|
|
This section describes the AquaLogic Data Services Platform client-side application programming object model, Service Data Objects (SDO). The following topics are covered:
SDO is a Java-based data programming model and architecture for accessing and updating data. SDO is defined in a joint specification proposed by BEA and IBM (JSR 235). SDO is intended to give applications an easy-to-use, uniform programming model for accessing and updating data, regardless of the underlying source or format of the data.
Unlike existing data access technologies such as JDO or JDBC, SDO specifies both a static and a dynamic interfaces for accessing data. The static (or strongly typed) interface gives client developers an easy-to-use, update-capable model for accessing values. A static interface function is in the form:
getCUSTOMERNAME() As implied by the sample function name, to use the static interface the developer must know the types of the data (that is, CUSTOMERNAME) at development time. If the types are unknown at development time, the developer can use the dynamic (or loosely typed) interface. Such calls are in the form:
cust.get("CUSTOMERNAME") A dynamic interface is useful when the data type is not known or defined at development time and is particularly useful for creating programming tools and frameworks across data source types.
In addition to a programming interface, SDO defines a data programming architecture. A component of this architecture called the mediator serves as the adapter between the client and data source. A mediator specializes in exchanging data with the data source. It knows how to retrieve data from a particular source and pass changes back to it. Data is passed in a datagraph, which consists of a graph of data objects.
As mentioned in the SDO specification, a particular SDO implementation is likely to have specialized mediators for particular source types, such as for databases. AquaLogic Data Services Platform provides a data service mediator that resides between SDO clients and the data integration layer.
With SDO, clients use data in an essentially stateless, disconnected fashion. When AquaLogic Data Services Platform gets data from a source, such as a database, it acquires one or more database connections only long enough to retrieve the data. Once the data is acquired, AquaLogic Data Services Platform releases the connections. The client works on a local copy of the data, disconnected from the data source.
The network is accessed again only when the client wants to apply the data changes to the source. Disconnected data access contributes to a scalable, efficient computing environment because back-end system resources are never tied up for very long.
Optimistic concurrency rules are used to ensure the integrity of data when updates occur. With optimistic concurrency, data at the data source is not locked while a client works with it. Instead, if updates are made to the data, potential conflicts (such as other clients changing the same data after the client got it) are detected when the data updates or propagated back to the sources.
For complete information on Service Data Objects, including the specification and Javadoc, go to:
AquaLogic Data Services Platform uses SDO as its client-side programming model. Simply put, this means that when a Java client invokes a data service's read function — either through the AquaLogic Data Services Platform Mediator API or through the Workshop Data Service control — it gets a return value in the form of an SDO data object. A data object is the fundamental component in the SDO programming model. It represents a unit of structured information, with static and dynamic interfaces for getting and setting its data values.
This section introduces you to SDO programming through a small code sample. The sample shows how SDO provides a simple, easy to use client-side data programming model.
The sample is written against the data service shown in Figure 5-1.
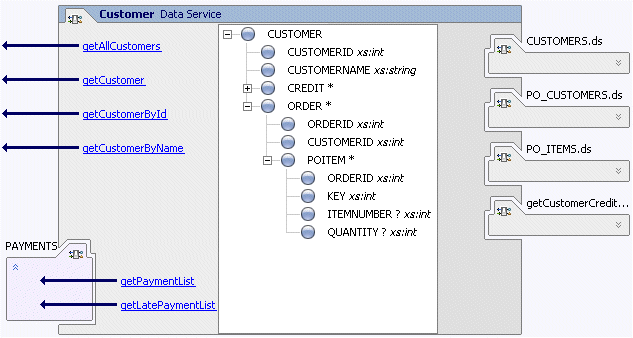
The data type for the Customer data service is CUSTOMER. A data type is a structured XML document known as a schema. In this example the data type is composed of properties such as customer ID, name, and orders. The data for a CUSTOMER instance comes from four other data services: CUSTOMERS, PO_CUSTOMERS, PO_ITEMS, and getCustomerCredit. Physically each of these is an XQuery document with a .ds extension (example: PO_CUSTOMERS.ds).
The sample Customer data service has several methods for getting data type instances, including getCustomer(), getCustomerById(), getPaymentList(), and so on. The function getPaymentList() is a navigation function. It does not return a CUSTOMER document; instead it returns data from a data service for which a logical relationship has been defined. In the case of getPaymentList(), the related data service named PAYMENTS returns the payment history for a given customer.
The navigation function makes it easy for client applications to acquire additional related data that is likely to be of interest when working with CUSTOMER documents. With the same data service handle used to get a customer, they can get that customer's list of payments.
The result is code that is concise, readable and easy to maintain, as shown in Listing 5-1.
import java.util.Hashtable;
import javax.naming.Context;
import javax.naming.InitialContext;
import com.bea.dsp.dsmediator.client.*;
import org.openuri.temp.schemas.customer.CUSTOMERDocument;
public class myCust {
public static void main(String[] args) throws Exception {
Hashtable h = new Hashtable();
h.put(Context.INITIAL_CONTEXT_FACTORY,
"weblogic.jndi.WLInitialContextFactory");
h.put(Context.PROVIDER_URL,"t3://localhost:7001");
h.put(Context.SECURITY_PRINCIPAL,"weblogic");
h.put(Context.SECURITY_CREDENTIALS,"weblogic");
DataService ds =
com.bea.dsp.dsmediator.client.DataServiceFactory.newXmlService(
new InitialContext(h),
"Demo",
"ld:DataServices/Customer");
Object arg[]={new Integer("987655")};
CUSTOMERDocument myCustomer =
(CUSTOMERDocument) ds.invoke("getCustomer",arg);
myCustomer.getCUSTOMER().setCUSTOMERNAME("BigCo, Inc");
ds.submit(myCustomer,"ld:DataServices/Customer");
System.out.println(" Customer information: \n" + myCustomer);
}
}
Notice that once the proper packages have been imported and the initial context to the server has been made, in about five lines of code the client application:
The complexity of this entire procedure is hidden from the client application developer. Instead, the complexity is handled at the data services layer and by the AquaLogic Data Services Platform framework.
As it does for reading data, SDO gives client applications a unified interface for updating data. With AquaLogic Data Services Platform, client application can modify and update data from heterogeneous, distributed sources as if the data were from a single entity. The complexity of propagating changes to diverse data sources is hidden from the client programmer.
Data source updates occur in a transactionally secure manner; that is, given an update call that affects multiple sources, all updates to individual data sources within the update call either succeed or fail together. (Note that it is possible to override this behavior as needed.)
From the data service implementor's point of view, the task of building a library of update-capable data services is considerably eased by the AquaLogic Data Services Platform update framework. For relational sources, AquaLogic Data Services Platform can typically propagate changes to the data sources automatically. For other sources, or to customize relational updates, you can use the AquaLogic Data Services Platform update framework and tools to quickly implement a wide range of update-capable services.
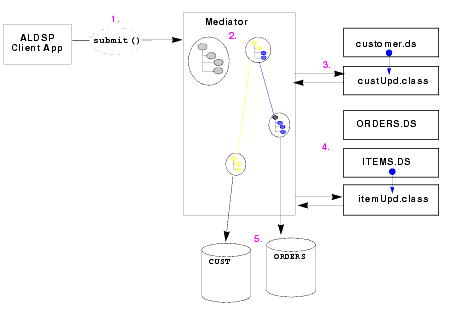
As shown in the Figure 5-2, updates occur through a process in which the requested change is first analyzed to determine, among other things, the lineage of the data. The AquaLogic Data Services Platform mediator then decomposes the submitted object into its constituent parts and propagates the changes to the data source.
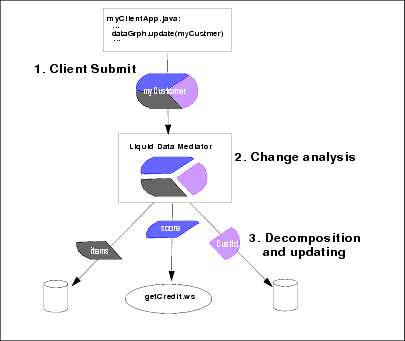
At any point in this process, you can have your own code programmatically intervene, for example, to validate the update values or for auditing purposes.
The Data Service Mediator is the core mechanism for the AquaLogic Data Services Platform update framework; the update framework also encompasses several programming artifacts, as follows:
From a lower-level perspective, an update plan is a Java object that comprises a tree of DataServiceToUpdate instances — the names of the data services that comprise the changed data objects. DataServiceToUpdate, KeyPair, UpdatePlan, and DataServiceMediatorContext have been implemented as classes in the SDO Mediator APIs, specifically in:
com.bea.ld.dsmediator.update packageSee the topic "Mediator API Javadoc" in the Introducing Data Services for Client Application Developers chapter of Application Developer's Guide.
An important characteristic of the SDO model is that back-end data sources associated with modified objects are not changed until the submit( ) method is called on the data service bound to the objects.
After receiving a data object (the changed SDO) from a calling client application, the Mediator always looks for an update override class first (regardless of whether the data service is a physical or logical data service). If an update override class is available, it is instantiated and executed.
The Mediator first determines the data lineage — the origins of the data — by using the data service's decomposition function to map each constituent in a data object to its underlying data source or data service. In addition, any inverse functions specified for the data service are used by the Mediator to define a complete decomposition map. (Inverse functions are described in the Best Practices and Advanced Topics chapter of the Data Services Developer's Guide.)
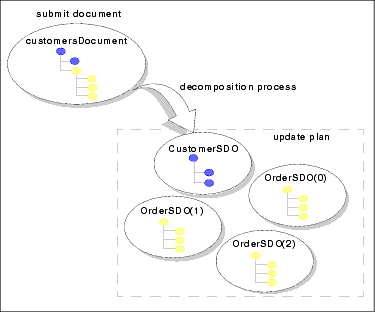
As shown in Figure 5-3, a customersDocument object that comprises updated customer information (from a Customer data service) and three updated Orders (from an Orders data service) would be decomposed into four objects.
An important distinction between logical and physical data service updates is as follows:
For a physical data service, changes to the data sources are propagated immediately (unless an update override class is associated with the data service). Neither a decomposition map nor an update plan is needed for a physical data service.
Upon receiving an SDO (whether from a submit( ) method invocation or as a projection from a higher-level data service), the Mediator first checks for an UpdateOverride class associated with the data service.
A logical data service can comprise any number of logical or physical data services. When a top-level data service function executes, the lower-level logical data services that it comprises are "folded in" so that the function appears to be written directly against physical data services. Only information that has been projected in the top-level data service is passed to the next lower-level data service.
Figure 5-4 provides an overview of the steps involved in updating a logical data service:
| Note: | An update override class can exist at each layer of a multi-layered data service. Thus, a logical data service comprising several layers of other logical data services checks for an update override at each constituent layer. If a mid-layer data service has no update override, the update framework bypasses the instantiation of an SDO object, instead directly creating the SDO objects for the underlying data service. This is true in the case of a logical data service with an update override or a physical data service. |
The performChange( ) method can access and modify the update plan and decomposition map, or perform any other custom processing, including taking over complete processing. The method returns a Boolean value that either continues or aborts processing by the Mediator, as follows:
Most RDBMSs can automatically generate primary keys, which means that if you are adding new data objects to a data service that is backed by a relational database, you may want or need to handle a primary key as a return value in your code. For example, if a submitted data graph of objects includes a new data object, such as a new Customer, AquaLogic Data Services Platform generates the necessary primary key.
For data inserts of autonumber primary keys, the new primary key value is generated and returned to the client. Only primary keys of top-level data objects (top-level of a multi-level data service) are returned; nested data objects that have computed primary keys are not returned.
By returning the top-level primary key of an inserted tuple, AquaLogic Data Services Platform allows you to re-fetch tuples based on their new primary keys, if necessary.
The Mediator saves logical primary-foreign keys as a KeyPair (see the KeyPair class in the Mediator API). A KeyPair object is a property map that is used to populate foreign-key fields during the process of creating a new data object:
The value of the property will be propagated from the parent to the child, if the property is an autonumber primary key in the container, which is a new record in the data source after the autonumber has been generated.
The KeyPair object is used to identify corresponding data elements at adjacent levels of a decomposition map; it ensures that a generated primary key value for a parent (container) object will be mapped to the foreign key field of the child (contained) element.
As an example, Figure 5-5 shows property mapping for the decomposition of a Customers data service.
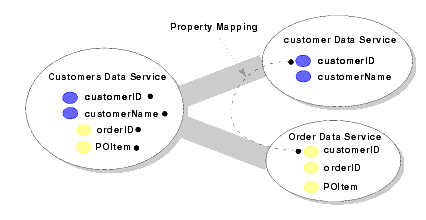
AquaLogic Data Services Platform manages the primary-foreign key relationships between data services; how the relationship is managed depends on the layer (of a multi-layered data service), as follows:
Properties[] keys = ds.submit(doc);
A tuble is basically a record; in the context of data services, a tuble may comprise data that spans several layers of data services.
AquaLogic Data Services Platform propagates the effects of changes to a primary or foreign key.
For example, given an array of Customer objects with a primary key field CustID into which two customers are inserted, the submit would return an array of two properties with the name being CustID, relative to the Customer type, and the value being the new primary key value for each inserted Customer.
AquaLogic Data Services Platform manages primary key dependencies during the update process. It identifies primary keys and can infer foreign keys in predicate statements. For example, in a query that joins data by comparing values, as in:
where customer/id = order/idThe Mediator performs various services given the inferred key/foreign key relationship when updating the data source.
If a predicate dependency exists between two SDOToUpdate instances (data objects in the update plan) and the container SDOToUpdate instance is being inserted or modified and the contained SDOToUpdate instance is being inserted or modified, then a key pair list is identified that indicates which values from the container SDO should be moved to the contained SDO after the container SDO has been submitted for update.
This Key Pair List is based on the set of fields in the container SDO and the contained SDO that were required to be equal when the current SDO was constructed, and the key pair list will identify only those primary key fields from the predicate fields.
The KeyPair maps a container primary key to container field only. If the KeyPair does not container's complete primary key is not identified by the map then no properties are specified to be mapped.
A Key Pair List contains one or more items, identifying the node names in the container and contained objects that are mapped.
When computable by SDO submit decomposition, foreign key values are set to match the parent key values.
Foreign keys are computed when an update plan is produced.
Each submit() to the Mediator operates as a transaction. Depending upon whether the submit() succeeds or fails, you should do one of two things:
All submits perform immediate updates to data sources. If a data object submit occurs within the context of a broader transaction, commits or rollbacks of the containing transaction have no effect on the submitted data object or its change summary, but they will affect any data source updates that participated in the transaction.


|