|
|
BEA Aqualogic Data Services Platform handles updates to relational data sources automatically. Non-relational data sources, including Web services, can be updated as well.
In the case of non-relational sources, update logic is always provided through an update override class that is associated with your logical or physical data service. In addition, there are times when you may want (or need) to provide custom update logic for relational data sources.
This chapter explains how to create an update override class (the class comprising update behavior) for your data service. It includes the following topics:
In reading this chapter it is important to keep your overall goal in mind: providing application developers with the capability to access and update enterprise information through data services.
From the application developer's perspective, a Service Data Objects (SDO) mediator API is the vehicle for flowing information through data services. (Similarly, a AquaLogic Data Services Platform Control can be used for the same purpose.) For more information on SDO as it applies to data services see Data Programming Model and Update Framework in the Client Application Developer's Guide.
An update override class can programmatically access several update framework artifacts, including:
The content available at any time depends on the data service context, as follows:
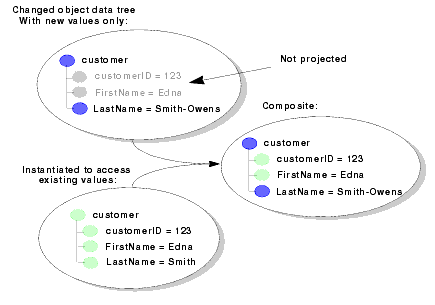
Figure 9-1 illustrates the context visibility within an update override.
Considerations for implementing update override classes for physical level data services include the following:
Additional considerations concerning update overrides for relational data services include:
For physical non-relational data services, your performChange( ) method must:
An update override provides you with a mechanism for customizing or completely replacing the default update process.
With an update override associated with your data service, you can:
For a more conceptual discussion of update overrides see the topic "Updating Data" in the Using Service Data Objects (SDO) chapter of the AquaLogic Data Services Platform Concepts Guide.
In programming terms, an update override is a compiled Java source code file that implements the UpdateOverride interface (<UpdateOverride>), one of the AquaLogic Data Services Platform APIs. This API is located in the com.bea.ld.dsmediator.update package. The UpdateOverride interface has a single, empty method named performChange( ).
It's important to understand how your application developer will use this method. As shown in Listing 9-1, the performChange( ) method takes a DataGraph object (passed to it by the dsmediator.update package, or Mediator). It is on this Mediator object that your update override class operates. The DataGraph contains the data object, the changes to the object, and other artifacts, such as metadata (as discussed in Data Programming Model and Update Framework in Client Application Developer's Guide.)
package com.bea.ld.dsmediator.update;
import commonj.sdo.DataGraph;
import commonj.sdo.Property;
public interface UpdateOverride
{
public boolean performChange(DataGraph sdo)
{
}
}
As you can see from the performChange( ) method signature in Listing 9-1, the method returns a Boolean value. This value serves as something of a flag to the mediator, as follows:
The performChange( ) method will be executed whenever a submit is issued for objects bound to the overridden data service.
If the object being passed in the submit( ) is an array of DataService objects, the array is decomposed into a list of singleton DataService objects. Some of these objects may have been added, deleted, or modified; therefore, the update override might be executed more than once (that is, once per changed object.)
Application developers need to verify that the root data object for the datagraph being passed at runtime is an instance of the singleton data object bound to the data service (configured with the update override).
You must create custom update classes in order for applications executing data service functions to update a non-relational data source. Web services, XML files, flat files, and AquaLogic Data Services Platform procedures all would require custom update classes if, in fact, updates are required.
Similar you would need to create custom update classes in the following types of situations:
For example, if the client application needs to add both a department and a manager; however, manager is also a required field of department. How can you set the department's manager field before the manager exists? As follows:
Once you have written and compiled the Java code that comprises the update override class, you must register the class with your data service. Update overrides can be registered with physical or logical data services. Each data service has an Override Class property that can be associated with a specific Java class file that comprises the implementation of the UpdateOverride for that data service.
The actual association can be done in WebLogic Workshop through Design View or Source View. Here are details on the two approaches:
.class extension) as an attribute of an empty javaUpdateExit element tag (in the pragma statement of the data service). For example:<javaUpdateExit className="SpecialOrderUpdate"/>
At runtime, the data service executes the UpdateOverride class identified in the data service through a property setting. See the topic "The Decomposition Process" in the Using Service Data Objects chapter of the AquaLogic Data Services Platform Concepts Guide.
Here are the general steps involved in creating an update override class:
import com.bea.ld.dsmediator.update.UpdateOverride;
import commonj.sdo.DataGraph;
public class SpecialOrders implements UpdateOverride
public boolean performChange(DataGraph graph)
package RTLServices;
import com.bea.ld.dsmediator.update.UpdateOverride;
import commonj.sdo.DataGraph;
import java.math.BigDecimal;
import java.math.BigInteger;
import retailer.ORDERDETAILDocument;
import retailerType.LINEITEMTYPE;
import retailerType.ORDERDETAILTYPE;
public class OrderDetailUpdate implements UpdateOverride
{
public boolean performChange(DataGraph graph){
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0);
BigDecimal total = new BigDecimal(0);
LINEITEMTYPE[] items = order.getLINEITEMArray();
for (int y=0; y < items.length; y++) {
BigDecimal quantity =
new BigDecimal(Integer.toString(items[y].getQuantity()));
total = total.add(quantity.multiply(items[y].getPrice()));
}
order.setSubTotal(total);
order.setSalesTax(
total.multiply(new BigDecimal(".06")).setScale(2,BigDecimal.ROUND_UP));
order.setHandlingCharge(new BigDecimal(15));
order.setTotalOrderAmount(
order.getSubTotal().add(
order.getSalesTax().add(order.getHandlingCharge())));
System.out.println(">>> OrderDetail.ds Exit completed");
return true;
}
}
In the sample class shown in Listing 9-2, an OrderDetailUpdate class implements the UpdateOverride class, and, as required by the interface, defines a performChange( ) method. The listing demonstrates a common coding pattern for update overrides:
ORDERDETAILDocument orderDocument =
(ORDERDETAILDocument) graph.getRootObject();
ORDERDETAILTYPE order =
orderDocument.getORDERDETAIL().getORDERDETAILArray(0)
See also Common Update Override Programming Patterns.
In some cases, such as those listed Table 9-3, update override logic is needed for relational update processing.
Most RDBMSs can automatically generate primary keys, which means that if you are adding new data objects to a data service that is backed by a relational database, you may want or need to handle a primary key as a return value in your code. For example, if a submitted data graph of objects includes a new data object, such as a new Customer, AquaLogic Data Services Platform generates the necessary primary key.
For data inserts of autonumber primary keys, the new primary key value is generated and returned to the client. Only primary keys of top-level data objects (top-level of a multi-level data service) are returned; nested data objects that have computed primary keys are not returned.
By returning the top-level primary key of an inserted tuple, AquaLogic Data Services Platform allows you to re-fetch tuples based on their new primary keys, if necessary.
The Mediator saves logical primary-foreign keys as a KeyPair (see the KeyPair class in the Mediator API). A KeyPair object is a property map that is used to populate foreign-key fields during the process of creating a new data object:
The value of the property will be propagated from the parent to the child, if the property is an autonumber primary key in the container, which is a new record in the data source after the autonumber has been generated.
The KeyPair object is used to identify corresponding data elements at adjacent levels of a decomposition map; it ensures that a generated primary key value for a parent (container) object will be mapped to the foreign key field of the child (contained) element.
As an example, Figure 9-4 shows property mapping for the decomposition of a Customers data service.
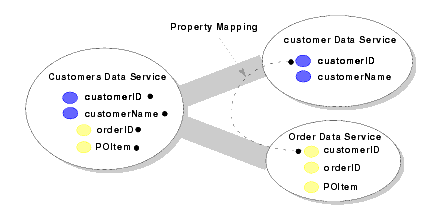
AquaLogic Data Services Platform manages the primary-foreign key relationships between data services; how the relationship is managed depends on the layer (of a multi-layered data service), as follows:
Properties[] keys = ds.submit(doc);
A tuble is basically a record; in the context of data services, a tuble may comprise data that spans several layers of data services.
AquaLogic Data Services Platform propagates the effects of changes to a primary or foreign key.
For example, given an array of Customer objects with a primary key field CustID into which two customers are inserted, the submit would return an array of two properties with the name being CustID, relative to the Customer type, and the value being the new primary key value for each inserted Customer.
AquaLogic Data Services Platform manages primary key dependencies during the update process. It identifies primary keys and can infer foreign keys in predicate statements. For example, in a query that joins data by comparing values, as in:
where customer/id = order/idThe Mediator performs various services given the inferred key/foreign key relationship when updating the data source.
If a predicate dependency exists between two SDOToUpdate instances (data objects in the update plan) and the container SDOToUpdate instance is being inserted or modified and the contained SDOToUpdate instance is being inserted or modified, then a key pair list is identified that indicates which values from the container SDO should be moved to the contained SDO after the container SDO has been submitted for update.
This Key Pair List is based on the set of fields in the container SDO and the contained SDO that were required to be equal when the current SDO was constructed, and the key pair list will identify only those primary key fields from the predicate fields.
The KeyPair maps a container primary key to container field only. If the KeyPair does not container's complete primary key is not identified by the map then no properties are specified to be mapped.
A Key Pair List contains one or more items, identifying the node names in the container and contained objects that are mapped.
When computable by SDO submit decomposition, foreign key values are set to match the parent key values.
Foreign keys are computed when an update plan is produced.
Each submit( ) to the Mediator operates as a transaction. Depending upon whether the submit() succeeds or fails, you should do one of two things:
All submits perform immediate updates to data sources. If a data object submit occurs within the context of a broader transaction, commits or rollbacks of the containing transaction have no effect on the submitted data object or its change summary, but they will affect any data source updates that participated in the transaction.
Listing 9-3 shows an example of an update override class that invokes a data service procedure. Since UpdateOverrides are invoked locally — that is, within the AquaLogic Data Services Platform server — the sample uses the typed Mediator API. In this case a data service based on the setCustomerOrder Web service setCustomerOrder( ) is created. The service contains an update function which is referenced from the data service by a side-effecting function of the same name. Finally the class that implements the update override is shown.
First, a Web service update is defined. For the update logic see in the RTLApp sample the ElecDBTest Web service (ElecDBTest.jws). The method is:
setCustomerOrder(String doc);
The a data service procedure (side-effecting function) is declared in the following data service:
ld:DataServices/ElectronicsWS/getCustomerOrderByOrderID
(::pragma function <f:function xmlns:f="urn:annotations.ld.bea.com"
kind="hasSideEffects" nativeName="setCustomerOrder"
nativeLevel1Container="ElecDBTest"
nativeLevel2Container="ElecDBTestSoap"
style="document">
<nonCacheable/>
</f:function>::)
Then the update logic can be written. It is shown, with comments, in Listing 9-3.
public boolean performChange(DataGraph datagraph){
String order = "ld:DataServices/ElectronicsWS/getCustomerOrderByOrderID";
System.out.println("INSIDE EXIT >>>> ");
ChangeSummary cs = datagraph.getChangeSummary();
if (cs.getChangedDataObjects().isEmpty()) {
System.out.println("WEB SERVICE EXIT COMPLETE!");
return false;
}
else {
GetCustomerOrderByOrderIDResponseDocument doc = (GetCustomerOrderByOrderIDResponseDocument) datagraph.getRootObject();
try {
Context cxt = getInitialContext();
// get the handle of the data service that contains the data service procedure update function
DataService creditDS =
DataServiceFactory.newDataService(cxt,
"RTLApp",
order);
// create a xmlbean object that will be passed into the side effect function
SetCustomerOrderDocument doc1 = SetCustomerOrderDocument.Factory.newInstance();
// populate the xmlbean object with values from SDO
doc1.addNewSetCustomerOrder().setDoc(doc.getDataGraph().toString());
creditDS.invokeProcedure( "setCustomerOrder",
new Object[]{ doc1 } );
} catch (Exception e) {
e.printStackTrace();
throw new RuntimeException("UPDATE ERROR: SQL ERROR: " + e.getMessage());Fine
System.out.println("WEB SERVICE EXIT COMPLETE!");
return false;
}
}The example in Listing 9-3 involves a Web service running locally on the WebLogic Server instance; it does not include setup code to obtain context and location. (If the Web service is not local to the WebLogic Server instance, your code must obtain an InitialContext and providing appropriate location and security properties. See "Obtaining a WebLogic JNDI Context" in the Accessing Data Services from Java Clients chapter of the Client Application Developer's Guide.
Listing 9-4 shows an update override that adjusts the update plan in order to enforce referential integrity by removing product information from the middle of a list and adding it to the end.
// delete order, item, product, due to RI between ITEM and Product
// product has to be deleted after items
public boolean performChange(DataGraph graph)
{
DataServiceMediatorContext context = DataServiceMediatorContext.currentContext();
UpdatePlan up =context.getCurrentUpdatePlan( graph, false );
Collection dsCollection = up.getDataServiceList();
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();)
{
ds2u = (DataServiceToUpdate)it.next();
if (ds2u.getDataServiceName().compareTo("ld:DataServices/PRODUCT.ds") == 0 ) {
// remove product from the mid of list and add it back at the end
up.removeContainedDataService( ds2u.getDataGraph() );
up.addDataService(ds2u.getDataGraph(), ds2u );
};
}
context.executeUpdatePlan( up );
return false;
}
}
Data service updates should always be tested to ensure that changes occur as expected. You can test submits using Test View. For information on Test View see Using Test View.
While Test View gives you a quick way to test simple update cases in the data services you create, for more substantial testing and troubleshooting you can use an update override class to inspect the decomposition mapping and update plan for the update.
This section provides code samples and commentary that illustrate common update override programming patterns. Topics include:
Your update override class must include an implementation of the performChange( ) method; it is inside this method that you provide all custom code required for the programming task at hand. The performChange( ) method returns a Boolean value that either continues or aborts processing by the Mediator, as discussed in the topic "How It Works: The Decomposition Process" in Data Programming Model and Update Framework chapter in the Client Application Developer's Guide.
For a logical data service to be properly updateable — in fact, for it to be a well-designed data service in general — the lineage for the data coming from the data service should be the same independent of which data service function is providing the data. For example, a CustomerProfile data service might have the following functions:
All three functions should be getting customer data from the same underlying data sources. It therefore follows that the correct way to propagate changes back to the underlying sources should be independent of which of these functions was used to obtain the customers being updated at any given point in time.
A recommended practice is to put all of the data integration logic for such a data service into a single function whenever possible (e.g., in getAllCustomers( )) and then to use that function when defining the remaining data service functions. An expression such as:
getAllCustomers( )[cid = $custId])
accomplishes this goal and saves you from having to replicate all of the data mappings, join predicates, and so on in each function in your data service.
When data service data is updated, AquaLogic Data Services Platform analyzes data lineage in order to determine how to propagate the changes to all affected data sources. To automatically perform such lineage analysis, a designated data service function is introspected ("reverse engineered"). If no such function is designated, the top-most read function in the data service is used.
The data service designer should ensure that the designated (or default) decomposition function for the data service is not dependent on other read functions in the same data service and is, in fact, an accurate representative function for lineage determination. In the example above, getAllCustomers( ) would be the proper function to choose, so it should either be the first read function in the data service or should be designated explicitly as the decomposition function through the Property Editor.
It is the data service designer's responsibility to ensure that the chosen decomposition function is valid for the purpose of lineage analysis. Violation of this requirement can lead to unexpected and undesirable runtime errors such as optimistic locking failures (or worse).
| Note: | In the event that the designated decomposition function for a data service calls other read functions in the same data service, an error condition will occur. Specifically, the update mediator will detect the error at runtime and throw an exception that informs the user about the errant internal data service read function dependency. |
To customize the entire decomposition and update process, the performChange( ) method can implement the following types of routines:
If your performChange( ) method takes over decomposition, it should be set to return False so that the Mediator does not proceed with automated decomposition.
The performChange( ) method can include code to inspect changed data object values and raise a DataServiceException to signal errors, rolling back the transaction in such cases.
Return True to have the Mediator proceed with update propagation using the objects as changed.
To access the change plan and decomposition map for an update, you first must get the data service's Mediator context. The context enables you to view the decomposition map, produce an update plan, execute the update plan, and access the container data service instance for the data service object currently being processed.
The following code snippet shows how to get the context:
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();Once you have the context, you can access the decomposition map as follows:
DecompositionMapDocument.DecompositionMap dm =
context.getCurrentDecompositionMap(); Once you have a decomposition map, you can use its toString( ) method to obtain the rendering of the XML map as a string value, as shown in Listing 9-5. (Note that although you can access the default decomposition map, you should not modify it.)
In addition to accessing the decomposition map, you can access the update plan in the override class. You can modify values in the tree, remove nodes, or rearrange them (to change the order in which they are applied). However, if you modify the update plan, you should execute the plan within the override if you want to keep the changes. As you modify the values in the tree, remove nodes or rearrange them, the update plan will track your changes automatically in the change list.
<xml-fragment xmlns:upd="update.dsmediator.ld.bea.com">
<Binding>
<DSName>ld:DataServices/CUSTOMERS.ds</DSName>
<VarName>f1603</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CUSTOMERID</ViewProperty>
<SourceProperty>CUSTOMERID</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<AttributeLineage>
<ViewProperty>CUSTOMERNAME</ViewProperty>
<SourceProperty>CUSTOMERNAME</SourceProperty>
<VarName>f1603</VarName>
</AttributeLineage>
<upd:DecompositionMap>
<Binding>
<DSName>ld:DataServices/getCustomerCreditRatingResponse.ds</DSName>
<VarName>getCustomerCreditRating</VarName>
</Binding>
<AttributeLineage>
<ViewProperty>CREDITSCORE</ViewProperty>
<SourceProperty>
getCustomerCreditRatingResult/TotalScore
</SourceProperty>
<VarName>getCustomerCreditRating</VarName>
</AttributeLineage>
...
</upd:DecompositionMap>
</upd:DecompositionMap>
<ViewName>ld:DataServices/Customer.ds</ViewName>
</xml-fragment>
After possibly validating or modifying the values in the submitted data object, the function retrieves the update plan by passing in the current data object to the following function:
DataServiceMediatorContext.getCurrentUpdatePlan()The update plan can be augmented in several ways, including:
After executing the update plan, the performChange( ) method should return False so that the Mediator does not attempt to apply the update plan.
The update plan lets you modify the values to be updated to the source. It also lets you modify the update order.
You can programmatically view an update plan's contents using your own method, similar to the navigateUpdatePlan( ). As shown in Listing 9-6, the navigateUpdatePlan( ) method takes a Collection object and uses an iterator to recursively walk the plan.
public boolean performChange(DataGraph datagraph){
UpdatePlan up = DataServiceMediatorContext.currentContext().
getCurrentUpdatePlan( datagraph );
navigateUpdatePlan( up.getDataServiceList() );
return true;
}
private void navigateUpdatePlan( Collection dsCollection ) {
DataServiceToUpdate ds2u = null;
for (Iterator it=dsCollection.iterator();it.hasNext();) {
ds2u = (DataServiceToUpdate)it.next();
// print the content of the SDO
System.out.println (ds2u.getDataGraph() );
// walk through contained SDO objects
navigateUpdatePlan (ds2u.getContainedDSToUpdateList() ); }
}
A sample update plan report would look like the following
UpdatePlan
SDOToUpdate
DSName: ... :PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be added
CUSOTMERID = 01
ORDERID = unset
PropertyMap = null
Now consider an example in which a line item is deleted along with the order that contains it. Given the original data, Listing 9-7 illustrates an update plan in which item 1001 will be deleted from Order 100, and then the Order is deleted.
UpdatePlan
SDOToUpdate
DSName:...:PO_CUSTOMERS
DataGraph: ns3:PO_CUSTOMERS to be deleted
CUSTOMERID = 01
ORDERID = 100
PropertyMap = null
SDOToUpdate
DSName:...:PO_ITEMS
DataGraph: ns4:PO_ITEMS to be deleted
ORDERID = 100
ITEMNUMBER = 1001
PropertyMap = null
In this case, the execution of the update plan is as follows: before deleting the PO_CUSTOMERS, the contained SDOToUpdates routines are visited and processed. So the PO_ITEMS is deleted first and then PO_CUSTOMERS is deleted.
If the contents of the update plan are changed, the new plan can then be executed. The update exit should then return False, signaling that no further automation should occur.
The plan can then be propagated to the data source.
After modifying an update plan, you can execute it. Executing the update plan causes the Mediator to propagate changes to the indicated data sources.
Given a modified update plan named up, the following statement executes it:
context.executeUpdatePlan(up);For a data service being processed for an update plan, you can obtain its SDO container. The container must exist in the original changed object tree, as decomposed. If no container exists, null is returned. Consider the following example:
String containerDS = context.getContainerDataServiceName();
DataObject container = context.getContainerSDO();
In this example, if in the update override class for the Orders data service for which you ask to see the container, the Customer data service object for the Order instance being processed would be returned. If that Customer instance was in the update plan, then it would be returned. If it was not in the update plan, then it would be decomposed from CustOrders and returned.
The update plan only shows what has been changed. In some cases, the container will not be in the update plan. When the code asks for the container, it will be returned from the update plan, if present; otherwise, it will be decomposed from the source SDO.
Other data services may be accessed and updated from an update override. The Mediator can be used to access data objects, modify and submit them. Alternatively, the modified data objects can be added to the update plan and updated when the update plan is executed. If the data object is added to the update plan, it will be updated within the current context and its container will be accessible inside its data service update override.
If the DataService Mediator API is used to perform the update, a new DataService context is established for that submit, just as if it were being executed from the client. This submit( ) acts just like a client submit — changes are not reflected in the data object. Instead, the object must be re-fetched to see the changes made by the submit.
AquaLogic Data Services Platform uses the underlying WebLogic Server for logging. WebLogic logging is based on the JDK 1.4 logging APIs (available in the java.util.logging package). You can open the log (from an update override) by acquiring a DataServiceMediatorContext instance, and then calling the getLogger( ) method on the context, as follows:
DataServiceMediatorContext context =
DataServiceMediatorContext().getInstance();
Logger logger = context.getLogger()
You can then write to the log by issuing the appropriate log level call. When WebLogic Server message catalogs and the NonCatalogLogger generate messages, they convert the message severity to a weblogic.logging.WLLevel object. A WLLevel object can specify any of the values listed in Table 9-5, from lowest to highest impact:
| Note: | Development_time logging is written to the following location: |
<bea_home>\user_projects\domains\<domain_name>
Given the specified logging level, the Mediator logs the information shown in Table 9-6.
Listing 9-8 shows a sample log entry.
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - begin client sumbitted DS: ld:DataServices/Customer.ds><Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - ld:DataServices/Customer.ds number of execution: 1 total execution time:171>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/CUSTOMERS.ds number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.CUSTOMERS set CUSTOMERNAME=? where CUSTOMERID=? AND CUSTOMERNAME=? number of execution: 1 total execution time:0>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - ld:DataServices/PO_ITEMS.ds number of execution: 3 total execution time:121>
<Nov 4, 2004 11:50:10 AM PST> <Info> <LiquidData> <000000> <Demo - EXECUTING SQL: update WEBLOGIC.PO_ITEMS set ORDERID=? , QUANTITY=? where ITEMNUMBER=? AND ORDERID=? AND QUANTITY=? AND KEY=? number of execution: 3 total execution time:91>
<Nov 4, 2004 11:50:10 AM PST> <Notice> <LiquidData> <000000> <Demo - end clientsumbitted ds: ld:DataServices/Customer.ds Overall execution time: 381>
Locking mechanisms are used in numerous types of multi-user systems for concurrency control. Concurrency control ensures that data is consistent across transactions and regardless of the number of users acting on the system at the same time. Optimistic locking mechanisms are so-called because they typically only lock data at the time it is being updated (written to), rather than having the default state of the data be locked. (See also Enable/Disable Optimistic Locking.)
AquaLogic Data Services Platform employs an optimistic locking concurrency control policy, locking data only when updates are being attempted.
When the WebLogic Server instance of AquaLogic Data Services Platform receives a submitted data graph, it compares the values of the data used to instantiate the original data objects with the original values in the data graph to ensure that the data was not changed by another user process during the time the data objects were being modified by a client application.
The Mediator compares fields from the original and the source; by default, Projected is used as the point of comparison (see Table 9-7).
You can specify the fields to be compared at the time of the update for each table. Note that primary key column must match, and BLOB and floating types might not be compared. Table 9-7 describes the optimistic update policy options.
| Note: | If AquaLogic Data Services Platform cannot read data from a database table because another application has a lock on the table, queries issued by AquaLogic Data Services Platform are queued until the application releases the lock. You can prevent this by setting transaction isolation (on your WebLogic Server's JDBC connection pool) to read uncommitted. See the topic "Setting the Transaction Isolation Level" in the Configuring Aqualogic Data Service Platform Applications chapter of the Administration Guide. |
Java custom update classes can be used to create JPD workflows to handle updates to different data services. You can then create server-side Java code that initiates synchronous or asynchronous JPDs using the JpdService interface.
As with other types of AquaLogic Data Services Platform server-side custom functionality, the update override interface facilitates the implementation.
The JPD and the data service containing the Java update override can be running in the same WebLogic Server domain or in different WebLogic Server domains.
The JpdService is invoked with the name of the JPD, the start method of the JPD, the service URI, and the server location and credentials for the JPD, as shown in this example:
JpdService jpd = JpdService.getInstance("CustOrderV1", "clientRequestwithReturn", env);JPD provides a public interface (as a JAR file containing the compiled class file for the JPD public contract or interface). Transparently to developers, the JpdService object uses the standard Java reflection API to find the JPD class that implements the JPD public contract.
The server-side update overrides Java code and then passes the DataGraph as an argument to the invoke method:
Object jpd.invoke( DataGraph sdoDataGraph );
The returned object is dependent on the JPD being invoked and may be null. Typically, if any top-level SDO is being inserted and its primary key is autogenerated, then this should be returned from the JPD (see Listing 9-9).
Any keys for the top-level DataObject in the serialized UpdatePlan are returned to the calling function as a Properties object (comprising a byte array). Thus, the return value from the workflow must be a serialized byte array, as in:
Properties [] jpd.invoke( byte[] serializedUpdatePlan );
The array returned is a Properties object array representing any keys for the top-level DataObject in the UpdatePlan that was serialized and sent to the workflow.
Support for JPDs from AquaLogic Data Services Platform is provided through two server-side APIs that can be invoked from within an UpdateOverride implementation (see Table 9-8).
Listing 9-9 shows how to invoke a JPD from an UpdateOverride. The code sample assumes that a JPD exists comprising a series of data services configured as part of a workflow.
public boolean performChange( DataGraph ) {
ChangeSummary changeSum = dataGraph.getChangeSummary();
//Size of 0 means no changes so there's nothing to do
if (changeSum.getChangedDataObjects().size()==0) {
return true;
}
Environment env = new Environment();
env.setProviderUrl( "t3://localhost:7001" );
env.setSecurityPrincipal( "weblogic" );
env.setSecurityCredentials( "weblogic" );
try {
JpdService jpd = JpdService.getInstance(
"CustOrderV1",
"clientRequestwithReturn",
env);
UpdatePlan updatePlan = DataServiceMediatorContext.
currentContext().getCurrentUpdatePlan( dataGraph );
byte[] bytePlan = UpdatePlan.getSerializedBytes( updatePlan );
Properties (Properties) returnProps = jpd.invoke( bytePlan );
}
catch( Exception e )
{
e.printStackTrace();
throw e;
}
return false;
}
}AquaLogic Data Services Platform supports JPD invocations both synchronously and asynchronously; both styles of invocation are handled the same way in the update override code. Invoke the JPD and get the response back as a byte array, as illustrated in Listing 9-9.
You must write your own error-handling code with the JPD. Calling a non-existent JPD raises the standard Java exception, ClassNotFoundException.
Using callbacks in your JPD is not supported. Business processes that include client callbacks will fail at runtime since the callback is sent to the JPD Proxy, rather than the originating client that started the JPD.


|