11g リリース1(11.1)
E05694-03
 目次 |
 索引 |
| Oracle Database 2日で開発者ガイド 11g リリース1(11.1) E05694-03 |
|

この章では、Oracle Databaseの命令型言語であるPL/SQLの使用について説明します。
この章の内容は次のとおりです。
SQLを使用してデータベースに問い合せる方法は学びました。ただし、この方法はエンタープライズ・アプリケーションの構築には不十分です。PL/SQLは予測されるプロシージャ構成およびネームスペース構成を持つ第3世代の言語で、SQLとの密接な統合により複雑で強力なアプリケーションを構築できます。これは、PL/SQLがデータベースで実行されるため、別の接続を確立することなくSQL文を含めることが可能です。
PL/SQLを使用して作成し、データベースに格納できるプログラム・ユニットの主要なタイプは、スタンドアロン・プロシージャ、スタンドアロン・ファンクションおよびパッケージです。一度データベースに格納されると、これらのPL/SQLコンポーネントは総称してストアド・プロシージャと呼ばれます。これは、複数の異なるアプリケーションに対するブロックの作成に使用できます。
スタンドアロン・プロシージャおよびファンクションは、一部のプログラム・ロジックのテストに便利ですが、パッケージ内にすべてのコードを配置することをお薦めします。パッケージは、他のシステムへの移植が容易で、さらにプログラム・ユニット名にプログラム名を組み込むことができます。たとえば、旧バージョンのOracle Databaseでcontinueというスキーマ・レベル・プロシージャを作成した場合、新しいバージョンのOracle Databaseをインストールしてこれを移入すると、コードはコンパイルできません。これは、Oracleが最近、現行のループの反復を終了し、制御を次の反復に転送する文CONTINUEを導入したためです。パッケージ内にプロシージャを作成した場合、プロシージャpackage_name.continueはその名前が取得されることを回避できます。
この章の次の項(「スタンドアロン・プロシージャおよびファンクションの作成および使用」)では、スタンドアロン・プロシージャおよびファンクションの作成および使用方法を説明します。必要がない場合は、次の項をスキップして「パッケージの作成および使用」へ移動してください。
Oracle Databaseでは、一度のみ記述し、テストしてから必要とするアプリケーションにアクセスしたコードをデータベース内に格納できます。データベース内に常駐するプログラム単位は、コードが呼び出されたときにデータを一貫して処理することで、アプリケーション開発プロセスを容易にし、一貫性を実現します。
ファンクション(値を戻すもの)およびプロシージャ(値を戻さないもの)などのスキーマ・レベルまたはスタンドアロン・サブプログラムは、Oracle Databaseでコンパイルされ、格納されます。一度コンパイルされると、そのようなサブプログラムはスキーマ・オブジェクトであるストアド・プロシージャまたはストアド・ファンクションになり、Oracle Databaseに接続しているアプリケーションから参照されるかコールされることがあります。起動時に、ストアド・プロシージャおよびストアド・ファンクションはパラメータを受け入れることができます。
プロシージャおよびファンクションは、基本的なPL/SQLブロック構造に従い、次の要素で構成されます。
DECLAREで場合により開始する宣言部分は、アプリケーション・ロジックで使用される変数および定数を識別します。この部分はオプションです。
BEGINで始まりENDで終了する実行可能部分には、アプリケーション・ロジックが含まれます。この部分は必須です。
EXCEPTIONで始まる例外処理部分は、ブロックの実行可能部分で発生する可能性のあるエラー条件を処理します。この部分はオプションです。
PL/SQLブロックの一般的な書式は次のとおりです。それぞれのストアド・プログラム・ユニットはユニットを名付けるヘッダーを持ち、ファンクション、プロシージャまたはパッケージのいずれかとして識別します。
Header AS [declaration statements ...] BEGIN ... [EXCEPTION ...] END;
プロシージャおよびファンクションの作成に関するSQL文は、それぞれCREATE PROCEDUREおよびCREATE FUNCTIONです。実際には、CREATE OR REPLACE文を使用するのが最適です。これらの文の一般的な書式は次のとおりです。
CREATE OR REPLACE procedure_name(arg1 data_type, ...) AS BEGIN .... END procedure_name; CREATE OR REPLACE procedure_name(arg1 data_type, ...) AS BEGIN .... END procedure_name;
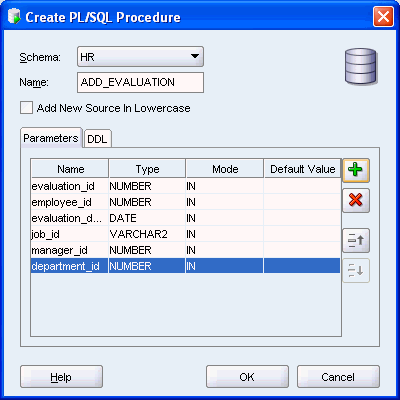
evaluation表に新規の行を作成するプロシージャadd_evaluationを作成します。
「Parameters」タブで、「Add Column」アイコン(プラス記号)をクリックしてプロシージャの最初のパラメータを指定します。「Name」をeval_idに、「Type」をNUMBERに、そして「Mode」をINに設定して、「Default Value」を空のままにします。
同様に、同じ順序で次のパラメータを追加します。
employee_id: 「Type」をNUMBERに、「Mode」をINに設定して、「Default Value」を空のままにします。
evaluation_date: 「Type」をDATEに、「Mode」をINに設定して、「Default Value」を空のままにします。
job_id: 「Type」をVARCHAR2に、「Mode」をINに設定して、「Default Value」を空のままにします。
manager_id: 「Type」をNUMBERに、「Mode」をINに設定して、「Default Value」を空のままにします。
department_id: 「Type」をNUMBERに、「Mode」をINに設定して、「Default Value」を空のままにします。
「OK」をクリックします。
ADD_EVALUATIONペインを次のコードを使用してオープンします。ペインのタイルがイタリック・フォントになっていることに注意してください。プロシージャがデータベースに保存されていないことを示しています。
CREATE OR REPLACE PROCEDURE ADD_EVALUATION ( evaluation_id IN NUMBER , employee_id IN NUMBER , evaluation_date IN DATE , job_id IN VARCHAR2 , manager_id IN NUMBER , department_id IN NUMBER ) AS BEGIN NULL; END ADD_EVALUATION;
Oracle Databaseにより、プロシージャは保存前に自動的にコンパイルされます。

add_evaluationペインのタイルがイタリックではなく標準フォントであることに注意してください。プロシージャがデータベースに保存されたことを示します。
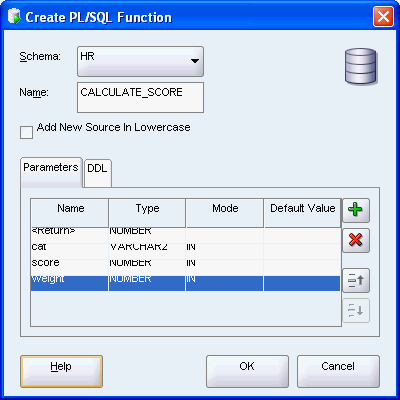
特定のカテゴリ内のパフォーマンスに基づいて重み付けされたスコアを計算する新規のファンクションcalculate_scoreを作成します。
「Parameters」ペインで、「<return> Type」 をNUMBERに設定します。
同様に、同じ順序で次のパラメータを追加します。
VARCHAR2に、「Mode」をINに設定して、「Default Value」を空のままにします。
NUMBERに、「Mode」をINに設定して、「Default Value」を空のままにします。
NUMBERに、「Mode」をINに設定して、「Default Value」を空のままにします。
「OK」をクリックします。
calculate_scoreペインを次のコードでオープンします。ペインのタイルがイタリック・フォントになっていることに注意してください。プロシージャがデータベースに保存されていないことを示しています。
CREATE OR REPLACE FUNCTION calculate_score ( cat IN VARCHAR2 , score IN NUMBER , weight IN NUMBER ) RETURN NUMBER AS BEGIN RETURN NULL; END calculate_score;
Oracle Databaseにより、ファンクションは保存前に自動的にコンパイルされます。
CALCULATE_SCOREペインのタイルがイタリックではなく標準フォントであることに注意してください。プロシージャがデータベースに保存されたことを示します。
すでに新規のプロシージャおよびファンクションを作成しました。ただし、サブプログラムの署名でしか構成されていないため、この項では、サブプログラムの本体を編集します。
ファンクションcalculate_scoreを編集して、特定のカテゴリに対する評価の重み付けの値を決定します。
calculate_scoreペインで、次のコードを使用して、ファンクションの本体を置換します。新規のコードは太字フォントで表示されます。
BEGIN RETURN score * weight; END calculate_score;
次に、変更を加えたファンクションをテストします。
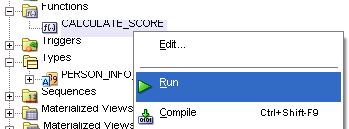
ファンクションcalculate_scoreをテストします。
calculate_scoreファンクションを右クリックします。「Run」を選択します。scoreおよびweight変数に対する割当を編集します。新規のコードは太字フォントで表示されます。
v_Return := CALCULATE_SCORE( CAT => CAT, SCORE => 8, WEIGHT => 0.2 );
「OK」をクリックします。
Connecting to the database hr_conn. v_Return = 1.6 Process exited. Disconnecting from the database hr_conn.
「Connection」ナビゲータまたはSQL文のDROPを使用して、データベースからプロシージャまたはファンクションを削除できます。
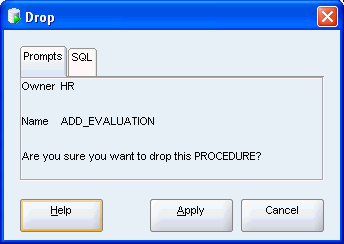
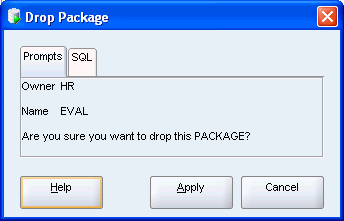
プロシージャADD_EVALUATIONを削除します。
ADD_EVALUATIONファンクションを右クリックします。「Drop」を選択します。

データベースからADD_EVALUATIONプロシージャが削除されました。
前述の項で、スキーマ・オブジェクトであるプロシージャおよびファンクションを作成し、テストしました。この方法は、アプリケーションのサブセットまたは小さい機能をテストするのに便利です。
エンタープライズ・レベル・アプリケーションは非常に複雑で、インタフェースおよび型の一部は表示されますが、それ以外は他のファンクションおよびプロシージャでのみ使用され、ユーザーからはコールされません。PL/SQLを使用すると、同一のパッケージ内に配置することによって、これらのサブプログラム間の関係を形式に従って指定できます。パッケージは、PL/SQL型、変数、ファンクションおよびプロシージャなどの関連要素を論理的にグループ化して、名前を指定するスキーマ・オブジェクトです。パッケージ内部へのこれらの要素のカプセル化は、「ストアド・プロシージャの概要」で説明されている名称の重複などの意図しない結果やアプリケーションの存続期間の超過を防ぎます。
パッケージ内で定義されたプロシージャおよびファンクションは、パッケージ済サブプログラムになります。他のサブプログラムまたはPL/SQLブロック内でネストされたプロシージャおよびファンクションは、ローカル・サブプログラムと呼ばれます。囲みブロック内にのみ存在し、外部からは参照されません。
「スタンドアロン・プロシージャおよびファンクションの作成および使用」のようなスタンドアロン・プロシージャおよびファンクションがサイズの大きな規模の開発に限定する理由は、スカラー・パラメータ(NUMBER、VARCHAR2およびDATE)のみが送受信可能であるためです。ただし、パッケージ仕様部で定義されていない場合、コンポジット構造RECORDを使用することはできません。
パッケージには仕様部および本体の2つの部分があります。
パッケージは、パッケージ外部から参照可能な型、変数、定数、例外、カーソル、ファンクションおよびプロシージャを宣言するパッケージ仕様部によって定義されます。仕様部はパッケージへのインタフェースです。パッケージ内のサブプログラムをコールするアプリケーションは、パッケージ仕様部の名前およびパラメータを知っておく必要があります。
標準的なパッケージ仕様部は次のような形式です。
CREATE OR REPLACE PACKAGE package_name AS type definitions for records, index-by tables constants exceptions global variable declarations procedure procedure_1(arg1, ...); ... function function_1(arg1,...) return datat_ype; ... END package_name;
パッケージ本体には、これらのサブプログラムを実装するコード、パッケージ内で開始されるすべてのプライベート・サブプログラムに対するコードおよびカーソルに対する問合せが含まれます。コールするアプリケーションを無効にすることなく、パッケージ本体の内部で実装の詳細を変更できます。
パッケージ本体は次のような形式です。
CREATE OR REPLACE PACKAGE BODY package_name AS PROCEDURE procedure_1(arg1,...) IS BEGIN ... EXCEPTION ... END procedure_1; ... FUNCTION function_1(arg1,...) RETURN data_type IS result_variable data_type BEGIN ... RETURN result_variable; EXCEPTION ... END function_1; ... END package_name;
Oracle Databaseによって供給されるパッケージに精通し、既存の機能と重複する書込みコードを回避する必要があります。
パッケージ本体に実装を書き込む前に、パッケージ仕様部を設計し定義する必要があります。仕様部には、コールするプログラムにパブリックに参照可能である部分のみが含まれ、パッケージ本体内のプライベートな宣言を非表示にします。これにより、実装詳細に関する他のプログラムの安全ではない依存性を回避できます。
パッケージの正常なコンパイルを妨げる、パッケージ本体内の正しく、有効なサブプログラム間の依存性を検出するため、PL/SQLはシングルパス・コンパイラを持ちます。パッケージ本体の上部でこれらの不明なサブプログラムを宣言し、後で指定する必要があります。このため、依存が無効化される可能性を最小限にするためにパッケージ仕様部または本体の最後に新しい要素を追加することをお薦めします。
従業員評価の実行に必要な機能すべてをカプセル化するパッケージを作成します。パッケージの作成後は、パッケージ本体を作成するためにパッケージの変更方法を説明する「パッケージの変更」を参照してください。
emp_evalペインをオープンします。
CREATE OR REPLACE PACKAGE emp_eval AS /* TODO enter package declarations (types, exceptions, methods etc) here */ END emp_eval;
ペインのタイトルがイタリック・フォントになっていることに注意してください。パッケージがデータベースに保存されていないことを示しています。
「Messages - Log」ペインで、パッケージを作成したことを確認します。
EMP_EVAL Compiled.
emp_evalペインのタイトルがイタリックではなく標準フォントであることに注意してください。プロシージャがデータベースに保存されたことを示します。
例4-1は、SQLワークシートにパッケージを直接作成する方法を示しています。
CREATE OR REPLACE PACKAGE eval AS /* package */ END eval;
スクリプトの結果が続きます。
PACKAGE eval Compiled.
この項では、パッケージemp_evalを変更します。
一部のファンクションおよびプロシージャの指定によってemp_evalのパッケージ仕様部を変更します。
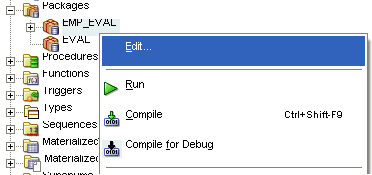
emp_evalを右クリックします。
EMP_EVALペインで、パッケージを編集します。新規のコードが太字フォントで表示されます。
create or replace PACKAGE emp_eval AS PROCEDURE eval_department(department_id IN NUMBER); FUNCTION calculate_score(evaluation_id IN NUMBER , performance_id IN NUMBER) RETURN NUMBER; END emp_eval;
パッケージが正常にコンパイルしたことを確認する次のメッセージが表示されます。
EMP_EVAL Compiled.
一部のファンクションおよびプロシージャの指定によってemp_evalのパッケージ本体を作成します。
emp_evalを右クリックします。
emp_eval本体ペインに、パッケージ本体の自動生成されたコードが表示されます。
CREATE OR REPLACE PACKAGE BODY emp_eval AS PROCEDURE eval_department(department_id IN NUMBER) AS BEGIN /* TODO implementation required */ NULL; END eval_department; FUNCTION calculate_score(evaluation_id IN NUMBER , performance_id IN NUMBER) RETURN NUMBER AS BEGIN /* TODO implementation required */ RETURN NULL; END calculate_score; END emp_eval;
パッケージ本体が正常にコンパイルしたことを確認する次のメッセージが表示されます。
EMP_EVAL Body Compiled.
「Connections」ナビゲータ階層か、SQL DROP文を使用してデータベースからパッケージを削除できます。パッケージを削除する際は、データベースからパッケージ仕様部およびパッケージ本体を削除します。
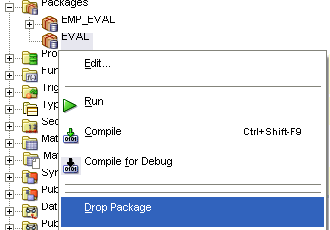
EVALを右クリックします。
PL/SQLによってSQLが得る重要な利点の1つは、プログラミング構成で変数および定数を使用できることです。
変数は、特定のデータ型の指定した値を保持するためにユーザーによって定義されます。この値は変更可能で、実行時に変更できます。
定数は、変更不可の値を保持します。コンパイラによってこの値が不変であることが確認されると、変更可能なコードもコンパイルしません。時間経過によるコード・ベースのメンテナンスをより容易にするため、ダイレクトな値のかわりにコードの定数を使用する必要があります。定数として変更を加えない値すべてを宣言する際、定数はコンパイル・コードを最適化します。
VARCHAR2、DATE、NUMBERなどのSQLデータ型に加えて、Oracle DatabaseはPL/SQLを介してのみ使用できるデータ型もサポートします。これらのデータ型には、BOOLEAN、RECORDなどのコンポジット・データ型、REF CURSOR、INDEX BY TABLEなどの参照型、および数字、文字および日付要素を示す多くの特殊な型が含まれます。数値型PLS_INTEGERは、整数のバイナリ演算を実行し、パフォーマンスを大幅に向上させるため、特に有効です。これらのPL/SQL型は、スキーマ・レベルでは使用できず(したがって、表でも使用できず)、パッケージ内で定義される型およびプロセスでのみ使用できることに注意してください。
変数および定数はあらゆるSQLまたはPL/SQLデータ型を持ち、サブプログラムの宣言ブロックで宣言されます。デフォルトでは、宣言された変数はNULL値を持ちます。定数を定義する場合、CONSTANT句を使用し、すぐに値を割り当てる必要があります。
PL/SQLでは、インライン・コメント(--)は二重ハイフンで始まり、ラインの末尾まで拡張されます。複数行にまたがるコメントの場合は、先頭はスラッシュおよびアスタリスク(/*)で、末尾はアスタリスクおよびスラッシュ(*/)である必要があります。
識別子によって、定数、変数およびサブプログラムなどのPL/SQLプログラム単位の名前が付けられます。すべての識別子は最大30文字で、文字で始まり、文字、数字および記号($'、'_'および'#')の組合せが続いている必要があります。他の記号は識別子に使用できません。
文字列および文字リテラルの管理時以外は、PL/SQLでは大文字、小文字の区別がないため、大文字および小文字を交互に使用できます。つまり、識別子last_nameはLAST_NAMEと同等です。2番目の識別子を宣言すると、エラーが発生します。
変数および定数に対して有効な名前を使用し、適切なネーミング規則を使用する必要があります。たとえば、各定数名をcons_で開始できます。また、識別子として予約語は使用できません。
emp_evalおよびcalculate_scoreパッケージの新しいファンクションを更新します。これらは、異なるカテゴリで重み付けされたスコアすべてを組み合せて、従業員評価の最終的なスコアを計算します。
emp_evalの横にあるプラス記号をクリックしてパッケージを展開します。
emp_eval本体ペインが表示されます。

emp_eval本体ペインで、変数および定数の追加によってファンクションcalculate_scoreを変更します。新しいコードは太字で表示されます。
FUNCTION calculate_score(evaluation_id IN NUMBER , performance_id IN NUMBER) RETURN NUMBER AS n_score NUMBER(1,0); -- a variable n_weight NUMBER; -- a variable max_score CONSTANT NUMBER(1,0) := 9; -- a constant limit check max_weight CONSTANT NUMBER(8,8) := 1; -- a constant limit check BEGIN RETURN NULL; END calculate_score;
「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Body Compiled
「変数および定数の宣言」で、2つの変数n_scoreおよびn_weightを追加してファンクションcalculate_scoreを変更します。これらの変数はデータベース内表の値であるscores表に格納されているn_score、およびperformance_parts表に格納されているn_weightを表します。これらの変数に使用したデータ型は、表の列データ型定義と一致します。
時間が経つにつれて、アプリケーションは進化し、列定義も変化する場合があります。これにより、calculate_scoreファンクションが無効になる場合があります。コードのメンテナンスをより容易にするために、適切な列および行の定義に一致するデータ型を含む変数を定義する特別な修飾子を使用する必要があります。たとえば、%TYPEおよび%ROWTYPEです。
%TYPE属性は、表の列または別の変数のデータ型を提供します。これは、表のデータ型が変更になる場合、正しいデータ型割当ておよびランタイム時のファンクションの正しい実装を保証する際に効果的です。
%ROWTYPE属性により、RECORD変数に対する表内の行が定義されます。表の行の列とRECORD内の対応するフィールドは、同名で同じデータ型を含みます。%ROWTYPEを使用する利点は、%TYPEと同じです。詳細は、「コンポジット・データ構造(レコード)の使用」を参照してください。
次のタスクは、ファンクションで%TYPE属性を使用する方法を示しています。calculate_scoreファンクションを編集して、ソース表の列に一致するデータ型をn_scoreおよびn_weight変数に割り当てます。max_scoreおよびmax_weight定数は表の値との等価性を確認するために使用されるため、これらの定数も表の型と一致する必要があることに注意してください。
emp_eval本体ペインで、変数の定義を変更してファンクションcalculate_scoreを変更します。新しいコードは太字で表示されます。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER AS n_score scores.score%TYPE; -- from SCORES n_weight performance_parts.weight%TYPE; -- from PERFORMANCE_PARTS max_score CONSTANT scores.score%TYPE := 9; -- a constant limit check max_weight CONSTANT performance_parts.weight%TYPE := 1; -- a constant limit check BEGIN RETURN NULL; END calculate_score;
emp_evalパッケージ仕様部で、関数calculate_scoreの宣言を変更します。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER;
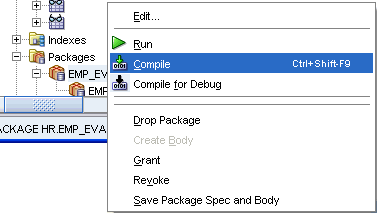
emp_evalパッケージを右クリックし、「Compile」を選択します。また、[Ctrl]、[Shift]および[F9]を押すとショートカットになります。「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Body Compiled
「明示的なカーソルの使用」のeval_departmentプロシージャで使用されるコードを参照してください。
次の3つの一般的な方法で変数に値を割り当てられます。3つの方法は、代入演算子の使用、変数への値の選択および変数のバインドです。この項では、3つの方法の内の最初の2つを説明します。変数のバインドは、Application Express、Java、.NETおよびPHPの2日ガイド・シリーズで説明されています。
サブプログラムの本体および宣言の両方で変数に値を割り当てられます。
次のコードは変数および定数の標準的な宣言を示します。プロシージャおよびファンクションでは、宣言ブロックはDECLAREキーワードを使用しません。かわりに、サブプログラム定義のASキーワードが続きます。
emp_eval本体ペインで、新しい変数running_totalを追加して関数calculate_scoreを変更します。running_totalの値も、この関数の新しい戻り値です。戻り変数の初期値は0に設定します。running_totalは、異なる精度と位取りを持つ2つのNUMBERの積を保持するため、一般NUMBERとして宣言されていることに注意してください。新しいコードは太字で表示されています。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER AS n_score scores.score%TYPE; -- from SCORES n_weight performance_parts.weight%TYPE; -- from PERFORMANCE_PARTS running_total NUMBER := 0; -- used in calculations max_score CONSTANT scores.score%TYPE := 9; -- a constant limit check max_weight CONSTANT performance_parts.weight%TYPE:= 1; -- a constant limit check BEGIN RETURN running_total; END calculate_score;
emp_eval本体をコンパイルします。
サブプログラムの本体の変数に値を割り当てられます。ファンクションの本体内のrunning_total変数の使用によってファンクションcalculate_scoreを編集して、式の値を保持します。
次のコードで説明しているように、emp_eval本体ペインで、式を変数running_totalに割り当てて、関数calculate_scoreを変更します。新しいコードは太字で表示されます。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER AS n_score scores.score%TYPE; -- from SCORES n_weight performance_parts.weight%TYPE; -- from PERFORMANCE_PARTS running_total NUMBER :=0; -- used in calculations max_score CONSTANT scores.score%TYPE := 9; -- a constant limit check max_weight CONSTANT performance_parts.weight%TYPE:= 1; -- a constant limit check BEGIN running_total := max_score * max_weight; RETURN running_total; END calculate_score;
emp_eval本体をコンパイルし、保存します。
最も簡単な値の割当て方法は、「代入演算子を使用した値の割当て」で変数running_totalを割り当てたように、代入演算子(:=)を使用する方法です。
ただし、関数calculate_scoreの目的は、データベース表に格納される値に基づいて計算することです。プロシージャ、ファンクションまたはパッケージにある既存のデータベースの値を使用するには、SELECT INTO文の使用によって変数にこれらの値を割り当てる必要があります。後続の計算で変数を使用できます。
次のコードで説明しているように、emp_eval本体ペインで、変数n_scoreおよびn_weightに表の値を割り当て、関数calculate_scoreを変更します。その後、それらの積をrunning_total変数へ割り当てます。新しいコードは太字で表示されます。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER AS n_score scores.score%TYPE; -- from SCORES n_weight performance_parts.weight%TYPE; -- from PERFORMANCE_PARTS running_total NUMBER := 0; -- used in calculations max_score CONSTANT scores.score%TYPE := 9; -- a constant limit check max_weight CONSTANT performance_parts.weight%TYPE:= 1; -- a constant limit check BEGIN SELECT s.score INTO n_score FROM scores s WHERE evaluation_id = s.evaluation_id AND performance_id = s.performance_id; SELECT p.weight INTO n_weight FROM performance_parts p WHERE performance_id = p.performance_id; running_total := n_score * n_weight; RETURN running_total; END calculate_score;
emp_eval本体をコンパイルし、保存します。
同様に、employees表の対応する行の内容に基づいて、evaluations表へ新しいレコードをインサートするため新しいadd_evalプロシージャを追加します。add_evalは順序evaluations_seqを使用することに注意してください。
emp_eval本体ペインのEND emp_evalの上で、evaluations表に行を挿入するためにemployees表の一部の列を使用するプロシージャadd_evalを追加します。emp_evalパッケージの本体でローカル・ファンクションadd_evalを作成しますが、パッケージ仕様部では宣言しないことに注意してください。これは、add_evalが他のサブプログラムによってemp_evalパッケージ内でのみ起動されるためです。
PROCEDURE add_eval(employee_id IN employees.employee_id%TYPE, today IN DATE) AS -- placeholders for variables job_id employees.job_id%TYPE; manager_id employees.manager_id%TYPE; department_id employees.department_id%TYPE; BEGIN -- extracting values from employees for later insertion into evaluations SELECT e.job_id INTO job_id FROM employees e WHERE employee_id = e.employee_id; SELECT e.manager_id INTO manager_id FROM employees e WHERE employee_id = e.employee_id; SELECT e.department_id INTO department_id FROM employees e WHERE employee_id = e.employee_id; -- inserting a new row of values into evaluations table INSERT INTO evaluations VALUES ( evaluations_seq.NEXTVAL, -- evaluation_id employee_id, -- employee_id today, -- evaluation_date job_id, -- job_id manager_id, -- manager_id department_id, -- department_id 0); -- total_score END add_eval;
emp_eval本体をコンパイルし、保存します。
制御構造は、SQLに対するPL/SQL拡張機能の最も強力な機能です。これによって、データを操作し、条件付き選択、反復の制御および連続した文を使用して処理します。条件付き選択は、データ値の異なる型を持ち、異なるプロセスの手順を実行する必要がある状況です。反復の制御は、同一のデータで反復プロセスの手順を実行する必要がある状況です。また、一般的に、プログラムのコードのすべての行は連続で実行されます。代替のラベル付けプログラミングのブランチ(GOTO文)を実行するために選択を行うのが、順次制御です。
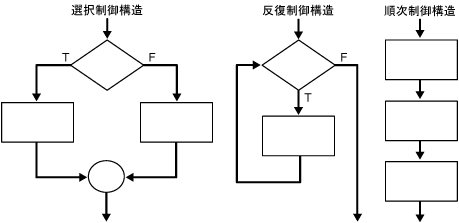
この項では、条件付き選択、およびIF...THEN...ELSE、CASE、FOR...LOOP、WHILE...LOOPやLOOP...EXIT WHENなどの反復プログラム・フロー構造について説明します。
条件付き選択構造は、BOOLEAN値をTRUEまたはFALSEと評価する式をテストします。値に応じて、制御構造は割り当てられた一連の文を実行します。一般的な制御構造のメカニズムには、IF...THEN...ELSEおよびその変数と、CASE文の2種類があります。
IF...THEN...ELSE文は条件付きで一連の文を実行します。テスト条件がTRUEと評価する場合、プログラムはTHEN句で文を実行します。この条件がFALSEと評価する場合、プログラムはELSE句で文を実行します。ELSIFキーワードを含めた場合、複数の条件のテストにこの構造を使用できます。IF...THEN...[ELSIF]...ELSE文の一般的な書式は、次のとおりです。
IF condition_1 THEN ...; ELSIF condition_2 THEN -- optional ...; ELSE -- optional ...; END IF;
たとえば、サンプルの企業が雇用の最初の10年は1年に2回(12月31日および6月30日)、ただしその後は1年に1回(12月31日)、従業員評価を必要とするルールがあるとします。評価が1年ごとに何回行われるかを決定するeval_frequency関数でこのルールを実装できます。これは、hire_date列の値でIF...THEN...ELSE句を使用して行われます。
関数eval_frequencyは評価が1年に1回行われるのか(10年以上の雇用)、または1年に2回行われる必要があるかを決定するemployees.hire_dateを使用します。
emp_evalパッケージの本体で関数eval_frequencyを作成できますが、パッケージ仕様部では宣言しないことに注意してください。これは、eval_frequencyが他のサブプログラムによってemp_evalパッケージ内でのみ起動されるためです。
次のコードで説明しているように、emp_eval本体ペインで、END emp_evalの直前にeval_frequencyファンクションを追加します。制御構造は太字で表示されます。
FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
emp_eval本体をコンパイルし、保存します。
CASE...WHEN構造は、アクションのコースを決定する変数が多くの可能値を持つ場合、ネストされたIF...THEN文の代替として便利です。CASEは条件を評価し、各可能値に対して異なるアクションを実行します。可能であれば、可読性および効率性のためにIF...THENのかわりにCASE...WHEN文を使用します。CASE...WHEN構造の一般的な書式は、次のとおりです。
CASE condition WHEN value_1 THEN expression_1; WHEN value_2 THEN expression_2; ... ELSE expression_default; END CASE;
「IF...THEN...ELSE選択制御の使用」からのmake_evaluationファンクションで、1つの役職で長年勤務した従業員に対して給与の値上げを検討する必要がある場合、hrユーザーに通知すると想定します。employees.job_idの値に応じて、プログラム・ロジックは給与の値上げを推奨するユーザーに通知します。
『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』で説明されているDBMS_OUTPUT.PUT_LINEプロシージャを使用することに注意してください。
次のコードで説明しているように、emp_eval本体ペインで、eval_frequencyファンクションを編集してjob_id変数およびjob_idの値に基づくCASE文を追加します。新しいコードは太字で表示されます。
FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations job_id employees.job_id%TYPE; -- category of the job BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; /* Suggesting salary increase based on position */ SELECT e.job_id INTO job_id FROM employees e WHERE employee_id = e.employee_id; CASE job_id WHEN 'PU_CLERK' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 8% salary increase for employee number ' || employee_id); WHEN 'SH_CLERK' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 7% salary increase for employee number ' || employee_id); WHEN 'ST_CLERK' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 6% salary increase for employee number ' || employee_id); WHEN 'HR_REP' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 5% salary increase for employee number ' || employee_id); WHEN 'PR_REP' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 5% salary increase for employee number ' || employee_id); WHEN 'MK_REP' THEN DBMS_OUTPUT.PUT_LINE( 'Consider 4% salary increase for employee number ' || employee_id); ELSE DBMS_OUTPUT.PUT_LINE( 'Nothing to do for employee #' || employee_id); END CASE; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
emp_eval本体をコンパイルし、保存します。
反復構造またはループは何度も一連の文を実行します。ループの基本的な種類には、FOR...LOOP、WHILE...LOOPおよびLOOP...EXIT WHENの3種類があります。
FOR...LOOPは、一連の手順の定義した回数を繰り返し、ループを実行する定義された整数の範囲である必要があるカウンタ変数を使用します。ループ・カウンタは、FOR...LOOP文で暗黙的に宣言され、ループが実行されるたびに暗黙的に増加します。ループ・カウンタの値はループの本体内で使用できますが、プログラム上で変更はできないことに注意してください。FOR...LOOP文は次の書式になります。
FOR counter IN integer_1..integer_2 LOOP ... END LOOP;
「CASE...WHEN選択制御の使用」で説明されている、一部の従業員に対する給与の値上げの推奨に加えて、ファンクションeval_frequencyは給与の値上げが継続される場合、従業員の給与が設定した年数でどう変化するかを出力します。
『Oracle Database PL/SQLパッケージ・プロシージャおよびタイプ・リファレンス』で説明されている DBMS_OUTPUT.PUT プロシージャを使用することに注意してください。
emp_eval本体ペインで、推奨した年数に応じた給与を出力するために、CASEブロックで割り当てられた推奨した給与の値上げ(sal_raise)を使用するようeval_frequencyファンクションを編集します。この出力は、現在の給与で開始されます(salary)。新しいコードは太字で表示されます。
FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations job_id employees.job_id%TYPE; -- category of the job salary employees.salary%TYPE; -- current salary sal_raise NUMBER(3,3) := 0; -- proposed % salary increase BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; /* Suggesting salary increase based on position */ SELECT e.job_id INTO job_id FROM employees e WHERE employee_id = e.employee_id; SELECT e.salary INTO salary FROM employees e WHERE employee_id = e.employee_id; CASE job_id WHEN 'PU_CLERK' THEN sal_raise := 0.08; WHEN 'SH_CLERK' THEN sal_raise := 0.07; WHEN 'ST_CLERK' THEN sal_raise := 0.06; WHEN 'HR_REP' THEN sal_raise := 0.05; WHEN 'PR_REP' THEN sal_raise := 0.05; WHEN 'MK_REP' THEN sal_raise := 0.04; ELSE NULL; -- job type does not match ones that should consider increases END CASE; /* If a salary raise is not zero, print the salary schedule */ IF (sal_raise != 0) THEN -- start code for salary schedule printout BEGIN DBMS_OUTPUT.PUT_LINE('If the salary ' || salary || ' increases by ' || ROUND((sal_raise * 100),0) || '% each year over 5 years, it would be '); FOR loop_c IN 1..5 LOOP salary := salary * (1 + sal_raise); DBMS_OUTPUT.PUT (ROUND(salary,2) ||', '); END LOOP; DBMS_OUTPUT.PUT_LINE('in successive years.'); END; END IF; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
emp_eval本体をコンパイルします。
WHILE...LOOPは条件がTRUEであるかぎり繰り返します。条件は各ループの上部で評価し、TRUEの場合、ループの本体で文を実行します。条件がFALSEまたはNULLの場合は、制御がループの後の次の文に渡されます。WHILE...LOOP制御構造の一般的な書式は次のとおりです。
WHILE condition LOOP ... END LOOP;
WHILE...LOOPは無限に実行される場合があるため、注意して使用してください。
「FOR...LOOPの使用」のEVAL_FREQUENCYファンクションは、FOR...LOOPのかわりにWHILE...LOOPを使用し、推奨した給与がjob_idの給与の上限に到達した後に終了します。
emp_eval本体ペインで、推奨した年数応じた給与を出力するために、CASEブロックで割り当てられた推奨した給与の値上げ(sal_raise)を使用し、job_idの最大レベルに到達したときに停止するように、eval_frequencyファンクションを編集します。新しいコードは太字で表示されます。
FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations job_id employees.job_id%TYPE; -- category of the job salary employees.salary%TYPE; -- current salary sal_raise NUMBER(3,3) := 0; -- proposed % salary increase sal_max jobs.max_salary%TYPE; -- maximum salary for a job BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; /* Suggesting salary increase based on position */ SELECT e.job_id INTO job_id FROM employees e WHERE employee_id = e.employee_id; SELECT e.salary INTO salary FROM employees e WHERE employee_id = e.employee_id; SELECT j.max_salary INTO sal_max FROM jobs j WHERE job_id = j.job_id; CASE job_id WHEN 'PU_CLERK' THEN sal_raise := 0.08; WHEN 'SH_CLERK' THEN sal_raise := 0.07; WHEN 'ST_CLERK' THEN sal_raise := 0.06; WHEN 'HR_REP' THEN sal_raise := 0.05; WHEN 'PR_REP' THEN sal_raise := 0.05; WHEN 'MK_REP' THEN sal_raise := 0.04; ELSE NULL; END CASE; /* If a salary raise is not zero, print the salary schedule */ IF (sal_raise != 0) THEN -- start code for salary schedule printout BEGIN DBMS_OUTPUT.PUT_LINE('If the salary ' || salary || ' increases by ' || ROUND((sal_raise * 100),0) || '% each year, it would be '); WHILE salary <= sal_max LOOP salary := salary * (1 + sal_raise); DBMS_OUTPUT.PUT (ROUND(salary,2) ||', '); END LOOP; DBMS_OUTPUT.PUT_LINE('in successive years.'); END; END IF; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
LOOP...EXIT WHEN構造を使用すると、移行の処理が必要ない場合にループを終了できます。EXIT WHEN条件がTRUEと評価する場合、ループは終了し、制御が次の文に渡されます。
「WHILE...LOOPの使用」のeval_frequencyファンクションはWHILE...LOOPを使用します。最後に計算された値は、最後のループの反復での給与に対する最大の可能値を超過する場合があることに注意してください(通常は超過します)。WHILE...LOOPのかわりにLOOP_EXIT WHEN構造を使用する場合、ループを終了するための詳細な制御を利用できます。
emp_eval本体ペインで、推奨した年数応じた給与を出力するために、CASEブロックで割り当てられた推奨した給与の値上げ(sal_raise)を使用し、job_idの最大レベルに到達したときに停止するように、eval_frequencyファンクションを編集します。新しいコードは太字で表示されます。
FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations job_id employees.job_id%TYPE; -- category of the job salary employees.salary%TYPE; -- current salary sal_raise NUMBER(3,3) := 0; -- proposed % salary increase sal_max jobs.max_salary%TYPE; -- maximum salary for a job BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; /* Suggesting salary increase based on position */ SELECT e.job_id INTO job_id FROM employees e WHERE employee_id = e.employee_id; SELECT e.salary INTO salary FROM employees e WHERE employee_id = e.employee_id; SELECT j.max_salary INTO sal_max FROM jobs j WHERE job_id = j.job_id; CASE job_id WHEN 'PU_CLERK' THEN sal_raise := 0.08; WHEN 'SH_CLERK' THEN sal_raise := 0.07; WHEN 'ST_CLERK' THEN sal_raise := 0.06; WHEN 'HR_REP' THEN sal_raise := 0.05; WHEN 'PR_REP' THEN sal_raise := 0.05; WHEN 'MK_REP' THEN sal_raise := 0.04; ELSE NULL; END CASE; /* If a salary raise is not zero, print the salary schedule */ IF (sal_raise != 0) THEN -- start code for salary schedule printout BEGIN DBMS_OUTPUT.PUT_LINE('If the salary ' || salary || ' increases by ' || ROUND((sal_raise * 100),0) || '% each year, it would be '); LOOP salary := salary * (1 + sal_raise); EXIT WHEN salary > sal_max; DBMS_OUTPUT.PUT (ROUND(salary,2) ||', '); END LOOP; DBMS_OUTPUT.PUT_LINE('in successive years.'); END; END IF; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
コンポジット・データ構造またはレコードは、フィールドに格納される関連データ・アイテムのグループで、それぞれに名称およびデータ型が含まれます。レコードを表の行を含む変数、または表の行の一部の列として考えることもできます。このフィールドは表の列に対応しています。レコード構造は、実行時に異なる表から関連フィールドを効率的に使用するために、単一のパラメータとしてサブプログラムに関連アイテムを渡すのに非常に効果的です。
RECORDを型として定義し、点表記法でこのフィールドにアクセスする必要があります。レコードの定義および使用の一般的な書式は、次のとおりです。
TYPE record_name IS RECORD( -- define record type field_1 data_type, -- define fields in record ... field_n data_type); ... variable_name record_name; -- define variable of new type ... BEGIN ... ...variable_name.field1...; -- use fields of new variable ...variable_name.fieldn...; ... END...;
「LOOP...EXIT WHENの使用」からのeval_frequencyファンクションで、様々な関連パラメータを使用しました。これらのアイテムの一部を組み合せて単一パラメータにするRECORD構造を使用できます。
ジョブ仕様部の上限および下限を含む型を作成します。
emp_evalペインが表示されます。これは、emp_evalパッケージの仕様部を示します。
emp_evalパッケージ仕様部で、END emp_evalパッケージ仕様部の終了行の直前に、給与レベルの評価に必要なフィールドを含んだレコード型の定義sal_infoを入力します。
TYPE sal_info IS RECORD -- type for salary, limits, raises, and adjustments ( job_id jobs.job_id%type , sal_min jobs.min_salary%type , sal_max jobs.max_salary%type , salary employees.salary%type , sal_raise NUMBER(3,3) );
emp_evalをコンパイルし、保存します。「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Compiled
一度パッケージ仕様部で新しいRECORD型を宣言すると、パッケージ本体内でこれを使用して、この型の変数を宣言できます。新しいプロシージャsalary_scheduleを作成し、sal_info型の変数を使用してeval_frequencyファンクションから起動できます。
PL/SQLのコンパイルは単一パス・プロセスで、サブプログラムがクライアント・サブプログラムの後に宣言される場合、PL/SQLコンパイラはエラーを発生させます。この状況を回避するには、パッケージ仕様部でまだ宣言していないサブプログラムすべてをパッケージ本体の上部で宣言します。サブプログラムの定義は、パッケージ本体内のあらゆる場所で可能です。ファンクションeval_frequencyおよびプロシージャsalary_schedule、add_evalの宣言方法の詳細は、次のタスクの手順2を参照してください。
emp_eval本体ペインで、END emp_eval文の直前にsalary_scheduleプロシージャの定義を追加します。このコードは、給与の値上げがゼロではない場合に実行するeval_frequencyでBEGIN...ENDブロックの内容と同様であることに注意してください。
PROCEDURE salary_schedule(emp IN sal_info) AS accumulating_sal NUMBER; -- accumulator BEGIN DBMS_OUTPUT.PUT_LINE('If the salary of ' || emp.salary || ' increases by ' || ROUND((emp.sal_raise * 100),0) || '% each year, it would be '); accumulating_sal := emp.salary; -- assign value of sal to accumulator WHILE accumulating_sal <= emp.sal_max LOOP accumulating_sal := accumulating_sal * (1 + emp.sal_raise); DBMS_OUTPUT.PUT (ROUND( accumulating_sal,2) ||', '); END LOOP; DBMS_OUTPUT.PUT_LINE('in successive years.'); END salary_schedule;
emp_eval本体ペインで、emp_evalの本体の定義の上部にeval_frequencyおよびsalary_scheduleの宣言を入力します。新しいコードは太字で表示されます。
create or replace PACKAGE BODY emp_eval AS /* local subprogram declarations */ FUNCTION eval_frequency (employee_id employees.employee_id%TYPE) RETURN NUMBER; PROCEDURE salary_schedule(emp IN sal_info); PROCEDURE add_eval(employee_id IN NUMBER, today IN DATE); /* subprogram definition */ PROCEDURE eval_department (dept_id IN NUMBER) AS ...
emp_eval本体ペインで、eval_frequencyファンクションを編集して、変数emp_salとして新しいsal_info型を使用し、このフィールドを移入して、salary_scheduleを起動します。給与の値上げがゼロではない場合に実行されたコードは、このファンクションの一部ではなく、salary_scheduleプロシージャに組み込まれていることに注意してください。また、ファンクション上部の宣言は変更されたことにも注意してください。新しいコードは太字で表示されます。
FUNCTION eval_frequency (employee_id employees.employee_id%TYPE) RETURN PLS_INTEGER AS hire_date employees.hire_date%TYPE; -- start of employment today employees.hire_date%TYPE; -- today's date eval_freq PLS_INTEGER; -- frequency of evaluations emp_sal SAL_INFO; -- record for fields associated -- with salary review BEGIN SELECT SYSDATE INTO today FROM DUAL; -- set today's date SELECT e.hire_date INTO hire_date -- determine when employee started FROM employees e WHERE employee_id = e.employee_id; IF((hire_date + (INTERVAL '120' MONTH)) < today) THEN eval_freq := 1; /* populate emp_sal */ SELECT e.job_id INTO emp_sal.job_id FROM employees e WHERE employee_id = e.employee_id; SELECT j.min_salary INTO emp_sal.sal_min FROM jobs j WHERE emp_sal.job_id = j.job_id; SELECT j.max_salary INTO emp_sal.sal_max FROM jobs j WHERE emp_sal.job_id = j.job_id; SELECT e.salary INTO emp_sal.salary FROM employees e WHERE employee_id = e.employee_id; emp_sal.sal_raise := 0; -- default CASE emp_sal.job_id WHEN 'PU_CLERK' THEN emp_sal.sal_raise := 0.08; WHEN 'SH_CLERK' THEN emp_sal.sal_raise := 0.07; WHEN 'ST_CLERK' THEN emp_sal.sal_raise := 0.06; WHEN 'HR_REP' THEN emp_sal.sal_raise := 0.05; WHEN 'PR_REP' THEN emp_sal.sal_raise := 0.05; WHEN 'MK_REP' THEN emp_sal.sal_raise := 0.04; ELSE NULL; END CASE; /* If a salary raise is not zero, print the salary schedule */ IF (emp_sal.sal_raise != 0) THEN salary_schedule(emp_sal); END IF; ELSE eval_freq := 2; END IF; RETURN eval_freq; END eval_frequency;
emp_eval本体をコンパイルし、保存します。「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Body Compiled
カーソルは、データベースへの問合せ、一連のレコードの取得(結果セット)、および開発者が一度に1行のこれらのレコードへアクセス可能にすることを目的としてPL/SQLに組み込まれたポインタの型です。カーソルは、解析された文および関連情報を含むプライベートなメモリー内にある領域のハンドルまたは名称です。Oracle Databaseは暗黙的にカーソルを管理します。ただし、埋込みSQL文を効果的に解析するためにプログラム内の名前付きリソースとして、カーソルを明示的に使用できる一部のインタフェースがあります。次は定義された2つの主要なカーソルの型です。
各ユーザー・セッションには、初期化パラメータOPEN_CURSORSによって設定された制限の数まで、多くのオープン・カーソルが含まれることがあります。この初期化パラメータはデフォルトで50に設定されています。アプリケーションがシステム・メモリーを保護するためにカーソルをクローズすることを確認する必要があります。OPEN_CURSORSの制限に到達し、カーソルがオープンできない場合は、データベース管理者に連絡をとってOPEN_CURSORS初期化パラメータを変更します。
FOR...LOOPなどで、暗黙カーソルは明示カーソルよりもより効果的です。ただし、明示カーソルはプログラムにより適切で、使用すると名前付きリソースとして特定のメモリー内の領域を管理できます。
明示カーソルには次の表で説明される属性が含まれます。
明示カーソルはフェッチする列として同一タイプの変数として定義される必要があり、レコードのデータ型はカーソル定義から導出されます。また、オープンする必要があり、LOOP...EXIT WHEN構造内で行を取得することがあります。カーソルを使用する場合の一般的な書式は次のとおりです。
DECLARE CURSOR cursor_name type IS query_definition; OPEN cursor_name LOOP FETCH record; EXIT WHEN cursor_name%NOTFOUND; ...; -- process fetched row END LOOP; CLOSE cursor_name;
次はカーソルの存続期間内に起こります。
OPEN文はカーソルによって識別される問合せを解析し、入力をバインドして、結果セットからのレコードを正常にフェッチできたかを確認します。
FETCH文は問合せを実行した後、一致する行を検索し取得します。カーソルによって戻されるデータのバッファとしてローカル変数を定義し、使用する必要があり、その後、特定のレコードを処理します。
CLOSE文はカーソルの処理を完了し、カーソルをクローズします。一度カーソルがクローズされると、結果セットから追加のレコードを取得できないことに注意してください。
問合せと一致する各従業員レコードのカーソルを使用して「パッケージの作成」で宣言したプロシージャeval_departmentを実行できます。
カーソルemp_cursorは個々の結果セットからの行をフェッチします。各行のeval_frequencyファンクションの値およびeval_departmentプロシージャが実行する年数に応じて、新しい評価レコードはadd_evalプロシージャの起動によって従業員に対して作成されます。バッファ変数emp_recordは、%ROWTYPEとして定義されます。
emp_evalパッケージ仕様部で、プロシージャeval_departmentの宣言を編集します。
PROCEDURE eval_department(department_id IN employees.department_id%TYPE);
emp_eval本体ペインで、eval_departmentプロシージャを編集します。
PROCEDURE eval_department(department_id IN employees.department_id%TYPE) AS -- declaring buffer variables for cursor data emp_record employees%ROWTYPE; -- declaring variable to monitor if all employees need evaluations all_evals BOOLEAN; -- today's date today DATE; -- declaring the cursor CURSOR emp_cursor IS SELECT * FROM employees e WHERE department_id = e.department_id; BEGIN -- determine if all evaluations must be done or just for newer employees; -- this depends on time of the year today := SYSDATE; IF (EXTRACT(MONTH FROM today) < 6) THEN all_evals := FALSE; ELSE all_evals := TRUE; END IF; OPEN emp_cursor; -- start creating employee evaluations in a specific department DBMS_OUTPUT.PUT_LINE('Determining evaluations necessary in department # ' || department_id); LOOP FETCH emp_cursor INTO emp_record; -- getting specific record EXIT WHEN emp_cursor%NOTFOUND; -- all records are been processed IF all_evals THEN add_eval(emp_record.employee_id, today); -- create evals for all ELSIF (eval_frequency(emp_record.employee_id) = 2) THEN add_eval(emp_record.employee_id, today); -- create evals; newer employees END IF; END LOOP; DBMS_OUTPUT.PUT_LINE('Processed ' || emp_cursor%ROWCOUNT || ' records.'); CLOSE emp_cursor; END eval_department;
emp_evalパッケージ仕様部、emp_eval本体の順にコンパイルします。
「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Body Compiled
カーソルは、カーソルを作成した問合せによって定義されるため静的です。場合によっては、問合せ自体が実行時に作成されます。REF CURSORと呼ばれるカーソル変数は、特定の問合せから独立しているためにカーソルよりも柔軟性があります。カーソル変数は、問合せに対してオープンされ、結果セットを実行でき、同一の一連の列を戻す問合せに再使用できます。また、サブプログラム間の問合せの結果を渡すためにREF CURSORを適切にします。
REF CURSORSには、結果セットの書式を指定する戻り型を使用して宣言するもの(強いもの)と、あらゆる結果セットを取得するために戻り型を持たずに宣言するもの(弱いもの)があります。エラー発生の可能性が少なくなる戻り型を使用してREF CURSORを宣言することをお薦めします。これは、正確に公式化された問合せと強力に関連付けられているためです。互換性のある型を関連付けることがあるより柔軟なカーソルを必要とする場合、事前定義のSYS_REFCURSORを使用します。
REF CURSORを使用する一般的な書式は次のとおりです。
DECLARE TYPE cursor_type IS REF CURSOR RETURN return_type; cursor_variable cursor_type; single_record return_type; OPEN cursor_variable FOR query_definition; LOOP FETCH record; EXIT WHEN cursor_name%NOTFOUND; ...; -- process fetched row END LOOP; CLOSE cursor_name;
これはREF CURSORおよびカーソル変数の存続時間期間に起こります。
REF CURSOR型(戻り型)が宣言されます。
REF CURSOR型定義の戻り型と同一である必要があります。
OPEN文はカーソル変数に対して問合せを解析します。
FETCH文は問合せを実行し、移行の処理のためREF CURSORの戻り型として同じ型のローカル変数に一致する行を取得します。
CLOSE文はカーソル・プロセスを完了し、REF CURSORをクローズします。
「明示的なカーソルの使用」で、プロシージャeval_departmentは結果セットの取得、カーソルを使用しての処理、カーソルのクローズ、および終了を実行します。REF CURSOR型としてカーソルを宣言する場合、カーソルの再使用によってより多くの部門(たとえば、3つの連続した部門など)を変更します。
ループのフェッチは、入力としてカーソル変数を使用する新しいeval_fetch_controlプロシージャの一部であることに注意してください。これは、問合せの定義からの結果セットの処理を区別する追加機能を持ちます。部門ベースではなく、企業内のすべての従業員への評価を開始するプロシージャ(eval_everyone)を記述します。
eval_departmentはプロシージャadd_evalをコールするレコードの単一フィールドを使用します。このプロシージャは、同一のレコード上で3つの異なる問合せを実行します。これは非常に非効率のため、REF CURSORのレコード・バッファ全体を使用するためにadd_evalを再度記述します。
emp_eval仕様部で、REF CURSOR型定義、emp_refcursor_typeを追加します。この型はすべてのサブプログラムを表示するようにパッケージ・レベルで定義されます。また、プロシージャeval_everyoneの宣言を追加します。新しいコードは太字で表示されます。
create or replace PACKAGE emp_eval AS PROCEDURE eval_department (department_id IN employees.department_id%TYPE); PROCEDURE eval_everyone; FUNCTION calculate_score(eval_id IN scores.evaluation_id%TYPE , perf_id IN scores.performance_id%TYPE) RETURN NUMBER; TYPE SAL_INFO IS RECORD -- type for salary, limits, raises, and adjustments ( job_id jobs.job_id%type , sal_min jobs.min_salary%type , sal_max jobs.max_salary%type , salary employees.salary%type , sal_raise NUMBER(3,3)); TYPE emp_refcursor_type IS REF CURSOR RETURN employees%ROWTYPE; -- the REF CURSOR type for result set fetches END emp_eval;
emp_eval本体ペインで、プロシージャeval_loop_controlの前の宣言を追加し、プロシージャadd_evalの宣言を編集します。新しいコードは太字で表示されます。
CREATE OR REPLACE PACKAGE BODY emp_eval AS /* local subprogram declarations */ FUNCTION eval_frequency (employee_id IN employees.employee_id%TYPE) RETURN NUMBER; PROCEDURE salary_schedule(emp IN sal_info); PROCEDURE add_eval(emp_record IN employees%ROWTYPE, today IN DATE); PROCEDURE eval_loop_control(emp_cursor IN emp_refcursor_type); ...
emp_eval本体ペインで、eval_departmentプロシージャを編集して部門に基づいた3つの異なる結果セットを取得し、eval_loop_controlプロシージャをコールします。
PROCEDURE eval_department(department_id IN employees.department_id%TYPE) AS -- declaring the REF CURSOR emp_cursor emp_refcursor_type; department_curr departments.department_id%TYPE; BEGIN department_curr := department_id; -- starting with the first department FOR loop_c IN 1..3 LOOP OPEN emp_cursor FOR SELECT * FROM employees e WHERE department_curr = e.department_id; -- create employee evaluations is specific departments DBMS_OUTPUT.PUT_LINE('Determining necessary evaluations in department #' || department_curr); eval_loop_control(emp_cursor); -- call to process the result set DBMS_OUTPUT.PUT_LINE('Processed ' || emp_cursor%ROWCOUNT || ' records.'); CLOSE emp_cursor; department_curr := department_curr + 10; END LOOP; END eval_department;
emp_eval本体ペインで、add_evalプロシージャを編集してemployee_idのかわりに、取得されたemployee%ROWTYPEのレコードを使用します。プロシージャの最初の部分ではあらゆる宣言が必要ないことに注意してください。
PROCEDURE add_eval(emp_record IN employees%ROWTYPE, today IN DATE) AS BEGIN -- inserting a new row of values into evaluations table INSERT INTO evaluations VALUES ( evaluations_seq.NEXTVAL, -- evaluation_id emp_record.employee_id, -- employee_id today, -- evaluation_date emp_record.job_id, -- job_id emp_record.manager_id, -- manager_id emp_record.department_id, -- department_id 0); -- total_score END add_eval;
emp_eval本体ペインでコードの最後に対して、eval_loop_controlプロシージャを追加して結果セットからの個々のレコードをフェッチし、処理します。このコードの多くは、「明示的なカーソルの使用」のeval_departmentプロシージャの初期の定義からのものです。新しい構造は太字で表示されています。
PROCEDURE eval_loop_control(emp_cursor IN emp_refcursor_type) AS -- declaring buffer variable for cursor data emp_record employees%ROWTYPE; -- declaring variable to monitor if all employees need evaluations all_evals BOOLEAN; -- today's date today DATE; BEGIN -- determine if all evaluations must be done or just for newer employees; -- this depends on time of the year today := SYSDATE; IF (EXTRACT(MONTH FROM today) < 6) THEN all_evals := FALSE; ELSE all_evals := TRUE; END IF; LOOP FETCH emp_cursor INTO emp_record; -- getting specific record EXIT WHEN emp_cursor%NOTFOUND; -- all records are been processed IF all_evals THEN add_eval(emp_record, today); -- create evaluations for all ELSIF (eval_frequency(emp_record.employee_id) = 2) THEN add_eval(emp_record, today); -- create evaluations for newer employees END IF; END LOOP; END eval_loop_control;
emp_eval本体ペインで、企業内のすべての従業員を含む結果セットを取得するeval_everyoneプロシージャを追加します。このコードは、手順3のプロシージャeval_departmentと同様であることに注意してください。
PROCEDURE eval_everyone AS -- declaring the REF CURSOR type emp_cursor emp_refcursor_type; BEGIN OPEN emp_cursor FOR SELECT * FROM employees; -- start creating employee evaluations in a specific department DBMS_OUTPUT.PUT_LINE('Determining the number of necessary evaluations'); eval_loop_control(emp_cursor); -- call to process the result set DBMS_OUTPUT.PUT_LINE('Processed ' || emp_cursor%ROWCOUNT || ' records.'); CLOSE emp_cursor; END eval_everyone;
emp_evalペインで、emp_eval仕様部をコンパイルし、保存します。「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Compiled
emp_eval本体ペインで、emp_eval本体をコンパイルし、保存します。「Messages - Log」ペインに次のメッセージが表示されます。
EMP_EVAL Body Compiled
PL/SQLで使用可能な別のグループのユーザー定義のデータ型は、Oracleバージョンの1次元配列であるコレクションです。コレクションは、1つの変数内に複数の行のデータを保持できるデータ構造です。様々な型のデータを持つ行を1行のみ保持するレコードとは対照的に、コレクションのデータはすべて同じ型である必要があります。他の開発言語では、コレクションで表される型の型は配列と呼ばれます。
コレクションは、情報のリストを保持するために使用されます。また、コレクションの要素には直接アクセスすることができるため、アプリケーションのパフォーマンスを大幅に向上させることができます。コレクションの構造には、索引付き表、ネストした表および可変配列の3つの型があります。
VARRAYは、アプリケーションによって全体が格納および取得される小さなコレクションに有効です。
ここでは、索引付き表に限定して説明します。
索引付き表は、連想配列またはキーと値のペア・セットとも呼ばれます。各キーは一意で、配列内の対応する値を検出するために使用されます。このキー(または索引)には、整数または文字列のいずれかを使用できます。
連想配列は、任意のサイズのデータ・セットを表します。これによって、配列内の相対位置の確認およびすべての配列要素のループを実行せずに、個々の要素にアクセスできるようになります。
データ検索用の単純な一時記憶域の場合は、連想配列によって、SQL表に必要なディスク領域およびネットワーク操作を使用せずにデータをメモリーに格納できます。連想配列は、データの永続記憶域ではなく一時記憶域を対象とするため、INSERT、SELECT INTOなどのSQL文は使用できません。ただし、パッケージに型を宣言してパッケージ本体に値を割り当てることで、データベース・セッションが存続している間、連想配列を永続的にすることができます。
初めてキーを使用して値を割り当てる際、そのキーが連想配列に追加されます。同じキーを使用する後続の割当てでは、同じエントリが更新されます。データベース表の主キー、有効な数値ハッシュ関数の結果または一意の文字列値を形成する文字列の連結などの一意のキーを選択します。
索引付き表を宣言する前に、表の型を決定する必要があります。この項の後半では、アプリケーションの一部として索引付き表を使用する方法について説明します。
(PLS_INTEGERおよびVARCHAR2で索引付けされた)2つの型の連想配列を効率的に実装するには、次の手順を実行します。
ROWTYPEまたはTYPEを使用して、索引付き表の構造を定義します。
BULK COLLECTを使用して、カーソル・データを索引付き表にフェッチします。
データを索引付き表にフェッチするカーソルを定義し、カーソルの要素型を使用して索引付き表を作成することをお薦めします。例4-12は、 hr.employees表からデータをフェッチするemployees_jobs_cursorおよびhr.jobs表からデータをフェッチするjobs_cursorの2つのカーソルの作成方法を示しています。2つ目のカーソルではORDER BY句が使用されていないことに注意してください。
CURSOR employees_jobs_cursor IS SELECT e.first_name, e.last_name, e.job_id FROM hr.employees e ORDER BY e.job_id, e.last_name, e.first_name; CURSOR jobs_cursor IS SELECT j.job_id, j.job_title FROM hr.jobs j;
カーソルを宣言した後、例4-13に示すように、%ROWTYPE属性を使用して索引付きPLS_INTEGER表employees_jobsおよびjobsを作成できます。
TYPE employees_jobs_type IS TABLE OF employees_jobs_cursor%ROWTYPE INDEX BY PLS_INTEGER; employees_jobs employees_jobs_type; TYPE jobs_type IS TABLE OF jobs_cursor%ROWTYPE INDEX BY PLS_INTEGER; jobs jobs_type;
job_idのjob_titles索引付き表などのVARCHAR2で索引付けされた表を作成するには、例4-14に示すように、元の表hr.jobsからVARCHAR2型の定義を使用します。
TYPE job_titles_type IS TABLE OF hr.jobs.job_title%TYPE INDEX BY hr.jobs.job_id%TYPE; job_titles job_titles_type;
ローカルPL/SQL変数として大量のデータを参照する必要がある場合は、1度に1行ずつ結果セットをループするより、BULK COLLECT句を使用する方がはるかに効率的です。一部の列のみを問い合せる場合は、すべての結果を別々のコレクション変数の各列に格納できます。表のすべての列を問い合せる場合は、結果セット全体をレコードのコレクションに格納できます。
例4-15に示すように、索引付きPLS_INTEGER表employees_jobsおよびjobsを使用すると、カーソルをオープンし、BULK COLLECTを使用してデータを取得できます。
OPEN employees_jobs_cursor; FETCH employees_jobs_cursor BULK COLLECT INTO employees_jobs; CLOSE employees_jobs_cursor; OPEN jobs_cursor; FETCH jobs_cursor BULK COLLECT INTO jobs; CLOSE jobs_cursor;
jobs表にデータを含めた後、例4-16に示すように、FOR ... LOOPを使用して索引付きVARCHAR2表job_titlesを作成します。
FOR i IN 1..jobs.COUNT() LOOP job_titles(jobs(i).job_id) := jobs(i).job_title; END LOOP;
構造employees_jobsは、PLS_INTEGERで索引付けされているため、稠密な索引付き表となっています。例4-17に示すように、索引付き表は、表の1からCOUNT()値をカウントするFOR ... LOOP内に操作を配置することで簡単に反復できます。太字の行は、job_titles表内の値の直接検索を表しています。
FOR i IN 1..employees_jobs.count() LOOP DBMS_OUTPUT.PUT_LINE( RPAD(employees_jobs(i).employee_id, 10)|| RPAD(employees_jobs(i).first_name, 15)|| RPAD(employees_jobs(i).last_name, 15)|| job_titles(employees(i).job_id)); END LOOP;
構造job_titlesは、VARCHAR2で索引付けされたスパースな索引付き表です。例4-18に示すように、この索引付き表は、最初のキー値と等しい事前定義済カウンタおよび表のNEXT()値を使用して、WHILE ... END LOOP内で反復できます。要素は、索引の字句順でソートされます。
DECLARE i hr.jobs.job_id%TYPE := job_titles.FIRST(); WHILE i IS NOT NULL LOOP DBMS_OUTPUT.PUT_LINE( RPAD(job_titles(i).job_id, 10)|| job_titles(i).job_title); i := job_titles.NEXT(i); END LOOP;
例外のエラー条件は、PL/SQLコードを使用して簡単に検出および処理します。エラー発生時、通常の処理を停止し、例外処理コードの制御を送信することで、例外が発生します。このコードはPL/SQLブロックの最後に位置されます。PL/SQLでは、固有の例外ハンドラを持つそれぞれの例外を使用し、エラー・ルーチンへのコールおよびチェックが自動的に実行されます。
変数またはデータベース処理を含む特定の共通するエラー条件に対して事前定義済の例外が自動的に発生します。ユーザーのプログラムに関連するエラーである条件に対して、または既存のOracleメッセージに対するラッパーとして、カスタム例外を宣言することもできます。
Oracle Databaseは、PL/SQLプログラムが既知のデータベース・ルールを違反する場合、例外を自動的に発生します。この既知のデータベース・ルールは、SELECT INTO文が行を戻さない場合の事前定義済の例外NO_DATA_FOUNDなどです。次の表は、共通の例外の一部を示したものです。
emp_eval本体ペインで、問合せが結果セットを戻さないケースを処理するためにeval_departmentプロシージャを編集します。新しいコードは太字で表示されます。
PROCEDURE eval_department(department_id IN employees.department_id%TYPE) AS -- declaring the REF CURSOR emp_cursor emp_refcursor_type; department_curr departments.department_id%TYPE; BEGIN department_curr := department_id; -- starting with the first department FOR loop_c IN 1..3 LOOP OPEN emp_cursor FOR SELECT * FROM employees e WHERE department_curr = e.department_id; -- create employee evaluations is specific departments DBMS_OUTPUT.PUT_LINE('Determining necessary evaluations in department #' || department_curr); eval_loop_control(emp_cursor); -- call to process the result set DBMS_OUTPUT.PUT_LINE('Processed ' || emp_cursor%ROWCOUNT || ' records.'); CLOSE emp_cursor; department_curr := department_curr + 10; END LOOP; EXCEPTION WHEN NO_DATA_FOUND THEN DBMS_OUTPUT.PUT_LINE ('The query did not return a result set'); END eval_department;
emp_eval本体をコンパイルし、保存します。
パッケージにはエラーを処理するカスタム例外が含まれる場合があります。例外はプログラムで宣言され、また、あらゆる宣言リージョンで、サブプログラム、パッケージ本体またはパッケージ仕様部によってどのように使用されるかに応じます。
例外宣言は次の形式を含みます。
exception_name EXCEPTION;
正しくない値に基づいて、カスタム例外をプログラム的に発生するには、次の形式を使用する必要があります。
IF condition THEN RAISE exception_name;
予期せぬOracleエラーをトラップするには、一般的にサブプログラムまたはパッケージの本体内の最後のブロックとしてコード内に指示を処理する例外を含める必要があります。(標準およびカスタムの両方を)処理する例外に特定の名前を付け、予期せぬエラーをトラップするOTHERSハンドラを使用する必要があります。例外本体は次の形式を含みます。
EXCEPTION WHEN exception_name_1 THEN ...; DBMS_OUTPUT.PUT_LINE(message_1); ... WHEN OTHERS THEN ... DBMS_OUTPUT.PUT_LINE(message_others);
または、例外の発生後に実行が継続するようにプログラムを設計できます。例外ハンドラを使用してBEGIN...ENDブロックの例外を生成したと思われるコードを囲む必要があります。たとえば、ループ構造内の例外をトラップするコードはエラーを生成する要素のエラーを処理し、次のループの反復を使用して継続できます。
次の作業では、2つの考えられる例外weight_wrongとscore_wrongを宣言し、これらの例外を発生させた後、トラップするようにファンクションcalculate_scoreを再設計します。
emp_eval本体ペインで、calculate_scoreファンクションを編集します。新しいコードは太字で表示されます。
FUNCTION calculate_score(evaluation_id IN scores.evaluation_id%TYPE , performance_id IN scores.performance_id%TYPE) RETURN NUMBER AS weight_wrong EXCEPTION; score_wrong EXCEPTION; n_score scores.score%TYPE; -- from SCORES n_weight performance_parts.weight%TYPE; -- from PERFORMANCE_PARTS running_total NUMBER := 0; -- used in calculations max_score CONSTANT scores.score%TYPE := 9; -- a constant limit check max_weight CONSTANT performance_parts.weight%TYPE:= 1; -- a constant limit check BEGIN SELECT s.score INTO n_score FROM scores s WHERE evaluation_id = s.evaluation_id AND performance_id = s.performance_id; SELECT p.weight INTO n_weight FROM performance_parts p WHERE performance_id = p.performance_id; BEGIN -- check that weight is valid IF n_weight > max_weight OR n_weight < 0 THEN RAISE weight_wrong; END IF; END; BEGIN -- check that score is valid IF n_score > max_score OR n_score < 0 THEN RAISE score_wrong; END IF; END; -- calculate the score running_total := n_score * n_weight; RETURN running_total; EXCEPTION WHEN weight_wrong THEN DBMS_OUTPUT.PUT_LINE( 'The weight of a score must be between 0 and ' || max_weight); RETURN -1; WHEN score_wrong THEN DBMS_OUTPUT.PUT_LINE( 'The score must be between 0 and ' || max_score); RETURN -1; END calculate_score;
emp_eval本体をコンパイルし、保存します。
|
 Copyright © 2005, 2008, Oracle Corporation. All Rights Reserved. |
|