

|
|
|
|
|
|
Preparing for BEA MessageQ Implementation
This chapter discusses BEA MessageQ basic terms and concepts as well as the planning necessary for a successful implementation of BEA MessageQ software on OpenVMS systems.
The following topics are covered in this chapter:
BEA MessageQ Basic Concepts and Terms
The basic unit of BEA MessageQ system management is the message queuing group. A message queuing group is a collection of message queues that are used by an application and that share access to a local interprocess communications (IPC) facility and BEA MessageQ Servers. A message queuing group can support more than one application. Message queuing groups are connected to one another using cross-group connections over network links.
Supported Network Protocols
BEA MessageQ has full heterogeneous communications capability for directing BEA MessageQ messages across message queuing groups to any supported platforms.
BEA MessageQ for OpenVMS software resides on top of DECnet and Transmission Control Protocol/Internet Protocol (TCP/IP) networking software and various intra-CPU communications mechanisms. On Compaq VAX and Alpha systems, BEA MessageQ for OpenVMS supports communications using DECnet, TCP/IP, LU6.2 protocol, and Ethernet.
Message Queues
The BEA MessageQ message queuing bus provides the interprocess communications vehicle that enables applications to exchange information using queued messaging. The message queuing bus is a set of BEA MessageQ message queuing groups that are configured to communicate with each other.
A message queue provides an area for an application to store and retrieve messages. A message queue is configured by the application developer and managed by BEA MessageQ. To receive BEA MessageQ messages, an application must be associated with at least one queue.
Message queues can be thought of as attachment points on the message queuing bus. A message queue is a physical resource with a unique ID within a group and can be permanent or temporary. A permanent queue exists whether or not a process is attached to it. A temporary queue exists only when a process is attached to the message queuing bus.
BEA MessageQ supports three types of message queues: primary, secondary, and multireader.
The primary queue acts as the main mailbox for a user process. An application can have only one primary queue, although it may be associated with queues of other types. When an application reads a message from its primary queue, or any other queue, the message is removed from the queue. Messages are read in first-in/first-out (FIFO) order unless another order is specified.
The secondary queue acts as an alternate mailbox for the user process to receive messages.
A multireader queue acts as a central mailbox that is used by several user processes (applications). Many user processes can simultaneously attach and read messages from a multireader queue.
The BEA MessageQ environment consists of two kinds of processes:
All user processes in a BEA MessageQ for OpenVMS message queuing group share several sections of global memory, run-time libraries (RTLs), and are served by the following BEA MessageQ Server processes:
Figure 1-1shows the servers and other process components of a message queuing group.
Figure 1-1 Components of a BEA MessageQ Message Queuing Group
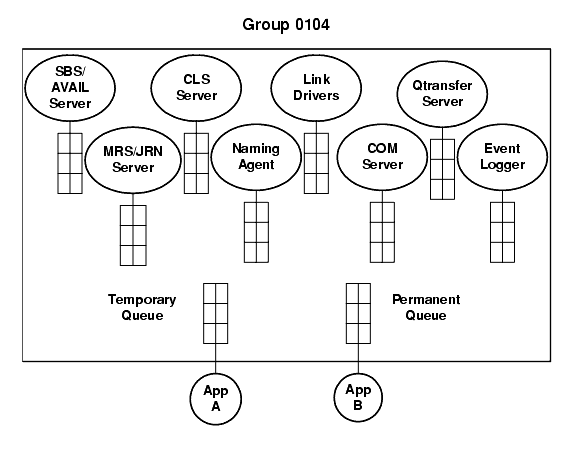
The COM Server creates and maintains the message queuing environment for the message queuing group and provides many of the BEA MessageQ message-based services. The COM Server also coordinates the actions of the link drivers which provide cross-group communication. It contains a DECnet link driver that is used to communicate to other OpenVMS systems and older versions of BEA MessageQ software.
The Message Recovery Services Server manages the disk storage required to handle recoverable message traffic. The BEA MessageQ message recovery system guarantees message delivery in the event of system, network, or application failures. Messages designated as recoverable are directed to an MRS Server for storage and removal from storage when delivery is confirmed by a user or another MRS Server.
The Selective Broadcast Services Server controls the broadcasting of data between an application program and multiple receiving application programs. In addition, the SBS Server provides AVAIL/UNAVAIL message-based services.
The Client Library Server controls the access of the Windows-based client applications to the message queuing functionality available using BEA MessageQ for UNIX, Windows NT, or OpenVMS.
A link driver provides transparent communications over a particular network transport. BEA MessageQ for OpenVMS supports cross-group communication in both DECnet and TCP/IP network environments.
The Journal Server controls journal management functions handling opening, closing, and dumping of all auxiliary journal files.
The Naming Agent maintains the namespace for name-to-queue address translation and performs the runtime lookup of the queue address when an application refers to a queue by name.
The event logger manages the common event log EVL_LOG. It serves as a single repository for logging all BEA MessageQ events. All entries are time stamped, and the file is sortable by various keywords, if error messages from a particular source needs to be isolated. The EVL_LOG can be closed, and moved and a new log started, from the DMQ$MGR_UTILITY menu.
The Queue Transfer Server manages the transfer of recoverable messages to a different queue.
Naming is a BEA MessageQ capability that enables applications to refer to queues by name instead of using their physical address in the BEA MessageQ environment. Using naming separates applications from the specifics of the network environment and enables system managers to make configuration changes without requiring developers to change the applications.
BEA MessageQ names can be defined to have a local or global scope. Local names are visible only to applications running in a particular group. Global names are available for use by any application attached to the message queuing group.
The BEA MessageQ process that supports the global naming capability is called the Naming Agent. The Naming Agent is responsible for creating and managing the name space of global name definitions and for name-to-queue address translation at runtime. In addition to its built-in ability to support global naming, the BEA MessageQ naming feature can also use a Distributed Name Server (DNS) to provide global naming capabilities.
Global Memory
The BEA MessageQ global memory provides storage for queue addresses and allocates memory space for message queuing groups and message buffers.
BEA MessageQ / BEA TUXEDO Bridge
BEA MessageQ V5.0 include a messaging bridge that allows the exchange of messages between BEA MessageQ V5.0 and BEA TUXEDO V6.5. This exchange of messages is made possible by two TUXEDO servers that are included in the BEA MessageQ kit and that run on the same machine as BEA MessageQ: TMQUEUE_BMQ and TMQFORWARD_BMQ. The messaging bridge is available only on OpenVMS Alpha 7.1 systems.
Configuring Distributed Systems Using BEA MessageQ
The basic unit of BEA MessageQ system management is the message queuing group. Message queuing groups consist of several message queues and share access to a common set of BEA MessageQ Servers. Message queuing groups are connected to one another by network links.
Management of each message queuing group is a relatively independent task. Therefore, it is best to assign each BEA MessageQ message queuing group a small set of application functions. Large or complex systems should be implemented as a network of queuing groups.
On large OpenVMS systems, the task of installing software is often assigned to a system manager who may not have detailed knowledge of each installed product. The system manager must learn the system resources required by each application, such as the size of the paging file, and amount of global memory and disk space required. OpenVMS SYSGEN parameters may have to be increased to accommodate installation of additional applications. To run BEA MessageQ and it applications, the system manager must configure the system with the appropriate resources to support the needs of all message queuing groups.
While some BEA MessageQ system parameters automatically adjust from default settings according to the load and available resources, the systems designer may have to make some decisions regarding BEA MessageQ resources and then set the parameters accordingly.
Queues need to be assigned to particular application services and various pools need to be sized. While this can be done in an iterative, ad-hoc way during the development stage, it is better to have a well-planned design and system model, and to make sizing decisions based on this model.
Design Paradigms
There are many design paradigms for distributed systems. No matter which paradigm is used, it should produce an abstract description that describes the information used by the system, and the things that happen in the system.
The abstract description is then transformed into a network of queues, application servers that read from the queues, and messages that flow between the application servers and encapsulate the characteristics and behavior. Each application server in a good design is assigned a specific function or a limited number of related functions to perform.
Traditional Functional Model
Using a traditional design methodology such as Yourdon/DeMarco1, the system would be described by a series of data flow diagrams which show data flowing to and from abstract processes and data stores.
When using such a methodology, once the system data flow is known, the process of breaking down the diagram into physical processes and messages can start. Often a one-to-one association between physical process and abstract process can be made; for example, a process bubble in the diagram becomes a physical process. In some cases, several actions will be assigned to one physical process.
You should also consider the storage of data in media under application control, such as shared memory, disk files, or data base packages. The details of the choice for the type of storage are driven by access time requirements: how long the data must be stored, and how the data will be used.
The decision to place data in some type of data store, necessitates the assignment of a physical process to manage writes or reads and writes to the data store. Data stores are often local to a particular computer or network node. The assignment of a server process to manage the store and a design that buffers access to the server by message queuing leads to a design with wide distributed access, fast and deterministic access times, and good scalability.
The location of physical processes on a network is sometimes well known because a data store managed by a service must be located on a particular node. In other cases, the decision to assign physical processes to network nodes is driven by load balancing considerations.
Object-Oriented Methodology
One of the difficulties that arise from a traditional design approach is that specification often becomes biased toward the flow of data rather than the understanding of the important underlying processes of the system. Object-oriented2 analysis and design changes the focus from the data to the process, and produces a series of models in addition to the traditional functional model.
The end result is a series of abstract objects and methods. When object-oriented systems are implemented using BEA MessageQ, each major object is assigned to an application server process and a queue. The invocation of a method on an object corresponds to sending a message to an application server associated with the object.
At this stage in the design, there is enough information to assign physical processes to BEA MessageQ groups and to assign network node locations to those groups.
Determining Queue Sizes
In addition to the system flow, you need to determine expected arrival rates to key inputs of the system. One way to estimate this is to look at the expected or required response times to any particular action. So, if a input stream needs an response time of 0.5 seconds, you might expect that the arrival rate for that particular input might be 2 events per second. (The worst case then, as far as the system load, would be that the 2 events per second rate would be maintained over some relatively long period of time, say five minutes.)
The sum of input rates from all the events to a particular service determines a maximum input rate (and queue size) that the service must handle. If the events are correlated closely to messages, then the input messaging rates to the system can be determined.
The messaging rates for key inputs to the system, as well as the service rates for various processes, determine the queue size that the system needs to be configured to handle.
A rough way to do this is to use the following calculation3 for each queue:
Let,
Then for most systems, the value of q should be between the two following values:
Q_DET = P/(1-P) - (P * P/2 * (1-P)) assumes constant service times
Q_EXP = P/(1-P) assumes random service times
In many systems, you will need to consider the effect of server outages. Server outages occur when a server is unable to perform its function because it is explicitly shut down or because a key network link is down. When the server is down, the application must be able to take some type of action, such as storing the messages to be forwarded when the server becomes active again. Queue sizing analysis should also be done for the case when the server is down, and for when it is restarting. The queuing load during restart operations is often significantly larger than during normal operation.
In the case where the service and arrival rates are not known, the design and implementation work can still proceed by using the trial-and-error method. If there is not enough of a particular resource, add more and try again until the operation works.
Simulating Worst-Case Load Scenario
Another scheme to determine the resources that are required is to write input driver programs that simulate the worst-case load. Test drivers of this type are highly recommended, even when a complete systems design is available. Test drivers can be used in many phases of the project cycle, including design, modeling, implementation, and testing.
Servers can be also simulated, in a simple way, by programs coded as simple loops that read from an input queue, then pause for some interval before reading the next item. Using this methodology, you can build a high-level simulation that runs on the hardware and network (or a very similar network) on which the target application will run. Examining the resources used by the model can be very helpful in successfully sizing the production system.
Failover Provisions
Failover provisions must be taken into account early in the design process. Failover requires at least operational planning, and in most cases, requires application code to be written to support the failover process. If failover capability is required, it should be designed as an integral part of the application. It is difficult to back fit a failover process once an application is in production.
For example, recovery journals resides on physical media and this media must be accessible to both the primary node where the application is originally running and the backup node to which the application will fail over. In a VMScluster, the media is easily accessible because access to disks can span network nodes. Outside of a VMScluster, it is still possible to provide failover capability by physically moving or copying the media.
Design Summary
The following list summarizes basic questions you should consider when planning a distributed system that uses BEA MessageQ:

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|