7 Transforms Nodes
A Transforms node performs one or more transformations on the table or tables identified in a Data node. Transformations are available in the Transforms section of the Components pane. The Evaluate and Apply Data nodes must be prepared in the same way that build data was prepared.
7.1 Aggregation
Aggregation is the process of consolidating multiple values into a single value. For example, you could aggregate sales in several states into sales for a region that consists of several states.
To preform aggregation use an Aggregate node. These topics describe Aggregate nodes:
See Also:
"About Parallel Processing"7.1.1 Creating Aggregate Nodes
To define an aggregation, you must identify a Data Source node and columns to aggregate.
-
Identify or create the node to aggregate. The node can be any node that provides a data flow, including Data Source nodes.
-
If the Components window is not open, then go to View and click Components. Expand the Transforms section.
-
Click Aggregate. Move the cursor to the workflow and click again.
-
Connect the Data Source node to the Aggregate node:
-
Right-click the Data Source node and click Connect.
-
Draw a line to the Aggregate node and click again.
-
-
Right-click the Aggregate node and click Edit.
-
Right-click the Aggregate node and click Run. Monitor the running of the node in the Workflow Jobs. If the Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs.
-
After the running of the node is complete, right-click the Aggregate node and select View Data to view the results of the aggregation.
See Also:
"Editing Aggregate Nodes"7.1.2 Editing Aggregate Nodes
You can define and edit aggregation elements of an Aggregate node in the Edit Aggregate Node dialog box.
To edit an Aggregate node:
-
Double-click or right-click the node and click Edit.
-
To select the Group By columns or Group By expression, click Edit. The Edit Group By dialog box opens.
-
You can define the following:
-
To use the Aggregation Wizard, click
 . The Define Aggregation wizard opens. You can add aggregations one by one.
. The Define Aggregation wizard opens. You can add aggregations one by one. -
To edit an already defined aggregation column, select the aggregation element and click
 . The Edit Aggregate Element dialog box opens.
. The Edit Aggregate Element dialog box opens. -
To delete aggregation columns, click
 .
. -
To add aggregation columns, click
 . The Add Column Aggregation dialog box opens.
. The Add Column Aggregation dialog box opens. -
To add custom aggregations (an expression), click
 . The Add Custom Aggregation dialog box opens.
. The Add Custom Aggregation dialog box opens.
-
-
When defining the aggregations is complete, click OK.
See Also:
7.1.2.1 Edit Group By
Default Type: Column
You can change the Type to: Expression
-
If Type is
Column,then select one or more columns in the Available Attributes list. You can search the list by name or by data type. Move the selected columns to the Selected Attributes list using the arrows. -
If the Type is
Expression,then type an appropriate expression in the Expression box.
Click Validate to validate the expression.
After you are done, click OK.
7.1.2.2 Define Aggregation
You can define aggregations using the Define Aggregations wizard.
To define aggregations:
-
Define the Function to use for aggregation. Available functions depend on the data type of the column that you are aggregating.
For example, you can selectSUMif you plan to aggregate one or more columns of numeric values.Click Next.
-
Select one or more Columns to aggregate. You must select columns with a data type compatible with the function that you selected.
For example, if the function isSUM,you must select columns that have numeric data types.Click Next.
-
Optionally, select a Sub-Group By column for aggregation. Specifying a Sub-Group By column creates a nested table.
For example, you could use sub-group by to calculate amount sold per product per customer. The nested table contains columns with data typeDM_NESTED_NUMERICALS.You can select a Sub Group By expression by changing
TypetoExpression.If you define an Expression, click Validate to validate the expression.Click Next.
-
Review the default names for the columns. You can change the names.
-
Review the definitions if necessary. You can click Back to make changes.
-
After you are done, click Finish.
7.1.2.3 Edit Aggregate Element
You can define or modify the individual elements of an aggregation. To define or modify the individual element:
-
In Output, you can provide a name. To provide a name, deselect Auto Generate and enter a name. By default, Auto Generate is selected.
Output is the name of the column that holds the results of the aggregation. -
Select or change the Column that is being aggregated.
-
Select the function to apply to the column. The functions available depend on the data type of the column.
-
Click Edit to define a new Sub-Group By column. The Edit Group By dialog box opens.
-
Once done, click OK.
See Also:
"Define Aggregation" for more information about Sub-Group By.7.1.2.4 Add Column Aggregation
You can define how a column is aggregated.
To add an attribute:
-
Click
. -
To provide a name, deselect Auto Generate and type in the name. By default, Auto Generate is selected.
Output is the name of the column that holds the results of the aggregation. -
Select Columns to aggregate from the list.
-
Select the Function to apply to the column. The functions available depend on the data type of the column. For example, you can specify average (AVG) for a numeric value.
-
To define a Sub Group By column, click Edit. The Edit Group By dialog box opens. It is not necessary to define a Sub Group By column.
-
After you are done, click OK.
See Also:
-
"Add Custom Aggregation" for information about how to create a custom aggregation.
-
"Define Aggregation" for more information about Sub-Group By.
7.1.2.5 Add Custom Aggregation
To add a custom aggregation, click ![]() and follow these steps:
and follow these steps:
-
Output is the name of column that holds the results of the aggregation. Specify a name.
-
Expression is the expression to add. To define an expression, click
to open Expression Builder.This expression calculates all products bought by a customer and casts the result to a nested data type:
CAST (COLLECT (TO_CHAR (PROD_ID)) AS ODMR_NESTED_VARCHAR2)
-
To define a Sub Group By column, click Edit. The Edit Group By dialog box opens.
It is not necessary to define a Sub Group By column. -
Click Validate to validate the expression.
-
After you are done, click OK.
See Also:
7.1.3 Aggregate Node Properties
To view the Properties pane, select the node. If the Properties pane is closed, then go to View and click Properties. Alternately, right-click the node and select Go to Properties from the context menu.
The Aggregate Node Properties pane has these sections:
See Also:
"Editing Aggregate Nodes" for more information about how to edit the columns.7.1.3.1 Cache
The default setting is to not generate the cache to optimize the viewing of results.
You can generate the cache. If you generate the cache, then specify the sampling size as either:
-
Number of rows. The default is 2000 rows
-
Percent. The default is 60 percent
7.1.4 Aggregate Node Context Menu
The Aggregate node context menu contains these entries:
-
Edit. See "Editing Aggregate Nodes" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed only if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.2 Data Viewer
You can view data when the Transform node is in a valid state.
To view data, right-click the node and select View Data from the context menu. The data viewer opens.
The data viewer has these tabs:
7.2.1 Data
The Data tab displays a sample of the data. The Data Viewer provides grid display of rows of data either from the sampling defined in the cache or pulled through the lineage of nodes back to the source tables.
The display is controlled with:
-
Refresh: To refresh the display, click
 .
. -
View: Enables you to select either Cached Data or Actual Data.
-
Sort: Displays the Select Column to Sort By dialog box.
-
Filter: Enables you to type in a
WHEREclause to select data.
7.2.1.1 Select Column to Sort By
The Select Column to Sort By dialog box enables you to:
-
Select multiple columns to sort.
-
Determine the column ordering.
-
Determine ascending or descending order by column.
-
Specify
Nulls Firstso that null values appear ahead of real data values.
The sort order is preserved until you clear it.
Column headers are also sort-enabled to provide a temporary override to the sort selection.
7.2.3 Columns
The Column tab is a list of all the columns that are output from the node. The display in the tab depends on the following conditions:
-
If the node has not run, then the Table or View structure provided by the database is displayed.
-
If the node has run successfully, then the structure of the sampled table is displayed. This is based on the sampling defined when the node was specified.
For each column, the following are displayed:
-
Name
-
Data type
-
Mining type
-
Length
-
Precision
-
Scale (for floating point)
-
Column ID
There are several filtering options that limit the columns displayed. The filter settings with the (or)/(and) suffixes allow you to enter multiple strings separated by spaces. For example, if the Name/Data Type/Mining Type(or) is selected, then the filter string A B produces all columns where the name or the data type or the mining type starts with the letter A or B.
7.2.4 SQL
In the SQL tab, the SQL Details text area displays the SQL code that generated the data provided by the actual view displayed in the Data tab.
The SQL can be a stacked expression that includes SQL from parent nodes, depending on what lineage is required to access the actual data.
You can perform the following tasks:
-
Copy and run the SQL query in a suitable SQL interface. The following options are enabled:
-
Select All (Ctrl+A)
-
Copy (Ctrl+C)
-
-
Search texts. The Search control is a standard search control that highlights matching text and searches forward and backward.
7.3 Expression Builder
Expression Builder helps you to enter and validate SQL expressions, such as constraints for filters. An expression is a SQL statement or clause that transforms data or specifies a restriction. Expression Builder displays the available columns, provides a selection of functions and commonly used operators, and validates expressions.
To build and validate expressions in Expression Builder:
-
Click
in the Add Custom Transform dialog box. The Expression Builder dialog box opens. -
The Expression Builder dialog box has the following components:
-
Attributes tab: Lists attributes (columns) in the source data. To insert an attribute into the query that you are creating in the Expression box, or to replace characters that you selected, double-click the attribute at the current character position.
-
Functions tab: Lists the commonly used SQL Functions, divided into folders. Double-click a folder to view the functions listed there. To insert a function into the expression at the current character position or to replace characters that you selected, double-click the function.
-
Expression box: The expression that you create is displayed in the Expression box. You can create an expression in any one of the following ways:
-
Type the expression in the Expression box directly.
-
Add Attributes and Functions by double-clicking them in the Attributes tab and the Functions tab respectively.
To add an operator into the expression, click the operator.
-
-
Commonly used operators are listed in below the Expression box. Click the appropriate operator, indicated by its symbols. If you prefer, you can enter an operator directly into the Expression box. Table 7-1 lists the operators that you can enter:
Table 7-1 Commonly Used Operators
To Enter this Operator Click Less than
<
Greater than
>
Less than or equal to
... for the symbol <=
Greater than or equal to
... for the symbol >=
Not equal to
!=
Equal to
=
Or (Logical Or)
...
And
...
Left parenthesis
(
Right parenthesis
)
Parallel symbol
||
Add
+
Minus
-
Multiply
*
Divide
/
Percent
%
-
Validation Results text area (read-only): Displays the validation results.
-
Validate: Click Validate to validate the expression in the Expression box. The results appear in Validation Results.
-
-
When you have finished creating the expression, click OK.
7.3.1 Functions
Expression Builder includes a variety of functions that can be applied to character, numeric, and date data. There are functions that support most of the common data preprocessing required for data mining, including missing values treatment. To see a list of the available functions, expand the category of interest.
Functions are divided into the following categories:
-
Character: Includes concatenate, trim, length, substring, and others.
-
Conversion: Converts to character, date, number, and others.
-
Date: Calculates next day, inserts time stamp, truncates, rounds, and performs other date operations.
-
Numeric: Includes functions such as absolute value, ceiling, floor, trigonometric functions, hyperbolic functions, logarithms, and exponential values.
-
Analytical: Performs analytical functions.
-
NULL Value Substitution: For dates, characters, and numbers.
The notation for the functions is that of SQL.
See Also:
Oracle Database SQL Language Reference7.4 Filter Columns
Filter Columns filters out columns so that the columns are not used in subsequent workflow calculations. For example, you might want to filter out or ignore columns that have more than 94 percent Null values.
Optionally, you can identify important attributes.
Filter Columns requires analysis after it runs. The transformation makes recommendations. You can decide which recommendation to accept.
Filter Columns can run in parallel.
These topics describe Filter Columns nodes:
7.4.1 Creating Filter Columns Node
Before you define filter columns, you must identify a Data Source node and decide whether to find important attributes. To define Filter Columns:
-
Identify or create the node to filter. The node can be any node that provides a data flow, including Data Source nodes.
-
In the Component pane, expand the Transform section.
If the Components pane is not open, then go to View and click Components. -
Click Filter Columns. Move the cursor to the workflow and click again.
-
Connect the Data Source node to the Filter Columns node:
-
Right-click the Data Source node, and select Connect.
-
Draw a line to the Filter Columns node and click again.
-
-
Right-click the filter columns node and click Edit.
-
Right-click the Filter Columns node and click Run. Monitor the running of the node in Workflow Jobs.
If the Workflow Jobs is not open, then in View, go to Data Miner and click Workflow Jobs. -
After the running of the node is complete, right-click the Filter Columns node and select View Data to view the results of the filtered columns.
After you examine the hints, you may want to filter out additional columns.
See Also:
"Editing Filter Columns Node"7.4.2 Editing Filter Columns Node
You can define or edit the filter performed by the Filter Columns node. You can perform the following tasks:
-
Exclude Columns when you first edit the Filter Columns node.
-
Edit or view Define Filter Columns Settings when you first edit the Filter Columns node.
-
Calculate important attributes. Click Settings to enable Attribute Importance.
-
Evaluate hints and decide which columns to filter out. Additional information is available in the form of Hints after the Filter Columns node runs.
7.4.2.1 Exclude Columns
By default, all columns are selected for output, that is, all columns are passed to the next node in the workflow.
-
To exclude a column, click
 . The arrow is crossed out, indicated by
. The arrow is crossed out, indicated by  . The excluded column is ignored, that is, it is not passed on.
. The excluded column is ignored, that is, it is not passed on. -
To view or change settings, click Settings. The Define Filter Columns Settings dialog box opens.
7.4.2.2 Define Filter Columns Settings
You can create and edit Filter Columns settings here. There are three kinds of settings:
-
Data Quality: Allows Filter Columns settings in terms of percent age of null values, percentage of values that are unique, and percentage of constants. The default values for Data Quality are specified in preferences. You can change the default.You can specify the following Data Quality criteria:
-
% Nulls less than or equal: Indicates the largest acceptable percentage of Null values in a column of the data source. You may want to ignore columns that have a larger percentage of Null values. The default value is 95 percent.
-
% Unique less than or equal: Indicates the largest acceptable percentage of values that are unique in a column of the data source. If a column contains many unique values, then it may not contain useful information for model building. The default value is 95 percent.
-
% Constant less than or equal: Indicates the largest acceptable percentage of constant values in a column of the data source. If most of the values in a column is the same, the column may not be useful for model building.
-
-
Attribute Importance: Enables you to build an Attribute Importance model to identify important attributes.
By default, this setting is turned OFF. Filter Columns does not calculate Attribute Importance. -
Sampling: Enables Filter Column settings according to the default size for random sample for calculating statistics. The default values for sampling are specified in preferences. You can change the default or even turn off sampling. The default sample size is 2000 records.
See Also:
-
"Attribute Importance" for information about how to find important attributes.
7.4.2.3 Performing Tasks After Running Filter Columns Node
After running the Filter Columns Node, you can perform the following tasks:
-
View hints: To view hints, double-click the Filter Columns node. The Edit Column Filter Details Node dialog box displays hints, to indicate attributes that did not pass the data quality checks. For more information, click
.-
Summary information is displayed about data quality.
-
Values are indicated graphically in the Data Viewer.
If you specified Attribute Importance:
-
Hints indicate attributes that do not have the minimum importance value.
-
The importance of each column is displayed.
-
-
Exclude columns: Go to the Output column for the attribute and click
. The icon in the Output column changes to . The selected columns are ignored or excluded, which means that the columns are not for subsequent nodes. It is not necessary to run the nodes again. -
Accept recommendations:
-
For several recommendations, select the attributes and click
 .
. -
For all recommendations, type Ctrl+A and click
.
-
-
Apply recommended output settings: Attributes that have Hints are not passed on. Attributes that have no hints are not changed and they are passed on.
-
Create a Table or View node: The output of this node is a data flow. To create a table containing the results, use a Create Table or View Node.
7.4.2.4 Columns Filter Details Report
After the node runs, the Columns Filter Details Report is generated in the Edit Column Details dialog box. Columns of the grid summarize the data quality information.
The default settings show both Attribute Importance and Data Quality.
-
When Attribute Importance is selected, the following are displayed:
-
Rank
-
Importance
-
-
When Data Quality is selected, the following columns are displayed:
-
% Null
-
% Unique
-
% Constant
-
The Hints column in the grid indicates the columns in the data set that do not pass data quality or do not meet the minimum importance value.
Bar graphs give a visual indication of values.
For example, if the percentage of Null values is larger than the value specified for % Nulls less than or equal, a hint is generated that indicates that the percentage of Null values is exceeded. If the percent of NULL values is very large for a column, you may want to exclude that column.
7.4.2.5 Attribute Importance
If a data set has many attributes, it is likely that not all attributes contribute to a predictive model. Some attributes may simply add noise, that is, they actually detract from the predictive value of the model. Oracle Data Miner ranks the attributes by significance in determining the target value. You can then filter out attributes that are not important in determining the target value.
Using fewer attributes does not necessarily result in loss of predictive accuracy. Using too many attributes, can affect the model and degrade its performance and accuracy. Mining using the smallest number of attributes can save significant computing time and may build better models.
The following are applicable for Attribute Importance:
-
Attribute Importance is most useful with Classification.
-
The target for Attribute Importance in Filter Column should be the same as the target of the Classification model that you plan to build.
-
Attribute Importance calculates the rank and importance for each attribute.
-
The rank of an attribute is an integer.
-
The Importance of an attribute is a real number, which can be negative.
-
Specify these values for attribute importance:
-
Target: The value for which to find important attributes. Usually the target of a classification problem.
-
Importance Cutoff: A number between 0 and 1.0. This value identifies the smallest value for importance that you want to accept. If the importance of an attribute is a negative number, then that attribute is not correlated with the target, so the cutoff should be nonnegative. The default cutoff is 0. The rank or importance of an attribute enables you to select the attribute to be used in building models.
-
Top N: The maximum number of attributes. The default is 100.
-
Select a Sample technique for the Attribute Importance calculation. The default is system determined. You can also select Stratified or Random.
System determined has a stratified cutoff value with a default value of 10.
-
If the distinct count of the selected column is greater than the cutoff value, then use random sampling.
-
If the distinct count of the selected column is less than or equal to the cutoff value, then use stratified sampling.
Certain combinations of target and sampling may result in performance problems. You are given a warning if there is a performance problem.
-
7.4.2.5.1 Attribute Importance Viewer
To view an Attribute Importance model, build a Filter Columns node with Attribute Importance selected. Right-click the node and select View Data. Results are displayed in a new Filter Columns Details tab. The viewer has these tabs:
-
Attribute Importance: Lists those attributes with Importance greater than or equal to 0. Attributes are listed in order of rank from lowest rank (most important) to highest rank. The tab also displays the data type of each attribute. A blue bar indicates the rank. You can sort any of the columns by clicking the column heading.
-
To filter columns, that is, to limit the number of columns displayed, use
 .
. -
To clear filter definition, click
. You can also search by name, type, rank or importance.
-
-
Data: Lists the important attributes in order of importance, largest first. For each attribute rank and importance, values are listed. Only those attributes with an importance value greater than or equal to 0 are listed.
-
Columns: Displays the columns created by Attribute Importance, that is attribute name, rank, and importance value.
-
SQL: This is the SQL that generates the details.
7.4.2.6 Specifying Values for Attributes Importance
Specify the following values for Attribute Importance:
-
Target: The value for which to find important attributes. Usually the target of a classification problem.
-
Importance Cutoff: A number between 0 and 1.0. This value identifies the smallest value for importance that you want to accept. If the importance of an attribute is a negative number, then that attribute is not correlated with the target, so the cutoff should be nonnegative. The default cutoff is 0. The rank or importance of an attribute enables you to select the attribute to be used in building models.
-
Top N: The maximum number of attributes. The default is 100.
-
Select a Sample technique for the Attribute Importance calculation. The default is system determined. You can also select Stratified or Random.
-
The system determined technique has a stratified cutoff value with a default of 10.
-
If the distinct count of the selected column is greater than the cutoff value, then use random sampling.
-
If the distinct count of the selected column is less than or equal to the cutoff value, then use stratified sampling
-
-
Certain combinations of target and sampling may result in performance problems. You are given a warning if there is a performance problem.
7.4.3 Filter Columns Node Properties
To view the Properties pane:
-
Select the Filter Column node.
-
The Properties pane of the node is displayed in the Properties tab. If the Properties tab is not visible, then go to View and click Properties. Alternately, right-click the node and select Go to Properties.
Filter Columns Node Properties has these sections:
-
Columns: Displays the columns of the data source. After the node runs, hints are displayed.
-
Filters: The specifications created with Define Filter Columns Settings.
7.4.4 Filter Columns Node Context Menu
The Filter Columns node context menu contains these entries:
-
Edit. See "Editing Filter Columns Node" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.5 Filter Columns Details
Filter Columns Details creates a data flow that consists of the result of Attribute Importance. For each attribute, the rank and importance values are listed.
Note:
Filter Columns Details must be connected to a Filter Columns Node that has Attribute Importance selected in Settings. Otherwise, the Filter Columns Details node is Invalid.Filter Columns Details can run in parallel.
This section consists of the following topics:
See Also:
"About Parallel Processing"7.5.1 Creating the Filter Columns Details Node
Before creating the Filter Columns Details node, you must identify a Filter Columns node, where Attribute Importance is selected in the Settings.
To create a Filter Columns Details node:
-
Identify or create the node to filter. You can only connect a Filter Columns node where Attribute Importance was calculated.
-
In the Components pane, expand the Transforms section.
If the Components pane is not open, then go to View and click Components. -
Click Filter Columns Details. Move the cursor to the workflow and click again.
-
Connect the Filter Columns node to the Filter Columns Details node:
-
Right-click the Filter Columns node, and select Connect.
-
Draw a line to the Filter Columns Details node and click again.
-
-
You can right-click the Filter Columns Details node and select Edit. In this release there are no options to select.
-
Right-click the Filter Columns Details node and select Run. Monitor the running of the node in the Workflow Jobs.
If the Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs. -
After the running of the node is complete, right-click the Filter Columns Details node and select View Data to view the results.
The output of this node is a data flow. To create a table containing the results, use a Create Table or View Node.
Note:
Filter Columns Details consists of the results of Attribute Importance only. It does not contain any information about Data Quality.7.5.2 Editing the Filter Columns Details Node
The Attribute Importance option is the only option available.
7.5.3 Filter Columns Details Node Properties
To view the properties of Filter Columns Details node:
-
Select the Filter Columns Detail node.
-
The properties of the node is displayed in the Properties tab. If the Properties tab is not visible, then go to View and click Properties. Alternately, right-click the node and select Go to Properties.
The Filter Columns Node Properties has these sections:
7.5.4 Filter Columns Details Node Context Menu
The filter columns details node context menu contains these options:
-
Edit. See "Editing the Filter Columns Details Node" for more information.
-
View Data. See "Attribute Importance Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.6 Filter Rows
A Filter Rows node enables you to select rows by specifying a SQL statement that describes the rows.
For example, to select all rows where CUST_GENDER is F, specify:
CUST_GENDER = 'F'
You can either write the SQL expression directly or use Expression Builder.
Filter Rows can run in parallel
This section consists of the following topics:
See Also:
"About Parallel Processing"7.6.1 Creating a Filter Rows Node
Prerequisite:
Identify a Data Source node. Identify or create the node to filter. The node can be any node that provides a data flow, including Data Source nodes.
To define a Filter Rows node:
-
In the Components pane, expand the Transform section.
If the Components pane is not open, then go to View and click Components. -
Click Filter Rows. Move the cursor to the workflow and click again.
-
Connect the Data Source node to the Filter Rows node:
-
Move the cursor to the Data Source node.
-
Right-click the Data Source node, and select Connect.
-
Drag the line to the Filter Rows node and click again.
-
-
Right-click the Filter Rows node and select Edit. Use the Edit Filter Rows dialog box to define the filter.
-
Right-click the Filter Rows node and select Run. Monitor the running of the node in the Workflow Jobs.
If the Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs. -
After the running of the node is complete, right-click the Filter Rows node and select View Data to view the results of the Filter Rows.
7.6.2 Edit Filter Rows
The Edit Filter Rows dialog box defines or edits the filter performed by the Filter Rows node.
The Edit Filter Rows dialog has two tabs:
7.6.2.1 Filter
The filter is one or more SQL expressions that describe the rows to select.
To create or edit a filter:
-
Open the Expression Builder by clicking
. -
Write the SQL query to use for filtering.
-
After specifying an expression, you can delete it. Select it and click
. -
After you are done, click OK. Data Miner validates the expression.
Either type the SQL expression or use Expression Builder to define it.
7.6.2.2 Columns
This tab lists the output columns. You can Filter in several ways.
Click OK when you have finished. Data Miner validates the expression.
7.6.3 Filter Rows Node Properties
To view the properties of the Filter Rows node:
-
Select the Filter Rows node.
-
The properties of the node is displayed in the Properties tab. If the Properties tab is not visible, then go to View and click Properties. Alternately, right-click the node and select Go to Properties.
The Filter Rows node Properties tab has these sections:
-
Filter: The SQL expression created with Edit Filter Rows. You can modify the expression in the Properties by clicking
. -
Columns: The output data columns. For each column, name, alias (if any), and data types are listed.
7.6.4 Filter Rows Node Context Menu
The Filter Rows node context menu contains these options:
-
Edit. See "Edit Filter Rows" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.7 Join
A Join node combines data from two or more Data Source nodes into a new data source.
Technically, a Join node is a query that combines rows from two or more tables, views, or materialized views. For example, a Join node combines tables or views (specified in a FROM clause), selects only rows that meet specified criteria (WHERE clause), and uses projection to retrieve data from two columns (SELECT statement).
Join can run in parallel.
This section contains the following topics:
See Also:
7.7.1 Create a Join Node
A Join node requires you to specify two or more Data Source nodes and at least one output column.
Joins are sometimes very slow. If you materialize the join input as an indexed table, then the join may be much faster.
The output of Join is a data flow. To materialize it as a table or view, connect it to a Create Table or View node.
Follow these steps to join two or more Data Source nodes:
-
Identify or create at least two nodes to join. The nodes can be any nodes that provide a data flow, including Data Source nodes.
-
In the Components pane, expand the Transform node.
If the Components pane is not open, then go to View and click Components. -
Drag and drop the Join node from the Components pane to the Workflow pane. This adds the Join node to the workflow.
-
Connect the Data Source nodes to be joined to the Join node:
-
Move the cursor to one of the nodes to join.
-
Right-click the node, and select Connect.
-
Draw a line to the Join node and click again.
-
Repeat until all nodes to join are connected to the Join node.
-
-
Right-click the Join node and select Edit. Use the Edit Join Node option to define the Join node.
-
Right-click the Join node and select Run. Monitor the running of the node in the Workflow Jobs.
If the Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs. -
After the running of the node is complete, right-click the Join node and select View Data to view the results of the join.
You can also define the join and view results through the Join Node Properties.
7.7.2 Edit a Join Node
You can define a Join node in one of the following ways:
-
Either double-click the Join node, or right-click the node and select Edit. Click the Join tab.
-
Select the node. In the Properties pane, select the Join tab. Click
.
In either case, the Edit Join Node dialog box opens.
7.7.2.1 Edit Join Node
Click the Join tab if it is not displayed. In the Edit Join Node dialog box, you can perform the following tasks:
-
To add a new Join column, click
. The Edit Join Column dialog box opens.-
In the Edit Join Column dialog box, select the Data Sources—Source 1 and Source 2. You can search columns in either Source by Name or by Data Type.
-
Select one entry in Source 1 and the corresponding entry in Source 2.
-
Click Add. Data Miner selects an appropriate Join Type.
Column 1 (from Source 1), Column 2 (from Source 2), and the Join type are displayed in a grid. You can search this grid by Column 1, Column 2, or Join Type. -
After you are done, click OK.
-
-
To select the columns in the Join, click the Columns tab to display Edit Columns dialog box.
-
To define a filter for the Join, select the Filter tab and enter an appropriate SQL expression. You can also use SQL Worksheet (part of SQL Developer) to write a filter.
If there are problems with the join, for example, if one of the data nodes is no longer connected to the Join node, then an information indicator is displayed as follows:
Click the Resolve Issues. This opens the Resolve dialog box.

Description of the illustration resolvejoin.gif
7.7.2.2 Edit Columns
The default setting is to use Automatic Settings for the list of columns displayed. To select columns, go to the Columns tab of Edit Joins Details in one of the following ways:
-
Right-click the Join node and select Edit. Click the Columns.
-
Select the Join node. In the Properties pane, click the Columns.
To make changes, deselect Automatic Settings. You can perform the following tasks:
-
Edit the list of columns: Open the Edit Output Data Column dialog box and click
 .
. -
Delete a column from the output: Select the column and click
.
If the node was run, you must run it again.
7.7.2.3 Edit Output Data Column
The default setting is to include all columns from both tables in the output.
To remove a column from the output:
-
Move the columns from the Selected Attributes list to the Available Attributes list.
-
Click OK.
7.7.2.4 Resolve
When a Data Source node is disconnected from a Join node, all the join specifications for that node are retained and are marked as Invalid. Before you run the Join node, you must resolve the issues.The Resolve dialog box provides two ways to resolve the join issues:
-
Remove: Removes all invalid entries from all specifications (Apply and Data).
-
Resolve: Displays a grid that enables you to associate an unassigned node with a missing node. The missing nodes are listed in the grid, and an action is suggested.
7.7.3 Join Node Properties
To view the properties of a Join node:
-
Select the Join Node.
-
The properties of the node is displayed in the Properties pane. If the Properties pane is not visible, then go to View and click Properties. Alternately, right-click the node and select Go to Properties.
The Properties pane for a Join node has these sections:
-
Join: Defines the Join.
-
Columns: Displays the output columns of the Join.
For each column, name, node, alias (if any) and data type are displayed. Up to 1000 columns are displayed. -
Filter results by defining filter conditions using the Expression Builder. Open the Expression Builder by clicking
.
7.7.4 Join Node Context Menu
The Join node context menu contains these entries:
-
Edit. See "Edit a Join Node" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.8 JSON Query
JSON or JavaScript Object Notation is a data format, that enables users to store and communicate sets of values, lists, and key-value mappings across systems. The support for the JSON data format in Oracle Data Miner (SQL Developer 4.1) is facilitated by the JSON Query node.
The JSON Query node projects the JSON data format to the relational format. It supports only one input data provider node, such as Data Source node. You can perform the following tasks in the JSON Query node:
-
Select any JSON attributes in the source data to project it as relational data.
-
Select relational columns in the source data to project it as relational data.
-
Define aggregation columns on JSON data.
-
Preview output data.
-
Construct a JSON Query based on user specifications.
Note:
JSON Query Node is supported when SQL Developer 4.1 is connected to the Oracle Database 12.1.0.2.7.8.1 Create JSON Query Node
A JSON Query node should be connected to an input provider node, such as a Data Source node. To run the nodes successfully, the input provide node must contain JSON data.
To create a JSON Query node:
-
In the Components pane, go to the Workflow Editor and expand Transform.
If the Components pane is not visible, then in the SQL Developer menu bar, go to View and click Components. Alternately, press Ctrl+Shift+P to dock the Components pane.
-
In the Transforms section, click JSON Query Node.
-
Drag and drop the JSON Query node from the Components pane to the Workflow pane. This adds the JSON Query node to the workflow.
Note:
Ensure that in the workflow there is a Data Source node, which contains JSON data. -
Right-click the node, for example a Data Source node, from which to create the connection and click Connect in the context menu.
-
Draw a line from the selected node to the JSON Query node and click again. This connects the JSON Query node to the Data Source node.
7.8.2 JSON Query Node Editor
In the Edit JSON Query Node dialog box, you can only operate on the input columns that are pseudo JSON types. To open the Edit JSON Query Node dialog box:
-
Double-click the JSON Query node, or
-
Right-click the node and click Edit.
The Edit JSON Query node consists of the following tabs:
7.8.2.1 JSON
You can select JSON data in the JSON tab. In the Columns drop-down list, only the input columns containing JSON data (pseudo JSON data types) are listed. Select an input column from the drop-down list. The data structure of the selected input column is displayed in the Structure tab.
The JSON tab consists of the following:
7.8.2.1.1 Structure
In the Structure tab, the JSON data structure for the selected column is displayed. The structure or the Data Guide table must be generated in the parent source node, for example, Data Source node. If the structure is not found, then a message is displayed to communicate the same.
The following information about the data structure is displayed:
-
JSON Attribute: Displays the generated JSON structure in a hierarchical format. You can select one or more attribute to import. When you select a parent attribute, all child attributes are automatically selected.
-
JSON Data Type: Displays the JSON data types of all attributes, derived from JSON data.
-
Unnest: All attributes inside an array are unnested in a relational format. By default, the Unnest option is enabled. When the Unnest option for an array attribute is disabled, then:
-
The child attributes are displayed but cannot be selected.
-
If the array attribute is selected for output, then the output column will contain JSON representation of the array.
-
7.8.2.1.2 Data
The Data tab displays the JSON data that is used to create the JSON structure. In the text panel, the data is displayed in read-only mode. You can select text for copy and paste operations.
You can query the data to be viewed. To query data, click ![]() .
.
7.8.2.2 Additional Output
In the Additional Output tab, you can select relational columns in the source data for the output. The input columns that are used by the aggregation definitions in the Aggregate tab are automatically added to the list for output.
You can perform the following tasks here:
-
Add relational columns: Click
to add relational columns in the Edit Output Data Column Dialog. -
Delete relational columns: Select the relational columns to delete and click
.
7.8.2.2.1 Edit Output Data Column Dialog
In the Edit Output Data Column dialog box, all the relational columns available in the data source are listed. You can select one or more columns to be added to the output. To add columns:
-
In the Available Attributes list, select the columns that you want to include in the output.
-
Click the right arrow to move the attributes to the Selected Attributes list. To exclude any columns from the output, select the attribute and click the left arrow.
-
Click OK. This includes the columns in the output, and they are listed in the Additional Output tab.
7.8.2.3 Aggregate
You can define aggregation column definitions on JSON attributes in the Aggregate tab. The Aggregate tab displays the information in two sections:
-
Group By Attribute section: Here, the Group By attributes are listed, along with the attribute count. You can perform the following tasks:
-
View JSON Paths: Click JSON Paths to display the attribute name with context information. For example,
$."customers"."cust_id".
If not enabled, then only the attribute name is displayed. -
Edit and Add Attributes: Click
to add Group By attributes in the Edit Group By dialog box. -
Delete Attributes: Select the attributes to delete and click
.
-
-
Aggregate Attributes section: Here, the aggregation columns are displayed along with the column count.
-
View JSON Paths: Click JSON Paths to display the attribute name with context information. For example,
$."customers"."cust_id".
If not enabled, then only the attribute name is displayed. -
Define Aggregations Columns: Click
to define an aggregation column in the Add Aggregations box. -
Delete Aggregation column: Click
to delete selected columns.
-
7.8.2.3.1 Add Aggregations
In the Add Aggregation dialog box, you can define functions for JSON attributes. The dialog box displays JSON structures in a hierarchical view. You can select multiple attributes and then apply an aggregation function to it.
Note:
Object and Array type attributes cannot be selected.You can perform the following tasks:
-
Define aggregation functions:
-
Select the JSON attributes. You can select multiple attributes by pressing the Ctrl key and clicking the attributes for which you want to define functions.
-
Click
 to select and apply a function for the selected attributes. The applicable functions are listed. Select the function that you want to apply.
to select and apply a function for the selected attributes. The applicable functions are listed. Select the function that you want to apply.Alternately, click the corresponding row in the Function column. The applicable functions are listed in a drop-down list. Select the function that you want to apply. Using this option you can define function for only one attribute at a time.
-
Click OK.
-
-
Clear Aggregation Definition: Select the attribute and click
 . The defined function along with the output and Sub Group By entries are deleted.
. The defined function along with the output and Sub Group By entries are deleted. -
Edit Sub Group By Elements: Select the attribute and click
 . The Edit Sub Group By dialog box opens.
. The Edit Sub Group By dialog box opens. -
Search: Click
 to find attribute based on partial attribute name.
to find attribute based on partial attribute name.
7.8.2.3.2 Edit Sub Group By
In the Edit Sub Group By dialog box, you can add Sub Group By attributes to the selected JSON attribute. To add attributes:
-
In the upper pane, expand the Available Attributes folder.
-
Select the attributes that you want to add as Sub Group By attributes. The selected attributes are listed in the lower pane, which also displays the count of attributes that are added.
-
Click OK.
7.8.2.3.3 Edit Group By
The Edit Group By dialog box displays the relational columns above the JSON attribute collection. You can add relational columns as part of the top level Group By. To add relational columns:
-
In the upper pane, expand the Available Attributes folder.
-
Select the columns that you want to add. The selected columns are listed in the lower pane.
-
Click OK.
7.8.2.4 Preview
You can preview the node output in the Preview tab. The output is displayed in two tabs:
7.8.2.4.1 Output Columns
In the Output Column tab, the columns in the header are displayed in a grid format. Click JSON Paths to view source attribute name.
-
If you click JSON Paths, then the source attribute name along with the contextual information is displayed. For example,
$."customers"."cust_id". -
If you do not click JSON Paths, then only the attribute name is displayed. For example,
cust_id.
The following details of the columns are displayed in the Output Columns tab:
-
Name: Displays the output column names
-
Data Type: Displays the data type of the output column
-
Data Source: Displays the source of the attribute name
-
JSON Paths: Displays the attribute source
-
Aggregate: Displays the aggregation function used for the aggregations
-
Group By: Displays the Group By attributes
-
Sub Group By: Displays the Sub-Group By attributes used in the aggregations
7.8.2.4.2 Output Data
In the Output Data tab, the query result of the top N rows is displayed. The query reflects the latest user specifications. The query result is displayed in a grid format.
7.8.3 JSON Query Node Properties
If the Properties pane is closed, then go to View and click Properties. Alternately, right-click the node and select Go to Properties from the context menu.
The JSON Query node Properties pane has these sections:
7.8.3.1 Output
The Output section in the Properties pane displays the Output Columns in read-only mode.
7.8.3.2 Cache
The Cache section provides the option to generate cache for the output data. To generate cache output:
-
Select Generate Cache of Output Data to Optimize Viewing of Results to generate cache output.
-
In the Sampling Size field, select an option:
-
Number of Rows (default): The default sampling size is 2000. Use the arrows to set a different number.
-
Percent: Move the pointer to set the percentage.
-
7.8.3.3 Details
The Details section displays the name of the node and any comments about it. You can change the name and add comments in the fields here:
-
Node Name
-
Node Comments
7.8.4 JSON Query Node Context Menu
The context menu for a JSON Query Node has these selections:
-
Edit. See "JSON Query Node Editor" for more information.
-
View Data
-
Parallel Query. See "About Parallel Processing" for more information.
7.9 Sample
A Sample node enables you to sample data in one of the following ways:
-
Random Sample: A sample in which every element of the data set has an equal chance of being selected.
-
Top N Sample: The default sample that selects the first N values.
-
Stratified Sample: A sample is created as follows:
-
First, the data set is divided into disjoint subsets or strata.
-
Then, a random sample is taken from each subsets.
This technique is used when the distribution of target values is skewed greatly.
For example, the response to a marketing campaign may have a positive target value of 1% of the time or less. -
Sampling nested data is best done with a Case ID.
The Sample node can run in parallel.
This section has the following topics:
7.9.1 Sample Nested Data
Sampling nested data may require a case ID. If you do not specify a case ID, the sample operation may fail for a nested column that is very dense and deep. Failure may occur if the amount of nested data per row exceeds the maximum of 30,000 for a specific column or row.
A case ID also allows Data Miner to perform stratified sorts on data that is dense and deep.
7.9.2 Creating a Sample Node
To specify a sample, you must identify a Data Source node and the details of the sample.
-
Identify or create the node to sample. The node can be any node that provides a data flow, including Data Source nodes.
-
In the Components pane, expand the Transforms section.
If the Components pane is not open, then go to View and click Components. -
Click Sample. Move the cursor to the workflow and click again.
-
Connect the Data Source node to the Sample node:
-
Move the cursor to the Data Source node.
-
Right-click the Data Source node and select Connect from the context menu.
-
Drag the line to the Sample node and click again.
-
-
Either double-click the Sample node, or right-click the Sample node, and click Edit. The Edit Sample Node dialog box opens.
-
Define the sample in the Edit Sample Node dialog box.
-
Right-click the Sample node and click Run. Monitor the running of the node in the Workflow Jobs.
If the Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs. -
After the running of the node is complete, right-click the Sample node and select View Data to view the results of the sample.
See Also:
"Edit Sample Node"7.9.3 Edit Sample Node
The settings describe the type of sample to create and the size of the sample. In the Edit Sample Node dialog box, you can define and edit a sample.
To edit the settings for the Sample node:
-
Open the Edit Sample Node dialog box:
-
Either double-click the Sample node, or right-click the Sample node, and select Edit.
-
Select the node and go to the Settings tab in the Sample node Properties pane.
-
-
In the Edit Sample Node dialog box, you can provide and edit the following details:
-
Sample Size: This is the number of rows in the sample. You can specify the number of rows in terms of:
-
Number of rows (default)
-
Percent. The default is 60 percent.
-
-
Rows: This is the number of rows in the sample. You can change the default value, and enter a different value.
The default is 2000. -
Sample Type: The options are:
-
Random (Default)
-
-
See Also:
"Sample Node Properties"7.9.3.1 Random
For a random sample, specify the following:
-
Seed: The default seed is 2345
You can specify a different integer. -
Case ID (optional): Select a case ID from the drop-down list.
If you specify a seed and a case ID, then the sample is reproducible.
7.9.3.2 Top N
No other specifications are available for Top N.
7.9.3.3 Stratified
For a stratified sample, specify the following:
-
Column: Select the column for stratification.
-
Seed: Default seed=12345
You can specify a different integer. -
Case ID (optional): Select a case ID from the drop-down list.
If you specify a seed and a case ID, the sample is reproducible.
-
Distribution: Specify how the sample is to be created. There are three options:
-
Original: The distribution of the selected column in the sample is the same as the distribution in data source.
For example, if the column GENDER has M as the value for 95 percent of the cases, then in the sample, the value of GENDER is M for 95% of the cases. -
Balanced: The distribution of the values of the column is equal in the sample, regardless of the distribution in the data source.
If the column is GENDER, and GENDER has two values M and F, then 50% of the time the value of GENDER is M. -
Custom: You define how the values of the columns are distributed in the sample. You must run the node once before you define the custom distribution. Click Edit to open the Custom Balance dialog box.
-
The Stratified dialog box displays a histogram of the values of the selected column at the bottom of the window.
To see more details, click View to display the Custom Balance dialog box.
See Also:
"Custom Balance"7.9.3.4 Custom Balance
The Custom Balance dialog box enables you to specify exactly how the selected column is balanced.
You must run the node to collect statistics before you create custom balance. After you run the node, edit it, select Custom Distribution, and click View. The Custom Balance dialog opens:
You can either create custom entries for each value of the stratify attribute, or you can click Original or Balanced to provide a starting point. You can click Reset to reset to the original values.
To create a custom value, select the attribute to change and click ![]() .
.
Change the value in the Sample Count column to the custom value. Press Enter. The new sample is displayed as output in the lower part of the screen. Change as many values as required. Click OK when you have finished.
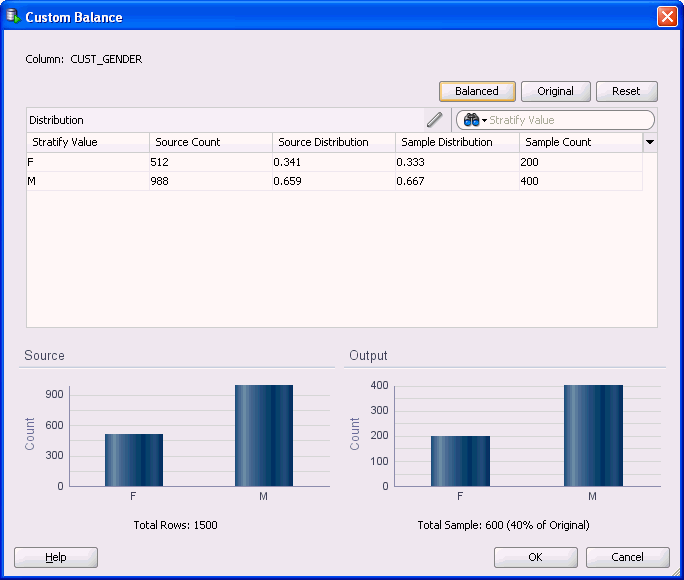
Description of the illustration stratified_custom.gif
7.9.4 Sample Node Properties
To view the properties of a Sample node:
-
Select the Sample node.
-
The properties of the node are displayed in the Properties pane.
If the Properties pane is not visible, then go to View and click Properties. Alternately, right-click the node and select Go to Properties.
The Sample node Properties pane has these sections:
-
Settings: You can specify the following:
-
Sample Size: Select a sample size in terms of:
-
Percent. Default=60%
-
Number of Rows. The default number of rows is 2000.
-
-
Sample Type: The options are:
-
Random (default)
-
-
Seed: The default seed is 12345. You can specify a different integer.
-
Case ID. This is an optional field. Select a case ID from the drop-down list.
If you specify a seed and a case ID, then the sample is reproducible.
-
See Also:
"Edit Sample Node"7.9.5 Sample Node Context Menu
The Sample node context menu has these options:
-
Edit. See "Edit Sample Node" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.
7.10 Transform
A Transform node can use either sampled data or all data to calculate statistics. You can use these statistics as a guide to defining one of several transformation.
These topics describe Transform nodes:
7.10.1 Transforms Overview
A Transform node can use either sampled data or all data to calculate statistics. You can use these statistics as a guide to defining one of several transformation.
The following transformations are supported:
The transformations available depend on the data type of the attribute. For example, normalization cannot be performed on character data.
You define transformation on a per-column basis. After you have defined a transformation, you can transform several columns in the same way.
The Transform node can run in parallel.
To use a Transform node, connect it to a data flow, that is a Data Source node or some other node such as a filtering node that produces attributes. Then select the attributes to transform.
See Also:
"About Parallel Processing"7.10.1.1 Binning
Binning converts the following:
-
A continuous variable into a categorical variable.
-
A continuous value into a continuous value. For example, age can be converted to 10 groups from 1 to 10.
-
A categorical value with many values into a categorical variable with fewer variables.
For example, salary is a continuous variable. If you divide salary into 10 bins, you convert salary into a categorical variable with 10 values, where each value represents a salary range.
You can bin both numbers and character types VARCHAR2 and CHAR.
7.10.1.2 Custom
Custom enables you to compute a new value for a field based on combinations of existing attributes and common function. Use Expression Builder to create the new attribute.
See Also:
"Expression Builder"7.10.1.3 Missing Values
The Missing Values Transform enables you to specify how missing values are treated.
A data value can be missing for a variety of reasons:
-
If the data value was not measured, that is, it has a Null value.
-
If the data value was not answered.
-
If the data value was unknown.
-
If the data value was lost.
Data Mining algorithms vary in the way they treat missing values:
-
Ignore the missing values, and then omit any records that contain missing values.
-
Replace missing values with the mode or mean.
-
Infer missing values from existing values.
7.10.1.4 Normalization
Normalization consists of transforming numeric values into a specific range, such as [–1.0,1.0] or [0.0,1.0] such that x_new = (x_old-shift)/scale. Normalization applies only to numeric attributes.
Oracle Data Miner enables you to specify the following kinds of normalization:
-
Min Max: Normalizes each attribute using the transformation
x_new = (x_old-min)/(max-min) -
Linear Scale: Normalizes each attribute using the transformation
x_new = (x_old-shift)/scale -
Z-Score: Normalizes numeric attributes using the mean and standard deviation computed from the data. Normalizes each attribute using the transformation
x_new = (x-mean)/standard deviation -
Custom: The user defines normalization.
Normalization provides transformations that perform min-max normalization, scale normalization, and z-score normalization.
Note:
You cannot normalize character data.7.10.1.5 Outlier
An Outlier is a data value that is not in the typical population of data, that is, extreme values. In a normal distribution, outliers are typically at least 3 standard deviations from the mean.
You specify a treatment by defining what constitutes an outlier (for example, all values in the top and bottom 5 percent of values) and how to replace outliers.
Note:
Usually, you can replace outliers with null or edge values.For example:
Mean of an attribute distribution=10
Standard deviation=5
Outliers are values that are:
-
Less than -5 (The mean minus 3 times the standard deviation)
-
Greater than 25 (The mean plus three times the standard deviation)
Then, in this case you can either replace the outlier -10 with Null or with 5.
7.10.2 Support for Date and Time Data Types
The Transform Node provides limited support for these data types for date and time:
-
DATE -
TIMESTAMP -
TIMESTAMP_WITH_TIMEZONE -
TIMESTAMP_WITH_LOCAL_TIMEZONE
You can bin date and time attributes using Equal Width or Custom binning. You can apply Statistic and Missing Value transformation with either Statistic or Value treatment.
7.10.3 Creating Transform Node
To specify a transform, you must identify a Data Source node or any other node which provides data, such as the Create Table Node, and the details of the transform.
-
Identify or create the node to transform. The node can be any node that provides a data flow, including Data Source nodes.
-
In the Components pane, expand the Transforms section.
If the Components pane is not open, then go to View and click Components. -
Click Transform. Move the cursor to the workflow and click again.
-
Connect the Data Source node to the Transform node:
-
Move the cursor to the Data Source node.
-
Right-click the Data Source node and select Connect.
-
Drag the line to the Transform node and click again.
-
-
Either double-click the Transform node or right-click it node and select Edit. Use the Edit Transform Node dialog box to define the transform.
-
Right-click the Transform node and select Run. Monitor the running of the node in Workflow Jobs.
If Workflow Jobs is not open, then go to View and click Data Miner. Under Data Miner, click Workflow Jobs. -
After the running of the node is complete, right-click the Transform node and select View Data to view the results of the transform.
See Also:
"Edit Transform Node"7.10.4 Edit Transform Node
You can define and edit the Transform node using the Edit Transform Node dialog box. This dialog box has two tabs:
-
Transformations
-
Statistics
In the Transformation tab, the statistics for each column is displayed. If you do not want to see statistics, then deselect Show Statistics.
Note:
You must run the node to see statistics.You can perform the following tasks in the Transformations tab:
-
Define Transformation: Select one or more original columns, that is, columns that are not transformed. Click
.The Add Transform dialog box opens if you selected one or fewer columns. Otherwise, the Apply Transform Wizard opens.
-
Define Custom Transformation: Select one or more original columns, that is, columns that are not transformed. Click
.The Add Custom Transform dialog box opens. You can add custom transformations here.
The default behavior is to ignore the original column and to use the transformed column as output. The values displayed in the Output column are indicated by:
-
: For a column that is included
-
: For a column that is ignored
-
-
Change Values in the Output Column: Click the icon displayed in the Output column to edit the values in the Add Transform dialog box.
-
Edit Transformed Column: You can edit transformed columns only. For example, you can edit AGE_BIN, but not AGE. To edit transforms, select one or more transformed columns and click
. The Edit Transform dialog box opens if you selected one or fewer columns. -
Delete Transform: Select one or more transformed columns and click
. -
Filter Column: To limit the number of columns displayed, click
. You can search by:-
Output Column
-
Transform
-
Source Column
-
-
Clear filter definition: To clear filter definitions, click
. -
View effects of transform: To view the effect of a transformation:
-
Run the node.
-
After running of the node is complete, double-click the node.
-
Select the transformed column to see histograms that compare the original column with the transformed column.
-
When a column has a transformation applied to it, a new row in the list of columns is generated. Because each column must have a name, the name of the new row is based on the name of the old column and the type of transformation performed. Typically users want to transform a column and only have the output of the transform node contained in the new column. The original column has an option set to prevent it from being passed as one of the output columns. For example, if you bin AGE creating AGE_BIN, then AGE is not passed on and AGE_BIN is passed on.
7.10.4.1 Add Transform
To add a transformation:
-
In the Edit Transform Node dialog box, click
. The Add Transform dialog box opens.
To add a custom transformation, click. -
In the Transform Type field, select a transform type, that is, the type of transformation that you want to define. Default type is Binning.
The field in the Add Transform dialog box depend on the transform type that you select:-
Binning. For binning transformation, enter the details as applicable.
-
-
After you are done, click OK.
See Also:
7.10.4.1.1 Binning
Binning is a transformation type that you can use to:
-
Transform a continuous variable to a discrete one.
-
Transform a variable with large number of discrete values to one with a smaller number of discrete values.
The default transformation type is Binning.
The types of binning supported depend on the data type of the column:
-
For numeric data type
NUMBER,the supported types of binning are:-
Bin Equal Width (Number) (Default)
-
-
For categorical data type
VARCHAR2,the supported types of binning are: -
For date and time data types
DATE, TIMESTAMP, TIMESTAMP WITH LOCAL TIMEZONE,andTIMESTAMP WITH TIMEZONE,the supported types of binning are:-
Bin Equal Width (Number) (Default)
-
Note:
The number of bins must be two.7.10.4.1.2 Bin Equal Width (Number)
This selection determines bins for numeric attributes by dividing the range of values into a specified number of bins of equal size. Edit the following fields:
-
Bin Count: You can change the Bin Count to any number greater than or equal to 2. The default count is set to 10.
-
Bin Label: Select a different Bin Label scheme from the list. The default is set to
Range.
Click OK when you have finished.
7.10.4.1.3 Bin Quantile
This selection divides attributes into bins so that each bin contains approximately the same number of cases. Edit the following fields:
-
Bin Count: You can change the Bin Count to any number greater than or equal to 2. The default count is set to
10. -
Bin Label: You can select a different Bin Label scheme from the list. The default is set to
Range.
Click OK when you have finished.
7.10.4.1.4 Bin Top N
The Bin Top N type bins categorical attributes. The bin definition for each attribute is computed based on the occurrence frequency of values that are computed from the data.
Specify N, the number of bins. Each of the bins bin_1, …, bin_N contains the values with the highest frequencies. The last bin_N contains all remaining values.
You can change the Bin Count to any number greater than or equal to 3. The default count is set to 10.
Click OK when you have finished.
7.10.4.1.5 Custom
Custom binning enables you to define custom bins.
To define bins, click Bin Assignment and then modify the default bins.
After you generate default bins, you can modify the generated bins in several ways:
-
Edit Bin Name: If it is a Range label.
-
Delete Bins: Select it and click
. -
Add Bins: Click
. -
Edit Bins: Select a bin and click
.
See Also:
7.10.4.1.6 Bin Assignment
Select the following options:
-
Binning Type: The default type depends on the data type of the attribute that you are binning:
-
If the data type of the attribute is Number, then the default binning type is Bin Equal Width.
-
If the data type of the attribute is Character, then the default binning type is Bin Top N.
You can change the binning type for numbers.
-
-
Bin Count: The default count is
10.You can change this to any integer greater than2. -
Bin Labels: The default label for numbers is
Range.You can change the bin label toNumber. -
Transform NULLs: If the Transform NULLs check-box is selected for a binning transformation that produces NUMBER data type, then null values are placed into the last bin. For example, if the AGE column has null values and Equal Width Binning was requested with Bin Labels value equal to Number, and the number of bins is 10, then null values will be in bin number 11.
For this option, the following conditions apply:-
When deselected, null values are excluded from the generated transformation SQL.
Note:
Applicable only for those binning transformations that produce VARCHAR2 data type after transformation. -
This field is not editable for those binning transformations which produce numeric data type after transformation.
-
For legacy workflows, this field is selected by default, and the corresponding field contains the value
Null bin.
-
Click OK when you have finished. You return to the Custom display where you modify the generated bins.
7.10.4.1.7 Edit Bin
The way to edit bins depends on the data type of the attribute:
-
For numbers: Edit lower bounds in the grid. You cannot edit a bin without a lower bound. You cannot add a value that is less than the prior bin lower bound value or greater than the following bin lower bound value.
-
For characters: The Edit Custom Categorical Bins dialog box has two columns:
-
Bins: You can add bins, delete a selected bin and change the name of the selected bin.
-
Bin Assignment: You can delete values for the selected Bin.
-
Click OK when you have finished editing bins. If you are editing custom bins for categorical, first click OK twice (once to closed the Edit Custom Categorical Bins dialog box).
7.10.4.1.8 Add Bin
You can add bins for:
-
Categoricals: Open the Edit Custom Categorical Bins and click
. The new bin has a default name that you can change. Add values to the bin in the Bin Assignment column. -
Numericals: Select a bin and click
. You can change the name of the bin and add a range of values.
7.10.4.1.9 Missing Values
Missing Values is a transformation type that replaces missing values with an appropriate value.
To specify a Missing Values transformation:
-
In the Transform Type field, select the option Missing Values.
-
In the Missing Values field, select an option:
-
Statistic: Replaces the missing value with a statistical measure. Statistic is the default treatment for missing values. The applicable Statistic type depends on the data type of the column:
-
For numeric columns, you can replace missing values with
Mean(default),Median, Minimum, Maximum. -
For categorical columns, you can replace missing values with
Mode(default).
-
-
Value: Replaces Missing Values with the specified value. Oracle Data Miner provides a default value that you can change.
-
If statistics are not available, then the default value is
0. -
If statistics are available, then the default value is:
Meanfor numerical columns
Modefor categorical columns
Both these treatments can be applied to attributes that have a date or time data type
DATE, TIMESTAMP, TIMESTAMP_WITH_LOCAL_ TIMEZONE,andTIMESTAMP_WITH_TIMEZONE. -
-
-
After you are done, click OK.
7.10.4.1.10 Normalization
Normalization consists of transforming numeric values into a specific range, such as [–1.0,1.0] or [0.0,1.0] so that x_new = (x_old-shift)/scale. Normalization usually results in values whose absolute value is less than or equal to 1.0.
Note:
Normalization applies only to numeric columns. Therefore, you can normalize numeric attributes only.To normalize a column:
-
In the Transform Type field, select the option Normalization.
-
In the Normalization Type field, select a type from the drop-down list. Oracle Data Miner supports these types of normalization:
-
Min Max: Normalizes the column using the transformation
x_new = (x_old-min)/ (max-min).The default is min-max. -
Z-score: Normalizes numeric columns using the mean and standard deviation computed from the data. Normalizes each column using the transformation
x_new = (x-mean)/standard deviation. -
Linear Scale: Normalizes each column using the transformation
x_new = (x-0)/ max(abs(max), abs(min)). -
Manual: Defines normalization by specifying the shift and scale for the transformation
x_new = (x_old-shift)/scale.If you select Manual, then specify the following:-
Shift
-
Scale
-
-
-
After you are done, click OK.
7.10.4.1.11 Outlier
An outlier is a data value that does not come from the typical population of data. In other words, it is an extreme value. In a normal distribution, outliers are typically at least 3 standard deviations from the mean. Outliers are usually replaced with values that are not extreme, or they are replaced with Null.
Note:
You can define outlier treatments for numeric columns only.To define an Outlier transformation:
-
In the Transform Type field, select the option Outlier.
-
In the Outlier Type field, select any one of the following options:
-
Standard Deviation: This is the default Outlier type. For this outlier type, enter a Standard Deviation to define the Outlier in the following field:
-
Multiples of Sigma: This is the number of standard deviations that define an outlier.
The default is3,that is, 3 standard deviations.
3 Standard Deviation means that an outlier is a value less thanmean - 3 * Standard Deviationor greater thanmean + 3* Standard Deviation.
-
-
Percent: Enables you to specify that outliers are values in a bottom percentage and a top percent. The default is to specify that outliers are in the bottom 5 percent or in the top 5 percent. You can change the defaults by entering values in these fields:
-
Lower Percent Value
-
Upper Percent Value
-
-
Value: Enables you to specify a lower value and an upper value so that outliers are those values less than the lower value or greater than the upper value.
You can change these values, but the upper value must be bigger than the lower value.-
Lower Value: If statistics are available, then the default is
-3* standard deviation.
If statistics are not available, then the default is0. -
Upper Value: If statistics are available, then the default is
+3* standard deviation.
If statistics are not available, then the default is1.
-
-
-
In the Replace With field, select an option to specify how to replace outliers. The options are:
-
Null (Default)
-
Edge Value
For example:
If the mean of a column distribution is 10, and
If standard deviation is 10
Then, outliers can be:-
Values that are less than
-5,that is,Mean-3*Standard Deviation -
Values that are greater than
25,that is,Mean+3*Standard Deviation
Outlier=
-10.You can replace-10withNullor with-5,which is the edge value. -
-
-
After you are done, click OK.
7.10.4.1.12 Use Existing Column
This selection is not displayed until at least one transformation exists.
This selection is used when you add, or edit multiple transformation.
See Also:
"Add or Edit Multiple Transforms"7.10.4.1.13 Add or Edit Multiple Transforms
You can define or edit transformations for several column at a time. You can also apply an existing transformation to one or more columns.
To add or edit transformations for multiple transforms:
-
Double-click the Transform node. The Transformation Editor opens.
-
To define the same transform for several columns, select the columns. You can select columns with different but compatible data types. For example, CHAR and VARCHAR are characters, and are compatible data types. If there are no transformations that apply to all the columns, you get a message. Click
.The Apply Transform Wizard opens.
-
Select the Transform type to apply to all columns.
-
Provide the specific details related to the transform type that you have selected.
-
Click Next.
-
Click Generate Statistic.
-
Click Finish.
-
-
If you have already transformed a column, then you can define the same transformation for several other columns.
Suppose you have binned AGE creating
AGE_BIN.To bin several columns in the same way, select AGE and the columns that you want to bin in the same way. Click.The Apply Transform Wizard opens.
-
For Transform Type, select <Use Existing>. AGE_BIN is listed as the Transformed column. You cannot change any other values.
-
Click Next. You can change the names of the output columns.
-
Select Generate Statistic on Finish.
-
Click Finish.
-
-
To edit several transformations at the same time, select the transformations and click
.The Apply Transform Wizard opens. Edit the transformation and click Finish.
7.10.4.2 Add Custom Transform
In the Add Custom Transform dialog box, you can define a custom transformation. The default name for the new attribute is EXPRESSION. You can change this name.
In the Add Custom Transform dialog box, you can perform the following tasks:
-
Add an expression: Click
. The Expression Builder opens. Use expression build to define an expression.-
Validate the expression.
-
Click OK.
-
-
Edit a custom transformation.
-
Delete a custom Transformation: Click
.
See Also:
"Edit Custom Transform"7.10.4.3 Apply Transform Wizard
The Apply Transform wizard enables you to define or edit transformations for several columns at the same time. The first step of the wizard is similar the Add Transform dialog box.
You cannot select custom transformations.
-
In the Choose Transformation section:
-
Transform: Select the transform type.
-
Provide the details related to the selected transformation type.
-
-
Click Next.
-
In the Choose Columns section, specify names for the transformed columns. You can accept the names or change them. The available transformations are those transformations that can be performed on all selected columns. This is an optional section.
-
Click Finish.
See Also:
"Add Transform"7.10.4.4 Edit Transform
The Edit Transform dialog box is similar to the Add Transform dialog box.
If the node has run, the Edit dialog displays information about both the untransformed column and transformed version:
-
The Histogram tab shows histogram for both the untransformed attribute and the transformed in two sets of histograms. On the left side of the tab are histograms for the untransformed column. On the right side of the tab are histograms for the transformed column.
-
The Statistics tab shows statistics for the transformed data and for the original data.
Note:
When you transform data, the transformed data may have a different data type from the type of the original data. For example, AGE has typeNUMBER and AGE_BIN has type VARCHAR2.See Also:
"Add Transform"7.10.4.5 Edit Custom Transform
To edit an expression:
-
Select the attribute and click
. The Expression Builder opens. -
Use the Expression Builder to modify the expression.
-
Validate the expression.
-
Click OK.
To delete an expression, click ![]() .
.
See Also:
"Expression Builder"7.10.5 Transform Node Properties
If Properties pane is closed, then go to View and click Properties. Alternately, right-click the node and select Go to Properties from the context menu.
The Transform node Properties pane has these sections:
-
Transform: Specifies how the transformations are defined. You can modify these values.
The transformations are summarized in a grid. For each column name (data) type, transform, and output are displayed. If you bin
AGEcreatingAGE_BIN, thenAGEis not used as output, that is, is not passed to subsequent nodes. -
Histogram: Specifies the number of bins used in histograms. You can specify a different number of bins for histograms created for numeric, categorical, and date data types. The default is
10bins for all data types.
See Also:
"Edit Transform Node"7.10.6 Transform Node Context Menu
The Transform node context menu contains these options:
-
Edit. See "Edit Transform Node" for more information.
-
View Data. See "Data Viewer" for more information.
-
Parallel Query. See "About Parallel Processing" for more information.
-
Show Runtime Errors. Displayed if there are errors.
-
Show Validation Errors. Displayed if there are validation errors.