



|
|
ALSB enables you to monitor and collect run-time information required for system operations. ALSB aggregates run-time statistics, which you can view on the dashboard. The dashboard allows you to monitor the health of the system and notifies you when alerts are generated in your services. With this information, you can quickly and easily isolate and diagnose problems as they occur.
This section provides information on the following topics:
You can monitor ALSB at run time to know how many messages in a particular service have processed successfully and how many have failed.
The ALSB monitoring framework provides access to information about the number of messages that were processed successfully or failed, which project the service belongs to, the average execution time of message processing, and the number of alerts associated with the service. Using the ALSB Console you can view monitoring statistics for the period of the current aggregation interval or for the period since you last reset statistics for this service or since you last reset statistics for all services. Using the public APIs you can access only the statistics since the last reset.
Monitoring in ALSB involves monitoring of the operational resources, servers, and Service Level Agreements (SLAs). Figure 3-1 is an illustration of the architecture of the ALSB monitoring framework.
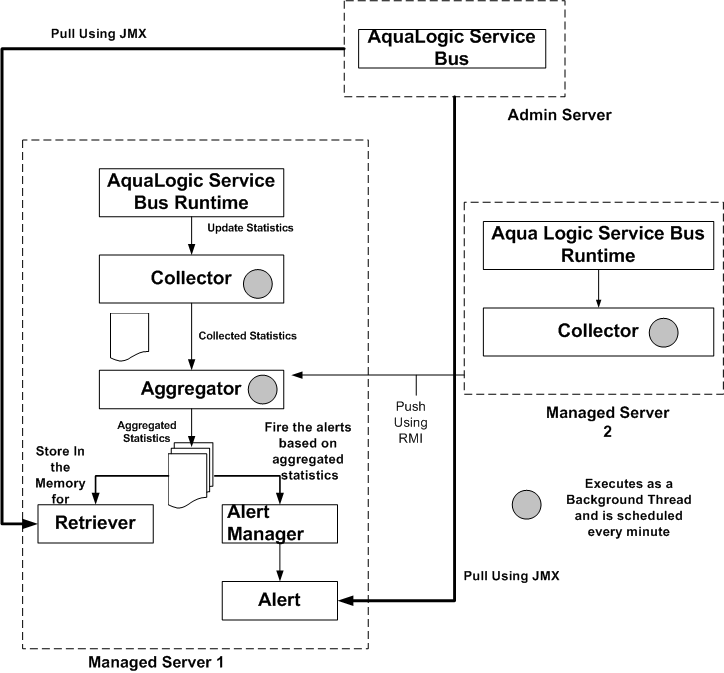
ALSB monitoring architecture consists of the following components:
| Note: | An operational resource is defined as the unit for which statistical information can be collected by the monitoring subsystem. Operational resources include proxy services, business services, service level resources such as Web Services Definition Language (WSDL) operations, flow components in a pipeline, and endpoint URIs. |
The Collector collects the updated statistics from ALSB run time and sends it to Aggregator.The Aggregator aggregates the statistics over the aggregation interval. The aggregated statistics are pushed to the Alert Manager. The Alert Manager triggers alerts based on these statistics. The aggregated statistics are also stored and can be retrieved by the Retriever. The following steps are executed when you monitor a service in ALSB run time:
In a cluster, all the statistics which are collected in the managed servers are pushed to the aggregator. You can access the cluster wide statistics from the Service Health tab. For more information, see How to Access Statistics in a Cluster. You can also access statistics using APIs. For more information, see How to Access Statistical Information Using the JMX Monitoring APIs.
The alerts are pulled from the managed server that hosts the aggregator, and they are displayed in the ALSB Console.
In ALSB, the monitoring subsystem collects statistics, such as message count over an aggregation interval. The aggregation interval is the time period over which statistical data is collected and displayed in the ALSB Console. Statistics which are not based on an aggregation interval are meaningless. In addition to statistics collected over well-defined aggregation interval you can also collect cumulative statistics.
Aggregation interval is a moving window, which always refers to an interval of time in minutes, hours or days. It does not move with infinite granularity or precision, but at regular intervals of time called the sampling interval. This enables an aggregation interval to move smoothly and produce accurate statistics.
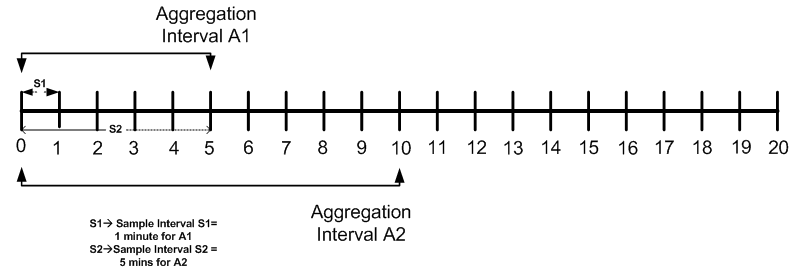
Figure 3-2 is an illustration of the of Aggregation interval. For example aggregation interval A1 is set at five minutes and aggregation interval A2 has been set at ten minutes. ALSB run time collects statistics for the service with aggregation interval A1 for every minute (S1). It aggregates the statistics at the end of the aggregation interval. Similarly for aggregation interval A2 it collects statistics for every five minutes (S2). Intervals S1 and S2 are called sampling intervals. For more information about sample interval, see Sample Intervals Within Aggregation Intervals .
In ALSB run time statistics are computed at regular intervals, within every aggregation interval. These regular sub intervals are known as the sample interval. The duration of the sample interval depends on the aggregation interval. Table 3-1 gives the length of sample interval for different aggregation intervals:
Aggregation interval in ALSB has the following properties:
You can only specify an aggregation interval less than or equal to seven days.
When you modify the aggregation interval of a service, the statistics of the service in the current aggregation interval is reset. However, the status of the endpoint URI for the service remains unaffected by the change in the aggregation interval. A running count metrics of the service is not reset when modify the aggregation interval.
When you rename or move a service within ALSB, all the monitoring statistics that have been collected in the ALSB Console are lost. All current aggregation interval and cumulative metrics are reset and the service is monitored from start. If endpoint URI for a service was marked offline before it was renamed or moved, then after you rename or move the service, the URIs are marked online again and the status of the URI is displayed as online.
You can monitor services in ALSB and collect statistics for all services. Monitoring system in ALSB supports the following types of statistics:
For more information about different types of statistics, see Monitoring Statistics in ALSB. For more information on how to access statistics using APIs, see How to Access Statistical Information Using the JMX Monitoring APIs.
You can access the statistical information for a service through the ALSB Console or directly by using the JMX monitoring APIs. This section describes accessing the information through the ALSB Console and the JMX monitoring APIs. For more information about accessing the statistical information through JMX monitoring APIs, see JMX Monitoring API Programming Guide.
You can access the service statistics from the ALSB Console for a stand alone server or a cluster. This section describes how to access statistics for a standalone server. For information on how to access service statistics for a cluster, see How to Access Statistics in a Cluster.
In the you can access the statistical information for services in the current aggregation interval or for time interval since the last reset. The Service Health tab of dashboard provides the statistical information for current aggregation interval and since last reset. For more information, see How to Access Service Statistics for the Current Aggregation Interval and How to Access Running Count Statistics for Services.
You can also access statistical information directly from a program using the Java Management Extensions (JMX) monitoring APIs. Using the JMX monitoring APIs you can access only the running count statistics. The JMX monitoring APIs provide an efficient lower level support for bulk operations. For more information about using JMX monitoring APIs, see JMX Monitoring API Programming Guide.
In a cluster environment, statistics are available at individual managed server level and the cluster level. In Service Health tab choose Cluster or the name of a managed server from the Server drop-down list, to view statistics for the cluster or the individual managed server.
To get detailed statistics for a particular service in a cluster, access the service monitoring details page for the service from the Service Health tab. On the Service Monitoring Details page, you can access the cluster wide statistics by setting the Server drop-down list to Cluster. By setting it to the individual managed server value, statistics pertaining to that specific server can be viewed.
Set Display Statistics to Current Aggregation Interval to view cluster statistics in the current aggregation interval or Since Last Reset to view the running count statistics for the cluster.
You can reset the statistics of business services and proxy services from the Service Health tab of the dashboard or from the Service Monitoring Details page for a service. Table 3-2 describes how to reset statistics in each case.
Click the Service Health tab to go to the Service Health page. Click Reset Statistics icon to reset statistics for a service. Click Reset All Statistics link to reset statistics for all the services for which monitoring is enabled.
For more information about how to reset statistics, see
Resetting Statistics for Services in Monitoring in Using the AquaLogic Service Bus Console.
|
|||
When you reset statistics for a service in the ALSB Console, all the statistics collected for the service since the last reset is lost. You cannot undo this action. The status of endpoint URIs is not reset when you reset statistics.
SLA alerts are raised in ALSB to indicate potential violation of the Service Level Agreements (SLAs). You can use alerts for:
Pipeline alerts can be raised in the message flow of the proxy service. You can use the alerts in a message flow for:
You can configure the severity of an alert in an alert rule for SLA alerts or in the Alert action of a message flow of a proxy service. The severity level of alerts is user configurable and has no absolute meaning. You can configure alerts with one of the following levels of severity:
The alert destinations are notified when an alert is raised. If you do not configure any alert destination in an alert rule or an alert action, the notifications are sent to the ALSB Console. For more information in alert destinations, see What are Alert Destinations?.
SLA alerts are automated responses to violations of Service Level Agreements (SLAs). These alerts are displayed on the ALSB dashboard. They are generated when the service violates the service level agreement or a predefined condition. To raise an SLA alert, you must enable SLA alerting both at the service level and at the global level. For more information about how to configure operational settings for services, see How to Configure the Operational Settings for a Service. The Alert History panel contains a customizable table displaying information about violations or occurrences of events in the system.
You must define alert rules to specify unacceptable service performance according to your business and performance requirements. Each alert rule allows you to specify the aggregation interval for that rule when configuring the alert rule. This aggregation interval is not affected by the aggregation interval set for the service. For more information about aggregation interval, see Aggregation Intervals. Alert rules also allow you to send notifications to the configured alert destinations. For information on defining alert rules, see Creating and Editing Alert Rules in Monitoring in Using the AquaLogic Service Bus Console.
Consider the following use case to verify the service level agreements:
Assume that a particular proxy service is generating SLA alerts due to slow response time. To investigate this problem, you must log into the ALSB Console and review the detailed statistics for the proxy service. At this level, you can able to identify that, a third-party Web service invocation stage in the pipeline is taking a lot of time and is the actual bottleneck. You can use these alerts as the basis for negotiating SLAs. After successfully renegotiating SLAs with the third-party Web service provider, you must configure alert metrics to track the Web service provider's compliance with the new agreement terms.
Pipeline alerts can be generated in a message flow whenever you define an Alert action available under the reporting category in the message flow.
You can also define conditions under which a pipeline alert is triggered using the conditional constructs available in the pipeline editor such as Xquery Editor or an if-then-else construct. The ALSB Console is the default alert destination for pipeline alerts. You can also configure the Alert Destination resource in an alert action, to define additional destinations for pipeline alerts.
You can have complete control over the alert body including the pipeline, and context variables. Also you can extract the portions of the message. For more information about how to configure Alert actions in a stage, see
Adding Alert Actions in Proxy Service: Actions in Using the AquaLogic Service Bus Console. When the alert action is executed the alerts are notified to the appropriate alert destinations.
You can obtain an integrated view of all the pipeline alerts generated by a service on the dashboard page in the ALSB Console.
Consider the following use case for pipeline alerts:
Consider a case when you want to be notified when special business conditions are encountered in a message flow. You can configure an alert action is a message flow to raise alerts when such predefined conditions are encountered. You can also configure email alert destination to receive an email notification of the alert. You can also send the details to the email recipient in the form of payload.
For example, in the case of a proxy service that routes orders to a purchase order website, and you want to be notified when an order exceeding $10 million is routed. For this you must configure an alert action in the appropriate place in the pipeline, with the condition and configure email alert destination with the email information and use it as the target destination in the alert action. You can also include the details of the order in the form of payload.
You can also use pipeline alerting to detect errors in a message flow. For example, in the case of a proxy service that validates the input document, you want to be notified when the validation fails so that you can contact the client to fix the problem. For this you must configure an alert action within the error handler for the message flow of the proxy service. In the action you can include the actual error message in the fault variable and other details in the SOAP header, to be sent as the payload. You can also configure additional alert destinations using an alert destination resource in the alert action.
In the ALSB Console the extended alert history page for the SLA alerts contains information about all the SLA alerts that have been generated in the domain. You can view all the alerts that were triggered or search for specific alerts from the table. For more information about data displayed in the extended SLA alert history page, see Locating Alerts in Monitoring in Using the AquaLogic Service Bus Console.
You can delete the alerts from the Extended Alert History page or the View Alert Details page. You can filter your search using the Extended Alert History Filters pane. For more information on how to filter your search, see How to Filter a Search for SLA Alerts.
To view a pie or bar chart of the alerts, click View Bar Chart or View Pie Chart in the page. Click Purge SLA Alert History to delete all the SLA alerts. You can also purge the alerts based on the date and time they were raised.
The extended alert history page for the pipeline alerts contains information about all the pipeline alerts that have been generated in the domain. You can view all the alerts that were triggered or search for specific alerts from the table. For more information about data displayed in the extended pipeline alert history page, see Locating Alerts in Monitoring in Using the AquaLogic Service Bus Console.
You can delete the alerts from the Extended Pipeline Alerts page or from the View Alert Details page. For more information on how to filter your search, see How to Filter a Search for Pipeline Alerts. To view a pie or bar chart of the alerts, click View Bar Chart or View Pie Chart link in the page. Click Purge Pipeline Alert History to delete all the pipeline alerts. You can also purge the alerts based on the date and time they were raised.
Use Extended Alert History to filter a search for specific alerts. The following sections describe how to search for SLA alerts and pipeline alerts using extended alert history filters.
Use Extended Alert History Filters pane to filter a search for SLA alerts. Table 3-3 describes the various criteria on which you can filter SLA alerts.
Use Extended Alert History Filters pane to filter a search for pipeline alerts. Table 3-4 describes the various criteria on which you can filter pipeline alerts.
Alert destinations are resources to which alerts are sent. The ALSB Console is the default alert destination for the notification of any alert. The alerts are notified to the ALSB Console console regardless of whether you configure an alert destination or not. The console provides information about the alerts generated due to SLA violations or as a result of alert actions configured in the pipeline. The dashboard page displays the overall health of ALSB. It provides an overview of the state of the system comprising server health, services health, and alerts.
For more information about how to interpret the information on the dashboard, see The ALSB Dashboard.
In ALSB you can configure Email, SNMP Traps, Reporting and JMS as alert destinations.
E-mail alert destination, allows you to receive messages when alerts are raised in the ALSB Console. To configure this alert destination you have to use the SMTP server global resource or a JavaMail session in the WebLogic server. For more information on configuring a default SMTP Server resource, see Configuring a Default SMTP Server in Global Resource in Using the AquaLogic Service Bus Console. For more information about configuring JavaMail sessions, see Configure Access to JavaMail in WebLogic Server Administration Console Online Help
The SMTP server global resource captures the address of the SMTP server, port number, and if required, the authentication credentials. The authentication credentials are stored inline and are not stored as a service account. The alert manager makes use of the e-mail alert destination to send the outbound e-mail messages when both pipeline alerts and SLA alerts are generated. When an alert is delivered, an e-mail metadata consisting of the details about the alert is prefixed to the details of the payload that is configured.
You can specify the e-mail ID of the recipients in the Mail Recipients field. For more information about configuring an e-mail alert destination, see Adding E-Mail Recipients in Adding E-mail and JMS Recipients in Alert Destinations in Using the AquaLogic Service Bus Console.
The Simple Network Management Protocol (SNMP) traps allow any third-party software to interface monitoring service level agreements within ALSB. By enabling the notification of alerts using SNMP, Web Services Management (WSM) and the Enterprise Service Management (ESM) tools can monitor SLA violations and pipeline alerts by monitoring alert notifications.
SNMP is an application-layer protocol which allows the exchange of information on the management of a resource across a network. It enables you to monitor a resource and, if required, take some action based on the data obtained from the resource. Both the SNMP version 1 and SNMP version 2 are supported by ALSB. SNMP includes the following components:
For more information, see SNMP Components.
The Reporting destination allows you to send notifications of pipeline alerts or SLA alerts to the custom reporting provider that can be developed using the reporting APIs provided with ALSB. This allows third parties to receive and process alerts in custom Java code.
Java Messaging Service (JMS) is another destination for pipeline alerts and SLA alerts. You must configure a JNDI URL for the JMS destination for alerts. When you configure an alert rule to post a message to a JMS destination, you must create a JMS connection factory and a queue or topic, and target them to the appropriate JMS server in the WebLogic Server Administration Console. For information on how to do this, see Configuring a JMS Connection Factory and JMS Resource Naming Rules for Domain Interoperability in Configuring JMS System Resources in Configuring and Managing WebLogic JMS. When you define the JMS alert destination you can either use a destination queue or a destination topic. The message type can be bytes or text. For more information about how to configure JMS alert destination see Adding JMS Recipients in Adding E-mail and JMS Recipients in Alert Destinations in Using the AquaLogic Service Bus Console.
Operational settings enable you to control the state of a service in the ALSB Console. Table 3-5 describes operational settings for services in the ALSB Console.
The operational settings at the service level is overridden by the global settings. For more information about configuring operational settings globally, see How to Configure the Operational Settings at the Global Level.
You can enable or disable the operational settings for an individual service from the Operation Settings view of the View a Proxy Service (see Figure 3-3) or View a Business Service page (see Figure 3-4). For more information, see Creating and Configuring Business Services in Business Services: Creating and Managing and Creating and Configuring Proxy Services in Proxy Services: Creating and Managing in Using the AquaLogic Service Bus Console.
Some operational settings such as service state, monitoring, SLA alerting, and pipeline alerting can enabled or disabled through public APIs. For more information, see Javadoc for AquaLogic Service Bus.
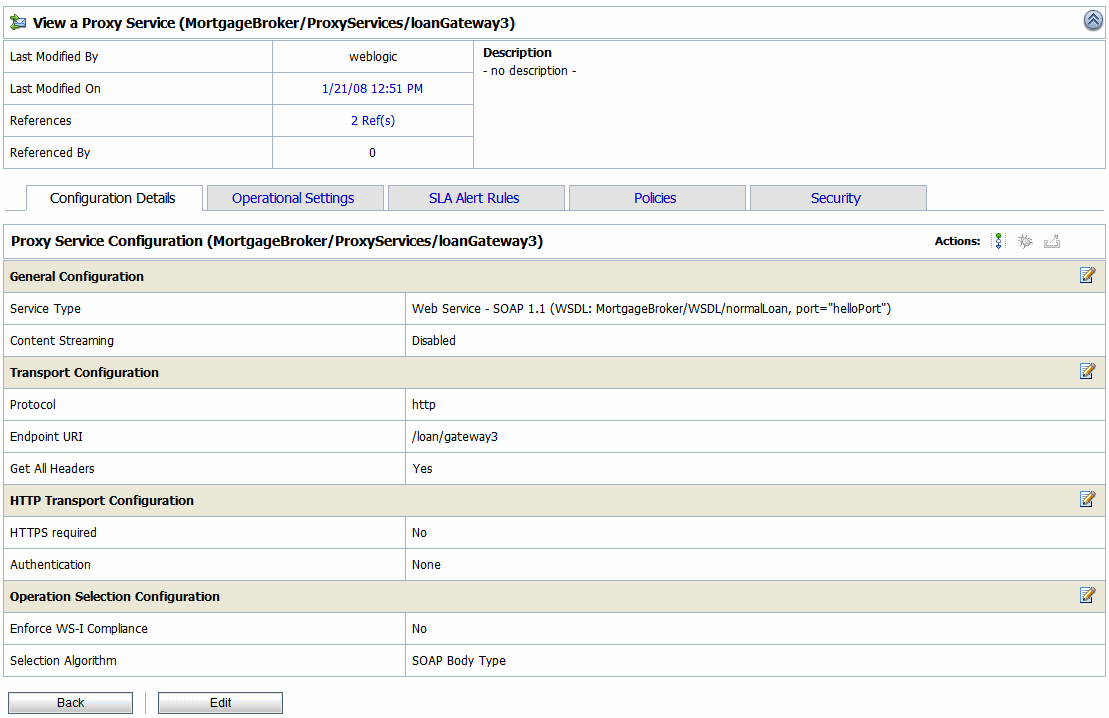
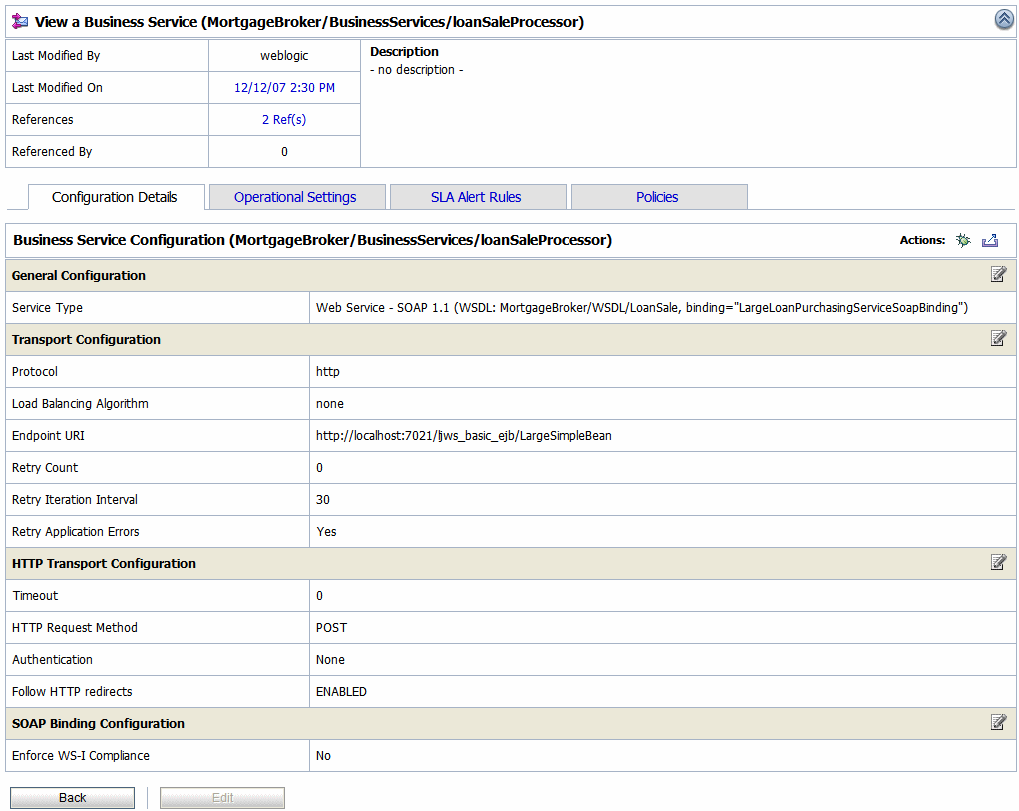
You can perform the following operational settings for proxy services and business services:
For a detailed description of the usage of each operational setting for business services, see Configuring Operational Settings for Business Services in Monitoring in Using the AquaLogic Service Bus Console. For a detailed description of the usage of each operational setting for proxy services, see Configuring Operational Settings for Proxy Services in Monitoring in Using the AquaLogic Service Bus Console.
You can access the Global Settings page from the operations module. You can use the Global Settings page (see Figure 3-5) to configure the operational settings for services. Table 3-6 describes the usage of the operational settings at the global level.
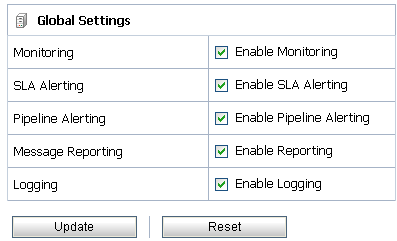
For more information, see Enabling Global Settings in Configuration in Using the AquaLogic Service Bus Console.
| Notes: |
When a service is overwritten by the way of importing configuration from a config jar, the operational settings of this service can be also be overwritten. To preserve the operational settings during import, you must set the Preserve Operational Settings flag to true while importing the service. For more information, see What Happens to Alert Rules When You Import ALSB Configurations?
When you import ALSB configurations, if the config jar that is being imported also contains the global settings of the domain from which it is being imported, then these domain level settings can get overwritten. In order to prevent this, set Preserve Operational Settings flag to true while importing the service.
You can preserve operational settings during import of ALSB configurations using APIs. For more information, see Importing and exporting configuration using the new API in Interface ALSBConfigurationMBean. Modify the MBean as shown in Listing 3-1 to preserve the during the import.
/**
// Imports a configuration jar file, applies customization, activates it and exports the resources again
// @throws Exception
/
static private void simpleImportExport(String importFileName, String passphrase) throws Exception {SessionManagementMBean sm = ... // obtain the mbean to create a session;
// obtain the raw bytes that make up the configuration jar file
File importFile = new File(importFileName);
byte[] bytes = readBytes(importFile);
// create a session
String sessionName = "session." + System.currentTimeMillis();
sm.createSession(sessionName);
// obtain the ALSBConfigurationMBean that operates on the
// session that has just been created
ALSBConfigurationMBean alsbSession = getConfigMBean(sessionName);
// import configuration into the session. First we upload the
// jar file, which will stage it temporarily.
alsbSession.uploadJarFile(bytes);
// then get the default import plan and modify the plan if required
ALSBJarInfo jarInfo = getImportJarInf();
ALSBImportPlan importPlan = jarInfo.getDefaultImportPlan();
// preserve operational values
importPlan. setPreserveExistingOperationalValues(true);
// Modify the plan if required and pass it to importUploaeded method
ImportResult result = alsbSession.importUploaded(importPlan);
// Pass null to importUploaded method to mean the default import plan.
//ImportResult result = alsbSession.importUploaded(null);
// print out status
if (result.getImported().size() > 0) { System.out.println("The following resources have been successfully imported."); for (Ref ref : result.getImported()) { System.out.println("\t" + ref);}
}
if (result.getFailed().size() > 0) { System.out.println("The following resources have failed to be imported."); for (Map.Entry e : result.getFailed().entrySet()) {Ref ref = e.getKey();
// Diagnostics object contains validation errors
// that caused the failure to import this resource
Diagnostics d = e.getValue();
System.out.println("\t" + ref + ". reason: " + d);}
// discard the changes to the session and exit
System.out.println("Discarding the session.");sm.discardSession(sessionName);
System.exit(1);
}
// peform the customization to assign/replace environment values and
// to modify the references.
...
// activate the session
sm.activateSession(sessionName, "description");
// export information from the core data
ALSBConfigurationMBean alsbcore = getConfigMBean(null);
//export the information at project level, pass only a collection of project refs to this method
byte[] contentsProj = alsbcore.exportProjects(Collections.singleton(Ref.DEFAULT_PROJECT_REF),null);
// the byte contents can be saved as jar file
}
In ALSB you must define conditions based on which alerts are raised. The conditions are configured in an SLA alert rule. The alert rule also configures the severity level and an alert destination for an alert.
SLA alerts are automated responses to SLAs violations, which are displayed on the dashboard. You must define alert rules to specify unacceptable service performance according to your business and performance requirements. When you configure an alert rule, you must specify the aggregation interval. The alert aggregation interval is not affected by the aggregation interval set for the service. For more information about aggregation interval, see Aggregation Intervals.
Creating an alert rule involves the following steps:
| Note: | You can create alert rules even if you have not enabled for monitoring for a service. |
For more information about creating an alert rule, see Creating And Editing Alert Rules in Monitoring in Using the AquaLogic Service Bus Console.
For a service for which monitoring is enabled, Alert rule is evaluated at discrete intervals. Once an alert rule is created it is first evaluated at the end of the aggregation interval, and after that at the end of each sample interval. For example, if the aggregation interval of an alert rule is five mins, it is evaluated five minutes after it is created, and then every minute after that (since sample interval for five mins, is one min).
If a rule evaluates to false no alert is generated. If the rule evaluates to true the alert generation is governed by the Alert Frequency. If the frequency is Every Time, an alert is generated every time an alert rule evaluates to true. If the frequency is Notify Once, an alert is generated only if no alert is generated in the previous evaluation. In other words, an alert is generated the first time the alert rule evaluates to true and no more notifications are generated until the condition resets itself and evaluates to True again.
The View Alert Rule Details page displays complete information about a specific alert rule, as shown in Figure 3-6. You can view the details of the alert rule in this page. You can edit an alert rule configuration from this page. For more information about how to edit an alert rule, see Creating and Editing Alert Rules in Monitoring in Using the AquaLogic Service Bus Console.
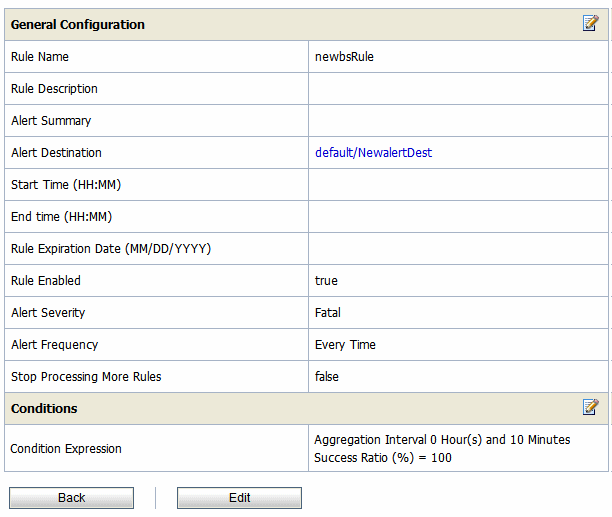
You can rename the alert rules from the SLA Alert Rules tab of View a Business Service or View a Proxy Service page. To rename an alert rule click Rename Alert Rule icon. Enter the new name for the alert rule in New Alert Rule Name field of the Rename Alert Rule window. Click Rename.Click Update and activate the session to complete. For more information, see Viewing Alert Rules in Monitoring in Using the AquaLogic Service Bus Console. The Rename icon for the renamed alert is now disabled.
When alerts are triggered, they are listed on the alert history page. Click View Alert Rule Details action icon to access the alert rule page. However, when you rename an alert rule, you cannot access the alert rule by clicking the View Alert Rule Details action from the alert history page, for the alerts that were raised before it was renamed. You can access the Alert Details page from the alert history page for the alerts that are raised before-and after renaming the alert rule. The alert name is greyed in the Alert Details page for the alerts that were raised before the alert rule was renamed. When you rename an alert details icon for the renamed alert gets disabled.
Similar limitations exist when you attempt to access the alert rule page by clicking the alert name link on the alert details page. The alert name generated by alerts rules that are later renamed refers to an outdated name. You can view the old alert rule, but the name is grayed out indicating that the alert rule has been renamed.
When you rename an alert rule, the conditions on which a rule is based are preserved. The aggregation interval of the alert rule is also preserved. The alert is raised at the end of the first aggregation interval after the alert rule is renamed. For example, consider an alert rule a1 with aggregation interval five minutes. If the alert rule is renamed to a2 after two minutes of execution the next alert under the name a2 is generated three minutes after the is renamed.
You can preserve the alert rule configurations when you import ALSB configurations. When you import ALSB configurations, the operational settings are preserved. When services with alert rules exists in a jar that you import but does not exist in the target domain, then these services along with the alerts rules are imported as is. However, if the same service exists in the target domain as well, then the import behavior is governed by the state of the Preserve Operational Settings during the import operation. For more information on how to preserve operational settings, see Updates to Operational Settings During Import of ALSB Configurations.
The ALSB dashboard displays service health, server health and details of all the alerts that have been triggered in ALSB run time. The dynamic refresh of this display is controlled by the Dashboard Refresh Rate setting in the User Preferences page. The default option for this setting is No Refresh. These alerts can be the result of SLA violations or pipeline alerts. Service Level Agreements(SLAs) are agreements that define the precise level of service expected from the business and proxy services in ALSB. Pipeline alerts are defined in the message flow for business purposes such as record the number of message that flow through the message pipeline, to track occurrences of certain business events, or to report errors but not for the health of the system.
Each row of the table displays the information that you have configured, such as the severity, timestamp, and associated service. Clicking the Alert Name link displays Alert Details page for more details about the SLA alert. This helps you to analyze the cause of the SLA alert. Clicking the Alert Summary link displays the Alert Details for more details about the pipeline alert. This helps you to analyze the cause of the SLA alert.
From the dashboard, you can drill-down into the system and easily find specific information, such as the average execution time of a service, the date and time an alert occurred, or the duration for which server has been running.
The following sections helps you to understand the information displayed on ALSB dashboard.
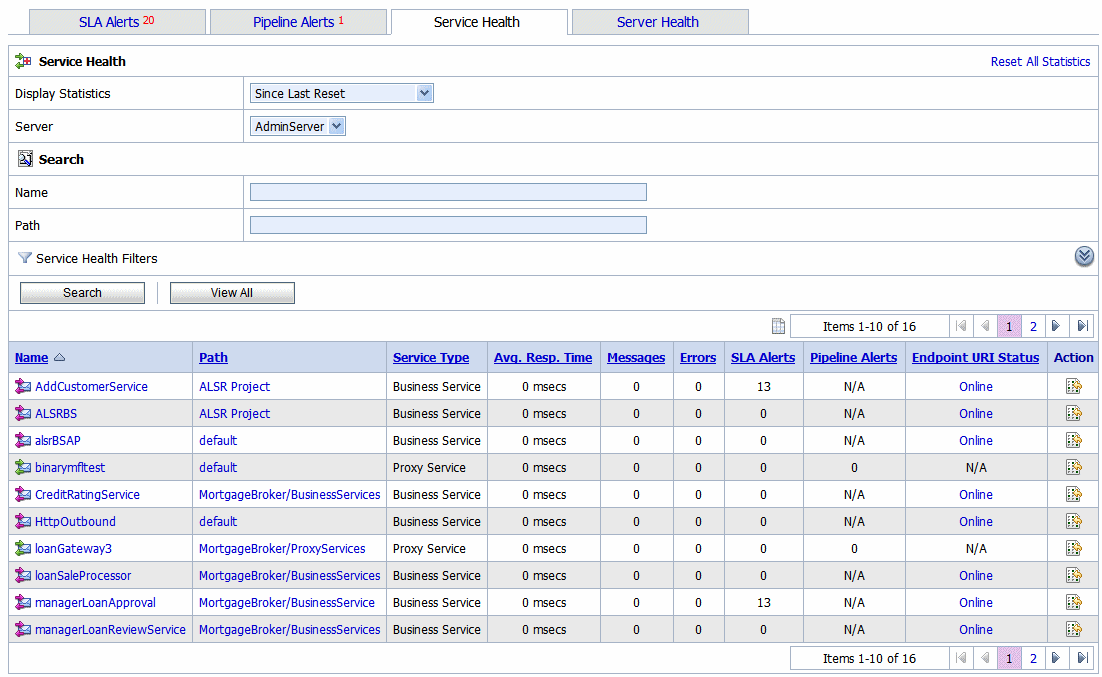
Click the Service Health tab to access the Service Health page. The Service Health page is displayed as shown in Figure 3-8.
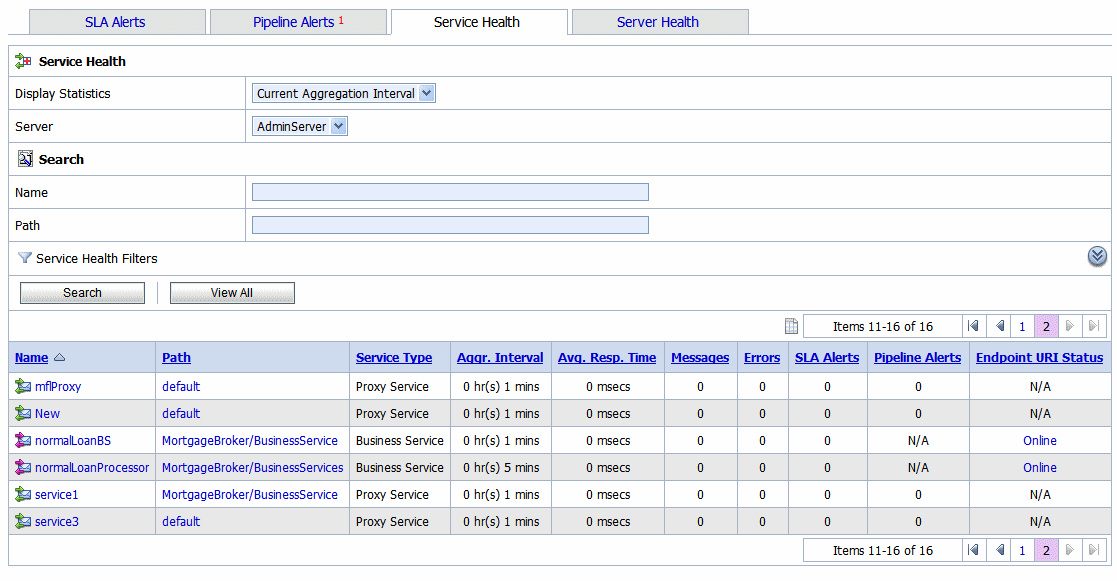
This is a dynamic view of statistical data collected by each service. This view is available when you select Current Aggregation Interval in the Display Statistics field. The aggregation interval displayed in this view determines the statistics that are displayed. For example, if the aggregation interval of a particular service is twenty minutes, that service’s row displays the data collected in the last twenty minutes. From this page you can view all services or search for services based on the given criteria. For more information about the statistics displayed in this page, in the Current Aggregation Interval view, see Viewing Service Metrics in Monitoring in Using the AquaLogic Service Bus Console.
The Service Monitoring Details page provides you with two views of detailed information about a specific service. Figure 3-9 shows the Service Monitoring Details page for a business service in the current aggregation interval. Figure 3-10 shows the Service Monitoring Details page for a proxy service. To access this page click the name of the service in the Service With Most Alerts section, Alert History table, or extended alert history table for SLA alerts and pipeline alerts. Also the name of the service in Service Health tab is a link to Service Monitoring Details page.
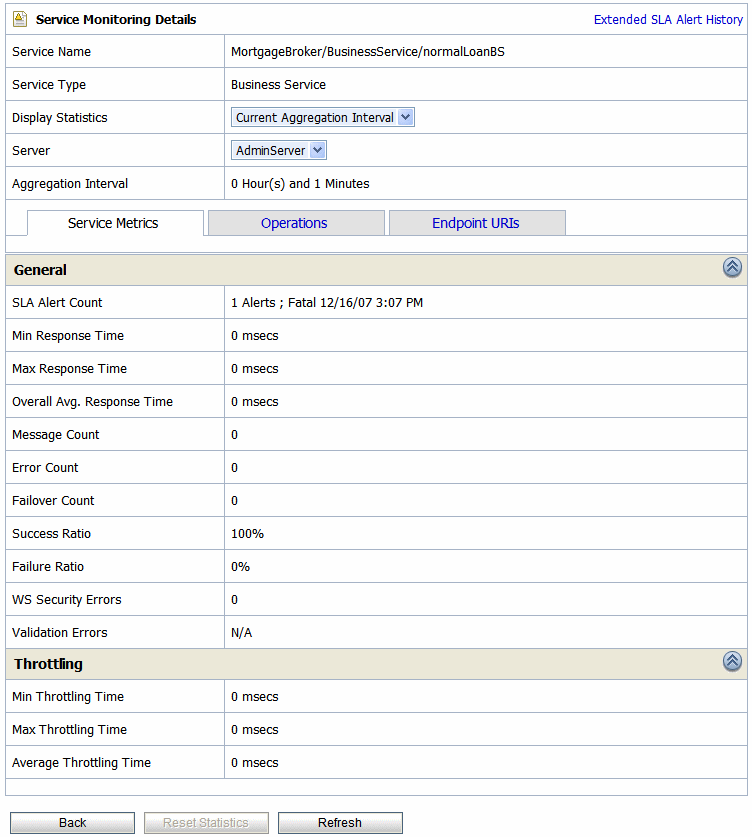
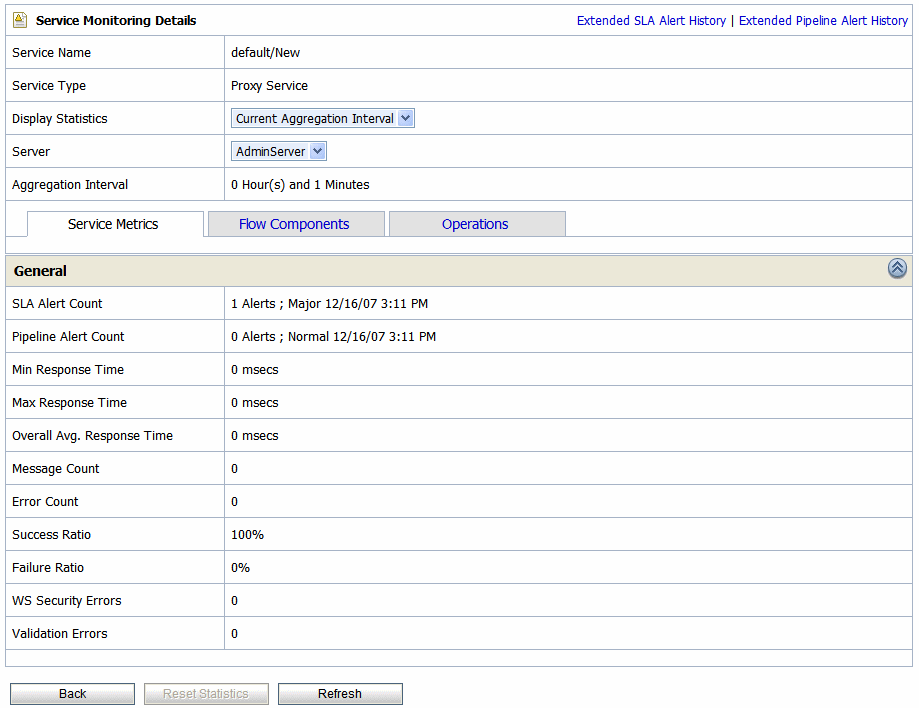
This is a dynamic view of statistical data collected by each service. This view is available when you select Current Aggregation Interval in the Display Statistics field. The aggregation interval displayed in this view determines the statistics that are displayed. For example, if the aggregation interval of a particular service is twenty minutes, this page displays the data collected in the last twenty minutes for that service. For more information on different tabs available for a business service, see Service Metrics, Operations, and Endpoint URIs. For more information on different tabs available for a proxy service, see Service Metrics and Flow Components and Operations.
For more information about the statistics displayed in this page, in the Current Aggregation Interval view, see Viewing Service Metrics in Monitoring in Using the AquaLogic Service Bus Console.
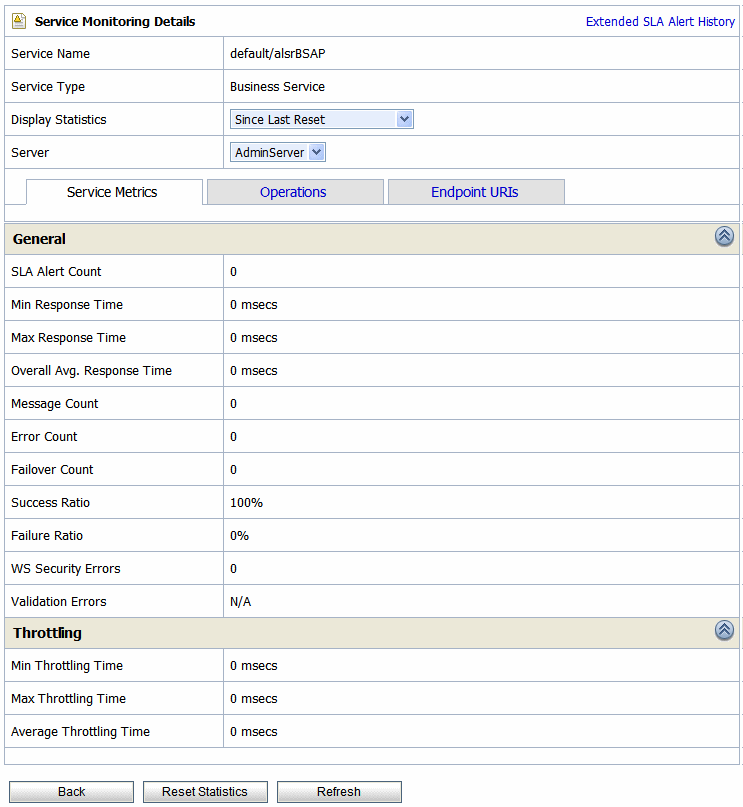
The running count statistics for a service are statistics that are available since the last reset.
This view is a running count of the service health metrics. This view is available when you select Since Last Reset in the Display Statistics field. The statistics displayed in each row are for the period since you last reset the statistics for an individual service or since you last reset the statistics for all services. You can also reset statistics for selected services or for all services. For more information about the statistics displayed in this page, in the Since Last Reset view, see Viewing Service Metrics in Monitoring in Using the AquaLogic Service Bus Console.
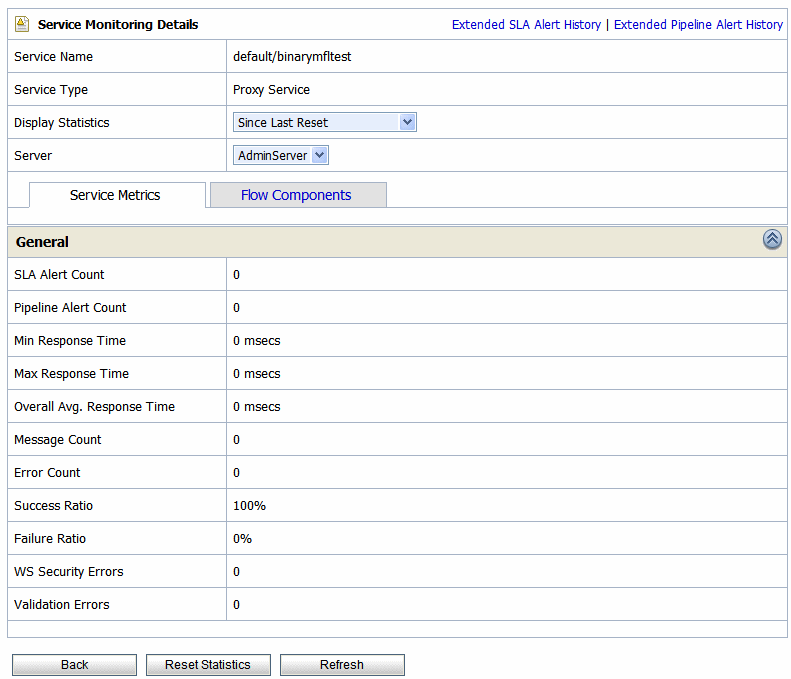
This view is a running count of the service monitoring metrics. This view is available when you select Since Last Reset in the Display Statistics field. The statistics displayed in each row are for the period since you last reset the statistics for an individual service or since you last reset the statistics for all services. From this page you can view all services or search for services based on the given criteria. You can also reset statistics for this service. For more information about the statistics displayed in this page, in the Since Last Reset view, see Viewing Service Metrics in Monitoring in Using the AquaLogic Service Bus Console.
You have the following tabs in the Service Monitoring Details page for each of the views:
The Service Metrics (see Figure 3-14) view displays the metrics for a proxy service or a business service.
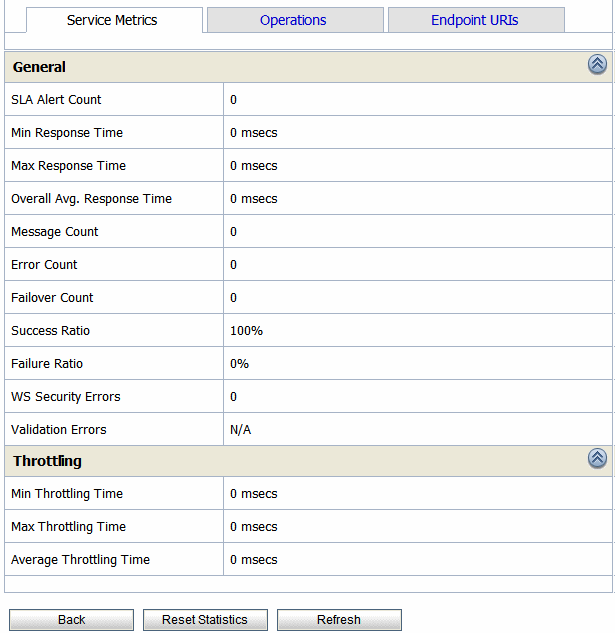
The Service Metrics tab displays the following types of metrics:
These metrics are displayed for WSDL based services for which you have defined operations. The Operations tab (see Figure 3-15) displays the statistics for the operation defined in a WSDL based service . For more information statistics displayed in this tab, see Viewing Operations Metrics for WSDL Based Services in Monitoring in Using the AquaLogic Service Bus Console.

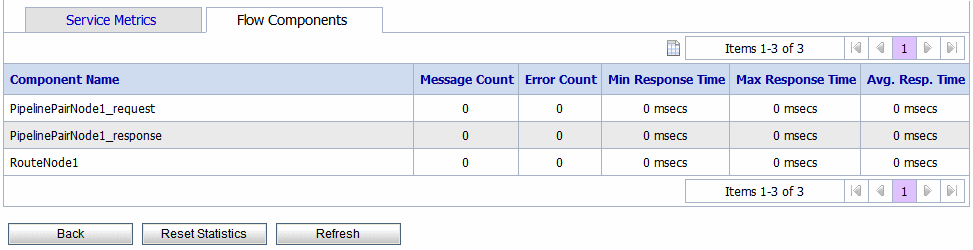
This view (see Figure 3-16) gives information on various components of the pipeline of the service. The Flow Components tab is available only for proxy services. For more information about the statistics displayed in this tab, see Viewing Flow Components Metrics in Monitoring in Using the AquaLogic Service Bus Console.
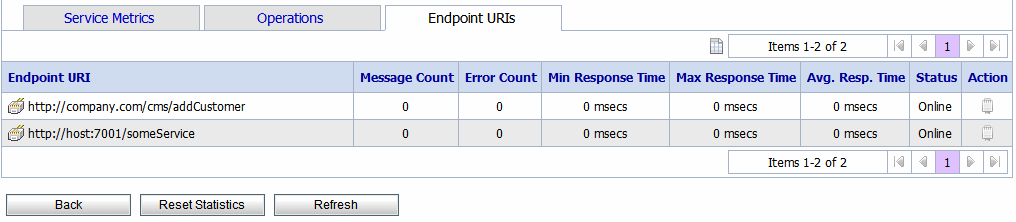
The Endpoint URIs tab of the Service Monitoring page for a business service gives statistics of the various endpoint URIs configured for a business service and their status. For more information about the statistics displayed in this view, see Viewing Business Services Endpoint URIs Metrics in Monitoring in Using the AquaLogic Service Bus Console.
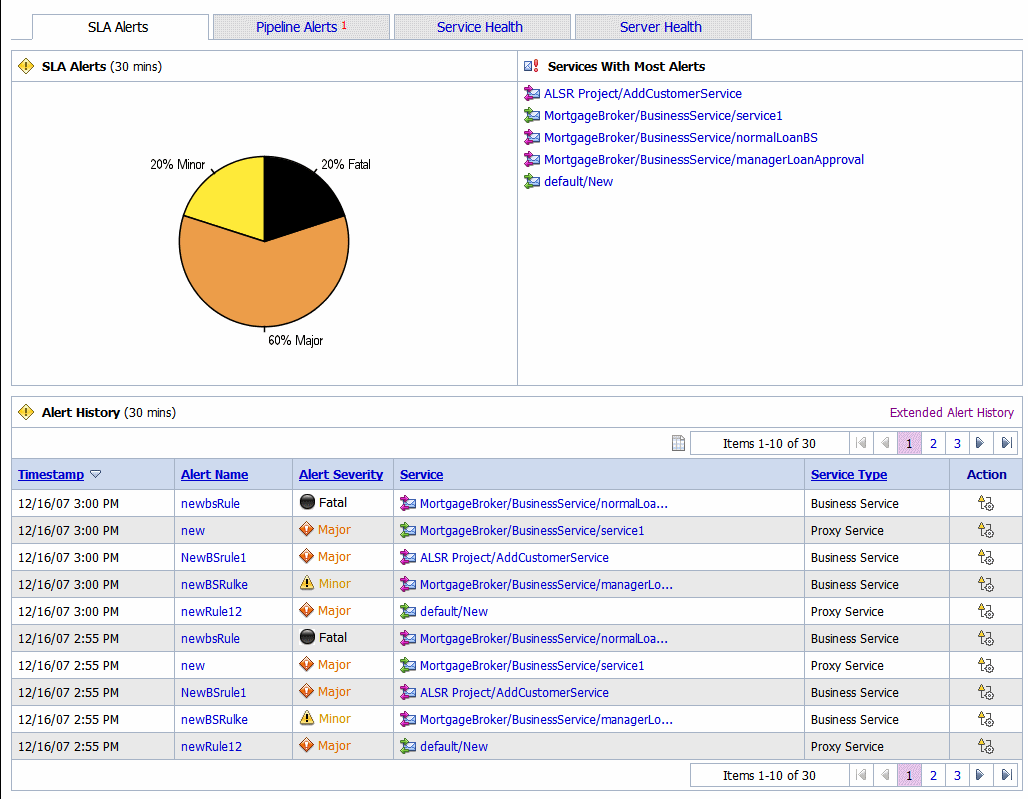
You can view the details of SLA alerts in the SLA Alerts tab of the dashboard. Table 3-7 describes the dashboard for SLA alerts:
The pie chart shows the distribution of SLA alerts based on their severity for the duration set for alert history in the dashboard settings page. The severity level of alerts is user configurable and has no absolute meaning. For more information about alert severity, see Assigning Severity for Alerts.
|
|
This section gives details for all the SLA alerts generated during the alert history duration. For more information, see Viewing the Alert History for Pipeline Alerts.
|
The Alert History (Figure 3-7) for SLA alerts table shows all the SLA alerts, which have occurred in the alert history duration you have set in the User Preferences page. For more information about alert history table, see Viewing SLA Alerts in Monitoring in Using the AquaLogic Service Bus Console.
To view a complete list of alerts, click Extended Alert History. For more information about Extended Alert History, see How to View or Delete SLA Alerts.
You can view the pipeline alerts in the Pipeline Alerts tab of the dashboard (see Figure 3-18). Table 3-8 describes the dashboard for pipeline alerts.
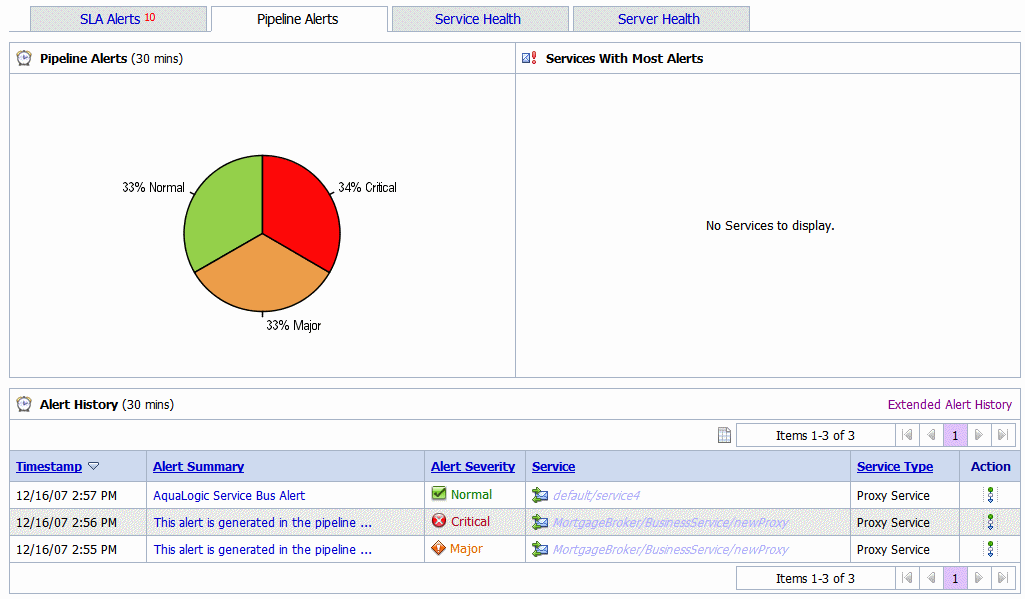
The pie chart shows the distribution of pipeline alerts based on their severity for the duration set for alert history in the dashboard settings page. The severity level of alerts is user configurable and has no absolute meaning. For more information about alert severity, see Assigning Severity for Alerts.
|
|
This section gives details for all the pipeline alerts generated during the alert history duration. For more information, see Viewing the Alert History for Pipeline Alerts.
|
The Alert History (Figure 3-7) for pipeline alerts table shows all the pipeline alerts, which have occurred in the alert history duration you have set in the User Preferences page. For more information about Alert History table, see Viewing Pipeline Alerts in Monitoring in Using the AquaLogic Service Bus Console.
To view a complete list of alerts, click Extended Alert History. For more information about Extended Alert History, see How to View or Delete Pipeline Alerts.
You can view the server summary in Server Health tab of the dashboard.
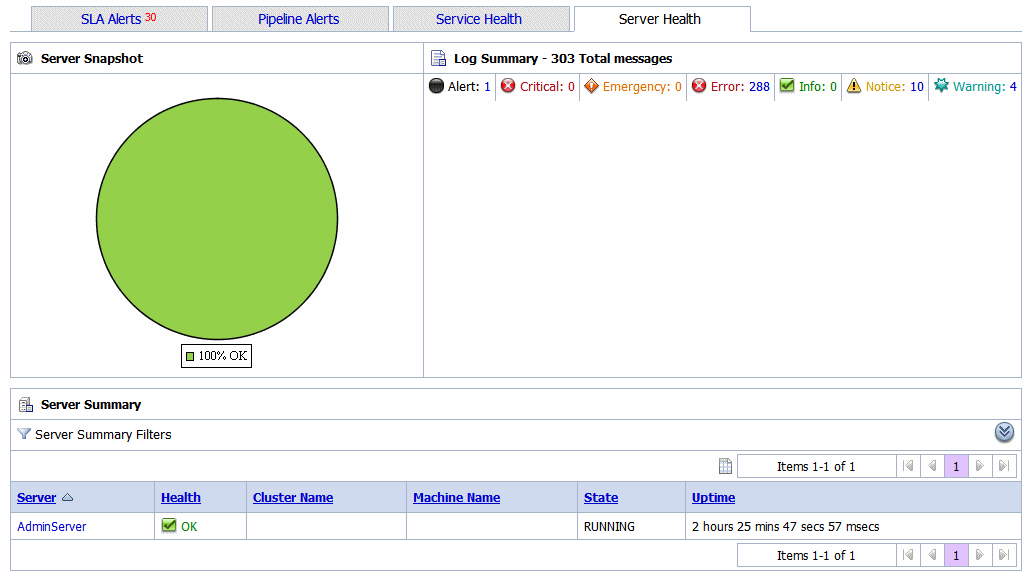
The Log Summary section in the Server Health tab displays the summary log for the servers associated with the domain. The domain log file provides a central location from which to view the overall status of the domain. Each server instance forwards a subset of its messages to a domain-wide log file. By default, servers forward only messages of severity level Notice or higher. You can modify the set of messages that are forwarded. For more information, see
Understanding WebLogic Logging Services in Configuring Log Files and Filtering Log Messages.
If you configure the logging action in a pipeline, the log is forwarded to the admin server log. You can view the logging messages in the Server Health tab of the ALSB Console. In a cluster it is forwarded to the managed server. You cannot view the logging messages in the ALSB Console. Unless you configure WebLogic Server to forward these messages to the domain log, you cannot view this log from the ALSB Console. For information on how to do this, see Create Log Filters in the WebLogic Server Administration Console Online Help.
To see the number of messages currently raised by the system, click the View Log Summary link in the Server Summary panel. A table is displayed that contains the number of messages grouped by severity, as shown in Figure 3-19.
You can view the log summary only if you posses administrator privileges in the WebLogic Server Console.
Table 3-9 describes the status messages in the log summary.
This display is based on the health state of the running servers, as defined by the WebLogic Diagnostic Service. For more information about the WebLogic Diagnostic Service, see Configuring and Using the WebLogic Diagnostics Framework.
To view the domain log for a particular status of alert message, click the number corresponding with the status of alert message. shows an example of a domain log file displayed in the ALSB Console.
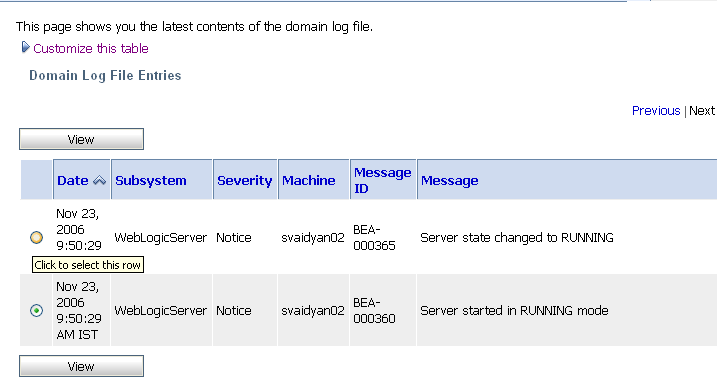
For more information about domain log file, see Viewing Domain Log Files in Monitoring in Using the AquaLogic Service Bus Console.
For more information, see Message Attributes in Understanding WebLogic Logging Services in Configuring Log Files and Filtering Log Messages.
To display details of a single log file on the page, select the appropriate log, then click the View. You can also customize the Domain Log File Entries table to view the following additional information:
For additional description of these information, see Viewing Details of Server Log Files in Monitoring in Using the AquaLogic Service Bus Console. For more information about how to customize the Domain Log File Entries table, see Customizing Your View of Domain Log File Entries in Monitoring in Using the AquaLogic Service Bus Console.
You can view the Server Summary in the Server Health tab of the dashboard. In a single node domain, the Server Summary displays the summary of the admin server. In a cluster domain, it displays the health of all the servers in a cluster, in case of a cluster environment. For more information on Server Summary, see Viewing Server Information in Monitoring in Using the AquaLogic Service Bus Console.
You can access this page by clicking the name of a server under server summary or by clicking the name of a server in the Servers Summary page.
This page enables you to view more server monitoring details, as shown in Figure 3-21.

The information displayed on this page is a subset of the Monitoring tab in the ALSB Console Server Settings page. Table 3-10 describes the available information.
For more information, see WebLogic Server Administration Console Online Help.


|