 Running Shared Lookup Jobs
Running Shared Lookup JobsAfter running the initial setup jobs, which setup your hash files and bring operational source data into the Operational Warehouse - Staging (OWS), you must run the remaining setup jobs. The remaining setup jobs are common to all EPM products and are referred to as cross-product setup jobs. These jobs setup your shared lookups, common dimensions, and OWE tables. Optionally, you can also run the multilanguage support utility (language swap utility) at this point. The utility is useful when the base language used by the EPM database differs from the base language used by your source system.
This chapter discusses how to:
Run shared lookup jobs
Run setup - OWE jobs
Run common dimension jobs
Set up multilanguage processing
Run language swap utility (optional)
Running Shared Lookup JobsShared lookups function the same as hash file lookups—they act as views of specific EPM warehouse tables and contain only a subset of the data available in a warehouse table. These streamlined versions of warehouse tables are used to perform data validation (lookups) within an ETL job and select specific data from lookup tables (such as sourceID fields in dimensions). The only difference between a regular lookup and a shared lookup is that the shared lookups are used across all EPM products.
Because shared lookups are essential in the lookup process, jobs cannot function properly until all hash files are created and populated with data. Before you run any job that requires a hash file, you must first run all jobs that create and load the hash files—also called initial hash file load jobs.
Steps Required to Run Shared Lookup Jobs
Perform the following steps to run the shared lookup jobs:
In DataStage Manager, attach to your project and expand the Shared_Lookups node in the left navigation panel of the window.
The following sub-folders exist in the Shared_Lookups node:
Control_Tables
DimensionMapper_Lookups
E1CurrConv_Lookups
E1UOM_Lookups
GetDecimalShift_Lookups
Language_Lookups
System_Lookups
Select one of the sub-folders.
Select the lookup jobs in the Job Status view and select Job, Run Now... from the menu.
The Job Run Options box appears.
Update the job parameters if necessary and click Run.
The job is scheduled to run with the current date and time, and the job’s status is updated to Running.
Repeat steps two and three for the remaining sub-folders.
Running Setup - OWE JobsSetup - OWE jobs load the setup tables used in standard OWE jobs (jobs that move your operational data from the OWS to the OWE). You can run these jobs manually or use the Master Run Utility. To run the jobs automatically with the Master Run Utility, follow the steps described in the previous chapter of this book.
See Using the Master Run Utility to Automatically Run Your ETL Jobs.
Running Setup - OWE Jobs for an Enterprise Source
Perform the following steps to run the setup - OWE jobs manually:
In DataStage Director, navigate to the setup OWE jobs by expanding the nodes in the left navigation panel using the following path: Setup_E, OWE, Base, Load_Tables, Sequence.
Select each setup - OWE sequence job in the Job Status view and select Job, Run Now... from the menu.
The Job Run Options box appears.
Update the job parameters if necessary and click Run.
The job is scheduled to run with the current date and time, and the job’s status is updated to Running.
Running Setup - OWE Jobs for an Enterprise One Source
If you are sourcing from an Enterprise One transaction system, you must run the setup - OWE sequence jobs that are located in the following DataStage Director path: Setup_E1, OWE, Base, Load_Tables, Sequence
Running Common Dimension ETL JobsCommon dimensions are dimensions that are shared across all EPM products. Not only do these dimensions play an important role in all reporting and analytical analysis, but they are particularly important to the Allocation Manager data enhancement tool. In Allocation Manager, these dimensions are used to determine the divisor, therefore the ratio, for the spread even and prorata methods.
Common dimension jobs can be divided into the following five categories:
Business_Unit
Calendar
Currency
Language
Unit_Of_Measure
The common dimension master sequence jobs can be found in the following DataStage Director paths:
Common_Dimensions\E\Business_Unit\Master_Sequence
Common_Dimensions\E\Calendar\Master_Sequence
Common_Dimensions\E\Currency\Master_Sequence
Common_Dimensions\E\Language\Master_Sequence
Common_Dimensions\E\Unit_Of_Measure\Master_Sequence
Note. For all dimension load jobs (common dimension, global dimension, local dimension, OWE dimension, MDW dimension), users can customize the error validation by providing the environmental variable with the appropriate values. If you want to skip error validation, set $ERR_VALIDATE to ‘N.’ If you want to perform error validation, set $ERR_VALIDATE to ‘Y.’ Also, you can specify the threshold limit for the error validation. If you want the job to abort if the lookup fails more than 50 times, set $ERR_VALIDATE to ‘Y’ and $ERR_THRESHOLD to 50. This can all be done using DataStage Administrator.
See Also
Using EPM Foundation Data Enhancement Tools
 Running Common Dimensions Jobs for an Enterprise Source
Running Common Dimensions Jobs for an Enterprise Source
Perform the following steps to run the common dimension jobs for an Enterprise source (the order reflects the master sequence order):
In DataStage Director, navigate to the MSEQ_E_Hash_Calendar (Calendar) master sequence by expanding the nodes in the left navigation panel using the path defined in the previous section.
Select the MSEQ_E_Hash_Calendar master sequence job in the Job Status view and select Job, Run Now... from the menu.
The Job Run Options box appears.
Update the job parameters if necessary and click Run.
The job is scheduled to run with the current date and time, and the job’s status is updated to Running.
Repeat steps one through three for the remaining master sequence jobs, using the following order:
MSEQ_E_OWE_BaseDim_Calendar (Calendar)
MSEQ_E_OWS_BaseDim_Calendar (Calendar)
MSEQ_E_Hash_BU (Business Unit)
MSEQ_E_OWE_BaseDim_BU (Business Unit)
MSEQ_E_OWS_BaseDim_BU (Business Unit)
MSEQ_E_Hash_Currency (Currency)
MSEQ_E_OWE_BaseDim_Currency (Currency)
Running Common Dimensions Jobs for an Enterprise One Source
Perform the following steps to run the common dimension jobs for an Enterprise One source (the order reflects the master sequence order):
In DataStage Director, navigate to the MSEQ_E1_Hash_Calendar (Calendar) master sequence by expanding the nodes in the left navigation panel using the path defined in the previous section.
Select the MSEQ_E1_Hash_Calendar master sequence job in the Job Status view and select Job, Run Now... from the menu.
The Job Run Options box appears.
Update the job parameters if necessary and click Run.
The job is scheduled to run with the current date and time, and the job’s status is updated to Running.
Repeat steps one through three for the remaining master sequence jobs, using the following order:
MSEQ_E1_BaseDim_Calendar (Calendar)
MSEQ_E1_Hash_Currency (Currency)
MSEQ_E1_OWE_BaseDim_Currency (Currency)
MSEQ_E1_Hash_BU (Business Unit)
MSEQ_E1_BaseDim_BU (Business Unit)
MSEQ_E1_Hash_UOM (Unit of Measure)
MSEQ_E1_BaseDim_UOM (Unit of Measure)
Setting Up Multilanguage Processing and Running the Language Swap Utility (Optional)This section provides an overview of multilanguage processing and the language swap utility, and discusses how to:
Map Enterprise One language codes to Enterprise language codes.
Run the language swap utility.
Understanding Multilanguage ProcessingMany organizations conduct business globally and deploy their PeopleSoft source systems in various locations throughout the world. PeopleTools can store multiple translations of application data and PeopleTools objects in a single database. Each PeopleSoft database has a single base language. The base language of a PeopleSoft database is usually the language most commonly used by application users, and is the language in which data is stored in the core PeopleSoft tables known as base language tables.
All PeopleTools objects (such as pages, fields and queries) can be maintained in multiple languages. Descriptions of application data elements (such as departments, locations and job codes) can also be maintained in multiple languages. The key to maintaining this data in multiple languages is the use of special tables known as related language tables.
Related language tables store descriptions and other language-sensitive elements in all languages other than the base language of the database. In this way, while any table in the database can store data in the base language of that database, only tables that have related language tables can maintain the same data in multiple languages simultaneously. For example, it is unlikely that you would maintain the descriptions of your general ledger journal lines in multiple languages—the sheer volume of the journal lines in most systems would preclude any effort to maintain translations of their descriptions. The cost of hiring a translator to translate each journal line would be prohibitive, and in most cases only the person entering the journal line, and possibly that person’s supervisor, would be likely to want to view that information again. However, for frequently used values, such as a chart of accounts, many users across your entire organization would often need to refer to this data. Therefore, you would most likely maintain the descriptions of each ChartField entry in each language spoken by your users. In this case, you would not need a related language table for your Journal Lines table, as you would be maintaining journal line descriptions in a single language, which would be in the base table. However, you would need a related language table for each of your ChartField tables.
When the system displays a language-sensitive field value, it retrieves the text from either the base table or the related language table, depending on the following:
The current language preference.
Whether any translated rows for the field exist in the related language table.
The language preference refers either to the PeopleSoft PIA sign-in language, or in the case of PeopleSoft Application Designer, to the language preference as determined by the PeopleSoft Configuration Manager language setting. If the current language preference is the system's base language, the text is retrieved from the base table. If the language preference is a non-base language, then the system looks for a translation of the text in the related language table. If it finds a translation, it displays the translated text; if no translation exists, the system uses the text in the base table. This enables developers to selectively translate portions of the data, while keeping the system fully functional at all times, even if not all rows have been translated.
EPM also uses related language tables to support multi-language processing. In each of the three data warehouse layers (the OWS, OWE, and MDW), all records that have translatable description fields have corresponding related language tables. Related language tables are defined for every OWS, DIM, and D00 table that contain translatable values. For example, the table CUSTOMER_D00 has a corresponding related language table CUSTOMER_LNG. Related language tables have key structures identical to the related DIM and D00 table plus one additional key field called language code (LANGUAGE_CD). The language code field holds the source language value. Prepackaged ETL jobs extract this data from a PeopleSoft source system and populate the field with your source language value.
EPM extracts data from PeopleSoft source systems, which have their own base languages and supported foreign languages. Multi-language infrastructure in PeopleSoft source systems store the base language in the base table and the foreign language descriptions in the related language table. If the base language of the source database and that of the EPM database are not the same (but the source database’s base language is one of EPM warehouse’s supported foreign languages), the description from the base table in source database must be stored in the related-language table in EPM to ensure consistency. If a supported foreign language in the source database is the EPM warehouse’s base language, then that foreign language description must be stored in the base table in the EPM database. We achieve this consistency through use of the Language Swap Utility.
The Language Swap Utility and multilanguage processing enables you to:
Import descriptions for any language into EPM target warehouse tables.
Exchange descriptions in source tables with the related-language tables, when source defined language is different than the EPM defined language.
Report in different languages.
The Language Swap utility abstracts the process of language swapping from all of the ETL maps that load data into the EPM database. As a result, the utility reduces the complexity and increases the maintainability of the ETL maps.
Understanding the Language Swap UtilityThe language swap utility automatically detects the mismatched languages between the language defined in the source and the language defined in the EPM database, and sets the correct base language for incoming data. The utility compares the base language of the source database (as it is stored in the SRC_SYSTEM_TBL) and the base language of the EPM database. If they are different, the utility swaps the descriptions that are found in the base table and the related-language tables whenever possible. Once the data are in OWS and the base language swap utility has been performed, the reference data and their related language data in OWS are conformed to the PeopleSoft infrastructure for related language. This ensures proper synchronization and enables you to process and report in multiple languages. Note, however, that this process requires that descriptions be available in the source record. This process cannot be performed if the related language record doesn't have any description fields, or any other fields that are translatable, from the base table.
The following graphic depicts the language swap process.
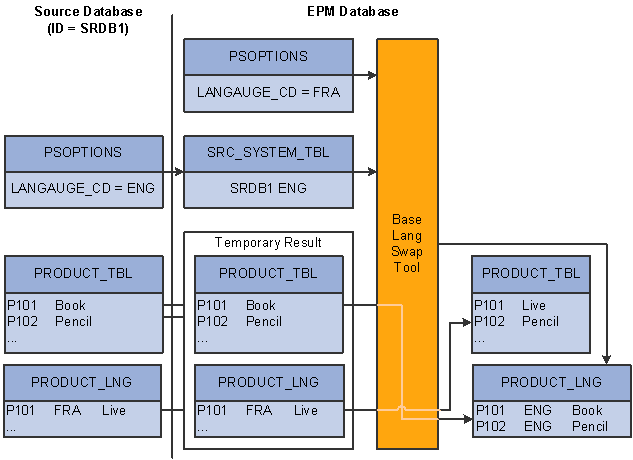
Language swap process
The swapping process works as follows:
Check if the base language of the source database is the same as the base language of the EPM database.
If the languages are the same, then continue to the last step in this process. Otherwise, proceed to the next step.
Check if the base language of the source database is a supported foreign language in the EPM database.
If the language is the same, then create a corresponding entry in the related-language table for every new (not yet swapped) row in the base table. The LANGUAGE_CD used for tagging the new entry in the related-language table is the LANGUAGE_CD for the source database as it is found in the SRC_SYSTEM_TBL table.
Locate the description in the related language table where LANGUAGE_CD for the row is the same as the base language code of the EPM database. Once identified, perform the swap between the description in the base table and the related-language table.
Delete from the related-language table any rows where the LANGUAGE_CD is the base language code of the EPM database or is not any of the supported foreign languages in the EPM
The language swap utility is embedded in prepackaged ETL jobs and should be run only when your source database language is different from the language defined for the EPM database. Run the Language Swap utility after your source data is completely extracted into the OWS, but before you run any subsequent ETL jobs to transform OWS data into OWE or MDW data.
Outrigger Tables for the Multidimensional Warehouse
An outrigger table in the MDW represents foreign language descriptions for data in the base dimension table. The structure of the outrigger table is the same as the structure of an MDW dimension related language table. It has the base table’s keys, an additional key to represent the language code (LANGUAGE_CD), and as many columns as there are translatable columns in the base table.
The difference between an outrigger table and a related language table lies in the content. Outrigger tables contain not only the foreign language descriptions of the data, but also the base language descriptions for every row of data found in the base table, even though some data do not have foreign language translations. For example, if there are ten entries in the base table and there are three supported languages, there will be 30 entries in the corresponding outrigger table. If, however, there is no corresponding description (that is, translation) for a particular entry for one of the languages in the related language, the description defaults to the value in the base table.
The advantage of an outrigger table over a related language table for reporting in third-party tools is that the outrigger table contains descriptions in the base language, as well as any supported foreign language, for all data in the base table. The completeness of the content in the outrigger table simplifies the logic for displaying the foreign language description in the third-party reporting tool, which does not have the built-in multi-language infrastructure like PeopleSoft applications do.
Sample Outcome of the Language Swap Process
Assume you have one source database, SRC01, whose base language is Spanish and supported foreign languages are English and French. In addition, assume your EPM database has English as the base language, and Spanish as the only supported foreign language.
Here is the Product table from the source database:
|
ProductID |
Description |
|
P101 |
Libro |
|
P102 |
Lápiz |
|
P103 |
Pluma |
Here is the Product Language table from the source database:
|
ProductID |
Lang CD |
Description |
|
P101 |
ENG |
Book |
|
P102 |
ENG |
Pencil |
|
P101 |
FRA |
Livre |
|
P102 |
FRA |
Crayon |
|
P103 |
FRA |
Stylo |
After the data is extracted into the OWS and the Language Swap utility is run, the following changes result in the tables:
Here is the OWS Product table from the EPM database:
|
ProductID |
Description |
|
P101 |
Book |
|
P102 |
Pencil |
|
P103 |
Pluma |
Here is the OWS Product Language table from the source database:
|
ProductID |
Lang CD |
Description |
|
P101 |
SPA |
Libro |
|
P102 |
SPA |
Lápiz |
|
P103 |
SPA |
Pluma |
Notice that the French translations that are available in the source database are no longer found in the EPM OWS because French is neither the EPM base language nor its supported foreign language. The Spanish descriptions that are originally in the base table are now in the related language table, while the English descriptions are now in the base table. Product P103 does not have an English description and retains its original description from the source database “pluma” – that is, “pen” in English.
This table shows an example of a Sales fact table:
|
Time Key |
Product Key |
Store Key |
Quantity |
Amount |
|
1 |
1 |
1 |
5 |
10 |
|
1 |
2 |
1 |
1 |
3 |
|
1 |
3 |
2 |
2 |
3 |
This table shows an example of the related Product dimension table:
|
Product Key |
SKU |
Description |
|
1 |
A123 |
Bread |
|
2 |
B234 |
Marmalade |
|
3 |
C345 |
Milk |
Typically, if a dimension table is used in conjunction with an outrigger table, the dimension table does not have any attributes that are country-specific. This is to prevent duplicate attributes in the dimension table and the outrigger table.
This table shows an example of the related Product outrigger table, assuming the base language is English (ENG) and the supported languages are English (ENG), German (GER), and Italian (ITA):
|
Product Key |
Language Code |
Description |
|
1 |
ENG |
Bread |
|
1 |
GER |
Brot |
|
1 |
ITA |
Pane |
|
2 |
ENG |
Marmalade |
|
2 |
GER |
Marmelade |
|
2 |
ITA |
Marmellata di agrumi |
|
3 |
ENG |
Milk |
|
3 |
GER |
Milch |
|
3 |
ITA |
Latte |
When you constrain language code to a single value, your reporting tool uses the attributes from the outrigger table (Product Description) and the Product dimension table (SKU and Description) to qualify the metrics (Amount and Quantity) and produce the description in the selected language.
Note. In this example, if the related language table did not contain a German description for Bread, the description for Bread in German in this outrigger table would contain Bread, rather than Brot.
You use ETL to populate outrigger tables at the time that you populate the MDW layer.
Understanding Multilanguage SetupYou must enable multilanguage processing before you can view your data in a different language or run multilanguage reports. Setting up multilanguage processing requires three simple steps:
Define the base language of your source systems: Use the Define Warehouse Source page to perform this task.
Map Enterprise One language codes to Enterprise language codes (for Enterprise One sources only).
Run the language swap utility.
Note. Language Swap is OWS post process and so before running this utility, make sure to run all the staging jobs for base and language tables.
Language Code Mapping for an Enterprise One Source
Enterprise One language codes are user defined so they do not conform to standard EPM language codes. For example, the language code for English in Enterprise One can be ES, while the language code for English in EPM is ENG. Mismatched language codes can create unexpected results with your EPM data. Therefore, you must map the Enterprise One language code to the standard EPM language code. The mapping information is used during the ETL process to reconcile the conflicting language codes. Use the E1 Language Code Mapping page to map Enterprise One language codes to Enterprise language codes.
Page Used to Map Language Codes (Enterprise One Source)
|
Page Name |
Object Name |
Navigation |
Usage |
|
E1 Language Code Mapping |
E1LANG_MAP |
EPM Foundation, EPM Setup, Common Definitions, E1 Language Code Mapping |
Map your Enterprise One language codes to Enterprise language codes. |
Mapping Language CodesAccess the E1 Language Code Mapping page.
|
Source System Identification |
Select the Enterprise One source system that contains the language code you are mapping. |
|
E1 Language Code |
Enter the Enterprise One language code that you are mapping. |
|
Language Code |
Select the language that your selected code represents. |
Running the Language Swap JobsThe language swap process is a part of the PeopleSoft ETL sequencer job SEQ_J_Run_LangSwap. Simply run the job to initiate the language swap process. Please note, however, that this process should not be run until you run all staging jobs that populate base tables and language tables.
Perform the following steps to run the language swap jobs:
In DataStage Director navigate to the language swap jobs by expanding the nodes in the left navigation panel using the following path: EPM90_Utilities, Sequence, SEQ_J_Run_LangSwap.
highlight the jobs and click run (or whatever).
If you want the job to use the values that are defined in the DataStage Administrator, then click “Run” button. If you want to override the values then type the appropriate values and then click “Run” button.