11g リリース1(11.1)
E05768-02
 目次 |
 索引 |
| Oracle Databaseユーティリティ 11g リリース1(11.1) E05768-02 |
|


この章では、Oracle Data Pump Importユーティリティについて説明します。この章の内容は、次のとおりです。
|
注意:
データ・ポンプ・インポート( |
データ・ポンプ・インポート(以降、インポート・ユーティリティと呼びます)は、エクスポート・ダンプ・ファイル・セットをターゲット・システムにロードするためのユーティリティです。ダンプ・ファイル・セットは、表データ、データベース・オブジェクトのメタデータ、制御情報を含む1つ以上のディスク・ファイルで構成されています。これらのファイルは独自のバイナリ形式で書き込まれています。データ・ポンプ・インポート・ユーティリティは、インポート操作中、これらのファイルを使用してダンプ・ファイル・セット内の各データベース・オブジェクトの位置を特定します。
また、ダンプ・ファイルを介さずに、ソース・データベースから直接ターゲット・データベースをロードするために使用することもできます。これはネットワーク・インポートと呼ばれます。
データ・ポンプ・インポート・ユーティリティでは、インポート・モードで設定されているとおりにジョブによって、データおよびメタデータのサブセットが、ダンプ・ファイル・セットまたはソース・データベース(ネットワーク・インポートの場合)から移動されるように指定できます。この指定は、インポート・ユーティリティのコマンドによって実装されるデータ・フィルタおよびメタデータ・フィルタを使用して行います。詳細は、「インポート操作中のフィルタ処理」を参照してください。
インポートを使用できる様々な方法の例については、「データ・ポンプ・インポートの使用例」を参照してください。
データ・ポンプ・インポート・ユーティリティは、impdpコマンドを使用して起動します。インポート操作の特性は、指定するインポート・パラメータによって決定されます。これらのパラメータは、コマンドラインまたはパラメータ・ファイルのいずれかで指定できます。
インポート・ユーティリティの起動の詳細は、次の項を参照してください。
データ・ポンプ・インポートは、コマンドライン、パラメータ・ファイルまたは対話方式コマンド・モードを使用して実行できます。
PARFILEパラメータのみが例外となります。値の指定に引用符が必要なパラメータを指定する場合は、パラメータ・ファイルを使用することをお薦めします。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
対話方式コマンド・モードで使用可能なコマンドの詳細は、「インポート・ユーティリティの対話方式コマンド・モードで使用可能なコマンド」を参照してください。
インポート操作の重要な特性の1つはモードです。これは、インポートされる内容の大部分がモードによって決定されるためです。指定したモードは、操作のソース(ダンプ・ファイル・セットまたはNETWORK_LINKパラメータが指定されている場合は別のデータベース)に適用されます。
インポート操作のソースがダンプ・ファイル・セットの場合、モードの指定はオプションです。モードを指定していない場合、インポート・ユーティリティは、エクスポート操作実行時のモードでダンプ・ファイル・セット全体をロードしようとします。
モードは、適切なパラメータを使用してコマンドラインで指定します。使用可能なモードは次のとおりです。
全体インポートは、FULLパラメータを使用して指定します。全体インポート・モードでは、ソース(ダンプ・ファイル・セットまたは別のデータベース)の全内容がターゲット・データベースにロードされます。これは、ファイル・ベース・インポートのデフォルトです。ソースが別のデータベースの場合は、IMP_FULL_DATABASEロールが必要です。
権限のないユーザーの場合、相互スキーマ参照はインポートされません。たとえば、インポートを実行するユーザーのスキーマ内の表にトリガーが定義されていても、そのトリガーが別のユーザーのスキーマに存在している場合はインポートされません。
NETWORK_LINKパラメータを完全インポートに使用する場合は、ターゲット・データベースではIMP_FULL_DATABASEロールが必要で、ソース・データベースではEXP_FULL_DATABASEロールが必要です。
スキーマ・インポートは、SCHEMASパラメータを使用して指定します。スキーマ・インポートでは、指定されたスキーマが所有しているオブジェクトのみがロードされます。ソースは、全体インポート・モード、表モード、表領域モードまたはスキーマ・モードのエクスポート・ダンプ・ファイル・セット、または別のデータベースです。IMP_FULL_DATABASEロールを所有している場合は、スキーマ・リストを指定できます。これにより、スキーマ内のオブジェクトに加えてスキーマ自体(システム権限を含む)もデータベース内に作成されます。
相互スキーマ参照は、残りのスキーマが現行のスキーマに再マップされないかぎり、権限のないユーザーに対してインポートされません。たとえば、インポートを実行するユーザーのスキーマ内の表にトリガーが定義されていても、そのトリガーが別のユーザーのスキーマに存在している場合はインポートされません。
表モードのインポートは、TABLESパラメータを使用して指定します。表モードでは、指定した表、パーティションおよびそれらの依存オブジェクトのみがロードされます。ソースは、全体インポート・モード、スキーマ・モード、表領域モードまたは表モードのエクスポート・ダンプ・ファイル・セット、または別のデータベースです。自分のスキーマに存在しない表を指定するには、IMP_FULL_DATABASEロールが必要です。
TRANPORTABLE=ALWAYSパラメータをTABLESパラメータと組み合せて指定することで、表モードのインポート中にトランスポータブル・オプションを使用できます。これには、NETWORK_LINKパラメータも使用する必要があることに注意してください。
表領域モードのインポートは、TABLESPACESパラメータを使用して指定します。表領域モードでは、指定した表領域内のすべてのオブジェクトが、依存オブジェクトとともにロードされます。ソースは、全体インポート・モード、スキーマ・モード、表領域モードまたは表モードのエクスポート・ダンプ・ファイル・セット、または別のデータベースです。権限のないユーザーの場合、現行のスキーマに再マッピングされていないオブジェクトは処理されません。
トランスポータブル表領域インポートは、TRANSPORT_TABLESPACESパラメータを使用して指定します。トランスポータブル表領域モードでは、トランスポータブル表領域エクスポート・ダンプ・ファイル・セットまたは別のデータベースからのメタデータがロードされます。TRANSPORT_DATAFILESパラメータで指定したデータ・ファイルは、ターゲット・データベースで使用するために、通常は、データ・ファイルをターゲット・システムにコピーすることによって、ソース・システムで使用可能にする必要があります。
暗号化された列は、トランスポータブル表領域モードではサポートされていません。
このモードには、IMP_FULL_DATABASEロールが必要です。
データ・ポンプ・インポート・ユーティリティの起動時、接続文字列には接続識別子を指定できます。この識別子では、現行のOracleシステム識別子(SID)によって指定した現行のインスタンスとは別のデータベース・インスタンスを指定できます。接続識別子には、Oracle*Net接続記述子または接続記述子にマップする名前を指定できます。これには、接続記述子を使用して検索できるアクティブ・リスナー(起動するには、lsnrctl startと入力)が必要です。
次に、ユーザーhrがinst1という接続記述子を使用してインポート・ユーティリティを起動する例を示します。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp TABLES=employees Import: Release 11.1.0.6.0 - Production on Monday, 27 August, 2007 12:25:57 Copyright (c) 2003, 2007, Oracle. All rights reserved. Password: password@inst1 Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production With the Partitioning, Data Mining and Real Application Testing options
ローカルのインポート・クライアントは、接続記述子inst1(通常はtnsnames.oraファイルで定義される単純なネット・サービス名)によって識別されるデータベース・インスタンスに接続し、ダンプ・ファイル・セットのデータをそのデータベースにインポートします。
接続識別子を使用したインポート・ユーティリティの起動と、インポート・コマンドライン・パラメータNETWORK_LINKを指定したインポート操作を混同しないでください。コマンドライン・パラメータを使用した方法では、データベース・リンクを使用してインポートが起動されます。この場合、ローカルのインポート・クライアントは、コマンドライン接続文字列によって指定されるデータベース・インスタンスに接続し、データベース・リンクによって指定されるデータベース・インスタンスからインポートするデータを取得して、接続したデータベース・インスタンスにそのデータを書き込みます。ダンプ・ファイル・セットは含まれません。
|
参照:
|
データ・ポンプ・インポート・ユーティリティで提供されるデータおよびメタデータのフィルタ機能は、オリジナルのインポート・ユーティリティと比較すると大幅に拡張されています。
データ固有のフィルタ処理は、QUERYおよびSAMPLEパラメータによって実装されます。このパラメータは、表のインポートされる行に対する制限を指定します。メタデータのフィルタ処理の結果として、間接的にデータのフィルタ処理が実行される場合もあります。この処理では、表オブジェクトおよび関連付けられた行データを含めたり、除外することができます。
各データ・フィルタは、表およびジョブごとにそれぞれ1回指定できます。同じ名前を使用する異なるフィルタが特定の表とジョブ全体の両方に適用された場合は、特定の表に対して提供されたフィルタ・パラメータが優先されます。
データ・ポンプ・インポート・ユーティリティで提供されるメタデータのフィルタ処理機能は、オリジナルのインポート・ユーティリティと比較すると大幅に拡張されています。メタデータのフィルタ処理は、EXCLUDEおよびINCLUDEパラメータによって実装されます。EXCLUDEおよびINCLUDEは、相互に排他的なパラメータです。
メタデータ・フィルタは、データ・ポンプ操作に含めるか、またはその操作から除外するオブジェクトを識別します。たとえば、パッケージ仕様またはパッケージ本体を含まない全体インポートを要求できます。
フィルタを正しく使用して必要な結果を得た場合は、識別されたオブジェクトの依存オブジェクトも、識別されたオブジェクトとともに処理されます。たとえば、パッケージを操作に含めるようにフィルタで指定すると、そのパッケージに対する権限も含まれます。同様に、フィルタで表を除外すると、その表に対する索引、制約、権限およびトリガーも除外されます。
1つのオブジェクト型に対して複数のフィルタが指定されている場合は、それらのフィルタに対して暗黙的なAND処理が適用されます。つまり、ジョブに関連するオブジェクトは、オブジェクト型に適用されるすべてのフィルタで処理される必要があります。
1つのジョブ内で同一のフィルタ名を複数回指定できます。
フィルタ処理できるオブジェクトを確認するには、DATABASE_EXPORT_OBJECTS(全体モード・インポートの場合)、SCHEMA_EXPORT_OBJECTS(スキーマ・モード・インポートの場合)およびTABLE_EXPORT_OBJECTS(表モードおよび表領域モード・インポートの場合)の各ビューに対して問合せを実行します。オブジェクトのフルパス名は、インポート・モードでなくエクスポート・モードで決定されることに注意してください。
例については、「メタデータ・フィルタ」を参照してください。
|
参照:
|
この項では、データ・ポンプ・インポート・ユーティリティのコマンドライン・モードで使用可能なパラメータについて説明します。ここで説明する内容の多くは、パラメータの使用例を含みます。
各項に示す例を試行する場合は、次の内容に注意してください。
Import: Release 11.1.0.6.0 - Production on Monday, 27 August, 2007 12:15:55 Copyright (c) 2003, 2007, Oracle. All rights reserved. Password: password Connected to: Oracle Database 11g Enterprise Edition Release 11.1.0.6.0 - Production With the Partitioning, Data Mining and Real Application Testing options
hr)スキーマを頻繁に使用します。
dpump_dir1およびdpump_dir2がすでに存在し、これらのディレクトリ・オブジェクトについてのREAD権限およびWRITE権限が、hrスキーマに付与されているものとします。ディレクトリ・オブジェクトの作成およびこれらへの権限の割当てについては、「ダンプ・ファイル、ログ・ファイルおよびSQLファイルのデフォルトの位置」を参照してください。
EXP_FULL_DATABASEロールおよびIMP_FULL_DATABASEロールが必要です。このような例では、hrスキーマにこれらのロールが付与されているものとします。
必要に応じて、これらのディレクトリ・オブジェクトの作成と、必要な権限やロールの割当てをDBAに依頼します。
これらのパラメータの構文図は、「データ・ポンプ・インポートの構文図」を参照してください。
特に指定がないかぎり、これらのパラメータはパラメータ・ファイルでも指定できます。
オペレーティング・システムによっては、コマンドラインの引用符を、バックスラッシュなどでエスケープする必要がある場合があります。バックスラッシュがない場合、インポートで使用するコマンドライン解析機能で引用符として認識されないため、引用符が削除されエラーが発生します。通常、そのような文は、パラメータ・ファイルに記述することをお薦めします。パラメータ・ファイルでは、エスケープ文字は不要なためです。
|
参照:
|
|
注意: オリジナルのインポート・ユーティリティを使い慣れている場合、オリジナルのインポート・ユーティリティと同様の操作の実行に使用するデータ・ポンプ・パラメータを特定できないことがあります。両者の対応関係は、「オリジナルのインポート・ユーティリティのパラメータへのデータ・ポンプ・インポート・パラメータのマップ方法」を参照してください。 |
デフォルト: ユーザーのスキーマで現在実行されているジョブ(実行中のジョブが1つのみの場合)
クライアント・セッションを既存のインポート・ジョブに接続し、自動的に対話方式コマンド・モードにします。
ATTACH [=[schema_name.]job_name]
schema_nameは、接続しているスキーマが、自分のスキーマにない場合に指定します。このパラメータを指定するには、IMP_FULL_DATABASEロールが必要です。
job_nameは、スキーマに対応する実行中ジョブが1つのみで、そのジョブがアクティブな場合、指定する必要はありません。停止しているジョブに接続する場合は、このジョブ名を指定する必要があります。DBA_DATAPUMP_JOBSビューまたはUSER_DATAPUMP_JOBSビューを問い合せて、データ・ポンプ・ジョブ名の一覧を表示できます。
ジョブに接続している場合、インポート・ユーティリティでは、ジョブの説明が表示され、次にインポート・プロンプトが表示されます。
ATTACHパラメータを指定する場合、コマンドラインで他に指定できるデータ・ポンプ・パラメータは、ENCRYPTION_PASSWORDのみです。
ENCRYPTION_PASSWORDパラメータを再入力してそのパスワードを再指定する必要があります。唯一の例外は、ジョブが最初にENCRYPTION=ENCRYPTED_COLUMNS_ONLYパラメータを使用して開始されている場合です。この場合、ジョブへの接続時に暗号化パスワードは必要ありません。
次に、ATTACHパラメータの使用例を示します。
> impdp hr ATTACH=import_job
この例では、import_jobというジョブが、hrスキーマに存在するとします。
デフォルト: ALL
インポート操作でロードする内容をフィルタ処理できます。
CONTENT={ALL | DATA_ONLY | METADATA_ONLY}
ALLを指定すると、ソースに含まれているすべてのデータおよびメタデータがロードされます。これがデフォルトです。
DATA_ONLYを指定すると、表の行データのみが既存の表にロードされます。データベース・オブジェクトは作成されません。
METADATA_ONLYを指定すると、データベース・オブジェクト定義のみがロードされます。表の行データはロードされません。
CONTENT=METADATA_ONLYパラメータおよび値は、パラメータTRANSPORT_TABLESPACES(トランスポータブル表領域モード)と組み合せて使用することはできません。
CONTENT=ALLおよびCONTENT=DATA_ONLYパラメータおよび値は、SQLFILEパラメータと組み合せて使用することはできません。
次に、CONTENTパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp CONTENT=METADATA_ONLY
このコマンドは、expfull.dmpダンプ・ファイルのメタデータのみをロードする全体インポートを実行します。全体インポートが実行されるのは、インポート・モードを指定しないファイル・ベースのインポートでは、全体インポートがデフォルトであるためです。
デフォルト: デフォルト値は設定されていません。このパラメータが使用されていない場合、このパラメータが提供する特別なデータ処理オプションは無効になります。
DATA_OPTIONSパラメータを使用すると、エクスポートおよびインポート中に特定のタイプのデータを処理するためのオプションが提供されます。インポート操作の場合、DATA_OPTIONSパラメータに対して唯一有効なオプションはSKIP_CONSTRAINT_ERRORSです。
DATA_OPTIONS=SKIP_CONSTRAINT_ERRORS
SKIP_CONSTRAINT_ERRORSオプションは、データ・オブジェクト(表、パーティションまたはサブパーティション)のロード中の非遅延の制約違反における処理方法に適用されます。遅延制約違反が発生しても、ロードへの影響はありません。遅延制約違反は常に、ロード全体のロール・バックの原因となります。
SKIP_CONSTRAINT_ERRORSオプションでは、非遅延の制約違反が発生した場合もインポート操作を続行することを指定します。非遅延の制約違反の原因となっているすべての行はログに記録されますが、違反が発生しているデータ・オブジェクトのロードは停止されません。
SKIP_CONSTRAINT_ERRORSが設定されていない場合のデフォルトの動作では、非遅延の制約違反が発生しているデータ・オブジェクトのロード全体がロール・バックされます。
SKIP_CONSTRAINT_ERRORSが使用され、データ・オブジェクトがロード時にそのデータ・オブジェクトに対して定義された一意の索引または制約を持つ場合、そのデータ・オブジェクトのロードにAPPENDヒントは使用されません。したがって、SKIP_CONSTRAINT_ERRORSオプションを使用した場合、このようなデータ・オブジェクトのロードにはより時間がかかります。
SKIP_CONSTRAINT_ERRORSは、たとえ指定されていても使用されません。
この例では、SKIP_CONSTRAINT_ERRORSが有効化されているデータのみの表モード・インポートを示します。
> impdp hr TABLES=employees CONTENT=DATA_ONLY DUMPFILE=dpump_dir1:table.dmp DATA_OPTIONS=skip_constraint_errors
このインポート操作中に非遅延の制約違反が発生した場合、それはログに記録されますが、インポートは完了するまで続行されます。
デフォルト: DATA_PUMP_DIR
インポート・ジョブがダンプ・ファイル・セットを検出し、ログ・ファイルおよびSQLファイルが作成されるデフォルトの位置を指定します。
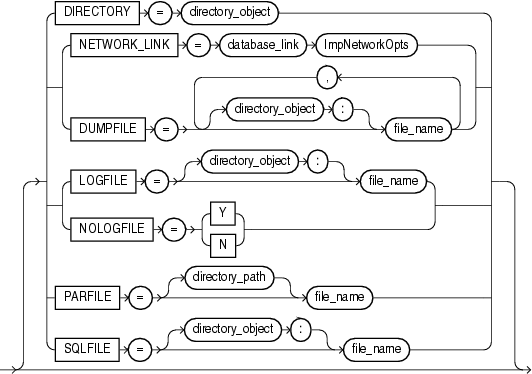
DIRECTORY=directory_object
directory_objectは、データベースのディレクトリ・オブジェクトの名前です(実際のディレクトリのファイル・パスではありません)。インストール時に、特権ユーザーにDATA_PUMP_DIRという名前のデフォルトのディレクトリ・オブジェクトへのアクセス権が付与されます。DATA_PUMP_DIRへのアクセス権を持つユーザーがDIRECTORYパラメータを使用する必要はありません。
DUMPFILEパラメータ、LOGFILEパラメータまたはSQLFILEパラメータで指定したディレクトリ・オブジェクトは、DIRECTORYパラメータに指定したディレクトリ・オブジェクトよりも優先されます。ダンプ・ファイル・セット用に使用するディレクトリに対する読取り権限と、ログ・ファイルおよびSQLファイルの作成に使用するディレクトリに対する書込み権限が必要です。
次に、DIRECTORYパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp LOGFILE=dpump_dir2:expfull.log
このコマンドによって、インポート・ジョブが、dpump_dir1ディレクトリ・オブジェクトに示されたディレクトリのexpfull.dmpダンプ・ファイルを検索します。LOGFILEパラメータに指定したdpump_dir2ディレクトリ・オブジェクトは、DIRECTORYパラメータよりも優先されるため、ログ・ファイルは、dpump_dir2に書き込まれます。
|
参照:
|
デフォルト: expdat.dmp
Exportによって作成されたダンプ・ファイル・セットの名前を指定します。オプションで、これらのディレクトリ・オブジェクトを指定します。
DUMPFILE=[directory_object:]file_name [, ...]
DIRECTORYパラメータで指定されている場合、directory_objectはオプションです。ここで値を指定する場合は、すでに存在しアクセス権があるディレクトリ・オブジェクトを指定します。DUMPFILEパラメータの一部に指定されるデータベース・ディレクトリ・オブジェクトは、DIRECTORYパラメータで指定された値よりも優先されます。
file_nameには、ダンプ・ファイル・セット内のファイルの名前を指定します。ファイル名には、置換変数%Uを含むテンプレートを指定することもできます。%Uを使用した場合、インポート・ユーティリティは、テンプレートと一致する各ファイルを一致するファイルが検出されなくなるまで調べ、ダンプ・ファイル・セットの一部となるすべてのファイルの位置を特定します。%Uは、01から始まる2桁の整数に変換されます。
DUMPFILEパラメータでのファイル指定にセット全体が含まれている場合は、インポート・ユーティリティでセット全体の位置を特定するための十分な情報がファイルに含まれます。ファイルの名前、位置または順序は、エクスポート時と同じである必要はありません。
次に、インポートのDUMPFILEパラメータの使用例を示します。この例では、ExportのDUMPFILEパラメータで示した例を実行して、ダンプ・ファイルを作成できます。詳細は、「DUMPFILE」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=dpump_dir2:exp1.dmp, exp2%U.dmp
exp1.dmpダンプ・ファイルに、ディレクトリ・オブジェクト(dpump_dir2)が指定されているため、インポート・ジョブは、そのファイルを検索します。また、dpump_dir1にある、exp2<nn>.dmpの形式のダンプ・ファイルも検索します。ログ・ファイルは、dpump_dir1に書き込まれます。
デフォルト: デフォルト値は設定されていません。ユーザーが値を指定します。
ダンプ・ファイル・セット内の暗号化列のデータにアクセスするためのパスワードを指定します。これにより、暗号化されたダンプ・ファイル・セットへの不正なアクセスを防ぎます。
ENCRYPTION_PASSWORD = password
このパラメータは、エクスポート操作で暗号化パスワードが指定された場合に、インポート操作で必要になります。このパスワードは、エクスポート操作で指定されたものと同じものを指定する必要があります。
ENCRYPTION_PASSWORDパラメータは無効です。
ENCRYPTION_PASSWORDパラメータは、ネットワーク・インポート・ジョブには無効です。
EMP表にEMPNOという列があるとします。次のいずれの場合も、ソース表のEMP列の暗号化属性が、ターゲット表のEMP列の暗号化属性と一致していないためエラーになります。
次の例では、暗号化パスワード123456を指定する必要があります。これは、ダンプ・ファイルdpcd2be1.dmpの作成時に、そのパスワードが指定されたためです(「ENCRYPTION_PASSWORD」を参照)。
> impdp hr TABLES=employee_s_encrypt DIRECTORY=dpump_dir DUMPFILE=dpcd2be1.dmp ENCRYPTION_PASSWORD=123456
インポート操作時、エクスポート操作時に暗号化されたemployee_s_encrypt表のすべての列は、複合化されてからインポートされます。
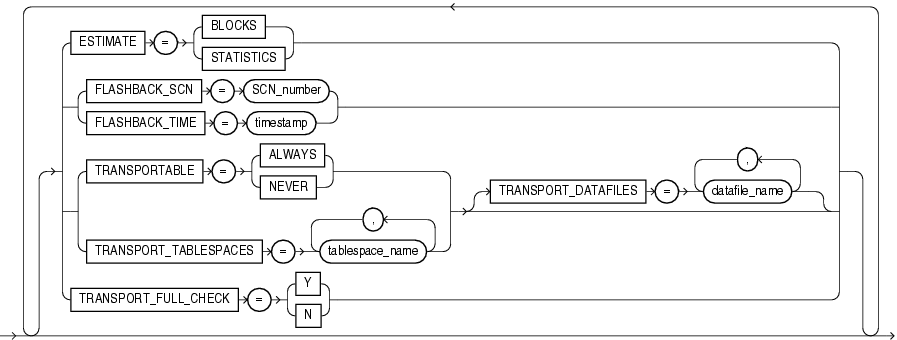
デフォルト: BLOCKS
このパラメータによって、ネットワーク・インポート操作のソース・システムで、データの生成量が見積もられます。
ESTIMATE={BLOCKS | STATISTICS}
ESTIMATEパラメータでは、次の値を選択できます。
BLOCKS: 見積りは、ソース・オブジェクトで使用されるデータベース・ブロックの数に、適切なブロック・サイズを掛けて計算されます。
STATISTICS: 見積りは、表別の統計を使用して計算されます。この方法による見積りをできるかぎり正確にするには、すべての表を新しく分析しておく必要があります。
生成される見積りは、インポート・ジョブの完了率の確認に使用されます。
ESTIMATEパラメータは、NETWORK_LINKパラメータも指定されている場合のみ有効です。
QUERYパラメータ、SAMPLEパラメータまたはREMAP_DATAパラメータを使用する場合、見積りが不正確になることがあります。
次の例では、source_database_linkにソース・データベースに対する有効なリンク名を指定します。
> impdp hr TABLES=job_history NETWORK_LINK=source_database_link DIRECTORY=dpump_dir1 ESTIMATE=statistics
hrスキーマのjob_history表が、ソース・データベースからインポートされます。デフォルトでログ・ファイルが作成され、dpump_dir1ディレクトリ・オブジェクトで示されたディレクトリに書き込まれます。ジョブが開始すると、表の統計に基づいて、そのジョブの見積りが計算されます。
デフォルト: デフォルト値は設定されていません。
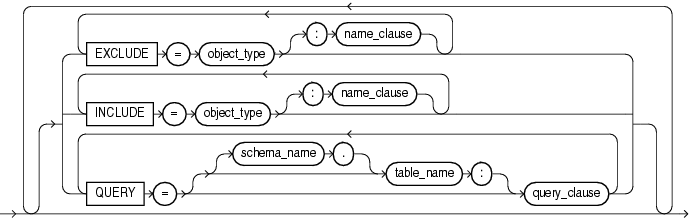
インポート・ジョブから除外するオブジェクトおよびオブジェクト型を指定して、インポートの対象となるメタデータをフィルタ処理できます。
EXCLUDE=object_type[:name_clause] [, ...]
指定したインポート・モードでは、EXCLUDE文に指定されたオブジェクト型を除き、ソースに含まれるすべてのオブジェクト型およびその依存オブジェクトが含まれます。オブジェクトが除外されると、そのオブジェクトのすべての依存オブジェクトも除外されます。たとえば、表を除外すると、その表のすべての索引およびトリガーも除外されます。
name_clauseは、オプションです。このオプションを使用すると、あるオブジェクト型のうち、特定のオブジェクトをファイングレイン選択できます。オプションの名前句は、その型のオブジェクト名に対するフィルタとして使用されるSQL式です。SQL演算子および指定した型のオブジェクト名の比較対象となる値で構成されています。この名前句は、名前付きのインスタンスを持つオブジェクト型にのみ適用されます(たとえば、TABLEおよびVIEWには適用されますが、GRANTには適用されません)。オプションの名前句は、コロンでオブジェクト型と区切り、二重引用符(一重引用符は名前文字列の区切りに使用する必要があるため)で囲む必要があります。たとえば、EXCLUDE=INDEX:"LIKE 'DEPT%'"と設定した場合、deptで始まる名前を持つすべての索引を除外できます。
2つ以上のEXCLUDE文を指定できます。オペレーティング・システム固有のエスケープ文字をコマンドラインで使用する必要がないように、EXCLUDE文は、パラメータ・ファイルで指定することをお薦めします。
次の項で説明するとおり、特定のオブジェクト(特にCONSTRAINT、GRANTおよびUSER)を除外対象として指定した場合の効果を認識しておく必要があります。
次の制約は除外できません。
次に、EXCLUDE文の例およびその解釈を示します。
EXCLUDE=CONSTRAINTは、NOT NULL制約および表の正常な作成とロードに必要な制約を除き、参照制約以外のすべての制約を除外します。
EXCLUDE=REF_CONSTRAINTは、参照整合性(外部キー)制約を除外します。
EXCLUDE=GRANTを指定すると、すべてのオブジェクト型に対するオブジェクト権限およびシステム権限が除外されます。
EXCLUDE=USERを指定すると、ユーザーの定義のみが除外され、そのユーザーのスキーマ内のオブジェクトは除外されません。
特定のユーザーとそのユーザーのすべてのオブジェクトを除外するには、次のフィルタを指定します(hrは除外するユーザーのスキーマ名です)。
EXCLUDE=SCHEMA: "= 'HR' "
EXCLUDE=USER:"= 'HR'"などの文を使用してユーザーを除外しようとすると、DDL文CREATE USER hr のみが除外され、期待した結果が得られない場合があります。
DBAまたはIMP_FULL_DATABASEロールを持つ他のユーザーが、パラメータ・ファイルexclude.parで次のように実行するとします。(例を試す場合は、このファイルを作成する必要があります。)
EXCLUDE=FUNCTION EXCLUDE=PROCEDURE EXCLUDE=PACKAGE EXCLUDE=INDEX:"LIKE 'EMP%' "
次のコマンドを発行します。このコマンドでは、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp system DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp PARFILE=exclude.par
expfull.dmpダンプ・ファイルから、empで始まる名前を持つファンクション、プロシージャ、パッケージおよび索引を除くすべてのデータがロードされます。
デフォルト: デフォルト値は設定されていません。
インポートで使用されるシステム変更番号(SCN)を指定して、フラッシュバック・ユーティリティを使用可能にします。
FLASHBACK_SCN=scn_number
インポート操作は、指定したscn_numberにおけるデータの一貫性を維持したまま実行されます。
FLASHBACK_SCNパラメータは、NETWORK_LINKパラメータも指定されている場合のみ有効です。
FLASHBACK_SCNパラメータは、Oracle Databaseのフラッシュバック問合せ機能にのみ関係します。フラッシュバック・データベース、フラッシュバック削除およびフラッシュバック・データ・アーカイブには適用できません。
FLASHBACK_SCNおよびFLASHBACK_TIMEは、相互に排他的なパラメータです。
次に、FLASHBACK_SCNパラメータの使用例を示します。
> impdp hr DIRECTORY=dpump_dir1 FLASHBACK_SCN=123456 NETWORK_LINK=source_database_link
この例のsource_database_linkには、データのインポート元であるソース・データベース名を指定します。
デフォルト: デフォルト値は設定されていません。
インポートで使用されるシステム変更番号(SCN)を指定して、フラッシュバック・ユーティリティを使用可能にします。
FLASHBACK_TIME="TO_TIMESTAMP()"
指定された時刻に最も近いSCNを検出し、このSCNを使用してフラッシュバック・ユーティリティを使用可能にします。インポート操作は、このSCNにおけるデータの一貫性を維持したまま実行されます。TO_TIMESTAMPの値は引用符で囲まれるため、パラメータ・ファイルに記述することをお薦めします。コマンドラインの場合は、引用符の前にエスケープ文字を入力する必要があります。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
NETWORK_LINKパラメータも指定されている場合にのみ有効です。
FLASHBACK_TIMEパラメータは、Oracle Databaseのフラッシュバック問合せ機能にのみ関係します。フラッシュバック・データベース、フラッシュバック削除およびフラッシュバック・データ・アーカイブには適用できません。
FLASHBACK_TIMEおよびFLASHBACK_SCNは、相互に排他的なパラメータです。
DBMS_FLASHBACK.ENABLE_AT_TIMEプロシージャで使用可能な形式で時刻を指定できます。たとえば、次の内容のパラメータ・ファイルflashback_imp.parを作成したとします。
FLASHBACK_TIME="TO_TIMESTAMP('25-08-2003 14:35:00', 'DD-MM-YYYY HH24:MI:SS')"
次のコマンドを発行します。
> impdp hr DIRECTORY=dpump_dir1 PARFILE=flashback_imp.par NETWORK_LINK=source_database_
link
インポート操作は、指定した時間に最も近いSCNと整合性のあるデータで実行されます。
デフォルト: Y
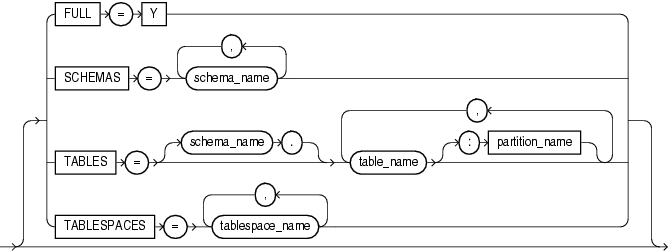
全データベース・インポートの実行を指定します。
FULL=y
FULL=yの値は、ソース(ダンプ・ファイル・セットまたは他のデータベース)からのすべてのデータおよびメタデータがインポートされることを示します。
このインポート・モードを使用したインポート対象を、フィルタ処理によって制限できます(詳細は、「インポート操作中のフィルタ処理」を参照してください)。
NETWORK_LINKパラメータが使用されている場合、インポート・ジョブを実行するUSERIDはターゲット・データベースのIMP_FULL_DATABASEロールを持ち、そのユーザーは、ソース・データベースのEXP_FULL_DATABASEロールも持っている必要があります。
ファイルのインポート権限が付与されていないユーザーの場合は、自分のスキーマにマップするスキーマのみインポートされます。
FULLは、ファイル・ベース・インポートを実行する際のデフォルト・モードです。
次に、FULLパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DUMPFILE=dpump_dir1:expfull.dmp FULL=y LOGFILE=dpump_dir2:full_imp.log
この例では、expfull.dmpダンプ・ファイルのすべての内容をインポートします。ここでは、DIRECTORYパラメータは指定されていません。そのため、DUMPFILEパラメータおよびLOGFILEパラメータの両方にディレクトリ・オブジェクトを指定する必要があります。例に示すとおり、ディレクトリ・オブジェクトは、別のものを指定することができます。
デフォルト: n
インポート・ユーティリティのオンライン・ヘルプを表示します。
HELP=y
HELP=yが指定されている場合は、インポート・ユーティリティのすべてのコマンドライン・パラメータと対話方式コマンドの要約が表示されます。
> impdp HELP = Y
この例では、すべてのインポート・パラメータおよびコマンドの簡単な説明が表示されます。
デフォルト: デフォルト値は設定されていません。
現行のインポート・モードにオブジェクトとオブジェクト型を指定して、インポート対象のメタデータをフィルタ処理できます。
INCLUDE = object_type[:name_clause] [, ...]
INCLUDE文に明示的に指定した、ソース内のオブジェクト型とその依存オブジェクトのみがインポートされます。
name_clauseは、オプションです。このオプションを使用すると、あるオブジェクト型のうち、特定のオブジェクトをファイングレイン選択できます。オプションの名前句は、その型のオブジェクト名に対するフィルタとして使用されるSQL式です。SQL演算子および指定した型のオブジェクト名の比較対象となる値で構成されています。この名前句は、名前付きのインスタンスを持つオブジェクト型にのみ適用されます(たとえば、TABLEには適用されますが、GRANTには適用されません)。オプションの名前句は、コロンでオブジェクト型と区切り、二重引用符(一重引用符は名前文字列の区切りに使用する必要があるため)で囲む必要があります。
2つ以上のINCLUDE文を指定できます。オペレーティング・システム固有のエスケープ文字をコマンドラインで使用する必要がないように、INCLUDE文は、パラメータ・ファイルで指定することをお薦めします。
DATABASE_EXPORT_OBJECTS(全体モードの場合)、SCHEMA_EXPORT_OBJECTS(スキーマ・モードの場合)、TABLE_EXPORT_OBJECTS(表および表領域モードの場合)ビューを問い合せて、INCLUDEパラメータで使用する有効なパスの一覧を表示できます。
DBAまたはIMP_FULL_DATABASEロールを持つ他のユーザーに使用されているパラメータ・ファイルimp_include.parが、次のように指定されているとします。
INCLUDE=FUNCTION INCLUDE=PROCEDURE INCLUDE=PACKAGE INCLUDE=INDEX:"LIKE 'EMP%' "
次のコマンドを発行します。
> impdp system SCHEMAS=hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp PARFILE=imp_include.par
この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
このインポートでは、hrスキーマのファンクション、プロシージャ、パッケージ、および名前がEMPで始まる索引のみロードされます。これは特権モードのインポート(ユーザーにIMP_FULL_DATABASEロールがある)ですが、USERオブジェクト型がINCLUDE文に指定されていないため、スキーマ定義はインポートされません。
デフォルト: SYS_<IMPORTまたはSQLFILE>_<mode>_NNという書式のシステム生成による名前
ジョブ名は、ジョブへの接続にATTACHパラメータを使用したり、DBA_DATAPUMP_JOBSまたはUSER_DATAPUMP_JOBSビューを使用してジョブを指定する場合など、後続処理でインポート・ジョブを指定するために使用されます。ジョブ名は、現在のユーザーのスキーマでのマスター表の名前となります。インポート・ジョブは、マスター表によって制御されます。
JOB_NAME=jobname_string
jobname_stringには、このインポート・ジョブの名前を、30バイト以内で指定します。これらのバイトは印字可能文字と空白を表します。空白を含む場合は、一重引用符で囲みます(たとえば、'Thursday Import'とします)。ジョブ名は、インポート操作を実行しているユーザーのスキーマによって暗黙的に修飾されます。
デフォルトのジョブ名はSYS_IMPORT_mode_NNまたはSYS_SQLFILE_mode_NNという形式で、システムによって生成されます。NNは、01から始めて増加する2桁の整数です。デフォルト名は、'SYS_IMPORT_TABLESPACE_02'などです。
次に、JOB_NAMEパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp JOB_NAME=impjob01
デフォルト: import.log
インポート・ジョブのログ・ファイルの名前を指定します。オプションで、そのログ・ファイルのディレクトリ・オブジェクトを指定します。
LOGFILE=[directory_object:]file_name
directory_objectには、DBAによって作成済で、自分にアクセス権があるディレクトリ・オブジェクトを指定する必要があります。この指定は、DIRECTORYパラメータに指定されたディレクトリ・オブジェクトよりも優先されます。デフォルトでは、DIRECTORYパラメータに指定されているディレクトリ・オブジェクトによって参照されるディレクトリ内に、import.logが作成されます。
file_nameに指定したファイルがすでに存在する場合、そのファイルは上書きされます。
処理中の作業、完了した作業および発生したエラーに関するすべてのメッセージがログ・ファイルに書き込まれます。(ジョブのリアルタイムの状態を把握するには、対話方式モードでSTATUSコマンドを使用します。)
NOLOGFILEパラメータが指定されていないかぎり、常に、ログ・ファイルは作成されます。ダンプ・ファイル・セットと同様に、ログ・ファイルの基準となるのは、クライアントではなく、サーバーです。
LOGFILEパラメータには、ASMの+表記法を含まないディレクトリ・オブジェクトを含める必要があります。つまり、ログ・ファイルはディスク・ファイルに書き込まれ、ASMの記憶域には書き込まれません。かわりに、NOLOGFILE=Yを指定することもできます。ただし、この場合はログ・ファイルの書込みは行われません。
次に、LOGFILEパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr SCHEMAS=HR DIRECTORY=dpump_dir2 LOGFILE=imp.log DUMPFILE=dpump_dir1:expfull.dmp
LOGFILEパラメータにはディレクトリ・オブジェクトが指定されていないため、ログ・ファイルは、DIRECTORYパラメータに指定したディレクトリ・オブジェクトに書き込まれます。
デフォルト: デフォルト値は設定されていません。
有効なデータベース・リンクによって指定される(ソース)データベースからのインポートを使用可能にします。ソース・データベース・インスタンスのデータは、接続されたデータベース・インスタンスに直接書き込まれます。
NETWORK_LINK=source_database_link
NETWORK_LINKパラメータは、データベース・リンクを使用してインポートを開始します。つまり、impdpクライアントの接続先となるシステムから、source_database_linkで指定されたソース・データベースに接続し、そこからデータを取り出して、接続されたインスタンスのデータベースに書き込みます。ダンプ・ファイルは含まれません。
source_database_linkには、使用可能なデータベースへのデータベース・リンク名を指定する必要があります。対象インスタンスのデータベースにデータベース・リンクが指定されていない場合、ユーザーまたはDBAが、データベース・リンクを作成する必要があります。CREATE DATABASE LINK文の詳細は、『Oracle Database SQL言語リファレンス』を参照してください。
トランスポータブル・メソッドを使用してネットワーク・インポートを実行する場合は、インポートを開始する前に、ソース・データ・ファイルをターゲット・データベースにコピーする必要があります。
ソース・データベースが読取り専用の場合、接続ユーザーには、ソース・データベース上のデフォルトの一時表領域として、ローカル管理表領域が割り当てられている必要があります。それ以外の場合、ジョブは失敗します。詳細は、『Oracle Database管理者ガイド』のローカル管理の一時表領域の作成に関する説明を参照してください。
このパラメータは、FLASHBACK_SCN、FLASHBACK_TIME、ESTIMATE、TRANSPORT_TABLESPACESまたはTRANSPORTABLEのいずれかのパラメータを指定する場合に必要です。
NETWORK_LINKパラメータをTABLESパラメータと組み合せて使用する場合は、表全体のみをインポートできます(表のパーティションはインポートできません)。唯一の例外は、TRANSPORTABLE=ALWAYSも指定されている場合で、この場合は、指定した表の単一または複数のパーティションをインポートできます。
USERIDがターゲット・データベースのIMP_FULL_DATABASEロールを持っている場合、そのユーザーは、ソース・データベースのEXP_FULL_DATABASEロールも持っている必要があります。
次の例では、source_database_linkを有効なデータベース・リンクの名前に置き換えます。
> impdp hr TABLES=employees DIRECTORY=dpump_dir1 NETWORK_LINK=source_database_link EXCLUDE=CONSTRAINT
この例では、ソース・データベースからemployees 表(制約を除く)がインポートされます。ログ・ファイルは、DIRECTORYパラメータに指定したdpump_dir1に書き込まれます。
デフォルト: n
デフォルトでログ・ファイルを作成するかどうかを指定します。
NOLOGFILE={y | n}
NOLOGFILE=Yを指定すると、ログ・ファイルは作成されません。ただし、進捗とエラーに関する情報が、接続されているいずれかのクライアント(オリジナルのエクスポート操作を開始したクライアントを含む)の標準出力デバイスに書き込まれます。実行中のジョブに接続されているクライアントが存在しない場合にNOLOGFILE=Yを指定すると、重要な進捗情報およびエラー情報が失われる危険性があります。
次に、NOLOGFILEパラメータの使用例を示します。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp NOLOGFILE=Y
このコマンドを実行すると、expfull.dmpダンプ・ファイルの全体インポート・モード(ファイル・ベース・インポートのデフォルト)が実行されます。NOLOGFILE にyが設定されているため、ログ・ファイルは書き込まれません。
デフォルト: 1
インポート・ジョブにかわり、アクティブな実行スレッドの最大数を指定します。
PARALLEL=integer
integerに指定する値は、インポート・ジョブの動作でアクティブな実行操作の最大スレッド数です。この実行セットはワーカー・プロセスおよびパラレルI/Oサーバーの処理の組合せで構成されています。パラレルI/O操作でパラレル実行コーディネータとして動作するマスター制御プロセス、アイドル状態のワーカーおよびワーカー・プロセスは、この合計数には加算されません。このパラメータを使用して、リソース消費と経過時間のバランスをとることができます。
インポートのソースがファイルで構成されるダンプ・ファイル・セットの場合、同じファイルから複数のプロセスが読取り可能ですが、パフォーマンスは、I/O競合によって制限されます。
ジョブの実行中にPARALLELの値を増減するには、対話方式コマンド・モードを使用します。
並列度は、ユーザー・データおよびパッケージ本体のロード、索引の作成に使用します。
次に、PARALLELパラメータの使用例を示します。
> impdp hr DIRECTORY=dpump_dir1 LOGFILE=parallel_import.log JOB_NAME=imp_par3 DUMPFILE=par_exp%U.dmp PARALLEL=3
このコマンドは、ExportのPARALLELパラメータの例を実行した場合に作成されるダンプ・ファイル・セットをインポートします。(詳細は、「PARALLEL」を参照してください。)ダンプ・ファイル名は、par_exp01.dmp、par_exp02.dmpおよびpar_exp03.dmpです。
デフォルト: デフォルト値は設定されていません。
インポート・パラメータ・ファイルの名前を指定します。
PARFILE=[directory_path]file_name
サーバーによって作成され、書き込まれるダンプ・ファイル、ログ・ファイル、SQLファイルとは異なり、パラメータ・ファイルは、impdpイメージを実行しているクライアントによってオープンされ、読み込まれます。したがって、ディレクトリ・オブジェクトの名前は不要かつ不適切です。デフォルトは、ユーザーの現行のディレクトリです。値の指定に引用符が必要なパラメータを使用する場合は、パラメータ・ファイルを使用することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)
パラメータ・ファイルhr_imp.parの内容は、次のとおりです。
TABLES= countries, locations, regions DUMPFILE=dpump_dir2:exp1.dmp,exp2%U.dmp DIRECTORY=dpump_dir1 PARALLEL=3
このパラメータ・ファイルを指定するには、次のコマンドを実行します。
> impdp hr PARFILE=hr_imp.par
表countries、locationsおよびregions は、ExportのDUMPFILEパラメータの例を実行した場合に作成されるダンプ・ファイル・セットからインポートされます。(詳細は、「DUMPFILE」を参照してください。)インポート・ジョブは、dpump_dir2で示される位置にあるexp1.dmpファイルを検索します。また、dpump_dir1によって示される位置にあるexp2<nn>.dmpの形式のすべてのダンプ・ファイルも検索します。そのジョブのログ・ファイルも、dpump_dir1に書き込まれます。
デフォルト: パーティション名がTABLESパラメータで指定され、TRANPORTABLE=ALWAYSが(インポート操作時またはエクスポート中に)設定されている場合、デフォルトはdepartitionです。それ以外の場合、デフォルトはnoneとなります。
インポート操作中に表パーティションをどのように作成するかを指定します。
PARTITION_OPTIONS={none | departition | merge}
noneの値を指定した場合、エクスポート操作が実行されたシステム上に存在していたのと同様に表が作成されます。エクスポートがパーティションまたはサブパーティション・フィルタとともにトランスポータブル・メソッドを使用して実行されている場合、noneオプションまたはmergeオプションは使用できません。そのような場合は、departitionオプションを使用する必要があります。
departitionの値を指定した場合、各パーティションまたはサブパーティションは、新しい個々の表に昇格します。新規表のデフォルト名は、表とパーティションの名前、または表とサブパーティションの名前を適切に組み合せたものとなります。
mergeの値を設定した場合、すべてのパーティションおよびサブパーティションは1つの表に統合されます。
departitionオプションを使用する必要があります。
PARTITION_OPTIONS=mergeは使用できません。
次の例は、sh.sales表がsales.dmpという名前のダンプ・ファイルにエクスポートされていることを前提としています。ここでは、MERGEオプションを使用して、sh.sales内のすべてのパーティションをscottスキーマ内のパーティション化されていない表にマージします。
> impdp system TABLES=sh.sales PARTITION_OPTIONS=merge DIRECTORY=dpump_dir1 DUMPFILE=sales.dmp REMAP_SCHEMA=sh:scott
デフォルト: デフォルト値は設定されていません。
インポート対象となるデータをフィルタ処理する問合せ句を指定できます。
QUERY=[[schema_name.]table_name:]query_clause
通常、query_clauseでは、ファイングレイン行選択のためのSQL WHERE句を使用しますが、任意のSQL句を使用できます。たとえば、ORDER BY句を使用すると、ヒープ構成表から索引構成表への移行を高速化できます。スキーマおよび表名を指定しない場合は、ソース・ダンプ・ファイル・セットまたはデータベースのすべての表に問合せが適用されます(この場合、問合せは、これらのすべての表に対して有効である必要があります)。表固有の問合せは、すべての表に適用される問合せより優先されます。
特定の表に問合せを適用する場合は、表名と問合せ句をコロンで区切る必要があります。表固有の問合せは複数指定できますが、1つの表に指定できるのは1つの問合せのみです。
問合せは一重引用符または二重引用符で囲みます。句内の文字列を一重引用符で囲む必要があるため、二重引用符の使用をお薦めします。オペレーティング・システム固有のエスケープ文字をコマンドラインで使用する必要がないように、QUERYは、パラメータ・ファイルで指定することをお薦めします。詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。
QUERYパラメータを使用すると、外部表による方法(ダイレクト・パスによる方法ではなく)でデータベース・アクセスが実行されます。
表固有の問合せで自分のスキーマ以外のスキーマを指定するには、その特定の表に対するアクセス権限が付与されている必要があります。
QUERYパラメータは次のパラメータとは併用できません。
QUERYパラメータが指定されている場合、データ・ポンプは外部表を使用してターゲット表をロードします。外部表は、SQLのINSERT文をSELECT句とともに使用します。QUERYパラメータの値は、INSERT文のSELECT部分にあるWHERE句に含まれています。QUERYパラメータにロードする表と一致する名前の列がある他の表への参照が含まれていて、これらの列が問合せで使用される場合は、表別名を使用して、ロードする表内の列と、SELECT文内の同じ名前を持つ列を区別する必要があります。ロードする表に対してデータ・ポンプで使用される表別名は、KU$です。たとえば、sh.customers表にある顧客のクレジットの上限に基づいてsh.sales表のサブセットをインポートするとします。次の例では、KU$を使用して、sh.salesをロードするためにQUERYパラメータ内のcust_idフィールドを修飾します。この結果、データ・ポンプによって、クレジットの上限が$10,000を超える顧客の行のみがインポートされます。
QUERY='sales:"WHERE EXISTS (SELECT cust_id FROM customers c WHERE cust_credit_limit > 10000 AND ku$.cust_id = c.cust_id)"'
表別名としてKU$を使用しないと、すべての行がロードされることになります。
QUERY='sales:"WHERE EXISTS (SELECT cust_id FROM customers c WHERE cust_credit_limit > 10000 AND cust_id = c.cust_id)"'
次に、QUERYパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。QUERYの値には引用符が使用されるため、コマンドラインでエスケープ文字を使用する必要がないように、パラメータ・ファイルを使用することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)
次の内容のパラメータ・ファイルquery_imp.parを作成したとします。
QUERY=departments:"WHERE department_id < 120"
次のコマンドを入力します。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp PARFILE=query_imp.par NOLOGFILE=Y
expfull.dmp内のすべての表はインポートされますが、departments表については、QUERYパラメータに指定した基準を満たすデータのみがインポートされます。
デフォルト: デフォルト値は設定されていません。
REMAP_DATAパラメータを使用すると、新規データベースへの挿入時に、データを再マップできます。一般的には、プライマリ・キーを再生成して、ターゲット・データベース上の既存の表に表をインポートする場合の競合を回避するために使用されます。
ダンプ・ファイルまたはリモート・データベースのいずれかから、指定した列の値をソースとして取得するには、再マップ・ファンクションを指定します。再マップ・ファンクションを指定すると、ターゲット・データベースの元の値を置き換える再マップした値が返されます。
同じファンクションを、ダンプされる複数の列に適用できます。これは、参照制約で子と親両方の列を再マップするときに整合性を保つ必要がある場合に役立ちます。
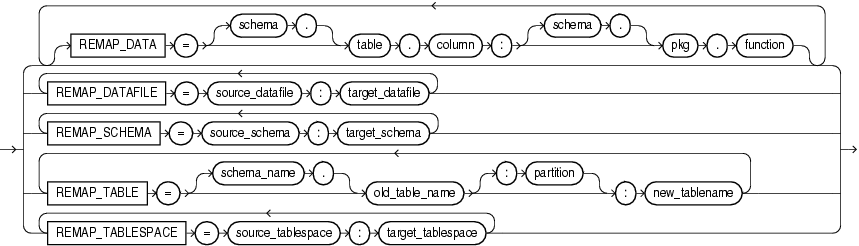
REMAP_DATA=[schema.]tablename.column_name:[schema.]pkg.function
次に、各構文要素の説明を構文で出現する順に示します。
schema: 再マップされる表を含むスキーマ。デフォルトでは、これはインポートを実行するユーザーのスキーマです。
tablename: 列の再マップが行われる表。
column_name: データの再マップが行われる列。
schema: 再マップ・ファンクションを含むユーザー作成のPL/SQLパッケージを含むスキーマ。デフォルトでは、これはインポートを実行するユーザーのスキーマです。
pkg: 再マップ・ファンクションを含むユーザー作成のPL/SQLパッケージの名前。
function: 指定した表の各行で、列表を再マップする場合にコールされるPL/SQL内のファンクションの名前。
次の例では、plusxという名前のファンクションを格納するremapという名前のパッケージが作成されており、このファンクションはemployees表内のfirst_nameの値を変更すると想定しています。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expschema.dmp TABLES=hr.employees REMAP_DATA=hr.employees.first_name:hr.remap.plusx
デフォルト: デフォルト値は設定されていません。
ソース・データ・ファイルが指定されるすべてのSQL文(CREATE TABLESPACE、CREATE LIBRARY、CREATE DIRECTORYなど)のソース・データ・ファイルの名前をターゲット・データ・ファイルの名前に変更します。
REMAP_DATAFILE=source_datafile:target_datafile
データ・ファイルの再マップは、ファイル名のネーミング規則が異なるプラットフォーム間でデータベースを移動する場合に有効です。source_datafileとtarget_datafileの名前は、SQL文で指定するとおりのものである必要があります。コロンが有効なファイル指定文字として使用されるプラットフォームでの曖昧さを排除するために、データ・ファイル名は引用符で囲むことをお薦めします。
このパラメータを指定するには、IMP_FULL_DATABASEロールが必要です。
REMAP_DATAFILEの値には引用符が使用されるため、コマンドラインでエスケープ文字を使用する必要がないように、パラメータは、パラメータ・ファイルで指定することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)たとえば、次の内容のパラメータ・ファイルpayroll.parを作成したとします。
DIRECTORY=dpump_dir1 FULL=Y DUMPFILE=db_full.dmp REMAP_DATAFILE="'DB1$:[HRDATA.PAYROLL]tbs6.f':'/db1/hrdata/payroll/tbs6.f'"
次のコマンドを発行します。
> impdp hr PARFILE=payroll.par
この例では、インポート時に、すべてのSQL DDL文に対するVMSファイル指定(DR1$:[HRDATA.PAYROLL]tbs6.f)をUNIXファイル指定(/db1/hrdata/payroll/tbs6.f)に再マップします。ダンプ・ファイルdb_full.dmpは、ディレクトリ・オブジェクトdpump_dir1によって位置が示されます。
デフォルト: デフォルト値は設定されていません。
ソース・スキーマにあるすべてのオブジェクトをターゲット・スキーマにロードします。
REMAP_SCHEMA=source_schema:target_schema
複数のREMAP_SCHEMA行を指定できますが、ソース・スキーマは行ごとに異なっている必要があります。ただし、異なるソース・スキーマを同じターゲット・スキーマにマップすることはできます。インポートで検出できない一部のスキーマ参照があるため、マッピングは完全ではない場合があります。たとえば、インポートでは、型定義、ビュー、プロシージャおよびパッケージの本体に埋め込まれたスキーマ参照は検出されません。
再マッピング先のスキーマが存在しない場合は、インポート操作によってそのスキーマが作成されます。ただし、ソース・スキーマに必要なCREATE USERメタデータがダンプ・ファイル・セットに含まれており、ユーザーが必要な権限を所有してインポートを実行していることが条件となります。たとえば、次のExportコマンドの場合、ユーザーSYSTEMには必要な権限があるため、スキーマの作成に必要なメタデータを含むダンプ・ファイル・セットが作成されます。
> expdp system SCHEMAS=hr Password: password > expdp system FULL=y Password: password
スキーマの作成に必要なメタデータがダンプ・ファイル・セットに含まれていない場合や、ユーザーに必要な権限がない場合は、インポート操作を実行する前にターゲット・スキーマを作成しておく必要があります。これは、権限が付与されていないダンプ・ファイルには、インポート操作でスキーマを自動作成するための情報が含まれないためです。
インポート操作によってスキーマが作成された場合は、インポートの完了後、そのスキーマに有効なパスワードを割り当てて、接続できるようにする必要があります。パスワードを割り当てるSQL文(権限が必要)は、次のとおりです。
SQL> ALTER USER schema_name IDENTIFIED BY new_password
SCOTTは、自分のBLAKEのオブジェクトをSCOTTに再マップできますが、SCOTTのオブジェクトをBLAKEに再マップすることはできません。
ユーザーSYSTEMとして、次のエクスポートおよびインポート・コマンドを実行して、hrスキーマをscottスキーマに再マップするとします。
> expdp system SCHEMAS=hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp > impdp system DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp REMAP_SCHEMA=hr.scott
この例では、インポート前にユーザーscottが存在する場合、インポートのREMAP_SCHEMAコマンドによって、hrスキーマにあるオブジェクトが既存のscottスキーマに追加されます。インポート後、scottスキーマに既存のパスワードで(パスワードの再設定なしで)接続できます。
インポート操作の実行前にユーザーscottが存在しない場合は、インポートによって、このユーザーがパスワードなしで自動作成されます。これは、ダンプ・ファイルhr.dmpが、スキーマの作成に必要なメタデータを含むダンプ・ファイルを作成する権限を所有するSYSTEMによって作成されたためです。ただし、インポート完了後に、ターゲット・データベース上のscottのパスワードを再設定しないかぎり、インポートの完了時にscottには接続できません。
デフォルト: デフォルト値は設定されていません。
トランスポータブル・メソッドを使用して実行されたインポート操作中に、表の名前を変更できます。
REMAP_TABLE=[schema.]old_tablename[.partition]:new_tablename
REMAP_TABLEパラメータを使用すると、表全体の名前を変更できます。
また、トランスポータブル・メソッドによりエクスポートされた表パーティションの自動名前付けオプションを変更する場合も、このパラメータを使用します。パーティション表がトランスポータブル・メソッドを使用してエクスポートされると、各パーティションおよびサブパーティションは固有の表に昇格され、その表は、デフォルトで、表とパーティションの名前を組み合せた名前(tablename_partitionname)になります。このデフォルト以外の名前を指定するには、REMAP_TABLEを使用します。
TABLE_EXISTS_ACTIONがTRUNCATEまたはAPPENDに設定されている場合は、再マップされません。
次の例では、REMAP_TABLEパラメータを使用して、employees表をempsという新しい名前に変更します。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expschema.dmp TABLES=hr.employees REMAP_TABLE=hr.employees:emps
デフォルト: デフォルト値は設定されていません。
ターゲット表領域に作成するソース表領域内の永続データを使用して、インポート用に選択されたすべてのオブジェクトを再マップします。
REMAP_TABLESPACE=source_tablespace:target_tablespace
複数のREMAP_TABLESPACEパラメータを指定できますが、ソース表領域はパラメータごとに1つのみです。ターゲット・スキーマのターゲット表領域には、十分な割当て制限が必要です。
データ・ポンプ・インポートで表領域を再マップする方法は、REMAP_TABLESPACEパラメータを使用する方法のみです。これは、オリジナルのインポート・ユーティリティの機能よりも簡単で正確な方法です。その方法には、表領域の副次句の数など多くの制限事項があり、一部のDDLコマンドを正常に実行できない場合がありました。
これに対し、REMAP_TABLESPACEパラメータを使用するデータ・ポンプ・インポートの方法は、ユーザーを含むすべてのオブジェクトに対して、DDL文に含まれる表領域副次句の数にかかわりなく有効に使用できます。
TABLE_EXISTS_ACTIONがSKIP、TRUNCATEまたはAPPENDに設定されている場合は、再マップされません。
次に、REMAP_TABLESPACEパラメータの使用例を示します。
> impdp hr REMAP_TABLESPACE=tbs_1:tbs_6 DIRECTORY=dpump_dir1 DUMPFILE=employees.dmp
デフォルト: n
インポート・ジョブで、表領域の作成に既存のデータ・ファイルを再利用するかどうかを指定します。
REUSE_DATAFILES={y | n}
デフォルト(n)が使用され、CREATE_TABLESPACE文で指定されているデータ・ファイルがすでに存在する場合は、CREATE_TABLESPACE文の失敗によるエラー・メッセージが発行されますが、インポート・ジョブは続行されます。
このパラメータにYを指定すると、既存のデータ・ファイルが再度初期化されます。この場合、データが失われる可能性があるため注意してください。
次に、REUSE_DATAFILESパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp LOGFILE=reuse.log REUSE_DATAFILES=Y
この例では、expfull.dmpファイルのCREATE TABLESPACE文で指定されたデータ・ファイルを再度初期化します。
デフォルト: デフォルト値は設定されていません。
スキーマ・モード・インポートの実行を指定します。
SCHEMAS=schema_name [,...]
IMP_FULL_DATABASEロールがある場合は、インポートするスキーマのリストをこのパラメータで指定して、スキーマ・モードのインポートを実行できます。まず、システムおよびロールの権限、パスワード履歴などを含むユーザー定義がインポートされます(存在しない場合)。次に、スキーマ内のすべてのオブジェクトがインポートされます。権限のないユーザーは、自分のスキーマか、自分のスキーマに再マップされているスキーマのみを指定できます。この場合、スキーマ定義についての情報はインポートされず、その定義内に含まれているオブジェクトのみがインポートされます。
このインポート・モードを使用したインポート対象を、フィルタ処理によって制限できます。詳細は、「インポート操作中のフィルタ処理」を参照してください。
スキーマ・モードは、ネットワーク・ベース・インポートを実行する際のデフォルト・モードです。
次に、SCHEMASパラメータの使用例を示します。この例では、ExportのSCHEMASパラメータで示した例を実行して、expdat.dmpファイルを作成できます。詳細は、「SCHEMAS」を参照してください。
> impdp hr SCHEMAS=hr DIRECTORY=dpump_dir1 LOGFILE=schemas.log DUMPFILE=expdat.dmp
hrスキーマは、expdat.dmpファイルからインポートされます。ログ・ファイルschemas.logは、dpump_dir1に書き込まれます。
デフォルト: Oracle Databaseの構成パラメータSKIP_UNUSABLE_INDEXESの値
インポートで、(システムまたはユーザーのいずれかによって)索引使用禁止に設定されている索引を持つ表をロードするかどうかを指定します。
SKIP_UNUSABLE_INDEXES={y | n}
SKIP_UNUSABLE_INDEXESがyに設定されているときに、索引が使用禁止になっている表またはパーティションが検出された場合、その表やパーティションは、使用禁止の索引が存在しない場合と同様にロードされます。
SKIP_UNUSABLE_INDEXESがnに設定されているときに、索引が使用禁止の表またはパーティションが検出された場合、その表やパーティションはロードされません。索引が使用禁止に設定されていない他の表に対しては、行の挿入時に更新が行われます。
SKIP_UNUSABLE_INDEXESパラメータが指定されていない場合は、Oracle Databaseの構成パラメータSKIP_UNUSABLE_INDEXESの設定値(デフォルト値はy)が参照され、使用禁止の索引の処理が決定されます。
制約の施行に使用される索引に使用禁止のマークが付けられている場合、その表にデータはインポートされません。
次に、SKIP_UNUSABLE_INDEXESパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp LOGFILE=skip.log SKIP_UNUSABLE_INDEXES=y
デフォルト: デフォルト値は設定されていません。
インポートが他のパラメータに基づいて実行するすべてのSQL DDLの書込み先のファイルを指定します。
SQLFILE=[directory_object:]file_name
file_nameには、インポート・ジョブが、ジョブで実行するDDLを書き込むファイル名を指定します。そのSQLは、実際には実行されず、ターゲット・システムも変更されません。ファイルは、他のdirectory_objectが明示的に指定されないかぎり、DIRECTORYパラメータに指定されたディレクトリ・オブジェクトに書き込まれます。このパラメータで指定した名前と一致する名前を持つ既存のファイルはすべて上書きされます。
パスワードは、SQLファイルに含まれないことに注意してください。たとえば、実行したDDLにCONNECT文が含まれている場合、その文はコメントで置き換えられ、スキーマ名のみが表示されます。次の例では、ダッシュの後に続くのがコメントです。また、hrというスキーマ名は表示されていますが、パスワードは表示されていません。
-- CONNECT hr
したがって、SQLファイルは、実行する前に、コメントを示すダッシュを削除し、hrスキーマのパスワードを追加して編集する必要があります。
StreamsなどのOracle Databaseオプションでは、無名PL/SQLブロックがSQLFILE出力に出現することがあります。これらは、直接実行しないでください。
SQLFILEが指定されている場合、CONTENTパラメータは、ALLまたはDATA_ONLYのいずれかに設定されていると無視されます。
SQLFILEパラメータには、ASMの+表記法を使用しないディレクトリ・オブジェクトを含める必要があります。つまり、SQLファイルはディスク・ファイルに書き込まれ、ASMの記憶域には書き込まれません。
次に、SQLFILEパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp SQLFILE=dpump_dir2:expfull.sql
SQLファイルexpfull.sqlは、dpump_dir2に書き込まれます。
デフォルト: 0
ジョブ状態が表示される頻度を指定します。
STATUS[=integer]
integerに値を入力すると、ロギング・モードでジョブの状態を表示する頻度を秒単位で指定できます。値を入力しなかった場合またはデフォルト値の0を使用した場合、各オブジェクト型、表またはパーティションの完了に関する情報のみ表示されます。
この状態情報は、標準出力デバイスのみに書き込まれ、ログ・ファイルには(使用可能な場合でも)書き込まれません。
次に、STATUSパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr NOLOGFILE=y STATUS=120 DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp
この例では、状態が2分(120秒)ごとに表示されます。
デフォルト: y
エクスポート・ダンプ・ファイル内に存在するStreamsメタデータをインポートするかどうかを指定します。
STREAMS_CONFIGURATION={y | n}
次に、STREAMS_CONFIGURATIONパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp STREAMS_CONFIGURATION=n
デフォルト: SKIP(CONTENT=DATA_ONLYが指定されている場合、デフォルトはSKIPではなく、APPENDです。)
インポート・ユーティリティに対して、作成しようとしている表がすでに存在する場合に行う操作を指定します。
TABLE_EXISTS_ACTION={SKIP | APPEND | TRUNCATE | REPLACE}
次の値を指定できます。
SKIP: 表はそのままにして、次のオブジェクトに移動します。CONTENTパラメータがDATA_ONLYに設定されている場合、このオプションは無効です。
APPEND: ソースから行をロードし、既存の行は変更しません。
TRUNCATE: 既存の行を削除した後、ソースから行をロードします。
REPLACE: 既存の表を削除した後、ソースから表を作成およびロードします。CONTENTパラメータがDATA_ONLYに設定されている場合、このオプションは無効です。
これらのオプションを使用する場合に考慮する事項は次のとおりです。
TRUNCATEまたはREPLACEを使用する場合は、影響を受ける表の行が参照制約のターゲットではないことを確認してください。
SKIP、APPENDまたはTRUNCATEを使用する場合は、索引、権限、トリガー、制約など、ソースの既存の表依存オブジェクトは無視されます。REPLACEを使用すると、依存オブジェクトが明示的または暗黙的に除外(EXCLUDEを使用して)され、それらがソースのダンプ・ファイルまたはシステムに存在する場合、依存オブジェクトは削除され、ソースから再作成されます。
APPENDまたはTRUNCATEを使用する場合は、操作を実行する前に、ソースにある行が既存の表に適合するかどうかがチェックされます。既存の表にアクティブな制約およびトリガーがある場合は、外部表によるアクセス方法を使用してロードされます。アクティブな制約に違反する行がある場合、ロードは失敗し、データはロードされません。この動作を変更するには、インポート・ユーティリティのコマンドラインでDATA_OPTIONS=SKIP_CONSTRAINT_ERRORSを指定します。
制約違反の可能性があるデータをロードする必要がある場合は、制約を無効にし、データをロードした後、制約を再度有効にする前に問題のある行を削除する方法を検討してください。
APPENDを使用すると、常に、データは新しい領域にロードされます。既存の領域は、使用可能な場合でも再利用されません。そのため、ロード後にデータを圧縮することもできます。
次に、TABLE_EXISTS_ACTIONパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr TABLES=employees DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp TABLE_EXISTS_ACTION=REPLACE
デフォルト: デフォルト値は設定されていません。
表モード・インポートの実行を指定します。
TABLES=[schema_name.]table_name[:partition_name]
表モード・インポートでは、表およびパーティションまたはサブパーティションをカンマで区切ったリストを指定して、ソースからインポートするデータをフィルタ処理できます。
schema_nameを指定しなかった場合は、デフォルトで現在のユーザーのスキーマ名になります。自分のスキーマ以外のスキーマを指定するには、IMP_FULL_DATABASEロールを持っているか、またはスキーマを現在のユーザーに再マップする必要があります。
このインポート・モードを使用したインポート対象を、フィルタ処理によって制限できます。詳細は、「インポート操作中のフィルタ処理」を参照してください。
partition_nameを指定する場合は、関連表にあるパーティションまたはサブパーティションの名前にする必要があります。
表名を指定する場合のワイルドカードの使用もサポートされていますが、指定できる表の式は1つのみです。たとえば、TABLES=emp%と指定すると、名前がEMPで始まるすべての表がインポートされます。
TABLESパラメータの値としてのシノニムの使用はサポートされていません。たとえば、hrスキーマのregions表にregnのシノニムが存在する場合、TABLES=regnを使用すると無効になります。この場合、エラーが返されます。
table_nameを指定する場合は、それらのすべてが同じスキーマに存在する必要があります。
PARTITION_OPTIONS=DEPARTITION も指定されている場合、1つの表からのパーティションのみを指定できます。
NETWORK_LINKパラメータをTABLESパラメータと組み合せて使用する場合は、表全体のみをインポートできます(表のパーティションはインポートできません)。唯一の例外は、TRANSPORTABLE=ALWAYSも指定されている場合で、この場合は、指定した表の単一または複数のパーティションをインポートできます。
TRANSPORTABLE=ALWAYSを指定する場合は、TABLESパラメータで指定されるすべてのパーティションが同じ表内に存在する必要があります。
TABLESパラメータに指定する表名のリストの長さは、最大4MBに制限されます。ただし、NETWORK_LINKパラメータで10.2.0.3以前のデータベースまたは読取り専用のデータベースが設定されている場合は異なります。この場合の上限は4KBです。
次に、TABLESパラメータを使用して、expfull.dmpファイルからemployeesおよびjobs表のみをインポートする簡単な例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp TABLES=employees,jobs
次に、 TABLESパラメータを使用したパーティションのインポート例を示します。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expdat.dmp TABLES=sh.sales:sales_Q1_2000,sh.sales:sales_Q2_2000
この例では、shスキーマのsales表のパーティションsales_Q1_2000およびsales_Q2_2000をインポートします。
デフォルト: デフォルト値は設定されていません。
表領域モード・インポートの実行を指定します。
TABLESPACES=tablespace_name [, ...]
TABLESPACESを使用して、表と依存オブジェクトがソース(全体インポート・モード、スキーマ・モード、表領域モードまたは表モードのエクスポート・ダンプ・ファイル・セット、あるいは別のデータベース)からインポートされる表領域名のリストを指定します。
インポートの次の状況では、データ・ポンプによりデータのインポート先に自動的に表領域が作成されます。
その他のすべての場合では、選択したオブジェクトの表領域がインポート先のデータベースにすでに存在している必要があります。REMAP_TABLESPACEインポート・パラメータを使用して、インポート先のデータベースにある表領域に表領域名をマッピングすることもできます。
このインポート・モードを使用したインポート対象を、フィルタ処理によって制限できます。詳細は、「インポート操作中のフィルタ処理」を参照してください。
TABLESPACESパラメータに指定する表領域名のリストの長さは、最大4MBに制限されます。ただし、NETWORK_LINKパラメータで10.2.0.3以前のデータベースまたは読取り専用のデータベースが設定されている場合は異なります。この場合の上限は4KBです。
次に、TABLESPACESパラメータの使用例を示します。表領域はすでに存在するものとします。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp TABLESPACES=tbs_1,tbs_2,tbs_3,tbs_ 4
この例では、表領域tbs_1、tbs_2、tbs_3およびtbs_4にデータがある表がすべてインポートされます。
デフォルト: デフォルト値は設定されていません。
インポート中のオブジェクトに対するオブジェクト作成DDLを変更できます。
TRANSFORM = transform_name:value[:object_type]
transform_nameには、変換の名前を指定します。使用可能なオプションは、次のとおりです。
SEGMENT_ATTRIBUTES: 値をyに指定すると、適切なDDLにセグメント属性(物理属性、記憶域属性、表領域およびロギング)が指定されます。デフォルトはyです。
STORAGE: 値をyに指定すると、適切なDDLにSTORAGE句が指定されます。デフォルトはyです。SEGMENT_ATTRIBUTES=nの場合、このパラメータは無視されます。
OID: 値をnに指定すると、オブジェクトの表と型の作成時に、エクスポートされたOIDの割当てが禁止されます。かわりに、新しいOIDが割り当てられます。これは、スキーマのクローニングに有効ですが、参照オブジェクトには影響しません。デフォルト値はyです。
PCTSPACE: この変換の値には、0より大きい数字を指定する必要があります。この値は、エクステントの割当てとデータ・ファイル・サイズの変更に使用する、割合の乗数を表します。なお、このPCTSPACE変換とデータ・ポンプ・エクスポートのSAMPLEパラメータを組み合せて使用すると、記憶域の割当てサイズを、サンプリングされたデータ・サブセットに合わせることができます。(詳細は、「SAMPLE」を参照してください。)
指定するvalueの型は、使用する変換によって異なります。SEGMENT_ATTRIBUTES、STORAGE、OIDの各変換では、ブール値(y/n)が必要です。PCTSPACE変換では、整数値が必要です。
object_typeはオプションです。このオプションで、変換が適用されるオブジェクト型を指定します。オブジェクト型を指定しなかった場合、変換はすべての有効なオブジェクト型に適用されます。表3-1に、変換ごとの有効なオブジェクト型を示します。
| SEGMENT_ATTRIBUTES | STORAGE | OID | PCTSPACE | |
|---|---|---|---|---|
|
|
X |
X |
|
X |
|
|
X |
X |
|
X |
|
|
|
|
X |
|
|
|
X |
X |
|
X |
|
|
X |
X |
|
X |
|
|
X |
X |
X |
X |
|
|
X |
|
|
X |
|
|
|
|
X |
|
次の例では、hrスキーマのemployees表をエクスポートしたとします。表をインポートした結果返されるSQL CREATE TABLE文は、次のようになります。
CREATE TABLE "HR"."EMPLOYEES" ( "EMPLOYEE_ID" NUMBER(6,0), "FIRST_NAME" VARCHAR2(20), "LAST_NAME" VARCHAR2(25) CONSTRAINT "EMP_LAST_NAME_NN" NOT NULL ENABLE, "EMAIL" VARCHAR2(25) CONSTRAINT "EMP_EMAIL_NN" NOT NULL ENABLE, "PHONE_NUMBER" VARCHAR2(20), "HIRE_DATE" DATE CONSTRAINT "EMP_HIRE_DATE_NN" NOT NULL ENABLE, "JOB_ID" VARCHAR2(10) CONSTRAINT "EMP_JOB_NN" NOT NULL ENABLE, "SALARY" NUMBER(8,2), "COMMISSION_PCT" NUMBER(2,2), "MANAGER_ID" NUMBER(6,0), "DEPARTMENT_ID" NUMBER(4,0) ) PCTFREE 10 PCTUSED 40 INITRANS 1 MAXTRANS 255 NOCOMPRESS LOGGING STORAGE(INITIAL 10240 NEXT 16384 MINEXTENTS 1 MAXEXTENTS 121 PCTINCREASE 50 FREELISTS 1 FREELIST GROUPS 1 BUFFER_POOL DEFAULT) TABLESPACE "SYSTEM" ;
STORAGE句またはTABLESPACE句は、保持しない場合、インポート・ユーティリティのTRANSFORMパラメータを使用してCREATE STATEMENT から削除できます。SEGMENT_ATTRIBUTESの値をnに指定します。これによって、セグメント属性(記憶域と表領域の両方)が表から除外されます。
> impdp hr TABLES=hr.employees \ DIRECTORY=dpump_dir1 DUMPFILE=hr_emp.dmp \ TRANSFORM=SEGMENT_ATTRIBUTES:n:table
この結果返される、employees表のCREATE TABLE文は次のようになります。STORAGEまたはTABLESPACE句は含まれていません。かわりに、HRスキーマのデフォルト表領域が使用されます。
CREATE TABLE "HR"."EMPLOYEES" ( "EMPLOYEE_ID" NUMBER(6,0), "FIRST_NAME" VARCHAR2(20), "LAST_NAME" VARCHAR2(25) CONSTRAINT "EMP_LAST_NAME_NN" NOT NULL ENABLE, "EMAIL" VARCHAR2(25) CONSTRAINT "EMP_EMAIL_NN" NOT NULL ENABLE, "PHONE_NUMBER" VARCHAR2(20), "HIRE_DATE" DATE CONSTRAINT "EMP_HIRE_DATE_NN" NOT NULL ENABLE, "JOB_ID" VARCHAR2(10) CONSTRAINT "EMP_JOB_NN" NOT NULL ENABLE, "SALARY" NUMBER(8,2), "COMMISSION_PCT" NUMBER(2,2), "MANAGER_ID" NUMBER(6,0), "DEPARTMENT_ID" NUMBER(4,0) );
前述の例で示したとおり、SEGMENT_ATTRIBUTES変換は、記憶域と表領域の両方の属性に適用されます。STORAGE句のみを省略して、TABLESPACE句を保持する場合は、STORAGE変換を次のように使用できます。
> impdp hr TABLES=hr.employees \ DIRECTORY=dpump_dir1 DUMPFILE=hr_emp.dmp \ TRANSFORM=STORAGE:n:table
SEGMENT_ATTRIBUTESおよびSTORAGE変換は、次のコマンドに示すとおり、TRANSFORMパラメータにオブジェクト型を指定しないことによって、すべての適用可能な表オブジェクトおよび索引オブジェクトに適用できます。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=hr.dmp \ SCHEMAS=hr TRANSFORM=SEGMENT_ATTRIBUTES:n
デフォルト: デフォルト値は設定されていません。
トランスポータブル・モード・インポート、またはTRANSPORTABLE=ALWAYSがエクスポート中に設定されている場合は表モードで、ターゲット・データベースにインポートするデータ・ファイルのリストを指定します。ソース・データベース・システムからターゲット・データベース・システムに、それらのファイルを事前にコピーしておく必要があります。
TRANSPORT_DATAFILES=datafile_name
datafile_nameには、ディレクトリ・オブジェクト名ではなく、ターゲット・データベースが存在するシステムで有効な絶対ディレクトリ・パスを指定する必要があります。
次に、TRANSPORT_DATAFILESパラメータの使用例を示します。TRANSPORT_DATAFILESの値は引用符で囲まれるため、コマンドラインでエスケープ文字を使用する必要がないように、パラメータ・ファイルを使用することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)次の内容のパラメータ・ファイルtrans_datafiles.parを作成したとします。
DIRECTORY=dpump_dir1 DUMPFILE=tts.dmp TRANSPORT_DATAFILES='/user01/data/tbs1.f'
次のコマンドを発行します。
> impdp hr PARFILE=trans_datafiles.par
デフォルト: n
指定したトランスポータブル表領域セットが他の表領域内のオブジェクトによって参照されていることを確認するかどうかを指定します。
TRANSPORT_FULL_CHECK={y | n}
TRANSPORT_FULL_CHECK=yを指定すると、インポート・ユーティリティによって、トランスポータブル・セットの内部にあるオブジェクトと外部にあるオブジェクトの間に依存性が存在しないことが確認されます。ここでは、双方向の依存性がチェックされます。たとえば、トランスポータブル・セット内に表は存在するが、その表の索引は存在しない場合は、エラーが返され、インポート操作が終了します。同様に、トランスポータブル・セット内に索引は存在するが表は存在しない場合も、エラーが返されます。
TRANSPORT_FULL_CHECK=nを指定すると、インポート・ユーティリティによって、トランスポータブル・セットの外部にあるオブジェクトの依存オブジェクトが、トランスポータブル・セット内に存在しないことのみ確認されます。ここでは、一方向の依存性がチェックされます。たとえば、表は索引に依存しませんが、索引は表に依存します。これは、索引は表なしでは意味を持たないためです。そのため、トランスポータブル・セット内に表は存在するが、表の索引は存在しない場合、このチェックは正常に終了します。ただし、トランスポータブル・セット内に索引は存在するが表は存在しない場合は、インポート操作が終了します。
このチェックに加えて、インポートでは、常に、TRANSPORT_TABLESPACESで指定された表領域セット内に定義されているすべての表(およびその索引)のすべての記憶域セグメントが、表領域セット内に実際に含まれていることが確認されます。
NETWORK_LINKパラメータを指定した場合にのみトランスポータブル・モード(またはTRANSPORTABLE=ALWAYSがエクスポート時に指定されていた場合は表モード)に対して有効です。
次の例では、source_database_linkを有効なデータベース・リンクの名前に置き換えます。また、この例では、tbs6.fというデータ・ファイルがすでに存在するものとします。
TRANSPORT_DATAFILESの値は引用符で囲まれるため、コマンドラインでエスケープ文字を使用する必要がないように、パラメータ・ファイルを使用することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)たとえば、次の内容のパラメータ・ファイルfull_check.parを作成したとします。
DIRECTORY=dpump_dir1 TRANSPORT_TABLESPACES=tbs_6 NETWORK_LINK=source_database_link TRANSPORT_FULL_CHECK=y TRANSPORT_DATAFILES='/wkdir/data/tbs6.f'
次のコマンドを発行します。
> impdp hr PARFILE=full_check.par
デフォルト: デフォルト値は設定されていません。
ネットワーク・リンクを介したトランスポータブル表領域モード・インポートの実行を指定します。
TRANSPORT_TABLESPACES=tablespace_name [, ...]
TRANSPORT_TABLESPACESパラメータは、ソース・データベースからターゲット・データベースにオブジェクト・メタデータがインポートされる表領域の名前のリストを指定するために使用します。
これはトランスポータブル・モード・インポートであるため、データのインポート先の表領域は、データ・ポンプによって自動的に作成されます。事前に表領域を作成しておく必要はありません。ただし、インポートを開始する前に、データ・ファイルをターゲット・データベースにコピーする必要があります。
TRANSPORT_TABLESPACESパラメータは、NETWORK_LINKパラメータも指定されている場合のみ有効です。
次の例では、source_database_linkを有効なデータベース・リンクの名前に置き換えます。また、この例では、tbs6.fというデータ・ファイルが、ソース・データベースからローカル・システムにすでにコピーされているものとします。TRANSPORT_DATAFILESの値は引用符で囲まれるため、コマンドラインでエスケープ文字を使用する必要がないように、パラメータ・ファイルを使用することをお薦めします。(詳細は、「データ・ポンプ・コマンドラインでの引用符の使用」を参照してください。)次の内容のパラメータ・ファイルtablespaces.parを作成したとします。
DIRECTORY=dpump_dir1 NETWORK_LINK=source_database_link TRANSPORT_TABLESPACES=tbs_6 TRANSPORT_FULL_CHECK=n TRANSPORT_DATAFILES='user01/data/tbs6.f'
次のコマンドを発行します。
> impdp hr PARFILE=tablespaces.par
デフォルト: NEVER
表モードのインポート(TABLESパラメータで指定)の実行時にトランスポータブル・オプションを使用するかどうかを指定します。
TRANSPORTABLE = {ALWAYS | NEVER}
使用可能な値の定義は、次のとおりです。
ALWAYS: インポート・ジョブでトランスポータブル・オプションを使用するように指示します。トランスポータブルが使用できない場合、ジョブは失敗します。
NEVER: インポート・ジョブでトランスポータブル・オプションではなくダイレクト・パスまたは外部表による方法を使用してデータをロードするように指示します。これがデフォルトです。
TRANSPORTABLEパラメータは、NETWORK_LINKパラメータも指定されている場合のみ有効です。
TRANSPORTABLEパラメータは、表モード・インポートでのみ有効です(表はパーティション化またはサブパーティション化されている必要はありません)。
TRANSPORTABLEパラメータをすべて使用するには、COMPATIBLE初期化パラメータを11.0.0以上に設定する必要があります。
次に、ネットワーク・リンク・インポート中にTRANSPORTABLEパラメータを使用した例を示します。
> impdp system TABLES=hr.sales TRANSPORTABLE=always DIRECTORY=dpump_dir1 NETWORK_LINK=dbs1 PARTITION_OPTIONS=departition TRANSPORT_DATAFILES=datafile_name
デフォルト: COMPATIBLE
インポートするデータベース・オブジェクトのバージョンを指定します。なお、これは、10.1より前のバージョンのOracle Databaseでデータ・ポンプ・インポートが使用可能ということではありません。データ・ポンプ・インポートは、Oracle Database 10g リリース1(10.1)以降でのみ動作します。VERSIONパラメータを使用して可能になるのは、インポートするオブジェクトのバージョンの識別のみです。
VERSION={COMPATIBLE | LATEST | version_string}
このパラメータは、ソース・システムのバージョンより古い互換バージョンのOracle Databaseが稼働しているターゲット・システムのロードに使用できます。指定したバージョンと互換性のないソース・システム上のデータベース・オブジェクトまたは属性はターゲットに移動されません。たとえば、指定したバージョンではサポートされていない新しいデータ型を含む表はインポートされません。このパラメータの有効な値は次のとおりです。
COMPATIBLE: デフォルト値。メタデータのバージョンは、データベースの互換性レベルに対応します。データベースの互換性は、9.2.0以上に設定する必要があります。
LATEST: メタデータのバージョンは、データベースのバージョンに対応します。
version_string: 特定のデータベース・バージョン(11.1.0など)。Oracle Database 11g の場合、9.2.0以上の値を指定する必要があります。次に、VERSIONパラメータの使用例を示します。この例では、ExportのFULLパラメータで示した例を実行して、expfull.dmpダンプ・ファイルを作成できます。詳細は、「FULL」を参照してください。
> impdp hr DIRECTORY=dpump_dir1 DUMPFILE=expfull.dmp TABLES=employees VERSION=LATEST
表3-2は、データ・ポンプ・インポート・パラメータをオリジナルのインポート・パラメータにできるかぎり正確にマップしたものです。機能の設計変更で、オリジナルのインポート・パラメータが不要になったため、対応するデータ・ポンプ・コマンドがない場合もあります。また、表に示すとおり、パラメータ名が同じ場合もありますが、機能は多少異なります。
対話方式コマンド・モードでは、現行のジョブは継続して続行されますが、端末へのロギングは一時停止され、インポート・プロンプト(Import>)が表示されます。
|
注意: データ・ポンプ・インポートの対話方式コマンド・モードは、オリジナルのインポート・ユーティリティの対話方式モードとは異なります。このモードでは、入力のためのプロンプトが表示されます。オリジナルのインポート・ユーティリティの対話方式モードについては、「対話方式モード」を参照してください。 |
対話方式コマンド・モードを開始するには、次のいずれかの方法を使用します。
ATTACHパラメータを使用してジョブに接続します。この機能は、ある場所で開始したジョブを、後で別の場所から確認する場合に有効です。
表3-3に、現行のジョブに対して対話方式コマンド・モードでデータ・ポンプ・インポート・プロンプトから実行できる操作を示します。
次の項では、データ・ポンプ・インポートの対話方式コマンド・モードで使用可能なコマンドについて説明します。
モードを、対話方式コマンド・モードからロギング・モードに変更します。
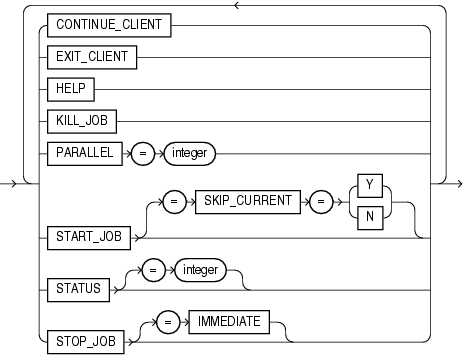
CONTINUE_CLIENT
ロギング・モードでは、ジョブの状態が端末に継続的に出力されます。ジョブが現在停止している場合、CONTINUE_CLIENTを指定すると、クライアントがジョブの開始を試みます。
Import> CONTINUE_CLIENT
インポート・クライアント・セッションを停止し、インポート・ユーティリティを終了して、端末へのロギングを中断します。ただし、現行のジョブの実行は続行します。
EXIT_CLIENT
EXIT_CLIENTでは、ジョブが実行されたままになるため、ジョブがまだ「実行中」または「停止」状態になっている場合は、後でこのジョブに接続できます。ジョブの状態を確認するには、ジョブのログ・ファイルを監視するか、USER_DATAPUMP_JOBSビューまたはV$SESSION_LONGOPSビューを問い合せることができます。
Import> EXIT_CLIENT
対話方式コマンド・モードで使用可能なデータ・ポンプ・インポート・コマンドの情報を表示します。
HELP
対話方式コマンド・モードで使用可能なコマンドの情報を表示します。
Import> HELP
現在接続中のすべてのクライアント・セッションを切断してから、現行のジョブを停止します。インポート・ユーティリティを終了し、端末プロンプトに戻します。
KILL_JOB
KILL_JOBを使用して中断されたジョブは、再開できません。接続中のすべてのクライアント(KILL_JOBコマンドを発行しているクライアントを含む)は、現在のユーザーがジョブを停止しているという警告を受け取った後、切断されます。すべてのクライアントが切断されると、ジョブのプロセス構造が即時に停止し、マスター表およびダンプ・ファイルが削除されます。ログ・ファイルは、削除されません。
Import> KILL_JOB
現行のジョブに対してアクティブなワーカー・プロセスまたはPQスレーブ(あるいはその両方)の数を増減できます。
PARALLEL=integer
PARALLELは、コマンドライン・パラメータおよび対話方式モードのパラメータとして使用可能です。必要な数のパラレル処理を設定できます。増加処理は、リソースが十分にありパラレル化を必要とする作業量が十分にある場合は、即時に実行されます。減少処理は、既存のプロセスが現行のタスクを終了してから実行されます。整数値を小さくすると、ワーカーはアイドル状態になりますが、ジョブが終了するまで削除はされません。
Import> PARALLEL=10
接続している現行のジョブを開始します。
START_JOB[=skip_current=y]
START_JOBコマンドは、(現在実行できない)接続中のジョブを再開します。ダンプ・ファイル・セットおよびマスター表が元のまま保持されている場合は、予期しない障害またはSTOP_JOBコマンドの発行後にデータの損失や破損なしにジョブが再開されます。
SKIP_CURRENTオプションは、以前一部のDDL文が失敗したために再開に失敗したジョブを再開できます。失敗する文はスキップされ、ジョブは次の項目から再開されます。
SQLFILEジョブもトランスポータブル表領域モード・インポートも再開できません。
Import> START_JOB
現行の操作の説明とともにジョブの状態を累積的に表示します。ジョブの完了率も返されます。
STATUS[=integer]
ロギング・モードでのこの状態の表示頻度を秒単位で指定できるオプションがあります。値を入力しなかった場合またはデフォルト値の0を使用した場合は、状態の定期表示はオフになり、状態は1回のみ表示されます。
この状態情報は、標準出力デバイスのみに書き込まれ、ログ・ファイルには(使用可能な場合でも)書き込まれません。
次に、現行のジョブの状態を表示し、ロギング・モードの表示間隔を2分(120秒)に変更する例を示します。
Import> STATUS=120
現行のジョブを即時にまたは手順に従って停止し、インポート・ユーティリティを終了します。
STOP_JOB[=IMMEDIATE]
STOP_JOBコマンド発行時または発行後にマスター表およびダンプ・ファイル・セットに障害が発生していない場合は、そのジョブに接続し、START_JOBコマンドを使用して再開できます。
手順に従って停止する場合は、関連する値を指定しないでSTOP_JOBを使用します。確認を要求する警告が発行されます。手順に従った停止では、ワーカー・プロセスで現行のタスクが終了した後、ジョブが停止されます。
即時に停止するには、STOP_JOB=IMMEDIATEを指定します。確認を要求する警告が発行されます。接続中のすべてのクライアント(STOP_JOBコマンドを発行しているクライアントを含む)は、現在のユーザーがジョブを停止および切断中であるという警告を受け取ります。すべてのクライアントが切断されると、ジョブのプロセス構造が即時に停止されます。マスター・プロセスは、ワーカー・プロセスで現行のタスクが終了するまで待機はしません。STOP_JOB=IMMEDIATEを指定した場合、データ破損やデータ損失の危険性はありません。ただし、停止時に完了しなかった一部のタスクは、再開時に再実行する必要があります。
Import> STOP_JOB=IMMEDIATE
この項では、データ・ポンプ・インポートの使用例を示します。
これらの例を正しく使用するために役立つ情報については、「インポート・パラメータの使用例」を参照してください。
例3-1に、employees表のデータのみ表モード・インポートの実行方法を示します。例2-1で作成されたダンプ・ファイルを使用します。
> impdp hr TABLES=employees CONTENT=DATA_ONLY DUMPFILE=dpump_dir1:table.dmp NOLOGFILE=y
CONTENT=DATA_ONLYパラメータは、すべてのデータベース・オブジェクト定義(メタデータ)をフィルタから除外します。表の行データのみロードされます。
例3-2に、例2-4で作成したダンプ・ファイル・セットのスキーマ・モード・インポートを示します。
> impdp hr SCHEMAS=hr DIRECTORY=dpump_dir1 DUMPFILE=expschema.dmp EXCLUDE=CONSTRAINT,REF_CONSTRAINT,INDEX TABLE_EXISTS_ACTION=REPLACE
EXCLUDEパラメータは、インポートしたメタデータをフィルタします。指定したインポート・モードでは、EXCLUDE文に指定されたオブジェクトを除き、ソースに含まれるすべてのオブジェクトおよびその依存オブジェクトが含まれます。オブジェクトが除外されると、そのオブジェクトのすべての依存オブジェクトも除外されます。TABLE_EXISTS_ACTION=REPLACEパラメータは、インポートに、すでに存在する場合は表を削除し、ダンプ・ファイルの内容を使用してその表を再作成してロードするように指定します。
例3-3では、ソースが、NETWORK_LINKパラメータで指定されたデータベースであるネットワーク・モード・インポートを実行します。
> impdp hr TABLES=employees REMAP_SCHEMA=hr:scott DIRECTORY=dpump_dir1 NETWORK_LINK=dblink
この例では、hrスキーマからscottスキーマへemployees表をインポートします。dblinkは、ターゲット・データベースとは異なるソース・データベースを示します。
スキーマを再マップするには、ユーザーhrに、ローカル・データベースのIMP_FULL_DATABASEロールおよびソース・データベースのEXP_FULL_DATABASEロールが必要です。
REMAP_SCHEMAは、ソース・スキーマにあるすべてのオブジェクトをターゲット・スキーマにロードします。
この項では、データ・ポンプ・インポートの構文図を示します。これらの構文図では、標準SQL構文の表記法を使用します。SQL構文の表記については、『Oracle Database SQL言語リファレンス』を参照してください。



|
 Copyright © 2007 Oracle Corporation. All Rights Reserved. |
|