Release 2 (9.2)
Part Number A96521-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Database Administrator's Guide Release 2 (9.2) Part Number A96521-01 |
|
This chapter discusses the management of indexes, and contains the following topics:
| See Also:
Chapter 14, "Managing Space for Schema Objects" is recommended reading before attempting tasks described in this chapter. |
Indexes are optional structures associated with tables and clusters that allow SQL statements to execute more quickly against a table. Just as the index in this manual helps you locate information faster than if there were no index, an Oracle index provides a faster access path to table data. You can use indexes without rewriting any queries. Your results are the same, but you see them more quickly.
Oracle provides several indexing schemes that provide complementary performance functionality. These are:
Indexes are logically and physically independent of the data in the associated table. Being independent structures, they require storage space. You can create or drop an index without affecting the base tables, database applications, or other indexes. Oracle automatically maintains indexes when you insert, update, and delete rows of the associated table. If you drop an index, all applications continue to work. However, access to previously indexed data might be slower.
This section discusses guidelines for managing indexes and contains the following topics:
See Also:
|
Data is often inserted or loaded into a table using the either the SQL*Loader or Import utility. It is more efficient to create an index for a table after inserting or loading the data. If you create one or more indexes before loading data, Oracle then must update every index as each row is inserted.
Creating an index on a table that already has data requires sort space. Some sort space comes from memory allocated for the index's creator. The amount for each user is determined by the initialization parameter SORT_AREA_SIZE. Oracle also swaps sort information to and from temporary segments that are only allocated during the index creation in the users temporary tablespace.
Under certain conditions, data can be loaded into a table with SQL*Loader's direct path load and an index can be created as data is loaded.
| See Also:
Oracle9i Database Utilities for information about using SQL*Loader for direct path load |
Use the following guidelines for determining when to create an index:
Some columns are strong candidates for indexing. Columns with one or more of the following characteristics are candidates for indexing:
WHERE COL_X > -9.99 * power(10,125)
Using the above phrase is preferable to:
WHERE COL_X IS NOT NULL
This is because the first uses an index on COL_X (assuming that COL_X is a numeric column).
Columns with the following characteristics are less suitable for indexing:
LONG and LONG RAW columns cannot be indexed.
The size of a single index entry cannot exceed roughly one-half (minus some overhead) of the available space in the data block.
The order of columns in the CREATE INDEX statement can affect query performance. In general, specify the most frequently used columns first.
If you create a single index across columns to speed up queries that access, for example, col1, col2, and col3; then queries that access just col1, or that access just col1 and col2, are also speeded up. But a query that accessed just col2, just col3, or just col2 and col3 does not use the index.
A table can have any number of indexes. However, the more indexes there are, the more overhead is incurred as the table is modified. Specifically, when rows are inserted or deleted, all indexes on the table must be updated as well. Also, when a column is updated, all indexes that contain the column must be updated.
Thus, there is a trade-off between the speed of retrieving data from a table and the speed of updating the table. For example, if a table is primarily read-only, having more indexes can be useful; but if a table is heavily updated, having fewer indexes could be preferable.
Consider dropping an index if:
When an index is created for a table, data blocks of the index are filled with the existing values in the table up to PCTFREE. The space reserved by PCTFREE for an index block is only used when a new row is inserted into the table and the corresponding index entry must be placed in the correct index block (that is, between preceding and following index entries).
If no more space is available in the appropriate index block, the indexed value is placed where it belongs (based on the lexical set ordering). Therefore, if you plan on inserting many rows into an indexed table, PCTFREE should be high to accommodate the new index values. If the table is relatively static without many inserts, PCTFREE for an associated index can be low so that fewer blocks are required to hold the index data.
PCTUSED cannot be specified for indexes.
| See Also:
"Managing Space in Data Blocks" for information about the |
Estimating the size of an index before creating one can facilitate better disk space planning and management. You can use the combined estimated size of indexes, along with estimates for tables, rollback segments, and redo log files, to determine the amount of disk space that is required to hold an intended database. From these estimates, you can make correct hardware purchases and other decisions.
Use the estimated size of an individual index to better manage the disk space that the index uses. When an index is created, you can set appropriate storage parameters and improve I/O performance of applications that use the index. For example, assume that you estimate the maximum size of an index before creating it. If you then set the storage parameters when you create the index, fewer extents are allocated for the table's data segment, and all of the index's data is stored in a relatively contiguous section of disk space. This decreases the time necessary for disk I/O operations involving this index.
The maximum size of a single index entry is approximately one-half the data block size.
| See Also:
"Setting Storage Parameters" for specific information about storage parameters |
Indexes can be created in any tablespace. An index can be created in the same or different tablespace as the table it indexes. If you use the same tablespace for a table and its index, it can be more convenient to perform database maintenance (such as tablespace or file backup) or to ensure application availability. All the related data is always online together.
Using different tablespaces (on different disks) for a table and its index produces better performance than storing the table and index in the same tablespace. Disk contention is reduced. But, if you use different tablespaces for a table and its index and one tablespace is offline (containing either data or index), then the statements referencing that table are not guaranteed to work.
You can parallelize index creation, much the same as you can parallelize table creation. Because multiple processes work together to create the index, Oracle can create the index more quickly than if a single server process created the index sequentially.
When creating an index in parallel, storage parameters are used separately by each query server process. Therefore, an index created with an INITIAL value of 5M and a parallel degree of 12 consumes at least 60M of storage during index creation.
See Also:
|
You can create an index and generate minimal redo log records by specifying NOLOGGING in the CREATE INDEX statement.
|
Note: Because indexes created using |
Creating an index with NOLOGGING has the following benefits:
In general, the relative performance improvement is greater for larger indexes created without LOGGING than for smaller ones. Creating small indexes without LOGGING has little affect on the time it takes to create an index. However, for larger indexes the performance improvement can be significant, especially when you are also parallelizing the index creation.
Improper sizing or increased growth can produce index fragmentation. To eliminate or reduce fragmentation, you can rebuild or coalesce the index. But before you perform either task weigh the costs and benefits of each option and choose the one that works best for your situation. Table 16-1 is a comparison of the costs and benefits associated with rebuilding and coalescing indexes.
In situations where you have B-tree index leaf blocks that can be freed up for reuse, you can merge those leaf blocks using the following statement:
ALTER INDEX vmoore COALESCE;
Figure 16-1 illustrates the effect of an ALTER INDEX COALESCE on the index vmoore. Before performing the operation, the first two leaf blocks are 50% full. This means you have an opportunity to reduce fragmentation and completely fill the first block, while freeing up the second. In this example, assume that PCTFREE=0.
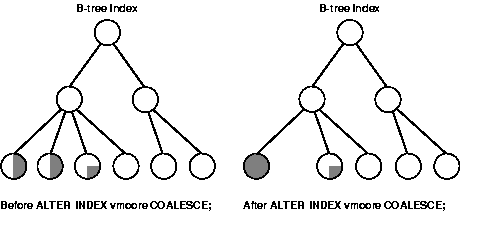
Because unique and primary keys have associated indexes, you should factor in the cost of dropping and creating indexes when considering whether to disable or drop a UNIQUE or PRIMARY KEY constraint. If the associated index for a UNIQUE key or PRIMARY KEY constraint is extremely large, you can save time by leaving the constraint enabled rather than dropping and re-creating the large index. You also have the option of explicitly specifying that you want to keep or drop the index when dropping or disabling a UNIQUE or PRIMARY KEY constraint.
This section describes how to create indexes. To create an index in your own schema, at least one of the following conditions must be true:
INDEX privilege on the table to be indexed.CREATE ANY INDEX system privilege.To create an index in another schema, all of the following conditions must be true:
CREATE ANY INDEX system privilege.UNLIMITED TABLESPACE system privilege.This section contains the following topics:
| See Also:
Oracle9i SQL Reference for syntax and restrictions on the use of the |
You can create indexes explicitly (outside of integrity constraints) using the SQL statement CREATE INDEX. The following statement creates an index named emp_ename for the ename column of the emp table:
CREATE INDEX emp_ename ON emp(ename) TABLESPACE users STORAGE (INITIAL 20K NEXT 20k PCTINCREASE 75) PCTFREE 0;
Notice that several storage settings and a tablespace are explicitly specified for the index. If you do not specify storage options (such as INITIAL and NEXT) for an index, the default storage options of the default or specified tablespace are automatically used.
Indexes can be unique or nonunique. Unique indexes guarantee that no two rows of a table have duplicate values in the key column (or columns). Nonunique indexes do not impose this restriction on the column values.
Use the CREATE UNIQUE INDEX statement to create a unique index. The following example creates a unique index:
CREATE UNIQUE INDEX dept_unique_index ON dept (dname) TABLESPACE indx;
Alternatively, you can define UNIQUE integrity constraints on the desired columns. Oracle enforces UNIQUE integrity constraints by automatically defining a unique index on the unique key. This is discussed in the following section. However, it is advisable that any index that exists for query performance, including unique indexes, be created explicitly
| See Also:
Oracle9i Database Performance Tuning Guide and Reference for more information about creating an index for performance |
Oracle enforces a UNIQUE key or PRIMARY KEY integrity constraint on a table by creating a unique index on the unique key or primary key. This index is automatically created by Oracle when the constraint is enabled. No action is required by you when you issue the CREATE TABLE or ALTER TABLE statement to create the index, but you can optionally specify a USING INDEX clause to exercise control over its creation. This includes both when a constraint is defined and enabled, and when a defined but disabled constraint is enabled.
To enable a UNIQUE or PRIMARY KEY constraint, thus creating an associated index, the owner of the table must have a quota for the tablespace intended to contain the index, or the UNLIMITED TABLESPACE system privilege. A constraint's associated index always assumes the name of the constraint, unless you optionally specify otherwise.
You can set the storage options for the indexes associated with UNIQUE and PRIMARY KEY constraints using the USING INDEX clause. The following CREATE TABLE statement enables a PRIMARY KEY constraint and specifies the associated index's storage options:
CREATE TABLE emp ( empno NUMBER(5) PRIMARY KEY, age INTEGER) ENABLE PRIMARY KEY USING INDEX TABLESPACE users PCTFREE 0;
If you require more explicit control over the indexes associated with UNIQUE and PRIMARY KEY constraints, Oracle allows you to:
These options are specified using the USING INDEX clause. The following statements present some examples.
Example 1:
CREATE TABLE a ( a1 INT PRIMARY KEY USING INDEX (create index ai on a (a1)));
Example 2:
CREATE TABLE b( b1 INT, b2 INT, CONSTRAINT bu1 UNIQUE (b1, b2) USING INDEX (create unique index bi on b(b1, b2)), CONSTRAINT bu2 UNIQUE (b2, b1) USING INDEX bi);
Example 3:
CREATE TABLE c(c1 INT, c2 INT); CREATE INDEX ci ON c (c1, c2); ALTER TABLE c ADD CONSTRAINT cpk PRIMARY KEY (c1) USING INDEX ci;
If a single statement creates an index with one constraint and also uses that index for another constraint, the system will attempt to rearrange the clauses to create the index before reusing it.
Oracle provides you with the opportunity to collect statistics at very little resource cost during the creation or rebuilding of an index. These statistics are stored in the data dictionary for ongoing use by the optimizer in choosing a plan for the execution of SQL statements. The following statement computes index, table, and column statistics while building index emp_ename on column ename of table emp:
CREATE INDEX emp_ename ON emp(ename) COMPUTE STATISTICS;
See Also:
|
When creating an extremely large index, consider allocating a larger temporary tablespace for the index creation using the following procedure:
CREATE TABLESPACE or CREATE TEMPORARY TABLESPACE statement.TEMPORARY TABLESPACE option of the ALTER USER statement to make this your new temporary tablespace.CREATE INDEX statement.DROP TABLESPACE statement. Then use the ALTER USER statement to reset your temporary tablespace to your original temporary tablespace.Using this procedure can avoid the problem of expanding your usual, and usually shared, temporary tablespace to an unreasonably large size that might affect future performance.
You can create and rebuild indexes online. This enables you to update base tables at the same time you are building or rebuilding indexes on that table. You can perform DML operations while the index build is taking place, but DDL operations are not allowed. Parallel execution is not supported when creating or rebuilding an index online.
The following statements illustrate online index build operations:
CREATE INDEX emp_name ON emp (mgr, emp1, emp2, emp3) ONLINE;
Function-based indexes facilitate queries that qualify a value returned by a function or expression. The value of the function or expression is precomputed and stored in the index.
Function-based indexes allow you to:
You can perform case-insensitive sorts with the UPPER and LOWER functions, descending order sorts with the DESC keyword, and linguistic-based sorts with the NLSSORT function.
An index can store computationally intensive expression that you access often. When you need to access a value, it is already computed, greatly improving query execution performance.
For example, consider the expression in the WHERE clause below:
CREATE INDEX idx ON Example_tab(column_a + column_b); SELECT * FROM example_tab WHERE column_a + column_b < 10;
The optimizer can use a range scan for this query because the index is built on (column_a + column_b). Range scans typically produce fast response times if the predicate selects less than 15% of the rows of a large table. The optimizer can estimate how many rows are selected by expressions more accurately if the expressions are materialized in a function-based index. (Expressions of function-based indexes are represented as virtual columns and analyze operation using the DBMS_STATS package can build histograms on such columns.)
They are treated as a special case of function-based indexes.
REF columns
Methods that describe objects can be used as functions on which to build indexes. For example, you can use the MAP method to build indexes on an object type column.
See Also:
|
For the creation of a function-based index in your own schema, you must be granted the QUERY REWRITE system privileges. To create the index in another schema or on another schema's tables, you must have the CREATE ANY INDEX and GLOBAL QUERY REWRITE privileges.
You must have the following initialization parameters defined to create a function-based index:
QUERY_REWRITE_INTEGRITY set to TRUSTEDQUERY_REWRITE_ENABLED set to TRUECOMPATIBLE set to 8.1.0.0.0 or a greater valueAdditionally, to use a function-based index:
NULL values from the indexed expression, since NULL values are not stored in indexes.
To illustrate a function-based index, lets consider the following statement that defines a function-based index (area_index) defined on the function area(geo):
CREATE INDEX area_index ON rivers (area(geo));
In the following SQL statement, when area(geo) is referenced in the WHERE clause, the optimizer considers using the index area_index.
SELECT id, geo, area(geo), desc FROM rivers WHERE Area(geo) >5000;
Table owners should have EXECUTE privileges on the functions used in function-based indexes.
Because a function-based index depends upon any function it is using, it can be invalidated when a function changes. If the function is valid, you can use an ALTER INDEX ... ENABLE statement to enable a function-based index that has been disabled. The ALTER INDEX ... DISABLE statement allows you to disable the use of a function-based index. Consider doing this if you are working on the body of the function.
Some examples of using function-based indexes follow.
The following statement creates function-based index idx on table emp based on an uppercase evaluation of the ename column:
CREATE INDEX idx ON emp (UPPER(ename));
Now the SELECT statement uses the function-based index on UPPER(ename) to retrieve all employees with names that start with JOH:
SELECT * FROM emp WHERE UPPER(ename) LIKE 'JOH%';
This example also illustrates a case-insensitive search.
This statement creates a function-based index on an expression:
CREATE INDEX idx ON t (a + b * (c - 1), a, b);
SELECT statements can use either an index range scan (in the following SELECT statement the expression is a prefix of the index) or index full scan (preferable when the index specifies a high degree of parallelism).
SELECT a FROM t WHERE a + b * (c - 1) < 100;
You can use function-based indexes to support a linguistic sort index. NLSSORT is a function that returns a sort key that has been given a string. Thus, if you want to build an index on name using NLSSORT, issue the following statement:
CREATE INDEX nls_index ON t_table (NLSSORT(name, 'NLS_SORT = German'));
This statement creates index nls_index on table t_table with the collation sequence German.
Now, the following statement selects from t_table using the NLS_SORT index:
SELECT * FROM t_table ORDER BY name;
Rows are ordered using the collation sequence in German.
The following example combines a case-insensitive sort and a language sort:
CREATE INDEX empi ON emp UPPER ((ename), NLSSORT(ename));
Here, an NLS_SORT specification does not appear in the NLSSORT argument because NLSSORT looks at the session setting for the language of the linguistic sort key. The previous example illustrated a case where NLS_SORT was specified.
Creating an index using key compression enables you to eliminate repeated occurrences of key column prefix values.
Key compression breaks an index key into a prefix and a suffix entry. Compression is achieved by sharing the prefix entries among all the suffix entries in an index block. This sharing can lead to huge savings in space, allowing you to store more keys for each index block while improving performance.
Key compression can be useful in the following situations:
ROWID is appended to make the key unique. If you use key compression here, the duplicate key is stored as a prefix entry on the index block without the ROWID. The remaining rows become suffix entries consisting of only the ROWID.You enable key compression using the COMPRESS clause. The prefix length (as the number of key columns) can also be specified to identify how the key columns are broken into a prefix and suffix entry. For example, the following statement compresses duplicate occurrences of a key in the index leaf block:
CREATE INDEX emp_ename ON emp(ename) TABLESPACE users COMPRESS 1;
The COMPRESS clause can also be specified during rebuild. For example, during rebuild you can disable compression as follows:
ALTER INDEX emp_ename REBUILD NOCOMPRESS;
| See Also:
Oracle9i Database Concepts for a more detailed discussion of key compression |
To alter an index, your schema must contain the index or you must have the ALTER ANY INDEX system privilege. Among the actions allowed by the ALTER INDEX statement are:
LOGGING or NOLOGGINGYou cannot alter an index's column structure.
More detailed discussions of some of these operations are contained in the following sections:
Alter the storage parameters of any index, including those created by Oracle to enforce primary and unique key integrity constraints, using the ALTER INDEX statement. For example, the following statement alters the emp_ename index:
ALTER INDEX emp_ename STORAGE (PCTINCREASE 50);
The storage parameters INITIAL and MINEXTENTS cannot be altered. All new settings for the other storage parameters affect only extents subsequently allocated for the index.
For indexes that implement integrity constraints, you can choose to adjust storage parameters by issuing an ALTER TABLE statement that includes the USING INDEX subclause of the ENABLE clause. For example, the following statement changes the storage options of the index created on table emp to enforce the primary key constraint:
ALTER TABLE emp ENABLE PRIMARY KEY USING INDEX PCTFREE 5;
Before rebuilding an existing index, compare the costs and benefits associated with rebuilding to those associated with coalescing indexes as described in Table 16-1.
When you rebuild an index, you use an existing index as the data source. Creating an index in this manner enables you to change storage characteristics or move to a new tablespace. Rebuilding an index based on an existing data source removes intra-block fragmentation. Compared to dropping the index and using the CREATE INDEX statement, re-creating an existing index offers better performance.
The following statement rebuilds the existing index emp_name:
ALTER INDEX emp_name REBUILD;
The REBUILD clause must immediately follow the index name, and precede any other options. It cannot be used in conjunction with the DEALLOCATE UNUSED clause.
If have the option of rebuilding the index online. The following statement rebuilds the emp_name index online:
ALTER INDEX REBUILD ONLINE;
If you do not have the space required to rebuild an index, you can choose instead to coalesce the index. Coalescing an index can also be done online.
Oracle provides a means of monitoring indexes to determine if they are being used or not used. If it is determined that an index is not being used, then it can be dropped, thus eliminating unnecessary statement overhead.
To start monitoring an index's usage, issue this statement:
ALTER INDEX index MONITORING USAGE;
Later, issue the following statement to stop the monitoring:
ALTER INDEX index NOMONITORING USAGE;
The view V$OBJECT_USAGE can be queried for the index being monitored to see if the index has been used. The view contains a USED column whose value is YES or NO, depending upon if the index has been used within the time period being monitored. The view also contains the start and stop times of the monitoring period, and a MONITORING column (YES/NO) to indicate if usage monitoring is currently active.
Each time that you specify MONITORING USAGE, the V$OBJECT_USAGE view is reset for the specified index. The previous usage information is cleared or reset, and a new start time is recorded. When you specify NOMONITORING USAGE, no further monitoring is performed, and the end time is recorded for the monitoring period. Until the next ALTER INDEX ... MONITORING USAGE statement is issued, the view information is left unchanged.
If key values in an index are inserted, updated, and deleted frequently, the index can lose its acquired space efficiently over time. Monitor an index's efficiency of space usage at regular intervals by first analyzing the index's structure, using the ANALYZE INDEX ... VALIDATE STRUCTURE statement, and then querying the INDEX_STATS view:
SELECT PCT_USED FROM INDEX_STATS WHERE NAME = 'index';
The percentage of an index's space usage varies according to how often index keys are inserted, updated, or deleted. Develop a history of an index's average efficiency of space usage by performing the following sequence of operations several times:
PCTUSEDWhen you find that an index's space usage drops below its average, you can condense the index's space by dropping the index and rebuilding it, or coalescing it.
To drop an index, the index must be contained in your schema, or you must have the DROP ANY INDEX system privilege.
Some reasons for dropping an index include:
When you drop an index, all extents of the index's segment are returned to the containing tablespace and become available for other objects in the tablespace.
How you drop an index depends on whether you created the index explicitly with a CREATE INDEX statement, or implicitly by defining a key constraint on a table. If you created the index explicitly with the CREATE INDEX statement, then you can drop the index with the DROP INDEX statement. The following statement drops the emp_ename index:
DROP INDEX emp_ename;
You cannot drop only the index associated with an enabled UNIQUE key or PRIMARY KEY constraint. To drop a constraint's associated index, you must disable or drop the constraint itself.
The following views display information about indexes:
| See Also:
Oracle9i Database Reference for a complete description of these views |
|
 Copyright © 2001, 2002 Oracle Corporation. All Rights Reserved. |
|

