| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
この章では、表の行へのアクセスを高速化できるスキーマ・オブジェクトである索引と、索引構造に格納される表である索引構成表について説明します。
この章の内容は、次のとおりです。
索引は、表または表クラスタに関連するオプションの構造であり、索引によってデータ・アクセスを高速化できる場合があります。表の1つ以上の列に索引を作成することによって、場合によって、ランダムに分散している行の小さなセットを表から取得できるようになります。索引は、ディスクI/Oを削減するための様々な手段のうちの1つです。
ヒープ構成表に索引がない場合、そのデータベースでは、値の検索に全表スキャンを実行する必要があります。たとえば、索引がない場合、hr.departments表の位置2700の問合せでは、データベースは、すべての表ブロックのすべての行でこの値を検索する必要があります。データ量が増加すると、この方法では適切に対応できなくなります。
たとえば、ある人事管理マネージャが複数の段ボール箱を棚に置いて管理しているとします。従業員情報を収めたフォルダが、それらの箱にランダムに収納されています。従業員Whalen(ID 200)のフォルダは、1つ目の箱の下から10フォルダ目であり、King(ID 100)のフォルダは3つ目の箱の一番下にあります。マネージャがフォルダを見つけるには、1つ目の箱の一番下から一番上まですべてのフォルダを確認し、目的のフォルダが見つかるまで次の箱で同じことを繰り返します。アクセスを高速化するために、マネージャは従業員全員のIDとフォルダの位置を順にリストした索引を作成できます。
ID 100: Box 3, position 1 (bottom) ID 101: Box 7, position 8 ID 200: Box 1, position 10 . . .
同様に、マネージャは従業員の姓や部門IDなどの個別の索引を作成できます。
通常、次のいずれかの場合は、列に索引を作成することを検討します。
索引付けされた列を頻繁に問い合せ、表内の合計行数に対して割合の小さい行数が戻される場合。
索引付けされた列に参照整合性制約が存在する場合。索引は、全表ロックを回避する手段ですが、親表の主キーを更新したり、親表に主キーをマージしたり、親表から主キーを削除する場合は必須です。
表に一意キー制約を適用し、索引およびすべての索引オプションを手動で指定する場合。
索引は、関連するオブジェクトのデータから論理的にも物理的にも独立したスキーマ・オブジェクトです。そのため、索引を削除または作成しても、索引の表に物理的な影響はありません。
|
注意: 索引を削除しても、アプリケーションは引き続き機能します。ただし、索引設定されていたデータへのアクセスは低速になる場合があります。 |
索引の有無によって、SQL文の表現を変更する必要はありません。索引は、単一行のデータへの高速なアクセス・パスです。それは実行のスピードにのみ影響を与えます。索引の付いたデータ値では、索引はその値を含んでいる行の位置を直接示すポインタとして機能します。
作成された索引は、データベースによって自動的にメンテナンスされ、使用されます。また、行の追加、更新、削除など、データに対する変更が、関連するすべての索引に自動的に反映され、ユーザーによる操作は不要です。行が挿入されても、索引付きのデータ検索のパフォーマンスはほとんど一定です。ただし、表に対して数多くの索引が存在すると、データベースの索引も更新する必要があるため、DMLのパフォーマンスは低下します。
索引の特性は、次のとおりです。
使用可能性
索引は、使用可能(デフォルト)または使用禁止にできます。使用禁止索引はDML操作により維持されず、オプティマイザによって無視されます。使用禁止索引により、バルク・ロードのパフォーマンスが向上します。索引を削除し、後から再作成するかわりに、索引を使用禁止にし、後から再構築できます。使用禁止索引と索引パーティションは、領域を使用しません。使用可能索引を使用禁止にすると、データベースによりその索引セグメントが削除されます。
可視性
索引は、参照用(デフォルト)または非参照用にできます。非参照用索引はDML操作により維持され、デフォルトではオプティマイザで使用されません。索引を非表示にするのは、使用禁止または削除の代替手段です。非参照用索引は、索引を削除する前に削除をテストする場合や、アプリケーション全体に影響を与えることなく一時的に索引を使用する場合に特に役立ちます。
|
関連項目:
|
キーとは、索引を作成できる列または式の集合です。 索引とキーという用語は同じ意味で使用されることがありますが、これらの用語には違いがあります。索引は、データベース内に格納される構造体であり、ユーザーはSQL文を使用して管理します。一方、キーは厳密に論理的な概念です。
次の文は、サンプル表oe.ordersのcustomer_id列に索引を作成します。
CREATE INDEX ord_customer_ix ON orders (customer_id);
この文では、customer_id列が索引キーです。索引自体はord_customer_ixという名前です。
|
関連項目: CREATE INDEXの構文およびセマンティクスについては、『Oracle Database SQL言語リファレンス』 |
コンポジット索引(連結索引とも呼ばれる)は、表の中の複数の列に対して作成される索引です。コンポジット索引の列は、データを取得する問合せにとって最も効果的な順序で指定する必要があり、表の中で隣接している必要はありません。
SELECT文のWHERE句でコンポジット索引のすべての列または列の先頭部分を参照する場合には、コンポジット索引によってデータの検索速度を向上させることができます。そのため、定義で使用する列の順序は重要です。通常、最も頻繁にアクセスされる列が最初になります。
たとえば、アプリケーションが頻繁にemployees表のlast_name、job_idおよびsalary列への問合せを発行するとします。また、last_nameはカーディナリティが高く、表の行数に比べて個別値の数が多いとします。次のような列の順序で、索引を作成します。
CREATE INDEX employees_ix ON employees (last_name, job_id, salary);
3つの列すべて、last_name列のみ、またはlast_nameおよびjob_id列のみにアクセスする問合せは、この索引を使用します。この例では、last_name列にアクセスしない問合せは索引を使用しません。
列の順列が索引ごとに異なる場合は、同じ表に複数の索引が存在してもかまいません。列の順列を個別に指定すると、同じ列を使用して複数の索引を作成できます。たとえば、次のSQL文では有効な順列を指定しています。
CREATE INDEX employee_idx1 ON employees (last_name, job_id); CREATE INDEX employee_idx2 ON employees (job_id, last_name);
|
関連項目: コンポジット索引の使用方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
索引には、一意索引と非一意索引の2種類があります。一意索引を使用すると、表の複数行のキー列に重複した値が入らないことが保証されます。たとえば、複数の従業員が同じ従業員IDを持つことはできません。このため、一意索引の場合、データ値ごとにROWIDが1つ存在します。リーフ・ブロックのデータはキーのみによってソートされます。
非一意索引では、索引付けされた1つ以上の列に重複値が許可されます。たとえば、employees表のfirst_name列に、複数のMike値が含まれていてもかまいません。非一意索引の場合、ROWIDはソートされた順序でキーに含まれるため、非一意索引は索引キーとROWIDによってソートされます(昇順)。
Oracle Databaseでは、すべてのキー列がNULLの表の行には、索引は作成されません。ただし、ビットマップ索引の場合や、クラスタ・キーの列値がNULLの場合は例外です。
Oracle Databaseは、パフォーマンスの機能性を補足する複数の索引体系を提供しています。索引は次のように分類できます。
Bツリー索引
これらの索引は標準索引タイプです。これらは主キーおよび高度に選択的な索引に適しています。Bツリー索引を連結索引として使用すると、索引付けされた列でソートされたデータを取得できます。Bツリー索引には次のサブタイプがあります。
索引構成表
索引構成表はデータ自体が索引であるため、ヒープ構成表とは異なります。「索引構成表の概要」を参照してください。
逆キー索引
このタイプの索引では、索引キーのバイトの並びが逆になり、たとえば、103は301として格納されます。バイトの並びを逆にすることにより、索引への挿入が多数のブロックに分散されます。「逆キー索引」を参照してください。
降順索引
このタイプの索引では、特定の列(1つまたは複数)のデータが降順で格納されます。「昇順索引と降順索引」を参照してください。
Bツリークラスタ索引
このタイプの索引は、表クラスタ・キーに索引付けするために使用されます。キーは行を指し示すのではなく、クラスタ・キーに関連する行を含むブロックを指します。「索引付きクラスタの概要」を参照してください。
ビットマップ索引とビットマップ結合索引
ビットマップ索引では、索引エントリはビットマップを使用して複数の行を指します。対照的に、Bツリー索引エントリは単一の行を指します。ビットマップ結合索引は、2つ以上の表を結合するためのビットマップ索引です。「ビットマップ索引」を参照してください。
ファンクション索引
このタイプの索引に含まれる列は、UPPERファンクションなどのファンクションによって変換されるか、式に含まれます。Bツリー索引またはビットマップ索引はファンクション索引です。「ファンクション索引」を参照してください。
アプリケーション・ドメイン索引
このタイプの索引は、ユーザーによってアプリケーション固有ドメインのデータ用に作成されます。物理索引は従来の索引構造を使用する必要はなく、表としてOracle Databaseに格納することも、ファイルとして外部に格納することもできます。「アプリケーション・ドメイン索引」を参照してください。
|
関連項目: 様々な索引タイプの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
Bツリー(バランス・ツリーの略)は、最も一般的なタイプのデータベース索引です。Bツリー索引は、複数の範囲に分割された順序付きの値リストです。Bツリーは、キーを行または行の範囲と関連付けることによって、完全一致や範囲検索など、広範囲の問合せに対して優れた検索パフォーマンスを提供します。
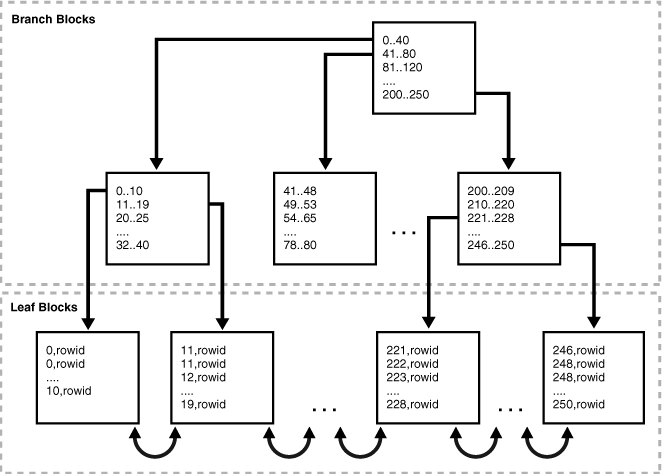
図3-1に、Bツリー索引の構造を示します。この例では、employees表の外部キー列であるdepartment_id列の索引を示しています。
Bツリー索引には、検索用のブランチ・ブロックと、値を格納するリーフ・ブロックの2種類のブロックがあります。Bツリー索引の上位ブランチ・ブロックには、下位レベルの索引ブロックを指す索引データが含まれます。図3-1では、ルート・ブランチ・ブロックに0-40のエントリがあり、次のブランチ・レベルの左端のブロックを指しています。このブランチ・ブロックには、0-10や11-19などのエントリがあります。これらの各エントリは、それぞれの範囲に該当するキー値を含むリーフ・ブロックを指します。
すべてのリーフ・ブロックは自動的に同じ深さになるため、Bツリー索引はバランスが保たれます。したがって、索引のどの位置からでも、レコード検索にかかる時間はほぼ同じになります。索引の高さは、ルート・ブロックからリーフ・ブロックに達するまでに必要なブロックの数です。ブランチ・レベルは高さから1を引いた数です。図3-1では、索引の高さは3、ブランチ・レベルは2です。
ブランチ・ブロックには、2つのキーの分岐を決定する際に必要な、最小のキー接頭辞が格納されます。このテクニックを使用すると、データベースでは各ブランチ・ブロックにできるかぎり多くのデータを収納できます。ブランチ・ブロックには、キーを含む子ブロックへのポインタが含まれます。キーおよびポインタの数は、ブロックのサイズによって制限されます。
リーフ・ブロックには、すべての索引付きデータ値と、実際の行を検索するための対応するROWIDが含まれています。各エントリは(キー、ROWID)によってソートされます。リーフ・ブロック内では、キーとROWIDは兄弟関係にある左右のエントリにリンクされます。リーフ・ブロック自体も二重にリンクされます。図3-1では、左端のリーフ・ブロック(0-10)が2番目のリーフ・ブロック(11-19)にリンクされます。
|
注意: 文字データを持つ列の索引は、データベース・キャラクタ・セットにおける文字のバイナリ値を基盤にしています。 |
索引スキャンの場合、データベースでは文に指定された索引付けされた列値を使用し、索引を読み込むことによって行を検索します。データベースでは、索引をスキャンして値を検索する場合、n回のI/Oでこの値を見つけます(nは、Bツリー索引の高さ)。これがOracle Database索引の基本原理です。
SQL文が索引付けされた列のみにアクセスする場合、データベースでは表ではなく索引から値を直接読み取ります。文が索引付けされた列に加えて列にもアクセスする場合、データベースではROWIDを使用して表の中の行を検索します。通常、データベースでは索引ブロックと表ブロックを交互に読み取って表データを取得します。
|
関連項目: 索引スキャンの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
全索引スキャンの場合、データベースでは索引全体を順に読み取ります。全索引スキャンは、SQL文の述語(WHERE句)が索引の列を参照している場合、および述語が指定されていない場合に使用できます。全スキャンでは、データが索引キーによって順序付けられるため、ソートが不要になります。
アプリケーションにより、次の問合せが実行されるとします。
SELECT department_id, last_name, salary FROM employees WHERE salary > 5000 ORDER BY department_id, last_name;
また、department_id、last_nameおよびsalaryが索引のコンポジット・キーであるとします。Oracle Databaseでは、ソートされた順序(部門IDおよび姓の順序)で索引を読み取り、salary属性でフィルタ処理して索引の全スキャンを実行します。これにより、データベースでは、問合せに含まれている列より多くの列を含むemployees表よりも小さいデータ・セットがスキャンされ、データのソートが不要になります。
たとえば、全スキャンによって次のような索引エントリが読み取られます。
50,Atkinson,2800,rowid 60,Austin,4800,rowid 70,Baer,10000,rowid 80,Abel,11000,rowid 80,Ande,6400,rowid 110,Austin,7200,rowid . . .
高速全索引スキャンは、データベースが特定の順序に従わずに索引ブロックを読み取る全索引スキャンで、表にアクセスすることなく、索引自体の中のデータにアクセスします。
高速全索引スキャンは、次に示す2つの条件が満たされている場合に全表スキャンの代替となるスキャンです。
問合せに必要なすべての列が索引に含まれていること。
すべてNULLの行が問合せの結果セットに現れないこと。この結果を保証するためには、索引内の少なくとも1つの列に次のいずれかが存在する必要があります。
NOT NULL制約。
問合せの結果セットにNULLが含まれないように考え抜かれた、列に適用される条件。
たとえば、アプリケーションにより、ORDER BY句を含まない次の問合せが発行されるとします。
SELECT last_name, salary FROM employees;
last_name列にはNOT NULL制約があります。姓と給与が索引のコンポジット・キーである場合、高速全索引スキャンでは索引エントリを読み取って、要求された情報を取得できます。
Baida,2900,rowid Zlotkey,10500,rowid Austin,7200,rowid Baer,10000,rowid Atkinson,2800,rowid Austin,4800,rowid . . .
索引レンジ・スキャンは、索引の順序付きスキャンであり、次の特性があります。
索引の1つ以上の先頭列を条件に指定します。条件は、1つ以上の式および論理(ブール)演算子の組合せを指定し、TRUE、FALSEまたはUNKNOWNの値を戻します。
0個、1個、または複数の値を索引キーにできます。
データベースでは一般的に、索引レンジ・スキャンを選択的なデータへのアクセスに使用します。選択性は、問合せで選択される表の中の行の割合で、0は行がないことを表し、1はすべての行を表します。選択性は、問合せの述語(WHERE last_name LIKE 'A%'など)や述語の組合せに関連します。述語は、値が0に近付くほど選択性が高くなり、値が1に近付くほど選択性が低く(非選択性が高く)なります。
たとえば、姓がAで始まる従業員を問い合せるとします。last_name列に索引が作成されており、次のエントリがあるとします。
Abel,rowid Ande,rowid Atkinson,rowid Austin,rowid Austin,rowid Baer,rowid . . .
last_name列が述語に指定されており、それぞれの索引キーに複数のROWIDが考えられるため、データベースではレンジ・スキャンを使用できます。たとえば、Austinという姓の従業員が2人いた場合、2つのROWIDがキーAustinに関連付けられます。
索引レンジ・スキャンは、10から40のIDを持つ部門の問合せのように、両側に境界がある場合と、40より大きいIDの問合せのように片側のみに境界がある場合があります。索引をスキャンするには、データベースではリーフ・ブロックを後方または前方に移動します。たとえば、10から40のIDを求めるスキャンでは、最小キー値10以上を含む最初の索引リーフ・ブロックが検索されます。次に、40より大きい値が見つかるまで、スキャンはリンクされたリーフ・ノード・リストを水平に進みます。
索引レンジ・スキャンとは対照的に、索引の一意スキャンでは、索引キーに関連付けられたROWIDは0個または1個である必要があります。データベースでは、述語が等価演算子を使用して一意索引キーのすべての列を参照する場合に、一意スキャンが実行されます。索引の一意スキャンでは、2つ目のレコードがないことがわかっているため、最初のレコードが見つかるとただちに処理が停止します。
例として、ユーザーが次の問合せを実行するとします。
SELECT * FROM employees WHERE employee_id = 5;
employee_id列が主キーで、次のようなエントリで索引が作成されているとします。
1,rowid 2,rowid 4,rowid 5,rowid 6,rowid . . .
この場合、データベースでは、索引の一意スキャンを使用してIDが5の従業員のROWIDが検索されます。
索引スキップ・スキャンでは、コンポジット索引の論理副索引を使用します。個別の索引を検索する場合と同様に、データベースでは単一の索引をスキップします。コンポジット索引の先頭列に含まれる個別値が少数であり、索引の先頭以外のキーに多数の個別値がある場合は、スキップ・スキャンが有効です。
コンポジット索引の先頭列が問合せの述語に指定されていない場合、データベースでは、索引スキップ・スキャンを選択できます。たとえば、sh.customers表の顧客に対して次の問合せを実行するとします。
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.com';
customers表にはcust_genderという列があり、この列の値はMまたはFです。列(cust_gender、cust_email)にコンポジット索引が存在するとします。例3-1は、索引エントリの一部を示しています。
例3-1 コンポジット索引エントリ
F,Wolf@company.com,rowid F,Wolsey@company.com,rowid F,Wood@company.com,rowid F,Woodman@company.com,rowid F,Yang@company.com,rowid F,Zimmerman@company.com,rowid M,Abbassi@company.com,rowid M,Abbey@company.com,rowid
cust_genderはWHERE句に指定されていませんが、データベースでは、この索引のスキップ・スキャンを使用できます。
スキップ・スキャンでは、論理副索引の数は、先頭列の個別値の数によって決定されます。例3-1では、先頭列に2つの可能な値があります。データベースでは、索引を、キーFを持つ1つの副索引と、キーMを持つ2つ目の副索引に論理的に分割します。
Abbey@company.comという電子メールを持つ顧客のレコードを検索するとき、データベースでは、値Fを持つ副索引を最初に検索し、次に、値Mを持つ副索引を検索します。その結果、データベースでは問合せが次のように処理されます。
SELECT * FROM sh.customers WHERE cust_gender = 'F' AND cust_email = 'Abbey@company.com' UNION ALL SELECT * FROM sh.customers WHERE cust_gender = 'M' AND cust_email = 'Abbey@company.com';
|
関連項目: スキップ・スキャンの詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
索引クラスタ化係数は、姓などの索引付きの値を対象に、行の順序性を測定した指標です。行の記憶域の中でこの値に関する順序性がよいほど、クラスタ化係数は小さくなります。
クラスタ化係数は、索引を使用した表全体の読取りに必要な入出力回数のおおよその目安として使用できます。特徴は次のとおりです。
クラスタ化係数が高いほど、大規模な索引のレンジ・スキャン実行時の入出力回数が増えます。索引エントリはランダムな表ブロックを指しているため、データベースは索引が示すデータを取得するために、同じブロックの読取りが何回も必要になることがあります。
クラスタ化係数が低いほど、大規模な索引のレンジ・スキャン実行時の入出力回数が減ります。同じ範囲の中にある索引キーは同じブロックを指していることが多いため、データベースは同じブロックを何度も読み取る必要がありません。
クラスタ化係数は、索引スキャンと深い関連性があります。これは、クラスタ係数で次の事項を判断できるからです。
データベースが大規模なレンジ・スキャンに索引を使用するかどうか
索引キーに対する表の編成の度合い
索引キーに従って行を順序付ける必要がある場合に、索引構成表、パーティション化、表クラスタのいずれを使用するのがよいか
たとえば、employees表が2つのデータ・ブロックに分かれているとします。表3-1は、2つのデータ・ブロック内の行を示しています(省略記号は省略したデータを示します)。
表3-1 Employees表内にある2つのデータ・ブロックの内容
| データ・ブロック1 | データ・ブロック2 |
|---|---|
100 Steven King SKING ... 156 Janette King JKING ... 115 Alexander Khoo AKHOO ... . . . 116 Shelli Baida SBAIDA ... 204 Hermann Baer HBAER ... 105 David Austin DAUSTIN ... 130 Mozhe Atkinson MATKINSO ... 166 Sundar Ande SANDE ... 174 Ellen Abel EABEL ... |
149 Eleni Zlotkey EZLOTKEY ... 200 Jennifer Whalen JWHALEN ... . . . 137 Renske Ladwig RLADWIG ... 173 Sundita Kumar SKUMAR ... 101 Neena Kochar NKOCHHAR ... |
行は姓(太字の部分)の順序に従ってブロックに格納されています。たとえば、データ・ブロック1は、最後の行から先頭に向ってAbel、Andeと続き、先頭のSteven Kingまでアルファベット順に並んでいます。データ・ブロック2は、最後の行から先頭に向ってKochar、Kumarと続き、先頭のZlotkeyまでアルファベット順に並んでいます。
姓の列に索引が付けられているとします。それぞれの名前エントリが、ROWIDに相当します。索引エントリは概念的には次のようになります。
Abel,block1row1 Ande,block1row2 Atkinson,block1row3 Austin,block1row4 Baer,block1row5 . . .
社員IDの列に別の索引が付けられているとします。索引エントリは概念的には次のようになり、社員IDは、2つのブロック全体にわたり、ほぼランダムな場所に分散しています。
100,block1row50 101,block2row1 102,block1row9 103,block2row19 104,block2row39 105,block1row4 . . .
表3-2では、この2つの索引のクラスタ化係数を求めるために、ALL_INDEXESビューを問い合せています。EMP_NAME_IXのクラスタ化係数は低く、同じリーフ・ブロック内の隣接する索引エントリは、同じデータ・ブロック内の行を指す傾向があります。EMP_EMP_ID_PKのクラスタ化係数は高く、同じリーフ・ブロック内の隣接する索引エントリが、同じデータ・ブロック内の行を指すことはほとんどありません。
例3-2 クラスタ化係数
SQL> SELECT INDEX_NAME, CLUSTERING_FACTOR
2 FROM ALL_INDEXES
3 WHERE INDEX_NAME IN ('EMP_NAME_IX','EMP_EMP_ID_PK');
INDEX_NAME CLUSTERING_FACTOR
-------------------- -----------------
EMP_EMP_ID_PK 19
EMP_NAME_IX 2
|
関連項目: ALL_INDEXESの詳細は、『Oracle Databaseリファレンス』 |
逆キー索引はBツリー索引の一種であり、列の順序は保ちながら、各索引キーのバイトを物理的に逆にします。たとえば、索引キーが20であり、このキーに対して標準Bツリー索引で格納される16進数の2バイトがC1,15である場合、逆キー索引では、バイトが15,C1として格納されます。
キーを逆にすると、Bツリー索引の右側にあるリーフ・ブロックの競合の問題が解決されます。この問題は、複数のインスタンスが同じブロックを繰り返し変更するOracle Real Application Clusters(Oracle RAC)データベースで特に深刻です。たとえば、orders表では、オーダーの主キーは順次キーです。クラスタ内の1つのインスタンスが注文20を追加し、別のインスタンスがオーダー21を追加し、各インスタンスが索引の右側にある同じリーフ・ブロックにキーを書き込みます。
逆キー索引では、バイト順を逆にすることにより、挿入が索引のすべてのリーフ・キー全体に分散されます。たとえば、標準キー索引では隣接する20や21などのキーは、離れた別々のブロックに格納されます。したがって、順次キーの挿入のためのI/Oは、より等分に分散されます。
索引のデータは格納されるときに列キーでソートされないため、逆キー配列を使用すると、場合によっては索引レンジ・スキャン問合せを実行できなくなります。たとえば、20より大きいオーダーIDを求める問合せを発行した場合、データベースではこのIDを含むブロックから開始できず、リーフ・ブロックが水平に処理されます。
|
関連項目: 逆キー索引の設計の考慮事項は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
昇順索引では、Oracle Databaseのデータは昇順に格納されます。デフォルトでは、文字データは値の各バイトに含まれるバイナリ値に従って順序付けられ、数値データは最小の数から最大の数へ、日付は古い値から新しい値への順になります。
CREATE INDEX emp_deptid_ix ON hr.employees(department_id);
Oracle Databaseでは、hr.employees表をdepartment_id列でソートします。department_idおよび対応するROWID値を、0から始まる昇順で昇順索引にロードします。索引を使用するとき、Oracle Databaseでは、ソートしたdepartment_id値が検索され、関連付けられたROWIDを使用して要求されたdepartment_id値を持つ行が検索されます。
CREATE INDEX文にDESCキーワードを指定すると、降順索引を作成できます。この場合、索引は指定された列(1つまたは複数)にデータを降順に格納します。図3-1のemployees.department_id列の索引が降順である場合、250を含むリーフ・ブロックがツリーの左側となり、0のブロックが右側になります。降順索引でのデフォルトの検索は、最大値から最小値への順です。
降順索引は、問合せで一部の列を昇順、他の列を降順でソートする場合に有効です。たとえば、last_name列およびdepartment_id列に対して、次のようにコンポジット索引を作成したとします。
CREATE INDEX emp_name_dpt_ix ON hr.employees(last_name ASC, department_id DESC);
ユーザーがhr.employeesに対して、昇順(AからZへ)の姓と降順(大きいIDから小さいIDへ)の部門IDを問い合せる場合、データベースではこの索引を使用してデータを検索するため、データをソートする余分な手順が不要になります。
|
関連項目:
|
Oracle Databaseでは、キー圧縮を使用して、Bツリー索引または索引構成表の主キー列値の一部を圧縮できます。キー圧縮によって、索引に使用される領域が大幅に減少します。
通常、索引キーには、グループ化要素と一意要素という2つの要素があります。キー圧縮では、索引キーを、グループ化要素である接頭辞エントリと、一意要素またはほぼ一意要素である接尾辞エントリに分割します。データベースでは、圧縮するために、接頭辞エントリが索引ブロック内の接尾辞エントリ間で共有されます。
|
注意: 一意要素を持つようにキーを定義しなければ、データベースによってグループ化要素にROWIDが追加され、一意要素が提供されます。 |
デフォルトでは、一意索引の接頭辞は最後のキー列を除くすべてのキー列で構成され、非一意索引の接頭辞はすべてのキー列で構成されます。たとえば、oe.orders表に次のようなコンポジット索引を作成したとします。
CREATE INDEX orders_mod_stat_ix ON orders ( order_mode, order_status );
order_mode列およびorder_status列で多数の繰返し値が発生します。索引ブロックに、例3-3に示すエントリがあるとします。
例3-3 Orders表の索引エントリ
online,0,AAAPvCAAFAAAAFaAAa online,0,AAAPvCAAFAAAAFaAAg online,0,AAAPvCAAFAAAAFaAAl online,2,AAAPvCAAFAAAAFaAAm online,3,AAAPvCAAFAAAAFaAAq online,3,AAAPvCAAFAAAAFaAAt
例3-3では、キー接頭辞は、order_modeとorder_statusの値を連結した値で構成されます。この索引がデフォルトのキー圧縮によって作成された場合、online,0やonline,2のような重複するキー接頭辞が圧縮されます。その結果、データベースでは次の例に示すように圧縮されます。
online,0 AAAPvCAAFAAAAFaAAa AAAPvCAAFAAAAFaAAg AAAPvCAAFAAAAFaAAl online,2 AAAPvCAAFAAAAFaAAm online,3 AAAPvCAAFAAAAFaAAq AAAPvCAAFAAAAFaAAt
接尾辞エントリは、索引行の圧縮版を形成します。各接尾辞エントリは、同じ索引ブロックに格納されている接頭辞エントリを参照します。
別の方法として、圧縮型索引を作成するときに接頭辞の長さを指定できます。たとえば、接頭辞の長さを1と指定した場合、接頭辞はorder_modeとなり、接尾辞はorder_status,rowidとなります。例3-3の値の場合、索引では重複するonlineが次のように除外されます。
online 0,AAAPvCAAFAAAAFaAAa 0,AAAPvCAAFAAAAFaAAg 0,AAAPvCAAFAAAAFaAAl 2,AAAPvCAAFAAAAFaAAm 3,AAAPvCAAFAAAAFaAAq 3,AAAPvCAAFAAAAFaAAt
索引では、特定の接頭辞がリーフ・ブロックごとに1回のみ格納されます。圧縮されるのは、Bツリー索引のリーフ・ブロックのキーのみです。ブランチ・ブロックの場合、キーの接尾辞は切り捨てることができますが、キーは圧縮されません。
|
関連項目:
|
ビットマップ索引では、各索引キーのビットマップがデータベースに格納されます。従来型のBツリー索引では、1つの索引エントリは単一の行を指します。ビットマップ索引では、各索引キーに複数の行へのポインタが格納されます。
ビットマップ索引は、主にデータ・ウェアハウス用または問合せが多数の列を非定型方式で参照する環境用に設計されています。 ビットマップ索引が適している状況として、次のような状況があります。
データ・ウェアハウスの例として、sh.customer表にcust_gender列があるとすると、この列に指定される値は、MとFの2つのみです。特定の性別の顧客の数に対する問合せが一般的だとします。このような場合、customer.cust_gender列はビットマップ索引の候補になります。
ビットマップの各ビットは、存在するROWIDに対応します。ビットが設定されている場合は、対応するROWIDを持つ行にはキー値が含まれます。マッピング機能がビット位置を実際のROWIDに変換するため、別の内部表現が使用されていても、ビットマップ索引はBツリー索引と同じ機能を提供します。
単一の行の索引付けされた列が更新された場合、データベースによって、更新された行にマッピングされた個別のビットではなく索引キー・エントリ(たとえば、MまたはF)がロックされます。キーは多数の行を指すため、索引付きデータに対するDMLは、通常、これらの行をすべてロックします。このため、ビットマップ索引は多くのOLTPアプリケーションに適していません。
|
関連項目:
|
例3-4に、sh.customers表の問合せを示します。この表の一部の列はビットマップ索引の候補です。
例3-4 customers表の問合せ
SQL> SELECT cust_id, cust_last_name, cust_marital_status, cust_gender
2 FROM sh.customers
3 WHERE ROWNUM < 8 ORDER BY cust_id;
CUST_ID CUST_LAST_ CUST_MAR C
---------- ---------- -------- -
1 Kessel M
2 Koch F
3 Emmerson M
4 Hardy M
5 Gowen M
6 Charles single F
7 Ingram single F
7 rows selected.
cust_marital_statusおよびcust_gender列のカーディナリティは低く、cust_idおよびcust_last_nameのカーディナリティは低くありません。このため、ビットマップ索引はcust_marital_statusおよびcust_genderに適切といえます。その他の列には、ビットマップ索引は効果がありません。この場合は、一意のBツリー索引を使用する方が、表示と検索が効率的になります。
表3-2に、例3-4に示したcust_gender列の出力に対するビットマップ索引を示します。これは、各性別に対応する2つのビットマップからなります。
マッピング関数はビットマップの各ビットをcustomers表のROWIDに変換します。各ビットの値は、表内の対応する行の値に依存しています。たとえば、customers表の最初の行で性別がMであるため、M値のビットマップには、最初のビットとして1が含まれます。ビットマップcust_gender='M'の行2、6、および7のビットは、これらの行が値としてMを含まないため、0になります。
|
注意: Bツリー索引とは異なり、ビットマップ索引は、完全にNULL値からなるキーを含む場合があります。NULLの索引作成は、集計関数COUNTによる問合せなど、一部のSQL文に使用できます。 |
顧客の人口統計を調べているアナリストが、女性顧客のうち独身者または離婚者はどれくらいいるかを尋ねてきたとします。この質問は、次のSQL問合せで表現できます。
SELECT COUNT(*)
FROM customers
WHERE cust_gender = 'F'
AND cust_marital_status IN ('single', 'divorced');
ビットマップ索引を使用すると、表3-3に示すように、結果のビットマップから1の値の数を数え、この問合せを効率よく処理できます。基準に該当する顧客を識別するときは、Oracle Databaseでは結果のビットマップを使用して表にアクセスできます。
表3-3 サンプル・ビットマップ
| 値 | 行1 | 行2 | 行3 | 行4 | 行5 | 行6 | 行7 |
|---|---|---|---|---|---|---|---|
|
|
1 |
0 |
1 |
1 |
1 |
0 |
0 |
|
|
0 |
1 |
0 |
0 |
0 |
1 |
1 |
|
|
0 |
0 |
0 |
0 |
0 |
1 |
1 |
|
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
|
0 |
0 |
0 |
0 |
0 |
1 |
1 |
ビットマップ索引は、WHERE句に指定されたいくつかの条件に対応する索引を効率的にマージします。すべての条件ではなく一部の条件のみを満たす行は、表自体がアクセスされる前に除外されます。これによってレスポンス時間が短縮されます(多くの場合は大幅に改善されます)。
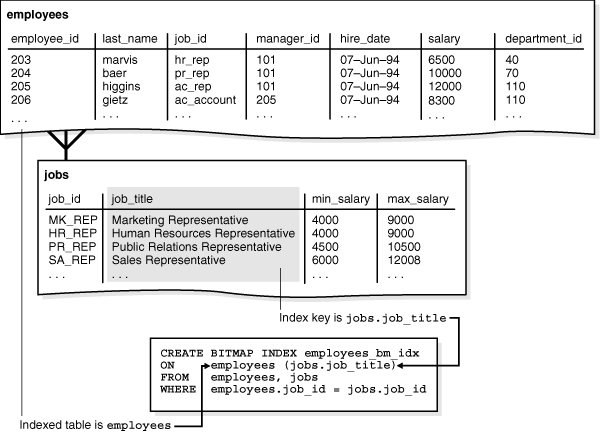
ビットマップ結合索引は、2つ以上の表を結合するためのビットマップ索引です。索引は、表列の値ごとに、対応する行のROWIDを索引付きの表に格納します。対照的に、標準ビットマップ索引は単一表に対して作成されます。
ビットマップ結合索引は、制限を事前に実行するため、結合するデータのボリュームを削減する効率的な方法です。ビットマップ結合索引が役に立つ場合の例として、ユーザーが特定の職種の従業員数を頻繁に問い合せるとします。一般的な問合せは次のようになります。
SELECT COUNT(*) FROM employees, jobs WHERE employees.job_id = jobs.job_id AND jobs.job_title = 'Accountant';
この問合せでは、通常、jobs.job_titleの索引を使用してAccountantの行を検索し、次にjob_idの行を検索し、employees.job_idの索引を使用して一致する行を検索します。表のスキャンではなく索引自体からデータを取り出すには、次のようにビットマップ結合索引を作成できます。
CREATE BITMAP INDEX employees_bm_idx
ON employees (jobs.job_title)
FROM employees, jobs
WHERE employees.job_id = jobs.job_id;
図3-2に示すように、索引キーはjobs.job_titleであり、索引付きの表はemployeesです。
概念的には、例3-5(サンプル出力を示しています)に示すSQL問合せのjobs.title列の索引はemployees_bm_idxです。索引のjob_titleキーは、employees表の行を指します。経理担当者の数を求める問合せでは、索引を使用すると、索引自体に要求された情報が含まれるため、employeesおよびjobs表へのアクセスを回避できます。
例3-5 employees表とjobs表の結合
SELECT jobs.job_title AS "jobs.job_title", employees.rowid AS "employees.rowid" FROM employees, jobs WHERE employees.job_id = jobs.job_id ORDER BY job_title; jobs.job_title employees.rowid ----------------------------------- ------------------ Accountant AAAQNKAAFAAAABSAAL Accountant AAAQNKAAFAAAABSAAN Accountant AAAQNKAAFAAAABSAAM Accountant AAAQNKAAFAAAABSAAJ Accountant AAAQNKAAFAAAABSAAK Accounting Manager AAAQNKAAFAAAABTAAH Administration Assistant AAAQNKAAFAAAABTAAC Administration Vice President AAAQNKAAFAAAABSAAC Administration Vice President AAAQNKAAFAAAABSAAB . . .
データ・ウェアハウスでは、結合条件は、ディメンション表の主キー列とファクト表の外部キー列の間の等価結合(等価演算子を使用する)になります。ビットマップ結合索引は、格納に関して、事前に結合をマテリアライズするマテリアライズド結合ビューよりもはるかに効率的な場合があります。
|
関連項目: ビットマップ結合索引の詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
Oracle Databaseでは、Bツリー索引構造を使用して各索引付きキーのビットマップを格納します。たとえば、jobs.job_titleがビットマップ索引のキー列である場合、索引データは1つのBツリーに格納されます。個々のビットマップはリーフ・ブロックに格納されます。
jobs.job_title列に一意の値であるShipping Clerk、Stock Clerk、およびその他いくつかの値があるとします。この索引のビットマップ索引エントリには、次のコンポーネントがあります。
索引キーとしての職種
ROWIDの範囲として小さいROWIDと大きいROWID
範囲内の特定のROWIDのビットマップ
その結果、この索引の索引リーフ・ブロックには次のようなエントリが含まれる場合があります。
Shipping Clerk,AAAPzRAAFAAAABSABQ,AAAPzRAAFAAAABSABZ,0010000100 Shipping Clerk,AAAPzRAAFAAAABSABa,AAAPzRAAFAAAABSABh,010010 Stock Clerk,AAAPzRAAFAAAABSAAa,AAAPzRAAFAAAABSAAc,1001001100 Stock Clerk,AAAPzRAAFAAAABSAAd,AAAPzRAAFAAAABSAAt,0101001001 Stock Clerk,AAAPzRAAFAAAABSAAu,AAAPzRAAFAAAABSABz,100001 . . .
ROWID範囲が異なるため、同じ職種が複数エントリに出現します。
セッションで、1人の従業員のジョブIDをShipping ClerkからStock Clerkに更新するとします。このような場合、セッションは古い値(Shipping Clerk)と新しい値(Stock Clerk)の索引キー・エントリに排他的にアクセスする必要があります。Oracle Databaseでは、UPDATEがコミットされるまで、これら2つのエントリで指し示された行がロックされます(ただし、Accountantまたはその他のキーで指し示された行はロックされません)。
ビットマップ索引のデータは1つのセグメントに格納されます。Oracle Databaseでは、各ビットマップを1つ以上の断片に格納します。各断片は単一データ・ブロックの一部を占めます。
表に索引を設定する場合、その表の1つ以上の列を含むファンクションと式について、索引を作成できます。ファンクション索引では、1つ以上の列を含むファンクションや式の値が計算され、索引に格納されます。ファンクション索引はBツリー索引またはビットマップ索引のいずれかです。
索引作成に使用するファンクションには、算術式あるいはSQL関数、ユーザー定義のPL/SQLファンクション、パッケージ・ファンクション、またはCコールアウトを含む式を使用できます。たとえば、ファンクションでは2つの列の値を加算できます。
|
関連項目:
|
ファンクション索引は、WHERE句にファンクションを含む文を効率的に評価します。データベースでは、ファンクションが問合せに含まれている場合にのみ、ファンクション索引を使用します。ただし、INSERT文とUPDATE文の処理中には、データベースでは文を処理するために従来どおりファンクションを評価する必要があります。
CREATE INDEX emp_total_sal_idx
ON employees (12 * salary * commission_pct, salary, commission_pct);
データベースでは、例3-6(部分的なサンプル出力を示しています)に示すような問合せを処理するときに、この索引を使用できます。
例3-6 算術式を含む問合せ
SELECT employee_id, last_name, first_name,
12*salary*commission_pct AS "ANNUAL SAL"
FROM employees
WHERE (12 * salary * commission_pct) < 30000
ORDER BY "ANNUAL SAL" DESC;
EMPLOYEE_ID LAST_NAME FIRST_NAME ANNUAL SAL
----------- ------------------------- -------------------- ----------
159 Smith Lindsey 28800
151 Bernstein David 28500
152 Hall Peter 27000
160 Doran Louise 27000
175 Hutton Alyssa 26400
149 Zlotkey Eleni 25200
169 Bloom Harrison 24000
SQLファンクションUPPER(column_name)またはLOWER(column_name)でファンクション索引を定義すると、大文字/小文字を区別しない検索が容易になります。たとえば、employeesのfirst_name列に大文字/小文字が含まれるとします。hr.employees表に次のようなファンクション索引を作成します。
CREATE INDEX emp_fname_uppercase_idx ON employees ( UPPER(first_name) );
emp_fname_uppercase_idx索引によって、次のような問合せが容易になります。
SELECT * FROM employees WHERE UPPER(first_name) = 'AUDREY';
ファンクション索引は、表の特定の行のみに索引を付ける場合にも役に立ちます。たとえば、sh.customers表のcust_valid列には、値としてIまたはAがあるとします。Aの行のみに索引を付けるには、A以外のすべての行に対してNULL値を戻すファンクションを作成できます。次のような索引を作成できます。
CREATE INDEX cust_valid_idx ON customers ( CASE cust_valid WHEN 'A' THEN 'A' END );
|
関連項目:
|
オプティマイザでは、WHERE句の式による問合せに、ファンクション索引に対する索引レンジ・スキャンを使用できます。レンジ・スキャンのアクセス・パスは、述語(WHERE句)の選択性が低い場合に特に便利です。例3-6では、式12*salary*commission_pctの索引が作成されていれば、オプティマイザは索引レンジ・スキャンを使用できます。
仮想列は、式から導出されるデータへのアクセスを高速化するために役立ちます。たとえば、仮想列annual_salを12*salary*commission_pctとして定義し、annual_salにファンクション索引を作成できます。
オプティマイザは、SQL文の式を解析し、文の式ツリーとファンクション索引を比較して、式のマッチングを実行します。この比較は大文字/小文字が区別され、ブランクは無視されます。
|
関連項目:
|
アプリケーション・ドメイン索引は、アプリケーション固有のカスタマイズされた索引です。Oracle Databaseでは、次の操作を行うために拡張索引作成機能を提供しています。
カスタマイズされた複合データ型(文書、空間データ、イメージ、ビデオ・クリップなど)の索引への対応(「非構造化データ」を参照)
特殊な索引作成方法の利用
アプリケーション固有の索引管理ルーチンを索引タイプ・スキーマ・オブジェクトとしてカプセル化し、オブジェクト型の表の列や属性のドメイン索引を定義できます。拡張索引作成機能により、アプリケーション固有の演算子を効率的に処理できます。
ドメイン索引の構造と内容は、カートリッジと呼ばれるアプリケーション・ソフトウェアによって制御されます。データベースは、ドメイン索引の作成、メンテナンス、および検索のために、このアプリケーションと対話します。索引構造そのものは、索引構成表としてデータベースに格納するか、ファイルとして外部に格納できます。
|
関連項目: Oracle Databaseの拡張性アーキテクチャ内のデータ・カートリッジの使用方法の詳細は、『Oracle Databaseデータ・カートリッジ開発者ガイド』を参照してください。 |
Oracle Databaseでは、索引データは索引セグメントに格納されます。データ・ブロックで索引データのために使用できる領域は、データ・ブロック・サイズから、ブロック・オーバーヘッド、エントリ・オーバーヘッド、ROWID、および索引が作成される値1つ当たり1バイトの合計を引いたものです。
索引セグメントの表領域は、所有者のデフォルト表領域またはCREATE INDEX文で明示的に指定された表領域です。管理を容易にするために、索引をその表とは別の表領域に格納できます。たとえば、索引のみを含む表領域は再構築できるため、これらの表領域をバックアップしないよう指定することによって、バックアップに必要な時間と記憶域を削減できます。
索引構成表は、一種のBツリー索引構造に格納される表です。ヒープ構成表では、行は収まる位置に挿入されます。索引構成表では、行は表の主キーに定義された索引に格納されます。Bツリーの各索引エントリには、非キー列値も格納されます。したがって、索引はデータであり、データは索引です。アプリケーションは、ヒープ構成表と同じように、SQL文を使用して索引構成表を操作します。
たとえば、索引構成表について、人事管理マネージャが複数の段ボール箱を棚に置いて管理しているとします。それぞれの箱には1、2、3、4というように番号のラベルが付いていますが、箱は棚の中で順番に並んではいません。それぞれの箱には、次の箱が棚のどの位置にあるかを示すポインタがあります。
それぞれの箱には従業員レコードが入っているフォルダが収納されています。フォルダは従業員IDによってソートされています。従業員KingのIDは100で、それが最小のIDであるため、Kingのフォルダは箱1の一番下にあります。従業員101のフォルダは100の上、102は101の上というように、箱1がいっぱいになるまでフォルダが収められています。この並びにおける次のフォルダは、箱2の一番下になります。
この例の場合、フォルダを従業員IDで並べると、専用の索引をメンテナンスすることなく、フォルダを効率的に検索できます。ユーザーが従業員107、120、および122のレコードを要求していると想定します。1つの手順で索引を検索し、別の手順でフォルダを取り出すかわりに、マネージャは、フォルダを順番に検索し、個々のフォルダを見つかり次第取り出すことができます。
索引構成表は、主キーまたはそのキーの有効な接頭辞の使用により、表の行に対するアクセスを高速化します。リーフ・ブロックの行に非キー列が存在することにより、追加のデータ・ブロックI/Oが回避されます。たとえば、従業員100の給与は索引行自体に格納されます。さらに、行が主キーの順序で格納されるため、主キーまたは接頭辞によるレンジ・アクセスでは最小限のブロックI/Oが行われます。もう1つの利点は、個別の主キー索引の空間オーバーヘッドが回避されることです。
索引構成表は、関連したデータ断片をまとめて格納する必要がある場合や、データを特定の順序で物理的に格納する必要がある場合に役立ちます。このタイプの表は、情報検索、空間(「Oracle Spatialの概要」を参照)、およびOLAPアプリケーション(「OLAP」を参照)によく使用されます。
|
関連項目:
|
データベース・システムは、Bツリー索引構造を操作することで、索引構成表に対するすべての操作を実行します。表3-4に、索引構成表とヒープ構成表の違いをまとめます。
表3-4 ヒープ構成表と索引構成表の比較
| ヒープ構成表 | 索引構成表 |
|---|---|
|
ROWIDが行を一意に識別します。主キー制約はオプションで定義できます。 |
主キーが行を一意に識別します。主キー制約を定義する必要があります。 |
|
|
|
|
ROWIDによって個々の行に直接アクセスできます。 |
個々の行には、主キーによって間接的にアクセスします。 |
|
順次全表スキャンは、特定の順序ですべての行を戻します。 |
全索引スキャンまたは高速全索引スキャンは、特定の順序ですべての行を戻します。 |
|
他の表とともに表クラスタに格納できます。 |
表クラスタには格納できません。 |
|
|
LOB列は格納できますが、 |
|
仮想列を格納できます(サポートされているのはリレーショナル・ヒープ表のみです)。 |
仮想列は格納できません。 |
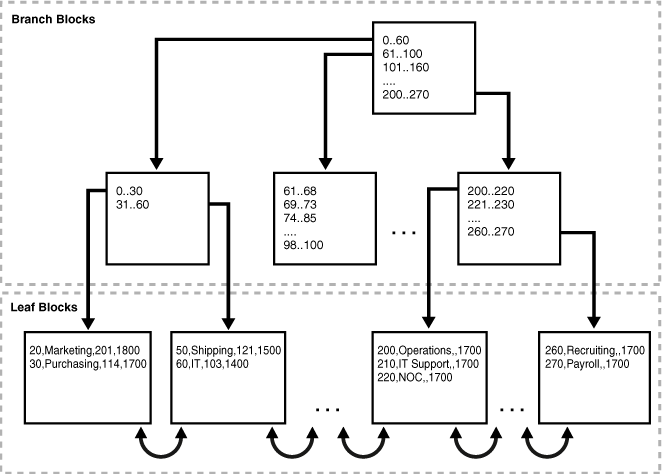
図3-3に、索引構成表departmentsの構造を示します。リーフ・ブロックには表の行が主キーの順序に従って格納されています。たとえば、最初のリーフ・ブロックの最初の値は、部門ID 20、部門名Marketing、マネージャID 201、および場所ID 1800を示しています。
索引構成表では、すべてのデータが同じ構造に格納され、ROWIDを格納する必要がありません。図3-3に示すように、索引構成表のリーフ・ブロック1には、主キーの順序に従った次のようなエントリが含まれます。
20,Marketing,201,1800 30,Purchasing,114,1700
索引構成表のリーフ・ブロック2には次のようなエントリが含まれます。
50,Shipping,121,1500 60,IT,103,1400
主キーの順序になっている索引構成表の行をスキャンすると、ブロックが次の順序で読み取られます。
ブロック1
ブロック2
ヒープ構成表でのデータ・アクセスを索引構成表でのデータ・アクセスと比較するため、ヒープ構成表departmentsのセグメントのブロック1に、次のように行が格納されているとします。
50,Shipping,121,1500 20,Marketing,201,1800
ブロック2には同じ表の行が次のように格納されています。
30,Purchasing,114,1700 60,IT,103,1400
このヒープ構成表のBツリー索引リーフ・ブロックには、次のエントリが格納されています。最初の値は主キーであり、2つ目の値はROWIDです。
20,AAAPeXAAFAAAAAyAAD 30,AAAPeXAAFAAAAAyAAA 50,AAAPeXAAFAAAAAyAAC 60,AAAPeXAAFAAAAAyAAB
主キーの順序になっている表の行をスキャンすると、表セグメント・ブロックが次の順序で読み取られます。
ブロック1
ブロック2
ブロック1
ブロック2
したがって、この例のブロックI/Oの数は、索引構成の例での数の倍になります。
索引構成表を作成するとき、別のセグメントを行オーバーフロー領域として指定できます。索引構成表では、行全体を格納しているBツリー索引エントリは大きくなる場合があり、エントリを格納する別のセグメントが役立ちます。これに対し、Bツリー・エントリはキーとROWIDで構成されるため、通常は小さくなります。
行オーバーフロー領域を指定した場合、データベースでは索引構成表の行を次の部分に分割できます。
索引エントリ
この部分には、主キー列すべての列値、行のオーバーフロー部分を指す物理ROWID、およびオプションで一部の非キー列が含まれます。この部分は索引セグメントに格納されます。
オーバーフロー部分
この部分には、残りの非キー列の列値が含まれます。この部分はオーバーフロー記憶域セグメントに格納されます。
|
関連項目:
|
2次索引は、索引構成表の索引です。ある意味では、これは索引の索引です。2次索引は独立したスキーマ・オブジェクトであり、索引構成表とは別に格納されます。
「ROWIDデータ型」で説明しているように、Oracle Databaseでは、索引構成表に対して論理ROWIDと呼ばれる行識別子を使用します。論理ROWIDは、表の主キーをbase64でエンコードした表現です。論理ROWIDの長さは、主キーの長さに応じて異なります。
索引リーフ・ブロック内の行は、挿入によってブロック内またはブロック間で移動できます。ヒープ構成の行とは異なり、索引構成表の行は移行されません(「行の連鎖と移行」を参照)。索引構成表の行には永続的な物理アドレスがないため、データベースでは主キーに基づいて論理ROWIDを使用します。
たとえば、departments表が索引構成表であるとします。location_id列には各部門のIDが格納されます。表には次のように行が格納され、最後の値が場所IDになります。
10,Administration,200,1700 20,Marketing,201,1800 30,Purchasing,114,1700 40,Human Resources,203,2400
location_id列の2次索引には、次のような索引エントリが含まれる場合があります。カンマに続く値が論理ROWIDです。
1700,*BAFAJqoCwR/+ 1700,*BAFAJqoCwQv+ 1800,*BAFAJqoCwRX+ 2400,*BAFAJqoCwSn+
2次索引は、主キーでも主キーの接頭辞でもない列を使用して、索引構成表への高速で効率的なアクセスを可能にします。たとえば、IDが1700より大きい部門名の問合せでは、2次索引を使用してデータ・アクセスを高速化できます。
|
関連項目:
|
2次索引では論理ROWIDを使用して表の行を検索します。論理ROWIDには、索引エントリの最初の作成時の物理ROWIDである物理推測が含まれます。Oracle Databaseは、物理推測を使用して、主キー検索をバイパスし、索引構成表のリーフ・ブロックを直接検証できます。行の物理位置が変化した場合、論理ROWIDは失効した物理推測が含まれていても引き続き有効です。
ヒープ構成表の場合、2次索引によるアクセスでは、行を含むデータ・ブロックをフェッチするために、2次索引のスキャンと付加的なI/Oが必要になります。索引構成表の場合、2次索引によるアクセスは、次のように物理推測を使用するかどうかと、その正確さに応じて異なります。
物理推測を使用しない場合、アクセスでは2次索引のスキャンとその後に主キー索引のスキャンという、2つの索引スキャンが行われます。
物理推測を使用する場合は、アクセスは物理推測の正確さに応じて異なります。
正確な物理推測を使用する場合、アクセス時には、2次索引スキャンと追加のI/Oによって行を含むデータ・ブロックがフェッチされます。
不正確な物理推測を使用する場合、アクセス時には2次索引スキャンとI/Oによって間違ったデータ・ブロック(物理推測が示すブロック)がフェッチされてから、主キー値による索引構成表の索引一意スキャンが実行されます。
索引構成表の2次索引は、ビットマップ索引にできます。「ビットマップ索引」で説明しているように、ビットマップ索引には各索引キーのビットマップが格納されます。
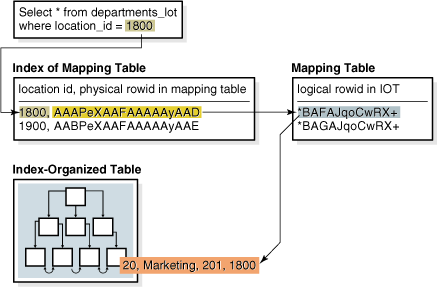
索引構成表にビットマップ索引が存在する場合、すべてのビットマップ索引はヒープ構成のマッピング表を使用します。マッピング表には索引構成表の論理ROWIDが格納されます。マッピング表の各行には対応する索引構成表の行の論理ROWIDが格納されます。
データベースでは、検索キーを使用してビットマップ索引にアクセスします。キーが見つかると、ビットマップのエントリは物理ROWIDに変換されます。ヒープ構成表の場合、この物理ROWIDは実表へのアクセスに使用されます。索引構成表の場合、この物理ROWIDはマッピング表へのアクセスに使用され、それにより、索引構成表へのアクセスに使用される論理ROWIDが取得されます。図3-4に、departments_iot表の問合せ用の索引アクセスを示します。
|
注意: 索引構成表で行を移動すると、その索引構成表に作成されたビットマップ索引の使用禁止状態が変化します。 |