|
|
| Sun ONE Message Queue, Version 3.0.1 Administrator's Guide |
Chapter 2 The MQ Messaging System
This chapter describes the Sun™ ONE Message Queue (MQ) messaging system, with specific attention to the main parts of the system, as illustrated in Figure 2-1, and explains how they work together to provide for reliable message delivery.
Figure 2-1 MQ System Architecture
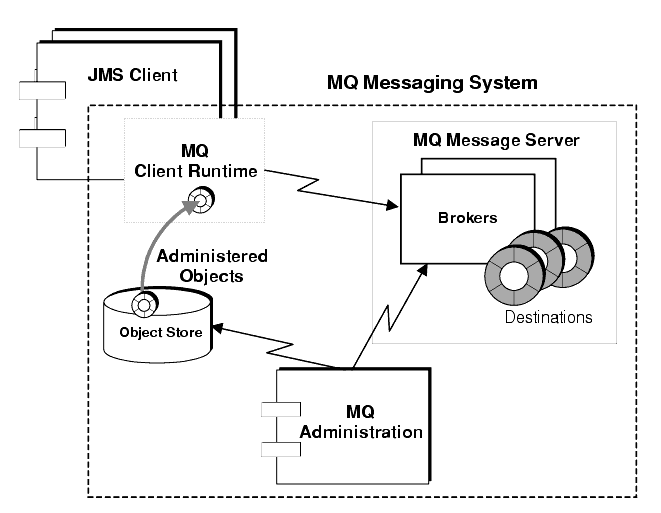
The main parts of an MQ messaging system, shown in Figure 2-1, are the following:
- MQ Message Server
- MQ Client Runtime
- MQ Administered Objects
- MQ Administration
The first three of these are examined in the following sections. The last is introduced in Chapter 3, "MQ Administration."
MQ Message Server
This section describes the different parts of the MQ message server shown in Figure 2-1. These include the following:
Broker An MQ broker provides delivery services for an MQ messaging system. Message delivery relies upon a number of supporting components that handle connection services, message routing and delivery, persistence, security, and logging (see "Broker" for more information). A message server can employ one or more broker instances (see "Multi-Broker Clusters (Enterprise Edition)").
Physical Destination Delivery of a message is a two-phase process—delivery from a producing client to a physical destination maintained by a broker, followed by delivery from the destination to one or more consuming clients. Physical destinations represent locations in a broker's physical memory and/or persistent storage (see "Physical Destinations" for more information).
Broker
Message delivery in an MQ messaging system—from producing clients to destinations, and then from destinations to one or more consuming clients—is performed by a broker (or a cluster of broker instances working in tandem). To perform message delivery, a broker must set up communication channels with clients, perform authentication and authorization, route messages appropriately, guarantee reliable delivery, and provide data for monitoring system performance.
To perform this complex set of functions, a broker uses a number of different components, each with a specific role in the delivery process. You can configure these internal components to optimize the performance of the broker, depending on load conditions, application complexity, and so on. The main broker components are illustrated in Figure 2-2 and described briefly in Table 2-1.
Figure 2-2 Broker Components
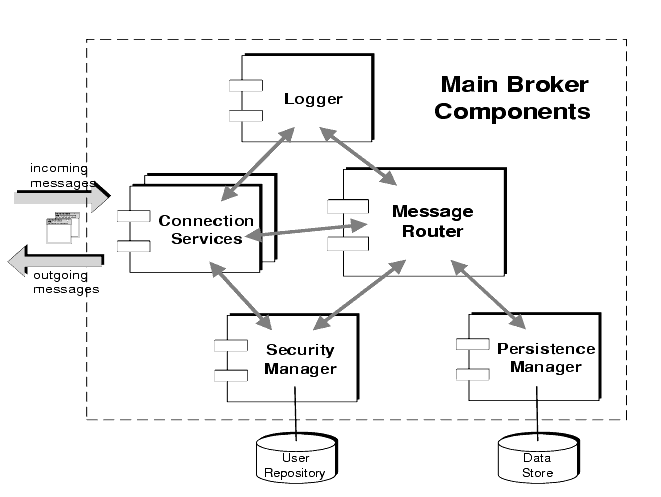
The following sections explore more fully the functions performed by the different broker components and the properties that can be configured to affect their behavior.
Connection Services
An MQ broker supports communication with both JMS clients and MQ administration clients (see "MQ Administration Tools"). Each service is specified by its service type and protocol type.
service type specifies whether the service provides JMS message delivery (NORMAL) or MQ administration (ADMIN) services
protocol type specifies the underlying transport protocol layer that supports the service.
The connection services currently available from an MQ broker are shown in Table 2-2:
You can configure a broker to run any or all of these connection services. Each service has a Thread Pool Manager and registers itself with a common Port Mapper service, as shown in Figure 2-3.
Figure 2-3 Connection Services Support
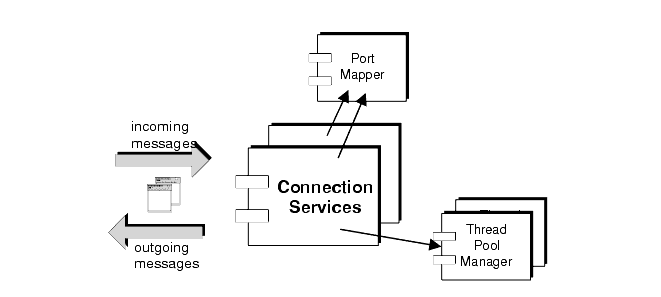
Each connection service is available at a particular port, specified by the broker's host name and a port number. The port can be statically or dynamically allocated. MQ provides a Port Mapper that maps dynamically allocated ports to the different connection services. The Port Mapper itself resides at a standard port number, 7676. When a client sets up a connection with the broker, it first contacts the Port Mapper requesting the port number of the connection service it desires.
You can also assign a static port number for the jms, ssljms, admin and ssladmin connection services when configuring these connection services, but this is not recommended. The httpjms and httpsjms services are configured using properties described in Table B-1 and Table B-3, respectively, in Appendix B, "HTTP/HTTPS Support (Enterprise Edition)."
Each connection service is multi-threaded, supporting multiple connections. The threads needed for these connections are maintained in a thread pool managed by a Thread Pool Manager component. You can configure the Thread Pool Manager to set a minimum number and maximum number of threads maintained in the thread pool. As threads are needed by connections, they are added to the thread pool. When the minimum number is exceeded, the system will shut down threads as they become free until the minimum number threshold is reached, thereby saving on memory resources. You want this number to be large enough so that new threads do not have to be continually created. Under heavy connection loads, the number of threads might increase until the thread pool's maximum number is reached, after which connections have to wait until a thread becomes available.
The threads in a thread pool can either be dedicated to a single connection (dedicated model) or assigned to multiple connections, as needed (shared model).
Dedicated model In the dedicated model, each connection to the broker requires two threads: one dedicated to handling incoming messages and one to handling outgoing messages. This limits the number of connections to half the maximum number of threads in the thread pool, however it provides for high performance.
Shared model (Enterprise Edition) In the shared thread model, connections are assigned to a thread only when sending or receiving messages. This model, in which connections share a thread, increases the number of connections that a connection service (and therefore, a broker) can support, however there is some performance overhead involved. The Thread Pool Manager uses a set of distributor threads that monitor connection activity and assign connections to threads as needed. You can improve performance by limiting the number of connections monitored by each such distributor thread.
Each connection service supports specific authentication and authorization (access control) features (see "Security Manager").The configurable properties related to connection services are shown in Table 2-3. (For instructions on configuring these properties, see Chapter 5, "Starting and Configuring a Broker.")
Table 2-3 Connection Service Properties
Property Name
Description
imq.service.activelist
List of connection services, by name, separated by commas, to be made active at broker startup. Supported services are: jms, ssljms, httpjms, httpsjms, admin, ssladmin. Default: jms, admin
imq.service_name.
min_threads
Specifies the number of threads, which once reached, are maintained in the thread pool for use by the named connection service. Default: Depends on connection service (see Table 5-1).
imq.service_name.
max_threads
Specifies the number of threads beyond which no new threads are added to the thread pool for use by the named connection service. The number must be greater than zero and greater in value than the value of min_threads. Default: Depends on connection service (see Table 5-1).
imq.service_name.
threadpool_model
Specifies whether threads are dedicated to connections (dedicated) or shared by connections as needed (shared) for the named connection service. Shared model (threadpool management) increases the number of connections supported by a broker, but is implemented only for the jms and admin connection services. Default: Depends on connection service (see Table 5-1).
imq.shared.
connectionMonitor_limit
For shared threadpool model only, specifies the maximum number of connections that can be monitored by a distributor thread. (The system allocates enough distributor threads to monitor all connections.) The smaller this value, the faster the system can assign active connections to threads. A value of 0 means no limit. Default: Depends on operating system (see Table 5-1).
imq.portmapper.port
The broker's primary port—the port at which the Port Mapper resides. If you are running more than one broker instance on a host, each must be assigned a unique Port Mapper port. Default: 7676
imq.service_name.
protocol_type1.port
For jms, ssljms, admin, and ssladmin services only, specifies the port number for the named connection service. Default: 0 (port is dynamically allocated by the Port Mapper)
To configure the httpjms and httpsjms connection services, see Appendix B, "HTTP/HTTPS Support (Enterprise Edition)."
imq.service_name.
protocol_type1.hostname
For jms, ssljms, admin, and ssladmin services only, specifies the host (hostname or IP address) to which the named connection service binds if there is more than one host available (for example, if there is more than one network interface card in a computer).
Default: null (any host)
1 protocol_type is specified in Table 2-2. Message Router
Once connections have been established between clients and a broker using the supported connection services, the routing and delivery of messages can proceed.
Basic Delivery Mechanisms
Broadly speaking, the messages handled by a broker fall into two categories: the JMS messages sent by producer clients, destined for consumer clients—payload messages, and a number of control messages that are sent to and from clients in order to support the delivery of the JMS messages.
If the incoming message is a JMS message, the broker routes it to consumer clients, based on the type of its destination (queue or topic):
- If the destination is a topic, the JMS message is immediately routed to all active subscribers to the topic. In the case of inactive durable subscribers, the Message Router holds the message until the subscriber becomes active, and then delivers the message to that subscriber.
- If the destination is a queue, the JMS message is placed in the corresponding queue, and delivered to the appropriate consumer when the message reaches the front of the queue. The order in which messages reach the front of the queue depends on the order of their arrival and on their priority.
Once the Message Router has delivered a message to all its intended consumers it clears the message from memory, and if the message is persistent (see "Reliable Messaging"), removes it from the broker's persistent data store.
Reliable Delivery: Acknowledgements, and Transactions
The delivery mechanism just described becomes more complicated when adding requirements for reliable delivery (see "Reliable Messaging"). There are two aspects involved in reliable delivery: assuring that delivery of messages to and from a broker is successful, and assuring that the broker does not lose messages or delivery information before messages are actually delivered.
To ensure that messages are successfully delivered to and from a broker, MQ uses a number of control messages called acknowledgements.
For example, when a producer sends a JMS message (a payload message as opposed to a control message) to a destination, the broker sends back a control message—a broker acknowledgement—that it received the JMS message. (In practice, MQ only does this if the producer specifies the JMS message as persistent.) The producing client uses the broker acknowledgement to guarantee delivery to the destination (see "Message Production").
Similarly, when a broker delivers a JMS message to a consumer, the consuming client sends back an acknowledgement that it has received and processed the message. A client specifies how automatically or how frequently to send these acknowledgments when creating session objects, but the principle is that the Message Router will not delete a JMS message from memory if it has not received an acknowledgement from each message consumer to which it has delivered the message—for example, from each of the multiple subscribers to a topic.
In the case of durable subscribers to a topic, the Message Router retains each JMS message in that destination, delivering it as each durable subscriber becomes an active consumer. The Message Router records client acknowledgements as they are received, and deletes the JMS message only after all the acknowledgements have been received (unless the JMS message expires before then).
Furthermore, the Message Router confirms receipt of the client acknowledgement by sending a broker acknowledgement back to the client. The consuming client uses the broker acknowledgement to make sure that the broker will not deliver a JMS message more than once (see "Message Consumption"). This could happen if, for some reason, the broker fails to receive the client acknowledgement).
If the broker does not receive a client acknowledgement and re-delivers a JMS message a second time, the message is marked with a Redeliver flag. The broker generally re-delivers a JMS message if a client connection closes before the broker receives a client acknowledgement, and a new connection is subsequently opened. For example, if a message consumer of a queue goes off line before acknowledging a message, and another consumer subsequently registers with the queue, the broker will re-deliver the unacknowledged message to the new consumer.
The client and broker acknowledgement processes described above apply, as well, to JMS message deliveries grouped into transactions. In such cases, client and broker acknowledgements operate on the level of a transaction as well as on the level of individual JMS message sends or receives. When a transaction commits, a broker acknowledgement is sent automatically.
The broker tracks transactions, allowing them to be committed or rolled back should they fail. This transaction management also supports local transactions that are part of larger, distributed transactions (see "Distributed Transactions"). The broker tracks the state of these transactions until they are committed. When a broker starts up it inspects all uncommitted transactions and, by default, rolls back all transactions except those in a PREPARED state.
Reliable Delivery: Persistence
The other aspect of reliable delivery is assuring that the broker does not lose messages or delivery information before messages are actually delivered. In general, messages remain in memory until they have been delivered or they expire. However, if the broker should fail, these messages would be lost.
A producer client can specify that a message be persistent, and in this case, the Message Router will pass the message to a Persistence Manager that stores the message in a database or file system (see "Persistence Manager") so that the message can be recovered if the broker fails.
Managing System Resources
The performance of a broker depends on the system resources available and how efficiently resources such as memory are utilized. For example, the Message Router has a memory management scheme that watches memory on the system. When memory resources become scarce, mechanisms for reclaiming memory and for slowing the flow of incoming messages are activated.
The memory management mechanism depends on the state of memory resources: green (plenty of memory is available), yellow (broker memory is running low), orange (broker is low on memory), red (broker is out of memory). As the state of memory resources progresses from green through yellow and orange to red, the broker takes increasingly serious action to reclaim memory and to throttle back message producers, eventually stopping the flow of messages into the broker.
You can configure the broker's memory management functions using properties that set limits on the total number and total size of messages in memory, and that adjust the utilization thresholds at which memory resources change to a new state.
These properties are detailed in Table 2-4. (For instructions on setting these properties, see Chapter 5, "Starting and Configuring a Broker.")
Table 2-4 Message Router Properties
Property Name
Description
imq.message.expiration.
interval
Specifies how often reclamation of expired messages occurs, in seconds. Default: 60
imq.system.max_count
Specifies maximum number of messages in both memory and disk (due to swapping). Additional messages will be rejected. A value of 0 means no limit. Default: 0
imq.system.max_size
Specifies maximum total size (in bytes, Kbytes, or Mbytes) of messages in both memory and disk (due to swapping). Additional messages will be rejected. A value of 0 means no limit. Default: 0
imq.message.max_size
Specifies maximum allowed size (in bytes, Kbytes, or Mbytes) of a message body. Any message larger than this will be rejected. A value of 0 means no limit. Default: 70m (Mbytes)
imq.resource_state.
threshold
Specifies the percent memory utilization at which each memory resource state is triggered. The resource state can have the values green, yellow, orange, and red. Defaults: 0, 60, 75, and 90, respectively
imq.redelivered.
optimization
Specifies (true/false) whether Message Router optimizes performance by setting Redeliver flag whenever messages are re-delivered (true) or only when it is logically necessary to do so (false). Default: true
imq.transaction.
autorollback
Specifies (true/false) whether distributed transactions left in a PREPARED state are automatically rolled back when a broker is started up. If false, you must manually commit or roll back transactions using imqcmd (see "Managing Transactions"). Default: false
Persistence Manager
For a broker to recover, in case of failure, it needs to recreate the state of its message delivery operations. This requires it to save all persistent messages, as well as essential routing and delivery information, to a data store. A Persistence Manager component manages the writing and retrieval of this information.
To recover a failed broker requires more than simply restoring undelivered messages. The broker must also be able to do the following:
- re-create destinations
- restore the list of durable subscriptions for each topic
- restore the acknowledge list for each message
- reproduce the state of all committed transactions
The Persistence Manager manages the storage and retrieval of all this state information.
When a broker restarts, it recreates destinations and durable subscriptions, recovers persistent messages, restores the state of all transactions, and recreates its routing table for undelivered messages. It can then resume message delivery.
MQ supports both built-in and plugged-in persistence modules (see Figure 2-4). Built-in persistence is based on a flat file data store. Plugged-in persistence uses a Java Database Connectivity (JDBC) interface and requires a JDBC-compliant data store. The built-in persistence is generally faster than plugged-in persistence; however, some users prefer the redundancy and administrative features of using a JDBC-compliant database system.
Figure 2-4 Persistence Manager Support
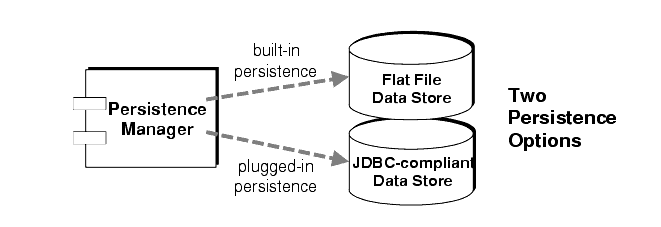
Built-in persistence
The default MQ persistent storage solution is a flat file store. This approach uses individual files to store persistent data, such as messages, destinations, durable subscriptions, and transactions.
The flat file data store is located at:
where brokerName is a name identifying the broker instance.
IMQ_VARHOME/instances/brokerName/filestore/
(/var/imq/instances/brokerName/filestore/ on Solaris)The file-based data store is structured so that persistent messages are each stored in their own respective file, one message per file. Destinations, durable subscriptions, and transactions, however, are all stored in a separate file for each, all destinations in one file, all durable subscriptions in another, and so on.
To create and delete files, as messages are added to and deleted from the data store, involves expensive file system operations. The MQ implementation therefore reuses these message files: when a file is no longer needed, instead of being deleted, it is added to a pool of free files available for re-use. You can configure the size of this file pool. You can also specify the percentage of free files in the file pool that are cleaned up (truncated to zero), as opposed to being simply tagged for reuse (not truncated). The higher the percentage of cleaned files, the less disk space—but the more overhead—is required to maintain the file pool. You can also specify whether or not tagged files will be cleaned up at shutdown. If the files are cleaned up, they will take up less disk space, but the broker will take longer to shut down.
The speed of storing messages in the flat file store is affected by the number of file descriptors available for use by the data store; a large number of descriptors will allow the system to process large numbers of persistent messages faster. For information on increasing the number of file descriptors, see the "Technical Notes" section of the MQ Release Notes.
Also, in the case of the destination file store, it is more efficient to add destinations to a fixed-size file than to increase the size of the file as destinations are added. Therefore, you can improve performance by setting the original size of the destination file in accordance with the number of destinations you expect it to ultimately store (each destination consumes about 500 bytes).
Because the data store can contain messages with proprietary information, it is recommended that the brokerName/filestore/ directory be secured against unauthorized access. For instructions, see the "Technical Notes" section of the MQ Release Notes.
Plugged-in persistence
You can set up a broker to access any data store accessible through a JDBC driver. This involves setting a number of JDBC-related broker configuration properties and using the Database manager utility (imqdbmgr) to create a data store with the proper schema. The procedures and related configuration properties are detailed in Appendix A, "Setting Up Plugged-in Persistence."
Persistence-related configuration properties are detailed in Table 2-5. (For instructions on setting these properties, see Chapter 5, "Starting and Configuring a Broker.")
Security Manager
MQ provides authentication and authorization (access control) features, and also supports encryption capabilities.
The authentication and authorization features depend upon a user repository (see Figure 2-5): a file, directory, or database that contains information about the users of the messaging system—their names, passwords, and group memberships. The names and passwords are used to authenticate a user when a connection to a broker is requested. The user names and group memberships are used, in conjunction with an access control file, to authorize operations such as producing or consuming messages for destinations.
MQ administrators populate an MQ-provided user repository (see "Using a Flat-File User Repository"), or plug a pre-existing LDAP user repository into the Security Manager component. The flat-file user repository is easy to use, but is also vulnerable to security attack, and should therefore be used only for evaluation and development purposes, while the LDAP user repository is secure and therefore best suited for production purposes.
Authentication
MQ security supports password-based authentication. When a client requests a connection to a broker, the client must submit a user name and password. The Security Manager compares the name and password submitted by the client to those stored in the user repository. On transmitting the password from client to broker, the passwords are encoded using either base 64 encoding or message digest (MD5). For more secure transmission, see "Encryption (Enterprise Edition)". You can separately configure the type of encoding used by each connection service or set the encoding on a broker-wide basis.
Authorization
Once the user of a client application has been authenticated, the user can be authorized to perform various MQ-related activities. The Security Manager supports both user-based and group-based access control: depending on a user's name or the groups to which the user is assigned in the user repository, that user has permission to perform certain MQ operations. You specify these access controls in an access control properties file (see Figure 2-5).
When a user attempts to perform an operation, the Security Manager checks the user's name and group membership (from the user repository) against those specified for access to that operation (in the access control properties file). The access control properties file specifies permissions for the following operations:
- establishing a connection with a broker
- accessing destinations: creating a consumer, a producer, or a queue browser for any given destination or all destinations
- auto-creating destinations
Figure 2-5 Security Manager Support
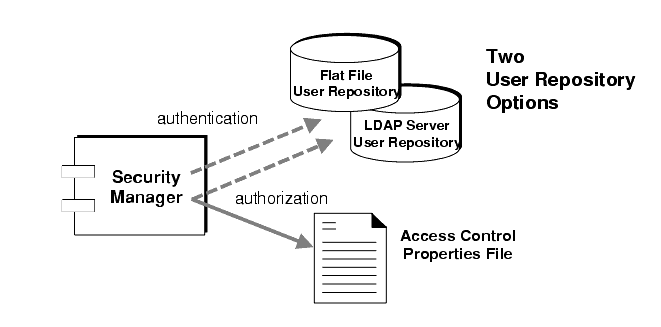
For MQ 3.0.1, the default access control properties file explicitly references only one group: admin (see "Groups"). A user in the admin group has admin service connection permission. The admin service lets the user perform administrative functions such as creating destinations, and monitoring and controlling a broker. A user in any other group you define cannot, by default, get an admin service connection.
As an MQ administrator you can define groups and associate users with those groups in a user repository (though groups are not fully supported in the flat-file user repository). Then, by editing the access control properties file, you can specify access to destinations by users and groups for the purpose of producing and consuming messages, or browsing messages in queue destinations. You can make individual destinations or all destinations accessible only to specific users or groups.
In addition, if the broker is configured to allow auto-creation of destinations (see "Auto-Created (vs. Admin-Created) Destinations"), you can control for whom the broker can auto-create destinations by editing the access control properties file.
Encryption (Enterprise Edition)
To encrypt messages sent between clients and broker, you need to use a connection service based on the Secure Socket Layer (SSL) standard. SSL provides security at a connection level by establishing an encrypted connection between an SSL-enabled broker and an SSL-enabled client.
To use an MQ SSL-based connection service, you generate a private key/public key pair using the Key Tool utility (imqkeytool). This utility embeds the public key in a self-signed certificate and places it in an MQ keystore. The MQ keystore is, itself, password protected; to unlock it, you have to provide a keystore password at startup time. See "Encryption: Working With an SSL Service (Enterprise Edition)".
Once the keystore is unlocked, a broker can pass the certificate to any client requesting a connection. The client then uses the certificate to set up an encrypted connection to the broker.
The configurable properties for authentication, authorization, encryption, and other secure communications are shown in Table 2-6. (For instructions on configuring these properties, see Chapter 5, "Starting and Configuring a Broker.")
Table 2-6 Security Properties
Property Name
Description
imq.authentication.type
Specifies whether the password should be passed in base 64 coding (basic) or as a MD5 digest (digest). Sets encoding for all connection services supported by a broker. Default: digest
imq.service_name.
authentication.type
Specifies whether the password should be passed in base 64 coding (basic) or as a MD5 digest (digest). Sets encoding for named connection service, overriding any broker-wide setting.
Default: inherited from the value to which imq.authentication.type is set.imq.authentication.
basic.user_repository
Specifies (for base 64 coding) the type of user repository used for authentication, either file-based (file) or LDAP (ldap). For additional LDAP properties, see Table 8-5. Default: file
imq.authentication.
client.response.timeout
Specifies the time (in seconds) the system will wait for a client to respond to an authentication request from the broker. Default: 180 (seconds)
imq.accesscontrol.
enabled
Sets access control (true/false) for all connection services supported by a broker. Indicates whether system will check if an authenticated user has permission to use a connection service or to perform specific MQ operations with respect to specific destinations, as specified in the access control properties file. Default: true
imq.service_name.
accesscontrol.enabled
Sets access control (true/false) for named connection service, overriding broker-wide setting. Indicates whether system will check if an authenticated user has permission to use the named connection service or to perform specific MQ operations with respect to specific destinations, as specified in the access control properties file.
Default: inherits the setting of the property imq.accesscontrol.enabledimq.accesscontrol.file.
filename
Specifies the name of an access control properties file for all connection services supported by a broker. The file name specifies a relative file path to the directory IMQ_HOME/etc (/etc/imq on Solaris). Default: accesscontrol.properties
imq.service_name.
accesscontrol.file.
filename
Specifies the name of an access control properties file for named connection service. The file name specifies a relative file path to the directory IMQ_HOME/etc (/etc/imq on Solaris).
Default: inherits the setting specified by imq.accesscontrol.file.filename.imq.passfile.enabled
Specifies (true/false) if user passwords (for SSL, LDAP, JDBC) for secure communications are specified in a passfile. Default: false
imq.passfile.dirpath
Specifies the path to the directory containing the passfile.
Default: IMQ_HOME/etc (/etc/imq on Solaris)imq.passfile.name
Specifies the name of the passfile. Default: passfile
imq.keystore.property_name
For SSL-based services: specifies security properties relating to the SSL keystore. See Table 8-8.
Logger
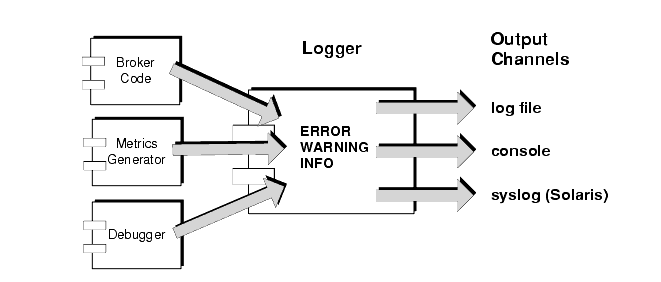
The broker includes a number of components for monitoring and diagnosing its operation. Among these are components that generate data (broker code, a metrics generator, and debugger) and a Logger component that writes out information through a number of output channels (log file, console, and Solaris syslog). The scheme is illustrated in Figure 2-6.
Figure 2-6 Logging Scheme
You can turn the generation of metrics data on and off, and specify how frequently metrics reports are generated.
You can also specify the Logger level—ranging from the most serious and important information (errors), to less crucial information (metrics data). The categories of information, in decreasing order of criticality, are shown in Table 2-7:
To set the Logger level, you specify one of these categories. The logger will write out data of the specified category and all higher categories. For example, if you specify logging at the WARNING level, the Logger will write out warning information and error information.
The Logger can write data to a number of output channels: to standard output (the console), to a log file, and, on Solaris platforms, to the syslog daemon process.
For each output channel you can specify which of the categories set for the Logger will be written to that channel. For example, if the Logger level is set to ERROR, you can specify that you want only errors and warnings written to the console, and only info (metrics data) written to the log file. For information on configuring and using the Solaris syslog, see the syslog(1M), syslog.conf(4) and syslog(3C) man pages.
In the case of a log file, you can specify the point at which the log file is closed and output is rolled over to a new file. Once the log file reaches a specified size or age, it is saved and a new log file created. The log file is saved at the following location:
IMQ_VARHOME/instances/brokerName/log/
(/var/imq/instances/brokerName/log /on Solaris)An archive of the 9 most recent log files is retained as new rollover log files are created. The log files are text files that are named sequentially as follows:
log.txt
log_1.txt
log_2.txt
...
log_9.txtThe log.txt is the most recent file, and the highest numbered file is the oldest.
The configurable properties for setting the generation and logging of information by the broker are shown in Table 2-8. (For instructions on configuring these properties, see Chapter 5, "Starting and Configuring a Broker.")
Physical Destinations
MQ messaging is premised on a two-phase delivery of messages: first, delivery of a message from a producer client to a destination on the broker, and second, delivery of the message from the destination on the broker to one or more consumer clients. There are two types of destinations (see "Programming Domains"): queues (point-to-point delivery model) and topics (publish/subscribe delivery model). These destinations represent locations in a broker's physical memory where incoming messages are marshaled before being routed to consumer clients.
You create physical destinations using MQ administration tools (see "Managing Destinations"). Destinations can also be automatically created as described in "Auto-Created (vs. Admin-Created) Destinations".
This section describes the properties and behaviors of the two types of physical destinations: queues and topics.
Queue Destinations
Queue destinations are used in point-to-point messaging, where a message is meant for ultimate delivery to only one of a number of consumers that has registered an interest in the destination. As messages arrive from producer clients, they are queued and delivered to a consumer client.
The routing of queued messages depends on the queue's delivery policy. MQ implements three queue delivery policies:
- Single This queue can only route messages to one message consumer. If a second message consumer attempts to register with the queue, it is rejected. If the registered message consumer disconnects, routing of messages no longer takes place and messages are saved until a new consumer is registered.
- Failover (Enterprise Edition) This queue can route messages to more than one message consumer, but it will only do so if its primary message consumer (the first to register with the broker) disconnects. In that case, messages will go to the next message consumer to register, and continue to be routed to that consumer until such time as that consumer fails, and so on. If no message consumer is registered, messages are saved until a consumer registers.
- Round-Robin (Enterprise Edition) This queue can route messages to more than one message consumer. Assuming that a number of consumers are registered for a queue, the first message into the queue will be routed to the first message consumer to have registered, the second message to the second consumer to have registered, and so on. Additional messages are routed to the same set of consumers in the same order. If a number of messages are queued up before consumers register for a queue, the messages are routed in batches to avoid flooding any one consumer. If any message consumer disconnects, the messages routed to that consumer are redistributed among the remaining active consumers. Because of such redistributions, there is no guarantee that the order of delivery of messages to consumers is the same as the order in which they are received in the queue.
Since messages can remain in a queue for an extended period of time, memory resources can become an issue. You don't want to allocate too much memory to a queue (memory is under-utilized), nor do you want to allocate too little (messages will be rejected). To allow for flexibility, based on the load demands of each queue, you can set physical properties when creating a queue: maximum number of messages in queue, maximum memory allocated for messages in queue, and maximum size of any message in queue (see Table 6-10).
Topic Destinations
Topic destinations are used in publish/subscribe messaging, where a message is meant for ultimate delivery to all of the consumers that have registered an interest in the destination. As messages arrive from producers, they are routed to all consumers subscribed to the topic. If consumers have registered a durable subscription to the topic, they do not have to be active at the time the message is delivered to the topic—the broker will store the message until the consumer is once again active, and then deliver the message.
Messages do not normally remain in a topic destination for an extended period of time, so memory resources are not normally a big issue. However, you can configure the maximum size allowed for any message received by the destination (see Table 6-10).
Auto-Created (vs. Admin-Created) Destinations
Because a JMS message server is a central hub in a messaging system, its performance and reliability are important to the success of enterprise applications. Since destinations can consume significant resources (depending on the number and size of messages they handle, and on the number and durability of the message consumers that register), they need to be managed closely to guarantee message server performance and reliability. It is therefore standard practice for an MQ administrator to create destinations on behalf of an application, monitor the destinations, and reconfigure their resource requirements when necessary.
Nevertheless, there may be situations in which it is desirable for destinations to be created dynamically. For example, during a development and test cycle, you might want the broker to automatically create destinations as they are needed, without requiring the intervention of an administrator.
MQ supports this auto-create capability. When auto-creation is enabled, a broker automatically creates a destination whenever a MessageConsumer or MessageProducer attempts to access a non-existent destination. (The user of the client application must have auto-create privileges—see "Destination Auto-Create Access Control").
However, when destinations are created automatically instead of explicitly, clashes between different client applications (using the same destination name), or degraded system performance (due to the resources required to support a destination) can result. For this reason, an MQ auto-created destination is automatically destroyed by the broker when it is no longer being used: that is, when it no longer has message consumer clients and no longer contains any messages. If a broker is restarted, it will only re-create auto-created destinations if they contain persistent messages.
You can configure an MQ message server to enable or disable the auto-create capability using the properties shown in Table 2-9. (For instructions on configuring these properties, see Chapter 5, "Starting and Configuring a Broker.")
Temporary Destinations
Temporary destinations are explicitly created and destroyed (using the JMS API) by client applications that need a destination at which to receive replies to messages sent to other clients. These destinations are maintained by the broker only for the duration of the connection for which they are created. A temporary destination cannot be destroyed by an administrator, and it cannot be destroyed by a client application as long as it is in use: that is, if it has active message consumers. Temporary destinations, unlike admin-created or auto-created destinations (that have persistent messages), are not stored persistently and are never re-created when a broker is restarted. They also are not visible to MQ administration tools.
Multi-Broker Clusters (Enterprise Edition)
The MQ Enterprise Edition supports the implementation of a message server using multiple interconnected broker instances—a broker cluster. Cluster support provides for scalability of your message server.
As the number of clients connected to a broker increases, and as the number of messages being delivered increases, a broker will eventually exceed resource limitations such as file descriptor and memory limits. One way to accommodate increasing loads is to add more brokers (that is, more broker instances) to an MQ message server, distributing client connections and message delivery across multiple brokers.
You might also use multiple brokers to optimize network bandwidth. For example, you might want to use slower, long distance network links between a set of remote brokers, while using higher speed links for connecting clients to their respective brokers.
While there are other reasons for using broker clusters (for example, to accommodate workgroups having different user repositories, or to deal with firewall restrictions), failover is not one of them. One broker in a cluster cannot be used as an automatic backup for another that fails. Automatic failover protection for a broker is not supported in MQ Version 3.0.1. (However, an application could be designed to use multiple brokers to implement a customized failover scheme.)
Information on configuring and managing a broker cluster is provided in "Working With Clusters (Enterprise Edition)".
The following sections explain the architecture and internal functioning of MQ broker clusters.
Multi-Broker Architecture
A multi-broker message server allows client connections to be distributed among a number of broker instances, as shown in Figure 2-7. From a client point of view, each client connects to an individual broker (its home broker) and sends and receives messages as if the home broker were the only broker in the cluster. However, from a message server point of view, the home broker is working in tandem with other brokers in the cluster to provide delivery services to the message producers and consumers to which it is directly connected.
In general, the brokers within a cluster can be connected in any arbitrary topology. However, MQ Version 3.0.1 only supports fully-connected clusters, that is, a topology in which each broker is directly connected to every other broker in the cluster, as shown in Figure 2-7.
Figure 2-7 Multi-Broker (Cluster) Architecture
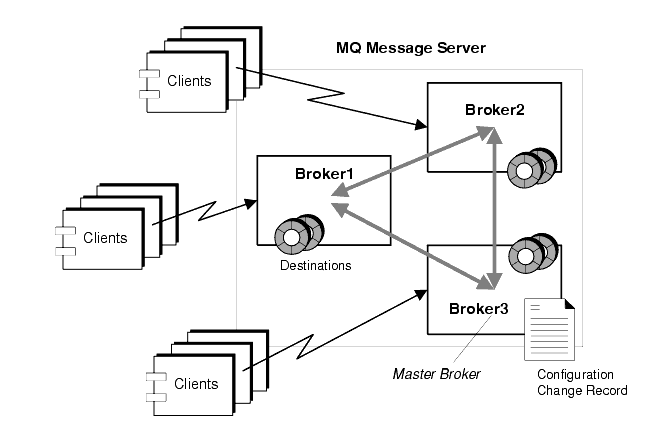
In a multi-broker configuration, instances of each destination reside on all of the brokers in a cluster. In addition, each broker knows about message consumers that are registered with all other brokers. Each broker can therefore route messages from its own directly-connected message producers to remote message consumers, and deliver messages from remote producers to its own directly-connected consumers.
In a cluster configuration, the broker to which each message producer is directly connected performs the routing for messages sent to it by that producer. Hence, a persistent message is both stored and routed by the message's home broker.
Whenever an administrator creates or destroys a destination on a broker, this information is automatically propagated to all other brokers in a cluster. Similarly, whenever a message consumer is registered with its home broker, or whenever a consumer is disconnected from its home broker—either explicitly or because of a client or network failure, or because its home broker goes down—the relevant information about the consumer is propagated throughout the cluster. In a similar fashion, information about durable subscriptions is also propagated to all brokers in a cluster.
The propagation of information about destinations and message consumers to a particular broker would normally require that the broker be on line when a change is made in a shared resource. What happens if a broker is off line when such a change is made—for example, if a broker crashes and is subsequently restarted, or if a new broker is dynamically added to a cluster?
To accommodate a broker that has gone off line (or a new broker that is added), MQ maintains a record of changes made to all persistent entities in a cluster: that is, a record of all destinations and all durable subscriptions that have been created or destroyed. When a broker is dynamically added to a cluster, it first reads destination and durable subscriber information from this configuration change record. When it comes on line, it exchanges information about current active consumers with other brokers. With this information, the new broker is fully integrated into the cluster.
The configuration change record is managed by one of the brokers in the cluster, a broker designated as the Master Broker. Because the Master Broker is key to dynamically adding brokers to a cluster, you should always start this broker first. If the Master Broker is not on line, other brokers in the cluster will not be able to complete their initialization.
If a Master Broker goes off line, the configuration change record cannot be accessed by other brokers, and MQ will not allow destinations and durable subscriptions to be propagated throughout the cluster. Under these conditions, you will get an exception if you try to create or destroy destinations or durable subscriptions (or attempt a number of related operations like re-activating a durable subscription).
In a mission-critical application environment it is a good idea to make a periodic backup of the configuration change record to guard against accidental corruption of the record and safeguard against Master Broker failure. You can do this using the -backup option of the imqbrokerd command (see Table 5-2), which provides a way to create a backup file containing the configuration change record. You can subsequently restore the configuration change record using the -restore option.
If necessary you can change the broker serving as the Master Broker by backing up the configuration change record, modifying the appropriate cluster configuration property (see Table 2-10) to designate a new Master Broker, and restarting the new Master Broker using the -restore option.
Using Clusters in Development Environments
In development environments, where a cluster is used for testing, and where scalability and broker recovery are not important considerations, there is little need for a Master Broker. In environments configured without a Master Broker, MQ relaxes the requirement that a Master Broker be running in order to start other brokers, and allows changes in destinations and durable subscriptions to be made and to be propagated to all running brokers in a cluster. If a broker goes off line and is subsequently restored, however, it will not sync up with changes made while it was off line.
Under test situations, destinations are generally auto-created (see "Auto-Created (vs. Admin-Created) Destinations") and durable subscriptions to these destinations are created and destroyed by the applications being tested. These changes in destinations and durable subscriptions will be propagated throughout the cluster. However, if you reconfigure the environment to use a Master Broker, MQ will re-impose the requirement that the Master Broker be running for changes to be made in destinations and durable subscriptions, and for these changes to be propagated throughout the cluster.
Cluster Configuration Properties
Each broker in a cluster must be passed information at startup time about other brokers in a cluster (host names and port numbers). This information is used to establish connections between the brokers in a cluster. Each broker must also know the host name and port number of the Master Broker (if one is used).
All brokers in a cluster should use the same cluster configuration properties. You can achieve this by placing them in one central cluster configuration file that is referenced by each broker at startup time.
(You can also duplicate these configuration properties and provide them to each broker individually. However, this is not recommended because it can lead to inconsistencies in the cluster configuration. Keeping just one copy of the cluster configuration properties makes sure that all brokers see the same information.)
MQ cluster configuration properties are shown in Table 2-10. (For instructions on setting these properties, see "Working With Clusters (Enterprise Edition)".)
The cluster configuration file can be used for storing all broker configuration properties that are common to a set of brokers. Though it was originally intended for configuring clusters, it can also be used to store other broker properties common to all brokers in a cluster.
MQ Client Runtime
The MQ client runtime provides client applications with an interface to the MQ message server—it supplies client applications with all the JMS programming objects introduced in "JMS Programming Model". It supports all operations needed for clients to send messages to destinations and to receive messages from such destinations.
This section provides a high level description of how the MQ client runtime works. Factors that affect its performance are discussed in the MQ Developer's Guide because they impact client application design and performance.
Figure 2-8 illustrates how message production and consumption involve an interaction between client applications and the MQ client runtime, while message delivery involves an interaction between the MQ client runtime and the MQ message server.
Figure 2-8 Messaging Operations
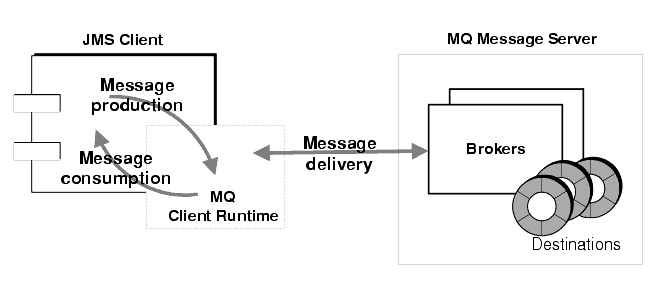
Message Production
In message production, a message is created by the client, and sent over a connection to a destination on a broker. If the message delivery mode of the MessageProducer object has been set to persistent (guaranteed delivery, once and only once), the client thread blocks until the broker acknowledges that the message was delivered to its destination and stored in the broker's persistent data store. If the message is not persistent, no broker acknowledgement message (referred to as "Ack" in property names) is returned by the broker, and the client thread does not block.
Message Consumption
Message consumption is more complex than production. Messages arriving at a destination on a broker are delivered over a connection to the MQ client runtime under the following conditions:
- the client has set up a consumer for the given destination
- the selection criteria for the consumer, if any, match that of messages arriving at the given destination
- the connection has been told to start delivery of messages.
Messages delivered over the connection are distributed to the appropriate MQ sessions where they are queued up to be consumed by the appropriate MessageConsumer objects, as shown in Figure 2-9. Messages are fetched off each session queue one at a time (a session is single threaded) and consumed either synchronously (by a client thread invoking the receive method) or asynchronously (by the session thread invoking the onMessage method of a MessageListener object).
Figure 2-9 Message Delivery to MQ Client Runtime
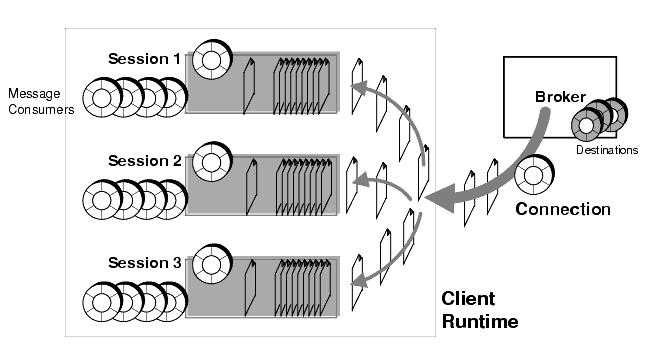
When a broker delivers messages to the client runtime, it marks the messages accordingly, but does not really know if they have been received or consumed. Therefore, the broker waits for the client to acknowledge receipt of a message before deleting the message from the broker's destination.
MQ Administered Objects
Administered Objects allow client application code to be provider-independent. They do this by encapsulating provider-specific implementation and configuration information in objects that are used by client applications in a provider-independent way. Administered objects are created and configured by an administrator, stored in a name service, and accessed by client applications through standard JNDI lookup code.
MQ provides two types of administered objects: ConnectionFactory and Destination. While both encapsulate provider-specific information, they have very different uses within a client application. ConnectionFactory objects are used to create connections to the message server and Destination objects are used to identify physical destinations.
Administered objects make it very easy to control and manage an MQ message server:
- You can control the behavior of connections by requiring client applications to access pre-configured ConnectionFactory objects (see "Administered Object Attributes").
- You can control the proliferation of physical destinations by requiring client applications to access pre-configured Destination objects that correspond to existing physical destinations. (You also have to disable the brokers's auto-create capability—see "Auto-Created (vs. Admin-Created) Destinations").
- You can control MQ message server resources by overriding message header values set by client applications (see "Administered Object Attributes").
This arrangement therefore gives you, as an MQ administrator, control over message server configuration details, and at the same time allows client applications to be provider-independent: they do not have to know about provider-specific syntax and object naming conventions (see "JMS Provider Independence") or provider-specific configuration properties.
You create administered objects using MQ administration tools, as described in Chapter 7 "Managing Administered Objects". When creating an administered object, you can specify that it be read only—that is, client applications are prevented from changing MQ-specific configuration values you have set when creating the object. In other words, client code cannot set attribute values on read-only administered objects, nor can you override these values using client application startup options, as described in "Overriding Attribute Values at Client Startup".
While it is possible for client applications to instantiate both ConnectionFactory and Destination administered objects on their own, this practice undermines the basic purpose of an administered object—to allow you, as an MQ administrator, to control broker resources required by an application and to tune its performance. In addition, directly instantiating administered objects makes client applications provider-specific, rather than provider-independent.
Connection Factory Administered Objects
A ConnectionFactory object is used to establish physical connections between a client application and an MQ message server. It is also used to specify behaviors of the connection and of the client runtime that is using the connection to access a broker.
If you wish to support distributed transactions (see "Local Transactions"), you need to use a special XAConnectionFactory object that supports distributed transactions.
To create a ConnectionFactory administered object, see "Adding a Connection Factory".
By configuring a ConnectionFactory administered object, you specify the attribute values (the properties) common to all the connections that it produces. ConnectionFactory and XAConnectionFactory objects share the same set of attributes. These attributes are grouped into a number of categories, depending on the behaviors they affect:
- Connection specification
- Auto-reconnect behavior
- Client identification
- Message header overrides
- Reliability and flow control
- Queue browser behavior
- Application server support
- JMS-defined properties support
Each of these categories and its corresponding attributes is discussed in some detail in the MQ Developer's Guide. While you, as an MQ administrator, might be called upon to adjust the values of these attributes, it is normally an application developer who decides which attributes need adjustment to tune the performance of client applications. Table 7-3 presents an alphabetical summary of the attributes.
Destination Administered Objects
A Destination administered object represents a physical destination (a queue or a topic) in a broker to which the publicly-named Destination object corresponds. Its two attributes are described in Table 2-11. By creating a Destination object, you allow a client application's MessageConsumer and/or MessageProducer objects to access the corresponding physical destination.To create a Destination administered object, see "Adding a Topic or Queue".
Overriding Attribute Values at Client Startup
As with any Java application, you can start messaging applications using the command-line to specify system properties. This mechanism can also be used to override attribute values of administered objects used in client application code. For example, you can override the configuration of an administered object accessed through a JNDI lookup in client application code.
To override administered object settings at client application startup, you use the following command line syntax:
java [[-Dattribute=value ]...] clientAppName
where attribute corresponds to any of the ConnectionFactory administered object attributes documented in "Connection Factory Administered Objects".
For example, if you want a client application to connect to a different broker than that specified in a ConnectionFactory administered object accessed in the client code, you can start up the client application using command line overrides to set the imqBrokerHostName and imqBrokerHostPort of another broker.
If an administered object has been set as read-only, however, the values of its attributes cannot be changed using command-line overrides. Any such overrides will simply be ignored.