| Oracle® Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド 11gリリース2 (11.2) B61350-02 |
|



 前 |
 次 |
この章では、Oracle Warehouse Builderマッピングにおけるソースおよびターゲットとしての演算子の使用方法について説明します。
この章の内容は次のとおりです。
Oracleソースおよびターゲット演算子とは、ワークスペースのOracleデータ・オブジェクトにバインドされている演算子を指します。これらの演算子をマッピングで使用して、Oracleデータ・オブジェクトへのデータのロードまたはOracleデータ・オブジェクトからのデータのソーシングを実行します。
プロパティ・インスペクタに、選択した演算子のプロパティが表示されます。これにはソースおよびターゲット演算子のパラメータの次のカテゴリが含まれます。
チェンジ・データ・キャプチャ: このカテゴリは、表およびビューに対してのみ表示されます。これには、「キャプチャの一貫性」、「チェンジ・データ・キャプチャ・フィルタ」、「有効」および「トリガー・ベース・キャプチャ」の各プロパティが含まれます。
条件付きロード: 「更新用ターゲット・フィルタ」、「削除用ターゲット・フィルタ」および「制約による一致」の各プロパティを設定できます。
データのチャンク化: このカテゴリは、表、ビューおよびマテリアライズド・ビューに対して表示されます。これには、「フィルタ条件のチャンク化」、「チャンク化有効」および「パラレル・チャンクのフィルタ条件」の各プロパティが含まれます。これらのプロパティの詳細は、「表演算子のチャンク化」を参照してください。
エラー表: 「エラー表名」、「ロールアップ・エラー」および「この演算子からのエラーのみを選択」の各プロパティを設定できます。このプロパティのセクションは、表、ビュー、マテリアライズド・ビュー、外部表およびディメンションのマッピング演算子にのみ表示されます。
一般: 「一般」ノードに、「プライマリ・ソース」、「ターゲット・ロード順序」および「ロード・タイプ」を設定できます。ターゲットのタイプに応じて、「Oracleターゲット演算子のロード・タイプ」および「フラット・ファイルのロード・タイプ」で説明しているようにロード・タイプに異なる値を設定できます。
キー(読取り専用): 「キー名」、「キー・タイプ」および「参照キー」を表示できます。演算子がソースとして機能する場合は、キー設定は結合演算子とともに使用されます。演算子がターゲットとして機能する場合は、キー設定は「制約による一致」パラメータとともに使用されます。
ファイル・プロパティ: ファイル・プロパティでは、「バウンド名」を参照できます。
一時ステージ表: このカテゴリは、表、ビュー、マテリアライズド・ビューおよび外部表に対して表示されます。これには、「付加DDL句」、「一時ステージング表です」および「一時ステージ表ID」の各プロパティが含まれます。これらのプロパティの詳細は、「ETL実行中の一時表の作成」を参照してください。
キャプチャ一貫性によって実行されたチェンジ・データ・キャプチャのタイプが決まります。次のいずれかのオプションを選択します。
一貫セット: 一貫セットのチェンジ・データ・キャプチャが実行されます。
非一貫セット: 非一貫セットのチェンジ・データ・キャプチャが実行されます。
なし: チェンジ・データ・キャプチャは実行されません。
チェンジ・データ・キャプチャ・フィルタは、特定のサブスクライバの変更のキャプチャに使用されたフィルタを表します。
チェンジ・データ・キャプチャを実行する機能を有効化する場合に選択します。
ソース表でトリガーを使用して変更がキャプチャおよび伝播されたことを示す場合に使用します。
Oracle Application Embedded Data Warehouse(EDW)ユーザーは、EDWのドキュメントを参照してください。その他のユーザーは、このパラメータは無視してください。
ロード・タイプのプロパティを使用して各ターゲット演算子のロード・タイプを選択します。
ディメンションおよびキューブ演算子を除き、すべてのOracleターゲット演算子について、次のオプションを1つ選択します。
CHECK/INSERT: ターゲットに既存の行があるかどうかをチェックします。既存の行がない場合は、受信行がターゲットに挿入されます。
DELETE: 受信行セットを使用して、ターゲットの行のうち削除対象となる行がどれであるかを判別します。
DELETE/INSERT: ターゲットの行をすべて削除し、新規行を挿入します。
INSERT: 受信行セットをターゲットに挿入します。同じプライマリ・キーまたは一意のキーの行が存在する場合は、挿入操作に失敗します。
INSERT/UPDATE: それぞれの受信行について最初に挿入演算を実行します。挿入に失敗すると、更新演算が行われます。更新する一致レコードがない場合は、挿入が実行されます。INSERT/UPDATEを選択しており、「デフォルト・オペレーティング・モード」が「行ベース」に設定されている場合は、ターゲットに一意制約を設定する必要があります。オペレーティング・モードが「セット・ベース」に設定されている場合は、Oracle Warehouse BuilderによってMERGE文が生成されます。
NONE: ターゲットに対して演算は実行されません。この設定はテストに便利です。抽出と変換は実行されますが、ターゲットには何も影響しません。
TRUNCATE/INSERT: ターゲットを切り捨てた後、受信行セットを挿入します。このオプションを選択すると、マッピングの実行に失敗した場合でも、操作をロールバックできません。切捨てでは、ターゲットからデータを完全に削除します。
UPDATE: 受信行セットを使用してターゲットの既存の行を更新します。指定の一致条件に合致する行がない場合は、何も変更されません。
ターゲット・モジュールの構成パラメータ「PL/SQL生成モード」をOracle 10g、Oracle 10gリリース2、Oracle 11gリリース1またはOracle 11gリリース2に設定すると、ターゲットがセット・ベース・モードで更新されます。生成されるコードには、挿入句なしでMERGE文が含まれます。Oracle9i以前のバージョンのPL/SQLコードを生成するよう構成されたモジュールについては、ターゲットは行ベース・モードで更新されます。
UPDATE/INSERT: 「デフォルト・オペレーティング・モード」が各受信行に対して「行ベース」に設定されている場合、行が更新されていないときは最初に更新が実行され、続けて挿入が行われます。「デフォルト・オペレーティング・モード」が「セット・ベース」に設定されている場合は、MERGE文が生成されます。セット・ベース・モードを生成できるのは、ターゲット・モジュールの「PL/SQL生成モード」パラメータがOracle 10g以上の場合のみです。
ディメンジョンおよびキューブの場合、ロード・タイプのプロパティのオプションは、ロードおよび削除です。データをディメンジョンまたはキューブにロードする場合はロードを使用します。データをディメンジョンまたはキューブから削除する場合は削除を使用します。
SQL*Loaderパラメータを構成し、マッピングのSQL*Loaderオプションを定義します。構成中に選択した値は、生成されたSQL*Loaderと実行時の制御ファイルに直接影響します。SQL*Loaderには、データをロードする方法が2つあります。
従来型パスによるロード: SQL INSERT文を実行し、Oracleデータベースの表にデータを移入します。
ダイレクト・パス・ロード: Oracleデータ・ブロックをフォーマット化し、データベース・ファイルに直接データ・ブロックを書き込むことによってOracleデータベースのオーバーヘッドを大幅に削減します。直接ロードでは他のユーザーとのデータベース・リソースの競合がないため、通常ディスク・スピードに近い速度でデータをロードできます。
制限、セキュリティおよびバックアップ関連などの特定の考慮事項は、データベース・ファイルへのそれぞれのアクセス方法で検討する必要があります。詳細は、「Oracle Databaseユーティリティ」を参照してください。
SQL*Loaderを使用してフラット・ファイルからデータを抽出するマッピングの設計および実装では、生成されたSQL*Loaderスクリプトに影響を及ぼす様々なプロパティを構成できます。1つのマッピングの各ロード演算子には、ロード・タイプと呼ばれる演算子のプロパティがあります。このプロパティに含まれる値は、ロード演算子に対するSQL*Loader INTO TABLE句の生成方法に影響します。SQL*Loaderではデータの追加、挿入、置換または切捨てはできますが、この処理中はデータは更新できません。
表25-1に、各ロード・タイプに関連付けられたINTO TABLE句と、その既存ターゲットのデータに対する影響を示します。
表25-1 ロード・タイプとINTO TABLEの関係
| ロード・タイプ | INTO TABLE句 | 既存データのターゲットに対する影響 |
|---|---|---|
|
INSERT/UPDATE |
APPEND |
追加データをターゲットに追加します。 |
|
DELETE/INSERT |
REPLACE |
既存データを削除し、新規データと置換します(DELETEトリガーが起動します)。 |
|
TRUNCATE/INSERT |
TRUNCATE |
既存データを削除し、新規データと置換します(DELETEトリガーが起動します)。 |
|
CHECK/INSERT |
INSERT |
ターゲット表が空であるとみなされます。 |
|
NONE |
INSERT |
ターゲット表が空であるとみなされます。 |
このプロパティでは、同じマッピング内の複数のターゲットのロード順序を指定できます。Oracle Warehouse Builderは、デフォルトのロード順序を外部キー関係に基づいて決定します。このプロパティでデフォルト順序を上書きします。
条件でTRUEと評価された場合、その行は更新ロード操作に含まれます。
条件でTRUEと評価された場合、その行は削除ロード操作に含まれます。
ターゲット演算子をUPDATE条件またはDELETE条件付きでロードする場合は、一致基準を指定できます。一致基準とロード基準は手動で設定することも、複数の組込みオプションから選択することもできます。ターゲットの一意キーまたは主キーの情報で属性に手動で設定されている一致基準とロード基準を上書きするかどうかを指定する場合は、「制約による一致」を使用します。「制約による一致」プロパティをクリックすると、その演算子で定義されている制約と組込みロード・オプションがリスト表示されます。
「すべての制約」を選択すると、手動で設定した属性のロード設定がすべて無効になり、表25-2に示されているようにターゲット属性のロードおよび一致プロパティが設定されているものとしてデータがロードされます。
「すべての制約」を選択すると、ロード設定「行の更新中に列をロードする」はキー属性に対して自動的に いいえ」とはみなされません。ただし、MERGE生成を実行中は、この点が検証され、UPDATE一致に使用される特定の属性がUPDATEロードにも使用されている場合は検証警告が表示されます。
「制約なし」を選択すると、手動で設定したすべてのロード設定が優先され、データはその設定に従ってロードされます。
演算子にすでに定義されている制約を選択すると、手動で設定した属性のロード設定はすべて無効になり、表25-3に示されているようにターゲットのロードおよび一致プロパティが設定されているものとしてデータがロードされます。
すでに定義されている制約を選択すると、ロード設定「行の更新中に列をロードする」はキー属性に対して自動的に いいえ」とはみなされません。ただし、MERGE生成を実行中は、UPDATE一致に使用される特定の属性がUPDATEロードにも使用されている場合は検証警告が表示されます。
属性レベルで変更を加えた後、すべての設定をデフォルトに戻す場合は、「拡張」をクリックします。ロード・オプションを含むリストが表示されます。デフォルトに戻される設定は、選択する制約タイプに応じて異なります。
たとえば、すべてのキー属性の一致プロパティをリセットする場合は、「拡張」をクリックしてから「制約なし」を選択し、「OK」をクリックします。手動によるロード設定は上書きされ、データは表25-4の設定に基づきロードされます。
表25-4 拡張と制約なしを選択した場合のデフォルトのロード設定
| ロード設定 | すべてのキー属性 | その他すべての属性 |
|---|---|---|
|
行の挿入中に列をロードする |
はい |
いいえ |
|
行の更新中に列をロードする |
はい |
はい |
|
行の更新中に列を一致させる |
いいえ |
いいえ |
|
行の削除中に列を一致させる |
いいえ |
いいえ |
また、「拡張」をクリックしてから「すべての制約」を選択すると、手動で設定したロード設定が上書きされ、データは表25-5の設定に基づいてロードされます。
コード・ジェネレータで使用する名前です。演算子が現在バインドおよび同期化されている場合、このプロパティは読取り専用になります。演算子がまだバインドされていない場合は、ワークスペース・オブジェクトに対して同期化する前に、マッピング・エディタでバウンド名を編集できます。
主キー、外部キーまたは一意キーの名前です。
主キー、外部キーまたは一意キーのキー・タイプです。
演算子に外部キーがある場合は、「参照キー」に参照オブジェクトの主キーまたは一意キーが表示されます。
ロード操作中の無効なレコードを格納する、エラー表の名前です。
「はい」を選択し、エラー表からエラー名で選択したレコードをロールアップします。これにより、特定の入力レコードで生成されたエラーはすべて、エラー名属性で連結されたエラー名を持つ単一のレコードにロールアップされます。
エラー表から選択された行には、このマップ実行でこの演算子によって作成されたエラーのみが含まれます。
ソースおよびターゲット演算子の各属性に対して、パラメータは次のタイプに分類されます。
一般: 「一般」プロパティでは、「バウンド名」プロパティ、ビジネス名、物理名を表示できます。
チャンク化列: このカテゴリは、表、ビューおよびマテリアライズド・ビューの各演算子の属性に対してのみ表示されます。これには、「NUMBER列のチャンク化」プロパティのみが含まれます。
コード・テンプレートのメタデータ・タグ: このカテゴリには、「SCD」、「UD1」、「UD2」, 「UD3」、「UD4」、「UD5」および「UPD」の各プロパティが含まれます。
データ型情報: データ型のプロパティは、すべての演算子に適用できます。これには「データ型」、「精度」、「スケール」、「長さ」および「小数秒精度」があります。
ロード・プロパティ: 表、ディメンジョン、キューブ、ビューおよびマテリアライズド・ビューの演算子にはロード・プロパティ・カテゴリがあります。このカテゴリには、「行の挿入中に列をロードする」、「行の更新中に列をロードする」、「行の更新中に列を一致させる」、「更新: 演算」および「行の削除中に列を一致させる」の設定が含まれます。
特定の演算子にはその演算子に固有のプロパティが含まれます。これらのプロパティは演算子固有プロパティ・ノードにリスト表示され、その演算子の項で説明されています。
このアイテムを識別するためにコード・ジェネレータで使用される名前です。デフォルトでは、アイテムと同じ名前です。これは演算子がバインドされている場合は、読取り専用の設定になります。
属性のデータ型です。
データ型が数値型または浮動小数点型の場合、この属性の最大桁数になります。これは読取り専用の設定です。
小数点以下の桁数です。数値属性にのみ適用されます。
CHAR、VARCHARまたはVARCHAR2属性の最大長です。
日時フィールドの小数部の桁数です。0から9までの数値を入力できます。このプロパティは、TIMESTAMP、TIMESTAMP WITH TIME ZONEおよびTIMESTAMP WITH LOCAL TIME ZONEデータ型に対してのみ使用されます。
この設定により、そのようにマッピングされている場合でもデータはターゲットへ移動されません。「はい」(デフォルト)を選択すると、データはマップ済ターゲットに到達します。
この設定により、そのようにマッピングされている場合でも選択した属性データはターゲットへ移動されません。「はい」(デフォルト)を選択すると、 データはマップ済ターゲット属性に到達します。一意キーの列がまったくマップされていない場合は、一致条件の作成に一意キーは使用されません。一意キーの列がまったくマップされていない場合は、エラーが表示されます。キー列以外の列がマップされていない場合、その列はロードには使用されません。
この設定では、ソース属性とマップ先のターゲット属性の間で一致するものがあった場合のみ、データ・ターゲット行が更新されます。一致がある場合は、行が更新されます。このプロパティを「はい」(デフォルト)に設定すると、属性は一致属性として使用されます。この設定を使用する場合は、すべてのキー列をマップする必要があります。ターゲット・エンティティに定義されている一意キーが1つのみの場合は、制約を使用してこの設定を上書きします。
一致する行が検出された場合に更新演算を実行するように指定できます。更新演算はソース属性のデータを使用してターゲット属性で実行されます。表25-6は、指定できる更新演算を示し、その論理を説明したものです。
表25-6 更新演算
| 演算 | 例 | ソースの値が5で、ターゲットの値が10の場合の結果 |
|---|---|---|
|
= |
TARGET = SOURCE |
TARGET = 5 |
|
+= |
TARGET = SOURCE + TARGET |
TARGET = 15(5 + 10) |
|
-= |
TARGET = TARGET - SOURCE |
TARGET = 5(10 - 5) |
|
=- |
TARGET = SOURCE - TARGET |
TARGET = マイナス5(5 - 10) |
|
*= |
TARGET = SOURCE * TARGET |
TARGET = 50 (5 * 10) |
|
/= |
TARGET = TARGET / SOURCE |
TARGET = 2 (10 / 5) |
|
=/ |
TARGET = SOURCE / TARGET |
TARGET = 0.5 (5 /10) |
|
||= |
TARGET = TARGET || SOURCE |
TARGET = 105(10は5で切捨て) |
|
=|| |
TARGET = SOURCE || TARGET |
TARGET = 510(5は10で切捨て) |
ソース属性とマップ先のターゲット属性の間で一致するものがあった場合のみ、データ・ターゲット行が削除されます。一致がある場合は、行で削除演算が実行されます。このプロパティを「はい」(デフォルト)に設定すると、属性は一致属性として使用されます。この制約設定は上書きできます。
属性のチャンク化番号列を選択し、その属性をチャンク化属性として使用します。このプロパティはパラレル・チャンク化にのみ適用されます。
定数演算子を使用すると定数値を定義できます。定数はPL/SQLまたはABAPマッピングの任意の場所に配置できます。

1つ以上の定数属性を含む出力グループが1つ作成されます。Oracle Warehouse Builderでは、マッピング実行の最初に定数が初期化されます。
たとえば、現在のシステム日付の値を表演算子にロードするために定数演算子を使用します。式ビルダーで、事前定義済の変換のリストから、パブリック変換SYSDATEを選択します。
パブリック変換の詳細は、第4章、「データ変換の概要」を参照してください。
PL/SQLまたはABAPマッピングでの定数演算子の定義手順:
マッピング・エディタのキャンバスに定数演算子をドロップします。
定数演算子を右クリックして「開く」を選択します。
「定数エディタ」ダイアログ・ボックスが表示されます。
「出力」タブで、「属性」列の空白列をクリックし、出力属性の名前を入力して出力属性を作成します。
割り当てられているデフォルトのデータ型はNUMERICです。データ型と長さ、精度などの属性に関連付けられたその他のパラメータは変更できます。
出力属性に関連付けられた式を入力します。
出力属性の式フィールドを使用して、式を入力します。または、「式」フィールドの右の省略記号ボタンをクリックし、「式ビルダー」ダイアログ・ボックスを使用して式を定義します。
出力属性に割り当てられた長さ、精度およびスケールの各プロパティは、マッピングで定義した式によって戻される値と一致する必要があります。VARCHAR、CHARまたはVARCHAR2データ型の場合は、'my_string'のように、定数文字列リテラルを一重引用符で囲みます。
「OK」をクリックして、「定数エディタ」ダイアログ・ボックスを閉じます。
オブジェクトの構成演算子では、それを構成する個々の属性を使用して、マッピングにSQLオブジェクトのデータ型(オブジェクト・タイプおよびコレクション・タイプ)、PL/SQLオブジェクト・タイプおよびカーソルを作成できます。
たとえば、オブジェクトの構成演算子を使用して、データ型がオブジェクト・タイプの列を含む表へのデータのロードに使用するSQLオブジェクト・タイプを作成できます。また、この演算子を使用して、アドバンスト・キューにデータをロードするペイロードを作成することもできます。この演算子では、SYS.REFCURSORオブジェクトも構成できます。
オブジェクトの構成演算子には、入力グループと出力グループが1つずつあります。入力グループはオブジェクト・タイプを構成する各属性を表します。オブジェクトの構成演算子の出力は、各属性を使用して作成されるオブジェクト・タイプです。マッピングでは、オブジェクトの構成演算子の出力属性のデータ型はマップ先のターゲット属性と一致する必要があります。
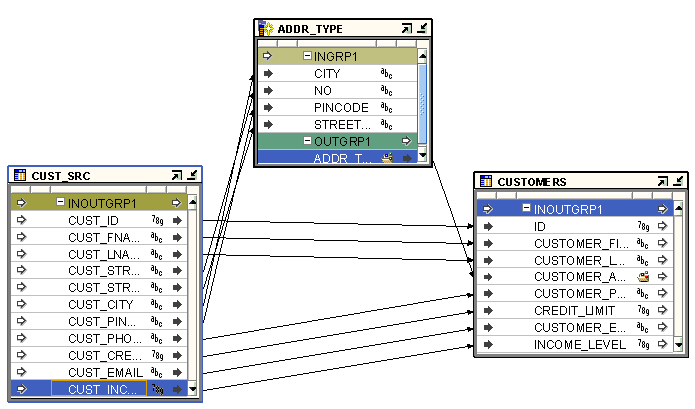
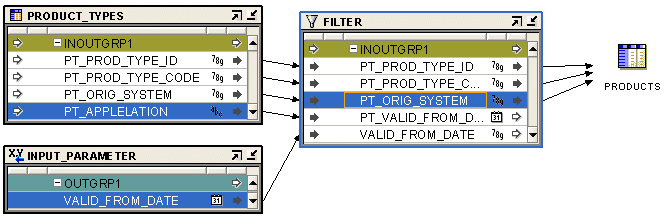
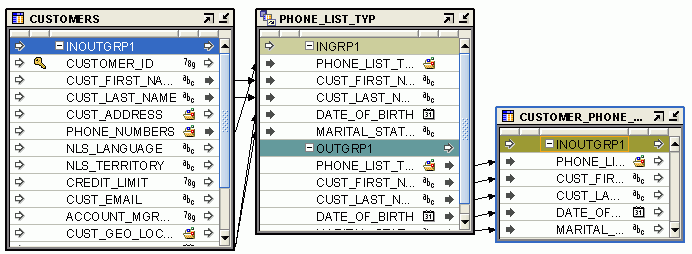
図25-1は、オブジェクトの構成演算子を使用するマッピングを示したものです。ソース表CUST_SRCは、個別の属性を使用して、顧客アドレスの各コンポーネントを格納します。ただし、ターゲット表CUSTOMERSは、顧客アドレスの格納にオブジェクト・タイプを使用します。CUST_SRC表からCUSTOMERS表にデータをロードするには、顧客アドレスのシグネチャがCUSTOMERSの顧客アドレスのシグネチャと一致するオブジェクト・タイプであることが必要です。オブジェクトの構成演算子は、顧客アドレスを入力として格納するCUST_SRCから各属性を取得してオブジェクト・タイプを構成します。オブジェクトの構成演算子は、ワークスペースに格納されているユーザー定義のデータ型CUST_ADDRにバインドされます。
マッピングでのオブジェクトの構成演算子の定義手順:
オブジェクトの構成演算子をマッピング・エディタにドラッグ・アンド・ドロップします。
「オブジェクトの構成の追加」ダイアログ・ボックスを使用して、オブジェクトを作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
オブジェクトの構成に使用する個々のソース属性を、オブジェクトの構成演算子の入力グループにマップします。
オブジェクトの構成演算子の出力属性をターゲット属性にマップします。ターゲット属性のデータ型はオブジェクト・タイプである必要があります。
オブジェクトの構成演算子の出力属性のシグネチャとターゲット属性のシグネチャは、同じである必要があります。
キューブ演算子を使用して、キューブからのデータのソーシングやキューブへのデータのロードを行います。

キューブ演算子には、キューブと同じ名前のグループが含まれます。このグループには、各キューブ・メジャーの属性があります。キューブが参照する各ディメンション・レベルのサロゲート識別子やビジネス識別子の属性も含まれます。また、キューブ演算子では、キューブが参照する各ディメンションに対してグループが1つ表示されます。
オーファン管理ポリシーを指定してキューブのエラー表を作成する場合、このキューブをマッピングに追加すると、キューブ演算子にはERROR_<cube_name>というグループが含まれます。これは、マッピング・キャンバスのキューブ演算子ではなく、キューブ演算子詳細に表示される属性を含む出力グループです。これらの属性を使用してデータ・フローを作成するには、キャンバス上のERROR_<cube_name>グループを選択してから、 「グラフ」メニューから「表示セットの選択」、「すべて」の順に選択してキャンバス上にこれらの属性を表示します。
キューブ演算子は、現在のプロジェクトの任意のOracleモジュールに定義されているキューブにバインドできます。また、キューブ演算子を同期化して、バインドされているキューブに対する変更内容で更新もできます。キューブ演算子を同期化するには、マッピング・エディタのキャンバスでキューブ演算子を右クリックして、「同期化」を選択します。
キューブ演算子には、キューブのロードに使用できる次のプロパティがあります。
ロード・タイプ キューブにデータをロード中、またはキューブからデータを削除中であることを示す場合は、このプロパティを使用します。このプロパティの次のいずれかの値を設定します。
INSERT_LOAD
ソース・データ・セットからのすべてのレコードがキューブに挿入されます。オーファン管理にはこのオプションを設定することをお薦めします。
LOAD
ソース・データ・セットからのレコードがキューブにマージされます。したがって、ソースからロード中のレコードがキューブに存在している場合、このレコードは更新されます。存在しないソース・データ・セット内のレコードが挿入されます。
REMOVE
受信ソース・レコードと一致するキューブ内のレコードがキューブから削除されます。
ターゲット・ロード順序 同じマッピング内の複数のターゲットのロード順序を指定します。Oracle Warehouse Builderは、デフォルトの順序を外部キー関係に基づいて決定します。このプロパティでデフォルト順序を上書きできます。
ソース集計の有効化 このプロパティをTrueに設定すると、キューブをロードする前にソース・データが集計されます。ソース・データはすべてのディメンジョン・キー別にグループ化されます。
キューブ・メジャー属性のデフォルト集計関数はSUMです。キューブ・メジャーのソース集計関数プロパティの設定は変更できます。
キューブのオーファン管理ポリシーをデフォルト・ディメンジョン・レコードに設定し、キューブ演算子のソース集計の有効化プロパティをFalseに設定すると、キューブ表を更新すると実行エラーが発生する場合があります。したがって、このシナリオの場合Oracle Warehouse Builderでは、キューブ検証中に警告が表示されます。
キューブの解決 キューブをロード中にキューブ・データを集計する場合は、このプロパティを「はい」に設定します。ロード時間が長くなりますが、問合せ時間は短くなります。データがロードされてから、次に集計されます。
増分集計 このオプションを選択すると、増分ロードを実行できます。以前にキューブが解決されている場合は、後続のロードでは新規データのみが集計されます。
AWステージ済ロード: TRUEに設定すると、セット・ベースのAWロード・データは、AWにロードされる前に一時表にステージされます。
AWロード前に切捨て キューブのロード開始前に既存の全キューブの値を切り捨てる必要があるかどうかを示します。このプロパティを「はい」に設定すると、既存のキューブ・データが切り捨てられます。
キューブ演算子で属性に次のプロパティを設定できます。
更新: 演算 このプロパティはROLAP実装を使用するキューブおよびキューブ・メジャーを表す属性にのみ適用できます。
キューブをロード中のキューブ・メジャーの更新操作のタイプを指定します。選択できるオプションは、+=、-=、/=、=、=-、=||および||=です。デフォルト値は=で、この値を使用してソースのファクト・レコードがキューブに挿入されます。
たとえば、このプロパティを+=に設定すると、キューブ・メジャーにマップされるソース属性値は既存のメジャー値に追加されます。同じディメンジョンに複数のソース・ファクト・レコードがある場合は、これらのレコードをキューブにロードする前に集計にアグリゲータ演算子を使用することを確認します。
NULLデータ値 キューブのオーファン管理ポリシーでNULLと解釈されている値を指定します。キューブをロードする際に、キューブ・エディタの「孤立」タブを使用してNULLディメンション・キー値と無効ディメンション・キー値を使用するレコードの取扱い方法を指定します。
このプロパティのデフォルト値はNULLです。
データ・ジェネレータ演算子を使用して、順序、レコード番号またはシステム日付をマッピングに取り込みます。単一のデータ・ジェネレータ演算子を使用してこれらの関数を複数マップできます。

フラット・ファイルのソースおよびターゲットのマッピングでは、データ・ジェネレータ演算子によってマッピングがSQL*Loaderに接続され、データベース・レコードに格納されるデータが生成されます。
次のファンクションを使用できます。
RECNUM
SYSDATE1
SEQUENCE
Oracle Warehouse Builderでは、フィールド指定として順序、レコード番号、システム日付および定数を指定するのみでデータを生成できます。SQL*Loaderでは、LOADキーワードで指定された数のレコードが挿入されます。
データ・ジェネレータ演算子には、レコード番号、システム日付および一般的な順序に対応する事前定義済の属性がある出力グループが1つあります。データ・ジェネレータ演算子を使用して、レコード番号、システム日付または順序を取得します。その他のすべてのファンクションには、定数演算子または式演算子を使用します。
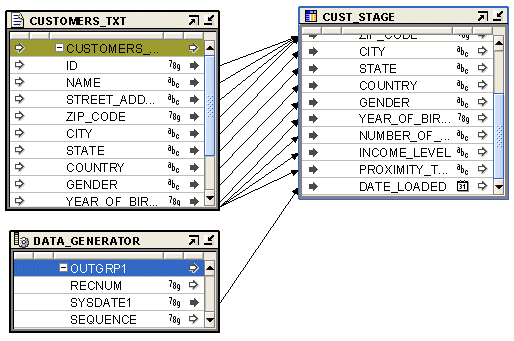
図25-2は、データ・ジェネレータ演算子を使用して現在のシステム日付を取得するマッピングを示したものです。フラット・ファイルCUSTOMERS_TXTのデータがステージング表CUST_STAGEにロードされます。ステージング表には、データがロードされた日付の追加属性が含まれます。データ・ジェネレータ演算子のSYSDATE1属性は、ステージング表CUST_STAGEのDATE_LOADED属性にマップされます。
SQL*Loaderマッピングでのデータ・ジェネレータの定義手順:
マッピング・エディタのキャンバスにデータ・ジェネレータ演算子をドロップします。
データ・ジェネレータ演算子からSEQUENCE属性を選択し、ターゲット列にマップします。
Oracle Warehouse Builderでは、プロパティ・インスペクタにこの属性のプロパティが表示されます。
「式」フィールドで省略記号のボタンをクリックして「式ビルダー」を開き、式を定義します。
(オプション)RECNUM属性に対して手順2と3を繰返します。
レコードのロード元であるレコード番号に属性を設定するには、RECNUM属性からマップします。レコードの番号は、最初のデータ・ファイルの先頭をレコード1として、順番にカウントされます。RECNUMは、1つの論理レコードがまとめられるたびに増分されます。これは廃棄、スキップ、拒否またはロードされたレコードについて増分されます。たとえば、オプションSKIP=10を使用すると、最初にロードされたレコードのRECNUMは11になります。
SYSDATEからマップした列は、SQL SYSDATEファンクションで定義した形式で現在のシステム日付を取得します。
ターゲット列のデータ型はCHARまたはDATEである必要があります。列のデータ型がCHARの場合、日付はdd-mon-yy形式でロードされます。システム日付がDATE列にロードされると、この列には時間形式と日付形式でアクセスできます。新規システム日付や時間は、従来型パスのロードで挿入されたレコードの各配列、ダイレクト・パス・ロード中にロードされたレコードの各ブロックに使用されます。
SEQUENCE属性をターゲット列にマップして、列の順序番号を生成します。SEQUENCEキーワードは列の一意の値を保証します。SEQUENCEは、ロードまたは拒否される各レコードを増分します。廃棄またはスキップされたレコードに対しては、値は増加しません。
生成されるデフォルト順序はSEQUENCE(COUNT)です。プロパティ式の順序式は編集できますが、構文を指定する必要があります。
列名とSEQUENCEファンクションの組合せにより、列の指定が完全になります。表25-7は、順序値に使用可能なオプションを示したものです。
表25-7 順序値のオプション
| 値 | 説明 |
|---|---|
|
COUNT |
順序は表にあるレコード数と増分を加算した数から始まります。 |
|
integer |
開始順序番号を指定します。 |
|
MAX |
順序は列に増分を加算した現在の最大値から始まります。 |
|
incr |
レコードのロード後または拒否後に順序番号が増分する値です。 |
ロード中にレコードが拒否されると、データ・エラーに関係なく、挿入の順序が保持されます。たとえば、ある列の4つの行に順序番号10、12、14、16が割り当てられている場合に、12の行が拒否されると、10、12、14ではなく、10、14、16が割り当てられている有効な行が挿入されます。拒否されたデータを修正して再度挿入すると、順序と一致するように列を手動で設定できます。
ディメンション演算子を使用して、ディメンションおよび緩やかに変化するディメンションからのデータのソーシングやディメンションへのデータのロードを行います。
ディメンション演算子には、ディメンションの各レベルにグループが1つ含まれます。グループにはディメンション・レベルと同じ名前を使用します。各レベルのレベル属性は、レベルを表すグループの下に示されています。
ディメンジョン・レベルのサロゲート識別子属性または親サロゲート識別子参照属性にはデータ・フローをマップできません。Oracle Warehouse Builderでは、ディメンションのロード時にこれらの列が自動的に入力されます。
ワークスペースに格納されているディメンションとディメンション演算子をバインドし、同期化できます。生成済コードのエラーを回避するには、ディメンション演算子を含むマッピングを配布する前に、ワークスペース・ディメンションの配布が完了していることを確認します。ディメンジョン演算子を同期化するには、マッピング・エディタのキャンバスでディメンジョンを右クリックして、「同期化」を選択します。
オーファン管理ポリシーを指定してディメンジョンのエラー表を作成する場合、このディメンジョンをマッピングに追加すると、ディメンジョン演算子にはERROR_<dimension_name>というグループが含まれます。これは、マッピング・キャンバスのディメンジョン演算子ではなく、ディメンジョン演算子詳細に表示される属性を含む出力グループです。これらの属性を使用してデータ・フローを作成するには、キャンバス上のERROR_<dimension_name>グループを選択してから、 「グラフ」メニューから「表示セットの選択」、「すべて」の順に選択してキャンバス上にこれらの属性を表示します。
マッピングでのディメンション演算子の使用手順:
ディメンション演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
Oracle Warehouse Builderにより、「ディメンションの追加」ダイアログ・ボックスが表示されます。
「ディメンションの追加」ダイアログ・ボックスでディメンションを選択します。
または、手順1と2を1つの手順に組み合せることができます。マッピング・エディタで、プロジェクト・ナビゲータにナビゲートします。ディメンジョンを選択し、マッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
ディメンション演算子からターゲットへ属性をマップ、またはソースからディメンション演算子へ属性をマップします。
プロパティ・インスペクタを使用して、ディメンションまたは緩やかに変化するディメンションからのデータのロードまたは削除に関する追加詳細を定義するオプションを設定します。
演算子、ディメンション内の各レベルを表すグループおよびレベル属性という3つのレベルでプロパティを設定できます。次の各項では、ディメンジョン演算子プロパティについて説明します。これらのプロパティは、AWプロパティ、ディメンション・プロパティ、エラー表、履歴ロギングおよび孤立した管理ポリシーに分類されます。
ターゲット・ロード順序 同じマッピング内の複数のターゲットのロード順序を指定します。Oracle Warehouse Builderは、デフォルトの順序を外部キー関係に基づいて決定します。このプロパティでデフォルト順序を上書きします。
AW名 ディメンジョン・データが格納されるアナリティック・ワークスペースの名前を表します。
AWステージ済ロード このプロパティはMOLAPディメンジョンにのみ適用できます。アナリティック・ワークスペースへのロード前にセット・ベースのロード・データを一時表にステージするには、このオプションを選択します。
ディメンション演算子内の各グループはディメンション・レベルを表します。ディメンション・レベルごとに次のプロパティを設定できます。
抽出タイプ: ディメンションがソースとして使用される場合に実行される抽出操作を表します。タイプ2のSCDから現行レコードのみを抽出するには、「現行のみ抽出(タイプ2のみ)」を選択します。このプロパティはタイプ2のSCDにのみ有効です。ディメンションまたはSCDからすべてのレコードを抽出するには、「すべて抽出」を選択します。
デフォルトのオープン・レコード終了時間: このプロパティは、タイプ2のSCDにのみ適用可能です。これは、新規に作成したオープン・レコードの終了時間として使用される日付値を表します。デフォルト値は「NULL」です。
|
注意: 「コミット制御」プロパティを「手動」に設定してある場合は、「自動ヒントが有効です」プロパティを「FALSE」に設定してください。それ以外の場合は、マッピングが正しく実行されない可能性があります。 |
AWロード前に切捨て: このプロパティはMOLAPディメンションにのみ適用可能です。これは、新規データをロードする前に既存のすべてのディメンション・データを切り捨てるかどうかを示します。新規データをロードする前に既存のすべてのディメンション・データを切り捨てるには、このプロパティをYESに設定します。
ロード・タイプ ディメンションについて実行される操作のタイプを表します。選択できるオプションは、次のとおりです。
LOAD: ディメンションまたは緩やかに変化するディメンションにデータをロードする場合は、この値を設定します。
REMOVE: ディメンションまたは緩やかに変化するディメンションからデータを削除する場合は、この値を設定します。
データをロードまたは削除する際に、ソース・レコードがディメンション内に存在するかどうかを判別するための検索が実行されます。照合は自然キー識別子によって実行されます。レコードが存在する場合、REMOVE操作により既存のデータが削除されます。LOAD操作では既存のデータが更新され、その後新規データがロードされます。
親レコードを削除すると、子レコードは存在しない親を参照します。
タイプ2 現行のみ抽出/削除 このプロパティは、タイプ2のSCDにのみ適用可能です。抽出または削除するレコードを指定するには、このプロパティを使用します。このプロパティには次の値を設定できます。
YES: タイプ2のSCDからデータを抽出する場合は、ソース・データ内のビジネス識別子と一致する現行レコードのみが抽出されます。タイプ2のSCDからデータを削除する場合は、ソース・データ内のビジネス識別子と一致する現行レコードのみがクローズされます(有効期限はSYSDATEまたは「デフォルトのオープン・レコード終了時間」プロパティで定義した日付のいずれかに設定されます)。
スノーフレーク実装を使用するタイプ2のSCDの場合、子レコードが含まれるレコードは削除できません。
NO: タイプ2のSCDからデータを抽出する場合は、データ・ソースのビジネス識別子と一致するすべてのレコード(履歴レコードを含む)がディメンションから抽出されます。
タイプ2のSCDからデータを削除する場合は、ソース・データ・セット内のビジネス識別子と一致するすべてのレコード(履歴レコードを含む)が削除されます。
DMLエラー表名 ディメンジョンに関連付けられたDMLエラーを格納する表の名前を表します。DMLエラーのログを作成するには、ディメンジョンに対するDMLエラー・ロギングを有効にする必要があります。DMLエラー・ロギングの詳細は、「DMLエラー・ロギングの使用」を参照してください。
エラー表名 データ・プロファイリングおよびオーファン管理の強制により発生する論理エラーを格納するエラー表の名前を表します。ディメンジョンのエラー表名プロパティの値を指定すると、このディメンジョンに関連付けられたディメンジョン演算子のエラー表名プロパティには同じ名前が表示され、名前は編集できません。それ以外の場合は、エラー表がある場合は名前を指定します。
エラー表の切り捨て このプロパティはエラー表にのみ適用でき、DMLエラー表には適用できません。使用するたびにエラー表を切捨てるには、このプロパティをはいに設定します。
デフォルトの初期レコード有効時間: このプロパティはタイプ2のSCDにのみ適用可能です。特定のディメンション・レコードの初期ロードに対する有効時間として割り当てられるデフォルト値を示します。このプロパティに設定されているデフォルト値はSYSDATEです。
デフォルトのオープン・レコード有効時間: このプロパティはタイプ2のSCDにのみ適用可能です。初期レコードの後のオープン・レコードの有効時間に設定されるデフォルト値を示します。このプロパティのデフォルト値はSYSDATEです。この値は変更しないでください。
デフォルトのオープン・レコード終了時間: このプロパティは、タイプ2のSCDにのみ適用可能です。これは、ディメンション内のすべてのレベルについて、新規に作成したオープン・レコードの終了時間として使用される日付値を表します。デフォルト値は「NULL」です。
複数の履歴ロードのサポート このプロパティはタイプ2のSCDにのみ適用可能です。単一ロード操作中に特定のビジネス識別子に対して複数行をロードする場合は、このオプションを選択します。このオプションを選択すると、マッピングは行ベースの非バルク・モードで実行されます。
特定のビジネス識別子に複数のレコードをロードする場合は、タイプ2レベルの有効日がソース演算子または変換演算子からロードされていることを確認してください。
通常、この状態は2つのディメンジョンの更新期間中に複数回ディメンジョン・レコードが変更される場合に発生します。たとえば、ディメンジョンは1日に1回のみ更新しますが、その日のうちにはディメンジョン・レコードの変更は複数回あります。
順不同履歴ロードのサポート このプロパティはタイプ2のSCDにのみ適用可能です。このプロパティをTrueに設定すると、履歴レコードの順不同変更を連続データ・ロードにロードできます。
このプロパティを「複数の履歴ロードのサポート」と併用することもできます。ただし、このプロパティを使用するとパフォーマンスのオーバーヘッドとなります。
Type2 Gap: このプロパティはタイプ2のSCDにのみ適用可能です。レコードがバージョン管理されている場合、古いレコードの終了時間と現行レコードの有効時間の時間間隔を示します。
トリガー属性の値が更新されると、現行レコードはクローズされ、更新された値で新しいレコードが作成されます。古いレコードのクローズおよび現行レコードのオープンは同時に行われるため、両方で同じ値を使用するのではなく、古いレコードの終了時間とオープン・レコードの有効時間の間に時間間隔を置くことをお薦めします。
Type2 Gap Units このプロパティはタイプ2のSCDにのみ適用可能です。「Type2 Gap」プロパティで示されたギャップ間隔を測定するために使用される時間単位を示します。オプションは、「秒」、「分」、「時間」、「日」および「週」です。デフォルト値は「秒」です。
デフォルト・レベル・レコードの作成 ディメンジョン演算子のバインド先のディメンジョンにデフォルト・レベル・レコードを作成する必要があるかどうかを示します。ディメンジョンのビジネス識別子およびサロゲート識別子にデフォルト行を作成する場合は、このプロパティを「はい」に設定します。
デフォルト・レコードで使用する値は、ディメンジョン演算子のバインド先のディメンジョンに選択したオーファン管理ポリシーによって異なります。ディメンジョンのオーファン管理ポリシーとしてメンテナンスなしを指定した場合は、ディメンジョン演算子の各レベルで属性のデフォルト値プロパティを使用してデフォルト・レコードで使用する値を指定します。ディメンジョンのオーファン管理ポリシーをデフォルト親に設定し、デフォルト・レコードに使用する属性値を指定した場合は、これらの値が属性のデフォルト値プロパティに自動的に表示され、デフォルト・レコードに使用されます。ディメンジョン・レベルの属性にデフォルト値を指定しないと、NULL値を使用してデフォルト・レコードが作成されます。
このプロパティを使用して時間ディメンジョンのデフォルト・レコードを生成することもできます。時間ディメンジョンには、オーファン管理ポリシーを設定できるオーファン・タブはありません。ただし、オーファン管理ポリシーが「メンテナンスなし」以外の値に設定されたキューブで時間ディメンションを使用する必要がある場合は、レベル属性の「デフォルト値」プロパティを設定してから、時間ディメンションの「デフォルトのレベル・レコードの作成」プロパティを「はい」に設定して、時間ディメンションのデフォルト・レコードを生成できます。
無効キーのLOADポリシー 無効の親レコードを含むレコードのロードに使用するオーファン管理ポリシーを表します。オプションは、メンテナンスなし、デフォルト親およびオーファン拒否です。
NULLキーのLOADポリシー NULL親キー参照を含むレコードのロードに使用するオーファン管理ポリシーを表します。オプションは、メンテナンスなし、デフォルト親およびオーファン拒否です。
レコード・エラー行 「はい」を選択し、ディメンジョンのロードに使用するソース・データ・セットに含まれるオーファン・レコードをエラー表に格納します。エラー表は「エラー表名」プロパティで表されます。
オブジェクトの拡張演算子を使用して、オブジェクト・タイプを拡張し、オブジェクト・タイプを構成する個々の属性を取得できます。
オブジェクトの拡張演算子をワークスペース・オブジェクト・タイプにバインドおよび同期化できます。マッピングの生成エラーを回避するため、ワークスペース・オブジェクト・タイプを配布してからマッピングを配布する必要があります。
オブジェクトの拡張演算子には、入力グループと出力グループが1つずつあります。入力グループは、個々の属性を取得するために拡張するオブジェクト・タイプを示します。オブジェクトの拡張演算子をワークスペース・オブジェクトにバインドすると、演算子の出力グループにはオブジェクト・タイプを構成する個々の属性が含まれます。
オブジェクトの拡張演算子を含むマッピングを正常に配布するには、次の条件が満たされていることを確認します。
ソース表を含むスキーマがウェアハウス・スキーマと同じインスタンス上にあること。
ソース表に対するSELECT権限がウェアハウス・スキーマに付与されていること。
オブジェクトの拡張演算子で使用されるすべてのオブジェクト・タイプおよびネストされた表に対するEXECUTE権限がウェアハウス・スキーマに付与されていること。
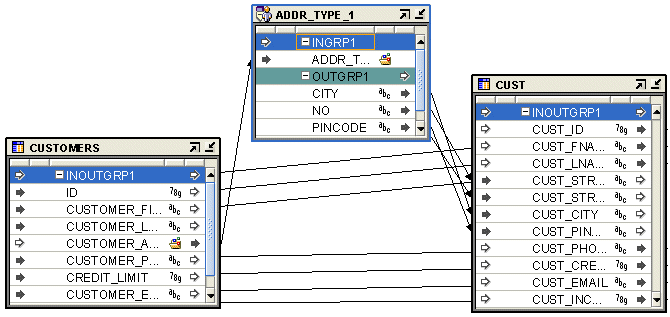
図25-3は、オブジェクトの拡張演算子を使用するマッピングを示したものです。ソース表CUSTOMERSには、SQLオブジェクト・タイプであるデータ型ADDR_TYPEのCUSTOMER_ADDRESS列が含まれています。ただし、ターゲット表CUSTには、Oracle組込みデータ型の4つの異なる列が含まれ、これらには顧客アドレスの各コンポーネントが格納されています。CUSTOMER_ADDRESS列の個々の属性を取得するには、オブジェクト・タイプADDR_TYPEにバインドされるオブジェクトの拡張演算子を作成します。次に、CUSTOMER_ADDRESS列をオブジェクトの拡張演算子の入力グループにマップします。オブジェクトの拡張演算子の出力グループには、CUSTOMER_ADDRESS列の個々の属性が含まれています。これらの出力属性をターゲット演算子にマップします。
マッピングのオブジェクトの拡張演算子の定義手順:
オブジェクトの拡張演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「オブジェクトの拡張の追加」ダイアログ・ボックスを使用して、オブジェクトを作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
拡張するソース属性をオブジェクトの拡張演算子の入力グループにマップします。
入力オブジェクト・タイプのシグネチャは、オブジェクトの拡張演算子のシグネチャと同じである必要があります。
オブジェクトの拡張演算子の出力属性をターゲット属性にマップします。
外部表演算子を使用して、ワークスペースの外部表に格納されているデータをソーシングできます。これで、外部表データを別のワークスペース・オブジェクトにロードしたり、データの変換を実行できます。たとえば、外部表に格納されているデータをソーシングし、マッピング演算子を使用してこのデータを変換してから、ディメンションまたはキューブにロードできます。
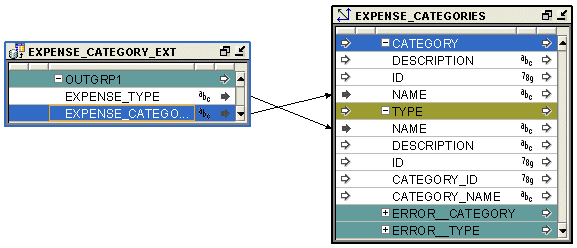
図25-4は、外部表演算子を使用するマッピングを示したものです。外部表演算子EXPENSE_CATEGORY_EXTは、ワークスペース内の同じ名前の外部表にバインドされます。この外部表に格納されているデータは、ディメンジョンEXPENSE_CATEGORIESのロードに使用されます。
外部表演算子を含むマッピングを作成する手順は、次のとおりです。
外部表演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「外部表の追加」ダイアログ・ボックスが表示されます。
「外部表の追加」ダイアログ・ボックスを使用して、外部表を作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
外部表演算子の出力グループの属性をターゲット演算子または中間変換演算子にマップします。
マッピング入力パラメータを使用して、Oracle Warehouse Builderの外部情報をマッピングへの入力として取り込むことができます。
たとえば、マッピング入力パラメータ演算子を使用して、データをステージング領域にロードするマッピングにSYSDATEを渡すことができます。同じマッピング入力パラメータ演算子を使用して、データをターゲットにロードする別のマッピングにタイムスタンプを渡すこともできます。
マッピングを生成すると、PL/SQLパッケージが作成されます。マッピング入力パラメータは、パッケージのメイン・プロシージャのシグネチャの一部になります。
マッピング入力パラメータ演算子のカーディナリティは1です。この場合、次の演算子への入力として別の行セットと組み合せることができる1つの行セットが作成されます。
各マッピング入力パラメータ演算子は、マッピング入力パラメータ演算子の出力属性となります。これらの出力属性は、マッピング・エディタ内の他の演算子と接続して使用できます。
マッピング入力パラメータ演算子を定義する場合は、データ型とオプションのデフォルト値を指定します。
マッピングのマッピング入力パラメータ演算子の定義手順:
マッピング入力パラメータ演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
マッピング入力パラメータ演算子を右クリックし、「詳細をオープン」を選択します。
マッピング入力パラメータ・エディタが表示されます。
左の「出力属性」を選択し、「出力属性」タブを表示します。
出力属性を追加するには、「属性」列の空白フィールドをクリックし、出力属性の名前を指定します。また、該当する属性のデータ型、長さ、精度、スケールおよび秒説明などの詳細を指定します。
属性の名前を変更し、データ型やその他の属性のプロパティを定義できます。
「OK」をクリックしてマッピング入力パラメータ・エディタを閉じます。
マッピング入力パラメータ演算子の出力属性をターゲット演算子の属性に接続します。
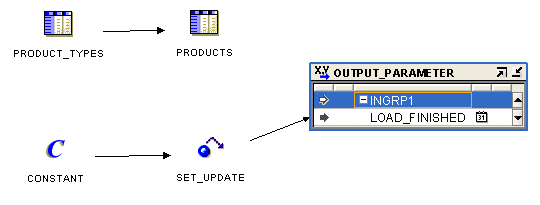
図25-5は、マッピング入力パラメータ演算子を使用するマッピングを示したものです。
単一のマッピング出力パラメータ演算子を使用して、PL/SQLマッピングの値をOracle Warehouse Builderの外部アプリケーションに送信します。
マッピング出力パラメータ演算子は、SQL*Loaderマッピングでは無効です。マッピングを生成すると、PL/SQLパッケージが作成されます。マッピング出力パラメータは、パッケージのメイン・プロシージャのシグネチャの一部になります。
マッピング出力パラメータ演算子にあるのは1つの入力グループのみであり、出力グループはありません。1つのマッピングで使用できるのは、1つのマッピング出力パラメータ演算子のみです。マッピング出力パラメータ演算子にマップできるのは、行セットに関連付けられていない属性のみです。たとえば、定数、入力パラメータ、マッピング前プロセスからの出力、またはマッピング後プロセスからの出力にはすべて、行セットに関連付けられていない属性を含めることができます。
マッピングのマッピング出力パラメータ演算子の定義手順:
マッピング出力パラメータ演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
マッピング出力パラメータ演算子を右クリックし、「詳細をオープン」を選択します。
マッピング出力パラメータ・エディタが表示されます。
左の「入力属性」タブのリンクをクリックし、「入力属性」ページを表示します。
入力属性を追加するには、「属性」列の空白フィールドをクリックし、入力属性の名前を指定します。また、該当する属性のデータ型、長さ、精度、スケールおよび秒説明などの詳細を指定します。
属性の名前を変更し、データ型やその他の属性のプロパティを定義できます。
「OK」をクリックしてマッピング出力パラメータ・エディタを閉じます。
マッピング出力パラメータ演算子の入力属性をターゲット演算子の属性に接続します。
図25-6に、マッピングに使用されるマッピング出力パラメータ演算子の例を示します。
マテリアライズド・ビュー演算子を使用すると、ワークスペースに格納されているマテリアライズド・ビューからのデータのソーシングやマテリアライズド・ビューへのデータのロードが可能です。

たとえば、マテリアライズド・ビューに格納されているデータを使用してキューブをロードできます。マテリアライズド・ビュー演算子には、INOUTGRP1と呼ばれるI/Oグループが1つあります。この演算子にはグループを追加できませんが、既存のI/Oグループには属性を追加できます。
マテリアライズド・ビュー演算子は、ワークスペース・マテリアライズド・ビューにバインドおよび同期化できます。生成されたコード・パッケージでのエラーを回避するため、ワークスペース・マテリアライズド・ビューを配布してから、マテリアライズド・ビュー演算子を含むマッピングを生成する必要があります。
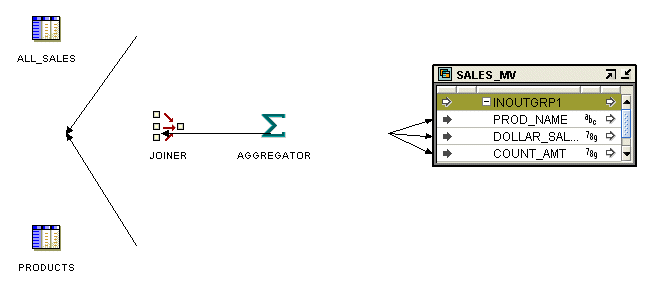
図25-7は、マテリアライズド・ビュー演算子を使用するマッピングを示したものです。2つのソース表PRODUCTSおよびALL_SALESからのデータは、ジョイナ演算子を使用して結合されます。次に、このデータはアグリゲータ演算子を使用して集計されます。集計されたデータを使用してマテリアライズド・ビューSALES_MVがロードされます。
マテリアライズド・ビュー演算子を含むマッピングの作成手順:
マテリアライズド・ビュー演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「マテリアライズド・ビューの追加」ダイアログ・ボックスが表示されます。
「マテリアライズド・ビューの追加」ダイアログ・ボックスを使用して、マテリアライズド・ビューを作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
マテリアライズド・ビュー演算子の属性をマップします。
マテリアライズド・ビュー演算子をターゲットとして使用している場合は、ソース属性をマテリアライズド・ビュー演算子の属性に接続します。マテリアライズド・ビュー演算子をソースとして使用している場合は、マテリアライズド・ビュー演算子の属性をターゲットに接続します。
キュー演算子を使用すると、アドバンスト・キューをマッピングでソースまたはターゲットとして使用できます。
データ・ウェアハウスの作成およびメンテナンスで最も重要なタスクは、既存データのリフレッシュ、オペレーショナル・データベースからの新規データの追加などです。キュー演算子を使用してソース・オブジェクトの変更をキャプチャし、その変更をステージング・データベースに、または直接データ・ウェアハウスまたはオペレーショナル・データ・ストアに送信します。
|
注意: キュー演算子は同じマッピング内のソースおよびターゲットとして使用することはできません。 |
キュー演算子の使用には、次のオプションが用意されています。
新しいキュー演算子の定義: キュー演算子をパレットからマッピングにドラッグします。マッピング・エディタにウィザードが表示されます。
既存のキュー演算子の編集: キュー演算子を右クリックして「詳細をオープン」を選択します。
キュー演算子の使用例は、「LCRキャスト演算子」を参照してください。
演算子ウィザードまたは演算子エディタのどちらを使用する場合も、次のタスクを実行します。
実行する必要があるタスクは、キュー演算子がバインドされているアドバンスト・キューのペイロード・タイプによって異なります。SYS.ANYDATA以外のすべてのペイロード・タイプの場合は、キュー演算子のバインド先のキューを選択する必要があります。SYS.ANYDATAタイプのペイロードの場合は、リストされているすべてのタスクを実行する必要があります。
キュー演算子ウィザードの「キューの選択」ページまたはキュー演算子エディタの「選択」ページを使用して、演算子をバインドするアドバンスト・キューを選択します。
このページのノード・ツリーには、現行プロジェクトのアドバンスト・キューがリストされます。キュー演算子をバインドする必要があるアドバンスト・キューを選択します。
ソース・タイプの選択ページを使用して、キューをリアルタイム・キューとして使用するか、バッチ・キューとして使用するかを指定します。キューが受信するメッセージのタイプも指定します。
次のいずれかのオプションを選択し、キューのタイプを指定します。
リアルタイム・ソース
キュー演算子がリアルタイム・ソースであることを示す場合は、このオプションを選択します。リアルタイム・キューを使用すると、ターゲット・オブジェクトのソース変更を瞬時に移入できます。キュー演算子に関連付けられたソース・オブジェクトのすべてのDML変更は、「ソース・オブジェクトの選択」で指定されているように、瞬時にAQに追加されます。
リアルタイム・ソースを含むマッピングはリアルタイム・マッピングといいます。リアルタイム・マッピングを配布する必要があります。その後、キューにソースの変更が加えられるたびに、Oracle Warehouse Builderによって自動的にマッピングが実行され、ターゲット・オブジェクトの変更が公開されます。
バッチ・ソース
キュー演算子がバッチ・ソースであることを示す場合は、このオプションを選択します。バッチ・マッピングによって、マッピングを明示的に実行する場合のみ、ソースからの変更が加えられたターゲット・オブジェクトが移入されます。
バッチ・ソースを定義する場合は、ウィザードまたはエディタでバッチ・ソースの詳細を指定しません。キュー演算子を定義するその他のタスク関連のすべてのウィザードまたはエディタ・ページは無効になります。
SYS.ANYDATAペイロードを使用するリアルタイム・キューの場合は、キュー内のメッセージの書式を指定する必要があります。次のいずれかのオプションを選択して、メッセージの書式を指定します。
Oracleキャプチャ・プロセスのメッセージ書式
受信したメッセージの書式がLCRであることを指定します。Oracle Warehouse Builderは、DML変更をキャプチャ、変更をLCRにフォーマット化、LCRをキューに追加します。
LCRの詳細は、「Oracle Streamsの概念および管理」を参照してください。
このオプションを選択する場合は、「ソース・オブジェクトの選択」および「プロセスのソース変更の指定」で説明するように、キャプチャする必要があるソース表とDML操作を指定する必要があります。
ユーザー定義のメッセージ書式
キューが受信したメッセージがユーザー定義書式であることを指定します。このオプションを選択する場合は、「キュー演算子のユーザー定義タイプまたは主タイプの選択」で説明するように、「ユーザー定義タイプの選択」ページまたは「主タイプの選択」ページを使用してメッセージ書式を表すユーザー定義タイプを指定します。
キューでユーザー定義メッセージ書式を使用する場合は、メッセージ書式を表すユーザー定義タイプを指定する必要があります。「ユーザー定義タイプ」ページまたは「主タイプ」ページを使用して、ユーザー定義タイプを選択します。
このページにはユーザー定義タイプを選択できるノート・ツリーが含まれます。主データ・タイプ・ノードには選択できる主データ・タイプがリストされます。メッセージ書式で主データ・タイプを使用する場合は、このノードを展開して主データ・タイプを選択します。ユーザー定義タイプを含む各Oracleモジュールに個別ノードが表示されます。必要なモジュール・ノードを展開し、キュー・メッセージ書式を表すユーザー定義タイプを選択します。
「ソースの選択」ページを使用して、データ変更をキャプチャするソース表を指定します。このページは、キューがOracleキャプチャ・メッセージ書式を使用するリアルタイム・ソースの場合にのみ有効化されます。
「使用可能表」セクションには、データ変更をキャプチャできる表がリストされます。表を選択し、矢印を使用して表を「選択済表」セクションへ移動します。[Ctrl]キーを押しながら表を選択すると、複数の表を選択できます。
「プロセスのソース変更」ページを使用して、「ソースの選択」ページで選択した表にキャプチャする必要があるDML変更を指定します。このページは、キューがOracleキャプチャ・メッセージ書式を使用するリアルタイム・ソースの場合にのみ有効化されます。
「プロセスへの変更を特定」セクションには、「オブジェクトの選択」ページで選択した表がリストされます。各表に、表名の右のチェック・ボックスを使用してキャプチャする必要があるDML操作を選択します。表に挿入されたすべての行をキャプチャする表に対して、「挿入」を選択します。表のすべての変更をキャプチャするには、表の右の「更新」を選択します。表から削除された行をキャプチャするには、表名の右の「削除」を選択します。
順序演算子は、行ごとに増分する順序番号を生成します。

たとえば、順序演算子を使用すると、データをディメンション表にロードするときにサロゲート・キーを作成できます。順序は、ターゲット演算子の入力または他のタイプの演算子の入力に接続できます。順序の出力は、他の演算子からの出力と組み合せることができます。
順序番号は表とは関係なく生成されるため、同じ順序を複数の表に対して使用できます。同じ順序が複数のセッションで使用できるため、順序番号は連続していない場合があります。
この演算子には、次の出力属性のある出力グループが含まれます。
CURRVAL: 現在の値から生成されます。
NEXTVAL: 次の値から始まり、連続して増分する番号の行セットを生成します。
順序は、いずれかのモジュールのワークスペース順序にバインドおよび同期化できます。生成されたコード・パッケージでのエラーを回避するため、ワークスペース順序を生成および配布してから、順序を含むマッピングを配布する必要があります。詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
順序を含むマッピングは、行ベース・モードを使用して生成してください。行が選択されていなくても順序は増分されます。最後の番号から順序を開始する場合、セット・ベースまたはフェイルオーバー・オペレーティング・モードのセット・ベースでSQLパッケージを実行しないでください。モード設定の構成の詳細は、「ランタイム・パラメータ」を参照してください。
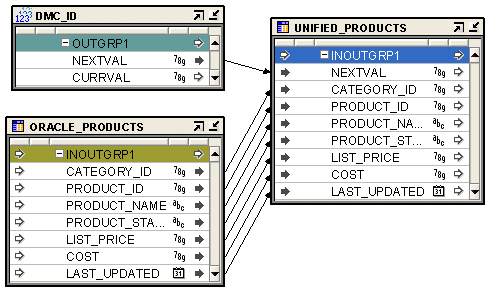
図25-8に、順序演算子を使用して表の主キーを自動的に生成するマッピングを示します。順序演算子のNEXTVAL属性は、ターゲット表UNIFIED_PRODUCTSの入力属性にマップされます。ソース表ORACLE_PRODUCTSの他の入力属性は、ターゲットに直接マップされます。
マッピングの順序演算子の定義手順:
順序演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「順序の追加」ダイアログ・ボックスが表示されます。
「順序の追加」ダイアログ・ボックスを使用して、順序を作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
必要な出力属性を順序演算子からターゲット属性に接続します。
表演算子を使用すると、ワークスペースに格納されている表からのデータのソーシングや表へのデータのロードが可能です。

表演算子は、ワークスペース表にバインドおよび同期化できます。生成されるコード・パッケージでのエラーを避けるため、表演算子を含むマッピングを生成する前にワークスペース表を配布しておく必要があります。
図25-8に、表演算子をソースとターゲットの両方として使用するマッピングを示します。図25-2に、表演算子をターゲットとして使用するマッピングを示します。
マッピングの表演算子の定義手順:
表演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「表の追加」ダイアログ・ボックスが表示されます。
「表の追加」ダイアログ・ボックスを使用して、表を作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
表演算子の属性をマップします。
表をターゲットとして使用する場合は、ソース属性を表演算子の属性に接続します。表をソースとして使用する場合は、表演算子の属性をターゲットに接続します。
表演算子のマージの最適化プロパティを有効化できます。このプロパティをTrueに設定すると、MERGE文で式および変換の呼出しまたは実行が最適化されます。
たとえば、更新操作のみの対象で変換にマップされる列がターゲット表に含まれるようなマッピングについて考えます。旧リリースのOracle Warehouse Builderでは、変換が不要な行も含め、すべての行に対して変換を実行していました。このリリースから、マージの最適化を有効化すると、Oracle Warehouse BuilderはMERGE文の更新部分でのみ変換を呼び出すようになりました。
チャンク化を使用すると、マッピングのソース・データをチャンクに分割できます。チャンクはデータ・パーティション・アルゴリズムで定義され、各チャンクは処理後、ターゲットに個別にロードされます。
チャンク化の詳細は、「PL/SQLマッピングのチャンク化について」を参照してください。
表演算子にソース・データ・チャンク化を使用するには、マッピング・キャンバスで表演算子を選択します。プロパティ・インスペクタに演算子のプロパティが表示されます。
シリアルまたはパラレル・チャンク化の両方を実行できます。シリアル・チャンク化を実行するには、「SCDの更新」ノードで「チャンク化有効」および「フィルタ条件のチャンク化」オプションを設定します。パラレル・チャンク化を実行するには、「チャンク化」ノードで「チャンク化式」オプションを設定します。
チャンク化有効
このオプションを選択すると、表演算子で表されるソース表のシリアル・データ・チャンク化を有効化できます。
マッピングの特定のソース表に対してのみデータ・チャンク化を有効にできます。たとえば、マッピングに3つの表演算子が含まれ、1つの表演算子に対してのみデータ・チャンク化を有効にすると、すべてのマッピング機能が各データ・チャンクに1回ずつ、複数回実行されます。ただし、残りの2つの表のチャンク化は有効でないため、これらのソースはマッピングの最初の反復中にのみデータ行を提供します。
チャンク・フィルタ条件
チャンク・フィルタ条件を使用すると、シリアル・チャンク化を実行中にソース・データを複数のチャンクに分割する際に使用する条件を指定できます。各反復中に、チャンク・フィルタ条件によってソース・データがソースからフィルタ処理されます。
Oracle Warehouse Builderには、すべてのチャンク・フィルタ条件で使用する必要がある事前定義マッピング定数get_chunk_iteratorが用意されています。これは1から開始される反復カウントで、チャンク処理で各マップを実行するたびに増分されます。データ・ソースの値を使用する条件を設定できます。
たとえば、フィルタ条件をget_chunk_iterator = INOUTGRP1.CHUNK_GRP_NUMと設定できます。この場合、CHUNK_GRP_NUMはソース表内の属性です。
チャンク化式
チャンク化式を使用して、パラレル・チャンク化に対してソース・データを複数のチャンクに分割する際に使用する条件を設定します。
Oracle Warehouse Builderを使用すると、データの抽出中およびロード中に一時表を使用できます。リモート・ソースから複数のターゲットにデータを抽出する必要がある場合には、一時表が役立ちます。
通常、一時ステージング表は、ディメンション演算子のサブマッピング拡張によって自動的に生成されるディメンション・ロード・ロジックで使用されます。これで、ターゲット表で参照を行うことにより発生する問題を回避できます。
次のプロパティを使用すると、ETLの実行中に一時表を作成できます。
一時ステージ表のプロパティを「True」に設定すると、表演算子に対する既存のバインドはすべて無視されます。一時ステージング表がマッピングとともに配布され、この表演算子からのすべてのロードおよび抽出操作はステージング表から実行されます。
配布された表のデータベース内での名前は演算子名に基づいており、名前の競合を避けるために一意の識別子が付加されています。マップが削除または再配布されると、表は自動的に削除されます。各マッピングの実行前に、表は自動的に切り捨てられます。
このプロパティをデフォルト値の「False」に設定した場合、このプロパティによる影響はありません。
ターゲット表でDMLエラー・ロギングを実行できます。表演算子のプロパティDMLエラー表名を使用して、その表でDML操作を実行中に発生するエラーを格納するエラー表の名前を指定します。エラー表は、表演算子を含むマッピングを実行すると作成されます。
DMLエラー・ロギングの詳細は、「DMLエラー・ロギングの使用」を参照してください。
ネストした表または可変長配列タイプのオブジェクトがある場合、可変長配列イテレータ演算子を使用して、この表タイプの値を反復できます。

この演算子は、表タイプ属性をソースとして受け入れ、ネストした表に定義されているベース要素タイプまたは可変長配列タイプの値を生成します。演算子がバインドされている場合、演算子に対して調整演算が実行されます。バインドされていない可変長配列イテレータ演算子については、調整演算はサポートされていません。
可変長配列イテレータ演算子は、バインドされている演算子またはバインドされていない演算子として作成できます。バインドされていない可変長配列イテレータ演算子は同期化または検証できません。この演算子の入力グループと出力グループは1つずつのみです。他のデータ型の属性を持つ入力グループも使用できます。ただし、少なくとも1つの表タイプ属性が必要です。
出力グループの属性は、入力グループの属性のコピーです。唯一異なるのは、出力グループは、演算子がバインドされている表タイプ(入力グループ属性の1つ)のかわりに、入力グループのベース要素タイプと同じ属性を持つという点です。入力グループは編集できます。出力グループは編集できません。
図25-9は、可変長配列イテレータ演算子を含むマッピングを示したものです。
マッピングの可変長配列イテレータ演算子の定義手順:
可変長配列イテレータ演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「可変長配列イテレータの追加」ダイアログ・ボックスが表示されます。
「可変長配列イテレータの追加」ダイアログ・ボックスで、バインドされていない演算子またはバインドされている演算子を選択します。
バインドされていない演算子を選択すると、属性のない可変長配列イテレータ演算子が作成されます。これらの属性は手動で作成する必要があります。
バインドされている演算子を選択する場合は、ツリーに表示されている使用可能なネストした表または可変長配列タイプの1つを選択する必要があります。出力属性はベース要素と同じです。
「OK」をクリックします。
可変長配列イテレータ演算子の属性をマップします。
バインドされていない演算子の場合、マッピング・エディタのキャンバスでバインドされていない可変長配列イテレータ演算子を右クリックし、「詳細をオープン」を選択します。これにより、「可変長配列イテレータ」エディタのダイアログ・ボックスが開きます。入力グループに属性を追加するには、「追加」ボタンを使用します。変更できるのは、出力グループの属性のデータ型のみです。
ビュー演算子を使用すると、ワークスペースに格納されているビューからのデータのソーシングやビューへのデータのロードが可能です。

ビュー演算子は、ワークスペース・ビューにバインドおよび同期化できます。生成されたコード・パッケージでのエラーを回避するため、ワークスペース・ビューを配布してから、ビュー演算子を含むマッピングを生成する必要があります。
マッピングのビュー演算子の定義手順:
ビュー演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「ビューの追加」ダイアログ・ボックスが表示されます。
「ビューの追加」ダイアログ・ボックスを使用して、ビューを作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
ビュー演算子の属性をマップします。
ビューをターゲットとして使用する場合は、ソース属性をビュー演算子の属性に接続します。ビューをソースとして使用する場合は、ビュー演算子の属性をターゲットに接続します。
マッピングのターゲット演算子は、Oracle Databaseのリモート・ロケーションまたはOracle以外のデータベースのロケーション(ゲイトウェイ経由のSQLサーバーまたはDB2など)のオブジェクトにバインドできます。このような演算子はゲートウェイ・ターゲットと呼びます。データベース・リンクを使用して、これらのターゲットにアクセスします。データベース・リンクはロケーションを使用して作成されます。OracleデータベースからリモートでSAP表にアクセスするデータベース・リンクを生成できないため、SAPターゲットはサポートされていません。
マッピングでリモート・ターゲットやゲートウェイ・ターゲットを使用する場合は、次の各項で説明する特定の制限が課されます。
マッピングでリモート・ターゲットまたはゲートウェイ・ターゲットを使用する場合は、次の制限が適用されます。
ターゲット演算子のロード・タイプのプロパティは「TRUNCATE/INSERT」に設定できません。
このため、マッピングを検証すると、検証エラーが発生します。
ゲートウェイ・ターゲットの場合、ターゲット演算子のロード・タイプのプロパティを「INSERT/UPDATE」に設定すると、ロード・タイプを「INSERT」に設定した場合と同じ結果になります。
DML文でRETURNING句はサポートされません。
RETURNING句を使用すると、行ベース・モードを使用してターゲットにロードされた行のROWIDを取得できます。これらのROWIDは、ランタイム監査システムによって記録されます。ただし、リモート・ターゲットまたはゲートウェイ・ターゲットの場合、RETURNING句は生成されず、NULLはROWIDフィールドのランタイム監査システムに渡されます。
セット・ベース・モードの場合、データはOracleデータベースからリモート・ターゲットまたはゲートウェイ・ターゲットにはロードできません。セット・ベースのフェイルオーバーを含め、他のすべてのモードはサポートされます。
ターゲット演算子の「オペレーティング・モード」プロパティをセット・ベースに設定すると、ランタイム・エラーが発生します。
行ベースのバルク処理はサポートされていません。
|
注意: リリース11.2.0.3以降は、セット・ベースから行ベースへのフェイルオーバー機能は非推奨です。 |
マッピングでリモート・ターゲットまたはゲートウェイ・ターゲットを使用する場合は、特定の制限があるアクティビティに対してはデフォルトの対応策が使用されます。これらの対応策は情報用のみです。これらの対応策を有効にするために、なんらかの作業を明示的に実行する必要はありません。
リモート・ターゲットまたはゲートウェイ・ターゲット用として使用されるデフォルトの対応策は、次のとおりです。
ターゲットのロード・タイプを「INSERT/UPDATE」または「UPDATE/INSERT」(Oracle9iデータベースの場合)、および「UPDATE」(Oracle Database 11gの場合)に設定すると、このマッピングをセット・ベース・モードで実装するMERGE文が生成されます。ただし、MERGE文はリモート・ターゲットまたはゲートウェイ・ターゲットに対しては実行できません。このため、マッピングでリモート・ターゲットまたはゲートウェイ・ターゲットを使用する場合は、MERGE文なしでコードが生成されます。生成されるコードは、PL/SQL生成モードがOracle8iに設定されている場合に生成されるコードと同じです。
リモート・ターゲットまたはゲートウェイ・ターゲットにロードされるデータベース順序を参照するセット・ベースのDML文の場合、GLOBAL_NAMESパラメータをTRUEに設定する必要があります。マッピング用のコードの生成時にマッピングにリモート・ターゲットまたはゲートウェイ・ターゲットが含まれる場合、このパラメータはTRUEに設定されます。
リモート・ターゲットまたはゲートウェイ・ターゲットへの複数表挿入の場合、複数表挿入文ではなく、INSERT文が表ごとに生成されます。
リモート・データベースまたはOracle以外のデータベースへのバルク挿入実行中は、バルク処理コードは生成されません。かわりに、一度に1行を処理するコードが生成されます。演算子のバルク生成プロパティは無視されます。
|
注意: リモート・ターゲットまたはゲートウェイ・ターゲットで使用されるロード・タイプは、他のOracleターゲット演算子で使用されるものと同じです。ロード・タイプのプロパティの詳細は、「Oracleターゲット演算子のロード・タイプ」を参照してください。 |
フラット・ファイル演算子を使用すると、フラット・ファイルをマッピングのソースまたはターゲットとして使用できます。次の項では、フラット・ファイル演算子の使用について説明します。
フラット・ファイル演算子を使用して、データをフラット・ファイルから抽出、またはフラット・ファイルにデータをロードします。

フラット・ファイル演算子は、マッピングでソースまたはターゲットとして使用できます。ただし、同じマッピング内では2つは相互に排他的です。フラット・ファイルのソースとターゲットのコード生成言語は異なります。このため、マッピングには、この項の後で説明する制限付きのフラット・ファイル、リレーショナル・オブジェクトおよび変換が混在する場合があります。
フラット・ファイル演算子には、次のオプションがあります。
前にインポートしたフラット・ファイルの使用
マッピングへの新規フラット・ファイルのインポートおよびバインド
マッピングでの新規フラット・ファイルのソースまたはターゲットの定義
マッピングでのフラット・ファイル演算子の使用手順:
フラット・ファイル演算子をマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
「フラット・ファイルの追加」ダイアログ・ボックスを使用して、オブジェクトを作成または選択します。これらのオプションの詳細は、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」を参照してください。
フラット・ファイル演算子からターゲットへ属性をマップ、またはソースからフラット・ファイル演算子へ属性をマップします。
マッピングでソースおよびターゲットとしてフラット・ファイルを使用する例は、第7章、「SQL*Loader、SAPおよびコード・テンプレート・マッピングの使用」を参照してください。
フラット・ファイルのデータは、フラット・ファイル演算子または外部表演算子を使用してマッピングに取り込むことができます。大量のデータをロードする場合、フラット・ファイルからロードすることにより、DIRECT PATH SQL*Loaderオプションを使用できるようになり、パフォーマンスが向上します。
大量のデータをロードしない場合、外部表機能で使用可能な多くのリレーショナル変換を利用できます。
|
関連項目: 外部表とフラット・ファイルの比較の詳細は、『Oracle Warehouse Builderソースおよびターゲット・ガイド』を参照してください。 |
ソースとして使用する場合、フラット・ファイル演算子は、SQL*Loaderユーティリティを使用してフラット・ファイルからデータを読み取る行セット・ジェネレータとして機能します。フラット・ファイル・ソース演算子は、フラット・ファイル・ターゲットまたは外部表へのマップ用としては使用しないでください。フラット・ファイル・ソース演算子を使用してマッピングを設計する場合は、次の演算子を使用できます。
|
注意: 順序、式または変換演算子を使用する場合、SQL*Loaderの直接ロード設定は構成パラメータとして使用できません。 |
マッピングでフラット・ファイルをソースとして使用する場合、マッピングを正常に配布するために、ターゲット・ロケーションからフラット・ファイル・ロケーションへのディレクトリを作成してください。
フラット・ファイル・ターゲットを使用したマッピングでは、データを表の行にロードするのではなく、データをフラット・ファイルにロードするPL/SQLパッケージが生成されます。
|
注意: 1つのマッピングは、最大50のフラット・ファイル・ターゲット演算子を含むことができます。 |
既存のフラット・ファイルは、レコード・タイプが単一でも複数でも使用できます。複数のレコード・タイプのフラット・ファイルをターゲットとして使用する場合は、1つのレコード・タイプに対してのみマップできます。同じソースからフラット・ファイルのすべてのレコード・タイプをロードする場合、同じフラット・ファイルをターゲットとしてマッピングに再ドロップし、別のレコード・タイプにマップできます。この例は、「SQL*Loaderマッピングでの参照整合性を確認するためのダイレクト・パス・ロードの使用」を参照してください。または、ロードするレコード・タイプごとに異なるマッピングを作成してください。
新規フラット・ファイル・ターゲットの作成の詳細は、『Oacle Warehouse Builderソースおよびターゲット・ファイル』を参照してください。
フラット・ファイル演算子のプロパティは、ソースまたはターゲットのいずれかとして設定できます。フラット・ファイルのロード・タイプおよび「1行目のフィールド名」を設定できます。他のすべての設定は読取り専用であり、フラット・ファイルをインポートした方法によって異なります。
リストからロード・タイプを選択します。
挿入: 新規ターゲット・ファイルを作成します。既存のターゲット・ファイルがある場合は、以前のファイルは新規に作成したファイルで置き換えられます。
更新: ターゲット・ファイルが存在しない場合は新規ターゲット・ファイルを作成します。既存のターゲット・ファイルが存在する場合は、そのファイルが追加されます。
なし: ターゲット・ファイルのデータ上では操作は実行されません。この設定はテスト目的の場合に便利です。ターゲットに影響することなく、すべての変換および抽出が実行されます。
演算子の1行目のフィールド名を書き込む場合、このプロパティを「True」に設定します。それ以外の場合は、「False」に設定します。