Release 1 (9.0.1)
Part Number A90236-02
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle9i Globalization Support Guide Release 1 (9.0.1) Part Number A90236-02 |
|
![]()
![]()
This chapter illustrates programming issues when dealing with Unicode. It contains the following topics:
Oracle9i offers several database access products for inserting and retrieving Unicode data. Oracle offers database access products for most commonly used programming environments such as Java and C/C++. Data is transparently converted between the database and client programs, which ensures that client programs are independent of the database character set and national character set. In addition, client programs are sometimes even independent of the character datatype, such as NCHAR or CHAR, used in the database.
To avoid overloading the database server with data conversion operations, Oracle9i always tries to move them to the client side database access products. In a few cases, data must be converted in the database, and you should be aware of the performance implications. Details of the data conversion paths taken are discussed in this chapter.
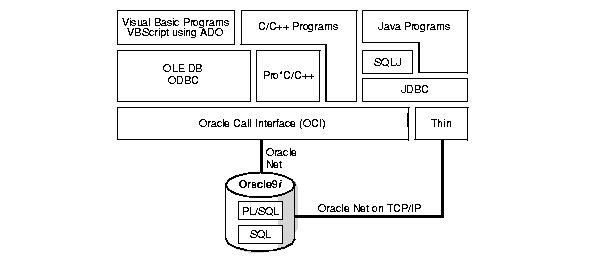
Oracle Corporation offers a comprehensive set of database access products that allow programs from different development environments to access Unicode data stored in the database. These products are listed in Table 6-1.
Figure 6-1 shows how the database access products can access the database.
CHAR and NCHAR datatypes. Using OCI, you can programmatically specify the character set (UTF-8, UTF-16, and others) for the data to be inserted or retrieved.
CHAR and NCHAR datatypes.
CHAR and NCHAR datatypes of the database. It provides UTF-16 data access by implementing the SQLWCHAR interface specified in the ODBC standard specification.
CHAR and NCHAR datatypes. It provides UTF-16 data access through wide string OLE DB datatypes.
CHAR and NCHAR datatypes in the database.
CHAR and NCHAR datatypes in the database.
NCHAR and NVARCHAR2 variables and access SQL NCHAR datatypes in the database.
The following sections describe how each of the above database access products supports Unicode data access to an Oracle9i database and offer examples for using those products.
SQL is the fundamental language with which all programs and users access data in an Oracle database either directly or indirectly. PL/SQL is a procedural language that combines the data manipulating power of SQL with the data processing power of procedural languages. Both SQL and PL/SQL can be embedded in other programming languages. This section describes Unicode-related features in SQL and PL/SQL that you can deploy for multilingual applications.
There are three SQL NCHAR datatypes:
When you define a table column or PL/SQL variables in NCHAR, the length specified is always in the number of characters. For example, the following statement:
CREATE TABLE tab1 (col1 NCHAR(30));
creates a column with a maximum character length of 30. The maximum byte length is the multiple of the maximum character length and the maximum number of bytes per character. For example, if the national character set is UTF8, the above statement defines a maximum byte length of 90 bytes.
The national character set is defined when the database is created. In Oracle9i, the national character set can be either UTF8 or AL16UTF16.
You can define a maximum column size of 2000 characters when the national character set is UTF8 and 1000 when it is AL16UTF16. The actual data is subject to the maximum byte limit of 2000. The two size constraints must be satisfied at the same time. In PL/SQL, the maximum length of NCHAR data is 32767 bytes. You can define an NCHAR variable of up to 32767 characters, but the actual data cannot exceed 32767 bytes. If you insert a value that is shorter than the column length, Oracle blank pads the value to the smaller value between maximum character length and maximum byte length.
The NVARCHAR2 datatype specifies a variable length national character set character string. When you create a table with an NVARCHAR2 column, you supply the maximum number of characters. Oracle subsequently stores each value in the column exactly as you specify it, provided the value does not exceed the column's maximum length. It does not pad the string value to the maximum length. Lengths for NVARCHAR2 are always treated as being in units of characters, just as for NCHAR.
The maximum column size allowed is 4000 characters when the national character set is UTF8 and 2000 when it is AL16UTF16. NVARCHAR2 columns can be defined up to 4000 bytes, the actual maximum length of a column allowed is the number of characters that fit into no more than 4000 bytes. In PL/SQL, the maximum length for NVARCHAR2 is 32767 bytes. You can define NVARCHAR2 variables up to 32767 characters, but the actual data cannot exceed 32767 bytes.
The following statement creates a table with one NVARCHAR2 column of 2000 characters in length. If the national character set is UTF8, the following will create a column with maximum character length of 2000 and maximum byte length of 4000.
CREATE TABLE tab1 (col1 NVARCHAR2(2000));
NCLOB is a character large object containing multibyte characters, with a maximum size of 4 gigabytes. Unlike BLOBs, NCLOBs have full transactional support so changes made through SQL, the DBMS_LOB package, or OCI participate fully in transactions. NCLOB value manipulations can be committed and rolled back. Note, however, that you cannot save an NCLOB locator in a PL/SQL or OCI variable in one transaction and then use it in another transaction or session.
NCLOB values are stored in the database using the UTF-16 character set, which has a fixed width. Oracle translates the stored Unicode value to the character set requested on the client or on the server, which can be fixed-width or variable-width. When you insert data into an NCLOB column using a varying-width character set, Oracle converts the data into UTF-16 Unicode before storing it in the database. This happens whether the national character set is UTF8 or AL16UTF16.
Oracle supports implicit conversions between SQL NCHAR datatypes and most Oracle datatypes, such as CHAR, VARCHAR2, NUMBER, DATE, ROWID, and CLOB. Any implicit conversions for CHAR/VARCHAR2 are also supported for SQL NCHAR datatypes. You can use SQL NCHAR datatypes the same way as SQL CHAR datatypes.
There are several points to keep in mind with implicit conversions:
CHAR datatypes and SQL NCHAR datatypes may involve character set conversion when database and national character sets are different, or blank padding if the target data is either CHAR or NCHAR.
CLOB and NCLOB datatypes is not possible. You can, however, use Oracle's explicit conversion functions for them.
Data loss can occur during type conversion when character set conversion is necessary. If a character in the first character set is not defined in the target character set, then a replacement character will be used in its place. For example, if you try to insert NCHAR data into a regular CHAR column, if the character data in NCHAR (Unicode) form cannot be converted to the database character set, the character will be replaced by a replacement character question mark. The NLS_NCHAR_CONV_EXCP initialization parameter controls the behavior of data loss during character type conversion. When this parameter is set to TRUE, any SQL statements that result in data loss return an ORA-12713 error and the corresponding operation is aborted. When this parameter is set to FALSE, data loss is not reported and the unconvertible characters are replaced with replacement characters. The default value is TRUE. This parameter works for both implicit and explicit conversion.
In PL/SQL, when data loss occurs during conversion of SQL CHAR and NCHAR datatypes, the exception LOSSY_CHARSET_CONVERSION is raised. It applies for both implicit and explicit conversion.
In some cases, conversion is only possible in one direction. In other cases, both directions are possible. In order to have predictable and unambiguous behavior, Oracle defines a set of specific rules for conversion direction.
INSERT/UPDATE statement
Values are converted to the type of target database column.
SELECT INTO statement
Data from the database is converted to the type of target variable.
Values on the right hand side of (=) are converted to the types of the variable on left hand side which is the target of assignment.
CHAR, VARCHAR2, NCHAR, and NVARCHAR2 overload in the same way. An argument of one with a CHAR, VARCHAR2, NCHAR or NVARCHAR2 type will match a formal parameter of any of the types CHAR, VARCHAR2, NCHAR or NVARCHAR2 for overloading. If the argument and formal parameter types do not match exactly, then implicit conversions will be introduced when data is copied into the parameter on function entry and copied out to the argument on function exit.
CONCAT function
If one operand is a SQL CHAR or NCHAR datatype and the other operand is a NUMBER or other non-character datatype, the other datatype is converted to VARCHAR2 or NVARCHAR2. For concatenation between character datatypes, see the discussion below.
CHAR or NCHAR datatypes and NUMBER: Character value is converted to NUMBER.
CHAR or NCHAR datatypes and DATE: Character string value is converted to DATE type.
CHAR or NCHAR datatypes and ROWID: Character types are converted to rowid type.
NCHAR datatypes and SQL CHAR datatypes, the character data is converted to NUMBER.
CHAR or NCHAR datatypes and NUMBER
Character values are converted to NUMBER.
CHAR or NCHAR datatypes and DATE
Character values are converted to DATE.
CHAR or NCHAR datatypes and ROWID
Character data is converted to ROWID.
NCHAR datatypes and SQL CHAR datatypes
Comparisons between SQL NCHAR datatypes and SQL CHAR datatypes are more complex because they can be encoded in different character sets. For comparisons between CHAR and VARCHAR2, or between NCHAR and NVARCHAR2, the direction is CHAR->VARCHAR2 or NCHAR->NVARCHAR2. When there is conversion between SQL NCHAR datatypes and SQL CHAR datatypes, character set conversion occurs if they are encoded in different character sets. The character set for SQL NCHAR datatypes is always Unicode and can be either UTF8 or AL16UTF16 encoding, which have equal character repertoires but are different encodings of the Unicode standard. SQL CHAR datatypes use the database character set, which can be any character set that Oracle supports. Unicode is always a superset of any character set supported by Oracle, so it is always convertible from SQL CHAR datatypes to SQL NCHAR datatypes without data loss.
SQL NCHAR datatypes can be converted to and from SQL CHAR datatypes and other datatypes using explicit conversion functions. Following are several examples using this table.
CREATE TABLE customers (id NUMBER, name NVARCHAR2(50), addr NVARCHAR2(200), dob DATE);
INSERT INTO customers VALUES (1000, TO_NCHAR('John Smith'), N'500 Oracle Parkway');
SELECT name FROM customers WHERE TO_CHAR(name) LIKE 'Sm%';
DECLARE ndstr NVARCHAR2(20) := N'12-SEP-1975'; BEGIN SELECT name FROM customers WHERE (dob)> TO_DATE(ndstr, 'DD-MON-YYYY', N'NLS_DATE_LANGUAGE = AMERICAN'); END;
As demonstrated in Example 6-3, not only can SQL NCHAR data be passed to explicit conversion functions, but also SQL CHAR and NCHAR data can be mixed together when using multiple string parameters.
|
See Also:
Oracle9i SQL Reference for more information about explicit conversion functions for SQL |
Most SQL functions can take arguments of SQL NCHAR datatypes as well as mixed character datatypes. The return datatype is based on the type of the first argument. If a non-string datatype like NUMBER or DATE is passed to these functions, it will be converted to VARCHAR2. Several examples using the customers table from above follow:
SELECT INSTR(name, N'Sm', 1, 2) FROM customers;
SELECT CONCAT(name || id) FROM customer;
id will be converted to NVARCHAR2 and then concatenated with name.
SELECT RPAD (name, 100, ' ') FROM customer;
Space character ' ' is converted to the corresponding character in the NCHAR character set and then padded to the right of name until the total display length reaches 100.
|
See Also:
Oracle9i SQL Reference for a list of all SQL functions that can accept SQL |
You can input Unicode string literals in SQL and PL/SQL as follows:
N in front of a single quote marked string literal. This explicitly indicates that the following string literals is an NCHAR string literal.
NCHAR datatypes, a string literal is converted to a SQL NCHAR datatype wherever necessary.
When a string literal is included in a query and the query is submitted through a client-side tool such as SQL*Plus, all the queries are encoded in the client's character set and then converted to the server's database character set before processing. Therefore, data loss can occur if the string literal cannot be converted to the server database character set.
NCHR(n) SQL function, which returns the character having the binary equivalent to n in the national character set, which is UTF8 or AL16UTF16. The result of concatenations of several NCHR(n) is NVARCHAR2. In this way, you can bypass the client and server character set conversions and create an NVARCHAR2 string directly. For example, NCHR(32) represents a blank character.
UNISTR(string) SQL function. UNISTR(string) takes a string and converts it to Unicode. The result is in database national character set (UTF8 or AL16UTF16). You can embed escape \bbbb inside the string. The escape represents the value of a UTF-16 code point with hex number 0xbbbb. For example, UNISTR('G\0061ry') represents 'Gary'.
The last two methods can be used to encode any Unicode string literals.
The UTL_FILE package has been enhanced in Oracle9i to handle Unicode national character set data. The following functions and procedures have been added:
FOPEN_NCHAR
This function opens a file in Unicode for input or output, with the maximum line size specified. With this function, you can read or write a text file in Unicode instead of in the database character set.
GET_LINE_NCHAR
This procedure reads text from the open file identified by the file handle and places the text in the output buffer parameter. With this function, you can read a text file in Unicode instead of in the database character set.
PUT_NCHAR
This procedure writes the text string stored in the buffer parameter to the open file identified by the file handle. With this function, you can write a text file in Unicode instead of in the database character set.
PUT_LINE_NCHAR
This procedure writes the text string stored in the buffer parameter to the open file identified by the file handle. With this function, you can write a text file in Unicode instead of in the database character set.
PUTF_NCHAR
This procedure is a formatted PUT_NCHAR procedure. With this function, you can write a text file in Unicode instead of in the database character set.
|
See Also:
Oracle9i Supplied PL/SQL Packages and Types Reference for more information about the |
OCI is the lowest-level API for accessing a database, so it offers the best possible performance. When using Unicode with OCI, you should consider these topics:
Unicode character set conversions take place between an OCI client and the database server if the client and server character sets are different. The conversion occurs on either the client or the server depending on the circumstances, but usually on the client side.
You can lose data during conversion if you call an OCI API inappropriately. If the server and client character sets are different, you can lose data when the destination character set is a smaller set than the source character set. You can avoid this potential problem if both character sets are Unicode character sets (for example, UTF8 and AL16UTF16).
When you bind or define SQL NCHAR datatypes, you should set OCI_ATTR_CHARSET_FORM to SQLCS_NCHAR. Otherwise, you can lose data because the data is converted to the database character set prior to converting to or from the national character set, but only if the database character set is not Unicode.
Redundant data conversions can cause performance degradation in your OCI applications. These conversions occur in two cases:
CHAR datatypes and set the OCI_ATTR_CHARSET_FORM attribute to SQLCS_NCHAR, data conversions take place from client character set to the national database character set, and from the national character set to the database character set. No data loss is expected, but two conversions happen, even though it requires only one.
NCHAR datatypes and do not set OCI_ATTR_CHARSET_FORM, data conversions take place from client character set to the database character set, and from the database character set to the national database character set. In the worst case, data loss can occur if the database character set is smaller than the client's.
To avoid performance problems, you should always specify the correct form of use based upon the datatype of the target columns. If you do not know the target datatype, you should set the OCI_ATTR_CHARSET_FORM attribute to SQLCS_NCHAR when binding and defining.
Data conversion can result in data expansion, which can cause a buffer to overflow. For binding operations, you need to set the OCI_ATTR_MAXDATA_SIZE attribute to a large enough size to hold the expanded data on the server. If this is difficult to do, you need to consider changing the table schema. For defining operations, client applications need to allocate enough buffer for the expanded data. The size of buffer should be the maximum expanded size of data length. You can estimate the maximum buffer length with the following calculation:
This method is the simplest and quickest way, but may not be accurate and can waste memory. It is applicable to any character set combination. For example, for UTF-16 data binding and defining, the following example calculates the client buffer:
ub2 csid = OCI_UTF16ID; oratext *selstmt = "SELECT ename FROM emp"; counter = 1; ... OCIStmtPrepare(stmthp, errhp, selstmt, (ub4)strlen((char*)selstmt), OCI_NTV_SYNTAX, OCI_DEFAULT); OCIStmtExecute ( svchp, stmthp, errhp, (ub4)0, (ub4)0, (CONST OCISnapshot*)0, (OCISnapshot*)0, OCI_DESCRIBE_ONLY); OCIParamGet(stmthp, OCI_HTYPE_STMT, errhp, &myparam, (ub4)counter); OCIAttrGet((void*)myparam, (ub4)OCI_DTYPE_PARAM, (void*)&col_width, (ub4*)0, (ub4)OCI_ATTR_DATA_SIZE, errhp); ... maxenamelen = (col_width + 1) * sizeof(utext); cbuf = (utext*)malloc(maxenamelen); ... OCIDefineByPos(stmthp, &dfnp, errhp, (ub4)1, (void *)cbuf, (sb4)maxenamelen, SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0, (ub4)OCI_DEFAULT); OCIAttrSet((void *) dfnp, (ub4) OCI_HTYPE_DEFINE, (void *) &csid, (ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp); OCIStmtFetch(stmthp, errhp, 1, OCI_FETCH_NEXT, OCI_DEFAULT); ...
You can use UTF8 and AL32UTF8 by setting NLS_LANG for OCI client applications. If you do not need surrogate characters, it does not matter whether you choose UTF8 or AL32UTF8. However, if your OCI applications might handle surrogate characters, you need to make a decision. Because UTF8 can require up to three bytes per character, one surrogate character is represented in two codepoints, totalling six bytes. With AL32UTF8, one surrogate character is represented in one codepoint, totalling four bytes.
Do not set NLS_LANG to AL16UTF16, because AL16UTF16 is the national character set for the server. If you need to use UTF-16, you should specify the client character set to OCI_UTF16ID using OCIAttrSet when binding or defining data.
To specify a Unicode character set for binding and defining data with SQL CHAR datatypes, you may need to call the OCIAttrSet function to set the appropriate character set ID after OCIBind or OCIDefine APIs. There are two typical cases:
OCIBind / OCIDefine followed by OCIAttrSet to specify UTF-16 Unicode character set encoding.
... ub2 csid = OCI_UTF16ID; utext ename[100]; /* enough buffer for ENAME */ ... /* Inserting Unicode data */ OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME", (sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename), SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0, OCI_DEFAULT); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &csid, (ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len, (ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp); ... /* Retrieving Unicode data */ OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename, (sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0, (ub4)OCI_DEFAULT); OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &csid, (ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp); ...
If bound buffers are of the utext datatype, you should add a cast (text*) when OCIBind or OCIDefine is called. The value of the OCI_ATTR_MAXDATA_SIZE attribute is usually determined by the size of column on the server character set because this size is only used to allocate temporary buffer for conversion on the server when you perform binding operations.
OCIBind or OCIDefine with NLS_LANG set to UTF8 or AL32UTF8.
UTF8 or AL32UTF8 can be set in NLS_LANG. You call OCIBind and OCIDefine in exactly the same manner as when you are not using Unicode. Set the environment variable NLS_LANG to UTF8 or AL32UTF8 and run the following OCI program:
... oratext ename[100]; /* enough buffer size for ENAME */ ... /* Inserting Unicode data */ OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME", (sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename), SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0, OCI_DEFAULT); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len, (ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp); ... /* Retrieving Unicode data */ OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename, (sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0, (ub4)OCI_DEFAULT); ...
Oracle recommends you access SQL NCHAR datatypes using UTF-16 binding or defining when using OCI. Starting from Oracle9i, SQL NCHAR datatypes have become pure-Unicode datatypes with an encoding of either UTF8 or AL16UTF16. To access data in SQL NCHAR datatypes, you need to set the OCI attribute OCI_ATTR_CHARSET_FORM to SQLCS_NCHAR after binding and defining until execution so that it performs an appropriate data conversion without data loss. The length of data in SQL NCHAR datatypes is always in the number of Unicode codepoints.
The following program is a typical example of inserting and fetching data against an NCHAR data column:
... ub2 csid = OCI_UTF16ID; ub2 cform = SQLCS_NCHAR; utext ename[100]; /* enough buffer for ENAME */ ... /* Inserting Unicode data */ OCIBindByName(stmthp1, &bnd1p, errhp, (oratext*)":ENAME", (sb4)strlen((char *)":ENAME"), (void *) ename, sizeof(ename), SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0, OCI_DEFAULT); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &csid, (ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &cform, (ub4) 0, (ub4)OCI_ATTR_CHARSET_FORM, errhp); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len, (ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp); ... /* Retrieving Unicode data */ OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename, (sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0, (ub4)OCI_DEFAULT); OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &csid, (ub4) 0, (ub4)OCI_ATTR_CHARSET_ID, errhp); OCIAttrSet((void *) dfn1p, (ub4) OCI_HTYPE_DEFINE, (void *) &cform, (ub4) 0, (ub4)OCI_ATTR_CHARSET_FORM, errhp); ...
In order to write (bind) and read (define) UTF-16 data for CLOB or NCLOB columns, the UTF-16 character set ID must be specified as OCILobWrite and OCILobRead. When you write UTF-16 data into a CLOB column, you should call OCILobWrite as follows:
... ub2 csid = OCI_UTF16ID; err = OCILobWrite (ctx->svchp, ctx->errhp, lobp, &amtp, offset, (void *) buf, (ub4) BUFSIZE, OCI_ONE_PIECE, (void *)0, (sb4 (*)()) 0, (ub2) csid, (ub1) SQLCS_IMPLICIT);
Where the parameter amtp is the data length in the number of Unicode codepoints. The parameter offset indicates the offset of data from the beginning of data column. The parameter csid must be set for UTF-16 data.
To read UTF-16 data from CLOB columns, call OCILobRead as follows:
... ub2 csid = OCI_UTF16ID; err = OCILobRead(ctx->svchp, ctx->errhp, lobp, &amtp, offset, (void *) buf, (ub4)BUFSIZE , (void *) 0, (sb4 (*)()) 0, (ub2)csid, (ub1) SQLCS_IMPLICIT);
The data length is always represented in the number of Unicode codepoints. Note one Unicode surrogate character is counted as two codepoints, because the encoding is UTF-16. After binding or defining LOB column, you can measure the data length stored in the LOB column using OCILobGetLength. The returning value is the data length in the number of codepoints if you bind or define as UTF-16.
err = OCILobGetLength(ctx->svchp, ctx->errhp, lobp, &lenp);
If you are using an NCLOB, you must set OCI_ATTR_CHARSET_FORM to SQLCS_NCHAR.
OCI supports UTF-16 metadata as well as UTF-16 data for binding and defining. SQL statements, usernames, error messages, and column names can be in UTF-16, and are thus independent of the NLS_LANG setting. Oracle provides a Unicode mode so you can use UTF-16 metadata. At the beginning of your OCI program, all you have to do is create OCI environment handle (OCIEnv) with the OCI_UTF16 flag. Any inherited handle is automatically set the mode to Unicode where OCI treats all string parameters as UTF-16 data.
To enable Unicode in OCI applications, Oracle offers an alternative approach using a Unicode API called OCI_UTF16ID. Before Oracle9i, OCI could only manipulate UTF-16 character set encoding for binding / defining to insert and fetch data against database columns, while metadata like SQL statement, username, and column name were restricted to the character set specified by NLS_LANG. For Oracle9i, the Unicode API is intended to be independent of NLS_LANG. In addition, all data manipulation by OCI is in the UTF-16 character set encoding. This is especially important for multilingual applications.
You activate the Unicode API by setting a Unicode mode when creating an OCI environment handle (OCIEnv). Any inherited handle from the OCI environment handle will be set to Unicode mode automatically. By changing to Unicode mode, all metatext data parameters (text*) are assumed to be Unicode text datatypes (utext*) in UTF-16 encoding. For binding and defining, the data is also assumed to be Unicode in UTF-16 encoding. For example, the following program shows how you can create an OCI environment handle as a Unicode mode. OCI_UTF16 indicates the default character set is UTF-16:
OCIEnv *envhp; status = OCIEnvCreate((OCIEnv **)&envhp, OCI_UTF16, (void *)0, (void *(*) ()) 0, (void *(*) ()) 0, (void(*) ()) 0, (size_t) 0, (void **)0);
To prepare the SQL statement, call OCIStmtPrepare with (utext*) string. The following example runs on Windows platforms only. You may need to change wchar_t datatypes for other platforms.
const wchar_t sqlstr[] = L"SELECT * FROM ENAME=:ename"; ... OCIStmt* stmthp; sts = OCIHandleAlloc(envh, (void **)&stmthp, OCI_HTYPE_STMT, 0, NULL); status = OCIStmtPrepare(stmthp, errhp,(const text*)sqlstr, wcslen(sqlstr), OCI_NTV_SYNTAX, OCI_DEFAULT);
You call OCIStmtPrepare exactly like other character sets, but the parameter is UTF-16 string data. For binding and defining data, you do not have to set the OCI_ATTR_CHARSET_ID attribute because you are already in the Unicode mode. Bind variable names must be UTF-16 strings. You must cast (text*) or (const(text*)) for metadata parameters.
/* Inserting Unicode data */ OCIBindByName(stmthp1, &bnd1p, errhp, (const text*)L":ename", (sb4)wcslen(L":ename"), (void *) ename, sizeof(ename), SQLT_STR, (void *)&insname_ind, (ub2 *) 0, (ub2 *) 0, (ub4) 0, (ub4 *)0, OCI_DEFAULT); OCIAttrSet((void *) bnd1p, (ub4) OCI_HTYPE_BIND, (void *) &ename_col_len, (ub4) 0, (ub4)OCI_ATTR_MAXDATA_SIZE, errhp); ... /* Retrieving Unicode data */ OCIDefineByPos (stmthp2, &dfn1p, errhp, (ub4)1, (void *)ename, (sb4)sizeof(ename), SQLT_STR, (void *)0, (ub2 *)0, (ub2*)0, (ub4)OCI_DEFAULT); ...
Then OCIExecute will perform the operation.
Pro*C/C++ provides three ways for you to insert or retrieve Unicode data into or from the database:
VARCHAR Pro*C/C++ datatype or the native C/C++ text datatype, a program can access Unicode data stored in SQL CHAR datatypes of a UTF8 or AL32UTF8 database. Alternatively, a program could use the C/C++ native text type.
UVARCHAR Pro*C/C++ datatype or the native C/C++ utext datatype, a program can access Unicode data stored in NCHAR datatypes of a database.
NVARCHAR Pro*C/C++ datatype, a program can access Unicode data stored in NCHAR datatypes. The difference between UVARCHAR and NVARCHAR in a Pro*C/C++ program is that the data for the UVARCHAR datatype is stored in a utext buffer while the data for the NVARCHAR datatype is stored in a text datatype.
Pro*C/C++ does not use the Unicode OCI API for SQL text. As a result, embedded SQL text must be encoded in the character set specified in the NLS_LANG environment variable.
Data conversion occurs in the OCI layer, but it is the Pro*C/C++ preprocessor that instructs OCI which conversion path should be taken based on the datatypes used in a Pro*C/C++ program. Table 6-3 illustrates the conversion paths:
The Pro*C/C++ VARCHAR datatype is preprocessed to a struct with a length field and text buffer field. An example is shown below using the C/C++ text native datatype and the VARCHAR Pro*C/C++ datatypes to bind and define table columns.
#include <sqlca.h> main() { ... /* Change to STRING datatype: */ EXEC ORACLE OPTION (CHAR_MAP=STRING) ; text ename[20] ; /* unsigned short type */ varchar address[50] ; /* Pro*C/C++ uvarchar type */ EXEC SQL SELECT ename, address INTO :ename, :address FROM emp; /* ename is NULL-terminated */ printf(L"ENAME = %s, ADDRESS = %.*s\n", ename, address.len, address.arr); ... }
When you use the VARCHAR datatype or native text datatype in a Pro*C/C++ program, the preprocessor assumes that the program intends to access columns of SQL CHAR datatypes instead of SQL NCHAR datatypes in the database. The preprocessor generates C/C++ code to reflect this fact by doing a bind or define using the SQLCS_IMPLICIT value for the OCI_ATTR_CHARSET_FORM attribute. As a result, if a bind or define variable is bound to a column of SQL NCHAR datatypes in the database, implicit conversion happens in the database server to convert the data from the database character set to the national database character set and vice versa. During the conversion, data loss occurs when the database character set is a smaller set than the national character set.
The Pro*C/C++ NVARCHAR datatype is similar to the Pro*C/C++ VARCHAR datatype. It should be used to access SQL NCHAR datatypes in the database. It tells Pro*C/C++ preprocessor to bind or define a text buffer to the column of SQL NCHAR datatypes. The preprocessor will specify the SQLCS_NCHAR value for the OCI_ATTR_CHARSET_FORM attribute of the bind or define variable. As a result, no implicit conversion occurs in the database.
If the NVARCHAR buffer is bound against columns of SQL CHAR datatypes, the data in the NVARCHAR buffer (encoded in the NLS_LANG character set) is converted to or from the national character set in OCI, and the data is then converted to the database character set in the database server. Data can be lost when the NLS_LANG character set is a larger set than the database character set.
The UVARCHAR datatype is preprocessed to a struct with a length field and utext buffer field. The following example code contains two host variables, ename and address. The ename host variable is declared as a utext buffer containing 20 Unicode characters. The address host variable is declared as a uvarchar buffer containing 50 Unicode characters, the len and arr fields are accessible as fields of a struct.
#include <sqlca.h> #include <sqlucs2.h> main() { ... /* Change to STRING datatype: */ EXEC ORACLE OPTION (CHAR_MAP=STRING) ; utext ename[20] ; /* unsigned short type */ uvarchar address[50] ; /* Pro*C/C++ uvarchar type */ EXEC SQL SELECT ename, address INTO :ename, :address FROM emp; /* ename is NULL-terminated */ wprintf(L"ENAME = %s, ADDRESS = %.*s\n", ename, address.len, address.arr); ... }
When you use the UVARCHAR datatype or native utext datatype in Pro*C/C++ programs, the preprocessor assumes that the program intends to access SQL NCHAR datatypes. The preprocessor generates C/C++ code by binding or defining using the SQLCS_NCHAR value for OCI_ATTR_CHARSET_FORM attribute. As a result, if a bind or define variable is bound to a column of a SQL NCHAR datatype, an implicit conversion of the data from the national character set occurs in the database server. However, there is no data lost in this scenario because the national character set is always a larger set than the database character set.
Oracle provides three JDBC drivers for Java programs to access Unicode data in the database. They are the JDBC OCI driver, JDBC Thin driver, and JDBC KPRB driver. Java programs can insert or retrieve Unicode data to and from columns of SQL CHAR and NCHAR datatypes. Specifically, JDBC allows Java programs to bind or define Java strings to SQL CHAR and NCHAR datatypes. Because Java's string datatype is UTF-16 encoded, data retrieved from or inserted into the database must be converted from UTF-16 to the database character set or the national character set and vice versa. The SQLJ preprocessor allows Java programs to embed SQL statements to simplify database access code. It translates the embedded SQL statements of a Java program to the corresponding JDBC calls. Similar to JDBC, SQLJ allows programs to bind or define Java String to a SQL CHAR or NCHAR column. JDBC and SQLJ also allow you to specify the PL/SQL and SQL statements in Java strings so that any non-ASCII schema object names can be referenced in Java programs.
Oracle JDBC drivers allow you to access SQL CHAR datatypes in the database using Java string bind or define variables. The following code illustrates how to bind or define a Java string to a CHAR column:
int empno = 12345; String ename = "Joe" PreparedStatement pstmt = conn.prepareStatement("INSERT INTO" + "emp (ename, empno) VALUES (?, ?)"); pstmt.setString(1, ename); pstmt.setInt(2, empno); pstmt.execute(); /* execute to insert into first row */ empno += 1; /* next employee number */ ename = "\uFF2A\uFF4F\uFF45"; /* Unicode characters in name */ pstmt.setString(1, ename); pstmt.setInt(2, empno); pstmt.execute(); /* execute to insert into second row */
For binding or defining Java string variables to SQL NCHAR datatypes, Oracle extends the JDBC specification to add the PreparedStatement.setFormOfUse() method through which you can explicitly specify the target column of a bind variable to be a SQL NCHAR datatype. The following code illustrates how to bind a Java string to an NCHAR column:
int empno = 12345; String ename = "Joe" oracle.jdbc.OraclePreparedStatement pstmt = (oracle.jdbc.OraclePreparedStatement) conn.prepareStatement("INSERT INTO emp (ename, empno) VALUES (?, ?)"); pstmt.setFormOfUse(1, oracle.jdbc.OraclePreparedStatement.FORM_NCHAR); pstmt.setString(1, ename); pstmt.setInt(2, empno); pstmt.execute(); /* execute to insert into first row */ empno += 1; /* next employee number */ ename = "\uFF2A\uFF4F\uFF45"; /* Unicode characters in name */ pstmt.setString(1, ename); pstmt.setInt(2, empno); pstmt.execute(); /* execute to insert into second row */
You can bind or define a Java string against an NCHAR column without explicitly specifying the form of use argument, but you then have the following implications:
setString() method, JDBC assumes the bind or define variable to be for the SQL CHAR column. As a result, it tries to convert them to the database character set. When the data gets to the database, the database implicitly converts the data in the database character set to the national character set. During this conversion, data can be lost when the database character set is a subset of the national character set. Because the national character set is either UTF8 or AL16UTF16, data loss would happen if the database character set is not UTF8 or AL32UTF8.
CHAR to SQL NCHAR datatypes happens in the database, database performance will be adversely impacted.
In addition, if you bind or define a Java string for a column of SQL CHAR datatypes but specify the form of use argument, performance of the database will be adversely affected. However, data should not be lost because the national character set is always a larger set than the database character.
You must place a setFormOfUse() statement before binding or defining Java variables to SQL NCHAR datatypes. The following code illustrates a sample setting of setFormOfUse():
//------------------------------------------------------------------ // Call dbms_lob.read(:clob, :read_this_time, :i+1, :string_this_time) //------------------------------------------------------------------ OracleCallableStatement cstmt = (oracle.jdbc.OracleCallableStatement) conn.prepareCall("BEGIN dbms_lob.read(:1, :2, :3, :4 ); END;"); while (i < length) { cstmt.setFormOfUse(1,oracle.jdbc.Const.NCHAR); cstmt.setFormOfUse(4,oracle.jdbc.Const.NCHAR); cstmt.registerOutParameter(2,oracle.jdbc.OracleTypes.BIGINT); // **** the following 2 lines have to be put after setFormOfUse() **** cstmt.registerOutParameter(4,oracle.jdbc.OracleTypes.CHAR); cstmt.setCLOB(1,clob); cstmt.setLong(2,chunk); cstmt.setLong(3,i+1); cstmt.execute(); }
Because Java strings are always encoded in UTF-16, JDBC drivers transparently convert data from the database character set to UTF-16 or the national character set.
The conversion paths taken are different for the three JDBC drivers:
string bind or define variables, Table 6-4 summarizes the conversion paths taken for different scenarios:
Table 6-4 OCI Driver Conversion Path
string bind and define variables, the conversion paths shown in Table 6-5 are taken for the Thin driver:
Table 6-5 Thin Driver Conversion Path
string bind or define variables are converted to the database character sets if the form of use argument is not specified. Otherwise, they are converted to the national character set.
You should use Oracle's ODBC and OLE DB drivers to access Oracle9i when using a Windows platform. This section describes how these drivers support Unicode.
Oracle's ODBC and OLE DB drivers can handle Unicode data properly without data loss. For example, you can run a Unicode ODBC application containing Japanese data on English Windows if you install Japanese fonts and an input method editor for entering Japanese characters.
In Oracle9i, Oracle provides Windows platform-specific ODBC and OLE DB drivers only. For Unix platforms, contact your vendor.
OCI Unicode binding and defining features are used by the ODBC and OLE DB drivers to handle Unicode data. As discussed in "OCI Programming with Unicode", OCI Unicode data binding and defining features are independent from NLS_LANG. This means Unicode data is handled properly, irrespective of the NLS_LANG setting on the platform.
In general, no redundant data conversion occurs unless you specify a different client datatype from that of the server. If you bind Unicode buffer SQL_C_WCHAR with a Unicode data column like NCHAR, for example, ODBC and OLE DB drivers bypass it between the application and OCI layer.
If you do not specify datatypes before fetching, and call SQLGetData with the client datatypes instead, the conversions in Table 6-6 occur:
Note that you must specify the datatype for inserting and updating operations.
[*1] Datatype of ODBC client buffer is given when you call SQLGetData but not immediately. Hence, SQLFetch does not have the information.
[*2] If database character set is a subset of NLS_LANG.
[*3] If database character set is not a subset of NLS_LANG.
Because the ODBC driver guarantees data integrity, if you perform implicit bindings, redundant conversion may result in performance degradation. Your choice is the trade off between performance with explicit binding or usability with implicit binding.
Unlike ODBC, OLE DB only allows you to perform implicit bindings for both inserting/updating and fetching data. The conversion algorithm for determining the intermediate character set is the same as the implicit binding cases of ODBC.
[*1] If database character set is a subset of NLS_LANG.
[*2] If database character set is not a subset of NLS_LANG.
In ODBC Unicode applications, use SQLWCHAR to store Unicode data. All standard Windows Unicode functions can be used for SQLWCHAR data manipulations. For example, wcslen counts the number of characters of SQLWCHAR data:
SQLWCHAR sqlStmt[] = L"select ename from emp"; len = wcslen(sqlStmt);
Additionally, Microsoft's ODBC 3.5 specification defines three Unicode datatype identifiers for the SQL_C_WCHAR, SQL_C_WVARCHAR, and SQL_WLONGVARCHAR clients; and three Unicode datatype identifiers for servers SQL_WCHAR, SQL_WVARCHAR, and SQL_WLONGVARCHAR.
For binding operations, specify both datatypes for client and server using SQLBindParameter. The following is an example of Unicode binding, where the client buffer Name indicates that Unicode data (SQL_C_WCHAR) is bound to the first bind variable associated with the Unicode column (SQL_WCHAR):
SQLBindParameter(StatementHandle, 1, SQL_PARAM_INPUT, SQL_C_WCHAR, SQL_WCHAR, NameLen, 0, (SQLPOINTER)Name, 0, &Name);
To determine the ODBC Unicode datatypes for server, Table 6-8 represents the datatype mappings against SQL NCHAR datatypes:
| ODBC Datatype | Oracle Datatype |
|---|---|
|
|
|
|
|
|
|
|
|
According to ODBC specifications, SQL_WCHAR, SQL_WVARCHAR, and SQL_WLONGVARCHAR are treated as Unicode data, and are therefore measured in the number of characters instead of bytes to represents the data length when you retrieve table column information. Because NCHAR, NVARCHAR2, and NCLOB are migrated into pure Unicode datatypes, the above mappings will fit in the expected ODBC behavior.
OLE DB offers you the choices of wchar_t *, BSTR, and OLESTR for the Unicode client C datatype. In practice, wchar_t is the most common datatype and the others are for specific purposes. The following example assigns a static SQL statement:
wchar_t *sqlStmt = OLESTR("SELECT ename FROM emp");
The OLESTR macro works exactly like an "L" modifier to indicate the Unicode string. If you need to allocate Unicode data buffer dynamically using OLESTR, use the IMalloc allocator (for example, CoTaskMemAlloc). However, using OLESTR is not the normal method for variable length data; use wchar_t* instead for generic string types. BSTR is similar but a string with a length prefix in the memory location preceding the string. Some functions and methods can accept only BSTR Unicode datatypes. Therefore, BSTR Unicode string must be manipulated with special functions like SysAllocString for allocation and SysFreeString for freeing memory.
Unlike ODBC, OLE DB does not allow you to specify the server datatype explicitly. When you set the client datatype, the OLE DB driver automatically performs data conversion if necessary.
Table 6-9 illustrates OLE DB datatype mapping:
| OLE DB Datatype | Oracle Datatype |
|---|---|
|
|
|
If DBTYPE_BSTR is specified, it is assumed to be DBTYPE_WCHAR because both are Unicode strings.
ADO is a high-level API to access database via OLE DB and ODBC drivers. Most database application developers use the ADO interface on Windows because it is easily accessible from Visual Basic, the primary scripting language for Active Server Pages (ASP) for the Internet Information Server (IIS). To OLE DB and ODBC drivers, ADO is simply an OLE DB consumer or ODBC application. ADO assumes that OLE DB and ODBC drivers are Unicode-aware components; hence, it always attempts to manipulate Unicode data.
To use an ODBC driver with ADO, check the Force SQL_WCHAR attribute on the ODBC Data Source control panel. OLE DB is automatically adjusted to the ADO environment and requires no such action.
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|