11g リリース1(11.1)
E05694-03
 目次 |
 索引 |
| Oracle Database 2日で開発者ガイド 11g リリース1(11.1) E05694-03 |
|

この章では、「データの問合せおよび操作」で説明されているデータベース・オブジェクトのタイプを作成および使用します。
CREATE TABLE、ALTER TABLE、DROP TABLEなどの文は、暗黙的なコミットを使用するため、ロールバックできないことに注意してください。
この章の内容は次のとおりです。
データ型により、データベースでこれらの値を使用できるように一連のプロパティが値と関連付けられます。データ型に応じて、Oracle Databaseのデータベースにおいて実行できる情報の操作の種類が異なります。たとえば、数値データ型を使用した場合、数値の合計は計算できますが文字は使用できません。
Oracle Databaseでは、最も一般的なVARCHAR2(長さ)、NUMBER(精度、スケール)、DATE、CHAR(長さ)、CLOB、TIMESTAMPおよびその他を含む様々なデータ型をサポートしています。表を作成するときに、各列のデータ型を指定する必要があり、(必要に応じて)列に格納できる最も長い値を示します。
ここで使用する一部のデータ型のおよびそのプロパティには、次の機能があります。
VARCHAR2は可変長の文字列を格納し、文字データの格納には最も効率のよいオプションです。VARCHAR2列を表に作成するときには、列に格納できる最大文字数を1から4000の間で指定します。employees表のfirst_name列にはVARCHAR(20)データ型があり、LAST_NAME列にはVARCHAR2(25)データ型があります。
VARCHAR2データ型のオプションのNVARCHAR2では、Unicodeの可変長の文字列が格納されます。
CHARデータ型には、1から2000の間で指定した固定長の文字列が格納され、値の空白埋めが使用されます。CHAR2データ型のオプションのNCHARでは、Unicodeの固定長の文字列が格納されます。
CLOBデータ型は、シングルバイト・キャラクタまたはマルチバイト・キャラクタが含まれるキャラクタ・ラージ・オブジェクトのデータ型です。CLOBの最大サイズは(4GB - 1)x(データベース・ブロック・サイズ)です。
NUMBERデータ型はゼロ、整数、および10進精度で固定小数点または浮動小数点を使用して、 1.0 x 10-130と1.0 X 10126の間の絶対値を持つ正と負の固定数としての実数を格納します。NUMBERデータ型は、異なるオペレーティング・システム間で移植可能であり、数値データを格納する必要がある場合にはこのデータ型を使用することをお薦めします。精度オプションを使用して数の最大桁数を設定し、スケール・オプションを使用して小数点以下の桁数をいくつにするかを定義します。employees表のsalary列はNUMBER(8,2)として定義され、基本通貨単位(ドル、ポンド、マルクなど)に対し6桁、補助通貨単位(セント、ペニー、ペニッヒなど)として2桁が与えられています。
NUMBERデータ型の拡張として数値BINARY_FLOATおよびBINARY_DOUBLEデータ型が用意されています。BINARY_FLOAT(32ビットIEEE 754規格)の範囲は1.17549 x e-38Fと3.40282 x e38Fの間の絶対値で、BINARY_DOUBLE(64ビットIEEE 754規格)の範囲は2.22507485850720 x e-308と1.79769313486231 x e308の間の絶対数です。両方とも2進精度を使用し、これにより高速な算術計算を可能とし、通常は記憶域要件が減少します。
DATEデータ型には、ある時点の値(日付および時間)が格納されます。これには年(世紀を含む)、月、日、時、分および秒が格納されます。有効な日付の範囲はBC 4712年1月1日からAD 9999年12月31日までです。Oracle Databaseでは日付と時間の値を表示するための様々な形式がサポートされています。employees表のhire_date列はDATEとして定義されています。
TIMESTAMPデータ型には小数秒までの正確な値が格納されるため、イベントの順序を追跡する必要があるアプリケーションにおいて役立ちます。
TIMESTAMP WITH TIME ZONEデータ型にはタイムゾーン情報が格納されるため、複数の地域にまたがって調整する必要がある日付情報を記録できます。表は、Oracleデータベースにおけるデータ記憶領域の基本単位であり、ユーザーがアクセスできるすべてのデータを保持します。表は、表のフィールドを表す縦方向の列および表の各レコードの値を表す横方向の行から構成される2次元オブジェクトです。
この項では、必要な表およびその他のスキーマ・オブジェクトを作成し、既存のhrスキーマの従業員のパフォーマンス評価プロセスを実装します。
従業員評価プロセスを実装するには、performance_parts、evaluationsおよびscoresという3つの表を作成する必要があります。
performance_parts表にはパフォーマンス測定のカテゴリおよび各項目に関連する重みがリストされます。
evaluations表には従業員情報、評価日、役職および評価時のマネージャと部門が含まれます。従業員の役職、マネージャまたは部門の変更はいつ起こるかわからないため、この表の情報は保護する必要があります。
scores表には、各評価の各カテゴリに割り当てられたスコアが含まれます。
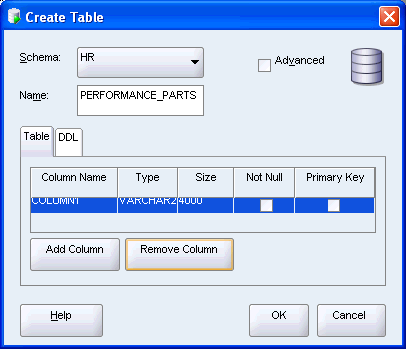
SQL Developerのグラフィカル・インタフェースを使用して、performance_parts表を作成します。
hr_connの横にあるプラス記号(+)をクリックしてスキーマ・オブジェクトのリストを展開します。
「Not Null」と「Primary Key」プロパティの値を残します。「データ整合性の保証」でここに戻ります。

「Add Column」をクリックします。
「Add Column」をクリックします。
SQL Developerにより新しい表performance_partsが生成されます。
performance_partsはhrスキーマの新しい表であり、locationsとregionsの間にリストされます。
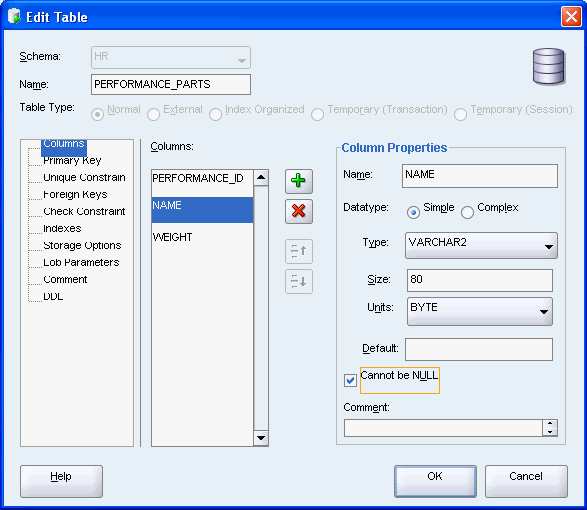
これで新しい表performance_partsが作成されました。表をクリックすると、SQL Developerウィンドウの右側に新しい列を含む表が表示されます。「SQL」タブをクリックすると、この表を作成したスクリプトが表示されます。
例3-1では、「SQL Worksheet」ペインで直接情報を入力して、evaluations表を作成します。
CREATE TABLE evaluations ( evaluation_id NUMBER(8,0), employee_id NUMBER(6,0), evaluation_date DATE, job_id VARCHAR2(10), manager_id NUMBER(6,0), department_id NUMBER(4,0), total_score NUMBER(3,0) )
スクリプトの結果が続きます。
CREATE TABLE succeeded.
これで新しい表evaluationsが作成されました。表をクリックすると、SQL Developerウィンドウの右側に新しい列を含む表が表示されます。「SQL」タブをクリックすると、この表を作成したスクリプトが表示されます。「Refresh」アイコンをクリックする必要があります。
例3-2では、「SQL Worksheet」ペインで情報を入力して、別の表scoresを作成します。
CREATE TABLE scores ( evaluation_id NUMBER(8,0), performance_id VARCHAR2(2), score NUMBER(1,0) );
文の結果が続きます。
CREATE TABLE succeed.
これで新しい表scoresが作成されました。表をクリックすると、SQL Developerウィンドウの右側に新しい列を含む表が表示されます。「SQL」タブをクリックすると、この表を作成したスクリプトが表示されます。「Refresh」アイコンをクリックする必要があります。
表のデータはアプリケーションでモデル化されたビジネス・ルールを満たす必要があります。これらのルールの多くは、どのタイプのデータ値が各列に対して有効であるかを明示的に宣言するSQLを使用する整合性制約で実装されます。
整合性制約を表に適用するとき、表内のすべてのデータが対応するルールに従う必要があります。このため、表にデータを挿入または変更するSQL文がアプリケーションに含まれているときに、制約が守られていることをOracle Databaseが自動的に確認します。制約に違反する行を挿入、更新または削除しようとすると、エラーが生成され、その文がロールバックされます。移入された表に新しい制約を適用しようとすると、既存の行のいずれかで新しい制約に違反している場合にエラーが生成される場合があります。
Oracle Databaseではアプリケーションより迅速に、表内のすべてのデータが整合性制約に従っているかを確認するため、アプリケーション・ロジックに同様のチェック・タイプを含めるよりも、整合性制約により定義することでさらに確実にビジネス・ルールを規定できます。
整合性制約には5つの基本タイプがあります。
NOT NULL制約は、列にNULLではないデータが含まれることを保証します。
NOT NULLとUNIQUE制約を組み合せます。これにより複数行で同じ列内または列の組合せに同じ値があることを禁止し、NULL値を禁止します。
「表の作成」で作成した表に異なる種類の制約を追加します。
SQL Developerのグラフィカル・インタフェースを使用して、表にNOT NULL制約を追加します。
performance_parts表を右クリックします。
これでperformance_parts表のname列に対してNOT NULL制約が作成されました。
performance_parts表のname列の定義は次のように変更されました。制約は自動的に有効になります。
"NAME" VARCHAR2(80) NOT NULL ENABLE
例3-3は、「SQL Statement」ウィンドウで必要な情報を直接入力し、performance_parts表にさらにNOT NULL制約を追加する方法を示しています。
ALTER TABLE performance_parts MODIFY weight NOT NULL;
スクリプトの結果が続きます。
ALTER TABLE performance_parts succeeded.
これでperformance_parts表のweight列に対してNOT NULL制約が作成されました。「SQL」タブをクリックすると、Weight列の定義が変更されたことを確認できます。「Refresh」アイコンをクリックする必要があります。
"WEIGHT" NUMBER NOT NULL ENABLE
SQL Developerのグラフィカル・インタフェースを使用して、scores表に一意制約を追加します。この作業を実行するために、NOT NULL制約の場合と同様に「Edit Table」ウィンドウを使用することもできます。
scores表を右クリックします。
SCORES_EVAL_PERF_UNIQUEに設定します。
EVALUATION_IDに設定します。
PERFORMANCE _IDに設定します。
「Apply」 をクリックします。

これでscores表に対する一意制約が作成されました。
次のSQL文が表定義に追加されました。
CONSTRAINT "SCORES_EVAL_PERF_UNIQUE" UNIQUE ("EVALUATION_ID", "PERFORMANCE_ID")
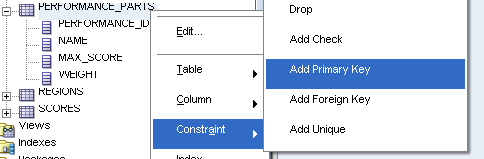
SQL Developerのグラフィカル・インタフェースを使用して、performance_parts表に主キー制約を追加します。この作業を実行するために、NOT NULL制約のように「Edit Table」ウィンドウを使用することもできます。
performance_parts表を右クリックします。
「Apply」 をクリックします。

これでperformance_parts表に対する主キー制約が作成されました。
次のSQL文が表定義に追加されました。
CONSTRAINT "PERF_PERF_ID_PK" PRIMARY KEY ("PERFORMANCE_ID")
例3-4では、「SQL Statement」ウィンドウで必要な情報を直接入力してevaluations表に主キー制約を作成します。
ALTER TABLE evaluations ADD CONSTRAINT eval_eval_id_pk PRIMARY KEY (evaluation_id);
スクリプトの結果が続きます。
ALTER TABLE evaluations succeeded.
evaluations表に主キーeval_eval_id_pkが作成されました。「SQL」タブをクリックすると、次のSQL文が表定義に追加されたことを確認できます。「Refresh」アイコンをクリックする必要があります。
CONSTRAINT "EVAL_EVAL_ID_PK" PRIMARY KEY ("EVALUATION_ID")
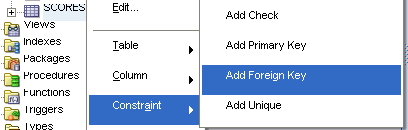
SQL Developerのグラフィカル・インタフェースを使用して、scores表に外部キー制約を追加します。この作業を実行するために、NOT NULL制約のように「Edit Table」ウィンドウを使用することもできます。
scores表を右クリックします。
SCORES_EVAL_FKに設定します。
EVALUATION_IDに設定します。
EVALUATIONSに設定します。
EVALUATION_IDに設定します。
「Apply」 をクリックします。

これでevaluations表のevalution_id列に対する外部キー制約が作成されました。
SCORES_PERF_FKに設定します。
PERFORMANCE_IDに設定します。
PERFORMANCE_PARTSに設定します。
PERFORMANCE_IDに設定します。
「Apply」 をクリックします。
次のSQL文が表定義に追加されました。
CONSTRAINT "SCORES_EVAL_FK" FOREIGN KEY ("EVALUATION_ID") REFERENCES "HR"."EVALUATIONS" ("EVALUATION_ID") ENABLE CONSTRAINT "SCORES_PERF_FK" FOREIGN KEY ("PERFORMANCE_ID") REFERENCES "HR"."PERFORMANCE_PARTS" ("PERFORMANCE_ID") ENABLE
例3-5では、「SQL Statement」ウィンドウで必要な情報を直接入力してevaluations表に外部キー制約を作成します。
ALTER TABLE evaluations ADD CONSTRAINT eval_emp_id_fk FOREIGN KEY (employee_id) REFERENCES employees(employee_id);
スクリプトの結果が続きます。
ALTER TABLE evaluations succeeded
これでemployees表のemployee_id列に外部キー制約が作成されました。「SQL」タブをクリックすると、次のSQL文が表定義に追加されたことを確認できます。「Refresh」アイコンをクリックする必要があります。
CONSTRAINT "EVAL_EMP_ID_FK" FOREIGN KEY ("EMPLOYEE_ID") REFERENCES "HR"."EMPLOYEES" ("EMPLOYEE_ID") ENABLE
SQL Developerのグラフィカル・インタフェースを使用して、scores表にチェック制約を追加します。この作業を実行するために、NOT NULL制約のように「Edit Table」ウィンドウを使用することもできます。
scores表を右クリックします。
SCORE_VALIDに設定します。
score >=0 and score <=9に設定します。
ENABLEに設定します。
「Apply」 をクリックします。

これでscores表のscore列に対するチェック制約が作成されました。
次のSQL文が表定義に追加されました。
CONSTRAINT "SCORE_VALID" CHECK (score >=0 and score <=9) ENABLE
SQL Developerを使用して、表へのデータの入力、編集、および既存のデータの削除ができます。次の作業では、performance_parts表に対するこれらのプロセスを説明します。
次の手順に従い、データ行をperformance_parts表に追加します。
performance_parts表をダブルクリックします。
performance_parts表の「Data」タブをクリックします。
[Enter]キーを押します。

PERFORMANCE_IDをBRに、NAMEをBuilding Relationshipsに、およびWEIGHTを0.2に設定します。[Enter]キーを押します。
PERFORMANCE_IDをCFに、NAMEをCustomer Focusに、およびWEIGHTを0.2に設定します。[Enter]キーを押します。
PERFORMANCE_IDをCMに、NAMEをCommunicationに、およびWEIGHTを0.2に設定します。[Enter]キーを押します。
PERFORMANCE_IDをTWに、NAMEをTeamworkに、およびWEIGHTを0.2に設定します。[Enter]キーを押します。
PERFORMANCE_IDをRDに、NAMEをResults Orientationに、およびWEIGHTを0.2に設定します。[Enter]キーを押します。
performance_parts表の新しいデータを確認します。これでperformance_parts表には6行が追加されました。
次の手順に従い、performance_parts表のデータを変更します。
performance_parts表をダブルクリックします。
performance_parts表の「Data」タブをクリックします。
Workload Management行で、weight値をクリックし、新しい値0.3を入力します。Building Relationships行で、weight値をクリックし、新しい値0.15を入力します。
Customer Focus行で、weight値をクリックし、新しい値0.15を入力します。

これでperformance_parts表の3つの行の値が変更されました。
hrスキーマでモデル化された企業において、workload ManagementとResults Orientationのカテゴリに非常に多くの重複があったと仮定します。このため、performance_parts表からResults Orientation行を削除します。
performance_parts表をダブルクリックします。
performance_parts表の「Data」タブをクリックします。
Results Orientation行をクリックします。
これでperformance_parts表から1行が削除されました。
表で主キーを定義するとき、Oracle Databaseでは主キーが含まれる列に索引が暗黙的に作成されます。たとえば、「Indexes」ペインを見ることでevaluations表の主キーに索引が作成されたことを確認できます。

この項では、以前に作成した表に対して様々な種類の索引を追加する方法を説明します。
次の手順に従い、evaluations表に新しい索引を作成します。
evaluations表を右クリックします。
または、「Connections」ナビゲーション階層で、「Indexes」を右クリックし「New Index」を選択することもできます。

プラス記号のような「Add Column Expression」アイコンをクリックします。
「OK」をクリックします。

これでevaluations表のJOB_ID列に新しい索引EVAL_JOB_IXが作成されました。この索引は、「Connections」ナビゲーション階層で索引のリストから見つけるか、またはevaluations表を開いて「Indexes」タブを参照することにより確認できます。次のスクリプトがこの索引を作成するためのSQL文です。
CREATE INDEX eval_job_ix ON evaluations (job_id ASC) NOPARALLEL;
次の手順に従い、EVAL_JOB_IX索引のソート順序を逆にします。
EVAL_JOB_IXを右クリックして、「Edit」を選択します。DESCに変更します。「OK」をクリックします。
索引が変更されました。次のスクリプトがこの索引を変更するためのSQL文です。
DROP INDEX eval_job_id; CREATE INDEX eval_job_ix ON evaluations (job_id DESC) NOPARALLEL;
次の手順に従い、EVAL_JOB_IX索引を削除します。
EVAL_JOB_IXを右クリックして、「Drop」を選択します。
これでEVAL_JOB_IX索引が削除されました。次のスクリプトがこの索引を削除するためのSQL文です。
DROP INDEX "HR"."EVAL_JOB_ID";
表およびその内容のすべてをスキーマから削除する必要がある場合があります。このためには、SQL文であるDROP TABLE文を使用してする必要があります。他の概要を学ぶために作成した表を使用し、「SQL Statement」ウィンドウで、削除できる単純な表を次のスクリプトを実行して作成します。
CREATE TABLE temp_table( id NUMBER(1,0), name VARCHAR2(10) );
次の手順に従い、hrスキーマからTEMP_TABLEを削除します。
TEMP_TABLEを右クリックします。
これでTEMP_TABLE表が削除されました。次のスクリプトがこの表を削除するためのSQL文です。
DROP TABLE "HR"."TEMP_TABLE";
ビューとは、1つ以上の表またはビューに基づく論理的な表です。ビューは、異なる複数の表に格納されている情報へ頻繁にアクセスする必要のあるビジネスにおいて特に役立ちます。
ビューを作成する標準的な構文は次のとおりです。
CREATE VIEW view_name AS query;
次の手順に従い、hrスキーマから新しいビューの作成を削除します。
これで新しいビューが作成されました。このビューを作成するためのSQL文は次のとおりです。
CREATE VIEW salesforce AS SELECT first_name || ' ' || last_name "Name", salary*12 "Annual Salary" FROM employees WHERE department_id = 80;
例3-6では、企業および作業場所にいるすべての従業員のビューを、「文字ファンクションの使用」で使用した問合せと同じように作成します。
CREATE VIEW emp_locations AS SELECT e.employee_id, e.last_name || ', ' || e.first_name name, d.department_name department, l.city city, c.country_name country FROM employees e, departments d, locations l, countries c WHERE e.department_id=d.department_id AND d.location_id=l.location_id AND l.country_id=c.country_id ORDER BY last_name;
スクリプトの結果が続きます。
CREATE VIEW succeeded.
これで4つの別々の表の情報を利用した、つまり4方向の結合を行った新しいビューが作成されました。「Connections」ナビゲーション階層では、「Views」のとなりのプラス記号をクリックすると、emp_locationsを確認できます。
マーケティング部門の従業員を追加してsalesforceビューを変更し、ビュー名をsales_marketingに変更します。
salesforceビューを右クリックします。
OR department_id = 20を追加してSQL問合せを変更します。「Test Syntax」をクリックします。
「OK」をクリックします。

salesforceを右クリックし、「Rename」を選択します。SALES_MARKETINGに設定します。「Apply」 をクリックします。

これでビューが変更されました。ビュー内容を変更し、ビュー名を変更するためのSQL文は次のとおりです。
CREATE OR REPLACE VIEW salesforce AS query; RENAME "SALESFORCE" to SALES_MARKETING;
DROP VIEW文を使用して、sales_marketingビューを削除します。
sales_marketingビューを右クリックします。
これでビューが削除されました。ビューを削除するためのSQL文は次のとおりです。
DROP VIEW sales_marketing;
順序は一意の連続した値を生成するデータベース・オブジェクトであり、一意の主キーが必要なときに非常に役立ちます。hrスキーマにはすでにdepartments_seq、employees_seqおよびlocations_seqという3つの順序があります。
順序は次の擬似列を介して使用します。
CURRVAL擬似列は、順序の現在の値を戻します。CURRVALは、NEXTVALへの最初の呼出しにより順序が開始された後にのみ使用できます。
NEXTVAL擬似列は順序を増分し、次の値を戻します。初めてNEXTVALを使用したときは、順序の初期値が戻されます。NEXTVALへの次の参照では、定義済の増分により順序値が増分され、新しい値が戻されます。
順序は使用規則を除いて他のオブジェクトに接続されません。表の主キーを移入するために順序を使用する場合は、順序を表にリンクするためにネーミング規則を使用することをお薦めします。この説明においては、そのような順序に対するネーミング規則はtable_name_seqです。
順序はSQL Developerインタフェースまたは「SQL Statement」ウィンドウを使用して作成できます。
次の手順では、evaluations表の主キーで使用できる順序、evaluations_seqを作成します。
「Properties」タブで、次を実行します。
「OK」をクリックします。

これでevaluations表の主キーで使用できる順序が作成されました。プラス記号をクリックして順序ツリーを展開すると、新しい順序を確認できます。順序を作成するためのSQL文は次のとおりです。
CREATE SEQUENCE evaluations_seq INCREMENT BY 1 START WITH 1 ORDER;
例3-7では、「SQL Statement」ウィンドウで必要な情報を直接入力して、さらに順序を作成します。
CREATE SEQUENCE test_seq INCREMENT BY 5 START WITH 5 ORDER;
スクリプトの結果が続きます。
CREATE SEQUENCE succeeded.
順序を削除するには、SQL文であるDROP SEQUENCEを使用します。SQL Developerでどのように順序が削除されるかを表示するには、以前に作成したtest_seq順序を使用します。新規順序が「Connections」階層ナビゲータに表示されない場合、「Refresh」アイコンをクリックします。
次の手順に従い、順序を削除します。
test_seq順序を右クリックします。
これでtest_seq順序が削除されました。順序を削除するためのSQL文は次のとおりです。
DROP SEQUENCE "HR"."TEST_SEQ";
シノニムはスキーマ・オブジェクトの別名であり、SQL文を簡素化するために、またはセキュリティ強化の目的で実際のデータベース・オブジェクトの名前をわからなくするために使用できます。さらに、データベースの表の名前を(departmentsからdivisionsのように)変更する場合、departmentsのシノニムを作成し、以前と同じアプリケーション・コードを使用し続けることができます。
次の手順では、jobsスキーマ・オブジェクトのかわりに使用できるシノニム、positionsを作成します。
「Properties」タブで、次を実行します。
「OK」をクリックします。

これでjobs表に対してpositionsシノニムが作成されました。シノニムを作成するSQL文は次のとおりです。
CREATE SYNONYM positions FOR jobs;
例3-8では、表名jobsのかわりに新しいpositionsシノニムを使用します。
SELECT first_name || ' ' || last_name "Name", p.job_title "Position" FROM employees e, positions p WHERE e.job_id = p.job_id ORDER BY last_name;
問合せの結果が表示されます。
Name Position --------------------- ------------------------- Ellen Abel Sales Representative Sundar Ande Sales Representative Mozhe Atkinson Stock Clerk David Austin Programmer ... 197 rows selected
次の手順に従い、positionsシノニムを削除します。
positionsシノニムを右クリックします。
これでpositionsシノニムが削除されました。シノニムを削除するためのSQL文は次のとおりです。
DROP SYNONYM positions;
|
 Copyright © 2005, 2008, Oracle Corporation. All Rights Reserved. |
|