| Oracle® Databaseセマンティク・テクノロジ開発者ガイド 11gリリース2 (11.2) E52974-01 |
|



 前 |
 次 |
Jena Adapter for Oracle Database (以降、Jena Adapter)は、既知のJenaグラフ、JenaモデルおよびJena DatasetGraphのAPIを実装することによって、Oracle Databaseセマンティク・テクノロジへのJavaベースのインタフェースを提供します。(Apache Jenaはオープン・ソースのフレームワークであり、そのライセンスと著作権条件についてはhttp://jena.sourceforge.net/license.htmlで説明されています。)
名前付きグラフ・データ(クワッドとも呼ぶ)の管理には、DatasetGraph APIを使用します。また、Jena Adapterは、Oracle Spatialのネットワーク・データ・モデルと統合することで、セマンティク・データでのネットワーク解析ファンクションを提供します。
この章では、第1章「Oracle Databaseセマンティク・テクノロジの概要」および第2章「OWLの概念」で説明されている主要な概念について十分に理解していることが前提です。Jena Javaフレームワークの全体的な機能および使用についても十分に理解していることを前提とします。Jenaフレームワークの詳細は、http://jena.apache.org/の、特に「Quick Links」の下にある「Documentation link」を参照してください。ネットワーク解析ファンクションを使用するには、『Oracle Spatialトポロジおよびネットワーク・データ・モデル開発者ガイド』に説明されているOracle Spatialのネットワーク・データ・モデルについても理解しておく必要があります。
Jena Adapterは、Oracle Databaseリリース11.2のRDFおよびOWLのセマンティク・データ管理機能を拡張します。
この章には次の主要なトピックがあります。
|
免責事項: 現行のJena Adapterリリースは、Jena 2.6.4、ARQ 2.8.8およびJoseki 3.4.4に対してテストされたものです。オープン・ソース・プロジェクトの性質上、これ以上のバージョンのJena、ARQまたはJosekiでは、このJena Adapterを使用しないでください。 |
Jena Adapterを使用するには、システム環境に必要なソフトウェア(Oracle Database 11gリリース2(SpatialオプションおよびPartitioningのオプションを含み、セマンティク・テクノロジのサポートが有効になっている)、Jenaバージョン2.6.4、Jena AdapterおよびJDK 1.6)があることを最初に確認する必要があります。次のアクションを実行することによって、ソフトウェア環境を設定できます。
Oracle Databaseリリース11.2 Enterprise Editionと、Oracle SpatialオプションおよびOracle Partitioningオプションをインストールします。
リリース11.2.0.3以上をまだインストールしていない場合は、Oracle Database Serverの11.2.0.2パッチ・セット(https://updates.oracle.com/Orion/PatchDetails/process_form?patch_num=10098816)をインストールします。
A.1項の説明のとおり、セマンティク・テクノロジのサポートを有効にします。
Jena (バージョン2.6.4)をインストールします(http://sourceforge.net/projects/jena/files/Jena/Jena-2.6.4/jena-2.6.4.zip/downloadから.zipファイルをダウンロードして解凍します)。(このファイルの解凍先となるディレクトリまたはフォルダは、<Jena_DIR>と表されます。)
Javaパッケージは<Jena_DIR>に解凍されます。
Jena 2.6.4にはARQバージョン2.8.7 (arq-2.8.7.jar)が付属していますが、実際は、このバージョンのJena Adapterには、より新しいARQバージョン(arq-2.8.8.jar)が必要です。http://sourceforge.net/projects/jena/files/ARQ/ARQ-2.8.8/arq-2.8.8.zip/downloadからarq-2.8.8.jarをダウンロードして、一時ディレクトリに解凍できます。<Jena_DIR>/Jena-2.6.4/lib/からarq-2.8.7.jarファイルを削除し、一時ディレクトリから<Jena_DIR>/Jena-2.6.4/lib/にarq-2.8.8.jarをコピーします。
Oracle Databaseセマンティク・テクノロジのページ(http://www.oracle.com/technetwork/database/options/semantic-tech/で「Downloads」をクリック)からJena Adapter (jena_adaptor_for_release11.2.0.3.zip)をダウンロード して、(Linuxシステムの) /tmp/jena_adapterなどの一時ディレクトリに解凍します。(この一時ディレクトリがまだ存在していない場合は、解凍操作の前に作成します。)
Jena Adapterのディレクトリとファイルの構造は、次のとおりです。
examples/
examples/Test10.java
examples/Test11.java
examples/Test12.java
examples/Test13.java
examples/Test14.java
examples/Test15.java
examples/Test16.java
examples/Test17.java
examples/Test18.java
examples/Test19.java
examples/Test20.java
examples/Test6.java
examples/Test7.java
examples/Test8.java
examples/Test9.java
examples/Test.java
jar/
jar/sdordfclient.jar
javadoc/
javadoc/javadoc.zip
joseki/
joseki/index.html
joseki/application.xml
joseki/update.html
joseki/xml-to-html.xsl
joseki/joseki-config.ttl
sparqlgateway/
default.xslt
noop.xslt
qb1.sparql
. . .
browse.jsp
index.html
. . .
application.xml
WEB-INF/
WEB-INF/web.xml
WEB-INF/weblogic.xml
WEB-INF/lib/
StyleSheets/
StyleSheets/paginator.css
StyleSheets/sg.css
StyleSheets/sgmin.css
Scripts/
Scripts/load.js
Scripts/paginator.js
Scripts/tooltip.js
admin/
admin/sparql.jsp
admin/xslt.jsp
web/
web/web.xml
ojdbc6.jarを<Jena_DIR>/lib (Linuxの場合)または<Jena_DIR>\lib (Windows)にコピーします。(ojdbc6.jarは、$ORACLE_HOME/jdbc/libまたは%ORACLE_HOME%\jdbc\libにあります。)
sdordf.jarを<Jena_DIR>/lib (Linuxの場合)または<Jena_DIR>\lib (Windows)にコピーします。(sdordf.jarは、$ORACLE_HOME/md/jlibまたは%ORACLE_HOME%\md\jlibにあります。)
JDK 1.6がまだインストールされていない場合は、インストールします。
JAVA_HOME環境変数にまだJDK 1.6インストールが指定されていない場合は、適切に定義します。次に例を示します。
setenv JAVA_HOME /usr/local/packages/jdk16/
SPARQLプロトコルをサポートするためのSPARQLサービスが設定されていない場合は、7.2項の説明のとおりに設定します。
ソフトウェア環境を設定した後、7.3項の説明にあるとおり、セマンティク・テクノロジ環境でJena Adapterを使用して問合せを実行できることを確認します。
Jena Adapterを使用してSPARQLエンドポイントを設定するには、Joseki (SPARQLプロトコルとSPARQL問合せをサポートするオープン・ソースのHTTPエンジン)をダウンロードする必要があります。この項では、WebLogic Serverにデプロイされるサーブレットを使用して、SPARQLサービスを設定する方法について説明します。Oracleではすべての依存するサードパーティ・ライブラリを.warまたは.earファイルにバンドルすることが許可されていないため、手順が多く複雑になっています。
Oracle WebLogic Server 11gリリース1 (10.3.1)をダウンロードしてインストールします。詳細は、http://www.oracle.com/technology/products/weblogic/およびhttp://www.oracle.com/technetwork/middleware/ias/downloads/wls-main-097127.htmlを参照してください。
Java 6がインストールされていることを確認します(Joseki 3.4.4に必要であるため)。
http://sourceforge.net/projects/joseki/files/Joseki-SPARQL/からJoseki 3.4.4 (joseki-3.4.4.zip)をダウンロードします。
joseki-3.4.4.zipを一時ディレクトリに解凍します。次に例を示します。
mkdir /tmp/joseki cp joseki-3.4.4.zip /tmp/joseki cd /tmp/joseki unzip joseki-3.4.4.zip
7.1項の説明にあるとおり、Jena Adapter for Oracle Databaseがダウンロードされ解凍されていることを確認します。
jena_adapterディレクトリと同じレベルにjoseki.warという名前のディレクトリを作成し、そのディレクトリに移動します。次に例を示します。
mkdir /tmp/joseki.war cd /tmp/joseki.war
前述の手順で作成したディレクトリに必要なファイルをコピーします。
cp /tmp/jena_adapter/joseki/* /tmp/joseki.war cp -rf /tmp/joseki/Joseki-3.4.4/webapps/joseki/StyleSheets /tmp/joseki.war
次のように、ディレクトリを作成し、必要なファイルをそれらのディレクトリにコピーします。
mkdir /tmp/joseki.war/WEB-INF cp /tmp/jena_adapter/web/* /tmp/joseki.war/WEB-INF mkdir /tmp/joseki.war/WEB-INF/lib cp /tmp/joseki/Joseki-3.4.4/lib/*.jar /tmp/joseki.war/WEB-INF/lib cp /tmp/jena_adapter/jar/*.jar /tmp/joseki.war/WEB-INF/lib ## ## Assume ORACLE_HOME points to the home directory of a Release 11.2.0.3 Oracle Database. ## cp $ORACLE_HOME/md/jlib/sdordf.jar /tmp/joseki.war/WEB-INF/lib cp $ORACLE_HOME/jdbc/lib/ojdbc6.jar /tmp/joseki.war/WEB-INF/lib
WebLogic Server管理コンソールを使用し、OracleSemDSという名前のJ2EEデータ・ソースを作成します。データ・ソースの作成中に、SPARQL問合せの実行対象になる関連セマンティク・データを含むデータベース・スキーマのユーザーとパスワードを指定できます。
このデータ・ソースの作成に関する情報は、7.2.1項「WebLogic Serverを使用した必要なデータ・ソースの作成」を参照してください。
次のように、WebLogic Serverのautodeployディレクトリに移動し、ファイルをコピーします。(開発ドメインでの自動デプロイ・アプリケーションの詳細は、http://docs.oracle.com/cd/E11035_01/wls100/deployment/autodeploy.htmlを参照してください。)
cd <domain_name>/autodeploy cp -rf /tmp/joseki.war <domain_name>/autodeploy
前述の例で、<domain_name>はWebLogic Serverドメインの名前です。
WebLogic Serverドメインを2つの異なるモード(開発とプロダクション)で実行することはできますが、自動デプロイメント機能を使用できるのは開発モードのみであることに注意してください。
ファイルとディレクトリの構造を調べて、次が反映されているかどうかを確認します。
. |-- META-INF | `-- MANIFEST.MF |-- StyleSheets | `-- joseki.css |-- WEB-INF | |-- lib | | |-- arq-2.8.8-tests.jar | | |-- arq-2.8.8.jar | | |-- icu4j-3.4.4.jar | | |-- iri-0.8.jar | | |-- jena-2.6.4-tests.jar | | |-- jena-2.6.4.jar | | |-- jetty-6.1.25.jar | | |-- jetty-util-6.1.25.jar | | |-- joseki-3.4.4.jar | | |-- junit-4.5.jar | | |-- log4j-1.2.14.jar | | |-- lucene-core-2.3.1.jar | | |-- ojdbc6.jar | | |-- sdb-1.3.4.jar | | |-- sdordf.jar | | |-- sdordfclient.jar | | |-- servlet-api-2.5-20081211.jar | | |-- slf4j-api-1.5.8.jar | | |-- slf4j-log4j12-1.5.8.jar | | |-- stax-api-1.0.1.jar | | |-- tdb-0.8.10.jar | | |-- wstx-asl-3.2.9.jar | | `-- xercesImpl-2.7.1.jar | `-- web.xml |-- application.xml |-- index.html |-- joseki-config.ttl |-- update.html `-- xml-to-html.xsl
/tmp/joseki.warディレクトリから.warファイルを作成する場合は(JosekiをOC4Jコンテナにデプロイする場合は、.warファイルが必要であることに注意します)、次のコマンドを入力します。
cd /tmp/joseki.war jar cvf /tmp/joseki_app.war *
WebLogic Serverを起動または再起動します。
Webブラウザを使用して、書式http://<hostname>:7001/josekiのURL (Webアプリケーションはポート7001でデプロイされているとします)に接続し、デプロイメントを確認します。
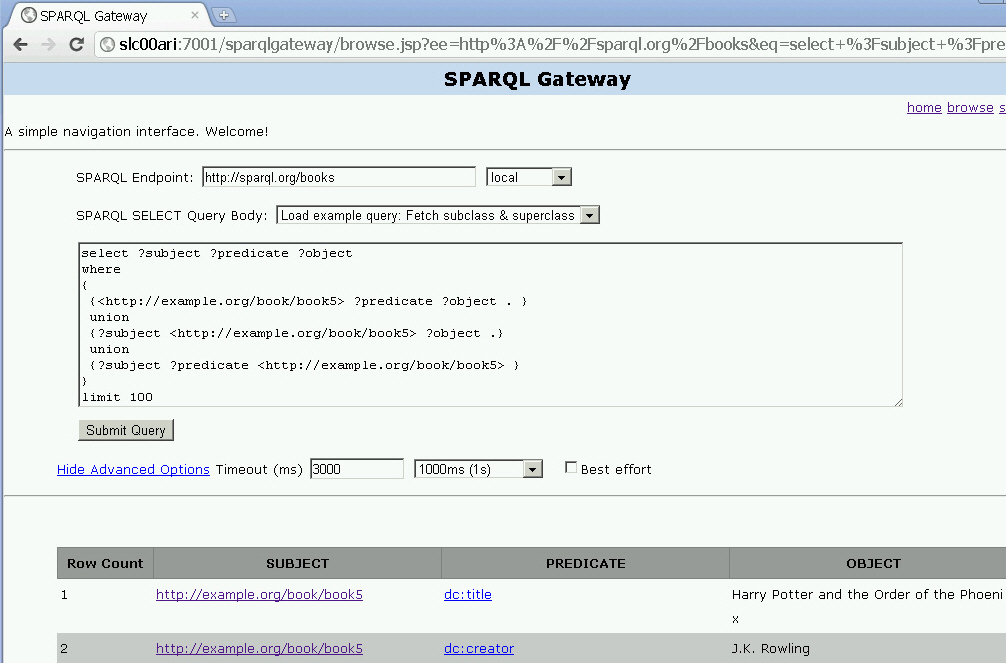
「Oracle SPARQL Service Endpoint using Joseki」というタイトルのページが表示され、最初のテキスト・ボックスにSPARQLの問合せ例が入力されています。
「Submit Query」をクリックします。
「Oracle SPARQL Endpoint Query Results」というタイトルのページが表示されます。問合せが実行される基礎となるセマンティク・モデルに応じて、結果がある場合とない場合があります。
デフォルトでは、joseki-config.ttlファイルには、M_NAMED_GRAPHSという名前のモデルを使用したoracle:Dataset定義が含まれます。次のスニペットは、構成を示しています。oracle:allGraphsの述語は、SPARQLサービス・エンドポイントがM_NAMED_GRAPHSモデルに格納されているすべてのグラフを使用して問合せを処理することを意味します。
<#oracle> rdf:type oracle:Dataset;
joseki:poolSize 1 ; ## Number of concurrent connections allowed to this dataset.
oracle:connection
[ a oracle:OracleConnection ;
];
oracle:allGraphs [ oracle:firstModel "M_NAMED_GRAPHS" ] .
M_NAMED_GRAPHSモデルがまだ存在しない場合は、初回のSPARQL問合せリクエスト時に自動的に作成されます。トリプルおよびクワッドの例をいくつか追加して、名前付きグラフ機能をテストできます。その例は次のとおりです。
SQL> CONNECT username/password
SQL> INSERT INTO m_named_graphs_tpl VALUES(sdo_rdf_triple_s('m_named_graphs','<urn:s>','<urn:p>','<urn:o>'));
SQL> INSERT INTO m_named_graphs_tpl VALUES(sdo_rdf_triple_s('m_named_graphs:<urn:G1>','<urn:g1_s>','<urn:g1_p>','<urn:g1_o>'));
SQL> INSERT INTO m_named_graphs_tpl VALUES(sdo_rdf_triple_s('m_named_graphs:<urn:G2>','<urn:g2_s>','<urn:g2_p>','<urn:g2_o>'));
SQL> COMMIT;
行を挿入した後、http://<hostname>:7001/josekiに移動し、次のSPARQL問合せを入力して、「Submit Query」をクリックします。
SELECT ?g ?s ?p ?o
WHERE
{ GRAPH ?g { ?s ?p ?o} }
結果は、4つの列と2つの結果バインディング・セットがあるHTML表になります。
http://<hostname>:7001/josekiページには、「JSON Output」オプションも含まれます。このオプションを選択する(有効にする)と、SPARQL問合せのレスポンスがJSON形式に変換されます。
WebLogic Server管理コンソールを使用して必要なJ2EEデータ・ソースを作成するには、次の手順に従います。
http://<hostname>:7001/consoleにログインします。
「ドメイン構造」パネルで、「サービス」をクリックします。
「JDBC」をクリックします。
「データ・ソース」をクリックします。
「JDBCデータ・ソースのサマリー」パネルで、「データ・ソース」表の下の「新規」をクリックします。
「新しいJDBCデータ・ソースの作成」パネルで、次の値を入力または選択します。
名前: OracleSemDS
JNDI名: OracleSemDS
データベースのタイプ: Oracle
データベース・ドライバ: Oracle's Driver (Thin) Versions: 9.0.1,9.2.0,10,11
「次」を2回クリックします。
「接続プロパティ」パネルで、「データベース名」、「ホスト名」、「ポート」、「データベース・ユーザー名」(セマンティク・データを含むスキーマ)、「パスワード」のフィールドに適切な値を入力します。
「次」をクリックします。
このOracleSemDSデータ・ソースをデプロイするターゲット・サーバー(1つまたは複数)を選択します。
「終了」をクリックします。
すべての変更がアクティブ化されており、再起動は必要ないというメッセージが表示されます。
デフォルトでは、SPARQLサービスのエンドポイントは、プリセット名を持つセマンティク・モデルに対して問合せが実行されることが前提になっています。このセマンティク・モデルは、JNDI名OracleSemDSを持つJ2EEデータ・ソースで指定されているスキーマに所有されています。このモデルはPL/SQLやJavaを使用して明示的に作成する必要はないことに注意してください(モデルがネットワークに存在しない場合は、必要なアプリケーション表や索引とあわせて自動的に作成されます)。
|
注意: 2011年11月のJena Adapterリリースから、アプリケーション表索引(<model_name>_idx)定義が、名前付きグラフ・データ(クワッド)に対応するように変更されました。以前のバージョンのJena Adapterで作成された既存のモデルについては、 |
ただし、<domain_name>/autodeploy/joseki.warに格納されているjoseki-config.ttl構成ファイルを編集することにより、SPARQLサービスを構成する必要があります。
用意されているjoseki-config.ttlファイルには、Oracleデータセット用に次のようなセクションが含まれます。
#
## Datasets
#
[] ja:loadClass "oracle.spatial.rdf.client.jena.assembler.OracleAssemblerVocab" .
oracle:Dataset rdfs:subClassOf ja:RDFDataset .
<#oracle> rdf:type oracle:Dataset;
joseki:poolSize 1 ; ## Number of concurrent connections allowed to this dataset.
oracle:connection
[ a oracle:OracleConnection ;
];
oracle:defaultModel [ oracle:firstModel "TEST_MODEL" ] .
ファイルのこのセクションでは、次のことができます。
joseki:poolSize値を変更します(この値は、データベース内の様々なRDFモデルをポイントする、このOracleデータセット(<#oracle> rdf:type oracle:Dataset;)に許可される同時接続数を指定します。)
問合せに対して異なるセマンティク・モデルを使用するために、defaultModelの名前(またはoracle:firstModel述語のオブジェクト値)を変更します。また、このdefaultModelに対して複数のモデルおよび1つ以上のルールベースを指定することもできます。
たとえば、次のように(ABOXとTBOXという名前の)2つのモデルとOWLPRIMEルールベースをデフォルトのモデルに対して指定できます。oracle:modelName述語を使用して指定されるモデルは存在している必要があることに注意します(これらのモデルは自動的には作成されません)。
<#oracle> rdf:type oracle:Dataset;
joseki:poolSize 1 ; ## Number of concurrent connections allowed to this dataset.
oracle:connection
[ a oracle:OracleConnection ;
];
oracle:defaultModel [ oracle:firstModel "ABOX";
oracle:modelName "TBOX";
oracle:rulebaseName "OWLPRIME" ] .
データセットで名前付きグラフを指定します。たとえば次のようにして、2つのOracleモデルと1つの伴意に基づき、<http://G1>と呼ばれる名前付きグラフを作成できます。
<#oracle> rdf:type oracle:Dataset;
joseki:poolSize 1 ; ## Number of concurrent connections allowed to this dataset.
oracle:connection
[ a oracle:OracleConnection ;
];
oracle:namedModel [ oracle:firstModel "ABOX";
oracle:modelName "TBOX";
oracle:rulebaseName "OWLPRIME";
oracle:namedModelURI <http://G1> ] .
namedModelオブジェクトには、defaultModelと同じ指定が可能であるため、仮想モデルがここでも同様にサポートされます(次の項目も参照)。
次の例に示すとおり、oracle:useVM "TRUE"を追加することによって、問合せに仮想モデルを使用します。指定した仮想モデルが存在しない場合は、必要に応じて自動的に作成されることに注意してください。
<#oracle> rdf:type oracle:Dataset;
joseki:poolSize 1 ; ## Number of concurrent connections allowed to this dataset.
oracle:connection
[ a oracle:OracleConnection ;
];
oracle:defaultModel [ oracle:firstModel "ABOX";
oracle:modelName "TBOX";
oracle:rulebaseName "OWLPRIME";
oracle:useVM "TRUE"
] .
詳細は、7.10.1項「仮想モデルのサポート」を参照してください。
次のTRIPLE_DATA_VM_0という名前の仮想モデルを使用する例に示すとおり、述語oracle:virtualModelNameを使用することで、SPARQL問合せに応答するためのデフォルトのモデルとして仮想モデルを指定します。
oracle:defaultModel [ oracle:virtualModelName "TRIPLE_DATA_VM_0" ] .
基礎となるデータがクワッドで構成される場合、oracle:virtualModelNameとともにoracle:allGraphsを使用できます。oracle:allGraphsを使用することで、DatasetGraphOracleSemオブジェクトのインスタンス化が名前付きグラフ問合せへの応答になります。次に例を示します。
oracle:allGraphs [ oracle:virtualModelName "QUAD_DATA_VM_0" ] .
仮想モデル名がデフォルトのグラフとして指定されると、エンドポイントは問合せリクエストのみに対応し、SPARQL更新操作はサポートされないことに注意してください。
問合せの動作と推定更新モードを変更するには、queryOptionsとinferenceMaintenanceプロパティを設定します。(QueryOptionsとInferenceMaintenanceModeの詳細は、Javadocを参照してください。)
デフォルトでは、問合せの柔軟性と効率を最大限にするため、QueryOptions.ALLOW_QUERY_INVALID_AND_DUPとInferenceMaintenanceMode.NO_UPDATEが設定されます。
Jena Adapterによって作成または使用されたデータベース接続ごとに、クライアント識別子が関連付けられます。クライアント識別子は、特にReal Application Cluster (Oracle RAC)環境で、パフォーマンス分析とチューニングを実行しているときに、他のデータベース・アクティビティからJena Adapter関連のアクティビティを分離するために役立ちます。
デフォルトで割り当てられるクライアント識別子は、JenaAdapterです。ただし、次の形式を使用してJava VM clientIdentifierプロパティを設定することによって、異なる値を指定できます。
-Doracle.spatial.rdf.client.jena.clientIdentifier=<identificationString>
データベース側でJena Adapter関連のアクティビティのみのトレースを開始するには、DBMS_MONITOR.CLIENT_ID_TRACE_ENABLEプロシージャを使用します。次に例を示します。
SQL> EXECUTE DBMS_MONITOR.CLIENT_ID_TRACE_ENABLE('JenaAdapter', true, true);
デフォルトでは、Jena Adapterは、次の構文に従った基本的な表圧縮を使用して、アプリケーション表と任意のステージング表(後者は7.11項で説明されているようにバルク・ロードに使用される)を作成します。
CREATE TABLE .... (... column definitions ...) ... compress;
ただし、データベースにOracle Advanced Compressionオプションの使用がライセンスされている場合は、次のJVMプロパティを設定してOLTP圧縮をオンにできますので、これによって基礎となるアプリケーション表とステージング表に対するすべてのDML操作時にデータが圧縮されます。
-Doracle.spatial.rdf.client.jena.advancedCompression="compress for oltp"
一部のアプリケーションでは長時間にわたるSPARQL問合せを終了できるようにする必要があるため、Jena AdapterとJosekiの設定で強制終了のフレームワークが導入されています。基本的に、実行に時間がかかる可能性がある問合せに対しては、それぞれに一意の問合せID (qid)値を指定する必要があります。
たとえば、次のSPARQL問合せでは、すべてのトリプルの主語を選択します。リクエストに応じてこの問合せを終了できるように、問合せID (qid)が設定されます。
PREFIX ORACLE_SEM_FS_NS: <http://example.com/semtech#qid=8761>
SELECT ?subject WHERE {?subject ?property ?object }
qid属性値は、長整数型です。qidの値は、独自のアプリケーション・ニーズに基づき、特定の問合せにあわせて選択できます。
qid値とともに送信されたSPARQL問合せを終了するには、アプリケーションから次の形式で強制終了リクエストをサーブレットに送信し、一致するQID値を指定します。
http://<hostname>:7001/joseki/querymgt?abortqid=8761
RDFリソースの字句表現において、文字がOracle Databaseに挿入される際に、非ASCII文字に対して\uHHHH N-Tripleエンコーディングが使用されます。(N-Tripleエンコーディングの詳細は、http://www.w3.org/TR/rdf-testcases/#ntrip_grammarを参照してください。)SPARQL問合せにおける定数リソースのエンコーディングは、同じように処理されます。
\uHHHH N-Tripleエンコーディングを使用することによって、サポートされるUnicodeキャラクタ・セットがOracle Databaseで使用されていない場合でも、国際的な文字(ノルウェー語とスウェーデンの文字の混在など)のサポートが可能になります。
Jena Adapterを使用して問合せを実行するには、(適切な権限を持つ)任意のユーザーで接続し、セマンティク・ネットワークで任意のモデルを使用します。セマンティク・テクノロジ環境が要件をすでに満たしている場合は、Jena Adapterを使用するJavaコードを直接コンパイルして実行できます。Jena Adapterを使用できるようにセマンティク・テクノロジ環境を設定していない場合は、次の例のような手順を実行します。
SYSDBAロールを持つSYSとして接続します。
sqlplus sys/<password-for-sys> as sysdba
システム表の表領域を作成します。次に例を示します。
CREATE TABLESPACE rdf_users datafile 'rdf_users01.dbf'
size 128M reuse autoextend on next 64M
maxsize unlimited segment space management auto;
セマンティク・ネットワークを作成します。次に例を示します。
EXECUTE sem_apis.create_sem_network('RDF_USERS');
(セマンティク・ネットワークとJena Adapterを使用するデータベースに接続するための)データベース・ユーザーを作成します。次に例を示します。
CREATE USER rdfusr IDENTIFIED BY <password-for-udfusr>
DEFAULT TABLESPACE rdf_users;
このデータベース・ユーザーに必要な権限を付与します。次に例を示します。
GRANT connect, resource TO rdfusr;
独自のセマンティク・データとともにJena Adapterを使用するには、1.10項「セマンティク・データを使用するためのクイック・スタート」の説明のとおり、適切な手順を実行してデータを格納し、モデルを作成して、データベース索引を作成します。その後、Javaコードをコンパイルして実行することで問合せを実行します(問合せの例については、7.15項を参照してください)。
Jena Adapterと提供されたサンプル・データを使用する場合は、7.15項を参照してください。
Oracle Databaseに格納されているセマンティク・データを問い合せるには、SEM_MATCHベースのSQL文と、Jena Adapterを介したSPARQL問合せの2つの方法があります。それぞれの方法での問合せは、表面的には類似していますが、動作には重要な違いがあります。アプリケーションの動作を一貫性のあるものにするには、SEM_MATCH問合せとSPARQL問合せの違いを理解し、その問合せ結果を処理する際に注意を払う必要があります。
2つの方法を次の簡単な例で示します。
問合せ1 (SEM_MATCHベース)
select s, p, o
from table(sem_match('{?s ?p ?o}', sem_models('Test_Model'), ....))
問合せ2 (Jena Adapterを介したSPARQL問合せ)
select ?s ?p ?o
where {?s ?p ?o}
これらの2つの問合せは、同じ種類の機能を実行しますが、いくつか重要な違いがあります。問合せ1 (SEM_MATCHベース)は次のようになります。
Test_Modelからすべてのトリプルを読み取ります。
URI、bNode、プレーン・リテラルおよび型付きリテラルを区別せず、長いリテラルを処理しません。
特定の文字('\n'など)はエスケープ解除しません。
問合せ2 (Jena Adapterを介して実行されるSPARQL問合せ)もTest_Modelからすべてのトリプルを読み取ります(同じ基礎となるTest_Modelを参照しているModelOracleSemに対してコールを実行したと想定します)。ただし、問合せ2は次のようになります。
(SEM_MATCHテーブル・ファンクションにおけるs、pおよびo列のみではなく)追加の列を読み取り、URI、bNodes、プレーン・リテラル、型付きリテラルおよび長いリテラルを区別します。これによって、Jena Nodeオブジェクトを適切に作成できるようになります。
Oracle Databaseに格納される際にエスケープされる文字をエスケープ解除します。
2つの方法でのもう1つの違いは、空白ノード処理です。
SEM_MATCHベースの問合せにおいて、空白ノードは常に定数とみなされます。
SPARQL問合せにおいて、<と>で囲まれていない空白ノードは、問合せがJena Adapterを介して実行されるときに変数とみなされます。これは、SPARQL標準セマンティクと一致します。ただし、<と>で囲まれた空白ノードは、問合せが実行されるときに定数とみなされ、空白ノード・ラベルには、基礎となるデータのモデル化で必要とされる適切な接頭辞が、Jena Adapterによって追加されます。
Jena Adapter APIを使用して作成されるセマンティク・モデルの名前の最大長は、22文字です。
この項では、SPARQL問合せ処理を強化できる、Jena Adapterのいくつかのパフォーマンス関連機能について説明します。これらの機能は、デフォルトでは自動的に実行されます。
この項では、CONSTRUCT機能やプロパティ・パスなど、SPARQLについての知識があることを前提としています。
DISTINCT、OPTIONAL、FILTER、UNION、ORDER BYおよびLIMITを含むSPARQL問合せは、単一のOracle SEM_MATCHテーブル・ファンクションに変換されます。SEM_MATCHでサポートされないSPARQL機能(CONSTRUCTなど)を使用しているために、問合せを直接SEM_MATCHに変換できない場合、Jena Adapterは、ハイブリッドな方法を採用し、単一のSEM_MATCHファンクションを使用して問合せの最も大きな部分を実行しながら、Jena ARQ問合せエンジンを使用して残りの部分の実行を試みます。
たとえば、次のSPARQL問合せは、単一のSEM_MATCHテーブル・ファンクションに直接変換されます。
PREFIX dc: <http://purl.org/dc/elements/1.1/>
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?person ?name
WHERE {
{?alice foaf:knows ?person . }
UNION {
?person ?p ?name. OPTIONAL { ?person ?x ?name1 }
}
}
一方、次の問合せ例は、CONSTRUCTキーワードのため、単一のSEM_MATCHテーブル・ファンクションに直接変換できません。
PREFIX vcard: <http://www.w3.org/2001/vcard-rdf/3.0#>
CONSTRUCT { <http://example.org/person#Alice> vcard:FN ?obj }
WHERE { { ?x <http://pred/a> ?obj.}
UNION
{ ?x <http://pred/b> ?obj.} }
この場合、Jena Adapterは、内側のUNION問合せを単一のSEM_MATCHテーブル・ファンクションに変換し、次にその結果セットをさらに評価するため、Jena ARQ問合せエンジンに渡します。
Jenaに定義されているとおり、プロパティ・パスは2つのグラフ・ノード間でRDFグラフを介して使用可能なルートです。プロパティ・パスはSPARQLの拡張機能であり、RDFグラフのパターン・マッチングでプロパティに正規表現を使用できるため、基本的なグラフ・パターン問合せよりも表現力が豊かです。プロパティ・パスの詳細は、Jena ARQ問合せエンジンのドキュメントを参照してください。
Jena Adapterは、Jena ARQ問合せエンジンとの統合によって、すべてのJenaプロパティ・パス・タイプをサポートしますが、いくつかの一般的なパス・タイプは、パフォーマンスを向上するため、(SEM_MATCHベースではない)ネイティブSQL階層問合せに直接変換されます。次のタイプのプロパティ・パスは、トリプル・データを処理する際、Jena AdapterによってSQLに直接変換されます。
述語選択肢: (p1 | p2 | … | pn) piはプロパティURIです。
述語順序: (p1 / p2 / … / pn) piはプロパティURIです。
逆パス: ( ^ p ) pは述語URIです。
複雑なパス: p+、p*、p{0, n} pは選択肢、順序、逆パスまたはプロパティURIです。
この文法で対応できないパス表現は、Jena AdapterによってSQLに直接変換することができず、Jena問合せエンジンを使用して応答されます。
次の例では、パス順序を使用したプロパティ・パス表現を使用するコード・スニペットが含まれます。
String m = "PROP_PATH";
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, m);
GraphOracleSem graph = new GraphOracleSem(oracle, m);
// populate the RDF Graph
graph.add(Triple.create(Node.createURI("http://a"),
Node.createURI("http://p1"),
Node.createURI("http://b")));
graph.add(Triple.create(Node.createURI("http://b"),
Node.createURI("http://p2"),
Node.createURI("http://c")));
graph.add(Triple.create(Node.createURI("http://c"),
Node.createURI("http://p5"),
Node.createURI("http://d")));
String query =
" SELECT ?s " +
" WHERE {?s (<http://p1>/<http://p2>/<http://p5>)+ <http://d>.}";
QueryExecution qexec =
QueryExecutionFactory.create(QueryFactory.create(query,
Syntax.syntaxARQ), model);
try {
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(System.out, results);
}
finally {
if (qexec != null)
qexec.close();
}
OracleUtils.dropSemanticModel(oracle, m);
model.close();
Jena Adapterにより、ヒントや追加の問合せオプションを渡すことができます。問合せオプションを含むOracle固有の名前空間を使用してSPARQL名前空間接頭辞の構文をオーバーロードすることで、これらの機能を実装できます。名前空間の形式はPREFIX ORACLE_SEM_xx_NSであり、xxの部分に機能のタイプ(ヒントならHT、APなら追加の述語など)が表されています。
SQLヒントは、次の形式の行を含むSEM_MATCH問合せに渡すことができます。
PREFIX ORACLE_SEM_HT_NS: <http://oracle.com/semtech#hint>
ここでのhintは、SEM_MATCHによってサポートされる任意のヒントです。次に例を示します。
PREFIX ORACLE_SEM_HT_NS: <http://oracle.com/semtech#leading(t0,t1)>
SELECT ?book ?title ?isbn
WHERE { ?book <http://title> ?title. ?book <http://ISBN> ?isbn }
この例で、t0,t1は、問合せの1番目と2番目のパターンを指します。
SEM_MATCHと比較すると、ヒントの指定に若干違いがあることに注意してください。名前空間の値の構文の制限により、t0とt1 (または他のヒント・コンポーネント)を区切るには、空白ではなく、カンマ(,)を使用する必要があります。
SQLヒントの使用の詳細は、1.6項「SEM_MATCHテーブル・ファンクションを使用したセマンティク・データの問合せ」、特にoptions属性でのHINT0キーワードに関する資料を参照してください。
Oracle Databaseでバインド変数を使用すると、問合せの解析時間を削減し、問合せ効率と同時実行性を向上させることができます。SPARQL問合せにおけるバインド変数のサポートは、ORACLE_SEM_FS_NSと同様の名前空間プラグマ指定を通して提供されます。
アプリケーションが2つのSPARQL問合せを実行する事例について考えます(2番目(問合せ2)は、1番目(問合せ1)の結果の一部または全部に応じて異なります)。バインド変数を必要としないいくつかの方法を次に示します。
問合せ1の結果を繰り返して、1組の問合せを生成します。(ただし、この方法は、問合せ1の結果の数と同数の問合せを必要とします。)
問合せ1の結果に基づいて、SPARQLフィルタ式を構築します。
問合せ1を副問合せとみなします。
この場合のもう1つの方法は、次のサンプル・シナリオのように、バインド変数を使用することです。
Query 1: SELECT ?x WHERE { ... <some complex query> ... }; Query 2: SELECT ?subject ?x WHERE {?subject <urn:related> ?x .};
次の例は、Jena Adapterでバインド変数を使用するための構文を含む問合せ2を示します。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#no_fall_back,s2s> PREFIX ORACLE_SEM_UEAP_NS: <http://oracle.com/semtech#x$RDFVID%20in(?,?,?)> PREFIX ORACLE_SEM_UEPJ_NS: <http://oracle.com/semtech#x$RDFVID> PREFIX ORACLE_SEM_UEBV_NS: <http://oracle.com/semtech#1,2,3> SELECT ?subject ?x WHERE { ?subject <urn:related> ?x };
この構文では、次の名前空間が使用されています。
ORACLE_SEM_UEAP_NSはORACLE_SEM_AP_NSと同様ですが、ORACLE_SEM_UEAP_NSの値の部分はURLエンコードされています。値の部分は、使用する前にURLデコードされている必要があり、それによってSPARQL問合せへの追加述語とみなされます。
この例では、URLデコードの後に、このORACLE_SEM_UEAP_NS接頭辞の値部分(#文字の後)が「x$RDFVID in(?,?,?)」になります。3つの疑問符は、問合せ1の3つの値に対する暗黙的なバインディングを示します。
ORACLE_SEM_UEPJ_NSは、関係する追加の投影を指定します。この場合、ORACLE_SEM_UEAP_NSがx$RDFVID列(問合せのSELECT句には出現しません)を参照するため、指定する必要があります。複数の投影は、カンマで区切ります。
ORACLE_SEM_UEBV_NSは、最初にURLエンコードされ、次に連結されてカンマで区切られたバインド値のリストを指定します。
前述の問合せ例は、次の非SPARQL構文の問合せと概念的に同じであり、1、2および3はバインド値とみなされます。
SELECT ?subject ?x
WHERE {
?subject <urn:related> ?x
}
AND ?x$RDFVID in (1,2,3);
前述の問合せ2のSPARQLの例では、3つの整数1、2および3は問合せ1からのものです。oext:build-uri-for-idファンクションを使用して、そのような内部の整数IDをRDFリソースのために生成できます。次の例は、問合せ1からの内部整数IDを取得します。
PREFIX oext: <http://oracle.com/semtech/jena-adaptor/ext/function#> SELECT ?x (oext:build-uri-for-id(?x) as ?xid) WHERE { ... <some complex query> ... };
?xidの値は、<rdfvid:integer-value>の形式です。アプリケーションは、山カッコと文字列rdfvid:を無視して整数値を取り出し、これらを問合せ2に渡します。
もう1つの例として、単一の問合せ構造だが、多数の異なる定数がある可能性がある場合について考えてみます。たとえば、次のSPARQL問合せは、趣味を持っており、アプリケーションにログインしている各ユーザーの趣味を検索します。アプリケーションのユーザーは異なるURIを使用して表現されるため、このSPARQL問合せに対して様々なユーザーから様々な<uri>値が提供されます。
SELECT ?hobby
WHERE { <uri> <urn:hasHobby> ?hobby };
1つの方法(バインド変数を使用しない)は、異なる<uri>値ごとに異なるSPARQL問合せを生成することです。たとえば、ユーザーJane Doeが、次のSPARQL問合せの実行をトリガーするとします。
SELECT ?hobby WHERE {
<http://www.example.com/Jane_Doe> <urn:hasHobby> ?hobby };
一方、もう1つの方法は、ユーザーJane Doeを指定している次の例のように、バインド変数を使用することです。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#no_fall_back,s2s>
PREFIX ORACLE_SEM_UEAP_NS: <http://oracle.com/semtech#subject$RDFVID%20in(ORACLE_ORARDF_RES2VID(?))>
PREFIX ORACLE_SEM_UEPJ_NS: <http://oracle.com/semtech#subject$RDFVID>
PREFIX ORACLE_SEM_UEBV_NS: <http://oracle.com/semtech#http%3a%2f%2fwww.example.com%2fJohn_Doe>
SELECT ?subject ?hobby
WHERE {
?subject <urn:hasHobby> ?hobby
};
前述の問合せ例は、次の非SPARQL構文の問合せと概念的に同じであり、http://www.example.com/Jane_Doeはバインド変数とみなされます。
SELECT ?subject ?hobby
WHERE {
?subject <urn:hasHobby> ?hobby
}
AND ?subject$RDFVID in (ORACLE_ORARDF_RES2VID('http://www.example.com/Jane_Doe'));
この例で、ORACLE_ORARDF_RES2VIDは、URIとリテラルを内部整数ID表現に変換するファンクションです。このファンクションは、Oracle Databaseへの接続にJena Adapterが使用される際、自動的に作成されます。
SEM_MATCH filter属性は、WHEREキーワードのないWHERE句の形式の文字列として、追加の選択基準を指定できます。追加のWHERE句述語は、次の形式の行を含むSEM_MATCH問合せに渡すことができます。
PREFIX ORACLE_SEM_AP_NS: <http://oracle.com/semtech#pred>
predは、問合せに追加されるWHERE句の内容を反映します。次に例を示します。
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX ORACLE_SEM_AP_NS:<http://www.oracle.com/semtech#label$RDFLANG='fr'>
SELECT DISTINCT ?inst ?label
WHERE { ?inst a <http://someCLass>. ?inst rdfs:label ?label . }
ORDER BY (?label) LIMIT 20
この例では、ラベル変数の言語タイプが'fr'である必要がある問合せに、制限事項が追加されます。
追加の問合せオプションは、次の形式の行を含むSEM_MATCH問合せに渡すことができます。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#option>
optionは、問合せに追加される問合せオプション(またはカンマで区切られた複数の問合せオプション)を反映します。次に例を示します。
PREFIX ORACLE_SEM_FS_NS:
<http://oracle.com/semtech#timeout=3,dop=4,INF_ONLY,ORDERED,ALLOW_DUP=T>
SELECT * WHERE {?subject ?property ?object }
次の問合せオプションがサポートされています。
ALLOW_DUP=tは、結果が重複する場合がありますが、複数のセマンティク・モデルを問い合せるための、より高速な方法を選択します。
TIMEOUT=nオプションを使用する場合、BEST_EFFORT_QUERY=tは、SPARQL問合せに対してn秒以内に検出されるすべての一致を戻します。
DEGREE=nは、問合せに対して並列度(n)を文レベルで指定します。マルチコアまたはマルチCPUのプロセッサでは、異なるDOP値(4または8など)を試すと、パフォーマンスが向上する場合があります。
DEGREEと比較すると、DOPはセッション・レベルで並列度を指定します。DEGREEはDOPよりも処理オーバーヘッドが少ないため、Jena Adapterでの使用にはDEGREEが推奨されます。
DOP=nは、問合せに対して並列度(n)をセッション・レベルで指定します。マルチコアまたはマルチCPUのプロセッサでは、異なるDOP値(4または8など)を試すと、パフォーマンスが向上する場合があります。
INF_ONLYを指定すると、推論されたモデルのみが問い合せられます。
JENA_EXECUTORは、SEM_MATCH (またはネイティブSQL)に対してSPARQL問合せのコンパイルを無効にし、かわりにJenaネイティブ問合せエグゼキュータが使用されます。
JOIN=nは、SPARQL SERVICEコールからフェデレーテッド問合せへの結果を、どのように問合せの他の部分と結合できるかを指定します。フェデレーテッド問合せとJOINオプションの詳細は、7.6.4.1項を参照してください。
NO_FALL_BACKは、SQL例外が発生した場合に、基礎となる問合せ実行エンジンがJena実行メカニズムにフォール・バックしないようにします。
ODS=nは、動的なサンプリングのレベルを、文レベルで指定します。(動的なサンプリングの説明については、『Oracle Databaseパフォーマンス・チューニング・ガイド』の動的なサンプリングによる統計の見積りに関する説明を参照してください。)nの有効値は1から10までです。たとえば、複雑な問合せにはODS=3を試すことができます。
ORDEREDは、最後に必要なRDF_VALUE$結合を実行している間、問合せトリプル・パターン結合のために主要なSQLヒントに変換されます。
PLAIN_SQL_OPT=Fは、問合せを直接SQLにネイティブ・コンパイルする機能を無効にします。
QID=nは、問合せID番号を指定します(この機能は、問合せに応答がない場合、その問合せを取り消すために使用できます)。
RESULT_CACHEは、問合せにOracle RESULT_CACHEディレクティブを使用します。
REWRITE=Fは、SEM_MATCHテーブル・ファンクションに対してODCI_Table_Rewriteを無効にします。
SKIP_CLOB=Tは、問合せに対してCLOB値が戻されないようにします。
S2S (SPARQL to pure SQL)は、基礎となるSEM_MATCHベースの問合せ、またはSPARQL問合せに基づいて生成された問合せを、SEM_MATCHテーブル・ファンクションを使用しないで、さらにSQL問合せに変換します。結果として生成されたSQL問合せはOracleコストベース・オプティマイザによって実行され、その結果はクライアントに渡される前にJena Adapterによって処理されます。S2Sオプションの利点と使用方法などの詳細は、7.6.4.2項を参照してください。
S2Sは、すべてのSPARQL問合せに対してデフォルトで有効化されています。S2Sを無効にするには、次のJVMシステム・プロパティを設定します。
-Doracle.spatial.rdf.client.jena.defaultS2S=false
TIMEOUT=n (問合せタイムアウト)は、問合せが終了されるまでに実行される秒数(n)を指定します。SPARQL問合せから生成される基礎となるSQLは、多数の一致を戻し、副問合せおよび割当てと同様の機能を使用することができ、これらのすべてには、多くの時間がかかることがあります。TIMEOUTオプションとBEST_EFFORT_QUERY=tオプションは、問合せに過度な処理時間がかからないようにするために使用できます。
SPARQLフェデレーテッド問合せは、W3Cドキュメントの説明のとおり、分散データ上の問合せであり、そのために、1つのソースを問い合せて、取得した情報を使用して次のソースの問合せを制約します。詳細は、SPARQL 1.1 Federation Extensions (http://www.w3.org/2009/sparql/docs/fed/service)を参照してください。
JOINオプション(7.6.4項を参照)とSERVICEキーワードは、Jena Adapterを使用するフェデレーテッド問合せで使用できます。たとえば、次の問合せを考えてみます。
SELECT ?s ?s1 ?o
WHERE { ?s1 ?p1 ?s .
{
SERVICE <http://sparql.org/books> { ?s ?p ?o }
}
}
ローカルの問合せ部分(?s1 ?p1 ?s,)が非常に選択的である場合、次の問合せに示すように、join=2を指定します。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#join=2>
SELECT ?s ?s1 ?o
WHERE { ?s1 ?p1 ?s .
{
SERVICE <http://sparql.org/books> { ?s ?p ?o }
}
}
この場合、ローカルの問合せ部(?s1 ?p1 ?s,)は、Oracle Databaseに対してローカルに実行されます。その後、結果からの?sの各バインディングは、SERVICE部分(リモート問合せ部)にプッシュされ、コールはエンドポイントが指定したサービスに行われます。この方法は、概念的にはネステッド・ループ結合と似ています。
リモートの問合せ部(?s ?s1 ?o)が非常に選択的である場合、次の問合せに示すように、join=3を指定することで、リモート部分は最初に実行され、結果はローカルの部分の実行をドライブするために使用されます。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#join=3>
SELECT ?s ?s1 ?o
WHERE { ?s1 ?p1 ?s .
{
SERVICE <http://sparql.org/books> { ?s ?p ?o }
}
}
この場合、単一のコールはリモートのサービス・エンドポイントに対して行われ、?sの各バインディングは、ローカルの問合せをトリガーします。join=2と同様に、この方法は概念的にはネステッド・ループ・ベースの結合ですが、違いは順序が切り替えられるということです。
ローカルの問合せ部もリモートの問合せ部もあまり選択的でない場合、次の問合せに示すように、join=1を選択できます。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#join=1>
SELECT ?s ?s1 ?o
WHERE { ?s1 ?p1 ?s .
{
SERVICE <http://sparql.org/books> { ?s ?p ?o }
}
}
この場合、リモートの問合せ部とローカルの部分は独立して実行され、結果はJenaによって結合されます。この方法は、概念的にはハッシュ結合と似ています。
フェデレーテッド問合せをデバッグまたはトレースするには、Oracle JDeveloperのHTTPアナライザを使用して、基礎となるSERVICEコールを調べます。
S2Sオプション(7.6.4項参照)には、潜在的に次の利点があります。
RESULT_CACHEオプションと連携し、問合せパフォーマンスを向上します。S2SとRESULT_CACHEオプションを使用すると、頻繁に実行される問合せに対して特に有用です。
SEM_MATCHテーブル・ファンクションの解析時間を削減し、多くの動的に生成されたSPARQL問合せを含むアプリケーションに有用です。
問合せ本体の4000バイトの制限(SEM_MATCHテーブル・ファンクションの最初のパラメータ)を除外し、より長く複雑な問合せがサポートされます。
S2Sオプションは、内部のインメモリー・キャッシュを、変換されたSQL問合せ文で使用されるようにします。この内部キャッシュのデフォルト・サイズは1024(つまり1024のSQL問合せ)ですが、サイズは、次のJava VMプロパティを使用して調整できます。
-Doracle.spatial.rdf.client.jena.queryCacheSize=<size>
セマンティク・データが格納されると、すべてのリソース値がIDにハッシュされ、トリプル表に格納されます。値IDからの完全なリソース値へのマッピングは、MDSYS.RDF_VALUE$表に格納されます。問合せ時、選択された変数ごとにOracle DatabaseでRDF_VALUE$表による結合を実行し、リソースを取得する必要があります。
ただし、結合の数を減らすため、中間層キャッシュ・オプションを使用して、値IDとリソース値の間のマッピングを格納するために中間層でのインメモリー・キャッシュが使用されるようにできます。この機能を使用するには、SPARQL問合せに次のPREFIXプラグマを含めます。
PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#midtier_cache>
インメモリー・キャッシュの最大サイズ(バイト)を制御するには、oracle.spatial.rdf.client.jena.cacheMaxSizeシステム・プロパティを使用します。デフォルトの最大キャッシュ・サイズは1GBです。
中間層リソース・キャッシングは、ORDER BYまたはDISTINCT(あるいはその両方の)構造体を使用した問合せ、または複数の投影変数による問合せに最も効果的です。中間層キャッシュは、7.6.4項で指定したその他のオプションと組み合せることができます。
モデルのすべてのリソースをキャッシュに事前挿入するには、GraphOracleSem.populateCacheメソッドまたはDatasetGraphOracleSem.populateCacheメソッドを使用します。どちらのメソッドも、内部の中間層キャッシュを構築するために使用されるスレッドの数を指定するパラメータをとります。どちらかのメソッドをパラレルに実行すると、複数のCPU (コア)を搭載したマシンで、キャッシュ構築パフォーマンスを大幅に向上させることができます。
Jena Adapterを介したSPARQL問合せは、次の種類のファンクションを使用できます。
Jena ARQ問合せエンジンのファンクション・ライブラリにあるファンクション
投影変数に関するOracle Databaseのネイティブ・ファンクション
ユーザー定義ファンクション
Jena Adapterを介したSPARQL問合せは、Jena ARQ問合せエンジンのファンクション・ライブラリにあるファンクションを使用できます。これらの問合せは、中間層で実行されます。
次の例は、upper-caseファンクションとnamespaceファンクションを使用します。これらの例で、接頭辞fnは<http://www.w3.org/2005/xpath-functions#>、接頭辞afnは<http://jena.hpl.hp.com/ARQ/function#>です。
PREFIX fn: <http://www.w3.org/2005/xpath-functions#>
PREFIX afn: <http://jena.hpl.hp.com/ARQ/function#>
SELECT (fn:upper-case(?object) as ?object1)
WHERE { ?subject dc:title ?object }
PREFIX fn: <http://www.w3.org/2005/xpath-functions#>
PREFIX afn: <http://jena.hpl.hp.com/ARQ/function#>
SELECT ?subject (afn:namespace(?object) as ?object1)
WHERE { ?subject <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> ?object }
Jena Adapterを介したSPARQL問合せは、投影変数に関するOracle Databaseのネイティブ・ファンクションを使用できます。これらの問合せとファンクションは、データベース内部で実行されます。この項で説明したファンクションは、(7.7.1項で説明した)ARQファンクションとともに使用できないことに注意してください。
この項では、サポートされるネイティブ・ファンクションの一覧と、いくつかの例を示します。例で、接頭辞oextは、<http://oracle.com/semtech/jena-adaptor/ext/function#>です。
|
注意: 前述のURLで、jena-adaptorの綴りに注意してください(これは、既存のアプリケーションとの互換性のために保持されており、問合せではこれを使用する必要があります)。Oracleドキュメントのスタイル・ガイドに従い、通常のテキストではadapterという綴りを使用します。 |
oext:upper-literalは、リテラル値(長いリテラルを除く)を大文字に変換します。次に例を示します。
PREFIX oext: <http://oracle.com/semtech/jena-adaptor/ext/function#>
SELECT (oext:upper-literal(?object) as ?object1)
WHERE { ?subject dc:title ?object }
oext:lower-literalは、リテラル値(長いリテラルを除く)を小文字に変換します。次に例を示します。
PREFIX oext: <http://oracle.com/semtech/jena-adaptor/ext/function#>
SELECT (oext:lower-literal(?object) as ?object1)
WHERE { ?subject dc:title ?object }
oext:build-uri-for-idは、URI、bNodeまたはリテラルの値IDをURIフォームに変換します。次に例を示します。
PREFIX oext: <http://oracle.com/semtech/jena-adaptor/ext/function#>
SELECT (oext:build-uri-for-id(?object) as ?object1)
WHERE { ?subject dc:title ?object }
出力の例としては、<rdfvid:1716368199350136353>のようになります。
このファンクションの1つの用途は、Javaアプリケーションがメモリー内で、それらの値IDからURI、bNodeまたはリテラルの字句形式へのマッピングを保持できるようにすることです。MDSYS.RDF_VALUE$表は、Oracle Databaseでこのようなマッピングを提供します。
指定された変数?varについて、oext:build-uri-for-id(?var)のみが投影される場合、問合せへの応答に必要な内部表の結合操作がより少なくなるため、問合せのパフォーマンスがより高速になる可能性があります。
oext:literal-strlenは、リテラル値(長いリテラルを除く)の長さを戻します。次に例を示します。
PREFIX oext: <http://oracle.com/semtech/jena-adaptor/ext/function#>
SELECT (oext:literal-strlen(?object) as ?objlen)
WHERE { ?subject dc:title ?object }
Jena Adapterを介したSPARQL問合せでは、データベースに格納されているユーザー定義ファンクションを使用できます。
次の例で、長いリテラル(CLOB)および短いリテラルを処理する文字列長ファンクション(my_strlen)を定義するとします。SPARQL問合せ側では、このファンクションをouext (http://oracle.com/semtech/jena-adaptor/ext/user-def-function#)という名前空間の下で参照できます。
PREFIX ouext: <http://oracle.com/semtech/jena-adaptor/ext/user-def-function#>
SELECT ?subject ?object (ouext:my_strlen(?object) as ?obj1)
WHERE { ?subject dc:title ?object }
データベース内では、この機能を実装するために、my_strlen、my_strlen_cl、my_strlen_la、my_strlen_ltおよびmy_strlen_vtのファンクションを定義します。概念的に、これらのファンクションの戻り値は、表7-1に示すようにマップされます。
表7-1 my_strlenのファンクションと戻り値の例
| ファンクション名 | 戻り値 |
|---|---|
|
my_strlen |
<VAR> |
|
my_strlen_cl |
<VAR>$RDFCLOB |
|
my_strlen_la |
<VAR>$RDFLANG |
|
my_strlen_lt |
<VAR>$RDFLTYP |
|
my_strlen_vt |
<VAR>$RDFVTYP |
SPARQLから参照できる1つのユーザー定義ファンクションは、(MDSYS.RDF_VALUE$内の)RDFリソースの内部表現で位置合せするため、これを実装するために一連のファンクション(合計5つ)が使用されます。RDFリソースの値、言語、リテラル・タイプ、LONG値および値タイプに関して記述する5つの主要な列があり、これらの5つの列はSEM_MATCHを使用して選択されます。この場合、ユーザー定義ファンクションは、5つの列で表される1つのRDFリソースをもう1つのRDFリソースに単純に変換します。
これらのファンクションは、次のように定義されます。
create or replace function my_strlen(rdfvtyp in varchar2, rdfltyp in varchar2, rdflang in varchar2, rdfclob in clob, value in varchar2 ) return varchar2 as ret_val varchar2(4000); begin -- value if (rdfvtyp = 'LIT') then if (rdfclob is null) then return length(value); else return dbms_lob.getlength(rdfclob); end if; else -- Assign -1 for non-literal values so that application can -- easily differentiate return '-1'; end if; end; / create or replace function my_strlen_cl(rdfvtyp in varchar2, rdfltyp in varchar2, rdflang in varchar2, rdfclob in clob, value in varchar2 ) return clob as begin return null; end; / create or replace function my_strlen_la(rdfvtyp in varchar2, rdfltyp in varchar2, rdflang in varchar2, rdfclob in clob, value in varchar2 ) return varchar2 as begin return null; end; / create or replace function my_strlen_lt(rdfvtyp in varchar2, rdfltyp in varchar2, rdflang in varchar2, rdfclob in clob, value in varchar2 ) return varchar2 as ret_val varchar2(4000); begin -- literal type return 'http://www.w3.org/2001/XMLSchema#integer'; end; / create or replace function my_strlen_vt(rdfvtyp in varchar2, rdfltyp in varchar2, rdflang in varchar2, rdfclob in clob, value in varchar2 ) return varchar2 as ret_val varchar2(3); begin return 'LIT'; end; /
ユーザー定義ファンクションには、VARCHAR2タイプのパラメータを指定することもできます。次の5つのファンクションはともに、部分文字列に整数(VARCHAR2形式)を受け入れ、部分文字列を戻すmy_shorten_strファンクションを定義します。(この例の部分文字列は12文字で、4000バイト以下である必要があります。)
-- SPARQL query that returns the first 12 characters of literal values.
--
PREFIX ouext: <http://oracle.com/semtech/jena-adaptor/ext/user-def-function#>
SELECT (ouext:my_shorten_str(?object, "12") as ?obj1) ?subject
WHERE { ?subject dc:title ?object }
create or replace function my_shorten_str(rdfvtyp in varchar2,
rdfltyp in varchar2,
rdflang in varchar2,
rdfclob in clob,
value in varchar2,
arg in varchar2
) return varchar2
as
ret_val varchar2(4000);
begin
-- value
if (rdfvtyp = 'LIT') then
if (rdfclob is null) then
return substr(value, 1, to_number(arg));
else
return dbms_lob.substr(rdfclob, to_number(arg), 1);
end if;
else
return null;
end if;
end;
/
create or replace function my_shorten_str_cl(rdfvtyp in varchar2,
rdfltyp in varchar2,
rdflang in varchar2,
rdfclob in clob,
value in varchar2,
arg in varchar2
) return clob
as
ret_val clob;
begin
-- lob
return null;
end;
/
create or replace function my_shorten_str_la(rdfvtyp in varchar2,
rdfltyp in varchar2,
rdflang in varchar2,
rdfclob in clob,
value in varchar2,
arg in varchar2
) return varchar2
as
ret_val varchar2(4000);
begin
-- lang
if (rdfvtyp = 'LIT') then
return rdflang;
else
return null;
end if;
end;
/
create or replace function my_shorten_str_lt(rdfvtyp in varchar2,
rdfltyp in varchar2,
rdflang in varchar2,
rdfclob in clob,
value in varchar2,
arg in varchar2
) return varchar2
as
ret_val varchar2(4000);
begin
-- literal type
ret_val := rdfltyp;
return ret_val;
end;
/
create or replace function my_shorten_str_vt(rdfvtyp in varchar2,
rdfltyp in varchar2,
rdflang in varchar2,
rdfclob in clob,
value in varchar2,
arg in varchar2
) return varchar2
as
ret_val varchar2(3);
begin
return 'LIT';
end;
/
Jena Adapterは、SPARULとも呼ばれる、SPARQLの更新(http://www.w3.org/TR/sparql11-update/)をサポートします。主要なプログラミングAPIには、(パッケージcom.hp.hpl.jena.updateの) JenaクラスUpdateAction、Jena AdapterクラスGraphOracleSemおよびDatasetGraphOracleSemが含まれます。例7-1は、SPARQLの更新操作によって、名前付きグラフ<http://example/graph>のすべてのトリプルが、データベースに格納されている関連したモデルから削除されることを示しています。
例7-1 単純なSPARQLの更新
GraphOracleSem graphOracleSem = .... ; DatasetGraphOracleSem dsgos = DatasetGraphOracleSem.createFrom(graphOracleSem); // SPARQL Update operation String szUpdateAction = "DROP GRAPH <http://example/graph>"; // Execute the Update against a DatasetGraph instance (can be a Jena Model as well) UpdateAction.parseExecute(szUpdateAction, dsgos);
Oracle Databaseでは、空の名前付きグラフに関する情報は保持されないことに注意してください。このことは、このグラフにトリプルを追加せずにCREATE GRAPH <graph_name>を起動した場合、アプリケーション表または基礎となるRDF_LINK$表に、追加の行が作成されないことを意味します。Oracle Databaseに対しては、例7-1の例に示すとおり、CREATE GRAPHの手順を安全にスキップできます。
例7-2は、複数の挿入操作と削除操作を含む(ARQ 2.8.8からの)SPARQLの更新操作を示しています。
例7-2 挿入と削除の操作によるSPARQLの更新
PREFIX : <http://example/>
CREATE GRAPH <http://example/graph> ;
INSERT DATA { :r :p 123 } ;
INSERT DATA { :r :p 1066 } ;
DELETE DATA { :r :p 1066 } ;
INSERT DATA {
GRAPH <http://example/graph> { :r :p 123 . :r :p 1066 }
} ;
DELETE DATA {
GRAPH <http://example/graph> { :r :p 123 }
}
空のDatasetGraphOracleSemに対して例7-2での更新操作を実行した後、SPARQL問合せSELECT ?s ?p ?o WHERE {?s ?p ?o}を実行すると、次のレスポンスが生成されます。
----------------------------------------------------------------------------------------------- | s | p | o | =============================================================================================== | <http://example/r> | <http://example/p> | "123"^^<http://www.w3.org/2001/XMLSchema#decimal> | -----------------------------------------------------------------------------------------------
同じデータを使用して、SPARQL問合せSELECT ?g ?s ?p ?o where {GRAPH ?g {?s ?p ?o}}を実行すると、次のレスポンスが生成されます。
------------------------------------------------------------------------------------------------------------------------- | g | s | p | o | ========================================================================================================================= | <http://example/graph> | <http://example/r> | <http://example/p> | "1066"^^<http://www.w3.org/2001/XMLSchema#decimal> | -------------------------------------------------------------------------------------------------------------------------
SPARQLの更新操作にJava APIを使用する以外に、joseki-config.ttlファイルの次の行の最初にあるコメント(##)文字を削除することによって、SPARQLの更新操作を受け入れるようにJosekiを構成できます。
## <#serviceUpdate> ## rdf:type joseki:Service ; ## rdfs:label "SPARQL/Update" ; ## joseki:serviceRef "update/service" ; ## # dataset part ## joseki:dataset <#oracle>; ## # Service part. ## # This processor will not allow either the protocol, ## # nor the query, to specify the dataset. ## joseki:processor joseki:ProcessorSPARQLUpdate ## . ## ## <#serviceRead> ## rdf:type joseki:Service ; ## rdfs:label "SPARQL" ; ## joseki:serviceRef "sparql/read" ; ## # dataset part ## joseki:dataset <#oracle> ; ## Same dataset ## # Service part. ## # This processor will not allow either the protocol, ## # nor the query, to specify the dataset. ## joseki:processor joseki:ProcessorSPARQL_FixedDS ; ## .
joseki-config.ttlファイルを編集したら、Joseki Webアプリケーションを再起動する必要があります。その後、次のようにして単純な更新操作を試行できます。
ブラウザで、http://<hostname>:7001/joseki/update.htmlを表示します。
テキスト・ボックスで次の内容を入力するか、または貼り付けます。
PREFIX : <http://example/>
INSERT DATA {
GRAPH <http://example/g1> { :r :p 455 }
}
「Perform SPARQL Update」をクリックします。
更新操作が成功したことを確認するには、http://<hostname>:7001/josekiに移動し、次の問合せを入力します。
SELECT *
WHERE
{ GRAPH <http://example/g1> {?s ?p ?o}};
レスポンスには、次のトリプルが含まれます。
<http://example/r> <http://example/p> "455"^^<http://www.w3.org/2001/XMLSchema#decimal>
SPARQLの更新は、HTTP POST操作を使用してhttp://<hostname>:7001/joseki/update/サービスに送信することもできます。たとえば、curl (http://en.wikipedia.org/wiki/CURL)を使用して更新操作を実行するHTTP POSTリクエストを送信できます。
curl --data "request=PREFIX%20%3A%20%3Chttp%3A%2F%2Fexample%2F%3E%20%0AINSERT%20DATA%20%7B%0A%20%20GRAPH%20%3Chttp%3A%2F%2Fexample%2Fg1%3E%20%7B%20%3Ar%20%3Ap%20888%20%7D%0A%7D%0A" http://hostname:7001/joseki/update/service
前述の例で、URLエンコードされた文字列は、名前付きグラフへの単純なINSERT操作です。デコーディングの後、次のように読み取ります。
PREFIX : <http://example/>
INSERT DATA {
GRAPH <http://example/g1> { :r :p 888 }
oracle.spatial.rdf.client.jenaパッケージのSemNetworkAnalystクラスを使用して、RDFデータで解析ファンクションを実行できます。このサポートは、Oracle Spatialのネットワーク・データ・モデル(NDM)のロジックを基礎となるRDFデータ構造体に統合します。そのため、RDFデータでの解析ファンクションを使用するには、『Oracle Spatialトポロジおよびネットワーク・データ・モデル開発者ガイド』に説明されている、Oracle SpatialのNDMについても理解しておく必要があります。
必要なNDM Javaライブラリ(sdonm.jarとsdoutl.jarを含む)は、ディレクトリ$ORACLE_HOME/md/jlibの下にあります。($ORACLE_HOME/xdk/lib下にある) xmlparserv2.jarをclasspath定義に含める必要があることに注意してください。
例7-3では、SemNetworkAnalystクラス(NDM NetworkAnalyst APIを内部的に使用)を使用します。
例7-3 RDFデータでの解析ファンクションの実行
Oracle oracle = new Oracle(jdbcUrl, user, password);
GraphOracleSem graph = new GraphOracleSem(oracle, modelName);
Node nodeA = Node.createURI("http://A");
Node nodeB = Node.createURI("http://B");
Node nodeC = Node.createURI("http://C");
Node nodeD = Node.createURI("http://D");
Node nodeE = Node.createURI("http://E");
Node nodeF = Node.createURI("http://F");
Node nodeG = Node.createURI("http://G");
Node nodeX = Node.createURI("http://X");
// An anonymous node
Node ano = Node.createAnon(new AnonId("m1"));
Node relL = Node.createURI("http://likes");
Node relD = Node.createURI("http://dislikes");
Node relK = Node.createURI("http://knows");
Node relC = Node.createURI("http://differs");
graph.add(new Triple(nodeA, relL, nodeB));
graph.add(new Triple(nodeA, relC, nodeD));
graph.add(new Triple(nodeB, relL, nodeC));
graph.add(new Triple(nodeA, relD, nodeC));
graph.add(new Triple(nodeB, relD, ano));
graph.add(new Triple(nodeC, relL, nodeD));
graph.add(new Triple(nodeC, relK, nodeE));
graph.add(new Triple(ano, relL, nodeD));
graph.add(new Triple(ano, relL, nodeF));
graph.add(new Triple(ano, relD, nodeB));
// X only likes itself
graph.add(new Triple(nodeX, relL, nodeX));
graph.commitTransaction();
HashMap<Node, Double> costMap = new HashMap<Node, Double>();
costMap.put(relL, Double.valueOf((double)0.5));
costMap.put(relD, Double.valueOf((double)1.5));
costMap.put(relC, Double.valueOf((double)5.5));
graph.setDOP(4); // this allows the underlying LINK/NODE tables
// and indexes to be created in parallel.
SemNetworkAnalyst sna = SemNetworkAnalyst.getInstance(
graph, // network data source
true, // directed graph
true, // cleanup existing NODE and LINK table
costMap
);
psOut.println("From nodeA to nodeC");
Node[] nodeArray = sna.shortestPathDijkstra(nodeA, nodeC);
printNodeArray(nodeArray, psOut);
psOut.println("From nodeA to nodeD");
nodeArray = sna.shortestPathDijkstra( nodeA, nodeD);
printNodeArray(nodeArray, psOut);
psOut.println("From nodeA to nodeF");
nodeArray = sna.shortestPathAStar(nodeA, nodeF);
printNodeArray(nodeArray, psOut);
psOut.println("From ano to nodeC");
nodeArray = sna.shortestPathAStar(ano, nodeC);
printNodeArray(nodeArray, psOut);
psOut.println("From ano to nodeX");
nodeArray = sna.shortestPathAStar(ano, nodeX);
printNodeArray(nodeArray, psOut);
graph.close();
oracle.dispose();
...
...
// A helper function to print out a path
public static void printNodeArray(Node[] nodeArray, PrintStream psOut)
{
if (nodeArray == null) {
psOut.println("Node Array is null");
return;
}
if (nodeArray.length == 0) {psOut.println("Node Array is empty"); }
int iFlag = 0;
psOut.println("printNodeArray: full path starts");
for (int iHops = 0; iHops < nodeArray.length; iHops++) {
psOut.println("printNodeArray: full path item " + iHops + " = "
+ ((iFlag == 0) ? "[n] ":"[e] ") + nodeArray[iHops]);
iFlag = 1 - iFlag;
}
}
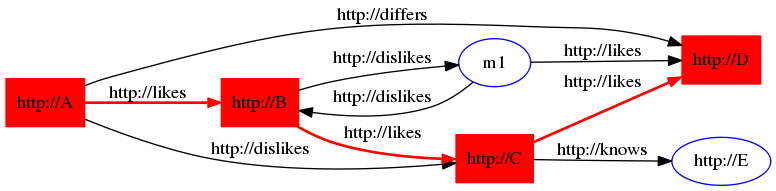
例7-3の内容:
GraphOracleSemオブジェクトが構築され、少数のトリプルがGraphOracleSemオブジェクトに追加されます。これらのトリプルは、複数の個人と、好き(likes)、嫌い(dislikes)、知人(knows)および他人(differs)などの関係を記述します。
コスト・マッピングは、数値コストの値を(RDFグラフの)異なるリンクおよび述語に割り当てるために作成されます。この場合、0.5、1.5および5.5は、それぞれ述語likes、dislikesおよびdiffersに割り当てられます。このコスト・マッピングはオプションです。このマッピングがない場合、すべての述語は同じコスト1に割り当てられることになります。コスト・マッピングが指定される場合、このマッピングは完全である必要はなく、コスト・マッピングに含まれない述語には、デフォルト値の1が割り当てられます。
例7-3の出力は、次のようになります。この出力には、指定された開始ノードと終了ノードの最短パスが示されます。これらの2つのノード間にはパスがないため、sna.shortestPathAStar(ano, nodeX)の戻り値はNULLになることに注意してください。
From nodeA to nodeC printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://A ## "n" denotes Node printNodeArray: full path item 1 = [e] http://likes ## "e" denotes Edge (Link) printNodeArray: full path item 2 = [n] http://B printNodeArray: full path item 3 = [e] http://likes printNodeArray: full path item 4 = [n] http://C From nodeA to nodeD printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://A printNodeArray: full path item 1 = [e] http://likes printNodeArray: full path item 2 = [n] http://B printNodeArray: full path item 3 = [e] http://likes printNodeArray: full path item 4 = [n] http://C printNodeArray: full path item 5 = [e] http://likes printNodeArray: full path item 6 = [n] http://D From nodeA to nodeF printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://A printNodeArray: full path item 1 = [e] http://likes printNodeArray: full path item 2 = [n] http://B printNodeArray: full path item 3 = [e] http://dislikes printNodeArray: full path item 4 = [n] m1 printNodeArray: full path item 5 = [e] http://likes printNodeArray: full path item 6 = [n] http://F From ano to nodeC printNodeArray: full path starts printNodeArray: full path item 0 = [n] m1 printNodeArray: full path item 1 = [e] http://dislikes printNodeArray: full path item 2 = [n] http://B printNodeArray: full path item 3 = [e] http://likes printNodeArray: full path item 4 = [n] http://C From ano to nodeX Node Array is null
基礎となるRDFグラフ・ビュー(SEMM_<model_name>またはRDFM_<model_name>)はNDMファンクションで直接使用することができないため、SemNetworkAnalystにより、必要な表(指定されたRDFグラフから導出されたノードとリンクを含む)が作成されます。これらの表は、RDFグラフが変更されても自動更新されないため、SemNetworkAnalyst.getInstanceのcleanupパラメータにtrueを設定して、古いノードとリンクを含む表を削除し、更新された表を再構築します。
例7-4は、セマンティク・データでのNDM nearestNeighborsファンクションを実装します。これによってSemNetworkAnalystインスタンスからNetworkAnalystオブジェクトを取得し、ノードIDを取得してPointOnNetオブジェクトを作成し、LogicalSubPathオブジェクトを処理します。
例7-4 セマンティク・データでのNDM nearestNeighborsファンクションの実装
%cat TestNearestNeighbor.java
import java.io.*;
import java.util.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
import com.hp.hpl.jena.sparql.core.DataSourceImpl;
import oracle.spatial.rdf.client.jena.*;
import oracle.spatial.rdf.client.jena.SemNetworkAnalyst;
import oracle.spatial.network.lod.LODGoalNode;
import oracle.spatial.network.lod.LODNetworkConstraint;
import oracle.spatial.network.lod.NetworkAnalyst;
import oracle.spatial.network.lod.PointOnNet;
import oracle.spatial.network.lod.LogicalSubPath;
/**
* This class implements a nearestNeighbors function on top of semantic data
* using public APIs provided in SemNetworkAnalyst and Oracle Spatial NDM
*/
public class TestNearestNeighbor
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
PrintStream psOut = System.out;
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
String szModelName = "test_nn";
// First construct a TBox and load a few axioms
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
String insertString =
" PREFIX my: <http://my.com/> " +
" INSERT DATA " +
" { my:A my:likes my:B . " +
" my:A my:likes my:C . " +
" my:A my:knows my:D . " +
" my:A my:dislikes my:X . " +
" my:A my:dislikes my:Y . " +
" my:C my:likes my:E . " +
" my:C my:likes my:F . " +
" my:C my:dislikes my:M . " +
" my:D my:likes my:G . " +
" my:D my:likes my:H . " +
" my:F my:likes my:M . " +
" } ";
UpdateAction.parseExecute(insertString, model);
GraphOracleSem g = model.getGraph();
g.commitTransaction();
g.setDOP(4);
HashMap<Node, Double> costMap = new HashMap<Node, Double>();
costMap.put(Node.createURI("http://my.com/likes"), Double.valueOf(1.0));
costMap.put(Node.createURI("http://my.com/dislikes"), Double.valueOf(4.0));
costMap.put(Node.createURI("http://my.com/knows"), Double.valueOf(2.0));
SemNetworkAnalyst sna = SemNetworkAnalyst.getInstance(
g, // source RDF graph
true, // directed graph
true, // cleanup old Node/Link tables
costMap
);
Node nodeStart = Node.createURI("http://my.com/A");
long origNodeID = sna.getNodeID(nodeStart);
long[] lIDs = {origNodeID};
// translate from the original ID
long nodeID = (sna.mapNodeIDs(lIDs))[0];
NetworkAnalyst networkAnalyst = sna.getEmbeddedNetworkAnalyst();
LogicalSubPath[] lsps = networkAnalyst.nearestNeighbors(
new PointOnNet(nodeID), // startPoint
6, // numberOfNeighbors
1, // searchLinkLevel
1, // targetLinkLevel
(LODNetworkConstraint) null, // constraint
(LODGoalNode) null // goalNodeFilter
);
if (lsps != null) {
for (int idx = 0; idx < lsps.length; idx++) {
LogicalSubPath lsp = lsps[idx];
Node[] nodePath = sna.processLogicalSubPath(lsp, nodeStart);
psOut.println("Path " + idx);
printNodeArray(nodePath, psOut);
}
}
g.close();
sna.close();
oracle.dispose();
}
public static void printNodeArray(Node[] nodeArray, PrintStream psOut)
{
if (nodeArray == null) {
psOut.println("Node Array is null");
return;
}
if (nodeArray.length == 0) {
psOut.println("Node Array is empty");
}
int iFlag = 0;
psOut.println("printNodeArray: full path starts");
for (int iHops = 0; iHops < nodeArray.length; iHops++) {
psOut.println("printNodeArray: full path item " + iHops + " = "
+ ((iFlag == 0) ? "[n] ":"[e] ") + nodeArray[iHops]);
iFlag = 1 - iFlag;
}
}
}
例7-4の出力は、次のようになります。
Path 0 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/likes printNodeArray: full path item 2 = [n] http://my.com/C Path 1 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/likes printNodeArray: full path item 2 = [n] http://my.com/B Path 2 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/knows printNodeArray: full path item 2 = [n] http://my.com/D Path 3 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/likes printNodeArray: full path item 2 = [n] http://my.com/C printNodeArray: full path item 3 = [e] http://my.com/likes printNodeArray: full path item 4 = [n] http://my.com/E Path 4 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/likes printNodeArray: full path item 2 = [n] http://my.com/C printNodeArray: full path item 3 = [e] http://my.com/likes printNodeArray: full path item 4 = [n] http://my.com/F Path 5 printNodeArray: full path starts printNodeArray: full path item 0 = [n] http://my.com/A printNodeArray: full path item 1 = [e] http://my.com/knows printNodeArray: full path item 2 = [n] http://my.com/D printNodeArray: full path item 3 = [e] http://my.com/likes printNodeArray: full path item 4 = [n] http://my.com/H
パスそのものに加え、グラフ内のパスに関する文脈情報を参照することは、有用な場合があります。SemNetworkAnalystクラスのbuildSurroundingSubGraphメソッドは、DOTファイル(グラフ記述言語ファイル、拡張子.gv)を、指定されたWriterオブジェクトに出力できます。パスのノードごとに、最大10の直接の隣接が、パス周辺のサブグラフを生成するために使用されます。例7-5に使用方法(具体的には例7-3「RDFデータでの解析ファンクションの実行」で使用されている解析ファンクションの出力)を示します。
例7-5 文脈情報によるDOTファイルの生成
nodeArray = sna.shortestPathDijkstra(nodeA, nodeD);
printNodeArray(nodeArray, psOut);
FileWriter dotWriter = new FileWriter("Shortest_Path_A_to_D.gv");
sna.buildSurroundingSubGraph(nodeArray, dotWriter);
例7-5で生成される出力DOTファイルは、次の例に示すとおり、単純な内容です。
% cat Shortest_Path_A_to_D.gv
digraph { rankdir = LR; charset="utf-8";
"Rhttp://A" [ label="http://A" shape=rectangle,color=red,style = filled, ];
"Rhttp://B" [ label="http://B" shape=rectangle,color=red,style = filled, ];
"Rhttp://A" -> "Rhttp://B" [ label="http://likes" color=red, style=bold, ];
"Rhttp://C" [ label="http://C" shape=rectangle,color=red,style = filled, ];
"Rhttp://A" -> "Rhttp://C" [ label="http://dislikes" ];
"Rhttp://D" [ label="http://D" shape=rectangle,color=red,style = filled, ];
"Rhttp://A" -> "Rhttp://D" [ label="http://differs" ];
"Rhttp://B" -> "Rhttp://C" [ label="http://likes" color=red, style=bold, ];
"Rm1" [ label="m1" shape=ellipse,color=blue, ];
"Rhttp://B" -> "Rm1" [ label="http://dislikes" ];
"Rm1" -> "Rhttp://B" [ label="http://dislikes" ];
"Rhttp://C" -> "Rhttp://D" [ label="http://likes" color=red, style=bold, ];
"Rhttp://E" [ label="http://E" shape=ellipse,color=blue, ];
"Rhttp://C" -> "Rhttp://E" [ label="http://knows" ];
"Rm1" -> "Rhttp://D" [ label="http://likes" ];
}
SemNetworkAnalystクラスとGraphOracleSemクラスのメソッドを使用して、より洗練されたビジュアル表現で解析ファンクション出力を生成することもできます。
前述のDOTファイルを、様々なイメージ形式に変換できます。図7-1は、前述のDOTファイルの情報を表現するイメージです。
この項では、Jena Adapterによって使用可能になるOracle Databaseのセマンティク・テクノロジ機能の一部について説明します。使用可能な機能をサポートするAPIコールの包括的なドキュメントについては、Jena Adapterのリファレンス情報(Javadoc)を参照してください。Jena Adapterによって使用可能なサーバー側機能の詳細は、このマニュアルの関連する章を参照してください。
仮想モデル(1.3.8項を参照)は、GraphOracleSemコンストラクタで指定され、透過的に処理されます。仮想モデルがモデルとルールベースの組合せのために存在している場合には、問合せの応答に使用されます(そのような仮想モデルが存在しない場合には、データベースに作成されます)。
|
注意: Jena Adapterを介した仮想モデルのサポートは、Oracle Databaseリリース11.2以上でのみ使用可能です。 |
次の例では、既存の仮想モデルを再利用します。
String modelName = "EX";
String m1 = "EX_1";
ModelOracleSem defaultModel =
ModelOracleSem.createOracleSemModel(oracle, modelName);
// create these models in case they don't exist
ModelOracleSem model1 = ModelOracleSem.createOracleSemModel(oracle, m1);
String vmName = "VM_" + modelName;
//create a virtual model containing EX and EX_1
oracle.executeCall(
"begin sem_apis.create_virtual_model(?,sem_models('"+ m1 + "','"+ modelName+"'),null); end;",vmName);
String[] modelNames = {m1};
String[] rulebaseNames = {};
Attachment attachment = Attachment.createInstance(modelNames, rulebaseNames,
InferenceMaintenanceMode.NO_UPDATE, QueryOptions.ALLOW_QUERY_VALID_AND_DUP);
// vmName is passed to the constructor, so GraphOracleSem will use the virtual
// model named vmname (if the current user has read privileges on it)
GraphOracleSem graph = new GraphOracleSem(oracle, modelName, attachment, vmName);
graph.add(Triple.create(Node.createURI("urn:alice"),
Node.createURI("http://xmlns.com/foaf/0.1/mbox"),
Node.createURI("mailto:alice@example")));
ModelOracleSem model = new ModelOracleSem(graph);
String queryString =
" SELECT ?subject ?object WHERE { ?subject ?p ?object } ";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
try {
ResultSet results = qexec.execSelect() ;
for ( ; results.hasNext() ; ) {
QuerySolution soln = results.nextSolution() ;
psOut.println("soln " + soln);
}
}
finally {
qexec.close() ;
}
OracleUtils.dropSemanticModel(oracle, modelName);
OracleUtils.dropSemanticModel(oracle, m1);
oracle.dispose();
また、次の例のように、GraphOracleSemコンストラクタを使用して仮想モデルを作成することもできます。
GraphOracleSem graph = new GraphOracleSem(oracle, modelName, attachment, true);
この例で、4番目のパラメータ(true)は、指定されたmodelNameとattachmentのために仮想モデルを作成する必要があることを示しています。
Oracle Databaseの接続プーリングは、Jena AdapterのOraclePoolクラスを介して提供されます。このクラスが初期化されると、使用可能な接続のプールからOracleオブジェクトを戻せます。Oracleオブジェクトは、基本的にデータベース接続ラッパーです。disposeがOracleオブジェクトでコールされた後、接続がプールに戻されますOraclePoolの使用の詳細は、APIリファレンス情報(Javadoc)を参照してください。
次の例では、5つの初期接続を使用するOraclePoolオブジェクトを設定します。
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
// test with connection properties
java.util.Properties prop = new java.util.Properties();
prop.setProperty("MinLimit", "2"); // the cache size is 2 at least
prop.setProperty("MaxLimit", "10");
prop.setProperty("InitialLimit", "2"); // create 2 connections at startup
prop.setProperty("InactivityTimeout", "1800"); // seconds
prop.setProperty("AbandonedConnectionTimeout", "900"); // seconds
prop.setProperty("MaxStatementsLimit", "10");
prop.setProperty("PropertyCheckInterval", "60"); // seconds
System.out.println("Creating OraclePool");
OraclePool op = new OraclePool(szJdbcURL, szUser, szPasswd, prop,
"OracleSemConnPool");
System.out.println("Done creating OraclePool");
// grab an Oracle and do something with it
System.out.println("Getting an Oracle from OraclePool");
Oracle oracle = op.getOracle();
System.out.println("Done");
System.out.println("Is logical connection:" +
oracle.getConnection().isLogicalConnection());
GraphOracleSem g = new GraphOracleSem(oracle, szModelName);
g.add(Triple.create(Node.createURI("u:John"),
Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.close();
// return the Oracle back to the pool
oracle.dispose();
// grab another Oracle and do something else
System.out.println("Getting an Oracle from OraclePool");
oracle = op.getOracle();
System.out.println("Done");
System.out.println("Is logical connection:" +
oracle.getConnection().isLogicalConnection());
g = new GraphOracleSem(oracle, szModelName);
g.add(Triple.create(Node.createURI("u:John"),
Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
// return the Oracle object back to the pool
oracle.dispose();
}
Jena Adapterを介して、複数のセマンティクPL/SQLサブプログラムを使用できます。表7-2に、サブプログラムと、対応するJavaクラスおよびメソッドを示します。
表7-2 PL/SQLサブプログラムと、対応するJena AdapterのJavaクラスおよびメソッド
| PL/SQLサブプログラム | 対応するJavaクラスとメソッド |
|---|---|
|
|
OracleUtils.dropSemanticModel |
|
|
OracleUtils.mergeModels |
|
|
OracleUtils.swapNames |
|
|
OracleUtils.removeDuplicates |
|
|
OracleUtils.renameModels |
これらのPL/SQLユーティリティ・サブプログラムの詳細は、第9章のリファレンス情報を参照してください。対応するJavaクラスとメソッドの詳細は、Jena AdapterのAPIリファレンス・ドキュメント(Javadoc)を参照してください。
(パッケージoracle.spatial.rdf.client.jena内にある) Attachmentクラスの次のメソッドを使用し、伴意コールにオプションを追加できます。
public void setUseLocalInference(boolean useLocalInference) public boolean getUseLocalInference() public void setDefGraphForLocalInference(String defaultGraphName) public String getDefGraphForLocalInference() public String getInferenceOption() public void setInferenceOption(String inferenceOption)
これらのメソッドの詳細は、Javadocを参照してください。
例7-6では、伴意の作成時に、パラレル推論(並列度4を使用)とRAW形式を有効化しています。また、伴意の作成にperformInferenceメソッドを使用します(SEM_APIS.CREATE_ENTAILMENT PL/SQLプロシージャの使用に相当します)。
例7-6 推論オプションの指定
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
import com.hp.hpl.jena.sparql.core.DataSourceImpl;
public class TestNewInference
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
PrintStream psOut = System.out;
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
String szTBoxName = "test_new_tbox";
{
// First construct a TBox and load a few axioms
ModelOracleSem modelTBox = ModelOracleSem.createOracleSemModel(oracle, szTBoxName);
String insertString =
" PREFIX my: <http://my.com/> " +
" PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> " +
" INSERT DATA " +
" { my:C1 rdfs:subClassOf my:C2 . " +
" my:C2 rdfs:subClassOf my:C3 . " +
" my:C3 rdfs:subClassOf my:C4 . " +
" } ";
UpdateAction.parseExecute(insertString, modelTBox);
modelTBox.close();
}
String szABoxName = "test_new_abox";
{
// Construct an ABox and load a few quads
ModelOracleSem modelABox = ModelOracleSem.createOracleSemModel(oracle, szABoxName);
DatasetGraphOracleSem dataset = DatasetGraphOracleSem.createFrom(modelABox.getGraph());
modelABox.close();
String insertString =
" PREFIX my: <http://my.com/> " +
" PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> " +
" INSERT DATA " +
" { GRAPH my:G1 { my:I1 rdf:type my:C1 . " +
" my:I2 rdf:type my:C2 . " +
" } " +
" }; " +
" INSERT DATA " +
" { GRAPH my:G2 { my:J1 rdf:type my:C3 . " +
" } " +
" } ";
UpdateAction.parseExecute(insertString, dataset);
dataset.close();
}
String[] attachedModels = new String[1];
attachedModels[0] = szTBoxName;
String[] attachedRBs = {"OWL2RL"};
Attachment attachment = Attachment.createInstance(
attachedModels, attachedRBs,
InferenceMaintenanceMode.NO_UPDATE,
QueryOptions.ALLOW_QUERY_INVALID);
// We are going to run named graph based local inference
attachment.setUseLocalInference(true);
// Set the default graph (TBox)
attachment.setDefGraphForLocalInference(szTBoxName);
// Set the inference option to use parallel inference
// with a degree of 4, and RAW format.
attachment.setInferenceOption("DOP=4,RAW8=T");
GraphOracleSem graph = new GraphOracleSem(
oracle,
szABoxName,
attachment
);
DatasetGraphOracleSem dsgos = DatasetGraphOracleSem.createFrom(graph);
graph.close();
// Invoke create_entailment PL/SQL API
dsgos.performInference();
psOut.println("TestNewInference: # of inferred graph " +
Long.toString(dsgos.getInferredGraphSize()));
String queryString =
" SELECT ?g ?s ?p ?o WHERE { GRAPH ?g {?s ?p ?o } } " ;
Query query = QueryFactory.create(queryString, Syntax.syntaxARQ);
QueryExecution qexec = QueryExecutionFactory.create(
query, DataSourceImpl.wrap(dsgos));
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(psOut, results);
dsgos.close();
oracle.dispose();
}
}
例7-6の出力は、次のようになります。
TestNewInference: # of inferred graph 9 -------------------------------------------------------------------------------------------------------------------- | g | s | p | o | ==================================================================================================================== | <http://my.com/G1> | <http://my.com/I2> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C3> | | <http://my.com/G1> | <http://my.com/I2> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C2> | | <http://my.com/G1> | <http://my.com/I2> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C4> | | <http://my.com/G1> | <http://my.com/I1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C3> | | <http://my.com/G1> | <http://my.com/I1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C1> | | <http://my.com/G1> | <http://my.com/I1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C2> | | <http://my.com/G1> | <http://my.com/I1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C4> | | <http://my.com/G2> | <http://my.com/J1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C3> | | <http://my.com/G2> | <http://my.com/J1> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> | <http://my.com/C4> | --------------------------------------------------------------------------------------------------------------------
OWL推論の使用の詳細は、2.2項を参照してください。
Jena Adapter内でのPelletInfGraphクラスのサポートは、非推奨になりました。かわりに、Oracle Database 11g向けの推論機能PelletDb OWL 2を介して、より最適化されたOracle/Pellet統合を使用する必要があります。(PelletDbの詳細は、http://clarkparsia.com/pelletdb/を参照してください。)
数千から数十万ものRDF/OWLデータ・ファイルをOracle Databaseにロードするには、OracleBulkUpdateHandler JavaクラスのprepareBulkメソッドとcompleteBulkメソッドを使用してタスクを簡略化します。
OracleBulkUpdateHandlerクラスのaddInBulkメソッドは、グラフまたはモデルのトリプルをOracle Databaseにバルク・ロード方式でロードできます。グラフまたはモデルがJenaインメモリー・グラフまたはモデルである場合、操作は物理メモリーのサイズによって制限されます。prepareBulkメソッドは、Jenaのインメモリー・グラフまたはモデルをバイパスし、RDFデータ・ファイルへの直接入力ストリームを取得してデータを解析し、基礎となるステージング表にトリプルをロードします。ステージング表および長いリテラルを格納するための添付表がまだ存在しない場合は、自動的に作成されます。
prepareBulkメソッドは、複数のデータ・ファイルを同じ基礎となるステージング表へロードするために複数回コールできます。ハードウェア・システムがロードバランシングされており、複数のCPUコアおよび十分なI/O容量が確保されている場合には、同時にコールすることもできます。
すべてのデータ・ファイルがprepareBulkメソッドによって処理されると、completeBulkを起動して、すべてのデータをセマンティク・ネットワークにロードできます。
例7-7に、ディレクトリdir_1のすべてデータ・ファイルを、基礎となるステージング表へロードする方法を示します。長いリテラルがサポートされ、別々の表に格納されます。記憶域容量を節約するため、GZIPを使用してデータ・ファイルを圧縮することができ、データ・ファイルがGZIPを使用して圧縮されているかどうかをprepareBulkメソッドで自動的に検出できます。
例7-7 ステージング表へのデータのロード(prepareBulk)
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
GraphOracleSem graph = new GraphOracleSem(oracle, szModelName);
PrintStream psOut = System.out;
String dirname = "dir_1";
File fileDir = new File(dirname);
String[] szAllFiles = fileDir.list();
// loop through all the files in a directory
for (int idx = 0; idx < szAllFiles.length; idx++) {
String szIndFileName = dirname + File.separator + szAllFiles[idx];
psOut.println("process to [ID = " + idx + " ] file " + szIndFileName);
psOut.flush();
try {
InputStream is = new FileInputStream(szIndFileName);
graph.getBulkUpdateHandler().prepareBulk(
is, // input stream
"http://example.com", // base URI
"RDF/XML", // data file type: can be RDF/XML, N-TRIPLE, etc.
"SEMTS", // tablespace
null, // flags
null, // listener
null // staging table name.
);
is.close();
}
catch (Throwable t) {
psOut.println("Hit exception " + t.getMessage());
}
}
graph.close();
oracle.dispose();
例7-7のコード(新しいOracleオブジェクトの作成から、そのOracleオブジェクトを破棄して終了するまで)は、パラレルで実行できます。データベースのハードウェア・システム上にクワッドコアCPUと十分なI/O容量があると想定した場合、すべてのデータ・ファイルを4つの別々のディレクトリ(dir_1、dir_2、dir_3およびdir_4)に分割して保存できます。4つのJavaプロセス・スレッドを起動し、それらのディレクトリで別々に同時に動作させることができます。(詳細は、7.11.1項「パラレル(マルチスレッド)・モードでのprepareBulkの使用」を参照してください。)
すべてのデータ・ファイルが処理された後、1回のみcompleteBulkメソッドを起動し、例7-8に示すとおり、ステージング表のデータをセマンティク・ネットワークにロードできます。長いリテラルを持つトリプルもロードされます。
例7-8 ステージング表からセマンティク・ネットワークへのデータのロード(completeBulk)
graph.getBulkUpdateHandler().completeBulk( null, // flags for invoking SEM_APIS.bulk_load_from_staging_table null // staging table name );
また、prepareBulkメソッドは、Jenaモデルも入力データ・ソースとして取得でき、この場合は、そのJenaモデルのトリプルが基礎となるステージング表にロードされます。詳細は、Javadocを参照してください。
Jenaモデルとデータ・ファイルからトリプルをロードする以外に、prepareBulkメソッドは、例7-9に示すとおり、RDFaをサポートします。(RDFaについては、http://www.w3.org/TR/xhtml-rdfa-primer/を参照してください。)
例7-9 prepareBulkでのRDFaの使用
graph.getBulkUpdateHandler().prepareBulk( rdfaUrl, // url to a web page using RDFa "SEMTS", // tablespace null, // flags null, // listener null // staging table name );
RDFaを解析するには、関連するjava-rdfaライブラリをクラスパスに含める必要があります。その他の設定やAPIコールは必要ありません。(java-rdfaの詳細は、http://www.rootdev.net/maven/projects/java-rdfa/およびProject Informationの下のその他のトピックを参照してください。)
rdfaUrlがファイアウォールの外側にある場合は、次のHTTPプロキシ関連のJava VMプロパティを設定する必要がある場合があります。
-Dhttp.proxyPort=... -Dhttp.proxyHost=...
この項の前述の例では、トリプル・データを単一のグラフにロードします。(NQUADS形式のデータなど)複数の名前付きグラフにわたる場合があるクワッド・データのロードには、DatasetGraphOracleSemクラスを使用する必要があります。例7-10に示すとおり、DatasetGraphOracleSemクラスはBulkUpdateHandler APIを使用しませんが、類似するprepareBulkおよびcompleteBulkインタフェースを提供します。
例7-10 DatasetGraphへのクワッドのロード
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
// Can only create DatasetGraphOracleSem from an existing GraphOracleSem
GraphOracleSem graph = new GraphOracleSem(oracle, szModelName);
DatasetGraphOracleSem dataset = DatasetGraphOracleSem.createFrom(graph);
// Don't need graph anymore, close it to free resources
graph.close();
try {
InputStream is = new FileInputStream(szFileName);
// load NQUADS file into a staging table. This file can be gzipp'ed.
dataset.prepareBulk(
is, // input stream
"http://my.base/", // base URI
"N-QUADS", // data file type; can be "TRIG"
"SEMTS", // tablespace
null, // flags
null, // listener
null, // staging table name
false // truncate staging table before load
);
// Load quads from staging table into the dataset
dataset.completeBulk(
null, // flags; can be "PARSE PARALLEL_CREATE_INDEX PARALLEL=4
// mbv_method=shadow" on a quad core machine
null // staging table name
);
}
catch (Throwable t) {
System.out.println("Hit exception " + t.getMessage());
}
finally {
dataset.close();
oracle.dispose();
}
例7-7「ステージング表へのデータのロード(prepareBulk)」には、ファイル・システム・ディレクトリ下の一連のファイルを、Oracle Database表(ステージング表)へ、順番にロードする方法が示されていました。例7-11では、一連のファイルを同時にOracle表(ステージング表)にロードします。並列度は、入力パラメータiMaxThreadsによって制御されます。
4つ以上のCPUコアを使用するロードバランシングされたハードウェア設定で、iMaxThreadsに8 (または16)を設定すると、多数のデータ・ファイルが処理される場合に、prepareBulk操作の速度を大幅に向上できます。
例7-11 prepareBulkでのiMaxThreadsの使用
public void testPrepareInParallel(String jdbcUrl, String user,
String password, String modelName,
String lang,
String tbs,
String dirname,
int iMaxThreads,
PrintStream psOut)
throws SQLException, IOException, InterruptedException
{
File dir = new File(dirname);
File[] files = dir.listFiles();
// create a set of physical Oracle connections and graph objects
Oracle[] oracles = new Oracle[iMaxThreads];
GraphOracleSem[] graphs = new GraphOracleSem[iMaxThreads];
for (int idx = 0; idx < iMaxThreads; idx++) {
oracles[idx] = new Oracle(jdbcUrl, user, password);
graphs[idx] = new GraphOracleSem(oracles[idx], modelName);
}
PrepareWorker[] workers = new PrepareWorker[iMaxThreads];
Thread[] threads = new Thread[iMaxThreads];
for (int idx = 0; idx < iMaxThreads; idx++) {
workers[idx] = new PrepareWorker(
graphs[idx],
files,
idx,
iMaxThreads,
lang,
tbs,
psOut
);
threads[idx] = new Thread(workers[idx], workers[idx].getName());
psOut.println("testPrepareInParallel: PrepareWorker " + idx + " running");
threads[idx].start();
}
psOut.println("testPrepareInParallel: all threads started");
for (int idx = 0; idx < iMaxThreads; idx++) {
threads[idx].join();
}
for (int idx = 0; idx < iMaxThreads; idx++) {
graphs[idx].close();
oracles[idx].dispose();
}
}
static class PrepareWorker implements Runnable
{
GraphOracleSem graph = null;
int idx;
int threads;
File[] files = null;
String lang = null;
String tbs = null;
PrintStream psOut;
public void run()
{
long lStartTime = System.currentTimeMillis();
for (int idxFile = idx; idxFile < files.length; idxFile += threads) {
File file = files[idxFile];
try {
FileInputStream fis = new FileInputStream(file);
graph.getBulkUpdateHandler().prepareBulk(
fis,
"http://base.com/",
lang,
tbs,
null, // flags
new MyListener(psOut), // listener
null // table name
);
fis.close();
}
catch (Exception e) {
psOut.println("PrepareWorker: thread ["+getName()+"] error "+ e.getMessage());
}
psOut.println("PrepareWorker: thread ["+getName()+"] done to "
+ idxFile + ", file = " + file.toString()
+ " in (ms) " + (System.currentTimeMillis() - lStartTime));
}
}
public PrepareWorker(GraphOracleSem graph,
File[] files,
int idx,
int threads,
String lang,
String tbs,
PrintStream psOut)
{
this.graph = graph;
this.files = files;
this.psOut = psOut;
this.idx = idx;
this.threads = threads;
this.files = files;
this.lang = lang;
this.tbs = tbs ;
}
public String getName()
{
return "PrepareWorker" + idx;
}
}
static class MyListener implements StatusListener
{
PrintStream m_ps = null;
public MyListener(PrintStream ps) { m_ps = ps; }
long lLastBatch = 0;
public void statusChanged(long count)
{
if (count - lLastBatch >= 10000) {
m_ps.println("process to " + Long.toString(count));
lLastBatch = count;
}
}
public int illegalStmtEncountered(Node graphNode, Triple triple, long count)
{
m_ps.println("hit illegal statement with object " + triple.getObject().toString());
return 0; // skip it
}
}
prepareBulkを使用すると、無効なトリプルとクワッドをスキップできます。この機能は、ソースのRDFデータに構文エラーが含まれる可能性がある場合に有用です。例7-12では、(パッケージoracle.spatial.rdf.client.jenaで定義される) StatusListenerインタフェースのカスタマイズされた実装が、prepareBulkへのパラメータとして渡されます。この例で、illegalStmtEncounteredメソッドは、prepareBulkが無効なトリプルをスキップして進むことができるように、その無効なトリプルのオブジェクト・フィールドを出力し、0を戻します。
例7-12 無効な構文によるトリプルのスキップ
....
Oracle oracle = new Oracle(jdbcUrl, user, password);
GraphOracleSem graph = new GraphOracleSem(oracle, modelName);
PrintStream psOut = System.err;
graph.getBulkUpdateHandler().prepareBulk(
new FileInputStream(rdfDataFilename),
"http://base.com/", // base
lang, // data format, can be "N-TRIPLES" "RDF/XML" ...
tbs, // tablespace name
null, // flags
new MyListener(psOut), // call back to show progress and also process illegal triples/quads
null, // tableName, if null use default names
false // truncate existing staging tables
);
graph.close();
oracle.dispose();
....
// A customized StatusListener interface implementation
public class MyListener implements StatusListener
{
PrintStream m_ps = null;
public MyListener(PrintStream ps) { m_ps = ps; }
public void statusChanged(long count)
{
// m_ps.println("process to " + Long.toString(count));
}
public int illegalStmtEncountered(Node graphNode, Triple triple, long count)
{
m_ps.println("hit illegal statement with object " + triple.getObject().toString());
return 0; // skip it
}
}
以前、SPARQL問合せで使用された変数名は、SQL文の一部としてOracle Databaseに直接渡されました。変数名にSQLまたはPL/SQLの予約済キーワードを含めると、その問合せは実行できませんでした。たとえば、次のSPARQL問合せは、dateという語がOracle DatabaseのSQL処理エンジンにとって特別な意味であることが理由で失敗していました。
select ?date { :event :happenedOn ?date }
現在ではこの問合せは失敗しませんが、これは問合せが実行のためにOracle Databaseに送信される前に、スマート・スキャンが実行され、特定の予約済変数名(あるいは非常に長い変数名)の自動置換が実行されるためです。置換は予約済キーワードのリストに基づいて実行され、このリストはsdordfclient.jarに組み込まれた次のファイルに格納されています。
oracle/spatial/rdf/client/jena/oracle_sem_reserved_keywords.lst
このファイルには100以上のエントリが含まれており、必要に応じてファイルを編集し、エントリを追加できます。
次は、SQLまたはPL/SQLの予約済キーワードを変数として使用するSPARQL問合せの例で、変数名が自動的に変更されるため、正常に実行されます。
変数名にSELECTを使用する問合せ:
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
select ?SELECT ?z
where
{ ?SELECT foaf:name ?y.
optional {?SELECT foaf:knows ?z.}
}
変数名にARRAYとDATEを使用する問合せ:
PREFIX x: <http://example.com#>
construct {
?ARRAY x:date ?date .
}
where {
?ARRAY x:happenedOn ?date .
}
JavaScript Object Notation (JSON)形式は、SPARQL問合せのレスポンスのためにサポートされます。JSONデータ形式は単純、コンパクトで、JavaScriptプログラムに適しています。
たとえば、ResultSetFormatter.outputAsJSONメソッドをコールする次のようなJavaコード・スニペットがあるとします。
Oracle oracle = new Oracle(jdbcUrl, user, password);
GraphOracleSem graph = new GraphOracleSem(oracle, modelName);
ModelOracleSem model = new ModelOracleSem(graph);
graph.add(new Triple(
Node.createURI("http://ds1"),
Node.createURI("http://dp1"),
Node.createURI("http://do1")
)
);
graph.add(new Triple(
Node.createURI("http://ds2"),
Node.createURI("http://dp2"),
Node.createURI("http://do2")
)
);
graph.commitTransaction();
Query q = QueryFactory.create("select ?s ?p ?o where {?s ?p ?o}",
Syntax.syntaxARQ);
QueryExecution qexec = QueryExecutionFactory.create(q, model);
ResultSet results = qexec.execSelect();
ResultSetFormatter.outputAsJSON(System.out, results);
JSON出力は次のとおりです。
{
"head": {
"vars": [ "s" , "p" , "o" ]
} ,
"results": {
"bindings": [
{
"s": { "type": "uri" , "value": "http://ds1" } ,
"p": { "type": "uri" , "value": "http://dp1" } ,
"o": { "type": "uri" , "value": "http://do1" }
} ,
{
"s": { "type": "uri" , "value": "http://ds2" } ,
"p": { "type": "uri" , "value": "http://dp2" } ,
"o": { "type": "uri" , "value": "http://do2" }
}
]
}
}
前述の例を、Oracle Databaseに対して直接ではなく、リモートのSPARQLエンドポイントを問い合せるようにするには、次のように変更します。(リモートのSPARQLエンドポイントがファイアウォールの外側にある場合、HTTPプロキシを設定する必要があります。)
Query q = QueryFactory.create("select ?s ?p ?o where {?s ?p ?o}",
Syntax.syntaxARQ);
QueryExecution qe = QueryExecutionFactory.sparqlService(sparqlURL, q);
ResultSet results = qexec.execSelect();
ResultSetFormatter.outputAsJSON(System.out, results);
この項の最初の例を名前付きグラフに拡張するため、次のコード・スニペットでは、同じOracleモデルに2つのクワッドを追加し、名前付きグラフベースのSPARQL問合せを実行して、問合せ出力をJSON形式にシリアライズします。
DatasetGraphOracleSem dsgos = DatasetGraphOracleSem.createFrom(graph);
graph.close();
dsgos.add(new Quad(Node.createURI("http://g1"),
Node.createURI("http://s1"),
Node.createURI("http://p1"),
Node.createURI("http://o1")
)
);
dsgos.add(new Quad(Node.createURI("http://g2"),
Node.createURI("http://s2"),
Node.createURI("http://p2"),
Node.createURI("http://o2")
)
);
Query q1 = QueryFactory.create(
"select ?g ?s ?p ?o where { GRAPH ?g {?s ?p ?o} }");
QueryExecution qexec1 = QueryExecutionFactory.create(q1,
DataSourceImpl.wrap(dsgos));
ResultSet results1 = qexec1.execSelect();
ResultSetFormatter.outputAsJSON(System.out, results1);
dsgos.close();
oracle.dispose();
JSON出力は次のとおりです。
{
"head": {
"vars": [ "g" , "s" , "p" , "o" ]
} ,
"results": {
"bindings": [
{
"g": { "type": "uri" , "value": "http://g1" } ,
"s": { "type": "uri" , "value": "http://s1" } ,
"p": { "type": "uri" , "value": "http://p1" } ,
"o": { "type": "uri" , "value": "http://o1" }
} ,
{
"g": { "type": "uri" , "value": "http://g2" } ,
"s": { "type": "uri" , "value": "http://s2" } ,
"p": { "type": "uri" , "value": "http://p2" } ,
"o": { "type": "uri" , "value": "http://o2" }
}
]
}
}
また、次の例のように、JosekiベースのSPARQLエンドポイントに対してHTTPを介してJSONレスポンスを取得することもできます。通常、SPARQL Webサービス・エンドポイントに対してSPARQL問合せを実行する場合、Accept request-headフィールドはapplication/sparql-results+xmlに設定されます。JSON出力形式の場合は、Accept request-headフィールドをapplication/sparql-results+jsonに置き換えます。
http://hostname:7001/joseki/oracle?query=<URL_ENCODED_SPARQL_QUERY>&output=json
この項では、SPARQL問合せに関連する様々な推奨事項およびその他の情報について説明します。
パフォーマンスをさらに向上するには、EXISTSやNOT EXISTSのかわりに、BOUNDや!BOUNDを使用します。
ファンクションが現在Oracle Databaseでサポートされていなくても、パフォーマンスに大きなオーバーヘッドを発生させることなく、SPARQL 1.1のSELECT表現を使用できます。例には次のものがあります。
-- Quyery using MD5 and SHA1 functions
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX eg: <http://biometrics.example/ns#>
SELECT ?name (md5(?name) as ?name_in_md5) (sha1(?email) as ?sha1)
WHERE
{
?x foaf:name ?name ; eg:email ?email .
}
-- Quyery using CONCAT function
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ( CONCAT(?G, " ", ?S) AS ?name )
WHERE
{
?P foaf:givenName ?G ; foaf:surname ?S
}
bnodeを含む構文を問合せパターンの中で自由に使用できます。たとえば、次のbnode関連の構文はパーサー・レベルでサポートされるため、各構文はそのトリプル問合せパターンベースの完全なバージョンと同等です。
:x :q [ :p "v" ] . (1 ?x 3 4) :p "w" . (1 [:p :q] ( 2 ) ) .
SPARQL 1.1のフェデレーテッド問合せを記述する際に、SERVICE句内の副問合せで戻される行に対して制限を設定できます。これによって、ローカルのリポジトリとリモートのSPARQLエンドポイントの間で転送されるデータ量を効果的に制限できます。
たとえば、次の問合せでは、SERVICE句の副問合せでlimit 100を指定しています。
PREFIX : <http://example.com/>
SELECT ?s ?o
WHERE
{
?s :name "CA"
SERVICE <http://REMOTE_SPARQL_ENDPOINT_HERE>
{
select ?s ?o
{?s :info ?o}
limit 100
}
}
Jena OntModelクラスを使用すると、Jenaモデルに格納されているオントロジを作成、変更および分析できます。ただし、OntModelの実装は、データベースに格納されているセマンティク・データにとって最適とはいえません。OracleモデルでOntModelを使用する場合は、次善のパフォーマンスとなりますしたがって、このようなパフォーマンスの問題を軽減するために、クラスOracleGraphWrapperForOntModelが作成されました。
OracleGraphWrapperForOntModelクラスは、Jena Graphインタフェースを実装し、Jena OntModel APIで使用するためのOracle RDF/OWLモデルに基づくグラフを表します。OracleGraphWrapperForOntModelクラスは、2つのセマンティク・ストアをハイブリッドな方法で使用して、変更の永続化と問合せに対する応答を行います。どちらのセマンティク・ストアにも同じデータが含まれますが、一方はメモリーに存在し、他方はOracle Databaseに存在します。
OntModelを介して問合せがあると、OracleGraphWrapperForOntModelグラフは、パフォーマンスを向上させるためにインメモリー・ストアに対して問合せを実行します。ただし、OracleGraphWrapperForOntModelクラスでは、クラスの追加または削除などのOntModelを介した変更の永続化を、両方のストアに変更を適用することによって行います。
ハイブリッドな方法を使用していることから、OracleGraphWrapperForOntModelグラフでは、メモリーにオントロジのコピーを格納するため、十分なメモリーがJVMに割り当てられている必要があります。内部の実験では、およそ3,000,000のトリプルによるオントロジで、6GB以上の物理メモリーを必要とすることがわかっています。
例7-13では、OntModel APIとOracleモデルに格納されている既存のオントロジを使用する方法を表示します。
例7-13 OntModelとOracle Databaseに格納されたオントロジの使用
// Set up connection to Oracle semantic store and the Oracle model
// containing the ontology
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
GraphOracleSem oracleGraph = new GraphOracleSem(oracle, szModelName);
// Create a new hybrid graph using the oracle graph to persist
// changes. This method will copy all the data from the oracle graph
// into an in-memory graph, which may significantly increase JVM memory
// usage.
Graph hybridGraph = OracleGraphWrapperForOntModel.getInstance(oracleGraph);
// Build a model around the hybrid graph and wrap the model with Jena's
// OntModel
Model model = ModelFactory.createModelForGraph(hybridGraph);
OntModel ontModel = ModelFactory.createOntologyModel(ontModelSpec, model);
// Perform operations on the ontology
OntClass personClass = ontModel.createClass("<http://someuri/person>");
ontModel.createIndividual(personClass);
// Close resources (will also close oracleGraph)!
hybridGraph.close();
ontModel.close();
OracleGraphWrapperForOntModelを使用して作成されたOntModelオブジェクトは、(別のOntModelを介した、または同じ基礎となるモデルを参照する別のOracleグラフを介した)別のプロセスによって行われた、基礎となるOracleモデルへの変更を反映しません。オントロジへのすべての変更は、モデルまたはグラフが閉じられるまで、単一のOntModelオブジェクトと、その基礎となるOracleGraphWrapperForOntModelグラフを介して実行される必要があります。
OracleGraphWrapperForOntModelによって使用されるデフォルトのインメモリー・セマンティク・ストアが、オントロジとシステムにとって十分ではない場合、インメモリー・ストアとして使用するカスタム・グラフを指定するためのインタフェースがクラスによって提供されます。例7-14に、カスタム・インメモリー・グラフを使用してOntModelからの問合せに応答するOracleGraphWrapperForOntModelを作成する方法を示します。
例7-14 カスタム・インメモリー・グラフの使用
// Set up connection to Oracle semantic store and the Oracle model // containing the ontology Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd); GraphOracleSem oracleGraph = new GraphOracleSem(oracle, szModelName); // Create a custom in-memory graph to use instead of the default // Jena in-memory graph for quickly answering OntModel queries. // Note that this graph does not *need* to be in-memory, but in-memory // is preferred. GraphBase queryGraph = new CustomInMemoryGraphImpl(); // Create a new hybrid graph using the oracle graph to persist // changes and the custom in-memory graph to answer queries. // Also set the degree of parallelism to use when copying data from // the oracle graph to the querying graph. int degreeOfParallelism = 4; Graph hybridGraph = OracleGraphWrapperForOntModel.getInstance(oracleGraph, queryGraph, degreeOfParallelism); // Build a model and wrap the model with Jena's OntModel Model model = ModelFactory.createModelForGraph(hybridGraph); OntModel ontModel = ModelFactory.createOntologyModel(ontModelSpec, model); // Perform operations on the ontology // ... // Close resources (will close oracleGraph and queryGraph)! hybridGraph.close(); ontModel.close();
この項では、Jena Adapterを使用した問合せの例を示します。各例は自己完結型で、通常はモデルの作成、トリプルの作成、推論を含む可能性のある問合せの実行、結果の表示およびモデルの削除を行います。
この項では、次の手順を実行する問合せについて説明します。
URLによるオントロジの参照、およびローカル・ファイルからオントロジをバルク・ロードする方法の両方によって、universityオントロジの例で表明されたトリプルと表明に加えて推論されたトリプルをカウントします。
familyオントロジを使用して複数のSPARQL問合せを実行します(LIMIT、OFFSET、TIMEOUT、DOP (並列度)、ASK、DESCRIBE、CONSTRUCT、GRAPH、ALLOW_DUP (複数のモデルによる重複トリプル)、SPARUL (データの挿入)などの機能が含まれます)。
ARQ組込みファンクションを使用します。
SELECTキャスト問合せを使用します。
OracleConnectionを使用してOracle Databaseをインスタンス化します。
Oracle Database接続プーリングを使用します。
問合せを実行するには、次の手順を実行する必要があります。
コードをJavaソース・ファイルに含めます。この項で使用される例は、Jena Adapterダウンロードのexamplesディレクトリのファイルで提供されています。
Javaソース・ファイルをコンパイルします。次に例を示します。
> javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test.java
|
注意: javacコマンドおよびjavaコマンドは、それぞれ1行のコマンドラインである必要があります。 |
コンパイルされたファイルを実行します。次に例を示します。
> java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
例7-15では、JohnがMaryの父であることを指定し、次に各fatherOf関係で主語と目的語を選択して表示します。
例7-15 家族関係の問合せ
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.query.*;
public class Test {
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
Model model = ModelOracleSem.createOracleSemModel(
oracle, szModelName);
model.getGraph().add(Triple.create(
Node.createURI("http://example.com/John"),
Node.createURI("http://example.com/fatherOf"),
Node.createURI("http://example.com/Mary")));
Query query = QueryFactory.create(
"select ?f ?k WHERE {?f <http://example.com/fatherOf> ?k .}");
QueryExecution qexec = QueryExecutionFactory.create(query, model);
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(System.out, results, query);
model.close();
oracle.dispose();
}
}
例7-15をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
---------------------------------------------------------
| f | k |
=========================================================
| <http://example.com/John> | <http://example.com/Mary> |
---------------------------------------------------------
例7-16では、OWLオントロジをロードして、OWLPrime推論を実行します。OWLオントロジがRDF/XML形式であり、Oracleにロードされた後にN-triple形式でシリアライズされることに注意してください。また、この例は表明および推論されたトリプルの数を問い合せます。
この例のオントロジはhttp://swat.cse.lehigh.edu/onto/univ-bench.owlから入手することができ、これには、ロール、リソースおよび大学環境での関係について記述されています。
例7-16 OWLオントロジのロードとOWLPrime推論の実行
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
public class Test6 {
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
Model model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
// load UNIV ontology
InputStream in = FileManager.get().open("./univ-bench.owl" );
model.read(in, null);
OutputStream os = new FileOutputStream("./univ-bench.nt");
model.write(os, "N-TRIPLE");
os.close();
String queryString =
" SELECT ?subject ?prop ?object WHERE { ?subject ?prop ?object } ";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
try {
int iTriplesCount = 0;
ResultSet results = qexec.execSelect() ;
for ( ; results.hasNext() ; ) {
QuerySolution soln = results.nextSolution() ;
iTriplesCount++;
}
System.out.println("Asserted triples count: " + iTriplesCount);
}
finally {
qexec.close() ;
}
Attachment attachment = Attachment.createInstance(
new String[] {}, "OWLPRIME",
InferenceMaintenanceMode.NO_UPDATE, QueryOptions.DEFAULT);
GraphOracleSem graph = new GraphOracleSem(oracle, szModelName, attachment);
graph.analyze();
graph.performInference();
query = QueryFactory.create(queryString) ;
qexec = QueryExecutionFactory.create(query,new ModelOracleSem(graph)) ;
try {
int iTriplesCount = 0;
ResultSet results = qexec.execSelect() ;
for ( ; results.hasNext() ; ) {
QuerySolution soln = results.nextSolution() ;
iTriplesCount++;
}
System.out.println("Asserted + Infered triples count: " + iTriplesCount);
}
finally {
qexec.close() ;
}
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-16をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test6.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test6 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
Asserted triples count: 294
Asserted + Infered triples count: 341
この出力には、以前のバージョンのLUBMオントロジが反映されていることに注意してください。最新バージョンのオントロジには、より多くのトリプルがあります。
例7-17では、7.15.2項と同じOWLオントロジ(バルク・ローダーを使用してローカル・ファイルに格納されるもの以外)をロードします。オントロジは増分およびバッチ・ローダーを使用してロードすることもでき、完全性を期すために例にはこれらの2つの方法も示されています。
例7-17 OWLオントロジのバルク・ロードとOWLPrime推論の実行
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.rdf.model.*;
import com.hp.hpl.jena.util.*;
import oracle.spatial.rdf.client.jena.*;
public class Test7
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
// in memory Jena Model
Model model = ModelFactory.createDefaultModel();
InputStream is = FileManager.get().open("./univ-bench.owl");
model.read(is, "", "RDF/XML");
is.close();
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem modelDest = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = modelDest.getGraph();
g.dropApplicationTableIndex();
int method = 2; // try bulk loader
String tbs = "SYSAUX"; // can be customized
if (method == 0) {
System.out.println("start incremental");
modelDest.add(model);
System.out.println("end size " + modelDest.size());
}
else if (method == 1) {
System.out.println("start batch load");
g.getBulkUpdateHandler().addInBatch(
GraphUtil.findAll(model.getGraph()), tbs);
System.out.println("end size " + modelDest.size());
}
else {
System.out.println("start bulk load");
g.getBulkUpdateHandler().addInBulk(
GraphUtil.findAll(model.getGraph()), tbs);
System.out.println("end size " + modelDest.size());
}
g.rebuildApplicationTableIndex();
long lCount = g.getCount(Triple.ANY);
System.out.println("Asserted triples count: " + lCount);
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-17をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test7.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test7 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
start bulk load
end size 293
Asserted triples count: 293
この出力には、以前のバージョンのLUBMオントロジが反映されていることに注意してください。最新バージョンのオントロジには、より多くのトリプルがあります。
例7-18では、SPARQL OPTIONAL問合せを示します。この例では、次の条件を持つトリプルを挿入します。
Johnは、Maryの親です。
Johnは、Jackの親です。
Maryは、Jillの親です。
次に親子関係を検出し、オプションで孫(gkid)の関係も含めます。
例7-18 SPARQL OPTIONAL問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test8
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(
Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(
Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(
Node.createURI("u:Mary"), Node.createURI("u:parentOf"),
Node.createURI("u:Jill")));
String queryString =
" SELECT ?s ?o ?gkid " +
" WHERE { ?s <u:parentOf> ?o . OPTIONAL {?o <u:parentOf> ?gkid }} ";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
try {
int iMatchCount = 0;
ResultSet results = qexec.execSelect() ;
ResultSetFormatter.out(System.out, results, query);
}
finally {
qexec.close() ;
}
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-18をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test8.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test8 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
----------------------------------
| s | o | gkid |
==================================
| <u:John> | <u:Mary> | <u:Jill> |
| <u:Mary> | <u:Jill> | |
| <u:John> | <u:Jack> | |
----------------------------------
例7-19では、LIMITおよびOFFSETを使用するSPARQL問合せを示します。この例では、次の条件を持つトリプルを挿入します。
Johnは、Maryの親です。
Johnは、Jackの親です。
Maryは、Jillの親です。
次に、1つの親子関係(LIMIT 1)を検出し、検出された最初の2つの親子関係(OFFSET 2)をスキップして、オプションで検出された親子に対する孫(gkid)の関係を追加します。
例7-19 LIMITおよびOFFSETを使用するSPARQL問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test9
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(Node.createURI("u:Mary"), Node.createURI("u:parentOf"),
Node.createURI("u:Jill")));
String queryString =
" SELECT ?s ?o ?gkid " +
" WHERE { ?s <u:parentOf> ?o . OPTIONAL {?o <u:parentOf> ?gkid }} " +
" LIMIT 1 OFFSET 2";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
int iMatchCount = 0;
ResultSet results = qexec.execSelect() ;
ResultSetFormatter.out(System.out, results, query);
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-19をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test9.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test9 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
------------------------------
| s | o | gkid |
==============================
| <u:John> | <u:Jack> | |
------------------------------
例7-20では、7.15.5項のSPARQL問合せに、タイムアウト設定(TIMEOUT=1、秒単位)およびパラレル実行設定(DOP=4)などの機能を追加した例を示します。
例7-20 TIMEOUTおよびDOPを使用するSPARQL問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test10 {
public static void main(String[] args) throws Exception {
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(Node.createURI("u:Mary"), Node.createURI("u:parentOf"),
Node.createURI("u:Jill")));
String queryString =
" PREFIX ORACLE_SEM_FS_NS: <http://oracle.com/semtech#dop=4,timeout=1> "
+ " SELECT ?s ?o ?gkid WHERE { ?s <u:parentOf> ?o . "
+ " OPTIONAL {?o <u:parentOf> ?gkid }} "
+ " LIMIT 1 OFFSET 2";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
int iMatchCount = 0;
ResultSet results = qexec.execSelect() ;
ResultSetFormatter.out(System.out, results, query);
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-20をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test10.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test10 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
------------------------------
| s | o | gkid |
==============================
| <u:Mary> | <u:Jill> | |
------------------------------
例7-21では、名前付きグラフを含む問合せを示します。これには、名前付きグラフのURIとその作成者に関する情報を持つデフォルト・グラフが含まれます。この問合せは、グラフ名とそのグラフの作成者を検索し、各名前付きグラフでfoaf:mbox述語を使用してメールボックスの値を検索します。
例7-21 名前付きグラフ・ベースの問合せ
import java.io.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.sparql.core.*;
import com.hp.hpl.jena.query.*;
import oracle.spatial.rdf.client.jena.*;
public class Test11
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
GraphOracleSem graph = new GraphOracleSem(oracle, szModelName);
DatasetGraphOracleSem dataset = DatasetGraphOracleSem.createFrom(graph);
// don't need the GraphOracleSem anymore, release resources
graph.close();
// add data to the default graph
dataset.add(new Quad(
Quad.defaultGraphIRI, // specifies default graph
Node.createURI("http://example.org/bob"),
Node.createURI("http://purl.org/dc/elements/1.1/publisher"),
Node.createLiteral("Bob Hacker")));
dataset.add(new Quad(
Quad.defaultGraphIRI, // specifies default graph
Node.createURI("http://example.org/alice"),
Node.createURI("http://purl.org/dc/elements/1.1/publisher"),
Node.createLiteral("alice Hacker")));
// add data to the bob named graph
dataset.add(new Quad(
Node.createURI("http://example.org/bob"), // graph name
Node.createURI("urn:bob"),
Node.createURI("http://xmlns.com/foaf/0.1/name"),
Node.createLiteral("Bob")));
dataset.add(new Quad(
Node.createURI("http://example.org/bob"), // graph name
Node.createURI("urn:bob"),
Node.createURI("http://xmlns.com/foaf/0.1/mbox"),
Node.createURI("mailto:bob@example")));
// add data to the alice named graph
dataset.add(new Quad(
Node.createURI("http://example.org/alice"), // graph name
Node.createURI("urn:alice"),
Node.createURI("http://xmlns.com/foaf/0.1/name"),
Node.createLiteral("Alice")));
dataset.add(new Quad(
Node.createURI("http://example.org/alice"), // graph name
Node.createURI("urn:alice"),
Node.createURI("http://xmlns.com/foaf/0.1/mbox"),
Node.createURI("mailto:alice@example")));
DataSource ds = DatasetFactory.create(dataset);
String queryString =
" PREFIX foaf: <http://xmlns.com/foaf/0.1/> "
+ " PREFIX dc: <http://purl.org/dc/elements/1.1/> "
+ " SELECT ?who ?graph ?mbox "
+ " FROM NAMED <http://example.org/alice> "
+ " FROM NAMED <http://example.org/bob> "
+ " WHERE "
+ " { "
+ " ?graph dc:publisher ?who . "
+ " GRAPH ?graph { ?x foaf:mbox ?mbox } "
+ " } ";
Query query = QueryFactory.create(queryString);
QueryExecution qexec = QueryExecutionFactory.create(query, ds);
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(System.out, results, query);
qexec.close();
dataset.close();
oracle.dispose();
}
}
例7-21をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test11.java java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test11 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
例7-22では、SPARQL ASK問合せを示します。この例では、JohnがMaryの親であるという条件のトリプルを挿入します。次に、JohnがMaryの親かどうかを検索します。
例7-22 SPARQL ASK問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test12
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
String queryString = " ASK { <u:John> <u:parentOf> <u:Mary> } ";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
boolean b = qexec.execAsk();
System.out.println("ask result = " + ((b)?"TRUE":"FALSE"));
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-22をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test12.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test12 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
ask result = TRUE
例7-23では、SPARQL DESCRIBE問合せを示します。この例では、次の条件を持つトリプルを挿入します。
Johnは、Maryの親です。
Johnは、Jackの親です。
Amyは、Jackの親です。
次に、Jackの親を含むすべての関係を検索します。
例7-23 SPARQL DESCRIBE問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test13
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(Node.createURI("u:Amy"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
String queryString = " DESCRIBE ?x WHERE {?x <u:parentOf> <u:Jack>}";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
Model m = qexec.execDescribe();
System.out.println("describe result = " + m.toString());
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-23をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test13.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test13 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
describe result = <ModelCom {u:Amy @u:parentOf u:Jack; u:John @u:parentOf u:Jack; u:John @u:parentOf u:Mary} | >
例7-24では、SPARQL CONSTRUCT問合せを示します。この例では、次の条件を持つトリプルを挿入します。
Johnは、Maryの親です。
Johnは、Jackの親です。
Amyは、Jackの親です。
それぞれの親は、自分の子ども全員を愛しています。
次に、だれがだれを愛しているかについての情報でRDFグラフを構築します。
例7-24 SPARQL CONSTRUCT問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test14
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(Node.createURI("u:Amy"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
String queryString = " CONSTRUCT { ?s <u:loves> ?o } WHERE {?s <u:parentOf> ?o}";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
Model m = qexec.execConstruct();
System.out.println("Construct result = " + m.toString());
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-24をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test14.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test14 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
Construct result = <ModelCom {u:Amy @u:loves u:Jack; u:John @u:loves u:Jack; u:John @u:loves u:Mary} | >
例7-25では、複数のモデルを問い合せ、重複の許可オプションを使用します。この例では、次の条件を持つトリプルを挿入します。
Johnは、Jackの親です(モデル1)。
Maryは、Jackの親です(モデル2)。
それぞれの親は、自分の子ども全員を愛しています。
次に、だれがだれを愛しているかについて検索します。両方のモデルを検索し、モデルでの重複トリプルを(この例に重複はありませんが)許可します。
例7-25 複数のモデルの問合せと重複の許可の指定
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
public class Test15
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName1 = args[3];
String szModelName2 = args[4];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model1 = ModelOracleSem.createOracleSemModel(oracle, szModelName1);
model1.getGraph().add(Triple.create(Node.createURI("u:John"),
Node.createURI("u:parentOf"), Node.createURI("u:Jack")));
model1.close();
ModelOracleSem model2 = ModelOracleSem.createOracleSemModel(oracle, szModelName2);
model2.getGraph().add(Triple.create(Node.createURI("u:Mary"),
Node.createURI("u:parentOf"), Node.createURI("u:Jack")));
model2.close();
String[] modelNamesList = {szModelName2};
String[] rulebasesList = {};
Attachment attachment = Attachment.createInstance(modelNamesList, rulebasesList,
InferenceMaintenanceMode.NO_UPDATE,
QueryOptions.ALLOW_QUERY_VALID_AND_DUP);
GraphOracleSem graph = new GraphOracleSem(oracle, szModelName1, attachment);
ModelOracleSem model = new ModelOracleSem(graph);
String queryString = " CONSTRUCT { ?s <u:loves> ?o } WHERE {?s <u:parentOf> ?o}";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
Model m = qexec.execConstruct();
System.out.println("Construct result = " + m.toString());
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName1);
OracleUtils.dropSemanticModel(oracle, szModelName2);
oracle.dispose();
}
}
例7-25をコンパイルして実行するコマンドと、想定されるjavaコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test15.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test15 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1 M2
Construct result = <ModelCom {u:Mary @u:loves u:Jack; u:John @u:loves u:Jack} | >
例7-26では、2つのトリプルをモデルに挿入します。
例7-26 SPARQLの更新
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
public class Test16
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
GraphOracleSem g = model.getGraph();
String insertString =
" PREFIX dc: <http://purl.org/dc/elements/1.1/> " +
" INSERT DATA " +
" { <http://example/book3> dc:title \"A new book\" ; " +
" dc:creator \"A.N.Other\" . " +
" } ";
UpdateAction.parseExecute(insertString, model);
ExtendedIterator ei = GraphUtil.findAll(g);
while (ei.hasNext()) {
System.out.println("Triple " + ei.next().toString());
}
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-26をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test16.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test16 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
Triple http://example/book3 @dc:title "A new book"
Triple http://example/book3 @dc:creator "A.N.Other"
例7-27では、2冊の本に関するデータを挿入し、その本のタイトルをすべて大文字で表示して、各タイトル文字列の長さも表示します。
例7-27 ARQ組込みファンクションを使用するSPARQL問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
public class Test17 {
public static void main(String[] args) throws Exception {
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle, szModelName);
GraphOracleSem g = model.getGraph();
String insertString =
" PREFIX dc: <http://purl.org/dc/elements/1.1/> " +
" INSERT DATA " +
" { <http://example/book3> dc:title \"A new book\" ; " +
" dc:creator \"A.N.Other\" . " +
" <http://example/book4> dc:title \"Semantic Web Rocks\" ; " +
" dc:creator \"TB\" . " +
" } ";
UpdateAction.parseExecute(insertString, model);
String queryString = "PREFIX dc: <http://purl.org/dc/elements/1.1/> " +
" PREFIX fn: <http://www.w3.org/2005/xpath-functions#> " +
" SELECT ?subject (fn:upper-case(?object) as ?object1) " +
" (fn:string-length(?object) as ?strlen) " +
" WHERE { ?subject dc:title ?object } "
;
Query query = QueryFactory.create(queryString, Syntax.syntaxARQ);
QueryExecution qexec = QueryExecutionFactory.create(query, model);
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(System.out, results, query);
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-27をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test17.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test17 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
----------------------------------------------------------
| subject | object1 | strlen |
==========================================================
| <http://example/book3> | "A NEW BOOK" | 10 |
| <http://example/book4> | "SEMANTIC WEB ROCKS" | 18 |
----------------------------------------------------------
例7-28では、2つの華氏温度(18.1と32.0)を摂氏温度に変換します。
例7-28 SELECTキャスト問合せ
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import oracle.spatial.rdf.client.jena.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
public class Test18 {
public static void main(String[] args) throws Exception {
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
Oracle oracle = new Oracle(szJdbcURL, szUser, szPasswd);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = model.getGraph();
String insertString =
" PREFIX xsd: <http://www.w3.org/2001/XMLSchema#> " +
" INSERT DATA " +
" { <u:Object1> <u:temp> \"18.1\"^^xsd:float ; " +
" <u:name> \"Foo... \" . " +
" <u:Object2> <u:temp> \"32.0\"^^xsd:float ; " +
" <u:name> \"Bar... \" . " +
" } ";
UpdateAction.parseExecute(insertString, model);
String queryString =
" PREFIX fn: <http://www.w3.org/2005/xpath-functions#> " +
" SELECT ?subject ((?temp - 32.0)*5/9 as ?celsius_temp) " +
"WHERE { ?subject <u:temp> ?temp } "
;
Query query = QueryFactory.create(queryString, Syntax.syntaxARQ);
QueryExecution qexec = QueryExecutionFactory.create(query, model);
ResultSet results = qexec.execSelect();
ResultSetFormatter.out(System.out, results, query);
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-28をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test18.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test18 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
------------------------------------------------------------------------
| subject | celsius_temp |
========================================================================
| <u:Object1> | "-7.7222223"^^<http://www.w3.org/2001/XMLSchema#float> |
| <u:Object2> | "0.0"^^<http://www.w3.org/2001/XMLSchema#float> |
------------------------------------------------------------------------
例7-29では、指定されたOracleConnectionオブジェクトを使用して、異なる方法でOracleオブジェクトをインスタンス化しています。(J2EE Webアプリケーションでは、ユーザーは通常、J2EEデータ・ソースからOracleConnectionオブジェクトを取得できます。)
例7-29 OracleConnectionを使用したOracle Databaseのインスタンス化
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
import oracle.spatial.rdf.client.jena.*;
import oracle.jdbc.pool.*;
import oracle.jdbc.*;
public class Test19 {
public static void main(String[] args) throws Exception {
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
OracleDataSource ds = new OracleDataSource();
ds.setURL(szJdbcURL);
ds.setUser(szUser);
ds.setPassword(szPasswd);
OracleConnection conn = (OracleConnection) ds.getConnection();
Oracle oracle = new Oracle(conn);
ModelOracleSem model = ModelOracleSem.createOracleSemModel(oracle,
szModelName);
GraphOracleSem g = model.getGraph();
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.add(Triple.create(Node.createURI("u:Mary"), Node.createURI("u:parentOf"),
Node.createURI("u:Jill")));
String queryString =
" SELECT ?s ?o WHERE { ?s <u:parentOf> ?o .} ";
Query query = QueryFactory.create(queryString) ;
QueryExecution qexec = QueryExecutionFactory.create(query, model) ;
ResultSet results = qexec.execSelect() ;
ResultSetFormatter.out(System.out, results, query);
qexec.close() ;
model.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
oracle.dispose();
}
}
例7-29をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test19.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test19 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
-----------------------
| s | o |
=======================
| <u:John> | <u:Mary> |
| <u:John> | <u:Jack> |
| <u:Mary> | <u:Jill> |
-----------------------
例7-30では、Oracle Database接続プーリングを使用します。
例7-30 Oracle Database接続プーリング
import java.io.*;
import com.hp.hpl.jena.query.*;
import com.hp.hpl.jena.rdf.model.Model;
import com.hp.hpl.jena.util.FileManager;
import com.hp.hpl.jena.util.iterator.*;
import com.hp.hpl.jena.graph.*;
import com.hp.hpl.jena.update.*;
import oracle.spatial.rdf.client.jena.*;
import oracle.jdbc.pool.*;
import oracle.jdbc.*;
public class Test20
{
public static void main(String[] args) throws Exception
{
String szJdbcURL = args[0];
String szUser = args[1];
String szPasswd = args[2];
String szModelName = args[3];
// test with connection properties (taken from some example)
java.util.Properties prop = new java.util.Properties();
prop.setProperty("MinLimit", "2"); // the cache size is 2 at least
prop.setProperty("MaxLimit", "10");
prop.setProperty("InitialLimit", "2"); // create 2 connections at startup
prop.setProperty("InactivityTimeout", "1800"); // seconds
prop.setProperty("AbandonedConnectionTimeout", "900"); // seconds
prop.setProperty("MaxStatementsLimit", "10");
prop.setProperty("PropertyCheckInterval", "60"); // seconds
System.out.println("Creating OraclePool");
OraclePool op = new OraclePool(szJdbcURL, szUser, szPasswd, prop,
"OracleSemConnPool");
System.out.println("Done creating OraclePool");
// grab an Oracle and do something with it
System.out.println("Getting an Oracle from OraclePool");
Oracle oracle = op.getOracle();
System.out.println("Done");
System.out.println("Is logical connection:" +
oracle.getConnection().isLogicalConnection());
GraphOracleSem g = new GraphOracleSem(oracle, szModelName);
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Mary")));
g.close();
// return the Oracle back to the pool
oracle.dispose();
// grab another Oracle and do something else
System.out.println("Getting an Oracle from OraclePool");
oracle = op.getOracle();
System.out.println("Done");
System.out.println("Is logical connection:" +
oracle.getConnection().isLogicalConnection());
g = new GraphOracleSem(oracle, szModelName);
g.add(Triple.create(Node.createURI("u:John"), Node.createURI("u:parentOf"),
Node.createURI("u:Jack")));
g.close();
OracleUtils.dropSemanticModel(oracle, szModelName);
// return the Oracle back to the pool
oracle.dispose();
}
}
例7-30をコンパイルして実行するコマンドと、想定されるjavaのコマンドの出力は次のとおりです。
javac -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:/slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar Test20.java
java -classpath ./:./jena-2.6.4.jar:./sdordfclient.jar:./ojdbc6.jar:./slf4j-api-1.5.8.jar:./slf4j-log4j12-1.5.8.jar:./arq-2.8.8.jar:./xercesImpl-2.7.1.jar:./iri-0.8.jar:./icu4j-3.4.4.jar:./log4j-1.2.14.jar Test20 jdbc:oracle:thin:@localhost:1521:orcl scott <password-for-scott> M1
Creating OraclePool
Done creating OraclePool
Getting an Oracle from OraclePool
Done
Is logical connection:true
Getting an Oracle from OraclePool
Done
Is logical connection:true
SPARQL Gatewayは、Jena Adapter for Oracle Databaseに含まれるJ2EE Webアプリケーションです。Oracle Business Intelligence Enterprise Edition (OBIEE) 11gなどの、リレーショナル・データおよびXMLデータで稼働するアプリケーションで、セマンティク・データ(RDF/OWL/SKOS)を簡単に使用できるように設計されています。
この項には、次の主要なトピックがあります。
SPQRQL Gatewayでは、セマンティク・データを非セマンティク・アプリケーションに公開する際の次のような課題に対処します。
RDF構文、SPARQL問合せ構文およびSPARQLプロトコルについて理解しておく必要があること。
SPARQL問合せのレスポンス構文を理解しておく必要があること。
変換で、SPARQL問合せのレスポンスを、アプリケーションが使用できる形に変更する必要があること。
このような課題に対処するため、SPARQL Gatewayは、SPARQL問合せとXSLT操作を管理し、標準準拠の任意のSPARQLエンドポイントに対してSPARQL問合せを実行して、必要なXSL変換を実行してから、アプリケーションへレスポンスを渡します。こうすると、アプリケーションは既存のデータ・ソースからの場合と同じようにセマンティク・データを使用できるようになります。
多くの場合、トリプル・ストアまたはクワッド・ストアごとに機能は異なります。たとえば、Oracle DatabaseによってサポートされるSPARQLエンドポイントは、指定された標準準拠のSPARQL問合せを解析して応答するというコア機能に加え、Jena AdapterおよびJosekiを使用して、パラレル実行、問合せタイムアウト、動的なサンプリング、結果キャッシュおよびその他の機能を実行できます。ただし、これらの機能は、指定された別のセマンティク・データ・ストアからは使用できない場合があります。
Oracleセマンティク・テクノロジのSPARQL Gatewayでは、実行時間の長い問合せに対するタイムアウトを設定する機能や、所定の時間で複雑な問合せから部分的な結果を取得する機能など、特に必要とされる特定の機能を利用できます。アプリケーションにレスポンス時間の制約があるように、問合せの終了をいつまでも待っていることはエンド・ユーザーにとって困難です。SPARQL Gatewayは、SPARQLエンドポイントにタイムアウト機能とベスト・エフォート型問合せ機能の両方を提供します。これによって、SPARQL問合せの実行を介してセマンティク・データを使用する際の不確実性がある程度は効率的に排除されます。(7.16.3.2項「タイムアウト値の指定」と7.16.3.3項「ベスト・エフォート型問合せ実行の指定」を参照してください。)
SPARQL Gatewayをインストールして構成するには、次の主要な手順を実行します(それぞれの手順については後に続く項で説明します)。
Jena Adapter (jena_adaptor_for_release11.2.0.3.zip)をまだダウンロードしていない場合は、7.1項の説明のとおり、Oracle Databaseセマンティク・テクノロジのページからダウンロードし、一時ディレクトリに解凍します。
SPARQL GatewayのJavaクラスの実装は、sdordfclient.jarに組み込まれています(7.16.5項「Using the SPARQL GatewayのJava APIの使用」を参照)。
Oracle WebLogic Serverで、次のようにSPARQL Gatewayをデプロイします。
一時ディレクトリ(/tmp/sgなど)を作成します。
ダウンロードしたSPARQL Gatewayファイルを解凍したディレクトリから、sparqlgatewayディレクトリおよびそのディレクトリ下にあるすべて(サブディレクトリを含む)を、手順1で作成した一時ディレクトリにコピーします。次に例を示します。
cd /tmp cp -rf sparqlgateway/* /tmp/sg
(このサンプル・ディレクトリの構造は、後から説明する手順で使用されます。)
ARQ 2.8.8パッケージがまだない場合は、http://sourceforge.net/projects/jena/files/ARQ/ARQ-2.8.8/arq-2.8.8.zip/downloadからダウンロードします。
ARQ 2.8.8パッケージから次のライブラリを/tmp/sg/WEB-INF/libにコピーします。
arq-2.8.8.jar icu4j-3.4.4.jar iri-0.8.jar jena-2.6.4.jar junit-4.5.jar log4j-1.2.14.jar lucene-core-2.3.1.jar slf4j-api-1.5.8.jar slf4j-log4j12-1.5.8.jar stax-api-1.0.1.jar wstx-asl-3.2.9.jar xercesImpl-2.7.1.jar
次のライブラリを/tmp/sg/WEB-INF/libにコピーします。
ojdbc6.jar (from $ORACLE_HOME/jdbc/lib/ojdbc6.jar ) sdordfclient.jar (from jena_adaptor_for_release11.2.0.3.zip under the jar/ directory) sdordf.jar from $ORACLE_HOME/md/jlib/sdordf.jar )
必要に応じて、/tmp/sg/WEB-INF/web.xmlファイルをカスタマイズします。sparql_gateway_repository_filedirパラメータおよびsparql_gateway_repository_urlパラメータに適切な値を指定してください。
必要に応じて、XSLTファイルまたはSPARQL問合せファイルを/tmp/sgディレクトリに追加します。
このディレクトリにはOracle提供のファイルdefault.xslt、noop.xsltおよびqb1.sparqlがあります。default.xsltファイルの主な目的は、SPARQL問合せレスポンス(XML)をOracle Business Intelligence Enterprise Edition (OBIEE)で利用可能な形式に変換することです。
(これらのファイルについては7.16.3.1項「SPARQL問合せとXSL変換の格納」を、SPARQL GatewayでのOBIEEの使用については7.16.7項「OBIEEへのXMLデータ・ソースとしてのSPARQL Gatewayの使用」を参照してください。)
次のように、WebLogic Serverのautodeployディレクトリに移動し、sparqlgateway.warディレクトリを作成し、ファイルをコピーします。(開発ドメインでの自動デプロイ・アプリケーションの詳細は、http://docs.oracle.com/cd/E11035_01/wls100/deployment/autodeploy.htmlを参照してください。)
cd <domain_name>/autodeploy mkdir sparqlgateway.war cp -rf /tmp/sg/* <domain_name>/autodeploy/sparqgateway.war
この例では、<domain_name>はWebLogic Serverドメインの名前です。
/tmp/sgディレクトリから.warファイルを作成する場合は、次のコマンドを入力します。
cd /tmp/sg jar cvf /tmp/sparqlgateway.war *
WebLogic Serverを起動または再起動します。
Webブラウザを使用して、次の書式のURLに接続し、デプロイメントを確認します(Webアプリケーションはポート7001でデプロイされているとします)。
http://<hostname>:7001/sparqlgateway
SPARQL Gatewayがファイアウォールの内側にあり、SPARQL Gatewayでファイアウォール内部のみでなくインターネット上のSPARQLエンドポイントとも通信する必要がある場合は、次のJVM設定を使用する必要があります。
-Dhttp.proxyHost=<your_proxy_host> -Dhttp.proxyPort=<your_proxy_port> -Dhttp.nonProxyHosts=127.0.0.1|<hostname_1_for_sparql_endpoint_inside_firewall>|<hostname_2_for_sparql_endpoint_inside_firewall>|...|<hostname_n_for_sparql_endpoint_inside_firewall>
これらの設定は、startWebLogic.shスクリプトで指定できます。
SPARQL GatewayのSPARQL問合せおよびXSL変換を格納してアクセスするためにOracle Databaseを使用する場合は、OracleSGDSという名前のデータ・ソースを構成する必要があります。
このデータ・ソースを作成するには、7.2.1項「WebLogic Serverを使用した必要なデータ・ソースの作成」の手順に従いますが、データ・ソース名にはOracleSemDSではなくOracleSGDSを指定します。
OracleSGDSデータ・ソースが構成されていて使用可能な場合、SPARQL Gatewayサーブレットは、すべての必要な表と索引を初期化時に自動作成します。
SPARQL Gatewayの次のJSPファイルは、Oracle Databaseに格納されているSPARQL問合せとXSL変換を表示、編集および更新するために役立ちます。
http://<host>:7001/sparqlgateway/admin/sparql.jsp http://<host>:7001/sparqlgateway/admin/xslt.jsp
これらのファイルは、HTTP Basic認証によって保護されています。WEB-INF/weblogic.xmlに、SparqlGatewayAdminGroupという名前のプリンシパルが定義されます。
これらのJSPページのいずれにでもログインできるように、WebLogic Serverを使用してSparqlGatewayAdminGroupという名前のグループを追加し、新しいユーザーを作成するか、または既存ユーザーをこのグループに割り当てる必要があります。
SPARQL Gatewayと対話するアプリケーションの主要なインタフェースには、次の形式のURLを使用します。
http://host:port/sparqlgateway/sg?<SPARQL_ENDPOINT>&<SPARQL_QUERY>&<XSLT>
前述の形式の説明:
<SPARQL_ENDPOINT>ではeeパラメータを指定しますが、これにはURLエンコード形式のSPARQLエンドポイントが含まれます。
たとえば、ee=http%3A%2F%2Fsparql.org%2Fbooksは、http://sparql.org/booksというSPARQLエンドポイントをURLエンコードした文字列です。これは、SPARQL問合せがエンドポイントhttp://sparql.org/booksに対して実行されることを意味します。
<SPARQL_QUERY>では、SPARQL問合せ、またはSPARQL問合せの場所を指定します。
アプリケーションで非常に長いURLを使用できる場合は、SPARQL問合せ全体をエンコードし、URLにeq=<encoded_SPARQL_query>を設定できます(非常に長いURLをアプリケーションで使用できない場合は、7.16.3.1項で説明される方法の1つを使用して、SPARQL問合せを格納し、これらをSPARQL Gatewayで使用できるようにすることが可能です)。
<XSLT>では、XSL変換またはXSL変換の場所を指定します。
アプリケーションで非常に長いURLを使用できる場合は、XSL変換全体をエンコードし、URLにex=<encoded_XSLT>を設定できます(非常に長いURLをアプリケーションで使用できない場合は、7.16.3.1項で説明される方法の1つを使用して、XSL変換を格納し、これらをSPARQL Gatewayで使用できるようにすることが可能です)。
関連トピック:
非常に長いURLをアプリケーションで使用できない場合は、7.16.3項で説明されているURL形式のうち<SPARQL_QUERY>と<XSLT>の部分で、SPARQL問合せとXSL変換の場所を指定できますが、このとき、次のいずれかの方法を使用します。
SPARQL問合せとXSL変換をSPARQL Gateway Webアプリケーション自体に格納します。
これを行うには、sparqlgateway.warファイルを解凍し、最上位ディレクトリにSPARQL問合せとXSL変換を格納した後、sparqlgateway.warファイルを圧縮して再デプロイします。
sparqlgateway.warファイルには、サンプル・ファイルqb1.sparql (SPARQL問合せ)およびdefault.xslt (XSL変換)が含まれています。
|
ヒント: SPARQL問合せファイルにはファイル拡張子.sparqlを使用し、XSL変換ファイルにはファイル拡張子.xsltを使用します。 |
(提供されているサンプル・ファイルの名前を使用して)これらのファイルを指定する構文は、SPARQL問合せファイルについてはwq=qb1.sparql、XSL変換ファイルについてはwx=default.xsltです。
デフォルトのXSL変換をカスタマイズする必要がある場合は、7.16.4項「デフォルトのXSLTファイルのカスタマイズ」の例を参照してください。
wx=noop.xsltを指定すると、XSL変換は実行されず、SPARQLレスポンスはそのままでクライアントに戻されます。
ファイル・システム・ディレクトリにSPARQL問合せとXSL変換を格納し、そのディレクトリがデプロイ済のSPARQL Gateway Webアプリケーションにアクセス可能なことを確認します。
デフォルトでは、次の<init-param>設定に示すとおり、そのディレクトリは/tmpに設定されています。
<init-param> <param-name>sparql_gateway_repository_filedir</param-name> <param-value>/tmp/</param-value> </init-param>
SPARQL Gatewayをデプロイする前に、このディレクトリをカスタマイズすることをお薦めします。ディレクトリ設定を変更するには、<param-value>タグと</param-value>タグの間のテキストを編集します。
次の例では、sparql_gateway_repository_filedirの<init-param>要素で指定されたディレクトリのSPARQL問合せファイルとXSL変換ファイルを指定します。
fq=qb1.sparql fx=myxslt1.xslt
SPARQL問合せとXSL変換をWebサイトからアクセス可能にします。
デフォルトでは、次の<init-param>設定に示すとおり、そのWebサイト・ディレクトリはhttp://127.0.0.1/queries/に設定されています。
<init-param> <param-name>sparql_gateway_repository_url</param-name> <param-value>http://127.0.0.1/queries/</param-value> </init-param>
このディレクトリは、SPARQL Gatewayをデプロイする前にカスタマイズします。Webサイト設定を変更するには、<param-value>タグと</param-value>タグの間のテキストを編集します。
次の例では、sparql_gateway_repository_urlの<init-param>要素で指定されたURLのSPARQL問合せファイルとXSL変換ファイルを指定します。
uq=qb1.sparql ux=myxslt1.xslt
SPARQL Gatewayの内部では、適切で完全なURLを計算し、内容をフェッチして、問合せ実行を開始し、問合せのレスポンスXMLにXSL変換を適用します。
SPARQL問合せとXSL変換をOracle Databaseに格納します。
この方法では、J2EEデータ・ソースOracleSGDSを定義しておく必要があります。SPARQL GatewayがOracleSGDSデータ・ソースからデータベース接続を取得すると、指定された整数IDを使用してデータベース表ORACLE_ORARDF_SG_QUERYからSPARQL問合せが読み取られます。
Oracle DatabaseからSPARQL問合せをフェッチするための構文はdq=<integer-id>で、Oracle DatabaseからXSL変換をフェッチするための構文はdx=<integer-id>です。
サーブレットの初期化時に、次の表がまだ存在しない場合は、自動的に作成されます(手動で作成する必要はありません)。
主キーがQID (整数型)のORACLE_ORARDF_SG_QUERY
主キーがXID (整数型)のORACLE_ORARDF_SG_XSLT
実行に長時間かかりそうな問合せを7.16.3項で説明されているURL形式を使用して送信する場合には、タイムアウト値をミリ秒単位で指定して実行時間を制限できます。たとえば次の例では、SPARQL Gatewayから開始されたSPARQL問合せの実行が1000ミリ秒(1秒)後に終了するようにURL形式とタイムアウトを指定しています。
http://host:port/sparqlgateway/sg?<SPARQL_ENDPOINT>&<SPARQL_QUERY>&<XSLT>&t=1000
タイムアウトが発生したときに問合せが終了していない場合、空のSPARQLレスポンスがSPARQL Gatewayによって構築されます。
SPARQL GatewayがHTTP接続レベルで問合せ実行をタイムアウトしても、サーバー側では問合せの実行が続く場合もあることに注意してください。実際の動作はベンダーによって異なります。
実行に長時間かかりそうな問合せを7.16.3項で説明されているURL形式を使用して送信する場合には、タイムアウト値を指定していれば、問合せに対してベスト・エフォートの制限も指定できます。たとえば、次に示すURL形式では、1000ミリ秒(1秒)のタイムアウトとベスト・エフォート型(&b=t)を指定しています。
http://host:port/sparqlgateway/sg?<SPARQL_ENDPOINT>&<SPARQL_QUERY>&<XSLT>&t=1000&b=t
web.xmlファイルには、ベスト・エフォート型オプションの動作に影響する2つのパラメータ設定(sparql_gateway_besteffort_maxroundsおよびsparql_gateway_besteffort_maxthreads)が含まれます。デフォルトの定義を次に示します。
<init-param> <param-name>sparql_gateway_besteffort_maxrounds</param-name> <param-value>10</param-value> </init-param> <init-param> <param-name>sparql_gateway_besteffort_maxthreads</param-name> <param-value>3</param-value> </init-param>
SPARQL SELECT問合せがベスト・エフォート型方式で実行される場合、一連の問合せが実行され、SPARQL問合せ本体のLIMIT値設定が大きくなります。(中心となる概念は、LIMIT設定を小さくするほどSPARQL問合せの実行が速くなるという観察結果に基づいています。)SPARQL Gatewayは、LIMIT 1設定で問合せ実行を開始します。タイムアウトの前に、この問合せを完了できることが理想です。そうなると仮定すると、次の問合せではLIMIT設定が大きくなり、後続の問合せではさらに制限が高くなります。問合せ実行の最大数は、sparql_gateway_besteffort_maxroundsパラメータによって制御されます。
一連の問合せをパラレルで実行可能な場合、sparql_gateway_besteffort_maxthreadsパラメータで並列度を制御します。
デフォルトでは、SPARQL GatewayはXSL変換がXMLを生成することを前提としているため、HTTPレスポンスに設定されているデフォルトのコンテンツ・タイプはtext/xmlです。ただし、アプリケーションでXML以外のレスポンス形式が必要である場合は、次の書式を使用して、その形式を追加のURLパラメータ(構文&rt=を使用)に指定できます。
http://host:port/sparqlgateway/sg?<SPARQL_ENDPOINT>&<SPARQL_QUERY>&<XSLT>&rt=<content_type>
<content_type>はURLエンコードされている必要があることに注意します。
デフォルトのXSL変換ファイル(wx=default.xsltを使用して参照されるファイル)をカスタマイズできます。この項では、いくつかのカスタマイズ例を示します。
次の例では、ある変数のバインディングがhttp://purl.org/goodrelations/v1#で始まるURIを戻す場合には、その部分がgr:によって置き換えられ、http://www.w3.org/2000/01/rdf-schema#で始まるURIを戻す場合には、その部分がrdfs:によって置き換えられる、という名前空間の接頭辞置換ロジックを実装します。
<xsl:when test="starts-with(text(),'http://purl.org/goodrelations/v1#')">
<xsl:value-of select="concat('gr:',substring-after(text(),'http://purl.org/goodrelations/v1#'))"/>
</xsl:when>
...
<xsl:when test="starts-with(text(),'http://www.w3.org/2000/01/rdf-schema#')">
<xsl:value-of select="concat('rdfs:',substring-after(text(),'http://www.w3.org/2000/01/rdf-schema#'))"/>
</xsl:when>
次の例では、先頭のhttp://localhost/または先頭のhttp://127.0.0.1/を切り捨てるロジックを実装します。
<xsl:when test="starts-with(text(),'http://localhost/')"> <xsl:value-of select="substring-after(text(),'http://localhost/')"/> </xsl:when> <xsl:when test="starts-with(text(),'http://127.0.0.1/')"> <xsl:value-of select="substring-after(text(),'http://127.0.0.1/')"/> </xsl:when>
Webインタフェースに加え、SPARQL Gateway管理サービスには、SPARQL問合せと関連するXSL変換を管理するための便利なJavaアプリケーション・プログラミング・インタフェース(API)があります。このJava APIは、Jena Adapterライブラリ(sdordfclient.jar)に含まれています。
Java APIリファレンス情報は、SPARQL Gatewayの.zipファイル(7.16.2.1項を参照)に含まれるjavadoc_sparqlgateway.zipファイルで入手できます。
このAPIのメイン・エントリ・ポイントはoracle.spatial.rdf.client.jena.SGDBHandlerクラス(SPARQL Gatewayデータベース・ハンドラ)で、問合せと変換を管理するために次のような静的メソッドを提供します。
deleteSparqlQuery(Connection, int)
deleteXslt(Connection, int)
insertSparqlQuery(Connection, int, String, String, boolean)
insertXslt(Connection, int, String, String, boolean)
getSparqlQuery(Connection, int, StringBuilder, StringBuilder)
getXslt(Connection, int, StringBuilder, StringBuilder)
これらのメソッドは、Oracle Databaseインスタンスに格納されているSPARQL Gateway関連の表のエントリを操作し、取得します。これらのメソッドを使用するには、必要な関連表がすでに存在している必要があります。表が存在しない場合は、SPARQL GatewayをWebサーバーにデプロイし、次の形式でURLにアクセスします。
http://<host>:<port>/sparqlgateway/sg?
<host>はWebサーバーのホスト名で、<port>はWebサーバーのリスニング・ポートです。表がまだ存在しない場合、このURLにアクセスすると、必要な表が自動的に作成されます。
Java APIを介して行われた変更は、管理Webインタフェースを介して行われた変更と同様に、SPARQL GatewayのWebサービスに影響を及ぼします。これにより、最も都合のよいインタフェースを使用して柔軟に問合せと変換を管理できます。
Java APIにより提供される挿入メソッドでは、表に格納されている既存の問合せや変換を置き換えることができない点に注意してください。既存の問合せまたは変換を置換しようとすると失敗します。問合せまたは変換を置き換えるには、削除メソッドの1つを使用して表にある既存のエントリを削除した後に、挿入メソッドの1つを使用して新しい問合せまたは変換を挿入する必要があります。
次の例に、Java APIを使用して一般的な管理タスクを実行する方法を示します。この例では、SPARQL Gatewayの基盤である、基礎となるOracle Databaseインスタンスへの接続がすでに確立されていることを前提としています。
例7-31では、SPARQL Gatewayの基盤となるデータベースに、問合せとXSL変換を追加します。問合せと変換が追加された後、他のプログラムでは、リクエストURLで適切な問合せID (qid)とXSL変換ID (xid)を指定することで、ゲートウェイを介して問合せと変換を使用できます。
|
注意: 例7-31では、問合せと変換の両方を挿入していますが、問合せと変換は必ずしも関連がある必要はなく、SPARQL Gatewayにアクセスするときに同時に使用される必要もありません。SPARQL Gatewayにリクエストを送信するときは、データベースの任意の問合せをデータベースの任意の変換とともに使用できます。 |
例7-31 SPARQL問合せとXSL変換の格納
String query = "PREFIX ... SELECT ..."; // full SPARQL query text
String xslt = "<?xml ...> ..."; // full XSLT transformation text
String queryDesc = "Conference attendee information"; // description of SPARQL query
String xsltDesc = "BIEE table widget transformation"; // description of XSLT transformation
int queryId = queryIdCounter++; // assign a unique ID to this query
int xsltId = xsltIdCounter++; // assign a unique ID to this transformation
// Inserting a query or transformation will fail if the table already contains
// an entry with the same ID. Setting this boolean to true will ignore these
// exceptions (but the table will remain unchanged). Here we specify that we
// want an exception thrown if we encounter a duplicate ID.
boolean ignoreDupException = false;
// add the query
try {
// Delete query if one already exists with this ID (this will not throw an
// error if no such entry exists)
SGDBHandler.deleteSparqlQuery( connection, queryId );
SGDBHandler.insertSparqlQuery( connection, queryId, query, queryDesc, ignoreDupException );
} catch( SQLException sqle ) {
// Handle exception
} catch( QueryException qe ) {
// Handle query syntax exception
}
// add the XSLT
try {
// Delete xslt if one already exists with this ID (this will not throw an
// error if no such entry exists)
SGDBHandler.deleteXslt( connection, xsltId );
SGDBHandler.insertXslt( connection, xsltId, xslt, xsltDesc, ignoreDupException );
} catch( SQLException sqle ) {
// Handle database exception
} catch( TransformerConfigurationException tce ) {
// Handle XSLT syntax exception
}
例7-32では、データベースから既存の問合せを取得し、それを変更した後、更新された問合せを再度データベースに格納します。これらの手順では、問合せの編集と変更の保存をシミュレートします。(問合せが存在しない場合は、例外がスローされます。)
例7-32 問合せの変更
StringBuilder query;
StringBuilder description;
// Populate these with the query text and description from the database
query = new StringBuilder( );
description = new StringBuilder( );
// Get the query from the database
try {
SGDBHandler.getSparqlQuery( connection, queryId, query, description );
} catch( SQLException sqle ) {
// Handle exception
// NOTE: exception is thrown if query with specified ID does not exist
}
// The query and description should be populated now
// Modify the query
String updatedQuery = query.toString( ).replaceAll("invite", "attendee");
// Insert the query back into the database
boolean ignoreDup = false;
try {
// First must delete the old query
SGDBHandler.deleteSparqlQuery( connection, queryId );
// Now we can add
SGDBHandler.insertSparqlQuery( connection, queryId, updatedQuery, description.toString( ), ignoreDup );
} catch( SQLException sqle ) {
// Handle exception
} catch( QueryException qe ) {
// Handle query syntax exception
}
例7-33では、既存のXSL変換を取得し、標準出力に出力します。(変換が存在しない場合は、例外がスローされます。)
例7-33 XSL変換の取得および出力
StringBuilder xslt;
StringBuilder description;
// Populate these with the XSLT text and description from the database
xslt = new StringBuilder( );
description = new StringBuilder( );
try {
SGDBHandler.getXslt( connection, xsltId, xslt, description );
} catch( SQLException sqle ) {
// Handle exception
// NOTE: exception is thrown if transformation with specified ID does not exist
}
// Print it to standard output
System.out.printf( "XSLT description: %s\n", description.toString( ) );
System.out.printf( "XSLT body:\n%s\n", xslt.toString( ) );
SPARQL Gatewayでは、問合せのテスト、セマンティク・データのナビゲート、SPQARQL問合せとXSLTファイルの管理に役立つブラウザベースのインタフェースがいくつか用意されています。
http://<host>:<port>/sparqlgateway/index.htmlは、SPARQL問合せを実行してからdefault.xsltファイルの変換をレスポンスに適用するための簡単なインタフェースを提供します。図7-2に、このインタフェースでの問合せの実行を示します。
「SPARQL Endpoint」を入力または選択し、「SPARQL SELECT Query Body」を指定して「Submit Query」を押します。
たとえば、SPARQLエンドポイントとしてhttp://dbpedia.org/sparqlを指定し、図7-2に示したSPARQL問合せ本体を使用すると、レスポンスは図7-3のようになります。この図では、(default.xsltの)デフォルトの変換がXML出力に適用されていることに注意してください。
http://<host>:<port>/sparqlgateway/browse.jspは、セマンティク・データ用のナビゲーション機能とブラウジング機能を提供します。標準に準拠したすべてのSPARQLエンドポイントに対して使用できます。図7-4に、このインタフェースでの問合せの実行を示します。
図7-4 グラフィカル・インタフェースによるナビゲーションとブラウジングのページ(browse.jsp)
「SPARQL Endpoint」を入力または選択し、「SPARQL SELECT Query Body」を指定し、オプションで「Timeout (ms)」値(ミリ秒)と「Best Effort」オプションを指定して、「Submit Query」を押します。
図7-5に示すとおり、SPARQLレスポンスが解析され、表形式で示されます。
図7-5で、URIはナビゲーションできるようにクリック可能であり、ユーザーがURI上にカーソルを移動すると、読みやすいように短縮されていたURIのツールチップが表示されることに注意してください(図ではdc:titleのツールチップとしてhttp://purl.org.dc/elements/1.1/titleが表示されています)。
図7-5に示されている出力のURI http://example.org/book/book5をクリックすると、新しいSPARQL問合せが自動的に生成され、実行されます。図7-6に示すとおり、この生成されたSPARQL問合せには、この特定のURIを主語、述語および目的語として使用する、3つの問合せパターンがあります。このような問合せによって、このURIがどのように使用されるか、およびデータセットの他のリソースとどのように関連するかを理解できます。
問合せの一致が多い場合には、結果がページ単位に編成され、任意のページをクリックできます。デフォルトでは50個の結果が1ページに表示されます。ブラウジングとナビゲーションのページ(browse.jsp)でのレスポンスを、ページ当たり50行よりも多く(あるいは少なく)表示するには、URLに&resultsPerPageパラメータを指定します。たとえば、ページ当たり100行を表示できるようにするには、URLに次を含めます。
&resultsPerPage=100
http://<host>:<port>/sparqlgateway/admin/xslt.jspは、単純なXSLT管理インタフェースを提供します。XSLT ID (整数)を入力して「Get XSLT」をクリックすると、説明とXSLT本体の両方を取得できます。XSLT本体のテキストを変更した後に「Save XSLT」をクリックすると、その変更を保存できます。使用可能なXSLT定義間のナビゲートに役立つプレビューアがあることに注意してください。
図7-7は、XSLTの管理ページを示しています。
http://<host>:<port>/sparqlgateway/admin/xslt.jspは、単純なSPARQL管理インタフェースを提供します。SPARQL ID (整数)を入力して「Get SPARQL」をクリックすると、説明とSPARQL本体を取得できます。SPARQL本体のテキストを変更した後に「Save SPARQL」をクリックすると、その変更を保存できます。使用可能なSPARQL定義間のナビゲートに役立つプレビューアがあることに注意してください。
図7-8は、SPARQLの管理ページを示しています。
この項では、SPARQL Gatewayをブリッジとして使用してOBIEEとRDFを統合することによって、Oracle Business Intelligence Enterprise Edition (OBIEE)で使用するXMLデータ・ソースを作成する方法について説明します。(具体的な手順と図は、Oracle BI管理ツールのバージョン11.1.1.3.0.100806.0408.000に基づいています。)
Oracle BI管理ツールを起動します。
「ファイル」と「メタデータのインポート」を順次クリックします。図7-9に示すとおり、メタデータのインポート・ウィザードの最初のページが表示されます。
接続タイプ: 「XML」を選択します。
URL: SPARQL Gatewayと対話するアプリケーションのURL (7.16.3項を参照してください)。タイムアウト・オプションおよびベスト・エフォート型オプションを含めることもできます。
「ユーザー名」フィールドと「パスワード」フィールドは無視します。
「次」をクリックします。図7-10に示すとおり、メタデータのインポート・ウィザードの2番目のページが表示されます。
インポートする必要なメタデータ型を選択します。選択したタイプに「表」が含まれていることを確認します。
「次」をクリックします。図7-11に示すとおり、メタデータのインポート・ウィザードの3番目のページが表示されます。
「データソース・ビュー」で、表アイコンを持つノードを展開し、(SPARQL SELECT構文に定義した投影変数からマップされた)列名を選択して右矢印(>)ボタンをクリックし、選択した列を「リポジトリ・ビュー」に移動します。
「終了」をクリックします。
(SPARQL GatewayまたはRDFデータに固有ではない)通常のBIビジネス・モデルの作業およびマッピングと表現定義の作業について、残りの手順を実行します。