| Oracle® Retail Demand Forecasting Implementation Guide Release 16.0 |
|

 Previous |
 Next |
RDF is a statistical forecasting solution that uses state-of-the-art modeling techniques to produce high quality forecasts with minimal human intervention. Forecasts produced by RDF enhance the retailer's supply-chain planning, allocation, and replenishment processes, which enables a profitable and customer-oriented approach to predicting and meeting product demand.
RDF supports pre-processing, new item/store processing, profile creation and forecast generation. To obtain good forecast results, the above features need to be configured to work together. RDF is highly configurable and extremely flexible. To streamline RDF implementation and shorten implementation time, several plug-ins are provided to work together with RPAS Configuration Tools. These plug-ins let users input configuration options through the GUI or xml files and automatically generate configuration solutions based on the RDF GA master template and user inputs. Plug-ins commonly used in RDF are Forecast Common, Prepare Demand, New Item, Curve, RDF and Promote. Another plug-in, Grade, is also included in the RDF package to generate clustering solutions. The plug-ins auto-generate the hierarchies, measures, rules, and workbook templates that are required by RDF to support the forecasting configuration entered in through the plug-in interface:
Table 5-1 Autogenerated Items from Plug-ins
| Autogenerated Item | Description |
|---|---|
|
Hierarchies |
The DATA hierarchy will be updated with the required base internal hierarchy and dimensions. |
|
Measures |
All measures necessary to support the base solution will be created. |
|
Rules |
All Rule Sets, Rule Groups, and Rules to support the base solution will be created. |
|
Workbook Templates |
All pre-defined workbook templates to support the base solution will be created. |
You may continue to make changes to the plug-in configurations, and the autogeneration process may be repeated as often as needed prior to the installation. Prior to domain build/patching, the plug-ins should also been invoked to generate the RDF internal hierarchy file and measure data files.
|
Note: RDF only supports global domain configuration. Simple domain configuration is not supported. |
Implementers are expected to start with the RDF/RDFCS GA configuration and create their own RDF configuration using the steps in the following sections. If an implementer wants to start their configuration from scratch, the new configuration must have all the hierarchies in the RDF GA configuration and the hierarchies must be in the same order. The easiest way to start fresh is to copy the hierarchy.xml file from the RDF GA configuration into the blank configuration and then make modifications.
Perform these steps in the order described to configure and create an RDF or RDF Cloud Service domain:
|
Note: This step must be skipped for RDF Cloud Service. In RDF Cloud Service, the hierarchy setup cannot be modified. |
Set up the Common, Grouping and PrepDemandCommon Solutions
|
Note: This step must be skipped for RDF Cloud Service. RDF Cloud Service does not allow customization of these modules. |
|
Note: This step can be skipped if you are not to configuring NewItem in your RDF Configuration. |
|
Note: This step must be skipped if you are configuring for RDF Cloud Service. Curve is not included in the RDF Cloud Service package. |
Prior to configuring the RDF, register the RDF libraries to support proper validation of the RDF-specific rules. Open the Function Library Manager and add AppFunctions, LostSaleFunctions, RdfFunctions, and ClusterEngine.
For more information on how to add the function libraries, refer to the Oracle Retail Predictive Application Server Configuration Tools User Guide.
|
Note: This step must be skipped for RDF Cloud Service. In RDF Cloud Service, the hierarchy setup cannot be modified. |
The following step only applies to RDF on premise:
|
Caution: From the GA configuration, do not:
For all RDF and RPAS internal hierarchies, do not change any dimension names. |
Table 5-2 lists the required hierarchies for RDF.
Table 5-2 RDF Required Hierarchies
| Required Hierarchy | Common Requirement |
|---|---|
|
Calendar |
The calendar hierarchy must have Day, Week, Day of Week (DOW) dimensions. |
|
Relative Week |
RDF internal hierarchy. Always use the GA data file. Do not edit. |
|
Run Round |
RDF internal hierarchy used by preprocessing. Always use the GA data file generated by Prepare Demand plug-in. |
|
Product |
The product hierarchy must have item and pgrp (Group) dimension. The pgrp (Group) dimension is the partition dimension of the global domain. It must only have one position in each local domain. The global domain partition must be performed on product hierarchy. |
|
Location |
The location hierarchy must have store (STR) dimensions |
|
Admu |
RPAS internal hierarchy. Do not edit. |
|
Data |
RPAS internal hierarchy. Do not edit. |
|
Promotions |
RDF internal hierarchy used by Promote. Always use the GA data file generated by Promote plug-in. |
|
Causal Levels |
RDF internal hierarchy used by Promote. Always use the GA data file generated by Promote plug-in. |
|
Product RHS (pror) |
This is a duplication of the product hierarchy. The dimensions and their roll ups have to be a mirror of the product hierarchy. The hierarchy name cannot be changed. |
|
Lngs |
RPAS internal hierarchy. Do not edit. |
|
Time Series Grouping |
The hierarchy used in grouping level forecast. |
|
Product Attributes |
The attribute hierarchy is needed for new item. The like item recommendation is generated based on product attribute. |
|
Location RHS |
This is a duplication of the location hierarchy. The dimensions and their roll ups have to be a mirror of the location hierarchy. The hierarchy name cannot be changed. |
|
Path |
RDF internal hierarchy used by preprocessing. Always use the GA data file generated by Prepare Demand plug-in. |
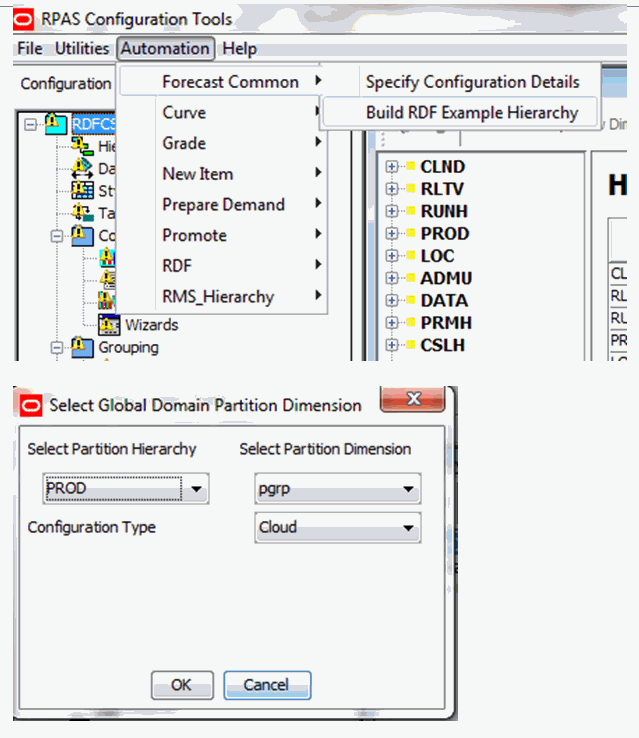
For this step, it is required to specify the partition dimension and configuration type through the Forecast Common plug-in:
From the Configuration Tools toolbar, select the Automation menu and then from the Forecast Common option, select Specify Configuration Details The partition hierarchy must be Product and the partition dimension must satisfy the requirement of one position per domain. The configuration type can be either Cloud Service or on-premise.
Click OK after setting up all inputs.
|
Note: RDF does not support simple domain configuration. RDF must be configured for the global domain. |
|
Note: This step must be skipped for RDF Cloud Service. RDF Cloud Service does not allow customization of these modules. |
Open a RDF GA configuration to see the common, grouping and prepdemand common modules.
The purpose of these three modules is to set up important input/output measures for the whole RDF project. The content created in these modules will not be modified by the plug-ins. The measures created in these modules are external measures for the plug-ins, and they will serve as inputs to plug-ins. It is strongly suggested that any customization to the RDF product should be done in these three modules, or you can create your own module to house the customized measures, rules, and workbook templates.
In RDF GA, the common solution is used to set up sales history inputs/outputs to:
PrepDemand
NewItem
Curve
RDF Solutions
The PrepDemandCommon solution is used to set up the optional inputs to PrepDemand solution, such as outlier indicator, out-of-stock indicator and seasonal profile.
The Grouping solution is used to set up rules to generate timeseries grouping membership if there is a forecast source level intersection containing the timeseries grouping dimension.
The current group solution has the group assignment intersection based on item/store. This is consistent with the RDF GA configuration. Because all forecast final levels were item/store/calendar. If the forecast final level intersection is changed, such as subclass/store. The group assignment measures needs to be modified to be on subclass/store too. There is a labeled intersection named GrpLevel defined for this purpose. The implementer needs to modify GrpLevel to be consistent with RDF final forecast level intersection.
An implementer can modify grouping rules and criteria in this solution. The GA measures and rules in the previously listed configurations are examples for the implementer. The implementer can modify them based on customer's needs.
The plug-ins reautomation should not change the contents of these modules except when named intersections generated by the plug-ins are used.
The purpose of the Prep Demand module, also referred to as Preprocessing, is to correct past data points that represent unusual sales values that are not representative of a general demand pattern. Such corrections may be necessary when an item is out-of-stock and cannot be sold, which usually results in low sales. Preprocessing will adjust for stockout for both the current week and the following week because it assumes that the out-of-stock indicators represent end-of-week-stockout. Data Correction may also be necessary in a period when demand is unusually high. The Preprocessing module allows you to automatically make adjustments to the raw POS (Point of Sales) data so that subsequent demand forecasts do not replicate undesired patterns that are caused by lost sales or unusually high demand. Preprocessing can also be used to remove promotion spikes when a promotion indicator is available. Inclusion of a promotion spike can seriously skew the baseline forecasting. It is ideal to remove seasonal effects from sales so that the seasonal pattern does not interfere with the causal estimation, especially when promotion and significant seasonal patterns overlap.
Based on the usage, sales history should be preprocessed in different ways. In RDF/ RDF Cloud Service GA configuration, two preprocessing paths are configured. Path 01 is used to preprocess sales for baseline forecasting. Path 02 is used to preprocess sales for causal forecasting. For baseline forecasting, the sales history goes through four stages:
Out-of-stock correction
Outlier correction
Promotional spike removal
Smoothing
For causal forecasting, the sales history goes through three stages: out-of-stock correction, outlier correction and seasonal pattern removal. Each stage is called RUN in preprocessing.
Based on the customer's needs, an implementer can decide how many paths to configure, what kinds of runs to include in each path, and what the input and output measures are for each path. Once the information is fed to the PrepDemand plug-in, the PrepDemand configuration will be auto-generated with all necessary measures, rules and workbook templates. The rdf_preprocessing.ctl file should also be updated to reflect the preprocessing path changes. For more information about the rdf_preprocessing.ctl file changes, refer to Chapter 7, "Batch Processing."
The following sections describe the PrepDemand configuration process.
There are several parameters within the PrepDemand configuration that may reference other measures that are configured external to the solution. Prior to configuring an PrepDemand solution, it is required that these measures already exist within the project:
| Measure | Description |
|---|---|
| Data Source | The prep demand plug-in provides a list of existing numeric measures based on the user-specified intersection for a preprocessing path. An implementer selects the measure that stores the input data for preprocessing. This measure should be configured in the Common module. |
| Output | The prep demand plug-in provides a list of existing numeric measures based on the user-specified intersection for a preprocessing path. An implementer selects the measure that stores the output data from the preprocess. This measure is also normally an input to NewItem/RDF plug-in. This measure should be configured in the Common module. |
| First Aux Measures | For each preprocessing path, the PrepDemand plug-in allows a maximum of six runs, which means six preprocessing stages (one preprocessing method per stage). Each preprocessing method may require supporting measures as inputs. Two supporting measures are allowed for each run. These supporting measures are specified in the fields of First and Second Aux measures. Examples of these measures include out-of-stock indicator or promotional indicator. These measures are external measures to PrepDemand and should be configured in PrepDemand Common. |
| Second Aux Measures |
Once all input measures are configured, perform the following steps in Configuration Tools and the Preprocessing Parameters utility.
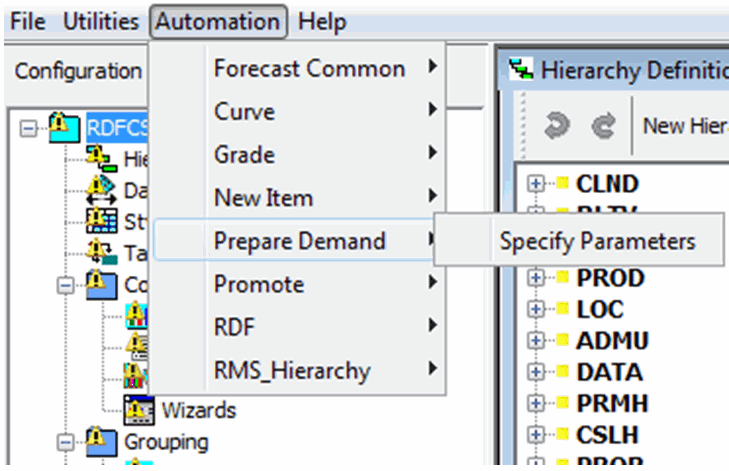
From the Configuration Tools toolbar, select the Automation menu and then, from the Prepare Demand option, select Specify Parameters.
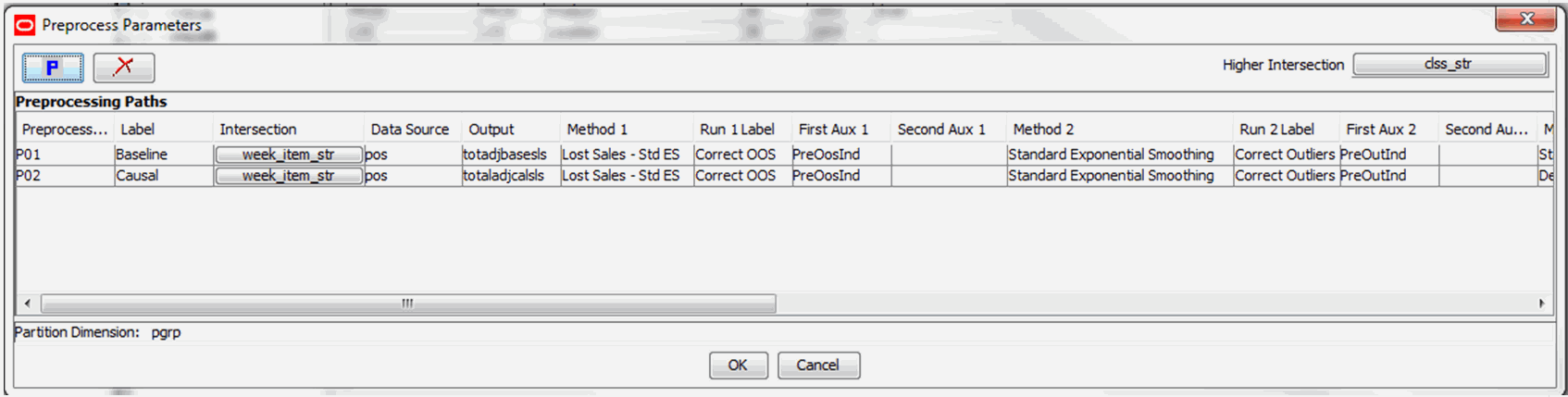
On the Preprocess Parameters utility, click P.
A new preprocessing path is added, and it is assigned the next available level number. To specify the properties for the preprocessing path, see Edit Preprocessing Parameters for details. The Higher Intersection selection box allows you to specify the intersection of default preprocessing parameters.
After finishing the configuration, click OK to start generating the preprocessing configuration.
Table 5-3 lists all of the Preprocessing Parameters. For details about preprocessing methods and associated parameters, see the Configuring the Preprocess Special Expression.
Table 5-3 Preprocessing Parameters
| Preprocessing Path Parameters | Description |
|---|---|
|
Preprocessing Path |
The field is the system-assigned path number when a preprocessing path is created. This is a read-only parameter. |
|
Label |
The field is the level description that is viewed by the user once the domain is created. |
|
Intersection |
The intersection of the preprocessing input and output measures. |
|
Data Source |
The data source is the measure to be used as the input data (for example, POS) for the preprocessing. |
|
Output |
The output is the measure to store preprocessed result, which may serve as input to Newitem /RDF modules. |
|
Method [n] |
There are six fields for preprocessing method (method 1 through method 6). The plug-in provides a list to select a specific method each field. Each method is considered a run. The maximum number of runs allowed per path is six. |
|
Run [n] Label |
There are six fields to label preprocessing runs. One label per preprocessing method. |
|
First Aux [n] |
First Aux and Second Aux are fields to specify supporting measures per preprocessing method, such as seasonal profile, outlier indicator, outage indicator and promotion indicator. For each preprocessing method, the plug-in allows for two optional measures to be used. Some preprocessing methods need only one, others need none. If it is not needed, then leave the field empty. There are six First Aux fields and six Second Aux fields, one per method. Always populate the First Aux field first before using Second Aux. Refer to Table 5-4 for the First Aux and Second Aux supporting measures. |
|
Second Aux [n] |
Table 5-4 lists the supporting measures for the First Aux and Second Aux preprocessing parameters.
Table 5-4 First Aux and Second Aux Supporting Measures.
| Method | First Aux | Second Aux |
|---|---|---|
|
Standard Median |
not applicable |
not applicable |
|
Oracle Retail Median |
not applicable |
not applicable |
|
Standard Exponential Smoothing |
Outage |
event flag |
|
Lost Sales -StdES |
Outage |
event flag |
|
Override |
Deviation |
reference |
|
Increment |
Deviation |
reference |
|
Clear |
not applicable |
not applicable |
|
Deprice |
Price |
not applicable |
|
Deseasonal |
Seasonal Profile |
not applicable |
Deleting a preprocessing path causes the system-assigned enumerated values in the path name to renumber such that paths are in consecutive order, starting with preprocessing path 01. Deleting a preprocessing path may impact any solution configuration that uses a specific preprocessing output.
|
Caution: If the domain using the configuration has previously been installed, there is potential to lose data associated with a path that has been deleted or renumbered. |
Perform the following steps to delete a preprocessing path:
On the Preprocessing Parameters utility, highlight the number of the path that you want to delete from the path window.
Click X to delete the path. The path is deleted.
Select OK to regenerate the solution with the changes to the PrepDemand configuration.
The PrepDemand autogeneration process creates all hierarchy dimensions, measures, rules and workbook template to support the essential PrepDemand functionality.
|
Note: It is recommended to leave the plug-in generated configuration alone and not to modify it manually. |
Table 5-5 outlines the configuration restrictions:
Table 5-5 RDF GA Configuration Restrictions
| Changes and Restrictions | Description |
|---|---|
|
Prep Demand Solution Extension Name |
The name assigned to the resulting PrepDemand solution after autogeneration occurs cannot be edited. |
|
Major and Minor Components |
Additional major components may be added to the Prep Demand. Additional minor components can only be added under the new major components. The Major and Minor components that are part of the GA configuration may not be edited. This restriction also applies to measure names and measure labels. Adding minor components to GA major components is forbidden. |
|
Rules |
Rule sets, rule groups, and rules that are part of the GA configuration may not be renamed. Existing rules that are part of the GA configuration may not be modified in any way. |
|
Workbook Templates |
New measures and rules cannot be added to the GA configuration workbook templates. No custom workbook template should be add to the module. |
|
Note: This step can be skipped if you are not to configuring NewItem in your RDF configuration. |
The NewItem module is designed to support the forecast for new item/store. RDF provides three approaches to forecast new item/store:
| Forecast Approach | Description |
|---|---|
| Clone Sales History | Cloning allows users to generate forecasts for new items and locations by copying, or cloning history, from other items and stores. Users can map items or stores that have similar business cases, clone the historical data, and generate forecasts. Cloning provides the ability to generate forecasts based on historical data and promotional calendars. |
| Copy Forecast | Copy forecast allows users to generate forecasts for new items and locations by copying forecast/sales history from other items and stores. The new items and stores can be mapped to existing items and stores using the same approach as cloning. |
| Base Rate of Sales | Base rate of sales expects users to provide a sales rate per new item/store (average sales volume per time period). Seasonal pattern generated using aggregated level is applied to the sales rate to generate a seasonal forecast at item/store/week. |
Both clone history and copy forecast require mapping of the new item/store. The New Item module provides tools to support the automatic and manual assignment of like item/store to new item/store. If the user can provide product attribute information, the new item can be automatically identified and provided a like item recommendation. If no product attribute information is available, the user has to assign like items manually. New store mapping is always done manually.
The implementer must decide that if a product attribute is available upfront, different workbook templates and rules are generated by plug-in based on that option.
RDF Cloud Service ships two different taskflow files with the packaged configuration:
taskflow.xml for when the product attribute is available
taskflow.xml_noattribute for when the product attribute is unavailable
If RDF Cloud Service is customized and configured with no attribute, then taskflow.xml_noattribute is renamed to taskflow.xml.
The following describes the process of configuring NewItem.
There are two parameters within the NewItem configuration that may reference other measures that are configured external to the solution. Prior to configuring a NewItem solution, it is required that these measures already exist within the project:
Clone Input
Clone Output
The NewItem plug-in provides a list of existing non-string and non-boolean measures for users to select clone input and output measures.
The clone input measure can be an output of PrepDemand plug-in, and the clone output measure can be the data source of RDF. These measures should be configured in Common module.
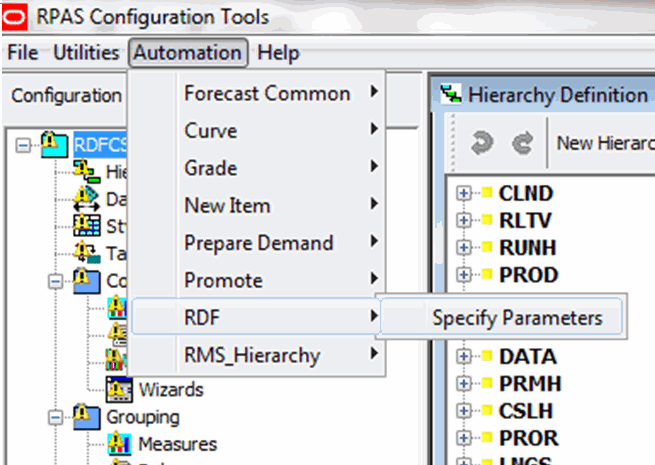
Perform the following steps to generate a New Item solution:
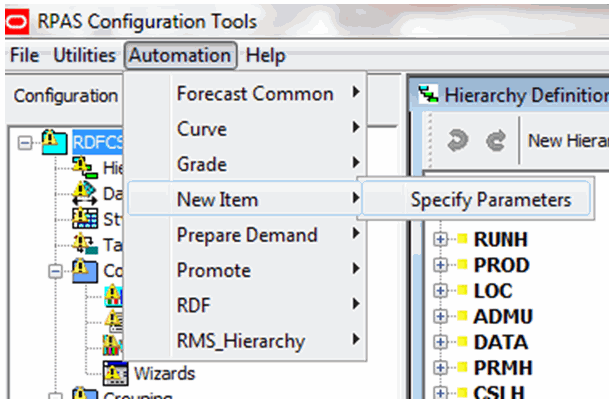
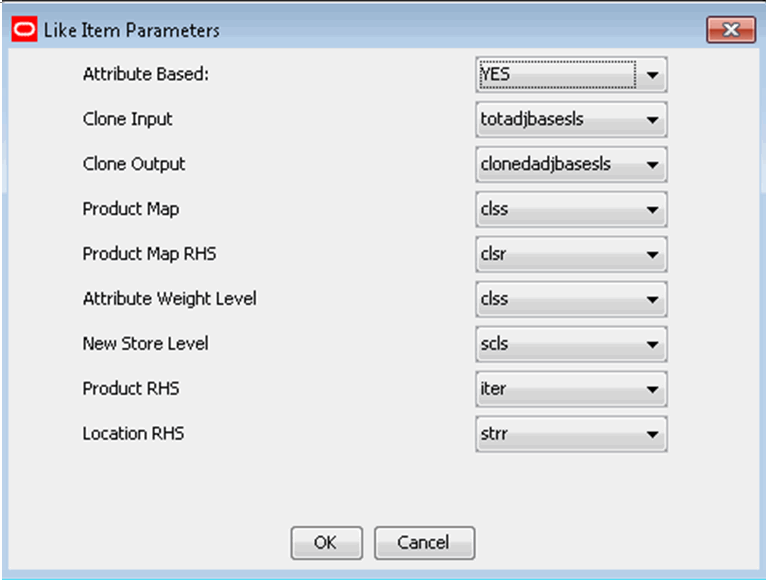
From the Configuration Tools toolbar, select the Automation menu and then, from the New Item option, select Specify Parameters.
From the Like Item Parameters utility, specify the properties for the New Item plug-in. Refer to Editing New Item Parameters for details.
Click OK once editing is finished.
Table 5-6 lists the New Item parameters available for editing.
Table 5-6 New Item Parameters
| Parameter | Description |
|---|---|
|
Attribute Based |
This field indicates if product attribute is available. |
|
Clone Input |
This field is the input measure name for clone. |
|
Clone Output |
This field is the output measure name for clone. |
|
Product Map |
This field specifies the range of the like item available to a new item. If the field is populated with clss, it means that only existing items under the same class as the new item are available as like item candidate. This parameter is only meaningful when product attribute is not available. |
|
Product Map RHS |
This is the corresponding Product RHS level of Product Map. If product map is clss, this field should be clsr. This parameter is only meaningful when product attribute is not available. |
|
Attribute Weight Level |
This field specifies the product level on which attribute weight is specified. If the field is set to clss, it means that the attribute weights can be different per class. |
|
New Store Level |
This field specifies the product level on which like store is assigned to new store. If the field is selected as scls, it means that the like store assignment can be different per subclass. |
|
Product RHS |
This field indicates for which product RHS level corresponds to New Item assignment's product level. |
|
Location RHS |
This field indicates for which location RHS level corresponds to new store assignment's location level. |
Table 5-7 outlines the configuration restrictions:
Table 5-7 RDF GA Configuration Restrictions
| Changes and Restrictions | Description |
|---|---|
|
NewItem Solution Extension Name |
The name assigned to the resulting NewItem solution after autogeneration occurs cannot be edited. |
|
Major and Minor Components |
Additional major components may be added to the Prep Demand. Additional minor components can only be added under the new major components. The major and minor components that are part of the GA configuration may not be edited. This restriction also applies to measure names and measure labels. Adding minor components to GA major components is forbidden. |
|
Rules |
Rule sets, rule groups, and rules that are part of the GA configuration may not be renamed. Existing rules that are part of the GA configuration may not be modified in any way. |
|
Workbook Templates |
New measures and rules cannot be added to the GA configuration workbook templates. No custom workbook template should be add to the module. |
|
Note: This step must be skipped if you are configuring for RDF Cloud Service. Curve is not included in the RDF Cloud Service package. |
This step is only necessary if RDF needs to provide seasonal profile, spread profile, and so on using Curve. For RDF Cloud Service and most RDF configurations, this step can be skipped. For details about Curve solution setup, refer to Appendix G, "Curve Configuration Process."
Forecast information is often required for items at the lowest levels in a hierarchy. Problems can arise when historic sales data for these items is too sparse and too noisy to identify clear selling patterns. In such cases, generating a reliable forecast requires aggregating sales data from a low level up to a higher level in the hierarchy. After a forecast is generated at the higher level, the resulting data can be allocated (spread) back down to the lower level. This is based on the lower level's relationship to the total at the aggregated level. Before the forecast data can be spread back down to a lower level, there must be an understanding of the relationship between the lower level and the higher level dimensions. Frequently, an additional forecast is generated at the low level to help determine this relationship. This low level is called the final forecast level. Forecast data at this level might be sufficient to generate reliable percentage-to-whole information, but the actual forecast numbers are more robust when they are generated at an aggregate level. This aggregate level from which forecast data is spread is referred to as the source forecast level.
Some high-volume items may possess sufficient sales data for robust forecast calculations directly at the final forecast level. In these cases, forecast data that is generated at an aggregate level and then spread down to lower levels can be compared to forecasts that are run directly at the low level. Comparing the two forecasts, each generated at a different hierarchy level, can be an invaluable forecast performance evaluation tool.
For causal forecasting, simple aggregation from lowest to aggregated level does not work because it is unrealistic to expect the same promotion activity schedule for every item/store under an aggregated level. The way to tackle the problem of sparse data is to chain the sales data and promotion calendar at each item/store per aggregated intersection. In this way, up to thousands of time series can be pooled together to generate averaged promotional effects at the aggregated level. The effects calculated at aggregated level are more reliable than the one calculated at final level. The effects at source level and final level can be combined with a user-specified weight to produce a final estimate. For a high volume item, the final level calculated promotional effects can have more weight than that of low volume items.
The RDF solution may include multiple final forecast levels. Different final forecast levels should have different purposes and parameters. In RDF CS configuration, two final forecast levels were configured. One is used to generation baseline forecast. The approved forecast from baseline forecasting serves as external baseline to another final level, which is configured to produce causal forecast. Forecast results must appear at some final level for the data to be approved and exported to other systems.
Using the RDF plug-in, final and source forecast levels are defined for the RDF solution.
There are several parameters within the RDF configuration that may reference other measures that are configured external to the solution. Prior to configuring an RDF solution, it is required that these measures already exist within the project.
| Parameter | Description |
|---|---|
| Source Data | The RDF plug-in populates a list with all non-Boolean and non-string measures that have been created in the project. This field is normally populated with the output of preprocessing or NewItem.
If the level is a source level, and the source data is the same as the final level source data, then leave the source data empty. It will automatically aggregate from the final level data source. If you would prefer to use data input that is different from the aggregation of final level source data, then you can place a measure name in data source for that source level. This measure should be at the same intersection as the source level. If the source level is an HBI level, then the measure must be an |
| Plan Data | This measure should already exist if the Plan Data to be used to support Bayesian forecasting is being defined within another solution. The entry of this parameter is not required within the configuration, and it can be entered in the resulting domains. |
| Spreading Profiles | If Curve is used to produce Spreading Profiles or Seasonal Profiles to support your Forecasting solution, these profiles should already have been configured in the Curve solution. If these profiles are being defined external to Curve, these measures should already exist within the project. |
| Seasonal Profiles |
Perform the following steps to generate an RDF solution.
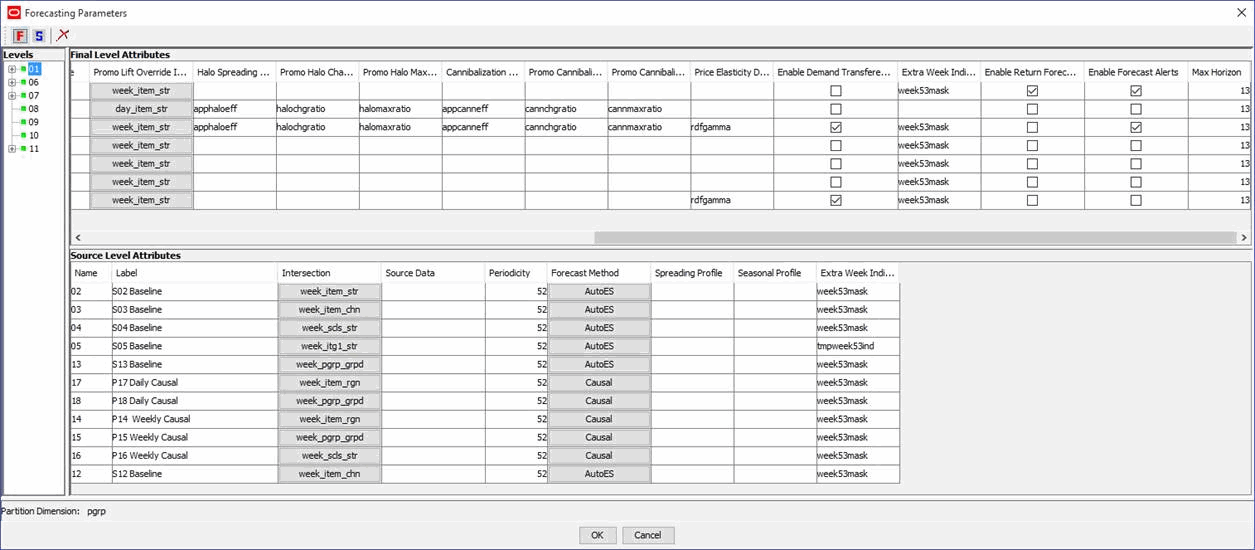
From the Configuration Tools toolbar, select the Automation menu and then, from the RDF option, select Specify Parameters. The following steps outline the process for configuring RDF forecast levels.
Configure a forecast level:
To configure a final forecast level:
From the Forecasting Parameters utility, click the F icon. A new final level is added, and it is assigned the next available level number. Specify the properties for the final level. See Editing Forecast Level Parameters for details. For RDF Cloud Service, skip the columns that do not apply.
To configure a source forecast level:
From the Forecasting Parameters utility, highlight the final level number in which the new source level will be associated from the Level window and then click the S icon. A new source level is added, and it is assigned the next available number. Specify the properties for the source level. See Editing Forecast Level Parameters for details.
Table 5-8 lists the forecast level parameters available for editing.
|
Note: For more information on Source Level Forecasting, see the Oracle Retail Demand Forecasting User Guide. |
Table 5-8 Forecast Level Parameters
| Parameter | Applies to RDF Cloud Service | Description |
|---|---|---|
|
Level Name |
yes |
The level name is the system-assigned level number when a forecast level is created. This is a read-only parameter. |
|
Level Label |
yes |
The level label is the level description that will be viewed by the user once the domain is created. Level labels may not exceed 40 characters. It is recommended, but not required, that Level labels include the Level Name (the system-assigned level number). Within the Forecast Administration workbook, the Default Source Level may be edited. This list is populated with the Level Name for all levels that are associated with a final level. Since this value can also be specified within this configuration, this recommendation may not be necessary if changes to the Default Source Level are not expected within the application. RPAS automatically places parentheses ( ) around Forecast Level labels. The configuration specialist should not include these in the level label configuration or the installer will fail. An example of a Forecast Level label that would violate this requirement is (1:itm/str/week - Final). This example is acceptable: 1- item/str/week - Final. A hyphen '-' should not be used before or after the Forecast Level label. An example of a Forecast Level label that would violate this requirement is: -1:itm/str/week - Final-. This example is acceptable as: 1-itm/str/week – Final A colon ':' should not be used at all in the Level label. An example of a Level label that would violate this requirement is 1: itm/str/week- |
|
Intersection |
yes |
The intersection is the hierarchy dimensions that define the forecasting level. If the product dimension is on the main trunk of the product hierarchy, it must be lower than the partition dimension. If the product dimension is on the alternative roll up of the product hierarchy, all the measures related to this level will be created as forced -non HBI measure. |
|
Source Data |
yes |
Assigned only at the final level, the source data is the measure to be used as the input data (for example, POS) for the generation of forecasts. The values in this list are populated with all non-string and non-Boolean type measures that are configured in the project. |
|
Periodicity |
yes |
Periodicity is the number of periods within the Calendar dimension, which are defined in the forecast level intersection. For example, if an intersection is defined at Week/item/store, the Periodicity value will be 52 (since there are 52 weeks within a year). |
|
Forecast Method |
yes |
The Forecast Method window displays all forecast generation methods that may be defined for a forecast level. The Default Forecast Method is also determined here. When a level is causal level (causal enabled), no other method except |
|
Default Source Level |
yes |
Assigned only at the Final level, the Default Source Level is the primary level at which the aggregate, more robust forecast is run. The desired Source Level must first be created within the RDF configuration for it to be a selection in the list. For more information on Source Level Forecasting, refer to the Oracle Retail Demand Forecasting User Guide.If no source level is required, the final level should be selected. |
|
Plan Data |
yes |
Assigned only at the final level, Plan Data (sales plans) provide details of the anticipated shape and scale of an item's selling pattern. Although not assignable at the source level, Plan Data can be specified for source level in forecast administration workbook. It is used in the same way as in the final level.This information is required when Bayesian or Load Plan is used as a Forecast Method. The value in this parameter is a measure name. |
|
Group Assignment Measure |
yes |
Assigned only at Final level, the Group Assignment measure contains the measure that is used to store the time series grouping. After the domain build, the values (specified measure names) for the Group Assignment measure are stored in a measure. |
|
Seasonal Profile |
yes |
A seasonal profile provides details of the anticipated seasonality of an item's selling pattern. The seasonal profile is required in conjunction with the Profile-based Forecast Method. The seasonal profile can be generated or loaded, depending on your configuration. The value in this parameter is a measure name. |
|
Promo Lift Override Intersection |
yes |
Assigned only at the final level, the Promo Lift Override Intersection window displays the intersection level allowed to override the promotion lift. |
|
Halo Spreading Profile Source |
no |
Assigned only at the final level, the Halo Profile Spreading Source specifies halo spreading profile used in calculating the halo promotion lifts. The value in this parameter is a measure name.For more information on the measure, refer to the section, Files Needed to Build the RDF Domain |
|
Promo Halo Change Ratio Source |
no |
This measure is specified at an intersection higher than item/store. The content of the measure is visible if you roll up to All Products on the product hierarchy. At a lower intersection. the cell displays as a hash mark.This parameter contains the name of the measure that determines the percentage of the promotional lift that is going to increase demand of complimentary items due to the halo effect. |
|
Promo Halo Max Change Ratio Source |
no |
This measure is specified at an intersection higher than item/store. The content of the measure is visible if you roll up to All Products on the product hierarchy. At a lower intersection, the cell displays as a hash mark.This parameter contains the name of the measure that determines an item's maximum allowed increase in sales due to halo. For instance, if the sales of an item for a given period are 15 units, and the maximum allowed percentage is 20%, the increase in sales due to halo for the period cannot exceed three units. |
|
Cannibalization Spreading Profile Source |
no |
Assigned only at the final level, the Cannibalization Profile Spreading Source specifies the cannibalization spread profile used in calculating the cannibalization promotion lifts. The value in this parameter is a measure name.For more information on the measure, refer to the section,Files Needed to Build the RDF Domain. |
|
Promo Cannibalization Change Ratio Source |
no |
This measure is specified at an intersection higher than item/store. The content of the measure is visible if you roll up to All Products on the product hierarchy. At a lower intersection, the cell displays as a hash mark.This parameter contains the name of the measure that determines the percentage of the promotional lift that is going to cannibalize related items. |
|
Promo Cannibalization Max Change Ratio Source |
no |
This measure is specified at an intersection higher than item/store. The content of the measure is visible if you roll up to All Products on the product hierarchy. At a lower intersection, the cell displays as a hash mark.This parameter contains the name of the measure that determines an item's maximum allowed drop in sales due to cannibalization. For instance, if the sales of an item for a given period are 20 units, and the maximum allowed percentage is 20%, the drop in sales due to cannibalization for the period cannot exceed four units. |
|
Price Elasticity Data |
no |
Assigned only at the final level, the Price Elasticity Data specifies the measure to be used as the input data (for example, rdfgamma) to calculate the regular price change lifts. The value in this parameter is a measure name.For more information on the measure, refer to the section,Files Needed to Build the RDF Domain. |
|
Enabled Demand Transference |
no |
Assigned only at the final level, the Enabled Demand Transference window defines if demand transference is enabled. If the check box is not enabled, demand transference function will not be applied to generate the forecast. |
|
Extra Week Indicator |
yes |
Assigned at both source level and final levels.The extra week indicator field should be populated with a measure name. This boolean measure indicates which week is the 53rd week. If the field is empty, then the 53 week processing is unavailable for that level. |
|
Enable Return Forecast |
yes |
Assigned at the final level. This field is a check box. when the check box is selected, then the return forecast is enabled for this particular final level. |
|
Enable Forecast Alert |
yes |
Assigned at the final level only. This field contains a check box. When the check box is selected, then the alerts are configured for this final level |
|
Spreading Profile |
yes |
Assigned only at the source forecasting level, the Spreading Profile is used to spread source level forecasts down to the final forecast level. The value in this parameter is either empty, a measure name, or several measure names separated by commas. When the value is several measure names separated by commas, it is these measures that are multiplied together to create the spreading profile., separated by commas. If Curve is used to generate the static (manually approved) spreading ratios, this parameter should be populated with the Approved Profile measure. For example: apvp11 (this is the Approved Profile for Curve level 11). |
The following is a list of forecast methods that may be selected. See the Oracle Retail Demand Forecasting User Guide for more information on each method.
No Forecast
Average
Moving Average
Simple
Intermittent
Simple/Intermittent
Trend
Additive Seasonal
Multiplicative Seasonal
Seasonal
AutoES
Causal
Bayesian
Profile-based
Load Plan
Copy
Moving Average
Components
The Causal method should be selected as a valid method only for levels in which causal forecasting will be used.
When enabling Causal as a valid forecast method for a source level, note that RDF Promotion variables need to be provided at the same dimension, along the product and location hierarchies as the forecast level for which Causal forecasting is run (Final or Source). RDF Causal does not support aggregation of promotion variables along any hierarchies other than Calendar (Clnd). Aggregation of promotion variables along either or both of product or location hierarchies needs to be handled externally through configuration. Aggregation along the calendar hierarchy is support by RDF Causal, using specified aggregation and spread profiles. Refer to the Oracle Retail Demand Forecasting User Guide for details.
Deleting a forecast level will cause the system-assigned enumerated values in the Level Name to renumber such that levels are in consecutive order, starting with forecast level 01. Deleting a forecast level may impact any solution configuration that uses a specific level.
|
Caution: If the domain using the configuration has previously been installed, there is potential to lose data associated with a level that has been deleted or has been renumbered. |
Perform the following steps to delete a forecast level:
From the Forecasting Parameters utility, highlight the number of the level that you want to delete from the Level window.
Click X. The level is deleted. If you delete a final level, any source levels that are associated with it will also be deleted.
Click OK to regenerate the solution with the changes to the RDF configuration.
The autogeneration process creates hierarchies, measures, rules, and workbook templates that are required to support the essential RDF functionality. This base configuration is referred to as the GA Configuration. Certain changes to the GA Configuration are allowed. Once edits to the GA Configuration are made and the autogeneration process occurs again, valid changes to the configuration will be preserved. There is nothing in the RPAS Configuration Tools to prevent invalid changes from being made.
Table 5-9 outlines acceptable changes and restrictions:
Table 5-9 RDF GA Configuration Restrictions
| Changes and Restrictions | Description |
|---|---|
|
RDF Solution Extension Name |
The name assigned to the resulting RDF solution after autogeneration occurs cannot be edited. |
|
Major and Minor Components |
Additional major components may be added to the Prep Demand. Additional minor components can only be added under the new major components. The major and minor components that are part of the GA configuration may not be edited. This restriction also applies to measure names and measure labels. Adding minor components to GA major components is forbidden. |
|
Rules |
Additional rule sets, rule groups, and rules may be added to the RDF GA configuration. This includes support for adding new rules to existing GA configuration rule groups. It is recommended that new rules added to the GA configuration rule groups include CUST (represents Custom) in the rule name. This allows for easy identification of rules that are not part of the GA configuration. Rule sets, rule groups, and rules that are part of the GA configuration may not be renamed. Existing rules that are part of the GA Configuration may not be modified in any way. |
|
Workbook Templates |
Additional workbook templates may be added to the RDF GA configuration. New measures and rules may also be added to the GA configuration workbook templates. This is done by adding new major and minor components, and adding new rules to existing rule groups in the GA configuration. |
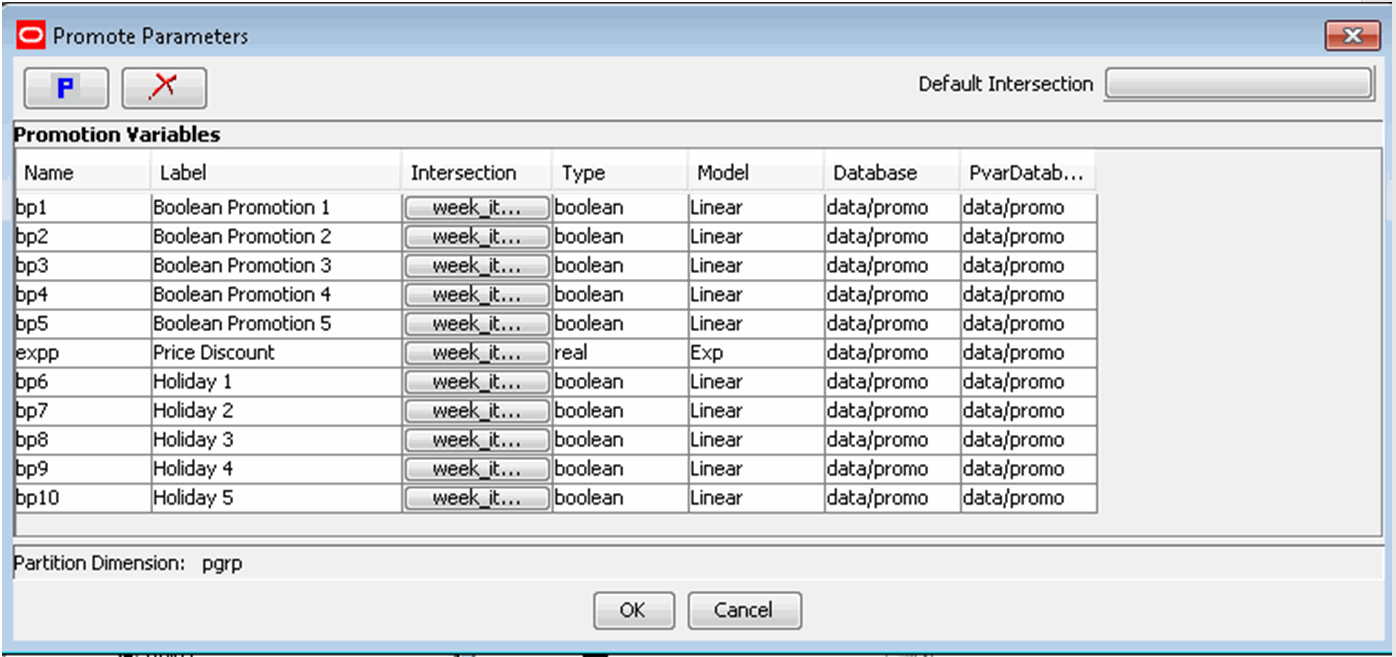
Promote (Promotional Forecasting) is an optional add-on solution to RDF that allows for the setup of promotional and causal events, such as radio advertisements and holiday occurrences. It is only necessary to configure the promote solution if a forecast level setup in the RDF solution is causal enabled. Past sales data and promotional information are used together to forecast future demand.
Using the Promote plug-in, promotions are defined to be used within the Promote solution.
Perform the following steps to create the Promote solution extension:
Open an existing configuration in which the RDF solution has already been defined.
|
Note: Promote Automation must be run last - after RDF. |
|
Note: Promotion/causal forecasting levels are determined within the RDF Solution by selecting Causal as a valid Forecasting Method for source or final forecasting levels. |
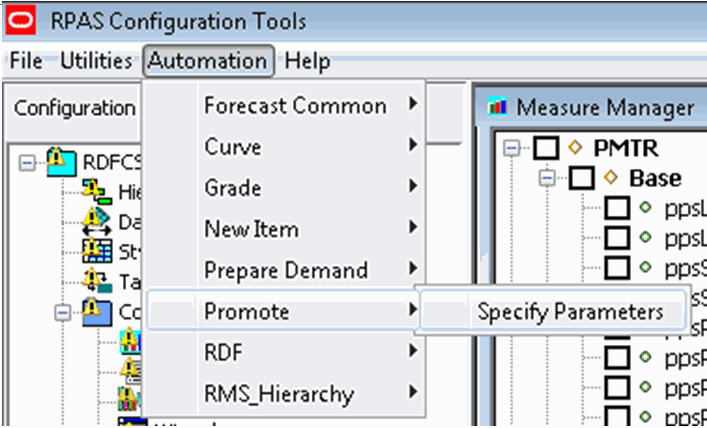
From the Configuration Tools toolbar, select the Automation menu and then, from the Promote option, select Specify Parameters.The following sections outline the process for configuring forecast levels.
Perform the following steps to create a promotion:
From the Promote Parameters utility, click the P icon.
A new promotion is added, and it is assigned a default promotion number for the Promotion Name (for example, P001).
Specify the properties for the promotion. See Editing Promote Parameters for details.
Table 5-10 lists the promotion parameters available for editing.
Table 5-10 Promote Parameters
| Parameter | Description |
|---|---|
|
Default Intersection |
The Default Intersection is the intersection at which any new promotion will be defined. Editing the Default Intersection will not affect any existing promotions. |
|
Promotion Name |
The Promotion Name is the internal system identifier of the promotion. The system will initially assign a generic Promotion Name (P001), but this value may be overwritten. The Promotion Name may not be greater than four characters. The following characters may not precede or follow the name that is entered in this field: '( )' Example: (xmas) '-' Example: -xmas- The following must not be used at all in the Promotion Name: ':' Example: xmas: |
|
Promotion Label |
The Promotion Label is the description of the promotion that will be viewed by the user once the domain is created. Promotion Labels may not exceed 40 characters. The following characters may not precede or follow the label that is entered in this field: '( )' Example: (xmas) '-' Example: -xmas- The following must not be used at all in the Promotion Name: ':' Example: xmas: |
|
Promotion Intersection |
Independent of the causal forecasting levels, the Promotion Intersection is the hierarchy dimension that defines the promotion. It is pre-populated with the value set in the Default Intersection at the time when the promotion is created. |
|
Type |
The Type is the data type of the promotion variable. Promotion Variables may be defined as Boolean or Real types. The value in this parameter defaults to Boolean. |
|
Model |
Model is the model type that the promotion variable is applied into. Model Types maybe defined as Linear or Exp. (Exponential). The value in this parameter defaults to Linear. |
|
Database |
The Database displays the database that will be used to store promotion variable information. The value in this parameter defaults to the data/promo database. |
|
PvarDataBase |
The PvarDataBase is the database used to store promotion variable information. The value in this parameter defaults to the data/promo database. |
Promotion Variable Type is defined through setting both Type and Model.
|
Note: Real Exponential and Real Linear promotion variables cannot be enabled at the same time for a given forecast level. Boolean with either Real Linear or Real Exponential promotion variables, is allowed. |
| When the Type is | And the Model is | Then the Promotion Variable Type is |
|---|---|---|
| Boolean | Linear | Boolean |
| Real | Linear | Real |
| Real | Exponential | Exponential |
|
Note: After autogeneration completes, the following rules display as invalid; however, these should be ignored:
|
Perform the following steps to delete a promotion:
From the Promote Parameters utility, highlight the promotion that you want to delete from the configuration.
Click X. The promotion is deleted.
Click OK to regenerate the solution with the changes to the promotion configuration.
Patch the domain with the new configuration.
The Promote autogeneration process creates all hierarchy dimensions, measures, rules and workbooks to support the essential Promote functionality. The Promote plug-in allows for fewer options than in RDF for edits to the GA Configuration.
Table 5-11 outlines acceptable changes and restrictions:
Table 5-11 Promote GA Configuration Restrictions
| Changes and Restrictions | Description |
|---|---|
|
Promote Solution Extension Name |
The name assigned to the resulting Promote solution after autogeneration occurs cannot be edited. |
|
Major and Minor Components |
Additional major components may be added to the Prep Demand. Additional minor components can only be added under the new major components. The major and minor components that are part of the GA configuration may not be edited. This restriction also applies to measure names and measure labels. Adding minor components to GA major components is forbidden. |
|
Rules |
Rule sets, rule groups, and rules that are part of the GA configuration may not be renamed. Existing rules that are part of the GA Configuration may not be modified in any way. |
|
Workbook Templates |
New measures and rules cannot be added to the GA configuration workbook templates. |
The process of setting up task flow is roughly same in a RDF project as any other RPAS based product. There is a major difference for a configuration with an existing taskflow settings. When taskflow exists in the configuration, the plug-in automations may cause the workbook template field in the taskflow to be empty.
RDF Cloud Service ships two different taskflow files with the packaged configuration:
taskflow.xml for when the product attribute is available
taskflow.xml_noattribute for when the product attribute is unavailable
If RDF Cloud Service is customized and configured with no attribute, then taskflow.xml_noattribute is renamed to taskflow.xml.
It is recommended to perform the automation in the following steps to preserve the taskflow:
Save a copy of taskflow.xml in an existing configuration and open the configuration with RPAS ConfigTools.
Run automation of all necessary plug-ins, save the configuration and close it.
Copy the backed up taskflow.xml back into the configuration.
Reopen the saved configuration and make appropriate adjustment to the taskflow or other components.
The process of building a RDF domain using the RDF/RDF Cloud Service configuration is about the same as any other RPAS based applications. However, for pre-domain installation, it is necessary to generate the RDF internal hierarchy files and RDF internal measure data files through the plug-ins.
For domain patching, these internal data files need to be copied manually into the RPAS domain's input directory. The script, rdf_build_domain.ksh has been coded to take care of the previously listed details. It should be used for both domain building and domain patching.
If an implementer wishes to use their own custom scripts, ensure all necessary steps in rdf_build_domain.ksh are included in the custom scripts. For more information, refer to "rdf_build_domain.ksh."
RDF Cloud Service configuration demonstrates the best practices that Oracle suggests when implementing RDF:
Preprocessing is set up to produce different data sources for baseline forecasting and causal estimation.
The number of forecast levels are limited to ten with a maximum of two final levels in RDF cloud configuration. The RDF plug-in will throw an error if this is broken. Baseline forecasting is configured on final level 1, with multiple source levels. The source levels are either on aggregated prod/location/week or custom-group/week. The custom-group assignment is provided by the user and is supposed to be loaded.
In RDF Cloud Service, the number of promotions is limited to five Boolean promotions, one exponential promotion and five holiday/floating-events.The Promote plug-in will throw an exception if more promotions are configured for cloud-type configuration. Going beyond 11 causal variables does not show significant improvement in promotion forecast accuracy. Promotion effects estimation are set up to estimate on both final and source levels. The source level pooled estimation can leverage either aggregated PROD/LOC or custom-groups of item/stores. The effects from individual item/store and pooled estimations can be merged before applying to baseline.
In RDF Cloud Service implementation, the configuration name must be RDFCS. It cannot be changed. An implementer is only allowed to perform the following steps:
Set up partition hierarchy and dimension.
Configure PrepDemand solution through the plug-in.
Configure NewItem solution through the plug-in.
Configure RDF solution through the plug-in.
Configure Promote Solution through the plug-in.
Configure the taskflow.
Configuration Files to Send
Oracle OCI does not require the whole configuration to be sent. OCI only needs the following four files from the configuration:
rdf_plugins_<date>.tar.gz
This file should be a tar and gzip of the entire RDFCS/plugins folder. Ensure the plugins folder contains the following directories:
Common
PrepDemand
NewItem
RDF
Promote
To create this file, change directory to the RDFCS folder and issue the following command (where <date> is the current date):
tar -cvf - plugins | gzip > rdf_plugins_<date>.tar.gz
rdf_hiers_<date>.tar.gz
This file should be a tar and gzip of the required hierarchies to build the initial RDF domain. Ensure it contains the following files:
clnd.csv.dat
grph.csv.dat
loc.csv.dat
prod.csv.dat
attr.csv.cat (If the New Item plug-in was configured to use attributes)
There should be no directories or folders in the rdf_hiers_<date>.tar.gz file.
The modified rdf-preprocess.ctl (must be located in $RPAS_HOME/bin)
The modified RDFCS/taskflow.xml
|
Note: OCI uses these files and directories to regenerate the configuration and build/patch the domain. Therdf-preprocess.ctl is used for batch setup. |