|
|
This section contains general guidelines and patterns for creating a BEA Aqualogic Data Services Platform services layer. The following topics are covered:
When planning a data service deployment, it is helpful to think of the data service layer in terms of an assembly line. In an assembly line, a product is built incrementally as it passes through a series of machines or assemblers that specialize in an aspect of the fabrication of the product.
Similarly, a well-designed data services layer transforms input (source data) into output (structured information) incrementally, through a series of small transformations. Such a design eases development and maintenance of the data services and increases the opportunity for reuse.
| Note: | Keep in mind that a multi-level data service implementation model described here is flattened when the data services are compiled for deployment. That is, adding a conceptual layers does not add overhead to the data integration work performed by the DSP deployment, and therefore does not affect performance. |
By this design, distinct subsets of data services comprise sub-layers in the overall transformation layer. As data passes from layer to layer data is transformed from a more generalized state to a more application-specific state.
To further illustrate this design, consider a deployment with the following sublayers:
This sublayer does most of what might be called the integration work of the overall data services layer; it is where the integration logic and predicates and primary relationships are specified. (In small projects, this layer may be combined with the second sublayer. That is, it would contain data services that both normalize the data and define data shapes for the integration layer.)
For very large database sources, instead of creating a single master data service, it is best to decide what a client application needs and build corresponding, minimal data services. The concept is to build client-specific data services from a manageable number of views that query a reasonable number of data sources, providing an abstraction from the lowest level and most common relationships while keeping the overall view reasonably simple. AquaLogic Data Services Platform also provides a metadata API that allows client applications to discover relationships between data services at runtime, allowing applications to navigate the data services without the need for a master data service.
The most significant benefit of this approach is that it increases the opportunity for reuse within the overall data services layer. As shown in Figure 10-1, once you have defined a single form of a business entity (such as a customer) in a data service dedicated to the task, you can have multiple application-specific data services use the information without having to repeat data normalization and integration tasks. An additional benefit is that it aids maintenance because there is a clear separation of concerns between the data service layers.
When dealing with disparate data sources it is often necessary to normalize data during updates. Typical normalization includes simple type casting, currency, weights and measures, handling of composite keys, and text and numeric formatting.
While transformational functions are easy to create in XQuery, such functions do not automatically take advantage of the processing power of underlying sources. This becomes especially noticeable when large amounts of relational data are being manipulated.
You can often use inverse functions to retain the benefits of high-performance data processing for your logical data. In addition, inverse functions make automated updates possible without the need to create Java update overrides. (See Handling Updates Through Data Services for a more detailed discussion of update overrides.)
Inverse functions are very useful in several types of commonly encountered situations, described in this section. For this topic you can assume underlying data sources with the following characteristics:
The US_EMPLOYEE and UK_EMPLOYEE tables are accessible through two functions in a logical data service: US_EMPLOYEE() and UK_EMPLOYEE().
Here are several examples where running queries against logical data can result in noticeably degraded performance when compared with operations against the physical data itself:
While a function collecting the names of customers entered after a particular date would succeed, the results would not be optimized. In other words, the processing required by the function would not take advantage of the underlying database's inherent processing power. If a large number of records were involved, the performance impact could be considerable.
The thing to keep in mind when creating inverse functions is that the functions you create need to be truly invertible.
For example, in the following case date is converted to a string value:
public static String dateToString(Calendar cal) {
SimpleDateFormat formatter;
formatter = new SimpleDateFormat("MM/dd/yyyy hh:mm:ss a");
return formatter.format(cal.getTime()) ;
}However, notice that the millisecond value is not in the return string value. You get data back but you have lost an element of precision. By default, all values projected are used for optimistic lock checking, so a loss of precision can lead to a mismatch with the database's original value and thus an update failure.
Instead the above code should have retained millisecond values in its return string value, thus ensuring that the data you return exactly the same as the original value.
Here are some additional scenarios where inverse functions can improve performance, especially when large amounts of data are involved:
The data architect creates the following XQuery function:
declare function tns:getEmpWithFixedHireDate() as element(ns0:usemp)*{
for $e in ns1:USEMPLOYEES()
return
<emp>
<eid>{fn:data($e1/ID)}</eid>
<name>{mkName($e1/LNAME, $e1/FNAME)}</name>
<hiredate>{int2date($e1/HIRED)}</hiredate>
<salary>)fn:data($e1/SAL)}</salary>
</emp>
}Given such a function, issuing a filter query on hiredate, on top of this function, results in inefficient execution since every record from the back-end must be retrieved and then processed in the middle tier.
Taking the first example in Considerations When Running Queries Against Logical Data, it is clear that performance would be adversely affected when running the fullname( ) function against large data sets.
The ideal would be to have a function or functions which decomposed fullname into its indexed components, passes the components to the underlying database, gets the results and reconstitutes the returned results to match the requirements of fullname( ). In fact, that is the basis of inverse functions.
Of course there are no XQuery functions to magically deconstruct a concatenated string. Instead you need to define, as part of your data service development process, custom functions that inverse engineer fullname( ).
Often complimentary inverse functions are needed. For example, FahrenheitToCentigrade() and centigradeToFahenheit() would be inverses of each other. Complimentary inverse functions are also needed to support fullname().
In addition to creating inverse functions, you also need to identify inverse functions as part of the metadata import process. The import process is described in Obtaining Enterprise Metadata. The specific application of this process for inverse functions is described in Step 4: Configure Inverse Functions.
The RTLApp contains several examples of inverse functions. In the case of the fullname() function, custom Java code provides the underlying inverse function logic. The following actions were involved in creating this example:
The following describes the detailed steps involved:
The string manipulation logic needed by the inverse function is in the following Java file in the RTLApp:
DataServices/Demo/InverseFunction/functions/LastNameFirstName.java This file defines several straightforward string manipulation functions.
package Demo.InverseFunction.functions;
public class LastNameFirstName
{
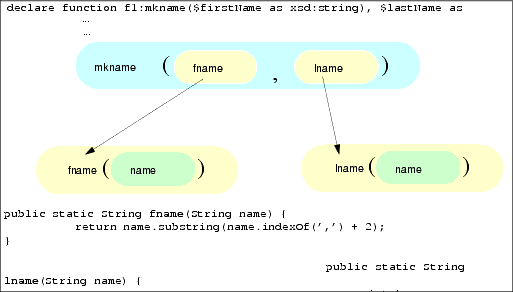
public static String mkname(String ln, String fn) { return ln + ", " + fn; }
public static String fname(String name) {
return name.substring( name.indexOf(',') + 2);
}
public static String lname(String name) {
int k = name.indexOf(',');
return name.substring( 0, k );
}
}
In Listing 10-1 the function mkname( ) simply concatenates first and last name. The fname( ) and lname( ) functions deconstruct the resulting full name using the required comma in the mkname string as the marker identifying the separation between first and last names.
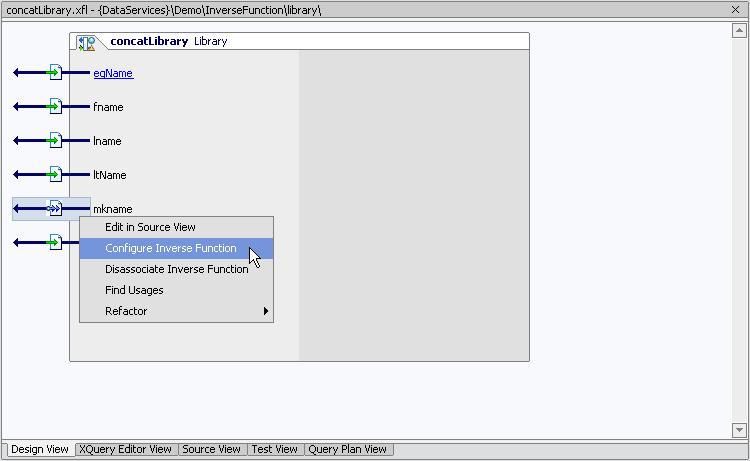
After you have compiled your Java function you can import metadata from its class file, in this case LastNameFirstName.class. The resulting functions will be imported into an XML file library (XFL) named concatLibrary.xfl. Figure 10-4 shows the resulting XFL as well as the right-click options available for the mkname() function.
As is often the case, some additional programming logic is necessary. In this case two functions need to be added to the concatLibrary XFL file:
declare function f1:precedesName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
f1:lname($x1) lt f1:lname($x2) or ( (f1:lname($x1) eq f1:lname($x2))
and (f1:fname($x1) lt f1:fname($x2)) )
};This function is necessary in order to retrieve an ordered list of names from an inverse function.
declare function f1:eqName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
(f1:lname($x1) eq f1:lname($x2) and f1:fname($x1) eq f1:fname($x2))
};Inverse functions can only be defined when the input and output function parameters are atomic types.
To improve code readability by making a change to the mkname() function. Replace the $x1 and $x2 variables with $lastName and $firstName, respectively. When you are done the function appears as:
declare function f1:mkname($lastName as xsd:string?, $firstName as xsd:string?) as xsd:string? external;
The benefits for doing this become apparent in the next step.
Since all the functions in concatLibrary.xfl have simple parameter types, you could create inverses for each. In this example you only need inverse functions to enable the XQuery engine to deconstruct the mkname() function into its component operations.
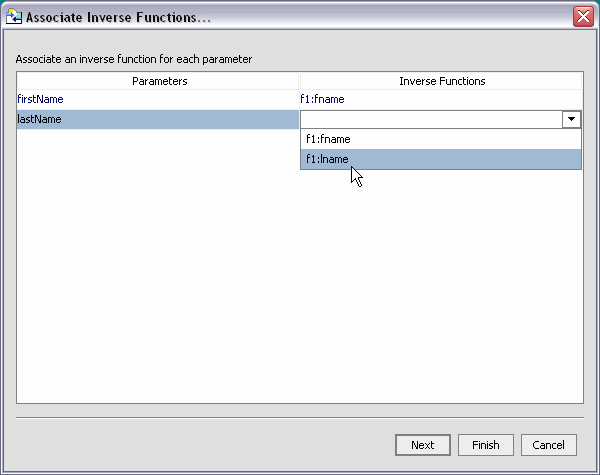
For each parameter in the mkname() function an inverse function is identified. A simplified view of the operation and relevant code can be seen in Figure 10-5.
In XFL Design View you can association the parameters of functions whose input and output types are atomic with inverse functions. To do this right-click on a function. The option Configure Inverse Function (shown in Figure 10-4) is available for functions that qualify.
Figure 10-6 illustrations the association of parameters with inverse functions.
Step 5: Configuring Conditions for Transformational Functions
After you have associated inverse functions with the correct parameters you may want to associate custom conditional logic with the functions. You do this by substituting a custom function for such generic conditions as eq (is equal to) and gt (is greater than). Table 10-7 lists conditional operations available for such transformations.
Associating a particular conditional (such as "is greater-than") with a transformational function allows the XQuery engine to substitute such custom logic for a simple conditional.
You can associate comparison operators with transformational functions. As is always the case with AquaLogic Data Services Platform, the original basis of the function does not matter. It could be created in your data service, in an XFL, or externally in a Java or other routine. In this example the transformational function, eqName( ), is in an XFL file.
The next step is to match comparison operators with an equivalent transform functions. Custom logic is needed to support pushdown operations in conjunction with comparison operations. In the current exercise the string-less-than (lt) operation is associated with the XFL precedesName( ) function; the string-equal (eq) operation is associated with the eqName( ) functions. When your query function encounters these operators, the corresponding custom logic is substituted.
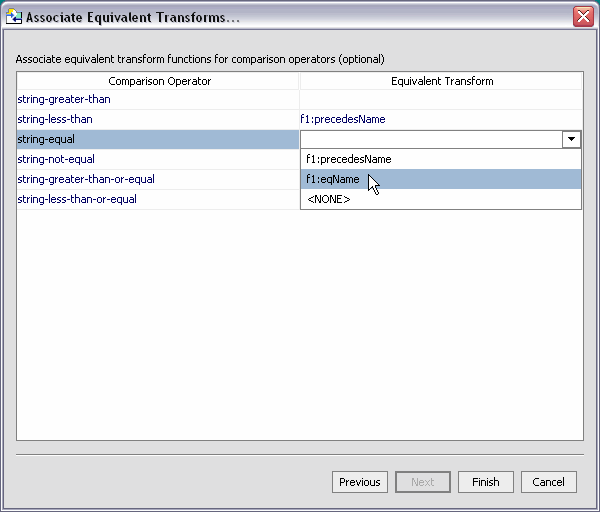
Two equivalent transform functions were created in the concatLibrary.xfl. The first, precedesName( ), tests names to make sure they are in ascending order. The second, eqName( ) simply compares two first names and two last names and makes sure they are identical.
Step 6: Create Your Data Service
Now you are ready to create a data service that will contain functions such as getCustomerByName() and getCustomerByNameLessThan(). In reviewing available facilities, you have:
The data service, called Concatenation, uses a XML type associated with the LastNameFirstName.xsd schema.
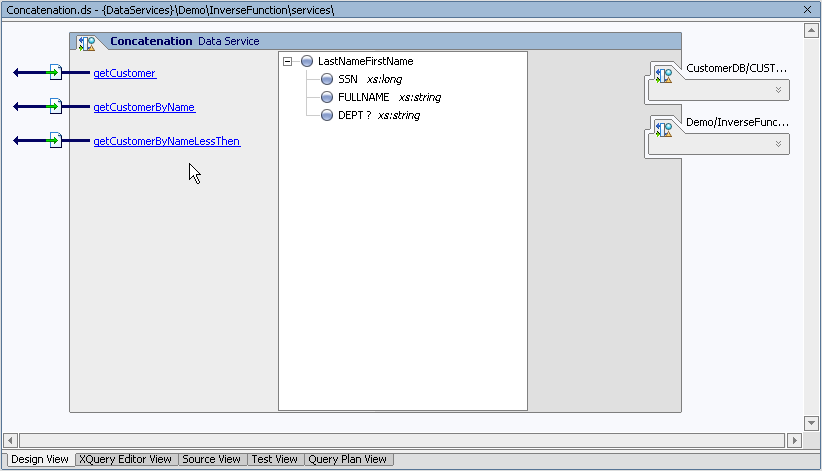
This schema could have been created through the XQuery Editor, through the AquaLogic Data Services Platform schema editor, or through a third-party editing tool. (Notice also that one of the building blocks of your data service is the concatLibrary XFL.)
The familiar getCustomer() function operates somewhat differently in this example.
declare function tns:getCustomer() as element(ns0:LastNameFirstName)* {
for $CUSTOMER in ns1:CUSTOMER()
return
<ns0:LastNameFirstName>
<SSN>{fn:data($CUSTOMER/SSN)}</SSN>
<FULLNAME>{ns2:mkname(fn:data($CUSTOMER/LAST_NAME),fn:data($CUSTOMER/FIRST_NAME))}</FULLNAME>
<DEPT?></DEPT>
</ns0:LastNameFirstName>
};
Using a U.S. social security number as the primary key, the routine relies on the Java-based mkName() function to retrieve first and last name from the data source and concatenate the results into a "fullname".
The getCustomerByName( ) routine takes fullname as input and returns $LastNameFullName and the associated social security number.
declare function tns:getCustomerByName($Name as xs:string) as element(ns0:LastNameFirstName)* {
for $LastNameFirstName in tns:getCustomer()
where $LastNameFirstName/FULLNAME eq $Name
return $LastNameFirstName
};
In the above code the equality (eq) test is evaluated by substituting the logic of the concatLibrary eqName() function.
The getCustomerByNameLessThan( ) routine uses the substitute condition logic available for the lt operator. First the routine.
declare function tns:getCustomerByNameLessThen($Name as xs:string) as element(ns0:LastNameFirstName)* {
for $LastNameFirstName in tns:getCustomer()
where $Name lt $LastNameFirstName/FULLNAME
return $LastNameFirstName
};
The logic of the less-than substitution can be derived from examining LastNameFirstName.java and the concatLibrary. The raw processing is containing in the Java file:
public static boolean ltName(String name1, String name2) {
String ln1 = lname(name1);
String ln2 = lname(name2);
return (ln1.compareTo(ln2)<0) || (ln1.equals(ln2) && fname(name1).compareTo(fname(name2))<0);
}
The XFL function, precedesName() is:
declare function f1:precedesName($x1 as xsd:string?, $x2 as xsd:string?) as xsd:boolean? {
f1:lname($x1) lt f1:lname($x2) or ( (f1:lname($x1) eq f1:lname($x2))
and (f1:fname($x1) lt f1:fname($x2)) )
};
A typical design pattern within a logical data service is to have a single read function that defines the data shape without filtering conditions. The function may be declared private so that it can only be called by other functions within the same data service. Also, it is the only function containing integration logic. This is known as the decomposition function. By default the decomposition function is the first function listed in Design View of your logical data service. However you can, through the Properties Editor, set the decomposition function to be any public or private function in your data service. Additional functions, either in the same data service or in other data services, can use the private function to specify filtering criteria. Figure 10-10 shows the design view of a data service exhibiting this pattern.
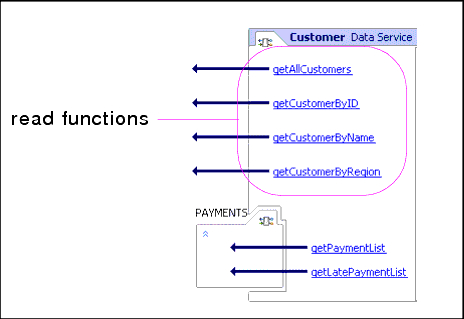
The following XQuery sample demonstrates the mechanics behind data service reuse. This function, getCustomerByName(), filters instances based on the customer name:
declare function l1:getCustomerByName($c_name as xs:string)
as element(t1:CUSTOMER)*
{
for $c in l1:getAllCustomers()
where $c/CUSTOMERNAME eq $c_name
return $c
};
The getAllCustomers() function, in turn, would assemble the data shape for the returned data and provide join logic and transformation, as shown its return clause:
...
return
<t1:CUSTOMER>
<CUSTOMERID>{fn:data($c/CUSTOMERID)}</CUSTOMERID>
<CUSTOMERNAME>{fn:data($c/CUSTOMERNAME)}</CUSTOMERNAME>
{
for $a in f2:ADDRESS()
where $c/CUSTOMERID eq $a/CUSTOMERID
return
<ADDRESS>
<STREET>{fn:data($a/RTL_STREET)}</STREET>
<CITY>{fn:data($a/RTL_CITY)}</CITY>
<STATE>{fn:data($a/RTL_STATE)}</STATE>
</ADDRESS>
}
</t1:CUSTOMER>
Keep in mind that client application themselves can specify filtering conditions on a data service function call. Therefore, you as the data service designer can choose whether to have broadly defined data access functions (that is, without filter conditions), and let the client to apply filtering as desired, or narrowly by defining the criteria in the API.
| Note: | All functions whose bodies are some variation of a flwor (for-let-where-order-return) statement should be declared to return a plural rather than a singular result; for example: |
element(purchase_order)*| Note: | rather than: |
element(purchase_order)| Note: | applies to both read and navigation functions. |
| Note: | The reason for declaring returns to be plural is that the XQuery compiler wants to be sure that you indeed deliver the declared result at runtime. If it cannot determine that something is singular it inserts a runtime typematch operator in the query evaluation plan. You won't get the wrong result, but that operator will cause important pushdown-related optimizations (function unfolding) to be defeated. |
There are several ways to implement a logical relationship between distinct units of information with data services:
When containment is implemented in the data shape, it means that the XML data type of the data service is nested; that is, one element is the parent of another element. For example, in the following sample a customer element contains orders:
<customer>
<customerId>...</customerId>
<customerName>...</customerName>
<orders>
<order>...</order>
<orderId>...</orderId>
</orders>
</customer>
A diagram of this XML structure would be:
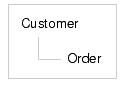
In this type of containment, the parent-child hierarchy between the customer and order is locked into the data shape. This nesting might make sense for most applications, particularly those oriented by customer. However, other applications may benefit from an orders-oriented view of the data. For example, an inventory application may prefer to work with the data in an orders-first fashion, with the customer as a child element of each order.
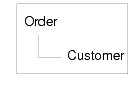
Conceptually, in this case it could also be said that an Order is not existence-dependent on a Customer. If a Customer record is deleted, it may not necessarily follow that the customer's order should be deleted as well.
Alternatively, other relationships do not require this type of hierarchical flexibility. In most cases, this also implies that the business entity's existence does depend on the existence of the parent. For example, consider an order that contains items.
In most logical data models, it would not make sense to have an item outside of the context of the order that contains it. When deleting an order, it is safe to say that composing order items would need to be deleted as well.
The choice when modeling such containment either through a relationship or through data shape nesting is informed by these considerations. When choosing whether to model containment either through data shape nesting or using relationships, it is recommended that:
By modeling independent entities with bi-directional relationships, data service users and designers can easily specialize the logical hierarchy between business entities as best suited for their applications.


|