|
|
This chapter contains information on the following subjects:
An Oracle BPEL PM project can be submitted to Oracle Enterprise Repository either from the command line, from Oracle JDeveloper, or using an Ant task.
The Harvester scans for artifacts such as the following and harvests those artifacts to detect the dependencies that exist between them:
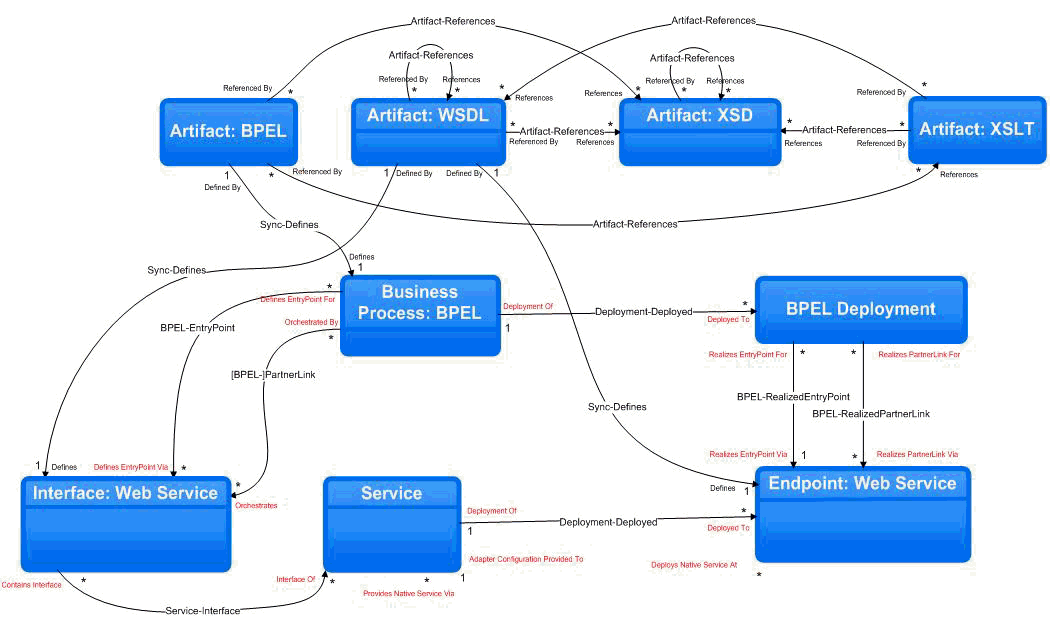
The Harvester creates entities for these artifacts in Oracle Enterprise Repository and creates the relationships between them.
Figure 3-1 shows the asset types created by the Harvester and the relationships between them.
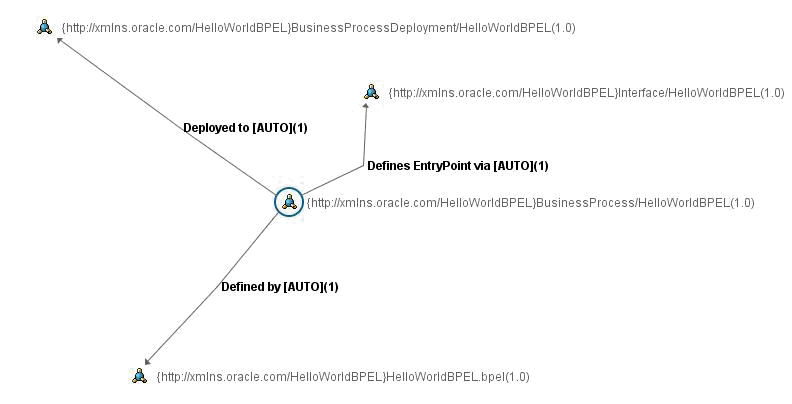
When a BPEL artifact is submitted to Oracle Enterprise Repository, it will result in the following in Oracle Enterprise Repository:
When a WSDL artifact is submitted to Oracle Enterprise Repository, it will result in the following in Oracle Enterprise Repository:
When a XSD artifact is submitted to Oracle Enterprise Repository, it will result in the following in Oracle Enterprise Repository:
When a XSL artifact is submitted to Oracle Enterprise Repository, it will result in the following in Oracle Enterprise Repository:
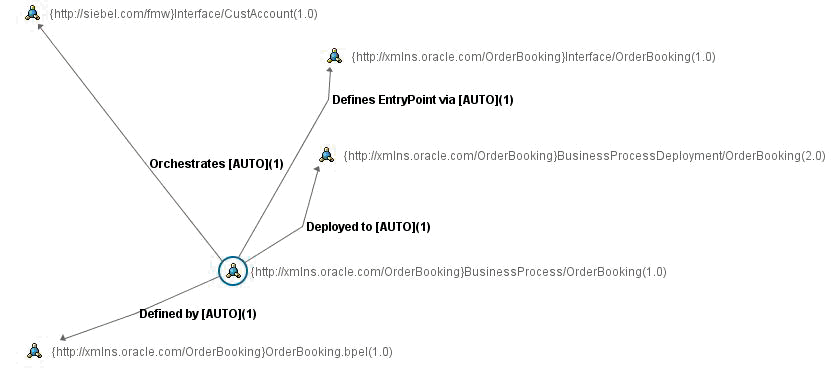
When an Oracle BPEL PM project is submitted to Oracle Enterprise Repository, the Harvester will look for the concrete information for the following:
Oracle BPEL PM uses the following format to construct the concrete WSDL URI:
<host>:<port>/orabpel/<BPELDomain>/<processName>/<version>/<ServiceName>?wsdl
The Harvester constructs the URI using the values from the property file. An example of a constructed concrete WSDL URI is:
http://localhost:8888/orabpel/default/OrderBooking/1.7/OrderBooking?wsdl
bpel.xml. This file is harvested so that the concrete information about where the dependent services are running is updated in Oracle Enterprise Repository.
The Harvester store files such as WSDLs, BPELs, and XSDs as artifacts in Oracle Enterprise Repository. To avoid storing the same artifact file twice, the Harvester will calculate a Software File ID ("SFID") for each artifact when it is stored. Before submitting a new artifact, the SFID can be compared against existing SFIDs in the repository to check for duplicates.
The SFID calculated is an MD5 hash. Some level of canonicalization is performed before calculating the SFID. In particular, if the artifact file is XML, it is canonicalized using the Canonicalizer class in the Apache XML Security library. This canonicalizes according to the W3C "Canonical XML" standard (see www.w3.org/TR/xml-c14n), which includes canonicalizing the text encoding, line breaks, whitespace, comments, and attribute ordering. Some extra canonicalization not specified in the W3C standard is performed, including normalizing of namespace prefixes, normalizing the order of the elements in WSDLs, removing documentation elements, and inlining any included/imported files.
The Harvester creates artifact bundles that may be downloaded from Business Processes, Interfaces, and Endpoints. The artifact bundles for these assets are stored in zip files. For example, for an Endpoint, a WSDL file and its associated XSD files are stored in relative locations within the zip payload.
When one artifact imports another artifact (for example, a WSDL imports a XSD), it always refers to the child artifact relative to the parent. For example, if MyWSDL.wsdl is located in c:\temp and if the child XSD that is being imported resides in c:\temp\schemas\MyXSD.xsd, the parent MyWSDL.wsdl imports the child using the relative path "./schemas/MyXSD.xsd". When the bundle is downloaded, the child artifact should be created in a folder called "schemas" relative to the parent so that the parent can resolve the child.
After the Harvester runs, you can download the asset bundle by following these steps:
| Note: | If the artifact bundle has only a single artifact as payload, then you will be provided the payload directly, instead of the payload being delivered within a zip file. |
If you harvest a series of files, change some of the files, and then harvest the bundles again, multiple payloads (ordered by harvesting date, with the most recent first) will be available for download on the Download page.
The following steps show how to create a sample BPEL project in Oracle JDeveloper, deploy the project to the BPEL Engine, and submit the project to Oracle Enterprise Repository along with the artifact dependencies and deployment information.
{http://xmlns.oracle.com/TestBPELProject}BusinessProcess/TestBPELProject
The Harvester tags each asset with properties that can be used for querying.
Figure 3-5 shows how to query for Business Processes that invoke the operation “Write.” To get the search screen, click More Search Options on the main page of the Oracle Enterprise Repository Web console.
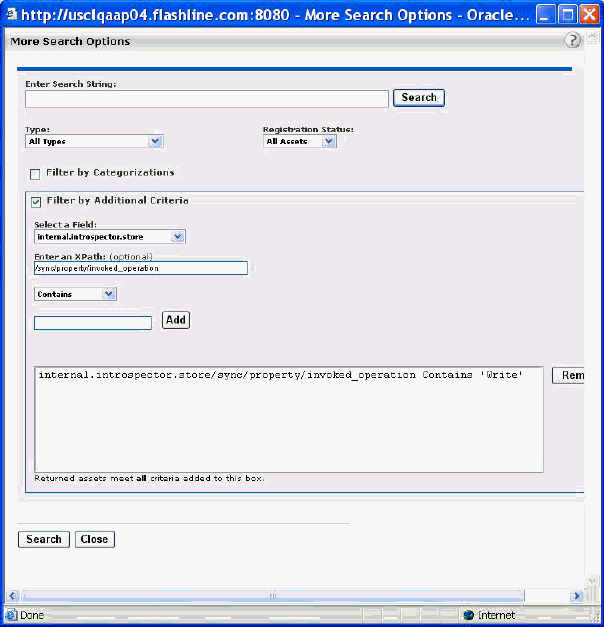
The following search criteria are available:
This section describes best practices for the Harvester.
Only Registrars or individuals with the authority to view all the assets in Oracle Enterprise Repository should harvest assets. If individuals do not have permission to view all assets in the repository, they may harvest assets that already exist and unintentionally duplicate assets.
It is recommended that you use a unique namespace for each unique interface, service, and endpoint.
Correlation to existing assets in the Oracle Enterprise Repository is done through QNames, so if you make significant changes to interface, service, or endpoint assets and do not change the QNames, you will overwrite the existing asset with the modified asset.
Table 3-1 shows the correlation of Oracle Enterprise Repository assets with WSDL structure:
It is recommended that you harvest only work that is completed or near completion. If you regularly harvest from a development environment, the Oracle Enterprise Repository can become cluttered with outdated versions of assets.
Some schema development patterns involve the "maintenance release" of schemas that fix defects or add minor structures but do not change the namespace of the schema. It should be recognized that subsequent harvesting of slightly modified schema artifacts can have the effect of creating a significant number of new artifact assets in the repository. Oracle Enterprise Repository correlates artifact assets based on a hash, or Software File ID (SFID), of the contents of the artifacts. The SFID is calculated over the contents of each artifact after all imports and includes have been inlined. Consequently, a change in an XSD that is imported by a WSDL will result in both a new XSD artifact and a new WSDL artifact.
This is particularly important to keep in mind when considering schemas that are widely used throughout the enterprise. For example, consider a low-level schema such as customer.xsd that is widely imported by other schemas, WSDLs, XSLTs, BPELs, etc. A material change to customer.xsd, and a subsequent re-harvesting of all of an enterprise’s artifacts (for example, some kind of regular batch harvesting) would result in a large number of similar artifact assets in the repository that reference customer.xsd either directly or indirectly.
This section describes some known Harvester issues:
As a prerequisite to using Harvester features, the asset types must be present in the system. The necessary asset types are installed with the Harvester Solution Pack.
If some of the existing asset type names in your Oracle Enterprise Repository have the same names as the asset types installed with the Harvester Solution Pack, the asset type names for the Harvester will have a version number appended to them. This does not affect the functioning of the Harvester asset types.
When the Harvester creates assets during the harvesting proces, it attaches metadata entries to the asset of metadata entry Type: internal.inspector.store and internal.introspector.manifest.store. Do not modify or delete these meteada entries. Doing so can cause the system to behave unpredictably.
Note that it is not possible to delete these metadata entries using Oracle Enterprise Repository user interface.


|