| Oracle® Databaseパフォーマンス・チューニング・ガイド 11gリリース2 (11.2) B56312-06 |
|



 前 |
 次 |
この章では、SQL処理、最適化方式およびSQL文を実行する特定の計画を問合せオプティマイザ(通常はオプティマイザと呼ばれる)が選択する方法を説明します。
この章には次の項があります。
オプティマイザは、SQL文を実行する最も効率的な方法を判断する組込みソフトウェアです。
この項では、次の項目について説明します。
SQL文は、全表スキャン、索引スキャン、ネステッド・ループおよびハッシュ結合などにおいて、様々な方法で実行されます。オプティマイザは、問合せのオブジェクトと条件に関連する様々な要素を考慮して、実行計画を決定します。この決定はSQL処理における重要な手順であり、これによって実行時間に大きな差が生じる可能性があります。
|
注意: オプティマイザは、Oracle Databaseのあるバージョンとその次のバージョンで同じ決定を行うとはかぎりません。最新バージョンのオプティマイザは、より高度な情報を使用できるので、異なる決定を行います。 |
ユーザーがSQL文実行を送信すると、オプティマイザは次のステップを実行します。
使用可能なアクセス・パスおよびヒントに基づき、SQL文の可能な計画のセットを生成します。
オプティマイザは、データ・ディクショナリ内の統計に基づき、各計画のコストを見積ります。統計には文がアクセスする表、索引およびパーティションのデータ配分および記憶特性に関する情報が含まれます。
コストとして見積られる値は、特定の計画での文の実行に必要と予測されるリソース使用量に比例しています。オプティマイザは、I/O、CPU、メモリーなどのコンピュータ・リソースの見積りに基づいて、アクセス・パスや結合順序のコストを計算します。
コストの大きいシリアル計画の実行には、コストの小さい計画の実行よりも多くの時間が必要です。パラレル計画を使用する場合は、リソース使用量は経過時間に直接関係しません。
オプティマイザは計画を比較して、コストが最も小さい計画を選択します。
オプティマイザからは、最適な実行方法を説明する実行計画が出力されます。この計画により、SQL文を実行するためにOracle Databaseで使用するステップの組合せが示されます。実行される各ステップでは、データベースからの行の物理的な取出し、またはユーザーが発行する文に戻す行の準備のどちらかが実行されます。
オプティマイザは、Oracle Databaseで処理されるSQL文に、表11-1に示す操作を実行します。
表11-1 オプティマイザ操作
| 操作 | 説明 |
|---|---|
|
式と条件の評価 |
オプティマイザは、まず、定数が含まれている式と条件を可能なかぎり完全に評価します。 |
|
文の変換 |
たとえば、相関副問合せやビューなどに関連する複合文について、オプティマイザは元の文を同等の結合文に変換する場合があります。 |
|
オプティマイザの目標の選択 |
オプティマイザでは、最適化の目標が判別されます。「オプティマイザの目標の選択」を参照してください。 |
|
アクセス・パスの選択 |
文がアクセスするそれぞれの表について、オプティマイザは、表データを取得するために1つ以上の使用可能なアクセス・パスを選択します。「オプティマイザ・アクセス・パスの概要」を参照してください。 |
|
結合順序の選択 |
2つ以上の表を結合する結合文について、オプティマイザは、最初に結合する表のペアを選択し、その後、その結果に結合する表を順次選択していきます。「問合せオプティマイザによる結合の実行計画の選択方法」を参照してください。 |
場合によっては、特定のアプリケーションのデータに関して、オプティマイザよりも多くの情報を入手できることがあります。このような場合には、SQL文のヒントを使用して、文の実行方法についてオプティマイザに指示を与えることができます。
問合せオプティマイザ操作には、次のものがあります。
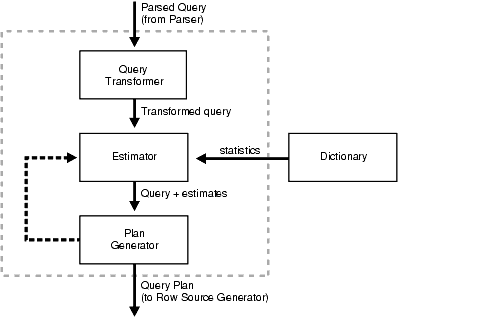
図11-1はオプティマイザの構成要素を示しています。
文の各問合せ部分は、問合せブロックと呼ばれます。問合せトランスフォーマへの入力は、一連の問合せブロックによって表される解析済問合せです。
次の例では、SQL文は2つの問合せブロックで構成されています。括弧内の副問合せは、内側の問合せブロックです。SQL文の残りの部分が外側の問合せブロックで、副問合せによって提供されたIDを持つ部門内の従業員の名前を取り出します。
SELECT first_name, last_name FROM employees WHERE department_id IN (SELECT department_id FROM departments WHERE location_id = 1800);
問合せの形式によって、問合せブロックの相互関係が判断されます。トランスフォーマは、元のSQL文をより効率的に処理できる意味的に同等のSQL文にリライトすることが有利かどうかを判断します。
問合せトランスフォーマは、複数の問合せ変換手法を備えています。次のような方法があります。
これらの変換の組合せを問合せに適用できます。
問合せで参照されるビューは、パーサーによって個別の問合せブロックに拡張されます。ブロックは、基本的にはビュー定義を表しますが、このため必然的にビューの結果も表すことになります。オプティマイザには、ビューの問合せブロックの1つを分離して分析し、ビュー・サブプランを生成するというオプションがあります。オプティマイザは、問合せ計画全体の生成にビュー・サブプランを使用することで、残りの問合せを処理します。この手法は、そのビューが個別に最適化されるため、通常は最適な問合せ計画とはなりません。
ビューのマージでは、トランスフォーマはビューを表す問合せブロックを包含的な問合せブロックにマージします。たとえば、次のようにビューを作成します。
CREATE VIEW employees_50_vw AS SELECT employee_id, last_name, job_id, salary, commission_pct, department_id FROM employees WHERE department_id = 50;
それから次のようにしてビューを問い合せます。
SELECT employee_id FROM employees_50_vw WHERE employee_id > 150;
オプティマイザはビューのマージを使用して、employees_50_vwの問合せを次の同等の問合せに変換できます。
SELECT employee_id FROM employees WHERE department_id = 50 AND employee_id > 150;
ビューのマージによる最適化は、選択、射影、および結合のみを含むビューに適用されます。つまり、マージ可能なビューには、集合演算子、集計機能、DISTINCT、GROUP BY、CONNECT BYなどは含まれません。
オプティマイザがユーザーによって発行されるすべての問合せにビューのマージを使用できるようにするには、MERGE ANY VIEW権限をユーザーに付与する必要があります。オプティマイザが特定のビューに対する問合せにビューのマージを使用できるようにするには、これらのビューのMERGE VIEW権限をユーザーに付与します。これらの権限は、セキュリティで障害をチェックするためにビューがマージされない場合などの特定の状況でのみ必要です。
|
関連項目:
|
述語のプッシュでは、オプティマイザは関連する述語を、それを含む問合せブロックからビューの問合せブロックにプッシュします。マージされていないビューでは、プッシュされた述語は、索引へのアクセスまたはフィルタとして使用できるので、この方法を使用するとマージされていないビューのサブプランが改善されます。
たとえば、2つの従業員表を参照するビューを作成するとします。ビューは、次のようにUNION集合演算子を使用した複合問合せによって定義されます。
CREATE VIEW all_employees_vw AS
( SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM employees )
UNION
( SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM contract_workers );
それから次のようにしてビューを問い合せます。
SELECT last_name
FROM all_employees_vw
WHERE department_id = 50;
ビューは複合問合せのため、オプティマイザはビューの問合せをアクセス問合せブロックにマージすることはできません。そのかわりに、オプティマイザは、その述語であるWHERE句の条件department_id=50をビューの複合問合せにプッシュすることで、アクセス文を変換できます。同等の変換された問合せは次のとおりです。
SELECT last_name
FROM ( SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM employees
WHERE department_id=50
UNION
SELECT employee_id, last_name, job_id, commission_pct, department_id
FROM contract_workers
WHERE department_id=50 );
副問合せのネスト解除では、オプティマイザはネストされた問合せを同等の結合文に変換してから、その結合を最適化します。この変換により、オプティマイザは結合オプティマイザ手法を活用することができます。オプティマイザがこの変換を実行できるのは、結果の結合文が元の文とまったく同じ行を戻すことが保証されており、副問合せにAVGなどの集計機能が含まれていない場合のみです。
たとえば、ユーザーshとして接続して、次の問合せを実行するとします。
SELECT * FROM sales WHERE cust_id IN ( SELECT cust_id FROM customers );
customers.cust_id columnはプライマリ・キーのため、オプティマイザは複雑な問合せを、同じデータを戻すことが保証されている次の結合文に変換できます。
SELECT sales.* FROM sales, customers WHERE sales.cust_id = customers.cust_id;
オプティマイザが複雑な文を結合文に変換できない場合は、親の文と副問合せを個別の文として、それぞれに対して実行計画を選択します。それからオプティマイザは副問合せを実行し、戻された行を使用して親の問合せを実行します。問合せ計画全体の実行速度を上げるため、オプティマイザはサブプランを効率的な順序で並べます。
マテリアライズド・ビューは、問合せの結果をマテリアライズして表に保存するのと同じです。ユーザーの問合せが、マテリアライズド・ビューに関連付けられた問合せと互換性がある場合、データベースではその問合せをマテリアライズド・ビューの観点からリライトできます。この手法では、ほとんどの問合せ結果があらかじめ計算されているため、問合せの実行が改善されます。
問合せトランスフォーマは、ユーザー問合せと互換性のあるマテリアライズド・ビューを検索し、1つ以上のマテリアライズド・ビューを選択してユーザー問合せをリライトします。問合せをリライトするためのマテリアライズド・ビューの使用はコストベースです。したがって、マテリアライズド・ビューを使用せずに生成された計画のコストが、マテリアライズド・ビューを使用して生成された計画のコストより低い場合、問合せはリライトされません。
次のマテリアライズド・ビュー、cal_month_sales_mvについて検討します。これは各月の販売金額(ドル)を集計するものです。
CREATE MATERIALIZED VIEW cal_month_sales_mv ENABLE QUERY REWRITE AS SELECT t.calendar_month_desc, SUM(s.amount_sold) AS dollars FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
販売数は通常の月で約百万と仮定します。ビューには、各月の販売金額(ドル)について、あらかじめ計算されている集計があります。次の問合せを考えてみます。これは各月の販売金額の合計を問い合せるものです。
SELECT t.calendar_month_desc, SUM(s.amount_sold) FROM sales s, times t WHERE s.time_id = t.time_id GROUP BY t.calendar_month_desc;
クエリー・リライトを行わない場合、データベースはsalesディレクトリにアクセスして販売金額の合計を計算する必要があります。この方法ではsalesからの何百万行もの読取りが行われるため、問合せのレスポンス時間は必然的に遅くなります。また結合では、データベースが何百万もの行で結合を計算する必要があるため、問合せレスポンスはさらに遅くなります。クエリー・リライトを使用すると、オプティマイザは次のように問合せを透過的にリライトします。
SELECT calendar_month, dollars FROM cal_month_sales_mv;
|
関連項目: クエリー・リライトの詳細は、『Oracle Databaseデータ・ウェアハウス・ガイド』を参照してください。 |
エスティメータは、指定された実行計画の全体コストを判断します。エスティメータは、この目標を達成するために3つのタイプの異なるメジャーを生成します。
このメジャーは行セットの一部の行を表します。選択性は、last_name = 'Smith'などの問合せ述語、または述語の組合せに拘束されています。
このメジャーは、作業単位または使用されるリソースを表します。問合せオプティマイザはディスクI/O、CPU使用量、メモリー使用量を作業単位として使用します。
統計が使用可能な場合、エスティメータは統計を使用してメジャーを計算します。統計によって、メジャーの正確さの度合いは改良されます。
選択性は行セットの一部の行を表します。行セットとは、実表、ビュー、結合結果またはGROUP BY演算子の結果です。選択性は、last_name = 'Smith'などの問合せ述語、またはlast_name = 'Smith' AND job_type = 'Clerk'などの述語の組合せに拘束されています。
述語は、行セット内の特定の行数をフィルタします。したがって、述語の選択性は、どれだけの行数が述語テストを通過するかを示します。選択性には、0.0から1.0の範囲があります。選択性が0.0の場合、行セットから行は選択されません。一方、選択性が1.0の場合、すべての行が選択されます。値が0.0に近づくほど述語の選択性は高くなり、値が1.0に近づくほど選択性は低くなります。
オプティマイザは統計を使用できるかどうかに応じて、選択性を見積もります。
統計が使用不可
OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータの値に応じて、オプティマイザは、動的統計と内部のデフォルト値のいずれかを使用します。述語のタイプに応じて、使用する内部デフォルト値が異なります。たとえば、等価述語(last_name = 'Smith')の内部デフォルト値は範囲述語(last_name > 'Smith')の内部デフォルト値より小さくなります。これは等価述語の方が少ない行数を戻すことが予測されるためです。「動的統計の制御」を参照してください。
統計が使用可能
統計が使用可能な場合、エスティメータは統計を使用して選択性を推測します。150の個別の従業員の名字があると仮定します。等価述語last_name = 'Smith'の場合、選択性はlast_nameの個別値の数nの逆数です。この例では、問合せは150の個別値から1つの個別値を含む行を選択するため、選択性は.006になります。
last_name列でヒストグラムが使用可能な場合、エスティメータは個別値のかわりにヒストグラムを使用します。ヒストグラムには列内の異なる値の分散が示されているので、特に偏ったデータが含まれる列では、より適切な選択性の見積りが行われます。「ヒストグラムの表示」を参照してください。
カーディナリティは、行セット内の行数を表します。ここでの行セットとは、実表、ビュー、結合結果またはGROUP BY演算子の結果です。
コストは、作業単位または操作で使用されるリソースを表します。オプティマイザはディスクI/O、CPU使用量、メモリー使用量を作業単位として使用します。すなわち、操作には表をスキャンすること、索引を使用して表から行にアクセスすること、2つの表を結合すること、または行セットをソートすることなどがあります。コストは、データベースが問合せを実行してその結果を生成するときに発生すると予測される作業単位の数です。
アクセス・パスは、実表からデータを得るときに実行される作業単位数です。アクセス・パスには、表スキャン、高速全索引スキャンまたは索引スキャンがなどがあります。
表スキャンまたは高速全索引スキャン
表スキャンまたは高速全索引スキャンの間、データベースは単一I/Oでディスクから多数のブロックを読み取ります。そのため、スキャンのコストは、スキャンされるブロック数およびマルチブロックREADカウントに左右されます。
索引スキャン
索引スキャンのコストは、Bツリーにおけるレベル、つまりスキャンされる索引リーフ・ブロック数、索引キーのROWIDを使用してフェッチされる行数に左右されます。ROWIDを使用して行をフェッチするコストは、索引クラスタ化係数に依存します。「ブロックのI/O(行ではなく)の想定」を参照してください。
結合コストは、結合されている2つの行セットの個別のアクセス・コストの組合せと、結合操作のコストを表します。
プラン・ジェネレータは、別のアクセス・パス、結合方法および結合順序を試行することによって、問合せブロックに対する様々な計画を探索します。異なるアクセス・パス、結合方法および結合順序の様々な組合せを使用して、同じ結果をもたらすことができるため、様々な計画が可能になります。ジェネレータの目的は、コストが最も小さい計画を選択することです。
結合順序は、異なる結合項目(表など)がアクセスされて結合される順序です。データベースがtable1、table2、table3を結合するとします。結合順序は次のようになります。
データベースはtable1にアクセスします。
データベースはtable2にアクセスし、その行をtable1に結合します。
データベースはtable3にアクセスし、そのデータをtable1とtable2の結合結果に結合します。
オプティマイザは、ネストされた副問合せまたはマージされていないビューを、それぞれ個別の問合せブロックによって表し、サブプランを生成します。データベースは、問合せブロックを下位から上位へ順番に最適化します。このため、データベースは最も内側の問合せブロックを最初に最適化してそのサブプランを生成し、そして最後に問合せ全体を表す外側の問合せブロックを生成します。
問合せブロックに使用できる可能性のある計画の数は、FROM句にある結合項目の数に比例します。この数は、結合項目の数によって指数関数的に上昇します。たとえば、5つの表の結合に使用できる可能性のある計画の数は、2つの表の結合に使用できる可能性のある計画の数より大幅に多くなります。
バインド変数の照合(バインド照合とも呼ばれる)では、オプティマイザはデータベースが文のハード解析を実行しているときにバインド変数の値を参照します。
問合せがリテラルを使用する場合、オプティマイザはリテラル値を使用して最良の計画を見つけることができます。ただし、問合せがバインド変数を使用する場合は、オプティマイザはSQLテキストにリテラルが存在しない状態で最良の計画を選択する必要があります。このタスクはきわめて困難になる可能性があります。バインド値を照合することにより、まるでリテラルが使用されたかのようにWHERE句条件の選択性を判断することができ、これによって計画が改善されます。
例11-1 バインド照合
データベースに次のような100,000行のemp表が存在すると仮定します。表には次の定義があります。
SQL> DESCRIBE emp Name Null? Type ---------------------- -------- ---------------------------------- ENAME VARCHAR2(20) EMPNO NUMBER PHONE VARCHAR2(20) DEPTNO NUMBER
データはdeptno列で極端に偏っています。99.9%の行には値10が入っています。その他の各deptno値(0から9)は、1%の行に入っています。表の統計を収集し、結果としてdeptno列にヒストグラムが生成されました。次のように、バインド変数を定義して、バインド値9を使用してempの問合せを行います。
VARIABLE deptno NUMBER EXEC :deptno := 9 SELECT /*ACS_1*/ count(*), max(empno) FROM emp WHERE deptno = :deptno;
問合せは10行を戻します。
COUNT(*) MAX(EMPNO)
---------- ----------
10 99
問合せの実行計画を生成するために、データベースはハード解析中に値9で照合しました。オプティマイザは、ユーザーが次の問合せを実行したかのように選択性の見積りを生成しました。
select /*ACS_1*/ count(*), max(empno) from emp where deptno = 9;
計画を選択するときには、オプティマイザはハード解析中にバインド値でのみ照合します。この計画は値によっては最適でない場合があります。
適応カーソル共有機能により、バインド変数を含む1つの文が複数の実行計画を使用できるようになります。カーソル共有には「適応」機能があります。つまり、データベースが各実行または各バインド変数値に常に同じ計画を使用することがないように、カーソルがその動作を適応させます。
適切な問合せでは、データベースは、様々なバインド値に対して時間の経過とともにアクセスされるデータを監視し、特定のバインド値に対して最適なカーソルを確実に選択できるようにします。たとえば、オプティマイザは、バインド値9とバインド値10に対して、それぞれ異なる計画を選択することもあります。カーソル共有には「適応」機能があります。つまり、各実行または各バインド変数値に常に同じ計画が使用されることがないように、カーソルがその動作を適応させます。
適応カーソル共有は、デフォルトでデータベースに対して有効になっており、無効にできません。適応カーソル共有は、14を超えるバインド変数を含むSQL文に適用されません。
|
注意: 適応カーソル共有は、CURSOR_SHARING初期化パラメータとは無関係です(「既存アプリケーションのカーソルの共有」を参照してください)。適応カーソル共有は、ユーザー定義のバインド変数やシステム生成のバインド変数を含む文にも同様に適用できます。 |
バインド依存カーソルは、最適な計画がバインド変数の値に依存するカーソルです。データベースは、別の計画が有効であるかどうかを判断するために、別のバインド値を使用するバインド依存カーソルの動作を監視します。
オプティマイザは、次の基準を使用してカーソルがバインド依存かどうかを判断します。
オプティマイザはバインド値を照合して選択性の見積りを生成しました。
バインド値を含む列にヒストグラムが存在します。
例11-2 バインド依存カーソル
例11-1では、deptnoにバインド値9を使用して、emp表を問い合せました。ここで問合せ計画を表示するために、DBMS_XPLAN.DISPLAY_CURSOR機能を実行します。
SELECT * FROM TABLE(DBMS_XPLAN.DISPLAY_CURSOR);
出力は次のようになります。
---------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time| ---------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 2 (100)| | | 1 | SORT AGGREGATE | | 1 | 16 | | | | 2 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 16 | 2 (0)| 00:00:01| |* 3 | INDEX RANGE SCAN | EMP_I1 | 1 | | 1 (0)| 00:00:01| ----------------------------------------------------------------------------------
計画は、オプティマイザが索引レンジ・スキャンを選択したことを示しています。これは値9の選択性(1%のみ)から予測されます。V$SQLを問い合せてカーソルに関する統計を表示することができます。
COL BIND_SENSI FORMAT a10
COL BIND_AWARE FORMAT a10
COL BIND_SHARE FORMAT a10
SELECT CHILD_NUMBER, EXECUTIONS, BUFFER_GETS, IS_BIND_SENSITIVE AS "BIND_SENSI",
IS_BIND_AWARE AS "BIND_AWARE", IS_SHAREABLE AS "BIND_SHARE"
FROM V$SQL
WHERE SQL_TEXT LIKE 'select /*ACS_1%';
次の出力に表示されるように、この文には1つの子カーソルが存在し、1回実行されています。子カーソルに関係するバッファ読取りは少数です。deptnoデータに偏りがあるため、ヒストグラムが作成されました。このヒストグラムにより、データベースはカーソルをバインド依存(IS_BIND_SENSITIVEがY)としてマークします。
CHILD_NUMBER EXECUTIONS BUFFER_GETS BIND_SENSI BIND_AWARE BIND_SHARE
------------ ---------- ----------- ---------- ---------- ----------
0 1 56 Y N Y
新しいバインド値で問合せを実行するたびに、データベースは新しい値の実行統計を記録し、それらを前の値の実行統計と比較します。実行統計が大幅に異なると、データベースはカーソルをバインド対応としてマークします。
バインド対応カーソルは、バインド値ごとに異なる計画を使用するのに適したバインド依存カーソルです。カーソルをバインド対応にした後で、オプティマイザは、バインド値とその選択性の見積りを基に、今後の実行のための計画を選択します。
バインド依存カーソルを含む文を実行する場合、データベースはカーソルをバインド対応としてマークするかどうかを判断します。これは、カーソルが生成するデータ・アクセス・パターンが、バインド値によって大幅に異なるかどうかによって判断されます。データベースがカーソルをバインド対応としてマークすると、次回そのカーソルが実行されたときに、データベースは次のことを行います。
新しいバインド値に基づいて、新規計画を生成します。
その文に生成された元のカーソルを共有不可(V$SQL.IS_SHAREABLEがN)としてマークします。このカーソルは使用できなくなり、まず共有SQL領域から除去されます。
例11-3 バインド対応カーソル
例11-1では、バインド値9を使用してempを問い合せました。ここでバインド値10を使用してempを問い合せます。問合せは値10を含む99,900行を戻します。
COUNT(*) MAX(EMPNO) ---------- ---------- 99900 100000
この文のカーソルはバインド依存のため、オプティマイザはそのカーソルを共有可能とみなします。結果として、オプティマイザは値10に値9と同じ索引レンジ・スキャンを使用します。
V$SQL出力に、2回目(10を使用した問合せ)に同じバインド依存カーソルが実行され、最初の実行より多くのバッファ読取りが要求されたことが示されます。
SELECT CHILD_NUMBER, EXECUTIONS, BUFFER_GETS, IS_BIND_SENSITIVE AS "BIND_SENSI",
IS_BIND_AWARE AS "BIND_AWARE", IS_SHAREABLE AS "BIND_SHARE"
FROM V$SQL
WHERE SQL_TEXT LIKE 'select /*ACS_1%';
CHILD_NUMBER EXECUTIONS BUFFER_GETS BIND_SENSI BIND_AWARE BIND_SHARE
------------ ---------- ----------- ---------- ---------- ----------
0 2 1010 Y N Y
ここで2回目に値10を使用して問合せを実行します。データベースは前の実行の統計と比較して、カーソルをバインド対応としてマークします。この場合、オプティマイザは新しい計画が有効であると判断し、文のハード解析を実行して新しい計画を生成します。新しい計画は、索引レンジ・スキャンのかわりに全表スキャンを使用します。
--------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | --------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | 208 (100)| | | 1 | SORT AGGREGATE | | 1 | 16 | | | |* 2 | TABLE ACCESS FULL| EMP | 95000 | 1484K| 208 (1)| 00:00:03 | ---------------------------------------------------------------------------
V$SQLの問合せにより、全表スキャンを含む計画を表す別の子カーソル(子番号1)が作成されたことが示されます。この新しいカーソルはバッファ読取りの数が少なく、バインド対応としてマークされています。
SELECT CHILD_NUMBER, EXECUTIONS, BUFFER_GETS, IS_BIND_SENSITIVE AS "BIND_SENSI",
IS_BIND_AWARE AS "BIND_AWARE", IS_SHAREABLE AS "BIND_SHARE"
FROM V$SQL
WHERE SQL_TEXT LIKE 'select /*ACS_1%';
CHILD_NUMBER EXECUTIONS BUFFER_GETS BIND_SENSI BIND_AWARE BIND_SHARE
------------ ---------- ----------- ---------- ---------- ----------
0 2 1010 Y N Y
1 2 1522 Y Y Y
値10で問合せを2回実行した後で、選択性がより高い値9を使用してもう一度問合せを実行します。適応カーソル共有により、オプティマイザはカーソルを「適応」させて、この値に対して全表スキャンではなく索引レンジ・スキャンを選択します。
V$SQLの問合せにより、問合せの実行に対して新しい子カーソル(子番号2)が作成されたことが示されます。
CHILD_NUMBER EXECUTIONS BUFFER_GETS BIND_SENSI BIND_AWARE BIND_SHARE
------------ ---------- ----------- ---------- ---------- ----------
0 2 1010 Y N N
1 1 1522 Y Y Y
2 1 7 Y Y Y
適応カーソル共有が使用されるようになったため、バインド対応でない元のカーソル(子0)は今後使用されなくなります。使用されなくなったカーソルは、共有SQL領域から除去されます。
オプティマイザがバインド対応カーソルの計画を作成し、この計画が既存のカーソルと同じである場合、オプティマイザはカーソルのマージを実行できます。この場合、データベースは共有SQL領域を節約するためにカーソルをマージします。データベースは、新しいバインドの選択性を含めるために、カーソルの選択性の範囲を拡大します。
既存のカーソルの選択性の範囲内にないバインド値を使用して問合せを実行したと仮定します。データベースはハード解析を実行し、新規計画と新規カーソルを生成します。この新規計画が既存のカーソルで使用される計画と同じである場合、データベースはこれらの2つのカーソルをマージして、古いカーソルのもう一方を削除します。
適応カーソル共有では、V$ビューを使用して選択性の範囲、カーソル情報(カーソルがバインド対応かバインド依存かなど)および実行統計を表示できます。
V$SQLは、カーソルがバインド依存とバインド対応のどちらであるかを示します。
V$SQL_CS_HISTOGRAMは、3バケットの実行履歴ヒストグラムにより、実行カウントの配分を示します。
V$SQL_CS_SELECTIVITYは、カーソル共有をチェックするために選択性が使用された場合に、バインド変数を含むすべての述語に格納されている選択性の範囲を示します。
V$SQL_CS_STATISTICSは、カーソルをバインド対応としてマークするかどうかを判断するためにオプティマイザが使用する情報を示します。
アクセス・パスは、データベースからデータを取り出す経路です。一般に、表の行の小さいサブセットを取得する文には索引アクセス・パスが役立ちますが、表の大きな部分にアクセスする場合は全体スキャンのほうが効率的です。オンライン・トランザクション処理(OLTP)アプリケーションは、選択性が高く実行の短いSQL文から構成されており、多くの場合は索引アクセス・パスを使用するという特徴があります。ただし、意思決定支援システムでは、パーティション表を使用して、関連するパーティションの全体スキャンを実行する傾向があります。
この項では、表の行を検索して取得するために使用されるデータ・アクセス・パスについて説明します。
このタイプのスキャンでは、表にあるすべての行の読取り、選択基準を満たしていない行のフィルタが実行されます。全表スキャンでは、最高水位標以下の、表のすべてのブロックがスキャンされます。最高水位標は、使用済領域の量、またはデータを受け取るようにフォーマットされている領域を示します。各行が文のWHERE句を満たすかどうかを判断するために、各行が検査されます。
Oracle Databaseでは、全表スキャンを実行する際に、ブロックを順次読み取ります。ブロックは隣接しているため、単一ブロックよりも大きなI/Oコールによってプロセスを高速化できます。読取りコールのサイズは、1ブロックから初期化パラメータDB_FILE_MULTIBLOCK_READ_COUNTで示されるブロック数までです。マルチブロック読取りを使用すると、全表スキャンを効率的に実行できます。データベースは、各ブロックを1回のみ読み取ります。
例11-14「EXPLAIN PLAN出力」には、employees表の全表スキャン例が含まれています。
表の中の大部分のブロックにアクセスする場合、索引レンジ・スキャンより全表スキャンのほうがコストはかかりません。全表スキャンでは、より大きなI/Oコールを使用できます。少数の大きなI/Oコールのほうが、多数の小さなI/Oコールよりもコストがかかりません。
オプティマイザは、次のいずれかの場合に全表スキャンを使用します。
既存の索引を使用できない場合、問合せは全表スキャンを使用します。たとえば、問合せで索引付きの列にファンクションが使用されている場合、オプティマイザが索引を使用できないとき、かわりに全表スキャンを使用します。
大/小文字を区別しない検索に索引を使用する必要がある場合は、大/小文字混合データを検索列に許可しないか、検索列にUPPER(last_name)のようなファンクション索引を作成します。「パフォーマンスを考慮したファンクション索引の使用方法」を参照してください。
表のほとんどのブロックを必要とする問合せの場合、オプティマイザは、索引が使用可能であっても、全表スキャンを使用します。
表に含まれる最高水位標以下のブロック数が、1回のI/Oコールで読取り可能なDB_FILE_MULTIBLOCK_READ_COUNTブロック数に満たない場合は、アクセスされる表の部分や索引の有無にかかわらず、索引レンジ・スキャンよりも全表スキャンの方がコストがかかりません。
表の並列度が高いと、レンジ・スキャンよりも全表スキャンの方向にオプティマイザを偏らせます。表の並列度を判断するには、ALL_TABLES内のDEGREE列を調べます。
オプティマイザに全表スキャンの使用を指示する場合は、ヒントFULL(table alias)を使用します。FULLヒントの詳細は、「アクセス・パスに関するヒント」を参照してください。
取得したブロックがバッファ・キャッシュのどこに置かれるかを示すには、CACHEおよびNOCACHEヒントを使用できます。CACHEヒントは、全表スキャンを実行する際、取得されたブロックがバッファ・キャッシュ内で最後に使用されたLRUリストの最後に配置されるようオプティマイザに指示します。
小規模表は、表11-2の基準に従って自動的にキャッシュされます。
表11-2 表のキャッシュ基準
| 表サイズ | サイズ基準 | キャッシュ |
|---|---|---|
|
小規模 |
ブロックの数が20より少ない、またはキャッシュされているブロックの合計の2%のうち、大きいもの |
|
|
中規模 |
小規模表よりも大きいが、キャッシュされているブロックの合計が10%より少ない |
表スキャンおよびワークロードの履歴に基づいて、表をキャッシュするかどうかを決定します。キャッシュされるブロックが今後の表スキャンで検索される可能性がある場合にのみ、表をキャッシュします。 |
|
大規模 |
キャッシュされているブロックの合計が10%より大きい |
キャッシュされません。 |
小規模表の自動キャッシュは、CACHE属性で作成または変更された表に対しては使用禁止です。
全表スキャンが必要な場合、複数のパラレル実行サーバーを使用すると、レスポンス時間が改善されます。場合によっては、データベースのメモリーが大容量の場合、PGAへの直接読込みを使用するかわりに、パラレル問合せのデータをSGAにキャッシュできます。パラレル問合せは、リソースを使用する可能性があるため、通常では同時実行性の低いデータ・ウェアハウスで実行されます。
|
関連項目:
|
行のROWIDは、行が含まれるデータファイルとデータ・ブロック、およびブロック内での行の位置を指定します。ROWIDの指定による行の位置特定は、単一行を取得する最も高速な方法です。これは、取得する行のデータベース内での正確な位置が指定されるためです。
ROWIDによる表へのアクセスでは、最初に、文のWHERE句か、表の1つ以上の索引の索引スキャンにより、選択された行のROWIDを取得します。次に、ROWIDに基づいて、表内で選択された各行の位置を特定します。
例11-14「EXPLAIN PLAN出力」の計画には、jobs表およびdepartments表の索引スキャンが含まれます。データベースは、取得したROWIDを使用して行を返します。
通常、これは索引からROWIDを取得した後の第2のステップです。索引内に存在しない文の中の列には、表アクセスが必要になる場合があります。
ROWIDによるアクセスでは、すべての索引スキャンに従う必要はありません。文に必要な列がすべて索引に含まれていると、ROWIDによる表アクセスは行われない場合があります。
|
注意: ROWIDは、データがどこに格納されているかを表すOracleの内部表現です。ROWIDは、バージョン間で変わってしまう場合があります。行の移行、行チェーン、エクスポートとインポート、およびその他の操作によって、行は移動する可能性があるため、位置に基づいたデータへのアクセスはお薦めできません。外部キーは主キーに基づいている必要があります。ROWIDの詳細は、『Oracle Databaseアドバンスト・アプリケーション開発者ガイド』を参照してください。 |
この方法では、文で指定された索引付きの列の値を使用して索引が検索され、行が取得されます。索引スキャンでは、索引の1つ以上の列値に基づいて索引からデータが取得されます。索引スキャンでは、文がアクセスする索引列の値の索引を検索します。文が索引の列にのみアクセスする場合は、表からではなく、索引から直接に索引列の値を読み取ります。
索引には、索引の値の他に、その値を持っている行のROWIDも含まれています。したがって、文が索引列に加え、他の列にもアクセスする場合、ROWIDで表にアクセスするか、クラスタ・スキャンを使用して、表の行を見つけることができます。
索引スキャンには次のタイプがあります。
Oracle Databaseでは、ブロック単位でI/Oを実行します。したがって、全表スキャンを使用するかどうかのオプティマイザの決定は、行でなくアクセスされるブロックのパーセンテージに影響されます。これは索引クラスタ化係数と呼ばれています。ブロックに単一行が含まれている場合、アクセスされる行とアクセスされるブロックは同じです。
ただし、大半の表には各ブロック内に複数の行があります。したがって、目的の行数は、少数のブロックにクラスタ化されているか、多数のブロックにわたって分散している場合もあります。
クラスタ化係数は索引のプロパティですが、実際には、表のデータ・ブロック内の類似した索引付き列の値の拡散度合いに関連します。低いクラスタ化係数は、個々の行が表の少数のブロック内に集中されることを示します。逆に、高いクラスタ化係数は、個々の行が表の複数のブロックにわたってランダムに分散されることを示します。したがって、高いクラスタ化係数の場合はレンジ・スキャンを使用してROWIDで行をフェッチするのでよりコストがかかりますが、これはデータを戻すために表の中のさらに多くのブロックにアクセスする必要があるためです。例11-4では、クラスタ化係数がコストにどのような影響を与えるかを示しています。
9つの行を持つ表があります。
表のcol1に一意でない索引があります。
c1列は現在、値A、BおよびCを格納しています。
表には、3つのデータ・ブロックがあります。
ケース1: 次の図のように配置されている場合、行に対して索引クラスタ化係数は低くなります。
Block 1 Block 2 Block 3 ------- ------- ------- A A A B B B C C C
これは、c1に対して同じ索引付きの列の値を持つ行が、表の中の同じ物理ブロック内にあるためです。レンジ・スキャンを使用して値Aを持つすべての行を戻す場合、表の中のブロックを1つのみ読み取れば済むため、低いコストで済みます。
ケース2: 同じ行が、索引値が表ブロック間に分散する(並べるのではなく)ように再配置されると、索引クラスタ化係数が高くなります。
Block 1 Block 2 Block 3 ------- ------- ------- A B C A B C A B C
これは、表の中の3つのブロックを、col1内に値Aを持つすべての行を取得するために、すべて読み取る必要があるためです。
このスキャンは1つのROWIDしか戻しません。Oracle Databaseでは、1つの行にのみアクセスすることを保証するUNIQUE制約またはPRIMARY KEY制約が文に含まれる場合、一意スキャンを実行します。
「EXPLAIN PLAN出力」では、job_id_pk索引とdept_id_pk索引を使用してjobs表およびdepartments表の索引スキャンを実行します。
このアクセス・パスが使用されるのは、一意(Bツリー)索引または等価条件の指定された主キー制約によって作成された索引のすべての列をユーザーが指定した場合です。
|
関連項目: 索引構造の詳細とBツリーの検索方法の詳細は、『Oracle Database概要』を参照してください。 |
一般に、一意スキャンを行うためのヒントを使用する必要はありません。ただし、表がデータベース・リンクにまたがっていて、ローカル表からアクセスされる場合や、表が小さく、オプティマイザが全表スキャンを選択する場合があります。
ヒントINDEX(alias index_name)は使用する索引を指定しますが、アクセス・パス(レンジ・スキャンや一意スキャン)は指定しません。INDEXヒントの詳細は、「アクセス・パスに関するヒント」を参照してください。
索引レンジ・スキャンは、選択性の高いデータにアクセスする共通の操作です。このスキャンは、境界(両側で境界付き)スキャンまたは非有界(片側または両側で)スキャンとすることができます。データは、索引列の昇順に戻されます。同じ値を持つ複数の行は、ROWIDで昇順にソートされます。
データをソートする必要がある場合は、索引には依存せず、ORDER BY句を使用します。索引でORDER BY句を満たすことが可能な場合、オプティマイザはこのオプションを使用し、ソートを回避します。
例11-5では、順序がレガシー・システムからインポートされており、レガシー・システムで使用された参照順に問合せを行います。この参照がorder_dateであると仮定します。
例11-5 索引レンジ・スキャン
SELECT order_status, order_id
FROM orders
WHERE order_date = :b1;
---------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
---------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 20 | 3 (34)|
| 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | 1 | 20 | 3 (34)|
|* 2 | INDEX RANGE SCAN | ORD_ORDER_DATE_IX | 1 | | 2 (50)|
---------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("ORDERS"."ORDER_DATE"=:Z)
これは選択性の高い問合せである必要があり、問合せでは列の索引を使用して目的の行を取得します。戻されたデータは、order_dateのROWIDにより昇順でソートされます。索引列order_dateは、ここで選択された行と同じなので、データはROWIDでソートされます。
オプティマイザは、次のように条件で指定された索引の1つ以上の先頭列を検出したとき、レンジ・スキャンを使用します。
col1 = :b1
col1 < :b1
col1 > :b1
索引内の先頭列に対する前述の条件のAND組合せ
ワイルド・カード検索col1 like 'ASD%'は、先頭に指定しないでください。そうでない場合、条件col1 like '%ASD'によって、レンジ・スキャンが生じません。
レンジ・スキャンでは、一意索引または非一意索引を使用できます。レンジ・スキャンでは、索引列がORDER BY/GROUP BY句を構成しているときにソートを回避します。
オプティマイザが他の索引を選択したり、全表スキャンを使用する場合は、ヒントが必要になる場合があります。ヒントINDEX(table_alias index_name)では、特定の索引を使用するようにオプティマイザに指示します。INDEXヒントの詳細は、「アクセス・パスに関するヒント」を参照してください。
索引レンジ・スキャン降順は、データが降順で戻されること以外、索引レンジ・スキャンと同じです。デフォルトでは、索引は昇順に格納されます。通常、このスキャンが使用されるのは、最初に最新のデータを戻すためにデータを降順に並べる場合か、指定された値より小さい値を検索する場合です。
このアクセス・パスには、INDEX_DESC(table_alias index_name)ヒントを使用します。INDEX_DESCヒントの詳細は、「アクセス・パスに関するヒント」を参照してください。
索引スキップ・スキャンにより、接頭辞の付いていない列による索引スキャンが改善されます。多くの場合、索引ブロックをスキャンするほうが、表データ・ブロックをスキャンするより高速です。
スキップ・スキャンにより、コンポジット索引をさらに小さい副索引に論理的に分割できます。スキップ・スキャンでは、コンポジット索引の初期列が問合せで指定されていません。つまり、その列がスキップされます。
論理副索引の個数は、最初の列にある個別値の数によって判断されます。スキップ・スキャンは、コンポジット索引の先頭列に個別値がほとんどなく、索引の非先頭キーに個別値が多数ある場合に有効です。
コンポジット索引の先頭列が問合せ述語で指定されていない場合、データベースは索引スキップ・スキャンを選択することがあります。たとえば、sh.customers表の顧客に対して次の問合せを行うと仮定します。
SELECT * FROM sh.customers WHERE cust_email = 'Abbey@company.com';
customers表には列cust_genderがあり、この値はMかFのどちらかです。コンポジット索引が次のようにして作成された列(cust_gender、cust_email)に存在するとします。
CREATE INDEX customers_gender_email ON sh.customers (cust_gender, cust_email);
例11-6に、索引エントリの一部を示します。
例11-6 コンポジット索引エントリ
F,Wolf@company.com,rowid F,Wolsey@company.com,rowid F,Wood@company.com,rowid F,Woodman@company.com,rowid F,Yang@company.com,rowid F,Zimmerman@company.com,rowid M,Abbassi@company.com,rowid M,Abbey@company.com,rowid
この索引のスキップ・スキャンは、cust_genderがWHERE句で指定されていない場合でも使用できます。
スキップ・スキャンでは、論理副索引の個数は、先頭列にある個別値の数によって判断されます。例11-6では、先頭列に可能な値は2つあります。索引は、キーFを持つ1つの副索引と、キーMを持つ2番目の副索引に論理的に分割されます。
電子メールがAbbey@company.comの顧客のレコードを検索する場合、最初に値Fを持つ副索引が検索され、次に値Mを持つ副索引が検索されます。概念上、データベースで問合せが次のように処理されます。
SELECT * FROM sh.customers WHERE cust_gender = 'F' AND cust_email = 'Abbey@company.com' UNION ALL SELECT * FROM sh.customers WHERE cust_gender = 'M' AND cust_email = 'Abbey@company.com';
|
関連項目: スキップ・スキャンの詳細は、『Oracle Database概要』を参照してください。 |
全索引スキャンを行うとソート操作が必要なくなります。これはデータが索引キーで並べられるためです。全体スキャンではブロックが単独で読み取られます。Oracle Databaseでは全体スキャンを次のような状況で使用します。
次の要件を満たすORDER BY句が問合せに存在する場合。
ORDER BY句の列すべてが索引に含まれている。
ORDER BY句の列の順序が先行する索引列の順序と一致している。
ORDER BY句には、索引内のすべての列、または索引内の列のサブセットを含めることができます。
問合せにソート/マージ結合が必要な場合。問合せが次の要件を満たす場合、全表スキャンの後にソートを実行するのではなく、全索引スキャンを実行できます。
問合せで参照される列すべてが索引に含まれている。
問合せで参照される列の順序が先行する索引列の順序と一致している。
問合せには、索引内のすべての列、または索引内の列のサブセットを含めることができます。
GROUP BY句が問合せ内に存在し、GROUP BY句の列が索引内に存在する場合。列の順序を索引やGROUP BY句の順序と同じにする必要はありません。GROUP BY句には、索引内のすべての列、または索引内の列のサブセットを含めることができます。
高速全索引スキャンは、問合せに必要なすべての列が索引に含まれており、索引キーの1つ以上の列にNOT NULL制約が設定されている場合に、全表スキャンの代替となるスキャンです。高速全スキャンは、表にアクセスすることなく索引そのものに存在するデータにアクセスします。データが索引キー順にソートされていないため、このスキャンを使用してソート操作を排除できません。高速全スキャンでは、全索引スキャンとは異なり、マルチブロック読取りを使用して索引全体が読み取られ、パラレルでスキャンできます。
初期化パラメータOPTIMIZER_FEATURES_ENABLEまたはINDEX_FFSヒントを使用して高速全索引スキャンを指定できます。高速全スキャンは、表スキャンと同様にマルチブロックI/Oを使用してパラレルで実行できるため、通常の全索引スキャンより高速です。
|
注意: 索引にPARALLELを設定してもコスト計算には影響しません。 |
高速全体スキャンには、特別な索引ヒントINDEX_FFSがあります。この形式と引数は、通常のINDEXヒントと同じです。INDEX_FFSヒントの詳細は、「アクセス・パスに関するヒント」を参照してください。
索引結合は、問合せで参照される表の列すべてが含まれている複数の索引のハッシュ結合です。索引結合を使用すると、関連するすべての列値を索引から取得できるため、表にアクセスする必要はありません。索引結合を使用して、ソート操作を排除することはできません。
クラスタ・スキャンは、索引クラスタに格納された表から、同じクラスタ・キー値を持つすべての行を取得する場合に使用します。索引クラスタでは、同じクラスタ・キー値を持つすべての行が同じデータ・ブロックに格納されます。クラスタ・スキャンを実行するには、最初に、クラスタ索引をスキャンして、選択された行の1つのROWIDを取得します。次に、このROWIDに基づいて行の位置を特定します。
ハッシュ・スキャンでは、ハッシュ値に基づいてハッシュ・クラスタ内の行の位置を特定します。ハッシュ・クラスタ内においては、同一のハッシュ値を持つすべての行が同じデータ・ブロックに格納されています。ハッシュ・スキャンを実行するには、最初に、文で指定されたクラスタ・キー値にハッシュ関数を適用することによって、ハッシュ値を取得します。次に、そのハッシュ値を持つ行が含まれているデータ・ブロックをスキャンします。
サンプル表スキャンでは、単純な表、または結合およびビューを含む文などの複合SELECT文からデータのランダムなサンプルが取り出されます。このアクセス・パスは、文のFROM句にSAMPLE句またはSAMPLE BLOCK句が含まれているときに使用されます。SAMPLE句を使用した行単位のサンプリングでサンプル表スキャンを実行する場合、データベースは表の行を指定されたパーセントだけ読み取ります。SAMPLE BLOCK句を使用したブロック単位のサンプリングでサンプル表スキャンを実行する場合、データベースは表のブロックを指定されたパーセントだけ読み取ります。
例11-7は、サンプル表スキャンを使用して、ブロックによるサンプリングを行ってemployees表の1%にアクセスします。
例11-7 サンプル表スキャン
SELECT *
FROM employees SAMPLE BLOCK (1);
この文のEXPLAIN PLAN出力は、次のような形式になります。
------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| ------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 68 | 3 (34)| | 1 | TABLE ACCESS SAMPLE | EMPLOYEES | 1 | 68 | 3 (34)| -------------------------------------------------------------------------
問合せオプティマイザは、次の要因に従ってアクセス・パスを選択します。
文で使用可能なアクセス・パス
各アクセス・パスまたはパスの組合せを使用して文を実行するための見積りコスト
アクセス・パスを選択する場合、オプティマイザは、文のWHERE句、およびFROM句の条件を調べて、使用可能なアクセス・パスを最初に判断します。次に、オプティマイザは、使用可能なアクセス・パスを使用して可能な実行計画のセットを生成し、文にアクセス可能な索引、列および表の統計を使用して各見積りコストを生成します。そして最後に、オプティマイザは見積りコストが最も少ない実行計画を選択します。
アクセス・パスを選択する場合、問合せオプティマイザは次の影響を受けます。
結合は、複数の表からデータを取得する文です。結合の特徴は、FROM句内に複数の表が並んでいる点です。WHERE句に存在する結合条件は、表の関係を定義します。結合では、片方の行セットが内部と呼ばれ、もう一方が外部と呼ばれます。
この項では、次の内容を説明します。
結合文に実行計画を選択するために、オプティマイザは、相互に関連する次の決定を行う必要があります。
アクセス・パス
単純な文では、オプティマイザは、結合文の各表からデータを取り出すアクセス・パスを選択する必要があります。
結合方法
行ソースの各ペアを結合するには、結合操作を実行する必要があります。結合方法には、ネステッド・ループ結合、ソート/マージ結合、デカルト結合およびハッシュ結合があります。
結合順序
Oracle Databaseでは、3つ以上の表を結合する文を実行する場合、2つの表を結合し、その結果作成された行ソースを次の表に結合します。このプロセスは、すべての表が結合されて結果が生成されるまで続きます。
実行計画を選択するとき、問合せオプティマイザでは次の点が考慮されます。
オプティマイザは、2つ以上の表を結合した結果を、最大1つの行を含む行ソースに限定するかどうかを最初に判断します。オプティマイザは、このような状況を表のUNIQUE制約およびPRIMARY KEY制約に基づいて認識します。このような状況が存在する場合、オプティマイザはこれらの表を結合順序の最初に並べます。その後で、残りの表の結合を最適化します。
外部結合条件を持つ結合文では、外部結合演算子のある表の結合順序は、条件内のその他の表の後にしてください。オプティマイザは、この規則に違反する結合順序を考慮しません。同様に、副問合せがアンチ結合またはセミ結合に変換されたときは、その副問合せからの表は、それらが接続または相互に関連付けされた外部問合せブロック内の表の後に置きます。ただし、ある環境では、ハッシュ・アンチ結合およびセミ結合はこの順序条件を上書きできます。
問合せオプティマイザでは、適用可能な結合順序、結合方法および使用可能なアクセス・パスに従ってオプティマイザが実行計画のセットを生成します。次に、オプティマイザは各計画のコストを見積り、コストが最も小さいものを選択します。オプティマイザは、次の方法でコストを見積ります。
ネステッド・ループ操作のコストは、外部表で選択されている各行およびその行に対する内部表の一致行をメモリーに読み取るコストが基準になっています。オプティマイザは、データ・ディクショナリ内の統計を使用してこれらのコストを見積ります。
ハッシュ結合のコストは、主に、結合への入力側の1つ上にハッシュ表を作成するコストと、それを調べるために結合のもう一方からの行を使用するコストに基づきます。
オプティマイザは、各操作のコストを判断するときにはその他の要因についても考慮します。たとえば、次のようにします。
ソート領域のサイズが小さいと、小さいソート領域内でのソートにCPU時間とI/Oがより多く消費されるため、ソート/マージ結合のコストが大きくなる傾向があります。SQL作業領域のサイズ設定の詳細は、「PGAメモリー管理」を参照してください。
マルチブロックREADカウントが大きいと、ネステッド・ループ結合に関してソート/マージ結合のコストが少なくなる傾向があります。1回のI/Oでディスクから多数の連続ブロックが読み取られる場合は、ネステッド・ループ結合の内部表の索引によって、全表スキャンよりパフォーマンスが向上する可能性は低くなります。マルチブロック読取り数は、初期化パラメータDB_FILE_MULTIBLOCK_READ_COUNTによって指定されます。
ORDEREDヒントを使用して、オプティマイザが選択した結合順序を上書きできます。ORDEREDヒントによって、外部結合に関するこの規則に違反する結合順序が指定された場合、オプティマイザはこのヒントを無視して順序を選択します。結合方法に関するオプティマイザの選択も、ヒントを使用して上書きできます。
ネステッド・ループ結合は、次の条件に該当する場合に役立ちます。
小さなデータ・サブセットを結合する場合。
結合条件が第2の表へのアクセスの効率的な方法である場合。
内部表が、外部表によって駆動される(依存する)ことを確認することが重要です。内部表のアクセス・パスが外部表とは独立している場合は、外部ループを繰り返すたびに同じ行が取得されます。これは、パフォーマンスをかなり低下させてしまいます。そのような場合は、2つの独立した行ソースを結合するハッシュ結合のほうがパフォーマンスが優れています。
ネステッド・ループ結合には、次のステップがあります。
オプティマイザで駆動表が決定され、これが外部表に指定されます。
その他の表は、内部表に指定します。
外部表の行ごとに、内部表のすべての行がアクセスされます。外部ループは外部表にあるすべての行に対するものであり、内部ループは内部表の中にあるすべての行に対するものです。次のように、外部ループは実行計画の内部ループの前に表示されます。
NESTED LOOPS outer_loop inner_loop
Oracle Database 11gには、新しいネステッド・ループ結合の実装が含まれます。そのため、ネステッド・ループを含む実行計画は、以前のリリースのOracle Databaseとは異なる状態で表示されます。Oracle Database 11gでは、ネステッド・ループ結合の新規の実装と従来の実装の両方が可能です。そのため実行計画を分析する場合は、NESTED LOOPS結合の行ソースの数が異なることを理解しておくことが重要です。
次の問合せについて考えます。
SELECT e.first_name, e.last_name, e.salary, d.department_name
FROM hr.employees e, hr.departments d
WHERE d.department_name IN ('Marketing', 'Sales')
AND e.department_id = d.department_id;
Oracle Database 11gより前のリリースでは、この問合せの実行計画は、次の実行計画のように表示されます。
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 19 | 722 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 10 | 220 | 1 (0)| 00:00:01 |
| 2 | NESTED LOOPS | | 19 | 722 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DEPARTMENTS | 2 | 32 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 10 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("D"."DEPARTMENT_NAME"='Marketing' OR "D"."DEPARTMENT_NAME"='Sales')
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
この例では、結合の外部側はhr.departments表のスキャンで構成され、このスキャンによって、条件department_name IN ('Marketing', 'Sales')に一致する行が戻されます。内部ループにより、これらの部署に関連付けられている従業員がhr.employees表に取得されます。
Oracle Database 11gでは、新しいネステッド・ループ結合の実装が導入され、物理I/Oの全体の待機時間が短縮されました。バッファ・キャッシュに索引または表ブロックが存在せず、結合の処理に必要な場合、物理I/Oが必要となります。Oracle Database 11gでは、一度に1つのリクエストを処理するのではなく、ベクターI/Oを使用して複数の物理I/Oリクエストをまとめて処理できます。
ネステッド・ループ結合の新規の実装の一環として、NESTED LOOPS結合の2つの行ソースが実行計画に表示されます。以前のリリースでは1行のみが表示されていました。この場合、Oracle Databaseでは結合の外部側の表の値と内部側の索引とを結合するためにNESTED LOOPS結合の1つの行ソースを割り当てます。もう1つの行ソースは、最初の結合の結果を結合するために割り当てられます。これにより、索引に格納されている行IDが含まれ、結合の内部側に表が存在します。
「ネステッド・ループ結合の従来の実装」の問合せについて考えます。Oracle Database 11gの新しいネステッド・ループ結合の実装を使用すると、この問合せの実行計画は次の実行計画のように表示されます。
------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost(%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 19 | 722 | 3 (0)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 19 | 722 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | DEPARTMENTS | 2 | 32 | 2 (0)| 00:00:01 |
|* 4 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 10 | | 0 (0)| 00:00:01 |
| 5 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 10 | 220 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("D"."DEPARTMENT_NAME"='Marketing' OR "D"."DEPARTMENT_NAME"='Sales')
4 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
この場合、hr.departments表の行は、最初の結合の外部側で構成されます。最初の結合の内部側は索引emp_department_ixです。最初の結合の結果は、2番目の結合の外部側で構成されます。これにより、結合の内部側にhr.employees表が存在します。
2番目の結合の行ソースが割り当てられない場合があります。この場合、実行計画は以前のリリースと同様に表示されます。次にこのような状況について説明します。
結合の内部側で必要なすべての列が索引に存在するため、表にアクセスする必要がない。この場合、Oracle Databaseでは結合の1つの行ソースのみが割り当てられます。
戻された行の順序が以前のリリースの順序と異なっている。したがって、Oracle Databaseで行の特定の順序を予約しようとする場合(たとえばORDER BYソートを行う必要がない場合など)、Oracle Databaseではネステッド・ループ結合の従来の実装が使用されます。
OPTIMIZER_FEATURES_ENABLE初期化パラメータが、Oracle Database 11gより前のリリースに設定されている。この場合、Oracle Databaseではネステッド・ループ結合の従来の実装が使用されます。
オプティマイザは、2つの表の間で適切な駆動条件で少数の行を結合する場合に、ネステッド・ループ結合を使用します。外部ループから内部ループに起動するので、実行計画の中の表の順序が重要になります。
外部ループは駆動行ソースです。このループは、結合条件を駆動するための一連の行を生成します。行ソースは、索引スキャンまたは全表スキャンでアクセスされる表にすることができます。また、他の操作からでも行を生成できます。たとえば、ネステッド・ループ結合からの出力は、別のネステッド・ループ結合の行ソースとなります。
内部ループは外部ループから戻された行ごとに、索引スキャンによって反復されます。内部ループのアクセス・パスが外部ループに依存していない場合は、デカルト積で終了することが可能で、外部ループの反復ごとに、内部ループは同じ行セットを生成します。したがって、2つの独立した行ソースをまとめて結合する場合は、他の結合方法を使用することをお薦めします。
オプティマイザが他の結合方法の使用を選択した場合は、USE_NL(table1 table2)ヒントを使用できます。table1とtable2は、結合される表の別名です。
データが十分に小さいSQL例の場合は、オプティマイザは全表スキャンを優先してハッシュ結合を使用します。例11-8「ハッシュ結合」は、そのSQLの例です。ただし、USE_NLを追加してオプティマイザに指示し、結合方法をネステッド・ループに変更できます。USE_NLヒントの詳細は、「結合操作のヒント」を参照してください。
ハッシュ結合は、大きなデータ・セットの結合に使用されます。オプティマイザは、2つの表またはデータ・ソースの小さいほうを使用して、メモリー内の結合キーにハッシュ表を作成します。次に、大きいほうの表をスキャンし、ハッシュ表を調べて結合された行を見つけます。
この方法は、小さいほうの表が使用可能なメモリーに収まる場合に最適です。これにより、コストが2つの表のデータに対する1回のリード・パスに制限されます。
オプティマイザは、2つの表が等価結合で結合され、次の条件のいずれかが真である場合に、ハッシュ結合で2つの表を結合します。
大量のデータを結合する必要がある。
小規模表の大きな部分を結合する必要がある。
例11-8では、orders表を使用してハッシュ表を作成します。より大きなorder_itemsは、後でスキャンします。
例11-8 ハッシュ結合
SELECT o.customer_id, l.unit_price * l.quantity
FROM orders o ,order_items l
WHERE l.order_id = o.order_id;
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 665 | 13300 | 8 (25)|
|* 1 | HASH JOIN | | 665 | 13300 | 8 (25)|
| 2 | TABLE ACCESS FULL | ORDERS | 105 | 840 | 4 (25)|
| 3 | TABLE ACCESS FULL | ORDER_ITEMS | 665 | 7980 | 4 (25)|
--------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("L"."ORDER_ID"="O"."ORDER_ID")
2つの表を結合するときに、ハッシュ結合を使用するようにオプティマイザに指示するには、USE_HASHヒントを適用します。SQL作業領域のサイズ設定の詳細は、「PGAメモリー管理」を参照してください。USE_HASHヒントの詳細は、「結合操作のヒント」を参照してください。
ソート/マージ結合では、2つの独立したソースの行を結合できます。ハッシュ結合は、一般に、ソート/マージ結合よりパフォーマンスが優れています。ただし、次の条件が2つとも存在する場合は、ハッシュ結合よりソート/マージ結合のほうが優れたパフォーマンスを実現します。
行ソースはソート済。
ソート操作を終了する必要なし。
ソート/マージ結合に、より低速のアクセス方法(全表スキャンとは対照的な索引スキャン)の選択が含まれている場合、ソート/マージを使用する利点が失われる可能性があります。
ソート/マージ結合は、2つの表の間の結合条件が<、<=、>または>=などの等価条件ではない場合に有効です。ソート/マージ結合は、大きいデータ・セットの場合にネステッド・ループ結合よりパフォーマンスが優れています。等価条件がないかぎり、ハッシュ結合を使用できません。
マージ結合には、駆動表の概念はありません。結合には、2つのステップが含まれています。
ソート結合操作: 両方の入力が、結合キーでソートされる。
マージ結合処理: ソートされたリストがマージされる。
入力を結合列でソートすると、その行ソースのソート結合操作は行われません。ただし、ソート/マージ結合では、最後の一致に戻ることができるように結合の右側に対して位置調整できるソート・バッファが常に作成されます。この場合、重複した結合キー値は結合の左側から取り出されます。
オプティマイザは、次の条件が真である場合に、ハッシュ結合よりソート/マージ結合を選択して大量のデータを結合します。
2つの表の結合条件が、等価結合ではない。
他の操作でソートが必要なため、オプティマイザは、ハッシュ結合よりソート/マージを使用するほうがコストが低いと判断した。
ソート/マージ結合を使用するようオプティマイザに指示するには、USE_MERGEヒントを適用します。また、アクセス・パスを設定するためのヒントを与える必要がある場合があります。
USE_MERGEヒントを使用してオプティマイザを上書きすることが適切な場合もあります。たとえば、オプティマイザは表に対する全体スキャンを選択して問合せ内でのソート操作を回避できます。ただし、大きい表は全表スキャンによる高速アクセスの場合とは異なり、索引および単一ブロック読取りでアクセスされるため、コストがかかります。
USE_MERGEヒントの詳細は、「結合操作のヒント」を参照してください。
文に他の表との結合条件のない表が1つ以上存在する場合、デカルト結合が使用されます。オプティマイザは、データ・ソースにあるすべての行を、2つのセットのデカルト積を作成しながら、別のデータ・ソースにあるすべての行と結合します。
外部結合は単純結合の結果を拡張したものです。外部結合は、結合条件に一致するすべての行および結合条件が他の表のどの行とも一致しない、表の一部またはすべての行を戻します。
この操作は、2つの表の外部結合をループ処理する場合に使用されます。外部結合は、内部(オプション)表に対応する行がない場合でも、外部(保存されている)表の行を戻します。
正規の外部結合で、オプティマイザはコストに基づいて表(駆動する側と駆動される側)の順序を選択します。ただし、ネステッド・ループ外部結合では、結合条件によって表の順序が決まります。行が保存される外部表を使用して、内部表を駆動します。
オプティマイザは、ネステッド・ループ結合を使用し、次の状況で外部結合を処理します。
外部表から内部表まで起動できる。
データ量が少なく、ネステッド・ループ方法が効果的と判断できる。
ネステッド・ループ外部結合の例の場合は、USE_NLヒントを例11-9に追加して、ネステッド・ループを使用するようにオプティマイザに指示できます。たとえば、次のようにします。
SELECT /*+ USE_NL(c o) */ cust_last_name, SUM(NVL2(o.customer_id,0,1)) "Count" FROM customers c, orders o WHERE c.credit_limit > 1000 AND c.customer_id = o.customer_id(+) GROUP BY cust_last_name;
オプティマイザは、次の場合に外部結合にハッシュ結合を使用します。
データ量が十分に多く、ハッシュ結合法が効果的である。
外部表から内部表まで起動することができない。
表の順序はコストにより決定されます。外部表は、保存された行も含めて、ハッシュ表を作成する場合に使用されるか、またはハッシュ表を調べるときに使用される場合があります。
例11-9に、ハッシュ結合外部結合を使用した一般的な問合せを示します。この例では、与信限度が1000を超えるすべての顧客を問い合せています。外部結合は、オーダーを持たない顧客を見逃さないようにするために必要です。
例11-9 ハッシュ結合外部結合
SELECT cust_last_name, SUM(NVL2(o.customer_id,0,1)) "Count"
FROM customers c, orders o
WHERE c.credit_limit > 1000
AND c.customer_id = o.customer_id(+)
GROUP BY cust_last_name;
---------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
---------------------------------------------------------------------------------
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | | | 7 (100)| |
| 1 | HASH GROUP BY | | 168 | 3192 | 7 (29)| 00:00:01 |
|* 2 | HASH JOIN OUTER | | 318 | 6042 | 6 (17)| 00:00:01 |
|* 3 | TABLE ACCESS FULL| CUSTOMERS | 260 | 3900 | 3 (0)| 00:00:01 |
|* 4 | TABLE ACCESS FULL| ORDERS | 105 | 420 | 2 (0)| 00:00:01 |
---------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("C"."CUSTOMER_ID"="O"."CUSTOMER_ID")
PLAN_TABLE_OUTPUT
----------------------------------------------------------------------------------
3 - filter("C"."CREDIT_LIMIT">1000)
4 - filter("O"."CUSTOMER_ID">0)
この問合せは、様々な条件に一致する顧客を検索します。内部表に対応する行が見つからないと、外部結合は外部(保たれている)表の行とともに内部表の列に対してNULLを戻します。この操作で、orders行も持たないcustomers行がすべて検索されます。
この場合、外部結合条件は次のとおりです。
customers.customer_id = orders.customer_id(+)
この条件の構成要素を次に示します。
外部表はcustomersです。
内部表はordersです。
この結合は、orders内に対応する行を持たない行を含むcustomers行を保存します。
行を戻すには、NOT EXISTS副問合せを使用できます。ただし、表の全行の問合せを行っているため、ハッシュ結合のほうがパフォーマンスが優れています(NOT EXISTS副問合せがネストされていない場合を除く)。
例11-10では、外部結合はマルチ表ビューに対して行われます。オプティマイザは通常の結合のようにビューを操作したり、述語をプッシュできないので、ビューの行セット全体を作成します。
例11-10 マルチ表ビューへの外部結合
SELECT c.cust_last_name, sum(revenue)
FROM customers c, v_orders o
WHERE c.credit_limit > 2000
AND o.customer_id(+) = c.customer_id
GROUP BY c.cust_last_name;
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 144 | 4608 | 16 (32)|
| 1 | HASH GROUP BY | | 144 | 4608 | 16 (32)|
|* 2 | HASH JOIN OUTER | | 663 | 21216 | 15 (27)|
|* 3 | TABLE ACCESS FULL | CUSTOMERS | 195 | 2925 | 6 (17)|
| 4 | VIEW | V_ORDERS | 665 | 11305 | |
| 5 | HASH GROUP BY | | 665 | 15960 | 9 (34)|
|* 6 | HASH JOIN | | 665 | 15960 | 8 (25)|
|* 7 | TABLE ACCESS FULL| ORDERS | 105 | 840 | 4 (25)|
| 8 | TABLE ACCESS FULL| ORDER_ITEMS | 665 | 10640 | 4 (25)|
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - access("O"."CUSTOMER_ID"(+)="C"."CUSTOMER_ID")
3 - filter("C"."CREDIT_LIMIT">2000)
6 - access("O"."ORDER_ID"="L"."ORDER_ID")
7 - filter("O"."CUSTOMER_ID">0)
ビュー定義は、次のようになります。
CREATE OR REPLACE view v_orders AS
SELECT l.product_id, SUM(l.quantity*unit_price) revenue,
o.order_id, o.customer_id
FROM orders o, order_items l
WHERE o.order_id = l.order_id
GROUP BY l.product_id, o.order_id, o.customer_id;
外部結合で、外部(保たれている)表から内部(オプション)表への駆動ができない場合、外部結合ではハッシュ結合またはネステッド・ループ結合が使用できません。その場合、外部結合では結合操作を実行するためにソート/マージ外部結合を使用します。
オプティマイザは、次の場合に外部結合にソート/マージを使用します。
ネステッド・ループ結合の効率が悪い場合。データ量により、ネステッド・ループ結合は効率が悪い場合があります。
他の操作でソートが必要であるため、ハッシュ結合よりソート/マージを使用するほうがコストが低いと判断した場合。
完全外部結合は、左と右の外部結合の組合せのように動作します。内部結合では、内部結合の結果で戻されなかった両方の表からの行は保たれており、NULLで拡張されます。つまり、完全外部結合を使用すると、表をまとめて結合できますが、結合される表内に対応する行を持たない行も示すことができます。
例11-11の問合せでは、全部門と、その各部門に属する全社員を取得しますが、これには次の内容も含まれます。
部門に属さない全社員
社員のいない全部門
例11-11 完全外部結合
SELECT d.department_id, e.employee_id
FROM employees e
FULL OUTER JOIN departments d
ON e.department_id = d.department_id
ORDER BY d.department_id;
文からは、次の出力が作成されます。
DEPARTMENT_ID EMPLOYEE_ID
------------- -----------
10 200
20 201
20 202
30 114
30 115
30 116
...
270
280
178
207
125 rows selected.
Oracle Database 11g以上では、可能なかぎり、完全外部結合を実行する場合、ハッシュ結合に基づいたネイティブの実行方法が自動的に使用されます。新しい方法を使用して完全外部結合を実行する場合、問合せの実行計画にはHASH JOIN FULL OUTERが含まれます。例11-12に、例11-11の問合せの実行計画を示します。
例11-12 完全外部結合の実行計画
----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 122 | 4758 | 6 (34)| 00:0 0:01 |
| 1 | SORT ORDER BY | | 122 | 4758 | 6 (34)| 00:0 0:01 |
| 2 | VIEW | VW_FOJ_0 | 122 | 4758 | 5 (20)| 00:0 0:01 |
|* 3 | HASH JOIN FULL OUTER | | 122 | 1342 | 5 (20)| 00:0 0:01 |
| 4 | INDEX FAST FULL SCAN| DEPT_ID_PK | 27 | 108 | 2 (0)| 00:0 0:01 |
| 5 | TABLE ACCESS FULL | EMPLOYEES | 107 | 749 | 2 (0)| 00:0 0:01 |
----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
HASH JOIN FULL OUTERが計画に含まれている点に注意してください。そのため、問合せではハッシュ完全外部結合の実行方法が使用されます。2つの表の完全外部結合条件が等価結合の場合、通常はハッシュ完全外部結合の実行方法が可能であるため、Oracle Databaseでは自動的にこの方法が使用されます。
ハッシュ完全外部結合の実行方法の使用を考慮するようにオプティマイザに指示するには、NATIVE_FULL_OUTER_JOINヒントを適用します。ハッシュ完全外部結合の実行方法の使用を考慮しないようにオプティマイザに指示するには、NO_NATIVE_FULL_OUTER_JOINヒントを適用します。NO_NATIVE_FULL_OUTER_JOINヒントでは、オプティマイザに対して、指定した各表を結合する際にネイティブの実行方法を除外するように指示します。かわりに、左外部結合と逆結合を組み合せたものとして完全外部結合が実行されます。
Oracle Databaseでは、SQL文を実行するために多数のステップを実行する必要があります。実行される各ステップでは、データベースからのデータ行の物理的な取出し、またはユーザーが発行する文に返すデータ行の準備のどちらかが実行されます。文を実行するためにOracle Databaseが使用するステップの組合せが実行計画です。実行計画には、文がアクセスする各表へのアクセス・パスと、適切な結合方法に基づく表の順序(結合順序)が含まれています。
オプティマイザがSQL文に対して選択した実行計画を確認するには、EXPLAIN PLAN文を使用します。文が発行されると、オプティマイザが実行計画を選択した後で、計画を説明するデータがデータベース表に挿入されます。EXPLAIN PLAN文を発行して、出力表を問い合せます。
EXPLAIN PLAN文の基本的な使用方法は次のとおりです。
SQLスクリプトCATPLAN.SQLを使用し、使用しているスキーマ内にPLAN_TABLEというサンプル出力表を作成します。「PLAN_TABLE出力表」を参照してください。
SQL文の前に、EXPLAIN PLAN FOR句を含めます。「EXPLAIN PLANの実行」を参照してください。
EXPLAIN PLAN文を発行した後、Oracle Databaseから提供されるスクリプトまたはパッケージのいずれかを使用して最新の計画表出力を表示します。「PLAN_TABLE出力の表示」を参照してください。
EXPLAIN PLANの出力実行順序は、最も右端にインデントされている行から始まります。次のステップは、その行の親です。2つの行が等しくインデントされている場合、通常、一番上の行が最初に実行されます。
例11-13では、EXPLAIN PLANを使用して、IDが103より小さい従業員のemployee_id、job_title、salaryおよびdepartment_nameを選択するSQL文を確認します。
例11-13 EXPLAIN PLANの使用方法
EXPLAIN PLAN FOR
SELECT e.employee_id, j.job_title, e.salary, d.department_name
FROM employees e, jobs j, departments d
WHERE e.employee_id < 103
AND e.job_id = j.job_id
AND e.department_id = d.department_id;
例11-14の結果の出力表では、例にあるSQL文を実行するためにオプティマイザで選択された実行計画が示されています。
例11-14 EXPLAIN PLAN出力
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)|
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 10 (10)|
| 1 | NESTED LOOPS | | 3 | 189 | 10 (10)|
| 2 | NESTED LOOPS | | 3 | 141 | 7 (15)|
|* 3 | TABLE ACCESS FULL | EMPLOYEES | 3 | 60 | 4 (25)|
| 4 | TABLE ACCESS BY INDEX ROWID| JOBS | 19 | 513 | 2 (50)|
|* 5 | INDEX UNIQUE SCAN | JOB_ID_PK | 1 | | |
| 6 | TABLE ACCESS BY INDEX ROWID | DEPARTMENTS | 27 | 432 | 2 (50)|
|* 7 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 | | |
-----------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("E"."EMPLOYEE_ID"<103)
5 - access("E"."JOB_ID"="J"."JOB_ID")
7 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID"
-------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 3 | 189 | 8 (13)| 00:00:01 |
| 1 | NESTED LOOPS | | | | | |
| 2 | NESTED LOOPS | | 3 | 189 | 8 (13)| 00:00:01 |
| 3 | MERGE JOIN | | 3 | 141 | 5 (20)| 00:00:01 |
| 4 | TABLE ACCESS BY INDEX ROWID | JOBS | 19 | 513 | 2 (0)| 00:00:01 |
| 5 | INDEX FULL SCAN | JOB_ID_PK | 19 | | 1 (0)| 00:00:01 |
|* 6 | SORT JOIN | | 3 | 60 | 3 (34)| 00:00:01 |
| 7 | TABLE ACCESS BY INDEX ROWID| EMPLOYEES | 3 | 60 | 2 (0)| 00:00:01 |
|* 8 | INDEX RANGE SCAN | EMP_EMP_ID_PK | 3 | | 1 (0)| 00:00:01 |
|* 9 | INDEX UNIQUE SCAN | DEPT_ID_PK | 1 | | 0 (0)| 00:00:01 |
| 10 | TABLE ACCESS BY INDEX ROWID | DEPARTMENTS | 1 | 16 | 1 (0)| 00:00:01 |
-------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - access("E"."JOB_ID"="J"."JOB_ID")
filter("E"."JOB_ID"="J"."JOB_ID")
8 - access("E"."EMPLOYEE_ID"<103)
9 - access("E"."DEPARTMENT_ID"="D"."DEPARTMENT_ID")
出力表内の各行は、実行計画内の1つのステップに対応しています。アスタリスクの付いたステップIDは、Predicate Informationセクションにリストされています。
実行計画の各ステップは、行のセットを戻します。次のステップでは、これらの行を使用するか、最後のステップの場合は、SQL文を発行しているユーザーまたはアプリケーションに行を戻します。行セットは、各ステップで戻される行のセットです。
ステップIDの番号は、EXPLAIN PLAN文へのレスポンスに表示されるステップIDの順序を表しています。実行計画の各ステップでは、データベースから行を取り出すか、1つ以上の行ソースから行を入力として受け入れます。
例11-14の次のステップでは、データベース内のオブジェクトからデータが物理的に取り出されます。
ステップ3ではemployees表にあるすべての行を読み取ります。
ステップ5では、JOB_ID_PK索引の各job_idを参照して、jobs表内の対応する行のROWIDを検索します。
ステップ4では、jobs表からステップ5で戻されたROWIDを持つ行を取得します。
ステップ7では、DEPT_ID_PK索引の各department_idを参照して、departments表内の対応する行のROWIDを検索します。
ステップ6では、departments表からステップ7で戻されたROWIDを持つ行を取得します。
例11-14の次のステップでは、直前の行ソースから戻された行を処理します。
ステップ2では、ステップ3およびステップ4から戻される行ソースを受け入れ、ステップ3からの各行ソースをステップ4の対応する行に結合し、その結果の行をステップ2に戻す、ネステッド・ループ操作を、jobs表およびemployees表のjob_idで実行します。
ステップ1では、ステップ2およびステップ6から戻される行ソースを受け入れ、ステップ2からの各行をステップ6の対応する行に結合し、その結果の行をステップ1に戻すネステッド・ループ操作を実行します。
表11-3は、問合せオプティマイザの動作を制御するために使用できる初期化パラメータを示します。これらのパラメータを使用して、様々なオプティマイザの機能を有効にすることで、SQLの実行のパフォーマンスを向上できます。
表11-3 オプティマイザ動作を制御する初期化パラメータ
| 初期化パラメータ | 説明 |
|---|---|
|
|
SQL文のリテラル値をバインド変数に変換します。値を変換するとカーソル共有が改善され、SQL文の実行計画は影響を受けます。オプティマイザは、実際のリテラル値でなくバインド変数の有無に基づいて実行計画を生成します。 |
|
|
全表スキャンまたは高速全索引スキャン時に単一I/Oで読み取られるブロックの個数を指定します。オプティマイザは、 |
|
|
ネステッド・ループとともに索引プローブのコスト計算を制御します。値 |
|
|
索引プローブのコストを調整します。値の範囲は1から10000です。デフォルト値は100ですが、これは索引が標準のコスト計算モデルに基づいてアクセス・パスとして評価されることを意味します。値10は、索引アクセス・パスのコストが標準コストの1/10であることを意味します。 |
|
|
インスタンスの起動時のオプティマイザのモードを設定します。可能な値は、 |
|
|
ソートおよびハッシュ結合に割り当てられるメモリーの量を自動的に制御します。ソートまたはハッシュ結合に大量のメモリーが割り当てられると、これらの操作のオプティマイザ・コストが減少します。 |
|
|
オプティマイザはスター・クエリーのスター型変換のコストを計算できます( |
|
関連項目: 各初期化パラメータの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
OPTIMIZER_FEATURES_ENABLE初期化パラメータは、リリースに応じて、一連のオプティマイザ関連機能を有効にします。10.2.0.1または11.2.0.1などのリリース番号に対応する有効な文字列値のいずれかを受け入れます。
このパラメータを使用して、データベースのアップグレード後もオプティマイザの以前の動作を保持できます。たとえば、Oracle Database 11gをリリース1(11.1.0.7)からリリース2(11.2.0.2)にアップグレードすると、OPTIMIZER_FEATURES_ENABLEパラメータのデフォルト値は、11.1.0.7から11.2.0.2に変更されます。このアップグレードによって、11.2.0.2に基づいた最適化機能が有効になります。
下位互換性のために、問合せ計画が新規リリースのオプティマイザ機能によって変更されないようにする場合もあります。そのような場合は、OPTIMIZER_FEATURES_ENABLEパラメータを以前のバージョンに設定します。
|
注意: 以前のリリースにOPTIMIZER_FEATURES_ENABLEパラメータを明示的に設定することはお薦めしません。実行計画の変更から生じる可能性があるSQLパフォーマンスの低下を回避するには、かわりに、SQL計画の管理を使用することを検討してください。第15章「SQL計画の管理の使用方法」を参照してください。 |
OPTIMIZER_FEATURES_ENABLEの設定手順:
現在のオプティマイザ機能設定を問い合せます。
たとえば、次のSQL*Plusコマンドを実行します。
SQL> SHOW PARAMETER optimizer_features_enable NAME TYPE VALUE ------------------------------------ ----------- ------------------------------ optimizer_features_enable string 11.2.0.2
インスタンスまたはセッション・レベルでオプティマイザ機能設定を設定します。
たとえば、次のSQL文を実行してオプティマイザ・バージョンを10.2.0.5に設定します。
SQL> ALTER SYSTEM SET optimizer_features_enable='10.2.0.5';
前の文により、10.2.0.5より後のリリースで追加されたすべての新規オプティマイザ機能が無効になります。リリースをアップグレードし、使用可能な新機能を有効にする場合は、OPTIMIZER_FEATURES_ENABLE初期化パラメータを明示的に設定する必要はありません。
|
関連項目: OPTIMIZER_FEATURES_ENABLEパラメータを各リリースの値に設定すると有効になるオプティマイザ機能の詳細は、『Oracle Databaseリファレンス』を参照してください。 |
オプティマイザの目標の設定および問合せオプティマイザの代表的な統計の収集によって、オプティマイザの選択を変えることができます。次のオプティマイザの目標を使用できます。
最高のスループット(デフォルト)
データベースは最小限のリソースを使用して文がアクセスするすべての行を処理します。
Oracle Reportsアプリケーションのように、バッチで実行されるアプリケーションの場合は、最高のスループットを目標に最適化してください。アプリケーションを起動するユーザーの関心は、アプリケーションを完了するために必要な時間のみに向けられているため、通常、バッチ・アプリケーションではスループットの重要度が高くなります。アプリケーションの実行中に、ユーザーは個々の文の結果を検証しないため、レスポンス時間はそれほど重要ではありません。
最短のレスポンス時間
データベースは最小限のリソースを使用してSQL文がアクセスする最初の行を処理します。
Oracle FormsアプリケーションやSQL*Plusの問合せのような対話形式のアプリケーションの場合は、最短のレスポンス時間を目標に最適化してください。通常、対話形式のアプリケーションでは、文が最初の行または最初の数行にアクセスするのをユーザーが待機しているため、レスポンス時間は重要です。
SQL文の最適化アプローチおよび目標を選択する際のオプティマイザの動作は、次の要素に左右されます。
OPTIMIZER_MODE初期化パラメータで、インスタンスに最適化アプローチを選択するためのデフォルト動作を設定します。表11-4に、設定できる値および説明を示します。
表11-4 OPTIMIZER_MODE初期化パラメータ値
初期化ファイル内のパラメータ値を変更するか、ALTER SESSION SET OPTIMIZER_MODE文によって、セッション内のすべてのSQL文の問合せオプティマイザの目標を変更できます。たとえば、次のようにします。
初期化パラメータ・ファイル内の次の文は、インスタンスのすべてのセッションの問合せオプティマイザの目標を最短のレスポンス時間に設定します。
OPTIMIZER_MODE = FIRST_ROWS_1
次のSQL文は、現行セッションの問合せオプティマイザの目標を最短のレスポンス時間に変更します。
ALTER SESSION SET OPTIMIZER_MODE = FIRST_ROWS_1;
オプティマイザがコストベースのアプローチをSQL文に使用するときに、文がアクセスする一部の表に統計が存在しない場合、オプティマイザはそれらの表に割り当てられているデータ・ブロック数などの内部情報を使用して表に対する別の統計を見積ります。
|
関連項目: OPTIMIZER_MODEの詳細は、『Oracle Databaseリファレンス』を参照してください。 |
各SQL文に対するオプティマイザの目標を指定する場合は、表11-5のヒントを使用します。これらのヒントを各SQL文で使用して、SQL文のOPTIMIZER_MODE初期化パラメータを上書きできます。
表11-5 問合せオプティマイザの目標変更に対するヒント
| ヒント | 説明 |
|---|---|
|
このヒントは、個々のSQL文を最適化して最初のn行を最短レスポンス時間で戻すようOracle Databaseに指示します(nは正の整数)。このヒントでは、SQL文に対して、統計の存在の有無にかかわりなくコストベースのアプローチが使用されます。 |
|
|
このヒントでは、最高のスループットを目標としてSQL文を最適化するために、コストベースのアプローチが明示的に選択されます。 |
問合せオプティマイザで使用される統計は、データ・ディクショナリに格納されます。DBMS_STATSパッケージを使用して、これらのスキーマ・オブジェクト内の物理的な記憶域の特性とデータ配分に関する正確な統計または見積り統計を収集できます。
問合せオプティマイザの有効性を維持するには、データを代表する統計が必要です。値の重複数のバリエーションが多いデータ(偏ったデータと呼ばれる)が存在する表列については、ヒストグラムを収集する必要があります。
その結果の統計によって、データの一意性と配分についての情報が問合せオプティマイザに提供されます。この情報を使用することにより、問合せオプティマイザは計画コストを精密に計算し、最小のコストを基に最良の実行計画を選択できるようになります。
デフォルトでは、SQL文のコンパイル時に、オプティマイザは、最適な実行計画を生成するために使用可能な統計が十分にあるかどうかを検討し、動的統計を使用するかどうかを自動的に判断します(「オプティマイザで動的統計を使用するタイミング」参照)。使用可能な統計が不十分な場合、オプティマイザは動的統計を使用して既存の統計を拡張します。
Oracle Database 11gリリース2 (11.2.0.4)以上では、OPTIMIZER_DYNAMIC_SAMPLING初期化パラメータの値として11があり、オプティマイザは必要時に必ず動的統計を収集できるようになっています。たとえば、オプティマイザでは、表スキャン、索引アクセス、結合およびGROUP BY操作の動的統計を収集でき、その結果、オプティマイザの決定の品質が向上します。