|
| e-docs > WebLogic Server > Programming WebLogic Enterprise JavaBeans > WebLogic Server Container-Managed Persistence Service |
|
Programming WebLogic Enterprise JavaBeans
|
WebLogic Server Container-Managed Persistence Service
The following sections describe the container-managed persistence (CMP) features supported by the WebLogic Server EJB container.
Overview of Container Managed Persistence Service
The EJB container provides a uniform interface between the EJB and WebLogic Server. The container creates new instances of the EJBs, manages these bean resources, and provides persistent services such as, transactions, security, concurrency, and naming at runtime. In most cases, EJBs from earlier version of WebLogic Server run in the container. However, see the Migration Guide for information on when you would need to migrate your bean code. See DDConverter for instructions on using the conversion tool.
WebLogic Server's container-managed persistence (CMP) model handles persistence of CMP entity beans automatically at runtime by synchronizing the EJB's instance fields with the data in the database.
The entity bean relies on container-managed persistence to generate the methods that perform persistent data access for the entity bean instances. The generated methods transfer data between entity bean instances and the underlying resource manager. Persistence is handled by the container at runtime. The advantage of using container-managed persistence is that the entity bean can be logically independent of the data source in which the entity is stored. The container manages the mapping between the logical and physical relationships at runtime and manages their referential integrity.
Persistent fields and relationships make up the entity bean's abstract persistence schema. The deployment descriptors indicate that the entity bean uses container-managed persistence, and these descriptors are used as input to the container for data access.
WebLogic Server provides persistence services for entity beans. An entity EJB can save its state in any transactional or non-transactional persistent storage ("bean-managed persistence"), or the container can save the EJB's non-transient instance variables automatically ("container-managed persistence"). WebLogic Server allows both choices and a mixture of the two.
If an EJB will use container-managed persistence, you specify the type of persistence services that the EJB uses in the weblogic-ejb-jar.xml deployment file. High-level definitions for automatic persistence services is stored in the persistence-use element. The persistence-use element defines which service the EJB uses at deployment time.
Automatic persistence services use additional deployment files to specify their deployment descriptors, and to define entity EJB finder methods. For example, WebLogic Server RDBMS-based persistence services obtain deployment descriptors and finder definitions from a particular bean using the bean's weblogic-cmp-rdbms-jar.xml file, described in Using WebLogic Server RDBMS Persistence.
Third-party persistence services cause other file formats to configure deployment descriptors. However, regardless of the file type, you must reference the configuration file in the persistence-use element in weblogic-ejb-jar.xml.
Note: Configure container-managed persistence beans with a connection pool with maximum connections greater than 1. WebLogic Server's container-managed persistence service sometimes needs to get two connections simultaneously.
Using WebLogic Server RDBMS Persistence
To use WebLogic Server RDBMS-based persistence service with your EJBs:
If you use WebLogic Server's utility, DDConverter to create this file, it is named weblogic-cmp-rdbms-jar.xml. If you create the file from scratch, you can save it to a different filename. However, you must ensure that the persistence-type and persistence-use elements in weblogic-ejb-jar.xml refer to the correct file.
weblogic-cmp-rdbms-jar.xml defines the persistence deployment descriptors for EJBs using WebLogic Server RDBMS-based persistence services.
In each weblogic-cmp-rdbms-jar.xml file you define the following persistence options:
Writing for RDBMS Persistence for EJB 1.1 CMP
Clients use finder methods to query and receive references to entity beans that fulfill query conditions. This section describes how to write finders for WebLogic-specific 1.1 EJBs that use RDBMS persistence. You use EJB QL, a portable query language, to define finder queries for 2.0 EJBs with container-managed persistence. For more information about on EJB QL, see Using EJB QL for EJB 2.0.
WebLogic Server provides an easy way to write finders.
ejbc creates implementations of the finder methods at deployment time, using the queries in ejb-jar.xml.
The key components of a finder for RDBMS persistence are:
The following sections explain how to write EJB finders using XML elements in WebLogic Server deployment files.
Specify finder method signatures using the form findMethodName(). Finder methods defined in weblogic-cmp-rdbms-jar.xml must return a Java collection of EJB objects or a single object.
Note: You can also define a findByPrimaryKey(primkey) method that returns a single object of the associated EJB class.
The finder-list stanza associates one or more finder method signatures in EJBHome with the queries used to retrieve EJB objects. The following is an example of a simple finder-list stanza using WebLogic Server RDBMS-based persistence:
<finder-list>
<finder>
<method-name>findBigAccounts</method-name>
<method-params>
<method-param>double</method-param>
</method-params>
<finder-query><![CDATA[(> balance $0)]]></finder-query>
</finder>
</finder-list>
Note: If you use a non-primitive data type in a method-param element, you must specify a fully qualified name. For example, use java.sql.Timestamp rather than Timestamp. If you do not use a qualified name, ejbc generates an error message when you compile the deployment unit.
The finder-query element defines the WebLogic Query Language (WLQL) expression you use to query EJB objects from the RDBMS. WLQL uses a standard set of operators against finder parameters, EJB attributes, and Java language expressions. See Using WebLogic Query Language (WLQL) for EJB 1.1 CMP for more information on WLQL.
Note: Always define the text of the finder-query value using the XML CDATA attribute. Using CDATA ensures that any special characters in the WLQL string do not cause errors when the finder is compiled.
A CMP finder can load all beans using a single database query. So, 100 beans can be loaded with a single database round trip. A bean-managed persistence (BMP) finder must do one database round trip to get the primary key values of the beans selected by the finder. As each bean is accessed, another database access is also typically required, assuming the bean wasn't already cached. So, to access 100 beans, a BMP might do 101 database accesses.
Using WebLogic Query Language (WLQL) for EJB 1.1 CMP
WebLogic Query Language (WLQL) for EJB 1.1 CMP allows you to query 1.1 entity EJBs with container-managed persistence. In the weblogic-cmp-rdbms-jar.xml file, each finder-query stanza must include a WLQL string that defines the query used to return EJBs. Use WLQL for EJBs and their corresponding deployment files that are based on the EJB 1.1 specification.
Note: For queries to 2.0 EJBs, see Using EJB QL for EJB 2.0. Using the weblogic-ql query completely overrides the ejb-ql query.
WLQL strings use the prefix notation for comparison operators, as follows:
(operator operand1 operand2)
Additional WLQL operators accept a single operand, a text string, or a keyword.
The following are valid WLQL operators.
Note: You cannot use RDBMS column names as operands in WLQL. Instead, use the EJB attribute (field) that maps to the RDBMS column, as defined in the attribute-map in weblogic-cmp-rdbms-jar.xml.
The following example code shows excerpts from the weblogic-cmp-rdbms-jar.xml file that use basic WLQL expressions.
public Enumeration findBigAccounts(double balanceGreaterThan)
throws FinderException, RemoteException;
The sample <finder> stanza is:
<finder>
<method-name>findBigAccounts</method-name>
<method-params>
<method-param>double</method-param>
</method-params>
<finder-query><![CDATA[(> balance $0)]]></finder-query>
</finder>
Note that you must define the balance field n the attribute map of the EJB's persistence deployment file.
Note: Always define the text of the finder-query value using the XML CDATA attribute. Using CDATA ensures that any special characters in the WLQL string do not cause errors when the finder is compiled.
<finder-query><![CDATA[(& (> balance $0) (! (= accountType 'checking')))]]></finder-query>
public Enumeration findAllAccounts()
throws FinderException, RemoteException
<finder-query><![CDATA[(like lastName M%)]]></finder-query>
<finder-query><![CDATA[(isNull firstName)]]></finder-query>
<finder-query><![CDATA[WHERE >5000 (orderBy 'id' (> balance 5000))]]></finder-query>
<finder-query><![CDATA[(orderBy 'id desc' (> ))]]></finder-query>
Using SQL for CMP 1.1 Finder Queries
WebLogic Server allows you to use a SQL string instead of the standard WLQL query language to write SQL for a CMP 1.1 finder query. The SQL statement retrieves the values from the database for the CMP 1.1 finder query. Use SQL to write a CMP 1.1 finder query when a more complicated finder query is required and you cannot use WLQL.
For more information on WLQL, see Using WebLogic Query Language (WLQL) for EJB 1.1 CMP.
To specify this SQL finder query:
If you use characters in your SQL query that may confuse an XML parser, such as the.greater than (>) symbol and the less than (<) symbol, make sure that you declare the SQL query using the CDATA format shown in the preceding sample SQL statement.
Note: You can use any amount of vendor-specific SQL in the SQL query.
EJB Query Language (QL) is a portable query language that defines finder methods for 2.0 entity EJBs with container-managed persistence. Use this SQL-like language to select one or more entity EJB objects or fields in your query. Because of the declaration of CMP fields in a deployment descriptor, you can create queries in the deployment descriptor for any finder method other than findByPrimaryKey(). findByPrimaryKey is automatically handled by the container. The search space for an EJB QL query consists of the EJB's schema as defined in ejb-jar.xml (the bean's collection of container-managed fields and their associated database columns).
EJB QL Requirement for EJB 2.0 Beans
The deployment descriptors must define each finder query for EJB 2.0 entity beans by using an EJB QL query string. You cannot use WebLogic Query Language (WLQL) with EJB 2.0 entity beans. WLQL is intended for use with EJB 1.1 CMP.
If you have used previous versions of WebLogic Server, your container-managed entity EJBs may use WLQL for finder methods. This section provides a quick reference to common WLQL operations. Use this table to map the WLQL syntax to EJB QL syntax.
Using EJB 2.0 WebLogic QL Extension for EJB QL
WebLogic Server has an SQL-like language, called WebLogic QL, that extends the standard EJB QL. This language works with the finder expressions and is used to query EJB objects from the RDBMS. You define the query in the weblogic-cmp-rdbms-jar.xml deployment descriptor using the weblogic-ql element.
There must be a query element in the ejb-jar.file that corresponds to the weblogic-ql element in the weblogic-cmp-rdbms-jar.xml file. However, the weblogic-cmp-rdbms-jar.xml query element overrides the ejb-jar.xml query element.
The EJB WebLogic QL upper and lower extensions convert the case of arguments to allow finder methods to return results that match the characters in an search expression but not the case. The case change is transient, for the purpose of string matching, and is not persisted in database. The underlying database must also support upper and lower functions.
The upper function converts characters in its arguments from any case to upper case before string matching is performed. Use the upper function with an upper-case expression in a query to return all items that match the expression, regardless of case. For example:
select name from products where upper(name)='DETERGENT';
The lower function converts characters in its arguments from any case to lower case before string matching is performed. Use the lower function with an lower-case expression in a query to return all items that match the expression, regardless of case.
select type from products where lower(name)='domestic';
Note: The upper and lower extensions were added in WebLogic Server 7.0 SP03.
The EJB WebLogic QL extension SELECT DISTINCT allows your database to filter duplicate queries. Using SELECT DISTINCT means that the EJB container's resources are not used to sort through duplicated results when SELECT DISTINCT is specified in the EJB QL query.
If you specify a sql-select-distinct element with the value TRUE in a weblogic-ql element's XML stanza for an EJB 2.0 CMP bean, then the generated SQL STATEMENT for the database query will contain a DISTINCT clause.
You specify the sql-select-distinct element in the weblogic-cmp-rdbms-jar.xml file. However, you cannot specify sql-select-distinct if you are running an isolation level of READ_C0MMITED_FOR_UPDATE on an Oracle database. This is because a query on Oracle cannot have both a sql-select-distinct and a READ_C0MMITED_FOR_UPDATE. If there is a chance that this isolation level will be used, for example in a session bean, do not use the sql-select-distinct element.
The EJB WebLogic QL extension ORDERBY is a keyword that works with the Finder method to specify the CMP field selection sequence for your selections.
Figure 5-1 WebLogic QL ORDERBY extension showing order by id.
ORDERBY
SELECT OBJECT(A) from A for Account.Bean
ORDERBY A.id
Note: ORDERBY defers all sorting to the DBMS. Thus, the order of the retrieved result depends on the particular DBMS installation on top of which the bean is running
Also, you can specify an ORDERBY with ascending [ASC] or descending [desc] order for multiple fields as follows:.
Figure 5-2 WebLogic QL ORDERBY extension showing order by id. with ASC and DESC
ORDERBY <field> [ASC|DESC], <field> [ASC|DESC]
SELECT OBJECT(A) from A for Account.Bean, OBJECT(B) from B for Account.Bean
ORDERBY A.id ASC; B.salary DESC
WebLogic Server supports the use of the following features with subqueries in EJB QL:
The relationship between WebLogic QL and subqueries is similar to the relationship between SQL queries and subqueries. Use WebLogic QL subqueries in the WHERE clause of an outer WebLogic QL query. With a few exceptions, the syntax for a subquery is the same as a WebLogic QL query.
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies a subquery as shown the following sample.
The following query selects all above average students as determined by the provided grade number:
SELECT OBJECT(s) FROM studentBean AS s WHERE s.grade > (SELECT AVG(s2.grade) FROM StudentBean AS s2)
Note that in the above query the subquery, (SELECT AVG(s2.grade) FROM StudentBean AS s2), has the same syntax as an EJB QL query.
You can create nested subqueries.The depth is limited by the underlying database's nesting capabilities.
In a WebLogic QL query, the identifiers declared in the FROM clauses of the main query and all of its subqueries must be unique. This means that a subquery may not re-declare a previously declared identifier for local use within that subquery.
For example, the following example is not legal because employee bean is being declared as emp in both the query and the subquery:
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp.salary) FROM
EmployeeBean AS emp WHERE employee.state=MA)
Instead, this query should be written as follows:
SELECT OBJECT(emp)
FROM EmployeeBean As emp
WHERE emp.salary=(SELECT MAX(emp2.salary) FROM
EmployeeBean AS emp2 WHERE emp2.state=MA)
The above examples correctly declares the subquery's employee bean to have a different identifier from the main query's employee bean.
The return type of a WebLogic QL subquery can be one of a number of different types, such as:
Single cmp-field Type Subqueries
WebLogic Server supports a return type consisting of a cmp-field. The results returned by the subquery may consists of a single value or collection of values. An example of a subquery that returns value(s) of the type cmp-field is as follows:
SELECT emp.salary FROM EmployeeBean AS emp WHERE emp.dept = `finance'
This subquery selects all of the salaries of employees in the finance department.
WebLogic Server supports a return type consisting of an aggregate of a cmp-field. As an aggregate always consist of a single value, the value returned by the aggregate is always a single value. An example of a subquery that return a value of the type aggregate (MAX) of a cmp-field is as follows:
SELECT MAX(emp.salary) FROM EmployeeBean AS emp WHERE emp.state=MA
This subquery selects the single highest employee salary in Massachusetts.
For more information on aggregate functions, see Using Aggregate Functions.
WebLogic Server supports a return type consisting of a cmp-bean with a simple primary key.
Note: Beans with compound primary keys are NOT supported. Attempts to designate the return type of a subquery to a bean with a compound primary key will result in a failure when you compile the query.
An example of a subquery that returns the value(s) of the type bean with a simple primary key is as follows:
SELECT OBJECT(emp) FROM EMployeeBean As emp WHERE emp.department.budget>1,000,000
This subquery provides a list of all employee in departments with budgets greater than $1,000,000.
Subqueries as Comparison Operands
Use subqueries as the operands of comparison operators. WebLogic QL supports subqueries as the operands of the following Comparison Operators: [NOT]IN, [NOT]EXISTS, and the following Arithmetic Operators: <, >, <=, >=, =, <> with ANY and ALL.
The [NOT]IN comparison operator tests whether the left-had operand is or is not a member of the subquery operand on the right-hand side.
An example of a subquery which is the right-hand operand of the NOT IN operator is as follows:
SELECT OBJECT(item)
FROM ItemBean AS item
WHERE item.itemId NOT IN
(SELECT oItem2.item.itemID
FROM OrderBean AS orders2, IN(orders2.orderItems)oIttem2
The subquery selects all items from all orders.
The main query's NOT IN operator selects all the items that are not in the set returned by the subquery. So the end result is that the main query selects all unordered items.
The [NOT]EXISTS comparison operator tests whether the set returned by the subquery operand is or is not empty.
An example of a subquery which is the operand of the NOT EXISTS operand is as follows:
SELECT (cust) FROM CustomerBean AS cust
WHERE NOT EXISTS
(SELECT order.cust_num FROM OrderBean AS order
WHERE cust.num=order_num)
This is an example of a query with a correlated subquery. See Correlated and UnCorrelated Subqueries for more information. This query returns all customers that have not placed an order.
SELECT (cust) FROM CustomerBean AS cust
WHERE cust.num NOT IN
(SELECT order.cust_num FROM OrderBean AS order
WHERE cust.num=order_num)
Use arithmetic operators for comparison when the right-hand subquery operand returns a single value. If the right hand subquery instead returns multiple values, then the qualifiers ANY or ALL must precede the subquery.
An example of a subquery which uses the `=' operator is as follows:
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered =
(SELECT MAX (subOItem.quantityOrdered)
FROM Order ItemBean AS subOItem
WHERE subOItem,item itemID = ?1)
AND oItem.item.itemId = ?1
For a given itemId, the subquery returns the maximum quantity ordered of that item. Note that this aggregate returned by the subquery is a single value as required by the `=' operator.
For the same given itemId, the main query's `=' comparison operator checks which order's OrderItem.quantity Ordered equals the maximum quantity returned by the subquery. The end result is that the query returns the OrderBean that contains the maximum quantity of a given item that has been ordered.
Use arithmetic operators in conjunction with ANY or ALL, when the right-hand subquery operand may return multiple values.
An example of a subquery which uses ANY and ALL is as follows:
SELECT OBJECT (order)
FROM OrderBean AS order, IN(order.orderItems)oItem
WHERE oItem.quantityOrdered > ALL
(SELECT subOItem.quantityOrdered
FROM OrderBean AS suborder IN (subOrder.orderItems)subOItem
WHERE subOrder,orderId = ?1)
For a given orderId, the subquery returns the set of orderItem.quantityOrdered of each item ordered for that orderId. The main query's `>' ALL operator looks for all orders whose orderItem.quantityOrdered exceeds all values in the set returned by the subquery. The end result is that the main query returns all orders in which all orderItem.quantityOrdered exceeds every orderItem.quantityOrdered of the input order.
Note that since the subquery can return multi-valued results that they `>'ALL operator is used rather then the `>' operator.
All of the arithmetic operators, <, >, <= >=, =, <> are use, as in the above examples.
Correlated and UnCorrelated Subqueries
WebLogic Server supports both correlated and Uncorrelated subqueries.
Uncorrelated subqueries may be evaluated independently of the outer query. An example of an uncorrelated subquery is as follows:
SELECT OBJECT(emp) FROM EmployeeBean AS emp
WHERE emp.salary>
(SELECT AVG(emp2.salary) FROM EmployeeBean AS emp2)
This example of a uncorrelated subquery selects the employees whose salaries are above average. This examples uses the `>' arithmetic operator.
Correlated subqueries are subqueries in which values from the outer query are involved in the evaluation of the subquery. An example of a correlated subquery is as follows:
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
This example of a correlated subquery selects the last 10 shipped Orders. This example uses the NOT IN operator.
Note: Keep in mind that correlated subqueries can involve more processing overhead the uncorrelated subqueries.
DISTINCT Clause with Subqueries
Use the DISTINCT clause in a subquery to enable an SQL SELECT DISTINCT in the subquery's generated SQL. Using a DISTINCT clause in a subquery is different from using one in a main query because the EJB container enforces the DISTICNT clause in a main query; whereas the DISTICT clause in the subquery is enforced by the generated SQL, SELECT DISTINCT. An example of a DISTINCT clause in a subquery is as follows:
SELECT OBJECT (mainOrder) FROM OrderBean AS mainOrder
WHERE 10>
(SELECT COUNT (DISTINCT subOrder.ship_date)
FROM OrderBean AS subOrder
WHERE subOrder.ship_date>mainOrder.ship_date
AND mainOrder.ship_date IS NOT NULL
This example of a selects the last 10 shipped Orders.
WebLogic Server supports aggregate functions with WebLogic QL. You only use these functions as SELECT clause targets, not as other parts of a query, such as a WHERE clause. The aggregate functions behave like SQL functions. They are evaluated over the range of the beans returned by the WHERE conditions of the query
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies an aggregate function as shown in the samples shown in the following table.
A list of the supported functions and sample statements follow:
You can return aggregate functions in ResultSets as described below.
Using Queries that Return ResultSets
WebLogic Server supports ejbSelect() queries that return the results of multi-column queries in the form of a java.sql.ResultSet. To support this feature, WebLogic Server now allows you to use the SELECT clause to specify a comma delimited list of target fields as shown in the following query:
SELECT emmp.name, emp.zip FROM EmployeeBean AS emp
This query returns a java.sqlResultSet with rows whose columns are the values Employee's Name and Employee's Zip.
To specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a query specifying a ResultSet as shown in the above query to specify WebLogic QL, see Using EJB 2.0 WebLogic QL Extension for EJB QL. Use those instructions with a SELECT statement that specifies an aggregate query like the samples shown in the following table.
ResultSets created in EJB QL can only return cmp-field values or aggregates of cmp-field values, they cannot return beans.
In addition, you can create powerful queries, as described in the following example, when you combine cmp-fields and aggregate functions.
The following rows (beans) show the salaries of employees in different locations:
CMP fields showing salaries of employees in California
CMP fields showing salaries of employees in Arizona
CMP fields showing salaries of employees in Texas
Note: Each row represents a bean.
The following SELECT statement shows a query that uses ResultSets and the aggregate function (AVG) along with a GROUP BY statement and an ORDER BY statement using a descending sort to retrieve results from a multi-column query.
SELECT e.location, AVG(e.salary)
FROM Finder EmployeeBean AS e
GROUP BY e.location
ORDER BY 2 DESC
The query shows the average salary in of employees at each location in descending order. The number, 2 means that the ORDERBY sort is on the second item in the SELECT statement. The GROUP BY clause specifies the AVEAGE salary of employees with a matching e.location attribute.
The ResultSet, in descending order is as follows:
Note: You can only use integers as ORDERBY arguments in queries that return ResultSets. WebLogic Server does not support the use of integers as ORDERBY arguments in any Finder or ejbselect() that returns beans.
Properties-Based Methods of the Query Interface
The Query interface contains both find and execute methods. The find methods work like standard EJB methods, in that they return EJBObjects. The execute methods work more like Select statements in that you can select individual fields.
The Query interface return type is a disconnected ResultSet, meaning you access the information from the returned object the same way you would access it from a ResultSet, except that the ResultSet does not hold open a database connection.
The Query interface's properties-based methods offer an alternate way of specifying settings particular to a query. The QueryProperties interface holds standard EJB query settings while the WLQueryProperties interface holds WebLogic-specific query settings.
Although the Query interface extends QueryProperties, the actual Query implementation extends WLQueryProperties so it can be safely casted, as in the example in Figure 5-3, which sets field group settings:
Figure 5-3 Setting Field Group Settings with WLQueryProperties
Query query=qh.createQuery(); ((WLQueryProperties) query).setFieldGroupName("myGroup"); Collection results=query.find(ejbql); Query query=qh.createQuery(); Properties props = new Properties(); props.setProperty(WLQueryProperties.GROUP_NAME, "myGroup"); Collection results=query.find(ejbql, props);
Dynamic queries allow you to construct and execute EJB-QL queries programmatically in your application code. Queries are expressions that allow you to request information of EJB objects from the RDBMS. This feature is only available for use with EJB 2.0 CMP beans. Using dynamic queries provides the following benefits:
Setting method-permission for the createQuery() method of the weblogic.ejb.QueryHome interface controls access to the weblogic.ejb.Query object necessary to executes the dynamic queries.
If you specify method-permission for the createQuery() method, the method-permission settings apply to the execute and find methods of the Query class.
The following code sample demonstrates how to execute a dynamic query.
InitialContext ic=new InitialContext();
FooHome fh=(FooHome)ic.lookup("fooHome");
QueryHome qh=(QueryHome)fh;
Sring ejbql="SELECT OBJECT(e)FROM EmployeeBean e WHERE e.name='rob'"
Query query=qh.createQuery();
query.setMaxElements(10)
Collection results=query.find(ejbql);
WebLogic Server supports an EJB QL extension that allows you to pass INDEX usage hints to the Oracle Query optimizer. With this extension, you can provide a hint to the database engine. For example, if you know that the database you are searching can benefit from an ORACLE_SELECT_HINT, you can define an ORACLE_SELECT_HINT clause that will take ANY string value and then insert that String value after the SQL SELECT statement as a hint to the database.
To use this option, declare a query that uses this feature in the weblogic-ql element. This element is found in the weblogic-cmp-rdbms-jar.xml file. The weblogic-ql element specifies a query that contains a WebLogic specific extension to the EJB-QL language.
The WebLogic QL keyword and usage is as follows:
SELECT OBJECT(a) FROM BeanA AS a WHERE a.field > 2 ORDERBY a.field SELECT_HINT '/*+ INDEX_ASC(myindex) */'
This statement generates the following SQL with the optimizer hint for Oracle:
SELECT /*+ INDEX_ASC(myindex) */ column1 FROM .... (etc)
In the WebLogic QL ORACLE_SELECT_HINT clause, whatever is between the single quotes (' ') is what gets inserted after the SQL SELECT. It is the query writer's responsibility to make sure that the data within the quotes makes sense to the Oracle database.
"get" and "set" Method Restrictions
WebLogic Server uses container-generated accessor methods to read and modify container-managed fields. Their names begin with get or set and use the actual name of a persistent field defined in ejb-jar.xml. The methods are declared as public, protected, and abstract.
BLOB and CLOB DBMS Column Support for the Oracle DBMS
WebLogic Server supports Oracle Binary Large Object (BLOB) and Character Large Object (CLOB) DBMS columns with EJB CMP. BLOBs and CLOBs are data types used for efficient storage and retrieval of large objects. CLOBs are string or char objects; BLOBs are binary or serializable objects such as pictures that translate into large byte arrays.
BLOBs and CLOBs map a string variable, a value of OracleBlob or OracleClob, to a BLOB or CLOB column. WebLogic Server maps BLOBs to byte arrays or serializable objects. WebLogic Server maps CLOBs to the data type java.lang.string. At this time, no support is available for mapping char arrays to a CLOB column.
Using BLOB or CLOB may slow performance because of the size of the BLOB or CLOB object.
Specifying a BLOB Using the Deployment Descriptor
The following XML code shows how to specify a BLOB object using the dbms-column element in weblogic-cmp-rdbms-jar-xml file.
Figure 5-4 Specifying a BLOB object
<field-map>
<cmp-field>photo</cmp-field>
<dbms-column>PICTURE</dbms-column>
<dbms_column-type>OracleBlob</dbms-column-type>
</field-map>
Controlling Serialization of cmp-fields Mapped to OracleBlobs
By default, when WebLogic Server writes and reads a cmp-field of type byte[] that is mapped to an OracleBlob, it serializes and deserializes the field, respectively.
If WebLogic Server reads a BLOB that was written directly to the database by another program, errors can result, because the container assumes that the data is serialized.
To specify that the data is not serialized, compile the EJB with this flag:
java -Dweblogic.byteArrayIsSerializedToOracleBlob=false weblogic.ejbc std_ejb.jar ejb.jar
Specifying a CLOB Using the Deployment Descriptors
The following XML code shows how to specify a CLOB object using the dbms-column element in the weblogic-cmp-rdbms-jar-xml file.
Figure 5-5 Specifying a CLOB object
<field-map>
<cmp-field>description</cmp-field>
<dbms-column>product_description</dbms-column>
<dbms_column-type>OracleClob</dbms-column-type>
</field-map>
Tuned EJB 1.1 CMP Updates in WebLogic Server
EJB container-managed persistence (CMP) automatically support tuned updates because the container receives get and set callbacks when container-managed EJBs are read or written. Tuning EJB 1.1 CMP beans helps improve their performance.
WebLogic Server now supports tuned updates for EJB 1.1 CMP. When ejbStore is called, the EJB container automatically determines which container-managed fields have been modified in the transaction. Only modified fields are written back to the database. If no fields are modified, no database updates occur.
With previously versions of WebLogic Server, you could to write an isModified method that notified the container whether the EJB 1.1 CMP bean had been modified. isModified is still supported in WebLogic Server, but we recommend that you no longer use isModified methods and instead allow the container to determine the update fields.
This feature is enabled for EJB 2.0 CMP, by default. To enable tuned EJB 1.1 CMP updates, make sure that you set the following deployment descriptor element in the weblogic-cmp-rdbms-jar.xml file to true.
<enable-tuned-updates>true</enable-tuned-updates>
You can disable tuned CMP updates by setting this deployment descriptor element as follows:
<enable-tuned-updates>false</enable-tuned-updates>
In this case, ejbStore always writes all fields to the database.
Optimized Database Updates for CMP 2.0 Entity Beans
For CMP 2.0 entity beans, the setXXX() method does not write the values of unchanged primitive and immutable fields to the database. This optimization improves performance, especially in applications with a high volume of database transactions.
Updates made by a transaction must be reflected in the results of queries, finders, and ejbSelects issued during the transactions. Because this requirement can slow performance, a new option enables you to specify that the cache be flushed before the query for the bean is executed.
If this option is turned off, which is the default behavior, the results of the current transactions are not reflected in the query. If this option is turned on, the container flushes all changes for cached transactions written to the database before executing the new query. This way, the changes show up in the results.
To enable this option, in weblogic-cmp-rdbms-jar.xml file set the include-updates element to true.
Figure 5-6 Specifying that results of transactions be reflected in the query
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method_name>
<method-params>
<method-param>double</method-param>
</method-params>
</query-method>
<weblogic-ql>WHERE BALANCE>10000 ORDERBY NAME</weblogic-ql>
<include-updates>true</include-updates>
</weblogic-query>
The default is false, which provides the best performance. Updates made to the cached transaction are reflected in the result of a query; no changes are written to the database, and you do not see the changes in the query result.
Whether you use this feature depends on whether performance is more important than current and consistent data.
The primary key is an object that uniquely identifies an entity bean within its home. The container must be able to manipulate the primary key of an entity bean. Each entity bean class may define a different class for its primary key, but multiple entity beans can use the same primary key class. The primary key is specified in the deployment descriptor for the entity bean. You can specify a primary key class for an entity bean with container-managed persistence by mapping the primary key to either a single field or to multiple fields in the entity bean class.
Every entity object has a unique identity within its home. If two entity objects have the same home and the same primary key, they are considered identical. A client can invoke the getPrimaryKey() method on the reference to an entity object's remote interface to determine the entity object's identity within its home. The object identify associated with the a reference does not change during the lifetime of the reference. Therefore, the getPrimaryKey() method always returns the same value when called on the same entity object reference. A client that knows the primary key of an entity object can obtain a reference to the entity object by invoking the findByPrimaryKey(key) method on the bean's home interface.
Primary Key Mapped to a Single CMP Field
In the entity bean class, you can have a primary key that maps to a single CMP field. You use the primkey-field element, a deployment descriptor in the ejb-jar.xml file, to specify the container-managed field that is the primary key. The prim-key-class element must be the primary key field's class.
Primary Key Class That Wraps Single or Multiple CMP Fields
You can have a primary key class that maps to single or multiple fields. The primary key class must be public, and have a public constructor with no parameters. You use the prim-key-class element, a deployment descriptor in the ejb-jar.xml file to specify the name of the entity bean's primary key class. You can only specify the the class name in this deployment descriptor element. All fields in the primary key class must be declared public. The fields in the class must have the same name as the primary key fields in the ejb-jar.xml file.
If your entity EJB uses an anonymous primary key class, you must subclass the EJB and add a cmp-field of type java.lang.Integer to the subclass. Enable automatic primary key generation for the field so that the container fills in field values automatically, and map the field to a database column in the weblogic-cmp-rdbms-jar.xml deployment descriptor.
Finally, update the ejb-jar.xml file to specify the EJB subclass, rather than the original EJB class, and deploy the bean to WebLogic Server.
If you use the original EJB (instead of the subclass) with an anonymous primary key class, WebLogic Server displays the following error message during deployment:
In EJB ejb_name, an 'Unknown Primary Key Class' ( <prim-key-class> == java.lang.Object ) MUST be specified at Deployment time (as something other than java.lang.Object).
Some hints for using primary keys with WebLogic Server include:
WebLogic Server supports mapping a database column to a cmp-field and a cmr-field concurrently. The cmp-field is read-only in this case. If the cmp-field is a primary key field, specify that the value for the field be set when the create() method is invoked by using the setXXX method for the cmp-field.
Automatic Primary Key Generation for EJB 2.0 CMP
WebLogic Server supports an automatic primary key generation feature for container-managed persistence (CMP).
Note: This feature is supported for the EJB 2.0 CMP container only, there is no automatic primary key generation support for EJB 1.1 CMP. For 1.1 beans, you must use bean-managed-persistence (BMP.)
Generated key support is provided in two ways:
With this option, the container defers all key generation to the underlying database. To enable this feature, you specify the name of the supported DBMS and the generator name, if required by the database. The CMP code handles all details of implementing this feature.
For more information on this feature, see Specifying Primary Key Support for Oracle and Specifying Primary Key Support for Microsoft SQL Server.
Note: For instructions on creating a table in Oracle, use the Oracle database documentation.
In the weblogic-cmp-rdbms-jar.xml file, set the key_cache_size element to specify how many primary key values a database SELECT and UPDATE will fetch at one time. The default value of key_cache_size is 1. BEA recommends that you set this element to a value of >1, to minimize database accesses and to improve performance. For more information in this feature, see Specifying Primary Key Named Sequence Table Support.
At this time, WebLogic Server only provides DBMS primary key generation support for Oracle and Microsoft SQL Server. However, you can use named sequence tables with other unsupported databases. Also, this feature is intended for use with simple (non-compound) primary keys.
In the abstract `get' and `set' methods of the bean, you can declare the field to be either of these two types:
Specifying Primary Key Support for Oracle
Generated primary key support for Oracle databases uses Oracle's SEQUENCE feature. This feature works with a Sequence entity in the Oracle database to generate unique primary keys. The Oracle SEQUENCE is called when a new number is needed.
Once the SEQUENCE already exists in the database, you specify automatic key generation in the XML deployment descriptors. In the weblogic-cmp-rdbms-jar.xml file, you specify automatic key generation as follows:
Figure 5-7 Specifying automatic key generation for Oracle
<automatic-key-generation>
<generator-type>ORACLE</generator-type>
<generator_name>test_sequence</generator-name>
<key-cache-size>10</key-cache-size>
</automatic-key-generation>
Specify the name of the ORACLE SEQUENCE to be used, using the generator-name element. If the ORACLE SEQUENCE was created with a SEQUENCE INCREMENT value, then you must specify a key-cache-size. This value must match the Oracle SEQUENCE INCREMENT value. If these two values are different, then you will most likely have duplicate key problems.
Warning: Do not use the generator type USER_DESIGNATED_TABLE with Oracle, as doing so can cause the following exception:
javax.ejb.EJBException: nested exception is: java.sql.SQLException: Automatic Key Generation Error: attempted to UPDATE or QUERY NAMED SEQUENCE TABLE NAMED_SEQUENCE_TABLE, but encountered SQLException java.sql.SQLException: ORA-08177: can't serialize access for this transaction.
USER_DESIGNATED_TABLE mode sets the TX ISOLATION LEVEL to SERIALIZABLE which can cause problems with Oracle.
Instead, use the AutoKey option ORACLE.
Specifying Primary Key Support for Microsoft SQL Server
Generated primary key support for Microsoft SQL Server databases uses SQL Server's IDENTITY column. When the bean is created and a new row is inserted in the database table, SQL Server automatically inserts the next primary key value into the column that was specified as an IDENTITY column.
Note: For instructions on creating a table in Microsoft SQL Server, see the Microsoft SQL Server database documentation.
Once the IDENTITY column is created in the database table, you specify automatic key generation in the XML deployment descriptors. In the weblogic-cmp-rdbms-jar.xml file, you specify automatic key generation as follows:
Figure 5-8 Specifying automatic key generation for Microsoft SQL
<automatic-key-generation>
<generator-type>SQL_SERVER</generator-type>
</automatic-key-generation>
The generator-type element lets you specify the primary key generation method that you want to use.
Specifying Primary Key Named Sequence Table Support
Generated primary key support for unsupported databases uses a Named SEQUENCE TABLE to hold key values. The table must contain a single row with a single column that is an integer, SEQUENCE INT. This column will hold the current sequence value.
Note: For instructions on creating the table, see the documentation for the specific database product.
To use Named Sequence Table support, make sure that the underlying database supports the transaction isolation level, TRANSACTION_SERIALIZABLE. You specify this option for the isolation-level element, in the weblogic-ejb.xml file. The TRANSACTION_SERIALIZABLE option specifies that simultaneously executing a transaction multiple times has the same effect as executing the transaction multiple times in a serial fashion. If the database doesn't support the transaction isolation level, TRANSACTION_SERIALIZABLE, then you cannot use Named Sequence Table support.
Note: See the documentation for the underlying database to determine the type of isolation level support it provides and see Specifying and Editing the EJB Deployment Descriptors for instructions on setting the isolation level.
Once the NAMED_SEQUENCE_TABLE exists in the database, you specify automatic key generation by using the XML deployment descriptors in the weblogic-cmp-rdbms-jar.xml file, as follows:
Figure 5-9 Specifying automatic key generation for named sequence table support
<automatic-key-generation>
<generator-type>NAMED_SEQUENCE_TABLE</generator-type>
<generator_name>MY_SEQUENCE_TABLE_NAME</generator-name>
<key-cache-size>100</key-cache-size>
</automatic-key-generation>
Specify the name of the SEQUENCE TABLE to be used, with the generator-name element. Using the key-cache-size element, specify the optional size of the key cache that tells you how many keys the container will fetch in a single DBMS call.
For improved performance, BEA recommends that you set this value to >1, a number greater than one. This setting reduces the number of calls to the database to fetch the next key value.
Also, it is recommended that you define one NAMED SEQUENCE table per bean type. Beans of different types should not share a common NAMED SEQUENCE table. This reduces contention for the key table.
Multiple Table Mapping for EJB 2.0 CMP
Multiple table mapping allows you to map a single EJB to multiple DBMS tables within a single database for EJB 2.0 CMP beans. You configure this feature by mapping multiple DBMS tables and columns to the EJB and its fields in the EJB's weblogic-cmp-rdbms-xml file. This includes the following types of mappings:
When enabling multiple table mappings, the following requirement applies:
Previously, you could associate an EJB with a single table and a list of fields and columns. Now, you can associate sets of fields and columns for as many tables as the EJB maps to.
Note this restriction for multiple mapped tables on a single bean:
Tables that are mapped to a single entity bean must not have referential integrity constraints declared between their primary keys. Doing so may result in a runtime error upon bean removal.
Multiple Table Mappings for cmp-fields
Configure multiple table mappings for cmp-fields, in a weblogic-rdbms-bean stanza of the EJB's weblogic-cmp-rdbms-xml file, as follows:
The following sample XML shows an EJB that maps to a single DBMS table:
Figure 5-10 Mapping a single DBMS table
<table-name>TableName</table-name>
<field-map>
<cmp-field>name</cmp-field>
<dbms-column>name_in_tablename</dbms-column>
</field-map>
<field-map>
<cmp-field>street_address</cmp-field>
<dbms-column>street_address_in_tablename
</dbms_column>
</field-map>
<field-map>
<cmp-field>phone</cmp-field>
<dbms-column>phone_in_tablename</dbms-column>
</field-map>
The following sample XML shows an EJB that maps to two different tables:
Figure 5-11 Mapping to two DBMS tables
<table-map>
<table-name>TableName_1</table-name>
<field-map>
<!--Note `name'is the primary key field of this EJB -->
<cmp-field>name</cmp-field>
<dbms-column>name_in_tablename_1</dbms-column>
</field-map>
<field-map>
<cmp-field>street_address</cmp-field>
<dbms-column>street_address_in_tablename_1
</dbms-column>
</field-map>
</table-map>
<table-map>
<table-name>TableName_2</table-name>
<field-map>
<!--Note `name'is the primary key field of this EJB -->
<cmp-field>name</cmp-field>
<dbms-column>name_in_tablename_2</dbms-column>
</field-map>
<field-map>
<cmp-field>phone</cmp-field>
<dbms-column>phone_in_tablename_2</dbms-column>
</field-map>
</table-map>
Note: As shown in the above XML sample for a table mapping, you must map the primary key field to each table's primary key column.
For information about specifying CMRs when one of the beans in the relationship maps to multiple tables, see Specifying CMRs for EJBs that Map to Multiple Tables.
You can specify that WebLogic Server automatically create tables based on the descriptions in the XML deployment descriptor files and the bean class, if the table does not already exist. Tables are created for all beans and relationship join tables, if the relationships in the JAR files have joins. You explicitly turn on this feature by defining it in the deployment descriptors per each RDBMS deployment, for all beans in the JAR file.
If you enable automatic table creation, WebLogic Serve examines the value of the database-type element in weblogic-cmp-rdbms-jar.xml to determine the correct syntax and datatype conversions to use to create a table in your database. WebLogic Server version 7.0 uses the vendor-specific CREATE TABLE syntax and datatype conversions for the following databases and vendors:
For all other database systems, WebLogic Server makes a best attempt to create the new table using a basic syntax and the datatype conversions shown in the following table:
Table 5-1 Generic Java Field to DBMS Column Type Conversion
If, based on the descriptions in the deployment files, a field cannot be successfully mapped to an appropriate column type in the database, the CREATE TABLE fails, an error is thrown, and you must create the table yourself.
Automatic table creation is not recommended for use in a production environment. It is better suited for the development phase of design and prototype work. A production environment may require the use of more precise table schema definitions, for example; the declaration of foreign key constraints.
To define automatic table creation:
Container-Managed Relationships
Container-managed relationships (CMRs) are relationships that you define between two entity EJBs, analogous to the relationships between the tables in a database. If you define a CMR between two EJBs that are involved in the same processing task, your application can benefit from these features:
This section describes the features and limitations of WebLogic Server CMRs. For instruction on configuring CMRs, see Defining Container-Managed Relationships.
You can define a relationship between two WebLogic Server entity beans that will be packaged in the same .jar and whose data persist in the same database. Entities that participate in the same relationship must map to the same datasource. WebLogic Server does not support relationships between entity beans that are mapped to different datasources. The abstract schema for each bean that participates in a container-managed relationship must be defined the same ejb-jar.xml file.
Note: EJB 2.1 states that if an entity bean does not have a local interface, the only CMR in which it can participate is a unidirectional one, from itself to another entity bean.
However, WebLogic Server allows an entity bean with only a remote interface to:
Because this feature is not specified in EJB 2.1, entity beans that have only remote interfaces, and either participate in bidirectional relationships or are the target of a unidirectional relationship, may not be portable to other application servers.
An entity bean can have a one-to-one, one-to-many, or many-to-many relationship with another entity bean.
Any CMR, whether one-to-one, one-to-many, or many-to-many, can be either unidirectional or bidirectional. The direction of a CMR determines whether the bean on one side of the relationship can be accessed by the bean on the other side.
Unidirectional CMRs can be navigated in one direction only—the "dependent" bean" is unaware of the other bean in the relationship. CMR-related features such as cascade deletes can only be applied to the dependent bean. For example, if cascade deletes have been configured for a unidirectional CMR from to EJB1 to EJB2, deleting EJB1 will cause deletion of EJB2, but deleting EJB2 will not cause deletion of EJB1.
Note: For the cascade delete feature, the cardinality of the relationship is a factor—cascade deletes are not supported from the many side of a relationship, even if the relationship is bidirectional.
Bidirectional relationships can be navigated in both directions—each bean in the relationship is aware of the other. CMR-related features are supported in both directions. For example, if cascade deletes have been configured for a bidirectional CMR between EJB1 to EJB2, deleting either bean in the CMR will cause deletion of the other bean.
When a bean instance that participates in a relationship is removed, the container automatically removes the relationship. For instance, given a relationship between an employee and a department, if the employee is removed, the container removes the relationship between the employee and the department as well.
Defining Container-Managed Relationships
Defining a CMR involves specifying the relationship and its cardinality and direction in ejb-jar.xml. You define database mapping details for the relationship and enable relationship caching in weblogic-cmp-jar.xml. These sections provide instructions:
Specifying Relationship in ejb-jar.xml
Container-managed relationships are defined in the ejb-relation stanza of ejb-jar.xml. Figure 5-12 shows the ejb-relation stanza for a relationship between two entity EJBs: TeacherEJB and StudentEJB.
The ejb-relation stanza contains a ejb-relationship-role for each side of the relationship. The role stanzas specify each bean's view of the relationship.
Figure 5-12 One-to-Many, Bidirectional CMR in ejb-jar.xml
<ejb-relation>
<ejb-relation-name>TeacherEJB-StudentEJB</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>teacher-has-student
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>TeacherEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>teacher</cmr-field-name>
</cmr-field>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>student-has-teacher
</ejb-relationship-role-name>
<multiplicity>Many</multiplicity>
<relationship-role-source>
<ejb-name>StudentEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>student</cmr-field-name>
<cmr-field-type>java.util.Collection
<cmr-field>
</ejb-relationship-role>
Specifying Relationship Cardinality
The cardinality on each side of a relationship is indicated using the <multiplicity> element in its ejb-relationship-role stanza.
In Figure 5-12, the cardinality of the TeacherEJB-StudentEJB relationship is one-to-many—it is specified by setting multiplicity to one on the TeacherEJB side and Many on the StudentEJB side.
The cardinality of the CMR in Figure 5-13, is one-to-one—the multiplicity is set to one in both role stanza for the relationship
Figure 5-13 One-to-One, Unidirectional CMR in ejb-jar.xml
<ejb-relation>
<ejb-relation-name>MentorEJB-StudentEJB</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>mentor-has-student
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>MentorEJB</ejb-name>
</relationship-role-source>
<cmr-field>
<cmr-field-name>mentorID</cmr-field-name>
</cmr-field>
</ejb-relationship-role>
<ejb-relationship-role>
<ejb-relationship-role-name>student-has-mentor
</ejb-relationship-role-name>
<multiplicity>One</multiplicity>
<relationship-role-source>
<ejb-name>StudentEJB</ejb-name>
</relationship-role-source>
</ejb-relationship-role>
If a side of a relationship of a relationship has a <multiplicity> of Many, its <cmr-field> is a collection, and you must specify its <cmr-field-type> as java.util.Collection, as shown in the StudentEJB side of the relationship in Figure 5-12. It is not necessary to specify the cmr-field-type when the cmr-field is a single valued object.
Table 5-2 lists the contents of cmr-field for each bean in a relationship, based on the cardinality of the relationship.
Table 5-2 Cardinality and cmr-field-type
Specifying Relationship Directionality
The directionality of a CMR by configured by the inclusion (or exclusion) of a cmr-field in the ejb-relationship-role stanza for each side of the relationship
A bidirectional CMR has a cmr-field element in the ejb-relationship-role stanza for both sides of the relationship, as shown in Figure 5-12.
A unidirectional relationship has a cmr-field in only one of the role stanzas for the relationship. The ejb-relationship-role for the starting EJB contains a cmr-field, but the role stanza for the target bean does not. Figure 5-13 specifies a unidirectional relationship from MentorEJB to StudentEJB— there is no cmr-field element in the ejb-relationship-role stanza for StudentEJB.
Specifying Relationships in weblogic-cmp-jar.xml
Each CMR defined in ejb-jar.xml must also be defined in a weblogic-rdbms-relation stanza in weblogic-cmp-jar.xml. weblogic-rdbms-relation identifies the relationship, and contains the relationship-role-map stanza, which maps the database-level relationship between the participants in the relationship, for one or both sides of the relationship.
The relation-name in weblogic-rdbms-relation must be the same as the ejb-relation-name for the CMR in ejb-jar.xml.
One-to-One and One-to-Many Relationships
For one-to-one and one-to-many relationships, relationship-role-map is defined for only one side of the relationship.
For one-to-one relationships, the mapping is from a foreign key in one bean to the primary key of the other.
Figure 5-14 is the weblogic-rdbms-relation stanza for a the one-to-one relationship between MentorEJB and StudentEJB, whose <ejb-relation> is shown in Figure 5-13.
Figure 5-14 One-to-One CMR weblogic-cmp-jar.xml
<weblogic-rdbms-relation>
<relation-name>MentorEJB-StudentEJB</relation-name>
<weblogic-relationship-role>
<relationship-role-name>
mentor-has-student
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>student</foreign-key-column>
<key-column>StudentID/key-column>
</column-map>
<relationship-role-map>
</weblogic-relationship-role>
For one-to-many relationships, the mapping is also always from a foreign key in one bean to the primary key of another. In a one-to-many relationship, the foreign key is always associated with the bean that is on the many side of the relationship.
Figure 5-15 is the weblogic-rdbms-relation stanza for a the one-to-many relationship between TeacherEJB and StudentEJB, whose <ejb-relation> is shown in Figure 5-12.
Figure 5-15 weblogic-rdbms-relation for a One-to-Many CMR
<weblogic-rdbms-relation>
<relation-name>TeacherEJB-StudentEJB</relation-name>
<weblogic-relationship-role>
<relationship-role-name>
teacher-has-student
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>student</foreign-key-column>
<key-column>StudentID/key-column>
</column-map>
<relationship-role-map>
</weblogic-relationship-role>
For many-to-many relationships, specify a weblogic-relationship-role stanza for each side of the relationship. The mapping involves a join table. Each row in the join table contains two foreign keys that map to the primary keys of the entities involved in the relationship. The direction of a relationship does not affect how you specify the database mapping for the relationship.
Figure 5-16 shows the weblogic-rdbms-relation stanza for the friends relationship between two employees.
The FRIENDS join table has two columns, first-friend-id and second-friend-id. Each column contains a foreign key that designates a particular employee who is a friend of another employee. The primary key column of the employee table is id. The example assumes that the employee bean is mapped to a single table. If employee bean is mapped to multiple tables, then the table containing the primary key column must be specified in the relation-role-map. For an example, see Specifying CMRs for EJBs that Map to Multiple Tables.
Figure 5-16 weblogic-rdbms-relation for a Many-to-Many CMR
<weblogic-rdbms-relation>
<relation-name>friends</relation-name>
<table-name>FRIENDS</table-name>
<weblogic-relationship-role>
<relationship-role-name>first-friend
</relationship-role-name>
<relationship-role-map>
<column-map>
<foreign-key-column>first-friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map
</relationship-role-map>
<weblogic-relationship-role>
<weblogic-relationship-role>
<relationship-role-name>second-friend</relationship-role-
name>
<relationship-role-map>
<column-map>
<foreign-key-column>second-friend-id</foreign-key-column>
<key-column>id</key-column>
</column-map>
</relationship-role-map>
</weblogic-relationship-role>
</weblogic-rdbms-relation>
Specifying CMRs for EJBs that Map to Multiple Tables
A CMP bean that is involved in a relationship may be mapped to multiple DBMS tables.
If neither of the beans in a relationship is mapped to multiple tables, then the foreign-key-table and primary-key-table elements may be omitted since the tables being used are implicit.
Figure 5-17 contains a relationship-role-map for a CMR in which the bean on the foreign-key side of a one-to-one relationship, Fk_Bean, is mapped to two tables: Fk_BeanTable_1 and Fk_BeanTable_2.
The foreign key columns for the relationship, Fk_column_1 and Fk_column_2, are located in Fk_BeanTable_2. The bean on the primary key side, Pk_Bean, is mapped to a single table with primary-key columns Pk_table_pkColumn_1 and Pk_table_pkColumn_2.
The table that contains the foreign-key columns is specified by the <foreign-key-table> element.
Figure 5-17 One-to-One CMR, One Bean Maps to Multiple Tables
<relationship-role-map
<foreign-key-table>Fk_BeanTable_2</foreign-key-table>
<column-map>
<foreign-key-column>Fk_column_1</foreign-key-column>
<key-column>Pk_table_pkColumn_1</key-column>
</column-map>
<column-map>
<foreign-key-column>Fk_column_2</foreign-key-column>
<key-column>Pk_table_pkColumn_2</key-column>
</column-map>
</relationship-role-map>
Using Relationship Caching for CMRs
Relationship caching improves the performance of entity beans by loading related beans into the cache and avoiding multiple queries by issuing a join query for the related bean.
For example, given entity beans with the following relationships:
Consider the following EJB code for accountBean and addressBean, which have a 1-to-1 relationship:
Account acct = acctHome.findByPrimaryKey("103243");
Address addr = acct.getAddress();
Without relationship caching, a SQL query is issued by the first line of code to load accountBean and another SQL query is issued by the second line of code to load the addressBean; this results in two queries to the database.
With relationship caching, a single query is issued to load both the accountBean and addressBean by the first line of code, which should result in better performance. So, if you know that a related bean will be accessed after executing a particular finder method, its a good idea to let the finder method know via the relationship caching feature.
Specify relationship caching using these stanzas in weblogic-cmp-jar.xml
Note: Make sure that the finders-load-bean element, specified in the weblogic-ejb-jar.xml file, in the bean that specifies an relationship (for example, customerBean in the above sample XML code) is not set to False or relationship caching will not be enabled. The finder-load-bean element's default is True.
Figure 5-18 relationship-caching in weblogic-cmp-jar.xml
<relationship-caching>
<caching-name>cacheMoreBeans</caching-name>
<caching-element>
<cmr-field>accounts</cmr-field>
</caching-element>
</relationship-caching>
Figure 5-19 weblogic-query in weblogic-cmp-jar.xml
<weblogic-query>
<query-method>
<method-name>findBigAccounts</method-name>
<method-params>
<method-param>java.lang.String</method-param>
<method-param>java.lang.Integer</method-param>
</method-params>
</query-method>
<caching-name>cacheMoreBeans</caching-name>
</weblogic-query>
Using nested caching-elements enables the bean to load more than one level of related beans. Currently, there is no limitation on the number of caching-elements that you can specify. However, setting too many caching-element levels could have an impact on the performance of the current transaction.
Since relationship caching uses join queries, and a join query might duplicate results for a table in the ResultSet, the number of caching-element elements specified will have a direct impact on the number of duplicate results in the ResultSet. For one-to-many relationships, do not specify too many caching-element deployment descriptors in the relationship-caching element because the number of duplicate results might multiply for each caching-element deployment descriptor.
Relationship Caching Limitations
The relationship caching feature has the following limitations:
Use the cascade delete mechanism to remove entity bean objects. When cascade delete is specified for a particular relationship, the lifetime of one entity object depends on another. You can specify cascade delete for one-to-one and one-to-many relationships; many-to-many relationships are not supported. The cascade delete() method uses the delete features in WebLogic Server, and the database cascade delete() method instructs WebLogic Server to use the underlying database's built-in support for cascade delete.
To enable this feature, you must recompile the bean code for the changes to the deployment descriptors to take effect.
Use one of the following two methods to enable cascade delete.
With the cascade delete() method you use WebLogic Server to remove objects. If an entity is deleted and the cascade delete element is specified for a related entity bean, then the removal is cascaded and any related entity bean objects are also removed.
To specify cascade delete, use the cascade-delete element in the ejb-jar.xml deployment descriptor elements. This is the default method. Make no changes to your database settings, and WebLogic Server will cache the entity objects for removal when the cascade delete is triggered.
Specify cascade delete using the cascade-delete element in the ejb-jar.xml file as follows:
Figure 5-20 Specifying a cascade delete
<ejb-relation>
<ejb-relation-name>Customer-Account</ejb-relation-name>
<ejb-relationship-role>
<ejb-relationship-role-name>Account-Has-Customer
</ejb-relationship-role-name>
<multiplicity>one</multiplicity>
<cascade-delete/>
</ejb-relationship-role>
</ejb-relation>
Note: This cascade delete() method can only be specified for a ejb-relationship-role element contained in an ejb-relation element if the other ejb-relationship-role element in the same ejb-relation element specifies a multiplicity attribute with a value of one.
Database Cascade Delete Method
The database cascade delete() method allows an application to take advantage of a database's built-in cascade delete support, and possibly improve performance. If the db-cascade-delete element is not already specified in the weblogic-cmp-rdbms-jar.xml file, do not enable any of the database's cascade delete functionality, because this will produce incorrect results in the database.
The db-cascade-delete element in the weblogic-cmp-rdbms-jar.xml file specifies that a cascade delete operation will use the built-in cascade delete facilities of the underlying DBMS. By default, this feature is turned off and the EJB container removes the beans involved in a cascade delete by issuing an individual SQL DELETE statement for each bean.
If db-cascade-delete element is specified in the weblogic-cmp-rdbms-jar.xml, the cascade-delete element must be specified in the ejb-jar.xml.
When db-cascade-delete is enabled, additional database table setup is required. For example, the following setup for the Oracle database table will cascade delete all of the employees if the dept is deleted in the database.
Figure 5-21 Oracle table setup for cascade delete
CREATE TABLE dept
(deptno NUMBER(2) CONSTRAINT pk_dept PRIMARY KEY,
dname VARCHAR2(9) );
CREATE TABLE emp
(empno NUMBER(4) PRIMARY KEY,
ename VARCHAR2(10),
deptno NUMBER(2) CONSTRAINT fk_deptno
REFERENCES dept(deptno)
ON DELETE CASCADE );
WebLogic Server provides support for local interfaces for session and entity beans. Local interfaces allow enterprise javabeans to work together within the same EJB container using different semantics and execution contexts. The EJBs are usually co-located within the same EJB container and execute within the same Java Virtual Machine (JVM). This way, they do not use the network to communicate and avoid the over-head of a Java Remote Method Invocation-Internet Inter-ORB Protocol (RMI-IIOP) connection.
EJB relationships with container-managed persistence are now based on the EJB's local interface. Any EJB that participates in a relationship must have a local interface. Local interface objects are lightweight persistent objects. They allow you to do more fine grade coding than do remote objects. Local interfaces also use pass-by-reference. The getter is in the local interface.
In earlier versions of WebLogic Server, you can base relationships on remote interfaces. However, CMP relationships that use remote interfaces should probably not be used in new code.
The EJB container makes the local home interface accessible to local clients through JNDI. To reference a local interface you need to have a local JNDI name. The objects that implement the entity beans' local home interface are called EJBLocalHome objects. You can specify either a jndi-name or local-jndi-name in the weblogic-ejb-jar.xml file. For more information on how to specify deployment descriptors, see Specifying and Editing the EJB Deployment Descriptors
In earlier versions of WebLogic Server, ejbSelect methods were used to return remote interfaces. Now you can specify a result-type-mapping element in the ejb-jar.xml file that indicates whether the result returned by the query will be mapped to a local or remote object.
A local client of a session bean or entity bean can be another EJB, such as a session bean, entity bean, or message-driven bean. A local client can be a servlet as long as it is included as part of the same EAR file and as long as the EAR file is not remote. Clients of a local bean must be part of an EAR or a standalone JAR.
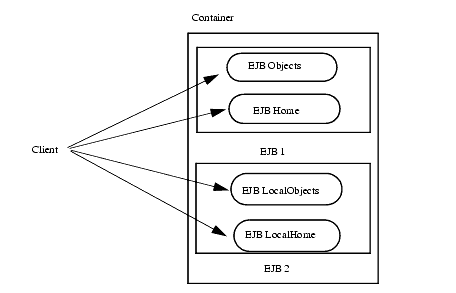
A local client accesses a session or entity bean through the bean's local interface and local home interfaces. The container provides classes that implement the bean's local and local home interfaces. The objects that implement these interfaces are local Java objects. The following diagram shows the container with a local client and local interfaces.
Figure 5-22 Local client and local interfaces
WebLogic Server provides support for both local and uni-directional remote relationships between EJBs. If the EJBs are on the same server and are part of the same JAR file, they can have local relationships. If the EJBs are not on the same server, the relationships must be remote. For a relationship between local beans, multiple column mappings are specified if the key implementing the relation is a compound key. For a remote bean, only a single column-map is specified, since the primary key of the remote bean is opaque. No column-maps are specified if the role just specifies a group-name. No group-name is specified if the relationship is remote.
Changes to the Container for Local Interfaces
Changes made to the structure of the container to accommodate local interfaces include the following additions:
In container-managed persistence, you use groups to specify certain persistent attributes of an entity bean. A field-group represents a subset of the cmp and CMR-fields of a bean. You can put related fields in a bean into groups that are faulted into memory together as a unit. You can associate a group with a query or relationship, so that when a bean is loaded as the result of executing a query or following a relationship, only the fields mentioned in the group are loaded.
A special group named "default" is used for queries and relationships that have no group specified. By default, the default group contains all of a bean's CMP-fields and any CMR-fields that add a foreign key to the persistent state of the bean.
A field can belong to multiple groups. In this case, the getXXX() method for the field will fault in the first group that contains the field.
Field groups are specified in the weblogic-rdbms-cmp-jar.xml file as follows:
<weblogic-rdbms-bean>
<ejb-name>XXXBean</ejb-name>
<field-group>
<group-name>medical-data</group-name>
<cmp-field>insurance</cmp-field>
<cmr-field>doctors</cmr-fields>
</field-group>
</weblogic-rdbms-bean>
You use field groups when you want to access a subset of fields.
WebLogic Server fully supports EJB links as defined in the EJB 2.0 Specification. You can link an EJB reference that is declared in one application component to an enterprise bean that is declared in the same J2EE application.
The value of the ejb-link element must be the ejb-name of the target EJB. The target EJB can be in any EJB JAR file in the same J2EE application as the referencing application component.
Because ejb-names are not required to be unique across EJB JAR files, you may need to provide the qualified path for the link.
<ejb-link>../products/product.jar#ProductEJB</ejb-link>
For instructions on specifying deployment descriptors, see Specifying and Editing the EJB Deployment Descriptors.
Java Data Types for CMP Fields
The following table provides a list of the Java data types for CMP fields used in WebLogic Server and shows how they map to the Oracle extensions for the standard SQL data types.
Table 5-3 Java data types for CMP fields
Do not use the SQL CHAR data type for database columns that are mapped to CMP fields. This is especially important for fields that are part of the primary key, because padding blanks that are returned by the JDBC driver can cause equality comparisons to fail when they should not. Use the SQL VARCHAR data type instead of SQL CHAR.
A CMP field of type byte[] cannot be used as a primary key unless it is wrapped in a user-defined primary key class that provides meaningful equals() and hashCode() methods. This is because the byte[] class does not provide useful equals and hashCode.
|

|

|