| Oracle Data Mining管理者ガイド 11g リリース2(11.2) E57718-01 |
|


 前 |
 次 |
Data Miningのサンプル・プログラムから、Oracle Data Mining APIについて多くを学ぶことができます。これらのプログラムは、データの準備、アルゴリズムの選択、アルゴリズムのチューニング、テストおよびスコアリングを行うための一般的な方法を示しています。各プログラムで、データベースにマイニング・モデルが作成されます。すべてのプログラムには、コードの理解に役立つインライン・コメントが多数含まれています。
|
関連項目: Data Mining APIの詳細は、Oracle Data Miningユーザーズ・ガイドを参照してください。 |
この章には、次の項が含まれます。
Data Miningのサンプル・プログラムは、Oracle Database Examplesとともにインストールされます。Oracle Technology Networkからもダウンロードできます。
プログラムでは、サンプル・スキーマを含んでいるデータベースへのアクセスが必要です。プログラムを実行する前に、2つの構成スクリプトを実行してデータを構成し、必要な権限をユーザーIDに割り当てる必要があります。
次の手順に従って、サンプル・プログラムをインストールします。
サンプル・スキーマを含めてOracle Databaseをインストールするか、サンプル・スキーマを含むデータベースへのアクセス権を取得します。
「Oracle Databaseのインストール」の手順に従った場合、サンプル・スキーマは自動的に初期データベースにインストールされています。必ずSHスキーマのロックを解除してください。
データベースにサンプル・スキーマが含まれていない場合は、Oracle Database Configuration Assistantを使用して、または手動でインストールすることができます。手順は、Oracle Databaseのサンプル・スキーマを参照してください。
Database ExamplesがOracle Databaseにインストールされたかどうかを確認します。Database Examplesには、Oracle Data Miningを含めてOracle Databaseの様々な機能を説明する一連のサンプル・プログラムが収録されています。プログラムは、OracleホームのRDBMS/demoサブディレクトリにロードされます。
Database Examplesがインストールされていない場合は、「Oracle Database Examplesのインストール(オプション)」の手順に従ってインストールを実行できます。あるいは、Oracle Technology NetworkからData Miningのサンプル・プログラムをダウンロードすることもできます。
http://www.oracle.com/technetwork/database/options/odm/index.html
次の手順を実行してサンプル・データを構成し、必要な権限をデータ・マイニング・ユーザーのIDに付与します。
システム権限を使用してSQL*Plusにログインします。
Enter user-name: sys / as sysdba
Enter password: password
データ・マイニング操作に必要なユーザーIDがない場合は、「例: SQL*Plusでのデータベース・ユーザーの作成」の手順に従ってユーザーIDを作成できます。
dmshgrants.sqlを実行して、データ・マイニング権限とSHアクセス権をユーザーIDに付与します。SHにあるいくつかの表を、データ・マイニングのサンプル・プログラムで使用します。 データ・マイニングのユーザー名をパラメータとして指定します。Oracleホーム・ディレクトリのフルパスを指定します。
@ ORACLE_HOME\RDBMS\demo\dmshgrants dmuser
データ・マイニング・ユーザーとしてデータベースにアクセスします。
CONNECT dmuser Enter password: password
dmsh.sqlを実行して、サンプル・プログラムに必要な表やビューなどのオブジェクトをデータ・マイニング・ユーザーのスキーマに移入します。Oracleホーム・ディレクトリのフルパスを指定します。
@ ORACLE_HOME\RDBMS\demo\dmsh
COMMIT;
この項では、Database Examplesとともにインストールされている場合にサンプル・プログラムを参照する方法について説明します。
PL/SQLプログラムを参照するには、親ディレクトリに移動し、dmで始まり.sqlで終わるファイルを検索します。
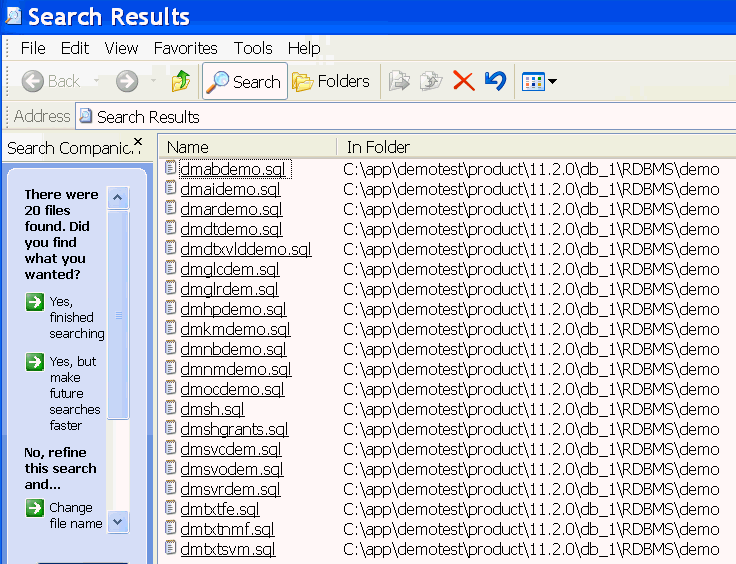
たとえば、Database ExamplesがC:\app\demotest\product\11.2.0\db_1\というOracleホームにインストールされている場合は、C:\app\demotest\product\11.2.0\db_1\RDBMS\demo\に移動し、Windowsの検索機能を使用してdm*.sqlという名前のファイルを検索します。図7-1に示すように、Windowsの検索でData MiningのPL/SQLプログラムのリストが返されます。
|
注意: 図7-1にリストされているファイルには、Data MiningのすべてのPL/SQLプログラムが含まれています。ただし、ファイルのうちdmhpdemo.sqlは、Data Miningプログラムではありません。 |
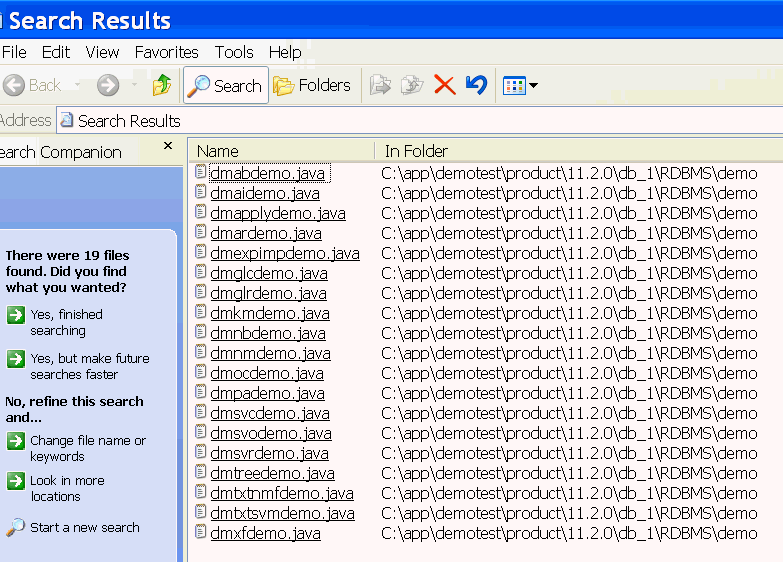
Windowsの検索機能を使用して、同じディレクトリでdm*.javaという名前のファイルを検索します。図7-2に示すように、Windowsの検索でData MiningのJavaプログラムが返されます。
サンプル・プログラムは、必要に応じて何回でも実行できます。前回の実行結果の削除後に、新規に実行されます。
プログラムを実行すると、プログラム・コードとプログラム出力が表示されます。
Javaプログラムを実行する際は、事前にJava環境を設定してプログラムをコンパイルしておく必要があります。
使用しているJavaのバージョンが1.5以上であることを確認します。コマンド・ウィンドウに次のように入力すると、Javaのバージョンを確認できます。
>java -version
PATH変数に、ORACLE_HOME\jdk\bin\を他のどのJavaバージョンのパスよりも前に追加します。ORACLE_HOMEは、Oracleホーム・ディレクトリのフルパスです。
WindowsのCLASSPATHに次のデータ・マイニングJARファイルを追加します。
ORACLE_HOME\RDBMS\jlib\jdm.jar
ORACLE_HOME\RDBMS\jlib\ojdm_api.jar
ORACLE_HOME\RDBMS\jlib\xdb.jar
ORACLE_HOME\jdbc\lib\ojdbc5.jar
ORACLE_HOME\oc4j\j2ee\home\lib\connector.jar
ORACLE_HOME\jlib\orai18n.jar
ORACLE_HOME\jlib\orai18n-mapping.jar
ORACLE_HOME\lib\xmlparserv2.jar
図7-2のプログラムをコンパイルします。JAVAC実行可能ファイルを使用するには、コマンド・ウィンドウを開いてOracleホームの\RDBMS\demoに移動します。
>javac program_name.java
次に例を示します。
>javac dmnbdemo.java
JAVACが見つからない場合は、PATH変数の値を確認します。
サンプル・プログラムによって作成されたマイニング・モデルは、例7-1に示すような問合せで表示できます。
例7-1 サンプルのデータ・マイニング・モデル
SQL> SELECT model_name, mining_function, algorithm FROM user_mining_models
ORDER BY model_name;
MODEL_NAME MINING_FUNCTION ALGORITHM
------------------------------ ------------------------------ ------------------------------
ABNMODEL_JDM CLASSIFICATION ADAPTIVE_BAYES_NETWORK
ABN_SH_CLAS_SAMPLE CLASSIFICATION ADAPTIVE_BAYES_NETWORK
AIMODEL_JDM ATTRIBUTE_IMPORTANCE MINIMUM_DESCRIPTION_LENGTH
AI_SH_SAMPLE ATTRIBUTE_IMPORTANCE MINIMUM_DESCRIPTION_LENGTH
APMODEL_JDM CLASSIFICATION NAIVE_BAYES
ARMODEL_JDM ASSOCIATION_RULES APRIORI_ASSOCIATION_RULES
AR_SH_SAMPLE ASSOCIATION_RULES APRIORI_ASSOCIATION_RULES
AR_SH_SAMPLE_STR_XNAL ASSOCIATION_RULES APRIORI_ASSOCIATION_RULES
AR_SH_SAMPLE_XNAL_SVAL ASSOCIATION_RULES APRIORI_ASSOCIATION_RULES
DT_SH_CLAS_SAMPLE CLASSIFICATION DECISION_TREE
GLMCMODEL_JDM CLASSIFICATION GENERALIZED_LINEAR_MODEL
GLMC_SH_CLAS_SAMPLE CLASSIFICATION GENERALIZED_LINEAR_MODEL
GLMRMODEL_JDM REGRESSION GENERALIZED_LINEAR_MODEL
GLMR_SH_REGR_SAMPLE REGRESSION GENERALIZED_LINEAR_MODEL
KMMODEL_JDM CLUSTERING KMEANS
KM_SH_CLUS_SAMPLE CLUSTERING KMEANS
NBEXPIMPMODEL_JDM CLASSIFICATION NAIVE_BAYES
NBMODEL_JDM CLASSIFICATION NAIVE_BAYES
NB_SH_CLAS_SAMPLE CLASSIFICATION NAIVE_BAYES
NMFMODEL_JDM FEATURE_EXTRACTION NONNEGATIVE_MATRIX_FACTOR
NMF_SH_SAMPLE FEATURE_EXTRACTION NONNEGATIVE_MATRIX_FACTOR
OCMODEL_JDM CLUSTERING O_CLUSTER
OC_SH_CLUS_SAMPLE CLUSTERING O_CLUSTER
SVMCMODEL_JDM CLASSIFICATION SUPPORT_VECTOR_MACHINES
SVMC_SH_CLAS_SAMPLE CLASSIFICATION SUPPORT_VECTOR_MACHINES
SVMOMODEL_JDM CLASSIFICATION SUPPORT_VECTOR_MACHINES
SVMO_SH_CLAS_SAMPLE CLASSIFICATION SUPPORT_VECTOR_MACHINES
SVMRMODEL_JDM REGRESSION SUPPORT_VECTOR_MACHINES
SVMR_SH_REGR_SAMPLE REGRESSION SUPPORT_VECTOR_MACHINES
TREEMODEL_JDM CLASSIFICATION DECISION_TREE
TXTNMFMODEL_JDM FEATURE_EXTRACTION NONNEGATIVE_MATRIX_FACTOR
TXTSVMMODEL_JDM CLASSIFICATION SUPPORT_VECTOR_MACHINES
T_NMF_SAMPLE FEATURE_EXTRACTION NONNEGATIVE_MATRIX_FACTOR
T_SVM_CLAS_SAMPLE CLASSIFICATION SUPPORT_VECTOR_MACHINES
Javaプログラムによって作成されたモデルと、PL/SQLプログラムによって作成されたモデルは、モデル名で区別できます。Javaプログラムによって作成されたモデルは、名前に「_JDM」が付いています。
PL/SQLサンプル・プログラムでは、モデル作成用のDBMS_DATA_MININGパッケージおよびマイニング・データ変換用のDBMS_DATA_MINING_TRANSFORMパッケージの使用例を示します。
|
関連項目:
|
表7-1では、PL/SQLプログラムをアルゴリズム別に示しています。
表7-1 PL/SQLサンプル・プログラムのアルゴリズム
| プログラム・ファイル | アルゴリズム | マイニング機能またはタスク |
|---|---|---|
|
|
||
|
|
相関 |
|
|
|
||
|
|
ディシジョン・ツリー(クロス・バリデーション) |
分類 |
|
|
分類 |
|
|
|
||
|
|
クラスタリング |
|
|
|
分類 |
|
|
|
||
|
|
||
|
|
||
|
|
サポート・ベクター・マシン |
|
|
|
サポート・ベクター・マシン |
|
|
|
||
|
|
||
|
|
サポート・ベクター・マシン |
SVMを使用したテキスト・マイニング |
表7-2では、PL/SQLサンプル・プログラムをマイニング機能別に示しています。各サンプル・プログラムの詳細は、ソース・コード中のコメントを参照してください。
表7-2 PL/SQLサンプル・プログラムのマイニング機能
3つのサンプル・プログラムで、PL/SQLを使用するテキスト・マイニングのプロセスを示します。1つのプログラムでは、マイニングするテキストの変換に必要な前処理が行われます。あとの2つでは、変換されたテキストを使用するモデルが作成されます。
|
関連項目:
|
PL/SQLテキスト・マイニングのサンプル・プログラムは、次のとおりです。
Javaのデモでは、Oracle Data Mining Java APIの特徴を説明しています。これは、Java Data Mining (JDM) 1.0.1.1標準に対するオラクル固有の機能拡張が実装されたAPIです。サンプルJavaプログラムでは、Data Miningのすべてのアルゴリズムと、データ変換技術、予測分析、エクスポート/インポートおよびテキスト・マイニングについてデモを示します。
|
関連項目:
|
表7-3では、Javaプログラムをアルゴリズム別に示しています。
表7-3 Javaサンプル・プログラムのアルゴリズム
| プログラム・ファイル | アルゴリズム | マイニング機能またはタスク |
|---|---|---|
|
|
||
|
|
||
|
|
||
|
|
エクスポート/インポート |
|
|
|
||
|
|
||
|
|
||
|
|
分類 |
|
|
|
||
|
|
||
|
|
||
|
|
分類 |
|
|
|
サポート・ベクター・マシン(1クラス) |
分類 |
|
|
サポート・ベクター・マシン |
回帰 |
|
|
分類 |
|
|
|
||
|
|
サポート・ベクター・マシン |
SVM分類によるテキスト・マイニング |
|
|
表7-4では、Javaサンプル・プログラムをマイニング機能別に示しています。各サンプル・プログラムの詳細は、ソース・コード中のコメントを参照してください。
表7-4 Javaサンプル・プログラムのマイニング機能
2つのJavaサンプル・プログラムで、テキスト・マイニングのプロセスを示します。一方は特徴抽出モデルを作成し、もう一方は分類モデルを作成します。
|
関連項目:
|
どちらのJavaテキスト・マイニング・プログラムも、マイニングするテキストを変換するdmtxtnmfdemo.javaインタフェースを使用しています。プログラムは次のとおりです。
dmsh.sqlスクリプトは、ユーザーのスキーマにビュー、表および索引を作成します。ビューにより、SHスキーマにある表の顧客データの列が定義されます。このデータは、データ・マイニングのサンプル・プログラムで使用されます。表もSHの同じ列を参照しますが、この表にはテキスト・マイニング用の特別なCOMMENTS列が含まれます。索引は、COMMENTS列のテキストから用語を抽出し、ネストした表列を作成するために使用されます。
データ・マイニング・ユーザーのスキーマ内のビューにより、SHスキーマ内のCUSTOMERS、SALES、PRODUCTS、COUNTRIESおよびSUPPLEMENTARY_DEMOGRAPHICSの各表のデータの列が定義されます。次のSQL文を使用して、これらのビューをリスト表示できます。
SQL>CONNECT dmuser
Enter password: password
SQL>SELECT view_name FROM user_views;
これらのビューを表7-5に示します。
表7-5 データ・マイニングのサンプル・プログラムで使用されるビュー
| ビュー名 | 説明 |
|---|---|
|
|
O-cluster用スコアリング・データ |
|
|
O-cluster用トレーニング・データ |
|
|
データ・マイニング(テキスト・マイニング以外)用スコアリング・データ |
|
|
データ・マイニング(テキスト・マイニング以外)用トレーニング・データ |
|
|
データ・マイニング(テキスト・マイニング以外)用テスト・データ |
|
|
相関ルール用データ |
|
|
1クラスSVM用データ |
ビューの定義をリスト表示すると、SH内の表への参照がわかります。ビューMINING_DATA_BUILD_Vの定義は次のとおりです。
SQL> set long 1000000
SQL> set longc 100000
SQL> set pagesize 100
SQL> SELECT text FROM all_views WHERE
owner='dmuser3'AND view_name='mining_data_build_v';
SELECT a.CUST_ID, a.CUST_GENDER, 2003-a.CUST_YEAR_OF_BIRTH AGE,
a.CUST_MARITAL_STATUS, c.COUNTRY_NAME, a.CUST_INCOME_LEVEL,
b.EDUCATION, b.OCCUPATION, b.HOUSEHOLD_SIZE, b.YRS_RESIDENCE,
b.AFFINITY_CARD, b.BULK_PACK_DISKETTES, b.FLAT_PANEL_MONITOR,
b.HOME_THEATER_PACKAGE, b.BOOKKEEPING_APPLICATION,
b.PRINTER_SUPPLIES, b.Y_BOX_GAMES, b.OS_DOC_SET_KANJI
FROM sh.customers a,
sh.supplementary_demographics b,
sh.countries c
WHERE a.CUST_ID = b.CUST_ID AND a.country_id = c.country_id
AND a.cust_id between 101501 and 103000
ビューは、サンプル・モデルの作成、テストおよびスコアリングに使用します。それぞれのビューに、CUSTOMER_ID列(ケースID)およびAFFINITY_CARD列(予測モデルで使用されるターゲット)があります。大部分のビューには、1,500人分の顧客データ(1,500の行)があります。1クラスSVMモデルで使用されるビューには、940人分の顧客データが含まれています。
MINING_DATA_BUILD_Vビューのトレーニング・データの列は次のとおりです。
SQL> DESCRIBE mining_data_build_v CUST_ID NOT NULL NUMBER CUST_GENDER NOT NULL CHAR(1) AGE NUMBER CUST_MARITAL_STATUS VARCHAR2(20) COUNTRY_NAME NOT NULL VARCHAR2(40) CUST_INCOME_LEVEL VARCHAR2(30) EDUCATION VARCHAR2(21) OCCUPATION VARCHAR2(21) HOUSEHOLD_SIZE VARCHAR2(21) YRS_RESIDENCE NUMBER AFFINITY_CARD NUMBER(10) BULK_PACK_DISKETTES NUMBER(10) FLAT_PANEL_MONITOR NUMBER(10) HOME_THEATER_PACKAGE NUMBER(10) BOOKKEEPING_APPLICATION NUMBER(10) PRINTER_SUPPLIES NUMBER(10) Y_BOX_GAMES NUMBER(10) OS_DOC_SET_KANJI NUMBER(10)
相関のデモでは、MARKET_BASKET_Vデータ・セットを使用します。このデータ・セットには、SHにおけるPRODUCTS表からの製品の列と、CUSTOMERS表からのCUSTOMER_ID列が含まれています。MARKET_BASKET_Vビューの列は、次のとおりです。
SQL> DESCRIBE market_basket_v CUST_ID NOT NULL NUMBER EXTENSION_CABLE NUMBER FLAT_PANEL_MONITOR NUMBER CD_RW_HIGH_SPEED_5_PACK NUMBER ENVOY_256MB_40GB NUMBER ENVOY_AMBASSADOR NUMBER EXTERNAL_8X_CD_ROM NUMBER KEYBOARD_WRIST_REST NUMBER SM26273_BLACK_INK_CARTRIDGE NUMBER MOUSE_PAD NUMBER MULTIMEDIA_SPEAKERS_3INCH NUMBER OS_DOC_SET_ENGLISH NUMBER SIMM_16MB_PCMCIAII_CARD NUMBER STANDARD_MOUSE NUMBER
テキスト・マイニングのデモでは、SH内の表の同じ顧客データを使用しますが、追加のテキスト列またはコレクション型列のいずれかが含まれます。このコレクション型は、型DM_NESTED_NUMERICALSのネストした表です。
|
ヒント: テキスト列から、ネストした表列に用語を抽出するプロセスは、Oracle Data Miningユーザーズ・ガイドを参照してください。 |
次のSQL文を使用すると、これらの表をリスト表示できます。
SQL>CONNECT dmuser
Enter password: password
SQL>SELECT table_name FROM user_tables WHERE table_name LIKE '%MINING%';
これらのテキスト・マイニングの表を表7-6に示します。
表7-6 テキスト・マイニング・サンプル・プログラムで使用される表
| 表名 | 説明 |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
MINING_BUILD_TEXT、MINING_TEST_TEXTおよびMINING_APPLY_TEXTの各表のCOMMENTS列の型はVARCHAR2(4000)です。
SQL> DESCRIBE mining_build_text Name Null? Type ----------------------------------------- -------- ---------------------------- CUST_ID NOT NULL NUMBER CUST_GENDER NOT NULL CHAR(1) AGE NUMBER CUST_MARITAL_STATUS VARCHAR2(20) COUNTRY_NAME NOT NULL VARCHAR2(40) CUST_INCOME_LEVEL VARCHAR2(30) EDUCATION VARCHAR2(21) OCCUPATION VARCHAR2(21) HOUSEHOLD_SIZE VARCHAR2(21) YRS_RESIDENCE NUMBER AFFINITY_CARD NUMBER(10) BULK_PACK_DISKETTES NUMBER(10) FLAT_PANEL_MONITOR NUMBER(10) HOME_THEATER_PACKAGE NUMBER(10) BOOKKEEPING_APPLICATION NUMBER(10) PRINTER_SUPPLIES NUMBER(10) Y_BOX_GAMES NUMBER(10) OS_DOC_SET_KANJI NUMBER(10) COMMENTS VARCHAR2(4000)
MINING_*_NESTED_TEXT表のCOMMENTS列の型はDM_NESTED_NUMERICALSです。
SQL> DESCRIBE mining_build_nested_text Name Null? Type ----------------------------------------- -------- ---------------------------- CUST_ID NOT NULL NUMBER CUST_GENDER NOT NULL CHAR(1) AGE NUMBER CUST_MARITAL_STATUS VARCHAR2(20) COUNTRY_NAME NOT NULL VARCHAR2(40) CUST_INCOME_LEVEL VARCHAR2(30) EDUCATION VARCHAR2(21) OCCUPATION VARCHAR2(21) HOUSEHOLD_SIZE VARCHAR2(21) YRS_RESIDENCE NUMBER AFFINITY_CARD NUMBER(10) BULK_PACK_DISKETTES NUMBER(10) FLAT_PANEL_MONITOR NUMBER(10) HOME_THEATER_PACKAGE NUMBER(10) BOOKKEEPING_APPLICATION NUMBER(10) PRINTER_SUPPLIES NUMBER(10) Y_BOX_GAMES NUMBER(10) OS_DOC_SET_KANJI NUMBER(10) COMMENTS DM_NESTED_NUMERICALS