| Oracle® Database概要 11gリリース2 (11.2) B56306-06 |
|


 前 |
 次 |
この章では、スキーマ・オブジェクトの概要、および最も一般的なスキーマ・オブジェクトである表について説明します。
この章の内容は、次のとおりです。
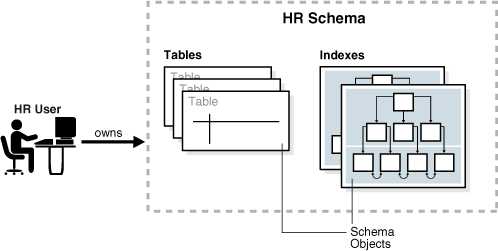
データベース・スキーマは、スキーマ・オブジェクトと呼ばれるデータ構造の論理コンテナです。スキーマ・オブジェクトの例には、表や索引があります。スキーマ・オブジェクトは、SQLで作成および操作します。
データベース・ユーザーは、パスワードと様々なデータベース権限を持ちます。各ユーザーは、ユーザーと同じ名前が付いた単一のスキーマを所有します。スキーマには、スキーマを所有するユーザーのデータが含まれています。たとえば、hrユーザーはhrスキーマを所有し、このスキーマにemployees表などのスキーマ・オブジェクトが含まれます。通常、本番データベースでは、スキーマ所有者は人ではなく、データベース・アプリケーションを表します。
スキーマ内の特定のタイプの各スキーマ・オブジェクトには、一意の名前が付きます。たとえば、hr.employeesはhrスキーマ内のemployees表を指します。図2-1に、hrという名前のスキーマ所有者とhrスキーマ内のスキーマ・オブジェクトを示します。
リレーショナル・データベースで最も重要なスキーマ・オブジェクトは、表です。表では、データは行に格納されます。
Oracle SQLでは、他にも次のような多数のタイプのスキーマ・オブジェクトを作成および操作できます。
索引
索引とは、表または表クラスタの索引付けされた各行のエントリを含むスキーマ・オブジェクトのことで、索引により行に直接かつ高速にアクセスできます。Oracle Databaseは、いくつかのタイプの索引をサポートしています。索引構成表は、データが索引の構造で格納される表です。第3章「索引と索引構成表」を参照してください。
パーティション
パーティションとは、大規模な表や索引の断片のことです。各パーティションには独自の名前があり、独自の記憶特性を持つ場合があります。「パーティションの概要」を参照してください。
ビュー
ビューとは、1つ以上の表または他のビューに含まれているデータの表現がカスタマイズされたものです。ビューは、ストアド・クエリーとみなすことができます。実際にはビューにデータは含まれていません。「ビューの概要」を参照してください。
順序
順序とは、複数のユーザーが整数を生成して共有できるユーザー作成オブジェクトのことです。通常、順序は主キー値の生成に使用されます。「順序の概要」を参照してください。
ディメンション
ディメンションは、列セットのペア間の親子関係を定義するもので、この列セットに含まれるすべての列は、同じ表の列である必要があります。ディメンションは、主に顧客、製品および時刻などのデータを分類するために使用されます。「ディメンションの概要」を参照してください。
シノニム
シノニムとは、他のスキーマ・オブジェクトの別名のことです。シノニムは単なる別名であるため、データ・ディクショナリ内の定義以外に記憶域は必要ありません。「シノニムの概要」を参照してください。
PL/SQLサブプログラムとPL/SQLパッケージ
PL/SQLは、SQLに対するOracleの手続き型の拡張機能です。PL/SQLサブプログラムとは、一連のパラメータを使用して起動できる、名前付きPL/SQLブロックのことです。PL/SQLパッケージとは、論理的に関連するPL/SQLタイプ、変数およびサブプログラムをグループ化するものです。「PL/SQLサブプログラム」および「PL/SQLパッケージ」を参照してください。
データベースには他のタイプのオブジェクトも保存されており、SQL文で作成および操作できますが、スキーマには含まれていません。これらのオブジェクトには、データベース・ユーザー、ロール、コンテキストおよびディクショナリ・オブジェクトなどがあります。
|
関連項目:
|
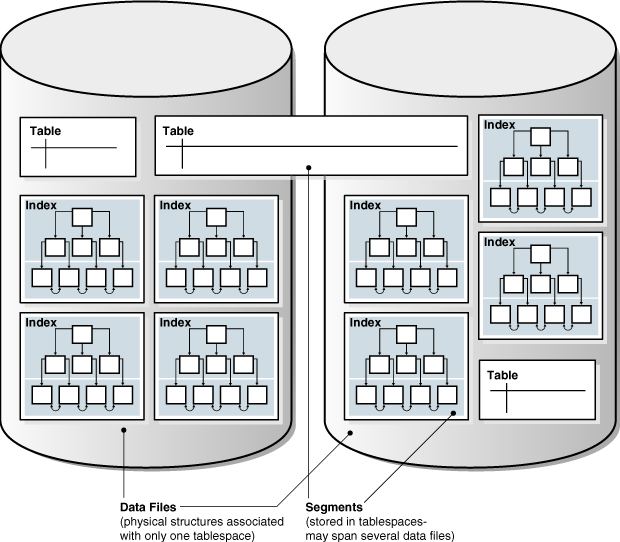
一部のスキーマ・オブジェクトでは、セグメントと呼ばれる論理記憶域構造にデータを格納します。たとえば、パーティション化されていないヒープ構成表や索引では、セグメントを作成します。ビューや順序などの他のスキーマ・オブジェクトは、メタデータのみで構成されます。この項では、セグメントを持つスキーマ・オブジェクトについてのみ説明します。
Oracle Databaseでは、スキーマ・オブジェクトは表領域内に論理的に格納されます。スキーマと表領域には関連はなく、表領域は異なるスキーマのオブジェクトを含むことができ、スキーマの各オブジェクトは異なる表領域に含めることができます。各オブジェクトのデータは、物理的には、1つ以上のデータファイルに格納されます。
図2-2に、表と索引のセグメント、表領域およびデータファイルの可能な構成を示します。1つの表のデータ・セグメントが2つのデータファイル(両方とも同じ表領域の一部)にまたがっています。セグメントが複数の表領域にまたがることはできません。
|
関連項目:
|
スキーマ・オブジェクトには、他のオブジェクトを参照し、スキーマ・オブジェクトの依存性を作成するものがあります。たとえば、ビューに表または他のビューを参照する問合せが含まれている場合や、PL/SQLサブプログラムが他のサブプログラムを起動する場合があります。オブジェクトAの定義がオブジェクトBを参照している場合、AはBに関する依存オブジェクト、BはAに関する参照オブジェクトです。
Oracle Databaseには、依存オブジェクトがその参照オブジェクトに関して常に最新であることを保証する自動メカニズムがあります。依存オブジェクトが作成されると、データベースは依存オブジェクトとその参照オブジェクトとの間の依存性を追跡します。参照オブジェクトに変更があり、依存オブジェクトがその影響を受ける可能性がある場合は、依存オブジェクトに無効のマークが付きます。たとえば、ユーザーが表を削除した場合、その表に基づくビューは使用できなくなります。
無効な依存オブジェクトを使用できるようにするには、その依存オブジェクトが参照オブジェクトの新しい定義で再コンパイルされる必要があります。再コンパイルは、無効な依存オブジェクトが参照されたときに自動的に実行されます。
スキーマ・オブジェクトでどのように依存性を作成できるかを示す例として、次のサンプル・スクリプトでは、表test_tableを作成し、この表を問い合せるプロシージャを作成します。
CREATE TABLE test_table ( col1 INTEGER, col2 INTEGER ); CREATE OR REPLACE PROCEDURE test_proc AS BEGIN FOR x IN ( SELECT col1, col2 FROM test_table ) LOOP -- process data NULL; END LOOP; END; /
次のようにプロシージャtest_procのステータスを問い合せると、プロシージャは有効であることが示されます。
SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC'; OBJECT_NAME STATUS ----------- ------- TEST_PROC VALID
test_tableにcol3列を追加しても、プロシージャにはこの列に対する依存性がないため、その後もプロシージャは有効です。
SQL> ALTER TABLE test_table ADD col3 NUMBER; Table altered. SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC'; OBJECT_NAME STATUS ----------- ------- TEST_PROC VALID
ただし、test_procプロシージャが依存しているcol1列のデータ型を変更すると、プロシージャは無効化されます。
SQL> ALTER TABLE test_table MODIFY col1 VARCHAR2(20); Table altered. SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC'; OBJECT_NAME STATUS ----------- ------- TEST_PROC INVALID
次の例に示すように、プロシージャを実行または再コンパイルすると、プロシージャは再び有効になります。
SQL> EXECUTE test_proc PL/SQL procedure successfully completed. SQL> SELECT OBJECT_NAME, STATUS FROM USER_OBJECTS WHERE OBJECT_NAME = 'TEST_PROC'; OBJECT_NAME STATUS ----------- ------- TEST_PROC VALID
|
関連項目: スキーマ・オブジェクトの依存性を管理する方法の詳細は、『Oracle Database管理者ガイド』および『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |
すべてのOracleデータベースには、デフォルトの管理アカウントが自動的に含まれています。管理アカウントは、高度な権限が付与され、データベースの起動と停止、メモリーと記憶域の管理、データベース・ユーザーの作成と管理などのタスクの実行を認可されたDBA専用のアカウントです。
管理アカウントSYSは、データベースが作成されたときに自動的に作成されます。このアカウントでは、すべてのデータベース管理機能を実行できます。SYSスキーマには、データ・ディクショナリの実表とビューが格納されています。これらの実表とビューは、Oracle Databaseの操作にとって重要です。SYSスキーマ内の表はデータベースによってのみ操作され、ユーザーからは決して変更されません。
SYSTEMアカウントも、データベースが作成されたときに自動的に作成されます。SYSTEMスキーマには、管理情報を表示する追加の表とビュー、およびOracle Databaseの様々なオプションとツールで使用される内部の表とビューが格納されます。SYSTEMスキーマは、管理ユーザー以外のユーザーが必要とする表の格納には決して使用しないでください。
|
関連項目:
|
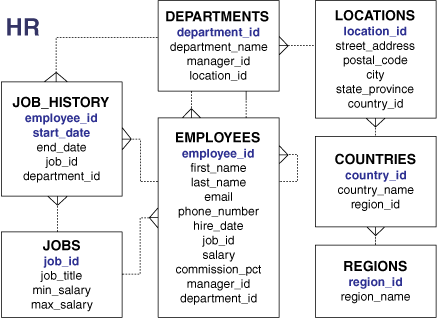
Oracleデータベースには、サンプル・スキーマが含まれることがあり、サンプル・スキーマとは、Oracleドキュメントや教材で共通のデータベース・タスクを説明できるように相互にリンクされた一連のスキーマのことです。hrスキーマは、従業員、部門、勤務地、職歴などの情報を含むサンプル・スキーマです。
図2-3は、hrスキーマに含まれる表のエンティティ関係ダイアグラムです。このマニュアルのほとんどの例では、このスキーマのオブジェクトを使用します。
|
関連項目: 『Oracle Databaseサンプル・スキーマ』 |
表は、Oracle Databaseにおけるデータ編成の基本単位です。表には、記録が必要な情報に関してなんらかの意味を持つエンティティが記述されます。たとえば、従業員がエンティティになることがあります。
Oracle Databaseの表は、次の基本カテゴリに分類されます。
リレーショナル表
リレーショナル表は、単純な列で構成された最も一般的な表タイプです。例2-1に、リレーショナル表のCREATE TABLE文を示します。
オブジェクト表
次の構成特性を持つリレーショナル表を作成できます。
ヒープ構成表では、行は特定の順序で格納されません。デフォルトでは、CREATE TABLE文でヒープ構成表が作成されます。
索引構成表では、主キー値に従って行が整列されます。アプリケーションによっては、索引構成表によりパフォーマンスが強化され、ディスク領域をより効率的に使用できるものがあります。「索引構成表の概要」を参照してください。
外部表は読取り専用の表であり、これらのメタデータはデータベースに格納されますが、データはデータベースの外部に格納されます。「外部表」を参照してください。
表は永続または一時のいずれかです。永続表の定義とデータは、セッションをまたいで存続します。一時表の定義も永続表の定義と同様に存続しますが、データはトランザクションまたはセッションの期間中にのみ存在します。一時表は、複数の操作の実行によって結果を作成する場合があるために、結果セットを一時的に保持する必要があるアプリケーションで役立ちます。
この項には次のトピックが含まれます:
|
関連項目: 表の管理方法の詳細は、『Oracle Database 2日でデータベース管理者』および『Oracle Database管理者ガイド』を参照してください。 |
表の定義には、表名と列の集合が含まれています。列は、表で示されるエンティティの属性を識別します。たとえば、employees表の列employee_idは、従業員エンティティの従業員ID属性を参照します。
通常は、表を作成するとき、各列に列名、データ型および幅を指定します。たとえば、employee_idのデータ型がNUMBER(6)である場合、この列に6桁以内の幅の数値データのみが格納されることを示します。幅は、DATEデータ型の場合のようにデータ型によって事前に決定されている場合があります。
表には、通常の列とは異なり、ディスク領域を使用しない仮想列を含めることができます。データベースによりユーザーが指定する一連の式または関数が計算され、必要に応じて仮想列から値が導出されます。たとえば、仮想列incomeが、salary列とcommission_pct列の関数になることがあります。
表の作成後に、SQL文を使用して行の挿入、問合せ、削除および更新ができます。行は、表内のレコードに対応する列情報の集まりです。たとえば、employees表の行には、特定の従業員の属性が記述されます。
|
関連項目: 仮想列の管理方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
表を作成するOracle SQLコマンドは、CREATE TABLEです。例2-1に、hrサンプル・スキーマに含まれるemployees表のCREATE TABLE文を示します。この文では、employee_idおよびfirst_nameなどの列を指定し、各列にNUMBERまたはDATEなどのデータ型を指定します。
例2-1 CREATE TABLE employees
CREATE TABLE employees
( employee_id NUMBER(6)
, first_name VARCHAR2(20)
, last_name VARCHAR2(25)
CONSTRAINT emp_last_name_nn NOT NULL
, email VARCHAR2(25)
CONSTRAINT emp_email_nn NOT NULL
, phone_number VARCHAR2(20)
, hire_date DATE
CONSTRAINT emp_hire_date_nn NOT NULL
, job_id VARCHAR2(10)
CONSTRAINT emp_job_nn NOT NULL
, salary NUMBER(8,2)
, commission_pct NUMBER(2,2)
, manager_id NUMBER(6)
, department_id NUMBER(4)
, CONSTRAINT emp_salary_min
CHECK (salary > 0)
, CONSTRAINT emp_email_uk
UNIQUE (email)
) ;
例2-2に、employees表に整合性制約を追加するALTER TABLE文を示します。整合性制約はビジネス・ルールを適用し、無効な情報が表に入力されるのを防止します。
例2-2 ALTER TABLE employees
ALTER TABLE employees
ADD ( CONSTRAINT emp_emp_id_pk
PRIMARY KEY (employee_id)
, CONSTRAINT emp_dept_fk
FOREIGN KEY (department_id)
REFERENCES departments
, CONSTRAINT emp_job_fk
FOREIGN KEY (job_id)
REFERENCES jobs (job_id)
, CONSTRAINT emp_manager_fk
FOREIGN KEY (manager_id)
REFERENCES employees
) ;
例2-3に、hr.employees表の8つの行と6つの列を示します。
例2-3 employees表の行
EMPLOYEE_ID FIRST_NAME LAST_NAME SALARY COMMISSION_PCT DEPARTMENT_ID
----------- ----------- ------------- ------- -------------- -------------
100 Steven King 24000 90
101 Neena Kochhar 17000 90
102 Lex De Haan 17000 90
103 Alexander Hunold 9000 60
107 Diana Lorentz 4200 60
149 Eleni Zlotkey 10500 .2 80
174 Ellen Abel 11000 .3 80
178 Kimberely Grant 7000 .15
例2-3の出力は、表、列および行に関する、次の重要な特徴のいくつかを示しています。
表の行には、1人の従業員の、名前、給与、部門などの属性が記述されます。たとえば、出力の最初の行には、Steven Kingという名前の従業員のレコードが表示されています。
列には、従業員の属性が記述されます。この例では、employee_id列が主キーであり、すべての従業員が一意の従業員IDで識別されることを意味します。2人の従業員が同じ従業員IDを持たないことが保証されます。
非キー列には、同じ値の行が含まれることがあります。この例では、従業員101と従業員102の給与の値が同じ17000です。
外部キー列は、同じ表または別の表の主キーや一意キーを参照します。この例では、department_idの90の値は、departments表のdepartment_id列に対応しています。
フィールドは、行と列の交差部分です。フィールドには1つの値のみが含まれます。たとえば、従業員104の部門IDのフィールドには、値60が含まれています。
フィールドには、値がないこともあります。この場合、フィールドにはNULL値が含まれることになります。従業員100のcommission_pct列の値はNULLですが、従業員149のこのフィールドの値は.2です。列にNULL値を入力できるのは、その列にNOT NULLまたは主キー整合性制約が定義されていない場合のみです。この場合、その列に値を持たない行は挿入できません。
|
関連項目: CREATE TABLEの構文およびセマンティクスについては、『Oracle Database SQL言語リファレンス』 |
列は、それぞれ特定の記憶域形式、制約および値の有効範囲に関連付けられたデータ型を持っています。値のデータ型により、固定された一連のプロパティが値に関連付けられます。これらのプロパティに従い、Oracle Databaseではあるデータ型の値を別のデータ型の値と異なる方法で扱います。たとえば、NUMBERデータ型の値は乗算できますが、RAWデータ型の値は乗算できません。
表の作成時には、その各列のデータ型を指定する必要があります。その後、列に挿入される各値は、その列のデータ型とみなされます。
Oracle Databaseには、いくつかの組込みデータ型が用意されています。最も一般的に使用されるデータ型は、次のカテゴリに分類されます。
組込みデータ型のその他の重要なカテゴリには、RAW、ラージ・オブジェクト(LOB)およびコレクションがあります。PL/SQLには、定数と変数のデータ型として、BOOLEAN、参照型、コンポジット型(レコード)およびユーザー定義型があります。
|
関連項目:
|
文字データ型は、文字(英数字)データを文字列で格納します。最も一般的に使用される文字データ型がVARCHAR2で、文字データを最も効率よく格納できます。
バイト値は、文字コード体系(通常、キャラクタ・セットまたはコード・ページと呼ばれます)に対応します。データベースのキャラクタ・セットは、データベースの作成時に設定されます。キャラクタ・セットの例には、7ビットASCII、EBCDICおよびUnicode UTF-8があります。
文字データ型の長さセマンティクスは、バイト数または文字数で測定できます。バイト・セマンティクスは、文字列を一連のバイトとして取り扱うことを意味します。これは、文字データ型のデフォルトです。キャラクタ・セマンティクスは、文字列を一連の文字として取り扱うことを意味します。文字は技術的に、データベース・キャラクタ・セットのコード・ポイントです。
|
関連項目:
|
VARCHAR2データ型には、可変長の文字リテラルが格納されます。リテラルと定数値という用語は同義であり、固定のデータ値を指します。たとえば、'LILA'、'St. George Island'および'101'はすべて文字リテラルで、5001は数値リテラルです。文字リテラルは一重引用符で囲み、これにより、データベースでスキーマ・オブジェクト名と区別されます。
|
注意: このマニュアルでは、テキスト・リテラル、文字リテラルおよび文字列という用語を同じ意味で使用します。 |
VARCHAR2の列を含む表の作成時には、文字列の最大長を指定します。例2-1では、last_name列にVARCHAR2(25)というデータ型が指定されており、これは、この列に最大25バイトの名前を格納できることを意味します。
それぞれの行で、列の値はOracle Databaseにより可変長のフィールドとして格納され、値が最大長を超えている場合は、データベースからエラーが戻されます。たとえば、シングルバイト・キャラクタ・セットで、ある行のlast_name列に10文字を入力すると、その行の列には25文字ではなく10文字(10バイト)のみが格納されます。VARCHAR2を使用することにより、領域の消費量を削減できます。
VARCHAR2とは異なり、CHARは、固定長の文字列を格納します。CHAR列を含む表の作成時には、列の文字列の長さを指定する必要があります。デフォルトは1バイトです。データベースは、空白を使用して指定された長さまで値を埋め込みます。
Oracle Databaseは、非空白埋め比較方法を使用してVARCHAR2値を比較し、空白埋め比較方法を使用してCHAR値を比較します。
|
関連項目: 空白埋め比較方法と非空白埋め比較方法の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
NCHARとNVARCHAR2データ型は、Unicode文字データを格納します。Unicodeはユニバーサル・エンコードされたキャラクタ・セットであり、1つのキャラクタ・セットで任意の言語の情報を格納できます。NCHARは、各国語キャラクタ・セットに対応する固定長の文字列を格納し、NVARCHAR2は、可変長の文字列を格納します。
データベースの作成時に各国語キャラクタ・セットを指定します。NCHARデータ型とNVARCHAR2データ型のキャラクタ・セットは、AL16UTF16またはUTF8のいずれかにする必要があります。どちらのキャラクタ・セットでも、Unicodeエンコーディングが使用されます。
NCHARまたはNVARCHAR2の列で表を作成すると、最大サイズは、必ず文字長セマンティクスになります。文字長セマンティクスはNCHARまたはNVARCHAR2のデフォルトであり、その唯一の長さセマンティクスです。
|
関連項目: Oracleのグローバリゼーション・サポート機能の詳細は、『Oracle Databaseグローバリゼーション・サポート・ガイド』を参照してください。 |
Oracle Databaseの数値データ型には、固定小数点数、浮動小数点数、ゼロおよび無限大が格納されます。いくつかの数値データ型には操作結果の未定義を示す値も格納され、これは、非数値つまりNANと呼ばれます。
Oracle Databaseでは、数値データが可変長形式で格納されます。それぞれの値は科学表記法で格納され、指数を格納するために1バイトが使用されます。データベースでは、仮数(浮動小数点数の一部で、有効桁数を含む部分)を格納するために最大20バイトが使用されます。Oracle Databaseでは、先行ゼロと後続ゼロは格納されません。
NUMBERデータ型には、固定小数点数および浮動小数点数が格納されます。実質的には、どのような大きさの数値でも、データベースに格納可能です。Oracle Databaseが稼働するオペレーティング・システムであれば、相互にデータを移植することが可能です。数値データの格納が必要となるほとんどの場合で、NUMBERデータ型をお薦めします。
固定小数点数は、NUMBER(p,s)という形式で指定します。このpおよびsは、次の文字を示しています。
精度
精度は、全体の桁数を指定します。精度を指定しない場合、値は丸められずに、アプリケーションから提供されたとおりに列に格納されます。
スケール
スケールは、小数点から最下位有効桁までの桁数を指定します。正のスケールは、小数点の右側から最下位有効桁まで(最下位有効桁を含む)の桁数を指定します。負のスケールは、小数点の左側から最下位有効桁まで(ただし、最下位有効桁を含まない)の桁数を指定します。NUMBER(6)のように、精度を指定してスケールを指定しない場合、スケールは0になります。
例2-1では、salary列はNUMBER(8,2)型であるため、精度は8でスケールは2です。したがって、100,000という給料は、データベースに100000.00という値で格納されます。
Oracle Databaseには、浮動小数点数専用にBINARY_FLOATおよびBINARY_DOUBLEという2つの数値データ型が用意されています。これらのデータ型は、NUMBERデータ型の基本機能をすべてサポートしています。ただし、NUMBERは10進精度を使用しますが、BINARY_FLOATおよびBINARY_DOUBLEは2進精度を使用します(2進精度により、算術計算が高速になり、通常は記憶域必要量が減少します)。
BINARY_FLOATとBINARY_DOUBLEは、近似値データ型です。どちらにも、10進値の正確な表現ではなく近似値表現が格納されます。たとえば、BINARY_DOUBLEまたはBINARY_FLOATでは、値0.1を正確に表現できません。この2つは、通常は科学関係の計算に使用されます。両者の動作は、JavaとXMLSchemaのデータ型FLOATおよびDOUBLEに似ています。
|
関連項目: 精度、スケールおよびその他の数値データ型の特性の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
日時データ型は、DATEとTIMESTAMPです。Oracle Databaseでは、タイムスタンプに対する包括的なタイムゾーン・サポートが提供されます。
DATEデータ型には、日付と時刻が格納されます。日時は、文字または数値のデータ型で表現できますが、DATEには、関連付けられた特別なプロパティがあります。例2-1のhire_date列には、DATEデータ型が指定されています。
データベースの内部では、日付が数字として格納されます。日付は、それぞれ世紀、年、月、日、時、分および秒に対応する7バイトの固定長フィールドに格納されます。
|
注意: 日付では算術演算が全面的にサポートされているため、数値の場合とまったく同様に日付を加算または減算できます。『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |
データベースでは、指定された書式モデルに従って日付が表示されます。書式モデルは、日時の書式を文字列で記述する文字リテラルです。標準の日付書式はDD-MON-RRであり、日付が01-JAN-11の形式で表示されます。
RRは、YY(年の最後の2桁)と似ていますが、戻り値の世紀は、指定された2桁の年と現在の年の最後の2桁に応じて異なります。1999年の日付がデータベースに01-JAN-11と表示されるとします。日付書式にRRを使用する場合、11は2011を指しますが、日付書式にYYを使用する場合、11は1911を指します。デフォルト日付書式は、インスタンスとセッションのどちらのレベルでも変更できます。
Oracle Databaseでは、時刻はHH:MI:SSの24時間形式で格納されます。時刻部分に何も指定しない場合、デフォルトでは、日付フィールドの時刻部分は00:00:00 A.M.になります。時刻のみを入力した場合、日付部分のデフォルトは現在の月の1日になります。
|
関連項目:
|
TIMESTAMPデータ型は、DATEデータ型を拡張したものです。DATEデータ型に格納される情報に加え、小数秒が格納されます。TIMESTAMPデータ型は、イベントの順序を追跡する必要があるアプリケーションなどで、正確な時間を格納するために役立ちます。
DATETIMEデータ型のTIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONEでは、タイム・ゾーンも認識されます。ユーザーがデータを選択すると、値はユーザー・セッションのタイム・ゾーンに調整されます。このデータ型は、複数の地理的地域にまたがって日付情報を収集および評価する場合に役立ちます。
|
関連項目: タイムスタンプ列のデータの作成と入力を実行する構文の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
データベースに格納されているすべての行にはアドレスがあります。Oracle Databaseでは、ROWIDデータ型にデータベース内の各行のアドレス(ROWID)が格納されます。ROWIDは、次のカテゴリに分類されます。
物理ROWIDは、ヒープ構成表、表クラスタ、および表パーティションや索引パーティションに行のアドレスを格納します。
論理ROWIDは、索引構成表に行のアドレスを格納します。
外部ROWIDは、ゲートウェイを介してアクセスされるDB2表などの外部表の識別子です。これは、Oracle Databaseの標準ROWIDではありません。
ユニバーサルROWIDまたはUROWIDと呼ばれるデータ型は、すべてのタイプのROWIDをサポートしています。
Oracle Databaseでは、ROWIDを内部的に使用して索引が構築されます。最も一般的なタイプはBツリー索引で、この索引は、複数の範囲に分割され、順序付けられたキーのリストから構成されます。それぞれのキーは、高速アクセスのために、対応する行のアドレスを指すROWIDに結び付けられています。エンド・ユーザーとアプリケーション開発者は、次のような重要な用途にROWIDを使用することもできます。
ROWIDは特定の行にアクセスする最も高速な方法です。
ROWIDは表の編成を把握する機能を提供します。
ROWIDは表の中の行の一意識別子です。
また、ROWIDデータ型を使用して定義した列を持つ表を作成することもできます。たとえば、データ型ROWIDの列を持つ例外表を定義して、整合性制約に違反する行のROWIDを格納できます。ROWIDデータ型を使用して定義されている列の動作は、値を更新できるなど、表の他の列と同様です。
Oracleデータベースのそれぞれの表は、ROWIDという名前の疑似列を持っています。疑似列は、表の列に似ていますが、実際には表に格納されません。疑似列からの選択はできますが、疑似列の値を挿入、更新または削除することはできません。疑似列は、引数のないSQLファンクションにも似ています。引数のない関数は通常、結果セットの各行に同じ値を戻しますが、疑似列は通常、行ごとに異なる値を戻します。
ROWID疑似列の値は、各行のアドレスを表す文字列です。これらの文字列は、ROWIDデータ型です。SELECTまたはDESCRIBEを実行して表の構造をリストしても疑似列は表示されず、疑似列は領域も使用しません。ただし、それぞれの行のROWIDは、予約語ROWIDを列名として使用すると、SQL問合せで取得できます。
例2-4では、ROWID擬似列を問い合せて、employees表にある従業員100の行のROWIDを表示します。
例2-4 ROWID擬似列
SQL> SELECT ROWID FROM employees WHERE employee_id = 100; ROWID ------------------ AAAPecAAFAAAABSAAA
|
関連項目:
|
書式モデルは、格納された日時または数値データの書式を文字列で記述する文字リテラルです。書式モデルによってデータベース内の値の内部表現が変更されることはありません。
文字列を日付または数値に変換する場合、データベースが文字列を解釈する方法は、書式モデルによって決まります。SQLでは、TO_CHAR関数とTO_DATE関数の引数として書式モデルを使用し、データベースから戻される値の書式またはデータベースに格納される値の書式を設定できます。
次の文は、部門80の従業員の給与を選択し、TO_CHAR関数を使用してそれらの給与を数値書式モデル'$99,990.99'で指定された書式の文字値に変換します。
SQL> SELECT last_name employee, TO_CHAR(salary, '$99,990.99') 2 FROM employees 3 WHERE department_id = 80 AND last_name = 'Russell'; EMPLOYEE TO_CHAR(SAL ------------------------- ----------- Russell $14,000.00
次の例では、TO_DATE関数で書式マスク'YYYY MM DD'を使用して採用日を更新し、文字列'1998 05 20'をDATE値に変換します。
SQL> UPDATE employees
2 SET hire_date = TO_DATE('1998 05 20','YYYY MM DD')
3 WHERE last_name = 'Hunold';
|
関連項目: 書式モデルの詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
整合性制約とは、表の1つ以上の列の値を制限する名前付きの規則のことです。これらの規則により、表に無効なデータが入力されないようにします。また、特定の依存性が存在する場合、制約によって表の削除を回避できます。
制約が使用可能である場合、データベースは、入力または更新の時点でのデータをチェックします。制約に準拠しないデータの入力は阻止されます。制約が使用禁止にされている場合、制約に準拠していないデータがデータベースに入力される可能性があります。
例2-1のCREATE TABLE文には、last_name、email、hire_dateおよびjob_idの各列にNOT NULL制約が指定されています。これらの制約句により、列と制約の条件が識別されます。これらの制約は、指定された列にNULL値が含まれないことを保証します。たとえば、職務IDのない新しい従業員を挿入しようとすると、エラーが発生します。
制約は、表の作成時または作成後に作成できます。必要に応じて、一時的に制約を使用禁止にできます。データベースでは、制約はデータ・ディクショナリに格納されます。
Oracleのオブジェクト型は、名前、属性およびメソッドを含むユーザー定義データ型です。オブジェクト型を使用すると、顧客や発注書などの実社会のエンティティをデータベース内のオブジェクトとしてモデル化できます。
オブジェクト型では論理構造が定義されますが、記憶域は作成されません。例2-5では、department_typという名前のオブジェクト型を作成します。
例2-5 オブジェクト型
CREATE TYPE department_typ AS OBJECT
( d_name VARCHAR2(100),
d_address VARCHAR2(200) );
/
オブジェクト表は、すべての行がオブジェクトを表す特殊な表です。例2-6のCREATE TABLE文は、オブジェクト型department_typのdepartments_obj_tという名前のオブジェクト表を作成します。この表の属性(列)は、オブジェクト型の定義から導出されます。INSERT文は、この表に行を挿入します。
例2-6 オブジェクト表
CREATE TABLE departments_obj_t OF department_typ;
INSERT INTO departments_obj_t
VALUES ('hr', '10 Main St, Sometown, CA');
リレーショナル列と同様に、オブジェクト表に含めることができるのは、表と同一の宣言された型のオブジェクト・インスタンスなど、1種類の行のみです。デフォルトで、オブジェクト表のすべての行オブジェクトに関連する論理オブジェクト識別子(OID)があり、この識別子によりオブジェクト表の行オブジェクトが一意に識別されます。オブジェクト表のOID列は、非表示の列です。
|
関連項目:
|
Oracle Databaseの一時表には、トランザクションまたはセッションの期間中にのみ存在するデータが保持されます。一時表内のデータはセッションのプライベートであり、各セッションが表示および変更できるのは、そのセッション自身のデータのみです。
一時表は、結果セットをバッファリングする必要があるアプリケーションで役立ちます。たとえば、スケジューリング・アプリケーションでは、大学生が学期のオプション・コースのスケジュールを作成できます。各スケジュールは、一時表の行によって表示されます。セッション中、スケジュール・データはプライベートです。学生がスケジュールを決定すると、アプリケーションは選択されたスケジュールの行を永続表に移します。セッションの終了時、一時表内のスケジュール・データは自動的に削除されます。
一時表は、CREATE GLOBAL TEMPORARY TABLE文で作成されます。ON COMMIT句では、表データをトランザクション固有(デフォルト)とセッション固有のどちらにするかを指定します。
他の一部のリレーショナル・データベース内の一時表とは異なり、Oracleデータベースに一時表を作成する場合は、静的な表定義を作成します。一時表は、データ・ディクショナリに記述される永続オブジェクトですが、セッションで表にデータが挿入されるまでは空のように見えます。それぞれのPL/SQLストアド・プロシージャではなく、データベース自体に一時表を作成します。
一時表は静的に定義されるため、CREATE INDEX文を使用して一時表の索引を作成できます。一時表に作成された索引も一時的です。その索引のデータは、一時表のデータと同じセッションまたはトランザクション・スコープを持ちます。また、一時表のビューまたはトリガーを作成することも可能です。
外部表では、外部ソースのデータに対して、データベース内の表にあるデータのようにアクセスできます。SQL、PL/SQLおよびJavaを使用して外部データを問い合せることができます。
外部表は、フラット・ファイルを問い合せる場合に便利です。たとえば、SQLベースのアプリケーションでテキスト・ファイル内のレコードにアクセスする必要があるとします。レコードは次の形式になっています。
100,Steven,King,SKING,515.123.4567,17-JUN-03,AD_PRES,31944,150,90 101,Neena,Kochhar,NKOCHHAR,515.123.4568,21-SEP-05,AD_VP,17000,100,90 102,Lex,De Haan,LDEHAAN,515.123.4569,13-JAN-01,AD_VP,17000,100,90
外部表を作成し、外部表の定義で指定した場所にファイルをコピーすると、SQLを使用してテキスト・ファイル内のレコードを問い合せることができます。
外部表は、データ・ウェアハウス環境で一般的なETLタスクを実行する場合にも役立ちます。たとえば、外部表を使用すると、ロード・フェーズと変換フェーズをパイプライン処理できるようになり、データベース内のデータに対してさらに処理を実行するために、データベース内でステージングする必要がなくなります。「データ・ウェアハウスとビジネス・インテリジェンスの概要」を参照してください。
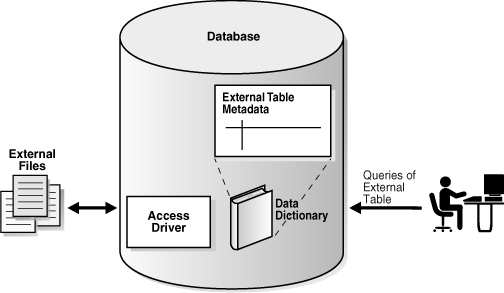
内部的には、外部表の作成はデータ・ディクショナリでのメタデータの作成を意味します。通常の表とは異なり、外部表にはデータベースに格納されているデータは示されず、外部でのデータの格納方法も示されません。かわりに、外部表のメタデータに外部表レイヤーでのデータベースに対するデータの表示方法が記述されています。
CREATE TABLE ... ORGANIZATION EXTERNAL文は、2つの部分に分かれています。外部表の定義には、列型を記述します。この定義は、外部データをデータベースにロードすることなくSQL問合せを実行できるビューに似ています。文の2番目の部分は、外部データを列にマップします。
外部表は、CREATE TABLE AS SELECTでORACLE_DATAPUMPアクセス・ドライバを指定して作成される場合を除き、読取り専用です。外部表の制限は、索引付けされた列、仮想列および列オブジェクトがサポートされないことです。
アクセス・ドライバとは、データベースの外部データを解釈するAPIのことです。アクセス・ドライバはデータベースの内部で動作し、データベースはアクセス・ドライバを使用して外部表のデータを読み取ります。外部表の定義に合うようにデータファイルのデータに必要な変換を行うのは、アクセス・ドライバおよび外部表レイヤーの役割です。図2-4に外部データへのアクセス方法を示します。
Oracleは、外部表用としてORACLE_LOADER(デフォルト)とORACLE_DATAPUMPアクセス・ドライバを用意しています。両方のドライバにとって、外部ファイルはOracleデータファイルではありません。
ORACLE_LOADERは、SQL*Loaderを使用した外部ファイルへの読取り専用アクセスを可能にします。ORACLE_LOADERドライバを使用して外部ファイルを作成または更新することや、外部ファイルへの追加を行うことはできません。
ORACLE_DATAPUMPドライバを使用すると、外部データをアンロードできます。この操作では、データベースからデータが読み取られ、1つ以上の外部ファイルで表される外部表にデータが挿入されます。外部ファイルが作成されると、データベースはデータの更新や外部ファイルへのデータの追加を実行できなくなります。このドライバを使用すると、外部データのロードも可能になり、外部表が読み取られ、そのデータがデータベースにロードされます。
|
関連項目:
|
Oracle Databaseは、表領域のデータ・セグメントを使用して表データを保持します。「ユーザー・セグメント」で説明しているように、セグメントにはデータ・ブロックからなるエクステントが含まれています。
表のデータ・セグメント(表クラスタを扱っている場合はクラスタ用のデータ・セグメント)は、表所有者のデフォルト表領域、またはCREATE TABLE文で指定された表領域に配置されます。
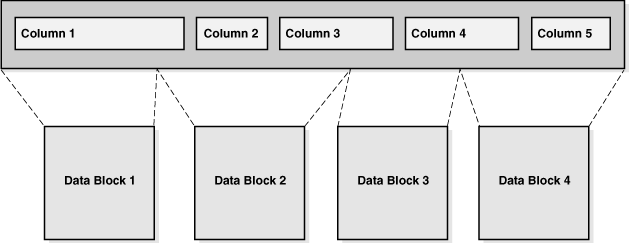
デフォルトでは、表はヒープとして編成され、データベースでは、ユーザーが指定する順序ではなく、最も収まりすいように行が配置されます。このため、ヒープ構成表は、順不同の行のコレクションとなります。ユーザーが行を追加すると、データベースではデータ・セグメントの最初の使用可能な空き領域に行が格納されます。挿入された順序どおりに行が取得されることは保証されていません。
hr.departments表は、ヒープ構成表です。この表には、部門ID、部門名、管理者ID、所在地IDの列があります。行が挿入されると、データベースでは、それらの行が収まる位置に格納されます。表セグメント内のデータ・ブロックには、例2-7に示すように、順不同の行が含まれることがあります。
例2-7 departments表の行
50,Shipping,121,1500 120,Treasury,,1700 70,Public Relations,204,2700 30,Purchasing,114,1700 130,Corporate Tax,,1700 10,Administration,200,1700 110,Accounting,205,1700
1つの表内のすべての行は、列の順序が同一です。データベースでは、通常、CREATE TABLE文でリストされた順序で列が格納されますが、この順序は保証されません。たとえば、表にLONG型の列があると、Oracle Databaseでは、この列は必ず最後に行に格納されます。また、表に新しい列を追加すると、その新しい列は最後に格納されます。
表には仮想列を含めることができ、仮想列は通常の列とは異なり、ディスク上の領域を使用しません。データベースによりユーザーの指定する一連の式または関数が計算され、必要に応じて仮想列から値が導出されます。仮想列には、索引付け、統計の収集および整合性制約の作成が可能です。このため、仮想列は通常の列とほとんど同じです。
|
関連項目: 仮想列の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。 |
データベースでは、行がデータ・ブロックに格納されます。列数が256未満のデータを含む表の各行は、1つ以上の行断片に格納されます。
Oracle Databaseは、可能なかぎり各行を1つの行断片として格納します。ただし、行データのすべてを1つのデータ・ブロックに挿入できない場合、または既存の行が更新されてそのデータ・ブロックの容量を超えた場合、データベースは複数の行断片を使用して行を格納します(「データ・ブロックの形式」を参照)。
表クラスタ内の行には、クラスタ化されていない表の行と同じ情報が格納されます。また、表クラスタ内の行には、それらの行が属するクラスタ・キーを参照する情報も格納されます。
ROWIDとは、実際には行の10バイトの物理アドレスのことです。「ROWIDデータ型」で説明しているように、ヒープ構成表のすべての行にはその表で一意のROWIDがあり、これは行断片の物理アドレスに相当します。表クラスタの場合、同じデータ・ブロックにある異なる表の行のROWIDが同一の場合もあります。
Oracle Databaseでは、ROWIDを内部的に使用して索引が構築されます。たとえば、Bツリー索引のそれぞれのキーは、高速アクセスのために、対応する行のアドレスを指すROWIDに結び付けられています(「Bツリー索引」を参照)。物理ROWIDを使用すると、表の1つの行に最速でアクセスでき、データベースではわずか1回のI/Oで行を取得できます。
データベースでは、表の圧縮を使用して、表に必要な記憶域を削減します。圧縮によりディスク領域を節約し、データベース・バッファ・キャッシュでのメモリー使用量を減らすことができ、場合によっては問合せ実行時間も短縮できます。表の圧縮は、データベース・アプリケーションに対して透過的です。
ディクショナリ・ベースの表圧縮は、ヒープ構成表に対する高い圧縮率を実現します。Oracle Databaseでは、次のタイプのディクショナリ・ベースの表圧縮をサポートしています。
このタイプの圧縮は、バルク・ロード操作向けのものです。データベースでは、従来型のDMLを使用して変更されたデータは圧縮されません。基本圧縮を実行するには、ダイレクト・パス・ロード(ALTER TABLE . . . MOVE操作)または表のオンライン再定義を使用する必要があります。
高度な行圧縮
このタイプの圧縮はOLTPアプリケーション向けで、すべてのSQL操作によって操作されたデータを圧縮します。
基本および高度な行圧縮の場合、データベースでは、圧縮された行は行優先形式で格納されます。この形式では、ある行のすべての列がまとめて格納され、それ以降の行も同様に行単位ですべての列がまとめて格納されます(図12-7を参照)。重複値は、ブロックの先頭に格納されているシンボル表の短い参照で置き換えられます。このため、非圧縮データを再作成するために必要な情報は、データ・ブロック自体に格納されます。
圧縮されたデータ・ブロックは、通常のデータ・ブロックとほぼ同じです。通常のデータ・ブロックに対して動作するデータベース機能のほとんどは、圧縮ブロックに対しても動作します。
表領域、表、パーティションまたはサブパーティション・レベルで圧縮を宣言できます。表領域レベルで指定した場合、その表領域に作成されたすべての表はデフォルトで圧縮されます。
次の文は、OLTP圧縮をorders表に適用します。
ALTER TABLE oe.orders COMPRESS FOR OLTP;
次の部分的なCREATE TABLE文の例では、1つのパーティションにOLTP圧縮を指定し、もう1つのパーティションに基本圧縮を指定しています。
CREATE TABLE sales (
prod_id NUMBER NOT NULL,
cust_id NUMBER NOT NULL, ... )
PCTFREE 5 NOLOGGING NOCOMPRESS
PARTITION BY RANGE (time_id)
( partition sales_2010 VALUES LESS THAN(TO_DATE(...)) COMPRESS BASIC,
partition sales_2011 VALUES LESS THAN (MAXVALUE) COMPRESS FOR OLTP );
|
関連項目:
|
ハイブリッド列圧縮では、行グループの同じ列がまとめてデータベースに格納されます。データ・ブロックのデータは行優先形式では格納されませんが、行および列の両方を組み合せた方法が使用されます。
同じデータ型で、類似した特性を持つ列データをまとめて格納することで、圧縮によって節減できる記憶域が大幅に増加します。データベースでは、任意のSQL操作によって処理されるデータを圧縮しますが、ダイレクト・パス・ロードでは圧縮レベルがより高くなります。データベース操作は圧縮オブジェクトに対して透過的に実行されるため、アプリケーションを変更する必要はありません。
基礎となるストレージがハイブリッド列圧縮をサポートしている場合は、必要に応じて次の圧縮タイプを指定できます。
このタイプの圧縮は、記憶域の節減用に最適化されており、データ・ウェアハウス・アプリケーション向けです。
このタイプの圧縮は、最大の圧縮レベル用に最適化されており、履歴データおよび変更されないデータ向けです。
ウェアハウスまたはオンライン・アーカイブ圧縮を実行するには、ダイレクト・パスのロード、ALTER TABLE . . . MOVE操作または表のオンライン再定義を使用する必要があります。
ハイブリッド列圧縮は、データ・ウェアハウス用またはExadataストレージ上の意思決定支援アプリケーション用に最適化されています。Exadataでは、ハイブリッド列圧縮を使用して圧縮された表の問合せパフォーマンスが最大化され、Exadataストレージ・サーバーに統合されている処理能力、メモリーおよびインフィニバンド・ネットワーク帯域幅の利点を活用できます。
その他のOracleストレージ・システムでは、ハイブリッド列圧縮がサポートされ、Exadataストレージと同様の領域の節減は可能ですが、Exadataストレージと同じレベルの問合せパフォーマンスは得られません。これらのストレージ・システムでは、まれにしかアクセスしない古いデータのインデータベースでのアーカイブには、ハイブリッド列圧縮が理想的です。
ハイブリッド列圧縮では、行の集合を格納するために、圧縮ユニットと呼ばれる論理的な構造が使用されます。表にデータをロードする場合、データベースでは、行のグループは列形式で、それぞれの列の値としてまとめて圧縮されて格納されます。データベースでは、一連の行の列データが圧縮された後、そのデータが圧縮ユニットに収められます。
たとえば、ハイブリッド列圧縮をdaily_sales表に適用するとします。1日の終わりに、品目と販売数が表に移入され、品目IDと日付がコンポジット主キーになります。表2-1にdaily_sales内の行のサブセットを示します。
表2-1 サンプル表daily_sales
| Item_ID | Date | Num_Sold | Shipped_From | Restock |
|---|---|---|---|---|
|
1000 |
01-JUN-11 |
2 |
WAREHOUSE1 |
Y |
|
1001 |
01-JUN-11 |
0 |
WAREHOUSE3 |
N |
|
1002 |
01-JUN-11 |
1 |
WAREHOUSE3 |
N |
|
1003 |
01-JUN-11 |
0 |
WAREHOUSE2 |
N |
|
1004 |
01-JUN-11 |
2 |
WAREHOUSE1 |
N |
|
1005 |
01-JUN-11 |
1 |
WAREHOUSE2 |
N |
表2-1の行が1つの圧縮ユニットに格納されるとします。ハイブリッド列圧縮では、各列の値がまとめて格納され、その後で複数のアルゴリズムを使用してそれぞれの列が圧縮されます。データベースでは、列のデータ型、列内の実際の値のカーディナリティ、ユーザーの選択した圧縮レベルなどの様々な要因に基づいてアルゴリズムが選択されます。
図2-5に示すように、各圧縮ユニットは、複数のデータ・ブロックにまたがることができます。特定の列の値は、複数のブロックにまたがる場合とまたがらない場合があります。
ハイブリッド列圧縮は、行のロックと密接に関連しています(「行のロック(TX)」を参照)。非圧縮のデータ・ブロックで行の更新が発生した場合、更新される行のみがロックされます。これに対して、更新が圧縮ユニットのいずれかの行で発生した場合、データベースではそのユニットのすべての行をロックする必要があります。ハイブリッド列圧縮を使用している行を更新すると、ROWIDが変更されます。
|
注意: 表でハイブリッド列圧縮を使用する場合、Oracle DMLでは、比較的大きなデータ・ブロック(圧縮ユニット)がロックされるため、同時実行性が低下する可能性があります。 |
|
関連項目:
|
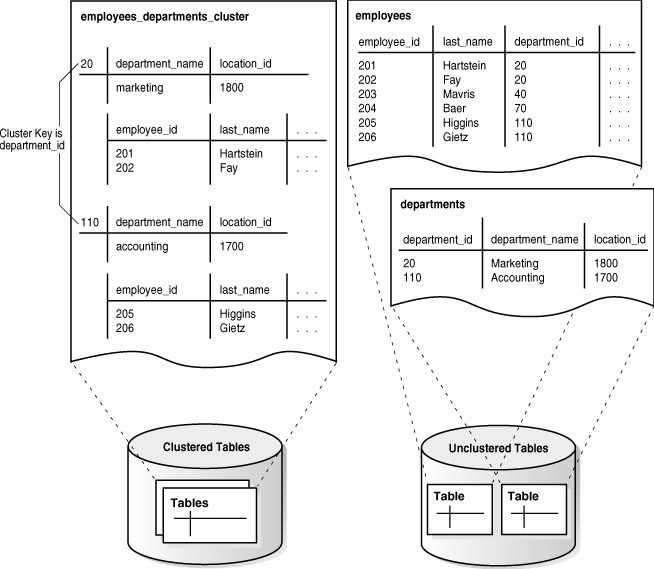
表クラスタとは、共通の列を共有し、関連するデータを同じブロックに格納する表のグループのことです。表がクラスタ化されると、1つのデータ・ブロックに複数の表の行を含めることができます。たとえば、ブロックにemployees表とdepartments表のいずれか1つのみでなく、両方の表の行を格納できます。
クラスタ・キーとは、クラスタ化表で共有される1つ以上の列のことです。たとえば、employeesおよびdepartments表はdepartment_id列を共有しています。表クラスタの作成時と表クラスタに追加されるすべての表の作成時にクラスタ・キーを指定します。
クラスタ・キー値とは、特定の行のセットに対するクラスタ・キー列の値のことです。department_id=20などの同じクラスタ・キー値を含むすべてのデータは、物理的にまとめて格納されます。各クラスタ・キー値は、その値を持つ行がいくつかの表に含まれているとしても、クラスタとクラスタ索引にそれぞれ一度のみ格納されます。
たとえば、HR管理者が2つの書棚を使用しており、1つの書棚には従業員フォルダの箱があり、もう1つの書棚には部門フォルダの箱があるとします。ユーザーは、特定の部門に属する全従業員のフォルダを頻繁に問い合せます。管理者は、取り出しやすいようにすべての箱を1つの書棚に配置しなおします。管理者は、部門IDごとに箱を分割します。その結果、部門20に属する従業員のすべてのフォルダと部門20自体のフォルダが1つの箱に入り、部門100の従業員のフォルダと部門100のフォルダも別の箱に入り、他の部門のフォルダもそれぞれの箱に入ります。
ある複数の表が主に問合せの対象となり(ただし変更はできない)、これらの表のレコードが、頻繁に同時に問い合されるか、結合される場合は、表のクラスタ化を検討できます。表クラスタは、異なる表の関連した行を、同じデータ・ブロック内に格納するため、表クラスタを適切に使用すると、クラスタ化されていない表と比較して次のような利点があります。
クラスタ化表を結合する場合のディスクI/Oが減少します。
クラスタ化表を結合する場合のアクセス時間が改善されます。
クラスタ・キー値が行ごとに繰り返し格納されないため、関連する表データと索引データの格納に必要な記憶域が少なくなります。
通常、表のクラスタ化は、次のような場合には適していません。
表が頻繁に更新される場合。
表の全表スキャンが頻繁に必要な場合。
表で切捨てが必要な場合。
|
関連項目: 表クラスタを使用する場合のガイドラインは、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。 |
索引付きクラスタとは、索引を使用してデータを検索する表クラスタのことです。クラスタ索引とは、クラスタ・キーのBツリー索引のことです。クラスタ索引は、クラスタ化表に行を挿入する前に作成しておく必要があります。
例2-8に示すように、department_idという名前のクラスタ・キーを指定してクラスタemployees_departments_clusterを作成するとします。HASHKEYS句は指定されないため、このクラスタは索引付きクラスタになります。次に、このクラスタ・キーにidx_emp_dept_clusterという名前の索引を作成します。
例2-8 索引付きクラスタ
CREATE CLUSTER employees_departments_cluster (department_id NUMBER(4)) SIZE 512; CREATE INDEX idx_emp_dept_cluster ON CLUSTER employees_departments_cluster;
その後、次のように、このクラスタにemployees表とdepartments表を作成し、クラスタ・キーとしてdepartment_id列を指定します(省略記号は、列が指定される場所のマークです)。
CREATE TABLE employees ( ... ) CLUSTER employees_departments_cluster (department_id); CREATE TABLE departments ( ... ) CLUSTER employees_departments_cluster (department_id);
最後に、employees表とdepartments表に行を追加します。データベースでは、employees表とdepartments表の各部門の行がすべて同じデータ・ブロックに物理的に格納されます。データベースでは、行がヒープに格納され、索引を使用してこれらの行が検索されます。
図2-6に、employeesとdepartmentsを含むemployees_departments_cluster表クラスタを示します。データベースでは、従業員20に属する従業員や部門110などの行がまとめて格納されます。表がクラスタ化されていない場合、データベースでは関連する行がまとめて格納されることは保証されません。
Bツリー・クラスタ索引は、データを含むブロックのデータベース・ブロック・アドレス(DBA)にクラスタ・キー値を関連付けます。たとえば、キー20の索引エントリには、部門20の従業員のデータを含むブロックのアドレスが表示されます。
20,AADAAAA9d
クラスタ索引は、クラスタ化されていない表の索引と同様に個別に管理され、表クラスタとは別の表領域に存在することがあります。
|
関連項目:
|
ハッシュ・クラスタは、索引キーがハッシュ関数に置き換わることを除いて、索引付きクラスタと似ています。別個のクラスタ索引は存在しません。ハッシュ・クラスタでは、データが索引になります。
索引付きの表または索引付きのクラスタでは、Oracle Databaseは、別個の索引に格納されたキー値を使用して、表の行を見つけます。索引付きの表または表クラスタを検索または格納するには、次のようにデータベースは、最低2回のI/Oを実行する必要があります。
索引内でキー値を検索または格納するために1回以上のI/O
表または表クラスタ内の行を読取り/書込みするためにさらに1回のI/O
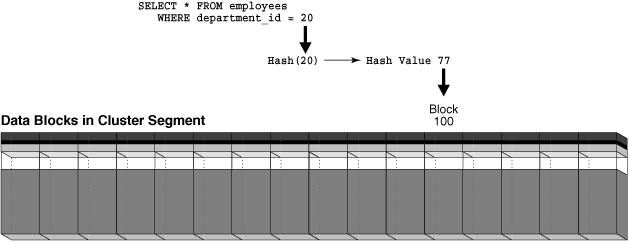
Oracle Databaseでは、ハッシュ・クラスタ内で行を検索または格納するため、ハッシュ関数を行のクラスタ・キー値に適用します。結果として得られるハッシュ値はクラスタ内の1つのデータ・ブロックに対応し、データベースにより、発行された文による読取り/書込みがそのデータ・ブロックに対して実行されます。
ハッシングは、データ検索のパフォーマンスを改善するために表データを格納するオプションの方法です。ハッシュ・クラスタは、次の条件が満たされている場合に便利です。
表の問合せが、表の変更よりもはるかに頻繁に行われる場合。
ハッシュ・キー列に対する問合せの条件が、多くの場合、WHERE department_id=20のような等価条件である場合。このような問合せでは、クラスタ・キー値がハッシュ化されます。ハッシュ・キー値は、行が格納されているディスク領域を直接指します。
当然、ハッシュ・キーの数が多くなれば、キー値も一緒に格納されるためデータのサイズが大きくなります。
クラスタ・キーは、索引付きクラスタのキーと同様に、単一の列、またはクラスタ内の表が共有するコンポジット・キーです。ハッシュ・キー値は、クラスタ・キー列に挿入される実際の値または推定値です。たとえば、クラスタ・キーがdepartment_idの場合は、ハッシュ・キー値が10、20、30のような値になります。
Oracle Databaseでは、無数にあるハッシュ・キー値を入力として受け付け、限定された数のバケットに選別するハッシュ関数が使用されます。各バケットにはハッシュ値という一意の数値IDが付与されます。各ハッシュ値は、ハッシュ・キー値(部門10、20、30など)に対応する行の格納ブロックのデータベース・ブロック・アドレスにマップされます。
ハッシュ・クラスタを作成するときは、索引付きクラスタの場合と同じCREATE CLUSTER文を使用しますが、ハッシュ・キーを別途指定する必要があります。クラスタのハッシュ値の数はハッシュ・キーに応じて増減します。図2-9では、存在すると推測される部門数が100であるため、HASHKEYSが100に設定されています。
例2-9 ハッシュ・クラスタ
CREATE CLUSTER employees_departments_cluster (department_id NUMBER(4)) SIZE 8192 HASHKEYS 100;
employees_departments_clusterの作成後に、そのクラスタ内にemployees表とdepartments表を作成できます。次に、例2-8で説明した索引付きクラスタの場合と同様に、ハッシュ・クラスタにデータをロードできます。
|
関連項目: ハッシュ・クラスタの作成方法と管理方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
ユーザーが入力するキー値をハッシュする方法は、ユーザーではなく、データベースが決定します。たとえば、ユーザーが次のような問合せを頻繁に実行し、p_idに様々な部門ID番号を入力するとします。
SELECT *
FROM employees
WHERE department_id = :p_id;
SELECT *
FROM departments
WHERE department_id = :p_id;
SELECT *
FROM employees e, departments d
WHERE e.department_id = d.department_id
AND d.department_id = :p_id;
ユーザーがdepartment_id=20の従業員を問い合せた場合は、この値がバケット77にハッシュされます。department_id=10の従業員を問い合せた場合は、この値がバケット15にハッシュされます。データベースは、内部的に生成されるハッシュ値を使用して、問合せ対象の部署に対応する従業員行を格納したブロックを検索します。
図2-7は、ハッシュ・クラスタ・セグメントを水平方向に並べたブロック行として示しています。この図に示すように、1件の問合せにつき、1回のI/Oでデータを取得できます。
ハッシュ・クラスタの制限は、索引のないクラスタ・キーのレンジ・スキャンを使用できないことです(「索引レンジ・スキャン」を参照)。例 2-9で作成したハッシュ・クラスタに、独立した索引が存在しないものとします。IDが20から100の部門の問合せは、20から100の間のすべての取り得る値をハッシュしていないため、ハッシュ・アルゴリズムを使用できません。索引が存在しないため、データベースでは全体スキャンを実行する必要があります。
単一表ハッシュ・クラスタとは、同時に1つの表のみをサポートするために最適化されたハッシュ・クラスタのバージョンのことです。ハッシュ・キーと行との間には、1対1のマッピングがあります。単一表ハッシュ・クラスタは、ユーザーが主キーを使用して表に迅速にアクセスする必要がある場合に便利です。たとえば、ユーザーがemployee_idを使用してemployees表の従業員レコードを頻繁に検索する場合などです。
ソート済のハッシュ・クラスタに、ハッシュ関数の各値に対応する行が格納されると、データベースは効率的に行を戻すことが可能になります。データベースは最適化されたソートを内部的に実行します。ソートされた状態のデータを常に使用するアプリケーションの場合は、この方式によりデータの取得が速くなる可能性があります。たとえば、アプリケーションがorders表のorder_date列で常にソートする場合が考えられます。
|
関連項目: 単一表ハッシュ・クラスタとソート済のハッシュ・クラスタの作成方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |
Oracle Databaseは、ハッシュ・クラスタのための領域を索引付きクラスタとは異なる方法で割り当てます。例2-9では、HASHKEYSに存在する可能性のある部門数を指定し、SIZEに各部門に関連付けられたデータのサイズを指定しています。次の式に従って記憶域領域の値が計算されます。
HASHKEYS * SIZE / database_block_size
したがって、図2-9のようにブロック・サイズが4096バイトの場合は、ハッシュ・クラスタに200以上のブロックが割り当てられます。
Oracle Databaseでは、クラスタに挿入可能なハッシュ・キー値の数に制限はありません。たとえば、HASHKEYSが100になっている場合でも、departments表に一意の部門を200個挿入することも可能です。ただし、ハッシュ値の数がハッシュ・キーの数よりも多くなると、ハッシュ・クラスタ取得の効率が悪くなります。
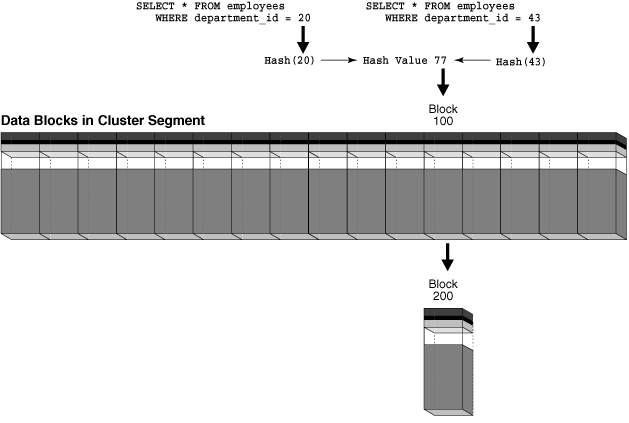
取得の問題について、図2-7でブロック100が部門20の行でまったく空きがない場合の例で説明します。ユーザーがdepartment_idが43の新しい部署をdepartments表に挿入します。部門の数がHASHKEYS値よりも大きいため、department_id 43はハッシュ値77にハッシュされますが、これは、department_id 20に使用されているハッシュ値と同じです。複数の入力値を同じ出力値にハッシュすることをハッシュ衝突と呼びます。
ユーザーが部門43のクラスタに行を挿入しようとしても、ブロック100はいっぱいであるため、行は格納されません。ブロック100は新しいオーバーフロー・ブロック(ここではブロック200とします)にリンクされ、その新しいブロックに挿入行が格納されます。つまり、ブロック100とブロック200の両方に、どちらの部門のデータも格納されている可能性があることになります。図2-8に示すように、部門20または部門43を問い合せると、ブロック100とその関連ブロックであるブロック200からデータが取得されるため、I/Oが2回必要になります。この問題を解決するには、別々のHASHKEYS値を持つクラスタを作成しなおす必要があります。
|
関連項目: ハッシュ・クラスタの領域を管理する方法の詳細は、『Oracle Database管理者ガイド』を参照してください。 |