




|
|
The following sections describe the basic architectural elements of a BEA Tuxedo ATMI environment:
The following figure illustrates the basic architectural elements of a BEA Tuxedo ATMI environment: external interfaces to the environment, the ATMI layer, the MIB, BEA Tuxedo system services, and the environment’s interface with standards-compliant resource managers.
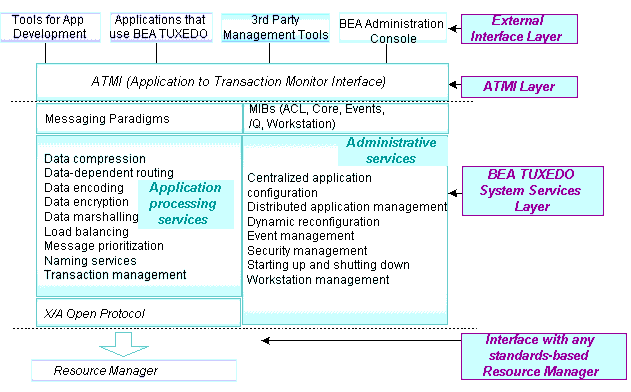
As shown in this illustration, the BEA Tuxedo ATMI environment contains the following components:
This layer consists of interfaces between the user and the environment. It includes both tools for application development and administration, such as the BEA Tuxedo Administration Console. The Administration Console can interact with standard management consoles. Thus a user can manage a BEA Tuxedo ATMI environment and a network configuration from one console. In addition, application architects and developers can build their own administrative tools or application- or market-specific tools on top of the MIB.
|
|
The interface between an application and the BEA Tuxedo ATMI environment. The ATMI and the BEA Tuxedo environment implement the X/Open DTP model of transaction processing. An abstract environment, the ATMI supports location transparency and hides implementation details. As a result, programmers are free to configure and deploy BEA Tuxedo applications to multiple platforms without modifying the application code.
|
|
The MIB is an interface that enables users to program and administer a BEA Tuxedo ATMI environment easily. MIB operations enable users to perform all management tasks (monitoring, configuring, tuning, and so on). The MIB allows users to perform one task to one object at a time or to build toolkits with which to batch tasks and/or objects. For information about the MIB and the MIB interface, see Oracle Tuxedo Management Tools.
|
|
Services and/or capabilities provided by the BEA Tuxedo ATMI environment infrastructure for developing and administering applications.
The application processing services available to BEA Tuxedo developers include
data compression,
data-dependent routing,
data encoding,
data encryption,
data marshalling,
load balancing,
message prioritization, and
service and event naming. These services are described in the discussions that follow.
The administrative services available to BEA Tuxedo administrators include startup and shutdown of an application, centralized application configuration, distributed application management, dynamic application reconfiguration, workstation management, security management, transaction management, message queuing management, and event management.
The system administration processes that provide the administrative services are described in Oracle Tuxedo System Administration and Server Processes and Oracle Tuxedo Management Tools.
|
|
A software product in which data is stored and available for retrieval through application-based queries. The resource manager (RM) interacts with the BEA Tuxedo ATMI environment and implements the XA standard interfaces. The most common example of a resource manager is a database. Resource managers provide transaction capabilities and permanence of actions; they are the entities accessed and controlled within a global (distributed) transaction.
|
The Application-to-Transaction Monitor Interface (ATMI), the BEA Tuxedo API, is an interface for communications, transactions, and management of data buffers that works in all environments supported by the BEA Tuxedo system. It provides the connection between application programs and the BEA Tuxedo system. The ATMI is a simple interface for a comprehensive set of capabilities. It implements the X/Open DTP model of transaction processing.
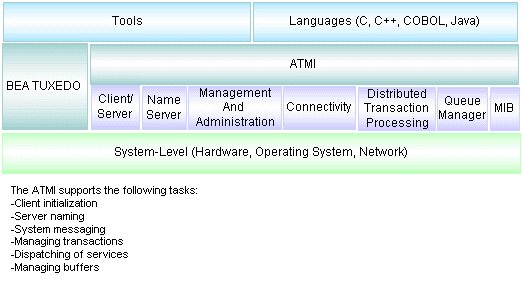
The ATMI library offers you a variety of functions (routines, verbs) for defining and controlling global transactions in a BEA Tuxedo ATMI application. Global transactions enable you to manage exclusive units of work spanning multiple programs and resource managers in your distributed application. All work in a single transaction is treated as a logical unit, so that if any one program cannot complete its task successfully, no work is performed by programs in the transaction.
The ATMI functions knit together distributed programs by enabling them to send and receive data. All ATMI functions send or receive data in typed buffers.
The following table presents a list of ATMI functions for C and COBOL bindings, and the tasks they perform. The functions are grouped by task.
| Note: | The use of the BEA Tuxedo ATMI transaction management functions is optional. Because BEA Tuxedo also supports the X/Open TX transaction management functions, you may want to use those functions for transaction management. |
Besides managing an application’s server processes and managing transactions, BEA Tuxedo ATMI also manages client/server communications, that is, allows clients (and servers) to invoke an application service using any of the messaging paradigms identified in the following table.
Request/response communication
|
|
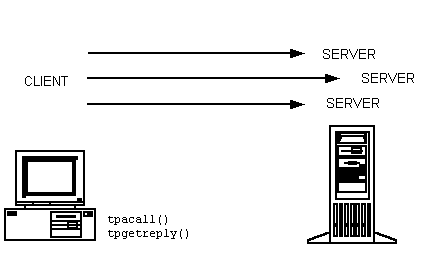
To implement request/response communication between ATMI clients and servers, the BEA Tuxedo system uses interprocess communication (IPC) message queues. Queues are the key to connectionless communication. Each server is assigned an IPC message queue called a request queue, and each client is assigned a reply queue. Therefore, rather than establishing and maintaining a connection with a server, a client application can send requests to the server by putting those requests on the server’s queue, and then check and retrieve messages from the server by pulling messages from its own reply queue.
The request/response model is used for both synchronous and asynchronous service requests.
In a synchronous call, a client sends a request to a server, which performs the requested action while the client waits. The server then sends the reply to the client, which receives the reply.

In an asynchronous call, the BEA Tuxedo client does not wait for a service request it has submitted to finish before undertaking other tasks. Instead, after issuing a request, the client performs additional tasks (which may include issuing more requests). When a reply to the first request is available, the client retrieves it.
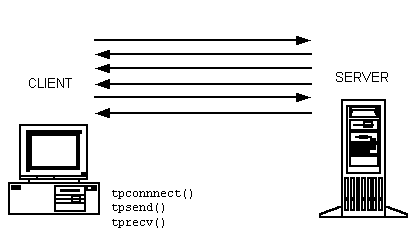
Conversational communication is the BEA Tuxedo system implementation of a human-like paradigm for exchanging messages between ATMI clients and servers. In this form of communication, a virtual connection is maintained between the client and server. Just as in a conversation between two people, a number of messages pass back and forth between the two entities until a conclusion is reached. Over the course of the communication, both sides “remember” the point (or state) of the conversation so that relatively long operations, such as ad hoc queries, reports, and file transfers, can be supported. By default, conversational servers are available, but more can be spawned automatically if needed.
The BEA Tuxedo system provides an API that can be used to create conversations in applications; specifically, to connect clients to servers, to send and receive messages, and to end the conversation.
Conversations can be nested but performance may be degraded as a result of doing so. Conversations may contain either transactions or service requests as appropriate. Although a conversational service can make service calls and establish conversations, those service calls and conversations cannot be forwarded. A conversation can be within the scope of—and controlled by—a transaction.
The BEA Tuxedo system offers a queue-based architecture known as /Q for ATMI applications that require persistent storage of data. The /Q component allows any client or server to store messages or service requests in queues and guarantees that any stored request is sent through the transaction protocol to ensure safe storage.
BEA Tuxedo system queues can be ordered as last in, first out (LIFO) or first in, first out (FIFO), or on the basis of time or priority. A collection of queues is administered and referred to as a single entity known as a queue space.
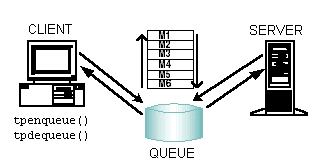
Application queues are appropriate if you must communicate in a time-independent fashion. Time-independence is a characteristic of programs that operate independently from one another and do not need to synchronize their communications simultaneously. Time-independent programs synchronize by leaving messages for each other in application queues. Messages can be dequeued in any of several ordering schemes, such as FIFO order, priority order, or time-based order. BEA Tuxedo client and server programs can enqueue messages and dequeue messages from queues. More than one client and server can access the same queue.
To use an application queue, your program must name the queue to be accessed and the queue space in which it resides. Your application can use more than one queue space and each space can contain more than one message queue.
Because application queues reside on a disk, the availability of stored messages is guaranteed even after machine failures. To determine when the use of application queues is appropriate, you need to determine when time-independent synchronization occurs in your business, for example, in filling orders. Orders can be enqueued to disk and depending on specific order criteria, such as items or shipment location, placed in different queue spaces. Within each queue space, you can determine additional criteria, such as cost, state, and so on.
The BEA Tuxedo publish-and-subscribe component, known as EventBroker, provides a communication paradigm in which an arbitrary number of suppliers can post messages for an arbitrary number of subscribers. ATMI client and server processes using EventBroker communicate with one another based on a set of subscriptions. EventBroker acts like a newspaper delivery person who delivers newspapers only to customers who have paid for a subscription.
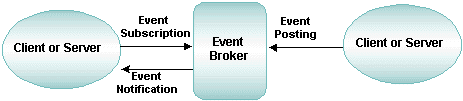
Event generators (either clients or servers) inform EventBroker of changes and problems as they occur. This process is called posting an event. EventBroker then matches the name of the event to an event name associated with a list of subscribers, and notifies each subscriber on the list of the event.
The BEA Tuxedo system supports two different types of event reports:
A process registers a subscription with EventBroker, indicating interest in a particular event. Subsequently, whenever EventBroker is notified by another process that the specified event has occurred, EventBroker reports the occurrence to any process that has subscribed for this event.
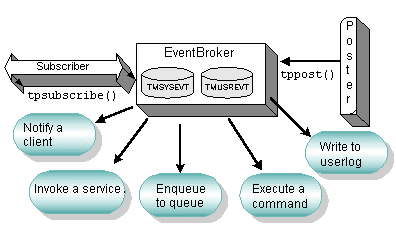
EventBroker uses several mechanisms for publishing (that is, issuing notices of) events:
The BEA Tuxedo system offers a powerful communication paradigm called unsolicited notification. When unsolicited notification occurs, an ATMI client receives a message that it has never requested. This capability, which is managed by EventBroker, makes it possible for application clients to receive notification of application-specific events as they occur, without having to request notification explicitly in real time.
Unsolicited messages can be sent to client processes by name (tpbroadcast) or by an identifier received with a previously processed message (tpnotify). Messages sent via tpbroadcast can originate either in a service or in another client. You can target a narrow or wide audience. You can send a message with or without guaranteed delivery to an individual client through point-to-point notification (tpnotify), or you can send information to a group of clients (tpbroadcast). For example, a server may alert a single client that the account about which the client is inquiring has been closed. Or, a server may send a message to all the clients on a machine to remind the users that the machine will be shut down for maintenance at a specific time.
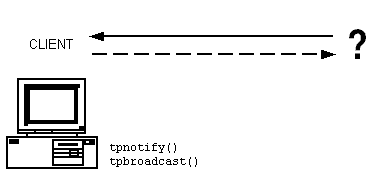
Any process that wants to be notified about a particular event (such as a machine being shut down for maintenance) can register a request, with the system, to be notified automatically. Once registered, a client or server is informed whenever the specified event occurs. This type of automatic communication about an event is called unsolicited notification.
Because there is no limit to the number of clients and servers that may generate events and receive unsolicited notification about such events, the task of managing this category of communication can become complex.
Nested and forwarded service requests allow BEA Tuxedo services to act as ATMI clients and call other services.
Nesting is limited to two levels, which works particularly well in a 3-tier client/server architecture, that is, a system that comprises a presentation logic layer, a business logic layer, and a database layer. In such a system, the presentation layer is used to formulate a request for a particular business function that involves one or more queries to a database. Because nesting is limited to two levels, it does not degrade performance.
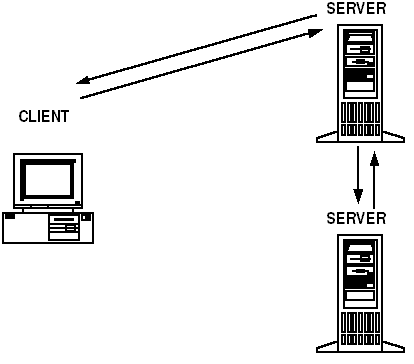
One benefit of using nested requests is that doing so enables you to keep your code small and reusable, such that each piece performs a limited task. However, if the services in your system are distributed across several servers, nested requests can lead to poor performance. While a nested request is being processed, the original service (that is, the service that issued the nested request) must wait for a response before continuing. Until a response is received, the original service cannot process another request. As a result, messages can get backed up in the request queue for the server on which this service resides.
A customer uses a cash machine to transfer money from his or her savings account to her checking account. A BEA Tuxedo application performs the work necessary to transfer the money. First, on behalf of the customer, the client issues a request for a service called TRANSFER, and the request is placed on a queue for a server that provides that service. Next, the TRANSFER service requests two other services, WITHDRAW and DEPOSIT, which are processed by a second server. The WITHDRAW and DEPOSIT services return responses to the TRANSFER service. Finally, TRANSFER sends a response to the client’s response queue. When the client retrieves the response from the queue, the system displays a message on the screen of the cash machine, notifying the customer that the transfer is complete.
One alternative to nesting service requests is called request forwarding. Instead of processing a client’s request, a service can pass the request to another service. The second service, also, can either process the request or pass it to another service.
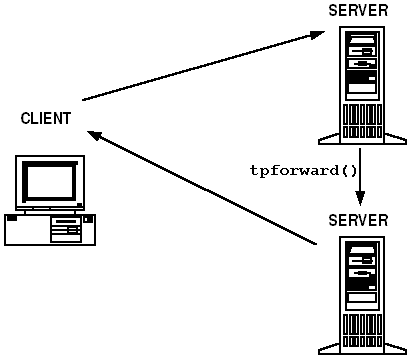
There is no limit to the number of times a request can be forwarded. Because a service that forwards a request does not need to wait for a reply from the service receiving the request, forwarding, unlike nesting requests, does not block servers. Forwarding, however, is not supported by the X/Open protocol X/ATMI, which may be a problem in some applications.
All communication within the BEA Tuxedo ATMI environment is accomplished by transferring messages. The BEA Tuxedo system passes service request messages between ATMI clients and servers through operating system (OS) interprocess communications (IPC) message queues. System messages and data are passed between OS-supported, memory-based queues of clients and servers in buffers. In the BEA Tuxedo ATMI environment, messages are packaged in typed buffers, buffers that contain both message data and data identifying the types of message data being sent.
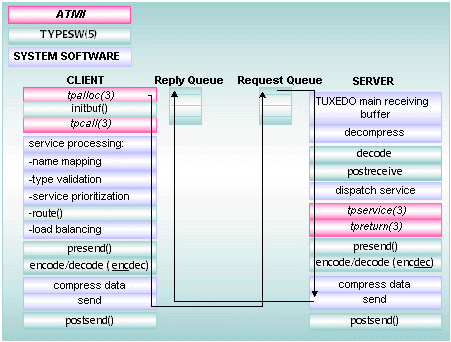
A client uses an ATMI function to request a service by name. A naming facility is used to check the MIB to determine whether the specified service is currently available.
The BEA Tuxedo system uses data-dependent routing, which is an automatic routing option to map messages that meet specific criteria (message value) to a specific server. If messages use data-dependent routing, the system uses the data in the buffer for the routing algorithm. This algorithm provides a method of selecting a group of servers that can process the service request.
To avoid burdening a few servers with many requests while leaving other servers that advertise the same services idle, the BEA Tuxedo system maintains a set of metrics in the MIB that help it distribute service requests evenly across all servers. This practice is called load balancing.
A local service request may be prepared for a selected server and enqueued on that server’s queue with a predefined priority. This practice is called service prioritization. Once the service request is on the server, the run-time system retrieves the message in priority order. The message is dispatched to the appropriate service and processed. Then the results are returned to the client queue.
BEA Tuxedo system-provided software offers features that an application can automatically and routinely use during message processing. These features include data encoding and decoding, data compression and decompression, transactional context setting, and security processing, to name a few. In addition, the BEA Tuxedo system software invokes application business logic by dispatching a service function and passing it to the appropriately preprocessed buffer.
The service routine is executed and returns a reply (also a typed buffer). The run-time system prepares the reply for the client by encoding the message automatically: it packages the data in such a way that it can be transmitted between machines on which different types of byte ordering are used, allowing data to cross network and platform boundaries. The system then sends the message to the client. This process is called data encoding. The run-time system on the client retrieves the reply message, decodes it if necessary, and delivers the Field Manipulation Language (FML) buffers (or buffers of another message buffer type) to package the application data. Type validation, encoding, routing, and load balancing are performed as required. Service requests can be performed synchronously or asynchronously.
Remote requests travel through the local bridge to the remote machine, where the remote bridge simply acts as a client and the request is processed as if the client and server were on the same machine. The bridge provides standard data encoding/decoding and uses standard network transports to communicate. Bridges look like ordinary local servers to clients and servers.
The benefits of service request processing include:
All ATMI functions send or receive data using typed buffers. The BEA Tuxedo system handles translations and data conversions between dissimilar machines. By using buffers, BEA Tuxedo programs avoid the need to translate data that crosses different platforms with different data representations.
A buffer is a memory area that serves as a logical container for data. When a buffer contains no metadata (that is, no information about itself), it is an untyped buffer. When a buffer includes metadata such as information that can be stored in it (for example, a type and subtype, or string names that characterize a buffer), it is a typed buffer.
Typed buffers can be transmitted over any network, on any operating system, with any protocol supported by the BEA Tuxedo system. They can also be used on platforms with different data representations. As a result, the use of typed buffers facilitates the tasks of translation and data conversion between dissimilar machines.
The BEA Tuxedo system supports five sorts of typed buffers:
You assign buffer types in the ENVFILE parameter defined in the MACHINES section of the Tuxedo (UBBCONFIG) configuration file. Assigning or overriding them in the ENVFILE parameter in the SERVERS section of the Tuxedo configuration file can make them unavailable to processes that require them.
Definitions of the various types of message buffers are provided in the description of tm_typesw in tux
types(5) in the BEA Tuxedo File Formats, Data Descriptions, MIBs, and System Processes Reference.
When you use ATMI communication functions, your application must first use tpalloc to get a buffer from the system, specifying its size, type, and optionally subtype. The BEA Tuxedo system recognizes and processes the buffer type, so that your data is transmitted over any type of network, protocol, and operating system supported by the BEA Tuxedo system. For descriptions of the different types of BEA Tuxedo buffers, see “Managing Typed Buffers” in
Programming a BEA Tuxedo ATMI Application Using C.
tuxtypes(5),
typesw(5), and
UBBCONFIG(5) in
BEA Tuxedo File Formats, Data Descriptions, MIBs, and System Processes Reference.
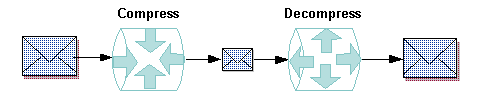
Data compression is the process of shrinking an application buffer so that it can be transmitted more quickly across a network or to a remote domain. By setting a maximum size for an application buffer, you can make sure that compression is triggered automatically for application buffers that match or exceed a specified size. When the buffer arrives at its destination, its data is decompressed, that is, restored to its original size.
Data compression, performed before files are shipped between machines, improves network performance. The process of compression enhances security slightly because it involves scrambling the data.
| Note: | Data compression also occurs frequently during encryption. |
The BEA Tuxedo system uses an operation called data-dependent routing to enable a client to send requests for the same service to multiple copies of that service. Which copy of the service eventually accepts and processes the request is determined by the data in the request message. Once an administrator has set up data-dependent routing for an application, client requests can be routed automatically to servers based on the data in the requests.
When an application includes multiple copies of the same service, each copy is assigned a unique purpose, just as the first volume of a multivolume encyclopedia contains entries that begin with the letter “A.” A list of all copies of the service, along with identifying information about the purpose of each, is kept in a set of routing tables in the BEA Tuxedo bulletin board (the dynamic part of the MIB). When the system receives a client request, it finds an identifying string in the request message and searches the routing tables in the bulletin board for the same string. On the basis of this match, the system identifies the appropriate server to which it can forward the client request.
| Note: | The bulletin board routing tables can be modified as necessary. |
Data-dependent routing is useful when clients issue service requests to:
A horizontally partitioned database is an information repository that has been divided into segments, each of which is used to store a different category of information. This arrangement is similar to a library in which each shelf of a bookcase holds books for a different category (for example, biography, fiction, and so on).
A rule-based server is a server that determines whether service requests meet certain, application-specific criteria before forwarding them to service routines. Rule-based servers are useful when you want to handle requests that are almost identical by taking slightly different actions for business reasons.
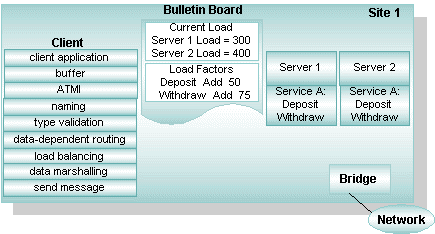
A distributed application consists of one or more local or remote clients that communicate with one or more servers on several machines linked through a network. A client (or server acting as a client) issues a request for a particular service. The address of the request is determined by data (carried in the same buffer that conveys the request), identifying the server that can fulfill the request. More than one server may be able to do so. The BEA Tuxedo system selects a server to receive the request by matching the data to the routing criteria provided in the bulletin board.
Suppose two clients in a banking application issue requests for the current balance in two accounts: Account 3 and Account 17. If data-dependent routing is being used in the application, then the BEA Tuxedo system performs the following actions:
The following figure illustrates this process.
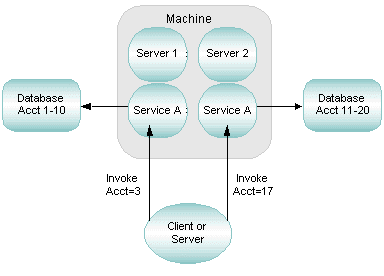
A banking application includes the following rules:
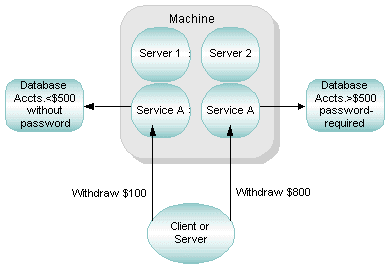
Two clients issue withdrawal requests: one for $100 and one for $800. If data-dependent routing is enabled to support the withdrawal rules, the BEA Tuxedo system performs the following actions:
The following figure illustrates this process.
The following diagram shows how client requests are routed to servers in a distributed application. In this example, a banking application called bankapp uses data-dependent routing. bankapp has three server groups (BANK1, BANK2, and BANK3) and two routing criteria (Account ID and Branch ID). The services WITHDRAW, DEPOSIT, and INQUIRY are routed using the Account_ID field; the services OPEN and CLOSE are routed using the Branch_ID field.
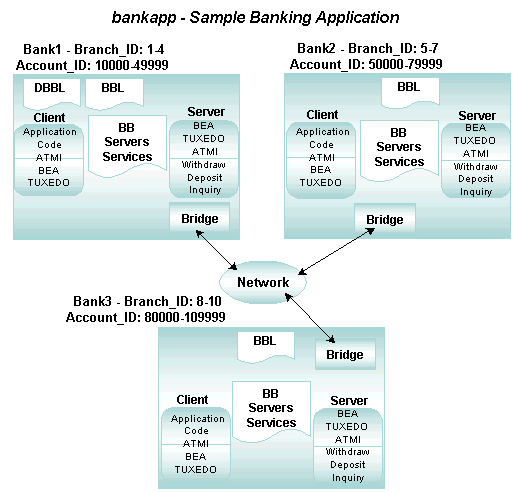
In the preceding figure, requests are routed as indicated in the following table.
Encoding and decoding enable messages with different data representations (for example, byte ordering or character sets) to be transferred between machines. The BEA Tuxedo system encodes and decodes data to a machine-independent representation for transmission to other machines involved in a BEA Tuxedo application.
The BEA Tuxedo system employs, by default, the External Data Representation (XDR) algorithm, which can be customized by replacing the BEA Tuxedo system functions with user-written functions. Encoding and decoding are used only between machines and only when a remote machine uses a data representation other than the one used on the local machine. Encoding and decoding allow machines with different data architectures to operate within a heterogeneous BEA Tuxedo system. Programmers can manage data in representations natural to their own environments.
The BEA Tuxedo system uses buffer types to determine the type of fields contained in a message, and to perform the mapping required for coding tasks. This mapping is not performed by unstructured buffer types such as X_OCTET and CARRAY. Thus, developers using X_OCTET and CARRAY buffers are free to deploy in mixed-machine environments.
Encryption is the act of converting a message into a coded format that is unintelligible to all users except the user for which the message is intended. When an encrypted message arrives at its destination, it is decrypted, that is, converted back to its original format.
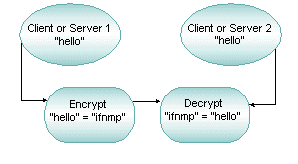
Encryption does not increase the number of bits in the data, but it adds processing time to the task of sending a message. Because data is compressed during encryption, however, lost processing time may be bought back, since less data is being sent across the network. When data is compressed, there is also a moderate boost to security, because the data is somewhat scrambled during compression.
Load balancing is a technique used by the BEA Tuxedo system for distributing service requests evenly among servers that offer the same service. Load balancing avoids overburdening some servers while leaving others idle or infrequently used. Before sending a request to a service routine, the BEA Tuxedo system identifies all servers capable of handling the request and selects the one most appropriate for maintaining a balanced load across all the servers in the configuration.
Load refers to a number assigned to a service request based on the amount of time required to execute that service. Loads are assigned to services so that the BEA Tuxedo system can understand the relationship between requests. To keep track of the amount of work, or total load, being performed by each server in a configuration, the administrator assigns a load factor to every service and service request. A load factor is a number indicating the amount of time needed to execute a service or a request. On the basis of these numbers, statistics are generated for each server and maintained on the bulletin board on each machine. Each bulletin board keeps track of the cumulative load associated with each server, so that when all servers are busy, the BEA Tuxedo system can select the one with the lightest load.
You can control whether a load-balancing algorithm is used on the system as a whole. Such as algorithm should be used only when necessary, that is, only when a service is offered by servers that use more than one queue. Services offered by only one server, or by multiple servers in a Multiple Server, Single Queue (MSSQ) do not need load balancing. The LDBAL parameter for these services should be set to N. In other cases, you may want to set LDBAL to Y.
To determine how to assign load factors (in the SERVICES section of UBBCONFIG), run an application for a long period of time and note the average time it takes to perform each service. Assign a LOAD value of 50 (LOAD=50) to any service that takes roughly the average amount of time. Any service taking longer than average should have a LOAD>50; any service taking less than the average should have a LOAD<50.
Priorities determine the order in which service requests are dequeued by a server. Priority is assigned by a client to individual services and can range from 1 to100, where 100 represents the highest priority.
All services are assigned a starting priority of 50. A server’s starting priority can be changed during application configuration. After you have defined your set of services, you can assign the appropriate priorities to them. For example, your business may require that some services have a relatively high priority of 70, which means those services are dequeued before those with the lower priority of 50. In the following illustration, a server offers services A (with a priority of 50), B (with a priority of 50), and C (with a priority of 70).
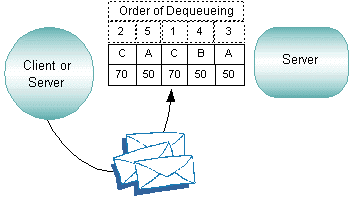
A request for service C is always dequeued before a request for A or B due to the higher priority of C. Requests for A and B have equal priority. This feature is useful in applications in which not all requests are equally urgent or important.
A “starvation prevention” mechanism prevents low-priority messages from waiting endlessly on the queue. Every tenth message is dequeued in first in, first out (FIFO) order regardless of priority; the first through the ninth messages are dequeued in order of priority.
The BEA Tuxedo system uses three naming devices: service names, message queue names, and event names. Names can be any words or alphanumeric strings, as long as they do not begin with a period (.). Because administrative servers use the BEA Tuxedo system infrastructure, system and application resources must be clearly distinguished.
When services are named, an application component can locate another component through a name. Names can be simple words (such as “deposit”) or alphanumeric strings (such as “deposit2”). Names should be selected on the basis of the scope of the application and a map that contains the global picture of the relationships among application components. These maps or services are like the pages in a telephone book for application components.
When a BEA Tuxedo system server is activated, the bulletin board advertises the names of its services. Service names are associated with a server’s physical address so that requests can be routed to that server. Names that programmers use in their applications are completely location transparent. When a client program asks for a service by name, the BEA Tuxedo system consults its name registry in the bulletin board. The name registry provides the information necessary to convert the string name (for example, TICKET) to a machine name and the physical address of a server that advertises that service. The BEA Tuxedo system then sends the request to the appropriate server.
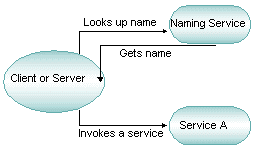
The BEA Tuxedo system offers a publish-and-subscribe mechanism: clients and servers can dynamically register or unregister a standing request to receive alerts (or messages) when a particular event occurs. Other clients and servers post user-defined or system events as they occur in the application. When a client or server no longer needs to be notified about a particular event, the relevant subscription can be cancelled.


|