Release 2 (9.2)
Part Number A96653-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Data Guard Concepts and Administration Release 2 (9.2) Part Number A96653-01 |
|
This chapter describes how to manage the physical standby environment. Oracle9i Data Guard provides the means to easily manage, manipulate, and change the physical standby database in many ways.
This chapter contains the following topics:
You can use the Recovery Manager utility (RMAN) to back up the primary database at the standby site. This allows the standby database to off-load the task of database backup from the primary database. Using RMAN at the standby site, you can back up the datafiles and the archived redo logs while the standby database is in managed recovery mode. These backups can be later restored to the primary database with RMAN.
The primary control file, however, still must be backed up at the primary site. This is not a problem, because the control file is significantly smaller than the datafiles.
| See Also:
Oracle9i Recovery Manager User's Guide for more details about RMAN backup and recovery of a primary database using a standby database and Section 10.1.10 for a relevant scenario |
To prevent possible problems, you should be aware of events that affect a standby database and learn how to monitor them. Most changes to a primary database are automatically propagated to a standby database through archived redo logs and thus require no user intervention. Nevertheless, some changes to a primary database require manual intervention at the standby site.
This section contains the following topics:
The Oracle database server contains a set of underlying views that are maintained by the server. These views are often called dynamic performance views because they are continuously updated while a database is open and in use, and their contents relate primarily to performance. These views are also called fixed views, because they cannot be altered or removed by the database administrator.
These view names are prefixed with either V$ or GV$, for example, V$ARCHIVE_DEST or GV$ARCHIVE_DEST.
Standard dynamic performance views (V$ fixed views) store information on the local instance. In contrast, global dynamic performance views (GV$ fixed views), store information on all open instances. Each V$ fixed view has a corresponding GV$ fixed view.
The following fixed views contain useful information for monitoring the Data Guard environment:
V$ARCHIVE_DEST
Describes the archived redo log destinations associated with the current instance on the primary site. You can use this view to find out the current settings of your archived redo log destinations.
V$ARCHIVE_DEST_STATUS
This view, an extension of the V$ARCHIVE_DEST view, displays runtime and configuration information for the archived redo log destinations. You can use this view to determine the progress of archiving to each destination. It also shows the current status of the archive destination.
V$ARCHIVE_GAP
Provides information about archive gaps on a standby database. You can use this view to find out the current archive gap that is blocking recovery.
V$ARCHIVED_LOG
Displays archived redo log information from the control file, including archived log names. This view gives you information on which log has been archived to where on your primary database. On the primary database, this view describes the logs archived to both the local and remote destinations. On a standby database, this view provides information about the logs archived to this standby database. You can use this fixed view to help you to track archiving progress to the standby system by viewing the applied field.
V$DATABASE
Contains database information from the control file. You can use this view to quickly find out if your database is a primary or a standby database, as well as its switchover status and standby database protection mode.
V$DATAFILE
Contains datafile information from the control file. You can query this fixed view to verify that the standby datafiles are correctly renamed after your standby database is re-created.
| See Also:
Table 10-1 and Section 10.1.3.2 for information on renaming standby datafiles when re-creating a standby database |
V$DATAGUARD_STATUS
Displays and logs events related to Data Guard since the instance was started.
V$LOG
Contains log file information from the online redo logs. You can use the information about the current online log on the primary database from this view as a reference point to determine how far behind your standby database is in receiving and applying logs.
V$LOGFILE
Contains static information about the online redo logs and standby redo logs.
V$LOG_HISTORY
Contains log history information from the control file, including a record of the latest archived log that was applied.
V$MANAGED_STANDBY
Displays current and status information for some Oracle database server processes related to Data Guard. This view can show both foreground and background processes. You can use this view to monitor the various Data Guard recovery and archiving processes on the standby system.
V$STANDBY_LOG
Provides information about the standby redo logs. Standby redo logs are similar to online redo logs, but they are only used on a standby database receiving logs from the primary database using the log writer process.
| See Also:
Chapter 14, "Views" and the Oracle9i Database Reference for additional information on view columns |
Table 8-1 indicates whether a primary database event is automatically administered by log transport services and log apply services or requires additional intervention by the database administrator (DBA) to be propagated to the standby database. It also describes how to respond to these events.
| Primary Database Event | Primary Site Problem Report Location | Standby Site Problem Report Location | Recommended Response |
|---|---|---|---|
|
Archiving errors |
Remote file server (RFS) process trace file |
Fix the problem reported in the alert log file or trace file and resume archiving to the destination. If the problem persists or archiving performance is degraded, you can create scripts to send the archived redo logs. |
|
|
Thread events |
Alert log |
Thread events are automatically propagated through archived logs, so no extra action is necessary. |
|
|
Redo log changes |
|
Alert log |
Redo log changes do not affect the standby database unless a redo log is cleared or lost. In these cases, you must rebuild the standby database. See Section 3.3. Clears the logs on the standby database with the |
|
Issue |
Alert log |
Database functions normally until it encounters redo depending on any parameter changes. |
Re-create the standby control file. See Section 8.3.8. Re-create the standby database if the primary database is opened with the |
|
Managed recovery performed |
Alert log |
Alert log |
Re-create the standby database if the |
|
Tablespace status changes (made read/write or read-only, placed online or offline) |
Status changes are automatically propagated, so no response is necessary. Datafiles remain online. |
||
|
Add datafile or create tablespace |
If you have not set the |
||
|
Drop tablespace |
Alert log |
If you have not set the |
|
|
Tablespace or datafile taken offline, or datafile is deleted offline |
The tablespace or datafile requires recovery when you attempt to bring it online. |
Datafiles remain online. The tablespace or datafile is fine after standby database activation. |
|
|
Rename datafile |
Alert log |
Alert log |
See Section 8.3.2. |
|
Unlogged or unrecoverable operations |
Alert log. File blocks are invalidated unless they are in the future redo, in which case they are not touched. |
Unlogged changes are not propagated to the standby database. See Section 8.3.7 on how to apply these changes. |
|
|
Recovery progress |
Check the views on the primary site and the standby site for recovery progress. See Section 6.4. |
||
|
Autoextend a datafile |
Alert log |
May cause operation to fail on standby database because it lacks disk space. |
Ensure that there is enough disk space for the expanded datafile. |
|
Issue |
Alert log |
Standby database is invalidated. |
Rebuild the standby database. See Section 3.3. |
|
Change initialization parameter |
Alert log |
May cause failure because of redo depending on the changed parameter. |
Dynamically change the standby parameter or shut down the standby database and edit the initialization parameter file. See Chapter 11, "Initialization Parameters". |
Query the V$LOG_HISTORY view on the standby database, which records the latest log sequence number that has been applied. For example, issue the following query:
SQL> SELECT THREAD#, MAX(SEQUENCE#) AS "LAST_APPLIED_LOG" 2> FROM V$LOG_HISTORY 3> GROUP BY THREAD#; THREAD# LAST_APPLIED_LOG ------- ---------------- 1 967
In this example, the archived redo log with log sequence number 967 is the most recently applied log.
You can also use the APPLIED column in the V$ARCHIVED_LOG fixed view on the standby database to find out which log is applied on the standby database. The column displays YES for the log that has been applied. For example:
SQL> SELECT THREAD#, SEQUENCE#, APPLIED FROM V$ARCHIVED_LOG; THREAD# SEQUENCE# APP ---------- ---------- --- 1 2 YES 1 3 YES 1 4 YES 1 5 YES 1 6 YES 1 7 YES 1 8 YES 1 9 YES 1 10 YES 1 11 NO 10 rows selected.
Each archive destination has a destination ID assigned to it. You can query the DEST_ID column in the V$ARCHIVE_DEST fixed view to find out your destination ID. You can then use this destination ID in a query on the primary database to discover logs that have not been sent to a particular standby site.
For example, assume the current local archive destination ID on your primary database is 1, and the destination ID of one of your remote standby databases is 2. To find out which logs have not been received by this standby destination, issue the following query on the primary database:
SQL> SELECT LOCAL.THREAD#, LOCAL.SEQUENCE# FROM 2> (SELECT THREAD#, SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=1) LOCAL 3> WHERE 4> LOCAL.SEQUENCE# NOT IN 5> (SELECT SEQUENCE# FROM V$ARCHIVED_LOG WHERE DEST_ID=2 AND 6> THREAD# = LOCAL.THREAD#); THREAD# SEQUENCE# ---------- ---------- 1 12 1 13 1 14
The preceding example shows the logs that have not yet been received by standby destination 2.
Changes to the primary database structure always affect a standby database. In cases such as the following, the standby database is updated automatically through applied redo data:
However, you might need to perform maintenance on the standby database when you add a datafile to the primary database or create a tablespace on the primary database, or perform unlogged DML operations.
In addition, you must re-create the standby database entirely when you restore a backup control file on the primary database or open the primary database with the RESETLOGS option.
This section contains the following topics:
Adding or dropping a tablespace or adding or deleting a datafile in the primary database generates redo logs that, when applied to the standby database, automatically add or delete the datafile name or add or drop the tablespace in the standby control file. If the standby database locates the file with the filename specified in the control file, then recovery continues. If the standby database is unable to locate a file with the filename specified in the control file, then recovery terminates.
Data Guard automatically updates tablespaces and datafiles on the standby site if you use the STANDBY_FILE_MANAGEMENT parameter with the auto option. For example:
STANDBY_FILE_MANAGEMENT=auto
| See Also:
Section 10.1.3.1 for more information on adding datafiles and tablespaces and Section 10.1.3.3 for more information on deleting datafiles and dropping tablespaces |
If you rename a datafile on your primary database, the new name does not take effect at the standby database until you refresh the standby database control file. To keep the datafiles at the primary and standby databases synchronized when you rename primary database datafiles, you must update the standby database control file.
| See Also:
Section 10.1.3.2 for a scenario that explains renaming a datafile on the primary database |
You can add redo log file groups or members to the primary database without affecting the standby database. Similarly, you can drop log file groups or members from the primary database without affecting your standby database. Enabling and disabling threads at the primary database has no effect on the standby database.
Consider whether to keep the online redo log configuration the same at the primary and standby databases. Although differences in the online redo log configuration between the primary and standby databases do not affect the standby database functionality, they do affect the performance of the standby database after activation. For example, if the primary database has 10 redo logs and the standby database has 2, and you then failover to the standby database so that it functions as the new primary database, the new primary database is forced to archive more frequently than the original primary database.
| See Also:
Section 8.3.8 for instructions on refreshing the standby database control file |
If you clear log files at the primary database by issuing the ALTER DATABASE CLEAR UNARCHIVED LOGFILE statement, or open the primary database using the RESETLOGS option, you invalidate the standby database. Because both of these operations reset the primary log sequence number to 1, you must re-create the standby database in order to be able to apply archived logs generated by the primary database.
| See Also:
Section 3.3 and Section 10.1.8 for information on re-creating the standby database |
If you use the CREATE CONTROLFILE statement at the primary database to perform any of the following operations, you may invalidate the control file for the standby database:
Using the CREATE CONTROLFILE statement with the RESETLOGS option on your primary database will force the next open of the primary database to reset the online logs, thereby invalidating the standby database.
If you have invalidated the control file for the standby database, re-create the file using the procedures in Section 8.3.8.
You can take standby database datafiles offline as a means to support a subset of your primary database's datafiles. For example, to skip recovery of datafiles that were not copied to the standby database, take the missing datafiles offline using the following statement on the standby database:
SQL> ALTER DATABASE DATAFILE 'MISSING00004' OFFLINE DROP;
If you execute this statement, then you must drop the tablespace containing the offline files after opening the standby database.
|
Caution: Unlogged or unrecoverable operations invalidate the standby database and may require substantial DBA administrative activities. |
When you perform a direct load originating from any of the following, the performance improvement applies only to the primary database (there is no corresponding recovery process performance improvement on the standby database):
Primary database operations using the UNRECOVERABLE option are not propagated to the standby database because these operations do not appear in the archived redo logs. If you perform an unrecoverable operation at the primary database and then recover the standby database, you do not receive error messages during recovery; instead, the Oracle database server writes error messages in the standby database alert log file. The following error message is displayed:
Errors in file /oracle/rdbms/log/rcv12_ora_150.trc: ORA-01578: ORACLE data block corrupted (file # 1, block # 36031) ORA-01110: data file 1: '/oracle/dbs/s1_t_db1.dbf' ORA-26040: Data block was loaded using the NOLOGGING option
To correct your standby database following an unrecoverable operation, you will need to perform one or more of the following tasks:
If you have performed unrecoverable operations on your primary database, determine whether a new backup is required.
V$DATAFILE view on the primary database to determine the system change number (SCN) or time at which the Oracle database server generated the most recent invalidation redo data.SELECT UNRECOVERABLE_CHANGE#, TO_CHAR(UNRECOVERABLE_TIME, 'mm-dd-yyyy hh:mi:ss') FROM V$DATAFILE;
| See Also:
V$DATAFILE in Chapter 14, "Views" and the Oracle9i Database Reference for more information about the |
The following steps describe how to refresh, or create a copy, of changes you have made to the primary database control file. Refresh the standby database control file after making major structural changes to the primary database, such as adding or deleting files.
|
Caution: Do this only if all archived logs have been applied to the standby database. Otherwise, the archived logs are lost when you create the new standby control file. |
CANCEL statement on the standby database to halt its recovery process.
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE CANCEL;
SQL> SHUTDOWN IMMEDIATE;
SQL> ALTER DATABASE CREATE STANDBY CONTROLFILE AS 'stbycf.ctl';
SQL> ALTER DATABASE MOUNT STANDBY DATABASE;
SQL> ALTER DATABASE RECOVER MANAGED STANDBY DATABASE DISCONNECT FROM SESSION;
After creating the standby database, you can clear online redo logs on the standby site to optimize performance by issuing the following statement, where 2 is the number of the log group:
SQL> ALTER DATABASE CLEAR LOGFILE GROUP 2;
This statement optimizes failover to the standby database because it is no longer necessary for the Oracle database server to clear the logs before failover. Clearing involves writing zeros to the entire contents of the redo log and then setting a new header to make the redo log look like it was when it was created.
If you clear the logs manually, the Oracle database server realizes at activation that the logs already have zeros and skips the clearing step. This optimization is important because it can take a long time to write zeros into all of the online logs. If you prefer not to perform this operation during maintenance, the Oracle database server clears the online logs automatically during failover.
You can configure a standby database to protect a primary database using Real Application Clusters. The following table describes the possible combinations of instances in the primary and standby databases:
| Instance Combinations | Single-instance Standby Database | Multi-instance Standby Database |
|---|---|---|
| Single-instance Primary Database |
Yes |
Yes (for read-only queries) |
| Multi-instance Primary Database |
Yes |
Yes |
In each scenario, each instance of the primary database archives its own online redo logs to the standby database. For example, Figure 8-1 illustrates a Real Application Clusters database with two primary database instances (a multi-instance primary database) archiving redo logs to a single-instance standby database.
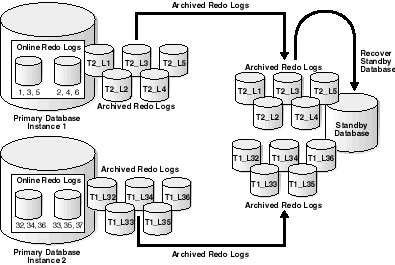
Text description of the illustration sbr81088.gif
In this case, Instance 1 of the primary database transmits logs 1, 2, 3, 4, 5 while Instance 2 transmits logs 32, 33, 34, 35, 36. If the standby database is in managed recovery mode, it automatically determines the correct order in which to apply the archived redo logs.
If both your primary and standby databases are in a Real Application Clusters configuration, and the standby database is in managed recovery mode, then a single instance of the standby database applies all sets of logs transmitted by the primary instances. In this case, the standby instances that are not applying redo cannot be in read-only mode while managed recovery is in progress; in most cases, the nonrecoverable instances should be shut down, although they can also be mounted.
| See Also:
Oracle9i Real Application Clusters Setup and Configuration for information about configuring a database for Real Application Clusters |
This section contains the following topic:
It is possible to set up a cross-instance archival database environment. Within a Real Application Clusters configuration, each instance directs its archived redo logs to a single instance of the cluster. This instance is called the recovery instance and is typically the instance where managed recovery is performed. This instance typically has a tape drive available for RMAN backup and restore support. Example 8-1 shows how to set up the LOG_ARCHIVE_DEST_n initialization parameter for archiving redo logs across instances. Execute this example on all instances except the recovery instance.
SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_1 = `LOCATION=archivelog MANDATORY REOPEN=120'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_1 = enable; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_2 = `SERVICE=prmy1 MANDATORY REOPEN=300'; SQL> ALTER SYSTEM SET LOG_ARCHIVE_DEST_STATE_2 = enable;
Destination 1 is the repository containing the local archived redo logs required for instance recovery. This is a mandatory destination. Because the expected cause of failure is lack of adequate disk space, the retry interval is 2 minutes. This should be adequate to allow the DBA to purge unnecessary archived redo logs. Notification of destination failure is accomplished by manually searching the primary database alert log.
Destination 2 is the primary database on the instance where RMAN is used to back up the archived redo logs from local disk storage to tape. This is a mandatory destination, with a reconnect threshold of 5 minutes. This is the time needed to fix any network-related failures. Notification of destination failure is accomplished by manually searching the primary or standby database alert log.
Cross-instance archiving is available using the ARCn process only. Using the LGWR process for cross-instance archiving results in the RFS process failing and the archive log destination being placed in the Error state.
|
 Copyright © 1999, 2002 Oracle Corporation. All Rights Reserved. |
|

