| Oracle® Warehouse Builderデータ・モデリング、ETLおよびデータ・クオリティ・ガイド 11gリリース2 (11.2) B61350-02 |
|



 前 |
 次 |
Warehouse Builderでデータ・オブジェクトの定義を作成した後は、データをソースからターゲットに移動する抽出、変換およびロード(ETL)の各操作を設計できます。Oracle Warehouse Builderでは、マッピングを使用してこれらの操作を設計します。
マッピング・デバッガを使用してマッピングでデータ・フローをデバッグすることもできます。
この章の内容は次のとおりです。
マッピングは、抽出、変換およびロード(ETL)を実行するために使用するOracle Warehouse Builderオブジェクトです。マッピングは、個別ソースからデータ・ウェアハウスまでのデータの移動についてのデータ・フローを定義します。
フラット・ファイル、Oracle Database、SAP、またはSQLサーバーやIBM DB2のようなその他の異機種データベースその他のデータを含むソースからデータを抽出することができます。マッピング演算子またはマッピング変換を使用して要件に応じてデータを変換して、変換されたデータをターゲット・オブジェクトにロードします。
|
関連項目:
|
マッピングは、Oracle Warehouse Builderの他のオブジェクトと同様、定義後に検証、生成および配布する必要があります。マッピングを定義および配布した後、コントロール・センター・マネージャを使用してマッピングを実行したり、後でマッピングを実行するためにスケジュールしたり、マッピングをプロセス・フローに組み込むことができます。
|
関連項目:
|
Oracle Warehouse Builderのマッピングは、マッピングで使用されたサポートされているデータ抽出技術に応じて分類されます。Oracle Warehouse Builderから生成されるコードは、マッピングで使用されるソースおよびターゲットによって異なります。
マッピングの様々なタイプは次のとおりです。
Oracle Warehouse Builderは、マッピング・タイプに応じた異なる言語でETLコードを生成します。生成されたコードはターゲット・ロケーションに配布され、そこで実行されます。適切なデータ抽出技術を選択することで、広範囲なデータ・ソース・タイプにアクセスしてパフォーマンスやセキュリティなど異なる技術要件を満たすことができます。
|
注意: PL/SQLマッピング以外のマッピングは、Oracle Warehouse Builderのすべてのデータ変換機能をサポートしているわけではありません。PL/SQL以外のマッピング・タイプを使用して、PL/SQLマッピングでのみサポートされる複雑な変換を実行する必要がある場合は、PL/SQL以外のマッピングを使用してステージング表にロードしてから、PL/SQLマッピングを使用して、必要な残りの変換を実行します。 |
PL/SQLマッピングは、Oracle Warehouse Builderのデフォルト・マッピング・タイプであり、ほとんどの状況で必要になります。PL/SQLマッピングの場合、Oracle Warehouse Builderによって生成されたPL/SQLコードがOracle Databaseロケーションに配布され、そこで実行されます。
その他のロケーションからのデータ抽出は、主にその他のOracle Databaseへのデータベース・リンクを経由して実行されるか、またはOracle以外のデータ・ソースのOracle Database gatewayを経由して実行されます。PL/SQLマッピングでは、Oracle Warehouse Builderのすべてのデータ変換機能が提供されます。
SQL*Loaderマッピングでは、SQL*Loader制御ファイルが生成されます。制御ファイルはターゲット・データベースに配布され、そこでSQL*Loaderが実行され、データベースにソース・データがロードされます。
|
注意: SQL*Loaderマッピングは、PL/SQLマッピングで変換可能なサブセットのみをサポートします。SQL*Loaderマッピングで可能な変換の制限の詳細は、第26章「データ・フロー操作」を参照してください。 |
SAP R/3ソース・システムからデータを抽出するメソッドのなかでABAPマッピングのみがサポートされているメソッドです。ABAPマッピングでは、Oracle Warehouse BuilderはABAPコードを生成します。次に、このコードは、管理者によってSAP R/3インスタンスにセキュリティおよびその他SAP環境固有の管理要件に応じて自動または手動で配布されます。ABAPコードが実行され、出力として生成されたフラット・ファイルが、ターゲット・データベース・システムに透過的に移動されて、Oracleのターゲット・データベースにロードされます。
コード・テンプレートでは、データ抽出の実装、移動、およびメカニズムのロードのための代表的なフレームワークを提供します。コード・テンプレート(CT)マッピングの場合、Oracle Warehouse Builderは、コード・テンプレートの内容に基づいて、データ抽出またはその他のマッピング・コードを生成します。このコードは、ターゲット・システム上のリモート・エージェントに配布され、そこで実行されます。データをターゲット・データベースにロードするために使用された技術は、コード・テンプレートの内容応じて異なります。Oracle Warehouse Builderは、共通のデータ抽出方法を実装するコード・テンプレートのコレクションを提供します。その他のコード・テンプレートは、さらに迅速で柔軟なデータ移動のためにバルクデータの抽出とツールのロードを使用します。
Oracle Database gatewayやODBCを使用しないデータソースへのアクセス、またはJDBC接続の必要性。Oracle Warehouse Builderは、JDBCデータ・ソースまたはターゲットへのアクセスをサポートするコード・テンプレートを提供します。
XMLソースファイルからのデータのロード。
最大限のデータ移動パフォーマンスのために、バルクデータのアンロードおよびロードを実行。Oracle Warehouse Builderでは、コード・テンプレートを提供して一部の共通データベースからのバルク・データ移動をサポートします。Oracle Warehouse Builder提供のコード・テンプレートによってサポートされていないソースのために、独自のコード・テンプレートを書き込むことができます。
Oracle以外のデータベース・ソースからOracle以外のデータベース・ターゲットに直接データを移動するETLプロセスを実装する必要がある場合。たとえば、IBM DB2ソースから抽出してMicrosoft SQL Serverターゲットに直接ロードするETLプロセスを定義できます。
Oracle Warehouse Builder自体の変更を必要とすることなく、新しいデータ統合パターンを実装する必要がある場合。コード・テンプレートは、Oracle Warehouse Builderのサポート範囲外のビジネス要件および技術要件にもすぐに対応できるように、データ統合に関する最大限の柔軟性を提供します。
|
注意: CTマッピングは、PL/SQLマッピングで変換可能なサブセットのみをサポートします。CTマッピングで変換可能な制限の詳細は、「OracleターゲットCT実行ユニットでのみサポートされるマッピング演算子」を参照してください。 |
マッピング内のソース・データをより小さなチャンクに分割することで、大規模な更新の処理をパラレル化できます。チャンクは、ユーザー定義されたチャンク基準によって定義されます。実行時、チャンクはパラレルで実行されて、各チャンクはターゲット・オブジェクトに別々にロードされます。
|
注意: チャンクは、PL/SQLマッピングに対してのみ実行されます。 |
チャンクを定義する場合、Oracle Warehouse Builderでは、配布時にターゲット・スキーマにチャンクのタスクが作成されます。実行中、各チャンクによって表されるDMLはパラレルに実行されます。
チャンクで使用するPL/SQLマッピングでは、マッピング構成エディタを使用する次のパラメータを構成できます。
コード生成パラメータ
マッピングの定義中または定義後に、マッピングを編集してチャンクのためのコード生成パラメータを設定できます。マッピング構成エディタを使用して、コード生成パラメータを設定します。これらのパラメータは、マッピングで定義されるロジックを実行するために必要なコードを生成するために使用されます。
ランタイム・パラメータ
実行時チャンク・パラメータは、マッピング構成エディタを使用することで設計時またはマッピング実行中に構成されます。実行時チャンク・パラメータを、設計時、実行時のどちらにおいても設定する場合に、実行時に設定される値は設計時に定義された値を上書きします。
Oracle Warehouse Builderでは、次のタイプのチャンクを実行できます。
シリアル・チャンク
シリアル・チャンクは、1つのセットですべてのソース・データを処理することができない状況で便利です。シリアル・チャンクの主な用途はタイプ2 SCDのロードで、そこでは1つのターゲット行に複数の更新が別々に実行される必要があります。
マッピングのためのシリアル・チャンク・パラメータを構成するには、マッピング構成エディタの「SCDの更新」および「ランタイム・パラメータ」ノードを使用します。
パラレル・チャンク
パラレル・チャンクでは、パラレルの表データを2つの上位レベルの手順の増分コミットで更新できます。最初の手順では、表内の行はより小さいサイズのチャンクにグループ化されます。2番目の手順で、ユーザー定義された文はこれらのチャンク上でパラレルに実行されて、コミットは処理完了後に発行されます。
パラレル・チャンクはパラレルDML処理で使用されます。マッピングのためのパラレル・チャンク・パラメータを構成するには、マッピング構成エディタの「チャンク化オプション」および「ランタイム・パラメータ」ノードを使用します。
マッピング・エディタはマッピング・エディタのキャンバス周辺に作成されて、その上にはマッピング内の演算子と接続が視覚的に表示されて操作することができます。その他のいくつかのデザイン・センター・パネルはコンテキスト依存であり、マッピング・エディタでマッピングを開くとマッピング関連のアイテムを表示します。これらには次のものがあります。
コンポーネント・パレット: マッピングで使用できる演算子を表示します。キャンバスまたはプロジェクト・ナビゲータからオブジェクトを選択すると、プロパティ・インスペクタにオブジェクト・プロパティが表示されます。
パレットの上部でフィルタを使用して、特定のタイプの演算子の表示を制限します。たとえば、フィルタの変換演算子を選択して、データを変換する演算子のみを表示します。
構造ビュー: 演算子、属性グループおよびマッピングの属性の階層ビューを表示します。
鳥瞰図: マッピング全体のレイアウトを表示します。1回のマウス・ドラッグ操作でキャンバスのビューを移動できます。つまり、スクロール・バーを使用せずにキャンバスのビューを再配置できます。
「鳥瞰図」には、キャンバス全体のミニチュア版が表示されます。青いボックスがあり、現在フォーカスされているキャンバスの部分を表しています。キャンバス・サイズよりも大きく広がっているマッピングの場合は、青いボックスをクリックしてキャンバス上でフォーカスを置く部分にドラッグします。
プロパティ・インスペクタ: マッピング・エディタのキャンバスで選択されたマッピング、演算子、属性グループのプロパティを表示します。
マッピング・デバッグ・ツールバー: デバッグのマッピングで使用される各コマンドのアイコンを表示します。マッピングをデバッグ中は、マッピング・エディタのキャンバスにデバッグ・ツールバーが表示されます。
ダイアグラム・ツールバー: キャンバスにナビゲートし、キャンバス上のオブジェクトの倍率を変更するのに使用する各コマンドのアイコンを表示します。
マッピング・エディタのキャンバスの領域を使用して、視覚的にマッピングを設計することができます。マッピングでは、ソースから抽出されたデータがターゲットにロードされる前にどのように変換されるか定義されます。
マッピング・エディタの論理ビューでは、マッピングを定義するデータ・フローを設計することができます。最初のドラッグ・アンド・ドロップ操作で、ソース・オブジェクト、ターゲット・オブジェクトおよび変換が表示されます。次に、操作間のデータ・フロー接続を描画することでデータ変換を表す、これらの操作間のデータ・フローを確立します。
|
関連項目:
|
マッピング・エディタの実行ビューを使用して、コード・テンプレート(CT)マッピングの実行ユニットを定義します。実行ビューは、CTマッピングを作成する場合にのみ使用可能です。
実行ユニットは、コード・テンプレートを使用して実行する関連タスクのセットを表します。コード・テンプレートには、2つのOracle Databaseインスタンス間でのデータの移動や、DB2データベースからフラット・ファイルへのデータのアンロードなど、実行時に特定のプラットフォームで特定のETL処理を実行するロジックが含まれます。実行ユニットは、PL/SQLパッケージなど単独に生成されたスクリプト、またはコード・テンプレートによって実装が可能です。
実行ユニットでは、マッピング実行をより小さな関連ユニットに分割できます。各実行ユニットは、指定されたプラットフォーム上で必要なデータ統合タスクを実行するテンプレートを含む、コード・テンプレートに関連付けられる場合があります。実行ユニットは、PL/SQLパッケージなど単独に生成されたスクリプト、またはコード・テンプレートによって実装が可能です。
マッピング・エディタの「実行ビュー」タブでは、論理ビューからの演算子とデータ・フローがアイコン化された形式で表示されます。実行ビューで演算子を編集またはデータ・フローを作成することはできません。これらのタスクは論理ビューを使用する場合のみ実行できます。
実行ユニット・ビューの内容は、選択した構成に基づきます。そのため、異なる構成に対して異なるコード・テンプレートを使用できます。たとえば、2つの構成、開発、およびQAがある場合に、開発およびその他のQAに対して1つのコード・テンプレート・セットを使用することができます。
「実行ビュー」タブを選択すると、デザイン・センターに実行メニューが表示されて、マッピング・エディタのキャンバスの上部に実行ツールバーが表示されます。実行メニューまたは実行ツールバーでは次のようなオプションを使用できます。
実行ユニットの作成および削除
デフォルト実行ユニットの定義
コード・テンプレートと実行ユニットの関連付け
メニュー・バーから「グラフ」を選択し、「オプション」を選択することにより、エディタがキャンバスにマッピングを表示する形式を制御できます。マッピング・エディタのキャンバスの表示オプションの設定が可能な「オプション」ダイアログ・ボックスが表示されます。
「オプション」ダイアログ・ボックスには、次のオプションがあります。これらのオプションを選択するか、選択を解除できます。
入力コネクタ: このオプションを選択すると、入力属性として使用可能な属性の左に、矢印アイコンが表示されます。
キー・インジケータ: このオプションを選択すると、演算子の外部キー属性である属性の左に、キー・アイコンが表示されます。
データ型: このオプションを選択すると、すべての演算子に、属性のデータ型が表示されます。
出力コネクタ: このオプションを選択すると、出力属性として使用可能な属性の右に、矢印アイコンが表示されます。
水平スクロールを有効化: このオプションを選択すると、演算子の水平スクロールが有効になります。
自動レイアウト: このオプションを選択すると、マッピングの自動レイアウトを使用できます。
この項では、ソース表からターゲット表にデータをロードする基本的なPL/SQLマッピングの作成について説明します。この例の目的は、マッピングの使用を図示してマッピング作成の到達目的の理解を助けることです。非常に基本的な例を示しているため、ソース・データの変換は実行されません。ただし一般的なデータ・ウェアハウス環境において、変換はマッピングの構成部分です。
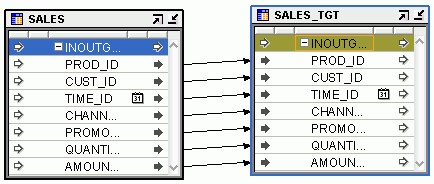
SALES表は組織の売上データを含みます。この表はOracle DatabaseのSRCスキーマにあります。この売上データを、データ・ウェアハウスのTGTスキーマにあるターゲット表SALES_TGTにロードする必要があります。スキーマとターゲット表の両方が同じ列名で同じ列数を含みます。
PL/SQLマッピングを定義してデータがソース表からターゲット表にどのようにロードされるかを定義します。
ソースのOracle Database表からターゲットのOracle Database表にデータをロードするマッピングを定義する手順は、次のとおりです。
まだ実行していない場合は、プロジェクト・ナビゲータで、ソースに対応するOracleモジュールを作成します。SRC_MODというこのモジュールは、SRCスキーマと対応するロケーションSRC_LOCに関連付けられています。さらに、SALES表をSRC_MODモジュールにインポートします。
プロジェクト・ナビゲータで、ターゲット表が位置するデータ・ウェアハウス・スキーマとそのロケーションが対応するターゲット・モジュールを作成します。
関連付られているロケーションTGT_LOCがTGTスキーマと対応するWH_TGT Oracleモジュールを作成します。
プロジェクト・ナビゲータで、WH_TGTモジュールを開きます。
「マッピング」ノードを右クリックし、「新規マッピング」を選択します。
「マッピングの作成」ダイアログ・ボックスが表示されます。
マッピングについての次の情報を入力して、「OK」をクリックします。
名前: マッピング名を入力します。
説明: マッピングの説明(オプション)を入力します。
マッピング・エディタが表示されます。このインタフェースを使用して、ソース・オブジェクトとターゲット・オブジェクトの間のデータ・フローを定義します。
SRC_MODモジュールの表ノードを開きます。
SALES表を、プロジェクト・ナビゲータからマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
SALES表を示す演算子がキャンバスに追加されます。左上隅に演算子名が表示されます。演算子名の下にあるのはグループ名です。グループの名前と数は演算子のタイプに基づきます。表演算子は、INOUTGRP1という1つのグループを持ちます。グループの下に属性名とデータ・タイプがリストされます。
プロジェクト・ナビゲータからWH_TGTモジュールのSALES_TGT表を、マップ・エディタ・キャンバスにドラッグ・アンド・ドロップします。
SALES_TGT表を示す演算子がキャンバスに追加されます。各属性名とデータ・タイプを表示することができます。
ソース表SALESの属性をターゲット表SALES_TGTの対応する属性に接続します。
演算子内のすべての属性を接続するには、SALES演算子のグループINOUTGRP1上のマウスの左ボタンをクリックしたままにしてドラッグし、SALES_TGT演算子のグループINOUTGRP1上でマウス・ボタンを放します。
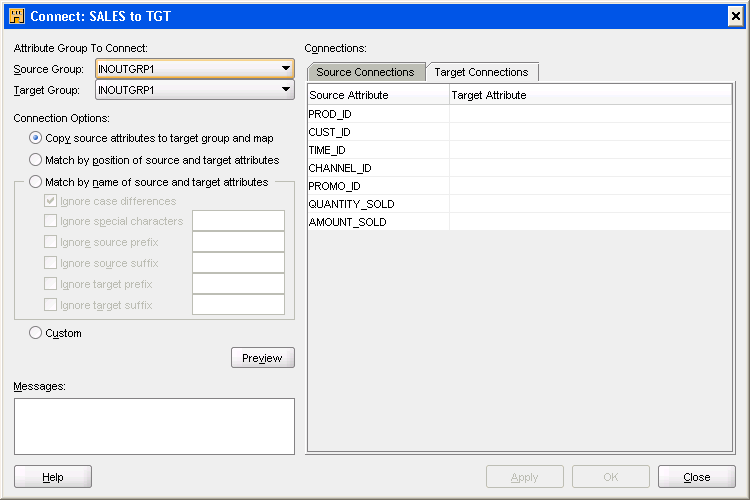
「接続」ダイアログ・ボックスが表示されます。
接続オプションで、ソースとターゲット演算子の名前による一致を選択し、「プレビュー」をクリックします。
「接続」セクションでは、ソース属性とターゲット属性の関連が表示されます。ソース属性列にはソース表属性がリストされ、ターゲット属性列にはソース属性がロードされるターゲット表属性がリストされます。
「OK」をクリックして、「接続」ダイアログ・ボックスを閉じます。
図5-1のようなコマンド・マッピングが表示されます。
プロジェクト・ナビゲータ内のマッピングを選択して、「検証」をクリックすることでマッピングを検証します。または、プロジェクト・ナビゲータのマッピングを右クリックして、「検証」を選択します。
検証のテストが実行されて、マッピング内のメタデータ定義と構成パラメータが検証されます。必要に応じて検証エラーを解決します。
プロジェクト・ナビゲータ内のマッピングを選択して、「生成」をクリックすることでマッピングを生成します。または、プロジェクト・ナビゲータのマッピングを右クリックして、「生成」を選択します。
生成では、ターゲット・スキーマでマッピングを作成するために使用する必要のあるスクリプトが作成されます。必要に応じて、生成エラーを解決して、マッピングを再度生成します。Oracle Warehouse Builderでは、このマッピングのスクリプトが作成されます。
SALESというソース表からデータを抽出して、SALES_TGTというターゲット表にロードするマッピングが定義されました。このマッピングのメタ・データがリポジトリに保存されます。生成が終了した後、ターゲット・スキーマでこのマッピングを作成するためのスクリプトが用意されます。
ETLを実行し、ソース表からターゲット表にデータを転送するには、「ETLジョブの開始」に定義されているように、最初にターゲット・スキーマにマッピングを配布し、その後にマッピングを実行する必要があります。
前提作業
最初に、プロジェクトがターゲット・モジュールまたは定義済ロケーションのあるテンプレート・マッピング・モジュールを含むことを検証します。このモジュールにマッピングを作成する必要があります。
さらに、マッピングでソースまたはターゲットとして使用するすべての既存のデータをインポートします。
ETLを実行するマッピングを定義する手順は次のとおりです。
プロジェクトナビゲータで、ETLを実行するための論理を含むマッピングを定義します。
マッピング定義の詳細は「マッピングの定義」を、CTマッピングの作成の詳細は「コード・テンプレート・マッピングの作成」をそれぞれ参照してください。
マッピング・エディタで、マッピングに必要な演算子を追加します。演算子によってETLを実行できます。
演算子の詳細は、「演算子のマッピングへの追加」を参照してください。
マッピング内の演算子を接続して、ターゲット・オブジェクトにロードされる前にソース・オブジェクトのデータがどのように変換されるかを定義します。
演算子間の接続の確立方法の詳細は、「演算子、グループおよび属性の接続」を参照してください。
マッピング内の演算子を編集して演算子、グループ、または属性プロパティを設定します(オプション)。演算子を編集して、特定の変換が実行される方法を指定する必要があります。たとえば、フィルタ演算子を使用してターゲットにロードする行を制限する場合は、フィルタ演算子を編集して、行のフィルタリングに必要な条件を指定します。
マッピング内の演算子の編集方法については、「演算子の編集」を参照してください。
マッピングを構成します。
PL/SQLマッピングについては、「マッピングの構成」を参照してください。CTマッピングについては、「コード・テンプレート・マッピング内のコード・テンプレートのオプションの設定」を参照してください。
プロジェクト・ナビゲータ内のマッピングを右クリックして、「検証」を選択することでマッピングを検証します。
検証では、Oracle Warehouse Builderで定義されたマッピングのルールに準拠しているかどうか、マッピングのメタデータ定義および構成パラメータが検証されます。
プロジェクト・ナビゲータ内のマッピングを右クリックして、「生成」を選択することでマッピングを生成します。
生成ではメタデータ定義と構成設定が使用されて、ターゲット・スキーマ内でマッピングを作成するために使用されるコードが作成されます。
マッピングを生成する場合に、生成されたコードにはコード生成の演算子を識別するために役立つコメントが含まれます。これによって、マッピングを配布するときに発生する可能性のあるエラーをデバッグできます。
ターゲット・スキーマにマッピングを配布して、ターゲット・スキーマへのマッピングのために生成されるPL/SQLコードを作成します。
配布については、「オブジェクトの配布」を参照してください。
マッピングを実行してソース表からデータを抽出し、ターゲット表にロードします。
ETLオブジェクトの実行方法については、「ETLジョブの開始」を参照してください。
後続の手順
マッピングを設計してマッピングのコードを生成した後、プロセス・フローを作成するか、直接配布を続行して実行できます。
プロセス・フローを使用して、マッピングを相互に関連付けます。たとえば、あるマッピングが完了すると電子メール通知がトリガーされて別のマッピングが開始するように、プロセス・フローを設計できます。詳細は、第8章「プロセス・フローの設計」を参照してください。
マッピングの設計後に、そのコードを生成してターゲットに配布する手順は次のとおりです。
すぐにマッピングを実行する場合は、「ETLジョブの開始」の説明に従います。
後で実行する場合は、「ETLジョブのスケジュール」の説明に従ってマッピングのスケジュールを調整します。
1つまたは複数のマッピングの実行を統括するためには、「プロセス・フローの設計」の説明に従って、その他のアクティビティに沿ってプロセス・フローを作成します。
マッピングは、マッピングによって実行される変換に関するメタデータを含むOracle Warehouse Builderオブジェクトです。メタデータには、データの抽出元であるソースの詳細、変換データがロードされるターゲット、およびそれらの操作の実行に使用される設定が含まれます。
マッピングを定義する手順
プロジェクト・ナビゲータで、プロジェクト、「データベース」ノード、続いてマッピングを定義する「Oracle」モジュールの順に開きます。
「マッピング」ノードを右クリックし、「新規マッピング」を選択します。
「マッピングの作成」ダイアログ・ボックスが表示されます。
新しいマッピングの名前と説明(オプション)を入力します。
マッピング名の指定と説明の記述に関するルールは、「マッピングでのネーミング規則」を参照してください。
「OK」をクリックします。
Oracle Warehouse Builderによりマッピングの定義が格納され、プロジェクト・ナビゲータにマッピング名が挿入されます。そのマッピングに対してマッピング・エディタが開き、タイトル・バーにマッピングの名前が表示されます。
以前に作成したマッピングを開く手順
プロジェクト・ナビゲータで、プロジェクト、「データベース」ノード、続いてマッピングが定義された「Oracle」モジュールの順に開きます。
「マッピング」ノードを開きます。
次のいずれかの方法で、マッピング・エディタを開きます。
マッピングをダブルクリックします。
マッピングを選択し、「ファイル」メニューから「開く」を選択します。
マッピングを選択し、[Ctrl]キーを押しながら[O]キーを押します。
マッピングを右クリックし、「開く」を選択します。
マッピング・エディタが表示されます。
|
注意: OMB*Plusを使用して作成されたマッピングを開く場合、マッピングに複数の演算子が含まれていても、1つの演算子のみが含まれているように表示される場合があります。すべての演算子を表示するには、ツールバーの「自動レイアウト」をクリックします。 |
マッピングのネーミングの規則は、「プリファレンス」ダイアログ・ボックスのネーミング・プリファレンス・セクションで選択するネーミング・モードに応じて異なります。Oracle Warehouse Builderでは、ワークスペースの各オブジェクトのビジネス名と物理名が維持されます。ビジネス名とは、一意の説明的な名前で、ビジネスレベルのユーザーにデータの意味を持ちます。物理名はOracle Warehouse Builderでコード生成時に使用される名前です。
あるネーミング・モードで作業中にオブジェクトに名前を付けると、Oracle Warehouse Builderでは他のモード用にデフォルト名が作成されます。したがって、ビジネス名モードで作業中に、大/小文字の両方、特殊文字および空白を含む名前をマッピングに割り当てると、Oracle Warehouse Builderではデフォルトの物理名が作成されます。たとえば、マッピングをMy Mapping (refer to doc#12345)というビジネス名で保存すると、デフォルトの物理名はMY_MAPPING_REFER_TO_DOC#12345となります。
マッピング・エディタでオブジェクトに名前を付けたり、名前を変更したりするときは、次のネーミング規則に従います。
マッピングのネーミングと説明
物理ネーミング・モードでは、マッピング名は1文字から30文字までの英数字で、空白は使用できません。ビジネス・ネーミング・モードでは、200文字以内という制限があり、空白と特殊文字を使用できます。両方のネーミング・モードにおいて、名前はプロジェクト全体で一意にする必要があります。
マッピングのスケジューリングに関する注意: マッピングの実行をスケジューリングする場合は、付加的な考慮事項があります。スケジューリングするETLオブジェクトの物理名は25文字以内、ビジネス名は1995文字以内に制限されます。この付加的な制限に従うと、Oracle Warehouse Builderでは、接尾辞_jobと配布および実行に必要な他の内部文字をマッピング名に追加できます。
マッピング定義の作成後、プロパティ・インスペクタで物理名とビジネス名を確認できます。
必要に応じてマッピングの説明を編集します。説明は4,000文字までの英数字を使用でき、空白を含めることができます。
属性とグループのネーミングの規則
ソースに依存しないグループおよび属性は名前を変更できます。属性名とグループ名は論理名です。通常、オブジェクトの属性名はバインド先演算子の属性名と同じですが、そのプロパティは相互に独立した状態で維持されます。
演算子のネーミング規則
演算子のビジネス名は、次の要件を満たす必要があります。
使用できる文字数は200文字以内です。
演算子名は、その親のグループ内において一意である必要があります。親グループは、マッピングまたはその親のプラッガブル・マッピング・コンテナのどちらかである場合があります。
演算子の物理名は、次の要件を満たす必要があります。
演算子名に使用できる文字数は1から30文字以内です。
演算子名は、その親のグループ内において一意である必要があります。親グループは、マッピングまたはその親のプラッガブル・マッピング・コンテナのどちらかである場合があります。
演算子名は、Oracle Database SQL言語リファレンスで定義されている基本要素の構文規則に準拠している必要があります。
一部の演算子には、物理名とビジネス名の他にバウンド名もあります。ワークスペース・オブジェクトに関連付けられている各演算子には、バウンド名があります。コード生成時、Oracle Warehouse Builderではバウンド名を使用し、そのワークスペース・オブジェクトに対する演算子を参照します。バウンド名には、次のような特性があります。
バウンド名は一意である必要はありません。
バウンド名は、一般的なOracle Warehouse Builderの物理ネーミング規則に準拠している必要があります。ただし、オブジェクトがインポートされたものであり、スペースなどの制限された文字が含まれている場合を除きます。
通常、バウンド名は直接変更しません。かわりに、マッピングの外部のワークスペース・オブジェクトと同期化することで、これらを変更します。
物理ネーミング・モードの場合、ユーザーが演算子属性の物理名を変更すると、同期化の際に、Oracle Warehouse Builderによって新しい物理名がバウンド名として伝播されます。
バインドは、ワークスペースのオブジェクトに演算子を関連付けるプロセスです。バインドとバインド方法の詳細は、第3章「ディメンション・オブジェクトの定義」の「バインド」を参照してください。
演算子によってデータ変換を実行できます。一部の演算子はワークスペース・オブジェクトにバインドされ、その他の演算子はバインドされません。組込み変換を表す多くの演算子(ジョイナ、アグリゲータ、フィルタなど)は、基礎となるワークスペース・オブジェクトを直接参照せず、また、バインドもされません。表、ビュー、ディメンション、キューブなどその他の演算子は、ワークスペースのオブジェクトを参照するため、バインドも可能です。
一般的に、表演算子などのデータ・ソースまたはターゲット演算子をマッピングに追加すると、その演算子は、表と異なるオブジェクトであっても、ワークスペース内で定義された表を参照します。つまり、マッピング内のソース演算子とターゲット演算子は、ワークスペース内の基礎となるオブジェクトにバインドされます。1つのマッピング内で複数の演算子が同一の基礎となるオブジェクトにバインドされることが可能です。たとえば、表EMPをマッピング内の2つの異なる操作のソースとして使用するために、EMP_1とEMP_2という2つの表演算子をマッピングに追加して、それらをワークスペース内の同じ基礎となるEMP表にバインドすることができます。
2つの演算子のバージョンを区別するために、この章では、ワークスペース内のオブジェクトを総称的にワークスペース・オブジェクトと呼び、具体的には、ワークスペース表、ワークスペース・ビューのように表現します。また、マッピングの演算子は表演算子、ビュー演算子のように表現します。したがって、ディメンションをマッピングに追加する場合、マッピングのディメンションはディメンション演算子、ワークスペースのディメンションはワークスペース・ディメンションと表されます。
Oracle Warehouse Builderでは、一部の演算子用に個別のワークスペース・オブジェクトが保持されています。そのため、これらのオブジェクトは個別操作が可能です。マッピングの論理に影響することなくワークスペースオブジェクトを変更できます。変更後、ワークスペース・オブジェクトと対応する演算子との間の相違を同期化する方法を決定できます。これにより、ウェアハウス設計において最大限の柔軟性が得られます。
たとえば、ワークスペース表の新規メタデータ定義を再インポートした場合は、これらの変更内容をマッピングの表演算子に伝播する必要があります。反対に、マッピングの表演算子を変更した場合は、これらの変更内容を関連するワークスペース表に伝播する必要があります。これらのタスクは、同期化と呼ばれる処理によって実現します。
ワークスペース・オブジェクトにバインドする演算子の追加
ワークスペース内の関連するオブジェクトにバインドできる演算子は次のとおりです。
演算子をマッピングに追加する手順は、次のとおりです。
マッピング・エディタを開きます。
コンポーネント・パレットから、演算子のアイコンをキャンバスにドラッグ・アンド・ドロップします。または、「グラフ」メニューから「追加」、追加する演算子のタイプ、演算子の順に選択します。
コンポーネント・パレットが表示されない場合は、「表示」メニューからコンポーネント・パレットを選択します。
ワークスペース・オブジェクトにバインド可能な演算子を選択する場合は、マッピング・エディタに「operator_name演算子の追加」ダイアログ・ボックスが表示されます。このダイアログ・ボックスの使用方法については、「演算子を追加するための演算子の追加ダイアログ・ボックスの使用」参照してください。
ワークスペース・オブジェクトにバインドできない演算子を選択した場合は、演算子を作成するためのウィザードまたはダイアログ・ボックスが表示されます。
Oracle Warehouse Builderに表示される指示に従い、「OK」をクリックします。
マッピング・エディタのキャンバスに演算子が最大化された状態で表示されます。左上隅に演算子名が表示されます。各属性名とデータ・タイプを表示することができます。
演算子を最小化するには、右上隅の矢印をクリックすると、マッピング・エディタのキャンバスに演算子がアイコンとして表示されます。演算子を最大化するには、キャンバス上で演算子をダブルクリックします。
演算子の追加ダイアログ・ボックスを使用して演算子をマッピングに追加できます。ワークスペース・オブジェクトにバインド可能な演算子を追加する場合は、マッピング・エディタに「operator_name演算子の追加」ダイアログ・ボックスが表示されます。
このダイアログ・ボックスで次のいずれかのオプションを選択します。
「バインドされていない演算子を属性なしで作成」を選択して、新規ステージング領域表や新規ターゲット表など、ワークスペース・オブジェクトにバインドされていない新しいワークスペース・オブジェクトを定義します。
「新規演算子名」フィールドに、新しい演算子の名前を入力します。演算子が属性なしでキャンバスに表示されます。
これで、演算子の属性を追加および定義できるようになりました(「演算子の編集」を参照)。次に、ターゲット・モジュールに新規ワークスペース・オブジェクトを作成するために、演算子を右クリックして「作成とバインド」を選択します。
このオプションをマッピング設計で使用する方法の例は、「例: マッピング・エディタによるステージング領域表の作成」を参照してください。
「既存リポジトリ・オブジェクトから選択してバインド」をクリックして、既存のワークスペース・オブジェクトに基づいて演算子を追加します。そのオブジェクトを、ワークスペースに定義またはインポートしている場合があります。
接頭辞を入力してオブジェクトを検索するか、選択したモジュール内のオブジェクトの表示リストからオブジェクトを選択します。
複数のアイテムを選択するには、[Ctrl]キーを押しながら各アイテムをクリックします。連続したアイテムのグループを選択するには、選択範囲の最初のオブジェクトをクリックし、[Shift]キーを押しながら最後のオブジェクトをクリックします。
演算子は、マッピングと同じモジュール内のワークスペース・オブジェクトまたは別のモジュールのワークスペース・オブジェクトに基づいて追加できます。別のモジュールのワークスペース・オブジェクトを選択すると、マッピング・エディタによってコネクタが作成されます(コネクタが存在していない場合)。このコネクタによって、マッピングのロケーションとワークスペース・オブジェクトのロケーション間のデータの移動パスが確立されます。
マッピング内で疑似列ROWIDおよびROWNUMを使用できます。ROWNUM疑似列は、表から行を選択した順序を示す数値を戻します。ROWID疑似列は、データベース表内の行のrowid(バイナリ・アドレス)を戻します。
マッピング内の表、ビューおよびマテリアライズド・ビュー演算子でROWIDおよびROWNUM疑似列を使用できます。これらの演算子には、COLUMN USAGEという追加の列が含まれており、ROWIDまたはROWNUMとして使用する属性の識別に使用されます。標準の属性の場合、この列のデフォルト値はTABLE USAGEとなります。ROWIDまたはROWNUM値の属性を使用するには、COLUMN USAGEをそれぞれROWIDまたはROWNUMに設定します。
データ型ROWID、 UROWIDまたはVARCHAR2の属性にROWID列をマッピングできます。ROWNUM列は、データ型NUMBERの属性か、NUMBERから暗黙的に変換できる他の任意のデータ型にマップできます。
ROWIDおよびROWNUM疑似列は実際の列ではないため、オブジェクト・エディタには表示されません。
マッピング・ソース演算子、データを変換する演算子およびターゲット演算子を選択した後は、これらの演算子を接続できます。データ・フローの接続により、ソースから演算子を通過してターゲットに至るデータ・フローの様子が視覚的に表されます。マッピングを接続するダイアログ・ボックスは、演算子間にデータ・フローを作成する際に役立ちます。
演算子は、次のいずれかの方法で接続できます。
演算子の接続: 2つの演算子間でグループを接続するための条件を定義します。
グループの接続: 2つのグループ間ですべての属性を接続するための条件を定義します。
属性の接続: 一度に個々の演算子属性を相互に接続します。
演算子ウィザードの使用: ピボット演算子、Name and Address演算子などの演算子は、ウィザードを使用してデータ・フロー接続を定義できます。
マッピング接続ダイアログ・ボックスの使用: 演算子、グループまたは属性を接続するための条件を定義します。
マッピングを接続するダイアログ・ボックスを表示するには、演算子、グループまたは属性を右クリックして、「接続」、接続を確立する演算子の名前の順に選択します。マッピング接続ダイアログ・ボックスが表示されます。
このダイアログ・ボックスの使用方法については、「マッピング接続ダイアログ・ボックスの使用」を参照してください。
演算子を接続した後は、接続した属性間にデータ・フロー接続が確立されます。
図5-2は、属性が接続されたマッピングを示しています。
演算子間に既存の接続がない場合、ある演算子を別の演算子に接続することができます。接続する2つの演算子は、アイコン形式で表示されている必要があります。
あるグループから1つの演算子に接続することもできます。グループ上でマウスの左ボタンを押したままドラッグし、演算子のタイトルの上にドロップします。
ある演算子から別の演算子に接続する手順は、次のとおりです。
接続を確立する演算子を選択します。
マウスの左ボタンをクリックしたまま、ポインタを演算子アイコンの上に置きます。
演算子から、接続を確立する演算子アイコンにマウスをドラッグします。
マウスをドラッグするとき、接続を示す行が表示されます。
ターゲット演算子の上でマウス・ボタンを放します。
マッピング接続ダイアログ・ボックスが表示されます。「マッピング接続ダイアログ・ボックスの使用」の説明に従って、このダイアログ・ボックスを使用して、グループ内でのグループと属性の間の接続を指定します。
グループを接続すると、属性が自動的にコピーされるか、詳細情報を入力するように指示されます(「マッピング接続ダイアログ・ボックスの使用」を参照)。
あるグループから別のグループに接続する手順は、次のとおりです。
接続を確立するグループを選択します。
マウスの左ボタンをクリックしたまま、ポインタをグループの上に置きます。
そのグループから、接続の確立先となるグループにマウスをドラッグします。
マウスをドラッグするとき、接続を示す行が表示されます。
ターゲット・グループの上でマウス・ボタンを放します。
ある演算子グループを、属性を持つターゲット・グループに接続する場合、マッピング接続ダイアログ・ボックスが表示されます。「マッピング接続ダイアログ・ボックスの使用」の説明に従って、このダイアログ・ボックスを使用して、属性間の接続を指定します。
ある演算子グループを、既存の属性を持たないターゲット・グループに接続する場合、属性が自動的にコピーされ、各属性が接続されます。これは、「例: マッピング・エディタによるステージング領域表の作成」に示すようなマッピングを設計する場合に便利です。
一方の演算子の単一の出力属性から、他方の演算子の単一の入力属性に線を引きます。
属性を接続する手順は、次のとおりです。
マウス・ボタンをクリックしたまま、ポインタを出力属性の上に置きます。
出力属性からデータのフロー先となる入力属性にマウスをドラッグします。
マウスをドラッグするとき、接続を示す行がマッピング・エディタ・キャンバスに表示されます。
入力属性の上でマウス・ボタンを放します。
ステップ1から3を繰り返し、必要なデータ・フロー接続をすべて作成します。
ステップ1で複数の属性を選択することもできます。複数の属性を選択するには、[Ctrl]キーを押したまま、属性をクリックして選択します。複数のソース属性を選択する場合は、出力属性ではなくグループの上でのみマウスを放すことができます。マッピング接続ダイアログ・ボックスが表示されます。このダイアログ・ボックスを使用して、ソース属性とターゲット属性の間のデータ・フローを定義します。
属性を接続するとき、必ず次のルールに従います。
同じ入力または入力属性には2度接続できません。
同じ演算子内の属性には接続できません。
入力専用の属性から接続することも、出力専用の属性に接続することもできません。
確立されているカーディナリティに矛盾する方法では演算子を接続できません。かわりに、ジョイナ演算子を使用します。
マッピング接続ダイアログ・ボックスを使用してマッピング内の演算子間の接続を定義できます。通常、データ・ロードプロセスに必要な複雑な変換ロジックを実装する数多くの演算子がマッピングには含まれています。接続する演算子がマッピング上で互いに離れているためスクロールが必要になる場合があります。マッピング接続ダイアログ・ボックスを使用して、効果的な方法で演算子、グループおよび属性を接続できます。
図5-3 マッピング接続ダイアログ・ボックスの表示
次の各セクションを実行して演算子間の接続を定義します。
(オプション)接続する属性グループ
このセクションを使用して、接続を確立するソース・グループとターゲット・グループを選択します。このセクションは、ソース演算子をターゲット・グループに、ソース・グループをターゲット演算子に、またはソース演算子をターゲット演算子に接続するときのみ表示されます。
ソース・グループ データのフロー元のソース演算子上のグループに対応するソース・グループ。「ソース・グループ」リストには、ソース演算子のすべての出力グループおよびI/Oグループがあります。データ・フローの作成元になるグループを選択します。
ターゲット・グループ データのフロー先の演算子上のグループに対応するターゲット・グループ。「ターゲット・グループ」リストには、ターゲット演算子のすべての入力グループおよびI/Oグループがあります。データ・フローを作成するグループを選択します。
ソース・グループとターゲット・グループを選択すると、ソース・グループとターゲット・グループの属性間の接続を指定できます。このため、ソース演算子とターゲット演算子のグループ間のデータ・フローを同時に確立することができます。
|
注意: 選択したソース・グループまたはターゲット・グループに対して接続を作成すると、異なるグループを選択したときに、変更を保存するかどうかを確認する警告が表示されます。 |
「接続オプション」セクションを使用して、すべてのソース属性をターゲット属性に異なる条件で自動的に接続することができます。
属性の接続について次のオプションを1つ選択します。
属性を接続するために使用するオプションを選択した後、グループの接続属性を使用して、「プレビュー」をクリックし、「接続」セクション内のソース属性とターゲット属性の間のマッピングを表示します。マッピングを確認して問題がない場合は、「OK」をクリックします。
ソース属性をターゲット・グループにコピーと一致
このオプションは、属性が含まれるターゲット・グループにソース属性をコピーする場合に使用します。マッピング・エディタでは、演算子の接続ダイアログ・ボックスでの選択内容に基づいて、ソース属性から新しいターゲット属性に演算子が接続されます。この操作は、ディメンション・ターゲット演算子やキューブ・ターゲット演算子など、新しい入力属性を受け入れないターゲット・グループには実行されません。
ソースとターゲット属性の位置による一致
このオプションは、各グループ内の属性の位置に基づいて、既存の属性間を接続する場合に使用します。ターゲットのすべての属性が一致している場合、ソース属性とターゲット属性は同じ順序になります。ソース演算子にターゲットよりも多くの属性が含まれている場合、残りのソース属性はターゲットに接続されません。
ソースとターゲット属性の名前による一致
このオプションは、名前が一致する属性間を接続する場合に使用します。オプションのリストから選択することで、一致しない双方の名前を接続します。次のオプションを組み合せて使用できます。
大/小文字の違いを無視: 小文字と大文字が同じ文字とみなされます。たとえば、属性FIRST_NAMEとFirst_Nameは一致と判断されます。
特殊文字を無視: 一致を処理する際に無視する文字を指定します。たとえば、ハイフンとアンダースコアを指定すると、属性FIRST_NAME、FIRST-NAME、FIRSTNAMEはすべて一致と判断されます。
ソースの接頭辞を無視、ソースの接尾辞を無視、ターゲットの接頭辞を無視、ターゲットの接尾辞を無視: 一致を処理する際に無視する接頭辞と接尾辞を指定します。たとえば、「ソースの接頭辞を無視」を選択してテキスト・フィールドにUSER_を入力すると、ソース属性USER_FIRST_NAMEとターゲット属性FIRST_NAMEは一致と判断されます。
このセクションには、接続オプションのプレビュー結果からの情報メッセージが表示されます。特定のソース属性またはターゲット属性などの情報は、セクション内に未解決の競合が表示されるため接続されません。
「接続」セクションには、ソース・グループに属するソース属性とターゲット・グループに属するターゲット属性との間の接続が表示されます。ソース・グループとターゲット・グループの属性間にある既存の接続は、このセクションに表示されます。
このセクションには、「ソース接続」と「ターゲット接続」の2つのタブがあります。両方のタブには「ソース属性」列と「ターゲット属性」列を含むスプレッドシートが表示されます。「ソース属性」列には、ソース・グループとして選択されたグループに対するすべての属性またはキャンバスで選択された属性がリストされます。「ターゲット接続」列には、ターゲット・グループとして選択されたグループのすべての属性がリストされます。「ソース接続」タブまたは「ターゲット接続」タブに変更を加えると、ただちにその他のタブに反映されます。
「ソース接続」タブ
「ソース接続」タブでは、ソース・グループからの接続を迅速に確立できます。このタブの「ターゲット属性」列では、ターゲット・グループからの属性をリストします。このタブを使用して、各ターゲット属性の接続元であるソース属性を指定します。各ターゲット属性については、0(ゼロ)または1個のソース属性をマップします。特定のソース属性をリストされたターゲット属性に接続するには、各ターゲット属性において対応する「ソース属性」列のソース属性の名前入力します。
属性名の入力を開始すると、Oracle Warehouse Builderにより、名前が入力した文字で始まるソース属性を含むリストが表示されます。接続するソース属性がこのリストにある場合は、その属性をクリックして選択します。*や?などのワイルド・カードを使用して、データ・フローを作成するソース属性を検索できます。「ターゲット属性」列にリストされている列をソートすることもできます。属性名にスペースやカンマが含まれる場合、ソース属性の名前を二重引用符で囲みます。
「ターゲット接続」タブ
「ターゲット接続」タブでは、ターゲット・グループへの接続を迅速に確立できます。「ソース属性」列には、ソース・グループからの属性のリストが表示されます。このタブを使用して、各ターゲット属性の接続元であるソース属性を指定します。各ソース属性について、「ターゲット属性」列に対応する1つまたは複数のターゲット属性名を入力します。1つのソース属性を複数のターゲット属性に接続する場合は、ソース属性の名前をカンマで区切って「ターゲット属性」列に入力します。
属性名の入力を開始すると、Oracle Warehouse Builderにより、名前が入力した文字で始まるターゲット属性を含むリストが表示されます。接続するターゲット属性がリストに表示されている場合は、その属性をクリックして選択します。*や?などのワイルド・カードを使用して、データ・フローを作成するターゲット属性を検索できます。「ソース属性」列にリストされている列をソートすることもできます。
各演算子には、エディタが関連付けられています。その演算子エディタを使用して、演算子、グループおよび属性に関する一般的な情報と構造的な情報を指定します。演算子エディタでは、グループおよび属性を追加または削除したり、名前を変更できます。演算子の名前も変更できます。
定数、式、アグリゲータ演算子の出力グループ内の属性などと関連付けられている式を持つ属性については、指定した式を編集することもできます。
演算子の編集は、ロード・プロパティや条件付き動作の割当てとは異なります。ロード・プロパティや条件付き動作を指定するには、プロパティ・ウィンドウ(「マッピングの設定」を参照)を使用します。
演算子、グループまたは属性を編集する手順は、次のとおりです。
マッピング・エディタのキャンバスから演算子を選択します。
あるいは、演算子内のグループまたは属性を選択します。
選択したアイテムを右クリックし、「詳細をオープン」を選択します。
マッピング・エディタに演算子エディタが表示され、「名前」タブ、「グループ」タブ、および各タイプの演算子のグループの「入力/出力」タブが表示されます。
いくつかの演算子には追加のタブが含まれます。たとえば、Match-Merge演算子には一致ルールおよびマージ・ルールを定義するタブが含まれます。
各タブに表示されるプロンプトに従い、「OK」をクリックして終了します。
「名前」タブには、演算子名と説明(オプション)が表示されます。ここでは、演算子の名前を変更したり、説明を追加したりすることができます。「マッピングでのネーミング規則」にリストされている規則に従って、演算子に名前を付けてください。
「グループ」タブで、グループ情報を編集します。
各グループには、名前、方向および説明(オプション)が表示されます。ほとんどの演算子のグループ名は変更できますが、どの演算子の場合もグループの方向は変更できません。グループの方向には、「入力」、「出力」、「I/O」のいずれかを指定できます。
演算子によっては、「グループ」タブでグループを追加および削除できます。たとえば、入力グループを「ジョイナ」に、出力グループを「スプリッタ」に追加します。
演算子エディタには、「グループ」タブに表示されているグループのタイプごとに、タブが1つずつ表示されます。これらのタブには、属性名、データ型、長さ、精度、スケール、秒精度および説明(オプション)が表示されます。表演算子やビュー演算子など、一部の演算子の場合は、「入力」タブと「出力」タブではなく、「I/O」タブのみが表示されます。それらのタブで、属性情報を編集します。
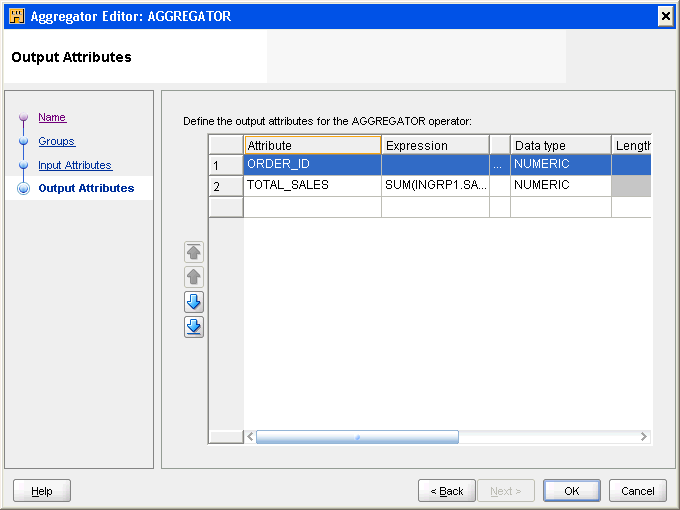
図5-4 は、演算子エディタの「出力属性」タブを示します。この例では、演算子は、個別の「入力」タブと「出力」タブを含むアグリゲータとなります。
このタブは、出力属性の定義に使用できる表を含みます。タブ上の各行は属性を表します。マッピング・エディタでは、編集できないプロパティは無効化されます。たとえば、データ型がNUMBERの場合、精度とスケールは編集できますが、長さは編集できません。
属性は追加、削除および編集できます。属性を追加するには、空白行の「属性」列をクリックして属性名を入力し、データ型、長さ、説明などその他の属性の詳細を指定します。属性を削除するには、属性の左側にあるグレー表示されたセルを右クリックし、「削除」を選択します。
属性のデータ型、長さ、精度およびスケールに正しい値を割り当てるには、PL/SQLルールに従います。演算子を同期化すると、Oracle Warehouse BuilderではSQLルールに基づいて属性がチェックされます。
入力タブおよび出力タブにリストされた属性の順序を変更することもできます。属性を表す列を選択して、属性の左側にある「>」ボタンを使用して、グループの属性の順序を変更します。または、マウスの左ボタンを押したままで、十字線が表示されたら、矢印を目的の場所にドラッグします。
演算子属性に関連付けられている式
式、ジョイナ、アグリゲータ、および検索などの特定の演算子には、それらと関連付けられている式を持つことができます。それらの属性については、属性の「式」列を使用して属性値を作成するために使用する式を指定します。「式」列に式を直接入力することができます。図5-4 は、アグリゲータ演算子内の出力属性の「式」列を示しています。式ビルダー・インタフェースを使用して式を定義するには、「式」列の右側で省略記号ボタンをクリックします。
たとえばアグリゲータ演算子で、集計されたソース列を格納する出力属性を作成します。出力属性の「式」列を使用して、属性値を作成するために使用する式を指定します。
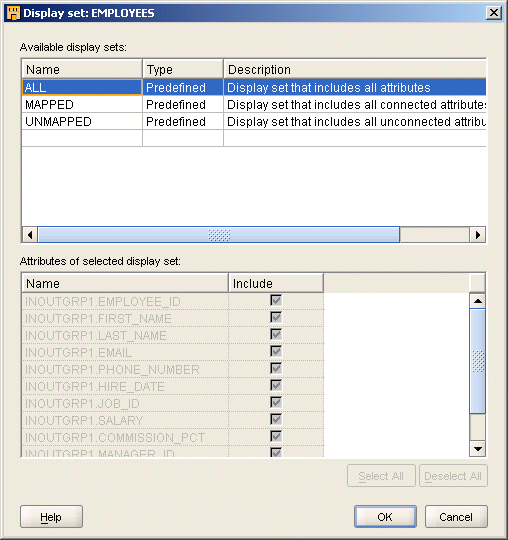
表示セットは、属性のサブセットのグラフィック表現です。表示セットを使用して、演算子に表示される属性の数を制限し、複合マッピングの表示を単純化します。
デフォルトで、演算子には「ALL」、「MAPPED」および「UNMAPPED」という3つの事前定義済表示セットが含まれています。表5-1 で、デフォルトの表示セットについて説明します。
表5-1 デフォルトのセット
| 表示セット | 説明 |
|---|---|
|
すべて |
演算子にすべての属性が含まれています。 |
|
MAPPED |
別の演算子に接続されている演算子の属性のみが含まれています。 |
|
UNMAPPED |
他の属性に接続されていない属性のみが含まれています。 |
マッピング内の任意の演算子に対して、表示セットを定義できます。
表示セットを定義する手順は、次のとおりです。
演算子を右クリックして「表示セット」を選択します。
図5-5のような「表示セット」ダイアログ・ボックスが表示されます。
「UNMAPPED」の下の行をクリックし、新規表示セットの名前と説明を入力します。
「選択された表示セットの属性」というセクションに、演算子に使用できるすべての属性が表示されます。「タイプ」列は自動的にユーザー定義に設定されます。
定義済の属性セットは編集および削除できません。
「挿入」列で、表示セットに含める属性を選択します。
すべての属性を指定するには「すべて選択」を、すべての属性を除外するには「すべて選択解除」をクリックします。
「OK」をクリックします。
演算子のグループには、表示用に選択した属性セットに含まれる属性のみがリストされます。
マッピングを定義した後、プロパティ・インスペクタを使用してマッピングのプロパティを設定することができます。
次のプロパティを設定できます。
マッピングのプロパティ: これはマッピング全体に影響を与えるプロパティです。たとえば、マッピング実行時にターゲットがロードされる順序を定義するターゲット・ロード順序パラメータを設定することができます。
演算子のプロパティ: これは演算子全体に影響を与えるプロパティです。設定できるプロパティは、演算子のタイプによって異なります。たとえば、Oracleソースおよびターゲット演算子の使用手順は、フラット・ファイルのソースおよびターゲット演算子の使用手順とは異なります。
グループのプロパティ: これは属性のグループに影響を与えるプロパティです。ほとんどの演算子には、グループのプロパティが設定されていません。グループ・プロパティが設定される演算子の例としては、スプリッタ演算子やデュプリケータ解除演算子があります。
属性のプロパティ: これはソース演算子とターゲット演算子の属性に関するプロパティです。属性のプロパティの例としては、データ型、精度、スケールがあります。
演算子、グループおよび属性プロパティの設定
マッピング・エディタのキャンバス上で演算子、グループ、または属性を選択する場合、それに関連付けられたプロパティはプロパティ・インスペクタに表示されます。プロパティ・インスペクタの使用に必要なプロパティの値を設定します。設定できるプロパティは、演算子を説明している章に記述されています。
マッピング・プロパティの設定
マッピングのプロパティを設定するには、プロジェクト・ナビゲータでマッピングを選択します。プロパティ・インスペクタにマッピングのプロパティが表示されます。
次のプロパティの値を設定できます。ビジネス名、物理名、説明、実行タイプ、およびターゲット・ロード順序。
「マッピングのロードにおけるターゲット・オブジェクトの順序の指定」の説明に従って、ターゲット・ロード順序の構成パラメータを使用してマッピング内でターゲットがロードされる順序を指定します。
マッピングに1つのターゲットのみが含まれている場合、あるいはマッピングがSQL*LoaderまたはABAPマッピングの場合は、ターゲット・ロード順序が適用されません。デフォルトの設定を受け入れてマッピングの設計を続行してください。
複数のターゲットがあるPL/SQLマッピングを設計すると、Oracle Warehouse Builderにより、ターゲットをロードするデフォルトの順序が計算されます。ターゲット間に外部キー関係を定義すると、親の次に子をロードするデフォルトの順序が作成されます。外部キー関係を作成しない場合、またはターゲット表に再帰的な関係がある場合は、無作為な順序がデフォルトとして割り当てられます。
デフォルトのロード順序は、「ターゲット・ロード順序」マッピング・プロパティを設定することで上書きできます。ターゲットの順序を変更する際に間違った変更を実行した場合は、「デフォルトにリセット」オプションを選択することで、デフォルトの順序に戻ります。または、「取消」を選択してターゲット順序の変更を破棄できます。
複数のターゲットのロード順序を指定する手順は、次のとおりです。
マッピング・キャンバスの空白をクリックすると、プロパティ・インスペクタにマッピングのプロパティが表示されます。
プロパティ・インスペクタが表示されない場合は、「表示」メニューから「プロパティ・インスペクタ」を選択します。
ターゲット・ロード順序プロパティに進み、このプロパティの右側にある省略記号ボタンをクリックします。
「ターゲット・ロード順序」ダイアログ・ボックスで、TARGET2がTARGET1の前に表示されています。
ロード順序を変更するには、ターゲットを選択し、ボタンを使用してリスト内でターゲットを上または下に移動します。
「デフォルトにリセット」ボタンは、ターゲット・ロード順序を再計算する場合に使用します。ターゲットの順序変更でエラーが発生した場合、または順序を割り当てた後に当初の順序が無効になるようなマッピングの設計変更があった場合は、再計算が必要になります。
マッピングを定義した後、それらを構成してマッピングおよびマッピングに含まれる演算子の物理プロパティを指定できます。マッピングを構成することでコード生成を制御し、ユーザー環境に合せて最適化されたマッピング・コードを生成できます。
マッピングを構成する手順は、次のとおりです。
プロジェクト・ナビゲータで、マッピングを右クリックして「構成」を選択します。
マッピングの構成パラメータを含む「構成」タブが表示されます。
このタブには、「配布可能」、「言語」、「生成コメント」および「参照カレンダ」の各パラメータが含まれています。また、「ランタイム・パラメータ」ノードと「コード生成オプション」ノードもあります。さらに、マッピング内の各演算子が、オブジェクトまたは演算子タイプを表すノードの下にリストされます。たとえば、マッピングに2つの表演算子と1つのフィルタ演算子が含まれる場合、「表演算子」ノードには2つの表の構成パラメータが表示され、「フィルタ演算子」ノードにはフィルタ演算子の構成パラメータが表示されます。
「配布可能」パラメータを「True」に設定します。
「言語」を、選択したマッピング用に生成するコードのタイプに設定します。
選択できるオプションは、マッピングにおける演算子の設計と使用に応じて異なります。Oracle Warehouse Builderでは、PL/SQL、「SQL*Plus」、「SQL*Loader」および「ABAP」(SAPソース・マッピングの場合)の各オプションが提供されます。
あらかじめ定義したスケジュールに基づいてマッピングを実行するように設定するには、「参照カレンダ」パラメータ上の省略記号ボタンをクリックします。
「参照カレンダ」ダイアログ・ボックスが表示されます。作成されたスケジュールは、ここにリストされます。現在のマッピングに関連付けるスケジュールを選択します。
スケジュールの作成および使用手順は、第11章「ETLジョブのスケジューリング」を参照してください。
「コード生成オプション」を開き、マッピング用に生成されたコードを最適化するパフォーマンス・オプションを有効化します。
各オプションの詳細は、「コード生成オプション」を参照してください。
(オプション)PL/SQLマッピングのチャンクを定義するには、次の操作を1つ実行します。
パラレル・チャンクを構成するには、「チャンク化オプション」、「詳細」の順に開いて、計画したパラレル・チャンクの方法に基づいてパラメータを設定します。また、シリアル・チャンクにはこのマッピングは使用できないことも確認してください。
パラレル・チャンクに対応するランタイム・パラメータを設定するには、「チャンク化オプション」で値を設定した後に、マッピング構成エディタを閉じてから再度開いてパラレル・チャンクに関連したランタイム・パラメータを表示します。
|
注意: PL/SQLマッピングのチャンクのみ実行できます。 |
「ランタイム・パラメータ」を開き、マッピングを配布用に構成します。
各ランタイム・パラメータの詳細は、「ランタイム・パラメータ」を参照してください。
マッピングの各演算子を表すノードに移動して、それぞれの物理プロパティを設定します。特定のノードに表示されるプロパティは、オブジェクトのタイプによって異なります。たとえば、表演算子ノードにリストされる表については、「表の構成」にリストされた表パラメータを構成できます。
|
関連項目:
|
|
注意: 一部の環境では、ロケーションをIPアドレスではなくホスト名に変更すると、パフォーマンスが低下します。 |
マッピングに使用する多くの演算子に対応する定義は、Oracle Warehouse Builderワークスペースにあります。これは、表およびビューの演算子などの、ソース演算子とターゲット演算子に該当します。また、順序および変換の演算子など、定義が複数のマッピングにまたがって使用される他の演算子にも該当します。これらの演算子を変更するときは、変更内容をワークスペース・オブジェクトに伝播させます。
変更の伝播方向は、次の選択肢から決定できます。
「マッピング演算子と関連付けられたワークスペース・オブジェクトの同期化」
これにより、ワークスペース・オブジェクトの定義内の変更を、ワークスペース・オブジェクトにバインドされるマッピング演算子に伝播できます。
また、マッピング内のすべての演算子を、ワークスペース内の対応する定義と同期化することもできます(「マッピングのすべての演算子の同期化」参照)。
これにより、マッピング演算子に加えられた変更を、対応するワークスペース定義に伝播できます。演算子を1つ選択し、指定したワークスペース・オブジェクトの定義と同期化できます。
同期化はリフレッシュとは異なります。リフレッシュ・コマンドでは、マルチユーザー環境で他のユーザーが行った変更にあわせて、確実に最新の状態が保たれます。同期化では、対応するワークスペース・オブジェクトと演算子が照合されます。
本番環境でマッピングの使用を開始した後、ETL設計に影響するソースまたはターゲットが変更される場合があります。通常、このような変更を管理する最善の方法は、第14章「マッピング・メタデータ依存性」で説明するようにメタデータ依存性マネージャを経由することです。メタデータ依存性マネージャを使用すると、変更による影響が自動的に評価され、影響を受けるすべてのマッピングが同期化されます。
この項の説明に従って、マッピング・エディタで、オブジェクトを手動で同期化することもできます。
ワークスペース・オブジェクトから演算子に同期化する時期
マッピング・エディタでは、次のような理由により、ワークスペース・オブジェクトから演算子への同期化を実行できます。
手動による変更の伝播: ワークスペース・オブジェクトの変更を、関連する演算子に伝播します。ワークスペース・オブジェクトの変更には、構造的な変更、属性名の変更、属性のデータ型の変更などがあります。
ワークスペース・オブジェクトの変更を複数のマッピングに自動的に伝播する方法は、第14章「マッピング・メタデータ依存性」を参照してください。
演算子と新規ワークスペース・オブジェクトの同期化: たとえば、マッピングをデータ・ウェアハウスの特定のバージョンから新しいバージョンに移行し、各バージョンの別のオブジェクト定義を維持する場合、演算子と新規のワークスペース・オブジェクトを同期化することができます。
表によるマッピングのプロトタイプ作成: 設計環境で作業している場合は、表を使用したETLロジックの設計を選択できます。ただし、本番環境では、他のワークスペース・オブジェクト・タイプ(ビュー、マテリアライズド・ビュー、キューブなど)に基づいたマッピングが可能です。
物理名とビジネス名の同期化
ワークスペースオブジェクトから演算子に同期化中に、演算子、グループおよび属性の物理名とビジネス名を同期化させるかどうかを指定することができます。デフォルトでは、演算子、グループおよび属性のバウンド名は、必ず対応するワークスペース・オブジェクトの物理名から導出されます。同期化の動作は、「プリファレンス」ダイアログ・ボックスの「ネーミング」ノードにリストされる「名前の変更の同期化」によって制御されます。
「プリファレンス」ダイアログ・ボックスの「ネーミング」ノードにある「名前の変更の同期化」プリファレンスを選択する場合、すべての演算子上の同期化操作で、演算子、グループおよび属性の物理名とビジネス名は同期化されます。「名前の変更の同期化」プリファレンスを選択解除する場合は、演算子、グループおよび属性の物理名とビジネス名は同期化されません。
|
関連項目: Oracle Warehouse Builderのプリファレンスの詳細は、『Oracle Warehouse Builder概要』を参照してください。 |
ワークスペース・オブジェクトから演算子への同期化の手順
バインド先のワークスペース・オブジェクトと同期化する手順は次のとおりです。
マッピング・エディタのキャンバスで、同期化する演算子を選択します。演算子が最大化された状態で表示されると、演算子名をクリックして選択します。
右クリックして「同期化」を選択します。
「同期化」ダイアログ・ボックスが表示されます。
同期化先のフィールドのリポジトリ・オブジェクトで、マッピング演算子を同期化するワークスペース・オブジェクトを選択します。
デフォルトでは、マッピング演算子が最初にバインドされるワークスペース・オブジェクトは、このフィールドに表示されます。
同期化の方向で、「インバウンド」を選択します。
「一致方針」フィールドで、同期化中に使用される一致方向を選択します。
一致方針の詳細は、「一致方針」を参照してください。
「同期化方針」フィールドで、同期化方針を選択します。
「置換」を選択して、マッピング演算子定義をワークスペース・オブジェクト定義と置換します。「マージ」を選択して新しいメタデータ定義を追加し、ワークスペース・オブジェクト内の定義と異なる場合は、既存のメタデータ定義を上書きします。
「OK」をクリックして同期化を完了します。
マッピングのすべての演算子を、1つの手順でバインド先のワークスペース・オブジェクトに同期化できます。演算子を同期化するには、同期化する演算子を含むマッピングを開きます。マッピング・エディタのキャンバスのアクティブなパネルで、「編集」メニューから「すべてを同期」を選択します。「すべてを同期」パネルが表示されます。このパネルを使用して同期化のオプションを定義します。
「すべてを同期」パネルには、ワークスペース・オブジェクトにバインドされるマッピング演算子それぞれに対して1行が表示されます。バインド先のワークスペース・オブジェクトと同期化する、すべてのオブジェクト名の左側にあるボックスを選択します。各演算子について、次の値を指定します。
リポジトリから: マッピング演算子のバインド先のワークスペース・オブジェクトを表示します。
演算子のバインド先のワークスペース・オブジェクトを変更するには、ワークスペース・オブジェクト名の右にある省略記号のボタンをクリックします。「ソース」ダイアログ・ボックスが表示されます。このページのリストをクリックして、新しいワークスペースオブジェクトを選択し「OK」をクリックします。
マッピング先: マッピング演算子の名前が表示されます。このフィールドは編集できません。
一致方針: 演算子の同期化中に使用される一致方針を選択します。一致方針の詳細は、「一致方針」を参照してください。
同期化方針: 演算子の同期化中に使用される同期化方針を選択します。同期化方針として「置換」または「マージ」を選択できます。
マッピングの演算子を変更するときは、変更内容をワークスペース・オブジェクトに伝播させます。同期化によって、表、ビュー、マテリアライズド・ビュー、変換およびフラット・ファイルの各演算子の変更を伝播できます。
次のような理由により、演算子からワークスペース・オブジェクトへの同期化を実行します。
変更の伝播: 演算子の変更を、関連するワークスペース演算子に伝播します。演算子または属性のビジネス名を変更すると、そのビジネス名の最初の30文字がバウンド名として伝播されます。
ワークスペース・オブジェクトの置換: 同期化により、既存のワークスペース・オブジェクトを置換します。
演算子からの同期化は、他の演算子とワークスペース・オブジェクトとの依存関係には影響を与えません。表5-2に、同期化に使用できる演算子をリストします。
表5-2 アウトバウンド同期化演算子
| マッピング・オブジェクト | ワークスペース・オブジェクトの作成 | 変更の伝播 | ワークスペース・オブジェクトの置換 | 注意 |
|---|---|---|---|---|
|
外部表 |
はい |
はい |
はい |
ワークスペースの外部表のみが更新され、その外部表に関連付けられているフラット・ファイルは更新されません。Oracle Warehouse Builderソースおよびターゲット・ガイドを参照してください。 |
|
フラット・ファイル |
はい |
はい |
いいえ |
シングル・レコード・タイプのフラット・ファイルに対してのみ、カンマ区切りの新しいフラット・ファイルが作成されます。 |
|
入力パラメータのマッピング |
はい |
はい |
はい |
入力属性とデータ型が入力パラメータとしてコピーされます。 |
|
出力パラメータのマッピング |
はい |
はい |
はい |
出力属性とデータ型がファンクションの戻り指定としてコピーされます。 |
|
マテリアライズド・ビュー |
はい |
はい |
はい |
属性とデータ型が列としてコピーされます。 |
|
表 |
はい |
はい |
はい |
属性とデータ型が列としてコピーされます。制約プロパティはコピーされません。 |
|
変換 |
いいえ |
いいえ |
いいえ |
該当なし |
|
ビュー |
はい |
はい |
はい |
属性とデータ型が列としてコピーされます。 |
次の手順を使用して、マッピング演算子からワークスペース・オブジェクトに同期化します。同期化では、ワークスペース・オブジェクトは、マッピング作成後にマッピング演算子に加えられた変更によって更新されます。
マッピング・エディタのキャンバスで、バインド先ワークスペース・オブジェクトに伝播する演算子を選択します。
「編集」メニューから、「同期化」を選択します。または、演算子のヘッダーを右クリックして「同期化」を選択します。
演算子の同期化ダイアログ・ボックスが表示されます。
同期化先のフィールドのリポジトリ・オブジェクトで、マッピング演算子定義の変更によって更新されるワークスペース・オブジェクトを選択します。
デフォルトでは、マッピング演算子が最初にバインドされていたワークスペース・オブジェクトが表示されます。
「同期化の方向」フィールドで、「アウトバウンド」を選択します。
(オプション)「一致方針」フィールドで、同期化中に使用される一致方向を選択します。「一致方針」を参照してください。
(オプション)「同期化方針」フィールドで、同期化方針を選択します。
「置換」を選択して、ワークスペース・オブジェクト定義をマッピング演算子定義と置換します。「マージ」を選択して新しいメタデータ定義を追加し、マッピング演算子内の定義と異なる場合は、既存のメタデータ定義を上書きします。
「OK」をクリックします。
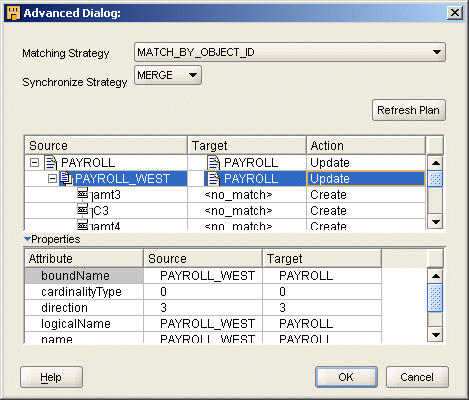
「同期化プラン」ダイアログ・ボックスを使用して、選択したオブジェクトがOracle Warehouse Builderによってどのように同期化されるかの詳細を表示および編集します。「一致方針」から選択した後、「リフレッシュ・プラン」をクリックして、Oracle Warehouse Builderで実行されるアクションを表示します。
同期化のコンテキスト内では、ソースは差分を継承するオブジェクトを指し、ターゲットは、変更されるオブジェクトを指します。
たとえば、図5-6では、フラット・ファイルPAYROLL_WESTがソースで、フラット・ファイル演算子PAYROLLがターゲットです。したがって、Oracle Warehouse Builderにより、PAYROLL_WESTフラット・ファイルのフィールドに対応するPAYROLL演算子の新規の属性が作成されます。
演算子とワークスペース・オブジェクトの比較方法を決定するには、一致方針を設定します。同期化によって変更(演算子の属性の追加、削除など)が適用されると、マッピング・エディタがリフレッシュされます。同期化によって演算子の属性が削除される場合は、属性とのデータ・フロー接続も削除されます。同期化によって演算子の属性が追加される場合は、マッピング・エディタの演算子の後に新しい属性が表示されます。一致する属性間のデータ・フロー接続は保持されます。ソース・オブジェクトの属性の名前を変更すると、当初の属性が削除されて新しい属性が追加されたように解釈されます。
マッピングのオブジェクトを同期化するには、次の方針を指定できます。
この方針では、演算子属性の一意のオブジェクト識別子をワークスペース・オブジェクトの識別子と比較します。オブジェクト識別子による一致は、ビュー演算子とワークスペース表など、演算子をタイプの異なるワークスペース・オブジェクトと同期化する場合には使用できません。
この方針は、ターゲット・オブジェクトをソース・オブジェクトへの変更と一致させる場合や、ターゲット・オブジェクト内での物理名の変更とは関係なく個別のビジネス名を維持する場合に使用します。
Oracle Warehouse Builderにより、ソース・オブジェクトの属性に対応しない属性はターゲット・オブジェクトから削除されます。これは、ソースに属性が追加された場合や、ソース・オブジェクトから属性が削除された場合に実施されます。
この方針では、演算子属性のバウンド名をワークスペース・オブジェクト属性の物理名と一致させます。一致では大文字/小文字が区別されます。
この方針は、バウンド名をワークスペース・オブジェクトの物理名と一致させる場合に使用します。演算子の構造が変化する変更がワークスペース・オブジェクトに生じた場合は、別のワークスペース・オブジェクトでこの方針を使用することもできます。
Oracle Warehouse Builderにより、ワークスペース・オブジェクトの属性と一致しない演算子の属性は削除されます。選択したワークスペース・オブジェクトの属性で、演算子の属性と一致しない属性は、新しい属性として演算子に追加されます。演算子をワークスペース・オブジェクトにバインドすると、バウンド名は読取り専用になるため、バウンド名を操作して異なる一致結果を取得することはできません。
この方針では、演算子属性と選択したワークスペース・オブジェクトの列、フィールドまたはパラメータを位置によって一致させます。つまり、演算子の最初の属性はワークスペース・オブジェクトの最初の属性と同期化され、2番目の属性はワークスペース・オブジェクトの2番目の属性と同期化されます。
この属性は、演算子を別のワークスペース・オブジェクトと同期化して、演算子属性のビジネス名を維持する場合に使用します。この方針は、ワークスペース・オブジェクトに対する変更が、オブジェクトの後への列、フィールドまたはパラメータの追加のみである場合に最も効果的です。
ソース・オブジェクトの属性よりターゲット・オブジェクトの属性が多い場合は、余分な属性が削除されます。ターゲット・オブジェクトの属性よりソース・オブジェクトの属性が多い場合は、新しい属性として追加されます。
シナリオ
会社では、発生する挿入、更新および削除トランザクションをすべてrecord.csvというフラット・ファイルに記録しています。これらのトランザクションは、格納順に正確に処理される必要があります。たとえば、あるトランザクションの順番が配置、更新、キャンセル、再入力となっていた場合、このトランザクションはこの順序に従って処理される必要があります。
ソース・ファイルrecord.csvのデータ・セットの例は次のように定義されます。
Action,DateTime,Key,Name,Desc I,71520031200,ABC,ProdABC,Product ABC I,71520031201,CDE,ProdCDE,Product CDE I,71520031202,XYZ,ProdXYZ,Product XYZ U,71620031200,ABC,ProdABC,Product ABC with option D,71620032300,ABC,ProdABC,Product ABC with option I,71720031200,ABC,ProdABC,Former ProdABC reintroduced U,71720031201,XYZ,ProdXYZ,Rename XYZ
次のようにターゲット表にデータをロードする必要があります。
SRC_TIMESTA KEY NAME DESCRIPTION ----------- --- ------- --------------------------- 71520031201 CDE ProdCDE Product CDE 71720031201 XYZ ProdXYZ Rename XYZ 71720031200 ABC ProdABC Former ProdABC reintroduced
Oracle Warehouse Builderを使用して特定の順序でトランザクション・データをロードするためのETLロジックを作成する必要があります。
解決策
Oracle Warehouse Builderを使用してETLロジックを設計し、トランザクションがソースに格納された時間的な順序に正確に従ってデータをロードできます。このためには、ターゲット表にデータをロードする前に、データの順序付けおよび条件付きの分割を行うマッピングを設計します。次に、行ベースのオペレーティング・モードでコードを生成するためのマッピングを構成します。次の例に示すように、行ベースのオペレーティング・モードでは、Oracle Warehouse Builderによりif-then-else構造を使用して行ごとにデータを処理するコードが生成されます。
CURSOR
SELECT
"DATETIME$1"
FROM
"JOURNAL_EXT"
ORDER BY "JOURNAL_EXT"."DATETIME" ASC
LOOP
IF "ACTION" = 'I' THEN
INSERT this row
ELSE
IF "ACTION" = 'U' THEN
UPDATE this row
ELSE
DELETE FROM
"TARGET_FOR_JOURNAL_EXT"
END LOOP;
これにより、確実に、一連のアクションは連続する順序で実装され、トランザクションが記録された順序に従ってデータがロードされます。
手順1: ソース・フラット・ファイルrecord.csvのインポートおよびサンプリング
この例では、フラット・ファイルrecord.csvにすべてのトランザクション・レコードおよびタイムスタンプが格納されます。Warehouse Builderのインポート・メタデータ・ウィザードを使用して、ソース・システムからこのフラット・ファイルをインポートします。次に、フラット・ファイル・サンプル・ウィザードを使用して、Oracle Warehouse Builder内のフラット・ファイルのメタデータを定義します。
手順2: 外部表の作成
マッピング内のサンプリングされたフラット・ファイルの使用を単純化するには、「手順1: ソース・フラット・ファイルrecord.csvのインポートおよびサンプリング」でインポートおよびサンプリングされたフラット・ファイルに基づき、外部表ウィザードを使用して外部表(JOURNAL_EXT)を作成します。
フラット・ファイルのかわりに外部表を使用する利点は、外部表によりフラット・ファイル内のデータに直接アクセスするSQLが提供される点です。したがって、データをステージングする必要はありません。
ステップ3: マッピングの設計
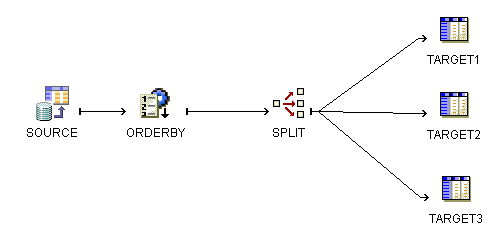
このマッピングでは、トランザクション・データを外部ソースから移動し、データを並べ替える演算子、続いて条件によりデータを分割する演算子を介してターゲット表にデータをロードします。
図5-7は、ソースの並替えおよび分割方法を示しています。
ソーター演算子により、データの順序付けが可能になり、またソースで記録された順序に正確に従ってトランザクションを処理できます。スプリッタ演算子により、生成済コード内でif-then-else制約として機能する分割条件を定義することで、ソース・データ内に記録されたすべての挿入、更新および削除を条件付きで処理できます。データは条件付きで分割され、ターゲット表にロードされます。このマッピングでは、条件付きロードを説明するために、同じターゲット表を3回使用します。マッピング表TARGET1、TARGET2およびTARGET3は、すべて同じワークスペース表TARGETにバインドされます。すべてのデータは、単一のターゲット表に挿入されます。
次の手順は、このマッピングを作成する方法を示します。
手順4: マッピングの作成
「マッピングの作成」ダイアログ・ボックスを使用してLOAD_JOURNAL_EXTというマッピングを作成します。Oracle Warehouse Builderによりマッピング・エディタが開かれ、そこでマッピングを作成できます。
手順5: 外部表演算子の追加
マッピング外部表演算子をマッピング・エディタのキャンバス上にドラッグ・アンド・ドロップし、外部表JOURNAL_EXTにマッピング外部表演算子をバインドします。
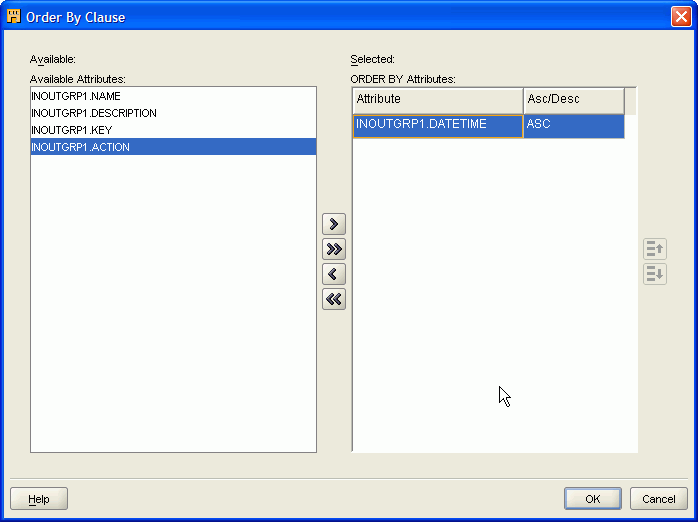
手順6: データの順序付け
ソーター演算子を追加して、ターゲットにロードされる必要のあるトランザクション・データの順序を指定するorder-by句を定義します。
図5-8は、昇順のトランザクション・データのタイムスタンプに基づいて表を順序付ける方法を示しています。
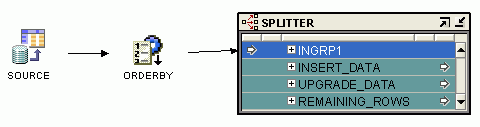
手順7: 分割条件の定義
スプリッタ演算子を追加して、トランザクション・データに格納された挿入、更新および削除を条件付きで分割します。この分割条件は、生成済コード内でif-then-else制約として機能します。
図5-9は、SOURCE演算子と、SPLITTER演算子にリンクするORDERBY演算子を結合する方法を示しています。
トランザクションの各タイプに対する分割条件を定義します。OutgroupのINSERT_DATAには、INGRP1.ACTION = 'I'という分割条件を定義します。UPGRADE_DATAには、INGRP1.ACTION = 'U'という分割条件を定義します。Oracle Warehouse Builderでは、スプリッタ演算子にREMAINING_ROWSと呼ばれるデフォルトのグループがあり、そのグループによりすべての削除(「D」)レコードが自動的に処理されます。
手順8: ターゲット表の定義
トランザクションの各タイプ(INSERT_DATA、UPDGRADE_DATAおよびREMAINING_ROWS)に対し、同じワークスペース・ターゲット表をそれぞれに使用します。
手順9: マッピングLOAD_JOURNAL_EXTの構成
マッピングを定義した後、コードを生成するためにマッピングを構成する必要があります。この例の目的は、格納された順序に正確に従ってデータを処理することであるため、デフォルトのオペレーティング・モードとして行ベースを選択する必要があります。このモードでは、行ごとにデータが処理され、ターゲット表での挿入、更新および削除アクションは、ソースでトランザクションが記録された順序に正確に従って発生します。
Oracle Warehouse Builderでは、すべての挿入トランザクションに対して1つの文が作成され、すべての更新トランザクションおよびすべての削除トランザクションに対してもそれぞれ1つの文が作成されるので、セット・ベース・モードは選択しないでください。コードによりこれらのプロシージャが次々にコールされ、1つのアクションが完了してから次のアクションを行います。たとえば、最初にすべての挿入が処理され、次にすべての更新が処理され、続いてすべての削除が処理されます。
トランザクション・データをロードするためのマッピングを構成する手順は、次のとおりです。
プロジェクト・ナビゲータで、LOAD_JOURNAL_EXTマッピングを右クリックして「構成」を選択します。
「ランタイム・パラメータ」ノードを開き、「デフォルト・オペレーティング・モード」パラメータを「行ベース」に設定します。
この例では、他のすべてのパラメータに対して、デフォルト値を使用します。コードを生成する前にマッピングを検証します。
手順10: コードの生成
マッピングを生成した後、Oracle Warehouse Builderでは、「ログ」ウィンドウに結果が表示されます。
コードを調べると、Oracle Warehouse Builderでは連続したアクションのすべてが行ベース・モードで実装されていることがわかります。これはデータが行ごとに処理されることを示し、また、Oracle Warehouse Builderによりif-then-else構造を使用して発生順にすべての条件が評価されることを示します。このため、結果のターゲット表ではソースで記録されたトランザクションの連続的な整合性が保持されます。
マッピング・エディタでバインドされていない表演算子を使用すると、ステージング領域表をすばやく作成できます。
次の手順は、既存のソース表に基づいてステージング表を作成する方法を示しています。この手順は、ビュー、マテリアライズド・ビュー、フラット・ファイルおよび変換の作成にも使用できます。
ソース表をステージング表にマップする手順は、次のとおりです。
マッピング・エディタで、ソース表を追加します。
メニュー・バーから「グラフ」、「追加」、「データ・ソース/ターゲット」、「表演算子」を選択します。または、ソース表を、プロジェクト・ナビゲータからマッピング・エディタのキャンバスにドラッグ・アンド・ドロップします。
表演算子の追加ダイアログ・ボックスを使用して、マッピング内のソース表の演算子を選択およびバインドします。表演算子の追加ダイアログ・ボックスから、「バインドされていない演算子を属性なしで作成」を選択します。
このマッピングは、図5-10のソース表と属性を持たないステージング領域表に類似しています。
ソース演算子のグループにマウス・ポインタを置き、マウス・ボタンを押したままにします。
ステージング領域表グループまでマウスをドラッグします。
ソース属性がステージング領域表にコピーされ、2つの演算子が接続されます。
マッピング・エディタでは、マッピングに追加したバインドされていない表を選択します。クリックして「作成とバインド」を選択します。
Oracle Warehouse Builderにより、「作成とバインド」ダイアログ・ボックスが表示されます。
「作成場所」フィールドに、表を作成するターゲット・モジュールを指定します。
指定したターゲット・モジュールに新しい表が作成されます。
マッピングのデータ・フローを再使用するには、再使用するデータ・フローの一部の周囲にプラッガブル・マッピングを作成します。プラッガブル・マッピングは、単一の演算子として機能するマッピング演算子の再使用可能なグループです。プラッガブル・マッピングは、プログラミング言語におけるファンクションの概念と似ており、ファンクションをグラフィカルに定義するための手段です。
プラッガブル・マッピングは、定義すると、マッピング内でネストした単一のマッピング演算子として表示されます。プラッガブル・マッピングは、同じマッピング内またはその他のマッピング内で複数回再使用できます。プラッガブル・マッピングはその他のプラッガブル・マッピング内に含めることができます。
その他の演算子と同様、プラッガブル・マッピングには、様々なマッピング内のその他の演算子に接続するための入出力属性で構成されるシグネチャがあります。シグネチャは、プログラミング言語におけるファンクションの入出力要件と類似しています。
|
関連項目: プラガッブル・マッピングの詳細は、Oracle Warehouse Builder概要を参照してください。 |
プラッガブル・マッピングは、再使用することや、埋め込むことができます。
プラッガブル・マッピングの再使用:プラッガブル・マッピングが参照するメタデータが該当するマッピングの外部に存在できる場合、プラッガブル・マッピングは再使用可能です。再使用可能なプラッガブル・マッピングは、プライベート使用のスタンドアロンのプラッガブル・マッピングとして格納するか、フォルダ(ライブラリ)に格納できます。これらのフォルダにアクセス権を持つユーザーは、プラッガブル・マッピングを作業用のテンプレートとして使用できます。
埋め込まれたプラッガブル・マッピング: プラッガブル・マッピングが参照するメタデータが該当するマッピングまたはプラッガブル・マッピングによって所有されている場合にのみ、プラッガブル・マッピングは埋め込まれます。埋め込まれたプラッガブル・マッピングは、スタンドアロン・マッピングとして、またはグローバル・ナビゲータのライブラリとして格納されません。埋め込まれたプラッガブル・マッピングを所有しているマッピングまたはプラッガブル・マッピング内にのみ格納され、マッピングを所有しているオブジェクトの編集によってのみアクセスできます。埋め込まれたプラッガブル・マッピングのコードを検証または生成するには、マッピングを所有しているオブジェクトのコードを検証または生成する必要があります。
プラッガブル・マッピングは、通常、必要に応じて事前に定義して使用されます。プラッガブル・マッピングは、マッピング・エディタを使用してマッピング内から、またはウィザードを使用してナビゲーション・ツリーから作成できます。ウィザードにはデフォルトが用意されている選択肢もあり、少ない選択肢でユーザーをガイドするため、プラッガブル・マッピングを速やかに作成できます。後でプラッガブル・マッピングのエディタから選択を追加できます。エディタには、すべての設定が一連のタブで表示されます。
ナビゲーション・ツリーの「プラッガブル・マッピング」ノードには、次のようなの2つのノードがあります。
スタンドアロン: スタンドアロン・プラッガブル・マッピングを含みます。
プラッガブル・マッピング・ライブラリ: ライブラリとして公開するうえで関連する機能を備えるプラッガブル・マッピングのセットを含みます。
これらのいずれかのノードでプラッガブル・マッピングを作成できます。
プロジェクト・ナビゲータで、プロジェクト・ノード、「プラッガブル・マッピング」ノードの順に開きます。
「スタンドアロン」を右クリックし、新規プラッガブル・マッピングを選択します。
プラッガブル・マッピングの作成ウィザードが表示されます。
名前と説明ページに、モジュールの名前と説明(オプション)を入力します。「次へ」をクリックします。
シグネチャ・グループページには、入力シグネチャ・グループのINGRP1と出力シグネチャ・グループのOUTGRP1が表示されます。「シグネチャ・グループ」の説明に従って、追加の入力シグネチャ・グループまたは出力シグネチャ・グループを作成します。「次へ」をクリックします。
入力シグネチャ・ページで、「入力シグネチャ」の説明に従って、プラッガブル・マッピングの入力シグネチャ属性を定義します。「次へ」をクリックします。
出力シグネチャ・ページで、「出力シグネチャ」の説明に従って、プラッガブル・マッピングの出力シグネチャ属性を定義します。「次へ」をクリックします。
サマリー・ページで、ウィザードで設定したオプションを確認します。オプションを変更するには、「戻る」をクリックします。「終了」をクリックしてデータをインポートします。
Oracle Warehouse Builderでは、プラッガブル・マッピング・エディタが開いて、タイトル・バーにはプラッガブル・マッピング名が表示されます。
プラッガブル・マッピング・エディタを使用して演算子を追加し、演算子間のデータ・フローを作成します。詳細は、「演算子のマッピングへの追加」を参照してください。
Oracle Warehouse Builderでは、マッピングで使用されたプラッガブル・マッピングは演算子とみなされます。プラッガブル・マッピングは任意のマッピングに挿入できます。マッピング内でプラッガブル・マッピングを使用するには、コンポーネント・パレットから、プラッガブル・マッピング演算子をキャンバスにドラッグ・アンド・ドロップします。プラッガブル・マッピングの追加ダイアログ・ボックスが表示されます。必要なプラッガブル・マッピングを選択してマッピングに追加します。
シグネチャは、プラッガブル・マッピングの入出力属性の組合せです。シグネチャ・グループは、入出力属性をグループ化するためのメカニズムです。
プラッガブル・マッピングには、少なくとも1つの入力または出力シグネチャ・グループが必要です。ほとんどのプラッガブル・マッピングは、論理フローの途中で使用され、入出力グループがあります。
追加のシグネチャ・グループを作成するには、「グループ」列で空のセルをクリックしてグループ名を入力し、「方向」列を使用してそのグループが入力グループか出力グループかを指定します。列で、列の説明(オプション)を入力できます。
シグネチャ・グループを削除するには、グループ名の左側にあるグレーのセルを右クリックし、「削除」を選択します。
「次へ」をクリックしてウィザードを続行します。
入力シグネチャとは、プラッガブル・マッピングにフローする入力属性の組合せのことです。作成した入力シグネチャ・グループごとの入力属性を定義します。
複数の入力シグネチャ・グループを定義した場合は、属性を追加するグループを「グループ」リスト・ボックスから選択します。属性を追加するには、「属性」列で空のセルをクリックしてから属性名を入力します。「データ型」フィールドを使用して、属性のデータ型を指定します。長さ、精度、スケールおよび秒精度などその他の属性詳細を指定するには、対応するフィールドをクリックし、フィールドの矢印を使用するか、数値を入力します。これらのフィールドの一部は、指定したデータ型によっては無効になります。
属性を削除するには、属性の左側にあるグレーのセルを右クリックし、「削除」を選択します。
「次へ」をクリックしてウィザードを続行します。
出力シグネチャとは、プラッガブル・マッピングからフローされる出力属性の組合せのことです。作成した出力シグネチャ・グループごとの出力属性を定義します。
複数の出力シグネチャ・グループを定義した場合は、属性を追加するグループを「グループ」リスト・ボックスから選択します。属性を追加するには、「属性」列で空のセルをクリックしてから属性名を入力します。「データ型」フィールドを使用して、属性のデータ型を指定します。長さ、精度、スケールおよび秒精度などその他の属性詳細を指定するには、対応するフィールドをクリックし、フィールドの矢印を使用するか、数値を入力します。これらのフィールドの一部は、指定したデータ型によっては無効になります。
属性を削除するには、属性名の左側にあるグレーのセルを右クリックし、「削除」を選択します。
「次へ」をクリックしてウィザードを続行します。
プラッガブル・マッピング・エディタのパレットから「入力シグネチャ」または「出力シグネチャ」を追加することもできます。プラッガブル・マッピングが保持できるのは、1つの「入力シグネチャ」と1つの「出力シグネチャ」のみです。また、プラッガブル・マッピングの「入力シグネチャ」および「出力シグネチャ」はプラッガブル・マッピング内でのみ追加できます。通常のマッピングには追加できません。
プラッガブル・マッピング・フォルダは、関連するプラッガブル・マッピングのセットを含みます。プラッガブル・マッピングは非公開のままにしておくことも、フォルダに配置して他のユーザーが設計作業時にアクセスできるように公開することもできます。
プラッガブル・マッピング・フォルダを作成する手順は、次のとおりです。
プロジェクト・ナビゲータで、プロジェクト・ノード、「プラッガブル・マッピング」ノードの順に開きます。
「プラッガブル・マッピング・フォルダ」ノードを右クリックして新規プラッガブル・マッピング・フォルダを選択します。
プラッガブル・マッピング・フォルダの作成ダイアログ・ボックスが表示されます。
新しいプラッガブル・マッピング・フォルダの名前と説明(オプション)を入力します。
このプラッガブル・マッピング・フォルダの作成後すぐに、プラッガブル・マッピングの作成ウィザードを起動してプラッガブル・マッピングを作成するには、「プラッガブル・マッピング・ウィザードへ進む」を選択します。
「OK」をクリックします。
プロジェクト・ナビゲータにライブラリが表示されます。「スタンドアロン・プラッガブル・マッピングの作成」の説明に従ってライブラリ内に個々のプラッガブル・マッピングを作成します。
プラッガブル・マッピングをツリー上の任意のライブラリに移動することもできます。
プラッガブル・マッピング・ライブラリ内において、ユーザー・フォルダを作成し、製品行、関数グループ、またはアプリケーション固有のカテゴリなどの条件を使用してプラッガブル・マッピングをグループ化することができます。
ユーザー・フォルダには、ユーザー・フォルダとその他のプラッガブルマッピングを含めることができます。ユーザー・フォルダのネスト・レベルに制限はありません。ユーザー・フォルダは移動、削除、編集または名前変更もできます。
ユーザー・フォルダとそこに含まれているオブジェクトを、同じプラッガブル・マッピング・ライブラリに、同じライブラリに属する任意のユーザー・フォルダに、または異なるライブラリに属するユーザー・フォルダに移動またはコピーできます。
ユーザー・フォルダを削除すると、ユーザー・フォルダとそこに含まれるすべてのオブジェクトがリポジトリから削除されます。
プラッガブル・マッピング・ライブラリ内でユーザー・フォルダを作成する手順は、次のとおりです。
ユーザーフォルダを作成するプラッガブル・マッピング・ライブラリまたはユーザー・フォルダを右クリックして「新規」を選択します。
「新規ギャラリ」ダイアログ・ボックスが表示されます。
「アイテム」セクションで「ユーザー・フォルダ」を選択します。
「ユーザー・フォルダの作成」ダイアログ・ボックスが表示されます。
ユーザー・フォルダ名を指定して「OK」をクリックします。
ユーザー・フォルダが作成され、ツリーに追加されます。
ユーザー・フォルダ内でプラッガブル・マッピングを作成する手順は、次のとおりです。
ユーザー・フォルダを右クリックして「新規」を選択します。
「新規ギャラリ」ダイアログ・ボックスが表示されます。
「アイテム」セクションで「プラッガブル・マッピング」を選択します。
このユーザー・フォルダ内に新しくユーザー・フォルダを作成するには、「ユーザー・フォルダ」を選択します。
「OK」をクリックします。
手順2で「プラッガブル・マッピング」を選択した場合、プラッガブル・マッピングの作成ウィザードが表示されます。手順2で「ユーザー・フォルダ」を選択した場合は、「ユーザー・フォルダの作成」ダイアログ・ボックスが表示されます。
プラッガブル・マッピングを、ユーザーフォルダ内、またはプラッガブル・マッピング・ライブラリからスタンドアロン・ノードまたは異なるユーザー・フォルダまたはライブラリに移動できます。移動するには、プラッガブル・マッピングを右クリックして、「切取り」を選択します。プラッガブル・マッピングにコピーするユーザー・フォルダまたはプラッガブル・マッピング・ライブラリを右クリックして、「貼付け」を選択します。
演算子では、マッピングまはたプラッガブル・マッピング内におけるユーザー定義の変換ロジックを作成できます。以前に別のマッピングまたはプラッガブル・マッピングで定義した演算子を再利用する場合があります。Oracle Warehouse Builderでは、別のマッピングおよびプラッガブル・マッピングで演算子または演算子属性を使用して定義されている既存の変換ロジックを、コピーおよび貼付けにより再使用できます。このセクションでは、マッピングという用語には、マッピングとプラッガブル・マッピングの両方が含まれます。
演算子または演算子属性をソース・マッピングからコピーしてそれらを目的のマッピングに貼り付けることで、変換ロジックを再利用できます。また、演算子グループ(入力、出力およびI/O)のコピーおよび貼付けも可能です。
演算子、グループ、および属性のコピーの手順
次の手順に従って、マッピング内にある定義済の演算子、グループ、および属性を同じプロジェクト内のその他のマッピングにコピーします。
コピーする演算子、グループまたは属性を含むマッピングを開きます。これがソース・マッピングになります。
「以前に作成したマッピングを開く手順」を参照してください。
演算子、グループまたは属性をコピーする先のマッピングを開きます。これがターゲット・マッピングになります。
ソース・マッピングで、演算子、グループまたは属性を選択します。「編集」メニューから「コピー」を選択します。複数の属性を選択するには、属性の選択時に[Ctrl]キーを押したままにします。
または
演算子、グループ、または属性を右クリックして「コピー」を選択します。複数の属性を選択する場合、右クリック時に[Ctrl]キーを押したままにします。
|
注意: ソース・マッピング内の演算子、グループ、または属性が必要ない場合は、「コピー」のかわりに「切取り」を選択できます。切り取りでは、ソース・マッピングからオブジェクトが削除されます。コピーされたオブジェクトは複数回貼り付けられるのに対して、切り取られたオブジェクトを貼り付けられるのは1回のみです。 |
ターゲット・マッピングで、演算子、グループまたは属性を貼り付けます。
演算子を貼り付けるには、「編集」メニューから「貼付け」を選択します。または、キャンバスの任意の空白上で右クリックしてショートカット・メニューから「貼付け」を選択します。
グループを貼り付けるには、最初に、グループを貼り付ける演算子を選択して、「編集」メニューから「貼付け」を選択します。または、グループを貼り付ける演算子を右クリックして、ショートカット・メニューから「貼付け」を選択します。
属性を貼り付けるには、属性を貼り付けるグループを選択して、「編集」メニューから「貼付け」を選択します。または、グループを貼り付けるグループを右クリックして、ショートカット・メニューから「貼付け」を選択します。
演算子をコピーして張り付ける場合、新しい演算子はソース演算子とは異なるUOIDを持ちます。
ターゲット・マッピングにコピーされる演算子と同じ名前の演算子がある場合は、新規演算子の名前に_nが追加されます。ここでnは、1から始まる順序番号です。
マッピング間でコピーされた情報
演算子、グループ、または属性をターゲット・マッピングにコピーする場合、次の情報がコピーされます。
オブジェクト・バインド詳細
表示セット詳細
演算子と属性の物理プロパティおよび論理プロパティ
オブジェクトに対して複数の構成がある場合は、すべての構成の詳細がコピーされます。
|
注意: 演算子をコピーして、ソース演算子とは異なるタイプの演算子に張り付ける場合、演算子の名前とデータ・タイプのみがコピーされます。その他の詳細はコピーされません。 |
演算子、グループ、および属性のコピーの制限は、次のとおりです。
マッピングから演算子、グループ、および属性をコピーして、それらを同じプロジェクト内にかぎり別のマッピングに貼り付けることができます。
ソース・マッピング内の演算子、グループ、および属性の間に存在する任意の接続は、ターゲット・マッピングにコピーされません。演算子、グループ、および属性のみがターゲット・マッピングに貼り付けられます。
プラッガブル・マッピングについては、ソース・プラッガブル・マッピング内の子演算子間の接続は、ターゲット・マッピングにコピーされます。
ソース演算子のグループ・プロパティは、ターゲット演算子のグループにコピーされません。ただし、グループ内に含まれるすべての属性はコピーされます。
ソース演算子からターゲット演算子にコピーして張り付ける前に、ターゲット演算子にグループを作成する必要があります。貼付け操作の実行時にグループは作成されません。
|
注意: 大量の演算子のコピーおよび貼付け操作には、長時間かかる場合があります。 |
複合マッピングとプラッガブル・マッピングには、必要なETLタスクを実行するために使用される多くの演算子が含まれています。通常、各データ変換タスクは1つまたは複数の演算子を使用して、その結果マッピングは雑然としているように見えて理解するのが難しくなります。一度にすべての演算子の表示を試行するということは、各演算子は、その名前を読むことができないほど非常に小さく表示されることになります。したがって、関連する変換タスクを個別のフォルダに実行する演算子のグループ化では、マッピングで実行される変換ロジック全体を表示する際に役立ちます。Oracle Warehouse Builderには、演算子のセットをフォルダにグループ化して不要な演算子をマッピング・キャンバスで非表示にする方法が用意されています。このセクションでは、マッピングという用語は、マッピングとプラッガブル・マッピングの両方を表します。
重要性の低い演算子を折りたたみ可能なフォルダにグループ化し、特定の時点において重要なコンポーネントに集中できます。また、キャンバス上で占める領域が少なくなり、マッピングの作業が容易になります。必要に応じて、フォルダのグループ化を解除して、含まれる演算子を表示または編集できます。
マッピングは、複数のグループ化されたフォルダを含みます。1つのフォルダにはマッピング演算子のセットとさらに1つまたは複数のフォルダが含まれる、ネストされたフォルダを作成することもできます。
マッピングとプラッガブル・マッピングの演算子をグループ化する手順は、次のとおりです。
演算子をグループ化するマッピングを開きます。
「以前に作成したマッピングを開く手順」を参照してください。
グループ化する演算子を選択します。
複数のオブジェクトを選択するには、オブジェクトの選択時に[Ctrl]キーを押したままにします。または、マウスの左ボタンを押したまま、選択するオブジェクトを含む矩形を描きます。
マッピング・エディタのキャンバスの上部のツールバーで、「選択したオブジェクトのグループ化」をクリックします。または、「グラフ」メニューから、「選択したオブジェクトのグループ化」を選択します。
選択した演算子はフォルダにグループ化されて、折りたたまれたフォルダがマッピング・エディタに表示されます。「Folder1」などのデフォルト名がそのフォルダに使用されます。
(オプション)より直感的に演算子のグループが実行するタスクを反映するには、フォルダ名を変更します。
フォルダの名前を変更する手順は、次のとおりです。
フォルダを右クリックして「詳細をオープン」を選択します。
フォルダの編集ダイアログ・ボックスで、フォルダ名を入力して、「OK」をクリックします。
選択した演算子のフォルダを作成するために演算子をグループ化する場合に、フォルダに含まれる演算子を表示するには、次のいずれかの方法を使用します。
フォルダのツールチップを使用
マウスをフォルダの上に置きます。フォルダに含まれる演算子がツールチップに表示されます。
スポットライトを使用してフォルダの内容を表示します。
フォルダを選択して、ツールバーの「選択したオブジェクトのスポットライト」をクリックします。または、フォルダを選択して「選択したオブジェクトのスポットライト」を選択します。フォルダが拡張されてそこに含まれる演算子が表示されます。マッピング内のその他のすべての演算子は非表示になります。これをスポットライトといいます。スポットライトの詳細は、「選択した演算子のスポットライト」を参照してください。
フォルダのダブルクリック
フォルダをダブルクリックして拡張します。フォルダに含まれるすべての演算子が表示されて、マッピング内の周囲の演算子は対応するフォルダ・コンテンツに移動されます。
演算子のグループ化を解除する手順は、次のとおりです。
演算子をグループ化するマッピングを開きます。
「以前に作成したマッピングを開く手順」を参照してください。
グループ化を解除するフォルダを選択します。
フォルダの選択時に、[Ctrl]キーを押し続けることで複数のフォルダを選択できます。
ツールバーで、選択したオブジェクトのグループ解除をクリックします。または、「グラフ」メニューから、選択したオブジェクトのグループ化を解除するを選択します。
グループ化されていた演算子は、マッピング・エディタ上で個別に表示されるようになります。
スポットライトでは、選択した演算子とその接続のみを表示することができます。その他のすべての演算子とその接続は一時的に非表示になります。1つの演算子、演算子のグループ、1つのフォルダ、フォルダのグループ、または任意のフォルダと演算子の組合せにおいてスポットライトを実行できます。スポットライトのオブジェクトを選択する場合、マッピング・エディタのレイアウトが再表示されて、選択したオブジェクト間の関係などが明白に表示されます。スポットライトされたコンポーネント間のエッジは表示されます。ただし、スポットライトされたコンポーネントとその他の選択されていないコンポーネントとの間のエッジは非表示になります。
グループ化された演算子を含むフォルダをスポットライトするには、フォルダを選択して、ツールバーの選択したアイテムのスポットライトをクリックします。フォルダが拡張されて、含まれるすべての演算子が表示されます。選択したアイテムのスポットライトを再度クリックすることで、スポットライトのモードのオン/オフを切り替えることもできます。フォルダが元のように閉じ、フォルダに含まれる演算子が非表示になります。
スポットライト・モードでは、演算子の移動やサイズ指定、演算子プロパティの変更、スポットライトされた演算子の削除、新規演算子の作成、および演算子間接続の作成など通常のマッピング操作のすべてを実行できます。一時的に非表示にされた演算子には影響しない任意の操作を実行できます。
スポットライト・モードで演算子を作成すると、切り替えてスポットライト・モードを終了するまで演算子は常にマッピング・エディタに表示されます。
マッピングとプラッガブル・マッピングには、必要なデータ変換の実行に使用される多数の演算子が含まれます。Oracle Warehouse Builderにより、マッピングおよびプラッガブル・マッピング内の演算子、グループおよび属性の場所を迅速に特定できます。オブジェクトを検索する場合、検索および検索条件のスコープを定義できます。このセクションでは、マッピングという用語は、マッピングとプラッガブル・マッピングの両方を表します。
検索タイプ
次のタイプの検索を実行できます。
標準検索
Oracle Warehouse Builderは、マッピング内のすべての演算子から検索文字列を検索します。検索文字列は、演算子、グループ、および属性の表示名と一致します。
拡張検索
マッピング内のオブジェクトを検索する、高度なメソッドです。検索するオブジェクトや検索条件を指定することによって、演算子、グループ、および属性を検索することができます。
「詳細検索」ダイアログ・ボックスを使用して標準検索および拡張検索を実行します。
マッピングおよびプラッガブル・マッピング内でのオブジェクトの検索
マッピングおよびプラッガブル・マッピング内の演算子、グループ、および属性を検索する方法は次のとおりです。
「以前に作成したマッピングを開く手順」に示す手順に従って、マッピングを開きます。
「検索」メニューから「検索」を選択します。
「詳細検索」ダイアログ・ボックスが表示されます。実行する検索のタイプに応じて、次の手順のいずれかを使用します。
拡張検索を実行するには、次の手順があります。
「検索」をクリックします。
「詳細検索」ダイアログ・ボックスでは、マッピングまたはプラッガブル・マッピング内の演算子、グループ、および属性を検索できます。デフォルトでは、このダイアログ・ボックスに、標準検索を実行するために必要なオプションが表示されます。標準検索では、表示名を使用して演算子、グループ、または属性を選択します。検索結果の表示方法を指定することもできます。
拡張検索には、検索のスコープと検索条件を定義する技術が用意されています。拡張検索を実行するには、詳細を表示をクリックします。拡張検索の定義に必要な追加のパラメータが表示されます。
検索するオブジェクトの指定
「検索」フィールドを使用して、位置を特定するオブジェクトを指定します。標準検索では、同じ表示名を含むオブジェクトは、「検索」フィールド内で指定された同一のものとして検索します。
拡張検索を実行中は、表示名に加えて、説明プロパティ、物理名、ビジネス名、または演算子がバインドされるワークスペース・オブジェクトの名前で指定された文字列を指定できます。
検索条件にワイルドカードを使用できます。たとえば、「検索」フィールドで「C*」を指定することによって、名前がCまたはcで始まるオブジェクトが検索されます。
検索結果を表示するために使用する方法の指定
「詳細検索」ダイアログ・ボックスの「強調表示のオン」ボタンを使用して、検索結果を表示するために使用するメソッドを指定します。トグル式ボタンになっていて、ハイライト表示のオンとオフを切り替えることができます。
強調表示のオン
ハイライト表示をオンにすると、検索操作によって検索されたすべてのオブジェクトがマッピング・エディタ上で黄色にハイライト表示されます。ハイライト表示によって、選択結果の一部としてオブジェクトを簡単に見つけやすくすることができます。
強調表示のオフ
デフォルトの動作です。ハイライト表示をオフにすると、検索操作によって検索されたオブジェクトはこれらのオブジェクトに移動したコントロールによって識別されます。コントロールが特定のオブジェクト上にあるとき、オブジェクトは青い枠で囲まれます。ハイライト表示をオフにすると、検索結果は同時に表示されます。
たとえば、1つの演算子が検索によって見つかると、演算子を表すノードの枠線が青になります。
検索スコープの指定
検索のスコープを指定することによって、検索されるオブジェクトを制限することができます。「スコープ」セクションの「選択済内」フィールドによって、キャンバス上で選択されるオブジェクトの検索のスコープを限定することができます。
演算子の特定のセット内のオブジェクトを検索するには、最初にキャンバス上のすべての演算子を選択して、「選択済内」を選択します。演算子の選択時に、[Ctrl]キーを押したままにすると複数の演算子を選択できます。
検索条件の指定
拡張検索を実行するには、さらに検索を絞り込むために追加の検索条件を指定する必要があります。
検索基準
「検索基準」リストを使用して、オブジェクトの検索に必要な名前を指定します。選択できるオプションは、次のとおりです。
表示名: ネーミング・モード・セットに応じて、物理名またはビジネス名を検索します。
物理名: 「検索」フィールドで指定された名前と同じ物理名を含むオブジェクトを検索します。
ビジネス名: 「検索」フィールドで指定された名前と同じビジネス名を含むオブジェクトを検索します。
バウンド名: このプロパティがオブジェクトに使用可能な場合は、「検索」フィールドで指定された名前と同じバウンド名を含むオブジェクトを検索します。
説明: このプロパティがオブジェクトを定義する場合は、「検索」フィールドで指定された名前と同じ説明を含むオブジェクトを検索します。
一致オプション
「一致オプション」セクションを使用して、オブジェクト検出中に使用される「一致オプション」を指定します。選択できるオプションは、次のとおりです。
大/小文字一致: 名前と大文字小文字が、「検索」フィールドで指定された検索文字列と一致するオブジェクトを検索します。
物理名で検索する場合、一致ケースはデフォルトで「False」に設定されます。
物理名モードでは、ユーザーの作成するオブジェクトはすべて大文字になりますが、インポートされるオブジェクトに関しては、大/小文字が混在する可能性があります。
論理名で検索する場合、一致ケースはデフォルトで「True」に設定されます。
完全一致のみ: 特にワイルドカードで上書きされなければ、一致に制限して検索文字列全体と一致していないオブジェクトを除外します。
正規表現: 検索文字列としてのJavaの正規表現を使用して、パターンの仕様をサポートします。正規表現が「完全一致のみ」と組み合されている場合は、境界を一致させる「$」が検索文字列パターンに付加されます。
正規表現サポートの詳細は、「Oracle Database SQL言語リファレンス」を参照してください。
検索オプション
検索処理を管理するオプションを指定します。次のいずれかのオプションを選択します。
増分: 任意の文字が入力されるかまたは文字が検索文字列から削除された場合に、検索を実行します。「検索」ボタンを使用して、検索文字列と一致する追加オブジェクトを検出します。
検索の折返し: セット内の最後のオブジェクトに到達した場合、最初のオブジェクトで検索処理が続行されます。
先頭から検索: セット内の最初のオブジェクトで検索が続行されます。
スコープ
このセクションを使用して検索のスコープを制限します。
選択済内: このオプションを選択して、マッピング・エディタで現在選択されているオブジェクト内の検索文字列のみを検索します。
方向
「方向」セクションを使用して、検索結果セット内におけるオブジェクトを順方向または逆方向のどちらかに並べます。「次へ」を選択してその結果セットを順方向に並べて、「前へ」で結果セットを逆方向に並べることができます。
マッピング・エディタを使用して、マッピングで設計した複雑なデータ・フローをデバッグできます。デバッグ・セッションを開始して、有効なターゲット・スキーマに接続すると、マッピング・エディタのツールバーおよび「ログ」ウィンドウの下に、デバッグ機能が表示されます。定義済の一連のテスト・データを使用して、デバッグ・セッションを実行し、データが抽出、変換およびロードされるフローに従って、設計したデータ・フローが期待どおりに動作するかどうかを確認できます。問題が検出された場合は、それらを修正してからデバッグ・セッションを再開し、配布する前に問題が修正されたことを確認できます。
デバックされているマッピングを変更する場合、マッピング・プロパティは変更されます。演算子の表示セットが変更される場合を除いて、マッピング・デバッガが再初期化され、変更がマッピングに反映されます。
前提作業
コントロール・センターに接続されており、コントロール・センターが機能していることを確認してください。
次の制限が、マッピング・エディタに適用されます。
マッピング・エディタでデバッグ・モードを使用して実行されるマッピングは、デバッグのみの目的で使用されます。マッピング・エディタから実行されるマッピングとコントロール・センターから実行されるマッピングは、実行されません。これは、デバッグ機能をサポートするために必要な一時的オブジェクトの設定によるものです。コントロール・センターを使用してマッピングを実行します。
デバッグ・メニューのツールバーまたは関連するアイテム上の「一時停止」ボタンを使用して、アクティブなデバッグの実行を一時休止することはできません。
デバッグ・モードでのマッピングの結果を表示するために、リポジトリ・ブラウザを使用できません。
PL/SQLパッケージとして実装可能なマッピングのみが、現在デバッグ・モードで実行可能です。ABAPマッピングは、デバッグ・モードでサポートされません。
デバッグ・モードでマッピングを実行する場合、アドバンスト・キュー演算子はサポートされません。
デバッグ・セッションを開始するには、マッピング・エディタでデバッグするマッピングを開きます。「デバッグ」メニューから「開始」を選択します。または、マッピング・エディタ・ツールバーで「開始」をクリックします。マッピング・エディタがデバッグ・モードに切り替わり、「ログ」ウィンドウにデバッグ・パネルが表示されて、デバッガはプロジェクトに適したコントロール・センターに接続されます。デバッグで生成されるコードは、デバッグ対象のマップが格納されているモジュールの位置に基づいて、指定されたターゲット・スキーマに配布されます。
|
注意: 接続できない場合は、エラー・メッセージが表示されます。接続情報を編集して再試行するオプションがあります。 |
接続が確立された場合は、テスト・データを定義できることを示すメッセージが表示されます。テスト・データがすでに定義されている場合は、初期化を続行するかどうかを尋ねるメッセージが表示されます。
マッピングをデバッグするには、それぞれのソース演算子とターゲット演算子がデータベース・オブジェクトにバインドされている必要があります。ソース演算子とターゲット演算子に対するテスト・データの定義はオプションです。デフォルトでは、デバッガは、デバッグ以外のマップの配布に対して現在定義されているものと同一のソース・データとターゲット・データが使用されます。
マッピング・エディタがデバッグ・モードで起動している場合は、「ログ」ウィンドウに2つの新しいパネル(「情報」パネルと「データ」パネル)が表示されます。
マッピング・エディタがデバッグ・モードのときは、「ログ」ウィンドウに情報パネルが表示されます。このパネルには次のタブがあります。
メッセージ: すべてのデバッガ操作メッセージが表示されます。これらのメッセージにより、デバッグ・セッションのステータスを確認できます。これには、デバッグ・モードでマッピングを実行する間に発生したエラー・メッセージが含まれます。
ブレークポイント: マッピングに設定した全ブレークポイントのリストが表示されます。チェック・ボックスを使用して、ブレークポイントをアクティブ化したり非アクティブ化したりできます。詳細は、「ブレークポイントの設定」を参照してください。
テスト・データ: マッピングに使用されている全データ・オブジェクトのリストが表示されます。このリストは、どのデータ・オブジェクトにテスト・データが定義されているかも示します。
マッピング・エディタがデバッグ・モードのときには、「データ」パネルが「ログ」ウィンドウに表示されます。「データ」パネルには、デバッグ対象の演算子に関する入出力情報を含んだ「ステップのデータ」タブとウォッチ・ポイント・タブがあります。「ステップのデータ」タブには、デバッグ・セッションの現行ステップに関する情報が表示されます。他のタブは、設定するウォッチごとに追加できます。これらのウォッチ・タブでは、デバッグ・セッションで現在アクティブな演算子に関係なく、演算子を通じて渡したデータまたは渡す必要のあるデータを追跡して表示できます。複数の入力グループまたは複数の出力グループを持つ演算子の場合は、追加のリストが表示され、特定のグループを選択できます。
演算子が複数の入力グループまたは出力グループを持つ場合は、デバッガの右上隅の入力グループまたは出力グループの上にリストが表示されます。このリストを使用して、関心のあるグループを選択します。これは、ステップ・データとウォッチの両方に適用されます。
マッピング内のソース演算子またはターゲット演算子はすべて、下部の「情報」タブ・パネルの「テスト・データ」タブにリストされます。オブジェクト・タイプ、ソース、およびデータベース・オブジェクトがソース演算子またはターゲット演算子にバインドされているかどうかを示すチェック・マークも表示されます。
タブにリストされるオブジェクト・タイプは、選択したデータ・ソース(表など)の列名がマッピング演算子の列と一致するかどうかで決まります。次の2つのタイプがあります。
直接アクセス。完全に一致する場合は、タイプに直接アクセスと表示されます。
ビューとして配布。マッピング演算子の列と一致しない列が含まれるデータ・ソースを選択する場合は、列のマッピング方法を選択できます。この場合、オブジェクトはマッピングの実行時にビューとして配布され、タイプにはビューとして配布と表示されます。
バインド済データベース・オブジェクトで、演算子とテスト・データのバインドを追加または変更するには、「編集」をクリックします。デバッグ・モードでマッピングを実行するには、その前にリストされている各ソース演算子またはターゲット演算子がバインドされ、チェック・マークが付けられている必要があります。バインド済データベース・オブジェクトにテスト・データを定義して有効にする必要があるかどうかは、デバッグ・セッションを実行する際に、データ・フローのどの部分に焦点を置くかによって決まります。一般に、すべてのソース演算子には、テスト・データが必要です。ターゲット演算子のテスト・データは、通常、更新またはターゲットの制約を伴うロード・シナリオをデバッグする場合に必要です。
テスト・データを定義または編集する手順は、次のとおりです。
マッピング・エディタの「テスト・データ」タブで、リストから演算子を選択して「編集」をクリックします。テスト・データの定義ダイアログ・ボックスが表示されます。
「テスト・データの定義」ダイアログ・ボックスで、デバッグ時にOracle Warehouse Builderが使用するテスト・データの特性を指定します。数多くの特性を指定できます。たとえば、テスト・データが新規データベース・オブジェクトか既存のデータベース・オブジェクト、あるいはテスト・データを手動で編集できるかどうかを指定できます。詳細は、テスト・データの定義ダイアログ・ボックスの「ヘルプ」をクリックしてください。
「テスト・データの定義」ダイアログ・ボックスを使用して新しい表を作成する場合、デバッグ実行の開始時に指定したターゲット・スキーマに表が作成されます。デバッグ・セッション終了時、デバッガによって表が自動的に削除されることはないため、他のセッションにも同じ表を再利用できます。制約は新しい表には継承されません。ただし、デバッグ・セッションによって作成されたその他のすべてのステージング表は、デバッグ・セッションが終了すると削除されます。
ユーザーが新しい表を作成すると、その表は、接続されているランタイム・スキーマに作成されます。新しい表には名前が自動的に生成され、新しい表名を反映するようにデバッグ・バインド名の値が変更されます。新しい表には、マッピングのソース属性またはターゲット属性の名前とデータ型が完全に一致する属性に対して列が定義されます。また、表の作成時にグリッドに表示されるデータは、新しく作成された表にコピーされます。
テスト・データの定義ダイアログ・ボックスを使用して作成する表内のスカラー・データ型とユーザー定義データ型の両方を使用できます。
テスト・データの定義ダイアログ・ボックスを使用して、テストデータを編集できます。テスト・データの編集は、スカラー・データ型でのみ適用可能です。
演算子のバインドを別のデータベース・オブジェクトに変更した場合は、マッピングをデバッグ・モードで再実行する前に、デバッグ・セッションを再度初期化し、変更内容を実装する必要があります。
|
注意: ターゲット定義にロードされるデータは暗黙的にコミットされます。ターゲット・オブジェクトが更新されないようにする場合は、「新規表の作成」をクリックしてターゲット・オブジェクトのコピーを作成してください。 |
名前にDBG$という接頭辞の付いたデバッグ表は、マッピングのデバッグ時にランタイム・スキーマに作成されます。複数のインスタンスを持つ複数のユーザーが同じマッピングをデバッグできるため、デバッグオブジェクトは各デバッグ・セッション用に個別に作成されます。セッションのデバッグ・オブジェクトは、セッション後に自動的に削除されます。ただし、デザイン・センターに存在するユーザーで、既存のマッピング・デバッガを持たない場合、進行中のデバッグ・セッションのデバッグ・オブジェクトは削除されずに失効オブジェクトとなりますが、
ただし、ランタイム・スキーマのすべてのデバッグ・オブジェクトは、OWB_HOME/bin/admin/cleanupalldebugobjects.sqlスクリプトを使用してクリーンアップできます。このスクリプトは、接頭辞DBG$が付加されたすべての失効オブジェクトをランタイム・リポジトリ・ユーザー・スキーマから削除します。
管理者権限を持つOracle Warehouse Builderユーザーがこのスクリプトを実行する必要があります。このスクリプトを実行する前に、ランタイム・ユーザー・スキーマの接頭辞DBG$が付加されたすべてのオブジェクトが失効しているかどうかを判別します。複数のインスタンスを使用して同じマッピングをデバッグできるため、他のユーザーが同じマッピングをデバッグしている場合、このスクリプトを実行すると混乱を招きます。
特定の演算子についてデータ処理の様子を確認する場合は、デバッグ・セッションを中断させるブレークポイントをその演算子に設定できます。これにより、データ・フロー内のすべての演算子を順番に処理しなくても、目的の演算子まで速やかに進行できます。デバッグ・セッションがブレークポイントに到達した後、目的の演算子で順を追ってデータを実行し、期待どおりに機能するかどうかを確認します。
ブレークポイントを設定または削除する手順は、次のとおりです。
マッピング・エディタで、演算子を選択して「デバッグ」、「ブレーク・ポイントの設定」の順に選択します。または、ツールバーの「ブレーク・ポイントの設定」ボタンをクリックして、現在選択されている演算子のブレークポイントのオン/オフを切り替えることもできます。
ブレークポイントを設定すると、ブレークポイントとして設定された演算子の名前が、情報パネルの「ブレークポイント」タブにリストされます。ブレークポイントを削除すると、その演算子の名前も削除されます。ブレークポイントを削除するには、「ブレークポイント」タブの「クリア」ボタンを使用します。
ブレークポイントの選択/選択解除を切り替えるには、「ブレークポイント」タブのブレークポイントを選択または選択を解除します。
「データ」パネルにある「ステップのデータ」タブには、常に現在の演算子のデータが表示されます。アクティブな演算子に関係なく、他の演算子を通過したデータを追跡する場合は、ウォッチを設定します。
ウォッチを使用して、演算子を通過したデータや、バインド済データベース・オブジェクトに現在存在しているデータ(ソースまたはターゲットの場合)を追跡します。デバッグが目的の演算子で実行された後にウォッチを演算子に設定しても、データ・フローをさかのぼって、データがその演算子によってどのように処理されたかを確認できます。
ウォッチを設定する手順は、次のとおりです。
マッピング・エディタで、演算子を選択します。「デバッグ」メニューから「ウォッチの設定」を選択します。または、演算子を選択して、マッピング・エディタ・ツールバーの「ウォッチの設定」ボタンをクリックし、ウォッチのオン/オフを切り替えることもできます。
個別のウォッチ・パネルに、定数演算子、マッピング入力演算子、マッピング出力演算子、マッピング前プロセス演算子、マッピング後プロセス演算子、および順序演算子のデータが表示されます。これらの演算子が含む情報はその他の演算子よりも少ないため、これら複数の演算子に関する情報はウォッチ・パネルに表示されます。そのため、ウォッチの値を選択する場合、これらの演算子についてウォッチ・パネルのインスタンスが1個のみ表示されます。
ウォッチを削除する手順は、次のとおりです。
ウォッチを削除するには、マッピング・エディタのキャンバスで演算子を選択します。次にマッピング・エディタ・ツールバーで「ウォッチの設定」をクリックするか、またはデバッグ・メニューから「ウォッチの設定」を選択します。
ウォッチ・パネルが定数演算子、マッピング入力演算子、マッピング出力演算子、マッピング前プロセス演算子、マッピング後プロセス演算子、および順序演算子などのデータ以外の演算子で構成されている場合は、演算子を右クリックして「削除」を選択すると、これらを削除できます。「監視」パネルを閉じると、すべての演算子を削除できます。
ウォッチの保存
演算子のウォッチを設定する場合、「監視」パネルを閉じなければ、この演算子のウォッチ・ポイントは自動的に保存されます。デバッグ・セッションを終了してから再度開始すると、作成した演算子ウォッチのタブが表示されます。
ウォッチ・ポイントを保存しない場合は、マッピング・デバッガのツールバーで「ウォッチの設定」をクリックするか、ウォッチ・ポイントに関連するタブを閉じます。
各データ演算子についてテスト・データの接続を設定した後は、「デバッグ」メニューから「再初期化」を選択するか、またはマッピング・エディタのツールバーで「再初期化」をクリックして、初期デバッグ・コードを生成できます。Oracle Warehouse Builderにより、デバッグ・コードが生成され、指定したターゲット・スキーマにパッケージが配布されます。
デバッグ・セッションは、次のいずれかのモードで実行できます。
ツールバーの「再開」ボタンまたは対応するメニュー項目を使用して、次のブレークポイントまで、あるいはデバッグの実行が終了するまで処理を続行します。
ツールバーの「ステップ」ボタンまたは対応するメニュー項目を使用して、1行ずつ処理します。
ツールバーの「スキップ」ボタンまたは対応するメニュー項目を使用して、現在の演算子について残りの行をすべて処理します。
「リセット」ボタンまたは「デバッグ」メニューの対応する項目を使用して、デバッグの実行をリセットし、最初に戻ります。
マッピングには、複数のソースと複数のデバッグ・パスが含まれることがあります。
マッピングに複数のソースがあると、Oracle Warehouse Builderでは始点となるソースの指定が要求されます。たとえば、2つの表が1つのジョイナにマップされている場合は、デバッグ時に使用する最初のソース表を選択する必要があります。
パスの場合も、デバッガが1つのパスを終了した後で通過できる複数のパスが存在することがあります。たとえば、スプリッタを使用する場合などです。このような場合は、1つのパスが終了すると、他のパスも処理するかどうかを尋ねるメッセージが表示されます。
マッピングは、すべてのターゲット演算子が処理されるか、または発生したエラー数がそのマッピングに設定されている最大数に達すると終了します。デバッグ接続とテスト・データの定義は、Oracle Warehouse Builderワークスペースに変更をコミットする際に保存されます。ブレーク・ポイントとウォッチの構成は保存されないため、マッピングを開くたびに再設定する必要があります。
デバッガの実行に伴って、適宜デバッグ・メッセージが表示されます。演算子を介するデータ・フローに従うことができます。アクティブな演算子は、赤の破線で囲まれて示されます。
マッピングの「相関コミット」パラメータの設定(ONまたはOFF)によって、マッピングのデバッグ方法が変わります。
「相関コミット」パラメータがOFFに設定されているマッピングのデバッグ・セッションを開始すると、マッピングのデバッグには1回に1つのパスが使用されます。かわりに、選択したパスに関係なく、マッピングの最初のステップですべてのパスが実行され、ターゲットもすべてロードされます。また、いずれかのターゲットにステップの制約違反がある場合、そのステップではどのターゲットもロードされません。
「相関コミット」パラメータがOFFに設定されているマッピングのデバッグ・セッションを開始すると、マッピングのデバッグでは1回に1つのパスが使用されます。1つのパスが終了した後でステップを逆戻りし、マッピング内の別のパスを実行しないかぎり、その他すべてのパスは実行されず、他のターゲットもすべてロードされません。
たとえば、S1というソースを持つマッピングがあり、T1、T2という2つのターゲットに分岐するスプリッタに接続しているとします。
相関コミットがOFFの場合、マッピングはS1からデバッグされます。その後、T1に進むパスまたはT2に進むパスを選択できます。T1に進むパスを選択すると、T1に渡されるデータが処理および表示され、ターゲットT1がロードされます。T1のロードが完了すると、最初に戻り、もう1つのパスを実行してターゲットT2をロードするかどうかを選択できます。
相関コミットがONの場合、マッピングはS1からデバッグされ、パスを選択するオプションが表示されます。ただし、この選択は、データの処理に伴ってマッピング・エディタに表示するパスを単に決めるためのものです。パスはすべて同時に実行されます。相関コミットを使用したマッピングは、配布可能なコードを実行する場合も、このように実行されます。
演算子は、それがソースでない場合も開始ポイントとして選択できます。演算子を開始ポイントとして設定するには、デバッグ・セッションを開始した後、マッピング・エディタのツールバーで演算子を選択して「開始ポイントとして設定」をクリックします。または、「デバッグ」メニューから「開始ポイントとして設定」を選択します。
演算子を開始ポイントとして設定すると、その演算子よりも手前にあるすべての演算子とソースが単一の問合せに結合されてソースとして使用されます。その演算子は、マップのステップ実行時に自動的に最初のソースとして使用されます。開始ポイントが設定されている演算子より前の演算子は、ウォッチ・ポイントが設定されている場合でもステップ実行できず、表示可能データもありません。
「開始ポイントとして設定」は、単一のジョイナ演算子にすべて接続された3つのソース表のあるマッピングに使用するのが適切です。各ソース表は行数が多く(50000行を超過)、デバッガを介して効率よくステップ実行するには行が多すぎます。この場合、ジョイナ演算子を開始ポイントとして設定し、テスト・データ・エディタを使用して、1つ当たりのソース表の行数を管理しやすい行数(500)に制限します。また、ソース表の行数を制限してジョイナ(つまり、他のすべてのソースが結合条件で結合されているソース)を効率的に使用することが最善策です。
1つ以上のプラッガブル・サブマップ演算子が含まれているマップをデバッグできます。プラッガブル・サブマップ演算子には、プラッガブル・フォルダからのユーザー定義プラッガブル・サブマップ演算子、またはシステム定義のサブマップ演算子も含まれます。デバッグ・セッションを開始すると、マッピングはデバッグの初期化を経由し、最初の実行可能演算子でステップ実行が通常どおりに開始されます。
演算子のステップ実行中にデバッガがプラッガブル・サブマップ演算子に到達すると、他の演算子の場合と同様に、その演算子が現在のステップ演算子としてハイライト表示されます。この時点で「ステップ」をクリックすると、プラッガブル・マップの実装を示すマップのコンテキスト図は変化しないままで、プラッガブル・サブマップに組み込まれている演算子すべてがステップ実行されます。「ステップイン」をクリックすると、マップのコンテキスト図がプラッガブル・マップの実装を表すように変わり、現行ステップの演算子はプラッガブル・マップ内で最初に実行可能なソース演算子に設定されます。プラッガブル・サブマップの最初に実行可能なソース演算子は、入力シグネチャ演算子から接続された演算子の1つです。
プラッガブル・マップは、その他のマップ・タイプと同様にステップ実行できます。プラッガブル・サブマップ演算子にターゲットが含まれている場合は、最上位マップに対するロードと同様に、ターゲットがロードされます。最後の実行可能演算子の実行が終了し、次回、「ステップ」をクリックすると、コンテキストは最上位マップに戻り、前回実行したプラッガブル・サブマップの後方の次に実行可能な演算子に対して実行が開始されます。プラッガブルに出力接続がなく、そのプラッガブルが最上位マップ内の最後の実行可能演算子である場合は、ステップ実行が終了します。
プラッガブル・サブマップ内の演算子には、ブレークポイントおよびウォッチ・ポイントを設定できます。また、通常の編集時に「子グラフの表示」および「親グラフに戻る」をクリックすることで、通常の編集と同様に、コンテキスト図を変更できます。
マッピングを変更したり、ソース演算子またはターゲット演算子を別のデータベース・オブジェクトにバインドした場合は、新しい変更内容でマッピングのデバッグを続行するために、デバッグ・セッションを再初期化する必要があります。再初期化するには、ツールバーの「再初期化」ボタンをクリックするか、「デバッグ」メニューの「再初期化」メニュー項目を選択します。再初期化では、デバッグ・コードが再度生成されて配布されます。マッピングのデバッグ・セッションは、再初期化の後、先頭から開始されます。
マッピングをデバッグする際は、渡されるデータ量と「ステップのデータ」パネルに表示される列数の両方にスケーラビリティが適用されます。テスト・データの定義ダイアログ・ボックスには、行を制限するオプションがあり、マッピング全体のデータ量を制限できます。また、独自の表を作成してレコードを手動で操作することで、独自のデータ・セットを定義できます。
「ステップのデータ」タブやウォッチ・タブに表示される列数を制限するには、表示セットを使用できます。デフォルトでは、すべての演算子に表示セット「すべて」が設定されています。マッピングされている属性のみを表示するには、表示セット「マップ済」を使用します。マッピング・エディタを直接使用することで、表示セットをソースに手動で追加できます。表示セットを選択するには、入出力グループでマウスを右クリックし、「表示セットの使用」オプションを選択します。