| Oracle® Communications Data Model実装およびオペレーション・ガイド リリース11.3.1 B70212-01 |
|


 前 |
 次 |
この章では、Oracle Communications Data Modelウェアハウスを移入するために使用するETL(抽出、変換およびロード)プログラムについて説明します。内容は次のとおりです。
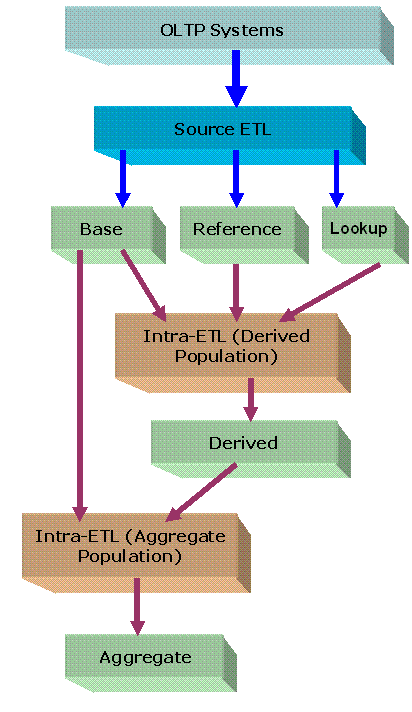
図2-1「Oracle Communications Data Modelウェアハウスのレイヤー」は、Oracle Communications Data Modelウェアハウスの3つのレイヤー、オプションのステージング・レイヤー、基盤レイヤーおよびアクセス・レイヤーを示しています。図4-1に示すように、2つのタイプのETL(抽出、変換およびロード)を使用して、これらのレイヤーを移入します。
Source-ETL。ステージング・レイヤー(存在する場合)および基盤レイヤー(つまり、実表、参照表および検索表)にOLTPシステムのデータを移入するETLは、ソースETLと呼ばれます。
Oracle Communications Data Modelは、Source-ETLスクリプトを含みません。Oracle Communications Data Modelのアプリケーション・アダプタを使用しないかぎり、ユーザーは、OLTPシステムの知識およびカスタマイズしたOracle Communications Data Modelを使用して、Source-ETLを作成する必要があります。Source-ETLの作成の詳細は、「Oracle Communications Data Modelウェアハウスの基盤レイヤーのETL」を参照してください。
Intra-ETL。基盤レイヤーのデータを使用してアクセス・レイヤー(つまり、導出表、集計表、マテリアライズド・ビュー、OLAPキューブおよびデータ・マイニング・モデル)を移入するETLは、Intra-ETLと呼ばれます。
Oracle Communications Data Modelは、Intra-ETLを含みます。デフォルトのIntra-ETLを変更して、カスタマイズした基盤レイヤーからカスタマイズしたアクセス・レイヤーに移入できます。Intra-ETLの詳細は、「Oracle Communications Data ModelのIntra-ETLのカスタマイズ」を参照してください。
Oracle Communications Data Modelウェアハウスの基盤レイヤー(つまり、実表、参照表および検索表)にOLTPシステムのデータを移入するETLは、Source-ETLと呼ばれます。
次の方法で、Oracle Communications Data Modelウェアハウスの基盤レイヤーを移入できます。
Oracle Communications Data Modelウェアハウスの基盤レイヤーを移入するシステムに対してOracle Communications Data Modelのアプリケーション・アダプタを使用できる場合、このアダプタを使用して基盤レイヤーを移入できます。詳細は、「アプリケーション・アダプタを使用した基盤レイヤーの移入」を参照してください。
Oracle Warehouse Builderまたは別のETLツールを使用して固有のSource-ETLスクリプトを書き込み、それらのスクリプトを使用して基盤レイヤーを移入します。詳細は、「固有のSource-ETLの書込み」を参照してください。
OLTPシステムを移入するアプリケーションに対してOracle Communications Data Modelのアプリケーション・アダプタを使用できる場合、このアダプタを使用してOracle Communications Data Modelウェアハウスの基盤レイヤーを移入します。
たとえば、Oracle Communications Network Charging and ControlシステムのデータからOracle Communications Data Modelウェアハウスの基盤レイヤーを移入する場合、Oracle Communications Data ModelのOracle Communications Network Charging and Controlアダプタを使用できます。詳細は、付録C「Oracle Communications Data ModelのNCCアダプタの使用」を参照してください。
Oracle Communications Data Modelのアプリケーション・アダプタを使用していない場合、Oracle Warehouse Builder、別のETLツールまたはマッピング・ツールを使用して、固有のSource-ETLスクリプトを書き込む必要があります。
|
関連項目: 『Oracle Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド』 |
|
Oracle By Example: Oracle Warehouse Builder:の詳細は、次のOBEチュートリアルを参照してください。
チュートリアルにアクセスするには、「Oracle Technology Network」の指示に従ってブラウザでOracle Learning Libraryを開き、名前でチュートリアルを検索します。 |
次のトピックでは、Source-ETLの書込みの一般的な情報について説明します。
Oracle Communications Data ModelのSource-ETLを設計および作成するときは、次の点に注意してください。
Oracle Communications Data Modelで提供され、『Oracle Communications Data Modelリファレンス』で説明されているカレンダ移入スクリプトを使用してカレンダ・データを移入できます。
表は次の順序で移入します。
検索表
参照表
実表
1つのカテゴリの表を分析してから、次のカテゴリの表をロードします(たとえば、検索表をロードする前に参照表を分析します)。また、Intra-ETLプロセスを実行する前に、Source-ETLでロードされたすべての表を分析する必要があります。
|
参照: 『Oracle Database管理者ガイド』の表、索引およびクラスタの分析に関するトピック。 |
ETLは、最初に元のソースからデータを抽出し、データの品質を確認して、元のソースのデータを一貫性のある状態にします。ETLは、問合せツール、レポート・ライター、ダッシュボードなどでデータにアクセスするため、物理オブジェクトに「クリーンな」データを移入します。
データの取得が行われる基本サービスは、次のとおりです。
データ・ソーシング
データ移動
データ変換
データのロード
論理アーキテクチャの観点から、データ取得サービスを提供するためにこれらの構築ブロックを構成する多くの異なる方法があります。データ・ウェアハウス・アーキテクチャ内を対象とする幅広いオプションを含む使用できる主要なアーキテクチャ・スタイルは、次のとおりです。
バッチ抽出、変換およびロードとバッチ抽出、ロード、変換、ロード
バッチ抽出、変換およびロード(ETL)およびバッチ抽出、ロード、変換、ロード(ELTL)は、データ・ウェアハウス実装の従来のアーキテクチャです。これらの違いは、変換がデータベースの内部または外部で発生するかどうかです。
バッチ・ハイブリッド抽出、変換、ロード、変換、ロード
バッチ・ハイブリッド抽出、変換、ロード、変換、ロード(ETLTL)は、ハイブリッド戦略です。この戦略は、変換設計に対するハンド・コーディング・アプローチを排除してメタデータドリブン・アプローチを適用する最も高い柔軟性を提供し、エンタープライズ・ウェアハウスのデータ処理機能を引き続き利用できます。このターゲットの設計では、ステージング表をロードする前の事前処理の手順として、変換処理がウェアハウスの外部で最初に実行され、サーゲット表に最後にロードする前に追加の変換処理がデータ・ウェアハウスの内部で実行されます。
リアルタイム抽出、変換、ロード
最新のデータのサービス・レベルでデータ・ウェアハウス環境の詳細な更新情報を要求する場合、リアルタイム抽出、変換、ロード(rETL)が適切です。このアプローチでは、rETLプロセスが適宜メッセージ・バス(キュー)から抽出するため、OLTPシステムで任意のイベントをアクティブに公開する必要があります。メッセージ・ベース・パラダイムは、公開およびサブスクライブ・メッセージ・バス構造または信頼性のあるキューのポイントツーポイント・メッセージングとともに使用します。
Oracle Communications Data ModelのSource-ETLを設計する場合、ビジネス・ニーズを最適に満たすアーキテクチャを使用します。
抽出システムの構築を開始する前に、表の元のソース・フィールドとターゲット宛先フィールドのリレーションシップをマップする論理データ・インタフェース・ドキュメントを作成します。このドキュメントは、ETLシステムの最初から最後まで適用されます。
データ・マッピング・ドキュメントの列は、結合される場合があります。たとえば、ソース・データベース、表名および列名が単一のターゲット列に結合される場合があります。連結された列内の情報は、ピリオドで区切られます。形式に関係なく、論理データ・マッピング・ドキュメントの内容がETLプロセスの十分な計画に必要となる重要な要素であることが証明されました。
データ・クリーニングは、表に提供するデータを消去および検証し、データを一貫性のある状態にする既知のビジネス・ルールを適用するために必要なすべての手順で構成されます。クリーニングおよび準拠の手順の視点は、データの利点の可能性というよりも包含および制御になります。
データ品質の問題がある場合、問題の解決方法について、ITおよびビジネス・ユーザーとともに計画を構築します。
次の質問に回答します。
データが見つかりませんか。
データは不正ですか、またはデータに一貫性がありませんか。
問題をソース・システムで修正する必要がありますか。
データ品質レポート、アクション・プログラムおよび人の責任を設定します。
次のプロセスおよびプログラムを設定します。
データ品質測定プロセスを設定します。
データ品質レポート、アクション・プログラムおよび人の責任を設定します。
ETLプロセス間のすべてのデータ移動は、ジョブで構成されます。ETLワークフローは、必要な依存性について、適切な順序でこれらのジョブを実行します。Oracle Warehouse Builderなどの一般的なETLツールは、このようなワークフロー、ジョブ設計および実行制御をサポートします。
ETLジョブおよびワークフローを設計する場合のヒントは、次のとおりです。
すべてのジョブで一般的な構造を使用します(ソース・システム、トランスフォーマ、ターゲット・データ・ウェアハウス)。
ソースからターゲットの1対1のマッピングを使用します。
ソース表ごとに1つのジョブを定義します。
汎用ジョブ構造およびテンプレート・ジョブを適用して、迅速な開発および一貫性を考慮します。
最適化されたジョブ設計を使用して、データ量に基づいてOracleロード・パフォーマンスを利用します。
パラメータ化されたジョブを設計して、ジョブのパフォーマンスおよび動作の高度な制御を考慮します。
ジョブのパラレル実行を最大化します。
使用しているETLツールまたは開発したマッピング・スクリプトは、ステータスおよびエラー処理表を生成します。
一般的な原則として、すべてのETLがステータスおよびエラーを表に記録します。ETLツールを使用するか、ログ表に直接問い合せて、実行ステータスを監視します。
マッピング・スクリプトを開発してステージング・レイヤーにロードするか、基盤レイヤーに直接ロードするかに関係なく、最も効率的な方法でデータをウェアハウスに格納することが目標です。ロード中の優れたパフォーマンスを実現するには、ロードするデータの場所およびデータベースにロードする方法から開始する必要があります。たとえば、シリアル・データベース・リンクまたは単一のJDBC接続を使用して、大量のデータを移動しないようにする必要があります。大量のデータをロードする最も一般的な推奨メカニズムは、フラット・ファイルからのロードです。
次のトピックでは、効率的なSource-ETLロードを保証するベスト・プラクティスについて説明します。
データ・ウェアハウス・システムのステージング・レイヤーにロードされる前にフラット・ファイルが格納される領域は、一般的にステージング領域と呼ばれます。ロードの全体の速度は、次の要素で決定されます。
ステージング領域からRAWデータを読み取ることができる速度。
RAWデータを処理してデータベースに挿入できる速度。
推奨: ステージング領域の使用
生データはできるだけ多くの物理ディスクにステージングし、生データの読取りがロード時のボトルネックにならないようにします。
また、Exadata Database Machineを使用している場合、データをステージングする最適な場所は、Exadataストレージ・セルに格納されているOracle Database File System(DBFS)内です。DBFSは、データベースに格納されたファイルへのアクセスに使用できるマウント可能なクラスタ・ファイル・システムを作成します。Database Machineの別のデータベースにDBFSを作成します。これにより、データ・ウェアハウスとは別にDBFSを管理および保守できます。
DIRECT_IOオプションを使用してファイル・システムをマウントし、ファイル・システムのRAWデータ・ファイルの移動中のシステム・ページ・キャッシュのスラッシングを回避します。
|
参照: DBFSの設定の詳細は、『Oracle Database SecureFilesおよびラージ・オブジェクト開発者ガイド』を参照してください。 |
データ・ロードをパラレル化するには、OracleデータベースでRAWデータ・ファイルをグラニュルと呼ばれるチャンクに論理的に分割できる必要があります。バランスのとれたパラレル処理を保証するため、通常グラニュルの数は、パラレル・サーバー・プロセスの数よりも非常に多くなります。特定の時点で、処理する1つのグラニュルにパラレル・サーバー・プロセスが割り当てられます。パラレル・サーバー・プロセスがグラニュルの処理を完了した後、すべてのグラニュルが処理されてデータがロードされるまで、別のグラニュルが割り当てられます。
推奨: Source-ETLのRAWデータ・ファイルの準備
次の推奨事項に従います。
改行やセミコロンなどの認識される文字を使用して、各行を区切ります。これにより、単一のファイル内に複数のグラニュルを作成するためにRAWデータ・ファイル内が参照され、各行のデータの開始場所および終了場所が決定されます。
ファイルが配置可能および検索可能(たとえば、圧縮ファイル、ZIPファイルなど)ではない場合、ファイルをグラニュルに分割できません。ファイル全体が単一のグラニュルとして処理されます。この場合、1つのパラレル・サーバー・プロセスのみ、ファイル全体で使用できます。圧縮されたデータ・ファイルのロードをパラレル化するには、複数の圧縮されたデータ・ファイルを使用します。使用される圧縮されたデータ・ファイルの数は、ロードで使用される最大の並列度を決定します。
複数のデータ・ファイルをロードする場合(圧縮または非圧縮)
可能な場合、単一の外部表を使用します。
ファイルのサイズを同じにします。
ファイルのサイズを10MBの倍にします。
異なるサイズのファイルを使用する必要がある場合、最大から最小までファイルをリストします。デフォルトでは、フラット・ファイルがデータベースと同じキャラクタ・セットであると想定します。該当しない場合、外部表定義のフラット・ファイルのキャラクタ・セットを指定して、適切なキャラクタ・セット変換を実行できることを確認します。
Oracleは、複数のデータ・ロード・オプションを提供します。
外部表またはSQL*Loader
Oracle Data Pump(インポートおよびエクスポート)
Change Data CaptureおよびTrickleフィード・メカニズム(Oracle GoldenGateなど)
システムおよびメインフレームを開くOracle Database Gateways
Generic Connectivity(ODBCおよびJDBC)
実行するアプローチは、受信するデータのソースおよび形式に依存します。
推奨: フラット・ファイルのロード
ファイルからOracleにロードする場合、2つのオプション、SQL*Loaderまたは外部表を使用します。
外部表を使用すると、次の利点があります。
データベース内の透過的なパラレル化を実行できます。ステージング・データを回避して、外部表にアクセスする場合に任意のSQLまたはPL/SQL構成を使用してファイル・データに直接変換を適用できます。SQL Loaderでは、データをそのままデータベースに最初にロードする必要があります。
外部表のロードをパラレル化すると、個々のパラレル・ローダーが固有のトランザクションを使用した個別のデータベース・セッションであるSQL*Loaderよりも効率的な領域管理を実行できます。多くパーティション化した表の場合、多くの未利用領域が発生する可能性があります。
標準のCREATE TABLE文を使用して、外部表を作成できます。ただし、フラット・ファイルからロードするには、データベース外部のフラット・ファイルの場所の情報を文に含める必要があります。外部表からデータをロードする場合の最も一般的なアプローチは、CREATE TABLE AS SELECT (CTAS)文またはINSERT AS SELECT (IAS)文を既存の表に発行することです。
ダイレクト・パス・ロードは、外部表定義の説明に従って入力データを解析し、各入力フィールドのデータを対応するOracleデータ・タイプに変換して、データの列配列構造を作成します。これらの列配列構造を使用して、Oracleデータ・ブロックをフォーマットし、索引キーを作成します。新しくフォーマットされたデータベース・ブロックはデータベースに直接書き込まれるため、標準SQL処理エンジンおよびデータベース・バッファ・キャッシュが省略されます。
優れたロード・パフォーマンスの秘訣は、可能なかぎりダイレクト・パス・ロードを使用することです。
CREATE TABLE AS SELECT (CTAS)文は、常にダイレクト・パス・ロードを使用します。
単純なINSERT AS SELECT (IAS)文は、ダイレクト・パス・ロードを使用しません。IAS文でダイレクト・パス・ロードを実現するには、APPENDヒントをコマンドに追加する必要があります。
ダイレクト・パス・ロードはパラレルでも実行できます。ダイレクト・パス・ロードの並列度を設定するには、次のいずれかを実行します。
PARALLELヒントをCTAS文またはIAS文に追加します。
外部表およびデータをロードする表にPARALLEL句を設定します。
並列度の設定後:
CTAS文は、パラレルのダイレクト・パス・ロードを自動的に実行します。
IAS文は、パラレルのダイレクト・パス・ロードを自動的に実行しません。IAS文でパラレルのダイレクト・パス・ロードを有効にするには、次の文を実行して、セッションを変更してパラレルDMLを有効にする必要があります。
alter session enable parallel DML;
パーティション化の利点は、EXCHANGE PARTITIONコマンドを使用してビジネス・ユーザーの影響を最小限にデータを迅速かつ容易にロードする機能です。EXCHANGE PARTITIONコマンドは、パーティション化されていない表のデータをパーティション化された表の特定のパーティションにスワップできます。EXCHANGE PARTITIONコマンドは物理的にデータを移動しません。かわりに、データ・ディクショナリを更新してパーティションおよび表のポインタを交換します。
データの物理的な移動がないため、交換はREDOおよびUNDOを生成しません。つまり、交換は1秒以内の処理で、INSERTなどの従来のデータ移動アプローチよりもパフォーマンスへの影響が大幅に少なくなります。
推奨: 表のパーティション化
Oracle Communications Data Modelウェアハウスの大きい表およびファクト表をパーティション化します。
例4-1 パーティション表でのパーティション交換文の使用
日単位でレンジ・パーティション化されるSalesという大きい表があるとします。各営業日の最後に、オンライン販売システムのデータがウェアハウスのSales表にロードされます。
次の手順により、日単位のデータがデータ・ウェアハウスのビジネス・ユーザーへの影響を最小限に最適な速度で正しいパーティションにロードされます。
オンライン・システムから取得するフラット・ファイル・データの外部表を作成します。
CTAS文を使用して、Sales表と同じ列構造を持つtmp_salesというパーティション化されていない表を作成します。
tmp_sales表のSales表の索引を作成します。
EXCHANGE PARTITIONコマンドを発行します。
Alter table Sales exchange partition p2 with
table top_sales including indexes without validation;
増分統計を使用して、新しく交換したパーティションのオプティマイザ統計を収集します。
この例のEXCHANGE PARTITIONコマンドは、名前が付いたパーティションおよびtmp_sales表の定義をスワップするので、パーティション表の正しい場所にデータがすぐに配置されます。また、INCLUDING INDEXESおよびWITHOUT VALIDATION句を使用すると、索引の定義をスワップし、データが実際にパーティションに属するかどうかを確認しないため、交換が非常に迅速になります。
|
注意: この例の想定では、データの整合性がデータ抽出時間に確認されました。データの整合性がわからない場合、データベースでデータの妥当性を確認するため、WITHOUT VALIDATION句を省略します。 |
Oracle Communications Data Modelは、Oracle Warehouse BuilderなどのETLツールの使用をサポートして、Intra-ETLプロセスを実行するワークフローを定義します。固有のIntra-ETLを書き込むことができます。ただし、Intra-ETLコンポーネントは、Oracle Warehouse Builderワークフロー・コンポーネントを使用して設計されたプロセス・フローのOracle Communications Data Modelで提供されます。このプロセス・フローは、INTRA_ETL_FLWと呼ばれます。
図4-1「ETLフロー・ダイアグラム」で示すように、INTRA_ETL_FLWプロセス・フローは、Oracle Communications Data Modelの実表、参照表および検索表のデータを使用して、他のすべてのOracle Communications Data Model構造を移入します。このパッケージ内で、各プログラムを適切な順序で実行するため、個々のプログラムの依存性が実装および適用されます。
特定の要件の元のIntra-ETLスクリプトを変更できます。ただし、変更を行う前に完全な影響分析を実行します。元のOracle Communications Data Model Intra-ETLマッピングのパッチとして、変更をパッケージ化します。
INTRA_ETL_FLWプロセス・フローは、次のサブプロセスから構成され、個々のサブプロセス・フローの依存関係を含み、それらを適切な順序で実行します。
DRVD_FLW
このサブプロセス・フローには、実表、参照表および検索表の内容に基づいて導出表を移入するためのすべてのOracle Warehouse Builderマッピングが含まれます。このプロセス・フローにより、マッピングを同時に実行できます。
このサブプロセスは、次のテクノロジを使用します。
MERGE句。この文は、初期ロードおよび増分ロードに使用します。ターゲット表に挿入または更新されるデータが受信データによるキー列の確認に基づいているかを識別し、INSERTおよびUPDATEの組合せと比較して非常に優れたパフォーマンスを提供します。
TABLEファンクション。このファンクションは、個別のステージング表の必要性を回避するため、導出表(およびソース・データ)に主に使用します。ステージング表がないと、ETL操作のパフォーマンスが向上し、データベースのメンテナンスが容易になります。
パイプライン句。この句は、作成した直後に追加処理用に段階的に結果セットを戻すためにTABLEファンクションで使用します。そのため、この句の使用で大量の戻りが回避され、完全なプロセスが通常の戻りよりも高速になります。
AGGR_FLW
このサブプロセス・フローには、パーティション変更追跡計画を使用してOracle Communications Data Model内のマテリアライズド・ビューであるすべての集計表をリフレッシュするPL/SQLコードが含まれます。
このサブプロセスは、次のテクノロジを使用します。
マテリアライズド・ビュー。マテリアライズド・ビューを使用して、集計データを保持します。リフレッシュされるたびに、変更されたデータが対応する集計表に反映され、問合せ実行パフォーマンスが大幅に向上します。また、マテリアライズド・ビューを使用すると、Oracle Communications Data Modelは優れたSQL最適化のためにOracleクエリー・リライト機能を使用して、パフォーマンスを向上できます。
高速リフレッシュ。このリフレッシュ・タイプを使用して、直前のリフレッシュの後に実表および導出表の増分データ(挿入および変更)のみの集計をリフレッシュし、この増分リフレッシュがさらに優れたパフォーマンスを実現するため、Intra-ETL期間が短くなります。
MINING_FLW
INTRA_ETL_FLWプロセス・フローには、OLAP_MAPマッピングも含まれます。OLAP_MAPは、PKG_OCDM_OLAP_ETL_AW_LOADパッケージの分析ワークスペース構築機能を呼び出して、Oracle Communications Data Modelの集計マテリアライズド・ビューからOracle Communications Data Model分析ワークスペースにデータをロードし、予測データを計算します。PKG_OCDM_OLAP_ETL_AW_LOADパッケージは、OLAP ETLパラメータをocdm_sysスキーマ内のDWC_OLAP_ETL_PARAMETER制御表から読み取って、データのロード方法と予測の実行方法の詳細を判断します。
|
注意: Oracle Communications Data Modelで提供されるシェル・スクリプトocdm_execute_wf.shは、Oracle Warehouse Builder Workflow INTRA_ETL_FLWと同じファンクションを実行します。このシェル・スクリプトは、Oracle Warehouse Builderワークフローを必要としません。このスクリプトの操作の詳細は、「ocdm_execute_wf.sh Scriptの手動実行」を参照してください。 |
|
参照: Oracle Communications Data Model Intra-ETLの詳細は、『Oracle Communications Data Modelリファレンス』を参照してください。 |
Oracle Communications Data Modelの初期ロードの実行は、複数ステップのプロセスです。
「基盤レイヤーの初期ロードの実行」の説明に従って、Oracle Communications Data Modelウェアハウスの基盤レイヤー(つまり、参照表、検索表および実表)をロードします。
「アクセス・レイヤーの初期ロードの実行」の説明に従って、Oracle Communications Data Modelウェアハウスのアクセス・レイヤー(つまり、導出表および集計表、マテリアライズド・ビュー、OLAPキューブおよびデータ・マイニング・モデル)をロードします。
Oracle Communications Data Modelウェアハウスの基盤レイヤー(つまり、参照表、検索表および実表)の初期ロードを実行する方法は、Oracle Communications Data Modelのアプリケーション・アダプタを使用しているかどうかによって異なります。
Oracle Communications Data Modelのアプリケーション・アダプタを使用している場合、このアダプタを使用して基盤レイヤーをロードします。たとえば、「Oracle Communications Data ModelのNCCアダプタを使用した初期ロード」の説明に従って、Oracle Communications Data ModelのNCCアダプタを使用して、Oracle Communications Data Modelウェアハウスの基盤レイヤーにOracle Communications Network Charging and Controlシステムのデータを移入できます。
アプリケーション・アダプタを使用していない場合、作成するSource-ETLを使用して基盤レイヤーの初期ロードを実行します。このETLの作成の詳細は、「固有のSource-ETLの書込み」を参照してください。
Oracle Communications Data Modelウェアハウスのアクセス・レイヤー(導出表、集計表、マテリアライズド・ビュー、OLAPキューブおよびデータ・マイニング・モデル)の初期ロードを実行するには、次の手順に従います。
ocdm_sysスキーマ内のDWC_ETL_PARAMETER制御表のパラメータを更新して、この情報(ETL期間の開始日と終了日)を導出と集計の表およびビューのロード時にETLで使用できるようにします。
Oracle Communications Data Modelウェアハウスの初期ロードでは、次の表に示す値を指定します。
| 列 | 値 |
|---|---|
PROCESS_NAME |
'OCDM-INTRA-ETL' |
FROM_DATE_ETL |
ETL期間の開始日。 |
TO_DATE_ETL |
ETL期間の終了日。 |
|
参照: DWC_ETL_PARAMETER制御表の詳細は、『Oracle Communications Data Modelリファレンス』を参照してください。 |
ocdm_sysスキーマ内のDWC_OLAP_ETL_PARAMETER制御表のOracle Communications Data Model OLAP ETLパラメータを更新して、構築メソッドおよびその他の構築特性を指定し、この情報をOLAPキューブ・データのロード時にETLで使用できるようにします。
分析ワークスペースの初期ロードの場合は、表4-1のガイドラインに従って値を指定します。
表4-1 初期ロード用のDWC_OLAP_ETL_PARAMETER表のOracle Communications Data Model OLAP ETLパラメータの値
| 列名 | 値 |
|---|---|
|
|
|
|
|
|
|
|
構築するキューブを指定する次の値のいずれか。
|
|
|
このジョブに割り当てるパラレル・プロセス数を指定する10進値。(デフォルト値は |
|
|
予測キューブを計算するかどうかに応じて、次のいずれかの値。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
「デフォルトのOracle Communications Data ModelのIntra-ETLの実行」で説明している方法の1つを使用して、Intra-ETLを実行します。
Oracle Communications Data Modelで提供されるIntra-ETLパッケージは、次の方法で実行できます。
「Oracle Warehouse BuilderのINTRA_ETL_FLWワークフローの実行」で説明しているように、Oracle Warehouse Builderのワークフローとして実行します。
「ocdm_execute_wf.shスクリプトの手動実行」で説明しているように、Oracle Warehouse Builderワークフローを使用しないで実行します。
どちらの場合でも、Intra-ETLを明示的に実行したり、他のプログラムまたはプロセス(たとえば、正常な実行の後のSource-ETLプロセスなど)または事前定義済のスケジュール(たとえば、Oracle Job Scheduling機能の使用など)で実行を起動したりできます。
デプロイ後、Oracle Warehouse Builder内からINTRA_ETL_FLWプロセスを実行できます。
INTRA_ETL_FLWプロセス・フローをデプロイするには、次の手順に従います。
『Oracle Communications Data Modelインストレーション・ガイド』の説明に従ってOracle Warehouse Builderワークフローがインストールされていることを確認します。
Oracle Warehouse Builder内で、Control Center Managerに移動します。
OLAP_PFLW、AGR_PFLWの順に選択し、メイン・プロセス・フローINTRA_ETL_FLWを選択します。
INTRA_ETL_FLWを右クリックして、「アクションの設定」を選択します。
これが最初のデプロイメントの場合、アクションを「作成」に設定します。
これが後のデプロイメントの場合、アクションを「置換」に設定します。
プロセス・フローをデプロイします。
デプロイメントが正常に完了すると、INTRA_ETL_FLWの実行準備ができます。
|
参照: Oracle Warehouse Builderの詳細は、『Oracle Warehouse Builderソースおよびターゲット・ガイド』を参照してください。 |
Oracle Communications Data Modelには、Oracle Warehouse Builderワークフローを使用せずにIntra-ETLを移入するために使用できるスクリプトが用意されています。このシェル・スクリプトの名前はocdm_execute_wf.shです。
ocdm_execute_wf.shスクリプトは、Oracle Warehouse BuilderワークフローのINTRA_ETL_FLWと同じ機能を実行します。スクリプトは、Source-ETLなどの別のプロセスによって呼び出すか、Oracle Job Schedulingなどの事前定義済スケジュールに従って呼び出すことができます。
ocdm_execute_wf.shプログラムは、次の表で説明する環境変数の入力を求めるプロンプトを表示します。
| 変数 | 説明 |
|---|---|
TSNAME |
ターゲット・データベースのtnsname。 |
SYSTEMパスワード |
ターゲット・データベースのSYSTEMアカウント・パスワード。 |
ocdm_sysパスワード |
ocdm_sysアカウントのパスワード。 |
ORACLE HOME |
Oracleデータベース・ホーム(/で終了するフルパス)。 |
適切な順序でマッピングを実行する前に、ocdm_sysスキーマ内のDWC_ETL_PARAMETERおよびDWC_OLAP_ETL_PARAMETER制御表から値を読み取ります。
「Intra-ETLプロセスの実行の監視」で説明するように、各表のロードの結果は、DWC_INTRA_ETL_PROCESSおよびDWC_INTRA_ETL_ACTIVITY制御表で追跡されます。
「アクセス・レイヤーの初期ロードの実行」では、Oracle Communications Data Modelデータ・ウェアハウスの初期ロードの実行方法について説明しています。この初期ロードの後に、ビジネス分析を容易にするという目的を満たせるように、Oracle Communications Data Modelデータ・ウェアハウスに新規データを定期的にロードする必要があります。
Oracle Communications Data Modelウェアハウスに新規データをロードするには、1つ以上の業務系システムからデータを抽出し、そのデータをウェアハウスにコピーする必要があります。データ・ウェアハウス環境では、多数のシステムにわたる大量のデータを統合、再配置および連結し、結果として、統一された新たな情報ベースをビジネス・インテリジェンスに提供することが課題になります。
継続的なロードおよび変換は、ビジネス・ニーズによって決定される特定の順序でスケジュールして処理する必要があります。操作または操作の一部が成功したか失敗したかに応じて、結果を追跡する必要があります。また、場合によっては後続の代替プロセスを開始できます。
Oracle Communications Data Modelウェアハウスの完全増分ロードを実行するか、次のようにデータを順次にリフレッシュできます。
どちらの場合でも、「Oracle Communications Data ModelのIntra-ETL実行中のエラーの管理」の説明に従って、Intra-ETLの実行中のエラーを管理できます。
次の方法で、Oracle Communications Data Modelウェアハウスの基盤レイヤー(つまり、参照表、検索表および実表)をリフレッシュできます。
Oracle Communications Data Modelウェアハウスの基盤レイヤーをリフレッシュするシステムに対してOracle Communications Data Modelのアプリケーション・アダプタを使用できる場合、このアダプタを使用して基盤レイヤーをリフレッシュできます。
たとえば、「Oracle Communications Data ModelのNCCアダプタを使用したデータのリフレッシュ」の説明に従って、Oracle Communications Data ModelのNCCアダプタを使用して、Oracle Communications Data Modelウェアハウスの基盤レイヤーをOracle Communications Network Charging and Controlシステムのデータでリフレッシュできます。
Oracle Warehouse Builderまたは別のETLツールを使用して書き込まれたSource-ETLスクリプトを使用して、基盤レイヤーをリフレッシュできます。Source-ETLの作成の詳細は、「固有のSource-ETLの書込み」を参照してください。
Oracle Communications Data Modelのアクセス・レイヤーのリフレッシュは、複数ステップのプロセスです。アクセス・レイヤーの完全増分ロードを一度に実行するか、次のようにデータを順次にリフレッシュできます。
どちらの場合でも、「Oracle Communications Data ModelのIntra-ETL実行中のエラーの管理」の説明に従って、Intra-ETLの実行中のエラーを管理できます。
Oracle Communications Data Modelのリレーショナル表およびビューのリフレッシュは、複数ステップのプロセスです。
書き込まれたSource-ETLを実行して、OLTPデータを使用してOracle Communications Data Modelウェアハウスの基盤レイヤー(つまり、参照表、検索表および実表)をリフレッシュします。
ocdm_sysスキーマ内のDWC_ETL_PARAMETER制御表のパラメータを更新します。Oracle Communications Data Modelウェアハウスの増分ロードの場合は、次の表で示す値を指定します(ETL期間の開始日と終了日)。
| 列 | 値 |
|---|---|
PROCESS_NAME |
'OCDM-INTRA-ETL' |
FROM_DATE_ETL |
ETL期間の開始日。 |
TO_DATE_ETL |
ETL期間の終了日。 |
|
参照: DWC_ETL_PARAMETER制御表の詳細は、『Oracle Communications Data Modelリファレンス』を参照してください。 |
INTRA_ETL_FLWプロセス・フローのDRVD_FLOWおよびAGGR_FLOWサブプロセスを実行することで、Oracle Communications Data Modelのマテリアライズド・ビューである導出表と集計表をリフレッシュします。詳細は、「デフォルトのOracle Communications Data ModelのIntra-ETLの実行」を参照してください。
|
関連項目: Oracle Warehouse Builderソースおよびターゲット・ガイド |
スケジュールに基づいて、OLAPキューブの初期ロード以降にOracle Communications Data Modelデータ・ウェアハウスに追加されたリレーショナル・データでOLAPキューブ・データを更新する必要があります。
次の方法で、Oracle Communications Data Model ETLを実行してOLAPキューブを更新できます。
「デフォルトのOracle Communications Data ModelのIntra-ETLの実行」で説明されているいずれかの方法で、Oracle Warehouse Builder Workflow INTRA_ETL_FLWを実行することでウェアハウス内のすべてのデータをリフレッシュします。
OLAPキューブは、Oracle Communications Data Model Intra-ETLのメイン・ワークフローINTRA_ETL_FLWの一部であるOLAP_MAPを介して移入されます。
Oracle Warehouse Builderコントロール・センターでOLAP_MAP Oracle Warehouse Builderマッピングを実行することにより、OLAPキューブ・データのみリフレッシュします。
|
注意: OLAP_MAPを実行する前にリフレッシュしているOLAPキューブの対応するマテリアライズド・ビューをリフレッシュする必要があります。OLAPキューブとマテリアライズド・ビュー間のマッピングは、『Oracle Communications Data Modelリファレンス』を参照してください。 |
次の手順に従って、Oracle Communications Data Modelウェアハウスの一部である分析ワークスペースの増分ロードを実行します。
Oracle Communications Data Modelのマテリアライズド・ビューである集計表を更新します。詳細は、「Oracle Communications Data Modelの導出表および集計表のリフレッシュ」を参照してください。
「デフォルトのOracle Communications Data ModelのIntra-ETLの実行」で説明している方法の1つを使用して、Intra-ETLを実行してキューブ・データをロードします。
必要に応じて、OLAP_MAPの実行中のエラーからリカバリするには、次の手順に従います。
ocdm_sys.DWC_OLAP_ETL_PARAMETER表のBUILD_METHOD列の値を"C"に変更します。
Oracle Warehouse Builderで、OLAP_MAPマップを再実行します。
INTRA_ETL_FLWプロセス・フローのMINING_FLWサブプロセス・フローは、データ・マイニング・モデルのリフレッシュをトリガーします。ウェアハウスの初期ロード後に、データ・マイニング・モデルを毎月リフレッシュすることをお薦めします。データ・モデルのリフレッシュは、MINING_FLWサブプロセス・フローに統合されています。データ・モデルを手動でリフレッシュすることもできます。
データ・マイニング・モデルをリフレッシュする方法は、すべてのモデルまたは1つのモデルのみをリフレッシュするかどうかによって異なります。
すべてのマイニング・モデルを手動でリフレッシュするには、次のプロシージャをコールします。
ocdm_mining.PKG_ocdm_mining.REFRESH_MODEL( MONTH_CODE,P_PROCESS_NO)
このプロシージャは、各モデルで次のタスクを実行します。
ocdm_sysスキーマの最新データに基づいてマイニング・ソース・マテリアライズド・ビューをリフレッシュします。
新しいトレーニング・データで各モデルをトレーニングします。
各モデルを新しい適用対象データ・セットに適用します。
1つのマイニング・モデルのみ手動で再作成するには、対応するプロシージャをコールします。たとえば、チャーンSVMモデルを再作成するには、次のプロシージャをコールできます。
ocdm_mining.create_churn_svm_model( MONTH_CODE );
「チュートリアル: チャーン予測モデルのカスタマイズ」に、単一のデータ・マイニング・モデルをリフレッシュする詳細な手順を示します。
このトピックでは、Intra-ETL実行中のエラーを識別および管理する方法について説明します。内容は次のとおりです。
Intra-ETLプロセスの実行は、2つのocdm_sysスキーマ制御表DWC_INTRA_ETL_PROCESSおよびDWC_INTRA_ETL_ACTIVITYによって監視されます。これらの表については、『Oracle Communications Data Modelリファレンス』に記載されています。
個別のIntra-ETL実行の(エラー・リカバリ実行ではなく)通常の各実行では、次のステップが実行されます。
単調に増加するシステム生成の一意のプロセス・キー、プロセス開始時刻としてのSYSDATE、プロセス・ステータスとしてのRUNNING、およびFROM_DATE_ETL列とTO_DATE_ETL列の入力日範囲で、DWC_INTRA_ETL_PROCESS表にレコードを挿入します。
適切な依存性の順序で各Intra-ETLプログラムが起動されます。各プログラムの起動前に、プロシージャは、次の値を使用してレコードをintra-ETLアクティビティ・ディテール表DWC_INTRA_ETL_ACTIVITYに挿入します。
システムで生成される一意のアクティビティ・キーのACTIVITY_KEY。
Intra-ETLプロセスに対応するプロセス・キー値のPROCESS_KEY。
個々のプログラム名のACTIVITY_NAME。
適切なアクティビティの説明のACTIVITY_DESC。
SYSDATEの値のACTIVITY_START_TIME。
RUNNINGの値のACTIVITY_STATUS。
個々のETLプログラムが(正常にまたはエラーを戻して)完了するたびに、DWC_INTRA_ETL_ACTIVITY表内の対応するレコードのアクティビティ終了時間およびアクティビティ・ステータスが更新されます。アクティビティが正常に完了した場合、プロシージャはステータスを'COMPLETED-SUCCESS'として更新します。エラーが発生した場合、プロシージャはアクティビティ・ステータスを'COMPLETED-ERROR'として更新し、ERROR_DTL列の対応するエラー詳細も更新します。
すべての個々のIntra-ETLプログラムが完了した後、DWC_INTRA_ETL_ PROCESS 表内のプロセスに対応するレコードのプロセス終了時間およびステータスが更新されます。すべての個々のプログラムが成功すると、プロシージャは'COMPLETED-SUCCESS'にステータスを更新し、それ以外の場合は'COMPLETED-ERROR'にステータスを更新します。
最大プロセス・キーに対応するDWC_INTRA_ETL_PROCESSおよびDWC_INTRA_ETL_ACTIVITY表の内容を表示することで、現在のプロセス進行状況、個々のプログラムに要した時間、完了プロセスなど、Intra-ETLの実行状態を監視できます。監視は、Intra-ETLプロシージャの実行中および実行後に行うことができます。
Intra-ETLプロセスをリカバリする手順は、次のとおりです。
DWC_INTRA_ETL_ACTIVITY表の個々のプログラムに対して追跡されているエラー詳細を参照することでエラーを識別します。
エラーの原因を修正します。
Intra-ETLプロセスを再起動します。
INTRA_ETL_FLWプロセスは、DWC_INTRA_ETL_ACTIVITY表を参照することで通常の実行かリカバリ実行かを識別します。リカバリ実行中は、INTRA_ETL_FLWは必要なプログラムのみ実行します。たとえば、前回の実行の一部として導出移入エラーが発生した場合、このリカバリ実行は、前回の実行でエラーを生成した個々の導出移入プログラムを実行します。正常完了後に、集計移入プログラムとマテリアライズド・ビューのリフレッシュが適切な順序で実行されます。
このように、Intra-ETLエラー・リカバリはほとんど透過的であり、データ・ウェアハウス管理者またはETL管理者は関与しません。管理者は、エラーの原因を修正して、Intra-ETLプロセスを再起動するだけです。Intra-ETLプロセスが、エラーを生成したプログラムを識別して実行します。
Intra-ETLのパフォーマンスをトラブルシューティングする手順は、次のとおりです。
「実行計画のチェック」の説明に従って、実行計画をチェックします。
「PARALLEL DML実行の監視」の説明に従って、パラレルDML実行を監視します。
「データ・マイニング・モデルの作成のトラブルシューティング」の説明に従ってデータ・マイニング・モデルが正しく作成されていることを確認します。
SQLDeveloperまたはその他のツールを使用して、Oracle Warehouse Builderで生成されたコードのパッケージ本体を表示します。
たとえば、マップを調べるには、次の手順に従います。
コード・ビューアからメインの問合せ文をコピーします。
"CURSOR "AGGREGATOR_c" IS …."から、別の"CURSOR "AGGREGATOR_c$1" IS"のすぐ上にある問合せの終了までコピーします。
SQLDeveloperワークシートで、次の文を発行してパラレルDMLをオンにします。
Alter session enable parallel dml;
メインの問合せ文を別のSQL Developerワークシートに貼り付け、F6をクリックして実行計画を表示します。
実行計画を慎重に調べて、有効な計画に従ってマッピングを実行します。
次のSQL文を実行して、実行された"Parallel DML/Query"文をカウントすることで、マッピングをパラレル・モードで実行していることを確認します。
column name format a50 column value format 999,999 SELECT NAME, VALUE FROM GV$SYSSTAT WHERE UPPER (NAME) LIKE '%PARALLEL OPERATIONS%' OR UPPER (NAME) LIKE '%PARALLELIZED%' OR UPPER (NAME) LIKE '%PX%' ;
マッピングをパラレル・モードで実行する場合は、マッピングが呼び出されるたびに"DML statements parallelized"が1つ増やされます。この増分が表示されない場合は、マッピングが"パラレルDML"として呼び出されていません。
かわりに"queries parallelized"が1つ増やされている場合は、通常、INSERTの内部のSELECT文はパラレル化されていますが、そのINSERT自体はパラレル化されていないことを意味します。
データ・マイニング・モデルが作成された後で、ocdm_sys.dwc_intra_etl_activity表内のエラー・ログをチェックします。たとえば、次のコードを実行します。
set line 160 col ACTIVITY_NAME format a30 col ACTIVITY_STATUS format a20 col error_dtl format a80 select activity_name, activity_status, error_dtl from dwc_intra_etl_activity;
すべてのモデルが正常に作成されている場合、activity_statusはすべて"COMPLETED-SUCCESS"になります。特定のステップのactivity_statusが"COMPLETED-ERROR"の場合は、ERROR_DTL列をチェックし、問題を適宜修正します。
次の例で、Oracle Communications Data Modelを操作する場合にERROR_DTLおよびACTIVITY_NAMEで戻される一般的なエラー・メッセージのトラブルシューティング方法を示します。
例4-2「Oracle Communications Data ModelのORA-20991エラーのトラブルシューティング」
例4-4「Oracle Communications Data ModelのORA-40113エラーのトラブルシューティング」
例4-5「Oracle Communications Data ModelのORA-40112エラーのトラブルシューティング」
例4-6「Oracle Communications Data ModelのORA-11130エラーのトラブルシューティング」
例4-2 Oracle Communications Data ModelのORA-20991エラーのトラブルシューティング
戻されるエラーがORA-20991: メッセージはありません... [言語=ZHS]CURRENT_MONTH_KEYとします。
このエラーは、DWR_BSNS_MO表に十分なデータがない場合に発生することがあります。たとえば、カレンダ・データに2004年から2009年のデータが移入されている場合、2010年についてマイニング・モデルをリフレッシュすると、このエラーが発生することがあります。
このエラーを解決するには、Oracle Communications Data Modelカレンダ・ユーティリティ・スクリプトを再度実行して、カレンダに十分なデータを移入します。次に例を示します。
Execute Calendar_Population.run('2005-01-01',10);
カレンダ移入ユーティリティ・スクリプトの詳細は、『Oracle Communications Data Modelリファレンス』を参照してください。
例4-3 メッセージはありません... [言語=ZHS]エラーのトラブルシューティング
戻されるエラーがメッセージはありません... [言語=ZHS]とします。
'ZHS'は言語のコードです。関連する言語名は、データベース環境に応じて異なる名前で表示されることがあります。このエラーは、ocdm_sys.DWC_MESSAGE.LANGUAGEに現在の言語用のメッセージが含まれていない場合に発生します。
DWC_MESSAGE表の値をチェックし、必要に応じて、Oracleセッション変数USERENV('lang')で指定されている言語コードに更新します。
例4-4 Oracle Communications Data ModelのORA-40113エラーのトラブルシューティング
戻されるエラーがcreate_churn_svm_modelに対するORA-40113: 個別ターゲット値の数が不足していますとします。
このエラーは、トレーニング・モデルのターゲット列に複数の値が期待されている場合に、1つの値のみ含まれているか、値が含まれていない場合に発生します。
たとえば、churn_svm_modelの場合、ターゲット列は次のとおりです。
ocdm_mining.DMV_CUST_CHRN_SRC_PRD.chrn_ind
このエラーをトラブルシューティングする手順は、次のとおりです。
SQL問合せを実行して、この列に十分な値があるかどうかを確認します。
たとえばchurn_svm_modelでは、次の文を発行します。
select chrn_ind, count(*) from DMV_CUST_CHRN_SRC_PRD group by chrn_ind;
問合せの結果を次に示します。
C COUNT(*) - ---------- 1 1228 0 4911
次の表をチェックして、顧客の解約率インジケータが正しく設定されていることを確認します。
ocdm_sys.dwr_cust.chrn_dtには、解約した顧客の値が含まれている必要があります。
ocdm_sys.dwd_acct_sttstcには、最近6か月間の顧客ごとの適切な値が含まれている必要があります。
次の文を実行して、ocdm_miningスキーマ内のマイニング・ソース・マテリアライズド・ビューをリフレッシュします。
exec pkg_ocdm_mining.refresh_mining_source;
例4-5 Oracle Communications Data ModelのORA-40112エラーのトラブルシューティング
戻されるエラーが"create_ltv_glmr_model"に対するORA-40112: 有効なデータ行数が不足していますとします。
このモデルでは、ターゲット列はocdm_mining.DMV_CUST_LTV_PRDCT_SRC.TOT_PYMT_RVNです。
このエラーをトラブルシューティングする手順は、次のとおりです。
次のSQL文を実行します。
select count(TOT_PYMT_RVN) from DMV_CUST_LTV_PRDCT_SRC;
この問合せで返される値が0(ゼロ)より大きく、顧客数と同等であることを確認します。数値が0以下の場合は、「パラレルDML実行の監視」の説明に従って、Oracle Communications Data Model Intra-ETLの実行ステータスを確認してください。
例4-6 Oracle Communications Data ModelのORA-11130エラーのトラブルシューティング
戻されるエラーが"create_sentiment_svm_model"に対するORG-11130: コレクションにデータが見つかりませんとします。
このエラーは、テキスト指向のモデル・トレーニングのソース表ocdm_mining.dm_cust_cmmntに十分なデータがない場合に発生します。
顧客指向分析用のテキストがロードされていることを確認する手順は、次のとおりです。
次のSQL文を発行します。
Select OVRAL_RSLT_CD, count(CUST_COMMENT) from DWB_EVT_PRTY_INTRACN group by OVRAL_RSLT_CD;
顧客対話表DWB_EVT_PRTY_INTRACNからのテキスト・コメント数をチェックします。
顧客対話表に十分なデータがない場合は、ソース・システムからOracle Communications Data ModelへのETLロジックを確認します。