Release 1 (9.0.1)
Part Number A87503-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Database Performance Guide and Reference Release 1 (9.0.1) Part Number A87503-02 |
|
![]()
![]()
This chapter explains how to use hints to force various approaches.
This chapter contains the following sections:
As an application designer, you might know information about your data that the optimizer does not know. For example, you might know that a certain index is more selective for certain queries. Based on this information, you might be able to choose a more efficient execution plan than the optimizer. In such a case, use hints to force the optimizer to use the optimal execution plan.
Hints allow you to make decisions usually made by the optimizer. You can use hints to specify the following:
Hints provide a mechanism to direct the optimizer to choose a certain query execution plan based on the following criteria:
Hints (except for the RULE hint) invoke the cost-based optimizer (CBO). If you have not gathered statistics, then defaults are used.
Hints apply only to the optimization of the statement block in which they appear. A statement block is any one of the following statements or parts of statements:
SELECT, UPDATE, or DELETE statement.
For example, a compound query consisting of two component queries combined by the UNION operator has two statement blocks, one for each component query. For this reason, hints in the first component query apply only to its optimization, not to the optimization of the second component query.
You can send hints for a SQL statement to the optimizer by enclosing them in a comment within the statement.
A statement block can have only one comment containing hints. This comment can only follow the SELECT, UPDATE, or DELETE keyword.
The syntax below shows hints contained in both styles of comments that Oracle supports within a statement block.
{DELETE|INSERT|SELECT|UPDATE} /*+ hint [text] [hint[text]]... */
or
{DELETE|INSERT|SELECT|UPDATE} --+ hint [text] [hint[text]]...
where:
If you specify hints incorrectly, then Oracle ignores them but does not return an error:
DELETE, SELECT, or UPDATE keyword.
Other conditions specific to index type appear later in this chapter.
The optimizer recognizes hints only when using the cost-based approach. If you include a hint (except the RULE hint) in a statement block, then the optimizer automatically uses the cost-based approach.
When using hints, in some cases, you might need to specify a full set of hints in order to ensure the optimal execution plan. For example, if you have a very complex query, which consists of many table joins, and if you specify only the INDEX hint for a given table, then the optimizer needs to determine the remaining access paths to be used, as well as the corresponding join methods. Therefore, even though you gave the INDEX hint, the optimizer might not necessarily use that hint, because the optimizer might have determined that the requested index cannot be used due to the join methods and access paths selected by the optimizer. In this particular example, we have specified the exact join order to be used via the ORDERED hint, as well as the join methods to be used on the different tables.
SELECT /*+ ORDERED INDEX (b, jl_br_balances_n1) USE_NL (j b) USE_NL (glcc glf) USE_MERGE (gp gsb) */ b.application_id , b.set_of_books_id , b.personnel_id, p.vendor_id Personnel, p.segment1 PersonnelNumber, p.vendor_name Name FROM jl_br_journals j, jl_br_balances b, gl_code_combinations glcc, fnd_flex_values_vl glf, gl_periods gp, gl_sets_of_books gsb, po_vendors p WHERE . . . . . . . . . . . .
By default, hints do not propagate inside a complex view. For example, if you specify a hint in a query that selects against a complex view, then that hint is not honored, because it is not pushed inside the view.
Unless the hints are inside the base view, they might not be honored from a query against the view.
Table hints (in other words, hints that specify a table) generally refer to tables in the DELETE, SELECT, or UPDATE statement in which the hint occurs, not to tables inside any views referenced by the statement. When you want to specify hints for tables that appear inside views, Oracle recommends using global hints instead of embedding the hint in the view. Any table hint described in this chapter can be transformed into a global hint by using an extended syntax for the table name.
|
Note: The SQL Analyze tool (available with the Oracle Tuning Pack), provides a graphical user interface for working with optimizer hints. The Hint Wizard (a feature of SQL Analyze) helps you easily add or modify hints in SQL statements. For more information on Oracle SQL Analyze, see the Database Tuning with the Oracle Tuning Pack manual. |
The hints described in this section allow you to choose between the cost-based and the rule-based optimization approaches. With the cost-based approach, this also includes the goal of best throughput or best response time.
If a SQL statement has a hint specifying an optimization approach and goal, then the optimizer uses the specified approach regardless of the presence or absence of statistics, the value of the OPTIMIZER_MODE initialization parameter, and the OPTIMIZER_MODE parameter of the ALTER SESSION statement.
The ALL_ROWS hint explicitly chooses the cost-based approach to optimize a statement block with a goal of best throughput (that is, minimum total resource consumption).
all_rows_hint::=
all_rows_hint
For example, the optimizer uses the cost-based approach to optimize this statement for best throughput:
SELECT /*+ ALL_ROWS */ empno, ename, sal, job FROM emp WHERE empno = 7566;
The hints FIRST_ROWS(n) (where n is any positive integer) or FIRST_ROWS instruct Oracle to optimize an individual SQL statement for fast response. FIRST_ROWS(n) affords greater precision, because it instructs Oracle to choose the plan that returns the first n rows most efficiently. The FIRST_ROWS hint, which optimizes for the best plan to return the first single row, is retained for backward compatibility and plan stability.
first_rows_hint::=
first_rows_hint
For example, the optimizer uses the cost-based approach to optimize this statement for best response time:
SELECT /*+ FIRST_ROWS(10) */ empno, ename, sal, job FROM emp WHERE deptno = 20;
In this example each department contains many employees. The user wants the first 10 employees of department #20 to be displayed as quickly as possible.
The optimizer ignores this hint in DELETE and UPDATE statement blocks and in SELECT statement blocks that contain any of the following syntax:
UNION, INTERSECT, MINUS, UNION ALL)
GROUP BY clause
FOR UPDATE clause
DISTINCT operator
These statements cannot be optimized for best response time, because Oracle must retrieve all rows accessed by the statement before returning the first row. If you specify this hint in any of these statements, then the optimizer uses the cost-based approach and optimizes for best throughput.
If you specify either the ALL_ROWS or the FIRST_ROWS hint in a SQL statement, and if the data dictionary does not have statistics about tables accessed by the statement, then the optimizer uses default statistical values (such as allocated storage for such tables) to estimate the missing statistics and, subsequently, to choose an execution plan.
These estimates might not be as accurate as those gathered by the DBMS_STATS package. Therefore, use the DBMS_STATS package to gather statistics. If you specify hints for access paths or join operations along with either the ALL_ROWS or FIRST_ROWS hint, then the optimizer gives precedence to the access paths and join operations specified by the hints.
|
See Also:
"How the CBO Optimizes SQL Statements for Fast Response" for an explanation of the difference between |
The CHOOSE hint causes the optimizer to choose between the rule-based and cost-based approaches for a SQL statement. The optimizer bases its selection on the presence of statistics for the tables accessed by the statement. If the data dictionary has statistics for at least one of these tables, then the optimizer uses the cost-based approach and optimizes with the goal of best throughput. If the data dictionary does not have statistics for these tables, then it uses the rule-based approach.
choose_hint::=
choose_hint
For example:
SELECT /*+ CHOOSE */ empno, ename, sal, job FROM emp WHERE empno = 7566;
rule_hint::=
rule_hint
For example:
SELECT --+ RULE empno, ename, sal, job FROM emp WHERE empno = 7566;
Each hint described in this section suggests an access path for a table.
Specifying one of these hints causes the optimizer to choose the specified access path only if the access path is available based on the existence of an index or cluster and on the syntactic constructs of the SQL statement. If a hint specifies an unavailable access path, then the optimizer ignores it.
You must specify the table to be accessed exactly as it appears in the statement. If the statement uses an alias for the table, then use the alias rather than the table name in the hint. The table name within the hint should not include the schema name if the schema name is present in the statement.
|
Note:
For access path hints, Oracle ignores the hint if you specify the |
The FULL hint explicitly chooses a full table scan for the specified table.
full_hint::=
full_hint
where table specifies the name or alias of the table on which the full table scan is to be performed. If the statement does not use aliases, then the table name is the default alias.
For example:
SELECT /*+ FULL(A) don't use the index on accno */ accno, bal FROM accounts a WHERE accno = 7086854;
Oracle performs a full table scan on the accounts table to execute this statement, even if there is an index on the accno column that is made available by the condition in the WHERE clause.
The ROWID hint explicitly chooses a table scan by rowid for the specified table.
rowid_hint::=
rowid_hint
where table specifies the name or alias of the table on which the table access by rowid is to be performed.
For example:
SELECT /*+ROWID(emp)*/ * FROM emp WHERE rowid > 'AAAAtkAABAAAFNTAAA' AND empno = 155;
The CLUSTER hint explicitly chooses a cluster scan to access the specified table. It applies only to clustered objects.
cluster_hint::=
cluster_hint
where table specifies the name or alias of the table to be accessed by a cluster scan.
For example:
SELECT --+ CLUSTER emp.ename, deptno FROM emp, dept WHERE deptno = 10AND emp.deptno = dept.deptno;
The HASH hint explicitly chooses a hash scan to access the specified table. It applies only to tables stored in a cluster.
hash_hint::=
hash_hint
where table specifies the name or alias of the table to be accessed by a hash scan.
The INDEX hint explicitly chooses an index scan for the specified table. You can use the INDEX hint for domain, B-tree, bitmap, and bitmap join indexes. However, Oracle recommends using INDEX_COMBINE rather than INDEX for bitmap indexes, because it is a more versatile hint.
index_hint::=

index_hint
where:
table |
Specifies the name or alias of the table associated with the index to be scanned. |
index |
Specifies an index on which an index scan is to be performed. |
This hint can optionally specify one or more indexes:
For example, consider this query that selects the name, height, and weight of all male patients in a hospital:
SELECT name, height, weight FROM patients WHERE sex = 'm';
Assume that there is an index on the SEX column and that this column contains the values m and f. If there are equal numbers of male and female patients in the hospital, then the query returns a relatively large percentage of the table's rows, and a full table scan is likely to be faster than an index scan. However, if a very small percentage of the hospital's patients are male, then the query returns a relatively small percentage of the table's rows, and an index scan is likely to be faster than a full table scan.
Barring the use of frequency histograms, the number of occurrences of each distinct column value is not available to the optimizer. The cost-based approach assumes that each value has an equal probability of appearing in each row. For a column having only two distinct values, the optimizer assumes each value appears in 50% of the rows, so the cost-based approach is likely to choose a full table scan rather than an index scan.
If you know that the value in the WHERE clause of the query appears in a very small percentage of the rows, then you can use the INDEX hint to force the optimizer to choose an index scan. In this statement, the INDEX hint explicitly chooses an index scan on the sex_index, the index on the sex column:
SELECT /*+ INDEX(patients sex_index) use sex_index because there are fewmale patients */ name, height, weightFROM patients WHERE sex = 'm';
The INDEX hint applies to IN-list predicates; it forces the optimizer to use the hinted index, if possible, for an IN-list predicate. Multicolumn IN-lists will not use an index.
The INDEX_ASC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, then Oracle scans the index entries in ascending order of their indexed values.
index_asc_hint::=

index_asc_hint
Each parameter serves the same purpose as in the INDEX hint.
Because Oracle's default behavior for a range scan is to scan index entries in ascending order of their indexed values, this hint does not specify anything more than the INDEX hint. However, you might want to use the INDEX_ASC hint to specify ascending range scans explicitly should the default behavior change.
The INDEX_COMBINE hint explicitly chooses a bitmap access path for the table. If no indexes are given as arguments for the INDEX_COMBINE hint, then the optimizer uses whatever Boolean combination of bitmap indexes has the best cost estimate for the table. If certain indexes are given as arguments, then the optimizer tries to use some Boolean combination of those particular bitmap indexes.
index_combine_hint::=
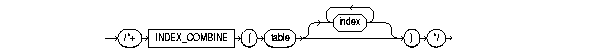
index_combine_hint
For example:
SELECT /*+INDEX_COMBINE(emp sal_bmi hiredate_bmi)*/ * FROM emp WHERE sal < 50000 AND hiredate < '01-JAN-1990';
The INDEX_JOIN hint explicitly instructs the optimizer to use an index join as an access path. For the hint to have a positive effect, a sufficiently small number of indexes must exist that contain all the columns required to resolve the query.
index_join_hint::=

index_join_hint
where:
table |
Specifies the name or alias of the table associated with the index to be scanned. |
index |
Specifies an index on which an index scan is to be performed. |
For example:
SELECT /*+INDEX_JOIN(emp sal_bmi hiredate_bmi)*/ sal, hiredate FROM emp WHERE sal < 50000;
The INDEX_DESC hint explicitly chooses an index scan for the specified table. If the statement uses an index range scan, then Oracle scans the index entries in descending order of their indexed values. In a partitioned index, the results are in descending order within each partition.
index_desc_hint::=

index_desc_hint
Each parameter serves the same purpose as in the INDEX hint.
The INDEX_FFS hint causes a fast full index scan to be performed rather than a full table scan.
index_ffs_hint::=

index_ffs_hint
For example:
SELECT /*+INDEX_FFS(emp emp_empno)*/ empno FROM emp WHERE empno > 200;
The NO_INDEX hint explicitly disallows a set of indexes for the specified table.
no_index_hint::=

no_index_hint
NO_INDEX hint that specifies a list of all available indexes for the table.
The NO_INDEX hint applies to function-based, B-tree, bitmap, cluster, or domain indexes.
If a NO_INDEX hint and an index hint (INDEX, INDEX_ASC, INDEX_DESC, INDEX_COMBINE, or INDEX_FFS) both specify the same indexes, then both the NO_INDEX hint and the index hint are ignored for the specified indexes and the optimizer considers the specified indexes.
For example:
SELECT /*+NO_INDEX(emp emp_empno)*/ empno FROM emp WHERE empno > 200;
The AND_EQUAL hint explicitly chooses an execution plan that uses an access path that merges the scans on several single-column indexes.
and_equal_hint::=
and_equal_hint
where:
Each hint described in this section suggests a SQL query transformation.
The USE_CONCAT hint forces combined OR conditions in the WHERE clause of a query to be transformed into a compound query using the UNION ALL set operator. Generally, this transformation occurs only if the cost of the query using the concatenations is cheaper than the cost without them.
The USE_CONCAT hint turns off IN-list processing and OR-expands all disjunctions, including IN-lists.
use_concat_hint::=
use_concat_hint
For example:
SELECT /*+USE_CONCAT*/ * FROM emp WHERE empno > 50 OR sal < 50000;
The NO_EXPAND hint prevents the cost-based optimizer from considering OR-expansion for queries having OR conditions or IN-lists in the WHERE clause. Usually, the optimizer considers using OR expansion and uses this method if it decides that the cost is lower than not using it.
no_expand_hint::=
no_expand_hint
For example:
SELECT /*+NO_EXPAND*/ * FROM emp WHERE empno = 50 OR empno = 100;
The REWRITE hint forces the cost-based optimizer to rewrite a query in terms of materialized views, when possible, without cost consideration. Use the REWRITE hint with or without a view list. If you use REWRITE with a view list and the list contains an eligible materialized view, then Oracle uses that view regardless of its cost.
Oracle does not consider views outside of the list. If you do not specify a view list, then Oracle searches for an eligible materialized view and always uses it regardless of its cost.
rewrite_hint::=

rewrite_hint
|
See Also:
Oracle9i Database Concepts and Oracle9i Application Developer's Guide - Fundamentals for more information on materialized views |
The NOREWRITE hint disables query rewrite for the query block, overriding the setting of the parameter QUERY_REWRITE_ENABLED. Use the NOREWRITE hint on any query block of a request.
norewrite_hint::=
norewrite_hint
The MERGE hint lets you merge a view on a per-query basis.
If a view's query contains a GROUP BY clause or DISTINCT operator in the SELECT list, then the optimizer can merge the view's query into the accessing statement only if complex view merging is enabled. Complex merging can also be used to merge an IN subquery into the accessing statement if the subquery is uncorrelated.
Complex merging is not cost-based--that is, the accessing query block must include the MERGE hint. Without this hint, the optimizer uses another approach.
merge_hint::=
merge_hint
For example:
SELECT /*+MERGE(v)*/ e1.ename, e1.sal, v.avg_sal FROM emp e1, (SELECT deptno, avg(sal) avg_sal FROM emp e2 GROUP BY deptno) v WHERE e1.deptno = v.deptno AND e1.sal > v.avg_sal;
The NO_MERGE hint causes Oracle not to merge mergeable views.
no_merge_hint::=
no_merge_hint
This hint lets the user have more influence over the way in which the view is accessed.
For example:
SELECT /*+NO_MERGE(dallasdept)*/ e1.ename, dallasdept.dname FROM emp e1, (SELECT deptno, dname FROM dept WHERE loc = 'DALLAS') dallasdept WHERE e1.deptno = dallasdept.deptno;
This causes view dallasdept not to be merged.
When the NO_MERGE hint is used without an argument, it should be placed in the view query block. When NO_MERGE is used with the view name as an argument, it should be placed in the surrounding query.
The STAR_TRANSFORMATION hint makes the optimizer use the best plan in which the transformation has been used. Without the hint, the optimizer could make a cost-based decision to use the best plan generated without the transformation, instead of the best plan for the transformed query.
Even if the hint is given, there is no guarantee that the transformation will take place. The optimizer only generates the subqueries if it seems reasonable to do so. If no subqueries are generated, then there is no transformed query, and the best plan for the untransformed query is used, regardless of the hint.
star_transformation_hint::=
star_transformation_hint
|
See Also:
|
The FACT hint is used in the context of the star transformation to indicate to the transformation that the hinted table should be considered as a fact table.
fact_hint::=
fact_hint
The NO_FACT hint is used in the context of the star transformation to indicate to the transformation that the hinted table should not be considered as a fact table.
no_fact_hint::=
no_fact_hint
The hints in this section suggest join orders:
The ORDERED hint causes Oracle to join tables in the order in which they appear in the FROM clause.
If you omit the ORDERED hint from a SQL statement performing a join, then the optimizer chooses the order in which to join the tables. You might want to use the ORDERED hint to specify a join order if you know something about the number of rows selected from each table that the optimizer does not. Such information lets you choose an inner and outer table better than the optimizer could.
ordered_hint::=
ordered_hint
For example, this statement joins table TAB1 to table TAB2 and then joins the result to table TAB3:
SELECT /*+ ORDERED */ tab1.col1, tab2.col2, tab3.col3 FROM tab1, tab2, tab3 WHERE tab1.col1 = tab2.col1AND tab2.col1 = tab3.col1;
The STAR hint forces a star query plan to be used, if possible. A star plan has the largest table in the query last in the join order and joins it with a nested loops join on a concatenated index. The STAR hint applies when there are at least three tables, the large table's concatenated index has at least three columns, and there are no conflicting access or join method hints. The optimizer also considers different permutations of the small tables.
star_hint::=
star_hint
Usually, if you analyze the tables, then the optimizer selects an efficient star plan. You can also use hints to improve the plan. The most precise method is to order the tables in the FROM clause in the order of the keys in the index, with the large table last. Then use the following hints:
/*+ ORDERED USE_NL(FACTS) INDEX(facts fact_concat) */
where facts is the table and fact_concat is the index. A more general method is to use the STAR hint.
Each hint described in this section suggests a join operation for a table.
You must specify a table to be joined exactly as it appears in the statement. If the statement uses an alias for the table, then you must use the alias rather than the table name in the hint. The table name within the hint should not include the schema name if the schema name is present in the statement.
Use of the USE_NL and USE_MERGE hints is recommended with the ORDERED hint. Oracle uses these hints when the referenced table is forced to be the inner table of a join, and they are ignored if the referenced table is the outer table.
The USE_NL hint causes Oracle to join each specified table to another row source with a nested loops join using the specified table as the inner table.
use_nl_hint::=
use_nl_hint
where table is the name or alias of a table to be used as the inner table of a nested loops join.
For example, consider this statement, which joins the accounts and customers tables. Assume that these tables are not stored together in a cluster:
SELECT accounts.balance, customers.last_name, customers.first_name FROM accounts, customers WHERE accounts.custno = customers.custno;
Because the default goal of the cost-based approach is best throughput, the optimizer chooses either a nested loops operation or a sort-merge operation to join these tables, depending on which is likely to return all the rows selected by the query more quickly.
However, you might want to optimize the statement for best response time or the minimal elapsed time necessary to return the first row selected by the query, rather than best throughput. If so, then you can force the optimizer to choose a nested loops join by using the USE_NL hint. In this statement, the USE_NL hint explicitly chooses a nested loops join with the customers table as the inner table:
SELECT /*+ ORDERED USE_NL(customers) to get first row faster */ accounts.balance, customers.last_name, customers.first_name FROM accounts, customers WHERE accounts.custno = customers.custno;
In many cases, a nested loops join returns the first row faster than a sort merge join. A nested loops join can return the first row after reading the first selected row from one table and the first matching row from the other and combining them, while a sort merge join cannot return the first row until after reading and sorting all selected rows of both tables and then combining the first rows of each sorted row source.
The USE_MERGE hint causes Oracle to join each specified table with another row source with a sort-merge join.
use_merge_hint::=
use_merge_hint
where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a sort merge join.
For example:
SELECT /*+USE_MERGE(emp dept)*/ * FROM emp, dept WHERE emp.deptno = dept.deptno;
The USE_HASH hint causes Oracle to join each specified table with another row source with a hash join.
use_hash_hint::=
use_hash_hint
where table is a table to be joined to the row source resulting from joining the previous tables in the join order using a hash join.
For example:
SELECT /*+use_hash(emp dept)*/ * FROM emp, dept WHERE emp.deptno = dept.deptno;
The DRIVING_SITE hint forces query execution to be done at a different site than that selected by Oracle. This hint can be used with either rule-based or cost-based optimization.
driving_site_hint::=
driving_site_hint
where table is the name or alias for the table at which site the execution should take place.
For example:
SELECT /*+DRIVING_SITE(dept)*/ * FROM emp, dept@rsite WHERE emp.deptno = dept.deptno;
If this query is executed without the hint, then rows from dept are sent to the local site, and the join is executed there. With the hint, the rows from emp are sent to the remote site, and the query is executed there, returning the result to the local site.
This hint is useful if you are using distributed query optimization.
The LEADING hint causes Oracle to use the specified table as the first table in the join order.
If you specify two or more LEADING hints on different tables, then all of them are ignored. If you specify the ORDERED hint, then it overrides all LEADING hints.
leading_hint::=
leading_hint
where table is the name or alias of a table to be used as the first table in the join order.
For a specific query, place the MERGE_AJ, HASH_AJ, or NL_AJ hint into the NOT IN subquery. MERGE_AJ uses a sort-merge anti-join, HASH_AJ uses a hash anti-join, and NL_AJ uses a nested loop anti-join.
As illustrated in Figure 5-1, the SQL IN predicate can be evaluated using a join to intersect two sets. Thus, emp.deptno can be joined to dept.deptno to yield a list of employees in a set of departments.
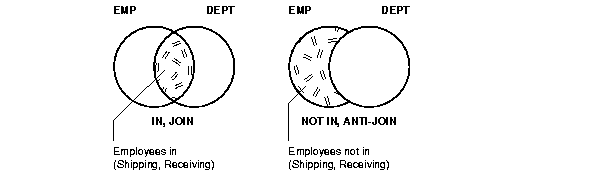
Alternatively, the SQL NOT IN predicate can be evaluated using an anti-join to subtract two sets. Thus, emp.deptno can be anti-joined to dept.deptno to select all employees who are not in a set of departments, and you can get a list of all employees who are not in the shipping or receiving departments.
For a specific query, place the HASH_SJ, MERGE_SJ, or NL_SJ hint into the EXISTS subquery. HASH_SJ uses a hash semi-join, MERGE_SJ uses a sort merge semi-join, and NL_SJ uses a nested loop semi-join.
For example:
SELECT * FROM dept WHERE exists (SELECT /*+HASH_SJ*/ * FROM emp WHERE emp.deptno = dept.deptno AND sal > 200000);
This converts the subquery into a special type of join between t1 and t2 that preserves the semantics of the subquery. That is, even if there is more than one matching row in t2 for a row in t1, the row in t1 is returned only once.
A subquery is evaluated as a semi-join only with these limitations:
GROUP BY, CONNECT BY, or ROWNUM references.
The hints described in this section determine how statements are parallelized or not parallelized when using parallel execution.
The PARALLEL hint lets you specify the desired number of concurrent servers that can be used for a parallel operation. The hint applies to the INSERT, UPDATE, and DELETE portions of a statement as well as to the table scan portion.
If any parallel restrictions are violated, then the hint is ignored.
parallel_hint::=

parallel_hint
The PARALLEL hint must use the table alias if an alias is specified in the query. The hint can then take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table, and the second value specifies how the table is to be split among the Oracle Real Application Cluster instances. Specifying DEFAULT or no value signifies that the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
In the following example, the PARALLEL hint overrides the degree of parallelism specified in the emp table definition:
SELECT /*+ FULL(scott_emp) PARALLEL(scott_emp, 5) */ ename FROM scott.emp scott_emp;
In the next example, the PARALLEL hint overrides the degree of parallelism specified in the emp table definition and tells the optimizer to use the default degree of parallelism determined by the initialization parameters. This hint also specifies that the table should be split among all of the available instances, with the default degree of parallelism on each instance.
SELECT /*+ FULL(scott_emp) PARALLEL(scott_emp, DEFAULT,DEFAULT) */ ename FROM scott.emp scott_emp;
The NOPARALLEL hint overrides a PARALLEL specification in the table clause. In general, hints take precedence over table clauses.
noparallel_hint::=
noparallel_hint
The following example illustrates the NOPARALLEL hint:
SELECT /*+ NOPARALLEL(scott_emp) */ ename FROM scott.emp scott_emp;
The PQ_DISTRIBUTE hint improves parallel join operation performance. Do this by specifying how rows of joined tables should be distributed among producer and consumer query servers. Using this hint overrides decisions the optimizer would normally make.
Use the EXPLAIN PLAN statement to identify the distribution chosen by the optimizer. The optimizer ignores the distribution hint if both tables are serial.
pq_distribute_hint::=
pq_distribute_hint
where:
table_name |
Name or alias of a table to be used as the inner table of a join. |
outer_distribution |
The distribution for the outer table. |
inner_distribution |
The distribution for the inner table. |
|
See Also:
Oracle9i Database Concepts for more information on how Oracle parallelizes join operations |
There are six combinations for table distribution. Only a subset of distribution method combinations for the joined tables is valid, as explained in Table 5-1.
For example: Given two tables, R and S, that are joined using a hash-join, the following query contains a hint to use hash distribution:
SELECT <column_list> /*+ORDERED PQ_DISTRIBUTE(s HASH, HASH) USE_HASH (s)*/ FROM r,s WHERE r.c=s.c;
To broadcast the outer table r, the query is:
SELECT <column list> /*+ORDERED PQ_DISTRIBUTE(s BROADCAST, NONE) USE_HASH (s) */ FROM r,s WHERE r.c=s.c;
The PARALLEL_INDEX hint specifies the desired number of concurrent servers that can be used to parallelize index range scans for partitioned indexes.
parallel_index_hint::=

parallel_index_hint
where:
table |
Specifies the name or alias of the table associated with the index to be scanned. |
index |
Specifies an index on which an index scan is to be performed (optional). |
The hint can take two values separated by commas after the table name. The first value specifies the degree of parallelism for the given table. The second value specifies how the table is to be split among the Oracle Real Application Cluster instances. Specifying DEFAULT or no value signifies the query coordinator should examine the settings of the initialization parameters (described in a later section) to determine the default degree of parallelism.
For example:
SELECT /*+ PARALLEL_INDEX(table1, index1, 3, 2) +/
In this example, there are three parallel execution processes to be used on each of two instances.
The NOPARALLEL_INDEX hint overrides a PARALLEL attribute setting on an index to avoid a parallel index scan operation.
noparallel_index_hint::=
noparallel_index_hint
Several additional hints are included in this section:
The APPEND hint lets you enable direct-path INSERT if your database is running in serial mode. (Your database is in serial mode if you are not using Enterprise Edition. Conventional INSERT is the default in serial mode, and direct-path INSERT is the default in parallel mode).
In direct-path INSERT, data is appended to the end of the table, rather than using existing space currently allocated to the table. In addition, direct-path INSERT bypasses the buffer cache and ignores integrity constraints. As a result, direct-path INSERT can be considerably faster than conventional INSERT.
append_hint::=
append_hint
The NOAPPEND hint enables conventional INSERT by disabling parallel mode for the duration of the INSERT statement. (Conventional INSERT is the default in serial mode, and direct-path INSERT is the default in parallel mode).
noappend_hint::=
noappend_hint
The CACHE hint specifies that the blocks retrieved for the table are placed at the most recently used end of the LRU list in the buffer cache when a full table scan is performed. This option is useful for small lookup tables.
cache_hint::=
cache_hint
In the following example, the CACHE hint overrides the table's default caching specification:
SELECT /*+ FULL (scott_emp) CACHE(scott_emp) */ ename FROM scott.emp scott_emp;
The NOCACHE hint specifies that the blocks retrieved for the table are placed at the least recently used end of the LRU list in the buffer cache when a full table scan is performed. This is the normal behavior of blocks in the buffer cache.
nocache_hint::=
nocache_hint
For example:
SELECT /*+ FULL(scott_emp) NOCACHE(scott_emp) */ ename FROM scott.emp scott_emp;
Setting the UNNEST_SUBQUERY session parameter to TRUE enables subquery unnesting. Subquery unnesting unnests and merges the body of the subquery into the body of the statement that contains it, allowing the optimizer to consider them together when evaluating access paths and joins.
UNNEST_SUBQUERY first verifies if the statement is valid. If the statement is not valid, then subquery unnesting cannot proceed. The statement must then must pass a heuristic test.
If the UNNEST_SUBQUERY parameter is set to true, then the UNNEST hint checks the subquery block for validity only. If it is valid, then subquery unnesting is enabled without Oracle checking the heuristics.
|
See Also:
|
unnest_hint::=
unnest_hint
If you enabled subquery unnesting with the UNNEST_SUBQUERY parameter, then the NO_UNNEST hint turns it off for specific subquery blocks.
no_unnest_hint::=
no_unnest_hint
The PUSH_PRED hint forces pushing of a join predicate into the view.
push_pred_hint::=
push_pred_hint
For example:
SELECT /*+ PUSH_PRED(v) */ t1.x, v.y FROM t1(SELECT t2.x, t3.y FROM t2, t3 WHERE t2.x = t3.x) vWHERE t1.x = v.x and t1.y = 1;
The NO_PUSH_PRED hint prevents pushing of a join predicate into the view.
no_push_pred_hint::=
no_push_pred_hint
The PUSH_SUBQ hint causes non-merged subqueries to be evaluated at the earliest possible place in the execution plan. Generally, subqueries that are not merged are executed as the last step in the execution plan. If the subquery is relatively inexpensive and reduces the number of rows significantly, then it improves performance to evaluate the subquery earlier.
This hint has no effect if the subquery is applied to a remote table or one that is joined using a merge join.
push_subq_hint::=
push_subq_hint
The ORDERED_PREDICATES hint forces the optimizer to preserve the order of predicate evaluation, except for predicates used as index keys. Use this hint in the WHERE clause of SELECT statements.
If you do not use the ORDERED_PREDICATES hint, then Oracle evaluates all predicates in the order specified by the following rules. Predicates:
WHERE clause.
WHERE clause.
WHERE clause (for example, predicates transitively generated by the optimizer) are evaluated next.
WHERE clause.
ordered_predicates_hint::=
ordered_predicates_hint
Oracle can replace literals in SQL statements with bind variables if it is safe to do so. This is controlled with the CURSOR_SHARING startup parameter. The CURSOR_SHARING_EXACT hint causes this behavior to be switched off. In other words, Oracle executes the SQL statement without any attempt to replace literals by bind variables.
cursor_sharing_exact_hint::=
cursor_sharing_exact_hint
Oracle does not encourage you to use hints inside or on views (or subqueries). This is because you can define views in one context and use them in another. However, such hints can result in unexpected plans. In particular, hints inside views or on views are handled differently depending on whether the view is mergeable into the top-level query.
If you decide, nonetheless, to use hints with views, the following sections describe the behavior in each case.
If you want to specify a hint for a table in a view or subquery, then the global hint syntax is recommended. The following section describes this in detail.
This section describes hint behavior with mergeable views.
Optimization approach and goal hints can occur in a top-level query or inside views.
Access path and join hints on referenced views are ignored unless the view contains a single table (or references an Additional Hints view with a single table). For such single-table views, an access path hint or a join hint on the view applies to the table inside the view.
Access path and join hints can appear in a view definition.
FROM clause of a SELECT statement), then all access path and join hints inside the view are preserved when the view is merged with the top-level query.
FROM clause of the SELECT statement contains only the view).
PARALLEL, NOPARALLEL, PARALLEL_INDEX, and NOPARALLEL_INDEX hints on views are applied recursively to all the tables in the referenced view. Parallel execution hints in a top-level query override such hints inside a referenced view.
PARALLEL, NOPARALLEL, PARALLEL_INDEX, and NOPARALLEL_INDEX hints inside views are preserved when the view is merged with the top-level query. Parallel execution hints on the view in a top-level query override such hints inside a referenced view.
With nonmergeable views, optimization approach and goal hints inside the view are ignored: the top-level query decides the optimization mode.
Because nonmergeable views are optimized separately from the top-level query, access path and join hints inside the view are preserved. For the same reason, access path hints on the view in the top-level query are ignored.
However, join hints on the view in the top-level query are preserved because, in this case, a nonmergeable view is similar to a table.
Table hints (in other words, hints that specify a table) normally refer to tables in the DELETE, SELECT, or UPDATE statement in which the hint occurs, not to tables inside any views referenced by the statement. When you want to specify hints for tables that appear inside views, use global hints instead of embedding the hint in the view. You can transform any table hint in this chapter into a global hint by using an extended syntax for the table name, described as follows.
Consider the following view definitions and SELECT statement:
CREATE VIEW v1 ASSELECT * FROM emp WHERE empno < 100;CREATE VIEW v2 ASSELECT v1.empno empno, dept.deptno deptno FROM v1, dept WHERE v1.deptno = dept.deptno;SELECT /*+ INDEX(v2.v1.emp emp_empno) FULL(v2.dept) */ *FROM v2 WHERE deptno = 20;
The view V1 retrieves all employees whose employee number is less than 100. The view V2 performs a join between the view V1 and the department table. The SELECT statement retrieves rows from the view V2 restricting it to the department whose number is 20.
There are two global hints in the SELECT statement. The first hint specifies an index scan for the employee table referenced in the view V1, which is referenced in the view V2. The second hint specifies a full table scan for the department table referenced in the view V2. Note the dotted syntax for the view tables.
A hint such as:
INDEX(emp emp_empno)
in the SELECT statement is ignored because the employee table does not appear in the FROM clause of the SELECT statement.
The global hint syntax also applies to unmergeable views. Consider the following SELECT statement:
SELECT /*+ NO_MERGE(v2) INDEX(v2.v1.emp emp_empno) FULL(v2.dept) */ * FROM v2 WHERE deptno = 20;
It causes V2 not to be merged and specifies access path hints for the employee and department tables. These hints are pushed down into the (nonmerged) view V2.
If a global hint references a UNION or UNION ALL view, then the hint is applied to the first branch that contains the hinted table. Consider the INDEX hint in the following SELECT statement:
SELECT /*+ INDEX(v.emp emp_empno) */ * FROM (SELECT *FROM emp WHERE empno < 50 UNION ALL SELECT * FROM emp WHERE empno > 1000) vWHERE deptno = 20;
The INDEX hint applies to the employee table in the first branch of the UNION ALL view v, not to the employee table in the second branch.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|