Release 9.0.1
Part Number A90122-01
Home |
Book List |
Contents |
Index | Master Index | Feedback |
| Oracle Text Application Developer's Guide Release 9.0.1 Part Number A90122-01 |
|
![]()
![]()
![]()
Indexing, 4 of 6
You can create three types of indexes with Oracle Text: CONTEXT, CTXCAT, and CTXRULE.
By default, the system expects your documents to be stored in a text column. Once this requirement is satisfied, you can create a text index using the CREATE INDEX SQL command as an extensible index of type context, without explicitly specifying any preferences. The system automatically detects your language, the datatype of the text column, format of documents, and sets indexing preferences accordingly.
|
See Also:
For more information about the out-of-box defaults, see Default CONTEXT Index Example in this chapter. |
To create an Oracle Text index, do the following:
You can optionally create your own custom index preferences to override the defaults. Use the preferences to specify index information such as where your files are stored and how to filter your documents. You create the preferences then set the attributes.
The following sections give examples for setting direct, multi-column, URL, and file datastores.
The following example creates a table with a CLOB column to store text data. It then populates two rows with text data and indexes the table using the system-defined preference CTXSYS.DEFAULT_DATASTORE.
create table mytable(id number primary key, docs clob); insert into mytable values(111555,'this text will be indexed'); insert into mytable values(111556,'this is a direct_datastore example'); commit; create index myindex on mytable(docs) indextype is ctxsys.context parameters ('DATASTORE CTXSYS.DEFAULT_DATASTORE');
The following example creates a multi-column datastore preference called my_multi on the three text columns to be concatenated and indexed:
begin ctx_ddl.create_preference('my_multi', 'MULTI_COLUMN_DATASTORE'); ctx_ddl.set_attribute('my_multi', 'columns', 'column1, column2, column3'); end;
This example creates a URL_DATASTORE preference called my_url to which the http_proxy, no_proxy, and timeout attributes are set. The defaults are used for the attributes that are not set.
begin ctx_ddl.create_preference('my_url','URL_DATASTORE'); ctx_ddl.set_attribute('my_url','HTTP_PROXY','www-proxy.us.oracle.com'); ctx_ddl.set_attribute('my_url','NO_PROXY','us.oracle.com'); ctx_ddl.set_attribute('my_url','Timeout','300'); end;
The following example creates a data storage preference using the FILE_DATASTORE. This tells the system that the files to be indexed are stored in the operating system. The example uses CTX_DDL.SET_ATTRIBUTE to set the PATH attribute of to the directory /docs.
begin ctx_ddl.create_preference('mypref', 'FILE_DATASTORE'); ctx_ddl.set_attribute('mypref', 'PATH', '/docs'); end;
If your document set is entirely HTML, Oracle recommends that you use the NULL_FILTER in your filter preference, which does no filtering.
For example, to index an HTML document set, you can specify the system-defined preferences for NULL_FILTER and HTML_SECTION_GROUP as follows:
create index myindex on docs(htmlfile) indextype is ctxsys.context parameters('filter ctxsys.null_filter section group ctxsys.html_section_group');
Consider a filter procedure CTXSYS.NORMALIZE that you define with the following signature:
PROCEDURE NORMALIZE(id IN ROWID, charset IN VARCHAR2, input IN CLOB, output IN OUT NOCOPY VARCHAR2);
To use this procedure as your filter, you set up your filter preference as follows:
beginctx_ddl.create_preference('myfilt', 'procedure_filter'); ctx_ddl.set_attribute('myfilt', 'procedure', 'normalize'); ctx_ddl.set_attribute('myfilt', 'input_type', 'clob'); ctx_ddl.set_attribute('myfilt', 'output_type', 'varchar2'); ctx_ddl.set_attribute('myfilt', 'rowid_parameter', 'TRUE'); ctx_ddl.set_attribute('myfilt', 'charset_parameter', 'TRUE');end;
Printjoin characters are non-alphanumeric characters that are to be included in index tokens, so that words such as web-site are indexed as web-site.
The following example sets printjoin characters to be the hyphen and underscore with the BASIC_LEXER:
begin ctx_ddl.create_preference('mylex', 'BASIC_LEXER'); ctx_ddl.set_attribute('mylex', 'printjoins', '_-'); end;
To create the index with printjoins characters set as above, issue the following statement:
create index myindex on mytable ( docs ) indextype is ctxsys.context parameters ( 'LEXER mylex' );
You use the MULTI_LEXER preference type to index a column containing documents in different languages. For example, you can use this preference type when your text column stores documents in English, German, and French.
The first step is to create the multi-language table with a primary key, a text column, and a language column as follows:
create table globaldoc ( doc_id number primary key, lang varchar2(3), text clob );
Assume that the table holds mostly English documents, with some German and Japanese documents. To handle the three languages, you must create three sub-lexers, one for English, one for German, and one for Japanese:
ctx_ddl.create_preference('english_lexer','basic_lexer'); ctx_ddl.set_attribute('english_lexer','index_themes','yes'); ctx_ddl.set_attribute('english_lexer','theme_language','english'); ctx_ddl.create_preference('german_lexer','basic_lexer'); ctx_ddl.set_attribute('german_lexer','composite','german'); ctx_ddl.set_attribute('german_lexer','mixed_case','yes'); ctx_ddl.set_attribute('german_lexer','alternate_spelling','german'); ctx_ddl.create_preference('japanese_lexer','japanese_vgram_lexer');
Create the multi-lexer preference:
ctx_ddl.create_preference('global_lexer', 'multi_lexer');
Since the stored documents are mostly English, make the English lexer the default using CTX_DDL.ADD_SUB_LEXER:
ctx_ddl.add_sub_lexer('global_lexer','default','english_lexer');
Now add the German and Japanese lexers in their respective languages with CTX_DDL.ADD_SUB_LEXER procedure. Also assume that the language column is expressed in the standard ISO 639-2 language codes, so add those as alternate values.
ctx_ddl.add_sub_lexer('global_lexer','german','german_lexer','ger'); ctx_ddl.add_sub_lexer('global_lexer','japanese','japanese_lexer','jpn');
Now create the index globalx, specifying the multi-lexer preference and the language column in the parameter clause as follows:
create index globalx on globaldoc(text) indextype is ctxsys.context parameters ('lexer global_lexer language column lang');
The following example sets the wordlist preference for prefix and substring indexing. Having a prefix and sub-string component to your index improves performance for wildcard queries.
For prefix indexing, the example specifies that Oracle create token prefixes between three and four characters long:
beginctx_ddl.create_preference('mywordlist', 'BASIC_WORDLIST'); ctx_ddl.set_attribute('mywordlist','INDEX_PREFIX','YES'); ctx_ddl.set_attribute('mywordlist','PREFIX_MIN_LENGTH',3); ctx_ddl.set_attribute('mywordlist','PREFIX_MAX_LENGTH', 4); ctx_ddl.set_attribute('mywordlist','SUBSTRING_INDEX', 'YES');end
When documents have internal structure such as in HTML and XML, you can define document sections using embedded tags before you index. This enables you to query within the sections using the WITHIN operator. You define sections as part of a section group.
The following code defines a section group called htmgroup of type HTML_SECTION_GROUP. It then creates a zone section in htmgroup called heading identified by the <H1> tag:
begin ctx_ddl.create_section_group('htmgroup', 'HTML_SECTION_GROUP'); ctx_ddl.add_zone_section('htmgroup', 'heading', 'H1'); end;
A stopword is a word that is not to be indexed. A stopword is usually a low information word such as this or that in English.
The system supplies a list of stopwords called a stoplist for every language. By default during indexing, the system uses the Oracle Text default stoplist for your language.
You can edit the default stoplist CTXSYS.DEFAULT_STOPLIST or create your own with the following PL/SQL procedures:
You specify your custom stoplists in the parameter clause of CREATE INDEX.
You can also dynamically add stopwords after indexing with the ALTER INDEX statement.
You can create multi-language stoplists to hold language-specific stopwords. A multi-language stoplist is useful when you use the MULTI_LEXER to index a table that contains documents in different languages, such as English, German, and Japanese.
To create a multi-language stoplist, use the CTX_DLL.CREATE_STOPLIST procedure and specify a stoplist type of MULTI_STOPLIST. You add language specific stopwords with CTX_DDL.ADD_STOPWORD.
In addition to defining your own stopwords, you can define stopthemes, which are themes that are not to be indexed. This feature is available for English only.
You can also specify that numbers are not to be indexed. A class of alphanumeric characters such a numbers that is not to be indexed is a stopclass.
You record your own stopwords, stopthemes, stopclasses by creating a single stoplist, to which you add the stopwords, stopthemes, and stopclasses. You specify the stoplist in the paramstring for CREATE INDEX.
You use the following procedures to manage stoplists, stopwords, stopthemes, and stopclasses:
You create an Oracle Text index as an extensible index using the CREATE INDEX SQL command.
You can create three types of indexes:
The context index type is well-suited for indexing large coherent documents such as MS Word, HTML or plain text. With a context index, you can also customize your index in a variety of ways.
The documents must be loaded in a text table.
The following command creates a default context index called myindex on the text column in the docs table:
CREATE INDEX myindex ON docs(text) INDEXTYPE IS CTXSYS.CONTEXT;
When you use CREATE INDEX without explicitly specifying parameters, the system does the following for all languages by default:
For document filtering to work correctly in your system, you must ensure that your environment is set up correctly to support the Inso filter.
To learn more about configuring your environment to use the Inso filter, see the Oracle Text Reference.
Note:
You can always change the default indexing behavior by creating your own preferences and specifying these custom preferences in the parameter string of CREATE INDEX.
To index an HTML document set located by URLs, you can specify the system-defined preference for the NULL_FILTER in the CREATE INDEX statement.
You can also specify your section group htmgroup that uses HTML_SECTION_GROUP and datastore my_url that uses URL_DATASTORE as follows:
begin ctx_ddl.create_preference('my_url','URL_DATASTORE'); ctx_ddl.set_attribute('my_url','HTTP_PROXY','www-proxy.us.oracle.com'); ctx_ddl.set_attribute('my_url','NO_PROXY','us.oracle.com'); ctx_ddl.set_attribute('my_url','Timeout','300'); end; begin ctx_ddl.create_section_group('htmgroup', 'HTML_SECTION_GROUP'); ctx_ddl.add_zone_section('htmgroup', 'heading', 'H1'); end;
You can then index your documents as follows:
create index myindex on docs(htmlfile) indextype is ctxsys.context parameters('datastore my_url filter ctxsys.null_filter section group htmgroup');
|
See Also:
"Creating Preferences" in this chapter for more examples on creating a custom |
The CTXCAT indextype is well-suited for indexing small text fragments and related information. If created correctly, this type of index can give better structured query performance over a CONTEXT index.
A CTXCAT index is transactional. When you perform DML (inserts, updates, and deletes) on the base table, Oracle automatically synchronizes the index. Unlike a CONTEXT index, no CTX_DDL.SYNC_INDEX is necessary.
A CTXCAT index is comprised of sub-indexes that you define as part of your index set. You create a sub-index on one or more columns to improve mixed query performance.
However, adding sub-indexes to the index set has its costs. The time Oracle takes to create a CTXCAT index depends on its total size, and the total size of a CTXCAT index is directly related to
Having many component indexes in your index set also degrades DML performance since more indexes must be updated.
Because of the added index time and disk space costs for creating a CTXCAT index, carefully consider the query performance benefit each component index gives your application before adding it to your index set.
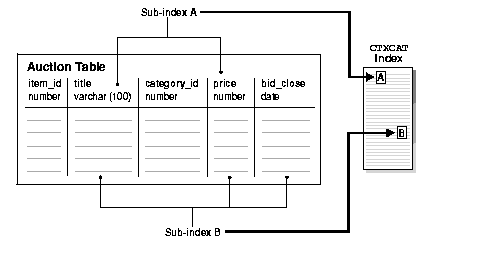
An online auction site that must store item descriptions, prices and bid-close dates for ordered look-up provides a good example for creating a CTXCAT index.
Figure 2-2 shows a table called AUCTION with the following schema:
create table auction(item_id number, title varchar2(100), category_id number, price number, bid_close date);
To create your sub-indexes, create an index set to contain them:
beginctx_ddl.create_index_set('auction_iset');end;
Next, determine the structured queries your application is likely to issue. The CATSEARCH query operator takes a mandatory text clause and optional structured clause.
In our example, this means all queries include a clause for the title column which is the text column.
Assume that the structured clauses fall into the following categories:
| Structured Clauses | Sub-index Definition to Serve Query | Category |
|---|---|---|
|
'order by price' |
'price' |
A |
|
'price = 100 order by bid_close' 'order by price, bid_close' |
'price, bid_close' |
B |
The structured query clause contains a expression for only the price column as follows:
SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'price < 200')> 0; SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'price = 150')> 0; SELECT FROM auction WHERE CATSEARCH(title, 'camera', 'order by price')> 0;
These queries can be served using sub-index B, but for efficiency you can also create a sub-index only on price, which we call sub-index A:
beginctx_ddl.add_index('auction_iset','price'); /* sub-index A */end;
The structured query clause includes an equivalence expression for price ordered by bid_close, and an expression for ordering by price and bid_close in that order:
SELECT FROM auction WHERE CATSEARCH(title, 'camera','price = 100 order by bid_ close')> 0; SELECT FROM auction WHERE CATSEARCH(title, 'camera','order by price, bid_ close')> 0;
These queries can be served with a sub-index defined as follows:
beginctx_ddl.add_index('auction_iset','price, bid_close'); /* sub-index B */end;
Like a combined b-tree index, the column order you specify with CTX_DDL.ADD_INDEX affects the efficiency and viability of the index scan Oracle uses to serve specific queries. For example, if two structured columns p and q have a b-tree index specified as 'p,q', Oracle cannot scan this index to sort 'order by q,p'.
The following example combines the examples above and creates the index set preference with the three sub-indexes:
beginctx_ddl.create_index_set('auction_iset'); ctx_ddl.add_index('auction_iset','price'); /* sub-index A */ ctx_ddl.add_index('auction_iset','price, bid_close'); /* sub-index B */end;
Figure 2-2 shows how the sub-indexes A and B are created from the auction table. Each sub-index is a b-tree index on the text column and the named structured columns. For example, sub-index A is an index on the title column and the bid_close column.
You create the combined catalog index with CREATE INDEX as follows:
CREATE INDEX auction_titlex ON AUCTION(title) INDEXTYPE IS CTXCAT PARAMETERS ('index set auction_iset');
You use the CTXRULE index to build a document classification application. You create a table of queries and then index them. With a CTXRULE index, you can use the MATCHES operator to classify single documents.
The first step is to create a table of queries that define your classifications. We create a table myqueries to hold the category name and query text:
CREATE TABLE myqueries (queryid NUMBER PRIMARY KEY, category VARCHAR2(30) query VARCHAR2(2000));
Populate the table with the classifications and the queries that define each. For example, consider a classification for the subjects US Politics, Music, and Soccer.:
INSERT INTO myqueries VALUES(1, 'US Politics', 'democrat or republican'); INSERT INTO myqueries VALUES(2, 'Music', 'ABOUT(music)'); INSERT INTO myqueries VALUES(3, 'Soccer', 'ABOUT(soccer)');
Use CREATE INDEX to create the CTXRULE index. You can specify lexer, storage, section group, and wordlist parameters if needed:
CREATE INDEX ON myqueries(query) INDEXTYPE IS CTXRULE PARAMETERS('lexer lexer_ pref storage storage_pref section group section_pref wordlist wordlist_pref');
With a CTXRULE index created on query set, you can use the MATCHES operator to classify a document.
Assume that incoming documents are stored in the table news:
CREATE TABLE news (newsid NUMBER, author VARCHAR2(30), source VARCHAR2(30), article CLOB);
You can create a before insert trigger with MATCHES to route each document to another table news_route based on its classification:
BEGIN -- find matching queries FOR c1 IN (select category from myqueries where MATCHES(query, :new.article)>0) LOOP INSERT INTO news_route(newsid, category) VALUES (:new.newsid, c1.category); END LOOP; END;
|
|
 Copyright © 1996-2001, Oracle Corporation. All Rights Reserved. |
|