| Oracle® Databaseセマンティク・テクノロジ開発者ガイド 11gリリース2 (11.2) E52974-01 |
|



 前 |
 次 |
この章では、Oracle Database Enterprise Editionでのセマンティク・テクノロジのサポート、特にResource Description Framework(RDF)およびWeb Ontology Language (OWL)のサブセットのサポートについて説明します。ここでは、読者がRDFおよびOWLに関する主要な概念({主語、述語、目的語}のトリプル、URI、空白ノード、プレーン・リテラル、型付きリテラル、オントロジなど)についてよく理解していることを前提とします。この章では、これらの概念に関する詳細な説明を省くかわりに、各概念がどのようにOracleに実装されているかについて重点的に解説します。
RDFの概念に関する優れた解説は、http://www.w3.org/TR/rdf-primer/にあるWorld Wide Web Consortium (W3C)の「RDF Primer」を参照してください。
OWLの詳細は、http://www.w3.org/TR/owl-ref/にある「OWL Web Ontology Language Reference」を参照してください。
セマンティク・データを操作するためのPL/SQLサブプログラムは、SEM_APISパッケージに含まれます(詳細は、第9章を参照してください)。
RDFおよびOWLのサポートはOracle Spatialの機能です。これらの機能を使用するには、Oracle Spatialをインストールする必要があります。ただし、RDFおよびOWLの使用は、空間データに制限されません。
この章には次の項が含まれます。
OWLの概念とOracle DatabaseによるOWL機能のサポートの詳細は、第2章を参照してください。
|
セマンティク・テクノロジ・サポートを有効化するために必要なアクション: このガイドに記載されている操作を実行する前に、データベースでセマンティク・テクノロジ・サポートを有効化し、他の前提条件を満たす必要があります(A.1項「セマンティク・テクノロジ・サポートの有効化」を参照)。 |
|
リリース11.2.0.2: セマンティク・テクノロジ・インストールが無効である場合に必要なアクション: リリース11.2.0.2.0へのアップグレード後にセマンティク・テクノロジ・インストールが無効である場合、追加アクションが必要になることがあります。詳細は、A.1.4項を参照してください。 |
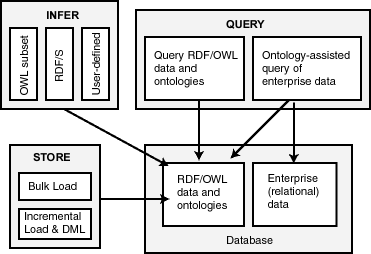
Oracle Databaseでは、セマンティク・データとオントロジを格納し、セマンティク・データを問い合せることや、エンタープライズ・リレーショナル・データに対してオントロジ支援問合せを実行することができ、また、付属の推論またはユーザー定義の推論を使用して、セマンティク・データに対する問合せ機能を拡張することも可能です。図1-1に、これらの機能の相互関係を示します。
図1-1に示されているとおり、データベースには、セマンティク・データおよびオントロジ(RDF/OWLモデル)に加え、従来のリレーショナル・データが含まれます。セマンティク・データをロードするには、バルク・ロードが最も効率的な方法ですが、トランザクション型のINSERT文を使用してデータを増分ロードすることも可能です。
セマンティク・データおよびオントロジは問合せ可能です。また、セマンティク・データや従来のリレーショナル・データに対してオントロジ支援問合せを実行し、セマンティク関係を検出することもできます。オントロジ支援問合せを実行するには、SEM_RELATED演算子を使用します(2.3項を参照)。
セマンティク・データに対する問合せ機能は、推論を使用して拡張できます。推論では、ルールベースのルールを使用します。推論により、データおよびルールに基づいて論理的な推測を行うことができます。推論でルールおよびルールベースを使用する方法の詳細は、1.3.6項を参照してください。
セマンティク・データには、その形式意味論に加え、有向グラフを使用して効率的にモデル化される単純なデータ構造が含まれます。メタデータ文は、トリプルとして表現されます。ノードはトリプルの2つの部分を示すために使用され、3番目の部分はノード間の関係を記述する有向リンクによって示されます。トリプルは、セマンティク・データ・ネットワークに格納されます。また、データベース・ユーザーにより作成された特定のセマンティク・データ・モデルに関する情報も保持されます。ユーザーにより作成されたモデルは、モデル名を持ち、指定した表の列に格納されているトリプルを参照します。
文は、{主語(リソース)、述語(プロパティ)、目的語(値)}のトリプルで表現されます。このマニュアルでは、{主語、プロパティ、目的語}を使用してトリプルを記述し、文という用語とトリプルという用語は、同義的に使用される場合があります。各トリプルは、特定のドメインに関する完全で一意のファクトであり、有向グラフのリンクで表現されます。
データベースに格納されるすべてのセマンティク・データに対して、単一の場所が用意されます。すべてのトリプルは、解析され、MDSYSスキーマの表内のエントリとしてシステムに格納されます。{主語、プロパティ、目的語}のトリプルは、1つのデータベース・オブジェクトとして処理されます。そのため、複数のトリプルを含む単一の文書は、複数のデータベース・オブジェクトになります。
トリプルのすべての主語および目的語は、セマンティク・データ・ネットワークのノードにマップされます。プロパティは、主語を開始ノード、目的語を終了ノードとするネットワーク・リンクにマップされます。使用可能なノード・タイプは、空白ノード、URI、プレーン・リテラルおよび型付きリテラルです。
URIの指定とデータベースへのセマンティク・データの格納には、次の要件が適用されます。
主語は、URIまたは空白ノードである必要があります。
プロパティは、URIである必要があります。
目的語は、URI、空白ノードまたはリテラルのいずれのタイプでもかまいません。(ただし、NULL値およびNULL文字列はサポートされません。)
MDSYS.SEM_MODEL$ビューには、データベースで定義されているすべてのモデルの情報が含まれます。SEM_APIS.CREATE_SEM_MODELプロシージャを使用してモデルを作成する場合、モデルの名前と、セマンティク・データへの参照を保持する表および列を指定します。システムにより、モデルIDが自動的に生成されます。
Oracleでは、モデルの作成および削除に応じてMDSYS.SEM_MODEL$ビューが自動的に管理されます。ユーザーがこのビューを直接変更することはできません。たとえば、このビューでSQLのINSERT、UPDATEまたはDELETE文を使用することはできません。
表1-1に、MDSYS.SEM_MODEL$ビューの列を示します。
表1-1 MDSYS.SEM_MODEL$ビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
モデルの所有者のスキーマ。 |
|
MODEL_ID |
NUMBER |
一意のモデルID番号(自動生成)。 |
|
MODEL_NAME |
VARCHAR2(25) |
モデルの名前。 |
|
TABLE_NAME |
VARCHAR2(30) |
モデルのセマンティク・データへの参照を保持する表の名前。 |
|
COLUMN_NAME |
VARCHAR2(30) |
モデルのセマンティク・データへの参照を保持する表に含まれるSDO_RDF_TRIPLE_S型の列の名前。 |
|
MODEL_TABLESPACE_NAME |
VARCHAR2(30) |
このモデルのトリプルを格納するための表領域の名前。 |
モデルを作成すると、そのモデルに関連付けられたトリプルのビューもMDSYSスキーマに作成されます。このビューは、SEMM_model-nameという形式の名前を持ち、モデルの所有者および適切な権限を持つユーザーにのみ表示されます。各MDSYS.SEMM_model-nameビューには、ネットワークにリンクとして格納されたトリプルごとに1つの行が保持されます。表1-2に、このビューの列を示します。
表1-2 MDSYS.SEMM_model-nameビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
P_VALUE_ID |
NUMBER |
トリプルの述語のテキスト値に対応するVALUE_ID。主キーの一部です。 |
|
START_NODE_ID |
NUMBER |
トリプルの主語のテキスト値に対応するVALUE_ID。主キーの一部です。 |
|
CANON_END_NODE_ID |
NUMBER |
トリプルの目的語の正規形のテキスト値に対応するVALUE_ID。主キーの一部です。 |
|
END_NODE_ID |
NUMBER |
トリプルの目的語のテキスト値に対応するVALUE_ID |
|
MODEL_ID |
NUMBER |
トリプルが属するRDFモデルに対応するID。 |
|
COST |
NUMBER |
(将来使用するために予約済) |
|
CTXT1 |
NUMBER |
(予約済の列。ファイングレイン・アクセス制御に使用可能) |
|
CTXT2 |
VARCHAR2(4000) |
(将来使用するために予約済) |
|
DISTANCE |
NUMBER |
(将来使用するために予約済) |
|
EXPLAIN |
VARCHAR2(4000) |
(将来使用するために予約済) |
|
PATH |
VARCHAR2(4000) |
(将来使用するために予約済) |
|
G_ID |
NUMBER |
トリプルのグラフ名のテキスト値に対応するVALUE_ID。NULLはデフォルト・グラフを示します(1.3.9項「名前付きグラフ」を参照)。 |
|
LINK_ID |
VARCHAR2(71) |
一意のトリプル識別子の値。(現在は計算結果列ですが、将来のリリースでは定義が変更される可能性があります。) |
|
注意: 表1-2の列P_VALUE_ID、START_NODE_ID、END_NODE_ID、CANON_END_NODE_IDおよびG_IDでは、実際のID値は対応する字句の値から計算されます。ただし、ある字句の値が常に同じID値にマップされるとはかぎりません。 |
MDSYS.RDF_VALUE$表には、RDF文を表すために使用される主語、プロパティおよび目的語に関する情報が含まれます。この表には、これらの情報の3要素に対応するテキスト値(URIまたはリテラル)が、各トリプルの要素ごとに用意された個別の行を使用して一意に格納されます。
Oracleでは、MDSYS.RDF_VALUE$表が自動的に管理されます。ユーザーがこのビューを直接変更することはできません。たとえば、このビューでSQLのINSERT、UPDATEまたはDELETE文を使用することはできません。
表1-3に、RDF_VALUE$表の列を示します。
表1-3 MDSYS.RDF_VALUE$表の列
| 列名 | データ型 | 説明 |
|---|---|---|
|
VALUE_ID |
NUMBER |
一意の値ID番号(自動生成)。 |
|
VALUE_TYPE |
VARCHAR2(10) |
VALUE_NAME列に格納されたテキスト情報のタイプ。使用される値は、 |
|
VNAME_PREFIX |
VARCHAR2(4000) |
字句の値の長さが4000バイト以下の場合、この列に字句の値の一部である接頭辞が格納されます。接頭辞の計算には、SEM_APIS.VALUE_NAME_PREFIXファンクションを使用できます。たとえば、山カッコを除く字句 |
|
VNAME_SUFFIX |
VARCHAR2(512) |
字句の値の長さが4000バイト以下の場合、この列に字句の値の一部である接尾辞が格納されます。接尾辞の計算には、SEM_APIS.VALUE_NAME_SUFFIXファンクションを使用できます。VNAME_PREFIX列の説明に記載されている字句の値の場合、接尾辞は |
|
LITERAL_TYPE |
VARCHAR2(4000) |
型付きリテラルの場合は型情報、それ以外の場合はNULL。たとえば、1999-08-16という作成日を示す行の場合、VALUE_TYPE列には |
|
LANGUAGE_TYPE |
VARCHAR2(80) |
言語タグ付きのリテラル(つまり、VALUE_TYPEが |
|
CANON_ID |
NUMBER |
現在の字句の値に対応する正規形の字句の値のID。(この列の使用は将来のリリースで変更される可能性があります。) |
|
COLLISION_EXT |
VARCHAR2(64) |
字句の値の衝突処理に使用されます。(この列の使用は将来のリリースで変更される可能性があります。) |
|
CANON_COLLISION_EXT |
VARCHAR2(64) |
正規形の字句の値の衝突処理に使用されます。(この列の使用は将来のリリースで変更される可能性があります。) |
|
LONG_VALUE |
CLOB |
字句の値の長さが4000バイトを超える場合の文字列。それ以外の場合、この列はNULL値です。 |
|
VALUE_NAME |
VARCHAR2(4000) |
これは計算結果列です。字句の値の長さが4000バイト以下の場合、この列の値はVNAME_PREFIX列とVNAME_SUFFIX列の値を連結したものになります。 |
重複するトリプルはデータベースに格納されません。あるトリプルが既存のトリプルと重複していないかどうかをチェックするため、新規トリプルの主語、プロパティおよび目的語は、指定したモデルのトリプル値と照合されます。新規の主語、プロパティおよび目的語がすべてURIの場合、それらの値が完全に一致した場合に重複であると判定されます。ただし、新規トリプルの目的語がリテラルの場合、主語とプロパティが完全に一致し、目的語の値が(正規化したときに)一致した場合に重複であると判定されます。たとえば、次の2つのトリプルは重複しています。
<eg:a> <eg:b> <"123"^^http://www.w3.org/2001/XMLSchema#int> <eg:a> <eg:b> <"123"^^http://www.w3.org/2001/XMLSchema#unsignedByte>
2番目のトリプルは、1番目のトリプルの重複と判定されます("123"^^<http://www.w3.org/2001/XMLSchema#int>には、(正規化したときに)"123"^^<http://www.w3.org/2001/XMLSchema#unsignedByte>と等価の値が含まれるためです)。2つのエンティティを同じ値に簡略化できる場合、それらのエンティティは正規化後に等価となります。
RDF以外の例をあげると、A*(B-C)、A*B-C*A、(B-C)*Aおよび-A*C+A*Bは、すべて同じ正規形に変換されます。
字句形式の値ベースの一致は、次のデータ型でサポートされます。
STRING: プレーン・リテラル、xsd:stringとその一部のXMLスキーマ・サブタイプ
NUMERIC: xsd:decimalとそのXMLスキーマ・サブタイプ、xsd:floatおよびxsd:double。(float/double INF、-INFおよびNaN値はサポートされません。)
DATETIME: タイムゾーンのサポート付きのxsd:datetime。(タイムゾーンなしの場合も、単一値に対して"2004-02-18T15:12:54"や"2004-02-18T15:12:54.0000"などの複数の表現が存在します。)
DATE: タイムゾーン付きまたはタイムゾーンなしのxsd:date
OTHER: その他すべて。(異なる表現を一致する試みは行われません。)
xsd:time型とxsd:dateTime型のリテラルにタイムゾーンが存在する場合、正規化が実行されます。
名前空間定義にはxmlns:xsd="http://www.w3.org/2001/XMLSchema"が使用されます。
RDF_VALUE$表で最初に出現するリテラルは、正規形として扱われ、それぞれCPL、CPL@、CTL、CPLL、CPLL@またはCTLLというVALUE_TYPE値が適切に割り当てられます(つまり、正規形の場合は実際の値タイプにCという接頭辞が付けられます)。以前挿入されたリテラルと同じ正規形を持つ(ただし異なる字句表現の)リテラルがRDF_VALUE$表に挿入されると、その新しい挿入に対してそれぞれPL、PL@、TL、PLL、PLL@またはTLLというVALUE_TYPE値が適切に割り当てられます。
したがって、正規化後に等価となる異なる字句表現を持つテキスト値は、RDF_VALUE$表に格納されますが、正規化後に等価となるトリプルはデータベースに格納されません。
RDFの主語と目的語は、セマンティク・データ・ネットワークのノードにマップされます。主語のノードはリンクの開始ノードで、目的語のノードはリンクの終了ノードです。リテラル以外のノード(URIや空白ノード)は、主語および目的語のノードとして使用できます。リテラルは、目的語のノードとしてのみ使用できます。
空白ノードは、セマンティク・ネットワークの主語および目的語のノードとして使用できます。空白ノード識別子は、1つのセマンティク・モデル内を有効範囲とする点において、URIとは異なります。つまり、単一のセマンティク・モデル内に同じ空白ノード識別子が複数出現した場合、それらは常に同じリソースを示しますが、異なる2つのセマンティク・モデル内に同じ空白ノード識別子が出現した場合、それらは同じリソースを示しません。
Oracleセマンティク・ネットワークにおいて、この動作は、空白ノードは常に1つのセマンティク・モデル内で再利用され、2つの異なるモデル間では再利用されない(つまり、同じ空白ノード識別子が使用される場合は同じリソースを表している)という要件の適用によりモデル化されます。このため、空白ノードを含むトリプルをモデルに挿入する場合、空白ノードの再利用をサポートするSDO_RDF_TRIPLE_Sコンストラクタを使用する必要があります。
プロパティは、開始ノード(主語)と終了ノード(目的語)を備えたリンクにマップされます。したがって、1つのリンクは完全なトリプルを表します。
トリプルがモデルに挿入されると、主語、プロパティおよび目的語のテキスト値について、それらがすでにデータベースに存在するかどうかがチェックされます。他のモデルの以前の文に基づくテキスト値がすでに存在する場合、新規エントリは作成されません。テキスト値が存在しない場合、RDF_VALUE$表(1.3.2項を参照)に新規行が挿入されます。
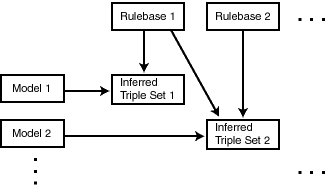
推論は、ルールに基づいて論理的な推測を行う機能です。推論により、文字列などの値に基づく構文的な一致機能ではなく、データの各要素間の意味的な関係に基づいてセマンティクな一致機能を実行する問合せを作成できます。推論では、ルールベースに格納されたルールを使用し、ルールには、Oracleに付属するものとユーザーが定義するものがあります。
図1-2に、モデル・データと1つ以上のルールベースにおけるルールの適用から推論されたトリプル・セットを示します。この図の場合、データベースには任意の数のセマンティク・モデル、ルールベース、および推論されたトリプル・セットがあり、推論されたトリプル・セットは1つ以上のルールベースのルールを使用して導出されます。
ルールは、セマンティク・データから推論を導く際に適用できるオブジェクトです。ルールは、名前で識別され、次の要素で構成されます。
前件に対応するIF側パターン
IF側パターンで一致したサブグラフをさらに絞り込むオプションのフィルタ条件
後件に対応するTHEN側パターン
たとえば、「会議の議長は会議のレビューアでもある」というルールは、次のように表現されます。
('chairpersonRule', -- rule name
'(?r :ChairPersonOf ?c)', -- IF side pattern
NULL, -- filter condition
'(?r :ReviewerOf ?c)', -- THEN side pattern
SEM_ALIASES (SEM_ALIAS('', 'http://some.org/test/'))
)
この場合、ルールにフィルタ条件はないため、表現内のその構成要素はNULLです。パフォーマンスを最大化するには、ルールのTHEN側に単一のトリプル・パターンを使用します。ルールのTHEN側に複数のトリプル・パターンが含まれる場合、THEN側でそれぞれ単一のトリプル・パターンを含むようにそれを複数のルールに簡単に分割できます。
ルールベースは、ルールを含むオブジェクトです。Oracleには、次のルールベースが付属しています。
RDFS
RDF (RDFSのサブセット)
OWLSIF (空)
RDFS++ (空)
OWL2RL (空)
OWLPrime (空)
SKOSCORE (空)
RDFSおよびRDFルールベースは、SEM_APIS.CREATE_SEM_NETWORKプロシージャをコールしてRDFサポートをデータベースに追加すると作成されます。RDFSルールベースでは、RDFS伴意ルールを実装します(詳細は、http://www.w3.org/TR/rdf-mt/にあるWorld Wide Web Consortium (W3C)のドキュメント「RDF Semantics」を参照してください)。RDFルールベースは、RDF伴意ルール(RDFS伴意ルールのサブセット)を表します。これらのルールベースの内容は、MDSYS.SEMR_RDFSおよびMDSYS.SEMR_RDFビューで確認できます。
SEM_APIS.CREATE_RULEBASEプロシージャを使用してユーザー定義のルールベースを作成することも可能です。ユーザー定義のルールベースを使用すると、特殊化された推論機能を追加できます。
ルールベースごとに、ルールベースのルールを保持するためのシステム表と、MDSYS.SEMR_rulebase-nameという形式の名前を持つシステム・ビューが作成されます(たとえば、FAMILY_RBというルールベースの場合、MDSYS.SEMR_FAMILY_RBという名前になります)。ルールベースのルールを挿入、削除および変更するには、このビューを使用する必要があります。表1-4に、各MDSYS.SEMR_rulebase-nameビューの列を示します。
表1-4 MDSYS.SEMR_rulebase-nameビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
RULE_NAME |
VARCHAR2(30) |
ルールの名前 |
|
ANTECEDENTS |
VARCHAR2(4000) |
前件に対応するIF側パターン |
|
FILTER |
VARCHAR2(4000) |
IF側パターンで一致したサブグラフをさらに絞り込むフィルタ条件。NULLは、適用されるフィルタ条件がないことを示します。 |
|
CONSEQUENTS |
VARCHAR2(4000) |
後件に対応するTHEN側パターン |
|
ALIASES |
SEM_ALIASES |
使用される1つ以上の名前空間。(SEM_ALIASESデータ型の詳細は、1.6項を参照。) |
すべてのルールベースに関する情報は、MDSYS.SEM_RULEBASE_INFOビューに保持されます。表1-5に、このビューの列を示します(1つの行が1つのルールベースに対応します)。
表1-5 MDSYS.SEM_RULEBASE_INFOビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
ルールベースの所有者 |
|
RULEBASE_NAME |
VARCHAR2(25) |
ルールベースの名前 |
|
RULEBASE_VIEW_NAME |
VARCHAR2(30) |
ルールベースのルールを挿入、削除または変更する任意のSQL文で使用する必要のあるビューの名前 |
|
STATUS |
VARCHAR2(30) |
|
例1-1では、family_rbというルールベースを作成し、そのfamily_rbルールベースにgrandparent_ruleというルールを挿入します。このルールは、ある人物がある子の親であり、その子がさらに別の子の親である場合、その人物が自分の子供の子供に対する祖父母である(つまり、自分の子供の子供に関してgrandParentOf関係を持つ)ことを示します。また、使用する名前空間も指定します。(この例は、1.11.2項の例1-44からの抜粋です。)
例1-1 ルールベースへのルールの挿入
EXECUTE SEM_APIS.CREATE_RULEBASE('family_rb');
INSERT INTO mdsys.semr_family_rb VALUES(
'grandparent_rule',
'(?x :parentOf ?y) (?y :parentOf ?z)',
NULL,
'(?x :grandParentOf ?z)',
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')));
例1-1に示されている祖父母ルールの種類は、OWL 2プロパティ・チェーン構成要素を使用して実装できることに注意してください。プロパティ・チェーンの処理の詳細は、3.2.2項を参照してください。
SEM_MATCHテーブル・ファンクション(1.6項を参照)をコールするときに1つ以上のルールベースを指定して、セマンティク・データに対する問合せの動作を制御できます。例1-2では、family_rbルールベースと、例1-1で作成したgrandParentOf関係を参照して、すべての祖父(祖父母の男性の方)とその孫を検索します。(この例は、1.11.2項の例1-44からの抜粋です。)
例1-2 推論でのルールベースの使用
-- Select all grandfathers and their grandchildren from the family model.
-- Use inferencing from both the RDFS and family_rb rulebases.
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
ネイティブOWL推論のサポートの詳細は、2.2項を参照してください。
伴意(ルール索引)は、指定したルールベースのセットを指定したモデルのセットに適用することで推論できる計算済のトリプルを含むオブジェクトです。SEM_MATCH問合せで任意のルールベースを参照する場合、問合せ内のルールベースとモデルの組合せごとに伴意が存在している必要があります。
伴意を作成するには、SEM_APIS.CREATE_ENTAILMENTプロシージャを使用します。伴意を削除するには、SEM_APIS.DROP_ENTAILMENTプロシージャを使用します。
伴意を作成すると、その伴意に関連付けられたトリプルのビューもMDSYSスキーマに作成されます。このビューは、SEMI_entailment-nameという形式の名前を持ち、伴意の所有者および適切な権限を持つユーザーにのみ表示されます。各MDSYS.SEMI_entailment-nameビューには、ネットワークにリンクとして格納されたトリプルごとに1つの行が保持され、また、SEMM_model-nameビューと同じ列が含まれます(1.3.1項の表1-2を参照)。
すべての伴意に関する情報は、MDSYS.SEM_RULES_INDEX_INFOビューに保持されます(表1-6に、このビューの列を示します(1つの行が1つの伴意に対応します))。
表1-6 MDSYS.SEM_RULES_INDEX_INFOビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
伴意の所有者 |
|
INDEX_NAME |
VARCHAR2(25) |
伴意の名前 |
|
INDEX_VIEW_NAME |
VARCHAR2(30) |
伴意のルールを挿入、削除または変更する任意のSQL文で使用する必要のあるビューの名前 |
|
STATUS |
VARCHAR2(30) |
|
|
MODEL_COUNT |
NUMBER |
伴意に含まれるモデルの数 |
|
RULEBASE_COUNT |
NUMBER |
伴意に含まれるルールベースの数 |
モデルやルールベースなど、伴意に関連するすべてのデータベース・オブジェクトの情報は、MDSYS.SEM_RULES_INDEX_DATASETSビューに保持されます。表1-7に、このビューの列を示します(1つの行がすべての列の値の一意の組合せに対応します)。
表1-7 MDSYS.SEM_RULES_INDEX_DATASETSビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
INDEX_NAME |
VARCHAR2(25) |
伴意の名前 |
|
DATA_TYPE |
VARCHAR2(8) |
伴意に含まれるデータのタイプ。たとえば、 |
|
DATA_NAME |
VARCHAR2(25) |
DATA_TYPE列に含まれるタイプのオブジェクトの名前 |
例1-3では、familyモデルとRDFSおよびfamily_rbルールベースを使用して、family_rb_rix_familyという伴意を作成します。(この例は、1.11.2項の例1-44からの抜粋です。)
仮想モデルとは、SEM_MATCH問合せで使用できる論理グラフのことです。仮想モデルは、1つ以上のモデルおよび対応する伴意(オプション)に対してUNIONまたはUNION ALL操作を実行した結果です。
仮想モデルを使用する場合の利点は次のとおりです。
セマンティク・データのアクセス権限の管理を簡略化できます。たとえば、3つのモデルおよびOWLPrimeルールベースに基づいて、3つのセマンティク・モデルおよび1つの伴意を作成したとします。仮想モデルを使用しない場合は、各モデルおよび伴意に対してアクセス権限の付与および取消しを個別に行う必要があります。しかし、3つのモデルと伴意を含む仮想モデルを作成すると、この1つの仮想モデルに対してのみアクセス権限の付与および取消しを行うだけで済みます。
セマンティク・モデルの更新を高速化できます。たとえば、仮想モデルVM1にモデルM1と伴意R1が含まれるとし(VM1 = M1 UNION ALL R1)、また、セマンティク・モデルM1_UPDは追加のトリプルで更新されたM1のコピーであり、R1_UPDはM1_UPDに作成された伴意であるとします。この場合、VM1に対するユーザー問合せで更新済のモデルおよび伴意が使用されるように、仮想モデルVM1を再定義できます(VM1 = M1_UPD UNION ALL R1_UPD)。
仮想モデルを問い合せることは、SEM_MATCH問合せで複数のモデルを問い合せることと等価であるため、問合せの指定を簡略化できます。たとえば、モデルm1、m2およびm3がすでに存在し、OWLPrimeルールベースを使用してm1、m2およびm3に対して伴意が作成されているとします。仮想モデルvm1を次のように作成できます。
EXECUTE sem_apis.create_virtual_model('vm1', sem_models('m1', 'm2', 'm3'),
sem_rulebases('OWLPRIME'));
仮想モデルを問い合せるには、SEM_MATCH問合せのモデルと同様の仮想モデル名を使用します。たとえば、仮想モデルに対する次の問合せがあるとします。
SELECT * FROM TABLE (sem_match('{…}', sem_models('vm1'), null, …));
これは、すべての個別モデルに対する次の問合せと同等です。
SELECT * FROM TABLE (sem_match('{…}', sem_models('m1', 'm2', 'm3'),
sem_rulebases('OWLPRIME'), …));
仮想モデルに対するSEM_MATCH問合せでは、それぞれのモデルおよび伴意のUNIONまたはUNION ALLを問い合せることなく、SEMVまたはSEMUビューを問い合せます(デフォルトはSEMUで、'ALLOW_DUP=T'オプションが指定されている場合はSEMV)。これらのビューおよびオプションの詳細は、SEM_APIS.CREATE_VIRTUAL_MODELプロシージャのリファレンスの項を参照してください。
仮想モデルに参加しているモデルでは、Oracle Workspace Managerのバージョン対応機能を使用できません。(Workspace ManagerによるRDFデータのサポートの詳細は、第6章を参照してください。)
仮想モデルは、ビューを使用し(この項の後の部分を参照)、いくつかのメタデータ・エントリを追加しますが、システム記憶域要件はそれほど増大しません。
仮想モデルを作成するには、SEM_APIS.CREATE_VIRTUAL_MODELプロシージャを使用します。仮想モデルを削除するには、SEM_APIS.DROP_VIRTUAL_MODELプロシージャを使用します。仮想モデルのコンポーネント・モデル、ルールベースまたは伴意が削除されると、その仮想モデルは自動的に削除されます。
仮想モデルを問い合せるには、例1-4に示すとおり、SEM_MATCHテーブル・ファンクションのmodelsパラメータで仮想モデル名を指定します。
例1-4 仮想モデルの問合せ
SELECT COUNT(protein)
FROM TABLE (SEM_MATCH (
FROM TABLE (SEM_MATCH (
'{?protein rdf:type :Protein .
?protein :citation ?citation .
?citation :author "Bairoch A."}',
SEM_MODELS('UNIPROT_VM'),
NULL,
SEM_ALIASES(SEM_ALIAS('', 'http://purl.uniprot.org/core/')),
NULL,
NULL,
'ALLOW_DUP=T'));
SEM_MATCHテーブル・ファンクションの詳細は、この項に、仮想モデルを問い合せるときの特定の属性の使用方法が示されている、1.6項を参照してください。
仮想モデルを作成すると、MDSYS.SEM_MODEL$ビューに仮想モデルのエントリが作成されます(1.3.1項の表1-1を参照)。ただし、表1-8の説明にあるとおり、いくつかの列では、仮想モデルの値はセマンティク・モデルの値と異なります。
表1-8 仮想モデルのMDSYS.SEM_MODEL$ビューの列の説明
| 列名 | データ型 | 説明 |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
仮想モデルの所有者のスキーマ。 |
|
MODEL_ID |
NUMBER |
一意のモデルID番号(自動生成)。これが仮想モデルであることを表すため、負の数になります。 |
|
MODEL_NAME |
VARCHAR2(25) |
仮想モデルの名前。 |
|
TABLE_NAME |
VARCHAR2(30) |
仮想モデルの場合はNULL。 |
|
COLUMN_NAME |
VARCHAR2(30) |
仮想モデルの場合はNULL。 |
|
MODEL_TABLESPACE_NAME |
VARCHAR2(30) |
仮想モデルの場合はNULL。 |
すべての仮想モデルに関する情報は、MDSYS.SEM_VMODEL_INFOビューに保持されます(表1-9に、このビューの列を示します(1つの行が1つの仮想モデルに対応します))。
表1-9 MDSYS.SEM_VMODEL_INFOビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
OWNER |
VARCHAR2(30) |
仮想モデルの所有者。 |
|
VIRTUAL_MODEL_NAME |
VARCHAR2(25) |
仮想モデルの名前。 |
|
UNIQUE_VIEW_NAME |
VARCHAR2(30) |
仮想モデル内に一意のトリプルを含むビューの名前。ビューが作成されていない場合は、NULL。 |
|
DUPLICATE_VIEW_NAME |
VARCHAR2(30) |
仮想モデル内に重複するトリプル(ある場合)を含むビューの名前。 |
|
STATUS |
VARCHAR2(30) |
|
|
MODEL_COUNT |
NUMBER |
仮想モデル内のモデルの数。 |
|
RULEBASE_COUNT |
NUMBER |
仮想モデルに使用されるルールベースの数。 |
|
RULES_INDEX_COUNT |
NUMBER |
仮想モデル内の伴意の数。 |
仮想モデルに関するすべてのオブジェクト(モデル、ルールベースおよび伴意)の情報は、MDSYS.SEM_VMODEL_DATASETSビューに保持されます。表1-10に、このビューの列を示します(1つの行がすべての列の値の一意の組合せに対応します)。
Oracle Databaseセマンティク・テクノロジでは、名前付きグラフの使用がサポートされます(詳細は、http://www.w3.org/TR/rdf-sparql-query/#rdfDatasetにあるW3C勧告「SPARQL Query Language for RDF」の「RDF Dataset」を参照してください)。
このサポートは、従来の主語、述語、目的語で構成されるRDFトリプルを、グラフ名を表す追加の構成要素を含めるように拡張することで実現されます。拡張されたRDFトリプルは、4つの構成要素を含みますが、このドキュメントでは引き続きRDFトリプルと呼びます。また、次の用語が使用されることもあります。
N-Tripleは、拡張トリプルを使用できない形式です。そのため、N-Tripleに含めることができるのは、3つの構成要素を持つトリプルのみです。
N-Quadは、標準トリプル(3つの構成要素)と拡張トリプル(グラフ名を含む4つの構成要素)の両方を使用できる形式です。詳細は、http://www.w3.org/TR/2013/NOTE-n-quads-20130409/を参照してください。
拡張トリプルを含むファイル(通常は標準トリプルが混在)をOracle Databaseにロードする場合、入力ファイルはN-Quad形式である必要があります。
RDFトリプルのグラフ名の構成要素は、NULLまたはURIである必要があります。これがNULLの場合、RDFトリプルはデフォルト・グラフに属していると言われます(それ以外の場合、URIで指定された名前を持つ名前付きグラフに属していると言われます)。
また、SDO_RDF_TRIPLE_Sオブジェクト型(1.5項を参照)の名前付きグラフをサポートするため、モデル-グラフ(モデルとグラフ(存在する場合)の組合せ)を指定するための新しい構文が用意され、RDF_M_ID属性はモデル-グラフの識別子(グラフ(存在する場合)のモデルIDと値IDの組合せ)を保持します。モデル-グラフの名前は、model_nameと、(グラフが存在する場合)それに続くコロン(:)区切り文字およびグラフ名(URIを山カッコ< >内に配置)で指定されます。
たとえば、医療データセットでは、各RDFトリプルの名前付きグラフの構成要素は患者の識別子に基づくURIになるため、一意の患者と同じ数の名前付きグラフが存在することになります(それぞれの名前付きグラフは特定の患者のデータで構成されます)。
名前付きグラフに特定の操作を実行する方法の詳細は、次の項を参照してください。
コンストラクタとメソッドの使用: 1.5項「セマンティク・データの型、コンストラクタおよびメソッド」
ロード: 1.7.1.1.2項「外部表を使用したステージング表へのN-Quad形式のデータのロード」および1.7.3.1項「INSERT文を使用した名前付きグラフへのデータのロード」
問合せ: 1.6.2.1項「GRAPHキーワードのサポート」および1.6.3項「グラフ・パターン: SPARQL SELECT構文のサポート」
TriG (http://wifo5-03.informatik.uni-mannheim.de/bizer/trig/)およびN-QUADS (http://www.w3.org/TR/2013/NOTE-n-quads-20130409/)は、トリプル・データにグラフ名(またはコンテキスト)を提供する2つの一般的なデータ形式です。(ただし、2011年11月の時点ではどちらの形式も標準ではありません。)グラフ名(コンテキスト)は、様々な方法で使用できます。一般的な使用方法には、管理、ローカライズされた問合せ、ローカライズされた推論、および起源を簡略化するためのトリプルのグループ化が含まれます(これに限定されるわけではありません)。
例1-5に、TriG形式でエンコードされたRDFデータセットを示します。これには、デフォルト・グラフと名前付きグラフが含まれます。
例1-5 TriG形式でエンコードされたRDFデータ
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix dc: <http://purl.org/dc/elements/1.1/> .
# Default graph
{
<http://my.com/John> dc:publisher <http://publisher/Xyz> .
}
# A named graph
<http://my.com/John> {
<http://my.com/John> foaf:name "John Doe" .
}
例1-5からDatasetGraphOracleSemオブジェクトにTriGファイルをロードすると(たとえば、7.11項「Jena Adapterを使用したバルク・ロード」の例7-10の定数"N-QUADS"を"TRIG"に置き換えて使用する場合など)、デフォルト・グラフのトリプルはNULLのグラフ名を持つトリプルとしてOracle Databaseにロードされ、名前付きグラフのトリプルは指定されたグラフ名でOracle Databaseにロードされます。
N-QUADS形式は、オプションの4番目の列(グラフ名またはコンテキスト)を追加することで既存のN-TRIPLES形式を単純に拡張したものです。例1-6に、例1-5に基づくTriGファイルのN-QUADS形式の表現を示します。
例1-6 N-QUADS形式の表現
<http://my.com/John> <http://purl.org/dc/elements/1.1/publisher> <http://publisher/Xyz> . <http://my.com/John> <http://xmlns.com/foaf/0.1/name> "John Doe" <http://my.com/John>
DatasetGraphOracleSemオブジェクトにN-QUADSファイルをロードすると(例7-10を参照)、4番目の列を含まない行はNULLのグラフ名を持つトリプルとしてOracle Databaseにロードされ、4番目の列を含む行は指定されたグラフ名でOracle Databaseにロードされます。
セマンティク・データを使用する場合、次のデータベース・セキュリティの考慮事項が適用されます。
モデルまたは伴意を作成すると、関連ビューに対するGRANTオプション付きのSELECT権限が所有者に付与されます。これらのビューに対してSELECT権限を持つユーザーは、関連モデルまたは伴意に対してSEM_MATCH問合せを実行できます。
ルールベースを作成すると、ルールベースに対するGRANTオプション付きのSELECT、INSERT、UPDATEおよびDELETE権限が所有者に付与されます。ルールベースに対してSELECT権限を持つユーザーは、ルールベースを含む伴意を作成できます。INSERT、UPDATEおよびDELETE権限により、ルールベースを変更できるユーザーと、その変更方法が制御されます。
モデルに対してデータ操作言語(DML)の操作を実行する場合、ユーザーは対応する実表に対するDML権限を持っている必要があります。
モデルに対応する実表の作成者は、他のユーザーに権限を付与できます。
ルールベースに対してデータ操作言語(DML)の操作を実行する場合、ユーザーは対応するデータベース・ビューに対する適切な権限を持っている必要があります。
モデルの作成者は、対応するデータベース・ビューに対するSELECT権限を他のユーザーに付与できます。
ユーザーは、対応するデータベース・ビューに対するSELECT権限を持っているモデルのみを問い合せることができます。
モデルまたはルールベースを削除できるのは、その作成者のみです。
Oracle Databaseでは、セマンティク・データに関連するメタデータを保持するために、MDSYSスキーマで複数の表およびビューが管理されます。(これらの表およびビューの一部は、1.10項に記載されているSEM_APIS.CREATE_SEM_NETWORKプロシージャによって作成され、一部は必要な場合にのみ作成されます。)表1-11に、これらの表およびビューをアルファベット順に示します。(また、Oracleで内部的に使用するためにいくつかの表およびビューも作成されますが、それらの表およびビューにはDBA権限を持つユーザーのみがアクセスできます。)
表1-11 セマンティク・メタデータ表およびビュー
| 名前 | 含まれる情報 | 参照先 |
|---|---|---|
|
RDF_VALUE$ |
文を表すのに使用される主語、プロパティおよび目的語 |
|
|
RDFOLS_SECURE_RESOURCE |
Oracle Label Security (OLS)ポリシーで保護されたリソースと、それらのリソースに関連付けられた機密性ラベル |
|
|
RDFVPD_MODELS |
RDFモデルとそれらに関連付けられたVPDポリシー |
|
|
RDFVPD_POLICIES |
スキーマに定義されているすべてのVPDポリシーまたはユーザーが完全なアクセス権を持っているポリシー |
|
|
RDFVPD_POLICY_CONSTRAINTS |
現在のユーザーがアクセスできるVPDポリシーに定義された制約 |
|
|
RDFVPD_PREDICATE_MDATA |
VPDポリシーに関連付けられた述語メタデータ |
|
|
RDFVPD_RESOURCE_REL |
VPDポリシーのリソース間に定義されているサブクラス、サブプロパティおよび等価プロパティの関係 |
|
|
SEM_DTYPE_INDEX_INFO |
ネットワークのすべてのデータ型索引 |
|
|
SEM_MODEL$ |
データベースに定義されているすべてのモデル |
|
|
SEM_NETWORK_INDEX_INFO$ |
セマンティク・ネットワーク索引 |
|
|
SEM_RULEBASE_INFO |
ルールベース |
|
|
SEM_RULES_INDEX_DATASETS |
伴意で使用されるデータベース・オブジェクト |
|
|
SEM_RULES_INDEX_INFO |
伴意(ルール索引) |
|
|
SEM_VMODEL_INFO |
仮想モデル |
|
|
SEM_VMODEL_DATASETS |
仮想モデルで使用されるデータベース・オブジェクト |
|
|
SEMCL_entailment-name |
|
|
|
SEMI_entailment-name |
指定した伴意のトリプル |
|
|
SEMM_model-name |
指定したモデルのトリプル |
|
|
SEMR_rulebase-name |
指定したルールベースのルール |
|
|
SEMU_virtual-model-name |
仮想モデル内の一意のトリプル |
|
|
SEMV_virtual-model-name |
仮想モデル内のトリプル |
|
SDO_RDF_TRIPLEオブジェクト型は、トリプル形式のセマンティク・データを表し、SDO_RDF_TRIPLE_Sオブジェクト型(_Sは格納の意味)は、データベースに永続セマンティク・データを格納します。実際のセマンティク・データはRDFスキーマにのみ一元的に格納されるため、SDO_RDF_TRIPLE_S型はデータに対する参照を保持します。この型には、トリプルの一部または全部を取得するためのメソッドがあります。
|
注意: 空白ノードは、常に1つのRDFモデル内で再利用されます。複数のモデル間で再利用することはできません。 |
SDO_RDF_TRIPLE型はトリプルの表示に使用し、SDO_RDF_TRIPLE_S型はデータベース表へのトリプルの格納に使用します。
SDO_RDF_TRIPLEオブジェクト型には、次の属性が含まれます。
SDO_RDF_TRIPLE ( subject VARCHAR2(4000), property VARCHAR2(4000), object VARCHAR2(10000))
SDO_RDF_TRIPLE_Sオブジェクト型には、次の属性が含まれます。
SDO_RDF_TRIPLE_S ( RDF_C_ID NUMBER, -- Canonical object value ID RDF_M_ID NUMBER, -- Model (or Model-Graph) ID RDF_S_ID NUMBER, -- Subject value ID RDF_P_ID NUMBER, -- Property value ID RDF_O_ID NUMBER) -- Object value ID
SDO_RDF_TRIPLE_S型には、RDFモデル(モデル-グラフ)の名前、トリプル、またはトリプルの一部(主語、プロパティまたは目的語)を取得する次のメソッドが含まれます。
GET_MODEL() RETURNS VARCHAR2 GET_TRIPLE() RETURNS SDO_RDF_TRIPLE GET_SUBJECT() RETURNS VARCHAR2 GET_PROPERTY() RETURNS VARCHAR2 GET_OBJECT() RETURNS CLOB
例1-7に、SDO_RDF_TRIPLE_Sのメソッドを示します。
例1-7 SDO_RDF_TRIPLE_Sのメソッド
SELECT a.triple.GET_MODEL() AS model_graph, a.triple.GET_TRIPLE() AS triple FROM articles_rdf_data a WHERE a.id = 99; MODEL_GRAPH -------------------------------------------------------------------------------- TRIPLE(SUBJECT, PROPERTY, OBJECT) -------------------------------------------------------------------------------- ARTICLES:<http://examples.com/ns#Graph1> SDO_RDF_TRIPLE('<http://nature.example.com/Article101>', '<http://purl.org/dc/elements/1.1/creator>', '"John Smith"') SELECT a.triple.GET_TRIPLE() AS triple FROM articles_rdf_data a WHERE a.id = 1; TRIPLE(SUBJECT, PROPERTY, OBJECT) -------------------------------------------------------------------------------- SDO_RDF_TRIPLE('<http://nature.example.com/Article1>', '<http://purl.org/dc/elem ents/1.1/title>', '<All about XYZ>') SELECT a.triple.GET_SUBJECT() AS subject FROM articles_rdf_data a WHERE a.id = 1; SUBJECT -------------------------------------------------------------------------------- <http://nature.example.com/Article1> SELECT a.triple.GET_PROPERTY() AS property FROM articles_rdf_data a WHERE a.id = 1; PROPERTY -------------------------------------------------------------------------------- <http://purl.org/dc/elements/1.1/title> SELECT a.triple.GET_OBJECT() AS object FROM articles_rdf_data a WHERE a.id = 1; OBJECT -------------------------------------------------------------------------------- <All about XYZ>
次のコンストラクタ書式は、トリプルをモデル表に挿入する場合に使用できます。2つの書式の唯一の違いは、2番目の書式における目的語のデータ型がCLOBであり、非常に長いリテラルに対応できることです。
SDO_RDF_TRIPLE_S ( model_name VARCHAR2, -- Model name subject VARCHAR2, -- Subject property VARCHAR2, -- Property object VARCHAR2) -- Object RETURN SELF; SDO_RDF_TRIPLE_S ( model_name VARCHAR2, -- Model name subject VARCHAR2, -- Subject property VARCHAR2, -- Property object CLOB) -- Object RETURN SELF; GET_OBJ_VALUE() RETURN VARCHAR2;
例1-8では、1番目のコンストラクタ書式を使用して複数のトリプルを挿入します。
例1-8 トリプルを挿入するSDO_RDF_TRIPLE_Sコンストラクタ
INSERT INTO articles_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Jane Smith"'));
INSERT INTO articles_rdf_data VALUES (98,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'<http://nature.example.com/Article102>',
'<http://purl.org/dc/elements/1.1/creator>',
'_:b1'));
INSERT INTO articles_rdf_data VALUES (97,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'_:b2',
'<http://purl.org/dc/elements/1.1/creator>',
'_:b1'));
セマンティク・データを問い合せるには、SEM_MATCHテーブル・ファンクションを使用します。このファンクションには、次の属性が含まれます。
SEM_MATCH( query VARCHAR2, models SEM_MODELS, rulebases SEM_RULEBASES, aliases SEM_ALIASES, filter VARCHAR2, index_status VARCHAR2, options VARCHAR2, graphs SEM_GRAPHS, named_graphs SEM_GRAPHS ) RETURN ANYDATASET;
query属性は必須です。その他の属性はオプションです(それぞれNULL値を指定できます)。
query属性は、通常は変数が含まれる1つ以上のトリプル・パターンを備えた文字列リテラル(または文字列リテラルを連結したもの)です。(query属性には、バインド変数またはバインド変数を含む式を指定することはできません。)トリプル・パターンは、3つのアトムとそれに続くピリオドです。各アトムには、変数(?xなど)、デフォルトの名前空間およびaliases属性の値に基づいて拡張された修飾名(rdf:type)、または完全なURI(<http://www.example.org/family/Male>など)を指定できます。また、3番目のアトムには、数値リテラル(3.14など)、プレーン・リテラル("Herman"など)、言語タグ付きのプレーン・リテラル("Herman"@enなど)または型付きリテラル("123"^^xsd:intなど)を指定できます。
たとえば、次のquery属性では、3つのトリプル・パターンを使用して祖父(祖父母の男性の方)とその孫の身長を検索します。
'{ ?x :grandParentOf ?y . ?x rdf:type :Male . ?y :height ?h }'
models属性では、使用する1つ以上のモデルを指定します。そのデータ型は、TABLE OF VARCHAR2(25)という定義を持つSEM_MODELSです。仮想モデルを問い合せる場合、他のモデル名は指定せず、その仮想モデルの名前のみを指定します。(仮想モデルの詳細は、1.3.8項を参照してください。)
rulebases属性では、問合せに適用するルールが含まれる1つ以上のルールベースを指定します。そのデータ型は、TABLE OF VARCHAR2(25)という定義を持つSDO_RDF_RULEBASESです。仮想モデルを問い合せる場合、この属性はNULLである必要があります。
aliases属性では、デフォルトの名前空間以外に、問合せパターンの修飾名の拡張に使用する1つ以上の名前空間を指定します。そのデータ型は、TABLE OF SEM_ALIASという定義を持つSEM_ALIASESです。各SEM_ALIAS要素により、名前空間IDと名前空間値が識別されます。SEM_ALIASデータ型は、(namespace_id VARCHAR2(30), namespace_val VARCHAR2(4000))という定義を持ちます。
SEM_MATCHテーブル・ファンクションとSEM_CONTAINSおよびSEM_RELATED演算子では、次のデフォルトの名前空間(namespace_id属性とnamespace_val属性)が使用されます。
('orardf', 'http://xmlns.oracle.com/rdf/')
('orageo', 'http://xmlns.oracle.com/rdf/geo/')
('owl', 'http://www.w3.org/2002/07/owl#')
('rdf', 'http://www.w3.org/1999/02/22-rdf-syntax-ns#')
('rdfs', 'http://www.w3.org/2000/01/rdf-schema#')
('xsd', 'http://www.w3.org/2001/XMLSchema#')
これらのデフォルトを上書きするには、aliases属性でnamespace_id値および異なるnamespace_val値を指定します。
filter属性では、追加の選択基準を指定します。この属性がNULLではない場合、WHEREキーワードのないWHERE句の形式で文字列を指定する必要があります。たとえば、この項で前に示したトリプル・パターンの例で'(h >= ''6'')'と指定すると、身長が6以上である祖父の孫に検索結果を絞り込めます。
|
注意: filter属性を使用するかわりに、問合せパターン内ではできるかぎりFILTERキーワードを使用することをお薦めします(1.6.2項を参照)。FILTERキーワードを使用すると、内部の最適化によってパフォーマンスが向上する可能性が高まります。ただし、filter引数は、FILTERキーワードで表現できないSQL構文を必要とする場合に役立ちます。 |
index_status属性では、関連する伴意のステータスが無効の場合でも、セマンティク・データを問い合せることができます。(仮想モデルを問い合せる場合、この属性は、その仮想モデルに関連付けられた伴意を参照します。)この属性がNULLの場合、伴意のステータスが無効であると、問合せによりエラーが戻されます。この属性がNULLではない場合、文字列INCOMPLETEまたはINVALIDを指定する必要があります。異なるindex_status値による問合せ動作の詳細は、1.6.1項を参照してください。
options属性は、問合せの結果に影響を与えることのできるオプションを指定します。オプションは、キーワードと値のペアで表記します。次のオプションがサポートされています。
ALL_BGP_HASHおよびALL_BGP_NLは、すべてのBGP間結合(ルートBGPとOPTIONAL BGP間の結合など)で、指定した結合タイプを使用するように指定するグローバル問合せオプティマイザ・ヒントです。(BGPとは、基本グラフ・パターンを意味します。W3C勧告の「SPARQL Query Language for RDF」の解説: 「SPARQLグラフ・パターンの一致は、基本グラフ・パターンの一致結果の組合せに基づいて定義されます。フィルタによって割り込まれた一連のトリプル・パターンは、単一の基本グラフ・パターンで構成されます。任意のグラフ・パターンによって、基本グラフ・パターンは終了します。」
例1-14に、SEM_MATCH問合せで使用されるALL_BGP_HASHオプションを示します。
ALL_LINK_HASHおよびALL_LINK_NLは、すべてのLINK$結合(BGP内のトリプル・パターン間のすべての結合)の結合タイプを指定するグローバル問合せオプティマイザ・ヒントです。ALL_LINK_HASHまたはALL_LINK_NLがHINT0ヒントで使用される場合、HINT0ヒントによってALL_ORDEREDヒントはオーバーライドされます。
ALL_ORDEREDは、問合せの各BGPのトリプル・パターンを順番に評価するように指定するグローバル問合せオプティマイザ・ヒントです。ALL_ORDEREDがHINT0ヒントで使用される場合、HINT0ヒントによってALL_ORDEREDヒントはオーバーライドされます。
例1-14に、SEM_MATCH問合せで使用されるALL_ORDEREDオプションを示します。
ALLOW_DUP=Tは、セマンティク・モデルと推論データ(適用可能な場合)のUNIONではなくUNION ALLを実行する、基礎となるSQL文を生成します。このオプションを使用した場合、結果セットに追加の行(重複するトリプル)が生成されるために、それに応じてアプリケーション・ロジックを調整する必要があることがあります。このオプションを指定しない場合、すべてのモデルと推論データにわたって、重複するトリプルは自動的に削除され、マージされたRDFグラフの設定済セマンティクが保持されます。ただし、重複するトリプルを削除すると、問合せの処理時間が長くなります。一般に、1つのSEM_MATCH問合せに複数のセマンティク・モデルが関連している場合、'ALLOW_DUP=T'を指定することで、パフォーマンスが大幅に向上します。
仮想モデルを問い合せる場合、ALLOW_DUP=Tを指定すると、SEMV_vm_nameビューが問合せされます。指定しない場合、SEMU_vm_nameビューが問合せされます。
DO_UNESCAPE=Tは、返却列のvar、var$_PREFIX、var$_SUFFIX、var$RDFCLOB、var$RDFLTYP、var$RDFLANGおよびvar$RDFTERMの文字を、W3CのN-Triples仕様(http://www.w3.org/TR/rdf-testcases/#ntriples)に従ってエスケープしません。SEM_APIS.ESCAPE_CLOB_TERM、SEM_APIS.UNESCAPE_CLOB_VALUE、SEM_APIS.ESCAPE_RDF_TERM、SEM_APIS.ESCAPE_RDF_VALUE、SEM_APIS.UNESCAPE_CLOB_TERM、SEM_APIS.UNESCAPE_CLOB_VALUE、SEM_APIS.UNESCAPE_RDF_TERMおよびSEM_APIS.UNESCAPE_RDF_VALUEも参照してください。
FINAL_VALUE_HASHおよびFINAL_VALUE_NLは、FILTER句で使用されていない問合せ変数の字句の値を取得するために使用する必要のある結合メソッドを指定するグローバル問合せオプティマイザ・ヒントです。
GRAPH_MATCH_UNNAMED=Tでは、名前のないトリプル(NULLのG_ID)をGRAPH句内で一致させることができます。つまり、2つのトリプルは、それらのグラフが等しい場合、またはグラフの一方または双方がNULLの場合、グラフ結合条件を満たします。このオプションは、データセットに名前のないTBOXトリプルまたは名前のない伴意トリプルが含まれる場合に役立ちます。
HINT0={<hint-string>}(発音および表記は"hint(ヒント)"と数字のゼロ)は、1つ以上のキーワードを、問合せの実行計画および結果に影響を与えるヒントとともに指定します。概念的には、n個のトリプル・パターンを持つグラフ・パターンで、m個の固有の変数を参照した場合、(n+m)方向の結合となります。つまり、ターゲットRDFモデルおよび対応する伴意(オプション)のn方向の自己結合が実行された後、値からm個の変数を検索するために、RDF_VALUE$でm個の結合が実行されます。ヒント指定は、問合せ実行で使用される結合順序と結合タイプに影響を与えます。
ヒント指定<hint-string>では、キーワードを使用します。一部のキーワードは、問合せで使用される各トリプル・パターンおよび変数ごとに、一連(一群)の別名または参照で構成されるパラメータを持ちます。トリプル・パターンの別名の形式は、tiです。iは、問合せ内のトリプル・パターンの0から始まる序数です。たとえば、問合せ内の最初のトリプル・パターンの別名はt0で、2番目のトリプル・パターンの別名はt1、...のようになります。問合せで使用される変数の別名は単に、その変数の名前です。このため、ヒント指定では、グラフ・パターンで使用される変数?xの別名として?xが使用されます。
問合せの実行計画に影響を与えるために使用するヒントには、LEADING(<sequence of aliases>)、USE_NL(<set of aliases>)、USE_HASH(<set of aliases>)およびINDEX(<alias> <index_name>)があります。これらのヒントの書式と基本的な意味は、SQL文のヒントと同じです(『Oracle Database SQL言語リファレンス』を参照)。
例1-10に、SEM_MATCH問合せで使用されるHINT0オプションを示します。
PLUS_RDFT=Tは、予測される問合せ変数ごとに追加でvar$RDFTERM CLOB列を戻すため、SPARQL SELECT構文(1.6.3項「グラフ・パターン: SPARQL SELECT構文のサポート」を参照)とともに使用できます。この列の値は、SEM_APIS.COMPOSE_RDF_TERMの結果(var、var$RDFVTYP、var$RDFLTYP、var$RDFLANG、var$RDFCLOB)に等しくなります。このオプションを使用する場合、各変数varの返却列は、var、var$RDFVID、var$_PREFIX、var$_SUFFIX、var$RDFVTYP、var$RDFCLOB、var$RDFLTYP、var$RDFLANGおよびvar$RDFTERMになります。
STRICT_DEFAULT=Tは、データセット情報が指定されていない場合、デフォルト・グラフを名前なしトリプルに制限します。
graphs属性は、SEM_MACH問合せのデフォルト・グラフを構成するための名前付きグラフのセットを指定します。そのデータ型は、TABLE OF VARCHAR2(4000)という定義を持つSEM_GRAPHSです。この属性のデフォルト値はNULLです。graphsがNULLの場合、デフォルト・グラフとして、問合せモデルのセットに含まれるすべてのグラフのUNION ALLが使用されます。
named_graphs属性は、GRAPH句によって一致させることができる名前付きグラフのセットを指定します。そのデータ型は、TABLE OF VARCHAR2(4000)という定義を持つSEM_GRAPHSです。この属性のデフォルト値はNULLです。named_graphsがNULLの場合、GRAPH句によって、問合せモデルのセットに含まれるすべての名前付きグラフを一致させることができます。
SEM_MATCHテーブル・ファンクションでは、入力変数に応じた要素とともにANYDATASET型のオブジェクトが戻されます。次の説明において、varは問合せで使用される変数名を示します。変数varごとに、結果要素にはvar、var$RDFVID、var$_PREFIX、var$_SUFFIX、var$RDFVTYP、var$RDFCLOB、var$RDFLTYPおよびvar$RDFLANGの各属性が含まれます。
このような場合、varは変数にバインドされた字句の値を保持し、var$RDFVIDは変数にバインドされた値のVALUE_IDを持ち、var$_PREFIXおよびvar$_SUFFIXは、変数にバインドされた値の接頭辞と接尾辞であり、var$RDFVTYPは、変数にバインドされた値のタイプ(URI、LIT [literal]またはBLN [blank node])を示し、var$RDFCLOBは、値がロング・リテラルの場合に変数にバインドされた字句の値を持ち、var$RDFLTYPは、リテラルがバインドされている場合にそのバインドされたリテラルのタイプを示し、var$RDFLANGは、言語タグ付きのリテラルがバインドされている場合に、そのバインドされたリテラルの言語タグを持ち、var$RDFCLOBはCLOB型ですが、他のすべての属性はVARCHAR2型です。
リテラル値または空白ノードの場合、接頭辞は値そのものになり、接尾辞はNULLになります。URI値の場合、接頭辞は値の一番右側にある/(スラッシュ)、#(ポンド)または:(コロン)の3つのいずれかの文字から左側の部分となり、接尾辞はそれより右側の値部分となります。たとえば、URI値http://www.example.org/family/grandParentOfの場合、接頭辞はhttp://www.example.org/family/、接尾辞はgrandParentOfとなります。
変数値の列とともに、SPARQL SELECT構文を使用するSEM_MATCH問合せは、追加のNUMBER列であるSEM$ROWNUMを戻します(この列は、SPARQL ORDER BY句を含む問合せの正しい結果順序を保証するために使用できます)。
例1-9では、RDFSとfamily_rbの2つのルールベースによる推論を使用して、familyモデルからすべての祖父(祖父母の男性の方)とその孫を選択します。(この例は、1.11.2項の例1-44からの抜粋です。)
例1-9 SEM_MATCHテーブル・ファンクション
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
例1-10は例1-9と同じ機能ですが、HINT0オプションが追加されています。
例1-10 SEM_MATCHテーブル・ファンクションを使用したHINT0オプション
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_Aliases(SEM_ALIAS('','http://www.example.org/family/')),
null,
null,
'HINT0={LEADING(t0 t1) USE_NL(?x ?y) GET_CANON_VALUE(?x ?y)}'));
例1-11では、Pathway/Genome BioPaxオントロジを使用して、ProteinsとComplexesの両方に属するすべての化学的複合タイプを取得します。
例1-11 SEM_MATCHテーブル・ファンクション
SELECT t.r
FROM TABLE (SEM_MATCH (
'{?r rdfs:subClassOf :Proteins .
?r rdfs:subClassOf :Complexes}',
SEM_Models ('BioPax'),
SEM_Rulebases ('rdfs'),
SEM_Aliases (SEM_ALIAS('', 'http://www.biopax.org/release1/biopax-release1.owl')),
NULL)) t;
例1-11のとおり、SEM_MATCHテーブル・ファンクションの検索パターンは、変数が疑問符文字(?)で始まるSPARQLと同様の構文を使用して指定します。この例の場合、変数?rは、同じ語に一致する必要があるため、ProteinsとComplexesの両方のサブクラスである必要があります。
SEM_RELATED演算子を使用してOWLオントロジを問い合せる方法の詳細は、2.3項を参照してください。
複数のモデルを問い合せる場合、または1つ以上のモデルおよびそれに対応する伴意を問い合せる場合、パフォーマンスの向上のため、仮想モデルを使用することを考慮してください(1.3.8項を参照)。
関連する伴意のステータスが無効の場合でも、SEM_MATCHテーブル・ファンクションのindex_status属性に文字列値INCOMPLETEまたはINVALIDを指定すると、セマンティク・データを問い合せることができます。(伴意のステータスは、1.3.7項に記載されているとおり、MDSYS.SEM_RULES_INDEX_INFOビューのSTATUS列に格納されます。SEM_MATCHテーブル・ファンクションの詳細は、1.6項を参照してください。)
index_status属性の値は、問合せの動作に次のように影響します。
伴意のステータスが有効の場合、問合せ動作はindex_status属性の値に影響を受けません。
index_statusに値を指定しないか、NULL値を指定すると、伴意のステータスが無効である場合、問合せによりエラーが戻されます。
index_status属性に文字列INCOMPLETEを指定すると、伴意のステータスが不完全または有効である場合、問合せが実行されます。
index_status属性に文字列INVALIDを指定すると、伴意の実際のステータス(無効、不完全または有効)にかかわらず問合せが実行されます。
ただし、伴意のステータスが不完全または無効の場合、次の考慮事項が適用されます。
ステータスが不完全の場合、基礎となるモデルに最近挿入されて推論可能となったいくつかのトリプルは、実際には伴意に存在しないことがあり、したがって問合せにより戻される結果は不正確となる可能性があるため、伴意の内容は近似値となる可能性があります。
ステータスが無効の場合、基礎となるモデルまたはルールベース(あるいはその両方)が最近変更されて推論不可能となったいくつかのトリプルは、まだ伴意に存在することがあり、したがって問合せにより戻される結果の正確性が影響を受ける可能性があるため、伴意の内容は近似値となる可能性があります。推論不可能となったトリプルが存在する可能性に加え、一部の推論可能な行が実際には伴意に存在しない可能性もあります。
SEM_MATCHテーブル・ファンクションは、一連のトリプル・パターンを中カッコで囲むグラフ・パターンの構文を受け入れます。OPTIONAL、FILTER、UNIONまたはGRAPHキーワードが続く場合以外は、セパレータとしてピリオドが必要です。この構文では、次の操作を任意に組み合せて実行できます。
OPTIONAL構成要素を使用して、部分一致の場合にも結果を取得できます。
FILTER構成要素を使用して、ソリューションを問合せに制限するグラフ・パターンのフィルタ式を指定できます。
UNION構成要素を使用して、複数の代替グラフ・パターンのいずれかを一致させることができます。
GRAPH構成要素(1.6.2.1項を参照)を使用して、グラフ・パターンの一致範囲を名前付きグラフのセットに制限できます。
例1-12は例1-9と同じ機能ですが、中カッコとピリオドを含む構文を使用してSEM_MATCHテーブル・ファンクション内のグラフ・パターンを表現しています。
例1-12 中カッコの構文
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
例1-13では、各祖父の参加する試合の名前(いずれの試合にも参加しない場合はNULL)が戻されるように、OPTIONAL構成要素を使用して例1-12を変更しています。
例1-13 中カッコの構文およびOPTIONAL構成要素
SELECT x, y, game
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,
null,
'HINT0={LEADING(t0 t1) USE_NL(?x ?y)}'));
OPTIONALグラフ・パターンに複数のトリプル・パターンが存在する場合、OPTIONALグラフ・パターンの各トリプル・パターンに一致が検出された場合にのみ、オプション変数の値が戻されます。例1-14では、各祖父とその孫の両方が参加する試合の名前(祖父と孫が一緒に参加している試合がない場合はNULL)が戻されるように、例1-13を変更しています。また、各BGP内でトリプル・パターンを順番に評価し、ルートBGPとOPTIONAL BGPを結合するためにハッシュ結合を使用するように指定するグローバル問合せオプティマイザ・ヒントも使用しています。
例1-14 中カッコの構文および複数パターンのOPTIONAL構成要素
SELECT x, y, game
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game . ?y :plays ?game}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,
'ALL_ORDERED ALL_BGP_HASH'));
単一の問合せには、ネストするかパラレルに設定できる複数のOPTIONALグラフ・パターンを含めることができます。例1-15では、ネストしたOPTIONALグラフ・パターンを使用して例1-14を変更しています。この例では、各祖父について、(1)祖父の参加する試合(いずれの試合にも参加しない場合はNULL)、および(2)祖父が試合に参加する場合は同じ試合に参加している孫の年齢(孫と一緒に参加している試合がない場合はNULL)が戻されます。例1-15では、ネストしたOPTIONALグラフ・パターンの?y :plays ?game . ?y :age ?ageに一致していなくても、?gameに値が戻されることに注意してください。
例1-15 中カッコの構文およびネストしたOPTIONAL構成要素
SELECT x, y, game, age
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game
OPTIONAL {?y :plays ?game . ?y :age ?age} }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
例1-16では、パラレルのOPTIONALグラフ・パターンを使用して例1-14を変更しています。この例では、各祖父について、(1)祖父の参加する試合(いずれの試合にも参加しない場合はNULL)、および(2)祖父の電子メール・アドレス(電子メール・アドレスがない場合はNULL)が戻されます。ネストしたOPTIONALグラフ・パターンとは異なり、パラレルのOPTIONALグラフ・パターンはそれぞれ個別に処理されます。つまり、電子メール・アドレスが見つかると、それは試合が見つかったかどうかにかかわらず戻され、試合が見つかると、それは電子メール・アドレスが見つかったかどうかにかかわらず戻されます。
例1-16 中カッコの構文およびパラレルのOPTIONAL構成要素
SELECT x, y, game, email
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male .
OPTIONAL{?x :plays ?game}
OPTIONAL{?x :email ?email}
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
例1-17では、NYまたはCAに居住している祖父のみの孫の情報が戻されるように、FILTER構成要素を使用して例1-12を変更しています。
例1-17 中カッコの構文およびFILTER構成要素
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :residentOf ?z
FILTER (?z = "NY" || ?z = "CA")}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
FILTER句では、算術演算子(+、-、*、/)、ブール演算子、論理結合子(||、&&、!)および比較演算子(<、>、<=、>=、=、!=)に加え、複数の組込みファンクションを使用できます。表1-12に、FILTER句で使用できる組込み関数を示します。表1-12の「説明」列で、x、yおよびzは、適切な型の引数です。
表1-12 FILTER句で使用できる組込みファンクション
| ファンクション | 説明 |
|---|---|
|
BOUND(variable) |
BOUND(x)は、xが結果でバインドされている(NULLではない)場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
DATATYPE(literal) |
DATATYPE(x)は、xのデータ型を表すURIを戻します。 |
|
isBLANK(RDF term) |
isBLANK(x)は、xが空白ノードの場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
isIRI(RDF term) |
isIRI(x)は、xがIRIの場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
isLITERAL(RDF term) |
isLiteral(x)は、xがリテラルの場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
isURI(RDF term) |
isURI(x)は、xがURIの場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
LANG(literal) |
LANG(x)は、xの言語タグをシリアライズするプレーン・リテラルを戻します。 |
|
langMATCHES(literal, literal) |
langMATCHES(x, y)は、言語タグxが言語範囲yに一致する場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
REGEX(string, pattern) |
REGEX(x,y)は、xが正規表現yに一致する場合はtrueを戻し、それ以外の場合はfalseを戻します。サポートされる正規表現の詳細は、『Oracle Database SQL言語リファレンス』の付録「Oracleの正規表現のサポート」を参照してください。 |
|
REGEX(string, pattern, flags) |
REGEX(x,y,z)は、xがzに指定されたオプションを使用して正規表現yに一致する場合はtrueを戻し、それ以外の場合はfalseを戻します。使用可能なオプション: 's' - ドット任意文字モード('.'は改行文字を含むすべての文字に一致します)、'm' - 複数行モード('^'は任意の行の先頭に一致し、'$'は任意の行の末尾に一致します)、'i' - 大/小文字無視モード、'x' - 一致の前に正規表現から空白文字を削除します。 |
|
sameTERM(RDF term, RDF term) |
sameTERM(x, y)は、xとyが同じRDF用語の場合はtrueを戻し、それ以外の場合はfalseを戻します。 |
|
STR(RDF term) |
STR(x)は、xの文字列表現のプレーン・リテラル(二重引用符で囲まれたMDSYS.RDF_VALUE$のVALUE_NAME列に格納された内容)を戻します。 |
SEM_MATCHで使用できる組込み関数を理解するには、SPARQL問合せ言語仕様(http://www.w3.org/TR/rdf-sparql-query/)に定義されている組込みファンクションの説明も参照してください。
例1-18では、REGEX組込みファンクションを使用して、Oracle電子メール・アドレスを持つすべての祖父を選択しています。正規表現パターンのバックスラッシュ文字(\)は、問合せ文字列でエスケープする必要があります(たとえば、\\.とすることで\.というパターンが生成されます)。
例1-18 中カッコの構文とREGEXおよびSTR組込みファンクションを使用したFILTER構成要素
SELECT x, y, z
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :email ?z
FILTER (REGEX(STR(?z), "@oracle\\.com$"))}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
例1-19では、祖父がNYまたはCAに居住しているか、NYまたはCAに不動産を所有している場合にのみ、あるいは両方の条件がtrueの場合(祖父がNYまたはCAに居住し、かつ不動産を所有している場合)に祖父が戻されるように、UNION構成要素を使用して例1-17を変更しています。
例1-19 中カッコの構文とUNIONおよびFILTER構成要素
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male
{{?x :residentOf ?z} UNION {?x :ownsPropertyIn ?z}}
FILTER (?z = "NY" || ?z = "CA")}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
中カッコを含む構文を使用してグラフ・パターンを表現した場合、次のようになります。
問合せは常に、変数の一致する値の正規字句形式を戻します。
HINT0={<hint-string>}を使用してoptions引数に指定するヒント(1.6項を参照)は、ルートBGP内のグラフ・パターン部分に基づいてのみ構成する必要があります。たとえば、例1-13の問合せのヒント指定で使用できる有効な別名は、t0、t1、?xおよび?yのみです。インライン問合せオプティマイザ・ヒントを使用すると、グラフ・パターンの他の部分に影響を与えることができます(1.6.4項を参照)。
FILTER構成要素は、ロング・リテラルにバインドされた変数ではサポートされません。
SEM_MATCH問合せは、RDFデータセットに対して実行されます。RDFデータセットは、デフォルト・グラフと呼ばれる1つの名前なしグラフと、URIによって識別される1つ以上の名前付きグラフを含む複数のグラフのコレクションです。GRAPH句内に出現するグラフ・パターンは、名前付きグラフのセットに対して照合され、GRAPH句内に出現しないグラフ・パターンは、デフォルト・グラフに対して照合されます。graphsおよびnamed_graphs SEM_MATCHパラメータを使用して、特定のSEM_MATCH問合せのデフォルト・グラフと名前付きグラフのセットを構成できます。表1-13に、使用可能なデータセット構成のサマリーを示します。
表1-13 SEM_MATCHのgraphsとnamed_graphsの値、および結果のデータセット構成
| パラメータ値 | デフォルト・グラフ | 名前付きグラフのセット |
|---|---|---|
|
|
すべての名前なしトリプルとすべての名前付きグラフ・トリプルのUNION ALL。(ただし、 |
すべての名前付きグラフ |
|
|
空のセット |
{g1,…, gn} |
|
|
{g1,…, gm}のUNION ALL |
空のセット |
|
|
{g1,…, gm}のUNION ALL |
{gn,…, gz} |
例1-20では、GRAPH構成要素を使用して、グラフ・パターンの一致範囲を特定の名前付きグラフに制限しています。この例では、<http://www.example.org/family/Smith>という名前付きグラフのすべての人物の名前と電子メール・アドレスが検出されます。
例1-20 名前付きグラフの構成要素
SELECT name, email
FROM TABLE(SEM_MATCH(
'{GRAPH :Smith {
?x :name ?name . ?x :email ?email } }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
GRAPHキーワードの後には、URI以外に変数を配置できます。例1-21では、GRAPHとともに変数?gを使用し、named_graphsパラメータを使用して?gの使用可能な値を<http://www.example.org/family/Smith>および<http://www.example.org/family/Jones>という名前付きグラフに制限しています。SEM_ALIASES引数に指定されている別名は、graphsおよびnamed_graphsパラメータで使用できます。
例1-21 named_graphsパラメータの使用
SELECT name, email
FROM TABLE(SEM_MATCH(
'{GRAPH ?g {
?x :name ?name . ?x :email ?email } }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,null,null,null,
SEM_GRAPHS('<http://www.example.org/family/Smith>',
':Jones')));
例1-22では、デフォルト・グラフを使用して、<http://www.example.org/family/Smith>と<http://www.example.org/family/Jones>の名前付きグラフのUNIONを問い合せています。
例1-22 graphsパラメータの使用
FROM TABLE(SEM_MATCH(
'{?x :name ?name . ?x :email ?email }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null,null,null,
SEM_GRAPHS('<http://www.example.org/family/Smith>',
':Jones'),
null));
RDFデータセットとGRAPH構成要素の詳細は、W3C SPARQL仕様(http://www.w3.org/TR/rdf-sparql-query/#rdfDataset)も参照してください。
中カッコのグラフ・パターンに加え、SEM_MATCHでは、完全に指定されたSPARQL SELECT問合せをqueryパラメータで使用できます。SPARQL SELECT構文オプションを使用する場合、SEM_MATCHでは、PREFIX、SELECT、SELECT DISTINCT、FROM、FROM NAMED、WHERE、ORDER BY、LIMITおよびOFFSETの各問合せ構成要素がサポートされます。SPARQL SELECT構文の各問合せには、SELECT句とグラフ・パターンを含める必要があります。
SEM_MATCHを使用する場合の中カッコとSPARQL SELECT構文の主な違いは、SPARQL SELECT構文を使用する場合、SPARQL SELECT句に出現している変数のみがSEM_MATCHから戻されるところにあります。
SPARQL SELECT構文を使用する場合、SEM$ROWNUMという1つの追加列がSEM_MATCHから戻されます。このNUMBER列を使用して、結果の順序がSPARQL ORDER BY句で指定された順序と一致するようにSEM_MATCH問合せの結果を並べ替えることができます。
例1-23では、次のSPARQL構成要素を使用しています。
SPARQL PREFIX句: http://www.example.org/family/およびhttp://xmlns.com/foaf/0.1/名前空間の略語を指定します。
SPARQL SELECT句: 問合せから抽出する変数のセットを指定します。
SPARQL WHERE句: 問合せグラフ・パターンを指定します。
例1-23 SPARQL PREFIX、SELECTおよびWHERE句
SELECT y, name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT ?y ?name
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
例1-23では、y、y$RDFVID、y$_PREFIX、y$_SUFFIX、y$RDFVTYP、y$RDFCLOB、y$RDFLTYP、y$RDFLANG、name、name$RDFVID、name$_PREFIX、name$_SUFFIX、name$RDFVTYP、name$RDFCLOB、name$RDFLTYP、name$RDFLANGおよびSEM$ROWNUMの各列が戻されます。
SPARQL SELECT句では、(A)一連の変数または式(あるいはその両方)、または(B) * (指定されたトリプル・パターンに出現するすべての変数を抽出)のいずれかを指定します。例1-24では、SPARQL SELECT句を使用して、指定されたトリプル・パターンに出現するすべての変数を選択しています。
例1-24 SPARQL SELECT * (トリプル・パターンのすべての変数)
SELECT x, y, name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT *
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
DISTINCTキーワードをSELECTの後に使用すると、重複する結果行を削除できます。例1-25では、SELECT DISTINCTを使用して個別の名前のみを選択しています。
例1-25 SPARQL SELECT DISTINCT
SELECT name
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
SELECT DISTINCT ?name
WHERE
{?x :grandParentOf ?y .
?x foaf:name ?name }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
SPARQL FROMおよびFROM NAMEDは、問合せにRDFデータセットを指定するために使用します。FROM句を使用してデフォルト・グラフを構成するグラフのセットを指定し、FROM NAMED句を使用して名前付きグラフのセットを構成するグラフのセットを指定します。例1-26では、FROMおよびFROM NAMEDを使用して、<http://www.friends.com/friends>グラフと<http://www.contacts.com/contacts>グラフのUNIONから電子メール・アドレスおよび関係の友人を選択し、<http://www.example.org/family/Smith>グラフと<http://www.example.org/family/Jones>グラフから祖父母の情報を選択しています。
例1-26 FROMおよびFROM NAMEDを使用したRDFデータセットの指定
SELECT x, y, z, email
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/family/>
PREFIX foaf: <http://xmlns.com/foaf/0.1/>
PREFIX friends: <http://www.friends.com/>
PREFIX contacts: <http://www.contacts.com/>
SELECT *
FROM friends:friends
FROM contacts:contacts
FROM NAMED :Smith
FROM NAMED :Jones
WHERE
{?x foaf:frendOf ?y .
?x :email ?email .
GRAPH ?g {
?x :grandParentOf ?z }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
null, null));
SPARQL ORDER BY句を使用すると、SEM_MATCH問合せの結果を並べ替えることができます。この句によって、指定された問合せの結果を並べ替えるために使用する一連のコンパレータを指定します。コンパレータは、変数、RDF用語、算術演算子(+、-、*、/)、ブール演算子、論理結合子(||、&&、!)、比較演算子(<、>、<=、>=、=、!=)、およびFILTER式で使用できる任意の関数で構成されます。
SPARQL ORDER BY句の場合:
単一の変数の順序付け条件には前後のカッコは不要ですが、より複雑な順序付け条件にはカッコが必要です。
オプションのASC()またはDESC()順序修飾子を使用して、それぞれ昇順または降順となる目的の順序を指定できます。デフォルトの順序は昇順です。
SEM_MATCHでSPARQL ORDER BYを使用する場合、取り囲んでいるSQLブロック全体を通じて目的の順序を維持するためには、格納側のSQL問合せをSEM$ROWNUMで並べ替える必要があります。
例1-27では、SPARQL ORDER BY句を使用してすべてのカメラを選択し、降順のタイプと昇順の総額(price * (1 - discount) * (1 + tax))によって順序を指定しています。
例1-27 SPARQL ORDER BY
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT *
WHERE
{?x :price ?p .
?x :discount ?d .
?x :tax ?t .
?x :cameraType ?cType .
}
ORDER BY DESC(?cType) ASC(?p * (1-?d) * (1+?t))',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
SPARQL LIMITおよびSPARQL OFFSETを使用すると、問合せソリューションの異なるサブセットを選択できます。例1-28では、SPARQL LIMITを使用して最も安い5つのカメラを選択し、例1-29では、SPARQL LIMITおよびOFFSETを使用して5番目から10番目の最も安いカメラを選択しています。
例1-28 SPARQL LIMIT
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
}
ORDER BY ASC(?p)
LIMIT 5',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
例1-29 SPARQL OFFSET
SELECT *
FROM TABLE(SEM_MATCH(
'PREFIX : <http://www.example.org/electronics/>
SELECT ?x ?cType ?p
WHERE
{?x :price ?p .
?x :cameraType ?cType .
}
ORDER BY ASC(?p)
LIMIT 5
OFFSET 5',
SEM_Models('electronics'),
SEM_Rulebases('RDFS'),
null, null))
ORDER BY SEM$ROWNUM;
SPARQL PREFIX、SELECT、SELECT DISTINCT、FROM、FROM NAMED、WHERE、ORDER BY、LIMITおよびOFFSET構成要素の詳細は、W3C SPARQL仕様(http://www.w3.org/TR/rdf-sparql-query/)も参照してください。
SEM_MATCHでは、HINT0インライン問合せオプティマイザ・ヒントを使用できるようにSPARQLコメント構成要素がオーバーロードされています。SPARQLでは、ハッシュ文字(#)は行の残り部分がコメントであることを示します。インライン・ヒントを特定のBGPに関連付けるには、SPARQLコメント内にHINT0ヒント文字列を配置し、開始中カッコ({)とBGPの最初のトリプル・パターンの間にコメントを挿入します。インライン・ヒントによって、問合せ内の各BGPの実行計画に影響を与えることができます。例1-30に、インライン問合せオプティマイザ・ヒントを使用した問合せを示します。
例1-30 インライン問合せオプティマイザ・ヒント
SELECT x, y, hp, cp
FROM TABLE(SEM_MATCH(
'{ # HINT0={ LEADING(t0) USE_NL(?x ?y ?bd) }
?x :grandParentOf ?y . ?x rdf:type :Male . ?x :birthDate ?bd
OPTIONAL { # HINT0={ LEADING(t0 t1) BGP_JOIN(USE_HASH) }
?x :homepage ?hp . ?x :cellPhoneNum ?cp }
}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
BGP_JOINヒントは、BGP間の結合に影響を与え、BGP_JOIN(<join_type>)という構文を使用します(<join_type>はUSE_HASHまたはUSE_NLです)。例1-30では、BGP_JOIN(USE_HASH)ヒントを使用して、OPTIONAL BGPとその親BGPを結合する際にハッシュ結合を使用するように指定しています。
インライン・オプティマイザ・ヒントによって、options引数を使用してSEM_MATCHに渡されるヒントはすべてオーバーライドされます。たとえば、グローバルALL_ORDEREDヒントは、インライン・オプティマイザ・ヒントの指定がない各BGPに適用されますが、インライン・ヒントのあるBGPは、ALL_ORDEREDヒントのかわりにインライン・ヒントを使用します。
Oracle固有のorardf:textContains SPARQL FILTER関数では、MDSYS.RDF_VALUE$表に対して全文索引を使用します。この関数の構文は次のとおりです(orardfは<http://xmlns.oracle.com/rdf/>に展開される組込み接頭辞です)。
orardf:textContains(variable, pattern)
orardf:textContainsの第1引数はローカル変数(orardf:textContainsフィルタを含むBGPに存在する変数)に、第2引数は定数のプレーン・リテラルにする必要があります。
たとえば、xが式yに一致する場合(yはOracle TextのSQL演算子CONTAINSに対して有効な式)、orardf:textContains(x, y)はtrueを戻します。この式の詳細は、『Oracle Textリファレンス』を参照してください。
orardf:textContainsを使用する前に、RDFネットワークのOracle Text索引を作成する必要があります。この索引を作成するには、次のようにSEM_APIS.ADD_DATATYPE_INDEXプロシージャを起動します。
EXECUTE SEM_APIS.ADD_DATATYPE_INDEX('http://xmlns.oracle.com/rdf/text');
テキスト索引のあるセマンティク・ネットワークに対して大規模バルク・ロードを実行する場合、テキスト索引を削除してバルク・ロードを実行してからテキスト索引を再作成すると、ロード時間全体が短縮される可能性があります。データ型の索引付けの詳細は、1.9項を参照してください。
テキスト索引を作成すると、SEM_MATCH問合せでorardf:textContains FILTER関数を使用できます。例1-31では、orardf:textContainsを使用して、文字AまたはBで始まる名前を持つすべての祖父を検出しています。
|
注意: Oracle Databaseセマンティク・テクノロジで空間のサポートを使用する前に、Oracle Spatial Patch 11828358: ORA-7445 ON SELECT WITH SDO_RELATE IN WHERE CLAUSEが適用されていることを確認してください。 |
Oracle Databaseセマンティク・テクノロジでは、orageo:WKTLiteral型付きリテラルとしてエンコードされた空間ジオメトリ・データの格納がサポートされ、空間操作用の問合せ機能のセットが提供されます。(orageoは、<http://xmlns.oracle.com/rdf/geo/>に展開される組込み接頭辞です。)
この項の内容は次のとおりです。
空間ジオメトリは、RDFでorageo:WKTLiteral型付きリテラルとして表現できます。例1-32に、単純な点ジオメトリのorageo:WKTLiteralエンコーディングを示します。
例1-32 orageo:WKTLiteralとして表現された点の空間ジオメトリ
"Point(-83.4 34.3)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral>
orageo:WKTLiteralエンコーディングは、オプションの空間参照システムURIと、その後に続く、ジオメトリ値をエンコードするWell-Known Text (WKT)文字列で構成されます。空間参照システムURIとWKT文字列は、空白文字で区切る必要があります。
空間参照システムURIの形式は、<http://xmlns.oracle.com/rdf/geo/srid/{srid}>です({srid}は、Oracle Spatialの有効な空間参照システムIDです)。orageo:WKTLiteralの値に空間参照システムURIが含まれない場合、デフォルトの空間参照システムのWGS84経度/緯度(URI <http://xmlns.oracle.com/rdf/geo/srid/8307>)が使用されます。orageo:WKTLiteralの値が問合せ文字列に出現する場合も、同じデフォルトの空間参照システムが使用されます。
複数のジオメトリ・タイプ(点、連結線、ポリゴン、多面体面、三角形、TIN、複数点、複数連結線、複数ポリゴン、ジオメトリ・コレクションなど)をorageo:WKTLiteralの値として表現できます。2次元ジオメトリでは、1ジオメトリ当たり最大500,000の頂点がサポートされます。
例1-33に、orageo:WKTLiteralの値を使用してエンコードされたRDF空間データ(N-Triple形式)を示します。この例の場合、lot1の最初の2つのジオメトリではデフォルトの座標系(SRID 8307)を使用していますが、lot2の他の2つのジオメトリではSRID 8265を指定しています。
例1-33 orageo:WKTLiteralの値を使用してエンコードされた空間データ
# spatial data for lot1 using the default WGS84 Longitude-Latitude spatial reference system <urn:lot1> <urn:hasExactGeometry> "Polygon((-83.6 34.1, -83.6 34.5, -83.2 34.5, -83.2 34.1, -83.6 34.1))"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . <urn:lot1> <urn:hasPointGeometry> "Point(-83.4 34.3)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . # spatial data for lot2 using the NAD83 Longitude-Latitude spatial reference system <urn:lot2> <urn:hasExactGeometry> "<http://xmlns.oracle.com/rdf/geo/srid/8265> Polygon((-83.6 34.1, -83.6 34.3, -83.4 34.3, -83.4 34.1, -83.6 34.1))"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> . <urn:lot2> <urn:hasPointGeometry> "<http://xmlns.oracle.com/rdf/geo/srid/8265> Point(-83.5 34.2)"^^<http://xmlns.oracle.com/rdf/geo/WKTLiteral> .
詳細は、『Oracle Spatial開発者ガイド』の座標系(空間参照システム)に関する章を参照してください。Open Geospatial Consortium (OGC)のSimple Featuresドキュメント(http://portal.opengeospatial.org/files/?artifact_id=25355)のWKTジオメトリ表現に関する資料も参照してください。
任意のSPARQL拡張関数(1.6.6.3項を参照)を使用して空間データを問い合せる前に、SEM_APIS.ADD_DATATYPE_INDEXプロシージャをコールしてRDFネットワークに空間索引を作成する必要があります。
空間索引を作成する場合、次の情報を指定する必要があります。
SRID: 空間索引を作成する空間参照システムのID。Oracle Spatialの有効な空間参照システムIDをSRID値として使用できます。
TOLERANCE: 空間索引の許容値。許容値は、2つの点が同じ点とみなされるためにどの程度近接している必要があるかを示す正数です。この値の単位は、使用されるSRIDのデフォルト単位によって決定されます(たとえば、WGS84経度/緯度の場合はメートル)。許容値の詳細は、『Oracle Spatial開発者ガイド』を参照してください。
DIMENSIONS: 空間索引のテキスト文字列エンコーディングの次元情報。各次元は、カンマ区切りの一連の3つの値(名前、最小値および最大値)で表現されます。各次元をカッコで囲み、それらの次元のセットを外側のカッコで囲みます。
例1-34では、WGS84経度/緯度の空間参照システム、10mの許容値、およびこの座標系を使用する空間データの索引付けに推奨される次元を指定して、RDFネットワークに空間データ型索引を追加しています。TOLERANCE、SRIDおよびDIMENSIONSキーワードは大/小文字が区別されるため注意してください。
例1-34 RDFデータへの空間データ型索引の追加
EXECUTE sem_apis.add_datatype_index('http://xmlns.oracle.com/rdf/geo/WKTLiteral', options=>'TOLERANCE=10 SRID=8307 DIMENSIONS=((LONGITUDE,-180,180) (LATITUDE,-90,90))');
RDFネットワークでは、1つの空間データ型索引のみがサポートされます。RDFネットワークに格納されたorageo:WKTLiteralの値は、索引で使用される空間参照システムに自動的に正規化されるため、単一の空間索引で異なる空間参照システムのorageo:WKTLiteralの値を同時にサポートできます。この座標変換は、索引付けと空間の計算に対して透過的に行われます。orageo:WKTLiteralの値がSEM_MATCH問合せから戻される場合、変換されていない元のジオメトリが戻されます。
空間索引の詳細は、『Oracle Spatial開発者ガイド』の空間データの索引付けと問合せに関する章を参照してください。
SEM_MATCHで空間問合せを実行するために、複数のSPARQL拡張関数を使用できます。たとえば、空間RDFデータでは、ジオメトリの領域と境界線(長さ)、2つのジオメトリ間の距離、およびジオメトリの重心と最小外接矩形を検出することや、ジオメトリ間の様々な位相関係を確認することができます。
付録Bに、次の関数のリファレンスと使用方法の情報があります。
この項では、SEM_MATCHテーブル・ファンクションを使用してセマンティク・データを問い合せる場合に推奨されるプラクティスについて説明します。この項の内容は次のとおりです。
デフォルトでは、SEM_MATCHは、xsd:date、xsd:timeおよびxsd:dateTimeの値の比較についてXMLスキーマ標準に準拠しています。この標準に従って2つのカレンダ値のc1とc2を比較すると(c1には明示的にタイムゾーンが指定され、c2にはタイムゾーンが指定されていません)、c2は[c2-14:00, c2+14:00]という間隔に変換されます。c2-14:00 <= c1 <= c2+14:00である場合、比較は未定義となり、常にfalseに評価されます。c1がこの間隔の外部にある場合、比較は定義されます。
ただし、このような比較(タイムゾーンのある値とタイムゾーンのない値)を評価するために必要な追加ロジックによって、カレンダ値を含むFILTER構成要素を使用した問合せの速度が大幅に低下する可能性があります。問合せのパフォーマンスを向上するため、SEM_MATCHテーブル・ファンクションのoptionsパラメータにFAST_DATE_FILTER=Tを指定して、この追加ロジックを無効化できます。FAST_DATE_FILTER=Tが指定されると、タイムゾーンのないカレンダ値は、すべてグリニッジ標準時(GMT)に含まれるものと仮定されます。
ただし、(1)データセットのすべてのカレンダ値にタイムゾーンがある場合、または(2)データセットのすべてのカレンダ値にタイムゾーンがない場合、FAST_DATE_FILTER=Tを使用することで問合せの正確さが影響を受けることはありません。
FILTER構成要素を含むSEM_MATCH問合せを評価する場合、通常、RDF_VALUE$表に対して1つ以上のSQLファンクションを実行する必要があります。たとえば、フィルタ(?x < "1929-11-16Z"^^xsd:date)によって、SEM_APIS.GETV$DATETZVALファンクションが起動されます。
ファンクション・ベース索引を使用すると、型付きリテラルを含むフィルタ条件が存在する問合せのパフォーマンスを向上できます。たとえば、xsd:dateファンクション・ベース索引によって、フィルタ(?x < "1929-11-16Z"^^xsd:date)の評価が高速化する可能性があります。
これらのファンクション・ベース索引の作成、変更および削除のために、便利なインタフェースが用意されています。詳細は、1.9項「データ型索引の使用」を参照してください。
ただし、MDSYS.RDF_VALUE$表にこれらのファンクション・ベース索引が存在することで、バルク・ロード操作の速度は大幅に低下する可能性があります。多くの場合、索引付きのままバルク・ロードを実行する場合と比較すると、索引を削除し、バルク・ロードを実行してから索引を再作成する方が高速です。
関係式を含むFILTER構成要素には次の推奨事項が適用されます。
問合せオプティマイザに十分な統計を確保することは、優れた問合せパフォーマンスのために非常に重要です。通常、SEM_PERF.GATHER_STATSプロシージャ(第11章を参照)を使用してセマンティク・ネットワークの基本統計を収集済であることを確認する必要があります。
RDFデータ・モデル固有の柔軟性のため、静的情報によってはSEM_MATCH問合せに最適な実行計画が生成されない可能性があります。通常、動的サンプリングの方が、より適切な問合せ実行計画を生成できます。動的サンプリングのレベルは、optimizer_dynamic_samplingパラメータを使用してセッション・レベルまたはシステム・レベルで設定するか、dynamic_sampling(level) SQL問合せヒントを使用して個々の問合せレベルで設定できます。一般的に、3から6までの動的サンプリング・レベルを試してみることをお薦めします。動的サンプリングで統計を評価する方法の詳細は、『Oracle Databaseパフォーマンス・チューニング・ガイド』を参照してください。
例1-35では、動的サンプリング・レベルが6のSQLヒントを使用しています。
複数のセマンティク・モデル、セマンティク・モデルと伴意、および仮想モデルの使用には、次の推奨事項が適用されます。
複数のセマンティク・モデルに対して、またはセマンティク・モデルと伴意に対してSEM_MATCH問合せを実行する場合、問合せ対象のすべてのモデルおよび伴意を含む仮想モデル(1.3.8項を参照)を作成してからその単一の仮想モデルを問い合せると、通常は問合せパフォーマンスが向上します。
ALLOW_DUP=T問合せオプションを使用してください。このオプションを使用しない場合、RDFデータの設定済セマンティクを保持するため、問合せの処理中に(処理に関して)コストのかかる複製と削除の手順が必要になります。一方、このオプションを使用すると、複製と削除の手順は実行されず、パフォーマンスが大幅に向上します。
セマンティク・データをモデルにロードするには、次の1つ以上のオプションを使用します。
RDFトリプル(およびオプションで名前付きグラフ)の3つの構成要素(主語、述語、目的語)を含む行を持つステージング表からセマンティク・データ・ストアにデータをバルク・ロードまたは追加します。詳細は、1.7.1項を参照してください。
このオプションは、大量のデータをロードする場合の最も高速な方法ですが、4000バイトを超える目的語の値を含むトリプルは処理できません。
バッチ・ロード: Javaクライアント・インタフェースを使用してN-Triple形式のファイルのデータをセマンティク・データ・ストアにロードまたは追加します(1.7.2項を参照)。
このオプションは、バルク・ロードより低速ですが、4000バイトを超える目的語の値を含むトリプルも処理できます。ただし、このオプションでは名前付きグラフは処理されません。
SDO_RDF_TRIPLE_SコンストラクタをコールするSQL INSERT文を使用してアプリケーション表にロードし、対応するRDFトリプル(状況によりグラフ名も含む)のセマンティク・データ・ストアに挿入します(1.7.3項を参照)。
このオプションは、小規模なデータをロードする場合に便利です。ただし、このオプションでは名前付きグラフは処理されません。
セマンティク・データをエクスポートするには、1.7.4項「セマンティク・データのエクスポート」を参照してください。
RDF_VALUE$表に存在するが、現在セマンティク・ネットワークに含まれるどのRDFトリプルまたはルールでも使用されなくなった値をパージするには、1.7.5項「未使用値のパージ」を参照してください。
ステージング表を使用して、セマンティク・データ(およびオプションでセマンティク・データ以外の関連データ)をバルク・ロードできます。SEM_APIS.LOAD_INTO_STAGING_TABLEプロシージャ(第9章を参照)をコールしてデータをロードします(ロード操作中に構文の正確性をチェックできます)。次に、SEM_APIS.BULK_LOAD_FROM_STAGING_TABLEプロシージャをコールして、ステージング表からセマンティク・ストアにデータをロードできます。(ステージング表へのロード操作中にデータが解析されていない場合、SEM_APIS.BULK_LOAD_FROM_STAGING_TABLEプロシージャのコール時にflagsパラメータにPARSEキーワードを指定する必要があります。)
次の例では、すべての必須列とそれらの列の必須名(およびロードする1つ以上のRDFトリプルにグラフ名が含まれる場合は、含まれる必要のあるオプションのRDF$STC_graph列)を含むステージング表の書式を示します。
CREATE TABLE stage_table (
RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_obj varchar2(4000) not null,
RDF$STC_graph varchar2(4000)
);
非セマンティク・データもロードする場合は、CREATE TABLE文に非セマンティク・データ用の追加列を指定します。非セマンティク列の名前の形式は、必須列の名前と異なる必要があります。次の例では、非セマンティク属性用の2つの追加列(SOURCEおよびID)を含むステージング表を作成します。
CREATE TABLE stage_table_with_extra_cols (
source VARCHAR2(4000),
id NUMBER,
RDF$STC_sub varchar2(4000) not null,
RDF$STC_pred varchar2(4000) not null,
RDF$STC_obj varchar2(4000) not null,
RDF$STC_graph varchar2(4000)
);
|
注意: いずれの形式のCREATE TABLE文でも、表を圧縮するためにCOMPRESS句を追加できます。このオプションにより、必要なディスク領域が減少し、バルク・ロードのパフォーマンスが向上する可能性があります。 |
起動側とMDSYSユーザーは、両方ともステージング表に対するSELECT権限と、アプリケーション表に対するINSERT権限を持っている必要があります。
次の項も参照してください。
セマンティク・ストアへのロードの準備として、複数の方法でセマンティク・データをステージング表にロードできます。一般的な方法は次のとおりです。
Oracle SQL*Loaderを使用したステージング表のロード(1.7.1.1.1項を参照)
外部表を使用したステージング表のロード(1.7.1.1.2項を参照)
SQL*Loaderユーティリティを使用して、セマンティク・データを解析し、ステージング表にロードします。Oracle Database Examplesメディアからデモ・ファイルをインストールしている場合(『Oracle Database Examplesインストレーション・ガイド』を参照)、サンプルの制御ファイル$ORACLE_HOME/md/demo/network/rdf_demos/bulkload.ctlを使用できます。入力データがN-Triple形式の場合、このファイルを変更して使用できます。
4000バイトを超える目的語はロードできません。サンプルのSQL*Loader制御ファイルを使用する場合、このような長い値を含むトリプル(行)は、自動的に拒否され、SQL*Loaderの不良ファイルに格納されます。ただし、これらの拒否された行は、SQL INSERT文を使用してアプリケーション表に挿入することでロードできます(1.7.3項を参照)。
次の方法によって、Oracle外部表を使用してステージング表にN-Quad形式のデータ(4つの構成要素を持つ拡張トリプル)をロードできます。
SEM_APIS.CREATE_SOURCE_EXTERNAL_TABLEプロシージャをコールして外部表を作成し、SQL STATEMENT ALTER TABLEを使用して、関連する1つ以上の入力ファイル名を含めるように外部表を変更します。1つ以上の入力ファイルを含むフォルダに関連付けられたディレクトリ・オブジェクトに対するREAD権限とWRITE権限を持っている必要があります。
外部表を作成したら、MDSYSユーザーに、表に対するSELECT権限とINSERT権限を付与します。
SEM_APIS.LOAD_INTO_STAGING_TABLEプロシージャをコールしてステージング表に移入します。
ロードが終了したら、COMMIT文を発行してトランザクションを完了します。
オブジェクトとグラフURI (結合)の長さが4000バイトを超える行は、拒否されて不良ファイルに格納されます。ただし、これらの拒否された行は、SQL INSERT文を使用してアプリケーション表に挿入することでロードできます(1.7.3項を参照)。
例1-36に、外部表を使用したステージング表へのロードを示します。
例1-36 外部表を使用したステージング表へのロード
-- Create a source external table (note: table names are case sensitive)
BEGIN
sem_apis.create_source_external_table(
source_table => 'stage_table_source'
,def_directory => 'DATA_DIR'
,bad_file => 'CLOBrows.bad'
);
END;
/
grant SELECT on "stage_table_source" to MDSYS;
-- Use ALTER TABLE to target the appropriate file(s)
alter table "stage_table_source" location ('demo_datafile.nt');
-- Load the staging table (note: table names are case sensitive)
BEGIN
sem_apis.load_into_staging_table(
staging_table => 'STAGE_TABLE'
,source_table => 'stage_table_source'
,input_format => 'N-QUAD');
END;
/
起動側のスキーマに表RDF$ET_TABが存在し、この表に対するINSERT権限とUPDATE権限がMDSYSユーザーに付与されている場合、SEM_APIS.BULK_LOAD_FROM_STAGING_TABLEプロシージャ実行中に実行されるタスクの一部に対するイベント・トレースが表に追加されます。バルク・ロードの問題を報告する必要がある場合は、この表の内容が役に立ちます。RDF$ET_TAB表は、次のようにして作成してください。
CREATE TABLE RDF$ET_TAB ( proc_sid VARCHAR2(30), proc_sig VARCHAR2(200), event_name varchar2(200), start_time timestamp, end_time timestamp, start_comment varchar2(1000) DEFAULT NULL, end_comment varchar2(1000) DEFAULT NULL ); GRANT INSERT, UPDATE on RDF$ET_TAB to MDSYS;
|
注意: この項で説明されているJavaクラスのoracle.spatial.rdf.client.BatchLoaderは非推奨になったため、N-Quadデータのロードはサポートされません。
かわりに、Jena Adapterのバルク・ロード機能を使用することをお薦めします(7.11項「Jena Adapterを使用したバルク・ロード」を参照)。 |
N-Triple形式のセマンティク・データのバッチ(バルク)・ロード操作を実行するには、<ORACLE_HOME>/md/jlib/sdordf.jarにパッケージされているJavaクラスoracle.spatial.rdf.client.BatchLoaderを使用します。バッチ・ロード操作を実行する前に、次のことを確認してください。
セマンティク・データがN-Triple形式であること。(RDF/XMLからN-Triple形式への変換に使用できるツールがいくつか存在します。Oracle Technology Networkを参照するか、RDF/XMLからN-Tripleへの変換に関する情報をWebで検索してください。)
Oracle Databaseリリース11(Oracle Spatial付き)がインストールされており、パーティショニング機能が有効であること。
セマンティク・テクノロジ・ネットワーク、アプリケーション表、および対応するセマンティク・モデルがデータベースに作成されていること。
CLASSPATH定義にojdbc6.jarが含まれていること。
JDKバージョン1.5以上を使用していること。(<ORACLE_HOME>/jdk/binにパッケージされたJavaバージョンを使用できます。)
oracle.spatial.rdf.client.BatchLoaderクラスを実行するには、単一のコマンドラインで次の一般的な形式のコマンドを使用します(サンプルのデータベース接続情報は、実際の接続情報で置き換えてください)。
Linuxシステム:
java -Ddb.user=scott -Ddb.password=password -Ddb.host=127.0.0.1 -Ddb.port=1522 -Ddb.sid=orcl -classpath ${ORACLE_HOME}/md/jlib/sdordf.jar:${ORACLE_HOME}/jdbc/lib/ojdbc6.jar oracle.spatial.rdf.client.BatchLoader <N-TripleFile> <tablename> <tablespaceName> <modelName>
Windowsシステム:
java -Ddb.user=scott -Ddb.password=password -Ddb.host=127.0.0.1 -Ddb.port=1522 -Ddb.sid=orcl -classpath %ORACLE_HOME%\md\jlib\sdordf.jar;%ORACLE_HOME%\jdbc\lib\ojdbc6.jar oracle.spatial.rdf.client.BatchLoader <N-TripleFile> <tablename> <tablespaceName> <modelName>
-Ddb.userと-Ddb.passwordの値は、モデル<modelName>の所有者またはDBAユーザーに一致している必要があります。
BatchLoaderでは、デフォルトでユーザーのアプリケーション表に少なくとも2つの列(NUMBER型のID列およびSDO_RDF_TRIPLE_S型のTRIPLE列)が存在するとみなされます。ただし、JVMプロパティ-DidColumn=<idColumnName>および-DtripleColumn=<tripleColumnName>を使用することでデフォルト名を上書きできます。ID列は必須ではありません。トリプルが挿入されるたびにBatchLoaderによって連番のような識別子がID列に生成されることを避けるには、JVMプロパティ-DjustTriple=trueを指定します。
アプリケーション表が空でなく、追加モードでバッチ・ロードを実行する場合、追加のJVMプロパティ-Dappend=trueを指定します。また、追加モードでは、ユーザーのアプリケーション表のID列に対して異なる開始値を選択できます。これを行うには、コマンドラインにJVMプロパティ-DstartID=<startingIntegerValue>を追加します。デフォルトでは、ID列は1から始まり、トリプルがアプリケーション表に新しく挿入されるたびに順番に増加します。
<N-TripleFile>の先頭のn個のトリプルをスキップするには、コマンドラインにJVMプロパティ-Dskip=<numberOfTriplesSkipped>を追加します。
デフォルトとは異なるキャラクタ・セットでN-Tripleファイルをロードするには、JVMプロパティ-Dcharset=<charsetName>を指定します。たとえば、-Dcharset="UTF-8"と指定すると、UTF-8エンコーディングとして認識されます。ただし、UTF-8文字をN-Tripleファイルに適切に格納するには、AL32UTF8などの対応する汎用キャラクタ・セットを使用するようOracle Databaseを構成する必要があります。
BatchLoaderクラスでは、圧縮形式のN-Tripleファイルのロードがサポートされます。<N-TripleFile>の拡張子が.zipや.jarである場合、そのファイルの解凍とロードが同時に実行されます。
INSERT文を使用してセマンティク・データをロードする場合、URIは< >(山カッコ)で、空白ノードは_:(アンダースコアとコロン)で、リテラルは" "(引用符)で囲む必要があります。URIまたは空白ノードに空白文字を使用することはできません。データを挿入するには、SDO_RDF_TRIPLE_Sコンストラクタを使用します(1.5.1項を参照)。アプリケーション表に対するINSERT権限を持っている必要があります。
|
注意: URIが< >で、リテラルが" "で囲まれていなくても、文はそのまま処理されます。ただし、VALUE_TYPE値の判定に余分な処理が必要とされるため、文によるロードに時間がかかります。 |
次の例には、URI、空白ノード、リテラル、言語タグ付きのリテラルおよび型付きリテラルを使用した文が含まれます。
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu', '<http://nature.example.com/nsu/rss.rdf>',
'<http://purl.org/rss/1.0/title>', '"Nature''s Science Update"'));
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu', '_:BNSEQN1001A',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq>'));
INSERT INTO nsu_data VALUES (SDO_RDF_TRIPLE_S('nsu',
'<http://nature.example.com/cgi-taf/dynapage.taf?file=/nature/journal/v428/n6978/index.html>',
'<http://purl.org/dc/elements/1.1/language>', '"English"@en-GB'));
INSERT INTO nature VALUES (SDO_RDF_TRIPLE_S('nsu', '<http://dx.doi.org/10.1038/428004b>',
'<http://purl.org/dc/elements/1.1/date>', '"2004-03-04"^^xsd:date'));
セマンティクXMLデータをINSERT文に変換するには、サンプルのrss2insert.xsl XSLTファイルを編集してセマンティク・データXMLファイルのすべての機能を変換します。空白ノード・コンストラクタは、空白ノードを含む文を挿入する場合に使用します。XSLTを編集したら、Xalan XSLTプロセッサ(http://xml.apache.org/xalan-j/index.html)をダウンロードし、そのインストール指示に従います。編集したバージョンのrss2insert.xslファイルを使用してセマンティク・データXMLファイルをINSERT文に変換するには、次の形式のコマンドを使用します。
java org.apache.xalan.xslt.Process –in input.rdf -xsl rss2insert.xsl –out output.nt
INSERT文を使用して、NULL以外のグラフ名を含むRDFトリプルをロードするには、次の例のように、モデル名とコロン(:)区切り文字の後に山カッコ(< >)で囲ったグラフ名を追加する必要があります。
INSERT INTO articles_rdf_data VALUES (99,
SDO_RDF_TRIPLE_S ('articles:<http://examples.com/ns#Graph1>',
'<http://nature.example.com/Article101>',
'<http://purl.org/dc/elements/1.1/creator>',
'"John Smith"'));
この項には、セマンティク・データのエクスポート(Oracle Databaseからのセマンティク・データの取得)に関連する次の内容が含まれます。
アプリケーション表からセマンティク・データを取得するには、例1-37のようにSDO_RDF_TRIPLE_Sのメンバー関数を使用します。
例1-37 アプリケーション表からのセマンティク・データの取得
-- -- Retrieves model-graph, subject, predicate, and object -- SQL> SELECT a.triple.GET_MODEL() AS model_graph, a.triple.GET_SUBJECT() AS sub, a.triple.GET_PROPERTY() pred, a.triple.GET_OBJECT() obj FROM articles_rdf_data a where id in (2,99); MODEL_GRAPH ------------------------------------------------------------ SUB ------------------------------------------------------------ PRED ------------------------------------------------------------ OBJ ------------------------------------------------------------ ARTICLES <http://nature.example.com/Article1> <http://purl.org/dc/elements/1.1/creator> "Jane Smith" ARTICLES:<http://examples.com/ns#Graph1> <http://nature.example.com/Article101> <http://purl.org/dc/elements/1.1/creator> "John Smith" -- -- Retrieves graph, subject, predicate, and object -- SQL> select (case sep_pos when 0 then NULL else substr(model_graph,sep_pos+1) end) graph, sub, pred, obj from (SELECT instr(a.triple.GET_MODEL(),':') AS sep_pos, a.triple.GET_MODEL() AS model_graph, a.triple.GET_SUBJECT() AS sub, a.triple.GET_PROPERTY() pred, a.triple.GET_OBJECT() obj FROM articles_rdf_data a where id in (2,99)); GRAPH -------------------------------------------------------------------------------- SUB ------------------------------------------------------------ PRED ------------------------------------------------------------ OBJ ------------------------------------------------------------ <http://nature.example.com/Article1> <http://purl.org/dc/elements/1.1/creator> "Jane Smith" <http://examples.com/ns#Graph1> <http://nature.example.com/Article101> <http://purl.org/dc/elements/1.1/creator> "John Smith"
RDFモデルからセマンティク・データを取得するには、例1-38のようにSEM_MATCHテーブル・ファンクションを使用します(1.6項を参照)。
例1-38 RDFモデルからのセマンティク・データの取得
--
-- Retrieves graph, subject, predicate, and object
--
SQL> select to_char(g$rdfterm) graph, to_char(x$rdfterm) sub, to_char(p$rdfterm) pred, y$rdfterm obj from table(sem_match('Select ?g ?x ?p ?y FROM NAMED <http://examples.com/ns#Graph1> {GRAPH ?g {?x ?p ?y}}',sem_models('articles'),null,null,null,null,' GRAPH_MATCH_UNNAMED=T PLUS_RDFT=T '));
GRAPH
------------------------------------------------------------
SUB
------------------------------------------------------------
PRED
------------------------------------------------------------
OBJ
---------------------------------------------------------------------------
<http://examples.com/ns#Graph1>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb2
<http://purl.org/dc/elements/1.1/creator>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb1
<http://examples.com/ns#Graph1>
<http://nature.example.com/Article102>
<http://purl.org/dc/elements/1.1/creator>
_:m99g3C687474703A2F2F6578616D706C65732E636F6D2F6E73234772617068313Egmb1
<http://examples.com/ns#Graph1>
<http://nature.example.com/Article101>
<http://purl.org/dc/elements/1.1/creator>
"John Smith"
<http://nature.example.com/Article1>
<http://purl.org/dc/elements/1.1/creator>
"Jane Smith"
セマンティク・データの取得中に取得した空白ノード識別子は、例1-39のコード部分(それぞれ、VARCHAR2(主語の構成要素など)およびCLOB(目的語の構成要素など)に適用可能)に示した変換を使用して、モデルおよびグラフ情報が出現しないように切り捨てることができます。
例1-39 アプリケーション表からのセマンティク・データの取得
--
-- Transformation on column "sub VARCHAR2"
-- holding blank node identifier values
--
Select (case substr(sub,1,2) when '_:' then '_:' || substr(sub,instr(sub,'m',1,2)+1) else sub end) from …
--
-- Transformation on column "obj CLOB"
-- holding blank node identifier values
--
Select (case dbms_lob.substr(obj,2,1) when '_:' then to_clob('_:' || substr(obj,instr(obj,'m',1,2)+1)) else obj end) from …
例1-40に、1.7.4.2項に説明されているセマンティク・データ取得問合せを使用して、それぞれsub列とobj列に対して例1-39の2つの変換を使用した後に取得された結果を示します。
例1-40 例1-39の変換の適用による結果
--
-- Results obtained by applying transformations on the sub and pred cols
--
SQL> select (case substr(sub,1,2) when '_:' then '_:' || substr(sub,instr(sub,'m',1,2)+1) else sub end) sub, pred, (case dbms_lob.substr(obj,2,1) when '_:' then to_clob('_:' || substr(obj,instr(obj,'m',1,2)+1)) else obj end) obj from (select to_char(g$rdfterm) graph, to_char(x$rdfterm) sub, to_char(p$rdfterm) pred, y$rdfterm obj from table(sem_match('Select ?g ?x ?p ?y FROM NAMED <http://examples.com/ns#Graph1> {GRAPH ?g {?x ?p ?y}}',sem_models('articles'),null,null,null,null,' GRAPH_MATCH_UNNAMED=T PLUS_RDFT=T ')));
SUB
------------------------------------------------------------
PRED
------------------------------------------------------------
OBJ
---------------------------------------------------------------------------
_:b2
<http://purl.org/dc/elements/1.1/creator>
_:b1
<http://nature.example.com/Article102>
<http://purl.org/dc/elements/1.1/creator>
_:b1
時間の経過に伴うトリプルの削除によって、RDF_VALUE$表の値のサブセットは、現在セマンティク・ネットワークに含まれるどのRDFトリプルまたはルールでも使用されなくなる可能性があります。このような使用されていない値の数が多くなり、RDF_VALUE$表の大部分を占めるようになった場合、SEM_APIS.PURGE_UNUSED_VALUESサブプログラムを使用して未使用値をパージできます。
パージする前に、MDSYSに、すべてのRDFモデルのアプリケーション表に対するSELECT権限を付与する必要があります。これを行うには、GRANTコマンドを直接使用するか、SEM_APIS.PRIVILEGE_ON_APP_TABLESサブプログラムを使用します。
パージ操作中に実行されたタスクのイベント・トレースは、RDF$ET_TAB表が起動側のスキーマに存在する場合、そこに記録できます(1.7.1.2項「バルク・ロード中のイベント・トレースの記録」を参照)。
例1-41では、RDF_VALUE$表から未使用値をパージしています。この例では、名前付きグラフまたはCLOBは考慮されていません。また、1.11.1項「例: 雑誌記事の情報」の例のデータがロードされていると仮定します。
例1-41 未使用値のパージ
-- Purging unused values
set numwidth 20
-- Create view to show the values actually used in the RDF model
CREATE VIEW values_used_in_model (value_id) as
SELECT a.triple.rdf_s_id FROM articles_rdf_data a UNION
SELECT a.triple.rdf_p_id FROM articles_rdf_data a UNION
SELECT a.triple.rdf_c_id FROM articles_rdf_data a UNION
SELECT a.triple.rdf_o_id FROM articles_rdf_data a;
View created.
-- Create views to show triples in the model
CREATE VIEW triples_in_app_table as
SELECT a.triple.GET_SUBJECT() AS s, a.triple.GET_PROPERTY() AS p, a.triple.GET_OBJ_VALUE() AS o
FROM articles_rdf_data a;
View created.
CREATE VIEW triples_in_rdf_model as
SELECT s, p, o FROM TABLE ( SEM_MATCH('{?s ?p ?o}', SEM_MODELS('articles'), null, null, null ));
View created.
--
-- Content before deletion
--
-- Values in mdsys.RDF_VALUE$
CREATE TABLE values_before_deletion as select value_id from mdsys.rdf_value$;
Table created.
-- Values used in the RDF model
CREATE TABLE used_values_before_deletion as
SELECT * FROM values_used_in_model;
Table created.
-- Content of RDF model
CREATE TABLE atab_triples_before_deletion
as select * from triples_in_app_table;
Table created.
CREATE TABLE model_triples_before_deletion
as select * from triples_in_rdf_model;
Table created.
-- Delete some triples so that some of the values become unused
DELETE FROM articles_rdf_data a
WHERE a.triple.GET_PROPERTY() = '<http://purl.org/dc/elements/1.1/title>'
OR a.triple.GET_SUBJECT() = '<http://nature.example.com/Article1>';
5 rows deleted.
-- Content of RDF model after deletion
CREATE TABLE atab_triples_after_deletion
as select * from triples_in_app_table;
Table created.
CREATE TABLE model_triples_after_deletion
as select * from triples_in_rdf_model;
Table created.
-- Values that became unused in the RDF model
SELECT * from used_values_before_deletion
MINUS
SELECT * FROM values_used_in_model;
VALUE_ID
--------------------
1399113999628774496
4597469165946334122
6345024408674005890
7299961478807817799
7995347759607176041
-- RDF_VALUE$ content, however, is unchanged
SELECT value_id from values_before_deletion
MINUS
select value_id from mdsys.rdf_value$;
no rows selected
-- Now purge the values from RDF_VALUE$ (requires that MDSYS has
-- SELECT privilege on *all* the app tables in the semantic network)
EXECUTE sem_apis.privilege_on_app_tables;
PL/SQL procedure successfully completed.
EXECUTE sem_apis.purge_unused_values;
PL/SQL procedure successfully completed.
-- RDF_VALUE$ content is NOW changed due to the purge of unused values
SELECT value_id from values_before_deletion
MINUS
select value_id from mdsys.rdf_value$;
VALUE_ID
--------------------
1399113999628774496
4597469165946334122
6345024408674005890
7299961478807817799
7995347759607176041
-- Content of RDF model after purge
CREATE TABLE atab_triples_after_purge
as select * from triples_in_app_table;
Table created.
CREATE TABLE model_triples_after_purge
as select * from triples_in_rdf_model;
Table created.
-- Compare triples present before purging of values and after purging
SELECT * from atab_triples_after_deletion
MINUS
SELECT * FROM atab_triples_after_purge;
no rows selected
SELECT * from model_triples_after_deletion
MINUS
SELECT * FROM model_triples_after_purge;
no rows selected
セマンティク・ネットワーク索引は、一意でないBツリー索引です(セマンティク・ネットワーク索引を追加、変更および削除して、セマンティク・ネットワーク内のモデルや伴意とともに使用できます)。このような索引を使用すると、ネットワーク内のモデルや伴意に対するSEM_MATCH問合せのパフォーマンスを調整できます。任意の索引と同様に、セマンティク・ネットワーク索引によって、問合せワークロードに適合する索引ベースのアクセスが可能になります。これによって、次の例のシナリオのようにパフォーマンスが大幅に向上する可能性があります。
グラフ・パターンが'{<John> ?p <Mary>}'の場合、問合せで使用されていれば、1つ以上のターゲット・モデルおよび対応する伴意に対して適切な'CSP'または'SCP'索引を使用できます。
グラフ・パターンが'{?x <talksTo> ?y . ?z ?p ?y}'の場合、先行キーのCを付けて('C'または'CPS'など)、関連する1つ以上のモデルおよび伴意に対して適切なセマンティク・ネットワーク索引を使用できます。
ただし、セマンティク・ネットワーク索引を使用すると、DML、ロードおよび推論操作に必要な時間が増加して、パフォーマンス全体が影響を受ける可能性があります。
セマンティク・ネットワーク索引は、次のサブプログラムを使用して作成および管理できます。
これらのサブプログラムはすべて、index_codeパラメータを持ち、このパラメータには、P、C、S、G、Mを任意の順序(繰返しなし)で含めることができます。index_code内で使用されたこれらの文字は、ビューSEMM_*およびSEMI_*の列P_VALUE_ID、CANON_END_NODE_ID、START_NODE_ID、G_IDおよびMODEL_IDに対応しています。
SEM_APIS.ADD_SEM_INDEXプロシージャは、セマンティク・ネットワーク索引を作成し、それによって既存のモデルおよび伴意それぞれに対して、一意でないBツリー索引がUNUSABLEステータスで作成されます。この索引の名前はRDF_LNK_<index_code>_IDXとなり、索引の所有者はMDSYSとなります。この操作は、起動側にDBAロールがある場合にのみ許可されます。次の例では、キー<P_VALUE_ID, START_NODE_ID, CANON_END_NODE_ID, G_ID, MODEL_ID>を使用してPSCGM索引を作成しています。
EXECUTE SEM_APIS.ADD_SEM_INDEX('PSCGM');
セマンティク・ネットワーク索引を作成した後、対応する一意でないBツリー索引はいずれもUNUSABLEステータスになります。これは、この索引を使用可能にすると、大量の時間とリソースが消費され、後続の索引のメンテナンス操作のパフォーマンスが低下する可能性があるためです。自分が所有する特定のモデルまたは伴意に対してセマンティク・ネットワーク索引を使用可能または使用不能にするには、SEM_APIS.ALTER_SEM_INDEX_ON_MODELおよびSEM_APIS.ALTER_SEM_INDEX_ON_ENTAILMENTプロシージャをコールし、commandパラメータとして'REBUILD'または'UNUSABLE'を指定します。このように、様々なセマンティク・ネットワーク索引を使用可能および使用不能にして実験を重ねることにより、パフォーマンスの違いを確認できます。たとえば、次の文は、FAMILYモデルに対してPSCGM索引を使用可能にします。
EXECUTE SEM_APIS.ALTER_SEM_INDEX_ON_MODEL('FAMILY','PSCGM','REBUILD');
また、次の点にも注意してください。
自分で作成したセマンティク・ネットワーク索引とは無関係に、セマンティク・ネットワークが作成されると自動的に作成される索引の1つに、この項に示したサブプログラムをコールするときにindex_codeを'PSCGM'と指定することで管理できる索引があります。
新規のモデルまたは新規の伴意を作成すると、セマンティク・ネットワーク索引ごとに一意でない新規のBツリー索引が作成されますが、このようなBツリー索引はいずれも、USABLEステータスになります。
(index_code値に'M'を含めることにより)セマンティク・ネットワーク索引キーにMODEL_ID列を含めると、問合せのパフォーマンスが向上することがあります。特に、仮想モデルを使用する場合はこの操作が有効です。
モデルと伴意のすべてのネットワーク索引に関する情報は、MDSYS.SEM_NETWORK_INDEX_INFOビューに保持されます(表1-14に、このビューの列(部分リスト)を示します(1つの行が1つのネットワーク索引に対応します))。
表1-14 MDSYS.SEM_NETWORK_INDEX_INFOビューの列(部分リスト)
| 列名 | データ型 | 説明 |
|---|---|---|
|
NAME |
VARCHAR2(30) |
RDFモデルまたは伴意の名前 |
|
TYPE |
VARCHAR2(10) |
索引が作成されるオブジェクトのタイプ( |
|
ID |
NUMBER |
モデルまたは伴意のID番号、またはネットワークに対する索引の場合は0 (ゼロ) |
|
INDEX_CODE |
VARCHAR2(25) |
索引のコード( |
|
INDEX_NAME |
VARCHAR2(30) |
索引の名前( |
|
LAST_REFRESH |
TIMESTAMP(6) WITH TIME ZONE |
このコンテンツがリフレッシュされた最終時刻のタイムスタンプ |
表1-14に示されている列に加え、MDSYS.SEM_NETWORK_INDEX_INFOビューには、ALL_INDEXESビューとALL_IND_PARTITIONSビュー(両方とも『Oracle Databaseリファレンス』を参照)の次のような列も含まれます。
ALL_INDEXESビュー: UNIQUENESS、COMPRESSION、PREFIX_LENGTH
ALL_IND_PARTITIONSビュー: STATUS、TABLESPACE_NAME、BLEVEL、LEAF_BLOCKS、NUM_ROWS、DISTINCT_KEYS、AVG_LEAF_BLOCKS_PER_KEY、AVG_DATA_BLOCKS_PER_KEY、CLUSTERING_FACTOR、SAMPLE_SIZE、LAST_ANALYZED
MDSYS.SEM_NETWORK_INDEX_INFOビューの情報は失効している場合があることに注意してください。この情報をリフレッシュするには、SEM_APIS.REFRESH_SEM_NETWORK_INDEX_INFOプロシージャを使用します。
データ型索引は、セマンティク・ネットワークに格納された型付きリテラルの値に対する索引です。これらの索引によって、特定のタイプのFILTER式を含むSEM_MATCH問合せのパフォーマンスが大幅に向上する可能性があります。たとえば、xsd:dateTimeリテラルに対するデータ型索引によって、フィルタ(?x < "1929-11-16T13:45:00Z"^^xsd:dateTime)の評価が高速化する可能性があります。表1-15に示されている複数のデータ型に対して索引を作成できます。
表1-15 データ型索引のデータ型
| データ型URI | Oracle型 | 索引タイプ |
|---|---|---|
|
http://www.w3.org/2001/XMLSchema#decimal |
NUMBER |
一意でないBツリー( |
|
http://www.w3.org/2001/XMLSchema#string |
VARCHAR2 |
一意でないBツリー( |
|
http://www.w3.org/2001/XMLSchema#time |
TIMESTAMP WITH TIMEZONE |
一意でないBツリー |
|
http://www.w3.org/2001/XMLSchema#date |
TIMESTAMP WITH TIMEZONE |
一意でないBツリー |
|
http://www.w3.org/2001/XMLSchema#dateTime |
TIMESTAMP WITH TIMEZONE |
一意でないBツリー |
|
http://xmlns.oracle.com/rdf/text |
(該当なし) |
CTXSYS.CONTEXT |
|
http://xmlns.oracle.com/rdf/geo/WKTLiteral |
SDO_GEOMETRY |
MDSYS.SPATIAL_INDEX |
データ型索引の適合性は、問合せワークロードに応じて変化します。xsdデータ型に対するデータ型索引は、変数と定数値を比較するフィルタに使用でき、非常に選択的なフィルタ条件を持つ非選択的グラフ・パターンが問合せに含まれる場合に特に便利です。空間フィルタまたはテキスト・フィルタを持つ問合せには、適切なデータ型索引が必要です。
データ型索引によって問合せパフォーマンスは向上しますが、徐々に増加する索引のメンテナンスによって、セマンティク・ネットワークに対するDMLおよびバルク・ロード操作のパフォーマンスが低下する可能性があります。バルク・ロード操作では、通常、データ型索引を削除し、バルク・ロードを実行してからデータ型索引を再作成する方が高速です。
次のプロシージャを使用してデータ型索引を追加、変更および削除できます(第9章を参照)。
既存のデータ型索引に関する情報は、MDSYS.SEM_DTYPE_INDEX_INFOビューに保持されます(表1-16に、このビューの列を示します(1つの行が1つのデータ型索引に対応します))。
表1-16 MDSYS.SEM_DTYPE_INDEX_INFOビューの列
| 列名 | データ型 | 説明 |
|---|---|---|
|
DATATYPE |
VARCHAR2(51) |
データ型URI |
|
INDEX_NAME |
VARCHAR2(30) |
索引の名前 |
|
STATUS |
VARCHAR2(8) |
索引のステータス: |
|
TABLESPACE_NAME |
VARCHAR2(30) |
索引の表領域 |
例1-42に示すとおり、誕生日が1929年11月16日より前のすべての祖父を見つける問合せの評価中にデータ型索引を使用するように、HINT0ヒントを使用できます。
例1-42 データ型索引を使用するためのHINT0の使用
SELECT x, y
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male . ?x :birthDate ?bd
FILTER (?bd <= "1929-11-15T23:59:59Z"^^xsd:dateTime) }',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null, null,
'HINT0={ LEADING(?bd) INDEX(?bd rdf_v$dateTime_idx) }
FAST_DATE_FILTER=T' ));
Oracle Databaseのセマンティク・データを操作するには、次の一般的な手順に従います。
システム表の表領域を作成します。表領域を作成する適切な権限を持つユーザーとして接続している必要があります。次の例では、RDF_TBLSPACEという表領域を作成します。
CREATE TABLESPACE rdf_tblspace DATAFILE '/oradata/orcl/rdf_tblspace.dat' SIZE 1024M REUSE AUTOEXTEND ON NEXT 256M MAXSIZE UNLIMITED SEGMENT SPACE MANAGEMENT AUTO;
セマンティク・データ・ネットワークを作成します。
セマンティク・データ・ネットワークを作成すると、Oracle Databaseにセマンティク・データ・サポートが追加されます。十分な領域を備えた有効な表領域を指定することで、DBA権限を持つユーザーとしてセマンティク・データ・ネットワークを作成する必要があります。このネットワークは、1つのOracle Databaseに対して1回のみ作成します。
次の例では、RDF_TBLSPACEという表領域を使用してセマンティク・データ・ネットワークを作成します(RDF_TBLSPACEはすでに存在している必要があります)。
EXECUTE SEM_APIS.CREATE_SEM_NETWORK('rdf_tblspace');
セマンティク・データの格納先となるスキーマを保有するデータベース・ユーザーとして接続します(SYS、SYSTEMまたはMDSYSとして接続している場合は、次の手順を実行しないでください)。
セマンティク・データへの参照を格納する表を作成します。(この手順と残りの手順では、DBA権限を持つユーザーとして接続している必要はありません。)
この表には、単一のモデルに関連付けられたすべてのデータへの参照を保持するSDO_RDF_TRIPLE_S型の列が含まれる必要があります。
次の例では、ARTICLES_RDF_DATAという表を作成します。
CREATE TABLE articles_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
モデルを作成します。
モデルを作成する場合、モデル名、モデルのセマンティク・データへの参照を保持する表、およびその表内のSDO_RDF_TRIPLE_S型の列を指定します。
次のコマンドでは、前の手順で作成した表を使用するARTICLESというモデルを作成します。
EXECUTE SEM_APIS.CREATE_SEM_MODEL('articles', 'articles_rdf_data', 'triple');
可能であれば、アプリケーション表のSDO_RDF_TRIPLE_S列に対する直接問合せのパフォーマンスを向上するため、SELECT文のWHERE句で指定される条件にOracle Databaseの索引を作成します。(これらの索引は、SEM_MATCHテーブル・ファンクションが使用される場合には無視されます。)次の例では、このような索引を作成します。
-- Create indexes on the subjects, properties, and objects -- in the ARTICLES_RDF_DATA table. CREATE INDEX articles_sub_idx ON articles_rdf_data (triple.GET_SUBJECT()); CREATE INDEX articles_prop_idx ON articles_rdf_data (triple.GET_PROPERTY()); CREATE INDEX articles_obj_idx ON articles_rdf_data (TO_CHAR(triple.GET_OBJECT()));
モデルを作成した後は、表にトリプルを挿入できます(1.11項の例を参照)。
この項には、次のPL/SQLの例が含まれます。
このガイドの例に加え、http://www.oracle.com/technetwork/indexes/samplecode/semantic-sample-522114.htmlにあるサンプル・コードを参照してください。
この項では、雑誌記事に関する文のモデルに対応する簡単なPL/SQLの例を示します。例1-43には、説明的なコメント(この章で説明されている各概念を参照)と、複数のファンクションおよびプロシージャ(第9章を参照)が含まれます。
例1-43 雑誌記事の情報に関するモデルの使用
-- Basic steps:
-- After you have connected as a privileged user and called
-- SEM_APIS.CREATE_SEM_NETWORK to add RDF support,
-- connect as a regular database user and do the following.
-- 1. For each desired model, create a table to hold its data.
-- 2. For each model, create a model (SEM_APIS.CREATE_RDF_MODEL).
-- 3. For each table to hold semantic data, insert data into the table.
-- 4. Use various subprograms and constructors.
-- Create the table to hold data for the model.
CREATE TABLE articles_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
-- Create the model.
EXECUTE SEM_APIS.CREATE_SEM_MODEL('articles', 'articles_rdf_data', 'triple');
-- Information to be stored about some fictitious articles:
-- Article1, titled "All about XYZ" and written by Jane Smith, refers
-- to Article2 and Article3.
-- Article2, titled "A review of ABC" and written by Joe Bloggs,
-- refers to Article3.
-- Seven SQL statements to store the information. In each statement:
-- Each article is referred to by its complete URI The URIs in
-- this example are fictitious.
-- Each property is referred to by the URL for its definition, as
-- created by the Dublin Core Metadata Initiative.
-- Insert rows into the table.
-- Article1 has the title "All about XYZ".
INSERT INTO articles_rdf_data VALUES (1,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/title>','"All about XYZ"'));
-- Article1 was created (written) by Jane Smith.
INSERT INTO articles_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S ('articles','<http://nature.example.com/Article1>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Jane Smith"'));
-- Article1 references (refers to) Article2.
INSERT INTO articles_rdf_data VALUES (3,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article1>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article2>'));
-- Article1 references (refers to) Article3.
INSERT INTO articles_rdf_data VALUES (4,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article1>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>'));
-- Article2 has the title "A review of ABC".
INSERT INTO articles_rdf_data VALUES (5,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/elements/1.1/title>',
'"A review of ABC"'));
-- Article2 was created (written) by Joe Bloggs.
INSERT INTO articles_rdf_data VALUES (6,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/elements/1.1/creator>',
'"Joe Bloggs"'));
-- Article2 references (refers to) Article3.
INSERT INTO articles_rdf_data VALUES (7,
SDO_RDF_TRIPLE_S ('articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>'));
COMMIT;
-- Query semantic data.
SELECT SEM_APIS.GET_MODEL_ID('articles') AS model_id FROM DUAL;
SELECT SEM_APIS.GET_TRIPLE_ID(
'articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>') AS RDF_triple_id FROM DUAL;
SELECT SEM_APIS.IS_TRIPLE(
'articles',
'<http://nature.example.com/Article2>',
'<http://purl.org/dc/terms/references>',
'<http://nature.example.com/Article3>') AS is_triple FROM DUAL;
-- Use SDO_RDF_TRIPLE_S member functions in queries.
SELECT a.triple.GET_TRIPLE() AS triple
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_SUBJECT() AS subject
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_PROPERTY() AS property
FROM articles_rdf_data a WHERE a.id = 1;
SELECT a.triple.GET_OBJECT() AS object
FROM articles_rdf_data a WHERE a.id = 1;
この項では、ファミリ・ツリー(家系)情報に関する文のモデルに対応する簡単なPL/SQLの例を示します。例1-43には、説明的なコメント(この章で説明されている各概念を参照)と、複数のファンクションおよびプロシージャ(第9章を参照)が含まれます。
この例の家族関係は、図1-3のファミリ・ツリーを反映しています。また、この図では、例における一部の情報(CathyはJackの姉妹、JackとTomは男性、Cindyは女性)が直接言明されています。
例1-44 家系の情報に関するモデルの使用
-- Basic steps:
-- After you have connected as a privileged user and called
-- SEM_APIS.CREATE_SEM_NETWORK to enable RDF support,
-- connect as a regular database user and do the following.
-- 1. For each desired model, create a table to hold its data.
-- 2. For each model, create a model (SEM_APIS.CREATE_SEM_MODEL).
-- 3. For each table to hold semantic data, insert data into the table.
-- 4. Use various subprograms and constructors.
-- Create the table to hold data for the model.
CREATE TABLE family_rdf_data (id NUMBER, triple SDO_RDF_TRIPLE_S);
-- Create the model.
execute SEM_APIS.create_sem_model('family', 'family_rdf_data', 'triple');
-- Insert rows into the table. These express the following information:
-----------------
-- John and Janice have two children, Suzie and Matt.
-- Matt married Martha, and they have two children:
-- Tom (male, height 5.75) and Cindy (female, height 06.00).
-- Suzie married Sammy, and they have two children:
-- Cathy (height 5.8) and Jack (male, height 6).
-- Person is a class that has two subslasses: Male and Female.
-- parentOf is a property that has two subproperties: fatherOf and motherOf.
-- siblingOf is a property that has two subproperties: brotherOf and sisterOf.
-- The domain of the fatherOf and brotherOf properties is Male.
-- The domain of the motherOf and sisterOf properties is Female.
------------------------
-- John is the father of Suzie.
INSERT INTO family_rdf_data VALUES (1,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/John>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Suzie>'));
-- John is the father of Matt.
INSERT INTO family_rdf_data VALUES (2,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/John>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Matt>'));
-- Janice is the mother of Suzie.
INSERT INTO family_rdf_data VALUES (3,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Janice>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Suzie>'));
-- Janice is the mother of Matt.
INSERT INTO family_rdf_data VALUES (4,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Janice>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Matt>'));
-- Sammy is the father of Cathy.
INSERT INTO family_rdf_data VALUES (5,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Sammy>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Cathy>'));
-- Sammy is the father of Jack.
INSERT INTO family_rdf_data VALUES (6,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Sammy>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Jack>'));
-- Suzie is the mother of Cathy.
INSERT INTO family_rdf_data VALUES (7,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Suzie>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Cathy>'));
-- Suzie is the mother of Jack.
INSERT INTO family_rdf_data VALUES (8,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Suzie>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Jack>'));
-- Matt is the father of Tom.
INSERT INTO family_rdf_data VALUES (9,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Matt>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Tom>'));
-- Matt is the father of Cindy
INSERT INTO family_rdf_data VALUES (10,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Matt>',
'<http://www.example.org/family/fatherOf>',
'<http://www.example.org/family/Cindy>'));
-- Martha is the mother of Tom.
INSERT INTO family_rdf_data VALUES (11,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Martha>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Tom>'));
-- Martha is the mother of Cindy.
INSERT INTO family_rdf_data VALUES (12,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Martha>',
'<http://www.example.org/family/motherOf>',
'<http://www.example.org/family/Cindy>'));
-- Cathy is the sister of Jack.
INSERT INTO family_rdf_data VALUES (13,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cathy>',
'<http://www.example.org/family/sisterOf>',
'<http://www.example.org/family/Jack>'));
-- Jack is male.
INSERT INTO family_rdf_data VALUES (14,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Jack>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Male>'));
-- Tom is male.
INSERT INTO family_rdf_data VALUES (15,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Tom>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Male>'));
-- Cindy is female.
INSERT INTO family_rdf_data VALUES (16,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cindy>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.example.org/family/Female>'));
-- Person is a class.
INSERT INTO family_rdf_data VALUES (17,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Person>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/2000/01/rdf-schema#Class>'));
-- Male is a subclass of Person.
INSERT INTO family_rdf_data VALUES (18,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Male>',
'<http://www.w3.org/2000/01/rdf-schema#subClassOf>',
'<http://www.example.org/family/Person>'));
-- Female is a subclass of Person.
INSERT INTO family_rdf_data VALUES (19,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Female>',
'<http://www.w3.org/2000/01/rdf-schema#subClassOf>',
'<http://www.example.org/family/Person>'));
-- siblingOf is a property.
INSERT INTO family_rdf_data VALUES (20,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/siblingOf>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Property>'));
-- parentOf is a property.
INSERT INTO family_rdf_data VALUES (21,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/parentOf>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#type>',
'<http://www.w3.org/1999/02/22-rdf-syntax-ns#Property>'));
-- brotherOf is a subproperty of siblingOf.
INSERT INTO family_rdf_data VALUES (22,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/brotherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/siblingOf>'));
-- sisterOf is a subproperty of siblingOf.
INSERT INTO family_rdf_data VALUES (23,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/sisterOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/siblingOf>'));
-- A brother is male.
INSERT INTO family_rdf_data VALUES (24,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/brotherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Male>'));
-- A sister is female.
INSERT INTO family_rdf_data VALUES (25,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/sisterOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Female>'));
-- fatherOf is a subproperty of parentOf.
INSERT INTO family_rdf_data VALUES (26,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/fatherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/parentOf>'));
-- motherOf is a subproperty of parentOf.
INSERT INTO family_rdf_data VALUES (27,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/motherOf>',
'<http://www.w3.org/2000/01/rdf-schema#subPropertyOf>',
'<http://www.example.org/family/parentOf>'));
-- A father is male.
INSERT INTO family_rdf_data VALUES (28,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/fatherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Male>'));
-- A mother is female.
INSERT INTO family_rdf_data VALUES (29,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/motherOf>',
'<http://www.w3.org/2000/01/rdf-schema#domain>',
'<http://www.example.org/family/Female>'));
-- Use SET ESCAPE OFF to prevent the caret (^) from being
-- interpreted as an escape character. Two carets (^^) are
-- used to represent typed literals.
SET ESCAPE OFF;
-- Cathy's height is 5.8 (decimal).
INSERT INTO family_rdf_data VALUES (30,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cathy>',
'<http://www.example.org/family/height>',
'"5.8"^^xsd:decimal'));
-- Jack's height is 6 (integer).
INSERT INTO family_rdf_data VALUES (31,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Jack>',
'<http://www.example.org/family/height>',
'"6"^^xsd:integer'));
-- Tom's height is 05.75 (decimal).
INSERT INTO family_rdf_data VALUES (32,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Tom>',
'<http://www.example.org/family/height>',
'"05.75"^^xsd:decimal'));
-- Cindy's height is 06.00 (decimal).
INSERT INTO family_rdf_data VALUES (33,
SDO_RDF_TRIPLE_S('family',
'<http://www.example.org/family/Cindy>',
'<http://www.example.org/family/height>',
'"06.00"^^xsd:decimal'));
COMMIT;
-- RDFS inferencing in the family model
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS'));
END;
/
-- Select all males from the family model, without inferencing.
SELECT m
FROM TABLE(SEM_MATCH(
'{?m rdf:type :Male}',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Select all males from the family model, with RDFS inferencing.
SELECT m
FROM TABLE(SEM_MATCH(
'{?m rdf:type :Male}',
SEM_Models('family'),
SDO_RDF_Rulebases('RDFS'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- General inferencing in the family model
EXECUTE SEM_APIS.CREATE_RULEBASE('family_rb');
INSERT INTO mdsys.semr_family_rb VALUES(
'grandparent_rule',
'(?x :parentOf ?y) (?y :parentOf ?z)',
NULL,
'(?x :grandParentOf ?z)',
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')));
COMMIT;
-- Because a new rulebase has been created, and it will be used in the
-- entailment, drop the preceding entailment and then re-create it.
EXECUTE SEM_APIS.DROP_ENTAILMENT ('rdfs_rix_family');
-- Re-create the entailment.
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'));
END;
/
-- Select all grandfathers and their grandchildren from the family model,
-- without inferencing. (With no inferencing, no results are returned.)
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
null,
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Select all grandfathers and their grandchildren from the family model.
-- Use inferencing from both the RDFS and family_rb rulebases.
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
-- Set up to find grandfathers of tall (>= 6) grandchildren
-- from the family model, with RDFS inferencing and
-- inferencing using the "family_rb" rulebase.
UPDATE mdsys.semr_family_rb SET
antecedents = '(?x :parentOf ?y) (?y :parentOf ?z) (?z :height ?h)',
filter = '(h >= ''6'')',
aliases = SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/'))
WHERE rule_name = 'GRANDPARENT_RULE';
-- Because the rulebase has been updated, drop the preceding entailment,
-- and then re-create it.
EXECUTE SEM_APIS.DROP_ENTAILMENT ('rdfs_rix_family');
-- Re-create the entailment.
BEGIN
SEM_APIS.CREATE_ENTAILMENT(
'rdfs_rix_family',
SEM_Models('family'),
SEM_Rulebases('RDFS','family_rb'));
END;
/
-- Find the entailment that was just created (that is, the
-- one based on the specified model and rulebases).
SELECT SEM_APIS.LOOKUP_ENTAILMENT(SEM_MODELS('family'),
SEM_RULEBASES('RDFS','family_rb')) AS lookup_entailment FROM DUAL;
-- Select grandfathers of tall (>= 6) grandchildren, and their
-- tall grandchildren.
SELECT x grandfather, y grandchild
FROM TABLE(SEM_MATCH(
'{?x :grandParentOf ?y . ?x rdf:type :Male}',
SEM_Models('family'),
SEM_RuleBases('RDFS','family_rb'),
SEM_ALIASES(SEM_ALIAS('','http://www.example.org/family/')),
null));
Oracle Databaseリリース11.1では、セマンティク・データのサポートが元のRDFの対象範囲を超えて拡張されているため、多くのソフトウェア・オブジェクト(PL/SQLパッケージ、ファンクションおよびプロシージャ、システム表およびビューなど)の名前が変更されています。ほとんどの場合、この変更で文字列RDFがSEMに置換されていますが、SDO_RDFがSEMに置換されている場合もあります。
リリース11.1より前の名前を使用しているすべての有効なコードは、引き続き動作します。既存のアプリケーションに障害は発生しません。ただし、古いアプリケーションは変更して新しいオブジェクト名を使用することをお薦めします。新規アプリケーションでは新しい名前を使用してください。このマニュアルでは、新しい名前のみを記載しています。
表1-17に、セマンティク・テクノロジのサポートに関連する一部のオブジェクトの旧名と新規名を、旧名のアルファベット順に示します。
表1-17 セマンティク・テクノロジのソフトウェア・オブジェクト: 旧名と新規名
| 旧名 | 新規名 |
|---|---|
|
RDF_ALIASデータ型 |
SEM_ALIAS |
|
RDF_MODEL$ビュー |
SEM_MODEL$ |
|
RDF_RULEBASE_INFOビュー |
SEM_RULEBASE_INFO |
|
RDF_RULES_INDEX_DATASETSビュー |
SEM_RULES_INDEX_DATASETS |
|
RDF_RULES_INDEX_INFOビュー |
SEM_RULES_INDEX_INFO |
|
RDFI_rules-index-nameビュー |
SEMI_rules-index-name |
|
RDFM_model-nameビュー |
SEMM_model-name |
|
RDFR_rulebase-nameビュー |
SEMR_rulebase-name |
|
SDO_RDFパッケージ |
SEM_APIS |
|
SDO_RDF_INFERENCEパッケージ |
SEM_APIS |
|
SDO_RDF_MATCHテーブル・ファンクション |
SEM_MATCH |
|
SDO_RDF_MODELSデータ型 |
SEM_MODELS |
|
SDO_RDF_RULEBASESデータ型 |
SEM_RULEBASES |
Oracle Databaseセマンティク・テクノロジ・サポートと関連トピックの詳細は、次のリソースを参照してください。
Semantic Technologies Center (OTN): ダウンロード用リンク、技術およびビジネス・ホワイト・ペーパー、ディスカッション・フォーラムおよび他の情報ソースが含まれます(http://www.oracle.com/technetwork/database/options/semantic-tech/)。
World Wide Web Consortium (W3C)の「RDF Primer」: http://www.w3.org/TR/rdf-primer/
World Wide Web Consortium (W3C)の「OWL Web Ontology Language Reference」: http://www.w3.org/TR/owl-ref/