|
|
|
|
| |
Understanding Object Clustering
This topic includes the following sections:
If an object is clustered, instances of the object are deployed on all WebLogic Servers in the cluster. The client has a choice about which instance of the object to call. Each instance of the object is referred to as a replica.
The key technology that underpins clustered objects in WebLogic Server is the replica-aware stub. When you compile an EJB that supports clustering (as defined in its deployment descriptor) ejbc passes the EJB's interfaces through the rmic compiler to generate replica-aware stubs for the bean. For RMI objects, you generate replica-aware stubs explicitly using command-line options to rmic, as described in WebLogic RMI Compiler.
Replica-aware Stubs
A replica-aware stub appears to the caller as a normal RMI stub. Instead of representing a single object, however, the stub represents a collection of replicas. The replica-aware stub contains the logic required to locate an EJB or RMI class on any WebLogic Server instance on which the object is deployed. When you deploy a cluster-aware EJB or RMI object, its implementation is bound into the JNDI tree. As described in Cluster-Wide JNDI Naming Service, clustered WebLogic Server instances have the capability to update the JNDI tree to list all servers on which the object is available. When a client accesses a clustered object, the implementation is replaced by a replica-aware stub, which is sent to the client.
The stub contains the load balancing algorithm (or the call routing class) used to load balance method calls to the object. On each call, the stub can employ its load algorithm to choose which replica to call. This provides load balancing across the cluster in a way that is transparent to the caller. If a failure occurs during the call, the stub intercepts the exception and retries the call on another replica. This provides a failover that is also transparent to the caller.
Clustered EJBs
EJBs differ from plain RMI objects in that each EJB can potentially generate two different replica-aware stubs: one for the EJBHome interface and one for the EJBObject interface. This means that EJBs can potentially realize the benefits of load balancing and failover on two levels:
The following sections provide an overview of the capabilities of different EJBs. See EJBs in WebLogic Server Clusters for a detailed explanation of the clustering behavior for different EJB types.
EJB Home Stubs
All bean homes can be clustered. When a bean is deployed on a server, its home is bound into the cluster-wide naming service. Because homes can be clustered, each server can bind an instance of the home under the same name. When a client looks up this home, it gets a replica-aware stub that has a reference to the home on each server that deployed the bean. When create() or find() is called, the replica-aware stub routes the call to one of the replicas. The home replica receives the find() results or creates an instance of the bean on this server.
Stateless EJBs
When a home creates a stateless bean, it returns a replica-aware EJBObject stub that can route to any server on which the bean is deployed. Because a stateless bean holds no state on behalf of the client, the stub is free to route any call to any server that hosts the bean. Also, because the bean is clustered, the stub can automatically fail over in the event of a failure. The stub does not automatically treat the bean as idempotent, so it will not recover automatically from all failures. If the bean has been written with idempotent methods, this can be noted in the deployment descriptor and automatic failover will be enabled in all cases.
Stateful EJBs
As with all EJBs, clustered stateful session EJBs utilize a replica-aware EJBHome stub. If you use stateful session EJB replication, the EJB also utilizes a replica-aware EJBObject stub that maintains the location of the EJB's primary and secondary states. The state of the EJB is maintained using a replication scheme similar to that used for HTTP session states. See Stateful Session Bean Replication for more information.
Entity EJBs
There are two types of entity beans to consider: read-write entities and read-only entities.
When a home finds or creates a read-write entity bean, it obtains an instance on the local server and returns a stub pinned to that server. Load balancing and failover occur only at the home level. Because it is possible for multiple instances of the entity bean to exist in the cluster, each instance must read from the database before each transaction and write on each commit.
When a home finds or creates a read-only entity bean, it returns a replica-aware stub. This stub load balances on every call but does not automatically fail over in the event of a recoverable call failure. Read-only beans are also cached on every server to avoid database reads.
For more information about using EJBs in a cluster, please read The WebLogic Server EJB Container.
Clustered RMI Objects
WebLogic RMI provides special extensions for building clustered remote objects. These are the extensions used to build the replica-aware stubs described in the EJB section. For more information about using RMI in WebLogic Server Clusters, see Using WebLogic RMI.
Stateful Session Bean Replication
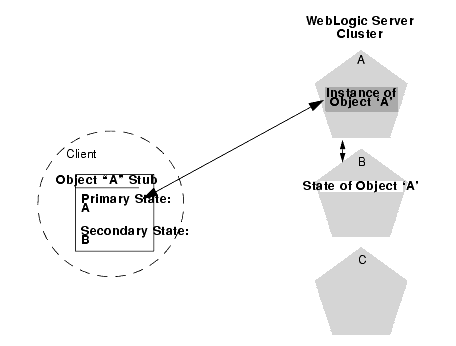
WebLogic Server version 6.0 replicates the state of stateful session EJBs similar to the way in which it replicates HTTP session states. When a client creates the EJBObject stub, the point-of-contact WebLogic Server instance automatically selects a secondary server instance to host the replicated state of the EJB. Secondary server instances are selected using the same rules defined in Understanding HTTP Session State Replication.
The client receives a replica-aware stub that lists the location of the primary and secondary servers in the cluster that host the EJB's state. The following figure shows a client accessing a clustered stateful session EJB.
The primary server hosts the actual instance of the EJB that the client interacts with. The secondary server hosts only the replicated state of the EJB, which consumes a small amount of memory. The secondary sever does not create an actual instance of the EJB unless a failover occurs. This ensures minimal resource usage on the secondary server; you do not need to configure additional EJB resources to account for replicated EJB states.
Replicating EJB State Changes
As the client makes changes to the state of the EJB, state differences are replicated to the secondary server instance. For EJBs that are involved in a transaction, replication occurs immediately after the transaction commits. For EJBs that are not involved in a transaction, replication occurs after each method invocation.
In both cases, only the actual changes to the EJB's state are replicated to the secondary server. This ensures that there is minimal overhead associated with the replication process.
Note: The actual state of a stateful EJB is non-transactional, as described in the EJB specification. Although it is unlikely, there is a possibility that the current state of the EJB can be lost. For example, if a client commits a transaction involving the EJB and there is a failure of the primary server before the state change is replicated, the client will fail over to the previously-stored state of the EJB.
If it is critical to preserve the state of your EJB in all possible failover scenarios, use an entity EJB rather than a stateful session EJB.
Failover for Stateful Session EJBs
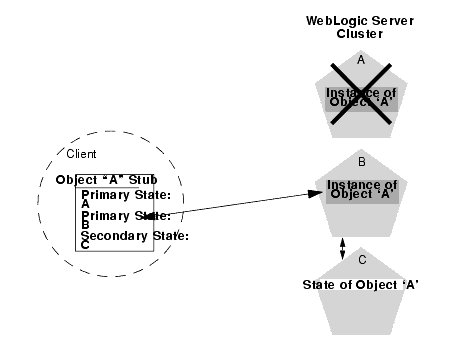
Should the primary server fail, the client's EJB stub automatically redirects further requests to the secondary WebLogic Server instance. At this point, the secondary server creates a new EJB instance using the replicated state data, and processing continues on the secondary server.
After a failover, WebLogic Server chooses a new secondary server to replicate EJB session states (if another server is available in the cluster). The location of the new primary and secondary server instances is automatically updated in the client's replica-aware stub on the next method invocation, as shown below.
Optimization for Collocated Objects
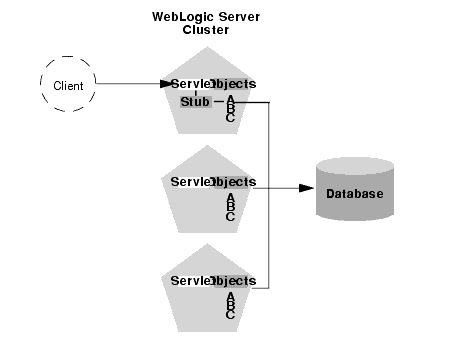
Although a replica-aware stub contains the load-balancing logic for a clustered object, WebLogic Server does not always perform load balancing for an object's method calls. In most cases, it is more efficient to use a replica that is collocated with the stub itself, rather than using an replica that resides on a remote server. The figure below details this situation.
In the above example, a client connects to a servlet hosted by the first WebLogic Server instance in the cluster. In response to client activity, the servlet obtains a replica-aware stub for Object A. Because a replica of Object A is also available on the same server, the object is said to be collocated with the client's stub.
WebLogic Server always uses the local, collocated copy of Object A, rather than distributing the client's calls to other replicas of Object A in the cluster. It is more efficient to use the local copy, because doing so avoids the network overhead of establishing peer connections to other servers in the cluster.
This optimization is often overlooked when planning WebLogic Server clusters. The collocation optimization is also frequently confusing for administrators or developers who expect or require load balancing on each method call. In single-cluster web architectures, this optimization overrides any load balancing logic inherent in the replica-aware stub.
If you require load balancing on each method call to a clustered object, see Planning WebLogic Server Clusters for information about how to plan your WebLogic Server cluster accordingly.
Transactional Collocation
As an extension to the basic collocation strategy, WebLogic Server also attempts to collocate clustered objects that are enlisted as part of the same transaction. When a client creates a UserTransaction object, WebLogic Server attempts to use object replicas that are collocated with the transaction. This optimization is depicted in the figure below.
In this example, a client attaches to the first WebLogic Server instance in the cluster and obtains a UserTransaction object. After beginning a new transaction, the client looks up Objects A and B to do the work of the transaction. In this situation WebLogic Server always attempts to use replicas of A and B that reside on the same server as the UserTransaction object, regardless of the load balancing strategies in the stubs for A and B.
This transactional collocation strategy is even more important than the basic optimization described in Optimization for Collocated Objects. If remote replicas of A and B were used, added network overhead would be incurred for the duration of the transaction, because the peer connections for A and B would be locked until the transaction committed. Furthermore, WebLogic Server would need to employ a multi-tiered JDBC connection to commit the transaction, incurring even further network overhead.
By collocating clustered objects in a transactional context, WebLogic Server reduces the network load for accessing the individual objects. The server also can make use of a single-tiered JDBC connection, rather than a multi-tiered connection, to do the work of the transaction.

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|