
1偮傑偨偼暋悢偺價僕僱僗丒傾僾儕働乕僔儑儞偐傜偺忣曬傪儅僢僠張棟偟偰挷惍偡傞昁梫惈偼丄條乆側忬嫷偱敪惗偟傑偡丅師偵椺傪帵偟傑偡丅
儗僐乕僪偑憡屳偵儅僢僠偟偰偄傞偐偳偆偐傪掕媊偡傞偙偲偼昁偢偟傕娙扨偱偼偁傝傑偣傫丅師偺2偮偺儗僐乕僪傪峫偊偰傒傑偡丅
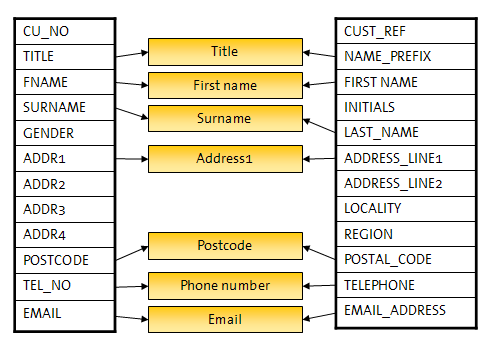
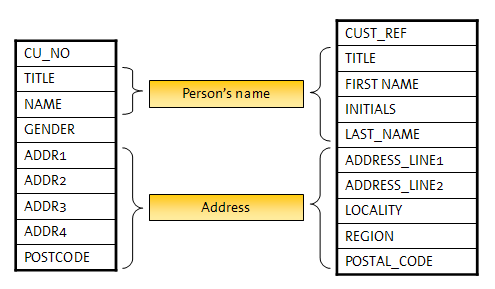
僨乕僞儀乕僗丒僼傿乕儖僪偑偡傋偰堎側偭偰偄傑偡偑丄専嵏偱偼儗僐乕僪娫偵柧傜偐偵椶帡揰偑偁傝傑偡丅師偵椺傪帵偟傑偡丅
偙傟傜傪乽摨偠乿偲偟偰張棟偡傞偐偳偆偐偺敾抐偼丄師偺傛偆側梫場偱堎側傝傑偡丅
岠壥揑側儅僢僠張棟偵偼丄僜乕僗丒僨乕僞偺崅搙側姰慡惈偲惓妋惈傪慜採偲偟偨廬棃偺僨乕僞暘愅媄弍傛傝傕偝傜偵戩墇偟偨僣乕儖偑昁梫偱偡丅偝傜偵丄堄巚寛掕僾儘僙僗偵偼丄忣曬偺巊梡曽朄偵娭偡傞價僕僱僗丒僐儞僥僉僗僩偑慻傒崬傑傟偰偄傞昁梫偑偁傝傑偡丅偨偲偊偽丄摨偠廧強偺娭楢偡傞暋悢偺屄恖傪1恖偺屭媞偲偡傞偐丄2恖偲傒側偡偐傪敾抐偡傞昁梫偑偁傝傑偡丅
Oracle偵偼丄儅僢僠張棟偑昁梫側嵟傕堦斒揑側價僕僱僗偺栤戣偵揔偟偨堦楢偺儅僢僠丒僾儘僙僢僒偑梡堄偝傟偰偄傑偡丅儅僢僠丒僾儘僙僢僒偱偼丄儐乕僓乕偑儅僢僠張棟偵偮偄偰巚偄偮偔曽朄偵懳墳偟偨條乆側榑棟僗僥乕僕偲娙扨側奣擮偑巊梡偝傟傑偡丅
EDQ偺儅僢僠丒僾儘僙僢僒偼丄儅僢僠丒儖乕儖偺昞尰傪屄乆偺僼傿乕儖僪丒儗儀儖偱儐乕僓乕偵嫮惂偡傞偺偱偼側偔丄幆暿巕偺嫮椡側奣擮傪棙梡偟傑偡丅
幆暿巕傪巊梡偡傞偙偲偱丄儐乕僓乕偼丄娭楢偡傞僼傿乕儖僪傪幚幮夛偺僄儞僥傿僥傿偵儅僢僾偟丄師偺傛偆側庡梫側堦楢偺棙揰傪妶梡偱偒傑偡丅
僋儔僗僞儕儞僌偼儅僢僠張棟偵晄壜寚側晹暘偱丄儅僢僠丒僾儘僙僢僒偑慡儗僐乕僪傪懠偺偡傋偰偺儗僐乕僪偲斾妑偟側偔偰偡傓傛偆偵丄僨乕僞丒僙僢僩傪僋儔僗僞偵暘妱偡傞嵺偵巊梡偝傟傑偡丅
EDQ偱偼丄帠慜宍惉偺僋儔僗僞丒僉乕偑偁傞僨乕僞偵埶懚偟側偄傛偆偵丄懡悢偺幆暿巕傪巊梡偟偰摨偠儅僢僠丒僾儘僙僢僒偵懡悢偺僋儔僗僞傪峔惉偱偒傑偡丅
僋儔僗僞儕儞僌偺徻嵶偼丄乽僋儔僗僞儕儞僌偺奣擮僈僀僪乿傪嶲徠偟偰偔偩偝偄丅
斾妑偼丄幆暿巕偺抣傪憡屳偵斾妑偟偰丄斾妑寢壥傪採嫙偡傞抲姺壜擻側傾儖僑儕僘儉偱偡丅採嫙偝傟傞寢壥偺庬椶偼斾妑偵傛偭偰堎側傝傑偡丅偨偲偊偽丄斾妑寢壥偼丄扨側傞乽True乿乮儅僢僠乯傑偨偼乽False乿乮僲乕丒儅僢僠乯偱偁傞応崌傗丄儅僢僠偺嫮搙傪帵偡僷乕僙儞僩抣偱偁傞応崌偑偁傝傑偡丅
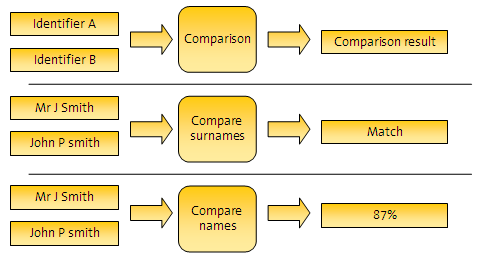
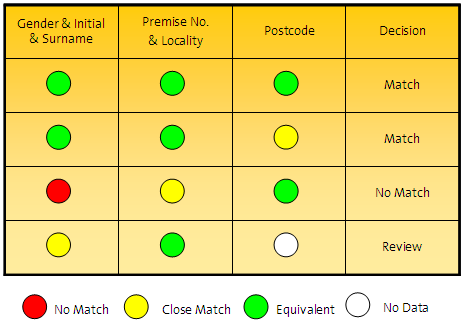
儅僢僠丒儖乕儖偼丄價僕僱僗偺廳梫惈偵墳偠偰斾妑寢壥傪夝庍偡傞曽朄傪採嫙偟傑偡丅斾妑寢壥傪夝庍偡傞偨傔偵偼丄弴彉晅偗傜傟偨儖乕儖傪昁梫側悢偩偗峔惉偱偒傑偡丅奺儖乕儖偺寢壥偼丄師偺3偮偺敾掕偺1偮偵側傝傑偡丅
儅僢僠丒儖乕儖偺巊梡偵傛偭偰丄偡傋偰偺斾妑偵傢偨傞儖乕儖昞偑宍惉偝傟丄儅僢僠偺敾掕憖嶌偑寛掕偟傑偡乮師偺椺傪嶲徠乯丅
EDQ偼丄怴偟偄儅僢僠丒僾儘僙僗傪偡偽傗偔娙扨偵峔抸偱偒傞傛偆偵愝寁偝傟偰偍傝丄帠慜峔惉偺儅僢僠丒僾儘僙僗乮撈帺偺僨乕僞傗摿掕偺儅僢僠梫審偵懳偟偰嵟揔壔偝傟偰偄側偄偱丄曄峏偑崲擄乯偵偼埶懚偟偰偄傑偣傫丅
偨偩偟丄応崌偵傛偭偰偼丄儅僢僠丒僥儞僾儗乕僩傪巊梡偡傞偲丄EDQ偺儅僢僠張棟偑偳偺傛偆偵摦嶌偡傞偺偐傪棟夝偱偒丄僨乕僞偺廳暋儗儀儖偺栚埨傪帵偡弶婜偺寢壥偑恦懍偵採嫙偝傟傑偡丅廳暋偟偰偄傞屭媞偺幆暿傗擣壜儕僗僩偵懳偡傞屭媞偺徠崌側偳丄摿掕偺價僕僱僗栤戣偵偮偄偰帠慜偵峔抸偝傟偨堦楢偺儅僢僠丒儖乕儖偵娭怱偑偁傞応崌偼丄屭媞扴摉偵楢棈偟偰偔偩偝偄丅
EDQ偼丄崅搙偵峔惉偍傛傃挷惍偱偒傞儅僢僠丒傾儖僑儕僘儉偺儔僀僽儔儕傪旛偊偰偄傞偨傔丄儐乕僓乕偼丄僨乕僞偵傛偭偰摼傜傟傞嵟慞偺寢壥傪払惉偱偒傞傛偆偵儅僢僠丒僾儘僙僗傪挷惍偱偒傑偡丅
偝傜偵丄EDQ偵偼丄怴偟偄儅僢僠丒傾儖僑儕僘儉偍傛傃傾僾儘乕僠傪掕媊偡傞婡擻偑梡堄偝傟偰偄傑偡丅嵟揔側儅僢僠張棟婡擻偼丄懳墳偟偰偄傞栤戣偍傛傃儅僢僠張棟懳徾僨乕僞偺庬椶偵姰慡偵埶懚偟傑偡丅儅僢僠丒僾儘僙僗偺庡梫側偡傋偰偺梫慺偼丄暋悢偺奼挘僐儞億乕僱儞僩傪巊梡偡傞壜擻惈偑偁傝傑偡丅師偵椺傪帵偟傑偡丅
峔惉壜擻惈偲奼挘惈偺慻崌偣偵傛偭偰丄壜擻側偐偓傝嵟抁偺帪娫偱嵟揔側夝寛傪僨僾儘僀偱偒傑偡丅
傾僾儕働乕僔儑儞傊偺儅僢僠張棟奼挘惈偺捛壛偺徻嵶偼丄乽EDQ偺奼挘乿傪嶲徠偟偰偔偩偝偄丅
EDQ偺儅僢僠張棟偵娷傑傟傞庡梫側婡擻偼丄師偺偲偍傝偱偡丅
Oracle (R) Enterprise Data Quality僆儞儔僀儞丒僿儖僾 僶乕僕儑儞8.1
Copyright (C) 2006,2011 Oracle and/or its affiliates.All rights reserved.