| Bookshelf Home | Contents | Index | PDF | |
|
Siebel Analytics Server Administration Guide > Setting Up Disconnected Analytics > Synchronizing Disconnected Analytics Applications > About Incremental SynchronizationTypically, the first data downloaded by mobile users from an enterprise environment is a full download of historical data. After the full download, mobile users periodically download updates of data. This requires that the Siebel Analytics allow the mobile user to download most recent data on a periodic basis. Incremental synchronization allows incremental data downloads. Because different organizations have different requirements, an administrator can set up incremental data in various ways, depending on their user characteristics and organizational policies. An administrator can control which users download incremental data sets and how often. They can also control what each data set contains. Incremental Data SetsThe primary difference between incremental synchronization and a full download is the way it handles data integrity and data set validity. In a typical environment, each disconnected analytics application contains at least one full data set and multiple incremental data sets. A full data set is a data set that does not depend on any other data set. Full data sets create tables and then load the data for the first time. For incremental data sets, the Disconnected Analytics Application Manager appends data using the SQL scripts specified in the incremental data set. The administrator needs to set up the SQL scripts correctly for this to work. Incremental data sets are defined in the same way as full data sets, by defining a data set in a configuration file. While an application can have multiple data sets, each data set has its own configuration file. A few special tags differentiate incremental data sets from a full data set. These tags also drive the behavior of the Disconnected Analytics Application Manager, when it downloads the data set definition. While the tags are defined in Disconnected Analytics Configuration File Reference and Siebel Analytics Installation and Configuration Guide, the general purpose for using these properties is explained in the following paragraphs. An incremental data set assumes that the table has been created and that the base data has been loaded. Different users may have downloaded data on different dates, so their data may differ depending on the following factors:
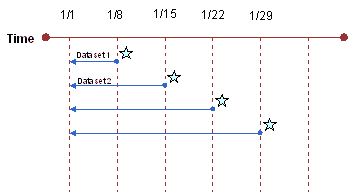
The Disconnected Analytics Application Manager does not automatically manage data integrity when the Disconnected Analytics Application Manager loads data from multiple data sets into the tables. An Administrator should make sure that the data loaded does not create duplicates. Data period characteristics are distinct from the validity checks and the dates that drive the validity checks. The data period or ranges are decided by the sourcing queries and how often the enterprise data itself is updated. For example, dimensional data is usually less dynamic than facts. Transactional data updates are tracked by the database itself as well as fields such as Last Updated Date. A sourcing query can pick up changed data fields by querying for the last updated date. Alternatively, a sourcing query can pick up data using the Created Date field. The Disconnected Analytics Application Manager does not use these dates to validate data. It is the responsibility of the Administrator to make sure that the range of dates are coordinated with the synchronization requirements and frequency of users. Incremental Data Set ValidityTo make sure that a mobile user has downloaded a full data set before they load incremental data, the Disconnected Analytics Application Manager performs certain validity checks. Validity checks make sure that data sets are loaded in a particular order and helps administrators maintain data integrity in the mobile user's disconnected database. This section contains descriptions of the types of validity checks. Date-Based Period ValidityDate-based periods are based on calendar dates and allow administrators to use key dates to control the use of data sets.
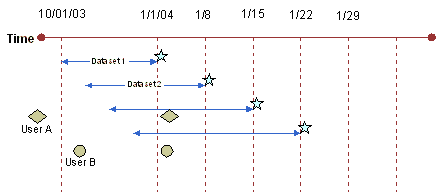
Rolling PeriodsRolling periods allow the administrator to create rolling windows of validity periods. This allows the administrator to control how users download recurrent or periodically created data sets, without having to update dates in the configuration files. A data set is valid is if the following rule applies: Last update date of table + validity period is after current date The periods can be set in various units ranging from days, weeks, or months. Figure 20 is an example of rolling periods. The horizontal axis is the time line. The vertical lines indicate dates on which hypothetical events occur. The stars indicate a preprocessed data set generation event. The arrows indicate the range of the data generated for each event. The diamond shape represents User A and the filled circle represents User B. You might have an environment in which the first, full data set was created sometime before 10/1/03. All mobile users are asked to synchronize immediately after that data set is created. User A downloads his full data set a few days before 10/1/03 (9/15/03), and User B synchronizes a few days later, as shown in Figure 20. The administrator sets up a rolling window (date range) of data set updates that generate every week, going back up to three months. An underlying assumption is that most mobile users synchronize at least every three months. In this scenario, mobile users are supposed to synchronize their incremental data sets as often as they want but no longer than three months apart. As the sliding window moves forward, mobile users who update their data continue receiving their updates. User A is not allowed to use the data set, because his two synchronization dates have a higher time difference in them than the validity period allows. If User A had been allowed to synchronize data set 1, synchronization would have created a data gap from 9/15 to 10/1. User B is allowed to synchronize using data set 1. The data creation can be either triggered by the user, so as to get the most current data, or the user could pick it up from a preprocessed data set, that the administrator has scheduled to be created on a weekly basis. While this is one scenario, several other scenarios can be modeled by manipulating the validity period length and the number of incremental data sets, their data characteristics and organizational usage requirements. The Siebel Disconnected Analytics Manager does not inspect or utilize the data ranges as defined by the sourcing query to perform any checks. It does so solely by the three dates indicated earlier. Data Set Validity ChecksData sets are a data delivery unit that combines multiple tables. Data sets allow Administrators to organize their tables in logical groupings and control their creation as well as availability. Validity tags explained above are applied at the data set levels. While data validity is specified at the data set level, it is enforced at the table level. This is to handle cases where the same table can exist in multiple data sets. A table can occur in the full data set as well as the incremental data set. Each table then inherits the validity conditions imposed on the data set. The Disconnected Analytics Application Manager then applies the validity conditions on each of the tables. For any data set to be valid, every single table in that data set has to be valid. Suppose a data set contains two tables. Table A is also present in one other data set, while Table B is present in two other data sets. Thus the last time the user updated table A may be different from that of table B. In order for the data integrity to be maintained, it is important that each table's validity is checked before making a data set available for synchronization. DependenciesA typical organization would have multiple incremental data sets, each with dependencies on other data sets. In order to manage the synchronization order, administrators can use the <dependson> tag. Using this tag, data sets can be configured such as users' are forced to follow certain order of synchronizations. Data IntegrityThe Disconnected Analytics Application Manager does not check for the data integrity when it loads downloaded data into the disconnected tables. Administrator should note this when designing the data sets. |
 |
|
| Siebel Analytics Server Administration Guide |