Release 2 (9.2)
Part Number A96653-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Guard Concepts and Administration Release 2 (9.2) Part Number A96653-01 |
|
This chapter describes how to manage a standby database. It includes the following topics:
Log apply services automatically apply archived redo logs to maintain transactional synchronization with the primary database, and allow transactionally consistent read-only access to the data.
The main difference between physical and logical standby databases is the manner in which log apply services apply the archived redo logs. For physical standby databases, log apply services maintain the standby database in managed recovery mode or open read-only mode. For logical standby databases, log apply services maintain the standby database in SQL apply mode. The following list summarizes these modes:
In this mode, log transport services archive logs to the standby site, and log apply services automatically apply these logs. If you want maximum protection against data loss or corruption, then maintain the standby database in managed recovery mode in a Data Guard environment.
Use read-only mode for supplemental reporting of data contained in the primary database. If you want to use the standby database for reporting purposes, then open it in read-only mode in a Data Guard environment. Log apply services cannot apply archived redo logs to the standby database when it is in this mode, but you can still execute queries on the database. While the standby database is in read-only mode, it can continue to receive archived redo logs from the primary database.
Log apply services manage logical standby databases in SQL apply mode only. Only logical standby databases can be opened in read/write mode, but the target tables for the regenerated SQL statements are available only in read-only mode for reporting purposes. The SQL apply mode supports the application of SQL statements and reporting activities simultaneously to the logical standby database.
The sections in this chapter describe these modes and log apply services in more detail.
The main difference between physical and logical standby databases is the manner in which log apply services apply the archived redo logs. For a logical standby database, log apply services manage the application of log information in archived redo logs from the primary database by transforming transaction information into SQL syntax.
This is done in SQL apply mode, which converts the redo data into SQL statements and applies the SQL statements to an open logical standby database. Because the logical standby database remains open, tables that are maintained can be used simultaneously for other tasks such as reporting, summations, and queries.
The logical standby database uses the following processes:
The remote file server (RFS) process receives archived redo logs from the primary database.
The ARCn process archives the archived redo logs to be applied by the logical standby process (LSP).
The logical standby process is the coordinator process for a collection of parallel server processes (Pnnn) that work concurrently to read, prepare, build, analyze, and apply completed SQL transactions from the archived redo logs. The number of processes used must be at least five and is controlled by the PARALLEL_MAX_SERVERS initialization parameter.
Logical standby databases use supplemental logging, an Oracle feature that adds information into the redo stream, so that LogMiner (and technologies like logical standby databases that use LogMiner) can correctly interpret the changes in the archived redo log. Logical standby databases require that primary key and unique index columns be supplementally logged so that row changes can be properly found and scheduled.
| See Also:
Section 4.1 and Section 13.4 for more information about supplemental logging and the |
The following sections describe how log apply services work with logical standby databases:
Using the DBMS_LOGSTDBY PL/SQL supplied package, you can:
You can use procedures in the DBMS_LOGSTDBY package to stop applying SQL statements or continue applying SQL statements after filtering out unsupported datatypes or statements. For example, DDL statements that are applied to the primary database can be filtered or skipped so that they are not applied on the logical standby database. You can use the procedures in the DBMS_LOGSTDBY package to:
CREATE, ALTER, or DROP INDEX operationsSome, all, or none of the preceding actions can be made for the same logical standby database.
The DBMS_LOGSTDBY PL/SQL package provides procedures to manage tasks on logical standby databases.
Table 6-1 summarizes the procedures of the DBMS_LOGSTDBY PL/SQL package. See Oracle9i Supplied PL/SQL Packages and Types Reference for complete information about the DBMS_LOGSTDBY package.
Specifying an apply delay interval (in minutes) on the primary database is the same for both logical and physical standby databases. However, you can also set up an apply delay on the standby databases that overrides the delay interval that you had set on the primary database. On a logical standby database, if the primary database is no longer available, you can cancel the apply delay by specifying the following command:
SQL> EXECUTE DBMS_LOGSTDBY.APPLY_UNSET('APPLY_DELAY');
In addition to using the DBMS_LOGSTDBY package to perform management tasks, you can verify information about the status of SQL apply operations to a logical standby database using views.
For example, to verify that the archived redo logs are being applied, query the V$LOGSTDBY view. This view provides information about the processes that are reading redo log information and applying it to the logical standby databases. You can also query the DBA_LOGSTDBY_PROGRESS view to find out the progress of SQL apply operations. The V$LOGSTDBY_STATS view shows the state of the coordinator process and information about the SQL transactions that have been applied to the logical standby database.
The physical standby database uses several processes to achieve the automation necessary for disaster recovery and high availability. On the standby database, log apply services use the following processes:
The remote file server (RFS) process receives redo logs from the primary database either in the form of archived redo logs or standby redo logs.
If standby redo logs are being used, the ARCn process archives the standby redo logs that are to be applied by the managed recovery process (MRP).
The managed recovery process (MRP) applies information from the archived redo logs or standby redo logs to the standby database.
Log apply services, in coordination with log transport services, manage the standby database by automatically applying archived redo logs to maintain transactional synchronization with the primary database.
Log apply services can apply logs to a physical standby database when the database is performing recovery (for example, in managed recovery mode), but not when it is open for reporting access (for example, in read-only mode).
For physical standby databases, you can easily change between managed recovery mode and read-only mode. In most implementations of a Data Guard environment, you may want to make this change at various times to either:
Table 6-2 summarizes the basic tasks for configuring log apply services.
| Step | Task | See ... |
|---|---|---|
|
1 |
Start the standby instance and mount the standby database. |
|
|
2 |
Enable managed recovery or read-only mode. |
Section 6.3.2 or Section 6.3.5, respectively |
|
3 |
If using managed recovery mode, set initialization parameters to automatically resolve archive gaps. |
Section 6.5 and the Oracle9i Net Services Administrator's Guide |
|
4 |
Monitor log apply services. |
Log transport services automate archiving to a standby database. Log apply services keep the standby database synchronized with the primary database by waiting for archived logs from the primary database and then automatically applying them to the standby database, as shown in Figure 6-1.
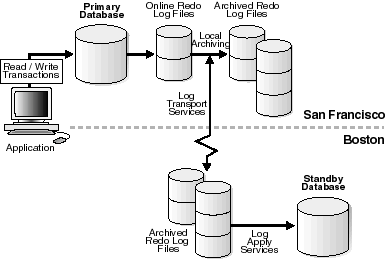
Text description of the illustration sbr81091.gif
After all necessary parameter and network files have been configured, you can start the standby instance. If the instance is not started and mounted, the standby database cannot receive archived redo logs that are automatically copied to the standby site from the primary database by log transport services.
To start the physical standby database instance, perform the following steps:
SQL> CONNECT SYS/CHANGE_ON_INSTALL@standby1 AS SYSDBA
NOMOUNT qualifier.) For example:
SQL> STARTUP NOMOUNT PFILE=initSTANDBY.ora;
SQL> ALTER DATABASE MOUNT STANDBY DATABASE;
As log transport services copy the archived redo logs to the standby site, log apply services can automatically apply them to the standby database.
Log apply services can run as a foreground session or as a background process with control options such as DELAY, DEFAULT DELAY, [NO]EXPIRE, FINISH, NEXT, NODELAY, [NO]PARALLEL, SKIP, THROUGH...SWITCHOVER, and [NO]TIMEOUT.
TIMEOUT or NO TIMEOUT keywords. For example:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE;
If you started a foreground session, by default, control is not returned to the command prompt after you execute the RECOVER statement unless you include the DISCONNECT keyword; this is the expected foreground behavior.
You can start a detached server process and immediately return control to the user by using the DISCONNECT FROM SESSION option to the ALTER DATABASE statement. Note this does not disconnect the current SQL session. For example:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT 2> FROM SESSION;
DISCONNECT [FROM SESSION] keyword on the SQL statement, and you can optionally include the NO TIMEOUT keyword. For example:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION NO TIMEOUT;
This statement starts a detached server process and immediately returns control to the user. While the managed recovery process is performing recovery in the background, the foreground process that issued the RECOVER statement can continue performing other tasks. This does not disconnect the current SQL session.
When you start managed recovery using either of these SQL statements, you can also include any of the keywords shown in Table 13-10 except for the CANCEL control option.
You can query views to monitor log apply services as follows:
V$MANAGED_STANDBY fixed view on the standby database. This view monitors the progress of a standby database in managed recovery mode. For example:
SQL> SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS 2> FROM V$MANAGED_STANDBY; PROCESS STATUS THREAD# SEQUENCE# BLOCK# BLOCKS ------- ------------ ---------- ---------- ---------- ---------- MRP0 APPLYING_LOG 1 946 10 1001
If you did not start a detached server process, you need to execute this query from another SQL session.
V$ARCHIVE_DEST_STATUS fixed view.
This section describes controlling managed recovery operations using the following control options:
Cancel the managed recovery operation at any time by issuing the CANCEL option of the ALTER DATABASE RECOVER MANAGED STANDBY DATABASE statement.
The CANCEL option directs log apply services to stop the managed recovery operation after completely processing the current archived redo log. The managed recovery operation is terminated on an archived log boundary.
The CANCEL IMMEDIATE option, however, directs log apply services to stop the managed recovery operation either before reading another block from the archived redo log or before opening the next archived redo log, whichever occurs first. The managed recovery operation is terminated on an I/O boundary or on an archived log boundary, whichever occurs first. Stopping the recovery on an I/O boundary will leave the database in an inconsistent state and, therefore, unable to be opened. Note the following scenarios:
By default, the CANCEL option waits for the managed recovery operation to terminate before control is returned. If you specify the NOWAIT option, control is returned to the process that issued the CANCEL option without waiting for the managed recovery operation to terminate.
The DEFAULT DELAY control option clears any value specified using the DELAY option, and directs the managed recovery operation to use any delay interval that may have been specified with the LOG_ARCHIVE_DEST_n (where n is a number from 1 to 10) initialization parameter on the primary database.
Use the DELAY control option to specify an absolute apply delay interval to the managed recovery operation. The apply delay interval begins once the archived redo logs have been selected for recovery.
The apply delay interval set by the DELAY control option supersedes any apply delay interval specified for the standby database by the primary database's corresponding LOG_ARCHIVE_DEST_n initialization parameter. The DELAY control option pertains to archived redo logs being applied by this managed recovery operation. (The DEFAULT DELAY control option returns the managed recovery operation behavior to the value that you set for the DELAY option.)
You can use the DELAY control option when starting a managed recovery operation or to alter the mode of an active managed recovery operation. A DELAY control option value of zero (0) directs the managed recovery operation to revert to default behavior.
In the following example, log apply services specify an absolute apply delay interval of 30 minutes to a foreground managed recovery operation:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DELAY 30;
Use the DISCONNECT control option to start managed recovery in background mode.
Using this option creates a managed recovery process (MRP) to perform the recovery in the background while the foreground process that issued the RECOVER statement continues performing other tasks. The optional FROM SESSION keywords can be added for clarity but do not change the behavior of the DISCONNECT option.
Use the EXPIRE control option to specify the number of minutes after which the managed recovery operation automatically terminates, relative to the current time. The managed recovery operation terminates at the end of the current archived redo log that is being processed. This means that the value of the EXPIRE control option is the earliest amount of time that the managed recovery operation will terminate, but it could be significantly later than the specified value.
The managed recovery operation expiration is always relative to the time the statement was issued, not when the managed recovery operation was started. To cancel an existing managed recovery operation, use the CANCEL control option.
Specifying a new EXPIRE control option overrides any previously specified value. Use the NO EXPIRE control option to cancel a previously specified expiration value.
When you use a detached managed recovery process, the MRP makes an alert log entry when it terminates. A foreground managed recovery process simply returns control to the SQL prompt.
In the following example, log apply services automatically terminates two hours from now:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE EXPIRE 120;
The EXPIRE control option cannot be specified in conjunction with the CANCEL control option.
The NO EXPIRE control option turns off a previously specified EXPIRE control option.
Use the FINISH control option to complete managed recovery in preparation for a failover from the primary database to the standby database.
Managed recovery, directed by the FINISH option, first applies all available archived redo logs and then recovers any available standby redo logs (but a recovery without the FINISH control option only applies the archived redo logs). This extra step brings the standby database up-to-date with the last committed transaction on the primary database. You can use the FINISH option when starting managed recovery operations or to alter the mode of an ongoing managed recovery operation. If you use the FINISH option to alter the mode of an ongoing managed recovery operation, use the NOWAIT option to allow control to be returned to the foreground process before the recovery completes. You can specify the following keywords:
SKIP [STANDBY LOGFILE] to indicate that it is acceptable to skip applying the contents of the standby redo logs (if used). The FINISH SKIP option recovers to the first unarchived SCN.NOWAIT to return control to the foreground process before the recovery completes.WAIT to return control to the foregrouond process after recovery completes.Once the RECOVER...FINISH statement has successfully completed, you must issue the COMMIT TO SWITCHOVER TO PRIMARY statement to convert the standby database to the primary database. You can no longer use this database as a standby database.
Use the NEXT control option to direct the managed recovery operation to apply a specified number of archived redo logs as soon as possible after log transport services have archived them. Any apply delay interval specified by the DELAY attribute of the LOG_ARCHIVE_DEST_n initialization parameter set on the primary database, or by the DELAY control option, is ignored by the managed recovery operation until the specified number of archived redo logs have been applied. Then, the managed recovery operation reverts to the default behavior.
You can use the NEXT control option when starting a managed recovery operation or to alter the mode of an active managed recovery operation.
In the following example, log apply services direct a foreground managed recovery operation to apply the next 5 archived redo logs without delay:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE NEXT 5;
Use the NODELAY control option to direct the managed recovery operation to apply the archived redo logs as soon as possible after log transport services have archived them. Any apply delay interval specified by the DELAY attribute of the LOG_ARCHIVE_DEST_n initialization parameter on the primary database, or by a DELAY control option, is ignored by the managed recovery operation when the NODELAY control option is specified. By default, the managed recovery operation respects any apply delay interval specified for the standby database by the primary database's corresponding LOG_ARCHIVE_DEST_n initialization parameter.
In the following example, log apply services direct a foreground managed recovery operation to apply archived redo logs without delay:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE NODELAY;
When running in managed recovery mode, log apply services apply the changes generated on the primary database by many concurrent processes. Therefore, applying the archived redo logs on the standby database can take longer than the time it took to initially generate the changes on the primary database. By default, log apply services use a single process to apply all of the archived redo logs sequentially. This is the same thing as specifying the NOPARALLEL control option, which disables a previously specified PARALLEL option, so that log apply services use a single process to apply all of the archived redo logs sequentially.
When using the parallel recovery option, several processes are able to apply the archived redo logs simultaneously.
In general, using the parallel recovery option is most effective at reducing recovery time when several datafiles on several different disks are being recovered concurrently. The performance improvement from the parallel recovery option is also dependent upon whether the operating system supports asynchronous I/O. If asynchronous I/O is not supported, the parallel recovery option can dramatically reduce recovery time. If asynchronous I/O is supported, the recovery time may be only slightly reduced by using parallel recovery.
| See Also:
Your Oracle operating system-specific documentation to determine whether the system supports asynchronous I/O |
In a typical parallel recovery situation, one process is responsible for reading and dispatching archived redo logs. This is the dedicated managed recovery server process (either the foreground SQL session or the background MRP0 process) that begins the recovery session. The managed recovery server process reading the archived redo logs enlists two or more recovery processes to apply the changes from the archived redo logs to the datafiles.
Figure 6-2 illustrates a typical parallel recovery session.
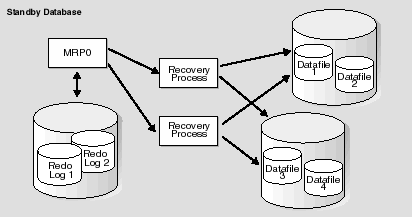
Text description of the illustration parallel.gif
Standby database recovery is a very disk-intensive activity (as opposed to a CPU-intensive activity). Therefore, the number of recovery processes needed is dependent entirely upon how many disk drives are involved in recovery. In most situations, one or two recovery processes per disk drive containing datafiles needing recovery are sufficient. In general, a minimum of eight recovery processes is needed before parallel recovery can show improvement over a serial recovery.
In the following example, log apply services specify a parallel managed recovery operation utilizing 8 background child processes:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE PARALLEL 8;
Use the THROUGH ALL ARCHIVELOG control option to specify the default behavior for managed recovery mode, which is to continue managed recovery operations until the operations are explicitly stopped. This clause is useful in altering a managed recovery operation that is currently running with the THROUGH THREAD n SEQUENCE n option so that it does not stop after applying the specified archived redo log.
Once started, log apply services continue to apply redo data until canceled or applied through the switchover indicator, which is an end-of-redo marker added to archived redo logs. The switchover indicator is added to archived redo logs in any of the following situations:
Use the THROUGH...SWITCHOVER control option to keep the managed recovery process operational after the archived redo log containing the switchover indicator has been applied. By using this control option, other standby databases not participating in the switchover operation can continue to receive and apply archived redo logs from the new primary database, rather than stopping the recovery process and then starting it again after the standby database has failed over to become the new primary database.
To use the THROUGH...SWITCHOVER control option, you must specify the ALL, LAST, or NEXT option to control the behavior of log apply services when encountering an end-of-redo marker:
THROUGH ALL SWITCHOVER control option to recover through all end-of-redo markers and continue applying archived redo logs received from the new primary database after a switchover operation. The ALL option is very beneficial when there are many other standby databases (that are not involved in the switchover operation) in the Data Guard configuration and you do not want to stop and restart the recovery process on each one.THROUGH LAST SWITCHOVER control option to continue managed recovery through all end-of-redo markers, stopping managed recovery only when an end-of-redo marker is encountered in the last archived redo log received.
THROUGH NEXT SWITCHOVER control option to cancel managed recovery at each switchover indicator (end-of-redo marker). This is the default.In the following example, log apply services specify that other standby databases (not involved in the switchover operation) should continue to receive and apply all archived redo logs after the switchover operation:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE THROUGH ALL SWITCHOVER;
Use the THROUGH...SEQUENCE control option to specify the thread number and sequence number of the archived redo log through which you want to recover. Once the specified archived redo log has been applied, managed recovery terminates. The THREAD keyword is optional. If you do not specify THREAD n, it defaults to thread 1.
Use the TIMEOUT control option to specify the number of minutes that foreground log apply services wait for log transport services to complete the archiving of the redo log required by the managed recovery operation. If the specified number of minutes passes without receiving the required archived redo log, the managed recovery operation is automatically terminated. By default, log apply services wait indefinitely for the next required archived redo log. The managed recovery operation is terminated only through use of the CANCEL option, a CTRL+C key combination, or an instance shutdown.
In the following example, log apply services initiate a foreground managed recovery operation with a timeout interval of 15 minutes:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE TIMEOUT 15;
The TIMEOUT control option cannot be used in conjunction with the DISCONNECT control option.
The NO TIMEOUT control option turns off a previously specified TIMEOUT control option.
If a physical standby system uses the same directory naming structure as the primary system, you do not have to rename the primary database files in the physical standby database control file. If the primary and standby databases are located on the same site, however, or if the primary and standby sites use different directory naming structures, then you must rename the database files in the standby control file so that the archived redo logs can be applied.
You can set initialization parameters so that your standby database automatically converts datafile and archived redo log filenames based on data in the standby database control file. If you cannot rename all primary database files automatically using these parameters, then you must rename them manually.
The initialization parameters in Table 6-3 perform automatic filename conversions.
Use the DB_FILE_NAME_CONVERT parameter to convert the filenames of one or more sets of datafiles on the primary database to filenames on the standby database; use the LOG_FILE_NAME_CONVERT parameter to convert the filename of a new redo log on the primary database to a filename on the standby database.
When the standby database is updated, the DB_FILE_NAME_CONVERT parameter is used to convert the datafile name on the primary database to a datafile name on the standby database. The file must exist and be writable on the standby database or the recovery process will halt with an error.
The DB_FILE_NAME_CONVERT and LOG_FILE_NAME_CONVERT parameters must have two strings. The first string is a sequence of characters to be looked for in a primary database filename. If that sequence of characters is matched, it is replaced by the second string to construct the standby database filename.
Adding a datafile or log to the primary database necessitates adding a corresponding file to the standby database. Use the STANDBY_FILE_MANAGEMENT initialization parameter with the DB_FILE_NAME_CONVERT initialization parameter to automate the process of creating files with identical filenames on the standby database and primary database.
The DB_FILE_NAME_CONVERT initialization parameter allows multiple pairs of filenames to be specified. For example:
DB_FILE_NAME_CONVERT="/private1/prmy1/df1", "/private1/stby1/df1", \ "/private1/prmy1", "/private1/stby1" STANDBY_FILE_MANAGEMENT=auto
This section contains the following topics:
When you set the STANDBY_FILE_MANAGEMENT initialization parameter to auto, it automatically creates on the standby database any datafiles that have been newly created on the primary database, using the same name that you specified on the primary database.
The STANDBY_FILE_MANAGEMENT initialization parameter works with the DB_FILE_NAME_CONVERT parameter to take care of datafiles that are spread across multiple directory paths on the primary database.
You cannot rename the datafile on the standby site when the STANDBY_FILE_MANAGEMENT initialization parameter is set to auto. When you set the STANDBY_FILE_MANAGEMENT initialization parameter to auto, the following operations are no longer necessary:
ALTER DATABASE RENAMEALTER DATABASE ADD/DROP LOGFILEALTER DATABASE ADD/DROP LOGFILE MEMBERALTER DATABASE CREATE DATAFILE ASIf you attempt to use any of these statements on the standby database, an error is returned. For example:
SQL> ALTER DATABASE RENAME FILE '/private1/stby1/t_db2.dbf' to 'dummy'; alter database rename file '/private1/stby1/t_db2.dbf' to 'dummy' * ERROR at line 1: ORA-01511: error in renaming log/data files ORA-01270: RENAME operation is not allowed if STANDBY_FILE_MANAGEMENT is auto
| See Also:
Section 8.3.1 to learn how to add datafiles to a database |
Read-only mode allows users to open and query a standby database without the potential for online data modifications. This mode reduces system overhead on the primary database by using the standby database for reporting purposes. You can periodically open the standby database in read-only mode to:
Figure 6-3 shows a standby database in read-only mode.
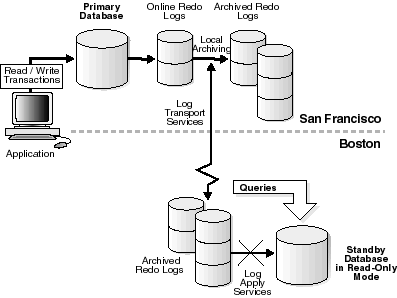
Text description of the illustration sbr81099.gif
This section contains the following topics:
As you decide whether to run the standby database in read-only mode, consider the following:
You can change from the managed recovery mode to read-only mode (and back again) using the following procedures. The following modes are possible for a standby database:
SQL> STARTUP NOMOUNT PFILE=initSTANDBY.ora;
SQL> ALTER DATABASE MOUNT STANDBY DATABASE;
SQL> ALTER DATABASE OPEN READ ONLY;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
SQL> ALTER DATABASE OPEN READ ONLY;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE;
Before you put your standby database in read-only mode, consider the following topics:
While the standby database is in read-only mode, the standby site can still receive archived redo logs from the primary site. However, these archived redo logs are not automatically applied to the standby database until the database is in managed recovery mode. Consequently, a read-only standby database is not synchronized with the primary database at the archive level. You should not fail over to the standby database unless all archived redo logs have been applied.
| See Also:
Section 5.5.2 for examples of initialization parameter settings you need to define to automatically archive from the primary site to the standby site |
To perform queries on a read-only standby database, the Oracle database server must be able to perform on-disk sorting operations. You cannot allocate space for sorting operations in tablespaces that cause Oracle to write to the data dictionary.
Temporary tablespaces allow you to add tempfile entries in read-only mode for the purpose of making queries. You can then perform on-disk sorting operations in a read-only database without affecting dictionary files or generating redo entries.
Note the following requirements for creating temporary tablespaces:
You should also follow these guidelines:
| See Also:
Oracle9i Database Administrator's Guide for more information about using tempfiles and temporary tablespaces |
On the primary database, perform the following steps:
SQL> CREATE TEMPORARY TABLESPACE temp1 TEMPFILE '/oracle/dbs/temp1.dbf' SIZE 20M REUSE EXTENT MANAGEMENT LOCAL UNIFORM SIZE 16M;
On the physical standby database, perform the following steps:
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL; SQL> ALTER DATABASE OPEN READ ONLY;
Opening the physical standby database in read-only mode allows you to add a tempfile. Because adding a tempfile does not generate redo data, it is allowed for a read-only database.
SQL> ALTER TABLESPACE temp1 ADD TEMPFILE '/oracle/dbs/s_temp1.dbf' SIZE 10M REUSE;
The redo data that is generated on the primary database automatically creates the temporary tablespace in the standby control file after the archived redo log is applied to the physical standby database. However, you must use the ADD TEMPFILE clause to actually create the disk file on the standby database.
| See Also:
Oracle9i SQL Reference for information about the |
If you attempt to sort without temporary tablespaces by executing a SQL SELECT * FROM V$PARAMETER statement when the database is not open, you will get an error. For example:
SQL> SELECT * FROM V$PARAMETER; select * from v$parameter * ERROR at line 1: ORA-01220: file based sort illegal before database is open
To look at the parameters when the database is not open:
SORT_AREA_SIZE parameter to a suitable value in your initialization parameter file. This enables you to execute the SELECT * FROM V$PARAMETER statement when the database is open. SORT_AREA_SIZE is a static parameter. Specify the parameter in your initialization parameter file or SPFILE prior to starting the instance.SORT_AREA_SIZE parameter to a sufficient value, you cannot select all of the columns from the V$PARAMETER view. If you need to select only a few columns, you can execute the SELECT statement in any database state.To determine the status of archived redo logs on the standby database, query the V$MANAGED_STANDBY, V$ARCHIVE_DEST_STATUS, V$ARCHIVED_LOG, V$LOG_HISTORY fixed views, and the DBA_LOGSTDBY_LOG and DBA_LOGSTDBY_PROGRESS views. You can also monitor the standby database using Oracle9i Data Guard Manager.
This section contains the following topics:
Query the physical standby database to monitor log apply and log transport services activity at the standby site.
SQL> SELECT PROCESS, STATUS, THREAD#, SEQUENCE#, BLOCK#, BLOCKS 2> FROM V$MANAGED_STANDBY; PROCESS STATUS THREAD# SEQUENCE# BLOCK# BLOCKS ------- ------------ ---------- ---------- ---------- ---------- RFS ATTACHED 1 947 72 72 MRP0 APPLYING_LOG 1 946 10 72
The previous query output shows an RFS process that has completed the archiving of redo log file sequence number 947. The output also shows a managed recovery operation that is actively applying archived redo log sequence number 946. The recovery operation is currently recovering block number 10 of the 72-block archived redo log file.
To quickly determine the level of synchronization for the standby database, issue the following query:
SQL> SELECT ARCHIVED_THREAD#, ARCHIVED_SEQ#, APPLIED_THREAD#, APPLIED_SEQ# 2> FROM V$ARCHIVE_DEST_STATUS; ARCHIVED_THREAD# ARCHIVED_SEQ# APPLIED_THREAD# APPLIED_SEQ# ---------------- ------------- --------------- ------------ 1 947 1 945
The previous query output shows the standby database is two archived log files behind in applying the redo logs received from the primary database. This may indicate that a single recovery process is unable to keep up with the volume of archived redo logs being received. Using the PARALLEL option may be a solution.
The V$ARCHIVED_LOG fixed view on the standby database shows all the archived redo logs received from the primary database. This view is only useful after the standby site has started receiving logs, because before that time the view is populated by old archived log records generated from the primary control file. For example, you can execute the following SQL*Plus script (sample output included):
SQL> SELECT REGISTRAR, CREATOR, THREAD#, SEQUENCE#, FIRST_CHANGE#, 2> NEXT_CHANGE# FROM V$ARCHIVED_LOG; REGISTRAR CREATOR THREAD# SEQUENCE# FIRST_CHANGE# NEXT_CHANGE# --------- ------- ---------- ---------- ------------- ------------ RFS ARCH 1 945 74651 74739 RFS ARCH 1 946 74739 74772 RFS ARCH 1 947 74772 74774
The previous query output shows three archived redo logs received from the primary database.
The V$LOG_HISTORY fixed view on the standby database shows all the archived redo logs that have been recovered. For example:
SQL> SELECT THREAD#, SEQUENCE#, FIRST_CHANGE#, NEXT_CHANGE# 2> FROM V$LOG_HISTORY; THREAD# SEQUENCE# FIRST_CHANGE# NEXT_CHANGE# ---------- ---------- ------------- ------------ 1 945 74651 74739
The previous query output shows that the most recently recovered archived redo log was sequence number 945.
The V$DATAGUARD_STATUS fixed view displays and logs events that would typically be triggered by any message to the alert log or server process trace files.
The following example shows V$DATAGUARD_STATUS output from a primary database:
SQL> SELECT MESSAGE FROM V$DATAGUARD_STATUS; MESSAGE -------------------------------------------------------------------------------- ARC0: Archival started ARC1: Archival started Archivelog destination LOG_ARCHIVE_DEST_2 validated for no-data-loss recovery Creating archive destination LOG_ARCHIVE_DEST_2: 'dest2' ARCH: Transmitting activation ID 0 LGWR: Completed archiving log 3 thread 1 sequence 11 Creating archive destination LOG_ARCHIVE_DEST_2: 'dest2' LGWR: Transmitting activation ID 6877c1fe LGWR: Beginning to archive log 4 thread 1 sequence 12 ARC0: Evaluating archive log 3 thread 1 sequence 11 ARC0: Archive destination LOG_ARCHIVE_DEST_2: Previously completed ARC0: Beginning to archive log 3 thread 1 sequence 11 Creating archive destination LOG_ARCHIVE_DEST_1: '/oracle/arch/arch_1_11.arc' ARC0: Completed archiving log 3 thread 1 sequence 11 ARC1: Transmitting activation ID 6877c1fe 15 rows selected.
The following example shows the contents of the V$DATAGUARD_STATUS view on a physical standby database:
SQL> SELECT MESSAGE FROM V$DATAGUARD_STATUS; MESSAGE -------------------------------------------------------------------------------- ARC0: Archival started ARC1: Archival started RFS: Successfully opened standby logfile 6: '/oracle/dbs/sorl2.log' ARC1: Evaluating archive log 6 thread 1 sequence 11 ARC1: Beginning to archive log 6 thread 1 sequence 11 Creating archive destination LOG_ARCHIVE_DEST_1: '/oracle/arch/arch_1_11.arc' ARC1: Completed archiving log 6 thread 1 sequence 11 RFS: Successfully opened standby logfile 5: '/oracle/dbs/sorl1.log' Attempt to start background Managed Standby Recovery process Media Recovery Log /oracle/arch/arch_1_9.arc 10 rows selected.
The DBA_LOGSTDBY_LOG view provides dynamic information about what is happening to log apply services. This view is very helpful when you are diagnosing performance problems during the SQL application of archived redo logs to the logical standby database, and it can be helpful for other problems.
For example:
SQL> SELECT SUBSTR(FILE_NAME,1,25) FILE_NAME, SUBSTR(SEQUENCE#,1,4)"SEQ#", 2> FIRST_CHANGE#, NEXT_CHANGE#, TO_CHAR(TIMESTAMP, 'HH:MM:SS') TIMESTAMP, 3> DICT_BEGIN BEG, DICT_END END, SUBSTR(THREAD#,1,4) "THR#" 4> FROM DBA_LOGSTDBY_LOG ORDER BY SEQUENCE#; SQL> SELECT FILE_NAME, SEQUENCE#, FIRST_CHANGE#, NEXT_CHANGE#, 2> TIMESTAMP, DICT_BEGIN, DICT_END, THREAD# FROM DBA_LOGSTDBY_LOG 3> ORDER BY SEQUENCE#; FILE_NAME SEQ# FIRST_CHANGE# NEXT_CHANGE# TIMESTAM BEG END THR# ------------------------- ---- ------------- ------------ -------- --- --- ---- /oracle/dbs/hq_nyc_2.log 2 101579 101588 11:02:58 NO NO 1 /oracle/dbs/hq_nyc_3.log 3 101588 142065 11:02:02 NO NO 1 /oracle/dbs/hq_nyc_4.log 4 142065 142307 11:02:10 NO NO 1 /oracle/dbs/hq_nyc_5.log 5 142307 142739 11:02:48 YES YES 1 /oracle/dbs/hq_nyc_6.log 6 142739 143973 12:02:10 NO NO 1 /oracle/dbs/hq_nyc_7.log 7 143973 144042 01:02:11 NO NO 1 /oracle/dbs/hq_nyc_8.log 8 144042 144051 01:02:01 NO NO 1 /oracle/dbs/hq_nyc_9.log 9 144051 144054 01:02:16 NO NO 1 /oracle/dbs/hq_nyc_10.log 10 144054 144057 01:02:21 NO NO 1 /oracle/dbs/hq_nyc_11.log 11 144057 144060 01:02:26 NO NO 1 /oracle/dbs/hq_nyc_12.log 12 144060 144089 01:02:30 NO NO 1 /oracle/dbs/hq_nyc_13.log 13 144089 144147 01:02:41 NO NO 1
The output from this query shows that a LogMiner dictionary build starts at log file sequence 5. The most recent archive log file is sequence 13 and it was received at the logical standby database at 01:02:41.
The DBA_LOGSTDBY_PROGRESS view describes the progress of SQL apply operations on the logical standby databases.
For example:
SQL> SELECT APPLIED_SCN, APPLIED_TIME, READ_SCN, READ_TIME, NEWEST_SCN, NEWEST_TIME FROM 2> DBA_LOGSTDBY_PROGRESS; APPLIED_SCN APPLIED_TIME READ_SCN READ_TIME NEWEST_SCN NEWEST_TIME ----------- ------------------ ---------- ------------------ ---------------------------- 165285 22-FEB-02 17:00:59 165285 22-FEB-02 17:12:32
The previous query output shows that transactions up to and including SCN 165285 have been applied.
To see the progression of the archiving of redo logs to the standby site, set the LOG_ARCHIVE_TRACE parameter in the primary and standby initialization parameter files.
The trace files for a database are located in the directory specified by the USER_DUMP_DEST parameter in the initialization parameter file. Connect to the primary and standby instances using SQL*Plus and issue a SHOW statement to determine the location, for example:
SQL> SHOW PARAMETER user_dump_dest NAME TYPE VALUE ------------------------------------ ------- ------------------------------ user_dump_dest string ?/rdbms/log
The format for the archiving trace parameter is as follows, where trace_level is an integer:
LOG_ARCHIVE_TRACE=trace_level
To enable, disable, or modify the LOG_ARCHIVE_TRACE parameter in a primary database, do one of the following:
ALTER SYSTEM SET LOG_ARCHIVE_TRACE=trace_level statement while the database is open or mounted.To enable, disable, or modify the LOG_ARCHIVE_TRACE parameter in a standby database in read-only or recovery mode, issue a SQL statement similar to the following:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_TRACE=15;
In the previous example, specifying 15 sets trace levels 1, 2, 4, and 8 as described in Section 6.4.8.3.
Issue the ALTER SYSTEM statement from a different standby session so that it affects trace output generated by the remote file service (RFS) and ARCn processes when the next archived log is received from the primary database. For example, enter:
SQL> ALTER SYSTEM SET LOG_ARCHIVE_TRACE=32;
The integer values for the LOG_ARCHIVE_TRACE parameter represent levels of tracing data. In general, the higher the level, the more detailed the information. The following integer levels are available:
You can combine tracing levels by setting the value of the LOG_ARCHIVE_TRACE parameter to the sum of the individual levels. For example, setting the parameter to 6 generates level 2 and level 4 trace output.
The following are examples of the ARC0 trace data generated on the primary site by the archiving of redo log 387 to two different destinations: the service standby1 and the local directory /oracle/dbs.
|
Note: The level numbers do not appear in the actual trace output: they are shown here for clarification only. |
Level Corresponding entry content (sample) ----- -------------------------------- ( 1) ARC0: Begin archiving log# 1 seq# 387 thrd# 1 ( 4) ARC0: VALIDATE ( 4) ARC0: PREPARE ( 4) ARC0: INITIALIZE ( 4) ARC0: SPOOL ( 8) ARC0: Creating archive destination 2 : 'standby1' (16) ARC0: Issuing standby Create archive destination at 'standby1' ( 8) ARC0: Creating archive destination 1 : '/oracle/dbs/d1arc1_387.dbf' (16) ARC0: Archiving block 1 count 1 to : 'standby1' (16) ARC0: Issuing standby Archive of block 1 count 1 to 'standby1' (16) ARC0: Archiving block 1 count 1 to : '/oracle/dbs/d1arc1_387.dbf' ( 8) ARC0: Closing archive destination 2 : standby1 (16) ARC0: Issuing standby Close archive destination at 'standby1' ( 8) ARC0: Closing archive destination 1 : /oracle/dbs/d1arc1_387.dbf ( 4) ARC0: FINISH ( 2) ARC0: Archival success destination 2 : 'standby1' ( 2) ARC0: Archival success destination 1 : '/oracle/dbs/d1arc1_387.dbf' ( 4) ARC0: COMPLETE, all destinations archived (16) ARC0: ArchivedLog entry added: /oracle/dbs/d1arc1_387.dbf (16) ARC0: ArchivedLog entry added: standby1 ( 4) ARC0: ARCHIVED ( 1) ARC0: Completed archiving log# 1 seq# 387 thrd# 1 (32) Propagating archive 0 destination version 0 to version 2 Propagating archive 0 state version 0 to version 2 Propagating archive 1 destination version 0 to version 2 Propagating archive 1 state version 0 to version 2 Propagating archive 2 destination version 0 to version 1 Propagating archive 2 state version 0 to version 1 Propagating archive 3 destination version 0 to version 1 Propagating archive 3 state version 0 to version 1 Propagating archive 4 destination version 0 to version 1 Propagating archive 4 state version 0 to version 1 (64) ARCH: changing ARC0 KCRRNOARCH->KCRRSCHED ARCH: STARTING ARCH PROCESSES ARCH: changing ARC0 KCRRSCHED->KCRRSTART ARCH: invoking ARC0 ARC0: changing ARC0 KCRRSTART->KCRRACTIVE ARCH: Initializing ARC0 ARCH: ARC0 invoked ARCH: STARTING ARCH PROCESSES COMPLETE ARC0 started with pid=8 ARC0: Archival started
The following is the trace data generated by the RFS process on the standby site as it receives archived log 387 in directory /stby and applies it to the standby database:
level trace output (sample) ---- ------------------ ( 4) RFS: Startup received from ARCH pid 9272 ( 4) RFS: Notifier ( 4) RFS: Attaching to standby instance ( 1) RFS: Begin archive log# 2 seq# 387 thrd# 1 (32) Propagating archive 5 destination version 0 to version 2 (32) Propagating archive 5 state version 0 to version 1 ( 8) RFS: Creating archive destination file: /stby/parc1_387.dbf (16) RFS: Archiving block 1 count 11 ( 1) RFS: Completed archive log# 2 seq# 387 thrd# 1 ( 8) RFS: Closing archive destination file: /stby/parc1_387.dbf (16) RFS: ArchivedLog entry added: /stby/parc1_387.dbf ( 1) RFS: Archivelog seq# 387 thrd# 1 available 04/02/99 09:40:53 ( 4) RFS: Detaching from standby instance ( 4) RFS: Shutdown received from ARCH pid 9272
An archive gap is a range of archived redo logs created whenever you are unable to receive the next archived redo log generated by the primary database at the standby database. For example, an archive gap occurs when the network goes down and automatic archiving from the primary database to the standby database stops. When the network is up and running again, automatic archiving of the archived redo logs from the primary database to the standby database resumes. However, if the standby database is specified as an optional archive destination, and one or more log switches occurred at the primary site, the standby database has an archive gap. The archived redo logs that were not transmitted represent the gap. The gap is automatically detected and resolved when the missing archived redo logs are transmitted to the standby database to resolve the gap.
In Oracle9i, you can set initialization parameters so that log apply services automatically identify and resolve archive gaps as they occur.
For log apply services to automatically identify and resolve archive gaps, you must:
FAL_CLIENT initialization parameter, and assign the net service name that you created for the FAL server to the FAL_SERVER initialization parameter.Log apply services automatically detect, and the FAL server process running on the primary database resolves, any gaps that may exist when you enable managed recovery with the ALTER DATABASE RECOVER MANAGED STANDBY DATABASE statement.
If the FAL process cannot resolve an archive gap, then you must resolve it manually. To manually identify archive gaps:
V$ARCHIVE_GAP fixed view to identify an archive gap.DBA_LOGSTDBY_LOG and the DBA_LOGSTDBY_PROGRESS views to identify an archive gap.
| See Also:
Section B.3 for a description of the manual steps and Oracle9i Net Services Administrator's Guide for information about Oracle Net |
Define the FAL_CLIENT and FAL_SERVER initialization parameters only for physical standby databases in the initialization parameter file:
The FAL server is a background Oracle process that services the incoming requests from the FAL client. In most cases, the FAL server is located on a primary database. However, it can be located on another standby database.
|
 Copyright © 1999, 2002 Oracle Corporation. All Rights Reserved. |
|

