|
|
This chapter describes miscellaneous features that are related to client programming with Oracle Data Service Integrator. It includes the following topics:
You need to upgrade ALDSP 2.x controls to Oracle Data Service Integrator 10gR3 using source upgrade. After the upgrade, a version of DSP_Control.jar is placed in the WEB-INF/lib folder. The DSP_Control.jar file contains control runtime classes.
While performing the upgrade, ensure that the domain to which the Web-App is to be deployed includes the following files:
Source upgrade also upgrades the schemas used by Data Service control.
Oracle Data Service Integrator maintains metadata about data services, application, functions, and schemas through Catalog Services, which is a system catalog-type data service. Catalog services provide a convenient way for client-application developers to programmatically obtain information about Oracle Data Service Integrator applications, data services, schemas, functions, and relationships.
Catalog Services are also data services; you can view them using the Oracle Data Service Integrator Administration Console, the Oracle Data Service Integrator Palette, and Data Service controls.
Some advantages of using Catalog Services are as follows:
This section provides details about installing and using Catalog Services to access metadata for any Oracle Data Service Integrator application. It includes the following topics:
You can install Catalog Services as a project for an Oracle Data Service Integrator application or as a JAR file that is added to the Library folder in Workshop for WebLogic. The Catalog Services project (_catalogservices) contains data services that provide information about the application, folders, data services, functions, schemas, and relationships available with the application.
DataServiceRef and SchemaRef are additional data services that consist of functions that retrieve the paths to the data services and schemas available with the Oracle Data Service Integrator application. For more information about the data services and functions available with Catalog Services, refer to Using Catalog Services on page 8-4.
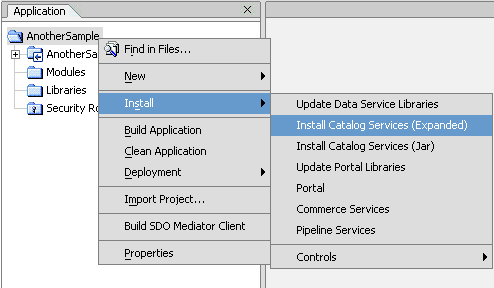
To install Catalog Services as a project:
After installing Catalog Services, the catalog services project, _catalogservices, is created for the Oracle Data Service Integrator application. All the data services associated with catalog services are available under this project. You can invoke the data service functions to access metadata. The client Mediator API is used to invoke the Catalog Service methods.
The data services available under _catalogservices include:
The following table provides the declaration and description for the getApplication()function in Application.ds.
Table 8-3 provides declaration and description information for the functions available in DataService.ds.
<urn:DataService kind="javaFunction" xmlns:acc="ld:RTLAppDataServices/CustomerDB/Customer" xmlns:urn="urn:metadata.ld.bea.com">
|
||
The following table provides the declaration and description for the functions available in DataServiceRef.ds.
The following table provides the declaration and description for the functions available in Folder.ds.
The following table provides the declaration and description for the functions in Function.ds.
The following table provides the declaration and description for the functions available in Relationship.ds.
| Note: | The functions in Relationship.ds can be used to access metadata only for navigation functions. |
<urn:Relationship xmlns:acc="ld:RTLAppDataServices/CustomerDB/CUSTOMER" xmlns:urn="urn:metadata.ld.bea.com">
|
The following table provides the declaration and description for the functions available in Schema.ds
SchemaRef (SchemaRef.ds)
The following table provides the declaration and description for the functions available in SchemaRef.ds.
The Filter API enables client applications to apply filtering conditions to the information returned by data service functions. In a sense, filtering allows client applications to extend a data service interface by allowing the application to specify more about how data objects are to be instantiated and returned by functions.
The Filter API alleviates data service designers from having to anticipate every possible data view that clients may require and to implement a data service function for each view. Instead, designers can choose to specify a broader, more generic interface for accessing a business entity and allow client applications to control views as desired through filters.
Using the API, you can specify that only objects that meet a particular condition in the function return set be returned to the client. A filter is therefore similar to a WHERE clause in an XQuery or SQL statement—it applies conditions to a possible result set. You can apply multiple filter conditions using AND and OR operators.
The effects of a filter can vary, depending on the desired results. Consider, for example, the CUSTOMERS data object shown in Figure 8-10. The data object contains multiple complex elements (CUSTOMER and ORDERS) and several simple elements, including ORDER_AMOUNT.
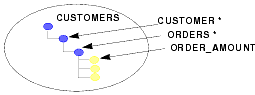
You can apply a filter to any element in this hierarchy. For example, you could apply a filter to return all CUSTOMER objects but filter ORDERS than have an ORDER_AMOUNT greater than 1000. Similarly, you could apply a filter to return only the CUSTOMER objects that have at least one large order.
You can also use a filter to specify the order criteria (ascending or descending) in which results should be returned from the data service. Finally, you can use a filter to set the maximum number of results to be returned.
| Note: | Filter evaluation occurs at the server, so objects that are filtered are not passed over the network. Often, objects that are filtered out are not even retrieved from the underlying data sources. |
You specify filters using the FilterXQuery object, which includes the following methods enabling you to add a filter, create a filter to apply later, specify the sort order, and set a limit on the number of results returned:
The addFilter() method enables you to create a filter and add it to the list of filters. The addFilter() method has several signatures with different parameters, including the following:
public void addFilter(java.lang.String appliesTo,
java.lang.String field,
java.lang.String operator,
java.lang.String value,
java.lang.Boolean everyChild)
This version of the method takes the following arguments:
appliesTo specifies the node (the XPath relative to the document element) that the filtering affects. That is, if a node specified by the field argument does not meet the condition, appliesTo nodes are filtered out.field is the node against which the filtering condition is tested.operator and value together comprise the condition statement. The operator parameter specifies the type of comparison to be made against the specified value. See
Table 8-11, Filter Operators, on page 8-20 for information about available operators.everyChild is an optional parameter. It is set to false by default. Specifying true for this parameter indicates that only those child elements that meet the filter criteria will be returned. For example, by specifying an operator of GREATER_THAN (or ">") and a value of 1000, only records for customers where all orders are over 1000 will be returned. A customer that has an order amount less than 1000 will not be returned, although other order amounts might be greater than 1000.
The createFilter() method enables you to create a filter that you can later apply to any of the objects in the hierarchy. The createFilter() method has several signatures with different parameters, including the following:
public void createFilter(java.lang.String field,
java.lang.String operator,
java.lang.String value,
java.lang.Boolean everyChild)
This version of the method takes the following arguments:
field is the node against which the filtering condition is tested (specified as the XPath relative to the document element).operator and value together comprise the condition statement. The operator parameter specifies the type of comparison to be made against the specified value. See
Table 8-11, Filter Operators, on page 8-20 for information about available operators.everyChild is an optional parameter. It is set to false by default. Specifying true for this parameter indicates that only those child elements that meet the filter criteria will be returned.
The addOrderBy() method enables you to add a sort criteria (either ascending or descending) to the specified object. The addOrderBy() method has the following signature:
public void addOrderBy(java.lang.String appliesTo,
java.lang.String field,
java.lang.String sort)
The method takes the following arguments:
The setLimit() method enables you to specify the maximum number of entries to return of the specified object. The setLimit() method has the following signature:
public void setLimit(java.lang.String appliesTo,
java.lang.String max)
The method takes the following arguments:
Table 8-11 describes the operators that you can apply to filter conditions.
| Note: | Filter API Javadoc, and other Oracle Data Service Integrator APIs are available on e-docs. |
Filtering capabilities are available to Mediator and Oracle Data Service Integrator Control client applications. To use filters in a mediator client application, import the appropriate package and use the supplied interfaces for creating and applying filter conditions.
Data service control clients get the interface automatically. When a function is added to a control, a corresponding "WithFilter" function is added as well.
The filter package is named as follows:
com.bea.ld.filter.FilterXQuery; To use a filter, perform the following steps:
FilterXQuery object, such as:FilterXQuerymyFilter = newFilterXQuery();
addFilter() method.
The following example shows how to add a filter to have orders with an order amount greater than 1000 returned (note that the optional everyChild parameter is not specified, so order amounts below 1000 will also be returned):
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
">",
"1000");setFilter() to add the filter to a RequestConfig object, and pass the RequestConfig as an argument to the data service operation invocation. For example,RequestConfig config = new RequestConfig();
config.setFilter(myFilter);
CUSTOMERDAS custDAS = CUSTOMER.getInstance(ctx, "RTLApp");
custDS.myOperation(config);For more information on invoking data service functions, see Chapter 3, “Invoking Data Services from Java Clients.”
In general, with nested XML data, a condition such as “CUSTOMER/ORDER/ORDER_AMOUNT > 1000” can affect what objects are returned in several ways. For example, it can cause all CUSTOMER objects to be returned, but filter ORDERS that have an amount less than 1000.
Alternatively, it can cause only CUSTOMER objects to be returned that have at least one large order, but containing all ORDERs (small and large) for each such CUSTOMER.
The following examples show how filters can be applied in several different ways:
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter(
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER", f1);
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
myFilter.addFilter("CUSTOMERS/CUSTOMER/ORDER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000");
FilterXQuery myFilter = new FilterXQuery();
myFilter.addFilter("CUSTOMERS/CUSTOMER",
"CUSTOMERS/CUSTOMER/ORDER/ORDER_AMOUNT",
FilterXQuery.GREATER_THAN,"1000",true);
Note that the everyChild flag is set to true; by default this parameter is false.
You can create a filter with two conditions using logical AND and OR operators. Listing 8-1 uses the AND operator to apply a combination of filters to a result set, given a data service instance customerDS.
FilterXQuery myFilter = new FilterXQuery();
Filter f1 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS/ISDEFAULT",
FilterXQuery.NOT_EQUAL,"0");
Filter f2 = myFilter.createFilter("CUSTOMER/ADDRESS/STATUS",
FilterXQuery.EQUAL,
"\"ACTIVE\"");
Filter f3 = myFilter.createFilter(f1,f2, FilterXQuery.AND);
You can specify the order criteria (ascending or descending) in which results should be returned from the data service. The addOrderBy() method accepts a property name as the criterion upon which the ascending or descending decision is based.
Listing 8-2 provides an example of creating a filter to return customer profiles in ascending order, based on the date each person became a customer.
FilterXQuery myFilter = new FilterXQuery();
myFilter.addOrderBy("CUSTOMER_PROFILE",
"CustomerSince" ,FilterXQuery.ASCENDING);
Similarly, you can set the maximum number of results to be returned using the setLimit() method. Listing 8-3 shows how to use the setLimit() method to limit the number of active addresses in the result set to 10.
FilterXQuery myFilter = new FilterXQuery();
Filter f2 = myFilter.createFilter("CUSTOMER_PROFILE/ADDRESS",
FilterXQuery.EQUAL,"\"INACTIVE\"");
myFilter.addFilter("CUSTOMER_PROFILE", f2);
myFilter.setLimit("CUSTOMER_PROFILE", "10");
An ad hoc query is an XQuery function that is not defined as part of a data service, but is instead defined in the context of a client application. Ad hoc queries are typically used in client applications to invoke data service functions and refine the results in some way. You can use an ad hoc query to execute any valid XQuery expression against a data service. The expression can target the actual data sources that underlie the data service, or can use the functions and procedures hosted by the data service.
To execute an XQuery expression, use the PreparedExpression interface, available in the Mediator API. Similar to JDBC PreparedStatement interface, the PreparedExpression interface takes the XQuery expression as a string in its constructor, along with the JNDI server context and application name. After constructing the prepared expression object in this way, you can call the executeQuery( ) method on it. If the ad hoc query invokes data service functions or procedures, the data service’s namespace must be declared by the query string before you can reference the methods in your ad hoc query.
Listing 8-4 shows a complete example; the code returns the results of a data service function named getCustomers( ), which is in the namespace:
ld:DataServices/RTLServices/Customer
import com.bea.dsp.das.DataAccessServiceFactory;
import com.bea.dsp.das.PreparedExpression;
String queryStr =
"declare namespace ns0=\"ld:DataServices/RTLServices/Customer\";" +
"<Results>" +
" { for $customer_profile in ns0:getCustomer()" +
" return $customer_profile }" +
"</Results>";
PreparedExpression adHocQuery =
DataServiceFactory.prepareExpression(context,"RTLApp",queryStr );
DASResult<Object> result = adHocQuery.executeQuery();
Note that the return type of the executeQuery( ) method is DASResult<Object>. The kinds of Objects that can be returned from this DASResult are the same as for data service operations invoked using the dynamic mediator API. Simple schema types, such as xs:int and xs:decimal are returned as Java Objects (java.lang.Integer, java.math.BigDecimal) according to the mapping described in
Table 2-5, “XML Schema to Java Data Type Mapping,” on page 2-6. Complex types are returned as SDO DataObjects.
A single ad-hoc query may return multiple Objects, corresponding to the sequence of items in the result of the XQuery expression. Each of these items are returned as a single Object from calls to result.next().
Because ad-hoc queries are defined inside the client code itself, the Mediator API cannot know the return type of the query. That is why the return value of executeQuery( ) is DASResult<Object> rather than a more specific type such as DASResult<Customer>, even if the query only returns Customer DataObjects.
However, if the query does return DataObjects whose schema is defined in a static mediator client JAR, as described in
Chapter 3, “Invoking Data Services from Java Clients,” and that static mediator client JAR is on the client’s CLASSPATH, it is possible to cast the Objects from the DASResult to the corresponding typed DataObject, just as it is with the dynamic mediator API. For instance,
DASResult<Object> result = adHocQuery.executeQuery();
Customer cust = (Customer) cust.next();
Note that if the results of the ad-hoc query are not actually Customer DataObjects, the above code throws a ClassCastException when attempting to cast the result of cust.next().
Security policies defined for a data service apply to the data service calls in an ad hoc query as well. If an ad hoc query uses secured resources, the appropriate credentials must be passed when creating the JNDI initial context. (For more information, see “Obtaining the WebLogic JNDI Context for Oracle Data Service Integrator” on page 3-47.)
As with the PreparedStatement interface of JDBC, the PreparedExpression interface supports dynamically binding variables in ad hoc query expressions. PreparedExpression provides several methods (bindType( ) methods; see Table 8-12), for binding values of various data types.
To use the bindType methods, pass the variable name as an XML qualified name (QName) along with its value; for example:
adHocQuery.bindInt(new QName("i"),94133);
Listing 8-5 shows an example of using a bindInt() method in the context of an ad hoc query. Note that all variables to be bound must be explicitly declared as external variables in the ad-hoc query, as shown in the example.
PreparedExpression adHocQuery = DataServiceFactory.preparedExpression(
context, "RTLApp",
"declare variable $i as xs:int external;
<result><zip>{fn:data($i)}</zip></result>");
adHocQuery.bindInt(new QName("i"),94133);
DASResult<Object> result = adHocQuery.executeQuery();
| Note: | For more information on QNames, see: |
Listing 8-6 shows a complete ad hoc query example, using the PreparedExpression interface and QNames to pass values in bind methods.
import com.bea.dsp.das.PreparedExpression;
import com.bea.dsp.das.DataAccessServiceFactory;
import commonj.sdo.DataObject;
import javax.naming.InitialContext;
import javax.xml.namespace.QName;
import weblogic.jndi.Environment;
public class AdHocQuery
{
public static InitialContext getInitialContext() throws NamingException {
Environment env = new Environment();
env.setProviderUrl("t3://localhost:7001");
env.setInitialContextFactory("weblogic.jndi.WLInitialContextFactory");
env.setSecurityPrincipal("weblogic");
env.setSecurityCredentials("weblogic");
return new InitialContext(env.getInitialContext().getEnvironment());
}
public static void main (String args[]) {
System.out.println("========== Ad Hoc Client ==========");
try {
StringBuffer xquery = new StringBuffer();
xquery.append("declare variable $p_firstname as xs:string external; \n");
xquery.append("declare variable $p_lastname as xs:string external; \n");
xquery.append(
"declare namespace ns1=\"ld:DataServices/MyQueries/XQueries\"; \n");
xquery.append(
"declare namespace ns0=\"ld:DataServices/CustomerDB/CUSTOMER\"; \n\n");
xquery.append("<ns1:RESULTS> \n");
xquery.append("{ \n");
xquery.append(" for $customer in ns0:CUSTOMER() \n");
xquery.append(" where ($customer/FIRST_NAME eq $p_firstname \n");
xquery.append(" and $customer/LAST_NAME eq $p_lastname) \n");
xquery.append(" return \n");
xquery.append(" $customer \n");
xquery.append(" } \n");
xquery.append("</ns1:RESULTS> \n");
PreparedExpression pe = DataAccessServiceFactory.prepareExpression(
getInitialContext(), "RTLApp", xquery.toString());
pe.bindString(new QName("p_firstname"), "Jack");
pe.bindString(new QName("p_lastname"), "Black");
DASResult<Object> results = pe.executeQuery();
} catch (Exception e) {
e.printStackTrace();
}
}
When designing and implementing data services, one of the principal goals is to provide a set of abstractions that enable client applications to see and manipulate integrated enterprise data in a clean, unified, meaningful, canonical form. Doing so invariably requires transforming data, which can include restructuring and unifying the schemas and the instance-level data formats of the disparate data sources.
In such cases, names may be reformatted, addresses normalized, and differences in units reconciled, among other operations, to provide application developers (the consumers of data services) with a natural and easily manipulable view of the underlying data. Such transformations, while highly useful to the end consumers of the data, can lead to performance challenges when retrieving underlying data.
When the resulting data is queried, it is crucial for performance that much of the query processing (especially for selections and joins) be pushable to the underlying sources, particularly to relational data sources. This requires updates to the transformed view of the data to be translatable back into appropriate source updates. Unfortunately, if data transformations are written in a general-purpose programming language, such as Java, both of these requirements can be difficult. This is because, unlike user-written XQuery functions, such general-purpose functions are opaque to the Oracle Data Service Integrator query and update processors.
To solve this issue, Oracle Data Service Integrator enables data service developers to register inverse functions with the system, enabling you to define and use general user-defined data transformations without sacrificing query pushdown and updatability. Using this information, Oracle Data Service Integrator is able to perform a reverse transformation of the data when analyzing query predicates or attempting to decompose updates into underlying data source updates.
This means that you can use inverse functions to retain the benefits of high-performance data processing for your logical data without giving up application-oriented convenience data functions. In addition, inverse functions enable automated updates without the need to create Java update overrides.
| Note: | Using inverse functions effectively and correctly requires careful design. In particular, you must ensure that the functions are true inverses of one another, otherwise Oracle Data Service Integrator may perform undesired operations on your data. While inverse functions are an intuitive and useful idea, be aware that the details require careful attention. |
The thing to keep in mind when creating inverse functions is that the functions you create need to be truly invertible.
For example, in the following case date is converted to a string value:
public static String dateToString(Calendar cal) {
SimpleDateFormat formatter;
formatter = new SimpleDateFormat("MM/dd/yyyy hh:mm:ss a");
return formatter.format(cal.getTime()) ;
}However, notice that the millisecond value is not in the return string value. You get data back but you have lost an element of precision. By default, all values projected are used for optimistic lock checking, so a loss of precision can lead to a mismatch with the database's original value and thus an update failure.
Instead the above code should have retained millisecond values in its return string value, thus ensuring that the data you return is exactly the same as the original value.
Here are some additional scenarios where inverse functions can improve performance, especially when large amounts of data are involved:
declare function tns:getEmpWithFixedHireDate() as element(ns0:usemp)*{
for $e in ns1:USEMPLOYEES()
return
<emp>
<eid>{fn:data($e1/ID)}</eid>
<name>{mkName($e1/LNAME, $e1/FNAME)}</name>
<hiredate>{int2date($e1/HIRED)}</hiredate>
<salary>)fn:data($e1/SAL)}</salary>
</emp>
}Given such a function, issuing a filter query on hiredate, on top of this function, results in inefficient execution since every record from the back-end must be retrieved and then processed in the middle tier.
You can use inverse functions in these and other situations to improve performance, especially when processing sizable amounts of data.
Consider the case of a logical data service that has a fullname operation that concatenates firstname and lastname elements. It is clear that performance would be adversely affected when running the fullname operation against large data sets.
The ideal would be to have a function or functions which decomposed fullname into its indexed components, passes the components to the underlying database, gets the results and reconstitutes the returned results to match the requirements of the fullname operation. In fact, that is the basis of inverse functions.
Of course there are no XQuery functions to magically deconstruct a concatenated string. Instead you need to define, as part of your data service development process, custom functions that inverse engineer fullname.
In many cases complimentary inverse functions are needed. For example, fahrenheitToCentigrade() and centigradeToFahenheit() would be inverses of each other. Complimentary inverse functions are also needed to support fullname.
In addition to creating inverse functions, you also need to identify inverse functions when defining the data service.
You need to complete the following actions to use inverse functions:
The inverse functions sample includes logic to perform transformations between:
The string manipulation logic to manipulate first and last names needed by the inverse function is in the following Java file in the JavaFunctionLib project:
JavaFunctionLib/JavaFuncs/NameLib.java
This file defines three string manipulation functions.
package JavaFuncs;
public class NameLib {
public static String fullname(String fn, String ln) {
return (fn == null || ln == null) ? null : (fn + " " + ln);
}
public static String firstname(String name) {
try {
int sepidx = name.indexOf(' ');
if (sepidx < 0) return null;
return name.substring(0, sepidx);
}
catch (Exception e) { return null; }
}
public static String lastname(String name) {
try {
int sepidx = name.indexOf(' ');
if (sepidx < 0) return null;
return name.substring(sepidx+1, name.length());
}
catch (Exception e) { return null; }
}
public static void main(String[] args) {
String first = "John";
String last = "Doe";
String full = "John Doe";
System.out.println(fullname(first, last));
System.out.println(firstname(full));
System.out.println(lastname(full));
System.out.println(firstname(first));
System.out.println(lastname(first));
}
}
Notice that the function fullname() simply concatenates the first and last names. In contrast, the firstnname() and lastname() functions deconstruct the resulting full name using the required space in the full name string as the marker identifying the separation between first and last names. Or, put another way, the fullname() function is the invertible of firstname() and lastname().
Similar functions are available in the DeptLib and EmpIdLib packages supporting transformations between department names and numbers, and employee IDs and names respectively.
After you have compiled the Java functions, you can create a physical data service from the resulting class file. In the sample, physical data services were created using the NameLib.class, DeptLib.class, and EmpIdLib.class files.
| Note: | See Create a Physical Data Service from a Java Function for step-by-step instructions for creating a physical data service from a class file. |
In the sample, the resulting operations corresponding to the string manipulation logic reside in the NameFunc.ds data service, as illustrated by the following:
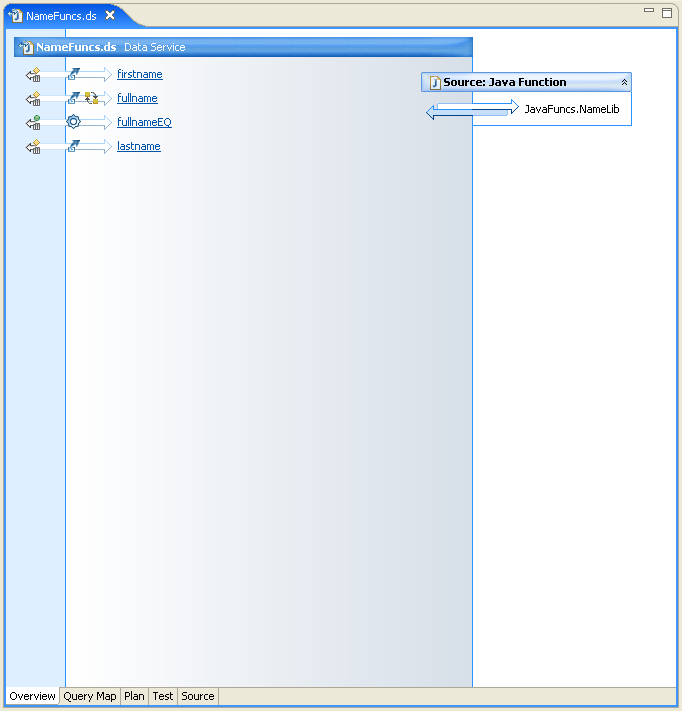
As is often the case, some additional programming logic is needed. In the case of the sample, a function, fullnameEQ(), compares names and returns a Boolean value indicating whether the names are identical.
declare function f1:fullnameEQ($full1 as xs:string?, $full2 as xs:string?) as xs:boolean? {
(f1:firstname($full1)eq f1:firstname($full2)) and (f1:lastname($full1) eq f1:lastname($full2))
};| Note: | You can define additional functions for specific conditions, such as "is greater-than" or "is-less-than." Later, when configuring the inverse functions, you can create associations for these conditionals enabling the the XQuery engine to substitute the custom logic for a simple conditional. |
You need to configure the inverse functions to perform the reverse transformation of the data.
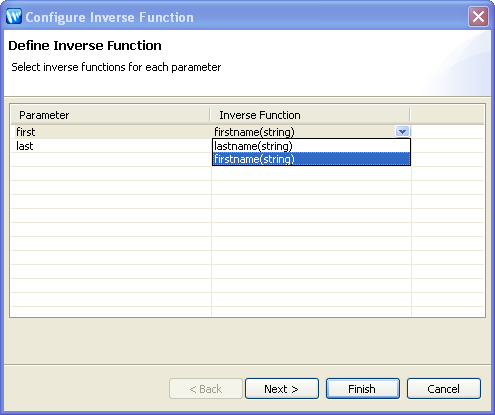
In this particular case, this means that you need to identify an inverse function for each parameter in the fullname() function.
| Note: | Inverse functions can only be defined when the input and output function parameters are atomic types. |
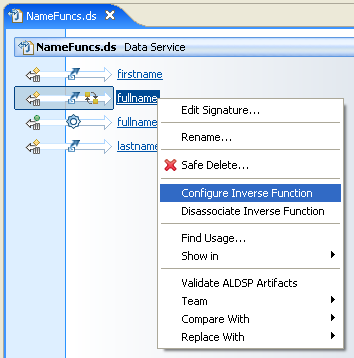
To association the parameters of a function with inverse functions:
A dialog appears enabling you to select the inverse functions for each parameter.
After you have associated inverse functions with the correct parameters, you may want to associate custom conditional logic with the functions. You do this by substituting a custom function for such generic conditions as eq (is equal to) and gt (is greater than). The following table lists conditional operations available for such transformations.
Associating a particular conditional (such as "is greater-than") with a transformational function allows the XQuery engine to substitute the custom logic for a simple conditional. As is always the case with Oracle Data Service Integrator, the original basis of the function does not matter. It could be created in your data service, or externally in a Java or other routine. In this example the transformational function, fullnameEQ, is in the Java-based physical data service.
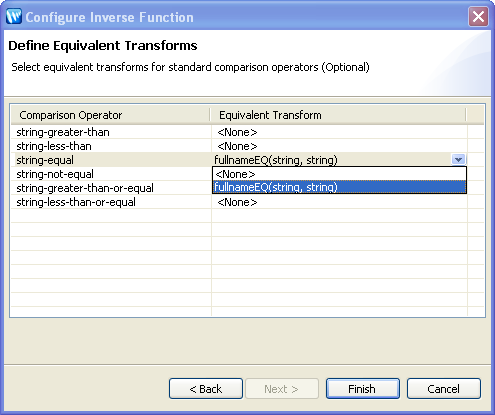
The final step is to build the data service that contains the operations to create, read, update, and delete the data. In the sample dataspace, this data service, Employee.ds, includes operations such as createEmployee, getAll, updateEmployee, and deleteEmployee. The data service also includes operations such as getByDeptName, getByEmpName, and getByEmpNo.
The following shows the overview of the Employee.ds data service.
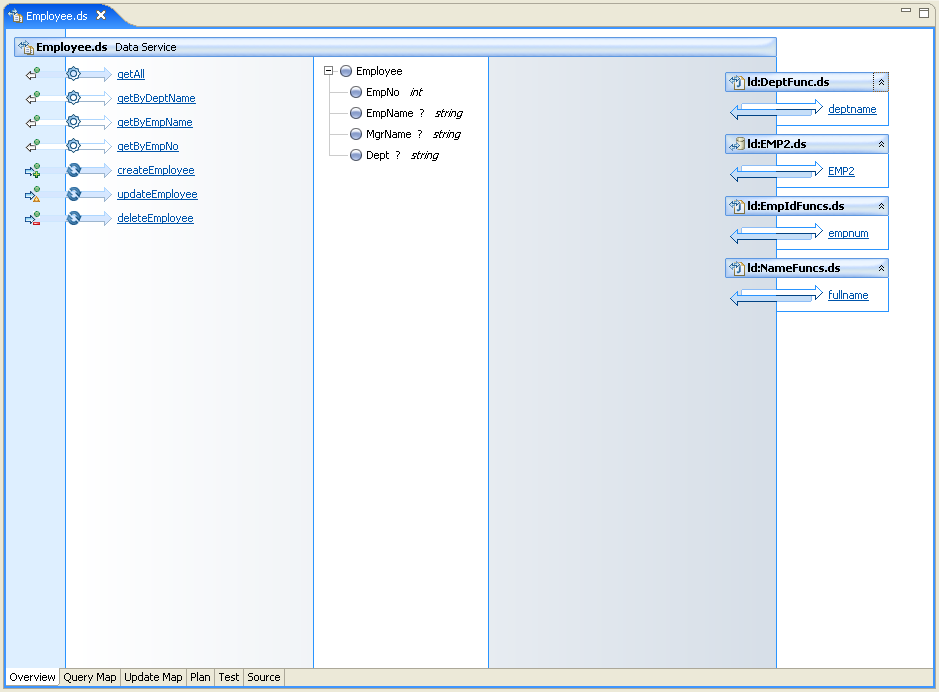
The data service uses XML types associated with the Employee.xsd schema. This schema could have been created through the XQuery Editor, through the Oracle Data Service Integrator schema editor, or through a third-party editing tool.
The getAll() operation returns all employee records, as shown in the following listing:
declare function ns1:getAll() as element(ns1:Employee)* {
for $EMP2 in emp2:EMP2()
return
<tns:Employee>
<EmpNo>{emp1:empnum($EMP2/EmpId)}</EmpNo>
<MgrName?>{fn:data($EMP2/MgrName)}</MgrName>
<Dept?>{dep:deptname($EMP2/Dept)}</Dept>
</tns:Employee>
};
Examining the query plan for the getAll() operation, as shown in the following, you can see that predicates are being pushed despite data transformations, because of the use of inverse functions.
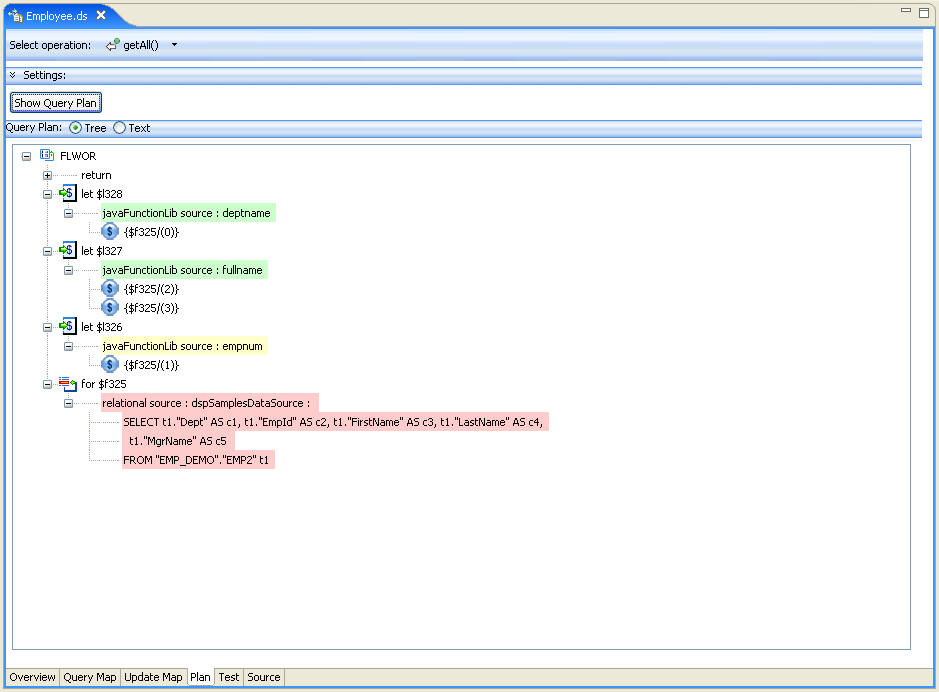
The case is the same for the other read methods getByDeptName(), getByEmpName(), and getByEmpNo(). Examining the corresponding query plans, you can see that predicates are being pushed regardless of the specific transformations because of the corresponding inverse functions.
| Note: | The getByEmpName() operation illustrates a typical case where the transformation involves performing a concatenation and the inverse function reverses the operation. In this case, N values are merged into 1 or vice versa. The getByDeptName() and getByEmpNo() operations are both 1:1 examples, transforming between numeric and string values. |
This section describes how to import and configure the Oracle Data Service Integrator inverse functions sample dataspace project.
You can install and work with the inverse function sample on any system with Oracle Data Service Integrator 10gR3 (Oracle WebLogic Server 10gR3) installed.
The inverse function sample is available as a ZIP file from:
It is recommended that the ZIP file be extracted into an Oracle Data Service Integrator directory such as:
<ALDSP_HOME>/user_projects/workspaces/default/InverseFunctionSample
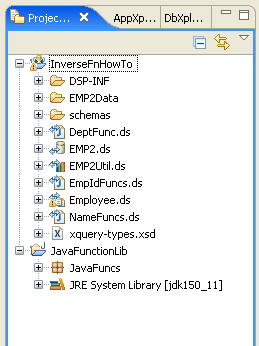
The inverse functions sample consists of two projects:
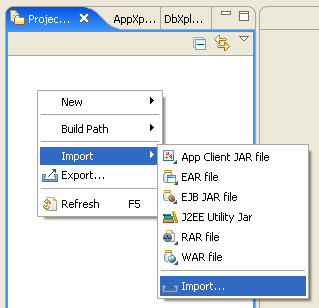
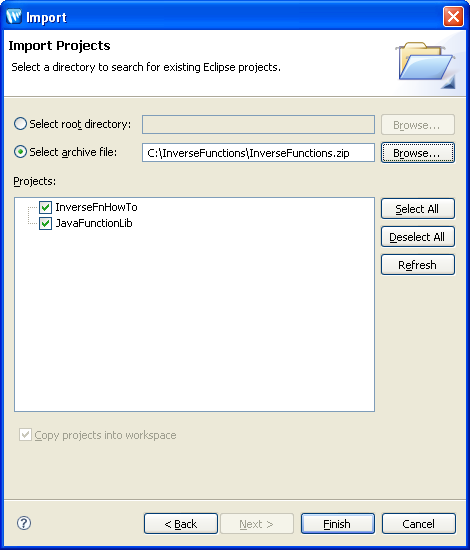
To import the dataspace project:
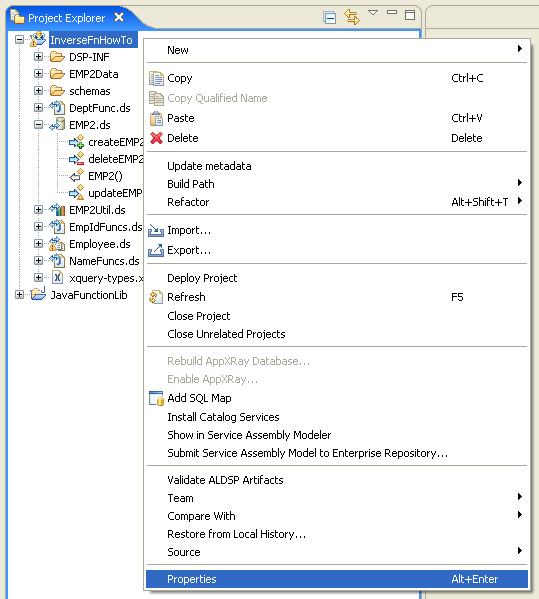
InverseFnHowTo and JavaFunctionLib.Before examining the inverse functions sample, you need to start an Oracle Data Service Integrator-enabled server and assigned a targeted runtime server to the project.
InverseFnHowTo project and choose Properties.The inverse functions sample consists of two projects.
This section describes the principal entities within the two projects that comprise the inverse functions sample.
The following table describes the data services defined in the InverseFnHowTo dataspace project:
The following table describes the data services defined in the JavaFunctionLib project:


|