|
| |
| Sun Java System Application Server Enterprise Edition 8.1 2005Q1 Deployment Planning Guide | |
Chapter 1
Product ConceptsThe Sun Java System Application Server provides a robust platform for the development, deployment, and management of J2EE applications. Key features include scalable transaction management, container-managed persistence runtime, web services performance, clustering, high availability session state, security, and integration capabilities.
The Application Server is available in Platform and Enterprise editions. The Platform edition is free and is intended for software development and department-level production environments. The Enterprise edition is designed for mission-critical services and large-scale production environments. It supports horizontal scalability and service continuity with a load balancer plug-in and cluster management. The Enterprise edition also supports reliable session state management with the high-availability database (HADB). Additionally, there is a Standard Edition, that provides all the features of the Enterprise Edition except for the HADB.
This chapter covers the following topics:
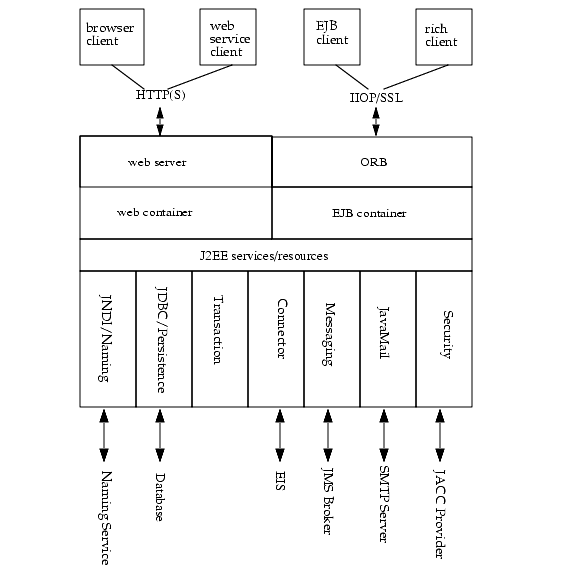
J2EE Platform OverviewThe Application Server implements Java 2 Enterprise Edition (J2EE) 1.4 technology. The J2EE platform is a set of standard specifications that describe application components, APIs, and the runtime containers and services of an application server.
J2EE Applications
J2EE applications are made up of components such as JavaServer Pages (JSP), Java servlets, and Enterprise JavaBeans (EJB) modules. These components enable software developers to build large-scale, distributed applications. Developers package J2EE applications in Java Archive (JAR) files (similar to zip files), which can be distributed to production sites. Administrators install J2EE applications onto the Application Server by deploying J2EE JAR files onto one or more server instances (or clusters of instances).
Figure 1-1 illustrates the components of the J2EE platform, which are discussed in the following sections.
Containers
Each server instance includes two containers: web and EJB. A container is a runtime environment that provides services such as security and transaction management to J2EE components. Web components, such as JSP pages and servlets, run within the web container. Enterprise JavaBeans run within the EJB container.
J2EE Services
The J2EE platform provides services for applications, including:
- Naming - A naming and directory service binds objects to names. A J2EE application can locate an object by looking up its Java Naming and Directory Interface (JNDI) name.
- Security - The Java Authorization Contract for Containers (JACC) is a set of security contracts defined for the J2EE containers. Based on the client’s identity, containers can restrict access to the container’s resources and services.
- Transaction management - A transaction is an indivisible unit of work. For example, transferring funds between bank accounts is a transaction. A transaction management service ensures that a transaction is either completed, or is rolled back.
- Message Service - Applications hosted on separate systems can communicate with each other by exchanging messages using the Java™ Message Service (JMS). JMS is an integral part of the J2EE platform and simplifies the task of integrating heterogeneous enterprise applications.
Web Services
Clients can access a J2EE 1.4 application as a remote web service in addition to accessing it through HTTP, RMI/IIOP, and JMS. Web services are implemented using the Java API for XML-based RPC (JAX-RPC). A J2EE application can also act as a client to web services, which would be typical in network applications.
Web Services Description Language (WSDL) is an XML format that describes web service interfaces. Web service consumers can dynamically parse a WSDL document to determine the operations a web service provides and how to execute them. The Application Server distributes web services interface descriptions using a registry that other applications can access through the Java API for XML Registries (JAXR).
Client Access
Clients can access J2EE applications in several ways. Browser clients access web applications using hypertext transfer protocol (HTTP). For secure communication, browsers use the HTTP secure (HTTPS) protocol that uses secure sockets layer (SSL).
Rich client applications running in the Application Client Container can directly lookup and access Enterprise JavaBeans using an Object Request Broker (ORB), Remote Method Invocation (RMI) and the internet inter-ORB protocol (IIOP), or IIOP/SSL (secure IIOP). They can access applications and web services using HTTP/HTTPS, JMS, and JAX-RPC. They can use JMS to send messages to and receive messages from applications and message-driven beans.
Clients that conform to the Web Services-Interoperability (WS-I) Basic Profile can access J2EE web services. WS-I is an integral part of the J2EE standard and defines interoperable web services. It enables clients written in any supporting language to access web services deployed to the Application Server.
The best access mechanism depends on the specific application and the anticipated volume of traffic. The Application Server supports separately configurable listeners for HTTP, HTTPS, JMS, IIOP, and IIOP/SSL. You can set up multiple listeners for each protocol for increased scalability and reliability.
J2EE applications can also act as clients of J2EE components such as Enterprise JavaBeans modules deployed on other servers, and can use any of these access mechanisms.
External Systems and Resources
On the J2EE platform, an external system is called a resource. For example, a database management system is a JDBC resource. Each resource is uniquely identified and by its Java Naming and Directory Interface (JNDI) name. Applications access external systems through the following APIs and components:
- Java Database Connectivity (JDBC) - A database management system (DBMS) provides facilities for storing, organizing, and retrieving data. Most business applications store data in relational databases, which applications access via JDBC. The Application Server includes the PointBase DBMS for use sample applications and application development and prototyping, though it is not suitable for deployment. The Application Server provides certified JDBC drivers for connecting to major relational databases. These drivers are suitable for deployment.
- Java Message Service - Messaging is a method of communication between software components or applications. A messaging client sends messages to, and receives messages from, any other client via a messaging provider that implements the Java Messaging Service (JMS) API. The Application Server includes a high-performance JMS broker, the Sun Java System Message Queue. The Platform Edition of Application Server includes the free Platform Edition of Message Queue. Application Server Enterprise Edition includes Message Queue Enterprise Edition, that supports clustering and failover.
- J2EE Connectors - The J2EE Connector architecture enables integrating J2EE applications and existing Enterprise Information Systems (EIS). An application accesses an EIS through a portable J2EE component called a connector or resource adapter, analogous to using JDBC driver to access an RDBMS. Resource adapters are distributed as standalone Resource Adapter Archive (RAR) modules or included in J2EE application archives. As RARs, they are deployed like other J2EE components. The Application Server includes evaluation resource adapters that integrate with popular EIS.
- JavaMail - Through the JavaMail API, applications can connect to a Simple Mail Transport Protocol (SMTP) server to send and receive email.
Figure 1-1 J2EE Platform Architecture
Application Server ComponentsThis section describes the components in the Sun Java System Application Server:
Figure 1-2 illustrates how these Application Server components interact using a simple example topology that provides high availability. In this example topology, one administrator manages two machines organized as a cluster. HADB and Application server processes are located on the same machine. The Domain Administration Server may be hosted on a separate machine by itself or on any one of the machines hosting application server instances. The lines in the diagram indicate communication or control.
The administration tools, such as the browser-based Admin Console, communicate with the domain administration server (DAS), which in turn communicates with the node agents and server instances.
Figure 1-2 Application Server Components
Server Instances
A server instance is a Application Server running in a single Java Virtual Machine (JVM) process. The Application Server is certified with Java 2 Standard Edition (J2SE) 5.0 and 1.4. The recommended J2SE distribution is included with the Application Server installation.
It is usually sufficient to create a single server instance on a machine, since the Application Server and accompanying JVM are both designed to scale to multiple processors. However, it can be beneficial to create multiple instances on one machine for application isolation and rolling upgrades. In some cases, a large server with multiple instances can be used in more than adminsitrative domain. The administration tools makes it easy to create, delete and manage server instances across multiple machines.
Administrative Domains
An administrative domain (or simply domain) is a group of server instances that are administered together. A server instance belongs to a single administrative domain. The instances in a domain can run on different physical hosts.
You can create multiple domains from one installation of the Application Server. By grouping server instances into domains, different organizations and administrators can share a single Application Server installation. Each domain has its own configuration, log files, and application deployment areas that are independent of other domains. Changing the configuration of one domain does not affect the configurations of other domains. Likewise, deploying an application on a one domain does not deploy it or make it visible to any other domain. At any given time, an administrator can be authenticated to only one domain, and thus can only perform administration on that domain.
Domain Administration Server (DAS)
A domain has one Domain Administration Server (DAS), a specially-designated application server instance that hosts the administrative applications. The DAS authenticates the administrator, accepts requests from administration tools, and communicates with server instances in the domain to carry out the requests.
The administration tools are the asadmin command-line tool, the browser-based Admin Console. The Application Server also provides a JMX-based API for server administration. The administrator can view and manage a single domain at a time, thus enforcing secure separation.
The DAS is also sometimes referred to as the admin server or default server. It is referred to as the default server because it is the default target for some administrative operations.
Since the DAS is an application server instance, it can also host J2EE applications for testing purposes. However, do not use it to host production applications. You might want to deploy applications to the DAS, for example, if the clusters and instances that will host the production application have not yet been created.
The DAS keeps a repository containing the configuration its domain and all the deployed applications. If the DAS is inactive or down, there is no impact on the performance or availability of active server instances, however administrative changes cannot be made. In certain cases, for security purposes, it may be useful to intentionally stop the DAS process; for example to freeze a production configuration.
Administrative commands are provided to backup and restore domain configuration and applications. With the standard backup and restore procedures, you can quickly restore working configurations. If the DAS host fails and you need to create a new DAS installation to restore the previous domain configuration. For instructions, see the Sun Java Application Server Administration Guide, “Getting Started” chapter.
Sun Cluster Data Services provides high availability of the DAS through failover of the DAS host IP address and use of the Global File System. This solution provides nearly continuous availability for DAS and the repository against many types of failures. Sun Cluster Data Services are available with the Sun Java Enterprise System or purchased separately with Sun Cluster. For more information, see the documentation for Sun Cluster Data Services.
Clusters
A cluster is a named collection of server instances that share the same applications, resources, and configuration information. You can group server instances on different machines into one logical cluster and administer them as one unit. You can easily control the lifecycle of a multi-machine cluster with the DAS.
Clusters enable horizontal scalability, load balancing, and failover protection. By definition, all the instances in a cluster have the same resource and application configuration. When a server instance or a machine in a cluster fails, the load balancer detects the failure, redirects traffic from the failed instance to other instances in the cluster, and recovers the user session state. Since the same applications and resources are on all instances in the cluster, an instance can failover to any other instance in the cluster.
Clusters, domains, and instances are related as follows:
Node Agents
A node agent is a lightweight process that runs on every machine that hosts server instances, including the machine that hosts the DAS. The node agent:
- Starts and stops server instances as instructed by the DAS.
- Restarts failed server instances.
- Provides a view of the log files of failed servers and assists in remote diagnosis
- Synchronizes each server instance’s local configuration repository with the DAS’s central repository, as it starts up the server instances under its watch.
- When an instance is initially created, creates directories the instance needs and synchronizes the instance’s configuration with the central repository.
- Performs appropriate cleanup when a server instance is deleted.
Each physical host must have at least one node agent for each domain to which the host belongs. If a physical host has instances from more than one domain, then it needs a node agent for each domain. There is no advantage of having more than one node agent per domain on a host, though it is allowed.
Because a node agent starts and stops server instances, it must always be running. Therefore, it is started when the operating system boots up. On Solaris and other Unix platforms, the node agent can be started by the inetd process. On Windows, the node agent can be made a Windows service.
For more information on node agents, see the chapter “Configuring Node Agents” in the Sun Java Application Server Administration Guide.
Named Configurations
A named configuration is an abstraction that encapsulates Application Server property settings. Clusters and stand-alone server instances reference a named configuration to get their property settings. With named configurations, J2EE containers’ configurations are independent of the physical machine on which they reside, except for particulars such as IP address, port number, and amount of heap memory. Using named configurations provides power and flexibility to Application Server administration.
To apply configuration changes, you simply change the property settings of the named configuration, and all the clusters and stand-alone instances that reference it pick up the changes. You can only delete a named configuration when all references to it have been removed. A domain can contain multiple named configurations.
The Application Server comes with a default configuration, called default-config. The default configuration is optimized for developer productivity in Application Server Platform Edition and for security and high availability in the Application Server Enterprise Edition.
You can create your own named configuration based on the default configuration that you can customize for your own purposes. Use the Admin Console and asadmin command line utility to create and manage named configurations.
HTTP Load Balancer Plug-in
The load balancer distributes the workload among multiple physical machines, thereby increasing the overall throughput of the system. The Application Server Enterprise Edition includes the load balancer plug-in for the Sun Java System Web Server, the Apache Web Server, and Microsoft Internet Information Server.
The load balancer plug-in accepts HTTP and HTTPS requests and forwards them to one of the application server instances in the cluster. Should an instance fail, become unavailable (due to network faults), or become unresponsive, requests are redirected to existing, available machines. The load balancer can also recognize when a failed instance has recovered and redistribute the load accordingly.
For simple stateless applications, a load-balanced cluster may be sufficient. However, for mission-critical applications with session state, use load balanced clusters with HADB.
To setup a system with load balancing, in addition to the Application Server, you must install a web server and the load-balancer plug-in. Then you must:
Server instances and clusters participating in load balancing have a homogenous environment. Usually that means that the server instances reference the same server configuration, can access the same physical resources, and have the same applications deployed to them. Homogeneity assures that before and after failures, the load balancer always distributes load evenly across the active instances in the cluster.
Use the asadmin command-line tool to create a load balancer configuration, add references to clusters and server instances to it, enable the clusters for reference by the load balancer, enable applications for load balancing, optionally create a health checker, generate the load balancer configuration file, and finally copy the load balancer configuration file to your web server config directory. An administrator can create a script to automate this entire process.
For more details and complete configuration instructions, see the Sun Java System Application Server Administration Guide, “Configuring Load Balancing and Failover” chapter.
Session Persistence
J2EE applications typically have significant amounts of session state data. A web shopping cart is the classic example of a session state. Also, an application can cache frequently-needed data in the session object. In fact, almost all applications with significant user interactions need to maintain a session state. Both HTTP sessions and stateful session beans (SFSBs) have session state data.
While the session state is not as important as the transactional state stored in a database, preserving the session state across server failures can be important to end users.The Application Server provides the capability to save, or persist, this session state in a repository. If the application server instance that is hosting the user session experiences a failure, the session state can be recovered. The session can continue without loss of information.
The Application Server supports the following types of session persistence stores:
With memory persistence, the state is always kept in memory and does not survive failure. With HA persistence, the Application Server uses HADB as the persistence store for both HTTP and SFSB sessions. With file persistence, the Application Server serializes session objects and stores them to the file system location specified by session manager properties. For SFSBs, if HA is not specified, the Application Server stores state information in the session-store sub-directory of this location.
Checking an SFSB’s state for changes that need to be saved is called checkpointing. When enabled, checkpointing generally occurs after any transaction involving the SFSB is completed, even if the transaction rolls back. For more information on enabling SFSB failover, see the chapter “Using Enterprise JavaBeans Technology” in the Sun Java System Application Server Developer’s Guide. See the Sun Java System Application Server Developer’s Guide for developer guidelines.
Apart from the number of requests being served by the Application Server, the session persistence configuration settings also affect the number of requests received per minute by the HADB, as well as the session information in each request.
See the Sun Java System Application Server Administration Guide for more information on configuring session persistence.
IIOP Load Balancing in a Cluster
With IIOP load balancing, IIOP client requests are distributed to different server instances or name servers. The goal is to spread the load evenly across the cluster, thus providing scalability. IIOP load balancing combined with EJB clustering and availability features in the Sun Java System Application provides not only load balancing but also EJB failover.
When a client performs a JNDI lookup for an object, the Naming Service creates a InitialContext (IC) object associated with a particular server instance. From then on, all lookup requests made using that IC object are sent to the same server instance. All EJBHome objects looked up with that InitialContext are hosted on the same target server. Any bean references obtained henceforth are also created on the same target host. This effectively provides load balancing, since all clients randomize the list of live target servers when creating InitialContext objects. If the target server instance goes down, the lookup or EJB method invocation will failover to another server instance.
Figure 1-3 IIOP Load Balancing in a Cluster
For example, as illustrated in Figure 1-3, ic1, ic2, and ic3 are three different InitialContext instances created in Client2’s code. They are distributed to the three server instances in the cluster. Enterprise JavaBeans created by this client are thus spread over the three instances. Client1 created only one InitialContext object and the bean references from this client are only on Server Instance 1. If Server Instance 2 goes down, the lookup request on ic2 will failover to another server instance (not necessarily Server Instance 3). Any bean method invocations to beans previously hosted on Server Instance 2 will also be automatically redirected, if it is safe to do so, to another instance. While lookup failover is automatic, Enterprise JavaBeans modules will retry method calls only when it is safe to do so.
IIOP Load balancing and failover happens transparently. No special steps are needed during application deployment. Adding or deleting new instances to the cluster will not update the existing client’s view of the cluster. You must manually update the endpoints list on the client side.
Message Queue and JMS Resources
The Sun Java System Message Queue (MQ) provides reliable, asynchronous messaging for distributed applications. MQ is an enterprise messaging system that implements the Java Message Service (JMS) standard. MQ provides messaging for J2EE application components such as message-driven beans (MDBs).
The Application Server implements the Java Message Service (JMS) API by integrating the Sun Java System Message Queue into the Application Server. The Enterprise Edition of the Application Server includes the Enterprise version of MQ which has failover, clustering and load balancing features.
For basic JMS administration tasks, use the Application Server Admin Console and asadmin command-line utility.
For advanced tasks, including administering a Message Queue cluster, use the tools provided in the install_dir/imq/bin directory. For details about administering Message Queue, see the Sun Java System Message Queue Administration Guide.
For information on deploying JMS applications and MQ clustering for message failover, see Planning Message Queue Broker Deployment.
High-Availability DatabaseThis section discusses the following topics:
Overview
J2EE applications’ need for session persistence was previously described in Session Persistence. The Application Server uses the high-availability database (HADB) as a highly available session store. HADB is included with the Application Server Enterprise Edition, but in deployment can be run on seprate hosts. HADB provides a highly available data store for HTTP session and stateful session bean data.
The advantages of this decoupled architecture include:
- Server instances in a highly available cluster are loosely coupled and act as high performance J2EE containers.
- Stopping and starting server instances does not affect other servers or their availability.
- HADB can run on a different set of less expensive machines (for example, with single or dual processors). Several clusters can share these machines. Depending upon the deployment needs, you can run HADB on the same machines as Application Server (co-located) or different machines (separate tier). For more information on the two options, see Co-located Topology and Separate Tier Topology.
For HADB hardware and network system requirements, see the Sun Java System Application Server 8.1 2005Q1 Release Notes. For additional system configuration steps required for HADB, see Sun Java System Application Server High Availability Administration Guide.
System Requirements
The recommended system requirements for HADB hosts are:
For additional requirements for very high availability, see Mitigating Double Failures.
HADB Architecture
HADB is a distributed system consisting of pairs of nodes. Nodes are divided into two data redundancy units (DRUs), with a node from each pair in each DRU, as illustrated in Figure 1-4.
Each node consists of:
A set of HADB nodes can host one or more session databases. Each session database is associated with a distinct application server cluster. Deleting a cluster also deletes the associated session database.
For HADB hardware requirements, see the Sun Java System Application Server Release Notes.
Nodes and Node Processes
There are two types of HADB nodes:
Each node has a parent process and several child processses. The parent process, called the node supervisor (NSUP), is started by the management agent. It is responsible for creating the child processes and keeping them running.
The child processes are:
- Transaction server process (TRANS), that coordinates transactions on distributed nodes, and manages data storage.
- Relational algebra server process (RELALG) that coordinates and executes complex relational algebra queries such as sorts and and joins.
- SQL shared memory server process (SQLSHM) that maintains the SQL dictionary cache.
- SQL server process (SQLC), that receives client queries, compiles them into local HADB instructions, sends the instructions to TRANS, receives the results and conveys them to the client. Each node has one main SQL server and one sub-server for each client connection.
- Node manager server process (NOMAN) that management agents use to execute management commands issued by the hadbm management client.
Data Redundancy Units
As previously described, an HADB instance contains a pair of DRUs. Each DRU has the same number of active and spare nodes as the other DRU in the pair. Each active node in a DRU has a mirror node in the other DRU. Due to mirroring, each DRU contains a complete copy of the database.
Figure 1-4 shows an example HADB architecture with six nodes: four active nodes and two spare nodes. Nodes 0 and 1 are a mirror pair, as are nodes 2 and 3. In this example, each host has one node. In general, a host can have more than one node if it has sufficient system resources (see System Requirements).
Figure 1-4 Sample HADB Configuration with Double Interconnects
The database is fragmented and distributed over the active nodes in a DRU. Each node in a mirror pair contains the same set of data fragments. Duplicating data on a mirror node is known as replication. Replication enables HADB to provide high availability: when a node fails, its mirror node takes over almost immediately (within seconds). Replication ensures availability and masks node failures or DRU failures without loss of data or services.
When a mirror node takes over the functions of a failed node, it has to perform double work: its own and that of the failed node. If the mirror node does not have sufficient resources, the overload will reduce its performance and increase its failure probability. When a node fails, HADB attempts to restart it. If the failed node does not restart (for example, due to hardware failure), the system continues to operate but with reduced availability.
HADB tolerates failure of a node, an entire DRU, or multiple nodes, but not a “double failure” when both a node and its mirror fail. For information on how to reduce the likelihood of a double failure, see Mitigating Double Failures.
Spare Nodes
When a node fails, its mirror node takes over for it. If the failed node does not have a spare node, then at this point, the failed node will not have a mirror. A spare node will automatically replace a failed node’s mirror. Having a spare node reduces the time the system functions without a mirror node.
A spare node does not normally contain data, but constantly monitors for failure of active nodes in the DRU. When a node fails and does not recover within a specified timeout period, the spare node copies data from the mirror node and synchronizes with it. The time this takes depends on the amount of data copied and the system and network capacity. After synchronizing, the spare node automatically replaces the mirror node without manual intervention, thus relieveing the mirror node from overload, thus balancing load on the mirrors. This is known as failback or self-healing.
When a failed host is repaired (by shifting the hardware or upgrading the software) and restarted, the node or nodes running on it join the system as a spare nodes, since the original spare nodes are now active.
Spare nodes are not required, but they enable a system to maintain its overall level of service even if a machine fails. Spare nodes also make it easy to perform planned maintenance on machines hosting active nodes. Allocate one machine for each DRU to act as a spare machine, so that if one of the machines fails, the HADB system continues without adversely affecting performance and availability.
Note
As a general rule, have a spare machine with enough Application Server instances and HADB nodes to replace any machine that becomes unavailable.
Example Spare Node Configurations
The following examples illustrate using spare nodes in HADB deployments. There are two possible deployment topologies: co-located, in which HADB and Application Servers reside on the same hosts, and separate tier, in which they reside on separate hosts. For more information on deployment topologies, see Chapter 3, "Selecting a Topology."
Example: co-located configuration
As an example of a spare node configuration, suppose you have a co-located topology with four Sun FireTM V480 servers, where each server has one Application Server instance and two HADB data nodes.
For spare nodes, allocate two more servers (one machine per DRU). Each spare machine runs one application server instance and two spare HADB nodes.
Example: separate tier configuration
Suppose you have a separate-tier topology where the HADB tier has two Sun FireTM 280R servers, each running two HADB data nodes. To maintain this system at full capacity, even if one machine becomes unavailable, configure one spare machine for the Application Server instances tier and one spare machine for the HADB tier.
The spare machine for the Application Server instances tier must have as many instances as the other machines in the Application Server instances tier. Similarly, the spare machine for the HADB tier must have as many HADB nodes as the other machines in the HADB tier.
Mitigating Double Failures
HADB’s built-in data replication enables it to tolerate failure of a single node or an entire DRU. By default, HADB won’t survive a double failure, when a mirror node pair or both DRUs fail. In such cases, HADB become unavailable.
In addition to using spare nodes as described in the previous section, you can minimize the likelihood of a double failure by taking the following steps:
- Providing independent power supplies: For optimum fault tolerance, the servers that support one DRU must have independent power (through uninterruptible power supplies), processing units, and storage. If a power failure occurs in one DRU, the nodes in the other DRU continue servicing requests until the power returns.
- Providing double interconnections: To tolerate single network failures, replicate the lines and switches between DRUs as shown in Figure 1-4.
These steps are optional, but will increase the overall availability of the HADB instance.
HADB Management System
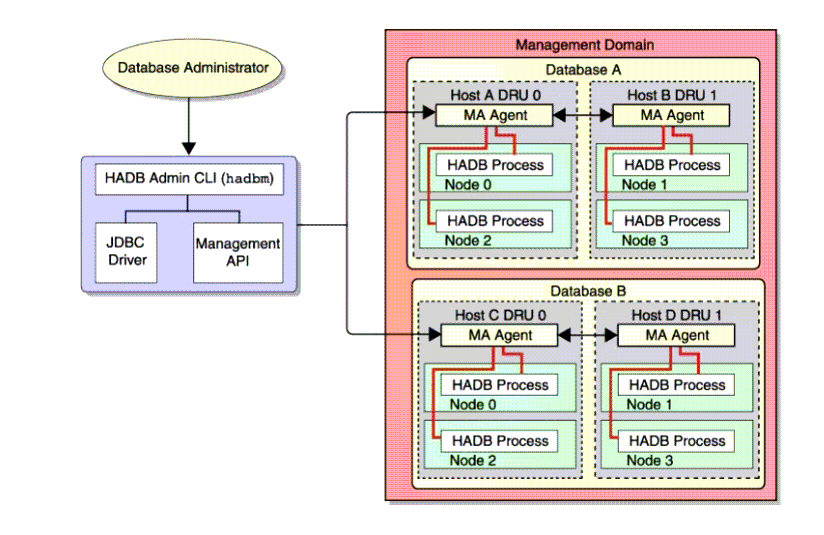
The HADB management system provides built-in security and facilitates multi-platform management. As illustrated in Figure 1-5, the HADB management architecture contains the following components:
As shown in Figure 1-5, one HADB management agent runs on every machine that runs the HADB service. Each machine typically hosts one or more HADB nodes. An HADB management domain contains many machines, similar to an Application Server domain. At least two machines are required in a domain for the database to be fault tolerant, and in genera there must be an even number of machines to form the DRU pairs. Thus, a domain contains many management agents.
As shown in the figure, a domain can contain one or more database instances. One machine can contain one or more nodes belonging to one or more database instances.
Figure 1-5 HADB Management Architecture
Management Client
The HADB management client is a command-line utility, hadbm, for managing the HADB domain and its database instances. HADB services can run continously— even when the associated Application Server cluster is stopped—but must be shut down carefully if they are to be deleted. For more information on using hadbm, see the Sun Java System Application Server Administration Guide.
You can use the asadmin command line utility to create and delete the HADB instance associated with a highly available cluster. For more information, see the Sun Java System Application Server Administration Guide.
Management Agent
The management agent is a server process (named ma) that can access resources on a host; for example, it can create devices and start database processes. The management agent coordinates and performs management client commands such as starting or stopping a database instance.
A management client connects to a management agent by specifying the address and port number of the agent. Once connected, the management client sends commands to HADB through the management agent. The agent receives requests and executes them. Thus, a management agent must be running on a host before issuing any hadbm management commands to that host. The management agent can be configured as a system service that starts up automatically.
Ensuring availability of management agents
The management agent process ensures the availability of the HADB node supervisor processes by restarting them if they fail. Thus, for deployment, you must ensure the availability of the ma process to maintain the overall availability of HADB. After restarting, the management agent recovers the domain and database configuration data from other agents in the domain.the system.
Use the host operating system (OS) to ensure the availability of the management agent. On Solaris or Linux, init.d ensures the availability of the ma process after a process failure and reboot of the operating system. On Windows, the management agent runs as a Windows service. Thus, the OS restarts the management agent if the agent fails or the OS reboots.
Management Domains
An HADB management domain is a set of hosts, each of which has a management agent running on the same port number. The hosts in a domain can contain one or more HADB database instances. A management domain is defined by the common port number the agents use and an identifier (called a domainkey) generated when you create or the domain or add an agent to it. The domainkey provides a unique identifier for the domain, crucial since management agents communicate using multicast. You can set up an HADB management domain to match with an Application Server domain.
Having multiple database instances in one domain can be useful in a development environment, since it enables different developer groups to use their own database instance. In some cases, it may also be useful in production environments.
All agents belonging to a domain coordinate their management operations. When you change the database configuration through an hadbm command, all agents will change the configuration accordingly. You cannot stop or restart a node unless the management agent on the node’s host is running. However, you can execute hadbm commands that read HADB state or configuration variable values even if some agents are not available.
Use the following management client commands to work with management domains:
- hadbm createdomain: creates a management domain with the specified hosts.
- hadbm extenddomain: adds hosts to an existing management domain.
- hadbm deletedomain: removes a management domain.
- hadbm reducedomain: removes hosts from the management domain.
- hadbm listdomain: lists all hosts defined in the management domain.
For more information on these commands, see the Sun Java Application Server Reference Manual (or the corresponding man pages).
Repository
Management agents store the database configuration in a repository. The repository is highly fault-tolerant, because it is replicated over all the management agents. Keeping the configuration on the server enables you to perform management operations from any computer that has a management client installed.
A majority of the management agents in a domain must be running to perform any changes to the repository. Thus, if there are M agents in a domain, at least M/2 + 1 agents (rounded down to a whole number) must be running to make a change to the repository.
If some of the hosts in a domain are unavailable, for example due to hardware failures, and you cannot perform some management commands because you don’t have a quorum, use the hadbm disablehost command to remove the failed hosts from the domain. For more information on this command, see the Sun Java System Application Server Reference Manual.
Setup and Configuration RoadmapFollow this procedure to setup and configure your Application Server system for high availability:
- Determine your performance and QoS requirements and goals, as described in Chapter 2, "Planning your Deployment."
- Size your system, as described in Design Decisions in Chapter 2, "Planning your Deployment." In particular, determine:
- Determine system topology, as described in Chapter 3, "Selecting a Topology," that is, whether you are going to intall HADB on the same host machines as Application Server or on different machines.
- Install Application Server instances, along with related subcomponents such as HADB and a web server.
- Create domains and clusters
- Configure your web server software.
- Install the Load Balancer Plug-in.
- Setup and configure load balancing
- Setup and configure HADB nodes and DRUs
- Configure AS Web container and EJB container for HA session persistence.
- Deploy applications and configure them for high availability and session failover.
- Configure JMS clusters for failover if you are using messaging extensively. For more information, see the Sun Java System Message Queue Adminstration Guide.