

|
|
|
|
|
|
What Is BEA MessageQ?
Message queuing is a technique for information exchange among distributed applications. Message queues can reside in computer memory or on disk. Message queues store messages until they are read by the receiver program. Through message queuing, application programs can execute independently-they do not need to know each other's location or wait for the receiver program to retrieve the message before continuing.
BEA MessageQ is the industry-leading message queuing product providing connectivity to a broad range of multivendor platforms. This chapter provides an overview of:
The Distributed Computing Revolution
During the last two decades, businesses have increasingly moved computing power out of the data center and into the hands of departments and end users. This trend, called distributed computing, has accelerated in the last several years due to the proliferation of powerful and easy-to-use PCs and the advent of high-powered workstations and servers that offer high reliability and failover capability. This section describes:
Traditional Versus Distributed Applications
An application is defined as a program or set of programs designed to perform a particular business task, for example, a payroll application. Applications can be designed and implemented in one large, monolithic structure or they can be broken into separate components. Application components can be assigned to different processes which work cooperatively to perform the desired tasks. Traditional application design places all application components on a single computer system. Therefore, the component programs can share information easily through global memory and synchronize processing through the features of a single operating system.
Distributed computing, on the other hand, spreads out the processing of component tasks onto several computers tied together by a computer network. Designing a distributed application allows application components to run on different computer systems which can maximize efficient use of computing resources while distributing end user access to a corporate information databases.
For example, a traditional payroll application requires all component tasks to be performed on the same computer system. Therefore, all of a company's business locations would have to send employee payroll information to a central site for data entry, processing, and check printing. A distributed payroll application would allow entry of payroll data, check printing, and check distribution to be handled at different locations throughout the company.
Distributing the payroll application can reduce cost and improve efficiency by:
Major Trends in Distributed Computing
Today, distributed computing is revolutionizing the way businesses and individuals process information through:
By implementing a distributed approach to application development and integration, companies are:
Though distributed processing is very powerful, it is also very complex. Because many different computer systems may be involved in information processing, new issues have arisen in sharing information, synchronizing processing, and sharing results.
The challenge to developers when integrating distributed applications is to provide an efficient means of communication for distributed applications in a heterogeneous networked environment. To manage their information sharing needs, it is most efficient to provide applications with a common mechanism for exchanging information
Middleware is a type of software designed to form a layer between the application and the underlying operating system and network software. It provides applications with a common means of communication and independence from the network and operating system. Middleware provides developers with an application programming interface that is common to all environments. When a function call is embedded in a program, it performs the communication function for the application using the capabilities of the particular operating system and network environment in which it runs.
Figure 1-1 contrasts the middleware approach with the previously used method of linking each individual application in the environment.
Figure 1-1 Contrasting Application Integration Approaches
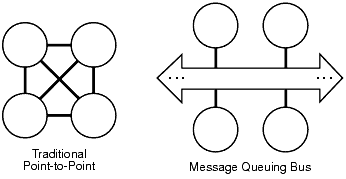
Without middleware to accomplish information exchange, application developers have to write the software for sending and receiving information by learning how to use the features of both network and operating system software to transport the data. And, without a standard approach to information exchange, each application must be programmed to communicate with each and every application in the multiplatform environment.
For example, to exchange information locally on OpenVMS systems, applications can use OpenVMS mailboxes. The same kind of information exchange on a UNIX system would require a knowledge of queues or pipes. Communicating between networked systems requires knowledge of how to exchange information over the network such as TCP/IP socket programming.
Distributed Computing Models
Decomposing an application into its component parts and distributing the parts across disparate computer systems is much more complex than implementing an application on a single system. Software developers use one of two communication models when designing applications to share information in a distributed environment as shown in Figure 1-2.
Figure 1-2 Client/Server versus Peer-to-Peer Information Exchange
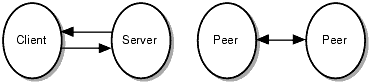
BEA MessageQ supports both the peer-to-peer or the client/server models of distributed computing.
Peer-to-Peer Communication Model
A message queuing system provides peer-to-peer communication through a standard message-passing mechanism. Communicating programs can operate independently while using the message queuing system to exchange information.
One program initiates communication with a remote program and exchanges messages with it, enabling two-way communication. Data and control information can flow in either direction. And, the communication can be synchronous or asynchronous. That is, the sender program can wait for a reply from the receiver program or continue immediately.
The peer-to-peer model is used by applications that work cooperatively to process information in a distributed environment. Each program in the distributed application may act as both a requester and fulfiller of service and information requests.
Client/Server Communication Model
The client/server model has emerged during the 1980s as an approach to distributed application design. Using this model, a distributed application is made up of two types of programs: ones that make requests and ones that fulfill requests for services or information.
Client programs require an easy-to-use interface to facilitate user requests for services or information. Because they do not process information, client programs do not need to run on powerful computers. Therefore, they can be designed to run on inexpensive personal computers which offer graphical user interface capabilities. Server programs, on the other hand, must run on faster, more powerful systems such as workstations which can also access large databases of corporate information.
The client/server design models fits well into today's corporate heterogeneous computing environment. With the large amount of PCs distributed throughout the corporation, this model can provide shared and efficient access to corporate information resources with appropriate safeguards.
Technologies for Building Distributed Applications
As with any trend in the computer industry, there is more than one product for building distributed applications. This section describes the three major approaches to distributed application design:
Remote Procedure Call (RPC) is a component of the Distributed Computing Environment (DCE), a software standard for application integration released by the Open Software Foundation. RPCs are modeled after the traditional programming approach where one program invokes another program through a function invocation. The invocation is in the form of a procedure call. Once called, the control of program is given over to the called procedure.
In an RPC implementation, the called procedure resides on and is executed on another system, which can be local or remote. When the called procedure is finished processing the input data, the results are returned to the calling program in the returned arguments of the procedure call. Program control is then returned to the calling program immediately after the RPC is completed.
Since RPCs imitate the call/return structure of a subroutine, they offer only synchronous data exchange between the client (calling program) and the server (called procedure). To overcome this limitation, developers must employ operating system features such as threads or subtasks to force the RPC to process in an asynchronous manner. Using asynchronous RPCs to integrate applications limits portability because the application code has become operating system dependent.
RPCs are best used when an application requires:
The CORBA (Common Object Request Broker Architecture) specification provides a broad and consistent model for building distributed client/server applications by defining:
The CORBA architecture and specification were developed by the Object Management Group (OMG), a consortium of information systems vendors. The goal of CORBA is to promote an object-oriented approach to building and integrating distributed software applications.
The BEA M3 system combines the best of distributed objects and transaction processing (TP) monitor technology into a new platform that is specifically aimed at providing high performance for enterprise distributed object applications using transactions.
The M3 system uses CORBA distributed object technology to provide a common programming model, leveraging from BEA TP monitor technology to provide an enhanced run time by extending the Object Request Broker (ORB) model with online transaction processing (OLTP) functions. The M3 system also leverages from the existing BEA core technology infrastructure for transaction management, security, message transport, administration and manageability, and XA-compliant database support.
Message Queuing
Message queuing offers a loosely-coupled approach to building distributed applications which can be implemented in a synchronous or asynchronous manner. Because messages are application defined, there is no restrictive structure specifying the way in which applications must be written. Instead, messaging API calls are embedded into new or existing application to provide the exchange of information through messages sent to and read from memory or disk-based queues.
Message queuing can be used in applications to perform a variety of functions such as requesting services, exchanging information, or synchronizing processing.
Message queuing is best used when an application requires:
Message queuing is a technique for sending messages from one program to another by providing an intermediate storage point in computer memory or in a disk file. Messages are stored in message queues until they can be read by the receiver program. By sending and receiving information using message queues, programs can execute independently-they do not need to know each other's location or wait for the receiver program to process the message before continuing. This section describes:
A message is an application-defined data structure. The application developer defines the content of the message. A message has the following components:
Communication through messaging requires both programs to agree upon the type of data in the message and the interpretation of the data. The software that delivers the message ignores its content message; the job of the message queuing system is simply to transport the message data.
What Is Message Queuing?
Message queuing is a technique for sending messages from one program to another by directing messages to a memory- or disk-based queue as an intermediate storage point. The queue stores the messages until they can be processed by the receiver program. By queuing messages, programs can execute independently-they do not need to wait for an application to process a message before continuing.
Message queuing works in the following way:
If the system cannot deliver the message because of a communications failure, receiver abort, or system crash, message recovery capabilities enable the message to be re-sent without further application intervention when communication is re-established.
Using message queuing, any program can send messages addressed to any other program that is attached to the message queuing bus. The sender program sends out the messages and can continue processing if an immediate response is not required. For this reason, message queuing adapts well to asynchronous interprocess communication needs.
Message queuing does not require applications to know the structure or state of another application in order to enable communication. As a result, queued communication offers a practical way to integrate applications running in distributed, multivendor environments.
How Does BEA MessageQ Work?
BEA MessageQ is an implementation of a message queuing system. To exchange information using BEA MessageQ, each program must attach to the BEA MessageQ message queuing bus at a particular queue address. The queue address identifies the message queue in which the program receives messages. To send a BEA MessageQ message, a program must know the queue address of the receiver program. In contrast to other message queuing systems, BEA MessageQ applications only attach to a queue in which they will receive messages. They do not attach to the queue to which they send messages.
The BEA MessageQ message queuing bus forms the data highway used to transfer messages between applications by creating a logical interconnection of message queues in a networked environment. Once an application is attached to the message queuing bus at a queue address, it can send messages to any other attached application and is also ready to read messages sent to its own queue or queues.
BEA MessageQ is said to provide a loosely-coupled approach to application integration because applications that share information do not have to:
A BEA MessageQ message queuing bus is composed of one or more message queuing groups. Message queuing groups offer applications an efficient way to share BEA MessageQ services such as recoverable messaging and message broadcasting on a network of computers. System managers configure cross-group connections to enable applications to exchange information when they are running in different message queuing groups on the same message queuing bus. Each message queuing group is identified by a unique number, the BEA MessageQ group ID. This group ID together with the unique queue number comprise the queue address of each message queue.
BEA MessageQ also allows the configuration of more than one message queuing bus in a networked environment. Applications attached to different message queuing buses cannot communicate with each other. Application developers can use this feature to set up a bus for communication of test programs and another bus for production applications. Mission-critical application processing is then separated from the testing environment. Test programs are easily moved into production by simply changing their bus ID-a configuration step in using BEA MessageQ that is external to the application. This feature may also be used to sparate multiple distributed business applications running on the same network.
Choosing the BEA MessageQ Server or Client
BEA MessageQ provides messaging services to applications running on desktop systems, workstations, mid-range systems, and high-end mainframes. BEA MessageQ offers these messaging services with two types of products:
All BEA MessageQ environments require the use of at least one message server implementation to offer full message routing to all other BEA MessageQ systems in the network. It is important to note that the terms client and server only refer to the messaging services provided by BEA MessageQ, they do not restrict the types of applications (clients or servers) that can be implemented in a particular environment.
How the BEA MessageQ Client Works
The BEA MessageQ Client is a client implementation of the BEA MessageQ Application Programming Interface (API). It provides message queuing support for distributed network applications along with a BEA MessageQ Server to provide reliable message queuing for distributed multiplatform network applications.
The BEA MessageQ Client is connected to the message queuing bus through a network connection with a Client Library Server (CLS) on a remote BEA MessageQ Server. The CLS acts as a remote agent to perform message queuing operations on behalf of the BEA MessageQ Client. The CLS runs as a background server to handle multiple BEA MessageQ Client connections.
The BEA MessageQ Client establishes a network connection to the CLS when an application attaches to the message queuing bus. The CLS performs all communication with the client application until the application detaches from the message queuing bus. The network connection to the CLS is closed when the application detaches from the message queuing bus. Figure 1-3 shows the BEA MessageQ Server and Client components.
Figure 1-3 How Client Applications Communicate using the CLS
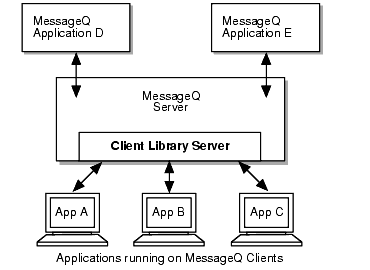
When to Choose the BEA MessageQ Client
The BEA MessageQ Client provides the following benefits:
The BEA MessageQ Client provides message queuing capabilities for BEA MessageQ applications using fewer system resources (shared memory and semaphores) and running fewer processes than a BEA MessageQ Server. Therefore, the BEA MessageQ Client enables distributed BEA MessageQ applications to run on smaller, less powerful systems than the systems required to run a BEA MessageQ Server. It also allows for a smaller client footprint for the client part of a client/server application.
Run-time configuration of the BEA MessageQ Client is extremely simple. A minimal configuration requires only the name of the server system, the network endpoint to be used by the CLS, and the desired network transport. Running the BEA MessageQ Client makes it unnecessary to install and configure a BEA MessageQ Server on each system in the network. Instead, a distributed BEA MessageQ environment can consist of a single system running a BEA MessageQ UNIX, Windows NT, or OpenVMS Server and one or more systems running BEA MessageQ Clients.
For example, suppose a small business has 10 networked workstations that need to run a BEA MessageQ application. Without the BEA MessageQ Client, it would be necessary to install, configure, and manage a message queuing group on each workstation. Using the BEA MessageQ Client, however, a BEA MessageQ Server need only be installed and configured on a single workstation. Installing the BEA MessageQ Client on the remaining nine workstations provides message queuing support for all other BEA MessageQ applications in the distributed network.
In this example, only one workstation needs to be sized and configured to optimize performance, reducing the burden of system management to a single machine. System management and configuration for the remaining systems is drastically simplified because managing the BEA MessageQ Client consists mainly of identifying the BEA MessageQ Server that provides full message queuing support. The BEA MessageQ Client can be reconfigured quickly and easily and multiple clients can share the same configuration settings to further reduce system management overhead. This also makes it easy to add additional clients to an application.
The BEA MessageQ Client performs all network operations for client applications making it unnecessary for a client program to be concerned about the underlying network protocol. The BEA MessageQ Client enhances the portability of applications enabling them to be ported to a different operating system and network environment supported by BEA MessageQ with no change to the application code.
Key Features of BEA MessageQ
BEA MessageQ has been recognized by independent industry consultants as the most feature-rich and fastest performing message queuing software available. Its key features are:
BEA MessageQ facilitates the development of distributed applications by enhancing:
Standardized Integration Approach
BEA MessageQ is communications middleware that provides software developers with a standard approach to information exchange between distributed applications in a multivendor environment. The BEA MessageQ interface is a set of application programming functions that are common to all BEA MessageQ products. To exchange information with other BEA MessageQ applications, a program simply includes the logic to attach to the BEA MessageQ message queuing bus and send a message and BEA MessageQ figures out how to deliver the message to the system on which the target application's queue resides.
BEA MessageQ API functions can be embedded in new or existing applications. Using BEA MessageQ, application developers no longer need to worry about the underlying transport to send and receive information between applications. In addition, applications no longer require constant maintenance to accommodate changes in operating system and network software. BEA MessageQ also provides productivity tools for developers to test message exchange before all components of the distributed application are complete.
Guaranteed Delivery
BEA MessageQ has built-in message recovery features that enable message delivery in the event of a system, process, or link loss with the network. To guarantee message delivery by BEA MessageQ, an application marks a message as recoverable when it is sent. BEA MessageQ stores each recoverable message in a disk file before sending it to the target queue.
If the message is successfully delivered to the target queue, it is deleted from the disk file. However, if the recoverable message cannot be delivered to the target system due to a system, process, or network failure, BEA MessageQ will automatically resend the messages stored in the disk file at a later time when the failure condition has been resolved.
Guaranteed delivery ensures that messages are delivered without further intervention by the sender program. The sender program need only ensure that the message was accepted by the message recovery system in order to be assured that it will be delivered to the target queue.
Application Portability
Because BEA MessageQ uses a common API for all environments, applications move easily using systems from different vendors. For example, if you develop BEA MessageQ applications for Intel PCs running Microsoft Windows NT, the same application programs will run on all major UNIX systems by recompiling and relinking the applications in their target environment.
Figure 1-4 illustrates how the BEA MessageQ API forms a layer between the application and the operating system and network environment-ensuring application portability and shielding applications from changes in underlying software. Note that DECnet is supported only on OpenVMS systems.
Figure 1-4 How the BEA MessageQ API Insulates Applications
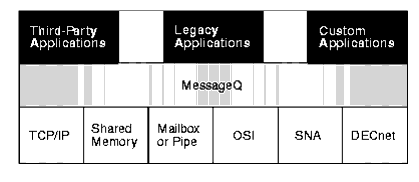
Message Bus Simplifies Communication
Message queuing provides a simplified approach to application integration in a distributed multivendor environment. Because BEA MessageQ handles all of the operating system and network-dependent tasks to move a message from one system to another, applications are easier to develop and maintain.
In addition, BEA MessageQ uses a simple application programming interface that consists of four basic callable functions:
Using these four functions, an application program has the ability to exchange information with any other attached application in a distributed, multivendor environment.
Broad Multiplatform Support
BEA MessageQ runs in all industry-leading environments. Refer to Table 1-1 for a listing of BEA MessageQ products illustrating the operating systems supported. TCP/IP networking is supported on all platforms.
|
Product Type |
Operating System |
|---|---|
|
Message Server |
IBM AIX |
|
NCR MP-RAS |
|
|
Compaq Tru64 UNIX |
|
|
Hewlett-Packard HP-UX |
|
|
Digital OpenVMS |
|
|
Sun Microsystems Solaris |
|
|
SCO UnixWare |
|
|
SCO OpenServer |
|
|
Sequent Dynix/ptx |
|
|
Microsoft Windows NT (Intel and Alpha) |
|
|
Messaging Client |
IBM AIX |
|
NCR MP-RAS |
|
|
Compaq Tru64 UNIX |
|
|
Hewlett-Packard HP-UX |
|
|
SCO UnixWare |
|
|
SCO OpenServer |
|
|
Sequent Dynix/ptx |
|
|
Digital OpenVMS |
|
|
Sun Microsystems Solaris |
|
|
Microsoft Windows 95 |
|
|
Microsoft Windows NT (Intel and Alpha) |
|
|
IBM MVS |
|
|
MQSeriesConnection |
Hewlett-Packard HP-UX |
|
IBM AIX |
|
|
Sun Microsystems Solaris |
|
|
Microsoft Windows NT |
Flexibility to Meet Changing Application Needs
BEA MessageQ provides the kind of flexibility applications need to evolve in a rapidly changing application environment through its support of Field Manipulation Language (FML) for self-describing messaging. Using FML, you have a built-in capability to make the following design changes:
BEA MessageQ allows you to use double pointers with buffer-style messages (messages using a pre-defined structure agreed upon by the sending and receiving applications). When the receiving application retrieves the message from the queue, the pams_get_msg call points to a pointer to dynamically allocated space. This allows for buffer reallocation if the message buffer received is larger than expected. This also means you can change the message structure without having to recode the application.

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|