11g リリース1(11.1)
E05768-02
 目次 |
 索引 |
| Oracle Databaseユーティリティ 11g リリース1(11.1) E05768-02 |
|


この章では、Oracle Data Pump Exportユーティリティについて説明します。この章の内容は、次のとおりです。
|
注意:
データ・ポンプ・エクスポート・ユーティリティ( |
データ・ポンプ・エクスポート(以降、エクスポート・ユーティリティと呼びます)は、ダンプ・ファイル・セットと呼ばれる一連のオペレーティング・システム・ファイルにデータおよびメタデータをアンロードするためのユーティリティです。ダンプ・ファイル・セットは、データ・ポンプ・インポート・ユーティリティによってのみインポートできます。ダンプ・ファイル・セットは、同一システムでインポートするか、または別のシステムへ移動してそのシステムにロードできます。
ダンプ・ファイル・セットは、表データ、データベース・オブジェクトのメタデータ、制御情報を含む1つ以上のディスク・ファイルで構成されています。これらのファイルは独自のバイナリ形式で書き込まれています。データ・ポンプ・インポート・ユーティリティは、インポート操作中、これらのファイルを使用してダンプ・ファイル・セット内の各データベース・オブジェクトの位置を特定します。
ダンプ・ファイルは、クライアントではなくサーバーによって書き込まれるため、データベース管理者(DBA)は、ディレクトリ・オブジェクトを作成する必要があります。ディレクトリ・オブジェクトの詳細は、「ダンプ・ファイル、ログ・ファイルおよびSQLファイルのデフォルトの位置」を参照してください。
データ・ポンプ・エクスポート・ユーティリティでは、データおよびメタデータのサブセットが、エクスポート・モードで設定されているとおりにジョブによって移動されるように指定できます。この指定には、エクスポート・パラメータで指定するデータ・フィルタおよびメタデータ・フィルタが使用されます。詳細は、「エクスポート操作中のフィルタ処理」を参照してください。
データ・ポンプ・エクスポートを使用できる様々な方法の例については、「データ・ポンプ・エクスポートの使用例」を参照してください。
データ・ポンプ・エクスポート・ユーティリティは、expdpコマンドを使用して起動します。エクスポート操作の特性は、指定するエクスポート・パラメータによって決定されます。これらのパラメータは、コマンドラインまたはパラメータ・ファイルのいずれかで指定できます。
エクスポート・ユーティリティの起動の詳細は、次の項を参照してください。
データ・ポンプ・エクスポートとは、コマンドライン、パラメータ・ファイルまたは対話方式コマンド・モードを使用して対話できます。
PARFILEパラメータのみが例外となります。値の指定に引用符が必要なパラメータを指定する場合は、パラメータ・ファイルを使用することをお薦めします。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
対話方式コマンド・モードで使用可能なコマンドの詳細は、「エクスポート・ユーティリティの対話方式コマンド・モードで使用可能なコマンド」を参照してください。
エクスポート・ユーティリティには、データベースの様々な部分をアンロードするための様々なモードがあります。モードは、適切なパラメータを使用してコマンドラインで指定します。使用可能なモードは次のとおりです。
全体エクスポートは、FULLパラメータを使用して指定します。全データベース・エクスポートでは、データベース全体がアンロードされます。このモードには、EXP_FULL_DATABASEロールが必要です。
スキーマ・エクスポートは、SCHEMASパラメータを使用して指定します。これがデフォルトのエクスポート・モードです。EXP_FULL_DATABASEロールを所有している場合は、スキーマのリストを指定し、オプションでスキーマ定義およびこれらのスキーマに対するシステム権限を指定することができます。EXP_FULL_DATABASEロールを所有していない場合は、自分のスキーマのみをエクスポートできます。
SYSスキーマは、エクスポート・ジョブのソース・スキーマとして使用できません。
相互スキーマ参照は、参照されるスキーマがエクスポート対象のスキーマのリストにも指定されないかぎり、エクスポートされません。たとえば、指定されたいずれかのスキーマ内の表にトリガーが定義されていても、そのトリガーが、明示的に指定されていないスキーマ内に常駐している場合はエクスポートされません。これは、指定されたスキーマ内の表に影響を及ぼす外部型定義についても同様です。この場合は、インポート時に、型定義がターゲット・インスタンスにすでに存在している必要があります。
表モード・エクスポートは、TABLESパラメータを使用して指定します。表モードでは、指定した表、パーティションおよびそれらの依存オブジェクトのみがアンロードされます。
TRANSPORTABLE=ALWAYSパラメータとTABLESパラメータを組み合せて指定するすると、オブジェクト・メタデータのみがアンロードされます。実際のデータを移動するには、データ・ファイルをターゲット・データベースにコピーします。これにより、エクスポート時間が短縮されます。異なるバージョンまたはプラットフォーム間でデータ・ファイルを移動する場合は、データ・ファイルをOracle Recovery Manager(RMAN)で処理することが必要な場合があります。
自分のスキーマに存在しない表を指定するには、EXP_FULL_DATABASEロールが必要です。指定するすべての表が、単一のスキーマ内に存在する必要があります。列の型定義は、表モードではエクスポートされません。この場合は、インポート時に、型定義がターゲット・インスタンスにすでに存在している必要があります。また、スキーマ・エクスポートの場合と同様に、相互スキーマ参照もエクスポートされません。
|
参照:
|
表領域エクスポートは、TABLESPACESパラメータを使用して指定します。表領域モードでは、指定した表領域内に存在する表のみがアンロードされます。表がアンロードされると、その表の依存オブジェクトもアンロードされます。オブジェクトのメタデータとデータは、両方ともアンロードされます。表領域モードでは、指定した表領域内に表の一部が存在する場合、その表とその表のすべての依存オブジェクトがエクスポートされます。特権ユーザーは、すべての表を取得します。権限のないユーザーは、自分のスキーマ内の表のみを取得します。
トランスポータブル表領域エクスポートは、TRANSPORT_TABLESPACESパラメータを使用して指定します。トランスポータブル表領域モードでは、指定した表領域セット内にある表のメタデータ(およびその表の依存オブジェクト)のみがエクスポートされます。表領域データ・ファイルは別の操作でコピーされます。次に、トランスポータブル表領域インポートが実行され、メタデータを含むダンプ・ファイルのインポートと、使用するデータ・ファイルの指定が行われます。
トランスポータブル表領域モードでは、指定した表がすべてその表領域に含まれている必要があります。つまり、表領域セット内に定義されているすべての表(およびその索引)のすべての記憶域セグメントも、セット内に含まれている必要があります。表領域セット内に違反が含まれている場合は、エクスポート・ユーティリティが実際にエクスポートを実行することなくすべての問題を識別します。
トランスポータブル表領域エクスポートは、停止すると再開できません。また、トランスポータブル表領域エクスポートには、1を超える並列度は指定できません。
暗号化された列は、トランスポータブル表領域モードではサポートされていません。
|
参照:
|
データ・ポンプ・エクスポート・ユーティリティの起動時、接続文字列には接続識別子を指定できます。この識別子では、現行のOracleシステム識別子(SID)によって指定した現行のインスタンスとは別のデータベース・インスタンスを指定できます。接続識別子には、Oracle*Net接続記述子または接続記述子にマップする名前を指定できます。これには、接続記述子を使用して検索できるアクティブ・リスナー(起動するには、lsnrctl startと入力)が必要です。次に、ユーザーhrがinst1という接続記述子を使用してエクスポート・ユーティリティを起動する例を示します。
expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp TABLES=employees Export: Release 11.1.0.6.0 - Production on Monday, 27 August, 2007 10:15:45 Copyright (c) 2003, 2007, Oracle. All rights reserved. Password: password@inst1 Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production With the Partitioning, Data Mining and Real Application Testing options
ローカルのエクスポート・クライアントは、接続記述子inst1(通常はtnsnames.oraファイルで定義される単純なネット・サービス名)によって識別されるデータベース・インスタンスに接続し、そのインスタンスのデータをエクスポートします。
接続識別子を使用したエクスポート・ユーティリティの起動と、エクスポート・ユーティリティのコマンドライン・パラメータNETWORK_LINKを指定したエクスポート操作を混同しないでください。エクスポートを実行してNETWORK_LINKパラメータを使用すると、データベース・リンクを介してエクスポートが開始されます。一方、エクスポート操作を開始して接続識別子を指定すると、ローカルのエクスポート・クライアントは、コマンドライン接続文字列によって指定されるデータベース・インスタンスに接続し、データベース・リンクによって指定されるデータベース・インスタンスからエクスポートするデータを取得して、接続したデータベース・インスタンスのダンプ・ファイル・セットにそのデータを書き込みます。
|
参照:
|
データ・ポンプ・エクスポート・ユーティリティで提供されるデータおよびメタデータのフィルタ機能は、オリジナルのエクスポート・ユーティリティと比較すると大幅に拡張されています。
データ固有のフィルタ処理は、QUERYおよびSAMPLEパラメータによって実装されます。このパラメータは、表のエクスポートされる行に対する制限を指定します。
メタデータのフィルタ処理の結果として、間接的にデータのフィルタ処理が実行される場合もあります。この処理では、表オブジェクトおよび関連付けられた行データを含めたり、除外することができます。
各データ・フィルタは、表ごとにジョブ内で1回指定できます。同じ名前を使用する異なるフィルタが特定の表とジョブ全体の両方に適用された場合は、特定の表に対して提供されたフィルタ・パラメータが優先されます。
メタデータのフィルタ処理は、EXCLUDEおよびINCLUDEパラメータによって実装されます。EXCLUDEおよびINCLUDEは、相互に排他的なパラメータです。
メタデータ・フィルタは、オブジェクトを、エクスポートまたはインポート操作に含めるか除外するかを識別します。たとえば、パッケージ仕様またはパッケージ本体を含まない全体エクスポートを要求できます。
フィルタを正しく使用して必要な結果を得た場合は、識別されたオブジェクトの依存オブジェクトも、識別されたオブジェクトとともに処理されます。たとえば、索引を操作に含めるようにフィルタで指定すると、その索引の統計も含まれます。同様に、フィルタで表を除外すると、その表に対する索引、制約、権限およびトリガーも除外されます。
1つのオブジェクト型に対して複数のフィルタが指定されている場合は、それらのフィルタに対して暗黙的なAND処理が適用されます。つまり、ジョブに関連するオブジェクトは、オブジェクト型に適用されるすべてのフィルタで処理される必要があります。
同じメタデータ・フィルタ名を、1つのジョブ内で複数回指定できます。
フィルタ処理できるオブジェクトを確認するには、DATABASE_EXPORT_OBJECTS(全体モードのエクスポートの場合)、SCHEMA_EXPORT_OBJECTS(スキーマ・モードのエクスポートの場合)およびTABLE_EXPORT_OBJECTS(表モードおよび表領域モードのエクスポートの場合)の各ビューに対して問合せを実行します。たとえば、次の問合せを実行できます。
SQL> SELECT OBJECT_PATH, COMMENTS FROM SCHEMA_EXPORT_OBJECTS 2 WHERE OBJECT_PATH LIKE '%GRANT' AND OBJECT_PATH NOT LIKE '%/%';
次に、この問合せの出力結果の例を示します。
OBJECT_PATH -------------------------------------------------------------------------------- COMMENTS -------------------------------------------------------------------------------- GRANT Object grants on the selected tables OBJECT_GRANT Object grants on the selected tables PROCDEPOBJ_GRANT Grants on instance procedural objects PROCOBJ_GRANT Schema procedural object grants in the selected schemas ROLE_GRANT Role grants to users associated with the selected schemas SYSTEM_GRANT System privileges granted to users associated with the selected schemas
この項では、データ・ポンプ・エクスポート・ユーティリティのコマンドライン・モードで使用可能なパラメータについて説明します。ここで説明する内容の多くは、パラメータの使用例を含みます。
各項に示す例を試行する場合は、次の内容に注意してください。
Export: Release 11.1.0.6.0 - Production on Monday, 27 August, 2007 11:45:35 Copyright (c) 2003, 2007, Oracle. All rights reserved. Password: password Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production With the Partitioning, Data Mining and Real Application Testing options
hr)スキーマを頻繁に使用します。
dpump_dir1およびdpump_dir2がすでに存在し、これらのディレクトリ・オブジェクトについてのREAD権限およびWRITE権限が、hrスキーマに付与されているものとします。ディレクトリ・オブジェクトの作成およびこれらへの権限の割当てについては、「ダンプ・ファイル、ログ・ファイルおよびSQLファイルのデフォルトの位置」を参照してください。
EXP_FULL_DATABASEロールおよびIMP_FULL_DATABASEロールが必要です。このような例では、hrスキーマにこれらのロールが付与されているものとします。
必要に応じて、これらのディレクトリ・オブジェクトの作成と、必要な権限やロールの割当てをDBAに依頼します。
これらのパラメータの構文図は、「データ・ポンプ・エクスポートの構文図」を参照してください。
特に指定がないかぎり、これらのパラメータはパラメータ・ファイルでも指定できます。
オペレーティング・システムによっては、コマンドラインの引用符を、バックスラッシュなどでエスケープする必要がある場合があります。バックスラッシュがない場合、Exportで使用するコマンドライン解析機能で引用符として認識されないため、引用符が削除されエラーが発生します。通常、そのような文は、パラメータ・ファイルに記述することをお薦めします。パラメータ・ファイルでは、エスケープ文字は不要なためです。
|
参照:
|
|
注意:
オリジナルのエクスポート・ユーティリティ( |
デフォルト: ユーザーのスキーマで現在実行されているジョブ(存在する場合)
クライアント・セッションを既存のエクスポート・ジョブに接続し、自動的に対話方式コマンド・インタフェースを有効にします。接続先のジョブの説明およびエクスポート・プロンプトが表示されます。
ATTACH [=[schema_name.]job_name]
schema_nameは、オプションです。自分のスキーマ以外のスキーマを指定するには、EXP_FULL_DATABASEロールが必要です。
job_nameは、スキーマに対応するエクスポート・ジョブが1つのみで、そのジョブがアクティブの場合はオプションです。停止しているジョブに接続する場合は、このジョブ名を指定する必要があります。DBA_DATAPUMP_JOBSビューまたはUSER_DATAPUMP_JOBSビューを問い合せて、データ・ポンプ・ジョブ名の一覧を表示できます。
ジョブに接続している場合、エクスポート・ユーティリティでは、ジョブの説明が表示され、次にエクスポート・プロンプトが表示されます。
ATTACHパラメータを指定する場合、コマンドラインで他に指定できるデータ・ポンプ・パラメータは、ENCRYPTION_PASSWORDのみです。
ENCRYPTION_PASSWORDパラメータを再入力してそのパスワードを再指定する必要があります。唯一の例外は、ジョブが最初にENCRYPTION=ENCRYPTED_COLUMNS_ONLYパラメータを使用して開始されている場合です。この場合、ジョブへの接続時に暗号化パスワードは必要ありません。
次に、ATTACHパラメータの使用例を示します。ジョブhr.export_jobがすでに存在するものとします。
> expdp hr ATTACH=hr.export_job
デフォルト: METADATA_ONLY
ダンプ・ファイル・セットに書き込む前に圧縮するデータを指定します。
COMPRESSION={ALL | DATA_ONLY | METADATA_ONLY | NONE}
ALLを指定すると、エクスポート操作全体について圧縮が有効になります。
DATA_ONLYを指定すると、すべてのデータが圧縮形式でダンプ・ファイルに書き込まれます。
METADATA_ONLYを指定すると、すべてのメタデータが圧縮形式でダンプ・ファイルに書き込まれます。これがデフォルトです。
NONEを指定すると、エクスポート操作全体について圧縮が無効になります。
COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
METADATA_ONLYオプションは、たとえCOMPATIBLE初期化パラメータが10.2に設定されていても使用できます。
次に、COMPRESSIONパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_comp.dmp COMPRESSION=METADATA_ONLY
このコマンドは、スキーマ・モードのエクスポートを実行し、すべてのメタデータを圧縮してからダンプ・ファイルhr_comp.dmpに書き出します。エクスポート・モードが指定されていないため、デフォルトでスキーマ・モードのエクスポートになります。
デフォルト: ALL
エクスポート・ユーティリティでアンロードする内容を、データのみ、メタデータのみ(あるいはその両方)でフィルタ処理できます。
CONTENT={ALL | DATA_ONLY | METADATA_ONLY}
ALLを指定すると、データとメタデータの両方がアンロードされます。これがデフォルトです。
DATA_ONLYを指定すると、表の行データのみがアンロードされます。データベース・オブジェクト定義はアンロードされません。
METADATA_ONLYを指定すると、データベース・オブジェクト定義のみがアンロードされます。表の行データはアンロードされません。
次に、CONTENTパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp CONTENT=METADATA_ONLY
このコマンドでは、hrのスキーマに関連付けられたメタデータのみをアンロードするスキーマ・モード・エクスポートが実行されます。エクスポート・モードが指定されていない場合は、デフォルトでhrのスキーマのスキーマ・モード・エクスポートになります。
デフォルト: デフォルト値は設定されていません。このパラメータが使用されていない場合、このパラメータが提供する特別なデータ処理オプションは無効になります。
DATA_OPTIONSパラメータを使用すると、エクスポートおよびインポート中に特定のタイプのデータを処理するためのオプションが提供されます。エクスポート操作の場合、DATA_OPTIONSパラメータに対して唯一有効なオプションはXML_CLOBSです。
DATA_OPTIONS=XML_CLOBS
XML_CLOBSオプションを指定すると、XMLType列は、列に対して定義されているXMLTypeの格納形式に関係なく非圧縮のCLOB形式でエクスポートされます。
表にCLOBとして格納されているXMLType列しかない場合は、データ・ポンプにより自動的にこれらの列がCLOB形式でエクスポートされるため、XML_CLOBSオプションを指定する必要はありません。表にオブジェクト・リレーショナル(スキーマベース)、バイナリまたはCLOB形式の組合せで格納されているXMLType列がある場合、デフォルトで、これらの列はデータ・ポンプにより圧縮形式でエクスポートされます。この方法をお薦めします。ただし、データを非圧縮のCLOB形式でエクスポートする必要がある場合は、XML_CLOBSオプションを使用してデフォルトの設定を上書きできます。
XML_CLOBSオプションを使用するには、エクスポート時とインポート時の両方で同じXMLスキーマを使用する必要があります。
DATA_OPTIONSパラメータを使用する場合は、ジョブ・バージョンを11.0.0以上に設定する必要があります。詳細は、「VERSION」を参照してください。
この例では、hr.xdb_tab1表のXMLType列を、列に対して定義されているXMLTypeの格納形式に関係なく、非圧縮のCLOB形式でエクスポートするエクスポート操作を示します。
> expdp hr TABLES=hr.xdb_tab1 DIRECTORY=dpump_dir1 DUMPFILE=hr_xml.dmp VERSION=11.1 DATA_OPTIONS=xml_clobs
デフォルト: DATA_PUMP_DIR
エクスポート・ユーティリティによるダンプ・ファイル・セットおよびログ・ファイルのデフォルトの書込み先を指定します。
DIRECTORY=directory_object
directory_objectは、データベースのディレクトリ・オブジェクトの名前です(実際のディレクトリのファイル・パスではありません)。インストール時に、特権ユーザーにDATA_PUMP_DIRという名前のデフォルトのディレクトリ・オブジェクトへのアクセス権が付与されます。DATA_PUMP_DIRへのアクセス権を持つユーザーがDIRECTORYパラメータを使用する必要はありません。
DUMPFILEパラメータやLOGFILEパラメータで指定したディレクトリ・オブジェクトは、DIRECTORYパラメータに指定したディレクトリ・オブジェクトよりも優先されます。
次に、DIRECTORYパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=employees.dmp CONTENT=METADATA_ONLY
ダンプ・ファイルemployees.dmpは、ディレクトリ・オブジェクトdpump_dir1に対応付けられたパスに書き込まれます。
|
参照:
|
デフォルト: expdat.dmp
名前を指定します。オプションで、エクスポート・ジョブに対するダンプ・ファイルのディレクトリ・オブジェクトを指定します。
DUMPFILE=[directory_object:]file_name [, ...]
DIRECTORYパラメータで指定されている場合、directory_objectはオプションです。ここで値を指定する場合は、すでに存在しアクセス権があるディレクトリ・オブジェクトを指定します。DUMPFILEパラメータの一部に指定されるデータベース・ディレクトリ・オブジェクトは、DIRECTORYパラメータによって指定された値またはデフォルトのディレクトリ・オブジェクトよりも優先されます。
カンマで区切ったリストまたは個別のDUMPFILEパラメータ指定で、複数のfile_name指定を定義できます。ファイル拡張子を指定しない場合は、デフォルトのファイル拡張子.dmpが使用されます。ファイル名には、複数のファイルを生成できることを示す置換変数(%U)を含めることができます。生成されるファイル名では、置換変数が、01〜99まで増加する固定幅の2桁の整数に変換されます。ファイル指定に2つの置換変数が含まれている場合は、両方の変数が同時に増加します。たとえば、exp%Uaa%U.dmpは、exp01aa01.dmp、exp02aa02.dmpというように変換されます。
FILESIZEパラメータを指定すると、各ダンプ・ファイルがそのサイズ(バイト)を上限とするため、拡張できなくなります。置換変数(%U)を持つテンプレートを指定していて、ダンプ・ファイル・セットに必要な領域が不足し、デバイスに余裕がある場合は、FILESIZEで指定したサイズの新しいダンプ・ファイルが自動的に作成されます。
置換変数が含まれているファイル指定またはファイル・テンプレートは、定義されているとおり、完全修飾されたファイル名としてインスタンス化され、エクスポート・ユーティリティによって作成されます。ファイル指定は、指定した順序で処理されます。ファイル・サイズが上限に達したか、またはパラレル処理をアクティブなままにするためにジョブにファイルを追加する必要がある場合、置換変数を持つファイル・テンプレートが指定されていれば、追加のファイルが作成されます。
DUMPFILEパラメータで複数のファイルを指定することもできますが、エクスポート・ジョブでエクスポート・データを保持するために必要となるのは、それらのファイルのサブセットのみの場合もあります。エクスポート・ジョブの最後に表示されるダンプ・ファイル・セットには、実際に使用されたファイルが示されます。このダンプ・ファイル・セットを使用するインポート操作には、このファイル・リストが必要になります。
REUSE_DUMPFILES=Yを指定します。
次に、DUMPFILEパラメータの使用例を示します。
> expdp hr SCHEMAS=hr DIRECTORY=dpump_dir1 DUMPFILE=dpump_dir2:exp1.dmp, exp2%U.dmp PARALLEL=3
ダンプ・ファイルexp1.dmpは、ディレクトリ・オブジェクトdpump_dir2に対応するパスに書き込まれます。これは、dpump_dir2が、ダンプ・ファイル名の一部として指定されたことによって、DIRECTORYパラメータで指定されたディレクトリ・オブジェクトよりも優先されるためです。このジョブでは、3つのパラレル処理がすべて実行されるため、ダンプ・ファイルexp201.dmpおよびexp202.dmpが作成され、DIRECTORYパラメータで指定されたディレクトリ・オブジェクトdpump_dir1に対応するパスに書き込まれます。
デフォルト: デフォルト値は、使用される暗号化関連のパラメータの組合せによって決まります。暗号化を有効にするには、ENCRYPTIONまたはENCRYPTION_PASSWORDパラメータ、あるいは両方を指定する必要があります。ENCRYPTION_PASSWORDパラメータのみが指定されている場合は、デフォルトでENCRYPTIONパラメータがALLに設定されます。ENCRYPTIONとENCRYPTION_PASSWORDのどちらも指定されていない場合は、デフォルトでENCRYPTIONがNONEに設定されます。
ダンプ・ファイル・セットに書き込む前にデータを暗号化するかどうかを指定します。
ENCRYPTION = {ALL | DATA_ONLY | ENCRYPTED_COLUMNS_ONLY | METADATA_ONLY | NONE}
ALLを指定すると、エクスポート操作ですべてのデータおよびメタデータについて暗号化が有効になります。
DATA_ONLYを指定すると、データのみが暗号化形式でダンプ・ファイル・セットに書き込まれます。
ENCRYPTED_COLUMNS_ONLYを指定すると、暗号化された列のみが暗号化形式でダンプ・ファイル・セットに書き込まれます。
METADATA_ONLYを指定すると、メタデータのみが暗号化形式でダンプ・ファイル・セットに書き込まれます。
NONEを指定すると、データは暗号化形式でダンプ・ファイル・セットに書き込まれません。
ALL、DATA_ONLYまたはMETADATA_ONLYの各オプションを指定するには、COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
次の例では、ダンプ・ファイルでデータのみが暗号化されるエクスポート操作を実行します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_enc.dmp JOB_NAME=enc1 ENCRYPTION=data_only ENCRYPTION_PASSWORD=foobar
デフォルト: AES128
暗号化の実行に使用する必要のある暗号化アルゴリズムを指定します。
ENCRYPTION_ALGORITHM = { AES128 | AES192 | AES256 }
暗号化アルゴリズムの詳細は、『Oracle Advanced Security管理者ガイド』を参照してください。
COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
ENCRYPTION_ALGORITHMパラメータを使用する場合は、ENCRYPTIONまたはENCRYPTION_PASSWORDパラメータも指定する必要があります。指定しないと、エラーが返されます。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_enc.dmp ENCRYPTION_PASSWORD=foobar ENCRYPTION_ALGORITHM=AES128
デフォルト: デフォルト・モードは、他に使用される暗号化関連のパラメータによって決まります。ENCRYPTIONパラメータのみが指定されている場合、デフォルト・モードはTRANSPARENTになります。ENCRYPTION_PASSWORDパラメータが指定され、Oracle Encryption Walletがオープン状態の場合、デフォルト設定はDUALになります。ENCRYPTION_PASSWORDパラメータが指定され、Oracle Encryption Walletが閉じられている場合、デフォルト設定はPASSWORDになります。
暗号化および復号化を実行する際に使用するセキュリティ・タイプを指定します。
ENCRYPTION_MODE = { DUAL | PASSWORD | TRANSPARENT }
DUALモードでは、後から透過的にインポートしたり、デュアルモードで暗号化されたダンプ・ファイル・セットの作成時に使用したパスワードを指定してインポートすることができるダンプ・ファイル・セットを作成します。DUALモードで作成されたダンプ・ファイル・セットを後からインポートするときは、Oracle Encryption Wallet、またはENCRYPTION_PASSWORDパラメータで指定されたパスワードのいずれかを使用できます。DUALモードは、Oracle Encryption Walletを使用する場合にはダンプ・ファイル・セットのインポートをオンサイトで行い、Oracle Encryption Walletが使用できない場合にはオフサイトでインポートを行う必要もある場合に最適です。
PASSWORDモードでは、暗号化されたダンプ・ファイル・セットの作成時にパスワードを指定する必要があります。ダンプ・ファイル・セットをインポートするときは同じパスワードを指定する必要があります。PASSWORDモードでは、ENCRYPTION_PASSWORDパラメータも指定する必要があります。PASSWORDモードは、ダンプ・ファイル・セットが別のデータベースやリモート・データベースにインポートされるときに、転送中もセキュリティで保護する必要がある場合に最適です。
TRANSPARENTモードでは、必要なOracle Encryption Walletを使用できる場合、暗号化されるダンプ・ファイル・セットをデータベース管理者(DBA)の介入なしで作成することができます。したがって、ENCRYPTION_PASSWORDパラメータは必要なく、実際には、TRANSPARENTモードで使用するとエラーの原因となります。この暗号化モードは、ダンプ・ファイル・セットがエクスポート元と同じデータベースにインポートされる場合に最適です。
DUALまたはTRANSPARENTモードを使用するには、COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
ENCRYPTION_MODEパラメータを使用する場合は、ENCRYPTIONまたはENCRYPTION_PASSWORDパラメータのいずれかを使用する必要があります。それ以外の場合は、エラーが返されます。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_enc.dmp ENCRYPTION=all ENCRYPTION_PASSWORD=secretwords ENCRYPTION_ALGORITHM=AES256 ENCRYPTION_MODE=dual
デフォルト: デフォルト値は設定されていません。ユーザーが値を指定します。
エクスポート・ダンプ・ファイル内の暗号化列のデータ、メタデータまたは表データを暗号化するためのパスワードを指定します。これにより、暗号化されたダンプ・ファイル・セットへの不正なアクセスを防ぎます。
ENCRYPTION_PASSWORD = password
指定するpassword値は、暗号化された表の列、メタデータまたは表データをダンプ・ファイル・セットにクリア・テキストとして書き込まないように、再度暗号化するキーを指定します。エクスポート操作の対象に暗号化された表の列がある場合に暗号化パスワードが指定されていなければ、暗号化された列はクリア・テキストとしてダンプ・ファイル・セットに書き込まれ、警告が発行されます。
エクスポート操作については、ENCRYPTION_MODEパラメータがPASSWORDまたはDUALに設定されている場合に、このパラメータが必要になります。
ENCRYPTION_PASSWORDが指定されているが、ENCRYPTION_MODEは指定されていない場合、ENCRYPTION_MODEがデフォルトでPASSWORDに設定されるため、透過的データ暗号化オプションを設定する必要はありません。
ENCRYPTION_PASSWORDパラメータは、指定した暗号化モードがTRANSPARENTの場合は有効になりません。
ENCRYPTION_MODEがDUALに設定されている場合にENCRYPTION_PASSWORDパラメータを使用するには、透過的データ暗号化オプションが設定されている必要があります。透過的データ暗号化オプションの詳細は、『Oracle Advanced Security管理者ガイド』を参照してください。
ENCRYPTION_PASSWORDパラメータとENCRYPTED_COLUMNS_ONLYの併用は、暗号化列があるユーザー定義の外部表ではサポートされていません。そのような表はスキップされ、エラー・メッセージが表示されますが、ジョブは続行されます。
EMP表にEMPNOという列があるとします。次のいずれの場合も、ソース表のEMP列の暗号化属性が、ターゲット表のEMP列の暗号化属性と一致していないためエラーになります。
次の例では、暗号化パスワード123456がダンプ・ファイルdpcd2be1.dmpに割り当てられています。
expdp hr TABLES=employee_s_encrypt DIRECTORY=dpump_dir DUMPFILE=dpcd2be1.dmp ENCRYPTION=ENCRYPTED_COLUMNS_ONLY ENCRYPTION_PASSWORD=123456
employee_s_encrypt表の暗号化列は、dpcd2be1.dmpダンプ・ファイルにクリア・テキストとして書き込まれません。この例で作成されたdpcd2be1.dmpファイルを後でインポートするには、同じ暗号化パスワードを指定する必要があることに注意してください。(ENCRYPTION_PASSWORDパラメータを使用したインポート操作の例は、「ENCRYPTION_PASSWORD」を参照してください。)
デフォルト: BLOCKS
エクスポート・ジョブ内の各表で使用されるディスク領域(バイト単位)を見積もる場合にエクスポートで使用される方法を指定します。見積りはログ・ファイルに出力され、クライアントの標準出力デバイスに表示されます。見積りの対象は、表の行データのみです。メタデータは含まれません。
ESTIMATE={BLOCKS | STATISTICS}
BLOCKS: 見積りは、ソース・オブジェクトで使用されるデータベース・ブロックの数に、適切なブロック・サイズを掛けて計算されます。
STATISTICS: 見積りは、表別の統計を使用して計算されます。この方法による見積りをできるかぎり正確にするには、すべての表を新しく分析しておく必要があります。
ESTIMATE=BLOCKSが使用されている場合、圧縮された表がデータ・ポンプのエクスポート・ジョブに含まれていると、その圧縮表に対するデフォルトのサイズ見積りは不正確になります。これは、データが圧縮形式で保存されていたことが、サイズの見積りに反映されないためです。圧縮された表に対するサイズ見積りをより正確に行うには、ESTIMATE=STATISTICSを使用してください。
QUERY、SAMPLEまたはREMAP_DATAパラメータが使用されている場合も、見積りが不正確になることがあります。
次の例に、ESTIMATEパラメータの使用例を示します。ここでは、employees表に対する統計を使用して見積りが計算されます。
> expdp hr TABLES=employees ESTIMATE=STATISTICS DIRECTORY=dpump_dir1 DUMPFILE=estimate_stat.dmp
デフォルト: n
エクスポート・ユーティリティで、ジョブが消費する領域を実際のエクスポート操作を行わずに見積もります。
ESTIMATE_ONLY={y | n}
ESTIMATE_ONLY=yの場合、エクスポート・ユーティリティは、使用される領域の見積りを行いますが、実際にエクスポート操作は実行せずに終了します。
次に、ESTIMATE_ONLYパラメータを使用して、HRスキーマが使用するエクスポート領域の大きさを判断する場合の例を示します。
> expdp hr ESTIMATE_ONLY=y NOLOGFILE=y SCHEMAS=HR
デフォルト: デフォルト値は設定されていません。
エクスポート操作から除外するオブジェクトおよびオブジェクト型を指定して、エクスポートの対象となるメタデータをフィルタ処理できます。
EXCLUDE=object_type[:name_clause] [, ...]
EXCLUDE文に指定したオブジェクト型を除き、実行されるエクスポート・モードに対応するすべてのオブジェクト型が、エクスポート操作の対象になります。オブジェクトが除外されると、そのオブジェクトのすべての依存オブジェクトも除外されます。たとえば、表を除外すると、その表のすべての索引およびトリガーも除外されます。
name_clauseは、オプションです。このオプションを使用すると、あるオブジェクト型のうち、特定のオブジェクトを選択できます。このオプションは、その型のオブジェクト名に対するフィルタとして使用されるSQL式です。SQL演算子および指定した型のオブジェクト名の比較対象となる値で構成されています。この名前句は、名前付きのインスタンスを持つオブジェクト型にのみ適用されます(たとえば、TABLEには適用されますが、GRANTには適用されません)。名前句は、コロンでオブジェクト型と区切り、二重引用符(一重引用符は名前文字列の区切りに使用する必要があるため)で囲む必要があります。たとえば、EXCLUDE=INDEX:"LIKE 'EMP%'"と設定した場合、EMPで始まる名前を持つすべての索引を除外できます。
name_clauseを指定しない場合、指定した型のすべてのオブジェクトが除外されます。
2つ以上のEXCLUDE文を指定できます。
エスケープ文字をコマンドラインで使用する必要がないように、EXCLUDE句は、パラメータ・ファイルで指定することをお薦めします。
object_typeにCONSTRAINT、GRANTまたはUSERを指定する場合、次に説明する影響があることに注意してください。
次の制約は明示的に除外できません。
次に、EXCLUDE文の例およびその解釈を示します。
EXCLUDE=CONSTRAINTは、NOT NULL制約および表の正常な作成およびロードに必要な制約を除き、すべての制約(非参照)を除外します。
EXCLUDE=REF_CONSTRAINTは、参照整合性(外部キー)制約を除外します。
EXCLUDE=GRANTを指定すると、すべてのオブジェクト型に対するオブジェクト権限およびシステム権限が除外されます。
EXCLUDE=USERを指定すると、ユーザーの定義のみが除外され、そのユーザーのスキーマ内のオブジェクトは除外されません。
特定のユーザーとそのユーザーのすべてのオブジェクトを除外するには、次のフィルタを指定します(hrは除外するユーザーのスキーマ名です)。
EXCLUDE=SCHEMA:"='HR'"
EXCLUDE=USER:"='HR'"のような文を使用してユーザーを除外しようとすると、DDL文CREATE USER hrDDL文内で使用される情報のみが除外され、期待した結果が得られない場合があります。
次に、EXCLUDE文の使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_exclude.dmp EXCLUDE=VIEW, PACKAGE, FUNCTION
これによって、hrスキーマ全体がエクスポートされるスキーマ・モード・エクスポートが実行されます。ただし、このスキーマのビュー、パッケージおよびファンクションは除外されます。
デフォルト: 0(無制限)
各ダンプ・ファイルの最大サイズを指定します。ダンプ・ファイル・セット内にあるダンプ・ファイルが最大サイズになると、そのファイルはクローズされ、ファイル指定に置換変数が含まれている場合は、新しいファイルが作成されます。
FILESIZE=integer[B | K | M | G]
integerの後に、B、K、MまたはG(それぞれバイト、キロバイト、メガバイト、ギガバイトを示す)を指定できます。デフォルトは、B(バイト)です。作成されるファイルの実際のサイズは、ダンプ・ファイル内で使用されている内部ブロックのサイズと一致するように切り捨てられる場合があります。
次に、サイズが3MBのダンプ・ファイルを設定する例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_3m.dmp FILESIZE=3M
3MBでもすべてのエクスポート・データを保持するのに十分でなかった場合、次のエラーが表示され、ジョブは中止されます。
ORA-39095: Dump file space has been exhausted: Unable to allocate 217088 bytes
割り当てることができなかった実際のバイト数は、場合によって異なります。また、この数字は、エクスポート操作全体を完了するために必要な容量を表しているわけではありません。この値は、ダンプ・ファイル領域がなくなった時点でエクスポート中だったオブジェクトのサイズのみを示しています。
この状況は、中止されたジョブに接続し、ADD_FILEコマンドを使用してファイルを1つ以上追加し、操作をやり直すことで解消できます。
デフォルト: デフォルト値は設定されていません。
エクスポートで使用されるシステム変更番号(SCN)を指定して、フラッシュバック問合せユーティリティを使用可能にします。
FLASHBACK_SCN=scn_value
エクスポート操作は、指定したSCNにおけるデータの一貫性を維持したまま実行されます。NETWORK_LINKパラメータが指定されている場合、SCNはソース・データベースのSCNを示します。
FLASHBACK_SCNおよびFLASHBACK_TIMEは、相互に排他的なパラメータです。
FLASHBACK_SCNパラメータは、Oracle Databaseのフラッシュバック問合せ機能にのみ関係します。フラッシュバック・データベース、フラッシュバック削除およびフラッシュバック・データ・アーカイブには適用できません。
次の例では、384632 というSCN値が存在するとします。この例では、hrスキーマをSCN 384632までエクスポートします。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr_scn.dmp FLASHBACK_SCN=384632
デフォルト: デフォルト値は設定されていません。
指定された時刻に最も近いSCNを検出し、このSCNを使用してフラッシュバック・ユーティリティを使用可能にします。エクスポート操作は、このSCNにおけるデータの一貫性を維持したまま実行されます。
FLASHBACK_TIME="TO_TIMESTAMP(time-value)"
TO_TIMESTAMPの値は引用符で囲まれるため、パラメータ・ファイルに記述することをお薦めします。コマンドラインの場合は、引用符の前にエスケープ文字を入力する必要があります。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
FLASHBACK_TIMEおよびFLASHBACK_SCNは、相互に排他的なパラメータです。
FLASHBACK_TIMEパラメータは、Oracle Databaseのフラッシュバック問合せ機能にのみ関係します。フラッシュバック・データベース、フラッシュバック削除およびフラッシュバック・データ・アーカイブには適用できません。
DBMS_FLASHBACK.ENABLE_AT_TIMEプロシージャで使用可能な形式で時刻を指定できます。たとえば、次の内容のパラメータ・ファイルflashback.parを作成したとします。
DIRECTORY=dpump_dir1 DUMPFILE=hr_time.dmp FLASHBACK_TIME="TO_TIMESTAMP('25-08-2003 14:35:00', 'DD-MM-YYYY HH24:MI:SS')"
次のコマンドを発行します。
> expdp hr PARFILE=flashback.par
エクスポート操作は、指定した時間に最も近いSCNと整合性のあるデータで実行されます。
デフォルト: n
全体データベース・モード・エクスポートの実行を指定します。
FULL={y | n}
FULL=yと指定すると、すべてのデータおよびメタデータがエクスポートされます。このエクスポート・モードを使用したエクスポート対象を、フィルタ処理によって制限できます。詳細は、「エクスポート操作中のフィルタ処理」を参照してください。
全体エクスポートを実行するには、EXP_FULL_DATABASEロールが必要です。
SYS、ORDSYS、MDSYSなどがあります。
SYSスキーマが所有しているオブジェクトに対する権限はエクスポートされません。
次に、FULLパラメータの使用例を示します。ダンプ・ファイルexpfull.dmpは、dpump_dir2ディレクトリに書き込まれます。
> expdp hr DIRECTORY=dpump_dir2 DUMPFILE=expfull.dmp FULL=y NOLOGFILE=y
デフォルト: N
エクスポート・ユーティリティのオンライン・ヘルプを表示します。
HELP = {y | n}
HELP=yが指定されている場合は、エクスポート・ユーティリティのすべてのコマンドライン・パラメータと対話方式コマンドの要約が表示されます。
> expdp HELP = y
この例では、すべてのエクスポート・パラメータおよびコマンドの簡単な説明が表示されます。
デフォルト: デフォルト値は設定されていません。
現行のエクスポート・モードにオブジェクトとオブジェクト型を指定して、エクスポート対象のメタデータをフィルタ処理できます。指定したオブジェクトおよびこれらのオブジェクトのすべての依存オブジェクトがエクスポートされます。これらのオブジェクトに対する権限もエクスポートされます。
INCLUDE = object_type[:name_clause] [, ...]
INCLUDE文で明示的に指定されたオブジェクト型とその依存オブジェクトのみがエクスポートされます。他のオブジェクト型(通常、EXP_FULL_DATABASEロールを所有している場合にスキーマ・モード・エクスポートの一部となるスキーマ定義情報など)はエクスポートされません。
DATABASE_EXPORT_OBJECTS(全体モードの場合)、SCHEMA_EXPORT_OBJECTS(スキーマ・モードの場合)、TABLE_EXPORT_OBJECTS(表および表領域モードの場合)ビューを問い合せて、INCLUDEパラメータで使用する有効なパスの一覧を表示できます。
name_clauseは、オプションです。このオプションを使用すると、あるオブジェクト型のうち、特定のオブジェクトをファイングレイン選択できます。オプションの名前句は、その型のオブジェクト名に対するフィルタとして使用されるSQL式です。SQL演算子および指定した型のオブジェクト名の比較対象となる値で構成されています。この名前句は、名前付きのインスタンスを持つオブジェクト型にのみ適用されます(たとえば、TABLEには適用されますが、GRANTには適用されません)。オプションの名前句は、コロンでオブジェクト型と区切り、二重引用符(一重引用符は名前文字列の区切りに使用する必要があるため)で囲む必要があります。
INCLUDE文は、パラメータ・ファイルで指定することをお薦めします。パラメータ・ファイルで指定しない場合、コマンドラインで引用符の前にオペレーティング・システム固有のエスケープ文字を記述することが必要な場合があります。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
たとえば、次の内容のパラメータ・ファイルhr.parを作成したとします。
SCHEMAS=HR DUMPFILE=expinclude.dmp DIRECTORY=dpump_dir1 LOGFILE=expinclude.log INCLUDE=TABLE:"IN ('EMPLOYEES', 'DEPARTMENTS')" INCLUDE=PROCEDURE INCLUDE=INDEX:"LIKE 'EMP%'"
この場合、コマンドラインで他のパラメータを入力しなくても、hr.parファイルを使用してエクスポート操作を開始することができます。
> expdp hr parfile=hr.par
指定したobject_typeがCONSTRAINTである場合は、次に説明する影響があることに注意してください。
次の制約を明示的に含めることはできません。
次に、INCLUDE文の例およびその解釈を示します。
INCLUDE=CONSTRAINTは、NOT NULL制約および表の正常な作成およびロードに必要な制約を除き、すべての制約(非参照)を含めます。
INCLUDE=REF_CONSTRAINTは、参照整合性(外部キー)制約を含めます。
次の例では、hrスキーマのすべての表(およびその依存オブジェクト)をエクスポートします。
> expdp hr INCLUDE=TABLE DUMPFILE=dpump_dir1:exp_inc.dmp NOLOGFILE=y
デフォルト: SYS_EXPORT_<mode>_NNという書式のシステム生成による名前
ジョブへの接続にATTACHパラメータを使用したり、DBA_DATAPUMP_JOBSまたはUSER_DATAPUMP_JOBSビューを使用してジョブを指定する場合など、後続処理でエクスポート・ジョブを指定するために使用されます。ジョブ名は、現在のユーザーのスキーマでのマスター表の名前となります。マスター表は、エクスポート・ジョブの制御に使用されます。
JOB_NAME=jobname_string
jobname_stringには、このエクスポート・ジョブの名前を、30バイト以内で指定します。これらのバイトは印字可能文字と空白を表します。空白を含む場合は、一重引用符で囲みます(たとえば、'Thursday Export'とします)。ジョブ名は、エクスポート操作を実行しているユーザーのスキーマによって暗黙的に修飾されます。
デフォルトのジョブ名はSYS_EXPORT_<mode>_NNという形式で、システムによって生成されます。NNは、01から始めて増加する2桁の整数です。デフォルト名は、'SYS_EXPORT_TABLESPACE_02'などです。
次に、ジョブ名exp_jobを割り当てるエクスポート操作の例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=exp_job.dmp JOB_NAME=exp_job NOLOGFILE=y
デフォルト: export.log
エクスポート・ジョブのログ・ファイルの名前を指定します。また、オプションで、そのログ・ファイルを格納するディレクトリを指定します。
LOGFILE=[directory_object:]file_name
directory_objectには、DBAによって作成済であるデータベースのディレクトリ・オブジェクトを指定できます(そのオブジェクトへのアクセス権がある場合)。この指定は、DIRECTORYパラメータに指定されたディレクトリ・オブジェクトよりも優先されます。
file_nameには、ログ・ファイル名を指定します。デフォルトでは、DIRECTORYパラメータで指定されたディレクトリ・オブジェクトが示すディレクトリに、export.logというファイルが作成されます。
処理中の作業、完了した作業および発生したエラーに関するすべてのメッセージがログ・ファイルに書き込まれます。(ジョブのリアルタイムの状態を把握するには、対話方式モードでSTATUSコマンドを使用します。)
NOLOGFILEパラメータを指定しないかぎり、エクスポート・ジョブには、常にログ・ファイルが作成されます。ダンプ・ファイル・セットと同様に、ログ・ファイルの基準となるのは、クライアントではなく、サーバーです。
このファイル名と一致する既存のファイルは上書きされます。
LOGFILEパラメータには、ASMの+表記法を含まないディレクトリ・オブジェクトを含める必要があります。つまり、ログ・ファイルはディスク・ファイルに書き込まれ、ASMの記憶域には書き込まれません。かわりに、NOLOGFILE=Yを指定することもできます。ただし、この場合はログ・ファイルの書込みは行われません。
次の例に、デフォルトの名前を使用しない場合に、ログ・ファイル名を指定する方法を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp LOGFILE=hr_export.log
デフォルト: デフォルト値は設定されていません。
有効なデータベース・リンクによって指定される(ソース)データベースからのエクスポートを使用可能にします。ソース・データベース・インスタンスのデータは、接続されたデータベース・インスタンスのダンプ・ファイル・セットに書き込まれます。
NETWORK_LINK=source_database_link
NETWORK_LINKパラメータは、データベース・リンクを使用してエクスポートを開始します。つまり、expdpクライアントの接続先となるシステムから、source_database_linkで指定されたソース・データベースに接続し、そこからデータを取り出して、接続されたシステムのダンプ・ファイルに書き込みます。
source_database_linkには、使用可能なデータベースへのデータベース・リンク名を指定する必要があります。対象インスタンスのデータベースにデータベース・リンクが指定されていない場合、ユーザーまたはDBAが、データベース・リンクを作成する必要があります。CREATE DATABASE LINK文の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
ソース・データベースが読取り専用の場合、ソース・データベースのユーザーには、デフォルトの一時表領域として、ローカル管理表領域が割り当てられている必要があります。それ以外の場合、ジョブは失敗します。詳細は、『Oracle Database管理者ガイド』のローカル管理の一時表領域の作成に関する説明を参照してください。
NETWORK_LINKパラメータをTABLESパラメータと組み合せて使用する場合は、表全体のみをエクスポートできます(表のパーティションはエクスポートできません)。
次に、NETWORK_LINKパラメータの使用例を示します。source_database_linkには、すでに存在する有効なデータベース・リンク名を指定します。
> expdp hr DIRECTORY=dpump_dir1 NETWORK_LINK=source_database_link DUMPFILE=network_export.dmp LOGFILE=network_export.log
デフォルト: n
ログ・ファイルを作成するかどうかを指定します。
NOLOGFILE={y | n}
デフォルトでログ・ファイルを作成しないようにするには、NOLOGFILE=yを指定します。ただし、進捗とエラーに関する情報は、接続されているいずれかのクライアント(元のエクスポート操作を開始したクライアントを含む)の標準出力デバイスに書き込まれます。実行中のジョブに接続されているクライアントが存在しない場合に、NOLOGFILE=yを指定すると、重要な進捗情報およびエラー情報が失われる危険性があります。
次に、NOLOGFILEパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp NOLOGFILE=y
このコマンドによって、ログ・ファイルの書込みを行わないスキーマ・モード・エクスポートが実行されます。
デフォルト: 1
エクスポート・ジョブにかわり、アクティブな実行スレッドの最大数を指定します。この実行セットはワーカー・プロセスおよびパラレルI/Oサーバーの処理の組合せで構成されています。パラレル問合せ操作で問合せコーディネータとして動作するマスター制御プロセスおよびワーカー・プロセスは、この合計数には加算されません。
このパラメータを使用して、リソース消費と経過時間のバランスをとることができます。
PARALLEL=integer
integerに指定する値は、ダンプ・ファイル・セット内のファイル数以下にする必要があります(または、ダンプ・ファイル指定に置換変数を指定する必要があります)。アクティブなワーカー・プロセスまたはI/Oサーバー・プロセスは、1つのファイルに対してそれぞれが同時に排他的に書込みを行うため、ファイル数が不足していると、逆効果になります。ファイルの待機中に、一部のワーカー・プロセスがアイドル状態になるため、そのジョブの全体的なパフォーマンスが低下します。また、パラレルI/Oサーバー・プロセスを共有で実行しているメンバーが出力用ファイルを取得できない場合は、ORA-39095エラーを返してエクスポート操作が停止します。いずれの場合も、データ・ポンプ・エクスポート・ユーティリティを使用してジョブに接続することによって、問題を解決できます。接続後、対話方式モードで、ADD_FILEコマンドを使用してファイルを追加し、ジョブが停止した場合は、ジョブを再開します。
ジョブの実行中にPARALLELの値を増減するには、対話方式コマンド・モードを使用します。並列度を下げても、ジョブに関連付けられたワーカー・プロセスは減少しません。任意の時点で実行されるワーカー・プロセスの数が減少するのみです。また、プロセス数が減少する前に、継続中の処理が適正な完了ポイントに到達する必要があります。そのため、値を小さくした効果の確認に時間がかかる場合があります。アイドル状態のワーカーは、ジョブが終了するまで削除されません。
パラレル実行できる処理が存在する場合、並列度の増加はすぐに反映されます。
次に、PARALLELパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 LOGFILE=parallel_export.log JOB_NAME=par4_job DUMPFILE=par_exp%u.dmp PARALLEL=4
この例では、hrスキーマのスキーマ・モード・エクスポートが実行され、ディレクトリ・オブジェクトdpump_dir1に指定されたパスに、最大4つのファイルが作成されます。
デフォルト: デフォルト値は設定されていません。
エクスポート・パラメータ・ファイルの名前を指定します。
PARFILE=[directory_path]file_name
Oracle Databaseによって作成され、書き込まれるダンプ・ファイルやログ・ファイルとは異なり、パラメータ・ファイルは、expdpイメージを実行しているクライアントによってオープンされ、読み込まれます。したがって、ディレクトリ・オブジェクトの名前は不要かつ不適切です。ディレクトリ・パスは、オペレーティング・システム固有のディレクトリ指定です。デフォルトは、ユーザーの現行のディレクトリです。
値の指定に引用符が必要なパラメータを使用する場合は、パラメータ・ファイルを使用することをお薦めします。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
パラメータ・ファイルhr.parの内容は、次のとおりです。
SCHEMAS=HR DUMPFILE=exp.dmp DIRECTORY=dpump_dir1 LOGFILE=exp.log
このパラメータ・ファイルを指定するには、次のExportコマンドを実行します。
> expdp hr parfile=hr.par
デフォルト: デフォルト値は設定されていません。
エクスポート対象となるデータをフィルタ処理するために使用する問合せ句を指定できます。
QUERY = [schema.][table_name:] query_clause
通常、query_clauseでは、ファイングレイン行選択のためのSQL WHERE句を使用しますが、任意のSQL句を使用できます。たとえば、ORDER BY句を使用すると、ヒープ構成表から索引構成表への移行を高速化できます。スキーマおよび表名を指定しなかった場合は、エクスポート・ジョブ内のすべての表に問合せが適用されます(この場合、問合せは、これらのすべての表に対して有効である必要があります)。表固有の問合せは、すべての表に適用される問合せより優先されます。
特定の表に問合せを適用する場合は、表名と問合せ句をコロンで区切る必要があります。表固有の問合せは複数指定できますが、1つの表に指定できるのは1つの問合せのみです。
問合せは一重引用符または二重引用符で囲みます。句内の文字列を一重引用符で囲む必要があるため、二重引用符の使用をお薦めします。オペレーティング・システム固有のエスケープ文字をコマンドラインで使用する必要がないように、QUERYは、パラメータ・ファイルで指定することをお薦めします。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
表固有の問合せで自分のスキーマ以外のスキーマを指定するには、その特定の表に対するアクセス権限が付与されている必要があります。
QUERYパラメータは次のパラメータとは併用できません。
QUERYパラメータが指定されている場合、データ・ポンプは外部表を使用してターゲット表をアンロードします。外部表は、SQLのCREATE TABLE AS SELECT文を使用します。QUERYパラメータの値は、CREATE TABLE文のSELECT部分にあるWHERE句です。QUERYパラメータにアンロードする表と一致する名前の列がある他の表への参照が含まれていて、これらの列が問合せで使用される場合は、表別名を使用して、アンロードする表内の列と、SELECT文内の同じ名前を持つ列を区別する必要があります。アンロードする表に対してデータ・ポンプで使用される表別名は、KU$です。たとえば、sh.customers表にある顧客のクレジットの上限に基づいてsh.sales表のサブセットをエクスポートするとします。次の例では、KU$を使用して、sh.salesをアンロードするためにQUERYパラメータ内のcust_idフィールドを修飾します。この結果、データ・ポンプによって、クレジットの上限が$10,000を超える顧客の行のみがエクスポートされます。
QUERY='sales:"WHERE EXISTS (SELECT cust_id FROM customers c WHERE cust_credit_limit > 10000 AND ku$.cust_id = c.cust_id)"'
次の問合せのように、表別名としてKU$を使用しないと、すべての行がアンロードされることになります。
QUERY='sales:"WHERE EXISTS (SELECT cust_id FROM customers c WHERE cust_credit_limit > 10000 AND cust_id = c.cust_id)"'
次に、QUERYパラメータの使用例を示します。
> expdp hr parfile=emp_query.par
emp_query.parファイルの内容は次のとおりです。
QUERY=employees:"WHERE department_id > 10 AND salary > 10000" NOLOGFILE=y DIRECTORY=dpump_dir1 DUMPFILE=exp1.dmp
この例では、hrスキーマのすべての表がアンロードされます。ただし、アンロードされるのは、問合せ式に適合する行のみです。この場合、hrスキーマ内のすべての表(employeesを除く)のすべての行がアンロードされます。employees表に対しては、問合せ基準を満たす行のみがアンロードされます。
デフォルト: デフォルト値は設定されていません。
REMAP_DATAパラメータを使用すると再マップ・ファンクションを指定できます。これにより、指定した列の元の値をソースとして再マップした値を返し、ダンプ・ファイル内の元の値をこの値に置き換えます。このオプションは、一般的に、本番システムからテスト・システムへ移動するときにデータをマスクするために使用されます。たとえば、クレジット・カード番号などの顧客の機密データの列を、REMAP_DATAファンクションで生成された番号に置き換えることができます。これにより、権限のないユーザーに個人データを公開することなく、データで必要な書式と処理特性を保持できます。
同じファンクションを、ダンプされる複数の列に適用できます。これは、参照制約で子と親両方の列を再マップするときに整合性を保つ必要がある場合に役立ちます。
REMAP_DATA=[schema.]tablename.column_name:[schema.]pkg.function
次に、各構文要素の説明を構文で出現する順に示します。
schema1: 再マップされる表を含むスキーマ。デフォルトでは、これはエクスポートを実行するユーザーのスキーマです。
tablename: 列の再マップが行われる表。
column_name: データの再マップが行われる列。
schema2: 再マップ・ファンクションを含むユーザー作成のPL/SQLパッケージを格納するスキーマ。デフォルトでは、これはエクスポートを実行するユーザーのスキーマです。
pkg: 再マップ・ファンクションを含むユーザー作成のPL/SQLパッケージの名前。
function: 指定した表の各行で、列表を再マップする場合にコールされるPL/SQL内のファンクションの名前。
次の例では、minus10およびplusxという名前のファンクションを格納するremapという名前のパッケージが作成されており、これらのファンクションはemployees表内のemployee_idおよびfirst_nameの値を変更すると想定しています。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=remap1.dmp TABLES=employees REMAP_DATA=hr.employees.employee_id:hr.remap.minus10 REMAP_DATA=hr.employees.first_name:hr.remap.plusx
デフォルト: N
すでに存在しているダンプ・ファイルを上書きするかどうかを指定します。
REUSE_DUMPFILES={Y | N}
通常、データ・ポンプ・エクスポートは、すでに存在するダンプ・ファイル名を指定するとエラーを返します。REUSE_DUMPFILESパラメータを使用すると、動作を変更してダンプ・ファイル名を再利用できます。たとえば、エクスポートを実行してDUMPFILE=hr.dmpおよびREUSE_DUMPFILES=Yを指定した場合、hr.dmpがすでに存在するときは、このファイルが上書きされます。このファイルの前の内容は消去され、かわりに現行のエクスポートのデータが格納されます。
次のエクスポート操作では、enc1.dmpという名前のダンプ・ファイルが作成されます。これは、この名前の付いたダンプ・ファイルがすでに存在する場合でも同様です。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=enc1.dmp TABLES=employees REUSE_DUMPFILES=y
デフォルト: デフォルト値は設定されていません。
サンプリングしてソース・データベースからアンロードするデータ・ブロックの割合を指定できます。
SAMPLE=[[schema_name.]table_name:]sample_percent
このパラメータを使用すると、サンプリングしてエクスポートするデータの割合を指定し、データのサブセットをエクスポートできます。sample_percentは、行のブロックがサンプルの一部として選択される可能性を示します。ただし、指定した正確な行数が表から取り出されるわけではありません。sample_percentには、0.000001から100未満の任意の数を指定できます。
sample_percentは特定の表に適用することができます。次の例では、HR.EMPLOYEES表の50%がエクスポートされます。
SAMPLE="HR"."EMPLOYEES":50
スキーマを指定する場合は、表も指定する必要があります。ただし、スキーマを指定せずに表を指定することはできます(その場合は、現在のユーザーが使用されます)。表の指定がない場合は、エクスポート・ジョブ全体にsample_percent値が適用されます。
なお、このパラメータとデータ・ポンプ・インポートのPCTSPACE変換を組み合せて使用すると、記憶域の割当てサイズをサンプリングされたデータ・サブセットに合わせることができます。(詳細は、「TRANSFORM」を参照してください。)
次の例では、表の名前が指定されていないため、全体のエクスポート・ジョブにSAMPLE値70が適用されます。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=sample.dmp SAMPLE=70
デフォルト: 現在のユーザーのスキーマ
スキーマ・モード・エクスポートの実行を指定します。これは、エクスポートのデフォルトのモードです。
SCHEMAS=schema_name [, ...]
EXP_FULL_DATABASEロールがある場合、自分のスキーマ以外の単一のスキーマまたはスキーマ名のリストを指定できます。EXP_FULL_DATABASEロールでは、インポート時にスキーマを再作成できるように、指定した各スキーマのスキーマ・オブジェクト以外の補足情報をエクスポートすることもできます。この補足情報には、ユーザー定義、関連するすべてのシステムおよびロールの権限、ユーザー・パスワードの履歴などが含まれます。スキーマ・モードを使用したエクスポート対象を、フィルタ処理によってより詳細に制限できます(詳細は、「エクスポート操作中のフィルタ処理」を参照してください)。
次に、SCHEMASパラメータの使用例を示します。前述の例でEXP_FULL_DATABASEロールがすでに割り当てられているため、ユーザーhrが複数のスキーマを指定できることに注意してください。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=expdat.dmp SCHEMAS=hr,sh,oe
このコマンドで、スキーマ・モード・エクスポートが実行され、dpump_dir1ディレクトリにあるexpdat.dmpダンプ・ファイルに、スキーマhr、shおよびoeが書き込まれます。
デフォルト: 0
ジョブ状態の表示が更新される頻度を指定します。
STATUS=[integer]
integerに値を入力すると、ロギング・モードでジョブの状態を表示する頻度を秒単位で指定できます。値を入力しなかった場合またはデフォルト値の0を使用した場合、各オブジェクト型、表またはパーティションの完了に関する情報のみ表示されます。
この状態情報は、標準出力デバイスのみに書き込まれ、ログ・ファイルには(使用可能な場合でも)書き込まれません。
次に、STATUSパラメータの使用例を示します。
> expdp hr DIRECTORY=dpump_dir1 SCHEMAS=hr,sh STATUS=300
この例では、hrおよびshスキーマをエクスポートし、エクスポート状態を5分ごと(60秒×5=300秒)に表示します。
デフォルト: デフォルト値は設定されていません。
表モード・エクスポートの実行を指定します。
TABLES=[schema_name.]table_name[:partition_name] [, ...]
このモードを使用したエクスポート対象を、フィルタ処理によって制限できます(詳細は、「エクスポート操作中のフィルタ処理」を参照してください)。表およびパーティションまたはサブパーティションをカンマで区切ったリストを指定して、エクスポート対象のデータおよびメタデータをフィルタ処理できます。パーティションの名前を指定する場合は、関連表にあるパーティションまたはサブパーティションの名前にする必要があります。指定した表、パーティションおよびそれらの依存オブジェクトのみがアンロードされます。
指定する表名の先頭にスキーマ名を修飾できます。指定するすべての表名が、同じスキーマ内に存在する必要があります。デフォルトのスキーマは、現在のユーザーのスキーマです。自分のスキーマ以外のスキーマを指定するには、EXP_FULL_DATABASEロールが必要です。
ワイルド・カードは、エクスポート操作ごとに1つの表名に対して使用できます。たとえば、TABLES=emp%とした場合、EMPで始まる名前の表がすべてエクスポートされます。
表モード・エクスポート中にトランスポータブル・オプションを使用するには、TRANSPORTABLE=ALWAYSパラメータとTABLESパラメータを組み合せて指定します。指定した表、パーティションまたはサブパーティションのメタデータはダンプ・ファイルにエクスポートされます。実際のデータを移動するには、データ・ファイルをターゲット・データベースにコピーします。
パーティション表がトランスポータブル・メソッドを使用してエクスポートされると、各パーティションおよびサブパーティションは固有の表に昇格されます。以降のインポート操作中は、自動的に表とパーティションの名前が組み合されて新しい表の名前(tablename_partitionname)になります。この自動名前付けオプションを変更するには、インポートのREMAP_TABLEパラメータを使用します。
TABLESパラメータの値としてのシノニムの使用はサポートされていません。たとえば、hrスキーマのregions表にregnのシノニムが存在する場合、TABLES=regnを使用すると無効になります。この場合、エラーが返されます。
NETWORK_LINKパラメータを使用した場合、個々の表パーティションのエクスポートはサポートされません。
TABLESパラメータに指定する表名のリストの長さは、最大4MBに制限されます。ただし、NETWORK_LINKパラメータで10.2.0.3以前のデータベースまたは読取り専用のデータベースが設定されている場合は異なります。この場合の上限は4KBです。
TRANSPORTABLE=ALWAYSも設定されている場合、1つの表からのパーティションのみを指定できます。
次の例に、hrスキーマにある3つ表employees、jobsおよびdepartmentsをエクスポートするためにTABLESパラメータを使用する簡単な例を示します。ユーザーhrは、hrスキーマ内の表をエクスポートしているため、表名の前にスキーマ名を指定する必要はありません。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=tables.dmp TABLES=employees,jobs,departments
次の例では、ユーザーhrにEXP_FULL_DATABASEロールが付与されていることを前提としています。ここでは、TABLESパラメータを使用したパーティションのエクスポートを示します。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=tables_part.dmp TABLES=sh.sales:sales_Q1_2000,sh.sales:sales_Q2_2000
この例では、shスキーマのsales表から、パーティションsales_Q1_2000およびsales_Q2_2000をエクスポートします。
デフォルト: デフォルト値は設定されていません。
表領域モードでエクスポートされる表領域名のリストを指定します。
TABLESPACES=tablespace_name [, ...]
表領域モードでは、指定した表領域内に存在する表のみがアンロードされます。表がアンロードされると、その表の依存オブジェクトもアンロードされます。オブジェクトのメタデータとデータは、両方ともアンロードされます。指定した表領域内に表の一部が存在する場合、その表とその表のすべての依存オブジェクトがエクスポートされます。特権ユーザーは、すべての表を取得します。権限のないユーザーは、自分のスキーマ内の表のみを取得します。
このモードを使用したエクスポート対象を、フィルタ処理によって制限できます(詳細は、「エクスポート操作中のフィルタ処理」を参照してください)。
TABLESPACESパラメータに指定する表領域名リストの長さは、最大4MBに制限されます。ただし、NETWORK_LINKパラメータで10.2.0.3以前のデータベースまたは読取り専用のデータベースが設定されている場合は異なります。この場合の上限は4KBです。
次に、TABLESPACESパラメータの使用例を示します。この例では、表領域tbs_4、tbs_5およびtbs_6がすでに存在するとします。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=tbs.dmp TABLESPACES=tbs_4, tbs_5, tbs_6
このコマンドによって、表領域エクスポートが実行され、指定した表領域(tbs_4、tbs_5およびtbs_6)から表(および表の依存オブジェクト)がアンロードされます。
デフォルト: n
トランスポータブル・セット内部のオブジェクトと外部のオブジェクト間の依存性をチェックするかどうかを指定します。このパラメータは、トランスポータブル表領域モード・エクスポートでのみ使用可能です。
TRANSPORT_FULL_CHECK={y | n}
TRANSPORT_FULL_CHECK=yを指定すると、エクスポート・ユーティリティによって、トランスポータブル・セットの内部にあるオブジェクトと外部にあるオブジェクトの間に依存性が存在しないことが確認されます。ここでは、双方向の依存性がチェックされます。たとえば、トランスポータブル・セット内に表は存在するが、その表の索引は存在しない場合は、エラーが返され、エクスポート操作が終了します。同様に、トランスポータブル・セット内に索引は存在するが表は存在しない場合も、エラーが返されます。
TRANSPORT_FULL_CHECK=nを指定すると、エクスポート・ユーティリティによって、トランスポータブル・セットの外部にあるオブジェクトの依存オブジェクトが、トランスポータブル・セット内に存在しないことのみ確認されます。ここでは、一方向の依存性がチェックされます。たとえば、表は索引に依存しませんが、索引は表に依存します。これは、索引は表なしでは意味を持たないためです。そのため、トランスポータブル・セット内に表は存在するが、表の索引は存在しない場合、このチェックは正常に終了します。ただし、トランスポータブル・セット内に索引は存在するが表は存在しない場合は、エクスポート操作が終了します。
他のチェックも実行されます。たとえば、エクスポートでは、常に、TRANSPORT_TABLESPACESで指定された表領域セット内に定義されているすべての表(およびその索引)のすべての記憶域セグメントが、表領域セット内に実際に含まれていることが確認されます。
次に、TRANSPORT_FULL_CHECKパラメータの使用例を示します。ここでは、表領域tbs_1が存在するとします。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=tts.dmp TRANSPORT_TABLESPACES=tbs_1 TRANSPORT_FULL_CHECK=y LOGFILE=tts.log
デフォルト: デフォルト値は設定されていません。
トランスポータブル表領域モード・エクスポートの実行を指定します。
TRANSPORT_TABLESPACES=tablespace_name [, ...]
TRANSPORT_TABLESPACESパラメータは、ソース・データベースからターゲット・データベースにオブジェクト・メタデータがエクスポートされる表領域名のリストを指定するために使用します。
エクスポートのログ・ファイルには、トランスポータブル・セットで使用されているデータ・ファイル、ダンプ・ファイルおよび制約違反が一覧表示されます。
TRANSPORT_TABLESPACESパラメータを使用すると、指定した表領域内のすべてのオブジェクトのメタデータがエクスポートされます。特定の表、パーティションまたはサブパーティションのみのトランスポータブル・エクスポートを実行する場合は、TABLESパラメータとTRANSPORTABLE=ALWAYSパラメータを併用する必要があります。
EXP_FULL_DATABASEロールが必要です。
SYSおよびSYSAUX表領域は転送できません。
次に、TRANSPORT_TABLESPACESパラメータを(ネットワークベースではなく)ファイル・ベースのジョブに使用した例を示します。表領域tbs_1は、移動する表領域です。この例では、表領域tbs_1がすでに存在し、読取り専用に設定されていると仮定しています。また、この例では、このエクスポート・コマンドの前にデフォルトの表領域が変更されていると仮定しています。
> expdp hr DIRECTORY=dpump_dir1 DUMPFILE=tts.dmp TRANSPORT_TABLESPACES=tbs_1 TRANSPORT_FULL_CHECK=y LOGFILE=tts.log
デフォルト: NEVER
特定の表、パーティションおよびサブパーティションのメタデータをエクスポートするために、表モードのエクスポート(TABLESパラメータで指定)中にトランスポータブル・オプションを使用する必要があるかどうかを指定します。
TRANSPORTABLE = {ALWAYS | NEVER}
使用可能な値の定義は、次のとおりです。
ALWAYS: エクスポート・ジョブでトランスポータブル・オプションを使用するように指定します。トランスポータブルが使用できない場合、ジョブは失敗します。トランスポータブル・オプションを使用すると、TABLESパラメータで指定した表、パーティションまたはサブパーティションのメタデータのみがエクスポートされます。実際のデータ・ファイルをターゲット・データベースにコピーする必要があります。詳細は、「データ・ファイル・コピーを使用したデータ移動」を参照してください。
NEVER: エクスポート・ジョブでトランスポータブル・オプションではなくダイレクト・パスまたは外部表による方法を使用してデータをアンロードするように指定します。これがデフォルトです。
TRANSPORTABLEパラメータは、表モードのエクスポートでのみ有効です。
EXP_FULL_DATABASE権限が必要です。
TRANSPORTABLEパラメータを使用するには、COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
次の例では、shスキーマがEXP_FULL_DATABASE権限を持ち、表sales2がパーティション化されて表領域tbs2内に格納されているとします。(tbs2表領域はソース・データベースで読取り専用に設定する必要があります。)
> expdp sh DIRECTORY=dpump_dir1 DUMPFILE=tto1.dmp TABLES=sh.sales2 TRANSPORTABLE=always
エクスポートが正常に完了した後は、データ・ファイルをターゲット・データベース領域にコピーする必要があります。次に、PARTITION_OPTIONSとREMAP_SCHEMAの各パラメータを使用してインポート操作を実行し、sales2の各パーティションを固有の表にします。
> impdp system PARTITION_OPTIONS=departition TRANSPORT_DATAFILES=oracle/dbs/tbs2 DIRECTORY=dpump_dir1 DUMPFILE=tto1.dmp REMAP_SCHEMA=sh:dp
デフォルト: COMPATIBLE
エクスポートするデータベース・オブジェクトのバージョンを指定します。このパラメータは、以前のリリースのOracle Databaseと互換性のあるダンプ・ファイル・セットの作成に使用できます。なお、これは、10.1より前のバージョンのOracle Databaseでデータ・ポンプ・エクスポートが使用可能ということではありません。データ・ポンプ・エクスポートは、Oracle Database 10g リリース1(10.1)以降でのみ動作します。VERSIONパラメータを使用して可能になるのは、エクスポートするオブジェクトのバージョンの識別のみです。
VERSION={COMPATIBLE | LATEST | version_string}
VERSIONパラメータで使用可能な値は、次のとおりです。
COMPATIBLE: デフォルト値。メタデータのバージョンは、データベースの互換性レベルに対応します。データベースの互換性は、9.2以上に設定する必要があります。
LATEST: メタデータのバージョンは、データベースのバージョンに対応します。
version_string: 特定のデータベース・バージョン(11.1.0など)。Oracle Database 11g の場合、9.2未満の値は指定できません。
指定したバージョンと互換性のないデータベース・オブジェクトまたは属性は、エクスポートされません。たとえば、指定したバージョンではサポートされていない新しいデータ型を含む表はエクスポートされません。
次の例は、メタデータのバージョンがデータベースのバージョンに対応している場合のエクスポートの例を示します。
> expdp hr TABLES=hr.employees VERSION=LATEST DIRECTORY=dpump_dir1 DUMPFILE=emp.dmp NOLOGFILE=y
表2-1は、データ・ポンプ・エクスポート・パラメータをオリジナルのエクスポート・パラメータにできるかぎり正確にマップしたものです。機能の設計変更で、オリジナルのエクスポートのパラメータが不要になったため、対応するデータ・ポンプ・パラメータがない場合もあります。また、表に示すとおり、パラメータ名が同じ場合もありますが、機能は多少異なります。
この表に示されていないデータ・ポンプ・エクスポート・のコマンドライン・パラメータもあります。エクスポートのすべてのコマンドライン・パラメータの一覧は、「エクスポート・ユーティリティのコマンドライン・モードで使用可能なパラメータ」を参照してください。
対話方式コマンド・モードでは、現行のジョブは継続して続行されますが、端末へのロギングは一時停止され、エクスポート・プロンプト(Export>)が表示されます。
|
注意: データ・ポンプ・エクスポートの対話方式コマンド・モードは、オリジナルのエクスポート・ユーティリティの対話方式モードとは異なります。このモードでは、入力のためのプロンプトが表示されます。オリジナルのエクスポート・ユーティリティの対話方式モードについては、「対話方式モード」を参照してください。 |
対話方式コマンド・モードを開始するには、次のいずれかの方法を使用します。
expdpコマンドでATTACHパラメータを指定してジョブに接続します。この機能は、ある場所で開始したジョブを、後で別の場所から確認する場合に有効です。
表2-2に、現行のジョブに対して対話方式コマンド・モードでデータ・ポンプ・エクスポート・プロンプトから実行できる操作を示します。
次の項では、データ・ポンプ・エクスポートの対話方式コマンド・モードで使用可能なコマンドについて説明します。
エクスポート・ダンプ・ファイル・セットに、追加ファイルまたは置換変数を追加します。
ADD_FILE=[directory_object:]file_name [,...]
file_nameに、ディレクトリ・パスの情報を含めないでください。ただし、置換変数(%U)を含めることはできます。この置換変数は、指定されたファイル名をテンプレートとして使用し、複数のファイルが生成できることを示します。別のdirectory_objectを指定することもできます。
追加されるファイルのサイズは、FILESIZEパラメータの設定によって決定されます。
次の例では、2つのダンプ・ファイルをダンプ・ファイル・セットに追加します。ダンプ・ファイルhr2.dmpに、ディレクトリ・オブジェクトが指定されていないため、ジョブに対するデフォルトのディレクトリ・オブジェクトを使用するとします。別のディレクトリ・オブジェクトdpump_dir2が、ダンプ・ファイルhr3.dmpに指定されています。
Export> ADD_FILE=hr2.dmp, dpump_dir2:hr3.dmp
エクスポート・モードを、対話方式コマンド・モードからロギング・モードに変更します。
CONTINUE_CLIENT
ロギング・モードでは、状態が端末に継続的に出力されます。ジョブが現在停止している場合、CONTINUE_CLIENTを指定すると、クライアントがジョブの開始を試みます。
Export> CONTINUE_CLIENT
エクスポート・クライアント・セッションを停止し、エクスポート・ユーティリティを終了して、端末へのロギングを中断します。ただし、現行のジョブの実行は続行します。
EXIT_CLIENT
EXIT_CLIENTでは、ジョブが実行されたままになるため、後でこのジョブに接続できます。ジョブの状態を確認するには、ジョブのログ・ファイルを監視するか、USER_DATAPUMP_JOBSビューまたはV$SESSION_LONGOPSビューを問い合せることができます。
Export> EXIT_CLIENT
ダンプ・ファイルのデフォルト・サイズを再定義して、その後のすべてのダンプ・ファイルに適用します。
FILESIZE=number
ファイル・サイズの後に、B、K、MまたはGを指定して、それぞれバイト、キロバイト、メガバイト、ギガバイトを示すことができます。デフォルトは、Bです。
ファイル・サイズ0は、新しいダンプ・ファイルに対してサイズ制限がないことを示します。ファイルは、そのファイルを含むデバイスの限界に到達するまで、必要に応じて大きくなります。
Export> FILESIZE=100M
対話方式コマンド・モードで使用可能なデータ・ポンプ・エクスポート・コマンドの情報を表示します。
HELP
対話方式コマンド・モードで使用可能なコマンドの情報を表示します。
Export> HELP
現在接続中のすべてのクライアント・セッションを切断してから、現行のジョブを停止します。エクスポート・ユーティリティを終了し、端末プロンプトに戻します。
KILL_JOB
KILL_JOBを使用して中断されたジョブは、再開できません。接続中のすべてのクライアント(KILL_JOBコマンドを発行しているクライアントを含む)は、現在のユーザーがジョブを停止しているという警告を受け取った後、切断されます。すべてのクライアントが切断されると、ジョブのプロセス構造が即時に停止し、マスター表およびダンプ・ファイルが削除されます。ログ・ファイルは、削除されません。
Export> KILL_JOB
現行のジョブに対してアクティブなプロセス(ワーカーおよびパラレル・スレーブ)の数を増減できます。
PARALLEL=integer
PARALLELは、コマンドライン・パラメータおよび対話方式コマンド・モードのパラメータとして使用可能です。(このパラメータは、Enterprise Editionのみで使用可能です。)必要な数のパラレル・プロセス(ワーカーおよびパラレル・スレーブ)を設定できます。増加処理は、ファイルとリソースが十分にある場合は即時に実行されます。減少処理は、既存のプロセスが現行のタスクを終了してから実行されます。値を小さくすると、ワーカーはアイドル状態になりますが、ジョブが終了するまで削除はされません。
Export> PARALLEL=10
接続している現行のジョブを開始します。
START_JOB
START_JOBコマンドは、ジョブが現在実行中の場合を除き、接続している現行のジョブを開始します。ダンプ・ファイル・セットおよびマスター表が元のまま変更されていない場合は、予期しない障害またはSTOP_JOBコマンドの発行後に、データの損失や破損なしにジョブが再開されます。
トランスポータブル表領域モード・エクスポートは再開できません。
Export> START_JOB
現行の操作の説明とともにジョブの状態を累積的に表示します。ジョブの推定完了率も返されます。ロギング・モードの状態を表示する間隔を再設定することもできます。
STATUS[=integer]
ロギング・モードでのこの状態の表示頻度を秒単位で指定できるオプションがあります。値を入力しなかった場合またはデフォルト値の0を使用した場合は、状態の定期表示はオフになり、状態は1回のみ表示されます。
この状態情報は、標準出力デバイスのみに書き込まれ、ログ・ファイルには(使用可能な場合でも)書き込まれません。
次に、現行のジョブの状態を表示し、ロギング・モードの表示間隔を5分(300秒)に変更する例を示します。
Export> STATUS=300
現行のジョブを即時にまたは手順に従って停止し、エクスポート・ユーティリティを終了します。
STOP_JOB[=IMMEDIATE]
STOP_JOBコマンド発行時または発行後にマスター表およびダンプ・ファイル・セットに障害が発生していない場合は、そのジョブに接続し、START_JOBコマンドを使用して再開できます。
手順に従って停止する場合は、関連する値を指定しないでSTOP_JOBを使用します。確認を要求する警告が発行されます。手順に従った停止では、ワーカー・プロセスで現行のタスクが終了した後、ジョブが停止されます。
即時に停止するには、STOP_JOB=IMMEDIATEを指定します。確認を要求する警告が発行されます。接続中のすべてのクライアント(STOP_JOBコマンドを発行しているクライアントを含む)は、現在のユーザーがジョブを停止および切断中であるという警告を受け取ります。すべてのクライアントが切断されると、ジョブのプロセス構造が即時に停止されます。マスター・プロセスは、ワーカー・プロセスで現行のタスクが終了するまで待機はしません。STOP_JOB=IMMEDIATEを指定した場合、データ破損やデータ損失の危険性はありません。ただし、停止時に完了しなかった一部のタスクは、再開時に再実行する必要があります。
Export> STOP_JOB=IMMEDIATE
この項では、データ・ポンプ・エクスポートの使用例を示します。
これらの例を正しく使用するために役立つ情報については、「エクスポート・パラメータの使用例」を参照してください。
例2-1に、TABLESパラメータを使用して、表モード・エクスポートを指定する例を示します。人事管理(hr)スキーマから、表employeesおよびjobsの表エクスポートを実行するには、次のデータ・ポンプ・エクスポート・コマンドを発行します。
expdp hr TABLES=employees,jobs DUMPFILE=dpump_dir1:table.dmp NOLOGFILE=y
ユーザーhrは、自分のスキーマ内の表をエクスポートしているため、表名の前にスキーマ名を指定する必要はありません。NOLOGFILE=yパラメータは、その操作のExport ログ・ファイルが生成されないことを示します。
例2-2に、人事管理(hr)スキーマから、表countriesおよびregionsを除くすべての表のデータのみをアンロードするために使用するパラメータ・ファイル(exp.par)の内容を示します。employees表から、department_idが50以外の行がアンロードされます。行は、employee_id順にソートされます。
DIRECTORY=dpump_dir1 DUMPFILE=dataonly.dmp CONTENT=DATA_ONLY EXCLUDE=TABLE:"IN ('COUNTRIES', 'REGIONS')" QUERY=employees:"WHERE department_id !=50 ORDER BY employee_id"
次のコマンドを使用して、exp.parパラメータ・ファイルを実行できます。
> expdp hr PARFILE=exp.par
スキーマ・モード・エクスポート(デフォルト・モード)が実行されますが、CONTENTパラメータによって、エクスポートが表のデータのみのアンロードに効果的に制限されます。ディレクトリ・オブジェクトdpump_dir1は、DBAによってすでに作成されています。このオブジェクトは、エクスポート・ダンプ・ファイルに対する読取りおよび書込み権限がユーザーhrに付与されているサーバー上のディレクトリを示しています。ダンプ・ファイルdataonly.dmpは、dpump_dir1に作成されます。
例2-3に、表モード・エクスポートで使用される領域を、ESTIMATE_ONLYパラメータを使用して、実際のエクスポート操作を実行しないで見積もる場合の例を示します。次のコマンドを実行し、BLOCKSメソッドを使用して、人事管理(hr)スキーマの3つの表employees、departmentsおよびlocationsのデータのエクスポートに必要なバイト数を見積もります。
> expdp hr DIRECTORY=dpump_dir1 ESTIMATE_ONLY=y TABLES=employees, departments, locations LOGFILE=estimate.log
見積りはログ・ファイルに出力され、クライアントの標準出力デバイスに表示されます。見積りの対象は、表の行データのみです。メタデータは含まれません。
例2-4に、hrスキーマのスキーマ・モード・エクスポートを示します。スキーマ・モード・エクスポートでは、対応するスキーマに属するオブジェクトのみがアンロードされます。スキーマ・モードは、デフォルトのモードであるため、複数のスキーマや自分のスキーマ以外を指定する場合以外、コマンドラインでSCHEMASパラメータを指定する必要はありません。
> expdp hr DUMPFILE=dpump_dir1:expschema.dmp LOGFILE=dpump_dir1:expschema.log
例2-5に、最大3つのパラレル・プロセス(ワーカーまたはPQスレーブ)を持つ全データベース・エクスポートを示します。
> expdp hr FULL=y DUMPFILE=dpump_dir1:full1%U.dmp, dpump_dir2:full2%U.dmp FILESIZE=2G PARALLEL=3 LOGFILE=dpump_dir1:expfull.log JOB_NAME=expfull
これは、全データベース・エクスポートであるため、データベースのすべてのデータおよびメタデータがエクスポートされます。full101.dmp、full201.dmp、full102.dmpなどのダンプ・ファイルが、dpump_dir1およびdpump_dir2ディレクトリ・オブジェクトで示されたディレクトリに、ラウンドロビン法で作成されます。最適なパフォーマンスを得るには、これらのファイルを個別のI/Oチャネルに配置する必要があります。各ファイルのサイズは、必要に応じて2GBまで拡張されます。最初に、最大3つのファイルが作成されます。必要に応じて、追加のファイルが作成されます。ジョブおよびマスター表は、expfullという名前になります。ログ・ファイルは、dpump_dir1ディレクトリのexpfull.logに書き込まれます。
この例を試す前に、例2-5のパラレル全体エクスポートを再実行します。エクスポートの実行中、[Ctrl]を押しながら[C]を押します。これによって、データ・ポンプ・エクスポートの対話方式コマンド・インタフェースを起動します。対話方式インタフェースでは、端末へのロギングは停止され、データ・ポンプ・エクスポートのプロンプトが表示されます。
エクスポート・プロンプトで、次のコマンドを実行してジョブを停止します。
Export> STOP_JOB=IMMEDIATE Are you sure you wish to stop this job ([y]/n): y
このジョブは停止状態でクライアントを終了します。
停止したジョブに再接続するには、次のコマンドを入力します。
> expdp hr ATTACH=EXPFULL
ジョブの状態が表示された後、CONTINUE_CLIENT コマンドを実行して、ロギング・モードを再開し、expfullジョブを再起動できます。
Export> CONTINUE_CLIENT
ジョブが再オープンされたことを示すメッセージが表示され、処理の状態がクライアントに出力されます。
この項では、データ・ポンプ・エクスポートの構文図を示します。これらの構文図では、標準SQL構文の表記法を使用します。SQL構文の表記については、『Oracle Database SQL言語リファレンス』を参照してください。


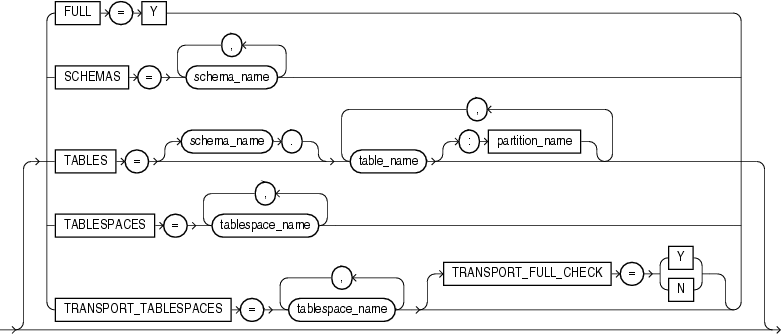
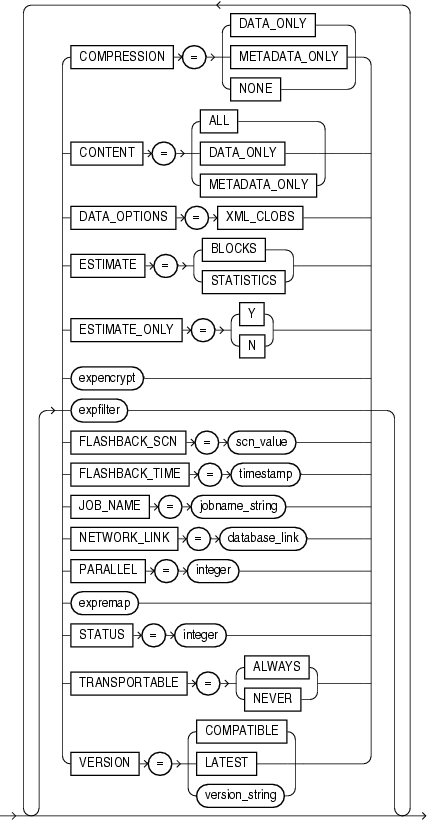
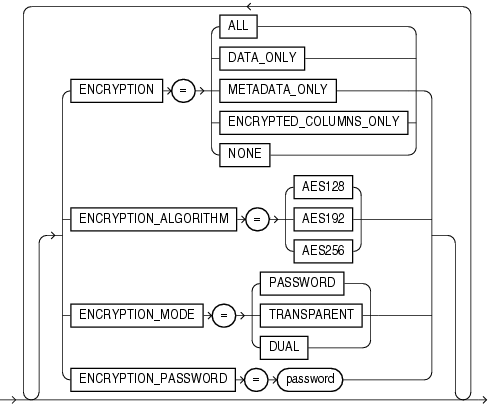
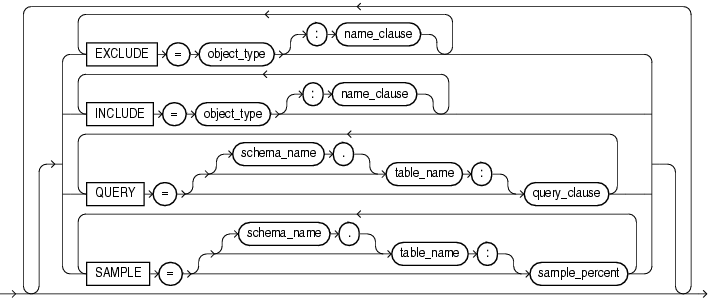

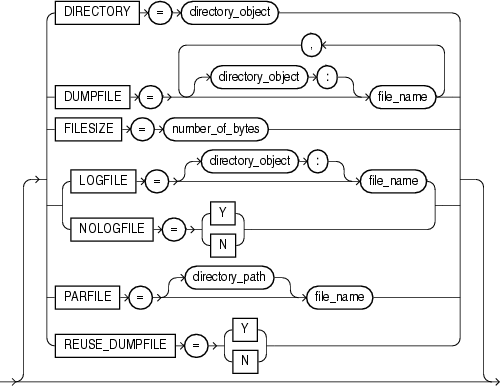
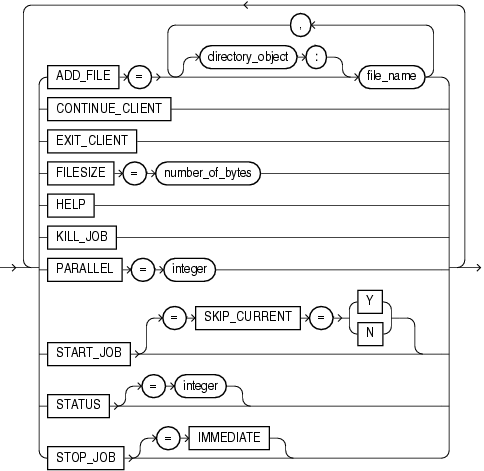
|
 Copyright © 2007 Oracle Corporation. All Rights Reserved. |
|