Release 2 (9.2)
Part Number A96571-01
 Home |
 Book List |
 Contents |
 Index |
 Master Index |
 Feedback |
| Oracle9i Streams Release 2 (9.2) Part Number A96571-01 |
|
This chapter explains the concepts and architecture of the Streams capture process.
This chapter contains these topics:
Every Oracle database has a set of two or more redo log files. The redo log files for a database are collectively known as the database's redo log. The primary function of the redo log is to record all changes made to the database.
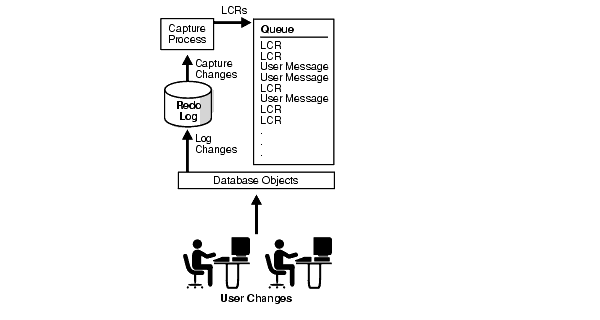
Redo logs are used to guarantee recoverability in the event of human error or media failure. A capture process is an optional Oracle background process that reads the database redo log to capture DML and DDL changes made to database objects.
A capture process reformats changes captured from the redo log into LCRs. An LCR is an object with a specific format that describes a database change. A capture process captures two types of LCRs: row LCRs and DDL LCRs.
After capturing an LCR, a capture process enqueues an event containing the LCR into a queue. A capture process is always associated with a single SYS.AnyData queue, and it enqueues events into this queue only. You can create multiple queues and associate a different capture process with each queue. Figure 2-1 shows a capture process capturing LCRs.
See Also:
|
A row LCR describes a change to the data in a single row or a change to a single LOB column in a row. The change results from a data manipulation language (DML) statement or a piecewise update to a LOB. For example, a DML statement may insert or merge multiple rows into a table, may update multiple rows in a table, or may delete multiple rows from a table. So, a single DML statement can produce multiple row LCRs. That is, an LCR is produced for each row that is changed by the DML statement. Further, the DML statement itself may be part of a transaction that includes many DML statements.
A captured row LCR may contain transaction control statements. These row LCRs contain directives such as COMMIT and ROLLBACK. These row LCRs are internal and are used by an apply process to maintain transaction consistency between a source database and a destination database.
Each row LCR contains the following information:
INSERT, UPDATE, DELETE, LOB ERASE, LOB WRITE, or LOB TRIMUPDATE or DELETE statement, then the values of some or all of the columns in the changed row before the DML statementUPDATE or INSERT statement, then the values of some or all of the columns in the changed row after the DML statementA DDL LCR describes a data dictionary language (DDL) change. A DDL statement changes the structure of the database. For example, a DDL statement may create, alter, or drop a database object.
Each DDL LCR contains the following information:
| See Also:
The "SQL Command Codes" table in the Oracle Call Interface Programmer's Guide for a complete list of command types possible in DDL statements |
A capture process captures changes based on rules that you define. Each rule specifies the database objects for which the capture process captures changes and the types of changes to capture. You can specify capture rules at the following levels:
When capturing changes made to tables, a capture process captures changes made to columns of the following datatypes:
CHARVARCHAR2NCHARNVARCHAR2NUMBERDATECLOBBLOBRAWTIMESTAMPTIMESTAMP WITH TIME ZONETIMESTAMP WITH LOCAL TIME ZONEINTERVAL YEAR TO MONTHINTERVAL DAY TO SECONDThe capture process does not capture DML changes in columns of the following datatypes: NCLOB, LONG, LONG RAW, BFILE, ROWID, and UROWID, and user-defined types (including object types, REFs, varrays, and nested tables). The capture process raises an error if it attempts to capture DML changes to a table that contains a column of an unsupported datatype.
See Also:
|
A capture process captures only certain types of changes made to a database and its objects. The following sections describe the types of DML and DDL changes that are captured. A capture process ignores changes that it does not capture.
| See Also:
Chapter 4, "Streams Apply Process" for information about the types of changes an apply process applies and ignores |
When you specify that DML changes made to certain tables should be captured, a capture process captures the following types of DML changes made to these tables:
INSERTUPDATEDELETEMERGESee Also:
|
A capture process captures the DDL changes that satisfy the rules in the capture process rule set, except for the following types of DDL changes:
Some types of DDL changes that are captured by a capture process cannot be applied by an apply process. If an apply process receives a DDL LCR that specifies an operation that cannot be applied, then the apply process ignores the DDL LCR and records information about it in the trace file for the apply process.
The following types of changes are ignored by a capture process
ALTER SESSION and SET ROLEALTER SYSTEMIn addition, online table redefinition using the DBMS_REDEFINITION package is not supported on a table or schema for which a capture process captures changes.
Supplemental logging places additional column data into a redo log whenever an UPDATE operation is performed. Such updates include piecewise updates to LOBs. The capture process captures this additional information and places it in LCRs.
There are two types of supplemental logging: database supplemental logging and table supplemental logging. Database supplemental logging specifies supplemental logging for an entire database, while table supplemental logging enables you to specify log groups for supplemental logging for a particular table. If you use table supplemental logging, then you can choose between unconditional and conditional log groups.
Unconditional log groups log the before images of specified columns any time the table is updated, regardless of whether the update affected any of the specified columns. This is sometimes referred to as an ALWAYS log group. Conditional log groups log the before images of all specified columns only if at least one of the columns in the log group is updated.
If you plan to use one or more apply processes to apply LCRs captured by a capture process, then you must enable supplemental logging at the source database for the following types of columns:
SET_KEY_COLUMNS procedure in the DBMS_APPLY_ADM package.dml_condition parameter in the ADD_SUBSET_RULES procedure in the DBMS_STREAMS_ADM package.If you do not use supplemental logging for these types of columns at a source database, then changes involving these columns might not apply properly at a destination database.
See Also:
|
You can configure a Streams capture process to capture changes in a Real Application Clusters environment. If you use one or more capture processes and Real Application Clusters in the same environment, then the environment must meet the following requirements:
DBMS_CAPTURE_ADM.START_CAPTURE procedure must be run on the instance that owns the queue that is used by the capture process. Calls to other procedures and functions that operate on a capture process can be performed from any instance.ARCHIVE_LAG_TARGET initialization parameter should be set to a value greater than zero. This initialization parameter specifies the duration after which the log files are switched automatically. LogMiner orders all LCRs by SCN. To do so, it needs the archived log files from all instances. Setting this parameter to switch the log files automatically ensures that LogMiner does not wait for an inordinately long time if one instance has far fewer transactions than another.If the owner instance for a queue table containing a queue used by a capture process becomes unavailable, then queue ownership is transferred automatically to another instance in the cluster. If this happens, then, to restart the capture process, connect to the owner instance for the queue and run the START_CAPTURE procedure. The DBA_QUEUE_TABLES data dictionary view contains information about the owner instance for a queue table. The capture process maintains a persistent start/stop state in a Real Application Clusters environment only if the owner instance for its queue does not change before the database instance owning the queue is restarted.
Also, any parallel execution processes used by a single capture process run on a single instance in a Real Application Clusters environment.
See Also:
|
A capture process is an Oracle background process whose process name is cpnn, where nn is a capture process number. Valid capture process names include cp01 through cp99. A capture process captures changes from the redo log by using the infrastructure of LogMiner. Streams configures LogMiner automatically. You can create, alter, start, stop, and drop a capture process, and you can define capture rules that control which changes a capture process captures.
The user who creates a capture process is the user who captures changes. This user must have the necessary privileges to capture changes.
| See Also:
"Setting Up Users and Creating Queues and Database Links" for information about the required privileges. In the example in this section, the privileges are granted to the |
This section discusses the following topics:
The components of a capture process depend on the setting specified for the parallelism capture process parameter. If parallelism is set to a value of 3 or greater, then a capture process uses the following parallel execution servers to capture changes concurrently:
parallelism capture process parameter minus two.For example, if parallelism is set to 5, then a capture process uses a total of five parallel execution servers, assuming five parallel execution servers are available: one reader server, three preparer servers, and one builder server.
If parallelism is set to 2 or lower, then a capture process itself (cpnn) performs all the work without using any parallel execution servers.
See Also:
|
The capture process uses LogMiner to capture changes that are recorded in the redo log. This section describes configuring LogMiner for use by one or more capture processes.
LogMiner tables include data dictionary tables and temporary tables used by LogMiner. By default, all LogMiner tables are created to use the SYSTEM tablespace, but the SYSTEM tablespace may not have enough space to accommodate the LogMiner tables. Therefore, Oracle Corporation strongly recommends creating an alternate tablespace for the LogMiner tables before you create a capture process at a database. Use the DBMS_LOGMNR_D.SET_TABLESPACE routine to re-create all LogMiner tables in an alternate tablespace.
See Also:
|
Each capture process uses one LogMiner session, and the LOGMNR_MAX_PERSISTENT_SESSIONS initialization parameter controls the maximum number of active LogMiner sessions allowed in the instance. The default setting for this initialization parameter is 1. Therefore, to use multiple capture processes in a database, set the LOGMNR_MAX_PERSISTENT_SESSIONS initialization parameter to a value higher than the number of capture processes.
In addition, if you run multiple capture processes on a single database, you might need to increase the SGA size for each instance. Use the SGA_MAX_SIZE initialization parameter to increase the SGA size.
|
Note: Oracle Corporation recommends that each capture process use a separate queue to keep LCRs from different capture processes separate. |
| See Also:
Oracle9i Database Reference for more information about the |
You can create a capture process using the DBMS_STREAMS_ADM package or the DBMS_CAPTURE_ADM package. Using the DBMS_STREAMS_ADM package to create a capture process is simpler because defaults are used automatically for some configuration options. In addition, when you use the DBMS_STREAMS_ADM package, a rule set is created for the capture process and rules are added to the rule set automatically. The DBMS_STREAMS_ADM package was designed for use in replication environments. Alternatively, using the DBMS_CAPTURE_ADM package to create a capture process is more flexible, and you create a rule set and rules for the capture process either before or after it is created. You can use the procedures in the DBMS_STREAMS_ADM package or the DBMS_RULE_ADM package to add rules to the rule set for the capture process.
When a capture process is created by a procedure in the DBMS_STREAMS_ADM package, a procedure in the DBMS_CAPTURE_ADM package is run automatically on the tables whose changes will be captured by the capture process. The following table lists which procedure is run in the DBMS_CAPTURE_ADM package when you run a procedure in the DBMS_STREAMS_ADM package.
More than one call to prepare instantiation is allowed. When a capture process is created by the CREATE_CAPTURE procedure in the DBMS_CAPTURE_ADM package, you must run the appropriate procedure manually to prepare each table, schema, or database whose changes will be captured for instantiation, if you plan to instantiate the table, schema, or database at a remote site.
| See Also:
Chapter 11, "Managing a Capture Process" and Oracle9i Supplied PL/SQL Packages and Types Reference for more information about the following procedures, which can be used to create a capture process: |
When the first capture process is created for a database, Streams populates a duplicate data dictionary called a Streams data dictionary for use by capture processes and propagation jobs. Initially, the Streams data dictionary is consistent with the primary data dictionary at the time when the capture process was created.
A capture process requires a Streams data dictionary because the information in the primary data dictionary may not apply to the changes being captured from the redo log. These changes may have occurred minutes or hours before they are captured by a capture process. For example, consider the following scenario:
In this case, to ensure data consistency, the capture process must begin capturing changes in the redo log at the time when it was stopped. The capture process starts at the SCN that it recorded when it was stopped.
The redo log contains raw data. It does not contain database object names and column names in tables. Instead, it uses object numbers and internal column numbers for database objects and columns, respectively. Therefore, when a change is captured, a capture process must reference the data dictionary to determine the details of the change.
The Streams data dictionary is updated when a DDL statement is processed by a capture process, if necessary. If there were any DDL changes to the relevant tables in the time between when a capture process is capturing changes and the current time, then the primary data dictionary may not contain the correct information for the captured changes. However, the Streams data dictionary always reflects the correct time for the captured changes because it versions a subset of the information in the primary data dictionary.
When a capture process determines whether or not to capture DDL changes involving a table, the capture process automatically adds information about the change to the Streams data dictionary. In addition, the capture process determines whether or not to capture the Streams data dictionary information for the new version of the table. To make these determinations, the capture rule set is evaluated with partial information that includes the name and owner of the table created or altered by the DDL statement. Capturing and propagating Streams data dictionary information makes it available in each destination queue, where it can be used by propagation jobs and apply processes.
If at least one rule in the capture rule set either evaluates to TRUE (true_rules) or could evaluate to TRUE given more information (maybe_rules), then the Streams data dictionary information is captured for the table. This rule can be either a DML rule or a DDL rule. A capture process at a source database performs a similar rule evaluation when a table is prepared for instantiation at another database.
Because the data dictionary is duplicated when the first capture process is created, it might take some time to create the first capture process for a database. The amount of time required depends on the number of database objects in the database.
The data dictionary is duplicated only once for a database. Additional capture processes use the same Streams data dictionary that the first capture process created in the database. Because the Streams data dictionary is multiversioned, each capture process is in sync with the Streams data dictionary.
Consider a scenario in which a capture process has been configured to capture changes to table t1, which has columns a and b, and the following changes are made to this table at three different points in time:
Time 1: Insert values a=7 and b=15.
Time 2: Add column c.
Time 3: Drop column b.
If for some reason the capture process is capturing changes from an earlier time, then the primary data dictionary and the relevant version in the Streams data dictionary contain different information. Table 2-1 illustrates how the information in the Streams data dictionary is used when the current time is different than the change capturing time.
The capture process captures the change resulting from the insert at time 1 when the actual time is time 3. If the capture process used the primary data dictionary, then it might assume that a value of 7 was inserted into column a and a value of 15 was inserted into column c, because those are the two columns for table t1 at time 3 in the primary data dictionary. However, a value of 15 was actually inserted into column b.
Because the capture process uses the Streams data dictionary, the error is avoided. The Streams data dictionary is synchronized with the capture process and continues to record that table t1 has columns a and b at time 1. So, the captured change specifies that a value of 15 was inserted into column b.
A capture process reads online redo logs whenever possible and archived redo logs otherwise. For this reason, the database must be running in ARCHIVELOG mode when a capture process is configured to capture changes. You must keep an archived redo log file available until you are certain that no capture process will ever need that file. When a capture process falls behind, there is a seamless transition from reading an online redo log to reading an archived redo log, and, when a capture process catches up, there is a seamless transition from reading an archived redo log to reading an online redo log.
| See Also:
Oracle9i Database Administrator's Guide for information about running a database in |
After creation, a capture process is disabled so that you can set the capture process parameters for your environment before starting it for the first time. Capture process parameters control the way a capture process operates. For example, the time_limit capture process parameter can be used to specify the amount of time a capture process runs before it is shut down automatically. After you set the capture process parameters, you can start the capture process.
See Also:
|
The parallelism capture process parameter controls the number of preparer servers used by a capture processes. The preparer servers concurrently format changes found in the redo log into LCRs.
| See Also:
"Capture Process Components" for more information about preparer servers |
You can configure a capture process to stop automatically when it reaches certain limits. The time_limit capture process parameter specifies the amount of time a capture process runs, and the message_limit capture process parameter specifies the number of events a capture process can capture. The capture process stops automatically when it reaches these limits.
The disable_on_limit parameter controls whether a capture process becomes disabled or restarts when it reaches a limit. If you set the disable_on_limit parameter to y, then the capture process is disabled when it reaches a limit and does not restart until you restart it explicitly. If, however, you set the disable_on_limit parameter to n, then the capture process stops and restarts automatically when it reaches a limit.
When a capture process is restarted, it starts to capture changes at the point where it last stopped. A restarted capture process gets a new session identifier, and the parallel execution servers associated with the capture process also get new session identifiers. However, the capture process number (cpnn) remains the same.
The start SCN is the time from which a capture process begins to capture changes. When you start a capture process for the first time, by default the start SCN corresponds to the time when the capture process was created. For example, if a capture process is started two days after it was created, then the capture process begins capturing changes from the redo log at the time of creation two days in the past.
You can specify a different start SCN during capture process creation, or you can alter a capture process to set its start SCN. The start SCN value specified must be from a time after the first capture process was created for the database.
See Also:
|
A running capture process completes the following series of actions to capture changes:
Prefiltering is a safe optimization done with incomplete information. This step identifies relevant changes to be processed subsequently, such that:
TRUE into LCRs based on prefiltering.For example, suppose the following rule is defined for a capture process: Capture changes to the hr.employees table where the department_id is 50. No other rules are defined for the capture process, and the parallelism parameter for the capture process is set to 1.
Given this rule, suppose an UPDATE statement on the hr.employees table changes 50 rows in the table. The capture process performs the following series of actions for each row change:
UPDATE statement in the redo log.UPDATE statement to the hr.employees table and must be captured. If the change was made to a different table, then the capture process ignores the change.department_id is 50.department_id is 50, or discards the LCR if it involves a row where the department_id is not 50 or is missing.Figure 2-2 illustrates capture process rule evaluation in a flowchart.
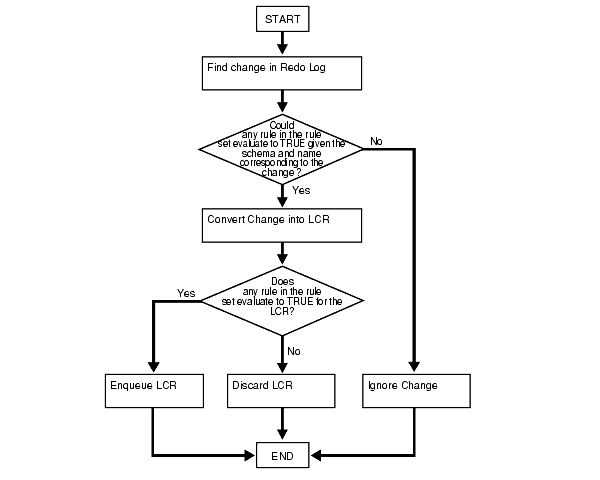
A capture process maintains a persistent state. That is, the capture process maintains its current state when the database is shut down and restarted. For example, if the capture process is running when the database is shut down, then the capture process automatically starts when the database is restarted, but, if the capture process is stopped when a database is shut down, then the capture process remains stopped when the database is restarted.
|
 Copyright © 2002 Oracle Corporation. All Rights Reserved. |
|

