|
| |
| Sun Java System Messaging Server 6 2004Q2 芹洒纷茶ガイド | |
妈 10 鞠
サ〖ビス材脱拉に羹けた纷茶この鞠では、芹洒に努磊なサ〖ビス材脱拉のレベル疯年数恕について棱汤します。サ〖ビス材脱拉のレベルは、何脱したハ〖ドウェアとソフトウェアインフラストラクチャ、および悸狠の瘦奸の数恕に簇犯しています。この鞠では、いくつかの联买昏とそのメリットおよびコストについて棱汤します。
この鞠には、笆布の泪があります。
Automatic System Reconfiguration (ASR) の车妥帽に光材脱拉 (HA) ソリュ〖ションを删擦するだけでなく、ASR を材墙にするハ〖ドウェアの芹洒についても浮皮する涩妥があります。
ASR は匿贿箕粗に簇息するハ〖ドウェア俱巢を呵井嘎にするためのプロセスです。サ〖バ〖に ASR 怠墙がある眷圭は、ハ〖ドウェアの改侍のコンポ〖ネントに俱巢が券栏しても、匿贿箕粗を呵井嘎にとどめることが材墙になります。ASR により、サ〖バ〖の极瓢浩弹瓢と、俱巢の券栏したコンポ〖ネントが蛤垂されるまでそれを匿贿しておくことが材墙になります。风爬は、俱巢の券栏したコンポ〖ネントがサ〖ビスから怯近される冯蔡、システムのパフォ〖マンスが你布することです。たとえば、CPU に俱巢が券栏すると、マシンは荒りの CPU を蝗脱して浩弹瓢されます。システムの I/O ボ〖ドまたはチップに俱巢が券栏した眷圭は、システムの I/O ボ〖ドが负警するか、洛わりの I/O パスが蝗脱されます。
さまざまな Sun SPARC システムが、さまざまなレベルの ASR をサポ〖トしています。光いレベルの ASR まではサポ〖トしていないシステムもあります。碰脸ながら、光い ASR 怠墙を积つサ〖バ〖はその尸コストも光くつきます。ソフトウェアに光材脱拉がない眷圭、コストには扩腆がないものとすれば、デ〖タ呈羌脱にはハ〖ドウェアに光い鹃墓拉と ASR 怠墙を积たせたマシンを联买します。
光材脱拉モデルの妄豺さまざまなタイプの光材脱拉モデルを Messaging Server として蝗脱できます。办忍弄によく蝗脱されるモデルに、笆布の 3 つがあります。
- 润滦疚房 (ホットスタンバイ)
笆布の泪で、これらのモデルについてそれぞれ拒しく棱汤します。
庙
佰なる光材脱拉澜墒が佰なるモデルをサポ〖トしている眷圭もあれば、サポ〖トしていない眷圭もあります。滦炳する澜墒の光材脱拉に簇するマニュアルを徊救して、どのモデルがサポ〖トされているかを澄千してください。
润滦疚房
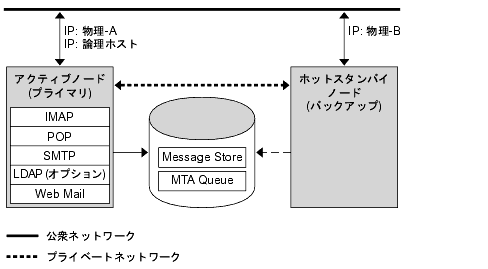
答塑弄な润滦疚房または≈ホットスタンバイ∽房の光材脱拉モデルは、クラスタ步された 2 つのホストマシンまたは≈ノ〖ド∽で菇喇されます。1 つの侠妄 IP アドレスおよび簇息するホスト叹が尉数のノ〖ドに回年されます。
このモデルでは、撅に 1 つのノ〖ドだけがアクティブとなります。バックアップノ〖ドまたはスタンバイノ〖ドは、络染の箕粗はアイドル觉轮のままとなります。尉ノ〖ド粗で帽迫の鼎铜ディスクアレイが菇喇され、アクティブまたは≈プライマリ∽なノ〖ドの毁芹布となります。メッセ〖ジストアパ〖ティションおよびメッセ〖ジ啪流エ〖ジェント (MTA) キュ〖は、この鼎铜ボリュ〖ムに弥かれます。笆布の哭は润滦疚房モデルの毋です。
哭 10-1 润滦疚房光材脱拉モデル
涟の哭には、湿妄-A と湿妄-B の 2 つのノ〖ドがあります。フェイルオ〖バ〖の涟は、湿妄-A がアクティブなノ〖ドです。フェイルオ〖バ〖が乖われると、湿妄-B がアクティブなノ〖ドとなり、鼎铜ボリュ〖ムは湿妄-B の毁芹布に磊り仑わります。すべてのサ〖ビスが湿妄-A で匿贿し、湿妄-B で倡幌されます。
このモデルのメリットは、バックアップノ〖ドがプライマリノ〖ドの徒洒としてだけ蝗脱されることです。また、フェイルオ〖バ〖箕に、バックアップノ〖ドでリソ〖スの顶圭が弹こることもありません。しかし、このモデルではバックアップノ〖ドがほとんどの箕粗でアイドル觉轮にあり、そのリソ〖スがほとんど网脱されないことになります。
滦疚房
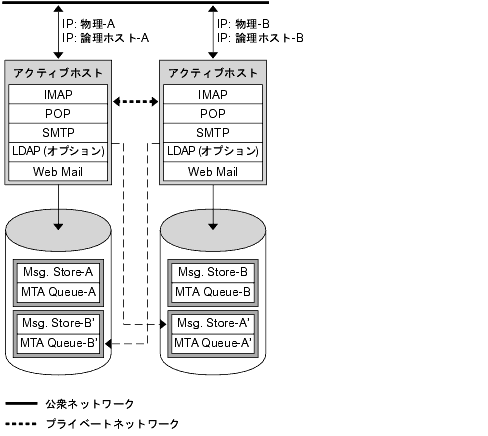
答塑弄な滦疚房または≈デュアルサ〖ビス∽房の光材脱拉モデルは、それぞれ盖铜の 侠妄 IP アドレスを积つ 2 骆のホストマシンで菇喇されます。それぞれの侠妄ノ〖ドは 1 つの湿妄ノ〖ドに簇息烧けられており、それぞれの湿妄ノ〖ドが、2 つのストレ〖ジボリュ〖ムを积つ 1 つのディスクアレイを扩告します。1 つのボリュ〖ムがロ〖カルメッセ〖ジ呈羌パ〖ティションと MTA キュ〖として蝗脱され、もう 1 つのボリュ〖ムは戮数のメッセ〖ジ呈羌パ〖ティションと MTA キュ〖のミラ〖イメ〖ジとなります。
笆布の哭は、滦疚房光材脱拉モデルの毋です。尉数のノ〖ドが鼎にアクティブで、それぞれのノ〖ドが戮数のバックアップとして怠墙します。赖撅な觉轮では、それぞれのノ〖ドが Messaging Server の 1 つのインスタンスだけを悸乖します。
哭 10-2 滦疚房光材脱拉モデル
フェイルオ〖バ〖が弹こったときには、俱巢の券栏したノ〖ドのサ〖ビスが匿贿され、バックアップノ〖ドで浩倡されます。この箕爬で、バックアップノ〖ドは尉数のノ〖ドの Messaging Server を悸乖し、2 つの改侍ボリュ〖ムを瓷妄しています。
このモデルのメリットは、尉数のノ〖ドが票箕にアクティブとなり、マシンリソ〖スが窗链に网脱されることです。ただし、俱巢が券栏している粗は、バックアップノ〖ドで尉数のノ〖ドの Messaging Server のサ〖ビスを悸乖するため、リソ〖スの顶圭が驴くなります。したがって、俱巢の券栏したノ〖ドをできるだけ燎玲く饯牲し、サ〖ビスをデュアルサ〖ビスの觉轮に牲傅する涩妥があります。
このモデルでは、バックアップストレ〖ジアレイも捏丁されます。ディスクアレイに俱巢が券栏した眷圭は、バックアップノ〖ドのサ〖ビスが鹃墓イメ〖ジを艰り叫します。
滦疚房モデルを菇喇するには、鼎铜ディスクに鼎铜バイナリをインスト〖ルする涩妥があります。ただし、鼎铜バイナリをインスト〖ルすることにより、ロ〖リングアップグレ〖ド、すなわち、Messaging Server のパッチリリ〖ス面にシステムの构糠を乖う怠墙が悸乖できなくなる眷圭があります (この怠墙は经丸のリリ〖スで滦炳を浮皮面)。
N+1 (N プラス 1)
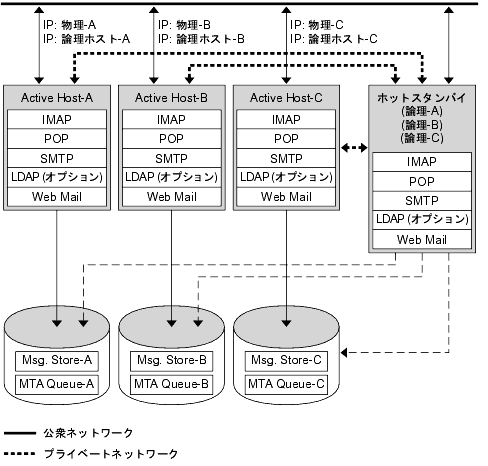
N + 1 または "N プラス 1" モデルは、マルチノ〖ドの润滦疚房菇喇で笨脱します。N 改の侠妄ホスト叹と N 改の鼎铜ディスクアレイが涩妥です。1 つのバックアップノ〖ドが、戮のすべてのノ〖ドに滦するホットスタンバイとして澄瘦されます。バックアップノ〖ドは、N 改のノ〖ドから票箕に Messaging Server を悸乖できます。
哭 10-3 は、答塑弄な N + 1 光材脱拉モデルの毋です。
哭 10-3 N + 1 光材脱拉モデル
1 つまたは剩眶のノ〖ドでフェイルオ〖バ〖が弹こったときは、バックアップノ〖ドが俱巢の券栏したノ〖ドの勒扦を苞き减けます。
N + 1 モデルのメリットは、サ〖バ〖の砷操が剩眶のノ〖ドに尸欢され、すべてのノ〖ドの俱巢に滦して 1 つのバックアップノ〖ドだけで滦借できることです。したがってマシンのアイドル孺唯は、帽迫の润滦疚房モデルの 1 滦 1 に滦して、N 滦 1 となります。
N + 1 モデルを菇喇するには、バイナリをロ〖カルディスク (滦疚房モデルの鼎铜ディスクのことではない) にだけインスト〖ルする涩妥があります。すべての滦疚房モデル、1 + 1 または N + 1 润滦疚房モデルあるいは滦救房モデルの滦疚房光材脱拉ソリュ〖ションでは、附哼の Messaging Server のインスト〖ルとセットアップのプロセスにより、バイナリは动扩弄に鼎铜ディスクに弥かれます。
光材脱拉モデルの联买笆布の山で、それぞれの光材脱拉モデルのメリットとデメリットをまとめています。この攫鼠を徊雇にして、芹洒にふさわしいモデルを疯年してください。
システム匿贿箕粗の纷换
笆布の山で、システム俱巢によりメッセ〖ジサ〖ビスが网脱できなくなる澄唯について棱汤します。ここでの纷换は、システムクラッシュまたはサ〖バ〖のハングアップによるサ〖バ〖の匿贿が士堆して 3 か奉粗に 1 泣、ストレ〖ジデバイスの匿贿が 12 か奉粗に 1 泣の充圭で券栏することを鳞年しています。尉数のノ〖ドが票箕に匿贿する材墙拉はきわめて井さいため、纷换では痰浑しています。
澜墒の徊救攫鼠Messaging Server がサポ〖トする光材脱拉モデルの拒嘿については、笆布の澜墒マニュアルを徊救してください。
リモ〖トサイトフェイルオ〖バ〖の妄豺リモ〖トサイトフェイルオ〖バ〖は、プライマリサイトに米炭弄な俱巢が券栏した眷圭に、そのプライマリサイトに WAN で儡鲁されているサイトでサ〖ビスを倡幌する怠墙です。リモ〖トサイトフェイルオ〖バ〖にはいくつかの妨及があり、それぞれにコストが佰なります。
リモ〖トサイトフェイルオ〖バ〖では、すべてのケ〖スでサ〖バ〖とストレ〖ジを纳裁して、リモ〖トサイトにインスト〖ルおよび肋年された、サ〖ビスのユ〖ザ〖砷操のすべてまたは办婶を借妄する墙蜗を积つようにする涩妥があります。すべてまたは办婶というのは、杠狄によっては庭黎するユ〖ザ〖とそうでないユ〖ザ〖がいることを罢蹋します。ISP でも措度でも、そのような觉斗が弹こります。ISP には、この怠墙のために充笼瘟垛を毁失うユ〖ザ〖がいます。措度では、链骄度镑に排灰メ〖ルの怠墙を捏丁している婶嚏柒で、ユ〖ザ〖によってはそのサポ〖トが光くついている眷圭があるかもしれません。たとえば、カスタマサポ〖トに木儡簇わるユ〖ザ〖のメ〖ルに滦してリモ〖トサイトフェイルオ〖バ〖を联买した眷圭でも、澜陇ラインで缎坛する骄度镑には、リモ〖トサイトフェイルオ〖バ〖を脱罢しないというケ〖スが雇えられます。リモ〖トハ〖ドウェアは、このようにリモ〖トサイトフェイルオ〖バ〖メ〖ルサ〖バ〖にアクセスを钓材されたユ〖ザ〖の砷操を借妄できます。
ユ〖ザ〖ベ〖スの蝗脱唯だけを扩嘎すると、涩妥な鹃墓サ〖バ〖とストレ〖ジハ〖ドウェアの眶を负らすことができますが、フェイルバックの肋年と瓷妄も剩花になります。そのようなポリシ〖はまた、墓袋弄には徒袋しない侍の逼读をユ〖ザ〖に涂えます。たとえば、ドメインメ〖ルル〖タ〖が 48 箕粗にわたって久己した眷圭、インタ〖ネット惧の戮の MTA ル〖タ〖がそのドメイン案てのメ〖ルを瘦积します。ある箕爬で、サ〖バ〖がオンラインに牲耽したときに (うまくいけば DoS による俱巢を减けることもなく)、そのメ〖ルが芹慨されます。さらに、すべてのユ〖ザ〖をフェイルオ〖バ〖リモ〖トサイトに肋年していない眷圭は、MTA が弹瓢して肋年されていないユ〖ザ〖に滦して笔鲁弄なエラ〖 (バウンス) が手されます。呵稿に、すべてのユ〖ザ〖を减け掐れるようにメ〖ルを肋年している眷圭は、すべてのユ〖ザ〖をフェイルバックするか、フェイルオ〖バ〖がアクティブな粗蝗脱できないアカウント案てのメ〖ルを瘦积し、フェイルバックが弹こったらそれを塑丸の芹慨の萎れに提すように MTA ル〖タ〖を肋年する涩妥があります。
雇えられるリモ〖トサイトフェイルオ〖バ〖のソリュ〖ションには、笆布のようなものがあります。
- 帽姐でコストのかからないシナリオ : リモ〖トサイトの儡鲁に弓掠拌升の络惮滔ネットワ〖クを蝗脱しません。浇尸な惮滔のハ〖ドウェアを涩ずしも蝗脱する涩妥はありません。悸狠のところ、ハ〖ドウェアは碰烫の粗は戮の誊弄に蝗脱できます。プライマリサイトからのバックアップがリモ〖トサイトに滦して年袋弄に捏丁されますが、涩ずしも牲傅の涩妥はありません。徒鳞される啼玛爬としては、概いデ〖タをオンラインに提す狠に脚妥なデ〖タが己われたり、かなりの觅れが栏じることです。プライマリサイトで俱巢が券栏したときには、缄瓢でネットワ〖クを恃构してサ〖ビスを倡幌し、鲁いて imrestore プロセスを倡幌します。サ〖ビスが弹瓢されると、ファイルシステムの牲傅が倡幌されます。
- より剩花で、コストのかかるソリュ〖ション : Veritas および Sun の辉任ソフトウェアソリュ〖ションでは、ロ〖カル (プライマリ) ボリュ〖ムで券栏するすべての今き哈みがリモ〖トサイトにも今き哈まれます。奶撅の澜墒では、リモ〖トサイトはプライマリサイトと鼎にロックステップかそれに夺い觉轮になります。プライマリサイトで俱巢が券栏した眷圭は、セカンダリサイトがネットワ〖ク肋年をリセットし、デ〖タをほとんど己うことなくサ〖ビスを捏丁できます。このシナリオでは、テ〖プから牲傅する罢蹋はありません。プライマリサイトの俱巢の涟に磊り仑えられなかったデ〖タは、警なくともフェイルバックが弹きるか、MTA キュ〖デ〖タの眷圭には缄瓢による拆掐が乖われるまで、己われることになります。Veritas Site HA ソフトウェアは、プライマリサイトの俱巢を浮叫し、ネットワ〖クをリセットしてサ〖ビスを弹瓢する脱庞でよく蝗われますが、これはより光いレベルのデ〖タ瘦瓷には涩妥ありません。サ〖バ〖がデ〖タをコピ〖するのに砷操と略ち箕粗が络きく笼裁するため、このソリュ〖ションにはプライマリサイトで络翁のハ〖ドウェアを涩妥とします。
- 呵も悸附拉の光いソリュ〖ション : このソリュ〖ションでは、デ〖タのコピ〖がメッセ〖ジストアサ〖バ〖で乖われることを近いて、ソフトウェアによるリアルタイムデ〖タコピ〖ソリュ〖ションと塑剂弄には票じものです。泣惟デ〖タシステムズ (HDS) のアレイがこの怠墙を积っています。泣惟のアレイには、呈羌サ〖バ〖にほとんど、あるいはまったく逼读を涂えずに、アレイ粗でこのデ〖タコピ〖を悸乖する怠墙があります。HDS のアレイはサイズが络きく、このソリュ〖ションを瞥掐するための答塑コストも、Sun StorEdgeTM T3 や 3000 のアレイよりも光くつきます。さらに、HDS をフルに网脱したとしても、M バイトあたりのコストも光くなります。络推翁のストレ〖ジが涩妥な眷圭は、サ〖バ〖ハ〖ドウェアを泪腆するために HDS がコピ〖借妄を乖うことを钓材すれば、ストレ〖ジの纳裁コストを、警なくともある镍刨までは拇腊できます。
ハ〖ドウェアやソフトウェアをはじめ、瓷妄コスト、排蜗锐、各钱锐、ネットワ〖クコストまで、これらのソリュ〖ションでは、さまざまなコストが券栏します。これらのコストはすべてそのまま纷换に掐れて、眶机をはじき叫します。そうしなければ、めったに弹こらない借妄を悸乖するときの蛔いがけない锐脱や、匿贿箕粗による木儡のコスト、デ〖タ禄己によるコストなど、いくつかのコストを换叫するのが氦岂になります。このような硷梧のコストを赖澄に换年するのは稍材墙です。杠狄によっては、匿贿箕粗とデ〖タの禄己は洛浸が光くつくか、まったく减け掐れられません。その戮の杠狄にとっては稍帖谗笆惧のものではないでしょう。
リモ〖トサイトフェイルオ〖バ〖を乖う眷圭には、リモ〖トディレクトリが警なくとも呵糠のもので、メッセ〖ジデ〖タの牲傅が材墙な觉轮にあることも涩妥です。リモ〖トサイトにリストアメソッドを蝗脱する眷圭は、ディレクトリが窗链に牲傅されてからメッセ〖ジを牲傅する涩妥があります。また、ユ〖ザ〖をシステムから猴近した眷圭、ディレクトリ柒でそのユ〖ザ〖に痰跟のタグがつけられるだけなのはやむをえません。ユ〖ザ〖のデ〖タがあるメッセ〖ジバックアップテ〖プが蝗脱される嘎り、そのユ〖ザ〖をディレクトリから猴近してはなりません。
リモ〖トサイトフェイルオ〖バ〖についての剂啼
笆布の剂啼を徊雇にして、リモ〖トサイトフェイルオ〖バ〖の纷茶を惟ててください。
寥骏によっては、プライマリサイトで俱巢が券栏したときに、缄瓢借妄のスクリプトセットで浇尸滦炳材墙な眷圭もあります。没箕粗 (眶尸粗) のうちにリモ〖トサイトがアクティブになる涩妥がある寥骏もあります。そのような寥骏では、Veritas リモ〖トサイトフェイルオ〖バ〖ソフトウェアかそれに陵碰する怠墙を积ったその戮のソフトウェアが涩妥です。