Release 9.0.1
Part Number A86647-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle Enterprise Manager Database Tuning with the Oracle Tuning Pack Release 9.0.1 Part Number A86647-01 |
|
![]()
![]()
This chapter contains the following topics:
Oracle SQL Analyze provides a wealth of information that is vital to your tuning efforts.
Information about the database environment, such as "Optimizer Mode" or "Sort Area Size," will influence the decisions the Oracle Optimizer makes when it generates an explain plan for a statement and how efficiently the operations are performed when the statement is executed. Oracle SQL Analyze shows you the values of these parameters in two locations:
Instance-based Initialization parameters are further discussed. Session-based Initialization parameters are discussed.
You can also examine many of the logical constructs within your database: views, tables, indexes, and clusters. These objects are created to help manage information and make data access more efficient, but only if used correctly. The Object Properties provided by Oracle SQL Analyze will help you determine whether the information the objects arrange is still in accordance with the way the database is used, and whether the optimizer is taking full advantage of these objects or bypassing them. The available object properties and their meaning are discussed.
Performance statistics, of course, are the ultimate measure of SQL statement effectiveness. Oracle SQL Analyze lets you execute statements using different explain plans and then compare their performance. Explain plans, performance statistics and their analysis are discussed.
Every time a database is started, a system global area (SGA) is allocated and Oracle background processes are started. The system global area is an area of memory used for database information shared by the database users. The combination of the background processes and memory buffers is called an Oracle instance.
Oracle SQL Analyze lets you examine instance- and session-based initialization parameters, as described in the following sections.
The instance-based initialization parameters displayed in the Database Parameters dialog affect memory and disk performance. You cannot edit these values from within Oracle SQL Analyze, but you should consider the effects these parameters have, and consider using Oracle Expert to tune them at a later date.
|
Note: The following information about initialization parameters and their tuning implications is meant as an introduction only. Please consult Oracle9i Database Administrator's Guide, Oracle9i Database Performance Guide and Reference, and the Oracle9i Database Reference for more detailed information. |
To open the Initialization Parameters view, click on the database node in the Navigation window, as shown.
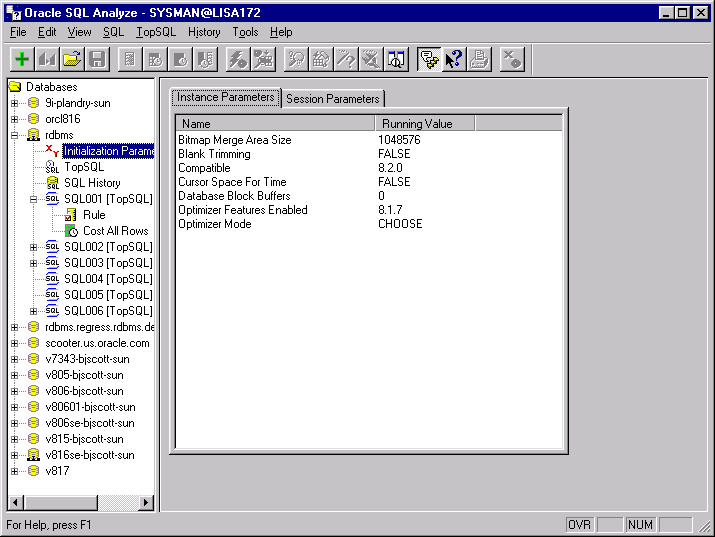
The Details Window on the right will display the following parameters:
Description: Sets the type of anti-join that the Oracle Server uses: NESTED_LOOPS, MERGE, or HASH. The system checks to verify that it is legal to perform an anti-join, and if it is, processes the subquery depending on the value of this parameter. The default setting is NESTED_LOOPS.
Tuning Considerations: Always Anti-Join is useful in cost-based optimizations to make the most efficient use of parallel processing of the NOT IN clause.
HASH processes the NOT IN clause most efficiently. It causes the NOT IN operator to be evaluated in parallel using a parallel hash anti-join. Without this parameter set to HASH, NOT IN is evaluated as a (sequential) correlated subquery.
NESTED LOOPS processes the NOT IN clause least efficiently.
This parameter often needs to be set in data warehousing applications.
Specifies the amount of memory used to merge bitmaps retrieved from a range scan of the index.
The default value is one megabyte. A larger value often improves performance because it will cause the optimizer to bitmap indexes more often.
Specifies the data assignment semantics of character datatypes.
A value of TRUE allows the data assignment of a source character string/variable to a destination character column/variable even though the source length is longer than the destination length. In this case, however, the additional length over the destination length is all blanks. A value of FALSE disallows the data assignment if the source length is longer than the destination length and reverts to SQL92 Entry Level semantics.
Specifies the release with which the Oracle Server must maintain compatibility. The default value is the earliest release with which compatibility can be guaranteed.
You can use this parameter to immediately take advantage of the maintenance improvements of a new release in your production systems without testing the new functionality in your environment. This parameter also allows you to use a new release while at the same time guaranteeing backward compatibility with earlier releases, in case it becomes necessary to revert to the earlier release.
If you set this parameter to an earlier release, however, you may restrict or disable some of the features of the current release. To be sure that you are getting the full benefit of the latest performance features, make sure this parameter is set equal to the current release.
Specifies when a shared SQL area can be deallocated from the library cache to make room for a new SQL statement. The default value of this parameter is FALSE.
If the value is FALSE, a shared SQL area can be deallocated from the library cache regardless of whether application cursors associated with its SQL statement are open. In this case, Oracle must verify that a shared SQL area containing the SQL statement is in the library cache.
Setting the value of the parameter to TRUE saves Oracle a small amount of time and may slightly improve the performance of execution calls. If the value of this parameter is TRUE, a shared SQL area can be deallocated only when all application cursors associated with its statement are closed. In this case, Oracle need not verify that a shared SQL area is in the cache, because the shared SQL area can never be deallocated while an application cursor associated with it is open.
Do not set the value to TRUE if:
For more information, see Oracle9i Database Concepts.
This parameter is used to define the number of buffers in the buffer cache in the System Global Area (SGA). Each individual buffer pool is created from this total amount with the remainder allocated to the default buffer pool.
The number of buffers affects the performance of the cache. Larger cache sizes reduce the number of disk writes of modified data. However, a large cache may take up too much memory and induce memory paging or swapping.
The Database Block Buffers parameter, together with the Database Block Size parameter, determines the total size of the buffer cache. Effective use of the buffer cache can greatly reduce the I/O load on the database. Since Database Block Size can be specified only when the database is first created, use Database Block Buffers to control the size of the buffer cache.
For more information, see Oracle9i Database Concepts. Also, see your operating system-specific Oracle documentation for the default value.
Database buffers of the SGA store the most recently used blocks of database data; the set of database buffers in an instance is the database buffer cache. The buffer cache contains modified as well as unmodified blocks. Because the most recently (and often the most frequently) used data is kept in memory, less disk I/O is necessary and performance is improved.
The first time an Oracle user process accesses a piece of data, the process must copy the data from disk to the buffer cache before accessing it. This is called a cache miss. When a process accesses a piece of data that is already in the cache, the process can read the data directly from memory. This is called a cache hit. Accessing data through a cache hit is faster than data access through a cache miss.
The size of the cache affects the likelihood that a request for data will result in a cache hit. If the cache is large, it is more likely to contain the data that is requested. Increasing the size of a cache increases the percentage of data requests that result in cache hits. However, too large a cache can induce excessive swapping and paging.
This parameter is used for multi-block I/O and specifies the maximum number of blocks read in one I/O operation during a sequential scan.
The total number of I/Os needed to perform a full table scan depends on factors such as these:
In general, a large value gives cheaper table scan cost and favors table scans over indexes. The default value is 8. OLTP and batch environments typically have values for this parameter in the range of 4 to 16. DSS database environments tend to get the most benefit from maximizing the value for this parameter.
This parameter sets the mode of the optimizer at instance startup: rule-based, cost-based optimized for throughput, cost-based optimized for response time, or choice-based on presence of statistics.
This parameter specifies the default behavior of the optimizer. In most cases, cost-based optimization will yield better results than rule-based optimization. Oracle SQL Analyze lets you test statements using all four optimizer choices, if the statement has been analyzed by the ANALYZE SQL command. You can override the default parameter using hints.
For more information about the optimizer, see Oracle9i Database Concepts and Oracle9i Database Performance Guide and Reference.
The session based parameters affect memory and disk performance. You can edit these values from within Oracle SQL Analyze to simulate a different environment, or to test the effect these parameters have on your database performance.
To show these parameters, select the desired Initialization Parameters object from the Navigator window. The details window will display the initialization session parameters, their current running values, and the new value you set for it (if any).
To edit a session based parameter setting:
A window opens in the right window displaying database parameters, their current running values, and the new value you set for it (if any).
A dialog window opens. The appearance of the dialog window depends on whether the value to be changed is numerical or Boolean.
If the value is Boolean (TRUE, FALSE, or AUTO), select the appropriate radio button.
The following session based parameters are available:
Maximum amount of memory, in bytes, to be used for hash joins.
A larger value causes hash join costs to be cheaper, causing the optimizer to choose more hash joins. If it is too large, the system may run out of memory. If this parameter is not set, its value defaults to twice the value of the Sort Area Size parameter.
The recommended value is approximately one half the square root of S, where S is the size (in megabytes) of the smaller of the inputs to the join operation. The value should not be less than 1 megabyte.
Enables or disables the hash join feature.
This parameter specifies whether the optimizer should consider using a hash join as a join method. When set to FALSE, hash join is turned off; that is, it is not available as a join method that the optimizer can consider. When set to TRUE, the optimizer will compare the cost of a hash join to other types of joins and selects the join with the best cost. This parameter should always be set to TRUE for data warehousing applications.
Specifies how many sequential blocks a hash join reads and writes in I/O.
This parameter strongly affects performance, because it controls the number of partitions into which the input is divided. A larger value causes hash join costs to be cheaper, giving more hash joins.
This parameter rarely needs to be changed. If you do change this parameter, try to make sure that the following formula remains true:
R/M <= Po2(M/C)
where R = size of(left input to the join), M=(Hash area size)*0.9, Po2(n)=largest power of 2 that is smaller than n, and C = (Hash Multi-block I/O Count)*(Database Block Size).
Lets you adjust the costing of index access paths in the cost-based optimizer.
This parameter makes the optimizer more or less prone to selecting an index access path over a full table scan. The default for this parameter is 100 percent, which makes the optimizer cost index access paths at the regular cost. Any other value will make the optimizer cost the access path at that percentage of the regular cost. For example, setting it to 50 percent will make the index access path look half as expensive as normal. The legal range of values for this parameter is 1 to 10000 percent. This parameter can be used to tune the performance of a system where it is felt that the optimizer chooses too few or too many index access paths. The adjustment does not apply to user-defined cost functions for domain indexes.
Lets you limit the amount of work the optimizer spends on optimizing queries with large joins.
By restricting the number of permutations of the tables the optimizer will consider, you can ensure that the parse time for the query stays within acceptable limits. However, in doing so, there is a slight risk that the optimizer will overlook a good plan it would otherwise have found. The default value for this parameter is 80000. Setting this parameter to a value less than 1000 should ensure parse times of a few seconds or less.
Determines how aggressively the optimizer will attempt to parallelize a given execution plan. The default of 0 means that the optimizer chooses the best serial plan. A value of 100 means that the optimizer uses each object's degree of parallelism in computing the cost of a full table scan.
Low values favor indexes, high values favor table scans.
The maximum number of tables in the FROM clause for which all possible join permutations will be considered.
This parameter specifies the search limit for the optimizer. Its recommended value is: 100/number_of_concurrent_users
Enables partition views.
If Partition View Enabled is set to TRUE, the optimizer prunes (or skips) unnecessary table accesses in a partition view. This parameter also changes the way the cost-based optimizer computes statistics on a partition view from statistics on underlying tables.
Specifies the maximum amount, in bytes, of Program Global Area (PGA) memory used for a sort.
If your system has a lot of memory, you can benefit from setting Sort Area Size to a large value. This can dramatically increase the performance of hash operations and large sorts, because the entire operation is more likely to be performed in memory.
If the sort area is too small, data is divided into smaller pieces and each piece, or run, is sorted individually. An excessive amount of I/O is then required to merge the runs back together into a single sort. If the sort area size is very small, there will be many runs to merge, and multiple passes may be necessary. The amount of I/O increases as the sort area size decreases.
If the sort area is too large, the operating system paging rate will be excessive. The cumulative sort area adds up fast, because each parallel server can allocate this amount of memory for each sort.
If memory is a concern for your system, you may want to limit the amount of memory allocated for sorts and hashing operations. Instead, increase the size of the buffer cache so that data blocks from temporary sort segments can be cached in the buffer cache.
Determines whether a cost-based query transformation will be applied to star queries. A star schema is best suited for large tables (gigabytes or terabytes of data) where transformation is worthwhile. Star trasformation is not supported for small tables that have a good single-table access path. For a list of other restrictions, see Oracle9i Database Concepts.
If set to TRUE, the optimizer will consider performing a cost-based query transformation on the star query. If set to FALSE, the transformation will not be applied.
Sets the statistics related to time to zero, or allows them to be recorded.
If this value is FALSE, the statistics related to time are always zero and the server can avoid the overhead of requesting the time from the operating system. A FALSE setting also disables the Query Progress Monitor. A TRUE setting enables the Query Progress Monitor and provides timing statistics for server operations.
This parameter controls whether sort data will bypass the buffer cache to write intermediate sort results to disk.
Sort Direct Writes can improve sort performance if memory and temporary space are available on your system.
When set to TRUE, additional buffers are allocated from memory during each sort, making sort costs lower and encouraging the optimizer to use more sort joins.
When set to the default of AUTO, and the value of the Sort Area Size is greater than ten times the block size, memory is allocated from the sort area.
When set to FALSE, the sorts that write to disk write through the buffer cache.
|
Note: For more information about the following NLS parameters, see Oracle9i Globalization Support Guide. Also see the Oracle9i Database Administrator's Guide or Oracle9i Database Performance Guide and Reference. Note that changing certain parameters will affect other parameters. Most notably, changing NLS Territory affects several other parameters that automatically change their values as a result. |
Specifies which calendar system Oracle uses. This parameter can have one of the following values: Arabic Hijrah, English Hijrah, Gregorian, Japanese Imperial, Persian, ROC Official (Republic of China), or Thai Buddha.
None.
NLS Comparison can be used to indicate that the comparisons must be linguistic according to the NLS Sort session parameter.
Lets you avoid the cumbersome process of using NLS Sort in SQL statements. Normally, comparison in the WHERE clause is binary. To use linguistic comparison, the NLS Sort function must be used. Sometimes this can be tedious, especially when the needed linguistic sort has been specified in the NLS Sort session parameter.
Specifies the string to use as the local currency symbol for the "L" number format element. The default value of this parameter is determined by NLS Territory.
None.
Specifies the default date format to use with the TO_CHAR and TO_DATE functions. The default value of this parameter is determined by NLS Territory. The value of this parameter can be any valid date format mask, for example, MM/DD/YYYY.
None.
Specifies the language to use for the spelling of day and month names and date abbreviations (AM, PM, AD, BC). The default value of this parameter is the language specified by NLS Language.
None.
Specifies the string to use as the international currency symbol for the "C" number format element. The default value of this parameter is determined by NLS Territory.
None.
Specifies the default language of the database. This language is used for messages, the day and month names, the symbols for AD, BC, AM, and PM, and the default sorting mechanism. Examples of supported languages are American, French, and Japanese. This parameter determines the default values of the parameters NLS Date Language and NLS Sort.
None.
Specifies the characters to use as the group separator and decimal and overrides those defined implicitly by NLS Territory. The group separator is the character that separates integer groups (that is, the thousands, millions, billions, and so on). The decimal separates the integer portion of a number from the decimal portion.
Any character can be the decimal or group separator. The two characters specified must be single-byte, [and both characters must be different from each other.] The characters cannot be any numeric character or any of the following characters: plus (+), hyphen (-), less than sign (<), greater than sign (>). The default value of this parameter is determined by NLS Territory.
None.
Specifies the collating sequence for ORDER BY queries.
If the value is BINARY, then the collating sequence for ORDER BY queries is based on the numeric value of characters (a binary sort that requires less system overhead). If the value is a named linguistic sort, sorting is based on the order of the defined linguistic sort. Most languages supported by the NLS_LANGUAGE parameter also support a linguistic sort with the same name.
Setting NLS Sort to anything other than BINARY causes a sort to use a full table scan, regardless of the path chosen by the optimizer. BINARY is the exception because indexes are built according to a binary order of keys. Thus the optimizer can use an index to satisfy the ORDER BY clause when NLS Sort is set to BINARY. If NLS_SORT is set to any linguistic sort, the optimizer must include a full table scan and a full sort into the execution plan.
The default value of this parameter depends on the value of the NLS_LANGUAGE parameter.
For more information on this parameter, see the Oracle Administrator's Guide.
Specifies the name of the territory whose conventions are to be followed for day and week numbering. Also specifies the default date format, the default decimal character and group separator, and the default ISO and local currency symbols. Supported territories include America, France, Japan, and so on.
This parameter determines the default values for the following parameters: NLS Currency, NLS ISO Currency, NLS Date Format, and NLS Numeric Characters.
This parameter can be used to override the default dual currency symbol defined in the territory. When starting a new session without setting NLS Union Currency, the default dual currency symbol defined in the territory of your current language environment will be used. When you set this parameter, you will start up a session with its value as the dual currency symbol.
None.
Tables, views, indexes, clusters; these objects are created to better manage and provide faster, more efficient access to the data in your database. These same objects, if not monitored, can grow to consume excessive memory, become inefficient if they are not modeled to reflect current user behavior, or may even become obsolete and unused.
Oracle SQL Analyze provides Object Properties information that can help you determine whether an index or cluster is efficient, or whether you might want to consider editing or re-creating some of these logical structures.
SQL Analyze shows you the details of any table, index, cluster, or view used by an explain plan.
You can view these objects from an explain plan in the following way:
A menu appears with an Object Properties choice.
The Object Properties dialog window opens.
In the Object Properties dialog, you can select table, index, cluster, and view statistics, if applicable. The meaning of the statistics is presented in the following sections.
|
Note: The following information about object properties and their tuning implications is meant as an introduction only. Please consult Oracle9i Database Administrator's Guide, Oracle9i Database Concepts, Oracle9i Database Performance Guide and Reference, and the Oracle9i Database Reference,for more detailed information. |
The general details provided about the object are:
Tables are the basic units of data storage in an Oracle database. When you create a table, Oracle allocates to the table's data segment an initial extent of a specified number of data blocks. When these blocks become full, database performance declines. Therefore, it's important to monitor the statistics listed in the following to ensure that your database is using its existing space efficiently, and that your database has the space it needs.
If you determine that block space allocated to tables is a problem, you will want to consider PCTFREE and PCTUSED parameters to:
For hints on managing tables, see the Oracle Server Application Developer's Guide.
To display Table properties, open the Object Properties dialog as described in "Viewing Object Properties."
You can review the following statistics in the Table Properties page:
A specific number of contiguous data blocks allocated for storing a specific type of information.
Proper sizing of extents is a key factor in managing the performance of full table scans. If the extents are not properly sized, the number and size of the extents can greatly increase the amount of work performed by the database during a full table scan. You can judge the size of an extent by the number of data blocks per extent.
Database objects frequently read via large scans--either full table scans or large index range scans--should be stored in a small number of extents. Keeping the number of extents small makes it more likely that the next data to be read is physically near the data currently being read.
To eliminate the potential impact of multiple extents on performance, you need to make sure that the size of each extent is a multiple of the number of blocks read during each multiblock read (see "Database File Multiblock Read Count" in the section on Database Parameters). In many systems, 64 Kb or 128 Kb is read during each read. Therefore, size your extents so that each is an even multiple of 64KB or 128 KB.
When you create a table, Oracle allocates to the table's data segment an initial extent of a specified number of data blocks. Although no rows have been inserted yet, the Oracle blocks that correspond to the initial extent are reserved or allocated for that table's rows.
Indicates size of extents.
Blocks that have already been allocated to a table.
Indicates size of extents.
Blocks that Oracle considers available to be used in a table's rows.
Indicates size of extents.
If a row is too large to fit into one data block when it is first inserted, Oracle stores the data for the row in a chain of data blocks (one or more) reserved for that segment. When row updates cause the storage requirements of the row to exceed the space available in the block, the row is "migrated" to another block with enough space. Row chaining or migration most often occurs with large rows, such as rows that contain a column of datatype LONG or LONG RAW.
Chained rows reduce I/O performance associated with these rows.
The value is the number of rows in the table.
Indicates size of table, number of rows that will need to be scanned in a Full Table Scan.
The average length of a row in the table, in bytes.
Processing costs increase if updates to rows or index entries cause rows to grow and span blocks (chained rows).
The average free space of all blocks on a free list. A free list is a list of database blocks that have been allocated for the segment's extents and have free space greater than the PCTFREE setting.
The more densely packed the rows are within your tables' blocks, the fewer blocks you will need to read. Each database block has a header/trailer area, an area used by the rows' data, and free space. To improve the row density within your blocks, you need to consider all three of these areas during your space management efforts.
Clusters store related rows of different tables together in the same data blocks. You get two primary benefits from this:
To identify data that would be better stored in clustered form, look for tables that are related through referential integrity constraints and tables that are frequently accessed together using a join. If you cluster tables on the columns used to join table data, you reduce the number of data blocks that must be accessed to process the query; all the rows needed for a join on a cluster key are in the same block.
Conversely, if the all the rows for a cluster key cannot fit in a single block, they may cause join statements to consume more resources.
Also note that clusters can reduce the performance of DML statements (INSERTs, UPDATEs, and DELETEs) as compared to storing a table separately with its own index. These disadvantages relate to the use of space and the number of blocks that must be visited to scan a table. Because multiple tables share each block, more blocks must be used to store a clustered table than if that same table were stored non-clustered. You should decide about using clusters with these trade-offs in mind.
For information on managing clusters, see Oracle9i Database Concepts and the Oracle9i Application Developer's Guide - Object-Relational Features.
To display Cluster Details:
The Cluster Statistics dialog displays the following statistics:
A specific number of contiguous data blocks allocated for storing a specific type of information.
See description of table extents
Blocks allocated to contain cluster keys and their associated rows.
Indicates the size of the clusters.
A value reached by dividing the number of blocks in the table by the number of hash keys.
By default, Oracle stores only one cluster key and its associated rows in each data block of the cluster's data segment. If all the rows for a given cluster key value cannot fit in one block, the blocks are chained together to speed access to all the values within a given key. Too few rows per cluster key value can waste space and result in negligible performance gains. Too many rows can cause the optimizer to perform excessive searches to find rows for that key.
Allocated blocks that are still available for storing cluster keys and their associated rows.
Indicates size of extents.
Number of distinct hash values, which are based on specific cluster key values.
Hash clusters are used to store individual tables or a group of clustered tables that are static and often queried by equality queries. Hashing is an optional way of storing table data to improve the performance of data retrieval. To use hashing, you create a hash cluster and load tables into the cluster.
Hashing is most advantageous when you have the following conditions:
SELECT . . . WHERE cluster_key = . . . ;
In such cases, the cluster key in the equality condition is hashed, and the corresponding hash key is usually found with a single read. In comparison, for an indexed table the key value must first be found in the index (usually several reads), and then the row is read from the table (another read).
Selecting the Column Statistics radio button displays the following column details:
The common column or columns that are shared by the tables in the cluster.
Number of unique values in the column.
Number of times a distinct value appears in the column, divided by the number of distinct values.
Indexes are used in Oracle to provide quick access to rows in a table. Indexes provide faster access to data for operations that return a small portion of a table's rows. While indexes can save considerable time, the SQL engine must maintain all indexes defined against a table whether they are used or not, presenting a significant CPU and I/O demand on any intensive I/O application. Therefore, you should drop indexes that are not used.
A method to determine whether an index is good is to create it, analyze it, and use SQL Analyze to run explain plans on your query to see if the optimizer uses it. If it does, keep the index unless it is very expensive to maintain. Another method is to compare the optimizer cost of the plans with and without the index.
It should be noted, however, that indexes sometimes have uses that are not immediately apparent from a survey of statement execution plans. In particular, Oracle8 uses "pins" (nontransactional locks) on foreign key indexes to avoid the need for share locks on the parent table when enforcing foreign key constraints. In many applications this foreign key index never (or rarely) supports a query.
For guidelines on creating and managing indexes, see Oracle9i Database Concepts, the Oracle9i Application Developer's Guide - Object-Relational Features, and Oracle9i Database Performance Guide and Reference.
To display Index Details:
The Index Properties dialog displays the following statistics:
A specific number of contiguous data blocks allocated for storing a specific type of information.
See description of table extents.
Blocks allocated to contain index keys and their associated rows.
Indicates size of index.
Depth of the B-Tree index.
If this value is greater than 4 (the B-tree index "branches out" four levels or more), consider dropping and re-creating this index.
Number of leaf blocks, the lowest level index blocks in a B-tree index, in the current index.
The lowest level index blocks (leaf blocks) contain every indexed data value and a corresponding ROWID used to locate an actual row. This value indicates the size and selectivity of the index.
Number of distinct indexed values.
If this value is low, a bitmap index may be more effective than a B*-tree index for accessing the data.
Average number of leaf blocks in which each distinct value in the index appears. This statistic is rounded to the nearest integer.
Indicates selectivity of the index. The higher the value, the more rows it will select in a query. For indexes that enforce UNIQUE and PRIMARY KEY constraints, this value is always 1.
Average number of data blocks in the table that are pointed to by a distinct value in the index. This statistic is the average number of blocks that contain rows that contain a given value for the indexed columns. It is rounded to the nearest integer.
Indicates selectivity of the index. For indexes that enforce UNIQUE and PRIMARY KEY constraints, this value is always 1.
Represents the amount of order of the rows in the table based on the values of the index.
If the value of the index is near the number of blocks, then the table is very well ordered. In such a case, the index entries in a single leaf block tend to point to rows in the same data blocks. If its value is near the number of rows, then the table is very randomly ordered. In such a case, it is unlikely that the index entries in the same leaf block point to rows in the same data blocks.
Views derive their data from the tables on which they are based, referred to as the base tables of the views. Base tables can in turn be tables or can themselves be views. Like tables, views can be queried, updated, inserted into, and deleted from, with restrictions. All operations performed on a view actually affect the base tables of the view.
At times, it is useful to understand the selection criteria behind the view.
To examine a view:
Optimization is the process of choosing the most efficient way to execute a SQL statement. This is an important step in the processing of any data manipulation language (DML) statement: SELECT, INSERT, UPDATE, or DELETE. Many different ways to execute a SQL statement often exist, for example, by varying the order in which tables or indexes are accessed. The procedure Oracle uses to execute a statement can greatly affect how quickly the statement executes.
A part of Oracle called the optimizer chooses what it believes to be the most efficient way. The optimizer evaluates a number of factors to select among alternative access paths. The access paths the optimizer chooses can be displayed by generating explain plans.
Although it is beyond the scope of this guide to fully explain the optimizer and how it selects access paths, the following section will explain some of the basic concepts that will help you better understand explain plans and how to identify inefficiencies in them.
For a more detailed explanation of the Oracle optimizer, see Oracle Server Concepts.
To choose an execution plan for a SQL statement, the optimizer uses one of two approaches: cost-based or rule-based.
Using the cost-based approach, the optimizer determines which execution plan is most efficient by considering available access paths and factoring in information based on statistics in the data dictionary for the schema objects (tables, clusters, or indexes) accessed by the statement. The cost-based approach also considers hints, or optimization suggestions placed in a Comment in the statement.
Conceptually, the cost-based approach consists of these steps:
The cost is an estimated value proportional to the expected resource use needed to execute the statement using the execution plan. The optimizer calculates the cost based on the estimated computer resources, including (but not limited to) I/O, CPU time, and memory, that are required to execute the statement using the plan.
Serial execution plans with greater costs take more time to execute than those with smaller costs. When using a parallel execution plan, however, resource use is not directly related to elapsed time.
By default, the goal of the cost-based approach is the best throughput, or minimal resource use necessary to process all rows accessed by the statement.
Oracle can also optimize a statement with the goal of best response time, or minimal resource use necessary to process the first row accessed by a SQL statement.
The cost-based approach uses statistics to estimate the cost of each execution plan. These statistics quantify the data distribution and storage characteristics of tables, columns, indexes, and partitions. You can generate these statistics using the ANALYZE command. The optimizer uses these statistics to estimate how much I/O, CPU time, and memory are required to execute a SQL statement using a particular execution plan.
Oracle SQL Analyze allows you to test both rule-based and cost-based approaches. However, it is useful to note the following guidelines for selecting either of these approaches. In general, you should use the cost-based approach for all new applications; the rule-based approach is provided for applications that were written before cost-based optimization was available. Cost-based optimization can be used for both relational data and object types.
The following features can only use cost-based optimization:
The cost-based approach generally chooses an execution plan that is as good as or better than the plan chosen by the rule-based approach, especially for large queries with multiple joins or multiple indexes. The cost-based approach also improves productivity by eliminating the need to tune your SQL statements yourself. Finally, many Oracle performance features are available only through the cost-based approach.
Cost-based optimization must be used for efficient star query performance. Similarly, it must be used with hash joins and histograms. Cost-based optimization is always used with parallel query and with partitioned tables. You must use the ANALYZE command to keep statistics current.
Using the rule-based approach, the optimizer chooses an execution plan based on the access paths available and the ranks of these access paths. You can use rule-based optimization to access both relational data and object types.
Oracle's ranking of the access paths is heuristic. If there is more than one way to execute a SQL statement, the rule-based approach always uses the operation with the lowest rank. Usually, SQL statement of lower rank execute faster than those associated with SQL statements of higher rank.
This section describes basic methods by which Oracle can access data.
A full table scan retrieves rows from a table. To perform a full table scan, Oracle reads all rows in the table, examining each row to determine whether it satisfies the statement's WHERE clause. Oracle reads every data block allocated to the table sequentially, so a full table scan can be performed very efficiently using multiblock reads. Oracle reads each data block only once.
A table access by ROWID also retrieves rows from a table. The ROWID of a row specifies the datafile and data block containing the row and the location of the row in that block. Locating a row by its ROWID is the fastest way for Oracle to find a single row.
To access a table by ROWID, Oracle first obtains the ROWIDs of the selected rows, either from the statement's WHERE clause or through an index scan of one or more of the table's indexes. Oracle then locates each selected row in the table based on its ROWID.
From a table stored in an indexed cluster, a cluster scan retrieves rows that have the same cluster key value. In an indexed cluster, all rows with the same cluster key value are stored in the same data blocks. To perform a cluster scan, Oracle first obtains the ROWID of one of the selected rows by scanning the cluster index. Oracle then locates the rows based on this ROWID.
Oracle can use a hash scan to locate rows in a hash cluster based on a hash value. In a hash cluster, all rows with the same hash value are stored in the same data blocks. To perform a hash scan, Oracle first obtains the hash value by applying a hash function to a cluster key value specified by the statement. Oracle then scans the data blocks containing rows with that hash value.
An index scan retrieves data from an index based on the value of one or more columns of the index. To perform an index scan, Oracle searches the index for the indexed column values accessed by the statement. If the statement accesses only columns of the index, Oracle reads the indexed column values directly from the index, rather than from the table. The index contains not only the indexed value, but also the ROWIDs of rows in the table having that value. Therefore, if the statement accesses other columns in addition to the indexed columns, Oracle can find the rows in the table with a table access by ROWID or a cluster scan.
See Oracle Server Concepts for a list of index scan types.
Oracle SQL Analyze gives you several ways to monitor and examine the performance of your SQL code:
The rest of this chapter discusses how to view performance statistics through Oracle SQL Analyze, including an explanation of explain plans and how Oracle SQL analyze can help you navigate through them more easily.
As discussed in"Selecting a Statement for Tuning", TopSQL is an integrated function of Oracle SQL Analyze that lets you measure the resources a SQL statement consumes. Using these statistics, you can determine which statements consume the most resources and select them for tuning.
A TopSQL object exists for each database session represented in the Navigator window. TopSQL displays statistics from the V$SQLAREA view that show you the resources consumed by a statement and help you identify performance problems.
The performance statistics it shows are discussed in Chapter 4, "Starting a Tuning Session".
The SQL History is a repository of SQL statements gathered from the database SQL cache (using the V$SQLAREA and V$SQLTEXT views).
Shared by Oracle SQL Analyze and Oracle Expert, the SQL History can be updated from Oracle SQL Analyze or Oracle Expert. If you update on a regular basis from either program, the time it takes to gather statistics for an analysis or tuning session can be greatly reduced.
SQL History is used for tuning operations that require a larger view of the SQL activity for the database, such as index tuning. As a set of SQL statements collected over a period of time, SQL History gives you a more accurate representation of the database and its use.
SQL History menu commands are the same as the TopSQL commands, with two differences:
A SQL statement that retrieves data from many tables can use many variations of table join methods, join orders, and access paths to produce the same set of results. The Oracle optimizer must figure out the optimal path for these operations based on a multitude of factors, such as, but not limited to:
These factors will vary depending on the approach used by the optimizer, whether it is rule-based, cost-based for response time, or cost-based for throughput. The SQL statement's execution path can be displayed through an explain plan, which provides a list of the operations involved in the statement's execution. By examining the execution plan, you can see exactly how Oracle executes your SQL statement.
Oracle SQL Analyze provides a facility for easily generating explain plans that can be used to assess how a given SQL statement will perform under different optimizer modes. You can run a SQL statement under each optimizer mode to produce an explain plan for the statement and the execution "cost"--a measurement of several factors, including the amount of computer resources (I/O and CPU consumption, for example), and the time to complete the execution of the statement-- if a cost-based optimizer is used.
To generate an explain plan, select the desired optimization path from the SQL => Explain menu choice. An explain plan appears in the Details window, as shown in Figure 5-2, and an explain plan object is added in the Navigator window, connected to the related SQL statement.
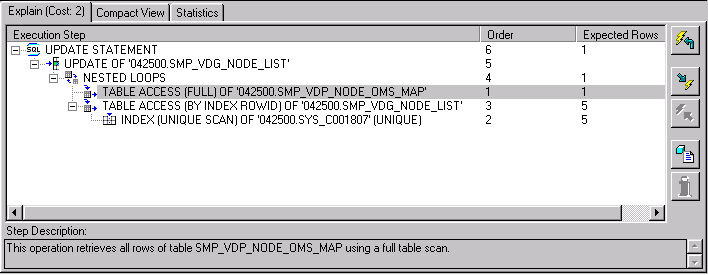
You can select four different optimization paths through which to view an explain plan for a SQL statement:
You can learn to follow the sequence of an explain plan by reading the section below, and get more information on explain plans in Oracle9i Database Performance Guide and Reference. An easier approach, however, is to let Oracle SQL Analyze guide you as you "step through" a plan.
To read an explain plan, you need to know where the processing will begin, and then follow the path, as described below. The following SQL statement:
SELECT "name", product_id, amount_in_stock, state FROM inventory, product, warehouse WHERE product.id = inventory.product_id AND amount_in_stock > 500 AND warehouse.id = inventory.warehouse_id;
is represented by the following explain plan using the rule-based optimizer:
SELECT STATEMENT NESTED LOOPSNESTED LOOPS TABLE ACCESS (BY ROWID) OF `INVENTORY' INDEX (RANGE SCAN) OF `AMOUNT_IN_STOCK_PK' (NON-UNIQUE) TABLE ACCESS (BY ROWID) OF `WAREHOUSE' INDEX (UNIQUE SCAN) of `WAREHOUSE_ID_PK' (UNIQUE)TABLE ACCESS (BY ROWID) of `PRODUCT'INDEX (UNIQUE SCAN) of `PRODUCT_ID_PK' (UNIQUE)
The execution path uses INVENTORY as the driving table and the execution path is as follows:
You can "step through" the plan and immediately understand how the statement will execute and what step each operation is performing. Each operation is highlighted in order of execution. You can control the pace of the walkthrough, and can back-up or start over at any point. As an operation is highlighted, a description of the operation is displayed in the "step description" window directly below the Explain Plan display. You can also choose to view details for any objects involved in a particular operation.
Once you have an explain plan open for viewing, you can use Oracle SQL Analyze to step through the plan in the order the steps would be executed. Oracle SQL Analyze describes the steps in SQL execution terms.
To step through an explain plan:
The Step Description frame borders the bottom and right side of the Details window. The right side contains four navigation buttons. The bottom contains a Step Description box. The Step Description frame is shown in Figure 5-3.
As you step through the explain plan, a description of the selected step appears at the bottom of the Details Window.
Explain plans display the following columns:
The ordering of the tables referenced by the statement.
The number of rows returned by that step in the execution plan.
Explain plans for Parallel Query contain the following additional columns:
Describes the order in which the output from the operation is consumed.
Describes the type of operation being performed.
Describes the query used by the query server.
Explain plans for Oracle8 partitions add the following three rows:
The start partition of a range of accessed partitions.
The stop partition of a range of accessed partitions.
The ID of the PARTITION step that computed the pair of Partition Start and Partition Stop values.
For a full explanation of these columns and their implications, see Oracle9i Database Performance Guide and Reference.
As Oracle SQL Analyze generates an explain plan for your SQL statement, it applies certain Explain Plan Rules-of-Thumb and identifies steps in the explain plan where problems may occur. These steps are flagged by an exclamation mark. You can get the details for these Rules-of-Thumb by selecting the identified row in the explain plan and selecting the Plan Step Properties button. See "Stepping Through Explain Plans" for more details.
The Rules-of-Thumb Oracle SQL applies are:
Index merges are often an indicator that a concatenated index could help speed a query. The rule of thumb indicator is found on any Explain Plan AND_EQUAL object, which indicates an index merge.
Cartesian products are usually an indicator of a logical mistake in the SQL statement. In general, they are only intended to assist in Star Query optimization. This rule-of-thumb indicator is found on any Explain Plan MERGE JOIN (CARTESIAN) objects.
There may be an opportunity for speeding up the access to the non-driving table when it is joined in the nested loops fashion via a full table scan lookup. Often an appropriatae concatenation of columns from the non-driving table is all that is required to perform the lookup. The rule -of-thumb indicator is found on any Explain Plan TABLE ACCESS (FULL) object which is a child of a NESTED LOOPS object and is not the first in the chain of tables being joined.
A parallel query bottleneck is an object in a Parallel Query Option plan which indicates that the output of a serial operation in a previous object is being made parallel in this one. The rule-of-thumb indicator will be found on the Explain Plan object which has the auxiliary data showing a PARALLEL_FROM_SERIAL parallelization has happened at this object.
Remote queries that extend over distributed databases in a system are noted in the explain plans by an icon and the word REMOTE, as shown in Figure 5-3.
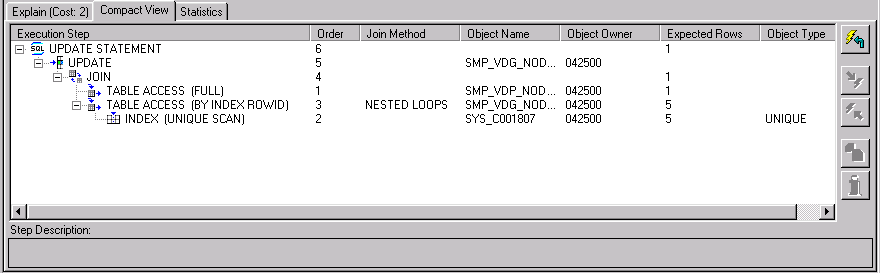
A second type of explain plan is the compact view. The compact view displays explain plans with an emphasis on the join methodologies used in the current explain plan. Joined tables are shown as peers, rather than as children, which allows you to see more clearly which tables have been joined, and what method was used to join them.
A sample compact view is shown in Figure 5-4.
Compact views show the following columns:
Shows the explain plan, reorganized to emphasize joins.
Displays the type of join used for each joined table in the explain plan.
Lists tables and indexes associated with the join.
The name of the session to which the object belongs.
The number of rows returned by that step in the execution plan.
Like standard explain plans, you can also walk through the compact view, study the object details, and review the execution statistics.
Execution statistics provide information about the performance of a SQL statement as it accesses data from a database.
To view execution statistics:
You might want to execute the statement several times to develop an average set of statistics that may better represent the actual performance of the SQL statement and its explain plan.
The performance of a SQL statement can be improved or hindered in a number of ways. In some cases simply changing the optimizer mode can affect your execution results. If you want to view the statistics for multiple explain plans to see where the execution statistics have been modified, follow these steps:
To compare execution statistics for multiple explain plans:
Or:
Choose View=>Compare Execution Statistics... from the SQL Analyze main menu. This will open an empty Compare Execution Statistics dialog. You can then drag and drop explain plans from the navigator to the dialog for comparison.
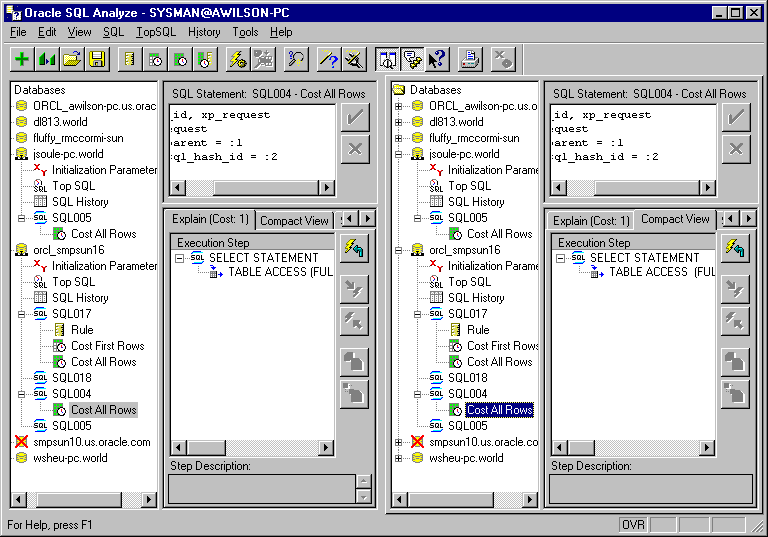
Comparing explain plans is a powerful tool to analyze the improvements you have made while tuning your SQL statements. Oracle SQL Analyze lets you create a split view in which you can open two different SQL statements and compare results.
To compare SQL statements and explain plans, select View=>Comparison from the menu.
The main window splits into two panes, each with identical navigation and main windows as shown in Figure 5-5.
You can then navigate in either pane to display and compare alternative SQL statements, explain plans, and performance statistics.
To return to a single main window, select View=>Comparison again.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|