers may not work as expected for LOB columns. This is because the triggers fire before SQL*Loader has a chance to load the LOB contents into the column. For instance, suppose you are loading a LOB column, C1, with data and that you want a BEFORE row trigger to examine the contents of this LOB column and derive a value to be loaded for some other column, C2, based on its examination. This is not possible because the LOB contents will not have been loaded at the time the trigger fires.
A direct path load parses the input records according to the field specifications, converts the input field data to the column datatype, and builds a column array. The column array is passed to a block formatter, which creates data blocks in Oracle database block format. The newly formatted database blocks are written directly to the database, bypassing most RDBMS processing. Direct path load is much faster than conventional path load, but entails several restrictions.
A parallel direct path load allows multiple direct path load sessions to concurrently load the same data segments (allows intrasegment parallelism). Parallel direct path is more restrictive than direct path.
An external table load creates an external table for data in a data file and executes INSERT statements to insert the data from the data file into the target table.
The advantages of using external table loads over conventional path and direct path loads are as follows:
INSERT statement that is used to create the external table.
You can use SQL*Loader to bulk load objects, collections, and LOBs. It is assumed that you are familiar with the concept of objects and with Oracle's implementation of object support as described in Oracle9i Database Concepts and in the Oracle9i Database Administrator's Guide.
SQL*Loader supports loading of the following two object types:
When a column of a table is of some object type, the objects in that column are referred to as column-objects. Conceptually such objects are stored in entirety in a single column position in a row. These objects do not have object identifiers and cannot be referenced.
If the object type of the column object is declared to be nonfinal, then SQL*Loader allows a derived type (or subtype) to be loaded into the column object.
These objects are stored in tables, known as object tables, that have columns corresponding to the attributes of the object. The object tables have an additional system-generated column, called SYS_NC_OID$, that stores system-generated unique identifiers (OIDs) for each of the objects in the table. Columns in other tables can refer to these objects by using the OIDs.
If the object type of the object table is declared to be nonfinal, then SQL*Loader allows a derived type (or subtype) to be loaded into the row object.
SQL*Loader supports loading of the following two collection types:
A nested table is a table that appears as a column in another table. All operations that can be performed on other tables can also be performed on nested tables.
VARRAYs are variable sized arrays. An array is an ordered set of built-in types or objects, called elements. Each array element is of the same type and has an index, which is a number corresponding to the element's position in the VARRAY.
When creating a VARRAY type, you must specify the maximum size. Once you have declared a VARRAY type, it can be used as the datatype of a column of a relational table, as an object type attribute, or as a PL/SQL variable.
|
See Also:
Loading Collections (Nested Tables and VARRAYs) for details on using SQL*Loader control file data definition language to load these collection types |
A LOB is a large object type. This release of SQL*Loader supports loading of four LOB types:
BLOB: a LOB containing unstructured binary data.
CLOB: a LOB containing character data.
NCLOB: a LOB containing characters in a database national character set.
BFILE: a BLOB stored outside of the database tablespaces in a server-side operating system file.
LOBs can be column datatypes, and with the exception of the NCLOB, they can be an object's attribute datatypes. LOBs can have an actual value, they can be null, or they can be "empty."
|
See Also:
Loading LOBs for details on using SQL*Loader control file data definition language to load these LOB types |
SQL*Loader supports loading partitioned objects in the database. A partitioned object in an Oracle database is a table or index consisting of partitions (pieces) that have been grouped, typically by common logical attributes. For example, sales data for the year 2000 might be partitioned by month. The data for each month is stored in a separate partition of the sales table. Each partition is stored in a separate segment of the database and can have different physical attributes.
SQL*Loader partitioned object support enables SQL*Loader to load the following:
Oracle Corporation provides a direct path load API for application developers. See the Oracle Call Interface Programmer's Guide for more information.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|