|
|
|
|
| |
Understanding HTTP Session State Replication
This topic includes the following sections:
To support automatic failover for servlet and JSP HTTP session states, WebLogic Server replicates the session state object in memory. This process creates a primary session state, which resides on the WebLogic Server to which the client first connects and a secondary replica of the session state on another WebLogic Server instance in the cluster. The replica is always kept up-to-date so that it may be used if the server that hosts the servlet fails. The process of copying a state from one instance to another is called in-memory replication.
Note: WebLogic Server also provides the ability to maintain the HTTP session state of a servlet or JSP using file-based or JDBC-based persistence. For more information on these persistence mechanisms, see Making Sessions Persistent in Programming WebLogic HTTP Servlets.
Requirements for HTTP Session State Replication
To utilize in-memory replication for HTTP session states, you must access the WebLogic Server cluster using either:
The WebLogic proxy plug-ins maintain a list of WebLogic Server instances that host a clustered servlet or JSP, and forward HTTP requests to those instances using a simple round-robin strategy. The proxy also provides the logic required to locate the replica of a client's HTTP session state if a WebLogic Server instance should fail.
Supported web server and proxy software includes:
If you choose to use load balancing hardware instead of a proxy plug-in, you must use hardware that supports SSL persistence and passive cookie persistence. Passive cookie persistence enables WebLogic Server to write cookies (containing information about the location of replicated HTTP session states) through the load balancer to the client. The load balancer, in turn, interprets an identifier in the client's cookie to maintain the relationship between the client and the primary WebLogic Server hosting the HTTP session state.
See Configure Load Balancing Hardware (Optional) for details on setting up supported load balancing solutions with WebLogic Server.
Session Requirements
When developing servlets or JSPs that you will deploy in a clustered environment, keep in mind the following requirements.
Session Data Must Be Serializable
In order to support in-memory replication for HTTP session states, all servlet and JSP session data must be serializable. If the servlet or JSP uses a combination of serializable and non-serializable objects, WebLogic Server does not replicate the session state of the non-serializable objects.
Use setAttribute() to Change Session State
Servlets must use either setAttribute() or removeAttribute() to change the session object. If you use other set methods to change objects within the session, WebLogic Server does not replicate those changes.
Consider Serialization Overhead for Session Objects
Serializing session data introduces some overhead for replicating the session state. The overhead increases as the size of serialized objects grows. If you plan to create very large objects in the session, first test the performance of your servlets to ensure that performance is acceptable.
Applications Using Frames Must Coordinate Session Access
If you are designing a web application that utilizes multiple frames, keep in mind that there is no synchronization of requests made by frames in a given frameset. For example, it is possible for multiple frames in a frameset to create multiple sessions on behalf of the client application, even though the client should logically create only a single session.
In a clustered environment, poor coordination of frame requests can cause unexpected application behavior. For example, multiple frame requests can "reset" the application's association with a clustered instance, because the proxy plug-in treats each request independently. It is also possible for an application to corrupt session data by modifying the same session attribute via multiple frames in a frameset.
To avoid unexpected application behavior, always use careful planning when accessing session data with frames. You can apply one of the following general rules to avoid common problems:
Configuring In-Memory HTTP Replication in a Cluster
To use in-memory HTTP session state replication across instances of a WebLogic Server cluster, set the property PersistentStoreType to replicated in the Web Application deployment descriptor, web.xml. For information about additional properties that affect all session persistence types, see Configuring Session Persistence.
Using Replication Groups
By default, WebLogic Server attempts to create session state replicas on a different machine than the one hosting the primary session state. WebLogic Server version 6.0 enables you to further control where secondary states are placed using replication groups. A replication group is simply a preferred list of clustered instances to be used for storing session state replicas.
Using the WebLogic Server administration console, you can define unique machine names that will host individual server instances. These machine names can be associated with new WebLogic Server instances to identify where the servers reside in your system. Machine names are generally used to indicate servers that run on multihomed machines. For example, you would assign the same machine name to all server instances that run on the same multihomed machine, or the same server hardware.
If you do not use a multihomed machine, or you do not run multiple WebLogic Server instances on a single piece of hardware, you do not need to specify WebLogic Server machine names. Servers without an associated machine name are automatically treated as though they reside on separate, physical hardware. See Define Machine Names for detailed instructions on setting machine names.
When you configure a clustered server instance, you can also assign the server membership within a replication group, as well as the preferred secondary replication group to be considered for hosting replicas of the primary HTTP session states created on the server.
When a client attaches to a server in the cluster and creates a primary session state, the server hosting the primary state ranks other servers in the cluster to determine which server should host the secondary. Server ranks are assigned using a combination of the server's location (whether or not it resides on the same machine as the primary server) and its participation in the primary server's preferred replication group. The following table shows the relative ranking of servers in a cluster.
|
Server Rank |
Server Resides on a Different Machine? |
Server Is a Member of Preferred Replication Group? |
|---|---|---|
|
1 |
Yes |
Yes |
|
2 |
No |
Yes |
|
3 |
Yes |
No |
|
4 |
No |
No |
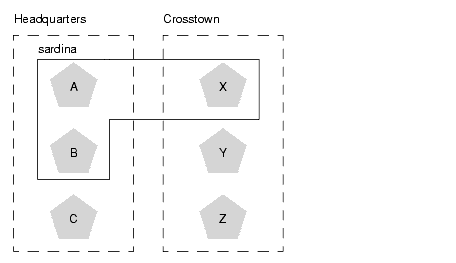
Using the ranking rules above, the primary WebLogic Server ranks other members of the cluster and chooses the highest-ranked server to host the secondary session state. For example, the following figure shows replication groups configured to account for distinct geographic locations.
In this example, servers A, B, and C are members of the replication group "Headquarters" and use the preferred secondary replication group "Crosstown." Conversely, servers X, Y, and Z are members of the "Crosstown" group and use the preferred secondary replication group "Headquarters." Servers A, B, and X reside on the same machine, "sardina."
If a client connects to server A and creates an HTTP session state, servers Y and Z are most likely to host the replica of this state, since they reside on separate machines and are members of server A's preferred secondary group. Server X holds the next-highest ranking because it is also a member of the preferred replication group (even though it resides on the same machine as the primary.) Server C holds the third-highest ranking since it resides on a separate machine but is not a member of the preferred secondary group. Server B holds the lowest ranking, because it resides on the same machine as server A (and could potentially fail along with A if there is a hardware failure) and it is not a member of the preferred secondary group.
To define machine names for clustered WebLogic Server instances, use the instructions in Define Machine Names. To configure a server's membership in a replication group, or to assign a server's preferred secondary replication group, use the instructions in Configure Replication Groups.
Accessing Clustered Servlets and JSPs Using a Proxy
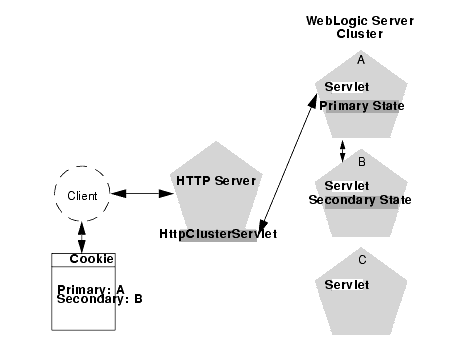
The following figure depicts a client accessing a servlet hosted in a two-tier cluster architecture. This example uses a single WebLogic Server to serve static HTTP requests only; all servlet requests are forwarded to the WebLogic Server via the HttpClusterServlet.
Note: The discussion that follows also applies if you use a third-party web server and WebLogic proxy plug-in, rather than WebLogic Server and the HttpClusterServlet.
When the HTTP client requests the servlet, the HttpClusterServlet proxies the request to the WebLogic Server cluster. The HttpClusterServlet maintains the list of all servers in the cluster, as well as the load balancing logic to use when accessing the cluster. In the above example, the HttpClusterServlet routes the client request to the servlet hosted on WebLogic Server A. WebLogic Server A becomes the primary server hosting the client's servlet session.
To provide failover services for the servlet, the primary server replicates the client's servlet session state to a secondary WebLogic Server in the cluster. This ensures that a replica of the session state exists even if the primary server fails (for example, due to a network failure). In the example above, Server B is selected as the secondary.
The servlet page is returned to the client through the HttpClusterServlet, and the client browser is instructed to write a cookie that lists the primary and secondary locations of the servlet session state. If the client browser does not support cookies, WebLogic Server can use URL rewriting instead.
Using URL Re-writing to Track Session Replicas
In its default configuration, WebLogic Server uses client-side cookies to keep track of the primary and secondary server that host the client's servlet session state. If client browsers have disabled cookie usage, WebLogic Server can also keep track of primary and secondary servers using URL rewriting. With URL rewriting, both locations of the client session state are embedded into the URLs passed between the client and proxy server. To support this feature, you must ensure that URL rewriting is enabled on the WebLogic Server cluster. See Configuring Session Cookies for more information.
Proxy Failover Procedure
Should the primary server fail, the HttpClusterServlet uses the client's cookie information to determine the location of the secondary WebLogic Server that hosts the replica of the session state. The HttpClusterServlet automatically redirects the client's next HTTP request to the secondary server, and failover is transparent to the client.
After the failure, WebLogic Server B becomes the primary server hosting the servlet session state, and a new secondary is created (Server C in the example above). In the HTTP response, the proxy updates the client's cookie to reflect the new primary and secondary servers, to account for the possibility of subsequent failovers.
In a two-server cluster, the client would transparently fail over to the server hosting the secondary session state. However, replication of the client's session state would not continue unless another WebLogic Server became available and joined the cluster. For example, if the original primary server was restarted or reconnected to the network, it would be used to host the secondary session state.
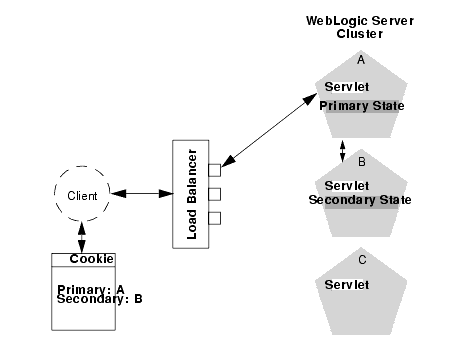
Accessing Clustered Servlets and JSPs with Load Balancing Hardware
To support direct client access via load balancing hardware, the WebLogic Server replication system enables clients to use secondary session states regardless of the server to which the client fails over. WebLogic Server version 6.0 continues to use client-side cookies or URL rewriting to record primary and secondary server locations. However, this information is used only as a history of the servlet session state location; when accessing a cluster via load balancing hardware, clients do not use the cookie information to actively locate a server after a failure. The following steps describe the connection and failover procedure when using HTTP session state replications with load balancing hardware.
When the client of a web application requests a servlet using a public IP address:
Note: You must enable WebLogic Server URL rewriting capabilities to support clients that disallow cookies. See Using URL Rewriting for more information.
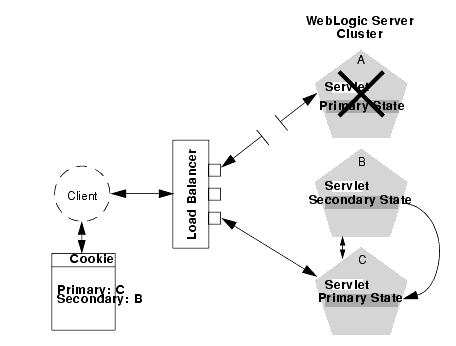
Failover with Load Balancing Hardware
Should Server A fail during the course of the client's session, the client's next connection request to Server A also fails.
In response to the connection failure:

|
|
|
Copyright © 2000 BEA Systems, Inc. All rights reserved.
|